1. Introduction
Unmanned Surface vehicles (USVs), also known as autonomous surface crafts, have attracted worldwide attention in commercial, scientific and military fields recently. USVs have the advantages of low operation and maintenance costs, reduced casualty risk, and good maneuverability and deployability for different operating conditions [
1]. With the aid of effective and reliable navigation equipment, such as global positioning systems (GPS), wireless communication units, and various types of sensors, USVs can be employed cost-efficiently for a variety of applications, including underwater surveying [
2], pollutant tracking [
3], acoustic navigation [
4], marine rescue [
5], and obstacle detection [
6]. Although rapid progress of corresponding techniques for USV systems have been achieved in recent times, it is still challenging in promoting the level of USV autonomy when faced with complex or hazardous environments. Key issues, including hull hydrodynamics, communication techniques, and navigation, guidance and control (NGC) strategies, require further developments.
As a vital component of USV guidance systems, path planning is of critical importance in designing and updating feasible and optimal trajectories for the control system on basis of navigation information, mission demands, and environmental conditions. Its effectiveness not only determines the autonomy of unmanned vehicles, but also affects the reliability and efficiency of mission execution. From the literature, plenty of intelligent techniques have been employed in the USV path planner [
7]. Meanwhile, it is a research hot pot to propose an algorithm having fast convergence speed, admirable robustness, low computation consumption, and satisfactory route planning.
The USV path planning problem is normally formulated as a travelling salesman problem (TSP), which is a typical combinatorial optimization problem. The specific description is to find a shortest loop that passes through all target cities without repetition. However, when a USV performs multi-objective tasks in a complex marine environment, the number of possible paths increases exponentially with the increase of target points’ number, resulting in the so-called “exponential explosion”. In this circumstance, traditional algorithms, such as the exhaustive method and branch-and-bound algorithm, are unable to find the optimal solution within reasonable time cost. Hence, it is vital to develop efficient and feasible heuristic algorithms instead of traditional methods to solve this kind of problem, although the optimality, accuracy, and completeness becomes sacrificed for running speed to some degree. Commonly used heuristic algorithms include elephant search algorithm (ESA) [
8], genetic algorithm (GA) [
9], particle swam optimization (PSO) [
10], firefly algorithm (FA) [
11], grey wolf optimizer (GWO) [
12], and so on.
However, the conventional type of each method has its inherent limitation. For instance, it is known that the ESA provides a random and improper replacement for an elephant with the worst fitness, which is likely to result in the deterioration of search space. The conventional GA has inherent issues of slow convergence speed, poor capability of local search and easy occurrence of premature convergence. In other words, the loss of population diversity is likely to appear during the implementation of GA, making individual genes tend to be same and terminating the search at local optimum. Additionally, the use of a real-number code also generates repetitive genes during crossover operations, which affects convergence speed greatly. For the PSO, the lack of a balanced mechanism would lead to the loss of population diversity and finally being trapped into the local optimum. In addition, the FA only considers the distance and maximum attractive force between two fireflies, and has intrinsic shortcomings of poor search capability during early iterations and severe oscillations around the optimal solution during later iterations. In terms of the GWO, the search mechanism of judging distance from prey would lead to a slow convergence speed for later iterations. Nowadays, it has become a tendency to combine two or more algorithms, making full use of their respective advantages to enhance the algorithm effectiveness.
Inspired by the combination strategy, this work optimizes the conventional PSO method by introducing a greedy mechanism to generate partial particles and 2-opt operation to eliminate path-crossing phenomena. Comparative study with some state-of-the-art algorithms is conducted to verify the effectiveness and reliability of the improved method in terms of solution quality, algorithm robustness, and computing efficiency. Then the improved algorithm is adopted to generate a feasible closed trajectory for a self-developed USV to follow in real marine environments.
It is worth noting that this work has certain connections and essential differences with our two recently published works [
13,
14]. In the first work, we optimized GA by multi-domain inversion for the purpose of increasing the number of offsprings. The inspiration comes from the biological theory foundation, where the number of offsprings needs to be larger than the number of parents so as to prevent species extinction and maintain species diversity in the process of biological evolution. In the other work, we optimized PSO by iteratively adjusting the control parameters of the PSO algorithm, such as inertia weight and acceleration coefficients, and introducing merit-based selection and uncertain mutation. The optimization is from the point of view of global searching. However, in this work, we start form the inspiration of the combination strategy of several intelligent algorithms and introduce the greedy mechanism and 2-opt operation in order to optimize the local search of PSO.
The main contributions of this work are as follows: (1) a greedy black box is established to generate the initial swarm of particles which avoids the randomness of the traditional method; (2) the strategy of greedy selection guarantees particles to move towards a higher fitness level and keeps the swarm diversity; (3) the 2-opt operation performs effectively in maintaining locally optimal fragments of relatively inferior particles and eliminate path crossovers; (4) the improved algorithm has been successfully applied to the path planning subsystem of a USV model with the aid of multi-sensors.
The rest of the paper is organized as follows. A brief literature review is presented in
Section 2 on the research status of the GSM and PSO methods. The conventional and improved PSO algorithms are introduced concisely in
Section 3. Results of Monte-Carlo simulations and sea trials are given in
Section 4. Conclusions are drawn and future researching interests are suggested in
Section 5.
4. Results and Discussions
In this section, the computational results are presented in detail. First, a quantitative comparison between the improved PSO and three existing algorithms is depicted in
Section 4.1. Then, in
Section 4.2, the improved PSO is applied to design feasible paths for a self-developed unmanned surface vehicle (USV) in real marine environments. Note that all algorithms are implemented in MATLAB
® using a i7-7700hq laptop (brand: ASUS, model: FX53VD) with 2.80 GHz and 8.0 GB RAM.
4.1. Comparison between Improved PSO with Existing Algorithms
Two other existing algorithms, the conventional genetic algorithm (CGA) and ant colony optimization (ACO) algorithm, are selected to compare with conventional PSO (CPSO) and improved PSO (IPSO) in this section. Eight instances from TSPLIB are used: eil51, rat99, kroa100, lin105, ch150, kroa200, tsp225, and lin318. For the purpose of eliminating algorithm randomness in MATLAB
® operation environment, one hundred Monte-Carlo simulations are performed to obtain the data set of the optimal route distance (
D) for each instance and each algorithm. Furthermore, the control parameters for each algorithm are shown in
Table 1 to facilitate the replicability of this work. It is worth highlighting that the maximum number of iterations (
MAX) depends on the number of planned points. It is determined through preliminary tests, pursuing the balance between complete convergence and economical time consumption. Corresponding with the eight instances, the
MAXs are 300, 400, 500, 600, 700, 800, 900, and 1000, respectively.
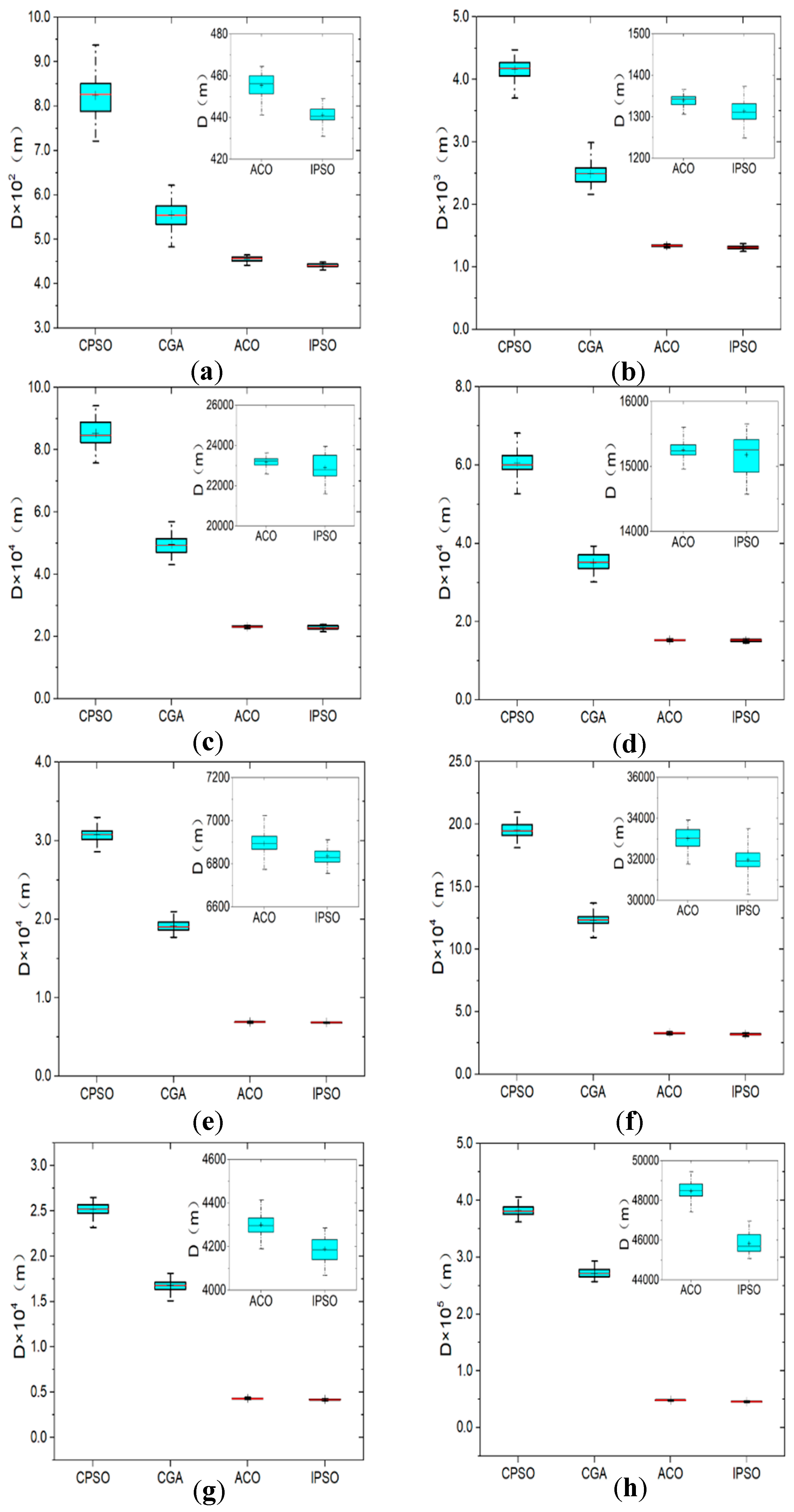
Figure 4 presents the comparative results in the form of box-and-whisker plots. The legend refers to the explanation by Spear [
37]. In every plot, a blue range bar is drawn to represent the interquartile range of the data set. It could reflect the degree of data dispersion, or the algorithm robustness to some extent. Moreover, a red line and a plus symbol are drawn in the bar to identify the median and average values of data set. There are also two whiskers extending on both sides of the bar, whose ends stand for the best and worst values, respectively. Results of ACO and IPSO is enlarged at the top right due to their minor difference. Furthermore, detailed information is provided in
Table 2, including the known optimal solution (KOS) form of, average value (AVG), standard deviation (SD), relatively percentage error (RPE) and critical iteration number (
Mcri). It should be noted that the SD is calculated to show how far all the data points (
Dk) depart from the average which is the quantification of algorithm robustness. In addition, the RPE is defined to reflect the gap between the average solution with the KOS from TSPLIB. The best values of the AVG among the four algorithms for the eight instances are given in bold and highlighted in grey. The SD and RPE are defined as:
In general, the CPSO and the CGA obtain worse solutions with larger average values and larger degrees of data dispersion for all the eight instances. There is a vast promotion room for their effectiveness. By contrast, the ACO and the IPSO show similar and satisfactory performance especially when more planned points are considered. By observing enlarged images, the IPSO could find a shorter route despite a relatively worse robustness. For the instance of lin105, the CPSO gives an exaggerated solution with the AVG of 60625 m and the SD of 2978 m. However, with the aid of the greedy mechanism and 2-opt, the IPSO effectively reduces the AVG by 74.9%, and the SD by 89.3%. For tsp225, the average optimal route distance of the ACO and IPSO are 4300 m and 4188 m, respectively. The SD value of the IPSO is only 0.6% larger than that of the ACO. In addition, it is found that the difference between the AVG of the IPSO and the KOS from TSPLIB is below 10% for all the instances.
Moreover,
Figure 5 shows the evolution history of the optimal path distance (
D) against iteration (
m) for each algorithm. Overall, the curve of each algorithm has similar development tendency. An obvious decrease in
D occurs with the increase of iterations until a critical iteration number (
Mcri) after which the solution achieves convergence. In this work, the criterion of
Mcri is utilized to evaluate the convergence speed or computing efficiency of each algorithm. It is found that the CPSO converges rapidly and terminates at a smallest
Mcri. Obviously, it results in being trapped into the local optimum with the longest path distance. The CGA has incredibly slow convergence speed for all instances when compared with the other three algorithms. This behavior helps to find a relatively better solution than the CPSO. Meanwhile, the IPSO and ACO are neck to neck in convergence speed and optimal route distance after convergence. For the instance of kroa100, 446 iterations are required for the CGA to achieve the convergence, seven times more than that for the CPSO. As a result, the CGA could reduce the average optimal route distance by about 42.9%. Moreover, the critical iteration numbers for the IPSO and CPSO are 113 and 62, respectively. The 82% increase of
Mcri makes the AVG value reduce from 85243.19 to 22981.74 m. It seems necessary to slow down the convergence speed appropriately in exchange for a high-quality solution.
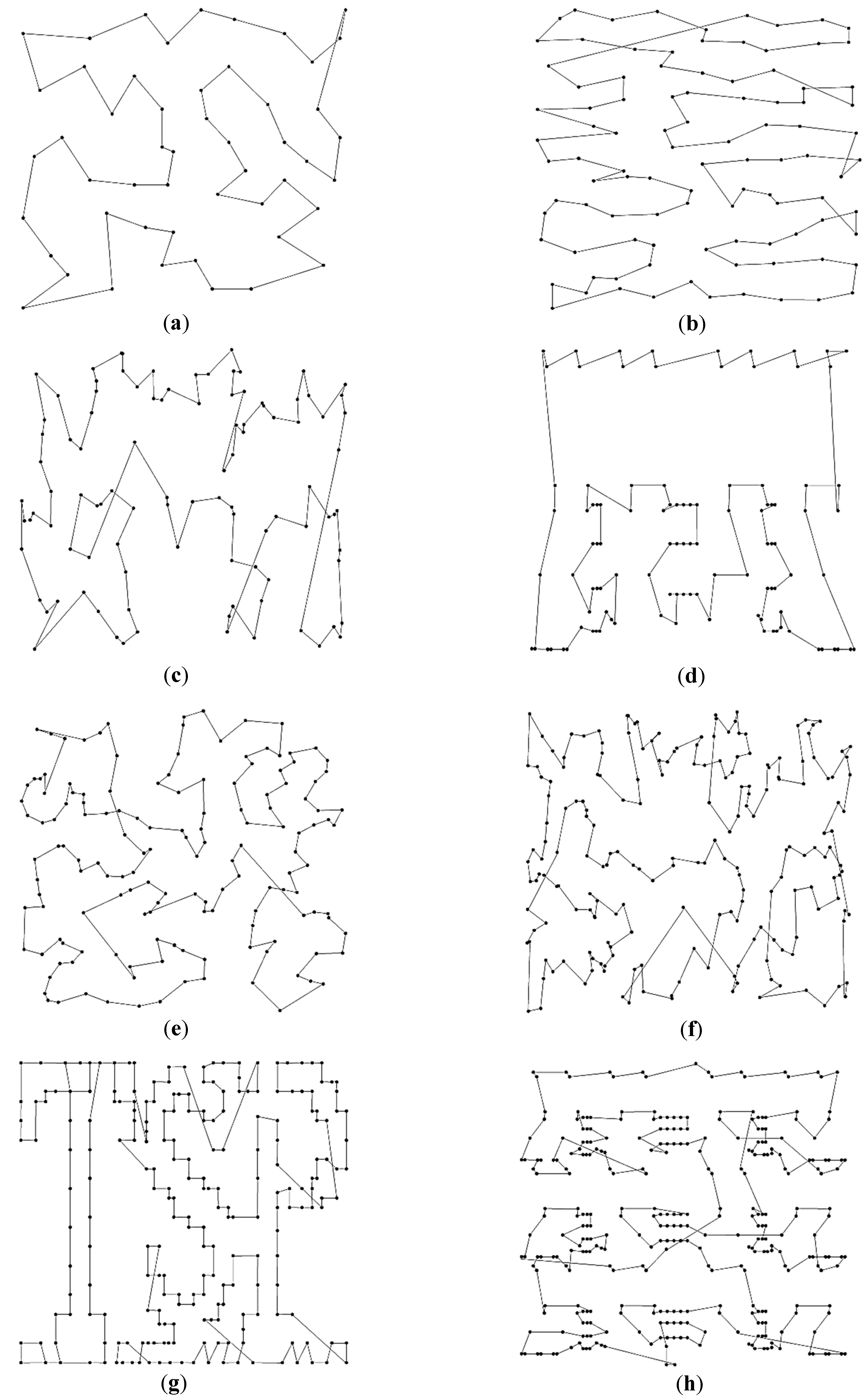
Since the CPSO and CGA would present chaotic routes for the eight TSPLIB instances, only the best trajectories generated by the ACO and IPSO are shown in
Figure 6 and
Figure 7, respectively. It can be visualized that the routes of ACO have different levels of path-crossing phenomenon, especially when considering more planned points. However, no path-crossing exists in the routes of the IPSO. It is the application of the 2-opt operation and the greedy selection strategy that helps avoid the intersection of route effectively and reduce the path complexity. This is also the reason why a longer path is obtained by the ACO than the IPSO under the same condition. The results indicate that it is crucial to retard the progress of convergence in order to improve the solution quality and to avoid being trapped into local optima.
4.2. Multi-Sensor-Based Application to USV Path Planning
The USV model is self-designed and constructed by Qingdao Municipal Engineering Laboratory of Intelligent Yacht Manufacturing and Development Technology, Qingdao University of Science and Technology (QUST). In the design stage, the USV is expected to be used in fields of military development, scientific research, and environmental protection to execute tasks, such as autonomous cruise, water quality sampling, water quality monitoring, and garbage collection. It is of crucial importance to design the feasible and shortest trajectories covering all preset points for the purpose of reducing costs and enhancing efficiency. Generally, path planning can be simplified into the TSP if the prior environmental information is inaccessible and the collision-free restriction is not taken in to account. Hence, in this section, the proposed IPSO is applied to the navigation, guidance and control (NGC) system of a self-developed unmanned surface vehicle, designing feasible trajectories to follow under real sea conditions. Note that the factors of wind, current, waves, and obstacles are not considered in this preliminary work.
The USV model is 1.8 m long and 0.9 m wide, and consists of five underwater bodies.
Figure 8 gives a schematic diagram of the USV NGC system. It involves three module subsystems: the navigation data processing subsystem, path planning subsystem, and autopilot subsystem. When the planned points are chosen in a personal computer, the improved PSO algorithm is adopted in the path planning subsystem, generating feasible trajectories for the USV to follow. The planned trajectories will be transferred to the autopilot subsystem, together with navigation information of the direction of the bow and the location data of the USV gathered by multi-sensors such as the electronic compass and GPS. Then a closed-loop controller is adopted to determine the heading and speed of the vehicle until the next target point is reached. More detailed information is provided in our previous published works.
The test site is located at the Qingdao Olympic Sailing Center in Fushan Bay. Due to the limited space, three testing conditions with three numbers of planned points are considered:
Q = 30,
Q = 40, and
Q = 50. The location coordinates of all planned points refer to
Table A1,
Table A2 and
Table A3. The swarm size is set as 500 and the maximum number of iterations is 300.
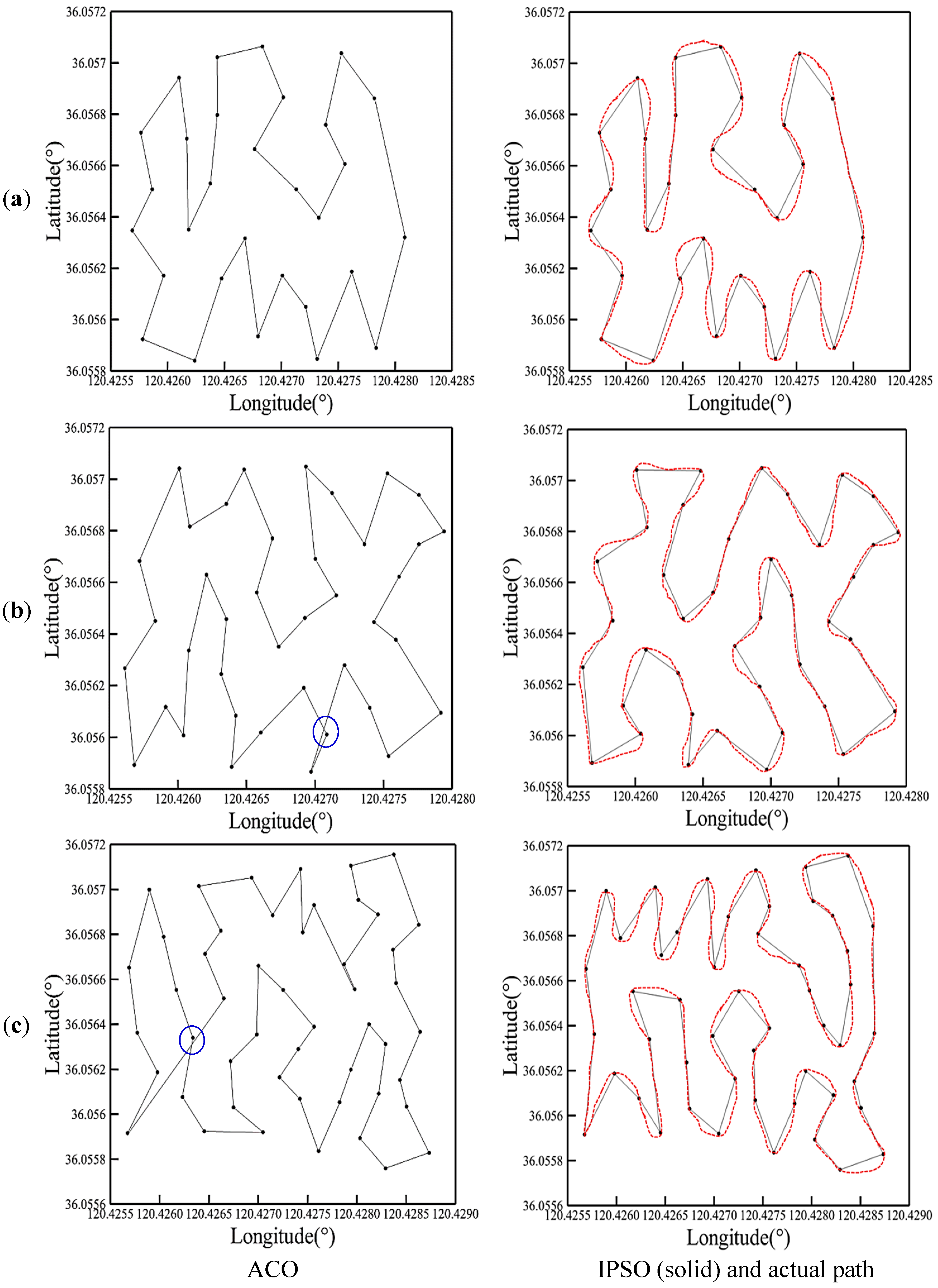
Optimal trajectories generated by the ACO and IPSO are presented by solid lines in
Figure 9 with detailed information listed in
Table 3. Certain self-crossing phenomena occur in the planned paths of the ACO for
Q = 40 and 50, as marked in blue circles. Whereas, the IPSO generates feasible routes with satisfactory lengths and no path-crossing. Since the number of planned points is not beyond 100, the IPSO performs better than the ACO in both the critical iteration number and optimal path distance. When the number is 30, the two algorithms provide the same route with the length of 1100 m. For
Q = 40, the IPSO converges at
Mcri = 33 with the optimal path distance of 1200 m, while the ACO terminates at a larger iteration of 59 with a longer distance of 1214 m. By comparison, the route designed by the IPSO is delivered to the USV model to follow under real sea conditions. The actual paths for the three sets of planned points are shown using the red dashed lines. It could be observed that the real path is smoother than the planned path. The path between any two planned points deviates from the planned trajectory to some degree due to the impact of wind, waves, and currents. However, the successful application of heading correction to the autopilot subsystem would finally guide the USV model to return to the planned points. The feather of this site-specific cruise would play an essential role in the fields of ocean ranching and multi-point water quality monitoring and sampling in vast water.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}








