For convenience, we refer to the proposed algorithm as Positive and Negative Evidence Accumulation Clustering (PN-EAC). The first step in the algorithm is to obtain the different data partitions. Each of these partitions can be obtained from a different data source (for example, measurements from a different sensor). Afterwards, evidence is extracted from each individual partition. In particular, we extract the information about the co-occurrence of two elements in the same cluster among the different partitions. This is normally referred to as evidence in the bibliography, but we shall call it
positive evidence. Positive evidence provides information about the elements that should be grouped together in the final partition. A novel aspect of PN-EAC is that it is not limited to using positive evidence, but it can also handle information regarding the elements that should not be grouped together in the final partition; we shall call this information
negative evidence [
29].
The different steps of the PN-EAC algorithm (see Algorithm 1) are explained in detail in the following sections. First, how the partitions are generated is explained, then how these partitions are combined, and finally how the final partition is extracted. Let be a finite set of n elements where each is a feature vector that represents the element i. A clustering algorithm will take X as input and will generate a data partition of the n elements of X divided in k groups, where represents the j-th group of the data partition. An ensemble is defined as a collection of m different data partitions , obtained using m different clustering algorithms, different parameters or different data representations. No assumption is made about the number of groups in each partition of the ensemble; i.e., each partition could have a different number of k groups. The partitions of the ensemble are combined in a final partition, , which is the final result of the evidence accumulation clustering and that, in general, will be more similar to the natural partition of the underlying data structure than most of the individual partitions separately. The technique also permits more expressiveness in the final results than each of the individual clustering algorithms, overcoming their limitations in the geometry and shape of the clusters.
2.1. Generation of the Partitions of the Ensemble
When using clustering techniques based on ensembles, it is necessary to generate different data partitions
(
m is the number of data partitions from the data set). The use of different representations of the data (possibly measured by different sensors), techniques to alter the data (like sampling or bagging [
30]), different clustering algorithms or different parametrizations of those algorithms, will produce, in general, different partitions of the same data. Ensembles can overcome the limitations of the individual results, abstracting the different representations, models or initializations and extracting the mutual information of the different data partitions.
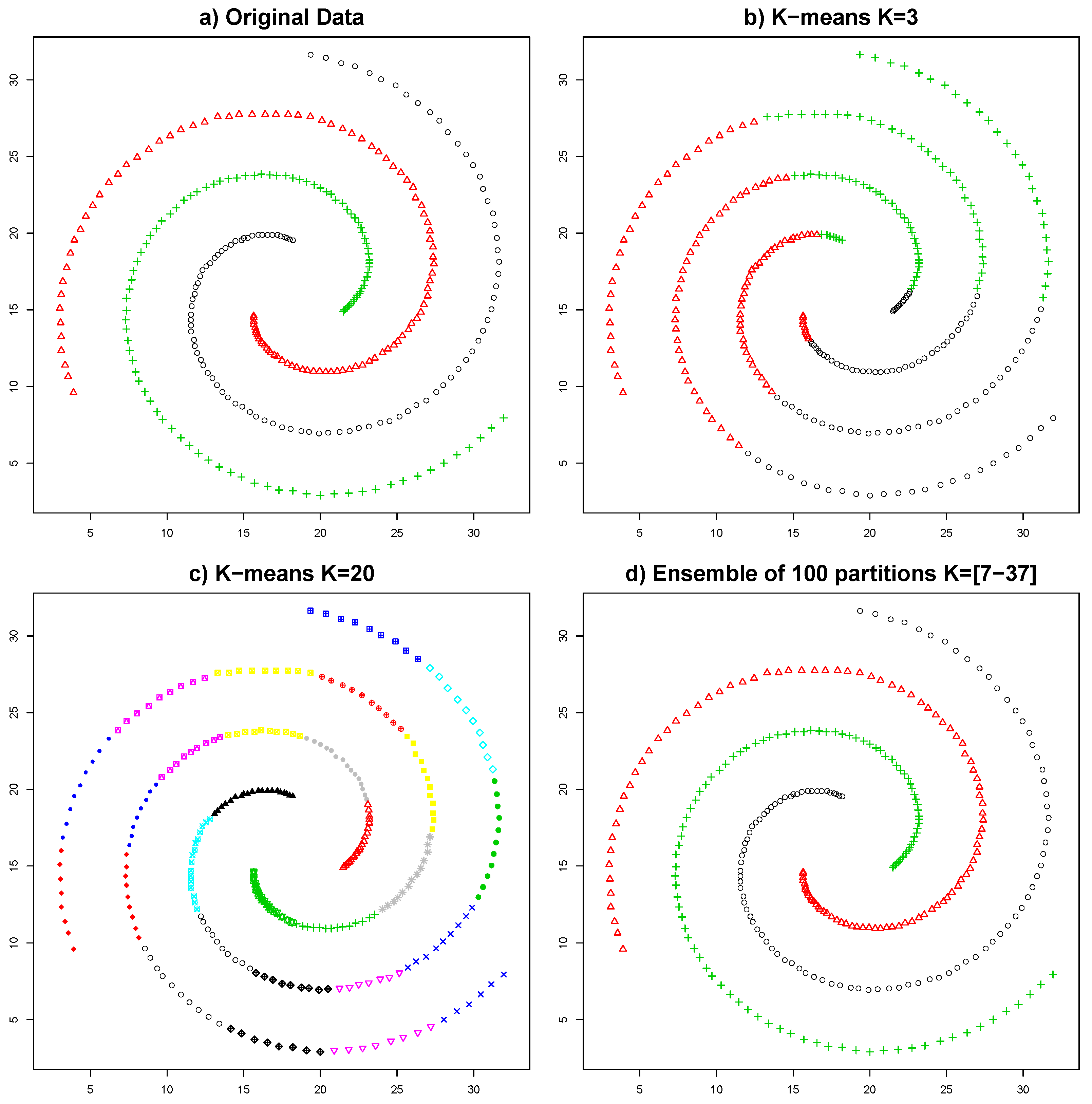
In the myriad of clustering methods, the K-means algorithm stands out as the most commonly used. The simplicity of this algorithm is one of its major advantages, being easy to understand, computationally efficient, and fast. Its reduced number of parameters (typically only the number of clusters) is another of its strengths. Its major limitation is the inflexibility on the clusters that it forms, which always have a hyper-spherical shape. This limitation makes impossible the identification of clusters with arbitrary shapes, making it unsuitable for many applications which need to model complex shapes. However, as shown in [
31], by combining several executions of the K-means algorithm, it is possible to overcome this limitation (see
Figure 1) and represent clusters of virtually any shape.
In this work, K-means will be used to generate the data partitions. This algorithm is used due to its efficiency and its reduced computational cost. K-means is executed several times with arbitrary initializations for the initial centroids. The number of clusters
k for each execution is obtained randomly in a given range; this value should be small compared with the number of elements
n in the data set, but large enough to capture the different underlying groups. In this work, we shall adopt a common rule of thumb used by other ensemble clustering algorithms where this range is given by [
23]:
where
n is the number of elements. Given that K-means is a greedy algorithm, it is possible to obtain different results if the initialization is different, even for the same
k.
2.2. Extraction and Combination of Positive and Negative Evidence from the Partitions
In the ensemble clustering literature, it is possible to find several approximations to combine the results of the different data partitions [
25,
32,
33]. This work adopts the proposal of [
23] based on evidence accumulation. This approach uses a voting mechanism to obtain the information of those pairs of elements that appear in the same cluster. The voting mechanism makes no assumptions about the individual partitions, making it possible to combine partitions with different numbers of clusters or even incomplete partitions (i.e., partitions without all the elements).
Positive Evidence Extraction
A subset of the original m partitions comprises the positive evidence partitions. Let , , be the ensemble of data partitions used to extract positive evidence, where q is the number of positive evidence partitions.
The information extracted by the voting mechanism will be gathered in a matrix
, whose size is
(
n is the number of elements). For each individual partition, the co-occurrence of a pair of elements
i and
j in the same cluster will be treated as a positive vote in the corresponding cell of the
matrix. The underlying idea is that those elements that belong to the same “natural” cluster will most likely be assigned to the same cluster in the different data partitions
. The
matrix, considering the
q data partitions, will be:
where
is the number of times that the pair of elements
i and
j has been assigned to the same cluster in the different data partitions
.
Negative Evidence Extraction
In some cases, due to the data representation used, the fact that two elements belong to the same cluster of a data partition can provide little information about the natural grouping of the data. This evidence could even introduce noise in the evidence matrix, worsening the final result. For example, let us suppose we want to group different types of physical activities in a set of subjects, and that we have inertial sensors and electromyographic sensors located in various parts of the subjects’ body, including their forearms. In this context, recording similar data from the forearm inertial sensors of two subjects provides evidence that subjects are performing similar actions with their forearms (positive evidence). However, presenting a similar electromyographic activity provides very weak evidence that the subjects are performing the same action. Riding a bicycle (and thus grabbing the handlebar), driving a car (and thus grabbing the steering wheel), carrying shopping bags in your hands, or paddling in a canoe involve a contraction of the forearm muscles to grasp an object with your hands; therefore, they can generate similar electromyographic recordings. However, presenting a different electromyographic activity in the forearms provides strong evidence that a different action is being performed: if the electromyographic activity indicates that there is no contraction in the forearms, it is possible to rule out that the subject is performing any of the four activities previously described (negative evidence).
This situation is usually addressed in ensemble clustering by discarding these features in the data representation. Nevertheless, there are scenarios in which the information of the elements belonging to different clusters can be valuable in order not to group those elements together in the final data representation. We have named this evidence as negative evidence. The data partitions that are used to extract negative evidence will be referred to as , , where o is the number of negative evidence partitions, to distinguish them from the partitions used to extract positive evidence. It must be noted that these o data partitions correspond to a subset of the original m data partitions, and that .
To gather this negative evidence, we also make use of a voting mechanism and a matrix. The difference is that, in this case, for each partition in which the elements
i and
j are not in the same cluster, we will compute a negative vote in the corresponding cell of the matrix. The negative evidence matrix
, whose size is
, will be:
where
is the number of times that the pair of elements
i and
j has been assigned to different clusters in the different data partitions
.
It is important to remark that the data partitions employed for extracting the negative evidence cannot be the same as those used for extracting the positive evidence. That is, each partition can only provide one type of evidence. Moreover, each type of evidence should be generated using suitable data representations. It is also important to note that negative evidence can only be used altogether with positive evidence. Negative evidence provides information about those elements that should not be grouped together, behaving like a sort of restrictions, but this information is only useful when jointly used with the information about which elements should be grouped together (obtained from the positive evidence).
After extracting the positive evidence and, when applicable, the negative evidence, the PN-EAC algorithm combines both evidence matrices in a single one to obtain the final evidence matrix
. This can be done by adding all the different matrices, as follows:
This simple combination of multiple data partitions supports the integration of different sources of information in parallel. Therefore, PN-EAC will be able to combine information from different sensors. The algorithm is versatile, allowing the customization of the ensemble scheme combining positive and negative evidence, using different algorithms to generate the partitions or changing the number of partitions.
2.3. Obtaining the Final Data Partition
The last step of PN-EAC is obtaining the final data partition
using the evidence matrix
, which behaves like a similarity matrix between all the elements. Any clustering algorithm that accepts as input a similarity matrix could be used to obtain the final partition. In the PN-EAC, the use of a hierarchical linking clustering algorithm [
34] is proposed for this purpose. This algorithm is designed to be applied to similarity matrices and, therefore, is suited to be applied to the evidence matrix
[
35].
This hierarchical clustering algorithm establishes a hierarchy of clusters, which are organised into a tree-like structure called a dendrogram [
36]. To create this structure, two different strategies can be used: agglomerative or divisive. In the agglomerative strategy, which is the one used in the PN-EAC, each element starts as a cluster and, in each iteration, two clusters are merged. In the divisive strategy, there is only one cluster at the beginning and in each iteration one cluster is split in two. To merge or split the clusters, a measure of distance between elements is needed. In the PN-EAC, the Euclidean distance is used. On the other hand, it is also necessary to decide the method to calculate the distance between two clusters; typical choices include using the mean of all the distances between their elements (average link), using only the longest distance (complete link) or using the smallest distance (simple link), among others [
37]. The average link [
38] was the choice for the PN-EAC. Therefore, the final partition
is obtained using a hierarchical linking clustering algorithm based on the Euclidean distance over the evidence matrix
. The results of the hierarchical algorithm are typically presented using a dendrogram, which is a tree-like diagram that shows the different clusters, their similarity values and how they are joined and split in the different iterations.
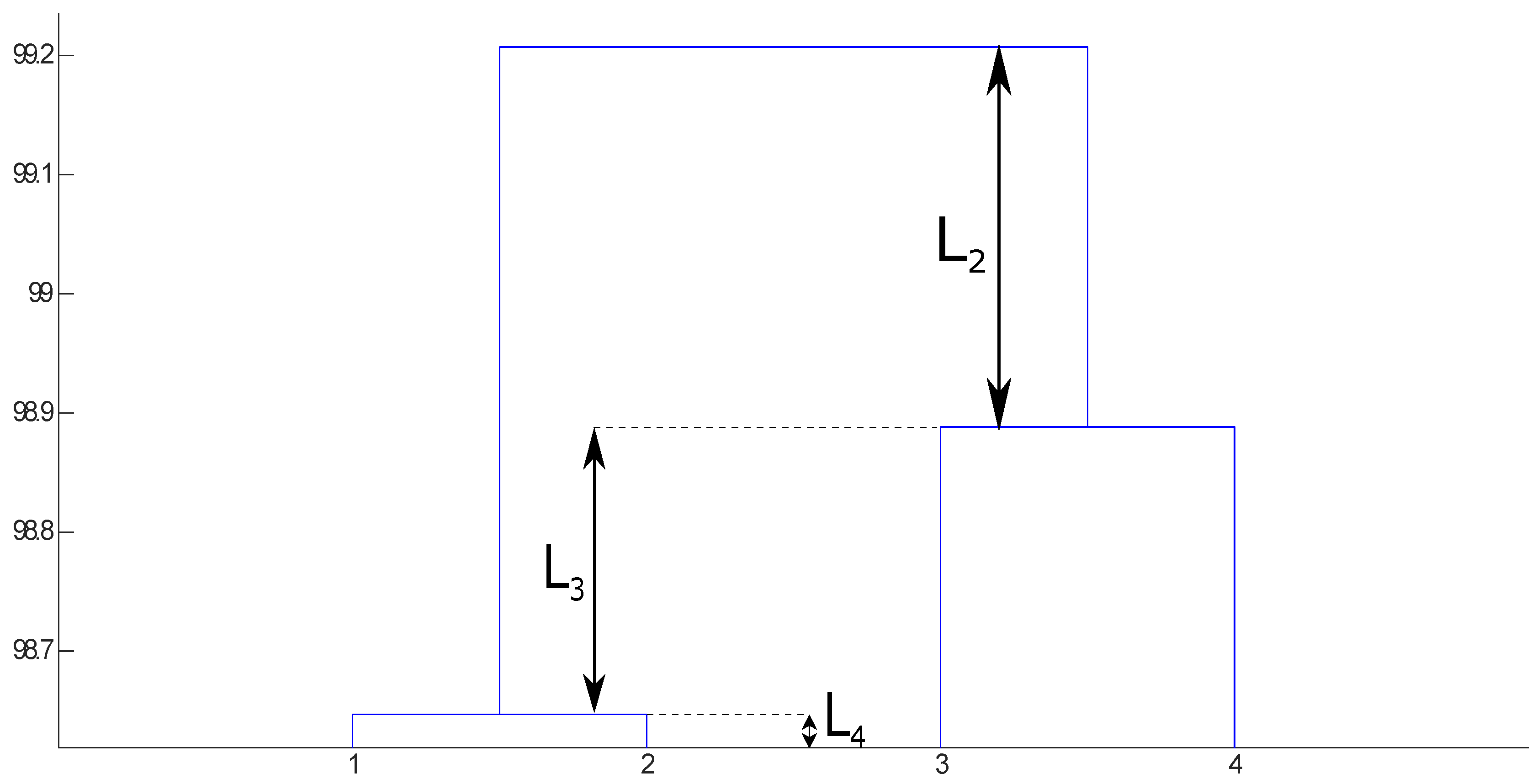
Most clustering ensemble algorithms leave the user with the decision concerning the final number of clusters. To that end, the user typically decides to “cut” the dendrogram at some point to generate a certain number of clusters. In [
31], an alternative is proposed: the use of a criterion based on the lifetime of each cluster in the dendrogram. It is possible to define the lifetime of a number of clusters
k as the absolute similarity difference in the dendrogram between the transition of
to
k clusters and the transition between
k to
clusters (see
Figure 2). This process is repeated for all the possible values of
k. The
k with the largest value is chosen as the final number of clusters.
Figure 2 shows an illustrative example: the lifetime values for two, three, and four clusters are shown, named
,
and
, respectively; the largest value is
and therefore
is chosen as the number of clusters. This criterion is based on the idea that the most similar partition to the “natural” partition of the data will be more stable in regard to merging or splitting clusters in the dendrogram; in other words, it will have the longest lifetime.
2.4. Usefulness of the Negative Evidence: An Illustrative Example
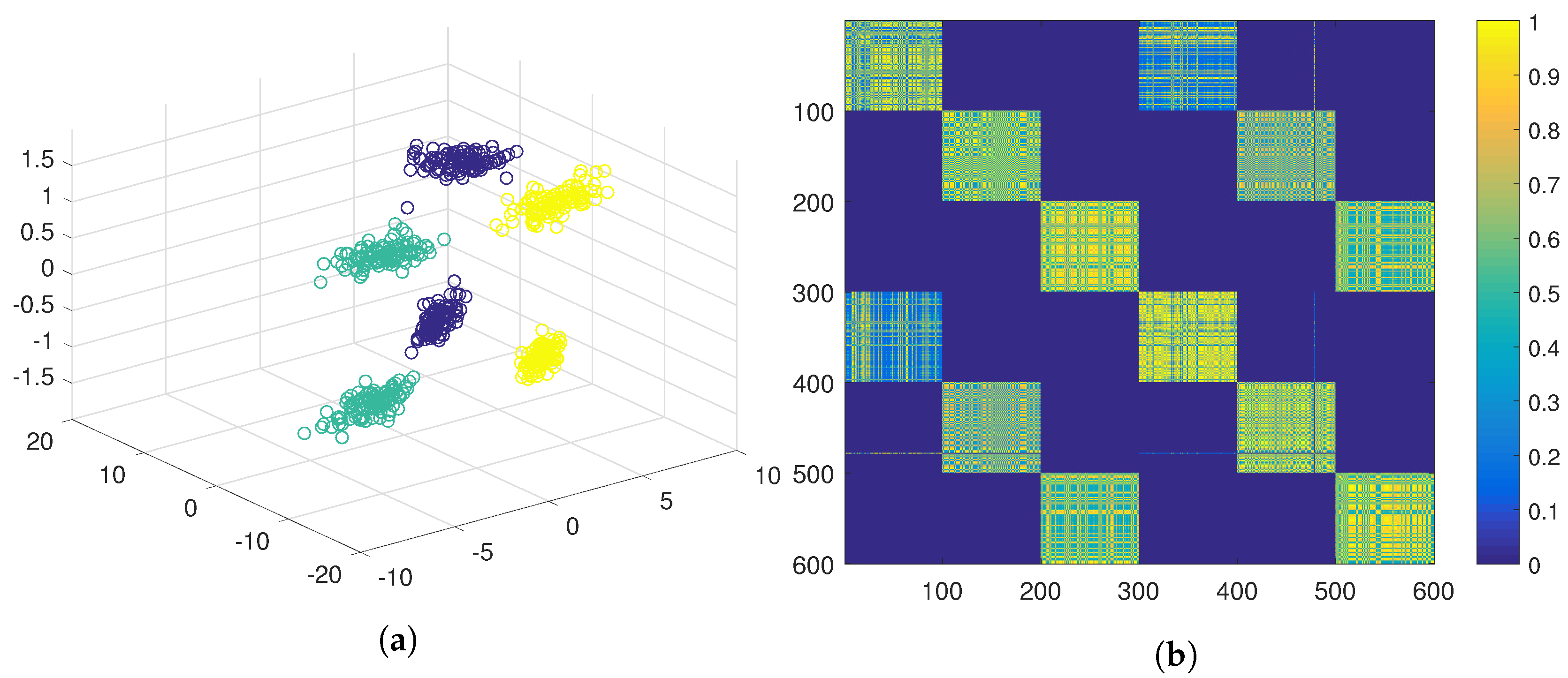
To illustrate the use of the negative evidence in the PN-EAC algorithm, a data set composed of 600 elements from six different Gaussian distributions was built. The data set has three features. The first two features are represented in
Figure 3, and the last feature is a Gaussian with mean of −1 for three clusters and another Gaussian with mean 1 for the other three clusters. A three-dimensional representation of the data can be seen in
Figure 4a.
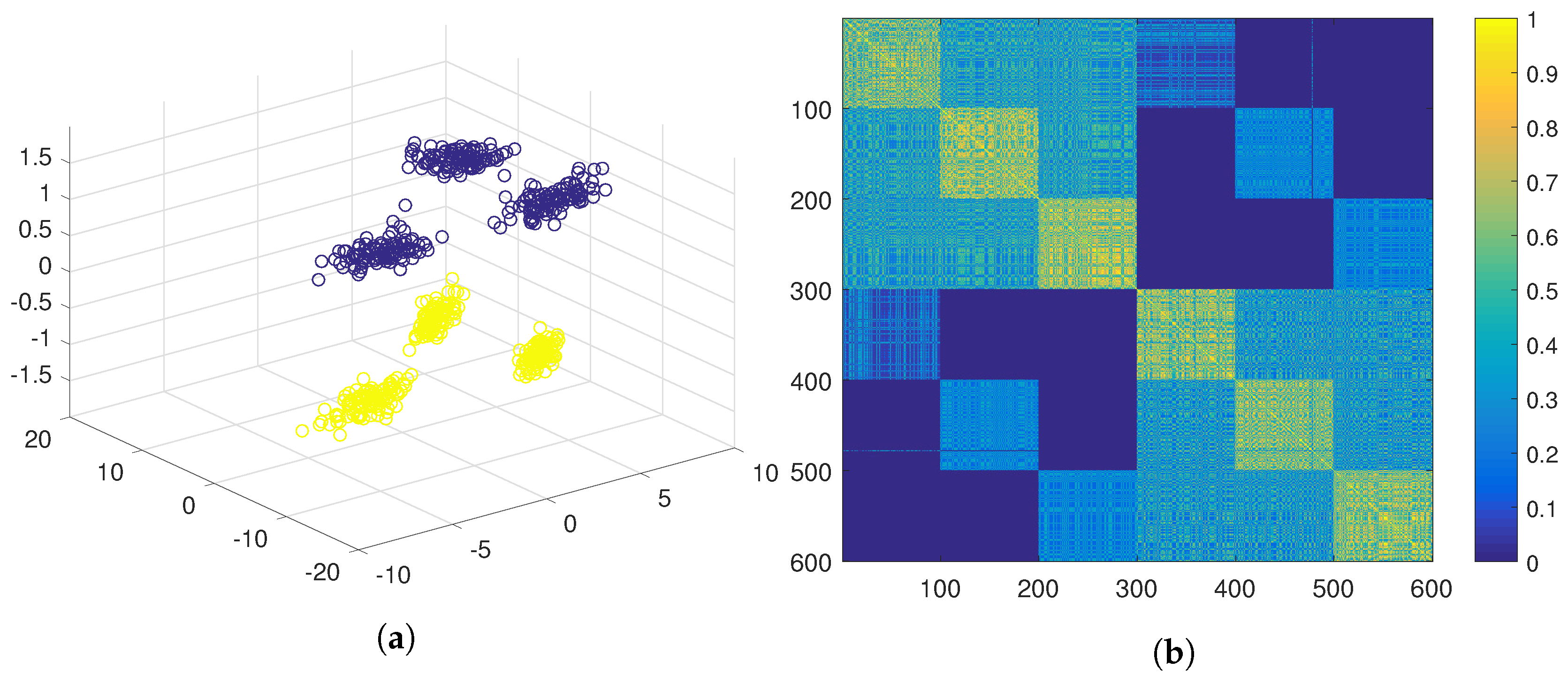
Using the traditional ensemble clustering, positive evidence would be extracted using the three features joined up in the same feature vector, and gathered in the evidence matrix,
(see Equation (
4)). This evidence matrix is displayed as a similarity matrix in
Figure 4b using a colour code, where yellow represents high similarity and blue represents low similarity. The similarity matrix has been ordered according to the ground true labels of the six clusters. In this similarity matrix, it can be observed that, although the elements belonging to the same natural cluster are very similar to the rest of the elements of the same cluster, they are also similar to the elements of a second cluster. When hierarchical clustering is applied over this matrix, the six natural clusters are grouped in pairs (see
Figure 4a), hence obtaining three clusters.
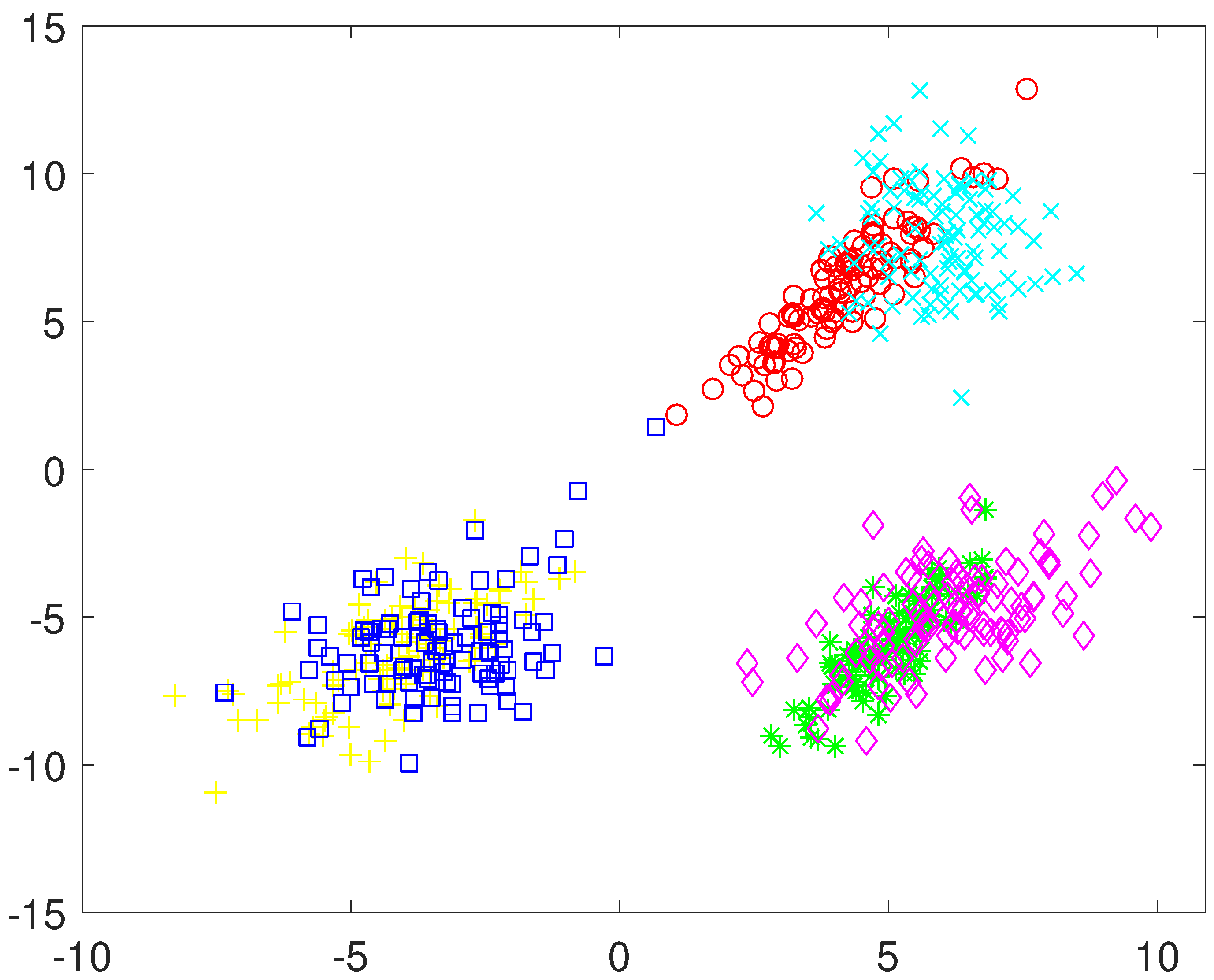
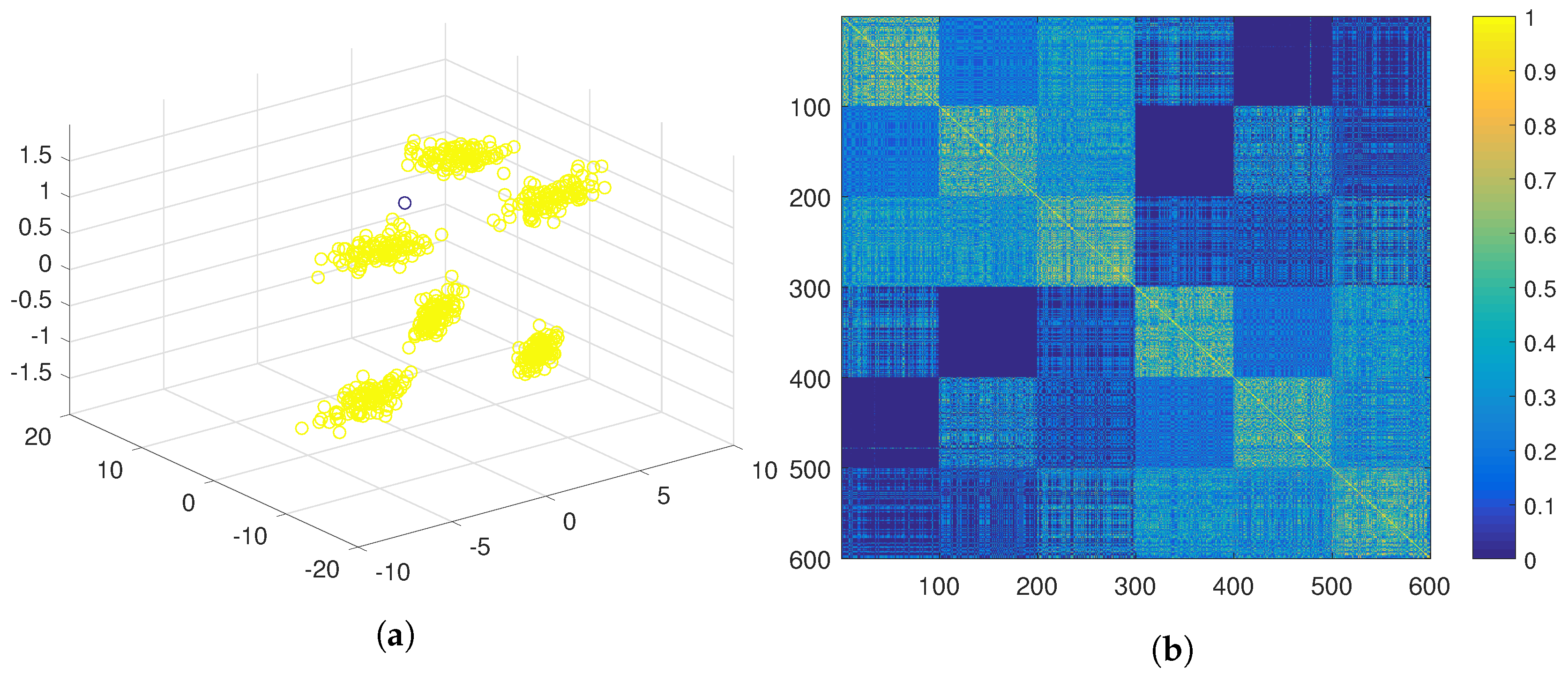
A different approach would be obtaining positive evidence separately from the first two features and from the third one independently. This approach yields a much less crisp similarity matrix (see
Figure 5b), which results in two clusters after the application of the hierarchical algorithm (see
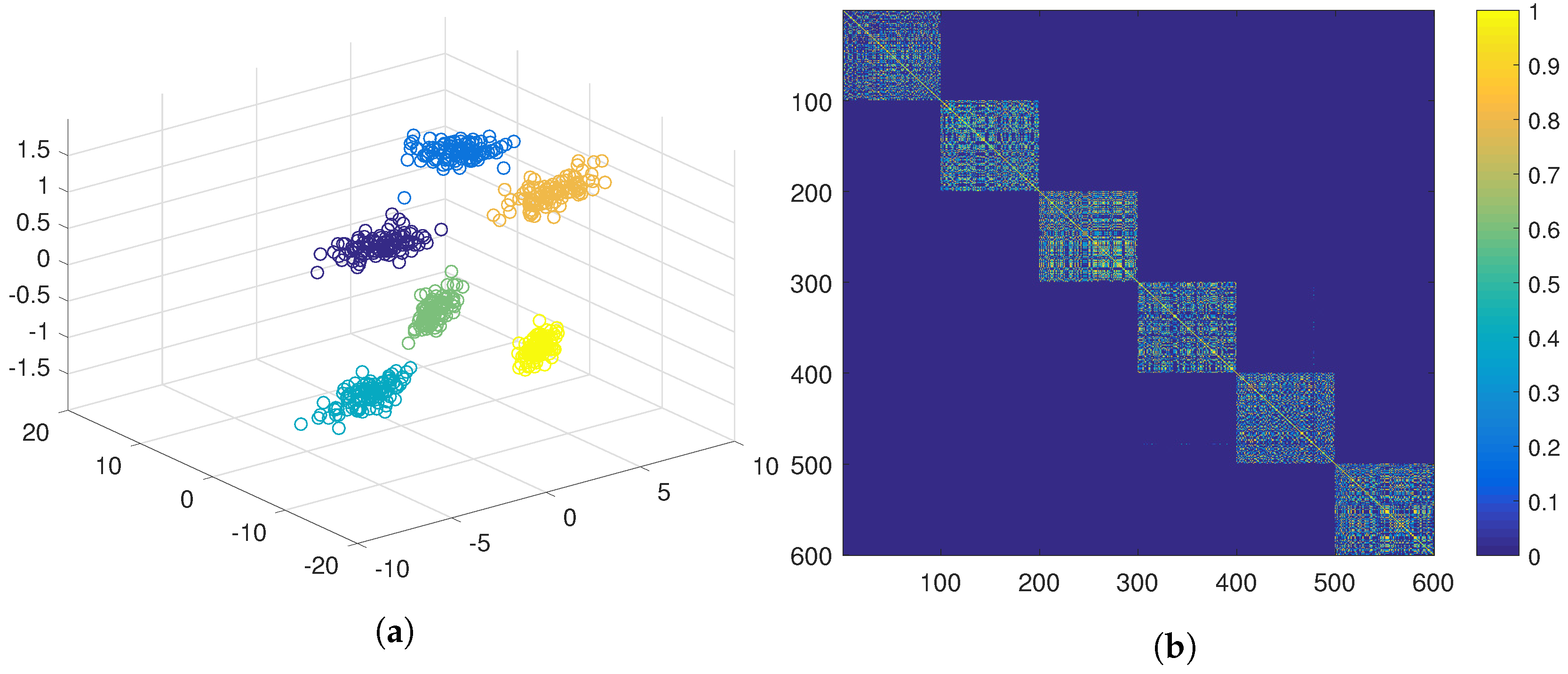
Figure 5a). Another option would be to obtain positive evidence separately from each of the three features. The similarity matrix obtained in this case is even less crisp than in the previous case (see
Figure 6b), which results in a cluster containing almost all the samples (see
Figure 6a).
At this point, the data analyst might think that the third feature is of poor quality and/or it introduces too much noise, and it could be a good solution to discard it. However, it is clear from
Figure 3 that, if the third feature is discarded, it is not possible to separate the six natural clusters from the two remaining features.
Figure 4,
Figure 5 and
Figure 6 show strategies framed in the classic evidence accumulation cluster paradigm. We will make a third attempt with the PN-EAC algorithm, proceeding in a similar way to the strategy of
Figure 5, but, in this case, the third feature is used to extract negative evidence (
, see Equation (
3)), which is combined with the positive evidence (
, see Equation (
2)) extracted from the two other features
(see Equation (
4)).
Figure 7b shows the similarity matrix resulting from this approach, and
Figure 7a shows the clusters obtained after the application of the hierarchical clustering. Note how, by using the third feature to extract information about which elements should not be grouped together, we get a more crisp similarity matrix that reflects more adequately the natural partition underlying the data set than any of the other two previous evidence matrices. At this point, we would like to emphasize that the only difference between the results presented in
Figure 5 and in
Figure 7 is the change in the type of evidence extracted from the third characteristic: positive in the first case and negative in the second one.
This is a simple toy example designed to illustrate how negative evidence can be useful to address some situations that it is not possible to solve satisfactorily in a paradigm that only contemplates positive evidence. As a general rule, any feature in which similarity means belonging to the same cluster should be used to extract positive evidence. If the feature does not fulfil this condition, it may be considered to extract negative evidence. To extract meaningful negative evidence, dissimilarity in that feature should be useful to distinguish between some clusters.
2.5. Computational Complexity of PN-EAC
To study the computation complexity of PN-EAC, a complexity analysis of each of its component parts is performed. The complexity of the K-means algorithm used to generate the partitions (see Algorithm 1, line 1) has been widely studied in the bibliography [
39]:
, where
n is the number of elements,
k is the number of clusters,
d is the number of dimensions of each feature vector, and
i is the number of iterations of the algorithm. The number of dimensions
d is usually fixed for almost any problem and is typically much smaller than
n. The same occurs with the number of iterations
i, which is often set to a fixed amount (typically 100). The number of clusters in our algorithm is given by Equation (
1) with a maximum of
. Therefore, the complexity of K-means can be approximated by
. The K-means algorithm is executed once per data partition (see Algorithm 1, line 1). Thus, the complexity of this step of the algorithm is
, where
m is the number of data partitions.
Extracting evidence from the partitions requires to iterate through the evidence matrix, thus the complexity is determined by the size of the matrix , being . The matrix is processed once per partition, so the final computational complexity of this step will be (see Algorithm 1, line 2).
Finally, it is necessary to consider the complexity of the hierarchical algorithm used to extract the final partition. In the algorithm, the first step is to calculate the similarity matrix between all the elements; this operation has a complexity of
. Afterwards,
n iterations will be executed, one per element, and, in each iteration, the pair of clusters with the smallest distance will be merged and the distance to the other clusters will be updated. The complexity of each iteration is
. Given that there are
n iterations, the total complexity will be
, this term being the one that determines the complexity of the hierarchical algorithm [
36] (see Algorithm 1, line 3).
The complexity of the hierarchical algorithm (
) can be larger than the complexity of extracting evidence (
), in the case of
is larger than
m. However, for typical values of
n and
m,
stands. For example, with 300 different data partitions (
m),
n is almost always smaller than
. Thus, the complexity of the PN-EAC algorithm will be
, as shown next:
Regarding the space complexity, it will be rendered by the size of the evidence matrix, . In an optimized representation, it could be reduced to , given that the matrix is symmetric.
2.6. PN-EAC for Heartbeat Clustering
One of the main difficulties in heartbeat clustering lies in the morphological complexity of the heartbeat. The inherent variability of any morphological family of heartbeats, namely, the group of heartbeats that shares origin of activation and propagation path, is not projected in the feature space in hyperspherical shape. No matter the heartbeat representation chosen, it has been shown that the different morphological families have a heterogeneous set of shapes in the feature space [
40].
To represent the morphology of the heartbeat, a decomposition based on the Hermite functions shall be used. This representation is robust and compact due to the similarity between the shape of the Hermite functions and the QRS complexes. Furthermore, the Hermite functions are orthonormal; thus, each feature provides independent information. An excerpt of 200 ms is extracted for each heartbeat around the beat position. By means of this window size, the complete QRS complex is extracted, whereas the P and T waves are ignored. The number of Hermite functions used in the decomposition is 16 (plus a
parameter to control the width of the QRS complex), since this value provides a good compromise between the length of the feature vector and the accuracy of the heartbeat representation [
41].
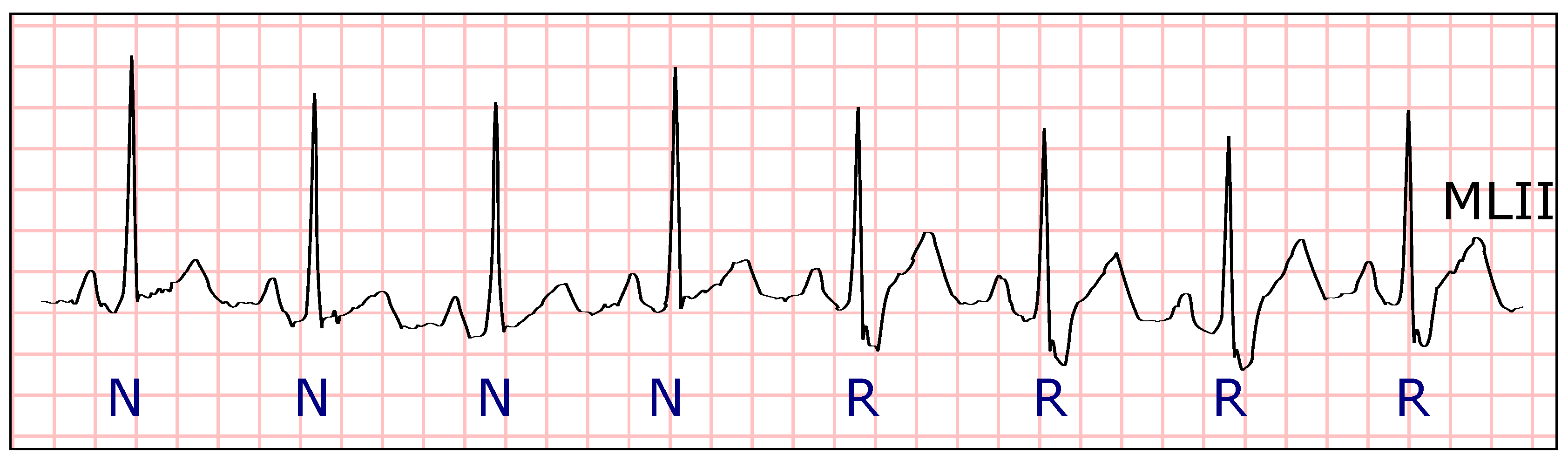
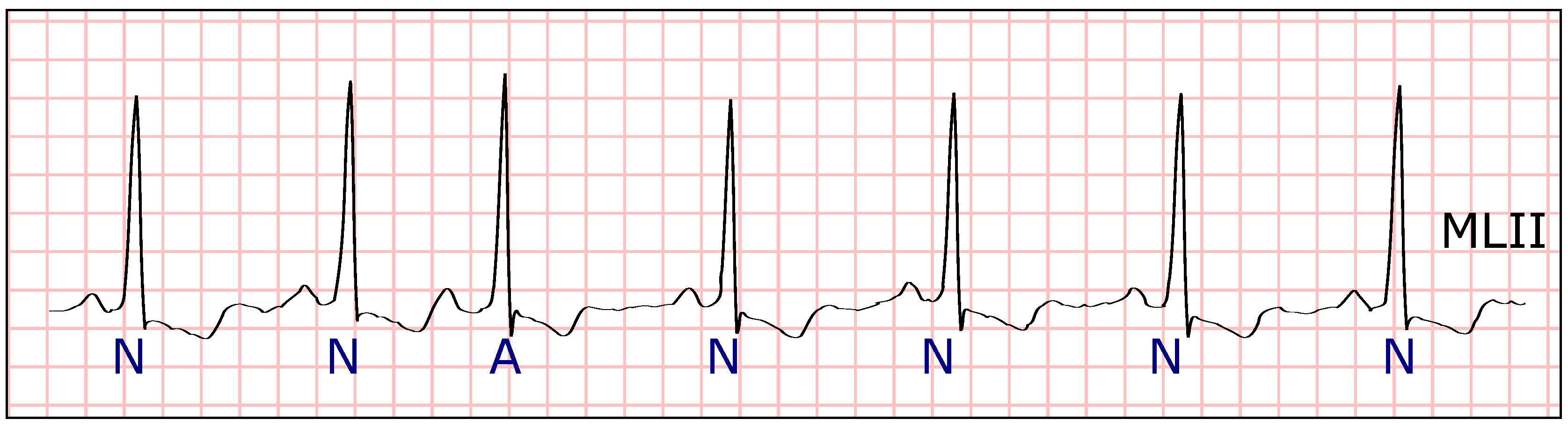
There are some types of arrhythmia, like premature atrial contractions and atrioventricular, or fusion and escape beats, in which the morphology of the QRS complexes is similar. Therefore, it is not feasible to distinguish between them using just QRS morphology information (see
Figure 8 and
Figure 9). The P wave does provide relevant information in these cases, but the difficulty in identifying it, especially in ambulatory ECG, often leads to attempts to obtain similar information from the distance between heartbeats [
13,
42]. Therefore, to allow the clustering algorithm to distinguish between different types of heartbeats with similar QRS morphology, two features based on the distance between heartbeats (
and
) were added as follows:
where
is the instant of time of the occurrence of the
i-th heartbeat, and
is the difference between the distance from the
i-th beat to the next one, and the distance from the
i-th beat to the previous one. The Heaviside step function
is:
This function is used to remove the negative values of
in Equation (
7) (clipping them to 0) while preserving the positive values. Equation (
6) measures the distance from a heartbeat to the previous one. By comparing the values of this equation, it is possible to identify if a heartbeat is premature. To this effect, Equation (
7) compares this distance with other two distances: the distance between the current beat and the next one, and the distance between the previous beat and its predecessor. A high
value in Equation (
7) provides evidence that the heartbeat could be premature. Thus, each heartbeat is represented by the coefficients of the Hermite functions for each of the different available leads, the
parameters and the features given by Equations (
6) and (
7).
Strategies for Generating Partitions
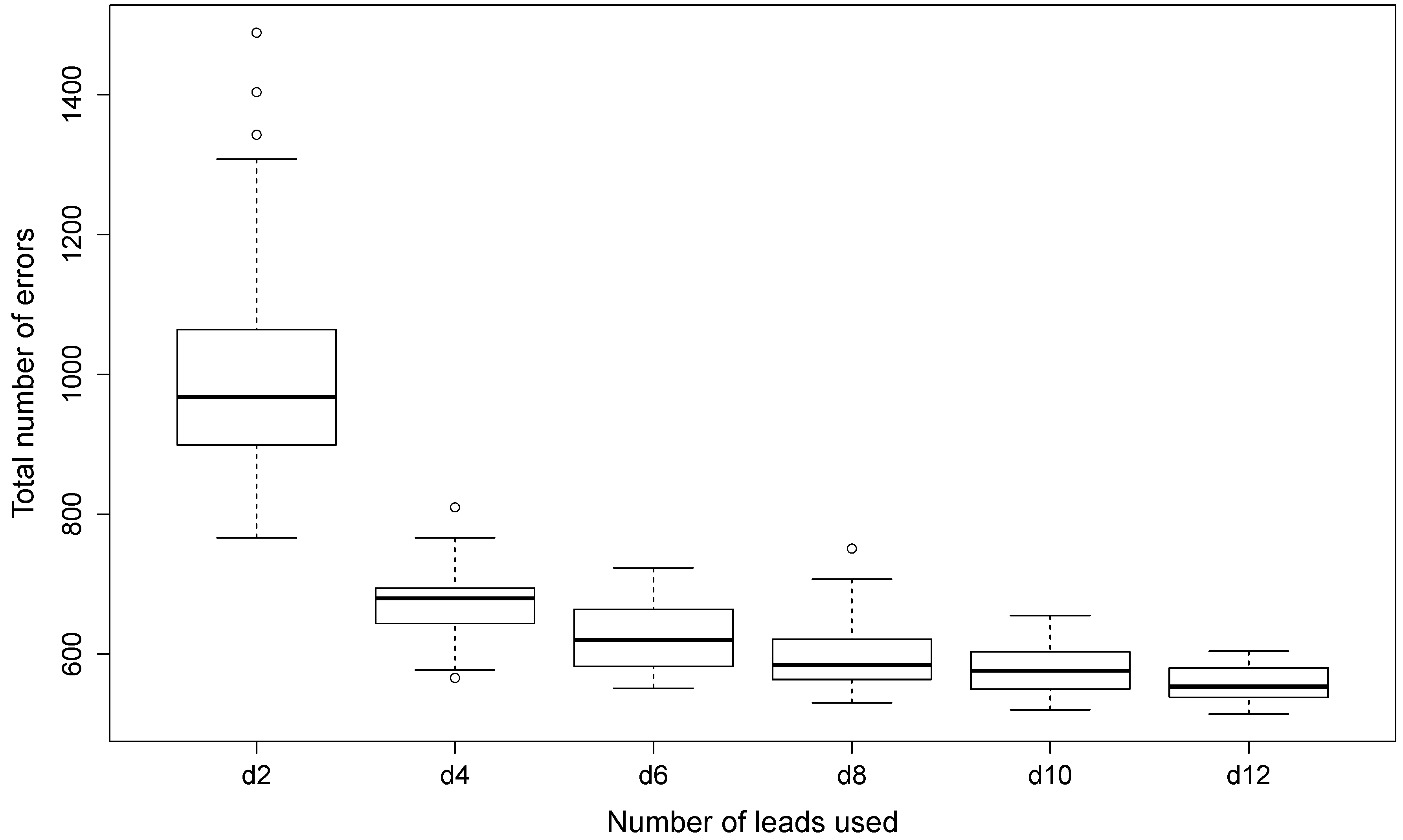
When applying the PN-EAC algorithm to heartbeat clustering, three different strategies are proposed to generate the data partitions. These three strategies have been designed to assess the value of the negative evidence, as well as to study the performance of the algorithm when integrating more data sources incrementally.
- Strategy 1
The first strategy is the classical approach of machine learning whereby all the available features of an element are grouped into a single feature vector. In this work, the vector has the parameters from the Hermite representation (coefficients and
) for all the ECG leads and the features given by Equations (
6) and (
7), as follows:
where
is the feature vector that represents the heartbeat
;
d is the number of leads,
denotes the Hermite coefficients that represent the QRS complex over the lead
j,
(in this case with
, i.e., the number of Hermite coefficients); and
is the value of
in the lead
j. Each partition uses the representation from Equation (
9) for each heartbeat, with which the positive evidence is extracted. To create the different partitions
, the K-means algorithm will be used with random initializations and a number of clusters in the range given by Equation (
1) (see Algorithm 2, lines 3–6).
- Strategy 2
The second strategy is based on the hypothesis that generating the data partitions from different data representations yields better results than integrating all the features in the same feature vector. This strategy is inspired by cardiologists, who typically study each derivation separately and then combine the findings on each of them to make the final interpretation. This strategy mimics this
modus operandi, extracting evidence from the information of each lead and combining it for a final decision. The information of the distance between the heartbeats given by Equations (
6) and (
7) is also processed separately. This is due to the fact that it is a different type of information compared to the morphology information. Thus, the features are divided in different representations of the heartbeats:
d feature vectors for the morphological information of all leads (represented by the Hermite functions) and another feature vector with the information derived from the distance between heartbeats, as follows:
where
,
, …,
are the feature vectors of the different leads representing the heartbeat
by means of the Hermite representation,
d is the number of leads and
is the representation of
based on the distance between heartbeats. Each representation is used separately to generate the data partitions to extract positive evidence. The final data partition is obtained by combining all the evidence (see Algorithm 3, lines 25–26).
- Strategy 3
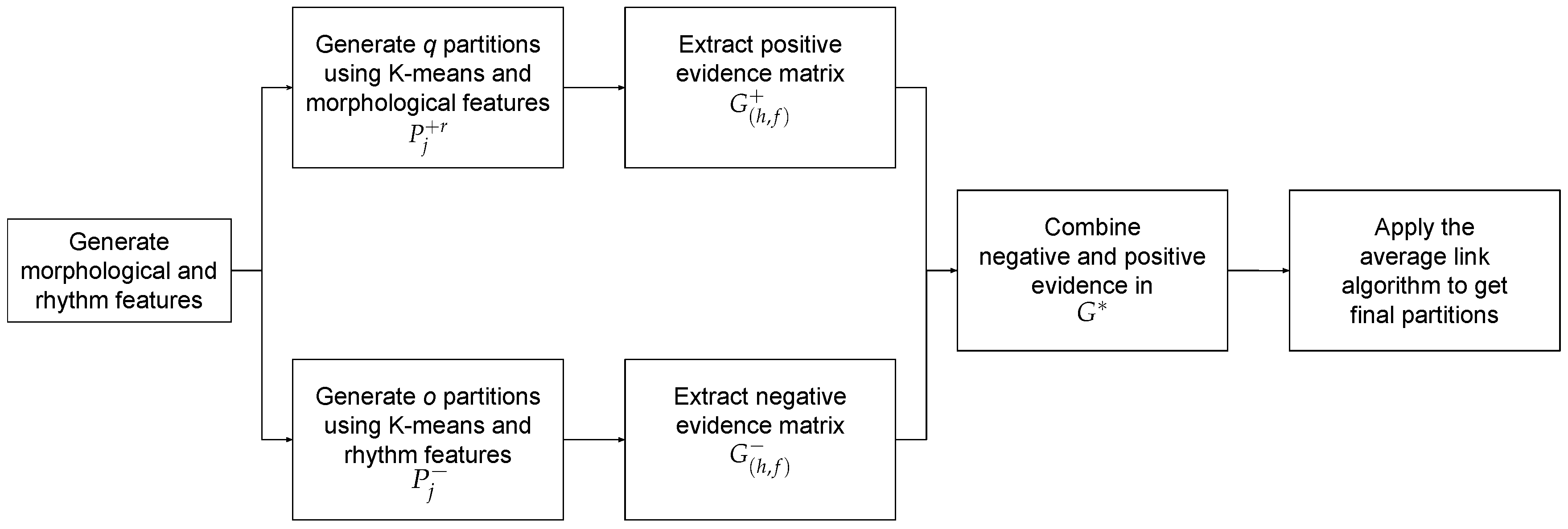
The third strategy is a variant of the second one, but, in this case, negative evidence is extracted using the features derived from the distances between heartbeats (
). This strategy is summarized in
Figure 10. The fact that the values of Equations (
6) and (
7) are not different, (i.e., the distance between heartbeats does not change) does not imply that there is not a change in the type of heartbeats; there is a wide variety of types of heartbeats that have a similar distance between beats. Thus, similar values for those features do not provide conclusive evidence whether two heartbeats belong to the same cluster (see
Figure 11). However, two heartbeats with remarkable differences in those values are very likely to belong to different types (see
Figure 12).
In this strategy, to model the information obtained from Equations (
6) and (
7), negative evidence will be used. To represent the heartbeats, the same representations that in the previous strategy are used (see Equations (
10) and (
11)). However, in this case, negative evidence is extracted from Equation (
11). The other representations are still used to generate positive evidence (see Algorithm 4, lines 21–25).
| Algorithm 2 Heartbeat Clustering with PN-EAC (Strategy 1). |
| Require: Set of heartbeats , number of partitions q |
| Ensure: final data partition of the n elements |
- 1:
for all heartbeat generate using Equation ( 9)
|
- 2:
|
- 3:
forj = 1 q do
| #Section 2.1 |
- 4:
| #Equation (1) |
- 5:
|
- 6:
end for
|
- 7:
| #Initialize positive evidence matrix |
- 8:
forj = 1 q do
| #For each partition (see Section 2.2) |
- 9:
if two heartbeats and are in the same cluster in then
|
- 10:
| #Equation (2); extract positive evidence |
- 11:
end if
|
- 12:
end for
|
- 13:
| #Equation (2) |
- 14:
| #Section 2.3 |
| Algorithm 3 Heartbeat Clustering with PN-EAC (Strategy 2). |
| Require: Set of heartbeats |
| Require: Number of partitions for each lead (q) and for the distances between beats (b) |
| Ensure: final data partition of the n elements |
- 1:
for all heartbeat generate ; ; … ; using Equations ( 10) and ( 11)
|
- 2:
forr = 1 d do
| #For each lead |
- 3:
|
- 4:
for j = 1 q do # Section 2.1; q partitions generated with morphological information
|
- 5:
|
- 6:
end for
|
- 7:
end for
|
- 8:
|
- 9:
forj = 1 b do # Section 2.1; b partitions generated from Equation ( 11)
|
- 10:
|
- 11:
end for
|
- 12:
| #Initialize positive evidence matrix |
- 13:
forj = 1 q do #For each partition obtained from morphological information (see Section 2.2)
|
- 14:
for r = 1 d do
| #For each lead |
- 15:
if the representations of two heartbeats and are in the same cluster in then
|
- 16:
| #Equation (2); extract positive evidence |
- 17:
end if
|
- 18:
end for
|
- 19:
end for
|
- 20:
forj = 1 b do #For each partition obtained from the distance between beats (see Section 2.2)
|
- 21:
if the representations of two heartbeats and are in the same cluster in then
|
- 22:
| #Equation (2); extract positive evidence |
- 23:
end if
|
- 24:
end for
|
- 25:
| #Equation (2) |
- 26:
| #Section 2.3 |
| Algorithm 4 Heartbeat Clustering with PN-EAC (Strategy 3). |
| Require: Set of heartbeats , number of positive partitions for each lead (q) |
| Require: Number of negative partitions for the distances between beats (o) |
| Ensure: final data partition of the n elements |
- 1:
for all heartbeat generate ; ; …; ; using Equations ( 10) and ( 11)
|
- 2:
forr = 1 d do
| #For each lead |
- 3:
|
- 4:
for j = 1 q do # Section 2.1; q partitions generated with morphological information
|
- 5:
|
- 6:
end for
|
- 7:
end for
|
- 8:
|
- 9:
forj = 1 o do # Section 2.1; o partitions generated from Equation ( 11)
|
- 10:
|
- 11:
end for
|
- 12:
| #Initialize positive evidence matrix |
- 13:
| #Initialize negative evidence matrix |
- 14:
forj = 1 q do #For each partition obtained from morphological information (see Section 2.2)
|
- 15:
for r = 1 d do
| #For each lead |
- 16:
if the representations of two heartbeats and are in the same cluster in then
|
- 17:
| #Equation (2); extract positive evidence |
- 18:
end if
|
- 19:
end for
|
- 20:
end for
|
- 21:
forj = 1 o do #For each negative evidence partition obtained from the distance between beats
|
- 22:
if the representations of two heartbeats and are not in the same cluster in then
|
- 23:
| #Equation (3); extract negative evidence |
- 24:
end if
|
- 25:
end for
|
- 26:
| #Equations (2), (3) and (4) |
- 27:
| #Section 2.3 |


 ,
, 














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}