1. Introduction
In recent years, the high penetration rate of Internet of Things (IoT) in all activities of everyday life is fostering the belief that for any kind of high-dimensional IoT data there is always a solution able to successfully deal with it. The proposed solution is the dimensionality reduction algorithm. It is well known that the high dimensionality of feature vectors is a critical problem in practical pattern recognition. Naturally, dimensionality reduction technology has been shown to be of great importance to data preprocessing, such as face recognition [
1] and image retrieval [
2]. It reduces the computational complexity through reducing the dimension and improving the performance at the same time. A general framework [
3] for dimensionality reduction defines a general process according to describing the different purposes of the dimensionality reduction algorithm that was proposed. Among this general framework, the dimensionality reduction is divided into unsupervised algorithms and supervised algorithms.
Unsupervised algorithms conduct datasets without labels, including principle component analysis (PCA) [
4], locality preserving projection (LPP) [
5], neighborhood preserving embedding (NPE) [
6], etc. Supervised algorithms conduct datasets with labels that aim to present better performance and low complexity. Linear discriminant analysis (LDA), local discriminant embedding (LDE) [
7], discriminant sparse neighborhood preserving embedding (DSNPE) [
8], regularized coplanar discriminant analysis (RCDA) [
9], marginal Fisher analysis (MFA) [
3,
5,
10], discriminant neighborhood embedding (DNE) [
11], locality-based discriminant neighborhood embedding(LDNE) [
12], and double adjacency graphs-based discriminant neighborhood embedding (DAG-DNE) [
13] are typical supervised algorithms.
The unsupervised algorithm PCA [
4] adopts linear transformation to achieve dimensional reduction commendably. However, PCA shows a noneffective performance in handling manifold data. Then, LLE [
14] is proposed, which firstly uses linear coefficients to represent the local geometry of a given point, then explores a low-dimensional embedding for reconstruction in the subspace. However, LLE only defines mappings on the training data which means it is ill-defined in defining mappings on the testing data. To remedy this problem, NPE [
6], orthogonal neighborhood preserving projection (ONPP) [
15] and LPP are put on the table. They figure out the problem of LLE while preserving the original structure. NPE and ONPP solve the generalized eigenvalue problem with different constraint conditions. LPP [
5] reserves the local structure by preferring an embedding algorithm. This algorithm extends to new points easily. However, as an unsupervised dimensionality reduction algorithm, LPP only shows good performance in datasets without labels.
To address the problem that unsupervised algorithms cannot work well in classification tasks, many supervised algorithms are proposed, such as linear discriminant analysis (LDA) [
16], which maximizes the inter-class scatter, minimizes the intra-class scatter simultaneously and finds appropriate project directions for classification tasks. However, LDA still has some limitations. For instance, LDA only considers the global Euclidean structure. Marginal Fisher analysis [
10] is proposed as an improved algorithm to surmount this problem. MFA constructs the penalty graph and the intrinsic graph to hold the local structure thereby solving the limitation problem of LDA. Both LDA and MFA can discover the projection directions that simultaneously maximize the inter-class scatter and minimize the intra-class scatter. DAG-DNE compensates for the small inter-class scatter in the subspace of DNE [
11]. DAG-DNE constructs a homogeneous neighbor graph and heterogeneous neighbor graph to maintain the original structure perfectly. It maximizes the margin between the inter-class scatter and intra-class scatter so that points in the same class are compact and points in the different classes become separable in the subspace at the same time. However, DAG-DNE and all above dimensionality reduction algorithms, optimize intra-class and inter-class simultaneously. The inter-class scatter is larger than the intra-class scatter, thus it will aim at inter-class but ignore the intra-class. Thus, the huge difference between the sum of inter-class distance and the sum of intra-class distance for distinct datasets may cause a bias problem, which means the impact of intra-class distance is tiny in optimization tasks. Naturally, the separation optimization idea comes to mind.
In this paper, we proposed a novel supervised subspace learning algorithm to further increase the performance, called hierarchical discriminant analysis. More concretely, we construct two adjacency graphs by distinguishing homogeneous and heterogeneous neighbors in HDA. Then HDA optimizes inter-class distance and intra-class distance independently. We minimize the intra-class distance first, then maximize the inter-class distance. Because of the hierarchical work, the optimization of intra-class distance and inter-class distance are detached. The process of optimization does not have to be biased to the inter-class scatter. Both of them get the best results. Thus, the influence between classes can be eliminated and we can find a good projection matrix.
The rest of this paper is structured as follows. In
Section 2 we introduce the background on MFA, LDNE and DAG-DNE.I.
Section 3, we dedicate to introducing HDA and revealing its connections with MFA, LDNE and DAG-DNE. In
Section 4, several simulation experiments applying our algorithm are presented to verify its effectiveness. This is followed by the conclusions in
Section 5.
3. Hierarchical Discriminant Analysis
This section discusses a novel dimensional reduction algorithm called hierarchical discriminant analysis. In MFA and DAG-DNE, two adjacency matrices for a node’s homogenous neighbors and heterogeneous neighbors are optimized simultaneously. The huge difference between the sum of inter-class distance and the sum of intra-class distance for distinct data may cause a bias problem, which is too weak for intra-class scatter to play a fundamental role. HDA considers the adjacency graphs respectively, which optimizes the sum of distances between each node and its neighbors of the same class firstly, and then optimizes the sum of distances between the nodes of different classes.
3.1. HDA
Suppose is the set of training points, where N is the number of training points, , is the class label of , d is the dimensionality of points, and c is classes’ number. For these unclassified training sets, we come up with a potential manifold subspace. We use matrix transformation to project the original high-dimensional data into a low-dimensional space. By doing so, homogeneous samples are compacted and the heterogeneous samples are scattered in low-dimensional data. Consequently, the computational complexity and classification performance are improved.
Similar to DAG-DNE [
13], HDA constructs two adjacency matrices respectively, the intra-class and inter-class adjacency matrices. Given a sample
, we suppose the set of its
k homogenous and heterogeneous neighbors are
and
. We construct the intra-class adjacency matrix
and the inter-class adjacency matrix
.
And the local intra-class scatter is defined as:
where
is a diagonal matrix and its entries are column sum of
, i.e.,
. First, we minimize the intra-class scatter, which means:
The objective function can be rewritten by some algebraic steps:
where
. Therefore, the form of trace optimization function can be rewritten as
While the local inter-class scatter is defined as:
where
is a diagonal matrix and its entries are the column sum of
, i.e.,
.
Now, we maximize the inter-class scatter:
It is worth noting that the training set has changed since first minimization, and we rewrite this function as:
where
.
So that the optimization problem as shown below:
Since and are real symmetric matrices, the optimization scatters (17) and (20) are same as the eigen-decomposition problem of the matrices and . The two projection matrices are composed of the egienvetors that corresponding to the egienvalues of and . The optimal solutions and have the form .
Therefore, the image of any point can be represented as . The details about HDA are given below (Algorithm 1).
| Algorithm 1 Hierarchical Discriminant Analysis |
Input: A training set , and the dimensionality of discriminant subspace r.
Output: Projection matrix .- 1:
Compute the intra-class adjacency graph and the inter-class adjacency matrix . - 2:
Minimize the intra-class distance by decomposing the matrix , where . Let egienvalues be , and their corresponding egienvectors be . - 3:
Choose the first r smallest egienvalues so that return . - 4:
Compute the new input . - 5:
Maximize the inter-class distance by decomposing the matrix , where . Let egienvalues be , and their corresponding egienvectors be . - 6:
Choose the first r largest egienvalues so that return .
|
3.2. Comparisons with MFA, LDNE and DAG-DNE
HDA, LDNE and DAG-DNE are all dimensionality reduction algorithms. In this section, we will probe into the relationships between HDA and the other three algorithms.
3.2.1. HDA vs. MFA
These two algorithms both build an intrinsic(intra-class) graph and penalty(inter-class) graph to keep the original structure of the given data. MFA designs two graphs to find the projection matrix which characterizes the intra-class closely and inter-class separately. However, MFA chooses the dimensionality of the discriminant subspace by experience, which causes some important information to be lost. HDA maximizes the distance of the inter-class and minimizes the distance of the intra-class hierarchically. It uses this method to find the projection matrix to estimate the dimension of the discriminant subspace.
3.2.2. HDA vs. LDNE
Both HDA and LDNE are supervised subspace learning algorithms and build two adjacency graphs to keep the original structure of the given data. LDNE assigns different weights to intra-class neighbors and inter-class neighbors of a given point. It follows the ‘locality’ idea of LPP, and produces balanced links through the set up connection between each point and its heterogeneous neighbors. By analyzing the experimental result, we get an effectiveness result on the subspace.
3.2.3. HDA vs. DAG-DNE
DAG-DNE algorithm maintains balanced links by constructing two adjacency graphs. Through this method, samples in the same class are compact and samples in different classes are separable in the discriminant subspace. However, DAG-DNE optimizes the heterogeneous neighbors and homogeneous neighbors simultaneously. By doing this, the distance of inter-class scatter is not wide enough in the subspace. The HDA algorithm also constructs two graphs, and separately minimizes the within-class distance first, then maximizes the inter-class distance. Because of the hierarchical work, the optimization of intra-class distance and inter-class distance are detached. The process of optimization is not biased to the inter-class scatter. As a consequence, the intra-class is compact while the inter-class is separated in the subspace.
4. Experiments
We illustrate a set of experiments to confirm the performance of HDA on image classification in this part. Several benchmark datasets are used, i.e., Yale, Olivetti Research Lab (ORL) and UMIST. The samples from three datasets are shown in
Figure 1,
Figure 2 and
Figure 3. We compare HDA with other representative dimensional reduction algorithms, including LPP, MFA and DAG-DNE.W. Then we choose the nearest neighbor parameter K for those algorithms when constructing the adjacency graphs. We exhibited the results in the form of mean recognition rate.
4.1. Yale Dataset
The Yale datset is constructed by the Yale Center for Computational Vision and Control. It contains 165 gray scale images of 15 individuals. These images display variations in lighting condition and facial expression (normal, happy, sad, sleepy, surprised and wink). Each image is 32 × 32 dimension.
We choose 60% from the dataset as training samples, and the rest of the samples for testing. The nearest neighbor parameter
K can be taken as 1, 3 and 5.
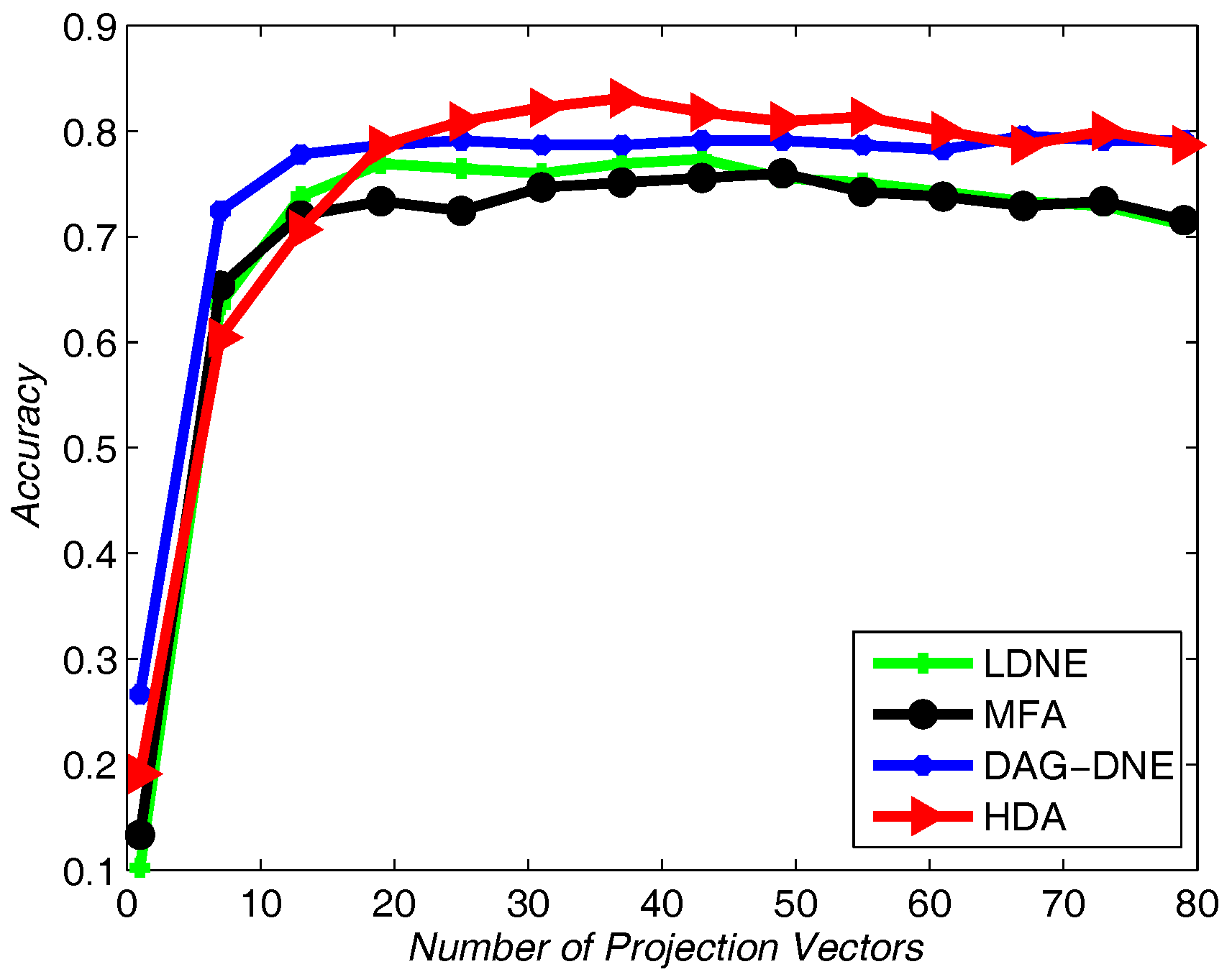
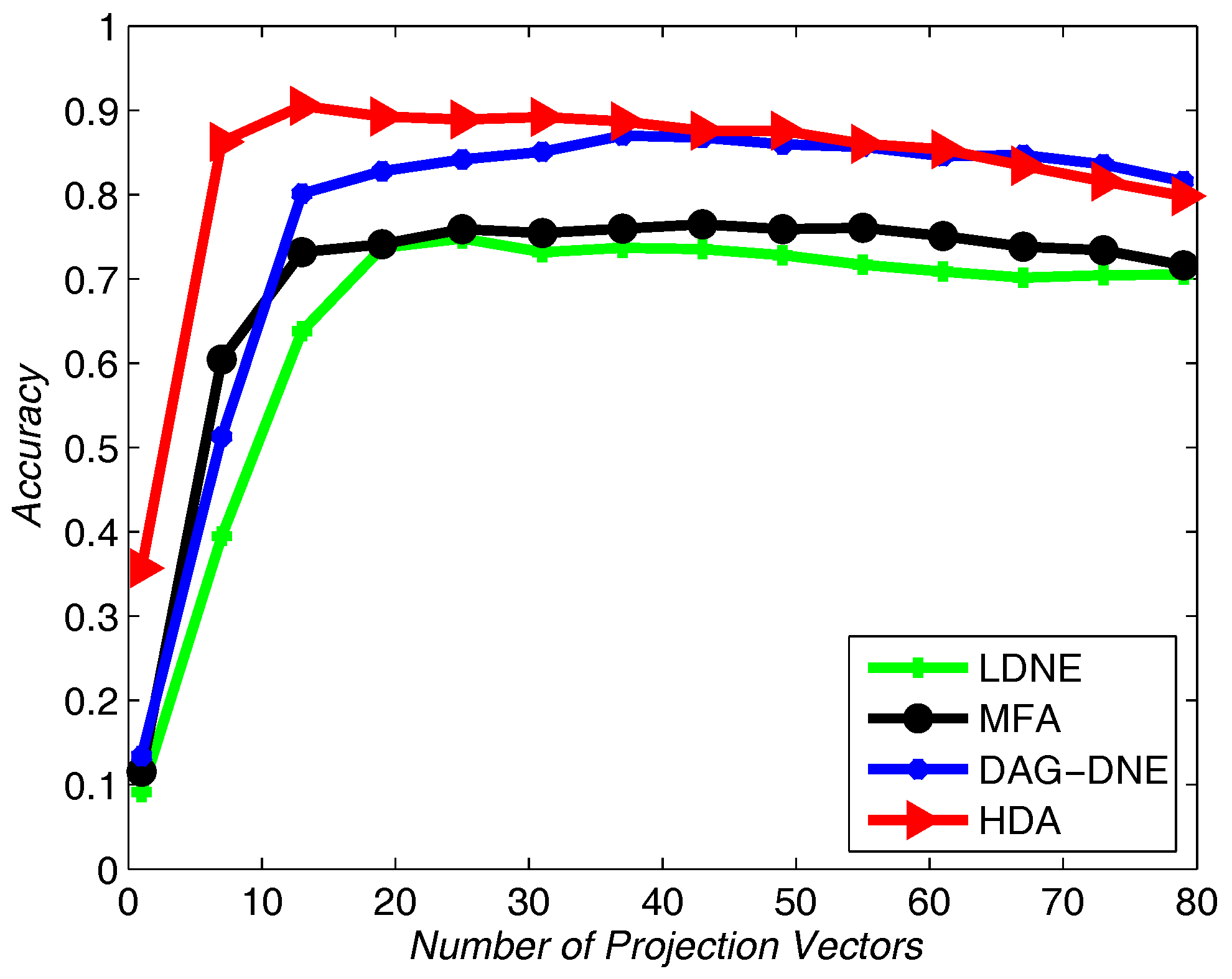
Figure 4 shows the average accuracy rate of
after running the four algorithms 10 times.
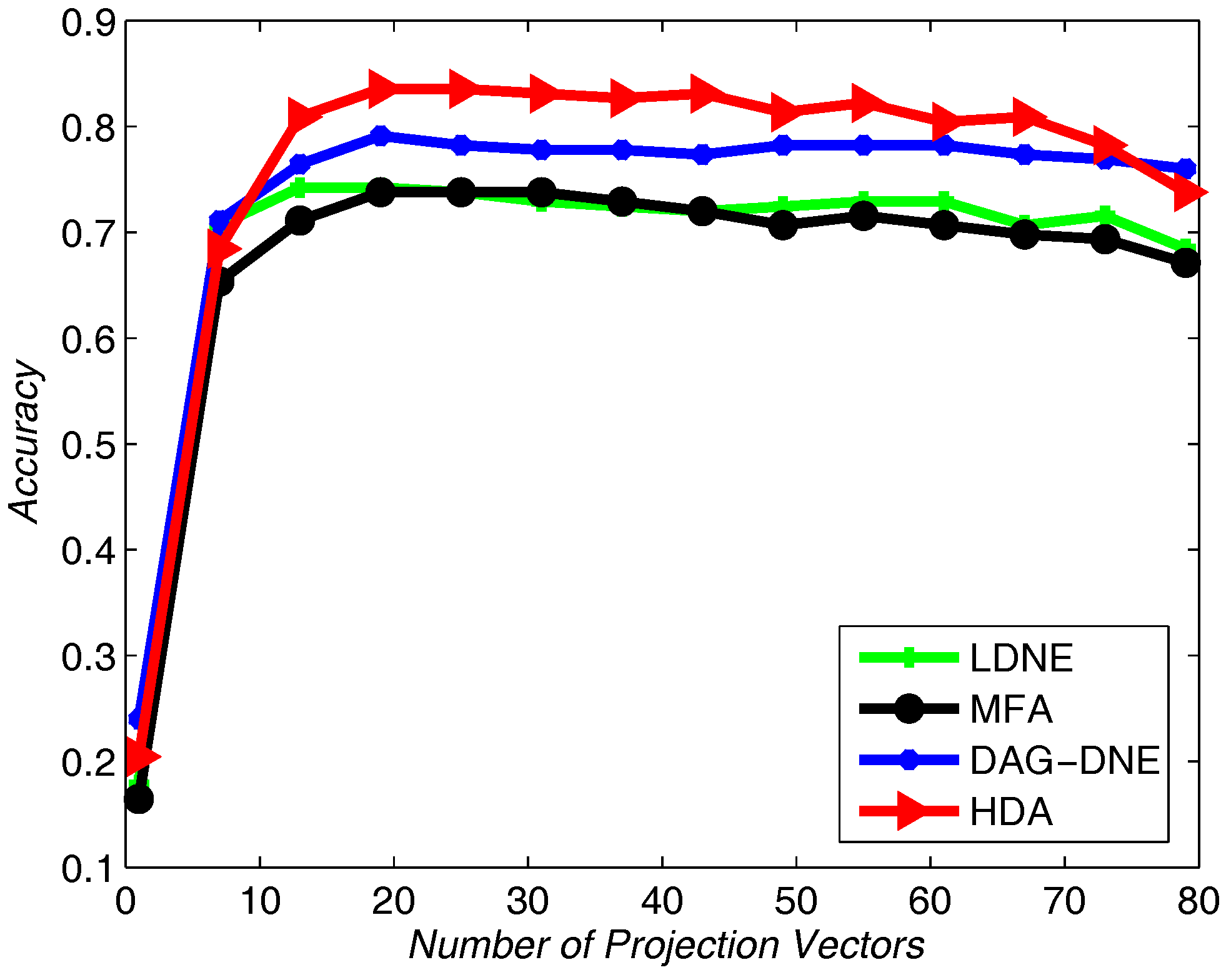
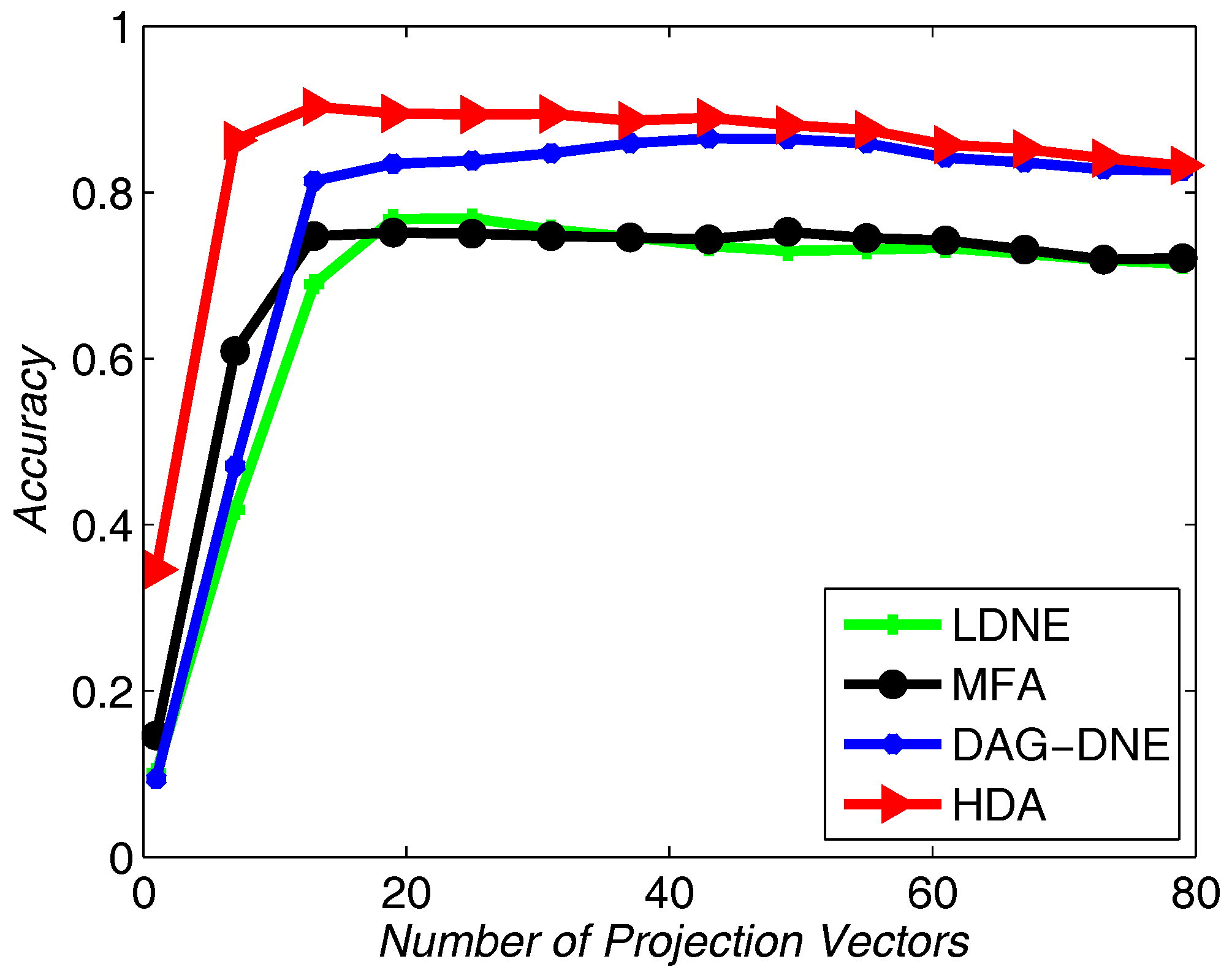
Figure 5 with
and
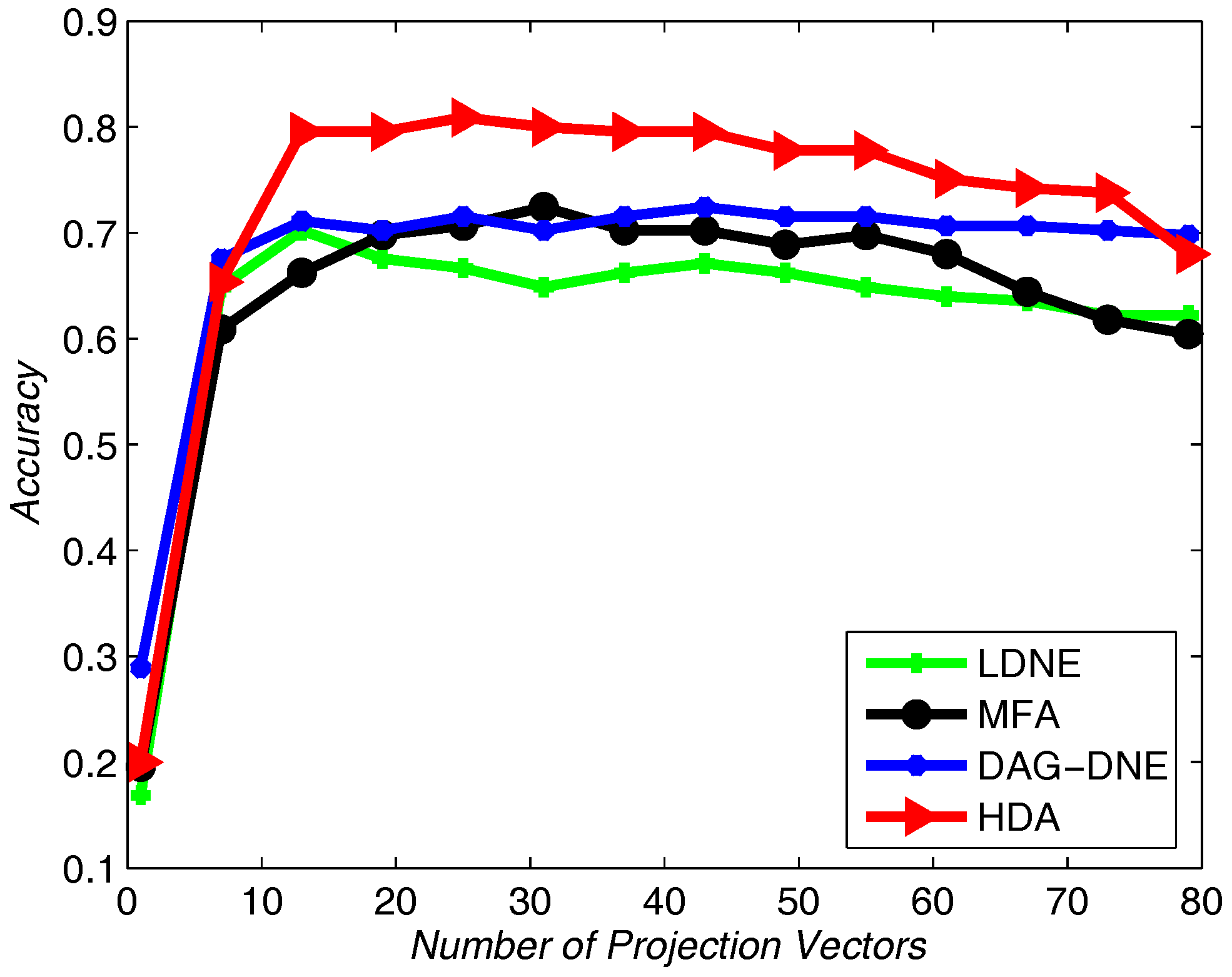
Figure 6 with
also obtain similar results like
Figure 4 after being run 10 times. From these three figures, we can see that HDA has a higher accuracy rate than other three algorithms and we can gain the best performance.
4.2. UMIST Dataset
The UMIST dataset consists of 564 images of 20 individuals. The dataset takes race, sex and appearance into account. Each individual takes several poses from profile to frontal views. The original size of each image is 112 × 92 pixels. In our experiments, the whole dataset is resized to 32 × 32 pixels.
Similar to applying the Yale dataset, we use UMIST dataset to test the recognition rate of the proposed algorithm and the other three algorithms. We select 20% from the UMIST dataset as training samples and use others as testing samples.
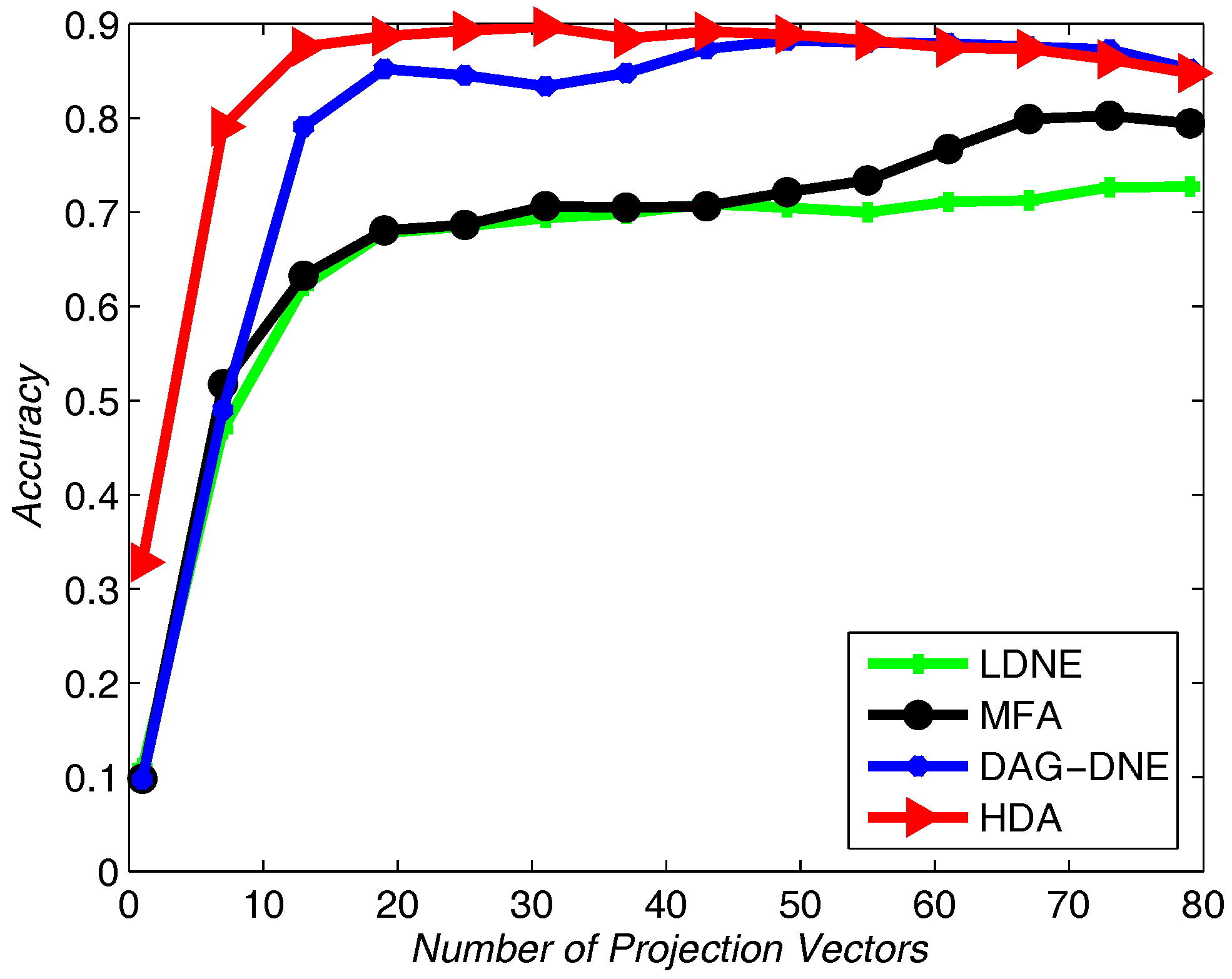
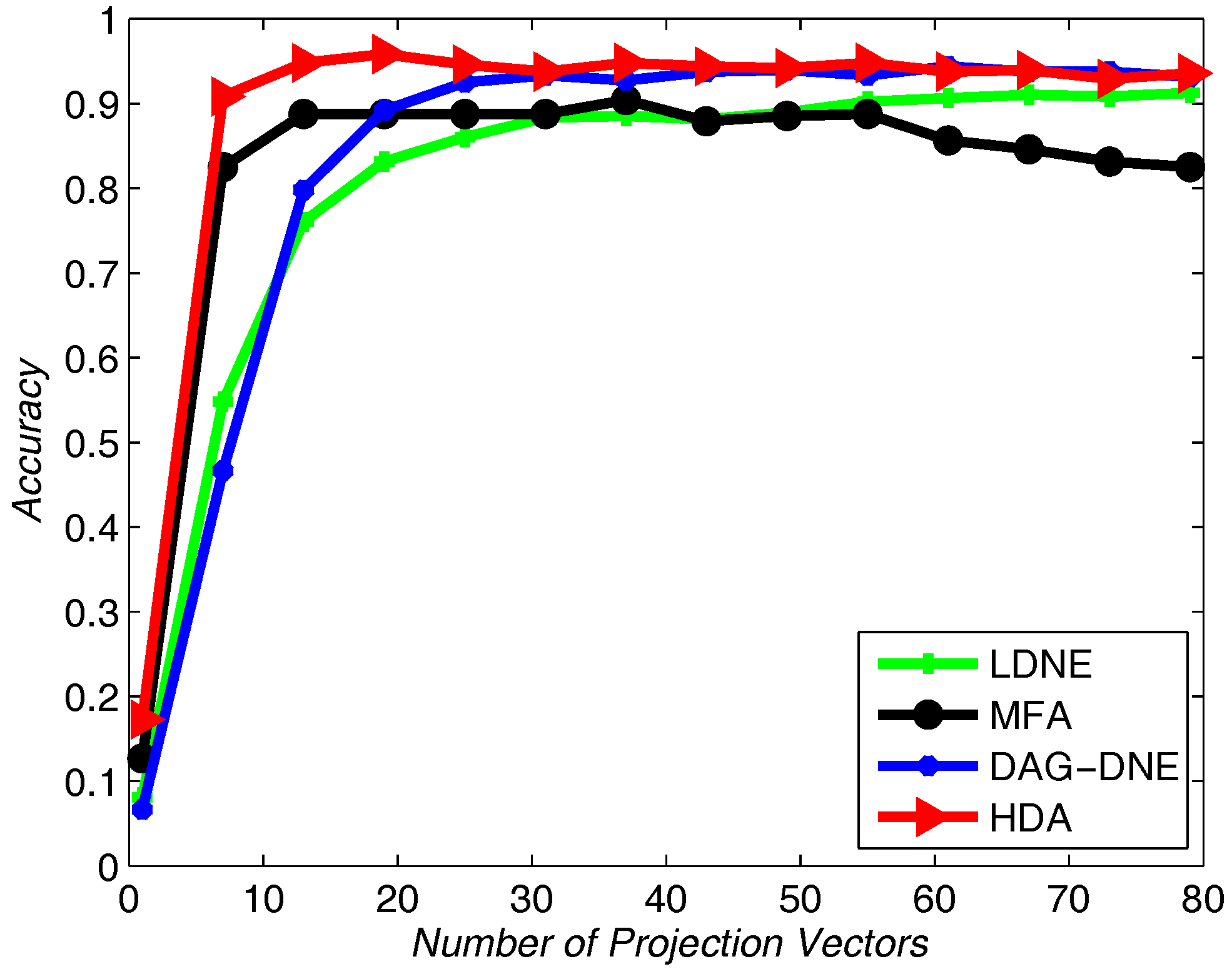
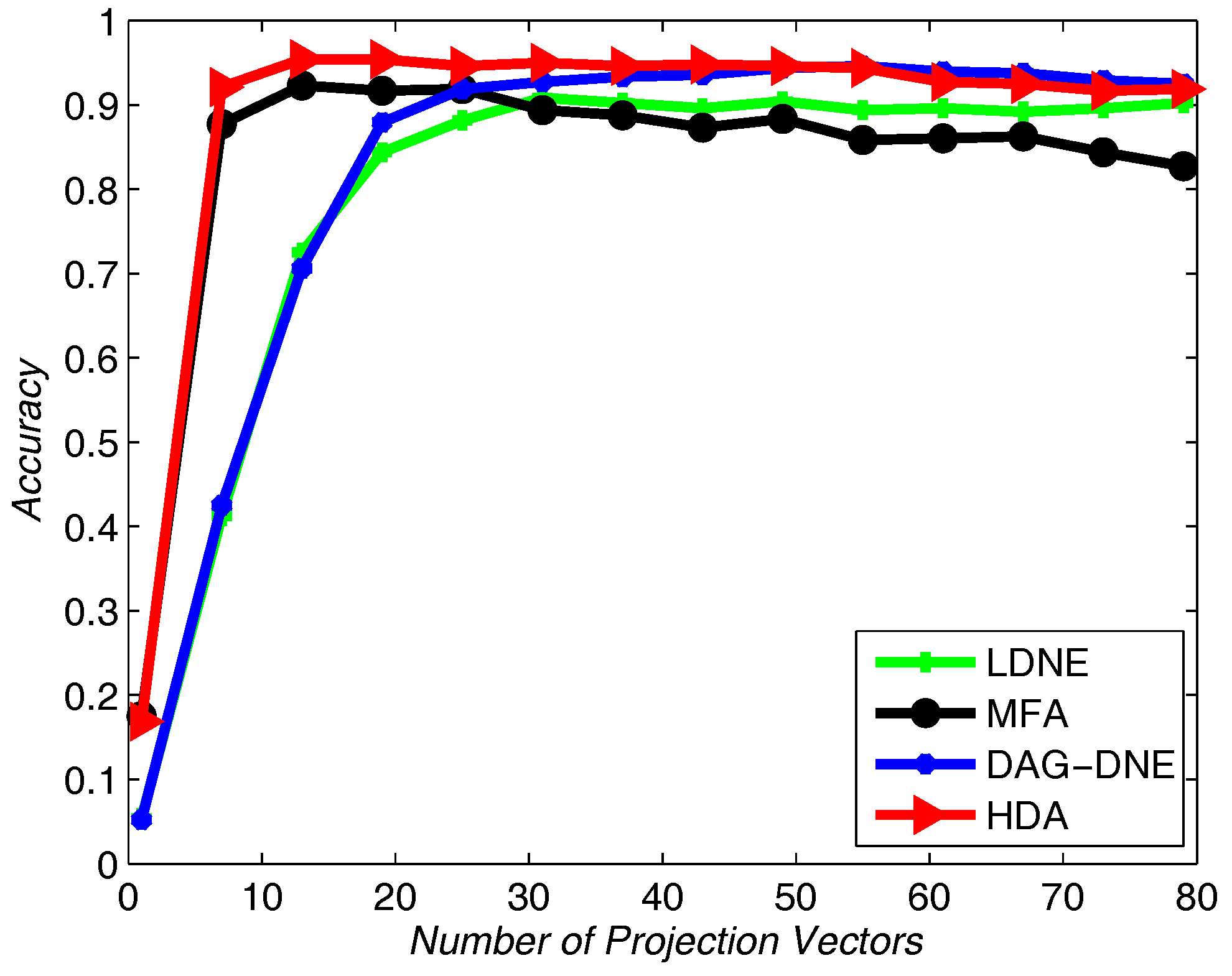
Figure 7,
Figure 8 and
Figure 9 show the average accuracy rate of different
K after running the four algorithms 10 times. As shown in these figures, our algorithm reaches the top and presents the best recognition accuracy compare to the other three algorithms.
4.3. ORL Dataset
The Olivetti Research Lab dataset is composed of 40 distinct objects. Each of them contains 10 different images. The ORL dataset contains images in different conditions, such us light conditions, facial expressions, etc. All of the images were taken under a dark homogenous background in an upright and frontal position. The size of each image is 112 × 92 pixels, with 256 gray levels per pixel. Similarly, we resize those image to 32 × 32.
Similarly, we choose the nearest neighbor parameter
K be 1, 3 and 5. Take 60% training samples from the original dataset, and the other 40% as testing samples. As shown in
Figure 10,
Figure 11 and
Figure 12, HDA presents the best accuracy rate compared to the other algorithms after 10 runs and HDA is almost the best one under a different number of projection vectors.
Table 1 shows the comparison of average recognition accuracy for different algorithms and different
K values. HDA has higher recognition accuracy than the other three algorithms. It improves the classification performance through a dimensional reduction method.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}