The Application of Social Characteristic and L1 Optimization in the Error Correction for Network Coding in Wireless Sensor Networks


Abstract
:1. Introduction
- Many 0 values are added to the original information to make the signal sparse; re-organize the transmitted signal from vector to matrix. The two methods allow L1 optimization method to be applied in network coding; therefore, L1 optimization technique can be introduced from the research field of image recognition to the research field of communication.
- The coding matrix in the original model by John and Yi is replaced by a specially designed matrix in which the bottom is identity matrix. The specially designed matrix can trap some errors and make these trapped errors known by the sink. The method will indirectly put down the fraction of propagated errors a little because we can know some errors a prior through the trapped errors.
- We use a secret channel to transmit a small amount messages in advance which will indirectly bring down the fraction of propagated errors slightly below 100%. Based on this method, John and Yi’s model can correct propagate errors in network coding.
- We propose a new distributed approach that establishes reputation-based trust among sensor nodes in order to identify the informative upstream sensor nodes. This will help L1 optimization have more opportunities to decode successfully and it will result in short delays and high throughputs.
2. Preliminaries and Related Works
2.1. Network Coding and Its Fundamental Concepts
| Algorithm 1. LOECNC Algorithm |
|
2.2. Error-Correcting Model in John and Yi’s Model
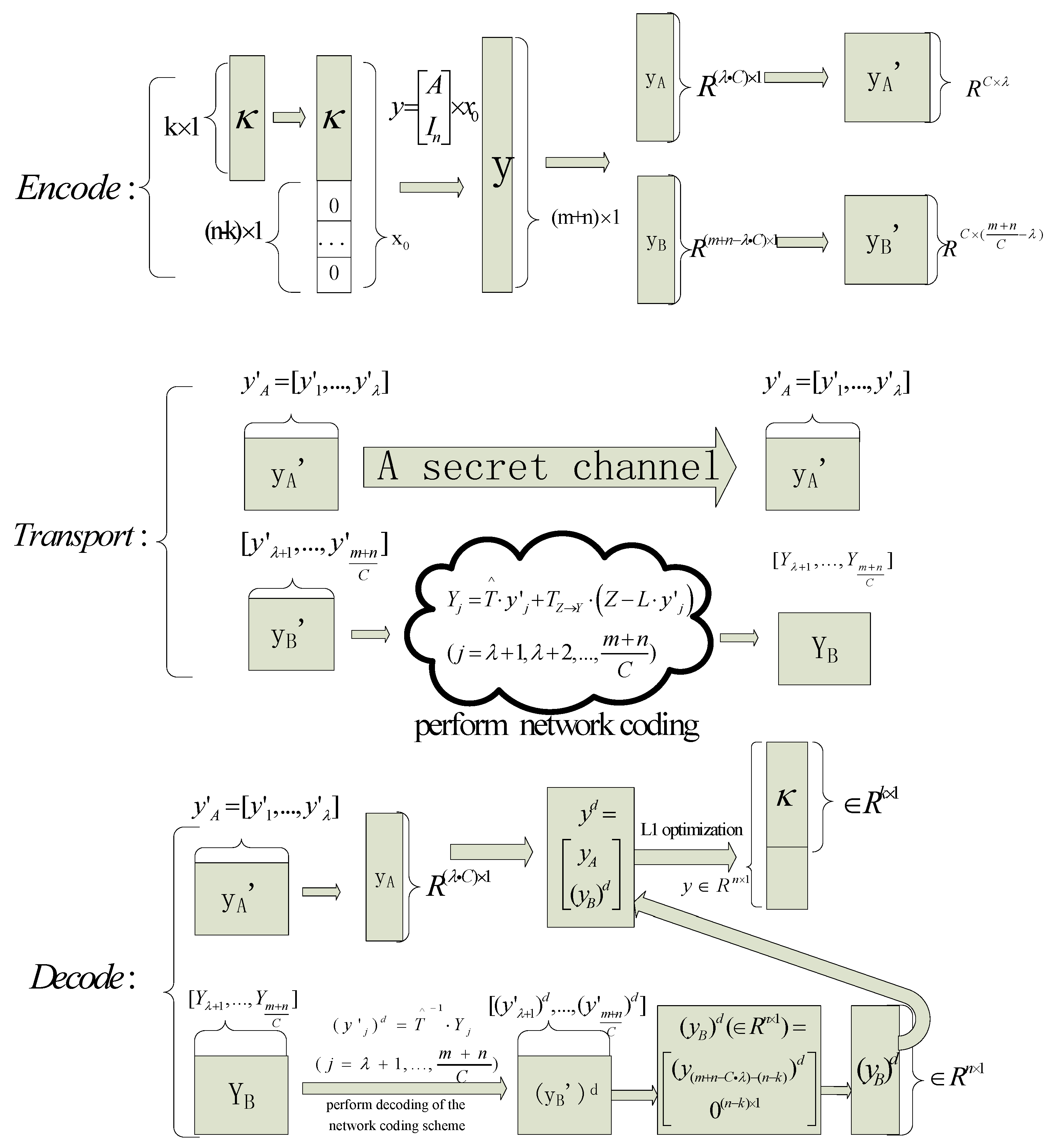
3. Improve L1 Optimization to Correct 100% of Corrupted Propagated Errors in Network Coding
3.1. The Variant of John and Yi’s Model
3.2. The Organization of Data for L1 Optimization
3.3. The Transfer Model in Non-Coherent Network
3.4. Formal Algorithm
3.5. The Notes on Algorithm 1
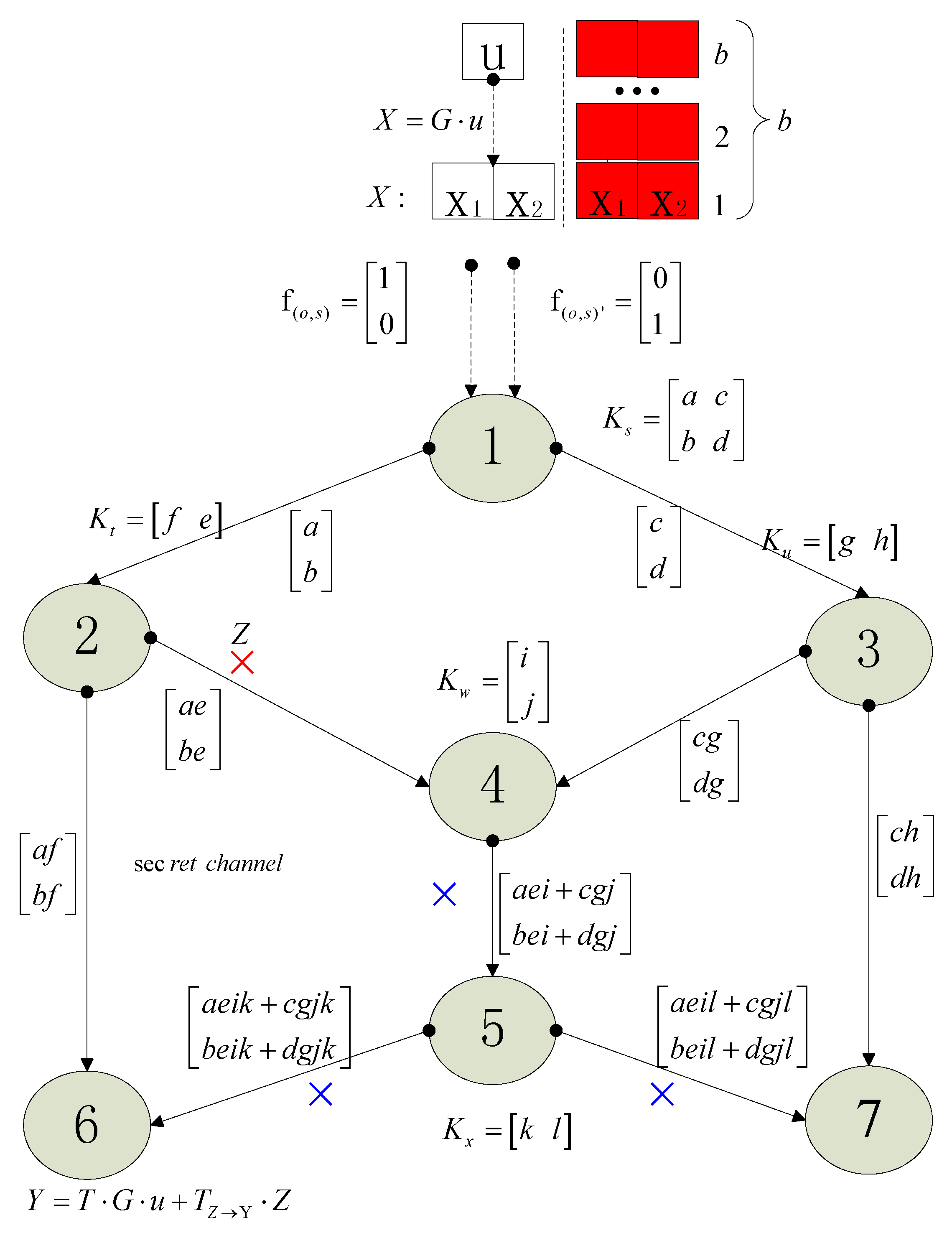
3.6. An Example about Algorithm 1
- Step 1
- Set involved parameters, among them, , , .
- Step 2
- , , . Here, is the trap matrix..
- Step 3
- In a finite field , perform encoding procedure of network coding scheme in every relay node. The corresponding transfer matrixes are: the message transfer matrix , the error message transfer matrix , and the error head vector transfer matrix .
- Step 4
- Reorganize the vector to the matrix , .Divide the matrix into two parts: . , . Set . Send the matrix through a secret channel. Send the matrix through the networks where the networks coding is performed in the relay nodes.
- Step 5
- , the result of network coding in relay nodes is expressed by the equation where is known by the coding vector in the head of packets, but and are all unknown.are received messages in the sink.
- Step 6
- Perform network coding decoding algorithm to . The result of network coding decoding is expressed by the equation where is known. Because is unknown, we cannot get . Thus, we let as the estimate of . Then we will perform decoding with L1 optimization to get based on . . is the estimate of .
- Step 7
- Reorganize the matrix to the vector .. Because , is the last 16 components of . Respectively, the last 4 components of is . However, is not equal to , and it is the estimate of . Thus, we cannot upload the last 4 blue components which are to where . We do not know in advance, but we know that . Thus, we know will be . UpdateThe numbers with blue are components which correspond to the known numbers in 408 which can be considered as the prior knowledge. The numbers with pinkish red are 409 components which correspond to the unknown numbers in .
- Step 8
- In the sink, receive matrix through the secret channel. Denote the vector .
- Step 9
- Reorganize the vector and the vector into . The first 4 red components are sent by the secret channel, and the last 2 components of are trapped by the trap matrix which is constructed specially. .. Thus, the green components are polluted. Up on , in the real field , perform L1 optimization of John and Yi’s scheme to get . Because we already know and of , we can certainly decoding with John and Yi’s scheme which can recover 100% of the corrupted observations where the corrupted ratio is (20 − 6)/20 = 70%. is decoded successfully. The numbers with green are components which correspond to the known numbers in which can be considered as the prior knowledge. The numbers with pinkish red are components which correspond to the unknown numbers in .
- Step 10
- Select the first symbols of as , that is . We recover the original message successfully.
3.7. Compressed Header Overhead
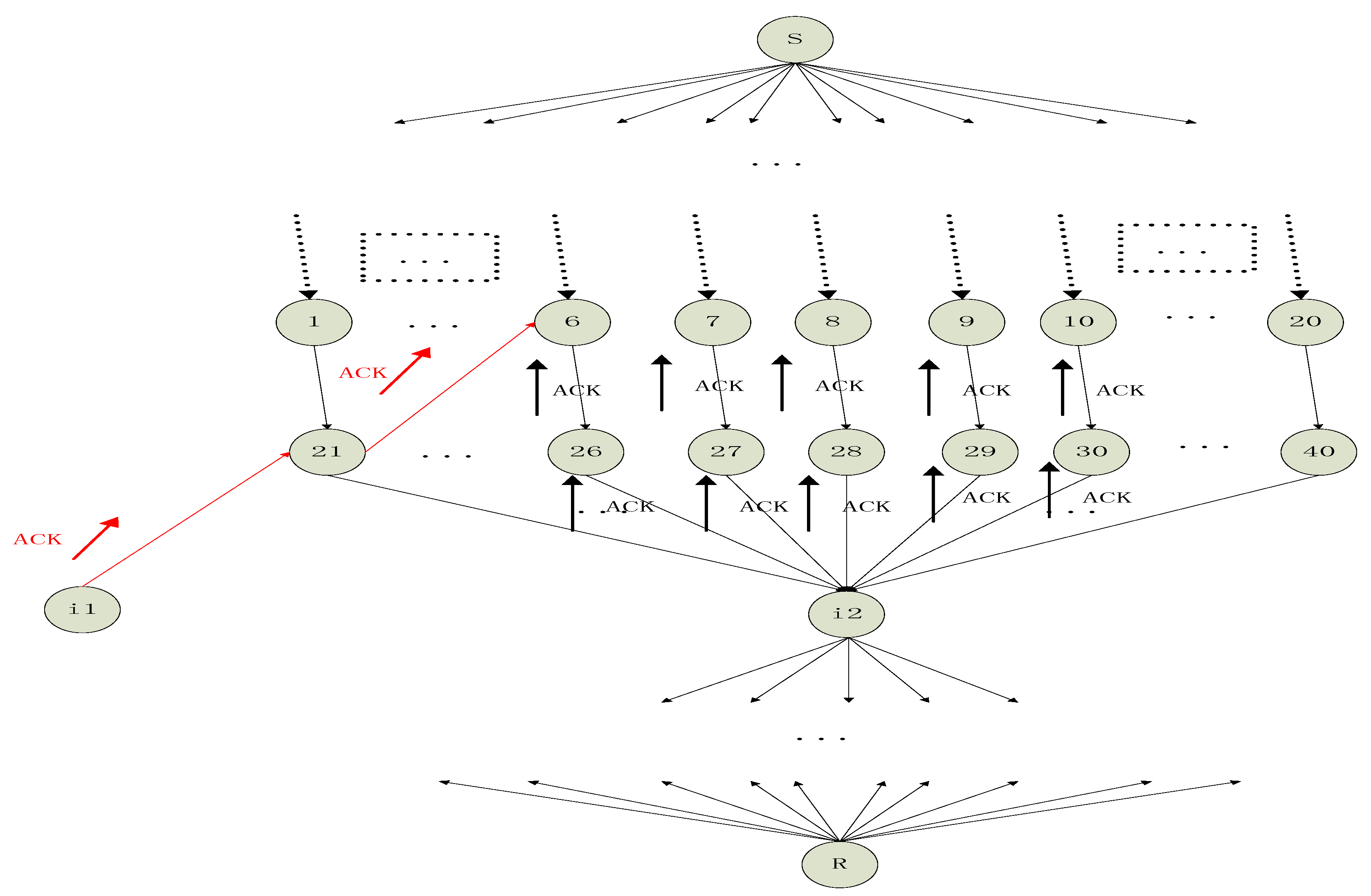
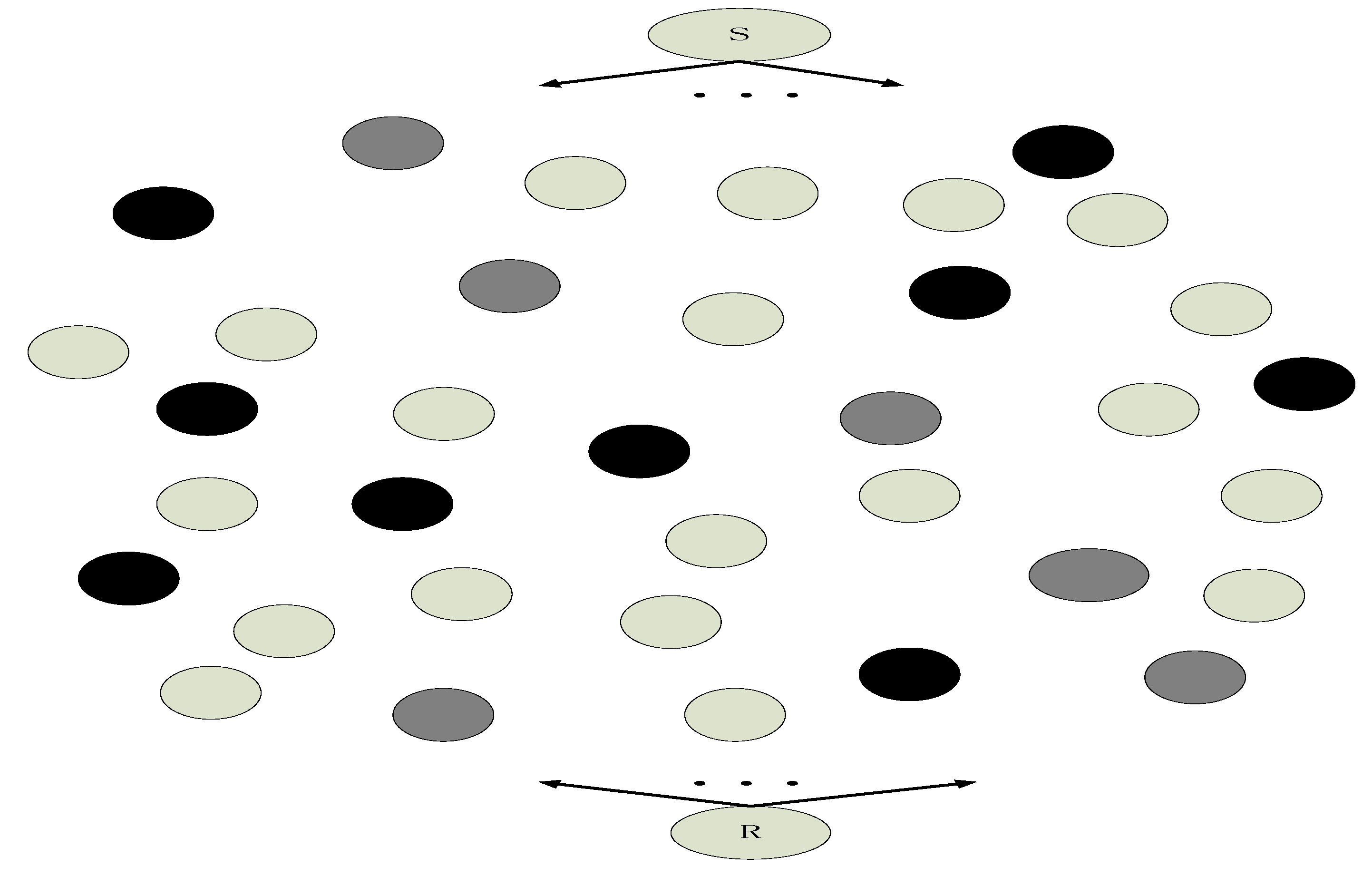
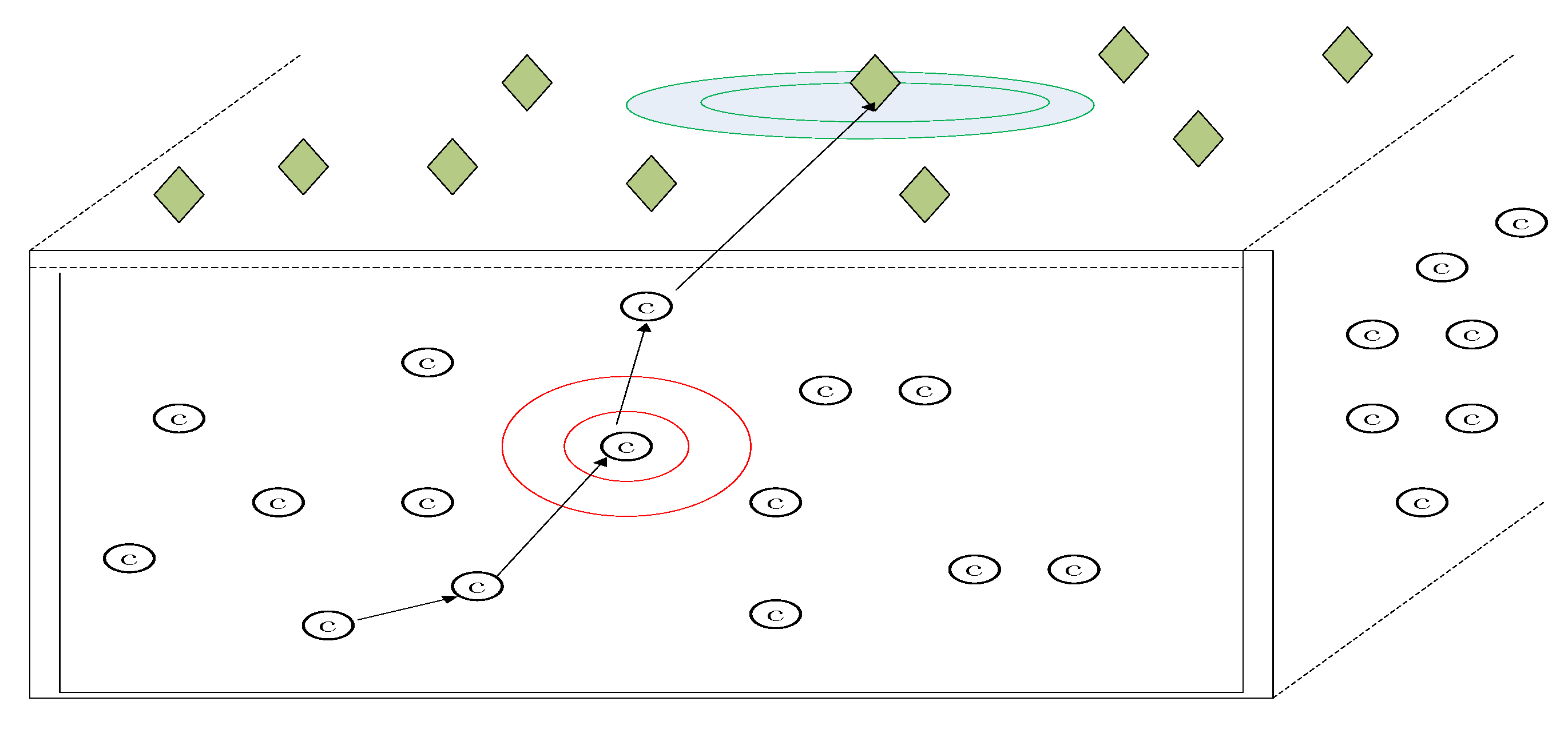
4. Find the Optimal Number and Optimal Positions of Relay Nodes in Network Coding with Social Networks
4.1. “All-or-Nothing” Problem about Network Coding in WSN
4.2. Overcome “All-or-Nothing” Problem with Reputation-Based Trust Model of Social Network
4.2.1. Stastical Trust Based on the Rank of Packets in the Downstream Nodes in WSN
4.2.2. Collecting Experiences to Build the Trust for an Intermediate Node in WSN
4.2.3. Network Coding Based on Reputation-Based Trust
5. Experimental Section
5.1. Experiments about L1 Optimization with MATLAB
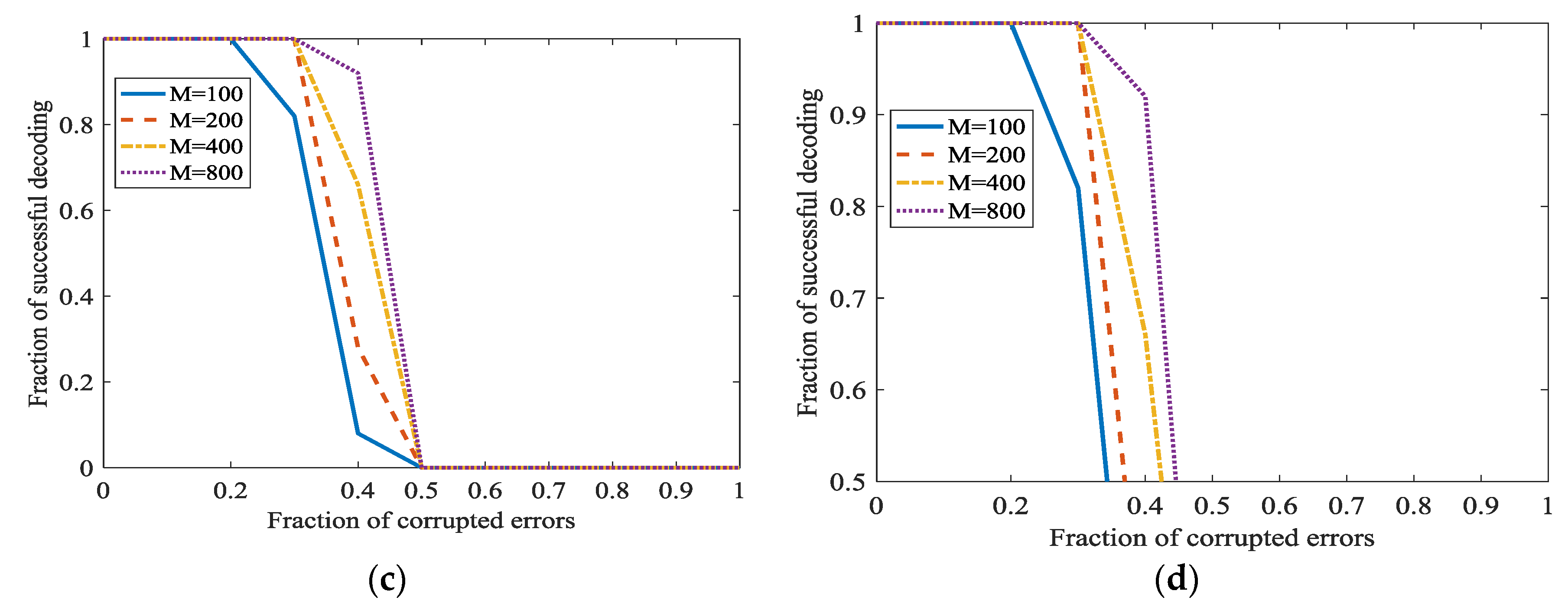
5.1.1. The Propagation Behavior of Original Errors
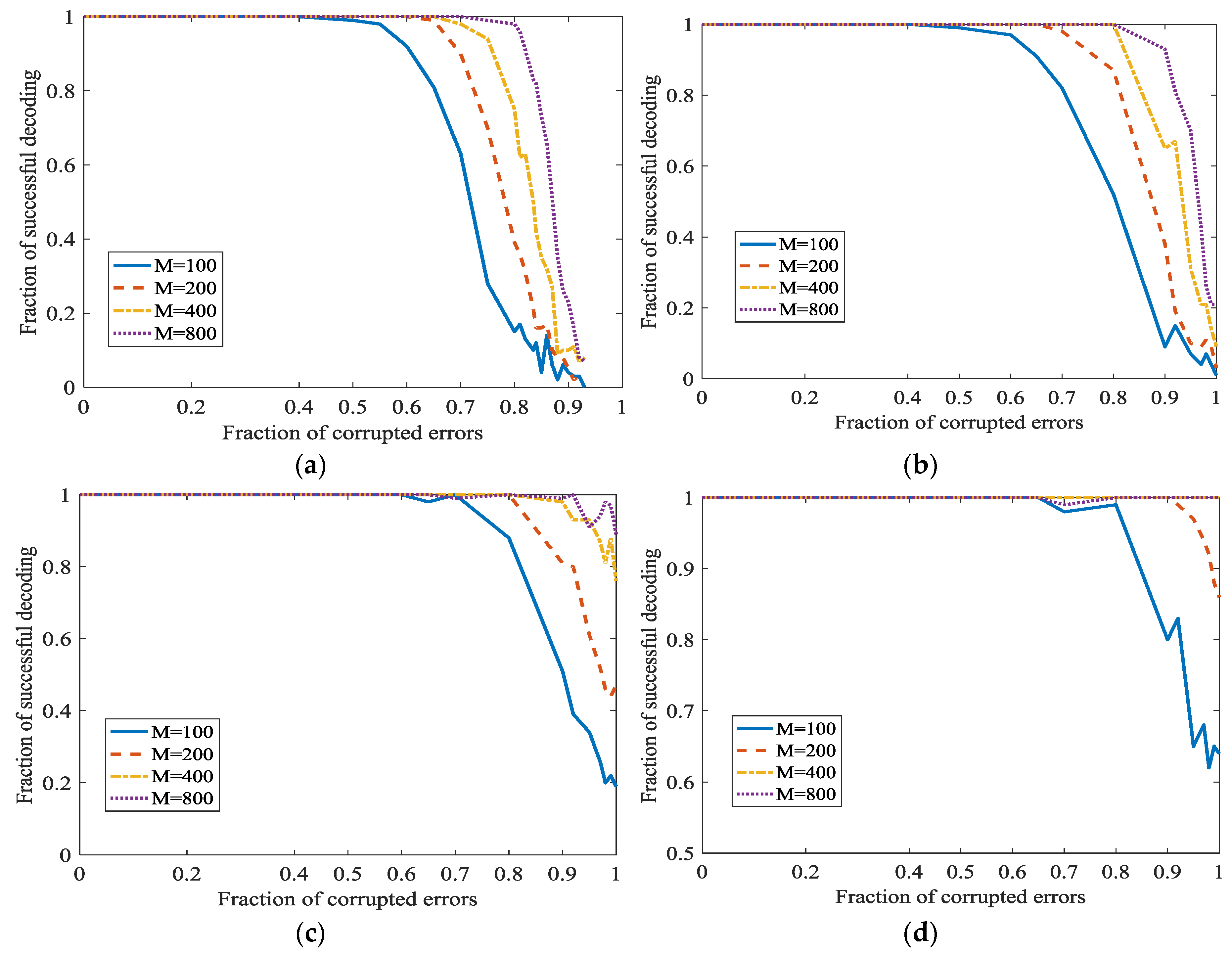
5.1.2. The Effect of L1 Optimization in Network Random Coding
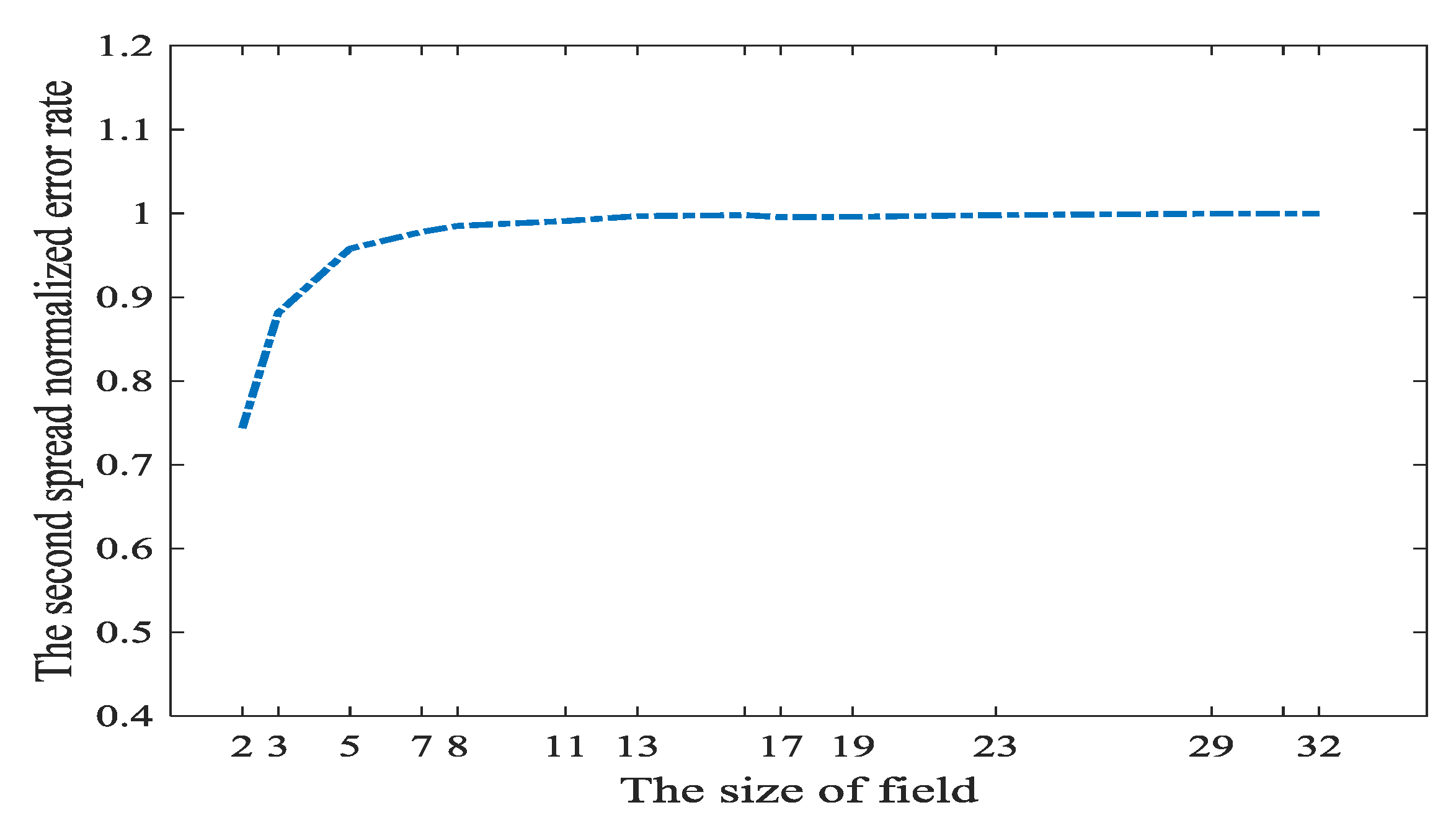
5.1.3. Set Other Parameters to Increase the Information Rate
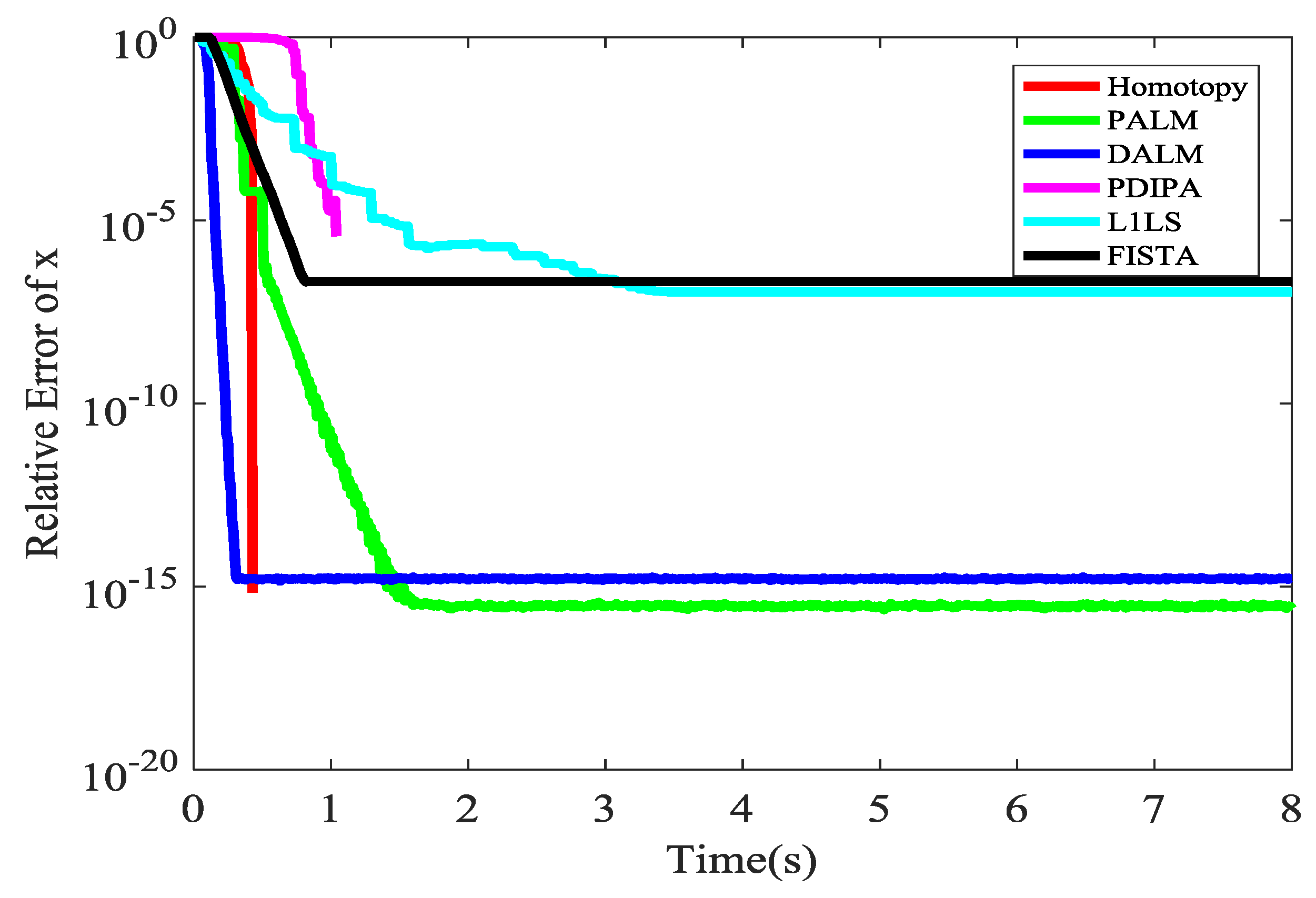
5.1.4. The Time for L1 Optimization
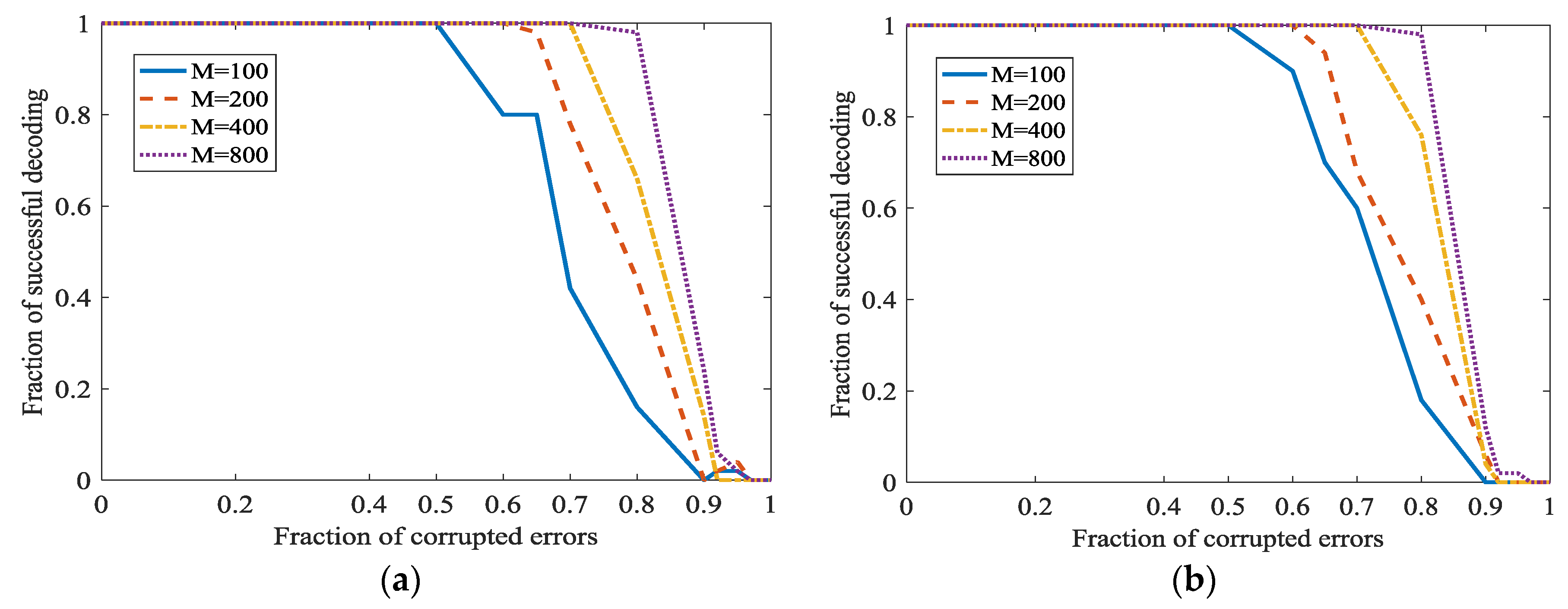
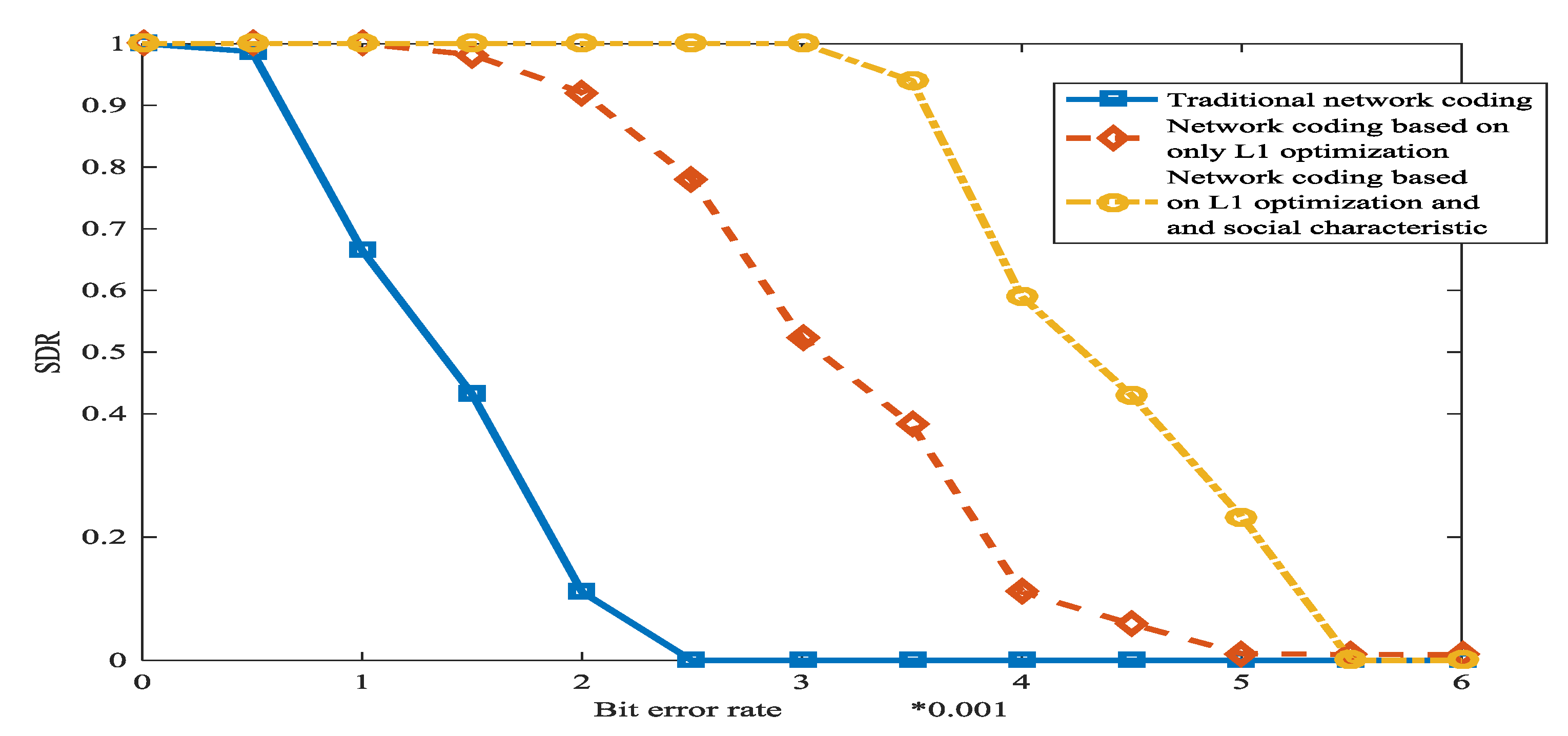
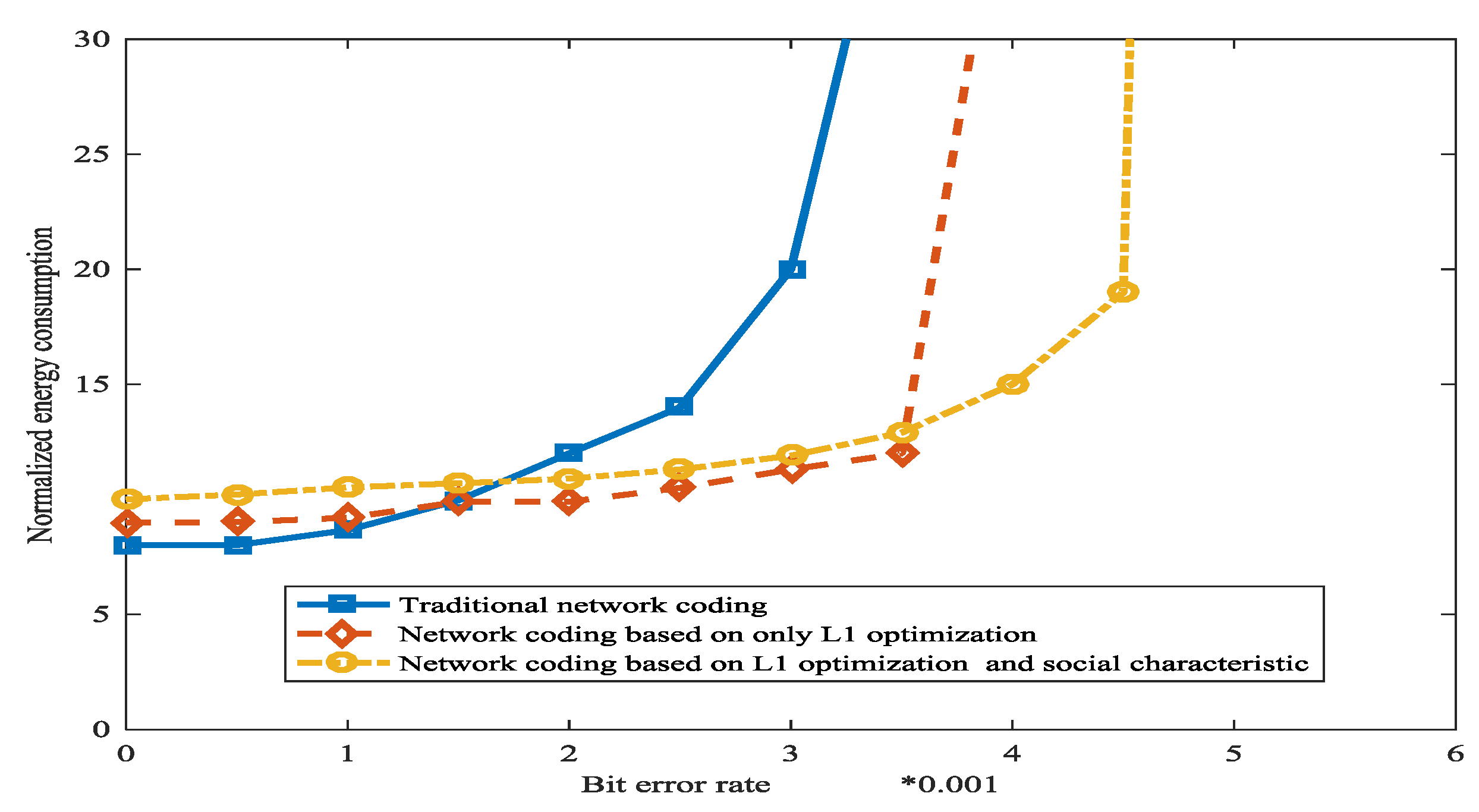
5.2. Experiments about the Error Correction in WSN Based on L1 Optimization and Social Networks Method
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Naranjo, P.G.V.; Shojafar, M.; Mostafaei, H.; Pooranian, Z.; Baccarelli, E. P-SEP: A prolong stable election routing algorithm for energy-limited heterogeneous fog-supported wireless sensor networks. J. Supercomput. 2017, 73, 733–755. [Google Scholar] [CrossRef]
- Valle, O.T.; Montez, C.; Araujo, G.M.D.; Vasques, F.; Moraes, R. NetCoDer: A Retransmission Mechanism for WSNs Based on Cooperative Relays and Network Coding. Sensors 2016, 16, 799. [Google Scholar] [CrossRef] [PubMed]
- Ahlswede, R.; Cai, N.; Li, S.Y.R.; Yeung, R.W. Network information flow. IEEE Trans. Inf. Theory 2000, 46, 1204–1216. [Google Scholar] [CrossRef]
- Assefa, T.D.; Kralevska, K.; Jiang, Y. Performance analysis of LTE networks with random linear network coding. In Proceedings of the 2016 39th International Convention on Information and Communication Technology, Electronics and Microelectronics, Opatija, Croatia, 30 May–3 June 2016. [Google Scholar]
- Kralevska, K.; Gligoroski, D.; Øverby, H. General Sub-Packetized Access-Optimal Regenerating Codes. IEEE Commun. Lett. 2016, 20, 1281–1284. [Google Scholar] [CrossRef]
- Cai, N.; Yeung, R.W. Network coding and error correction. In Proceedings of the 2002 IEEE Information Theory Workshop, Bangalore, India, 25 October 2002; pp. 119–122. [Google Scholar]
- Biczók, G.; Chen, Y.; Kralevska, K.; Øverby, H. Combining forward error correction and network coding in bufferless networks: A case study for optical packet switching. In Proceedings of the 2016 IEEE 17th International Conference on High Performance Switching and Routing, Yokohama, Japan, 14–17 June 2016; pp. 61–68. [Google Scholar]
- Kralevska, K.; Øverby, H.; Gligoroski, D. Joint balanced source and network coding. In Proceedings of the 2014 22nd Telecommunications Forum Telfor, Belgrade, Serbia, 25–27 November 2014; pp. 589–592. [Google Scholar]
- Zhang, G.; Cai, S.; Zhang, D. The Nonlinear Network Coding and Its Application in Error-Correcting Codes. Wirel. Pers. Commun. 2017. [Google Scholar] [CrossRef]
- Yu, Z.; Wei, Y.; Ramkumar, B.; Guan, Y. An Efficient Signature-Based Scheme for Securing Network Coding Against Pollution Attacks. In Proceedings of the 27th Conference on Infocom Conference on Computer Communications IEEE, Phoenix, AZ, USA, 13–18 April 2008; pp. 1409–1417. [Google Scholar]
- Yang, S.; Yeung, R.W.; Chi, K.N. Refined Coding Bounds and Code Constructions for Coherent Network Error Correction. IEEE Trans. Inf. Theory 2010, 57, 1409–1424. [Google Scholar] [CrossRef]
- Xuan, G.; Fu, F.W.; Zhang, Z. Construction of Network Error Correction Codes in Packet Networks. IEEE Trans. Inf. Theory 2013, 59, 1030–1047. [Google Scholar]
- Matsumoto, R. Construction Algorithm for Network Error-Correcting Codes Attaining the Singleton Bound; Oxford University Press: Oxford, UK, 2007; pp. 1729–1735. [Google Scholar]
- Bahramgiri, H.; Lahouti, F. Robust network coding against path failures. IET Commun. 2010, 4, 272–284. [Google Scholar] [CrossRef]
- Silva, D.; Kschischang, F.R. Using Rank-Metric Codes for Error Correction in Random Network Coding. In Proceedings of the IEEE International Symposium on Information Theory, Nice, France, 24–29 June 2007; pp. 796–800. [Google Scholar]
- Zhang, G.; Cai, S. Secure error-correcting (SEC) schemes for network coding through McEliece cryptosystem. Cluster Comput. 2017. [Google Scholar] [CrossRef]
- Zhang, G.; Cai, S. Universal secure error-correcting (SEC) schemes for network coding via McEliece cryptosystem based on QC-LDPC codes. Cluster Comput. 2017. [Google Scholar] [CrossRef]
- Koetter, R.; Kschischang, F.R. Coding for Errors and Erasures in Random Network Coding. IEEE Trans. Inf. Theory 2007, 54, 3579–3591. [Google Scholar] [CrossRef]
- Lin, F.; Zhou, X.; Zeng, W. Sparse Online Learning for Collaborative Filtering. Int. J. Comput. Commun. Control 2016, 11, 248–258. [Google Scholar] [CrossRef]
- Lin, S.; Lin, F.; Chen, H.; Zeng, W. A MOEA/D-based Multi-objective Optimization Algorithm for Remote Medical. Neurocomputing 2016, 220, 5–16. [Google Scholar] [CrossRef]
- Wright, J.; Ma, Y. Dense error correction via l1-minimization. In Proceedings of the 2009 IEEE International Conference on Acoustics, Speech and Signal Processing, Taipei, Taiwan, 19–24 April 2009; pp. 3033–3036. [Google Scholar]
- Padmanabh, K.; Paul, S.; Kumar, A. On social behavior of wireless sensor node. In Proceedings of the Second International Conference on Communication Systems and Networks, Bangalore, India, 5–9 January 2010; pp. 429–436. [Google Scholar]
- Probst, M.J.; Kasera, S.K. Statistical trust establishment in wireless sensor networks. In Proceedings of the 2007 International Conference on Parallel and Distributed Systems, Hsinchu, Taiwan, 5–7 December 2007; pp. 1–8. [Google Scholar]
- Farrag, M.; Abo-Zahhad, M.; Doss, M.M.; Fayez, J.V. A New Localization Technique for Wireless Sensor Networks Using Social Network Analysis. Arab. J. Sci. Eng. 2017, 42, 1–11. [Google Scholar] [CrossRef]
- Jaggi, S.; Langberg, M.; Katti, S.; Ho, T.; Katabi, D.; Médard, M.; Effros, M. Resilient network coding in the presence of Byzantine adversaries. In Proceedings of the INFOCOM 2007 26th IEEE International Conference on Computer Communications, Anchorage, AK, USA, 6–12 May 2007; pp. 616–624. [Google Scholar]
- Kwon, M.; Park, H.; Frossard, P. Compressed network coding: Overcome all-or-nothing problem in finite fields. In Proceedings of the 2014 IEEE Wireless Communications and Networking Conference, Istanbul, Turkey, 6–9 April 2014; pp. 2851–2856. [Google Scholar]
- Csisz, I. Review of "Information Theory and Network Coding" by Raymond W. Yeung, Springer, 2008; IEEE Press: Piscataway, NJ, USA, 2009; p. 3409. [Google Scholar]
- Koetter, R.; Medard, M. Beyond routing: An algebraic approach to network coding. In Proceedings of the Twenty-First Annual Joint Conference of the IEEE Computer and Communications Societies, New York, NY, USA, 23–27 June 2002; Volume 121, pp. 122–130. [Google Scholar]
- Eritmen, K.; Keskinoz, M. Improving the Performance of Wireless Sensor Networks through Optimized Complex Field Network Coding. IEEE Sens. J. 2015, 15, 2934–2946. [Google Scholar] [CrossRef]
- Chou, P.A.; Wu, Y. Practical Network Coding. In Proceedings of the Allerton Conference on Communication, Control, and Computing, Monticello, IL, USA, 1–3 October 2003. [Google Scholar]
- Wang, M.; Li, B. How Practical is Network Coding? In Proceedings of the 14th IEEE International Workshop on Quality of Service, New Haven, CT, USA, 19–21 June 2006; pp. 274–278. [Google Scholar]
- Jafari, M.; Keller, L.; Fragouli, C.; Argyraki, K. Compressed network coding vectors. In Proceedings of the IEEE International Symposium on Information Theory, Seoul, Korea, 28 June–3 July 2009; pp. 109–113. [Google Scholar]
- Gligoroski, D.; Kralevska, K.; Øverby, H. Minimal header overhead for random linear network coding. In Proceedings of the 2015 IEEE International Conference on Communication Workshop (ICCW), London, UK, 8–12 June 2015. [Google Scholar]
- Soleimani, H.; Tomasin, S.; Alizadeh, T.; Shojafar, M. Cluster-head based feedback for simplified time reversal prefiltering in ultra-wideband systems. Phys. Commun. 2017, 25, 100–109. [Google Scholar] [CrossRef]
- Javanmardi, S.; Shojafar, M.; Shariatmadari, S.; Ahrabi, S.S. FRTRUST: A fuzzy reputation based model for trust management in semantic P2P grids. Int. J. Grid Util. Comput. 2014, 6, 57–66. [Google Scholar] [CrossRef]
- Fast l-1 Minimization Algorithms: Homotopy and Augmented Lagrangian Method. Available online: https://people.eecs.berkeley.edu/~yang/software/l1benchmark/ (accessed on 31 January 2018).
- Pompili, D.; Melodia, T.; Akyildiz, I.F. Distributed Routing Algorithms for Underwater Acoustic Sensor Networks. IEEE Trans. Wirel. Commun. 2010, 9, 2934–2944. [Google Scholar] [CrossRef]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Definition |
|---|---|
| m | The number of rows of coding matrix |
| n | The number of columns of coding matrix |
| 0 norm | |
| ϑ | The fraction of messages sent by the secret channel |
| Algorithm | Time (s) |
|---|---|
| LDPC | 0.7527 |
| Our | 0.6285 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, G.; Cai, S.; Xiong, N. The Application of Social Characteristic and L1 Optimization in the Error Correction for Network Coding in Wireless Sensor Networks. Sensors 2018, 18, 450. https://doi.org/10.3390/s18020450
Zhang G, Cai S, Xiong N. The Application of Social Characteristic and L1 Optimization in the Error Correction for Network Coding in Wireless Sensor Networks. Sensors. 2018; 18(2):450. https://doi.org/10.3390/s18020450
Chicago/Turabian StyleZhang, Guangzhi, Shaobin Cai, and Naixue Xiong. 2018. "The Application of Social Characteristic and L1 Optimization in the Error Correction for Network Coding in Wireless Sensor Networks" Sensors 18, no. 2: 450. https://doi.org/10.3390/s18020450
APA StyleZhang, G., Cai, S., & Xiong, N. (2018). The Application of Social Characteristic and L1 Optimization in the Error Correction for Network Coding in Wireless Sensor Networks. Sensors, 18(2), 450. https://doi.org/10.3390/s18020450