1. Introduction
Nowadays, governmental authorities monitor air pollutants by using a limited number of measurement stations because of the high cost of these instruments, their maintenance, and their cumbersome nature [
1]. Within the low spatial resolution given by these stations of air quality monitoring, the data are combined with some modeling software in order to estimate the average pollution in urban areas. However, the dispersion of pollution is a very complex phenomenon that is highly affected by environmental factors and the urban structure. Therefore, densifying the network of air pollution monitoring to get a high spatial and also temporal resolution is a real necessity [
2,
3].
Due to technological advances, low cost sensors are now able to measure very low pollutant gas concentrations (parts per billion, ppb), which make them promising solutions to cope with the low resolution of the currently implemented air pollution monitoring networks [
4,
5,
6]. During recent years, many studies have revealed that electrochemical and metal oxide gas sensors (MOX) can perform at a ppb level of concentration [
7]. Metal oxide gas sensors tend to have higher sensitivity but suffer from the lack of reproducibility and stability. Electrochemical sensors present better stability and selectivity but have a short lifetime [
8]. The major difficulties of low cost gas sensors as reviewed in the literature can be summarized in two aspects [
9]:
Those related to the working principle of the sensors such as the dynamic boundaries, systematic errors, non-linear responses and signal drifts.
Those caused by external error sources, such as environmental dependencies and low selectivity.
To overcome these limitations, one can use a system called an electronic nose made up of a sensors array associated with machine learning algorithms [
10]. Using an electronic nose allows the exploitation of all the information from its sensors, including the cross-sensitivity and interference from environmental factors, to create a calibration model able to successfully predict pollutant concentrations [
11]. After the establishment of this initial calibration model, the other issues limiting the use of electronic noses are related to sensor response changes after a certain period of time or after sensor replacement. Consequently, the current calibration model becomes invalid and a new one must be generated [
12]. Each of the units should also be calibrated individually due to poor reproducibility in the sensors fabrication process [
13].
Techniques such as calibration transfer are an attractive solution to extend the lifetime of the calibration model by allowing the use of one calibration model for different units. Calibration transfer first appeared in the spectroscopy domain and has since been extended to the gas sensors array [
14]. Before presenting transfer calibration techniques, we consider that the transfer calibration is performed between two units, respectively called the master unit and the slave unit. The slave unit may be a different unit identical to the master unit, or it may be the master unit itself over time. Calibration transfer techniques can be divided into two categories. The first one is based on removing the dissimilarity between the master and the slave units by transforming sensor responses of both units to become more similar before creating a calibration model. Among the methods that use this technique, we can cite Orthogonal Signal Correction (OSC) [
15], Component Correction (CC) [
16] and Generalized Least Squares Weighting (GLSW) [
17]. The second category attempts to modify the data of the slave unit to be similar to that of the master unit. These techniques allow the use of the calibration model of the master unit for the data of the slave unit. This family of calibration transfer, called standardization methods, can be classified into three classes according to their strategies [
18]:
Standardization of the model coefficients: consists of modifying the calibration model, which is built on the master unit so as to be suitable for data from the slave unit.
Standardization of the sensors’ responses: based on transforming the sensors’ responses of the slave unit to be similar to those of the master unit. The calibration model of the master unit then becomes usable for the slave unit.
Standardization of the predicted values: the predictive values from the slave unit are corrected using a linear relationship calculated between predictive values of the master and the slave units. All standardization methods need a set of known samples from both units (slave and master) that allows matching between them.
The choice among standardization methods depends on the application itself, whether it is a simple or complex system [
18]. However, standardization of sensors response methods such as direct standardization (DS) [
19] and piece wise direct standardization (PDS) [
20] are the most popular.
In this work, we focused on DS and we proposed to use the kernel SPXY (sample set partitioning based on joint x-y distances) algorithm for selecting standardization samples. We also utilized the support vector machine regression (SVM) instead of the classical transformation matrix to make the calibration transfer. For this purpose, we considered the case of two identical systems exposed to the same gas concentrations under the same conditions. The rest of this paper is organized as follows: in
Section 2 we describe the experiment setup and data collection process performed in the laboratory. In
Section 3, we introduce the methods and algorithms used to make the calibration transfer. We compared the performance of our method with the performance of existing classical direct standardization method in
Section 4. Finally, a conclusion of this work and further directions are given in
Section 5.
2. Experiment Setup and Data Collection
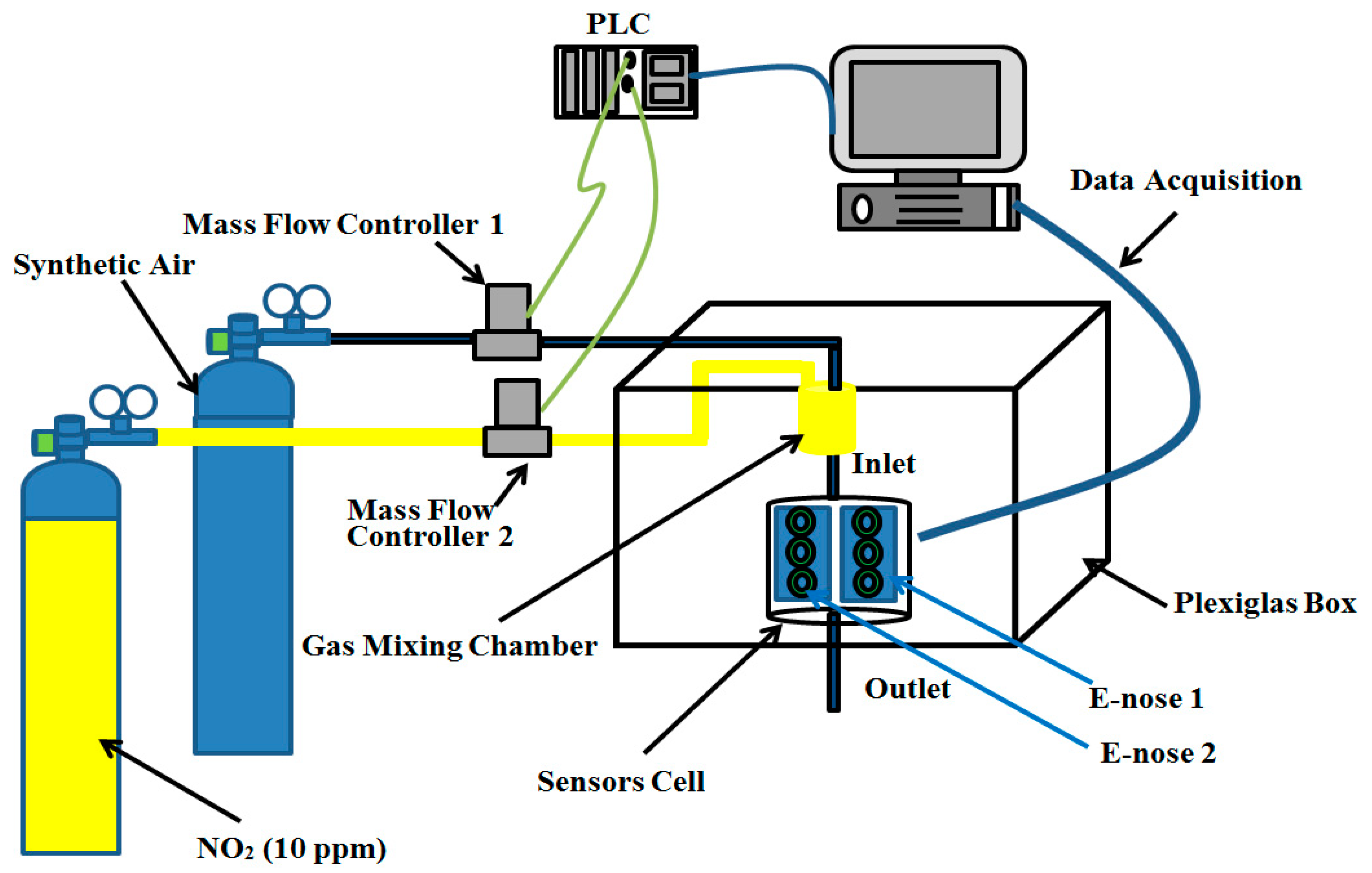
We have designed two identical E-noses for nitrogen dioxide (NO
2) monitoring. Each one was made up of three gas sensors, an electrochemical sensor (NO2-B43F from Alphasense, Essex, UK), and two MOX sensors (MICS-2714 from SGX Sensortech, Corcelles-Cormondreche, Switzerland and GGS7530 from UST Umweltsensortechnik, Geschwenda, Germany). We used a homemade diffuser system to control and generate different concentrations of NO
2 in pure air (
Figure 1). Two mass flow controllers were used to monitor the flow of the pure air and nitrogen dioxide cylinders. The total flowrate was set to 400 mL/min and we could generate different concentrations by varying the percentage of nitrogen dioxide flow over the total flow. The nitrogen dioxide cylinder had a dilution of 10 ppm (parts per million). Therefore, to generate 250 ppb, we had to dilute 10 mL/min of nitrogen dioxide in 390 mL/min of pure air. Nitrogen dioxide and pure air were first introduced in a gas-mixing chamber to ensure the homogeneity of the gas before crossing to the sensors cell which contained two identical electronic noses. We collected 508 measurements. Each measurement took 300 s to reach the steady state response of all sensors. The 508 measurements were distributed between different concentrations of NO
2 ranging from 25 ppb to 250 ppb, with a step of 25 ppb in order to simulate the real pollution rates found near highways. The collected data were organized in two matrices:
for unit 1 and
for unit 2. Their corresponding known concentration was grouped in
:
where
= 508 represents number of samples and
= 900 is the dimension of samples composed from 300 data points for each of the three sensors.
3. Calibration Transfer
Before introducing our proposal method, let us first present the DS method. We considered
and
to be the data matrices of the master unit and the slave unit, respectively, where
is the number of samples and
is the dimension of a sample. To match between these two units, we needed to select a subset of samples from both of them.
and
were the response matrices containing
samples selected respectively from each of
and
. The classical DS was based on using the transformation matrix
F given by:
where
is the generalized or pseudo-inverse of
.
Data from the slave unit can be standardized as:
Once the data from the slave unit was standardized, concentrations could be predicted using the calibration model of the master unit. Direct standardization was based on two essential elements:
An algorithm that can select the standardization samples in a way to be as representative as possible of the entire dataset.
A technique that can match the two units with a fewer number of standardization samples.
In our proposal method, we used kernel SPXY to select the standardization samples and we replaced the matrix transformation by applying SVM regression between and .
3.1. Kernel SPXY
All data selection algorithms used the same principle and were based on calculating the distance between samples. The algorithms started by taking the pair
of samples that had the largest distance
. To select a new sample, the distances of all the remaining samples with respect to all samples already selected were calculated. For each sample, these algorithms kept their minimum distance regarding other selected samples. The sample to be selected should then have the maximum distance. These algorithms stopped when they achieved the desired number of samples to be selected. The only difference between these algorithms was in their manner of calculating the distance between samples. The Kennard-Stone algorithm uses the Euclidian distance and is given by:
where
are samples and
is the dimension.
SPXY algorithms take in consideration not only data response but also target values (concentrations) to calculate the distance between two samples:
The kernel SPXY algorithm is a modified version of the SPXY algorithm in which the Euclidian distance of the SPXY algorithm is replace by a kernel distance (
) given by:
where
and
For further details about kernel SPXY, the reader can refer to Gani et al. [
21] in which the authors concluded that kernel SPXY algorithm performs better than the SPXY and Kennard-Stone algorithms.
3.2. Support Vector Machine Regression
Support vector machine regression is a machine learning method widely used for building calibration models [
22]. Its structure guarantees a good generalization and accuracy with a limited number of learning samples [
23]. Support vector machine establishes a linear regression function between dataset
and the target values
as follows:
where
w is the regression coefficients vector and
is the bias term.
In order to calculate the regression coefficients, SVM regression attempts to minimize the loss function as defined by:
where
is the maximum difference between the predicted value and the target value that can be neglected.
In order to simultaneously minimize the empirical risk and model complexity, support vector machine regression was formulated as an optimization problem with constraints:
where
is a constant regularization parameter which determines the tradeoff between the flatness of
and the empirical risk.
are slack variables which measure deviations larger than
.
Using Lagrange multipliers and the Karush-Kuhn-Tucker conditions, we can get the following solution:
where
and
are the Lagrange multipliers and
constitutes the kernel function. The kernel function used in this work was the Gaussian kernel defined as follows:
where
is the standard deviation of the kernel.
In any machine learning, the results depend on a good choice of their hyperparameters. For this work, we used the generalized pattern search (GPS) [
24] to optimize SVM regression hyperparameters by minimizing the cross validation prediction error. The parameters considered were:
Figure 2 summarizes our procedure for calibration transfer. We used kernel SPXY to select the desired number of standardization samples from the dataset of the master unit (E-nose 1). The remaining data were used to build a model calibration using SVM regression. Support vector machine regression hyperparameters were optimized using generalized pattern search (GPS). Next, from the slave unit (E-nose 2), we selected the analogue samples of the selected samples from the master unit. SVM regression was used again to create another model used to standardize data from the slave unit. Finally, we could predict concentration using the model calibration built on the master unit with data from the slave unit.
4. Results and Discussion
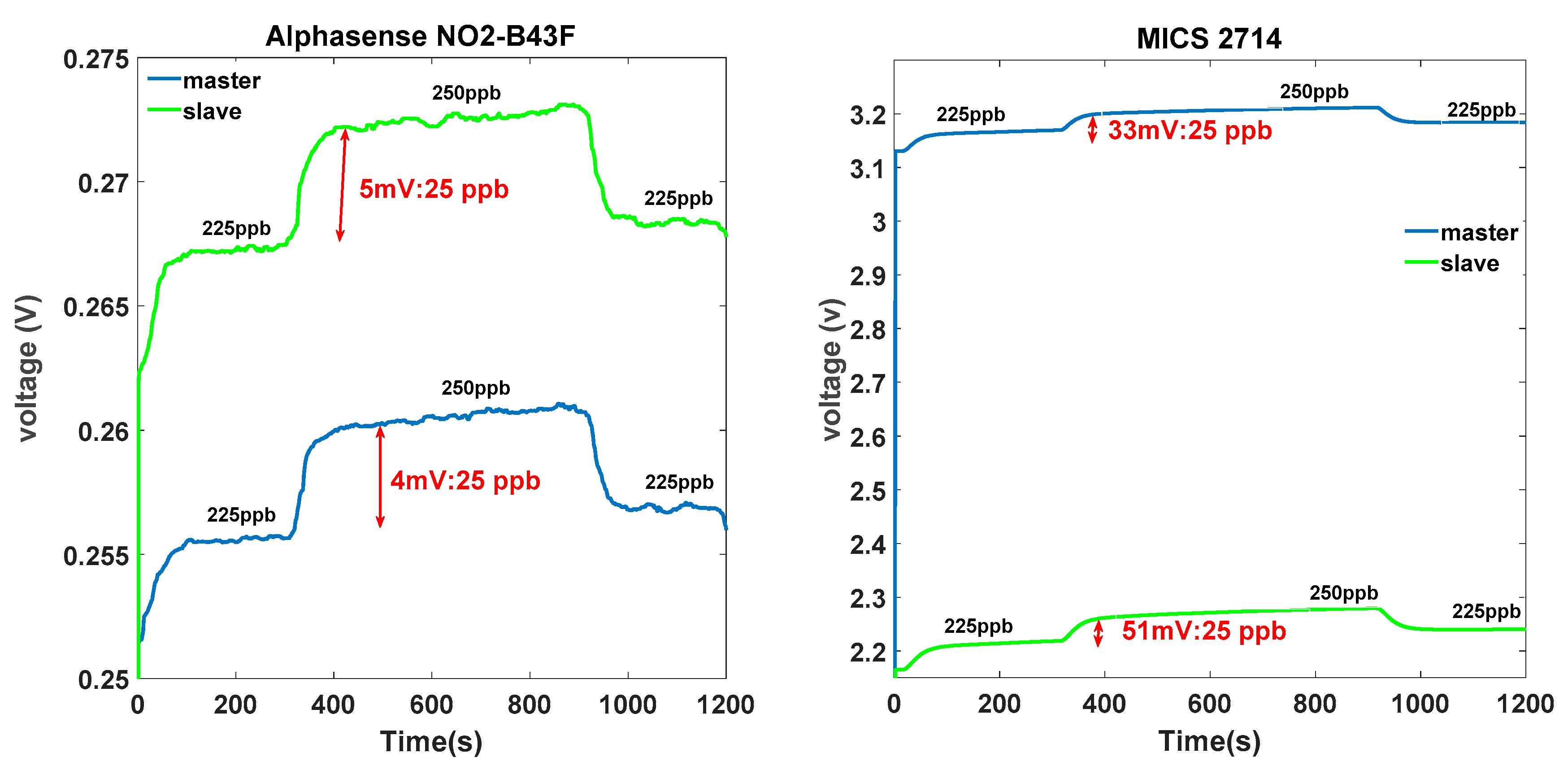
Signal responses acquired from two identical electronic noses exposed to the same gas concentration under the same conditions were different in terms of sensitivity and baseline.
Figure 3 presents the signal acquired from NO2-B43F Alphasense sensors and MICS-2714 sensors of the master unit and the slave unit. Even if the master and the slave units have undergone the same history of use, the signals collected from the same sensor type differed in terms of baseline and sensitivity. For example, concerning the baseline between the two electrochemical sensors, we observed a shift of about 12 mV, which can correspond to 75 ppb of NO
2. Additionally, for the two MOX sensors, the difference in baseline was very important. This considerable shift in MOX sensors may have been due to the large resistance margin of the initial resistor provided by the constructor (the initial resistor of GGS 7530 was 50 kΩ ± 35 kΩ). Concerning the sensitivity, we used a numerical indicator in
Figure 3 to indicate the variation because of the very low signal scale. For example, in the case of the MICS-2714 sensors, the sensor sensitivities were 33 mV and 51 mV, respectively, for 25 ppb of NO
2. This slight difference in terms of sensitivity could significantly deviate the NO
2 estimation with regard to the very low concentration range (0–250 ppb). As a consequence, any model built on E-nose 1 could not be useful for E-nose 2.
To show the ability of the proposed method to create a match between the sensor responses of a master unit and a slave unit, we used principal component analysis (PCA) projection. We plotted the first two PCA components of all the data obtained from the master and the slave units before and after the standardization.
Figure 4 shows that the data from each unit are gathered in different regions. By the use of only 10 samples for standardization, the data from the slave unit were shifted to the region of the master unit and they became more alike.
Our method was compared with the classical Direct Standardization. First, we built a calibration model on the master unit using SVM regression. Then, we used kernel SPXY to select a number of standardization samples. After standardization of the slave unit data, we used the calibration model built on the master unit to predict NO
2 concentrations. We repeated this procedure 60 times by adding in one sample for standardization each time. We determined the root mean square error prediction using 10-fold cross validation. In
Figure 5, we show that our method outperformed the classical DS. This method needed 10 samples to reach a prediction accuracy around 8.7 ppb while the classical DS method needed a least 30 samples to reach a stable and acceptable accuracy.
The aim of any calibration transfer method is to preserve time and prevent the high cost of a new calibration. In fact, if the standardization procedure needed as many samples as the master unit to build a new model for the slave unit, it is not useful for making the calibration transfer, and it would be better to calibrate each unit individually. So, we tested whether the number of samples used for standardization was enough to build a new calibration model directly on the slave unit. We used the same selected standardization samples to directly build a new calibration model on the slave unit. We started the operation from one sample to 60 samples by adding in one sample each time. In each time, we calculated the root mean square error prediction of 10-fold cross validation in the two cases: in the case of using the samples selected for standardization and in the case of using these samples to build a new calibration model on the slave unit. In
Figure 6, we plotted the evolution of the error prediction along with the number of samples. The figure shows that building a new calibration model needed a least 60 samples to obtain an acceptable prediction accuracy.
Figure 7 shows the predicted concentrations as a function of the real concentrations. The predicted values were obtained using a calibration model built on the master unit and the standardized data from the slave unit with 10 samples used for standardization. The estimated values and the real values were almost superposed. This was numerically confirmed by calculating the root mean square error prediction of 10-fold cross validation, which was equal to 8.7 ppb.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}






