An Improved Point Cloud Descriptor for Vision Based Robotic Grasping System

Abstract
:1. Introduction
2. Improved Global Feature Descriptor
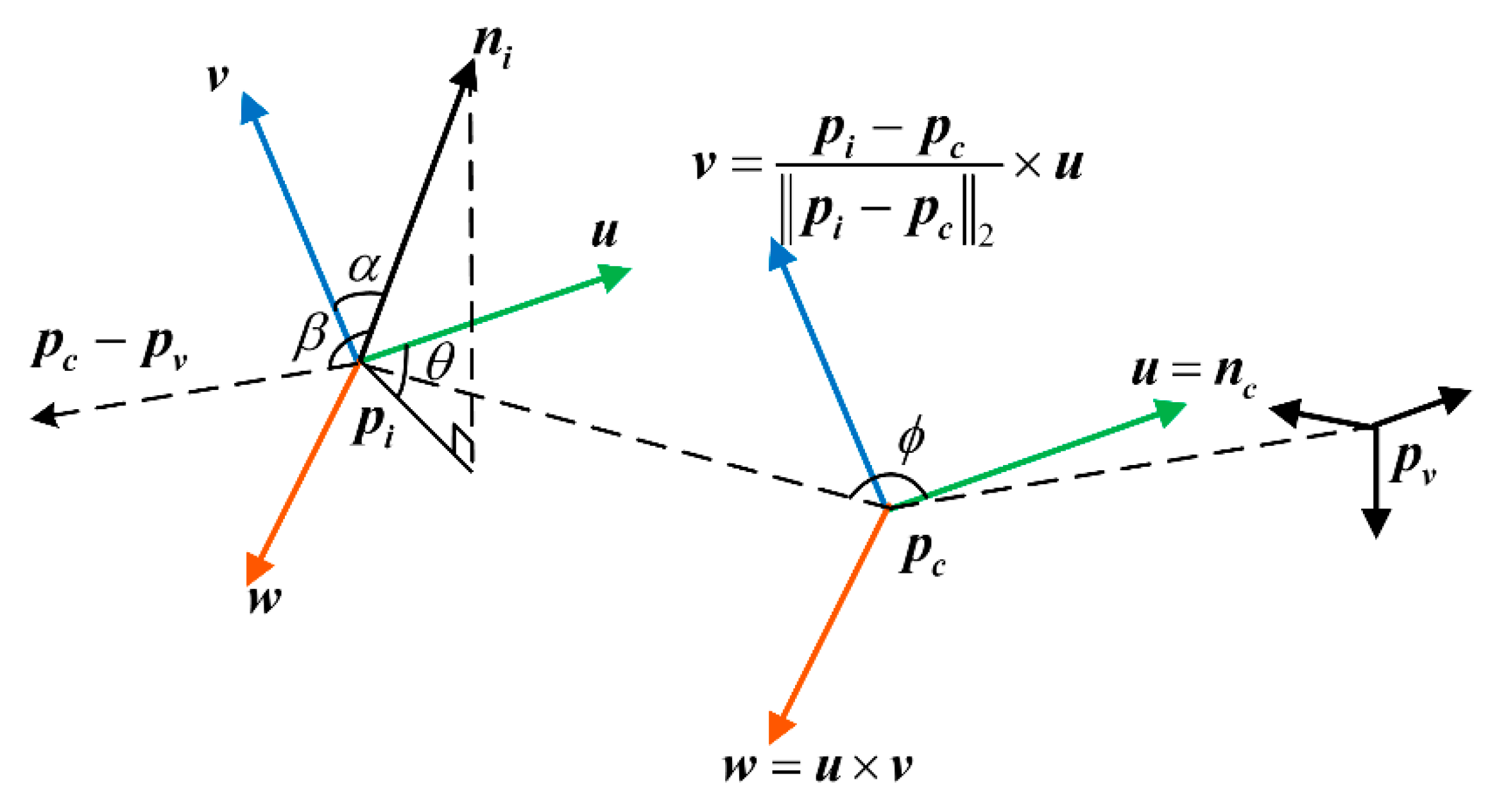
2.1. Global Feature Descriptor VFH
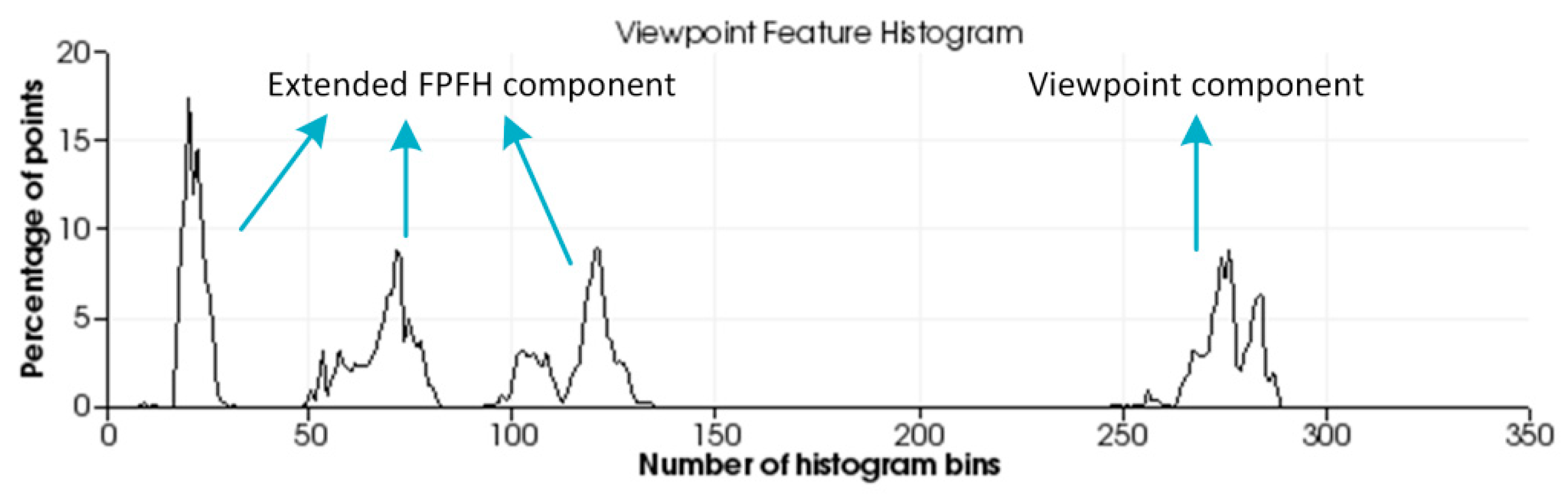
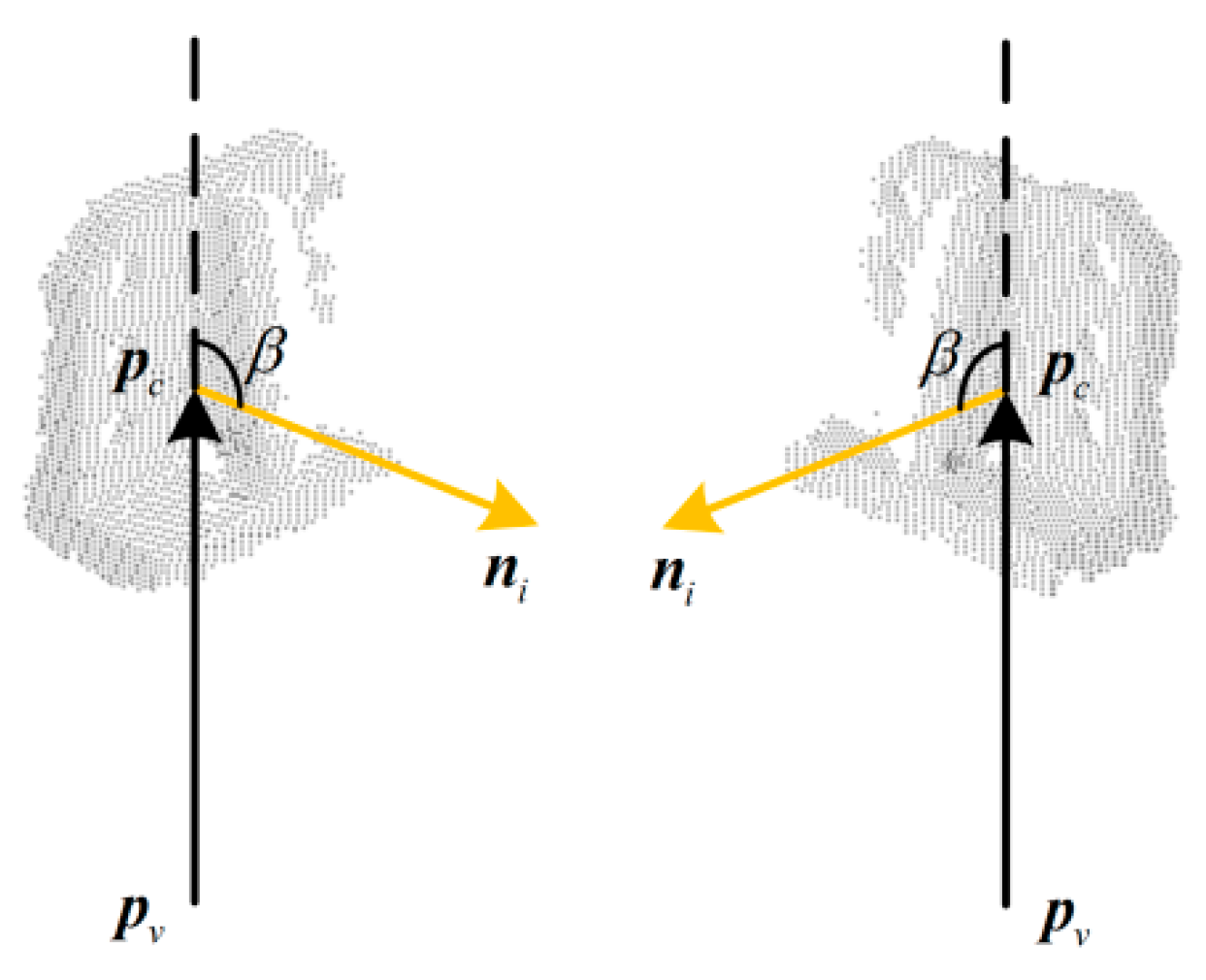
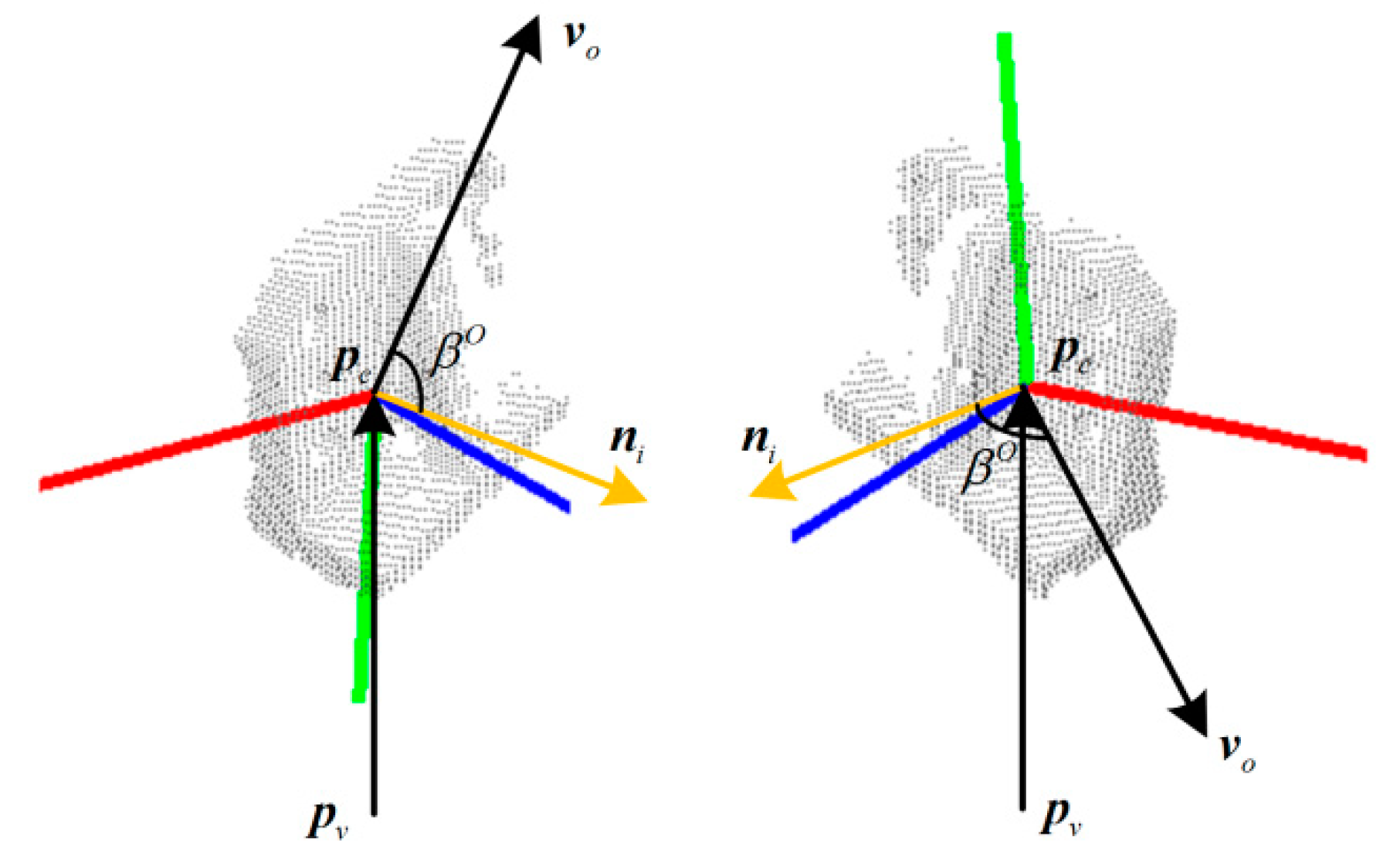
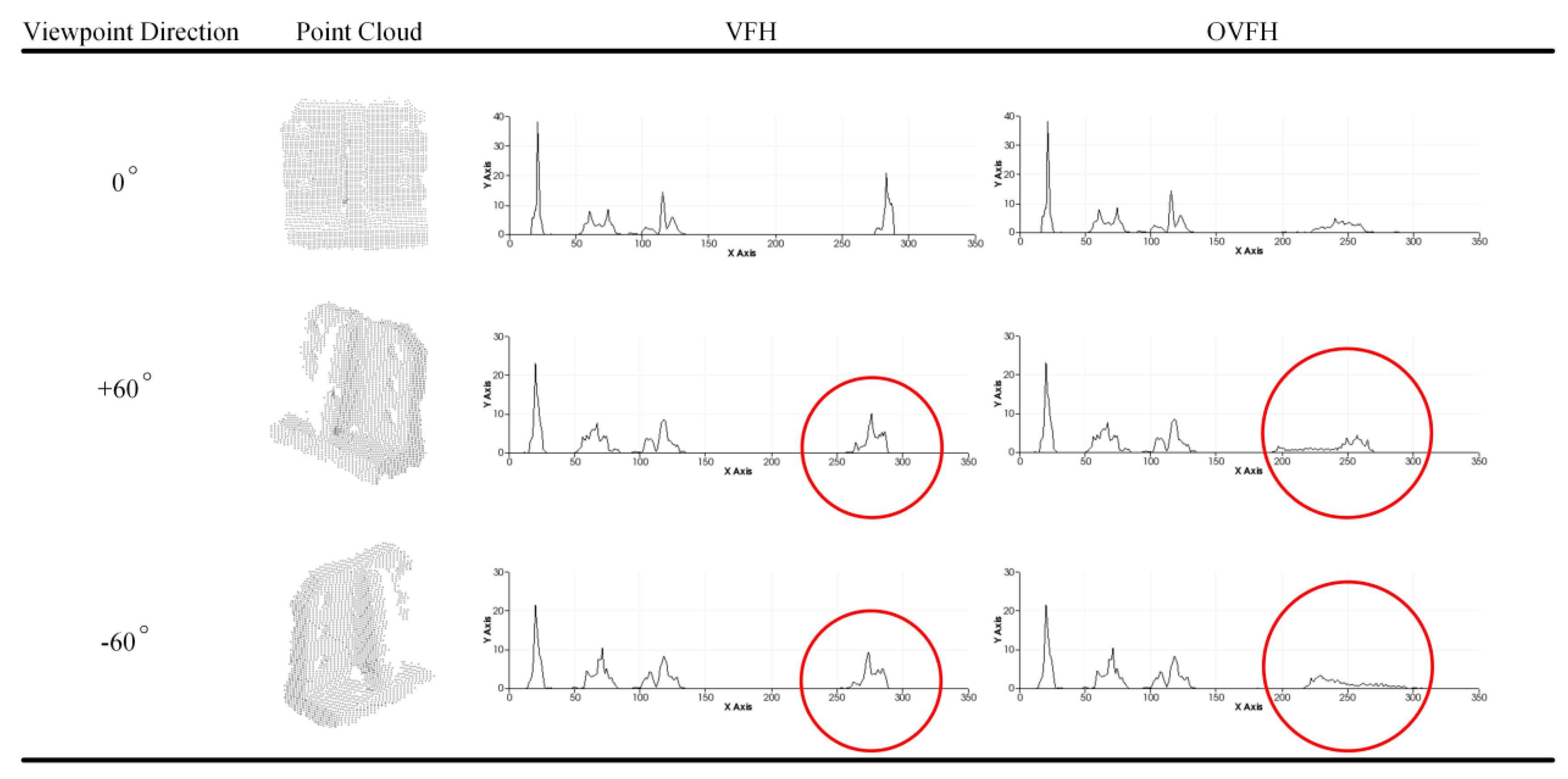
2.2. Improved Global Feature Descriptor OVFH
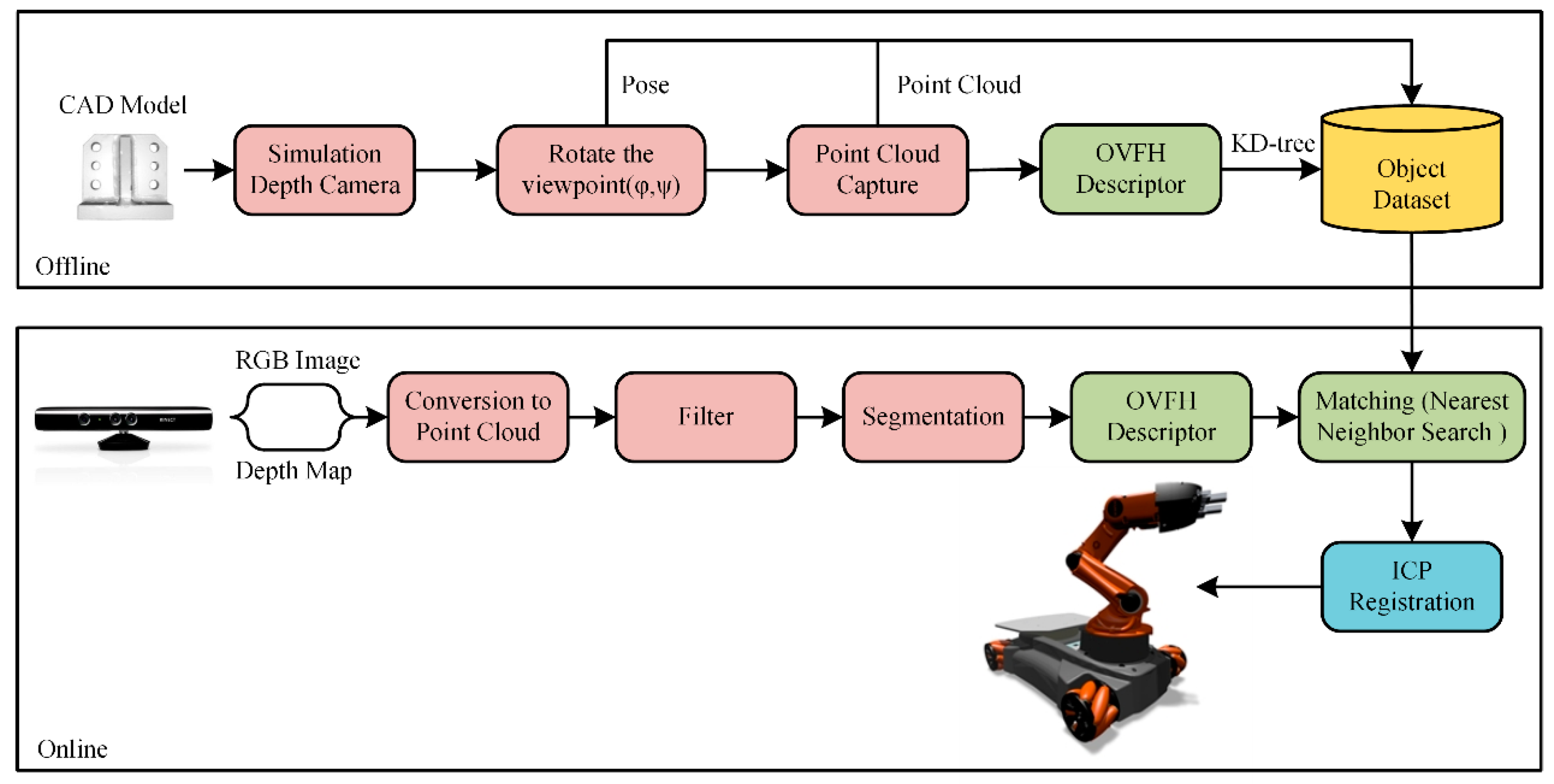
3. Visual Guidance Algorithm for the Robotic Grasping System
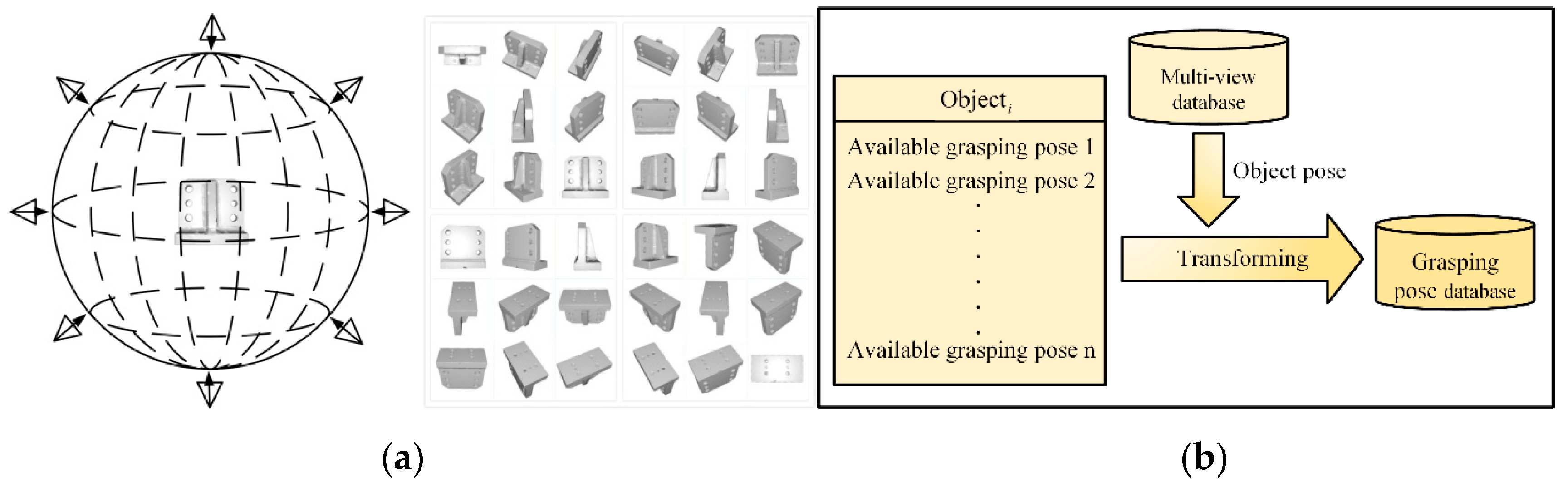
3.1. Creation of the Database
3.2. Object Recognition and Pose Estimation
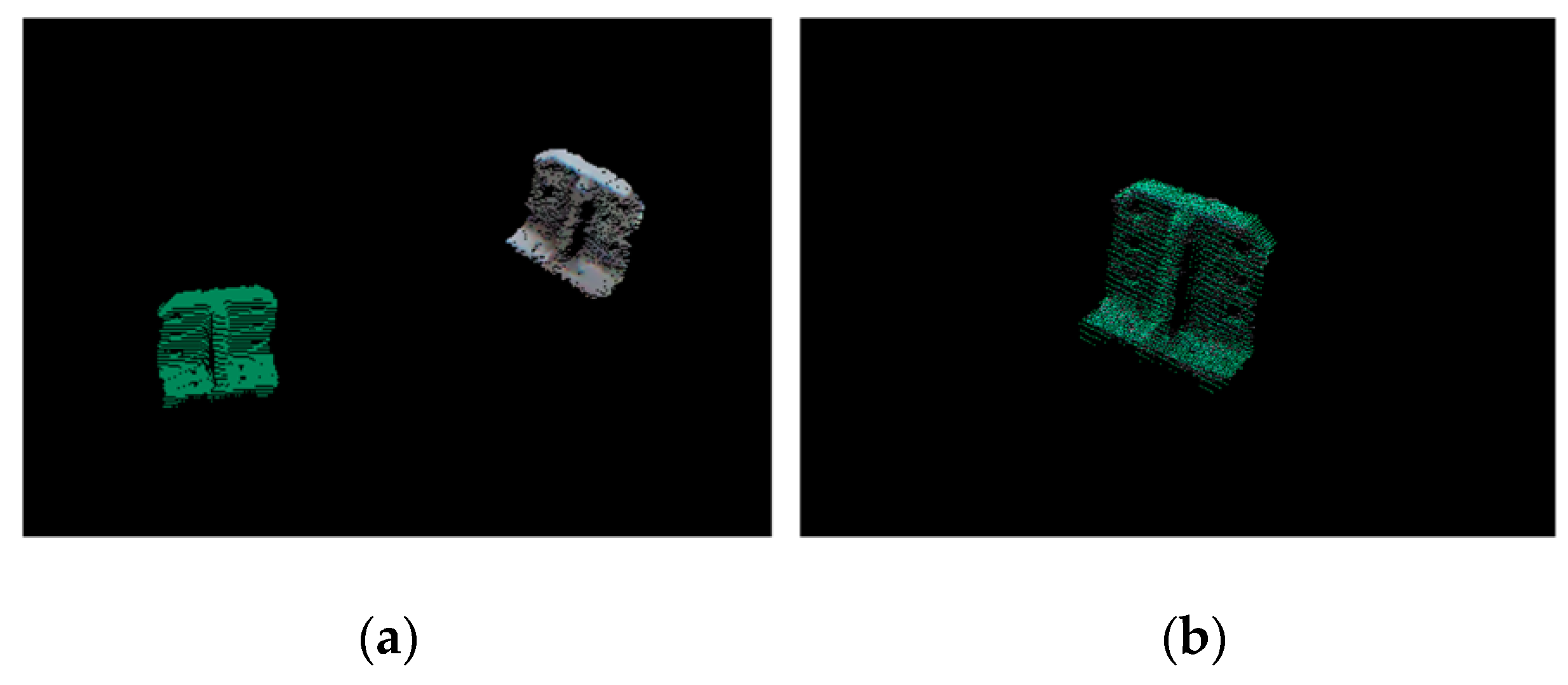
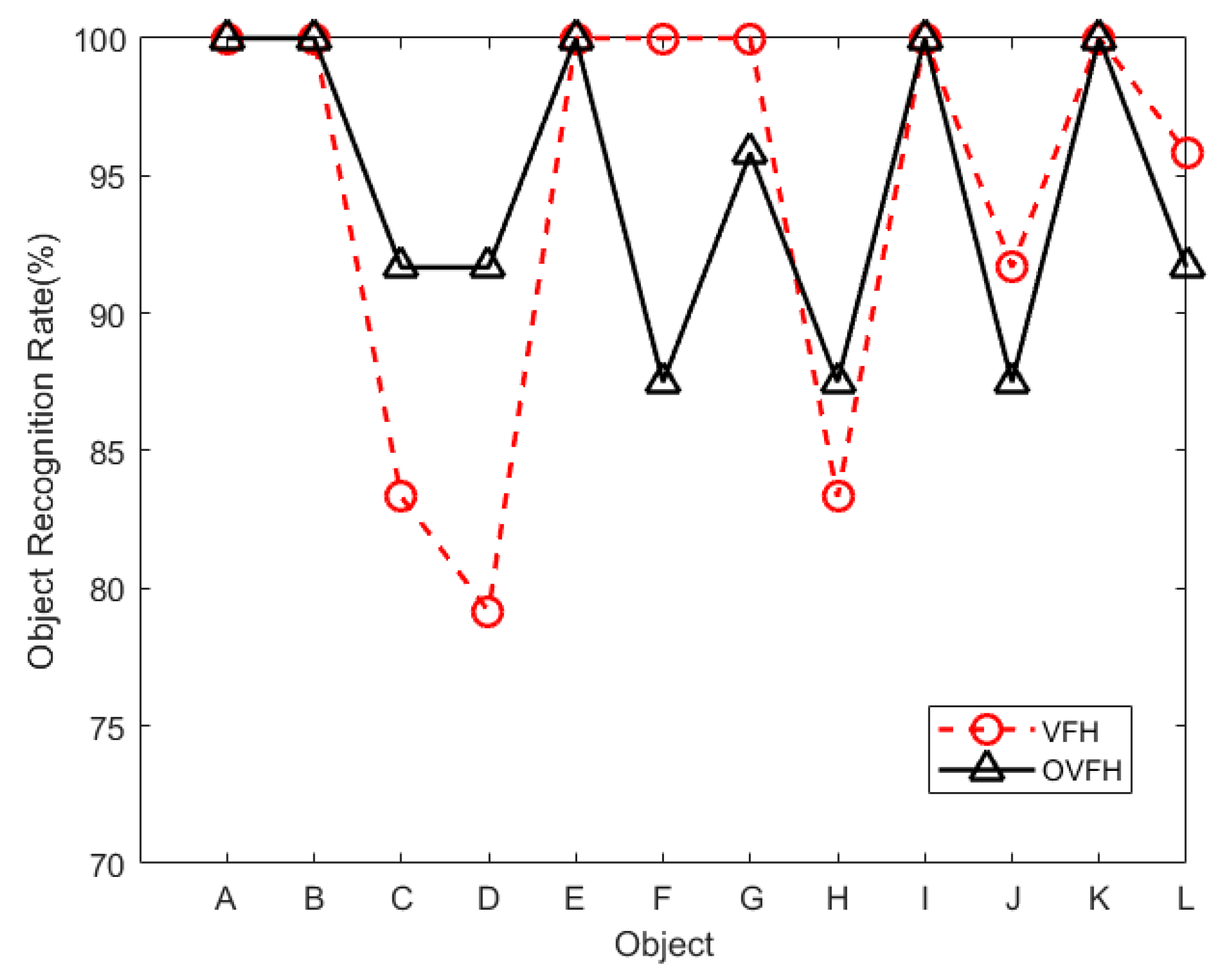
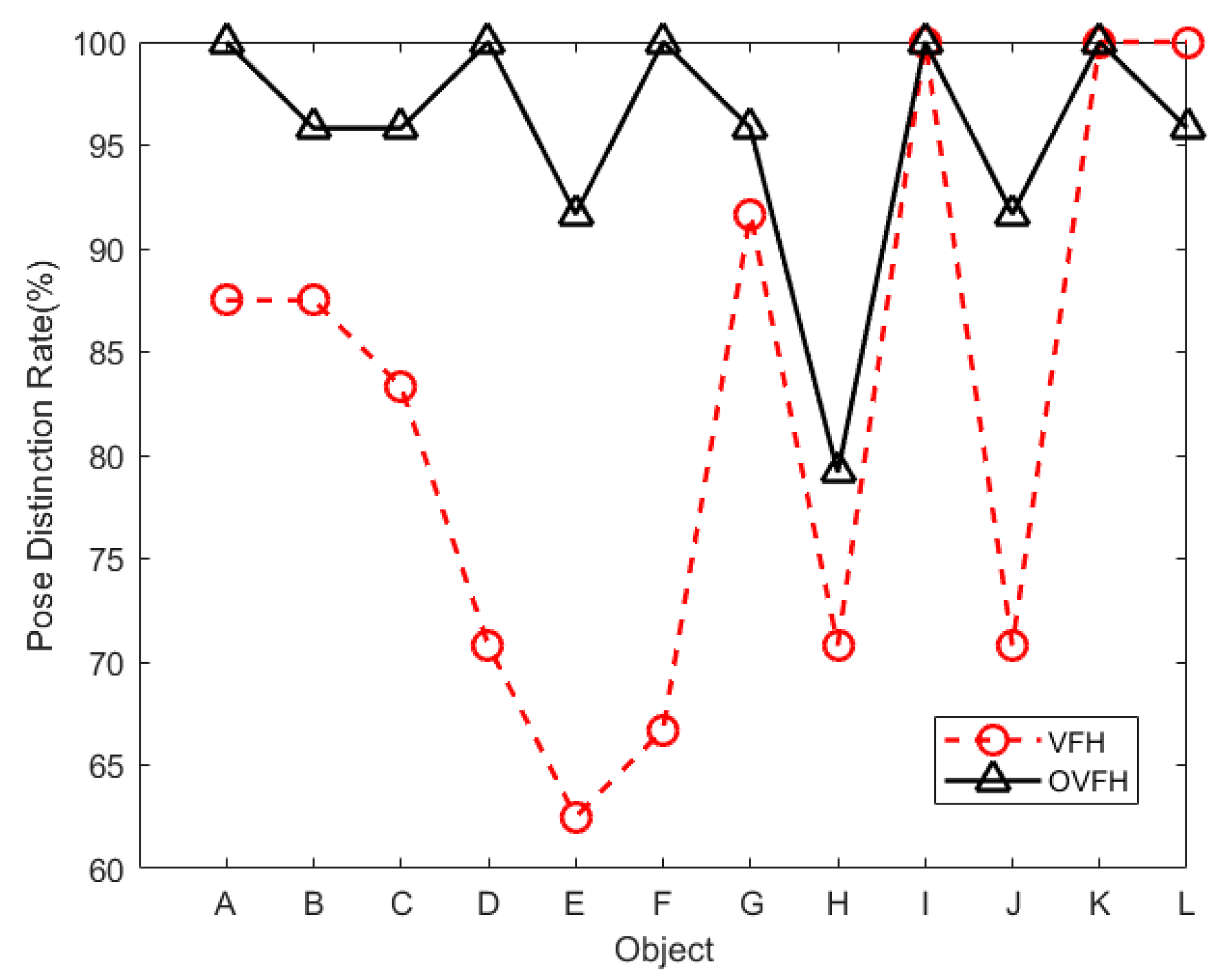
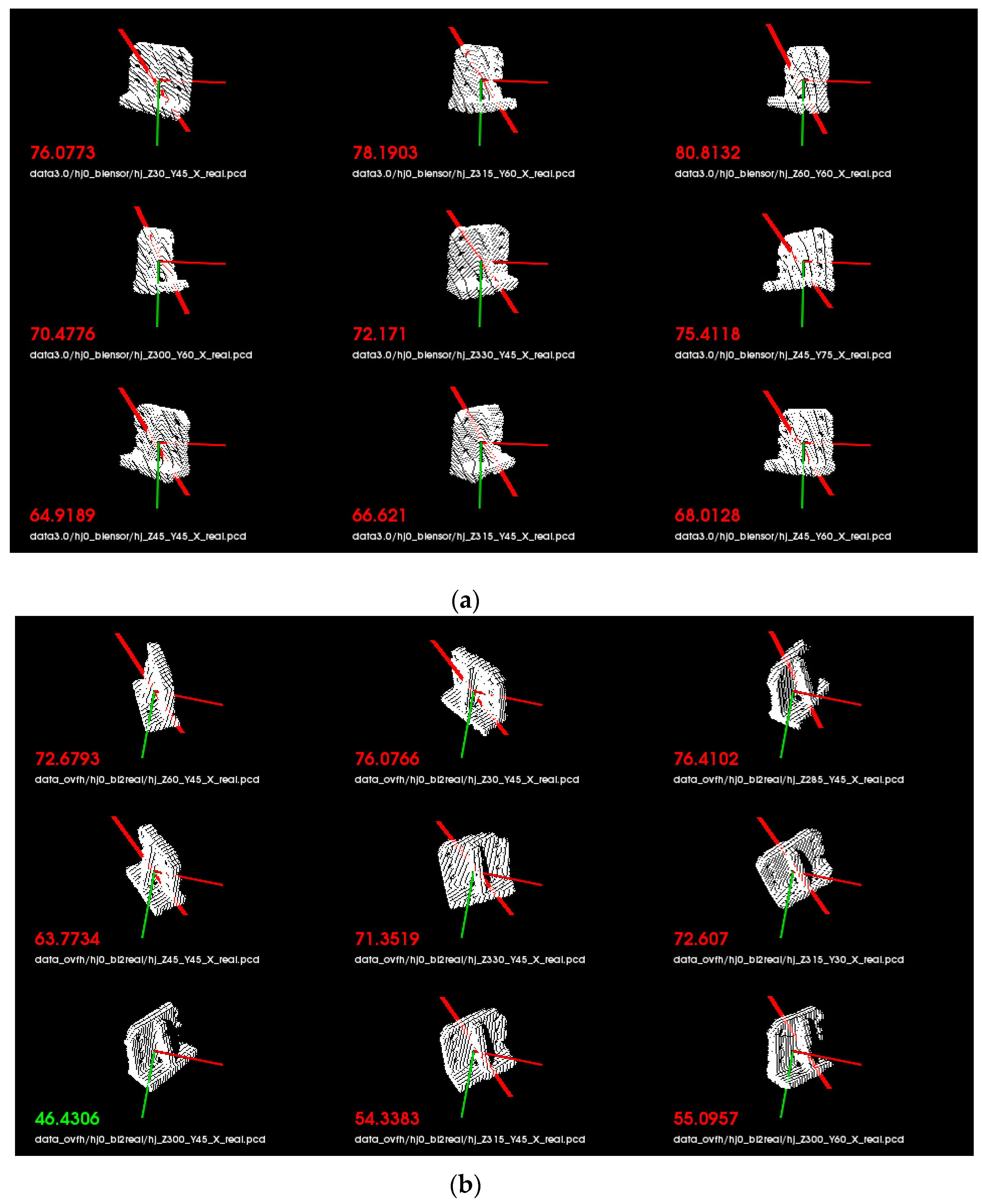
4. Experimental Results
4.1. Experimental Results on the Data Set
4.2. Robotic Grasping Experiment
5. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Luo, R.C.; Kuo, C.W. A scalable modular architecture of 3D object acquisition for manufacturing automati on. In Proceedings of the 2015 IEEE 13th International Conference on the Industrial Informatics (INDIN), Cambridge, UK, 22–24 July 2015; pp. 269–274. [Google Scholar]
- Rusu, R.B.; Marton, Z.C.; Blodow, N.; Beetz, M. Learning informative point classes for the acquisition of object model maps. In Proceedings of the 10th International Conference on Control, Automation, Robotics and Vision (ICARCV), Hanoi, Vietnam, 17–20 December 2008. [Google Scholar]
- Canny, J.F. Finding Edges and Lines in Images. Master’s Thesis, Massachusetts Institute of Technology, Artificial Intelligence Laboratory, Cambridge, MA, USA, 1983. [Google Scholar]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Rusu, R.B.; Blodow, N.; Beetz, M. Fast point feature histograms (FPFH) for 3D registration. In Proceedings of the IEEE International Conference on Robotics and Automation, Kobe, Japan, 12–17 May 2009; pp. 3212–3217. [Google Scholar]
- Tombari, F.; Salti, S.; Stefano, L.D. A combined texture-shape descriptor for enhanced 3D feature matching. In Proceedings of the 2011 18th IEEE International Conference on Image Processing, Brussels, Belgium, 11–14 September 2011; pp. 809–812. [Google Scholar]
- Nascimento, E.R.; Oliveira, G.L.; Campos, M.F.M.; Vieira, A.W.; Schwartz, W.R. Brand: A robust appearance and depth descriptor for rgb-d images. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, Vilamoura, Portugal, 7–12 October 2012; pp. 1720–1726. [Google Scholar]
- Rusu, R.B.; Bradski, G.; Thibaux, R.; Hsu, J. Fast 3d recognition and pose using the viewpoint feature histogram. In Proceedings of the 2010 IEEE/RSJ International Conference on the Intelligent Robots and Systems (IROS), Taipei, Taiwan, 18–22 October 2010; pp. 2155–2162. [Google Scholar]
- Aldoma, A.; Vincze, M.; Blodow, N.; Gossow, D.; Gedikli, S.; Rusu, R.B.; Bradski, G. Cad-model recognition and 6dof pose estimation using 3D cues. In Proceedings of the 2011 IEEE International Conference on Computer Vision Workshops (ICCV Workshops), Barcelona, Spain, 6–13 November 2011; pp. 585–592. [Google Scholar]
- Aldoma, A.; Tombari, F.; Rusu, R.B.; Vincze, M. Our-cvfh–oriented, unique and repeatable clustered viewpoint feature histogram for object recognition and 6dof pose estimation. Proceedings of Pattern Recognition: Joint 34th DAGM and 36th OAGM Symposium, Graz, Austria, 28–31 August 2012; pp. 113–122. [Google Scholar]
- Aldoma, A.; Tombari, F.; Prankl, J.; Richtsfeld, A.; Stefano, L.D.; Vincze, M. Multimodal cue integration through hypotheses verification for rgb-d object recognition and 6dof pose estimation. In Proceedings of the 2013 IEEE International Conference on Robotics and Automation, Karlsruhe, Germany, 6–10 May 2013; pp. 2104–2111. [Google Scholar]
- Lima, J.P.S.D.M.; Teichrieb, V. An efficient global point cloud descriptor for object recognition and pose estimation. In Proceedings of the 2016 29th SIBGRAPI Conference on Graphics, Patterns and Images (SIBGRAPI), Sao Paulo, Brazil, 4–7 October 2016. [Google Scholar]
- Zhang, K.; Zhang, L. 3D Object recognition and 6DoF pose estimation in scenes with occlusions and clutter based on C-SHOT 3D descriptor. J. Comput. Aided Des. Comput. Graph. 2017, 29, 846–853. (In Chinese) [Google Scholar]
- Shan, S.A.A.; Bennamoun, M.; Boussaid, F. Iterative deep learning for image set based face and object recognition. Neurocomputing 2016, 174, 866–874. [Google Scholar]
- Nafouki, K. Object Recognition and Pose Estimation from An Rgb-D Image; Technical Report; Technical University of Munich: Munich, Germany, 2016. [Google Scholar]
- Alodma, A.; Marton, Z.; Tombari, F.; Wohlkinger, W.; Potthast, C.; Zeisl, B.; Rusu, R.B.; Gedikli, S.; Vincze, M. Tutorial: Point cloud library: Three-dimensional object recognition and 6 dof pose estimation. IEEE Robot. Autom. Mag. 2012, 19, 80–91. [Google Scholar] [CrossRef]
- Luo, J.; Jiang, M. Object recognition method based on RGB-D image kernel descriptors. J. Comput. Appl. 2017, 37, 255–261. (In Chinese) [Google Scholar]
- Chen, C.-S.; Chen, P.-C.; Hsu, C.-M. Three-dimensional object recognition and registration for robotic grasping systems using a modified viewpoint feature histogram. Sensors 2016, 16, 1969. [Google Scholar] [CrossRef] [PubMed]
- Besl, P.J.; Mckay, N.D. A method for registration of 3-D shapes. IEEE Trans. Pattern Anal. Mach. Intell. 1992, 14, 239–256. [Google Scholar] [CrossRef]
- Gschwandtner, M.; Kwitt, R.; Uhl, A.; Pree, W. BlenSor: Blender sensor simulation toolbox. In Proceedings of the International Conference on Advances in Visual Computing, Las Vegas, NV, USA, 26–28 September 2011; Springer: Berlin, Germany, 2011; pp. 199–208. [Google Scholar]
- BigBIRD: (Big) Berkeley Instance Recognition Dataset. Available online: http://rll.berkeley.edu/bigbird/ (accessed on 12 January 2019).




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Procedure | Average Time (ms) | Average RMSE (m) |
|---|---|---|---|
| VFH + ICP | Description | 1.694 | 3.219 × 10−5 |
| Pose refinement | 855.172 | ||
| OVFH + ICP | Reference frame estimation | 10.767 | 1.391 × 10−5 |
| Description | 1.832 | ||
| Pose refinement | 533.613 |
| Object | VFH + ICP | OVFH + ICP | |||||
|---|---|---|---|---|---|---|---|
| Pose Distinction Rate (%) | Average Time (s) | Average RMSE (m) | Pose Distinction Rate (%) | Average Time (s) | Average RMSE (m) | ||
| A | 60 | 0.878 | 3.388 × 10−5 | 100 | 0.428 | 1.543 × 10−5 | |
| B | 70 | 0.973 | 6.895 × 10−5 | 100 | 0.574 | 2.258 × 10−6 | |
| C | 90 | 0.676 | 1.674 × 10−5 | 100 | 0.471 | 2.852 × 10−6 | |
| D | 70 | 0.747 | 1.044 × 10−5 | 90 | 0.338 | 2.994 × 10−6 | |
| E | 80 | 1.079 | 6.611 × 10−5 | 100 | 0.775 | 2.415 × 10−6 | |
| F | 100 | 0.501 | 4.317 × 10−6 | 100 | 0.494 | 4.062 × 10−6 | |
| G | 100 | 0.672 | 6.213 × 10−6 | 100 | 0.647 | 6.429 × 10−6 | |
| H | 100 | 0.446 | 5.379 × 10−6 | 100 | 0.457 | 5.240 × 10−6 | |
| Average Value | 83.75 | 0.747 | 2.650 × 10−5 | 98.75 | 0.523 | 5.210 × 10−6 | |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, F.; Liang, C.; Ru, C.; Cheng, H. An Improved Point Cloud Descriptor for Vision Based Robotic Grasping System. Sensors 2019, 19, 2225. https://doi.org/10.3390/s19102225
Wang F, Liang C, Ru C, Cheng H. An Improved Point Cloud Descriptor for Vision Based Robotic Grasping System. Sensors. 2019; 19(10):2225. https://doi.org/10.3390/s19102225
Chicago/Turabian StyleWang, Fei, Chen Liang, Changlei Ru, and Hongtai Cheng. 2019. "An Improved Point Cloud Descriptor for Vision Based Robotic Grasping System" Sensors 19, no. 10: 2225. https://doi.org/10.3390/s19102225
APA StyleWang, F., Liang, C., Ru, C., & Cheng, H. (2019). An Improved Point Cloud Descriptor for Vision Based Robotic Grasping System. Sensors, 19(10), 2225. https://doi.org/10.3390/s19102225