1. Introduction
With the development of the modern robotics, compliance control is becoming an important component for industrial robots. Control of contact force is crucial for successfully executing operational tasks that involve physical contacts, such as grinding, deburring, or assembly. In the structured environment, good performances could be achieved using classical force control methods [
1]. However, it is difficult to control the contact force effectively in the unstructured environment. Impedance control [
2] provides a suitable control architecture for robots in both unconstrained and constrained motions by establishing a suitable mass-spring-damper system.
Neuroscience studies have demonstrated how humans perform specific tasks by adapting muscle stiffness [
3]. Kieboom [
4] studied the impedance regulation rule for bipedal locomotion and found that variable impedance control can improve gait quality and reduce energy expenditure. The ability to task-dependently change the impedance is one important aspect of biomechanical systems that leads to its good performance. Recently, many researchers have explored the benefits of varying the impedance during the task for robotics [
5,
6,
7,
8,
9]. The basic idea is to adjust the impedance parameters according to the force feedback. Humanlike adaptivity was achieved in [
9] by adapting force and impedance, providing an intuitive solution for human-robot interactions. Considering ensuring safe interaction, Calinon [
6] proposed a learning-based control strategy with variable stiffness to reproduce the skill characteristics. Kronander [
10] has demonstrated the stability of variable impedance control for the control system. Variable impedance not only enables control of the dynamic relationship between contact forces and robot movements, but also enhances the flexibility of the control system. Generally, the methods of specifying the varying impedance can be classified into three categories.
(1) Optimal control. The basic idea is to dynamically adjust the gains by the feedback information using optimization techniques. They are usually robust to uncertain systems. Medina [
11] proposed a variable compliance control approach based on risk-sensitive optimal feedback control. This approach has the benefits of high adaptability to uncertain and variable environment. The joint torque and the joint stiffness are independently and optimally modulated using the optimal variable stiffness control in [
12]. Adaptive variable impedance control is proposed in [
13], it stabilizes the system by adjusting the gains online according to the force feedback. To guarantee stable execution of variable impedance tasks, a tank-based approach to passive varying stiffness is proposed in [
14].
(2) Imitation of human impedance. Humans have a perfect ability to complete a variety of interaction tasks in various environments by adapting their biomechanical impedance characteristics. These excellent abilities are developed over years of experience and stored in the central nervous system [
15]. For the purpose of imitating the human impedance modulation manner, some methods have been proposed [
6,
8]. Toshi [
16] discussed the impedance regulation law of the human hand during dynamic-contact tasks and proposed a bio-mimetic impedance control for robot. Lee [
17] designed a variable stiffness control scheme imitating human control characteristics, and it achieved force tracking by adjusting the target stiffness without estimating the environment stiffness. Yang [
18] introduced a coupling interface to naturally transfer human impedance adaptive skill to the robot by demonstration. Kronander [
19] and Li [
20] addressed the problem of compliance adjusting in a robot learning from demonstrations (RLfD), in which a robot could learn to adapt the stiffness based on human–robot interaction. Yang [
21] proposed a framework for learning and generalizing humanlike variable impedance skills, combining the merits of the electromyographic (EMG) and dynamic movement primitives (DMP) model. To enhance the control performance, the problem of transferring human impedance behaviors to the robot has been studied in [
22,
23,
24]. These methods usually use the EMG device to collect the muscle activities information, based on which variation of human limb impedance can be estimated.
(3) Reinforcement learning (RL). Reinforcement learning constitutes a significant aspect of the artificial intelligence field with numerous applications ranging from medicine to robotics [
25,
26]. Researchers have recently focused on learning an appropriate modulation strategy by means of RL to adjust the impedance characteristic of robot [
7,
27,
28,
29]. Du [
30] proposed a variable admittance control method based on fuzzy RL for human–robot interaction. It improves the positioning accuracy and reduces the required energy by dynamically regulating the virtual damping. Li [
31] proposed an BLF-based adaptive impedance control framework for a human–robot cooperation task. The impedance parameters were learned using the integral RL to get adaptive robot behaviors.
In summary, to derive an effective variable impedance controller, the first category and the second category of methods usually need advanced engineering knowledge about the robot and the task, as well as designing these parameters. Learning variable impedance control based on RL is a promising and powerful method, which can get the proper task-specific control strategy automatically through trial-and-error. RL algorithms can be broadly classified as two types: model-free and model-based. In model-free RL, policy is found without even building a model of the dynamics, and the policy parameters can be searched directly. However, for each sampled trajectory, it is necessary to interact with the robot, which is time-consuming and expensive. In model-based RL, the algorithm explicitly builds a transition model of the system, which is then used for internal simulations and predictions. The (local) optimal policy is improved based on the evaluations of these internal simulations. The model-based RL is more data-efficient than the model-free RL, but more computationally intensive [
32,
33]. In order to extend to high-dimensional tasks conveniently and avoid the model-bias of model-based RL algorithm, the existing learning variable impedance control methods are most commonly based on a model-free RL algorithm. Buchli [
5] proposed a novel variable impedance control based on PI
2, which is a model-free RL algorithm. It realized simultaneous regulation of motion trajectory and impedance gains using DMPs. This algorithm has been successfully extended to high-dimensional robotic tasks such as opening door, picking up pens [
34], box flipping task [
35] and sliding switch task for tendon-driven hand [
36]. Stulp [
29] further studied the applicability of PI
2 in stochastic force field, and it was able to find motor policies that qualitatively replicate human movement. Considering the coupling between degrees of freedom (DoFs), Winter [
37] developed a C-PI
2 algorithm based on PI
2. Its learning speed was much higher than that of previous algorithms.
However, these methods usually require hundreds or thousands of rollouts to achieve satisfactory performance, which is unexpected for a force control system. None of these works address the issue of sampling efficiency. Improving data-efficiency is critical to learning to perform force-sensitive tasks, such as operational tasks of fragile components, because too many physical interactions with the environment during the learning process is usually infeasible. Alternatively, model-based RL is a promising way to improve the sampling efficiency. Fast convergence towards an optimal strategy could be guaranteed. Shadmehr [
38] demonstrated that humans learn an internal model of the force field and compensate for external perturbations. Franklin [
39] presented a model which combines three principles to learn stable, accurate, and efficient movements. It is able to accurately model empirical data gathered in force field experiments. Koropouli [
27] investigated the generalization problem of force control policy. The force-motion mapping policy was learned from a set of demonstrated data to endow robots with certain human-like adroitness. Mitrovic [
28] proposed to learn both the dynamics and the noise properties through supervised learning, using locally weighted projection regression. This model was then used in a model-based stochastic optimal controller to control a one-dimensional antagonistic actuator. It improved the accuracy performance significantly, but the analytical dynamic model still had accuracy limitations. These methods did not solve the key problem of model bias well.
Therefore, in order to improve the sampling efficiency, we propose a data-efficient learning variable impedance control method based on model-based RL that enables the industrial robots to automatically learn to control the contact force in the unstructured environment. A probabilistic Gaussian process (GP) model is approximated as a faithful proxy of the transition dynamics of the system. Then the probabilistic model is used for internal system simulation to improve the data-efficiency by predicting the long-term state evolution. This method reduces the effects of model-bias effectively by incorporating model uncertainty into long-term planning. The impedance profiles are regulated automatically according to the (sub)optimal impedance control strategy learned by the model-based RL algorithm to track the desired contact force. Additionally, we present a way of taking the penalty of control actions into account during planning to achieve the desired impedance characteristics. The performances of the system are verified through simulations and experiments on a six-DoF industrial manipulator. This system outperforms other learning variable impedance control methods by at least one order of magnitude in terms of learning speed.
The main contributions of this paper can be summarized as follows: (1) A data-efficient learning variable impedance control method is proposed to improve the sampling efficiency, which could significantly reduce the required physical interactions with environment during force control learning process. (2) The proposed method learns an impedance regulation strategy, based on which the impedance profiles are regulated online in a real-time manner to track the desired contact force. In this way, the flexibility and adaptivity of compliance control could be enhanced. (3) The impedance strategy with humanlike impedance characteristics is learned automatically through continuous explorations. There is no need to use additional sampling devices, such as EMG electrodes, to transfer human skills to the robot through demonstrations.
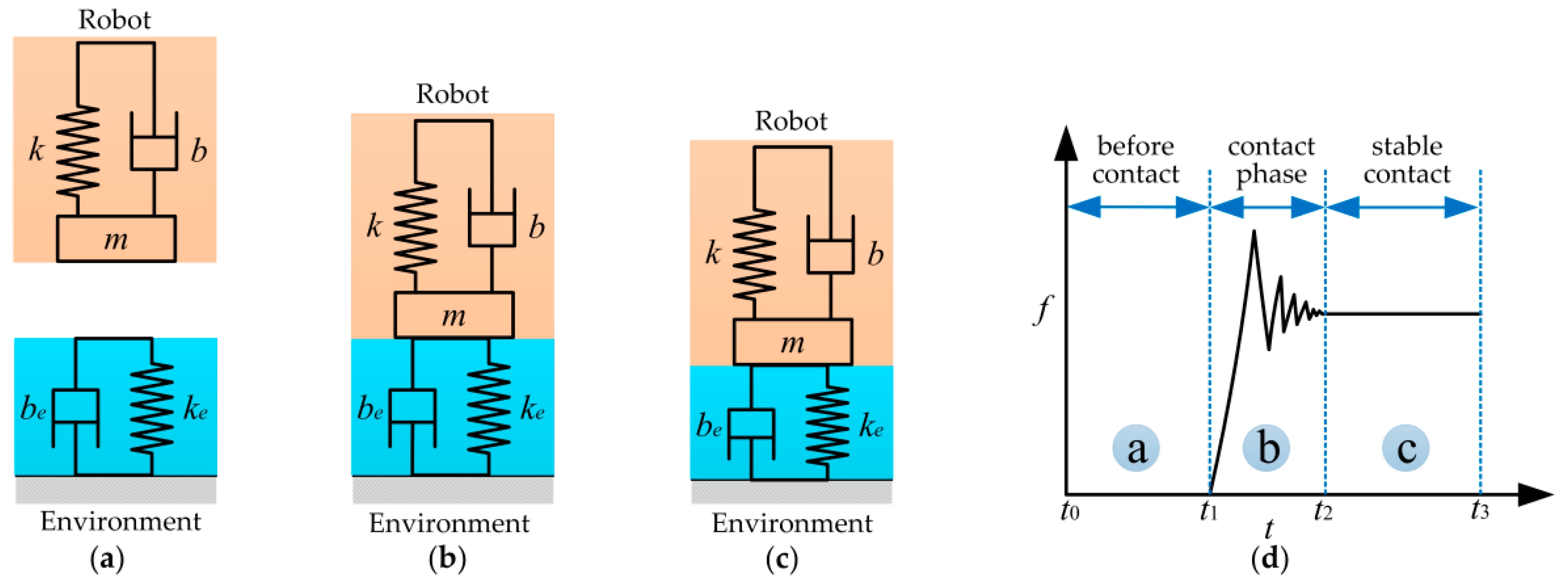
3. Position-Based Impedance Control for Force Control
One possible approach to achieve compliant behavior for robotics is the classical impedance control [
2], which sometimes is also called force-based impedance control. In typical implementations, the controller has the positions as inputs and gives the motor torques as outputs. Force-based impedance control has been widely studied [
44]. However, most commercial industrial robots emphasize the accuracy of trajectory following, and do not provide joint torque or motor current interfaces for users. Therefore, force-based impedance control is impossible on these robots.
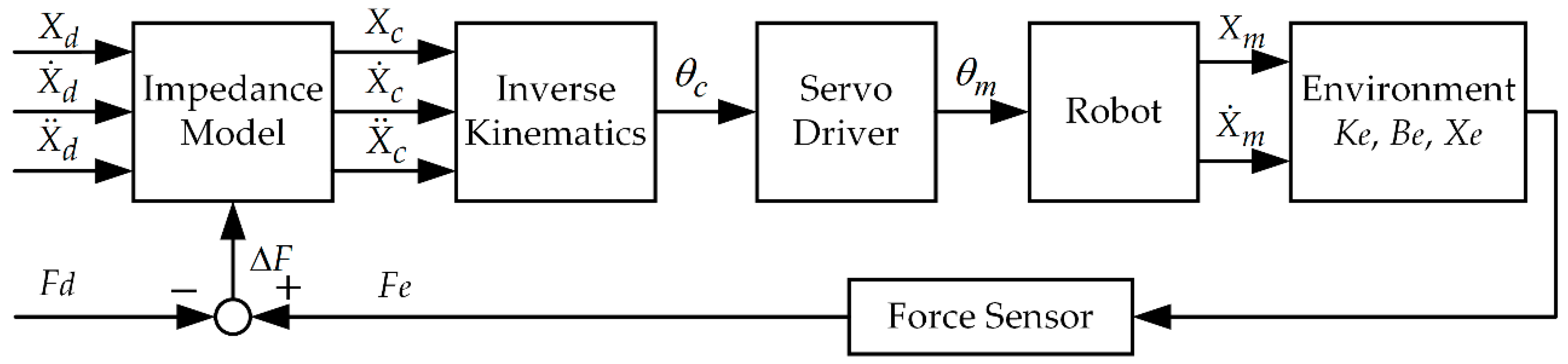
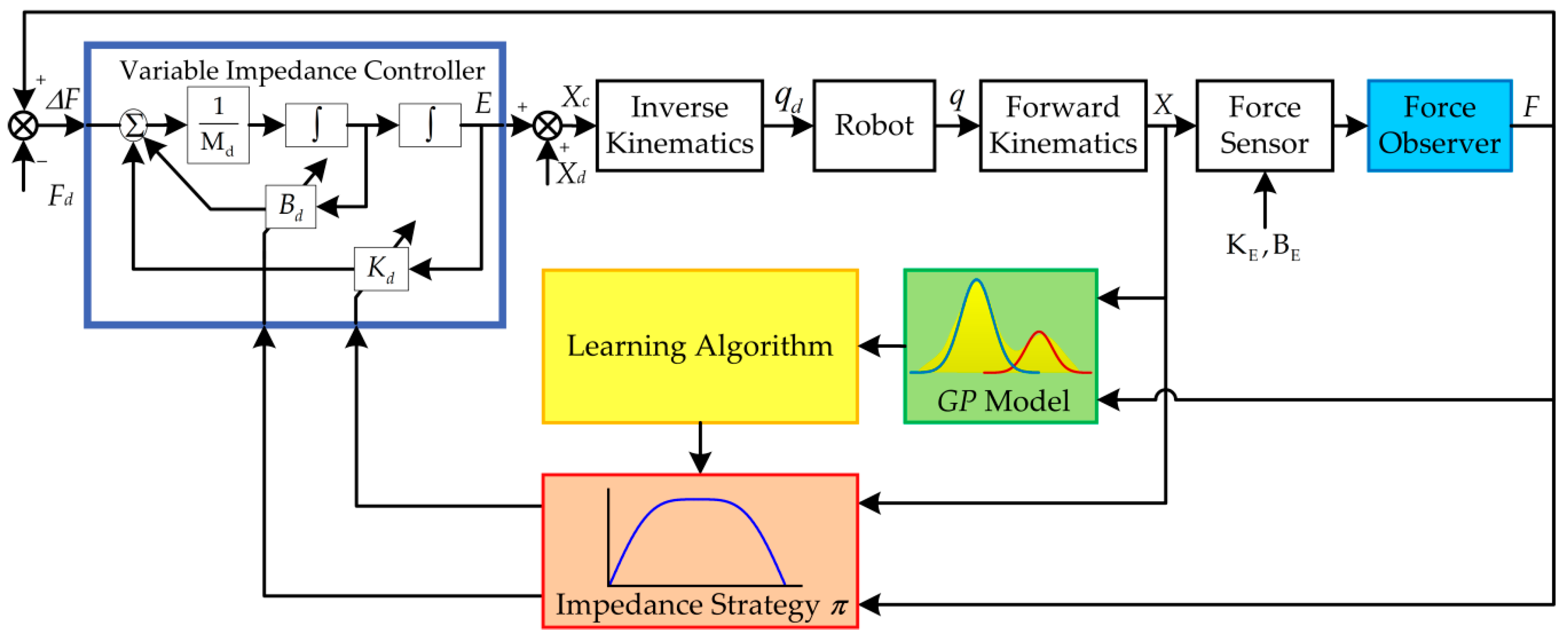
Alternatively, another possible approach, which is typically suited for industrial robots, is the concept of admittance control [
45], sometimes also called position-based impedance control. It maps from generalized forces to generalized positions. This control structure consists of an inner position control loop and an outer indirect force control loop. In constrained motion, the contact force measured by the F/T sensor modifies the desired trajectory in the outer impedance controller loop resulting in the compliant desired trajectory, which is to be tracked by the inner position controller. The position-based impedance control schematic for force control is shown in
Figure 4.
,
, and
denote the reference position trajectory, the commanded position trajectory which is sent to the robot, and the measured position trajectory, respectively. Assuming good tracking performance of the inner position controller for slow motions, the commanded trajectory is equal to the measured trajectory, i.e.,
.
Typically, the impedance model is chosen as a linear second order system
where
,
, and
are, respectively, the target inertial, damping, and stiffness matrices.
is the desired contact force.
is the actual contact force. The transfer-function of the impedance model is
where
denotes the force tracking error.
is the desired position increment, and it is used to modify the reference position trajectory
to produce the commanded trajectory
, which is then tracked by the servo driver system.
To compute the desired position increment, discretize (9) using bilinear transformation
Here,
is the control cycle. The desired position increment at time
is derived as
The environment is assumed to be a spring-damping model with stiffness
and damping
.
is the location of the environment. The contact force between the robot and the environment is then simplified as
Replacing
in (8) with the initial environment location
, and substituting (13) into (8), the new impedance equation is then converted to
Due to the fact that it is difficult to obtain accurate environment information. Therefore, if the environment stiffness and damping change, the dynamic characteristics of the system will change consequently. To guarantee the dynamic performance, the impedance parameters should be adjusted correspondingly.
4. Data-Efficient Learning Variable Impedance Control with Model-Based RL
Generally, too many physical interactions with the environment are infeasible for learning to execute force-sensitive tasks. In order to reduce the required interactions with the environment during force control learning process, a learning variable impedance control approach with model-based RL algorithm is proposed in the following to learn the impedance regulation strategy.
4.1. Scheme of the Data-Efficient Learning Variable Impedance Control
The scheme of the method is illustrated in
Figure 5.
is the desired value of contact force,
is the actual contact force estimated by the force observer, and
is the force tracking error. The desired position increment of the end-effector
is calculated using the variable impedance controller.
is the desired reference trajectory. The desired joints positions
are calculated by adopting inverse kinematics according to the commanded trajectory
. The actual Cartesian position of the end-effector
could be achieved using the measured joints positions
by means of forward kinematics. The joints are controlled by the joint motion controller of the industrial robot.
and
denote the unknown stiffness and damping of the environment, respectively.
The transition dynamics of the system is approximated by the GP model which is trained using the collected data. Then the learning algorithm is used to learn the (sub)optimal impedance control strategy
while predicting the system evolution using the GP model. Instead of the motion trajectory, the proposed method learns an impedance regulation strategy, based on which the impedance profiles are regulated online in a real-time manner to control the contact force. In this way, the dynamic relationship between contact force and robot movement could be controlled in a continuous manner. Moreover, the flexibility and adaptivity for compliance control could be enhanced. Positive definite impedance parameters could ensure the asymptotic stability of the original desired dynamics, but it is not recommended to modify the target inertia matrix because it is easy to cause the system to instability [
45]. To simplify the calculation, the target inertial matrix is chosen as
. Consequently, the target stiffness
and the damping
are the parameters that should be tuned in variable impedance control. Based on the learned impedance strategy, the impedance parameters
are calculated according to the states of the contact force and the position of the end-effector, which are then transferred to the variable impedance controller.
The learning process of variable impedance strategy consists of seven main steps:
Initializing the strategy parameters stochastically, applying the random impedance parameters to the system and recording the sampled data.
Training the system transition dynamics, i.e., the GP model, using all historical data.
Inferring and predicting the long-term evolution of the states according to the GP model.
Evaluating the total expected cost in steps, and calculating the gradients of the cost with respect to the strategy parameters .
Learning the optimal strategy using the gradient-based policy search algorithm.
Applying the impedance strategy to the system, then executing a force tracking task using the learned variable impedance strategy and recording the sampled data simultaneously.
Repeating steps (2)–(6) until the performance of force control is satisfactory.
4.2. Variable Impedance Strategy
The impedance control strategy is defined as
, where the inputs of the strategy are the observed states of the robot
, the outputs of the strategy are target stiffness
Kd and damping
Bd which can be written as matrix
, and
are the strategy parameters that to be learned. Here, the GP controller is chosen as the control strategy
where
is the test input.
are the training inputs, and they are the centers of the Gaussian basis functions.
n is the number of the basis functions.
is the training targets, which are initialized to values close to zero.
K is the covariance matrix with entries
.
is the length-scale matrix where
is the characteristic length-scale of each input dimension,
is the signal variance, which is fixed to one here,
is the measurement noise variance, and
is the hyper-parameters of the controller. Using the GP controller, more advanced nonlinear tasks could be performed thanks for its flexibility and smoothing effect. Obviously, the GP controller is functionally equivalent to a regularized RBF network if
and
. The impedance parameters are calculated in real-time according to the impedance strategy
and the states
. The relationship between the impedance parameters and the control strategy can be written as
In practical systems, the physical limits of the impedance parameters should be considered. The preliminary strategy
should be squashed coherently through a bounded and differentiable saturation function. The saturation function has to be on a finite interval, such that a maximum and minimum are obtained for finite function inputs. Furthermore, the function should be monotonically increasing. The derivative and second derivative of the saturation function have to be zero at the boundary points to require stationary points at these boundaries. Specifically, consider the third-order Fourier series expansion of a trapezoidal wave
, which is normalized to the interval [−1, 1]. Given the boundary conditions, the saturation function is defined as
If the function is considered on the domain , the function is monotonically increasing, and the control signal u is squashed to the interval .
4.3. Probabilistic Gaussian Process Model
Transition models have a large impact on the performance of model-based RL, since the learned strategy inherently relies on the quality of the learned forward model, which essentially serves as a simulator of the system. The transition models that have been employed for model-based RL can be classified into two main categories [
25]: the deterministic models and the stochastic models. Despite the intensive computation, the state-of-the-art approach for learning the transition models is the GP model [
46], because it is capable of modeling a wide spread of nonlinear systems by explicitly incorporating model uncertainty into long-term planning, which is a key problem in model-based learning. In addition, the GP model shows good convergence properties which are necessary for implementation of the algorithm. A GP model can be thought as a probabilistic distribution over possible functions, and it is completely specified by a mean function
and a positive semi-definite covariance function
, also called a kernel.
Here, we consider the unknown function that describes the system dynamics
with continuous state inputs
, control inputs
, training targets
, unknown transition dynamics
, and i.i.d. system noise
. In order to take the model uncertainties into account during prediction and planning, the proposed approach does not make a certainty equivalence assumption on the learned model. Instead, it learns a probabilistic GP model and infers the posterior distribution over plausible function
from the observations. For computation convenience, we consider a prior mean
and the squared exponential kernel
where
is the variance of the latent function
, the weighting matrix
depends on the different characteristic length-scale
of each input dimension. Given
training inputs
and corresponding training targets
, the GP hyper-parameters
could be learned using evidence maximization algorithm [
46].
Given a deterministic test input
, the posterior prediction
of the function value
is Gaussian distributed
where
, and
is the kernel matrix.
In our force control learning system, the function of the GP model is defined as ,, where is the training input tuples. Take the state increments as training targets, where is i.i.d. measurement noise. Since the state differences vary less than the absolute values, the underlying function that describes these differences varies less. Therefore, it implies that the learning process is easier and that less data is needed to find an accurate model. Moreover, when the predictions leave the training set, the prediction will not fall back to zero but remain constant.
4.4. Approximate Prediction for Strategy Evaluation
For the sake of reducing the required physical interactions with the robots while getting an effective control strategy, the effective utilization of sampled data must be increased. To this end, the learned probabilistic GP model is used as the faithfully dynamics of the system, which is then used for internal simulations and predictions about how the real system would behave. The (sub)optimal strategy is improved based on the evaluations of these internal virtual trials. Thus, the data-efficiency is improved.
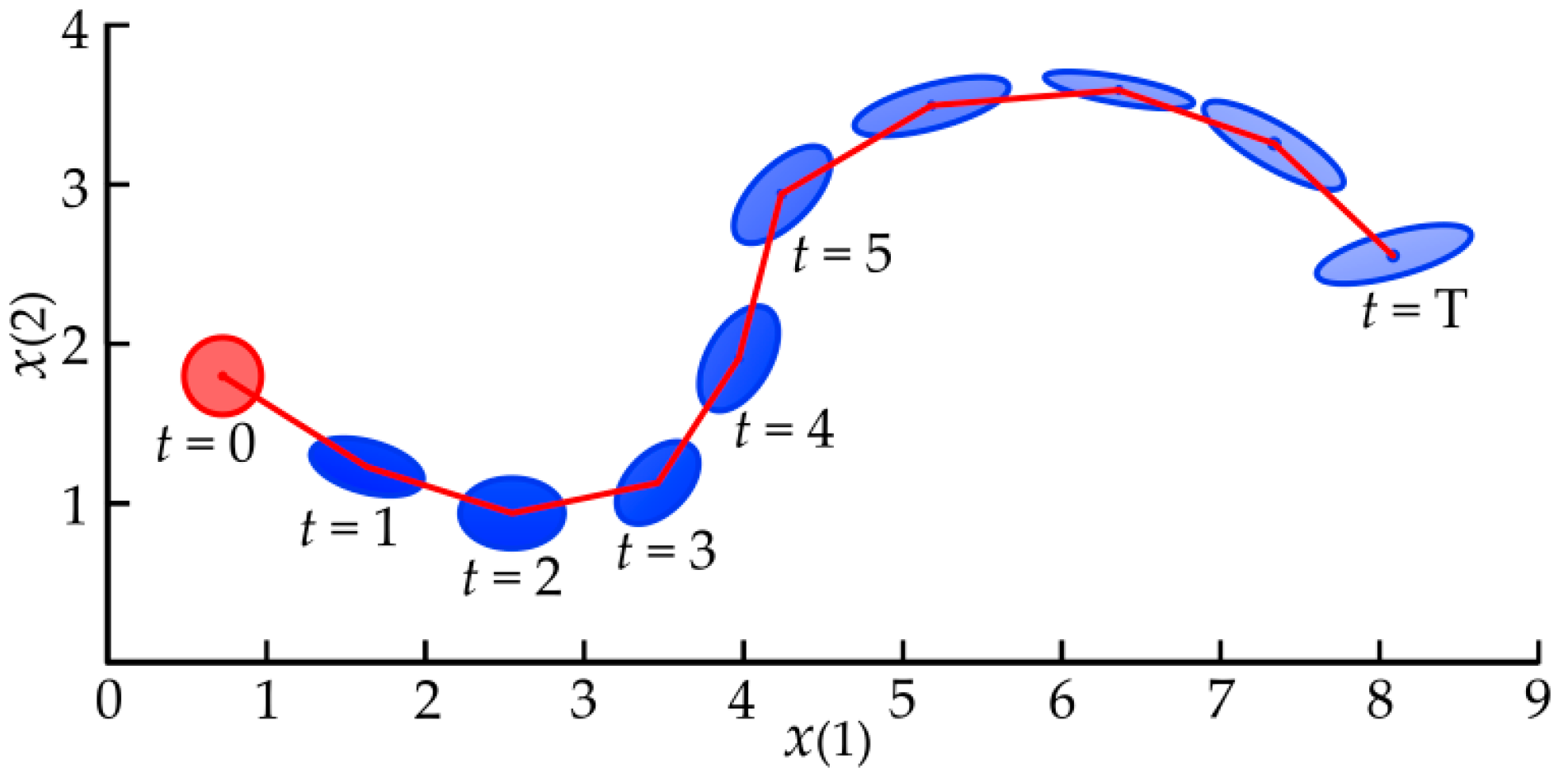
To evaluate the strategy, the long-term predictions of state
should be computed iteratively from the initial state distribution
by cascading one-step predictions [
47]. Since the GP model can map the Gaussian-distributed states space to the targets space, the uncertainties of the inputs can pass through the model, and the uncertainties of the model are taken into account in the long-term planning. A conceptual illustration of long-term predictions of state evolution [
48] is shown in
Figure 6.
The one-step prediction of the states can be summarized as
As
is a function of state
and
is known, the calculation of
requires a joint distribution
. First, we calculate the predictive control signal
and subsequently the cross-covariance
. Then,
is approximated by a Gaussian distribution [
47]
The distribution of the training targets
are predicted as
where the posterior predictive distribution of the transition dynamics
could be calculated using the Formulas (23)–(25). Using moment matching [
49],
could be approximated as a Gaussian distribution
. Then, a Gaussian approximation to the desired state distribution
is given as
4.5. Gradient-Based Strategy Learning
The goal of the learning algorithm is to find the strategy parameters that minimize the total expected costs
. The search direction can be selected using the gradient information. The total expected cost
in
steps is calculated according to the state evolution
where
is the instantaneous cost at time
, and
is the expected values of the instantaneous cost with respect to the predictive state distributions.
The cost function in RL usually penalizes the Euclidean distance from the current state to the target state, without considering other prior knowledge. However, in order to make robots with the ability of compliance, the control gains should not be high for practical interaction tasks. Generally, high gains will result in instability in stiff contact situations due to the inherent manipulator compliance, especially for an admittance-type force controller. In addition, low gains lead to several desirable properties of the system, such as compliant behavior (safety and/or robustness), lowered energy consumption, and less wear and tear. This is similar to the impedance regulation rules of humans. Humans learn a task-specific impedance regulation strategy that combines the advantages of high stiffness and compliance. The general rule of thumb thus seems to be “be compliant when possible; stiffen up only when the task requires it”. In other words, impedance increasing ensures tracking accuracy while impedance decreasing ensures safety.
To make the robots with these impedance characteristics, we present a way of taking the penalty of control actions into account during planning. The instantaneous cost function is defined
Here, is the cost caused by the state error, denoted by a quadratic binary saturating function, which saturates at unity for large deviations to the desired target state. is the Euclidean distance between the current state to the target state and is the width of the cost function. is the cost caused by the control actions, i.e., the mean squared penalty of impedance gains. The suitable impedance gains could be reduced by punishing the control actions. is the action penalty coefficient. is the current control signal, and is the maximum control signal amplitude.
The gradients of
with respect to the strategy parameters
are given by
The expected immediate cost
requires averaging with respect to the state distribution
, where
and
are the mean and the covariance of
, respectively. The derivative in Equation (38) can be written as
Given
, the item
and
could be calculated analytically. Then we will focus on the calculation of
and
. Due to the computation sequence of (26), we know that the predicted mean
and the covariance
are functionally dependent on
and the strategy parameters
through
. We thus obtain
By repeated application of the chain-rule, the Equations (39)–(43) can be computed analytically. We omit further lengthy details here and refer to [
47] for more information. Then the non-convex gradient-based optimization algorithm—e.g., conjugate gradient—can be applied to find the strategy parameters
that minimize
.
5. Simulations and Experiments
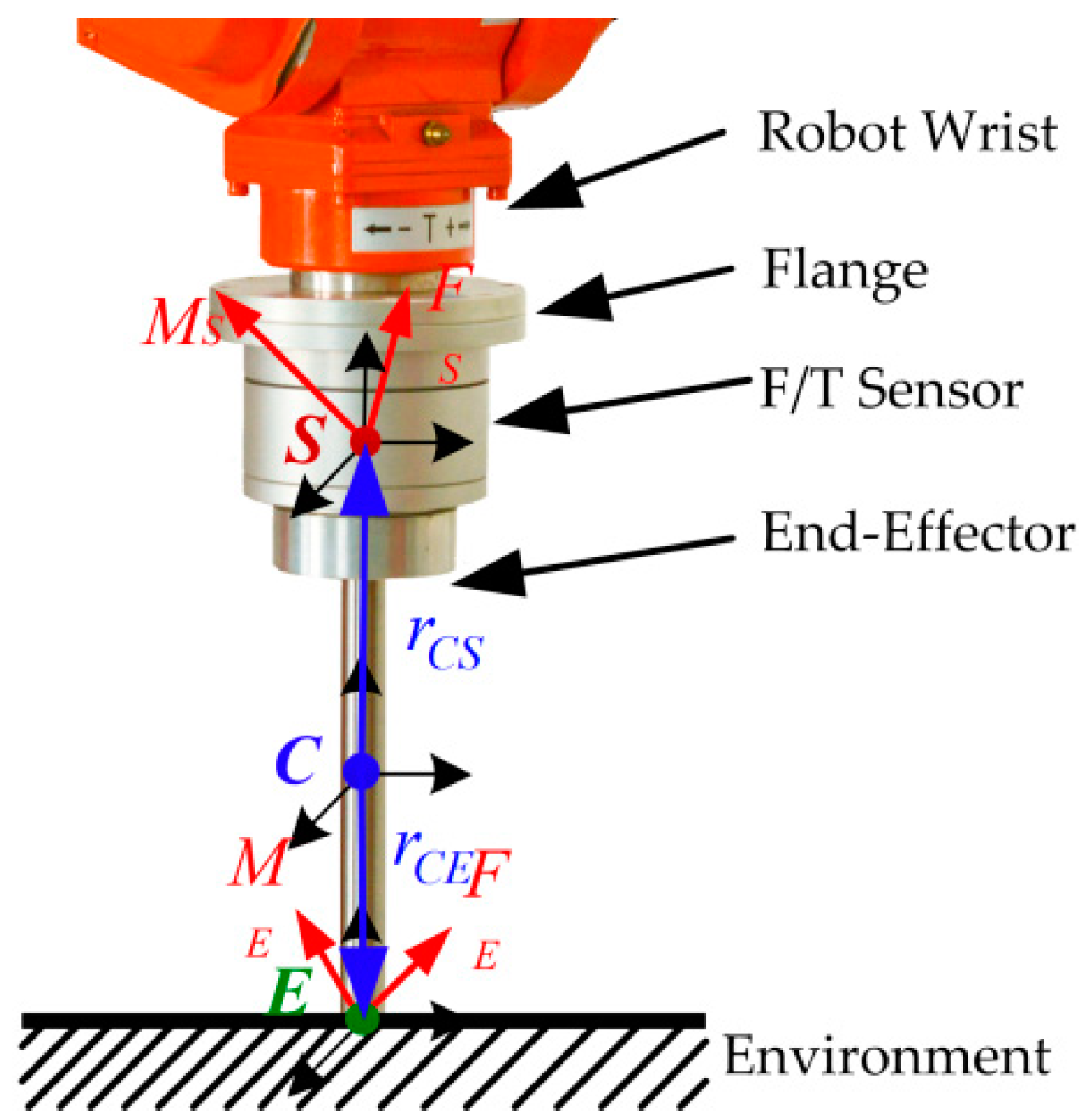
To verify the proposed force control learning system based on variable impedance control, a series of simulation and experiment studies on the Reinovo REBot-V-6R-650 industrial robot (Shenzhen Reinovo Technology CO., LTD, Shenzhen, China) are conducted and presented in this section. Reinovo REBot-V-6R-650 is a six-DoF industrial manipulator with a six-axis Bioforcen F/T sensor (Anhui Biofrcen Intelligent Technology CO., LTD, Hefei, China) mounted at the wrist. The F/T sensor is used to percept the contact force of the end-effector. The sensing range of the F/T sensor is , , , and with the total accuracy less than .
5.1. Simulation Study
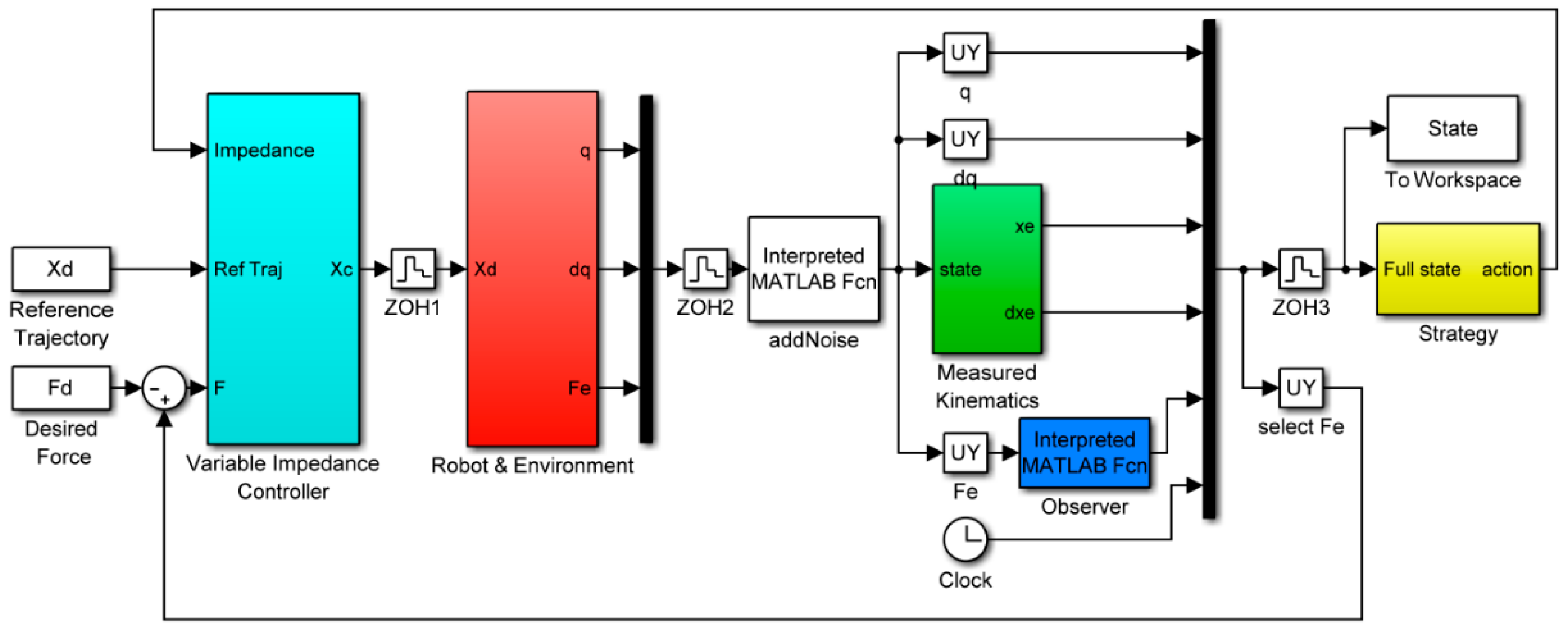
We first evaluated our system through a simulation of force control using MATLAB (R2015b Version 8.6) Simulink. The block diagram of simulation is shown in
Figure 7. In the simulation setup, a stiff contact plane is placed under the end-effector of the robot. The stiffness and damping of the plane are set 5000 N/m and 1 Ns/m, respectively. The robot’s base is located at
while the original position of the plane
is located at
. The plane’s length, width, and height are 0.9, 1, and 0.2 m, respectively. The robot should automatically learn to control the contact force to the desired value.
In the simulation, the episode length is set as . The control period of the impedance controller is 0.01 s, and the calculation period of the learning algorithm is 0.01 s. The number of total learning iterations, excluding the random initialization, is . The training inputs of the learning algorithm are the position and contact force of the end-effector . The training targets of the learning algorithm are the desired position and the desired contact force . The desired position is the initial position of the end-effector in Cartesian space. The desired contact force in z-axis direction is 15 N. If the steady state error of contact force and the overshoot is less than 3 N, the task is successful; otherwise, it is failed. The target state in cost function is . The strategy outputs are the impedance parameters . The number of the GP controller is . The ranges of the impedance parameters are set as and . The action penalty coefficient of the cost function is . The measurement noise of the joint position, joint velocities and the contact force are set as respectively. In the initial trial, the impedance parameters are initialized to stochastic variables that are subject to .
5.2. Simulation Results
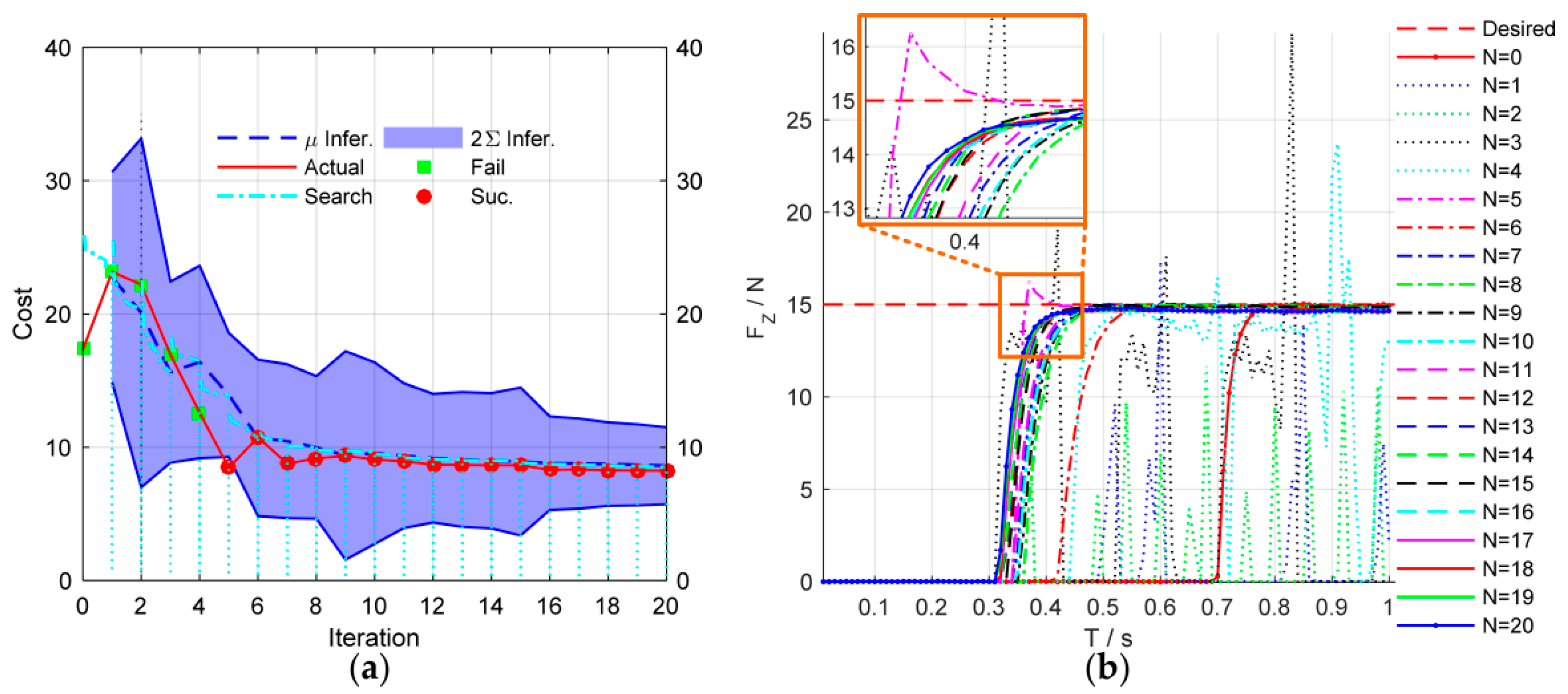
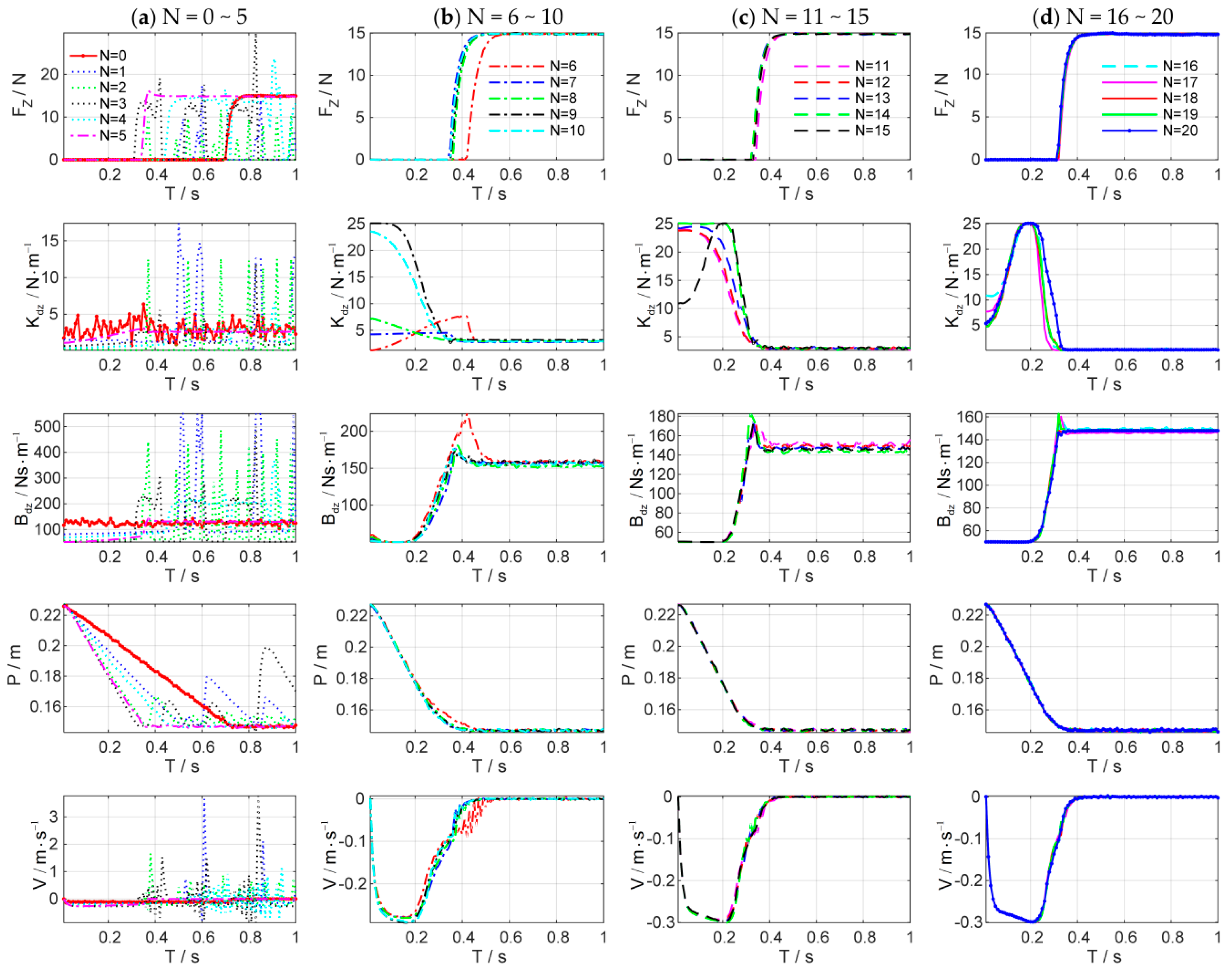
Figure 8 shows the simulation results of the force control learning system. The block marks in
Figure 8a indicate whether the task is successful or not. The light blue dash-dotted line represents the cumulative cost during the explorations.
Figure 9 details the learning process of the total 20 learning iterations.
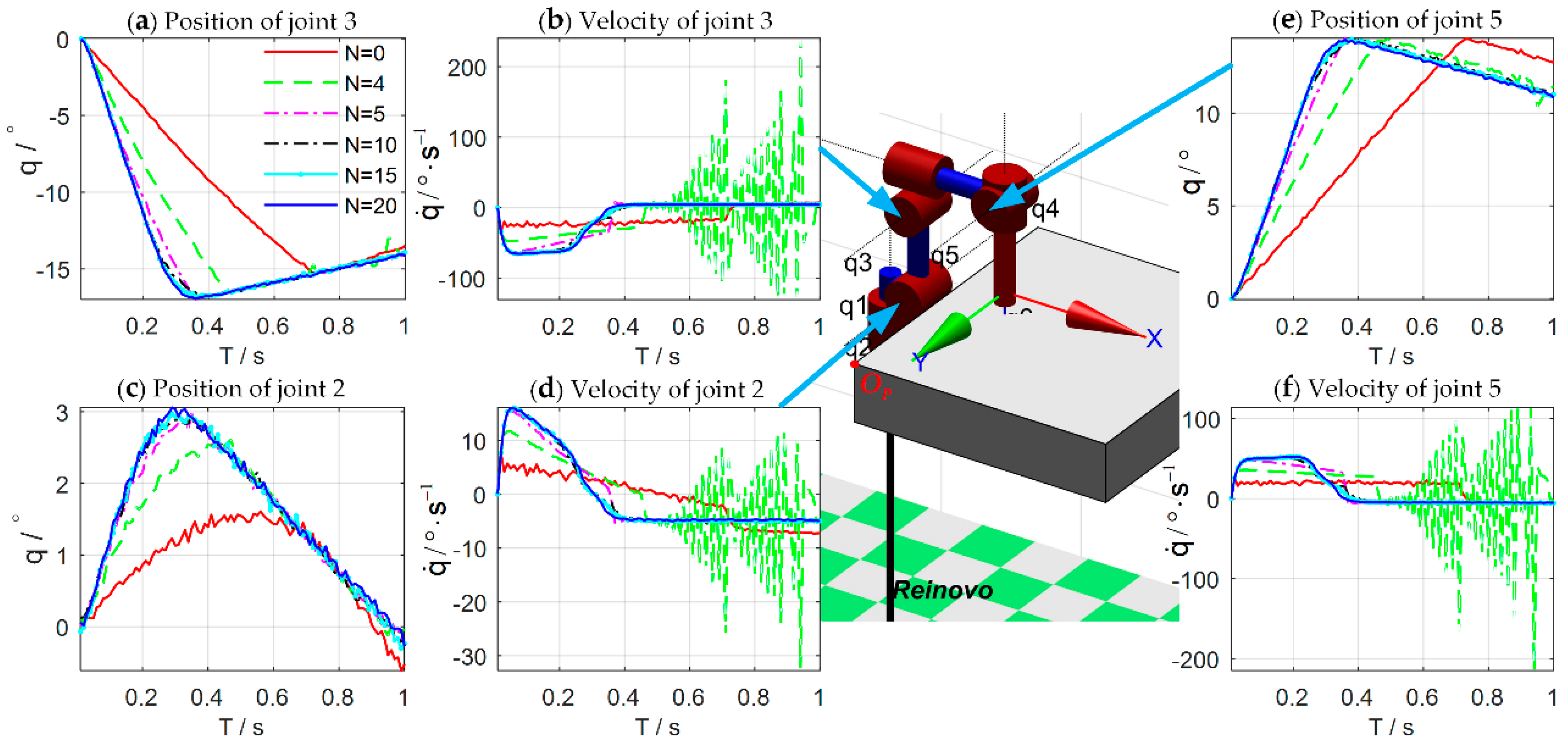
Figure 10 shows the joint trajectories after 4, 5, 10, 15, and 20 updates. Note that
denotes the initial trial, and the whole learning process is implemented automatically.
In the initial trial, the robot moves down slowly to search the contact plane and the end-effector begins to contact the plane at . Due to the large overshoot of the contact force, the task is failed until the fifth learning iteration. After the fifth learning iteration, the end-effector contacts the plane at , which is faster than the initial trial. The contact force reaches to the desired value rapidly with a little overshoot. The learning algorithm optimizes the control strategy continuously to reduce the cumulative cost. After seven iterations, the strategy’s performance is stable, and the contact force reaches the desired value quickly without overshoot by adjusting the impedance parameters dynamically. The optimal strategy is learned after 20 iterations, and its cumulative cost is the smallest. The end-effector can contact the plane at .
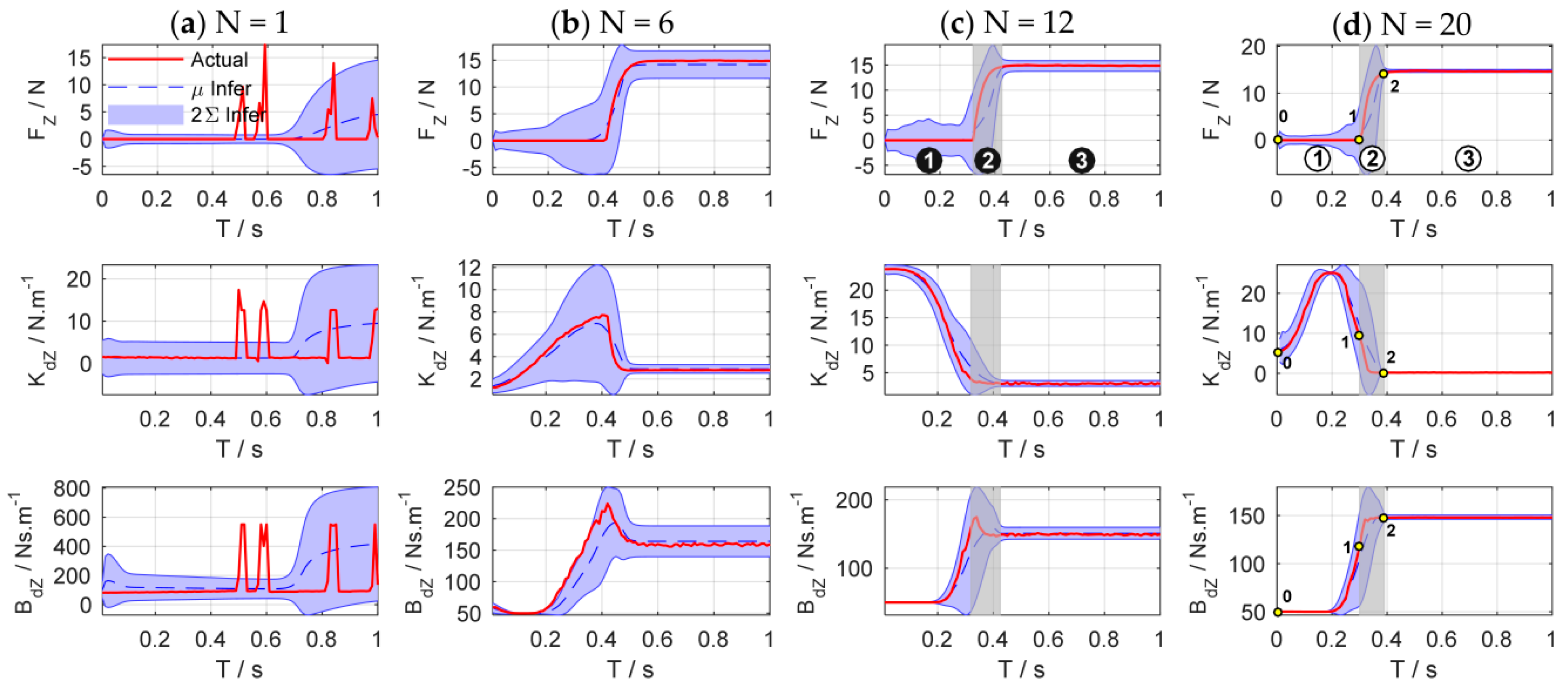
Figure 11 shows the evolutions of force control and impedance profiles. The state evolutions predicted by the GP model can be represented by the blue dotted line and the blue shade, which denote the mean and the 95% confidence interval of the state prediction respectively. The historical sampled data are constantly enriched with the increase of interaction time, and the learned GP model is optimized and stabilized gradually. When a good GP model is learned, it can be used as a faithful proxy of the real system (
Figure 11b–d).
As shown in
Figure 11d, the process of impedance regulation can be divided into three phases: (1) the phase before contacting the plane; (2) the phase of coming into contact with the plane; and (3) the stable phase of contact with the plane. When the end-effector contact the environment, the manipulator is suddenly converted from free space motion to constrained space motion, and the collision is inevitable. The stiffness of the environment increases suddenly. Consequently, the stiffness of the controller declines rapidly to make the system ‘soft’ to ensure safety. Meanwhile, the damping continues to increase to make the system ‘stiff’ to suppress the impact of environmental disturbance.
Throughout the simulation, only five interactions (5 s of interaction time) are required to learn to complete the force tracking task successfully. Besides, the impedance characteristics of the learned strategy are similar to that of humans for force tracking. The simulation results verify the effectiveness and the efficiency of the proposed system.
5.3. Experimental Study
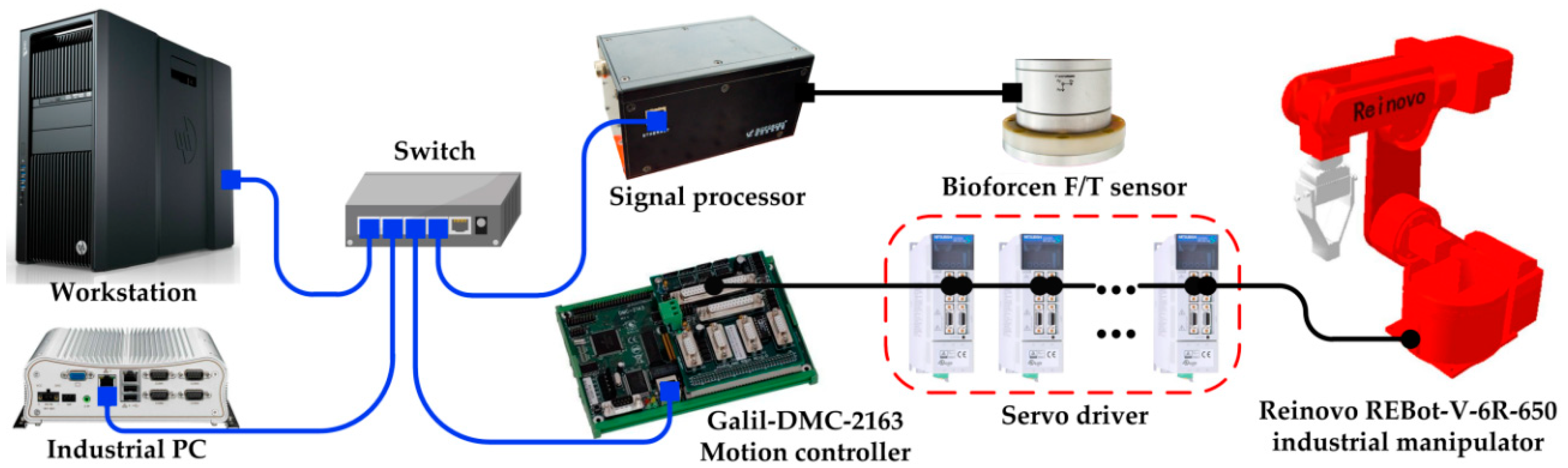
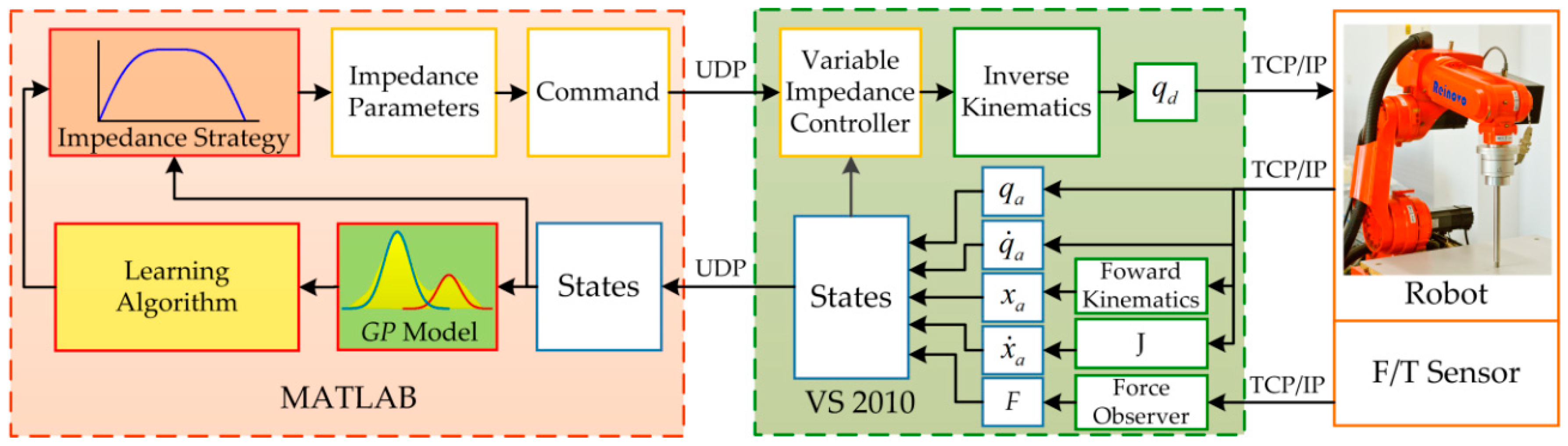
The hardware architecture of the system is shown in
Figure 12. The test platform consists of six parts, an industrial manipulator, servo driver, Galil-DMC-2163 motion controller, Bioforcen F/T sensor, an industrial PC, and a workstation. All parts communicate with others through the switch. The motion controller communicates with the industrial PC through TCP/IP protocol running at 100 Hz. The sensor communicates with the industrial PC via Ethernet interface through TCP/IP and samples the data at 1 kHz. The specific implementation diagram of the algorithm is shown in
Figure 13. The motion control of the robot is executed using Visual Studio 2010 on the industrial PC. The learning algorithm is implemented by MATLAB on the workstation. The workstation communicates with the industrial PC through UDP protocol.
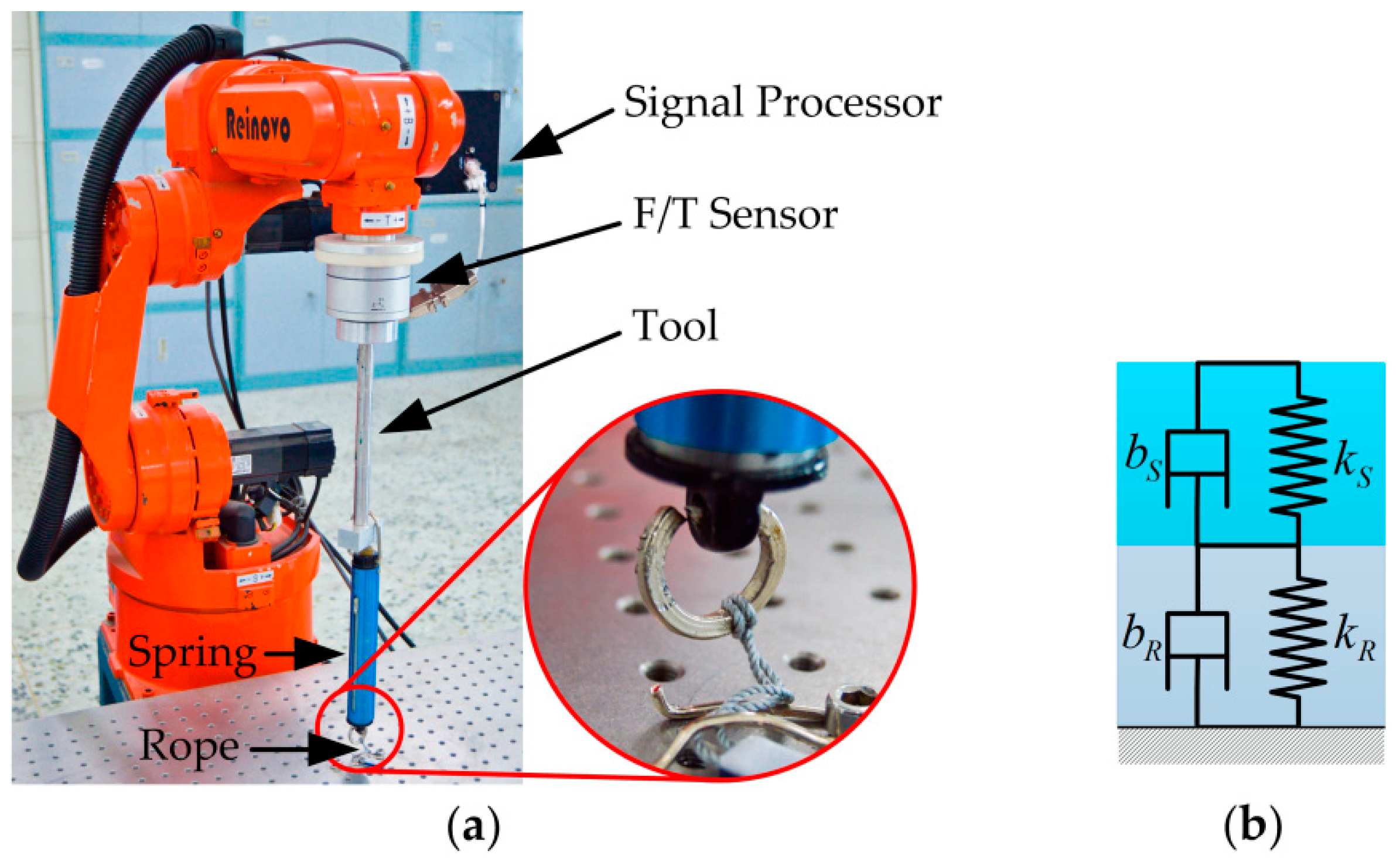
To imitate the nonlinear variable characteristics of the circumstance during the force tracking task, a combination of spring and rope is taken as the unstructured contact environment. As shown in
Figure 14, the experimental setup mainly consists of a spring dynamometer attached to the tool at the end-effector and a rope of unknown length tied to the spring with the other end fixed on the table. The contact force is controlled by stretching the rope and the spring. Here, the specifications of the rope are unknown, and the rope is in a natural state of relaxation. The measurement range, length, and diameter of the spring dynamometer are 30 Kg, 0.185 m, and 29 mm, respectively. The exact values of the stiffness and damping of the springs are unknown to the system. In the experiments, the episode length (i.e., the prediction horizon) is
. Other settings are consistent with those of simulations in
Section 5.1.
5.4. Experimental Results
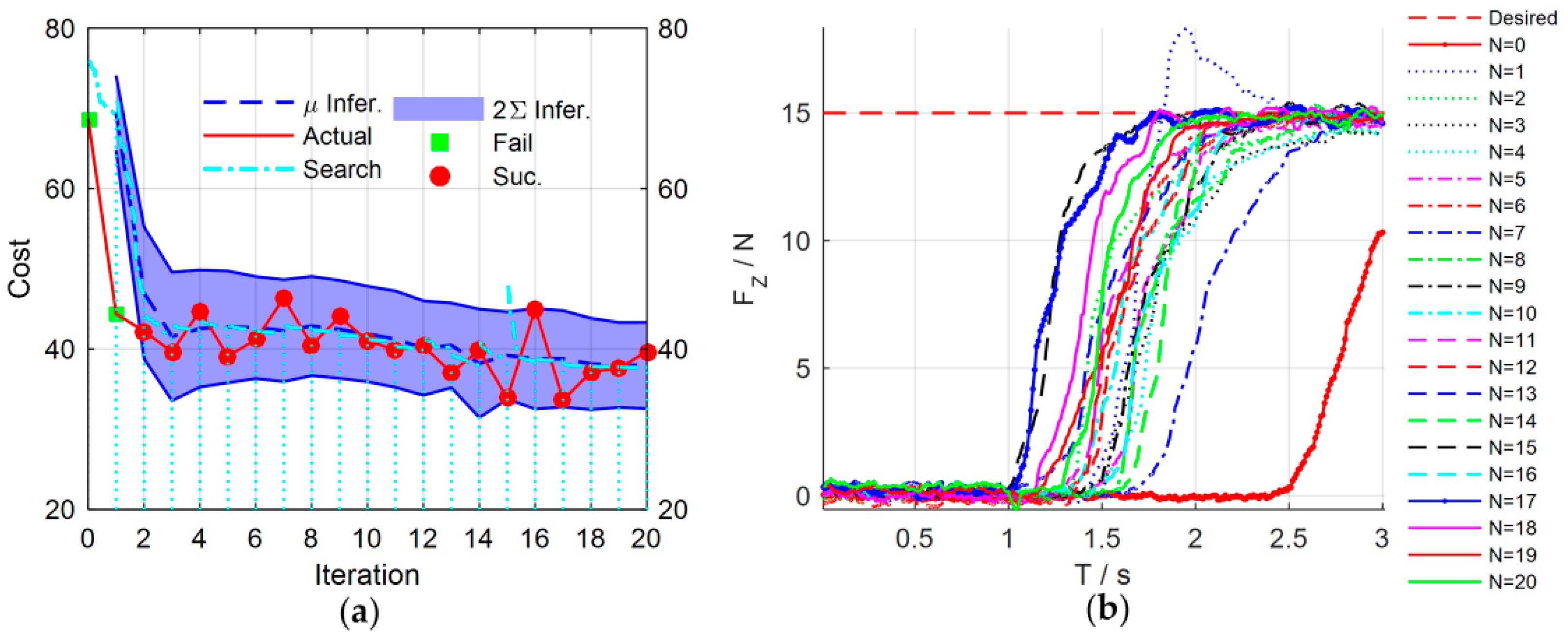
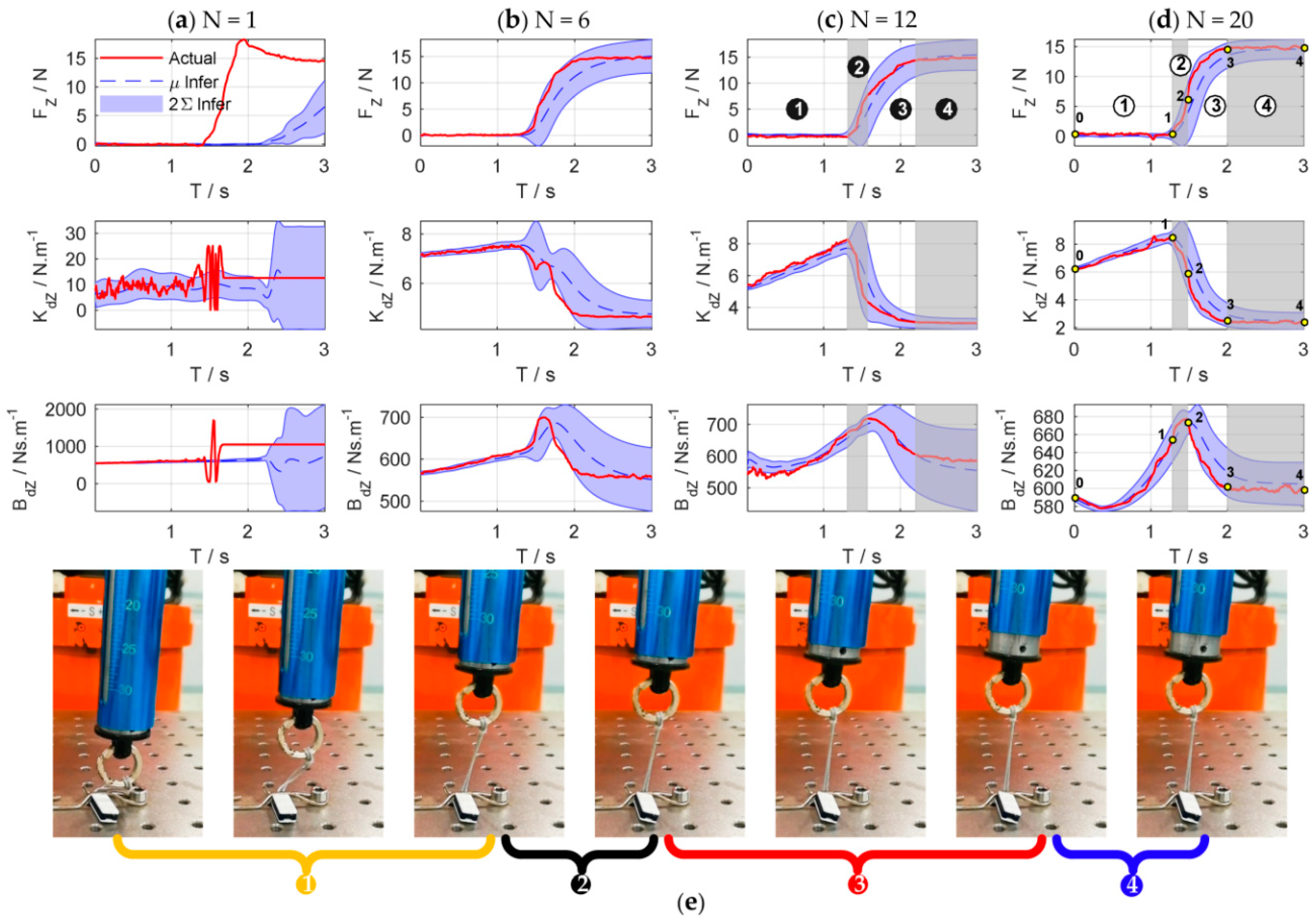
The experimental results are shown in
Figure 15.
Figure 16 details main iterations of the learning process. From the experimental results, we can see that in the initial trial, the manipulator moves slowly and the rope begins to be stretched at
to increase the contact force. The contact force reaches 10.5 N at the end of the test, which implies that the task failed. In the second trial, the rope and the spring can be stretched at
, which is faster than that of the first trial, and the contact force reaches the desired values rapidly, but the task failed because the overshoot is greater than 3 N. Only two learning iterations are needed to complete the task successfully. After 17 iterations, the cumulative cost is the smallest and the force control performance is also the best. The rope can be stretched at
, and the overshoot is suppressed effectively.
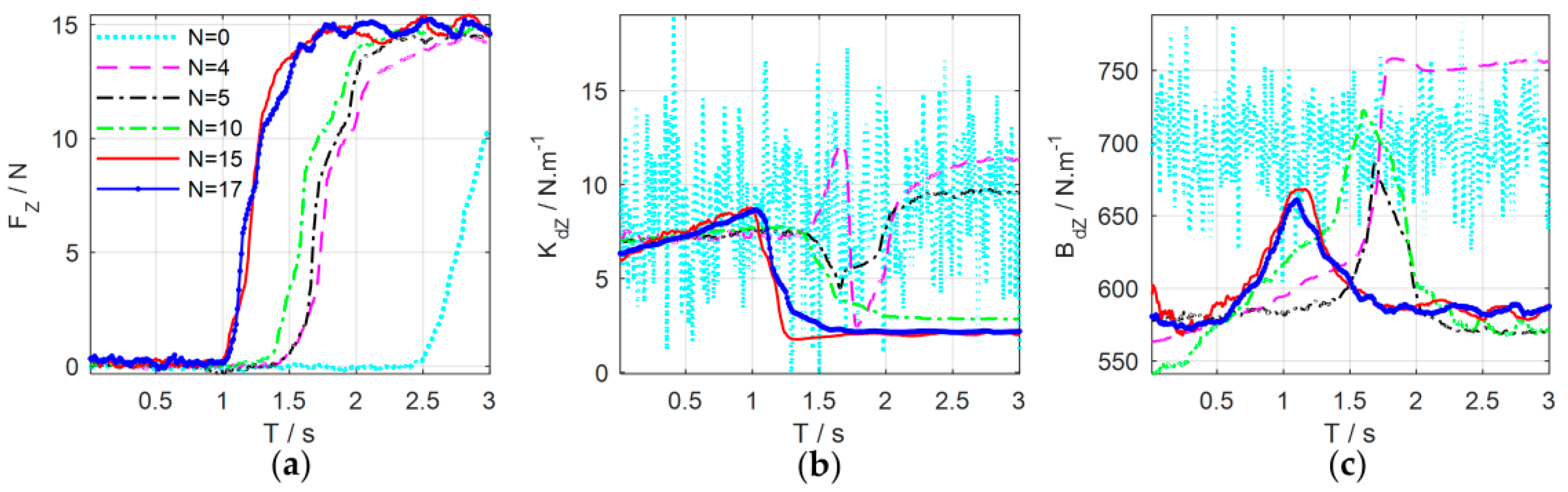
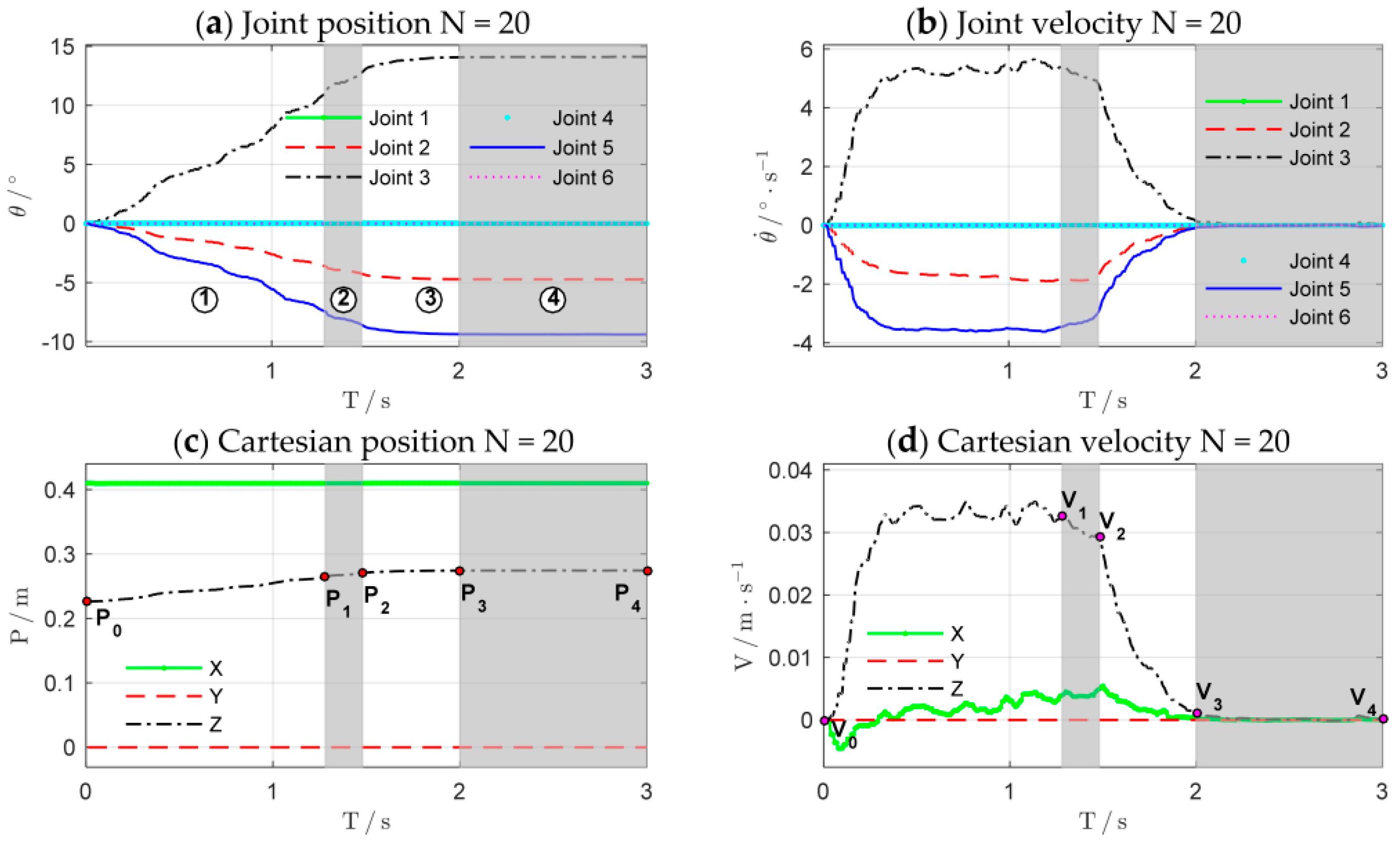
Figure 17 shows the evolutions of force control and impedance profiles. The bottom row shows the stretching process of the combination of the rope and the spring. The joint trajectories and Cartesian trajectories during the 20th experiment iteration are shown in
Figure 18. The trajectories of other iterations are similar to those of the 20th iteration. The stretching process of the combination can be divided into four phases, just as the shaded areas shown.
Table 1 summarizes the key states of the four phases. The corresponding subscripts of
,
, and
are shown in
Figure 17d while the subscripts of position (
) and velocity (
) are shown in
Figure 18c,d.
The four phases of impedance regulation are corresponded to the force control process mentioned above:
: Phase before stretching the rope. The manipulator moves freely in the free space. To tighten the rope quickly, the movement of the end-effector increases as the impedance increase. The contact force is zero in this phase.
: Phase of stretching the rope. When the rope is stretched, the manipulator is suddenly converted from free space motion to constrained space motion. The stiffness of the environment increases suddenly, and this can be seen as a disturbance of environment. Consequently, the stiffness of the controller declines rapidly to make the system ‘soft’ to ensure safety. Meanwhile, the damping continues to increase to make the system ‘stiff’ to suppress the impact of environmental disturbance and avoid oscillation. On the whole, the system achieves an appropriate strategy by weighting ‘soft’ and ‘stiff’. In this phase, the contact force increases rapidly until the rope is tightened.
: Phase of stretching the spring. The spring begins to be stretched after the rope is tightened. Although the environment changes suddenly, the controller does not select the strategy as Phase 2; it makes the system ‘soft’ by gradually reducing the stiffness and damping to suppress the disturbances. In this way, the contact force increases slowly to avoid overshoot when approaching the desired value.
: Stable phase of stretching the spring. The manipulator contacts with the environment continuously and the contact force is stabilized to the desired value. In this phase, the stiffness and damping of the controller are kept at minimum so that the system maintains the ability of compliance.
There are total 20 learning iterations throughout the experiment. In the early stage of learning, the uncertainties of the GP model are large due to the lack of collected data. With the increase of interaction time, the learned GP model can be improved gradually. After two learning iterations, which means that only 6 s of interaction time is required, a sufficient dynamic model and strategy can be learned to complete the force tracking task successfully. The experimental results above verify that the proposed force control learning system is data-efficient. It is mainly because the system explicitly establishes the transition dynamics that are used for internal virtual simulations and predictions, and the optimal strategy is improved by evaluations. In this way, more efficient information could be extracted from the sampled data.
5.5. Comparative Experiments
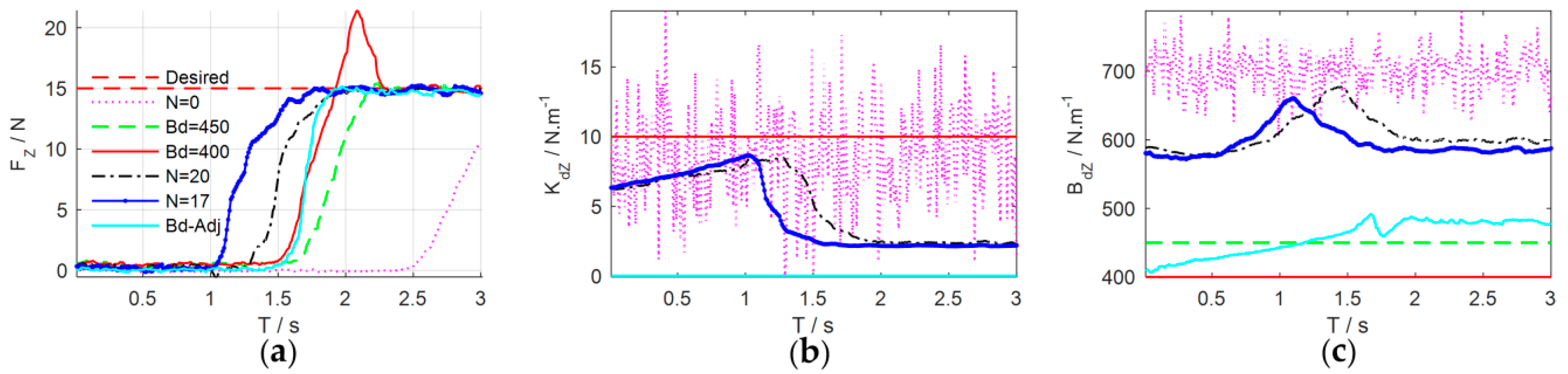
5.5.1. Environmental Adaptability
The results above have verified that the learned strategy could adjust the impedance profiles to adapt to the environmental change in the episodic case. However, what happens if the whole contact environment changes? In order to verify the environmental adaptability of the proposed learning variable impedance control method, we use another different spring dynamometer to build the unstructured contact environment. The measurement range, length, and diameter of the second spring dynamometer are 15 Kg, 0.155 m, and 20 mm, respectively. It implies that the stiffness and location of the environment are all changed. Other experimental setups are consistent with the
Section 5.3. The initial strategy for the second environment is the learned (sub)optimal strategy for the first spring (
N = 17 in
Section 5.4). The results are illustrated in
Figure 19.
From the experimental results, we can see that in the initial application of the control strategy, even though the impedance profile is regulated online according to the learned strategy, the task is failed. This is mainly because the whole environment is changed a lot, the strategy learned for the previous environment is not suitable for current environment. However, as the learning process continues to optimize, the learned (sub)optimal strategy could adapt to the new environment and successfully complete the task after two learning iterations. Therefore, the proposed method could adapt to new environments, taking advantage of its learning ability.
5.5.2. Comparison of Force Control Performance
Variable impedance control can regulate the task-specific impedance parameters at different phases to complete the task more effectively, which is the characteristic that the constant impedance control is not equipped. Next, the proposed learning variable impedance control is compared with the constant impedance control and the adaptive impedance control [
13] to verify the effectiveness of force control. The stiffness of the constant impedance controller is set as
while the stiffness of the adaptive impedance controller is set as
[
13]. The damping of the controller could be adjusted manually or automatically. Experimental comparison results are illustrated in
Figure 20.
In order to quantitatively compare the performances, we use four indicators to quantify the performances. The first indictor is the time
when the force begins to increase, i.e., the movement time of the robot in free space. The second indicator is the accumulated cost
which is defined in Equation (33). Note that the accumulated cost includes two parts: the cost caused by the error to the target state (Equation (36)) and the cost caused by the control gains (Equation (37)). The third one is the root-mean-square error (
RMSE) of the contact force
where
is the actual contact force in
Z-axis direction, and
is the desired contact force.
is the total number of the samples during the episode.
An energy indicator is defined to indicate the accumulated consumed energy during the control process
where
is the mass of the
joint and
is the angular velocity of the
joint. Actually, the masses of the joints are unknown accurately. Without loss of generality, the masses can be approximately set as
.
Table 2 reveals the performance indicators of the three impedance controllers. Compared with the constant/adaptive impedance control, the learning variable impedance control has the minimum indicator values, which indicates that the proposed system is effective. Obviously, the performance of the adaptive impedance control is better than the constant one, but still worse than the optimal impedance strategy learned by the proposed learning variable impedance control.
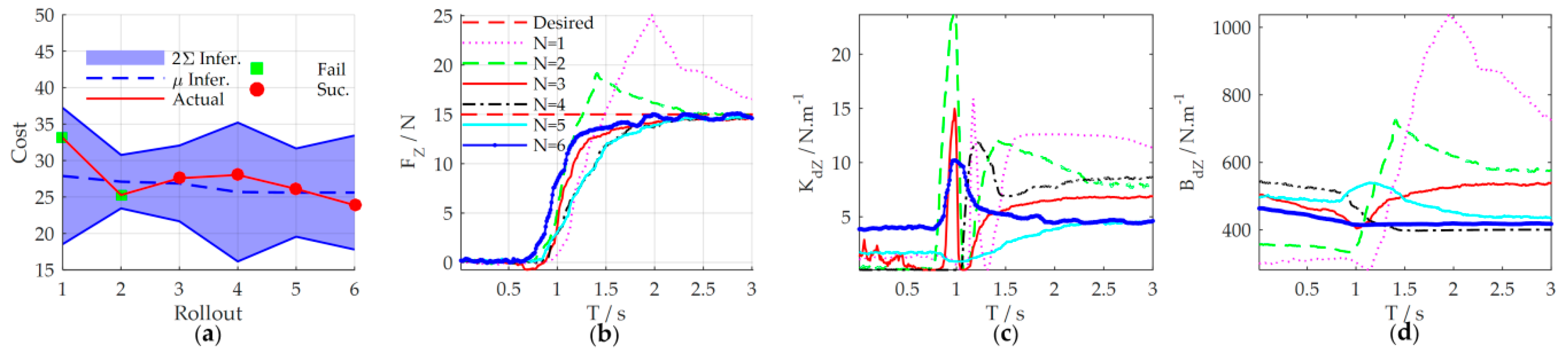
5.5.3. Learning Speed
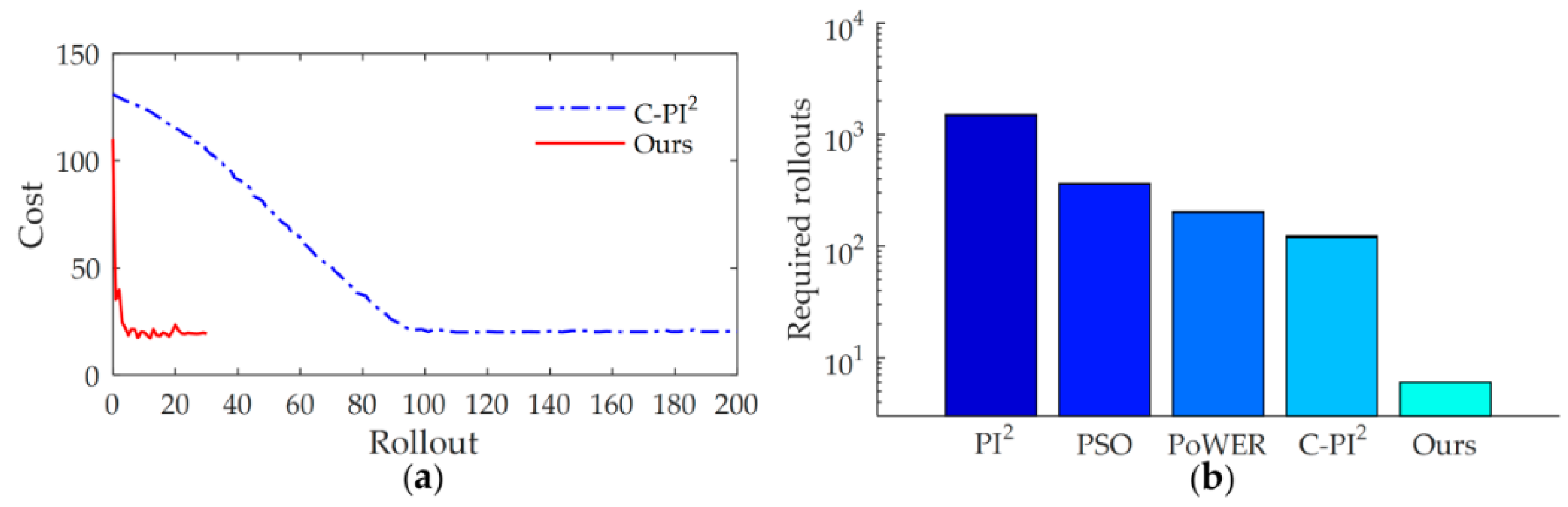
In order to further illustrate the efficiency of the proposed method, we compared the learning speed with state-of-the-art learning variable impedance control method, C-PI
2, through the via-gain task [
37]. The cost function of C-PI
2 is chosen as
with
. The cost function of our method is chosen as the Equation (35) with
,
. The cost curve of learning process is shown in
Figure 21a. Similar to other studies [
37], to indicate the data-efficiency of the method, we take the required rollouts to get the satisfactory strategy as the indicator of the learning speed. The results show that C-PI
2 converges after about 92 rollouts, whereas our method needs only 4 rollouts.
Current learning variable impedance control methods usually require hundreds or thousands of rollouts to get a stable strategy. For tasks that are sensitive to the contact force, too many physical interactions with the environment during the learning process are often infeasible. Improving the efficiency of learning method is critical.
Figure 21b shows the comparison of learning speed with other learning variable impedance control methods. From the results of [
4,
37,
50], we can see that, to get a stable strategy, PI
2 needs more than 1000 rollouts, whereas PSO requires 360 rollouts. The efficiency of PoWER is almost the same as that of C-PI
2, which requires 200 and 120 rollouts, respectively. The learning speed of C-PI
2 is much higher than that of previous methods but is still slower than our method. Our method outperforms other learning variable impedance control methods by at least one order of magnitude.
6. Discussion
According to the definition of the cost function (35)–(37), we can learn that decreasing the distance between and and keeping the impedance parameters at a low level will be beneficial for minimizing the accumulated cost. Consequently, small damping parameters will make the robot move quickly to contact with the environment to reduce the distance between and . Unfortunately, small damping could reduce the positioning accuracy of the robot and thus make the system with poor ability to suppress disturbances. On the contrary, large damping could improve the system’s ability of suppressing disturbances and reduce the speed of motion. It will lead to task failure if the impedance parameters cannot be regulated to suppress the overshoot. Hence, the learning algorithm must make a tradeoff between rapidity and stability to achieve the proper control strategy. By regulating the target stiffness and damping independently at different phases, the robot achieves rapid contact with the environment while the overshoot is effectively suppressed.
The impedance characteristics of the learned strategy are similar to the strategy that employed by humans for force tracking. Reduce the impedance by muscle relaxation to make the system ‘soft’ when it needs to guarantee safety, while increase the impedance by muscle contraction to makes the system ‘stiff’ when it needs to guarantee fast-tracking or to suppress disturbances. When the contact environment is stable, the arm is kept in a compliant state by muscle relaxation to minimize the energy consumption. Our system learns the optimal impedance strategy automatically through continuous explorations. This is different from the methods of imitating human impedance behavior, such as [
18] and [
24], which usually need additional device—e.g., EMG electrodes—to transfer human skills to the robots by demonstration.
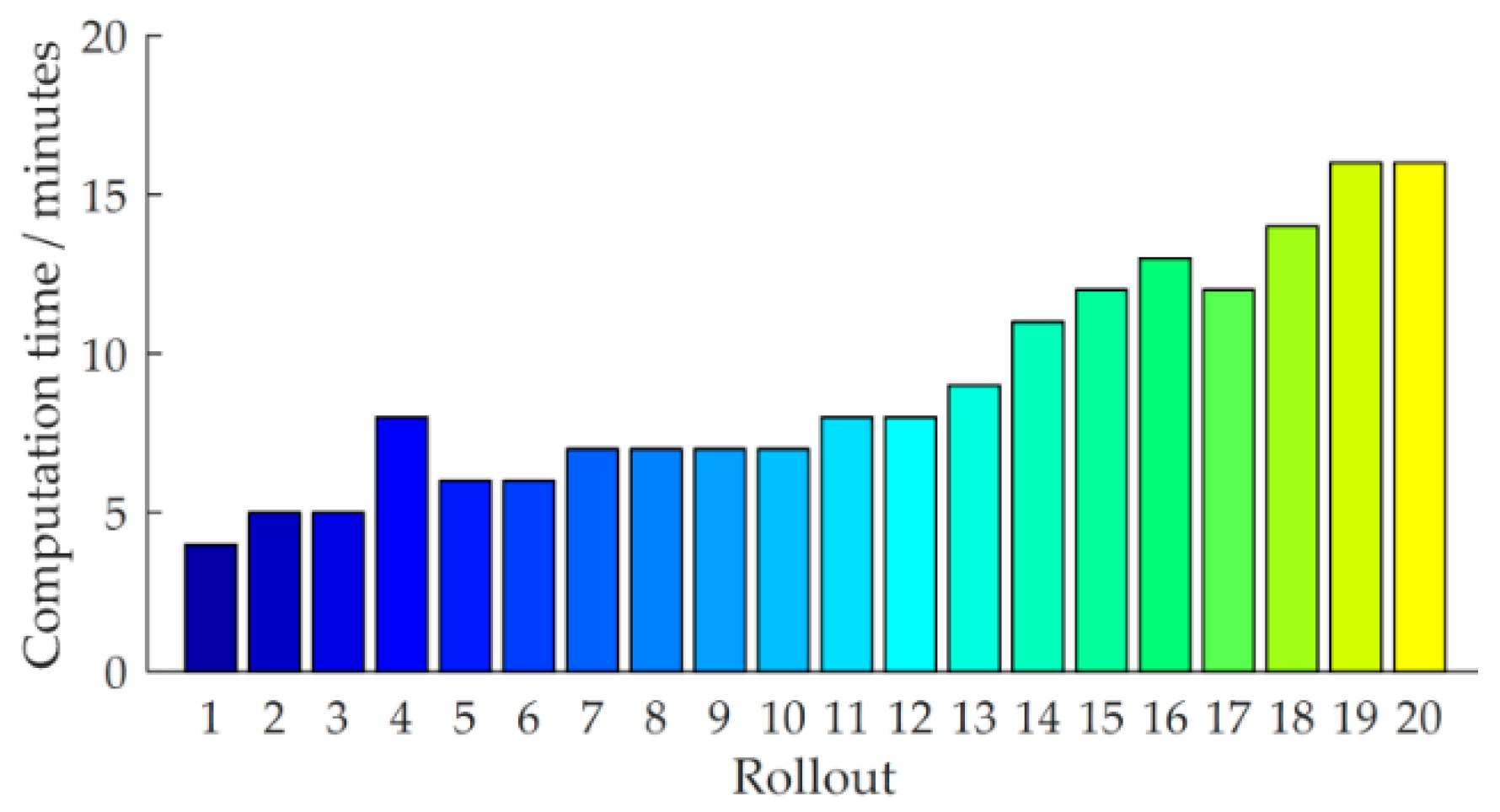
The proposed learning variable impedance control method emphasizes the data-efficiency, i.e., sample efficiency, by learning a GP model for the system. This is critical for learning to perform force-sensitive tasks. Note that only the application of the strategy requires physical interacting with the robot; internal simulations and strategy learning only use the learned GP model. Although a fast converging controller is found, the proposed method still has the computation intensive limitation. The computational time for each rollout on a workstation computer with an Intel(R) Core(TM) i7-6700 K
[email protected] GHz is detailed in
Figure 22.
Obviously, between the trials the method requires approximately 9 min to find the (sub)optimal strategy. With the increase of sample data set, the computational time is increasing gradually, because the kernel matrices need to be stored and inverted repeatedly. The most demanding computations are the predictive distribution and the derivatives for prediction using the GP model.

























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}