Road Environment Semantic Segmentation with Deep Learning from MLS Point Cloud Data





Abstract
:1. Introduction
2. Related Work
3. Methodology
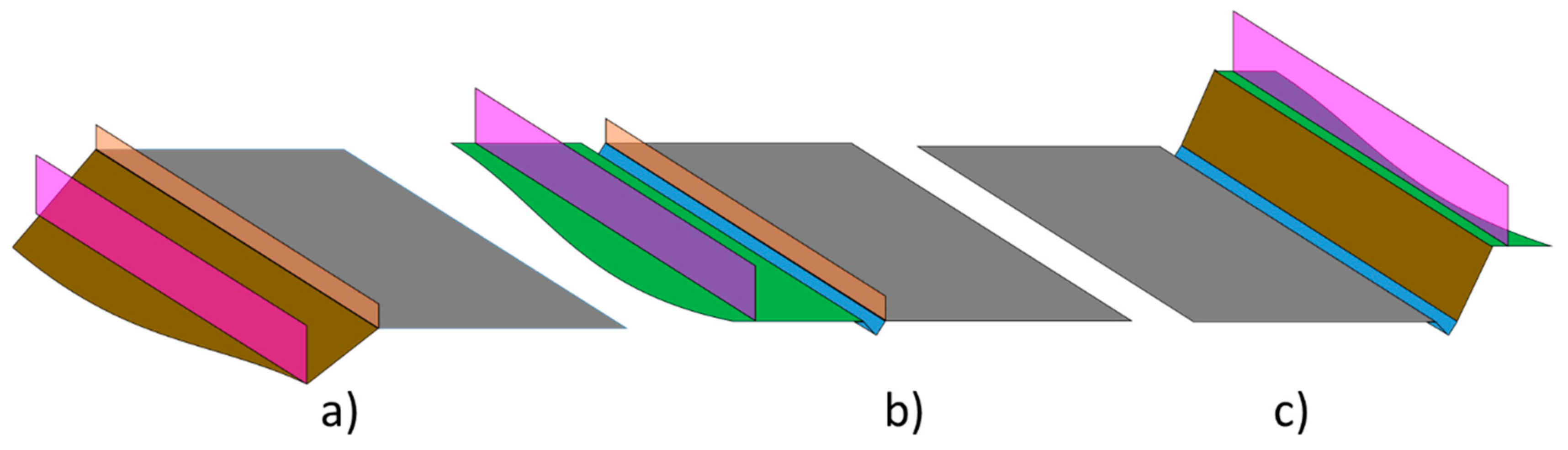
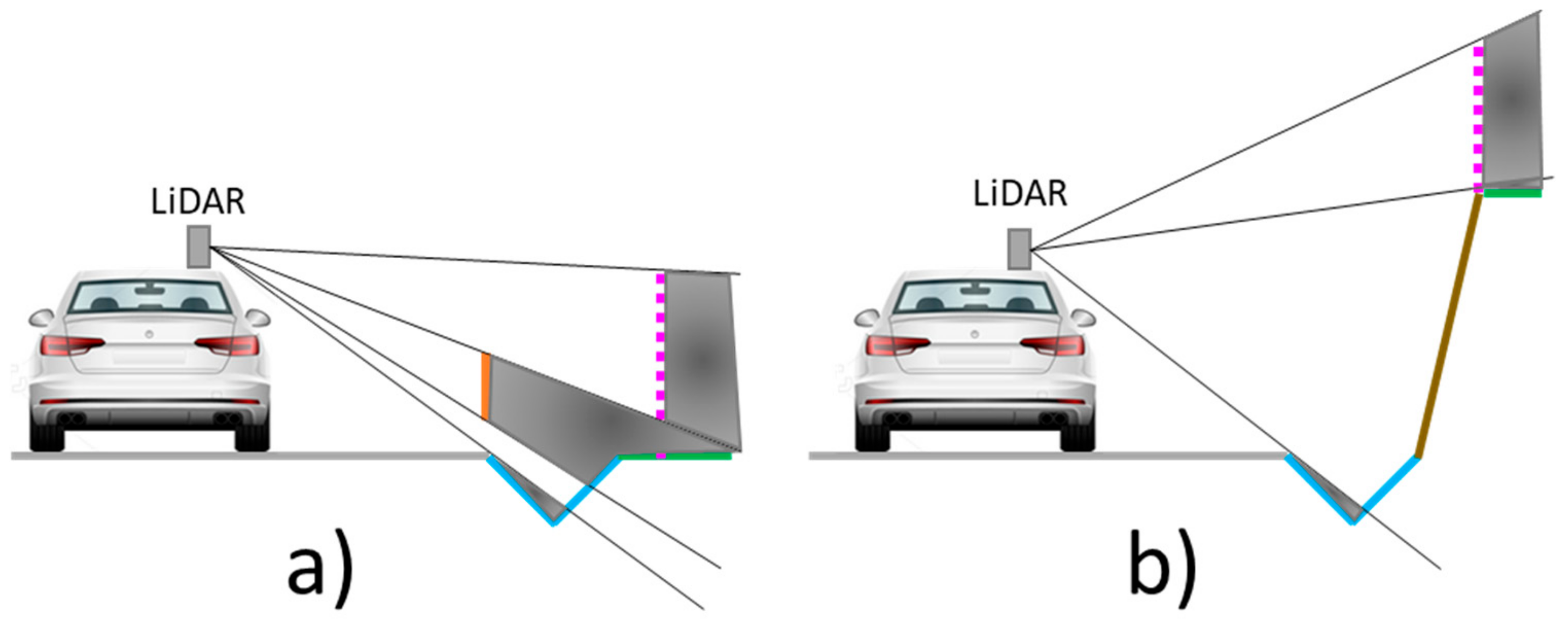
3.1. Element Distribution in Road Environment
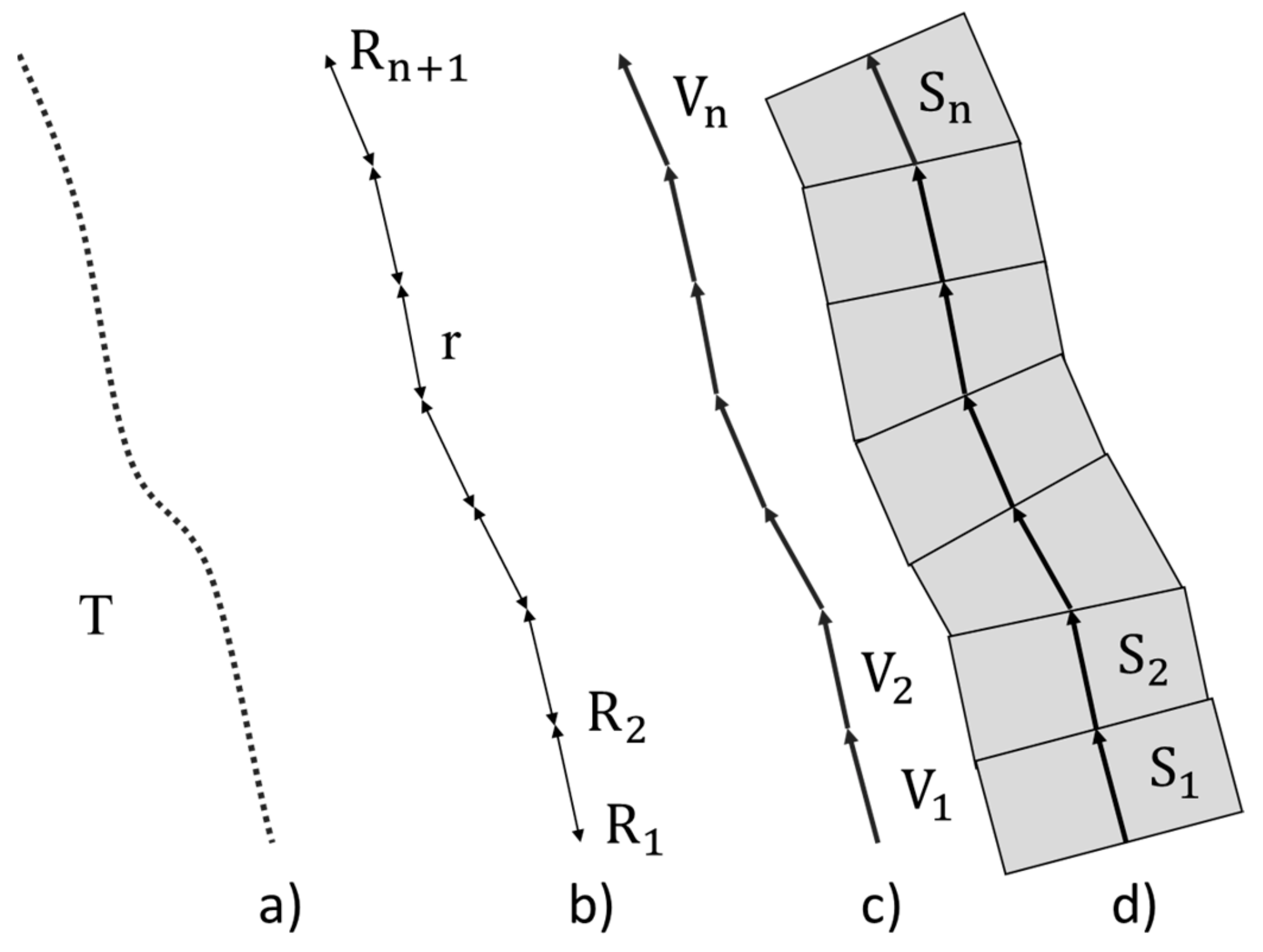
3.2. Sample Generation
3.3. Semantic Segmentation
4. Experiments
4.1. Case Study
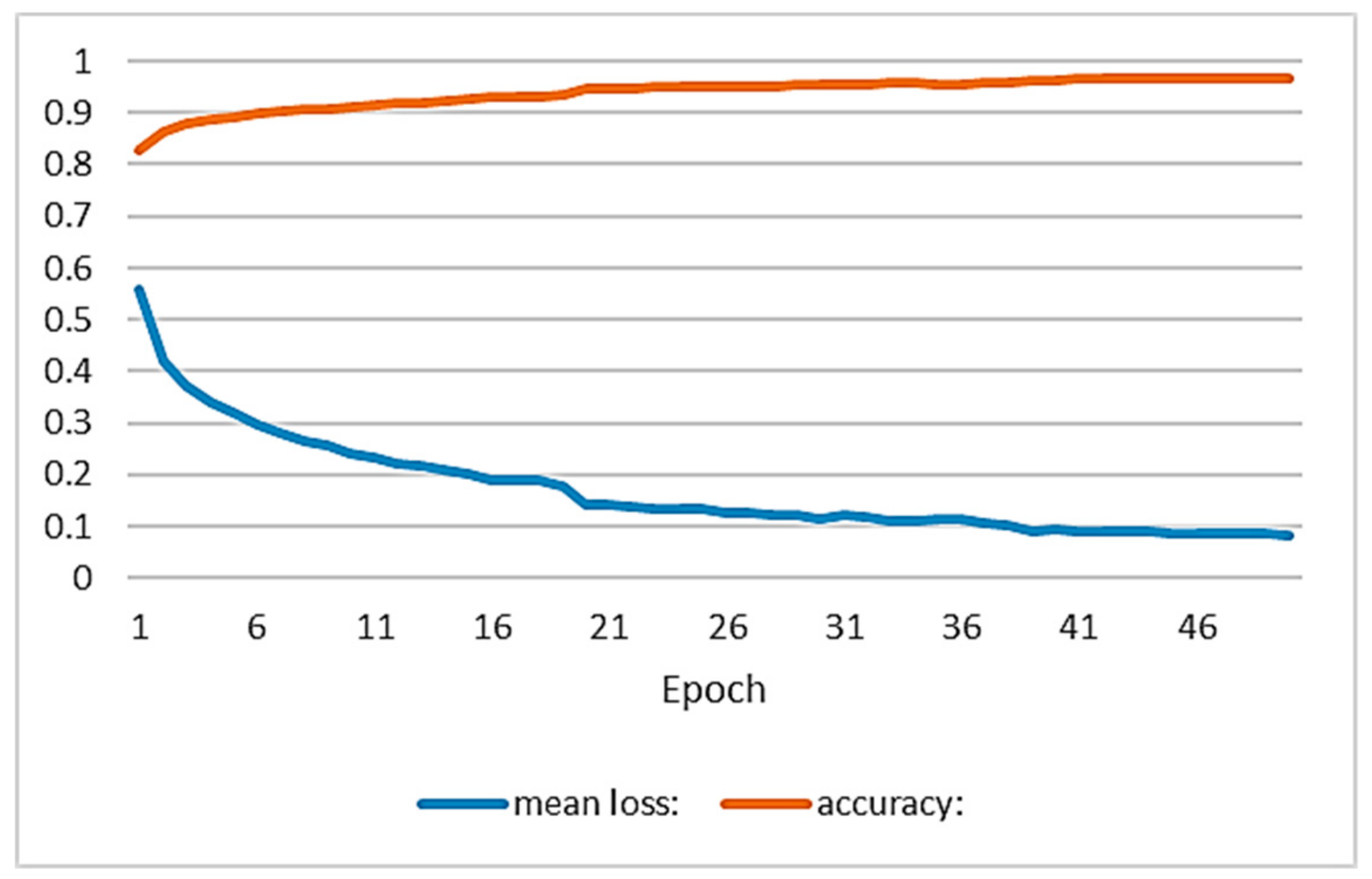
4.2. Training
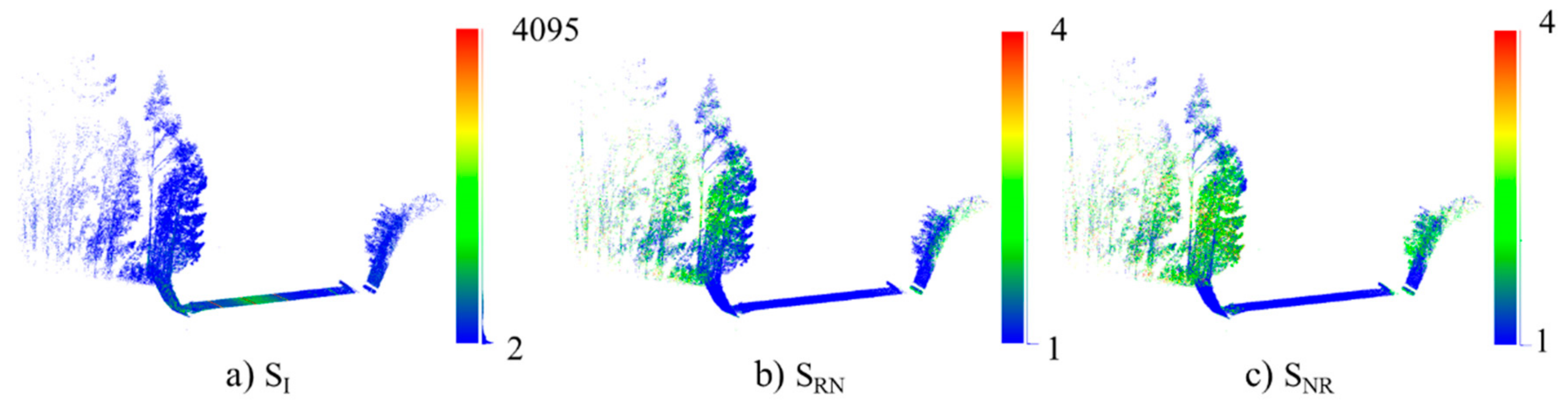
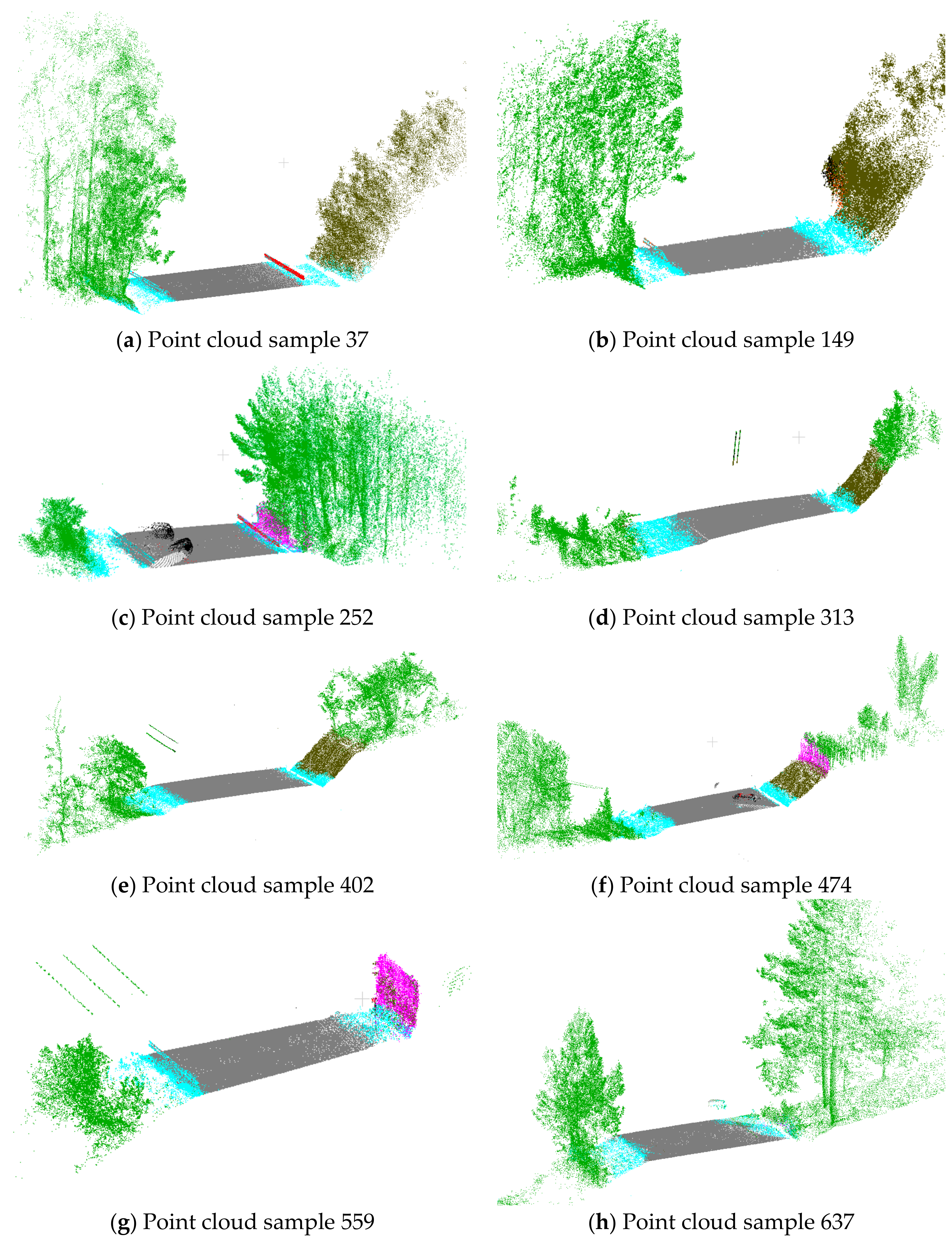
4.3. Results
4.4. Comparison with Results Obtained Using ANN
4.5. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Darms, M.; Rybski, P.; Urmson, C. Classification and tracking of dynamic objects with multiple sensors for autonomous driving in urban environments. In Proceedings of the IEEE Intelligent Vehicles Symposium, Eindhoven, The Netherlands, 4–6 June 2008; pp. 1197–1202. [Google Scholar]
- Wang, H.; Wang, B.; Liu, B.; Meng, X.; Yang, G. Pedestrian recognition and tracking using 3D LiDAR for autonomous vehicle. Rob. Auton. Syst. 2017, 88, 71–78. [Google Scholar] [CrossRef]
- Wirges, S.; Fischer, T.; Stiller, C.; Frias, J.B. Object detection and classification in occupancy grid maps using deep convolutional networks. In Proceedings of the IEEE Conference on Intelligent Transportation Systems ITSC, Maui, HI, USA, 4–7 November 2018; Volume 2018. [Google Scholar]
- Soilán, M.; Riveiro, B.; Martínez-Sánchez, J.; Arias, P. Traffic sign detection in MLS acquired point clouds for geometric and image-based semantic inventory. ISPRS J. Photogramm. Remote Sens. 2016, 114, 92–101. [Google Scholar] [CrossRef]
- Liu, Z.; Wang, J.; Liu, D. A new curb detection method for unmanned ground vehicles using 2D sequential laser data. Sensors 2013, 13, 1102–1120. [Google Scholar] [CrossRef] [PubMed]
- Balado, J.; Díaz-Vilariño, L.; Arias, P.; Garrido, I. Point Clouds to Indoor/Outdoor Accessibility Diagnosis. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2017, 4, 18–22. [Google Scholar] [CrossRef]
- Talebpour, A.; Mahmassani, H.S. Influence of connected and autonomous vehicles on traffic flow stability and throughput. Transp. Res. Part C Emerg. Technol. 2016, 71, 143–163. [Google Scholar] [CrossRef]
- Ros, G.; Sellart, L.; Materzynska, J.; Vazquez, D.; Lopez, A.M. The SYNTHIA dataset: A large collection of synthetic images for semantic segmentation of urban scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 3234–3243. [Google Scholar]
- Alvarez, J.M.; LeCun, Y.; Gevers, T.; Lopez, A.M. Semantic road segmentation via multi-scale ensembles of learned features. In Computer Vision—ECCV 2012, Proceedings of the Computer Vision—ECCV 2012. Workshops and Demonstrations, Florence, Italy, 7–13 October 2012; Fusiello, A., Murino, V., Cucchiara, R., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 586–595. [Google Scholar]
- Xiao, L.; Wang, R.; Dai, B.; Fang, Y.; Liu, D.; Wu, T. Hybrid conditional random field based camera-LIDAR fusion for road detection. Inf. Sci. 2018, 432, 543–558. [Google Scholar] [CrossRef]
- Han, X.; Wang, H.; Lu, J.; Zhao, C. Road detection based on the fusion of Lidar and image data. Int. J. Adv. Robot. Syst. 2017, 14, 1729881417738102. [Google Scholar] [CrossRef]
- Gu, S.; Lu, T.; Zhang, Y.; Alvarez, J.M.; Yang, J.; Kong, H. 3-D LiDAR + Monocular Camera: An Inverse-Depth-Induced Fusion Framework for Urban Road Detection. IEEE Trans. Intell. Veh. 2018, 3, 351–360. [Google Scholar] [CrossRef]
- Caltagirone, L.; Bellone, M.; Svensson, L.; Wahde, M. LIDAR–camera fusion for road detection using fully convolutional neural networks. Rob. Auton. Syst. 2019, 111, 125–131. [Google Scholar] [CrossRef]
- Wu, B.; Wan, A.; Yue, X.; Keutzer, K. SqueezeSeg: Convolutional Neural Nets with Recurrent CRF for Real-Time Road-Object Segmentation from 3D LiDAR Point Cloud. arXiv 2017, arXiv:1710.07368. [Google Scholar]
- Caltagirone, L.; Scheidegger, S.; Svensson, L.; Wahde, M. Fast LIDAR-based road detection using fully convolutional neural networks. In Proceedings of the IEEE Intelligent Vehicles Symposium (IV), Redondo Beach, CA, USA, 11–14 June 2017; pp. 1019–1024. [Google Scholar]
- Kumar, P.; Lewis, P.; McCarthy, T. The Potential of Active Contour Models in Extracting Road Edges from Mobile Laser Scanning Data. Infrastructures 2017, 2, 9. [Google Scholar] [CrossRef]
- Gu, S.; Zhang, Y.; Yang, J.; Kong, H. Lidar-based urban road detection by histograms of normalized inverse depths and line scanning. In Proceedings of the European Conference on Mobile Robots (ECMR), Paris, France, 6–8 September 2017; pp. 1–6. [Google Scholar]
- Zhang, W. LIDAR-based road and road-edge detection. In Proceedings of the 2010 IEEE Intelligent Vehicles Symposium, San Diego, CA, USA, 24–24 June 2010; pp. 845–848. [Google Scholar]
- Yu, Y.; Li, J.; Guan, H.; Jia, F.; Wang, C. Learning Hierarchical Features for Automated Extraction of Road Markings From 3-D Mobile LiDAR Point Clouds. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 709–726. [Google Scholar] [CrossRef]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. PointNet: Deep learning on point sets for 3D classification and segmentation. In Proceedings of the 2016 Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 652–660. [Google Scholar]
- Gong, J.; Zhou, H.; Gordon, C.; Jalayer, M. Mobile Terrestrial Laser Scanning for Highway Inventory Data Collection; American Society of Civil Engineers: Reston, VA, USA, 2012; ISBN 978-0-7844-1234-3. [Google Scholar]
- Manduchi, R.; Castano, A.; Talukder, A.; Matthies, L. Obstacle Detection and Terrain Classification for Autonomous Off-Road Navigation. Auton. Robot. 2005, 18, 81–102. [Google Scholar] [CrossRef] [Green Version]
- Jaakkola, A.; Hyyppä, J.; Hyyppä, H.; Kukko, A. Retrieval Algorithms for Road Surface Modelling Using Laser-Based Mobile Mapping. Sensors 2008, 8, 5238–5249. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pu, S.; Rutzinger, M.; Vosselman, G.; Oude Elberink, S. Recognizing basic structures from mobile laser scanning data for road inventory studies. ISPRS J. Photogramm. Remote Sens. 2011, 66, S28–S39. [Google Scholar] [CrossRef]
- Hervieu, A.; Soheilian, B. Semi-Automatic Road/Pavement Modeling using Mobile Laser Scanning. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2013, 2, 31–36. [Google Scholar] [CrossRef]
- Cabo, C.; Ordoñez, C.; García-Cortés, S.; Martínez, J. An algorithm for automatic detection of pole-like street furniture objects from Mobile Laser Scanner point clouds. ISPRS J. Photogramm. Remote Sens. 2014, 87, 47–56. [Google Scholar] [CrossRef]
- Cabo, C.; Kukko, A.; García-Cortés, S.; Kaartinen, H.; Hyyppä, J.; Ordoñez, C. An Algorithm for Automatic Road Asphalt Edge Delineation from Mobile Laser Scanner Data Using the Line Clouds Concept. Remote Sens. 2016, 8, 740. [Google Scholar] [CrossRef]
- Scharwächter, T.; Schuler, M.; Franke, U. Visual guard rail detection for advanced highway assistance systems. In Proceedings of the IEEE Intelligent Vehicles Symposium Proceedings, Dearborn, MI, USA, 8–11 June 2014; pp. 900–905. [Google Scholar]
- Jiang, Y.; He, B.; Liu, L.; Ai, R.; Lang, X. Effective and robust corrugated beam guardrail detection based on mobile laser scanning data. In Proceedings of the IEEE 19th International Conference on Intelligent Transportation Systems (ITSC), Rio de Janeiro, Brazil, 1–4 November 2016; pp. 1540–1545. [Google Scholar]
- Kiss, K.; Malinen, J.; Tokola, T. Comparison of high and low density airborne lidar data for forest road quality assessment. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2016, 167–172. [Google Scholar] [CrossRef]
- Hu, K.; Wang, T.; Li, Z.; Chen, D.; Li, X. Real-time extraction method of road boundary based on three-dimensional lidar. J. Phys. 2018, 1074, 012080. [Google Scholar] [CrossRef] [Green Version]
- Brostow, G.j.; Shotton, J.; Fauqueur, J.; Cipolla, R. Segmentation and recognition using structure from motion point clouds. In Proceedings of the 10th European Conference on Computer Vision, Marseille, France, 12–18 October 2008; Volume 5302. [Google Scholar]
- Roelens, J.; Höfle, B.; Dondeyne, S.; Van Orshoven, J.; Diels, J. Drainage ditch extraction from airborne LiDAR point clouds. ISPRS J. Photogramm. Remote Sens. 2018, 146, 409–420. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, Q.; Lu, H.; Liu, X.; Huang, X.; Song, C.; Huang, S.; Huang, J. Optimized 3D Street Scene Reconstruction from Driving Recorder Images. Remote Sens. 2015, 7, 9091–9121. [Google Scholar] [CrossRef] [Green Version]
- Oliveira, G.L.; Burgard, W.; Brox, T. Efficient deep models for monocular road segmentation. In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Korea, 9–14 October 2016; pp. 4885–4891. [Google Scholar]
- Ros, G.; Stent, S.; Alcantarilla, P.F.; Watanabe, T. Training Constrained Deconvolutional Networks for Road Scene Semantic Segmentation. arXiv 2016, arXiv:1604.01545. [Google Scholar]
- Engelmann, F.; Kontogianni, T.; Hermans, A.; Leibe, B. Exploring spatial context for 3D semantic segmentation of point clouds. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Wu, B.; Zhou, X.; Zhao, S.; Yue, X.; Keutzer, K. SqueezeSegV2: Improved Model Structure and Unsupervised Domain Adaptation for Road-Object Segmentation from a LiDAR Point Cloud. arXiv 2018, arXiv:1809.08495. [Google Scholar]
- Deng, L.; Yang, M.; Li, H.; Li, T.; Hu, B.; Wang, C. Restricted Deformable Convolution based Road Scene Semantic Segmentation Using Surround View Cameras. arXiv 2018, arXiv:1801.00708. [Google Scholar]
- Wang, P.; Chen, P.; Yuan, Y.; Liu, D.; Huang, Z.; Hou, X.; Cottrell, G. Understanding convolution for semantic segmentation. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 1451–1460. [Google Scholar]
- Roynard, X.; Deschaud, J.-E.; Goulette, F. Classification of Point Cloud Scenes with Multiscale Voxel Deep Network. arXiv 2018, arXiv:1804.03583. [Google Scholar]
- Ye, X.; Li, J.; Huang, H.; Du, L.; Zhang, X. 3D Recurrent neural networks with context fusion for point cloud semantic segmentation. In Computer Vision—ECCV 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 415–430. [Google Scholar]
- Chen, Y.; Li, W.; Van Gool, L. ROAD: Reality oriented adaptation for semantic segmentation of urban scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Balado, J.; Díaz-Vilariño, L.; Arias, P.; Soilán, M. Automatic building accessibility diagnosis from point clouds. Autom. Constr. 2017, 82, 103–111. [Google Scholar] [CrossRef] [Green Version]
- Griffiths, D.; Boehm, J. A Review on Deep Learning Techniques for 3D Sensed Data Classification. Remote Sens. 2019, 11, 1499. [Google Scholar] [CrossRef]
- Balado, J.; Arias, P.; Díaz-Vilariño, L.; González-deSantos, L.M. Automatic CORINE land cover classification from airborne LIDAR data. Procedia Comput. Sci. 2018, 126, 186–194. [Google Scholar] [CrossRef]
- Puente, I.; González-Jorge, H.; Martínez-Sánchez, J.; Arias, P. Review of mobile mapping and surveying technologies. Meas. J. Int. Meas. Confed. 2013, 46, 2127–2145. [Google Scholar] [CrossRef]
- Balado, J.; Díaz-Vilariño, L.; Arias, P.; González-Jorge, H. Automatic classification of urban ground elements from mobile laser scanning data. Autom. Constr. 2018, 86, 226–239. [Google Scholar] [CrossRef] [Green Version]
- Babahajiani, P.; Fan, L.; Gabbouj, M. Object recognition in 3D point cloud of urban street scene. In Computer Vision—ACCV 2014 Workshops; Jawahar, C.V., Shan, S., Eds.; Springer International Publishing: Cham, Swizerland, 2015; pp. 177–190. [Google Scholar]
- Weinmann, M.; Jutzi, B.; Hinz, S.; Mallet, C. Semantic point cloud interpretation based on optimal neighborhoods, relevant features and efficient classifiers. ISPRS J. Photogramm. Remote Sens. 2015, 105, 286–304. [Google Scholar] [CrossRef]
- Su, H.; Jampani, V.; Sun, D.; Maji, S.; Kalogerakis, V.; Yang, M.-H.; Kautz, J. SPLATNet: Sparse lattice networks for point cloud processing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 19–21 June 2018. [Google Scholar]
- Thomas, H.; Qi, C.R.; Deschaud, J.-E.; Marcotegui, B.; Goulette, F.; Guibas, L.J. KPConv: Flexible and Deformable Convolution for Point Clouds. arXiv 2019, arXiv:1904.08889. [Google Scholar] [Green Version]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref\Pred | Road S. | Ditch | Embank | Guard | Border | Fences | Objects | TOTAL |
|---|---|---|---|---|---|---|---|---|
| road surface | 668.5 | 14.5 | 0.2 | 1.1 | 9.5 | 0.3 | 1.1 | 695.1 |
| ditch | 21.6 | 134.4 | 8.0 | 2.0 | 36.7 | 2.1 | 0.5 | 205.5 |
| embank. | 0.9 | 10.9 | 283.1 | 0.1 | 22.9 | 2.5 | 0.2 | 320.5 |
| guardrail | 3.7 | 4.8 | 0.1 | 17.9 | 1.0 | 0.1 | 0.1 | 27.7 |
| border | 39.2 | 28.3 | 21.1 | 1.1 | 2450.7 | 7.9 | 15.5 | 2563.8 |
| fences | 0.4 | 1.4 | 4.1 | 0.2 | 6.8 | 23.0 | 0.0 | 35.9 |
| objects | 1.7 | 0.9 | 0.2 | 0.6 | 15.5 | 0.8 | 17.5 | 37.3 |
| TOTAL | 736.0 | 195.2 | 316.8 | 22.9 | 2543.2 | 36.7 | 35.0 |
| Ref\Pred | Road Surface | Ditch | Embankments | Guardrail | Border | Fences | Objects |
|---|---|---|---|---|---|---|---|
| road surface | 96.2% | 2.1% | 0.0% | 0.2% | 1.4% | 0.0% | 0.2% |
| ditch | 10.5% | 65.4% | 3.9% | 1.0% | 17.9% | 1.0% | 0.2% |
| embankments | 0.3% | 3.4% | 88.3% | 0.0% | 7.1% | 0.8% | 0.1% |
| guardrail | 13.3% | 17.4% | 0.4% | 64.5% | 3.8% | 0.3% | 0.4% |
| border | 1.5% | 1.1% | 0.8% | 0.0% | 95.6% | 0.3% | 0.6% |
| fences | 1.1% | 3.8% | 11.4% | 0.5% | 19.0% | 64.1% | 0.1% |
| objects | 4.7% | 2.3% | 0.6% | 1.6% | 41.7% | 2.1% | 47.0% |
| Method\Class | Road Surface | Ditch | Embankments | Guardrail | Border | Fences | Objects |
|---|---|---|---|---|---|---|---|
| PointNet | 0.962 | 0.654 | 0.883 | 0.645 | 0.956 | 0.641 | 0.470 |
| ANN | 0.964 | 0.503 | 0.360 | 0.836 | 0.386 | 0.644 | 0.279 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Balado, J.; Martínez-Sánchez, J.; Arias, P.; Novo, A. Road Environment Semantic Segmentation with Deep Learning from MLS Point Cloud Data. Sensors 2019, 19, 3466. https://doi.org/10.3390/s19163466
Balado J, Martínez-Sánchez J, Arias P, Novo A. Road Environment Semantic Segmentation with Deep Learning from MLS Point Cloud Data. Sensors. 2019; 19(16):3466. https://doi.org/10.3390/s19163466
Chicago/Turabian StyleBalado, Jesús, Joaquín Martínez-Sánchez, Pedro Arias, and Ana Novo. 2019. "Road Environment Semantic Segmentation with Deep Learning from MLS Point Cloud Data" Sensors 19, no. 16: 3466. https://doi.org/10.3390/s19163466
APA StyleBalado, J., Martínez-Sánchez, J., Arias, P., & Novo, A. (2019). Road Environment Semantic Segmentation with Deep Learning from MLS Point Cloud Data. Sensors, 19(16), 3466. https://doi.org/10.3390/s19163466