Optimized LOAM Using Ground Plane Constraints and SegMatch-Based Loop Detection

Abstract
:1. Introduction
- We proposed optimized lidar odometry and mapping method. Ground plane constraints based on random sample consensus (RANSAC) [3] were added to reduce the matching errors. At the same time, SegMatch could perform loop detection efficiently so that the global pose could be optimized.
- In order to verify our proposed solutions, extensive experiments were carried out in a variety of environments. Experiments showed that our method was suitable for completing inspection tasks and could also work well in the long-distance and large-scale outdoor environment.
2. Related Work
3. Proposed Methods
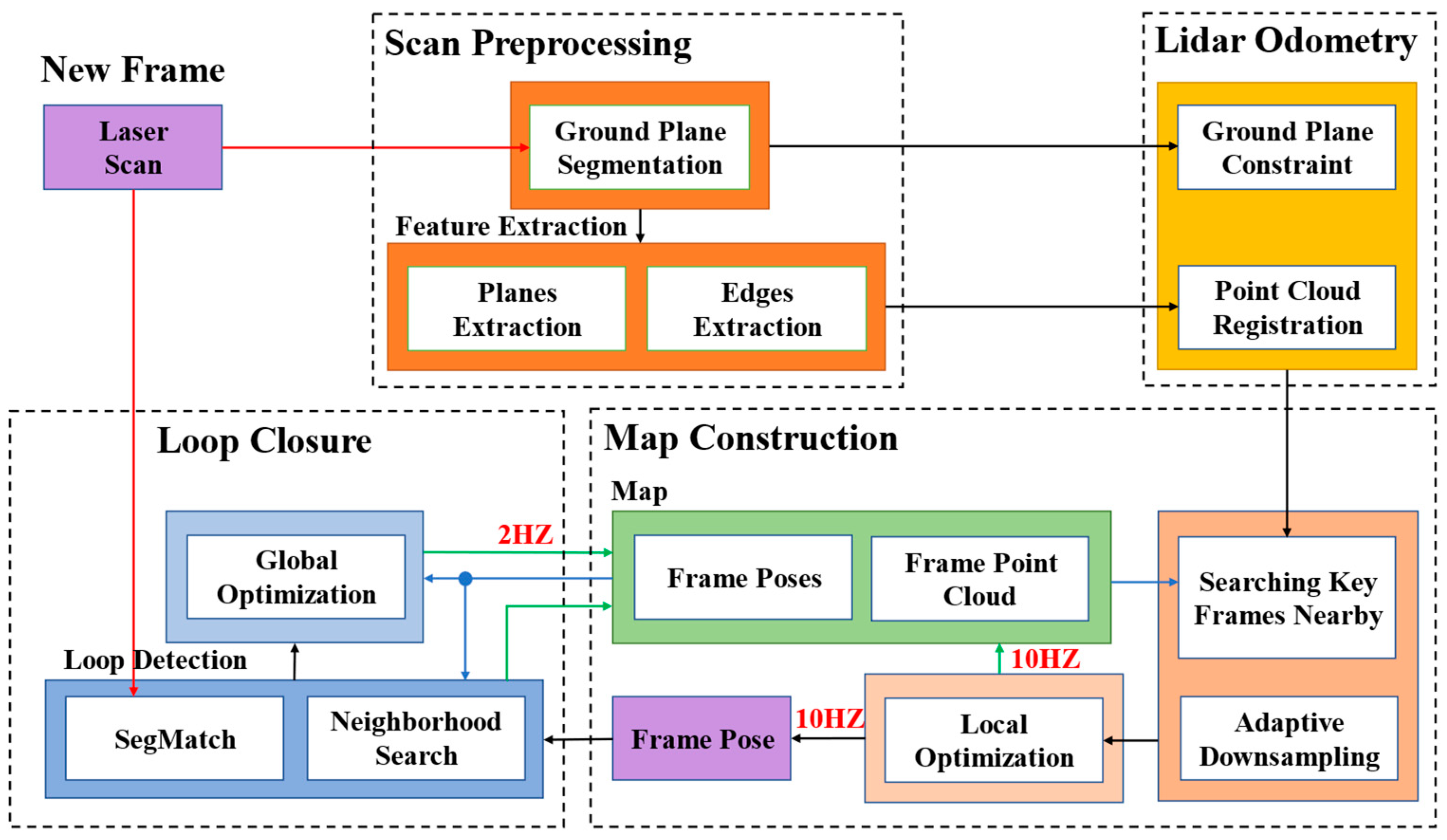
3.1. System Overview
3.2. Scan Preprocessing
3.2.1. Ground Plane Segmentation
- After the noise reduction processing, randomly select three points , , in the point cloud data P.
- The plane S is determined according to three points , , . The values of the a, b, c, d parameters are determined by Equation (1).
- Count the number of points on the plane S in P. Set the plane thickness (point to plane distance threshold) and calculate the distance di from any point in P to plane S, where di is calculated by Equation (2):Then, count the number of points of , and record it as the score of the plane S.
- Repeat the above three steps K times and select the plane with the highest score.In Equation (3), m is the number of points in the point cloud P, n is the number of points on the plane S, and is the probability that the ground plane is selected after K times of sampling. Since both m and n are large, we used approximate calculations here, and the simplified formula is as follows:In Equation (4), is the probability that the point is outside the plane , and after simplification, K is obtained, as shown in Equation (5):
- Re-fitting the selected ground plane data to obtain a ground plane parameter with less error.
3.2.2. Feature Extraction
3.3. Lidar Odometry
3.4. Map Construction
3.5. Loop Closure
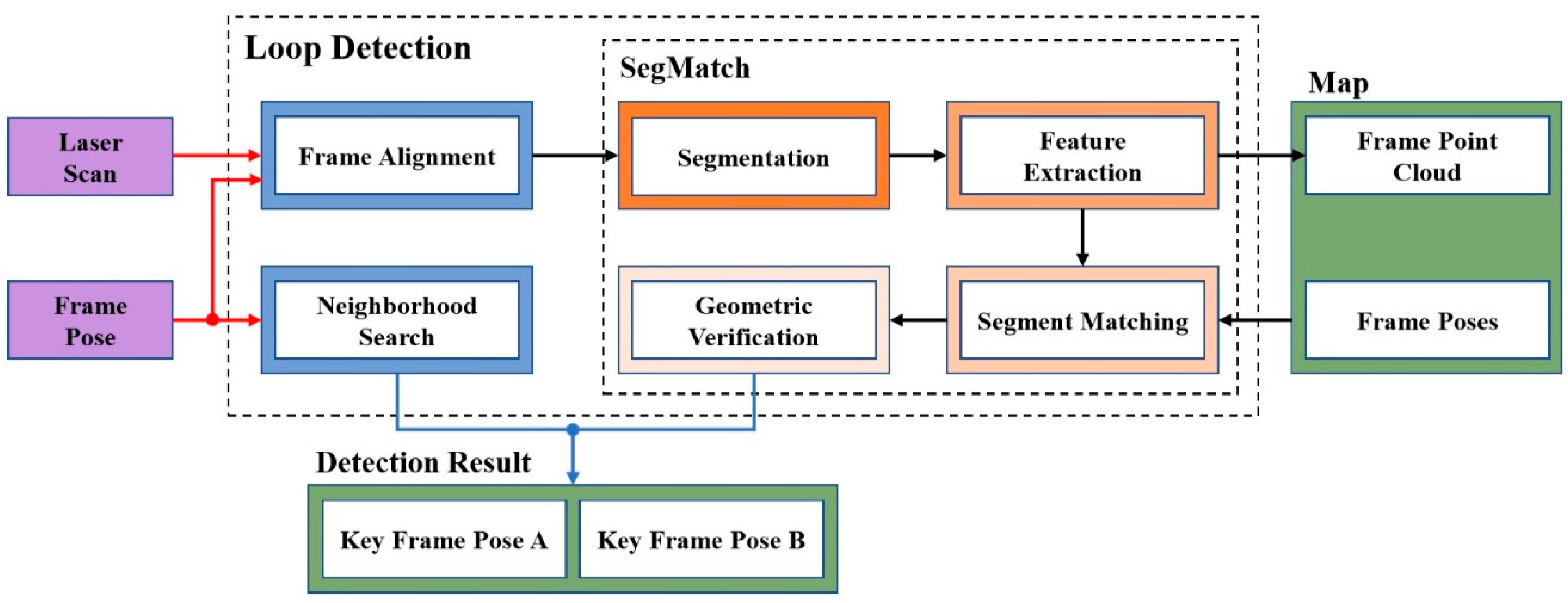
3.5.1. Loop Detection
- Segmentation. After the pose was associated with the point cloud , the local point cloud was extracted in the neighborhood of the current pose . The extracted point cloud was filtered using a voxel grid, and then the filtered point cloud was segmented into a set of point clusters using the “Cluster-All Method” of [31].
- Feature Extraction. Feature extraction was performed on the segmented cluster using several different descriptors. The descriptors used in this paper were calculated based on the feature vector . One of the descriptors contained seven features, as proposed in [32]: linearity, planarity, scattering, omnivariance, anisotropy, eigenentropy, and change of curvature. We stored the feature point cloud extracted every frame into the map for global recognition later, as shown in Figure 5.
- Segment Matching. The extracted point cluster of the current frame was matched with the extracted set of point clusters in the global map . The point cluster in the set of point clusters was associated with the pose , and the pose was updated in real-time. To determine whether there was a match between the current frame and the historical frame, we chose the deep learning method. In order for the random forest classifier to identify if the two clusters were matched, we calculated the absolute difference between the two eigenvectors:
- Geometric Verification. Finally, the geometric consistency of the segment cluster was determined using random sample consensus (RANSAC) [3], so that the pose of the current frame and the pose of the history frame satisfying the condition were obtained.
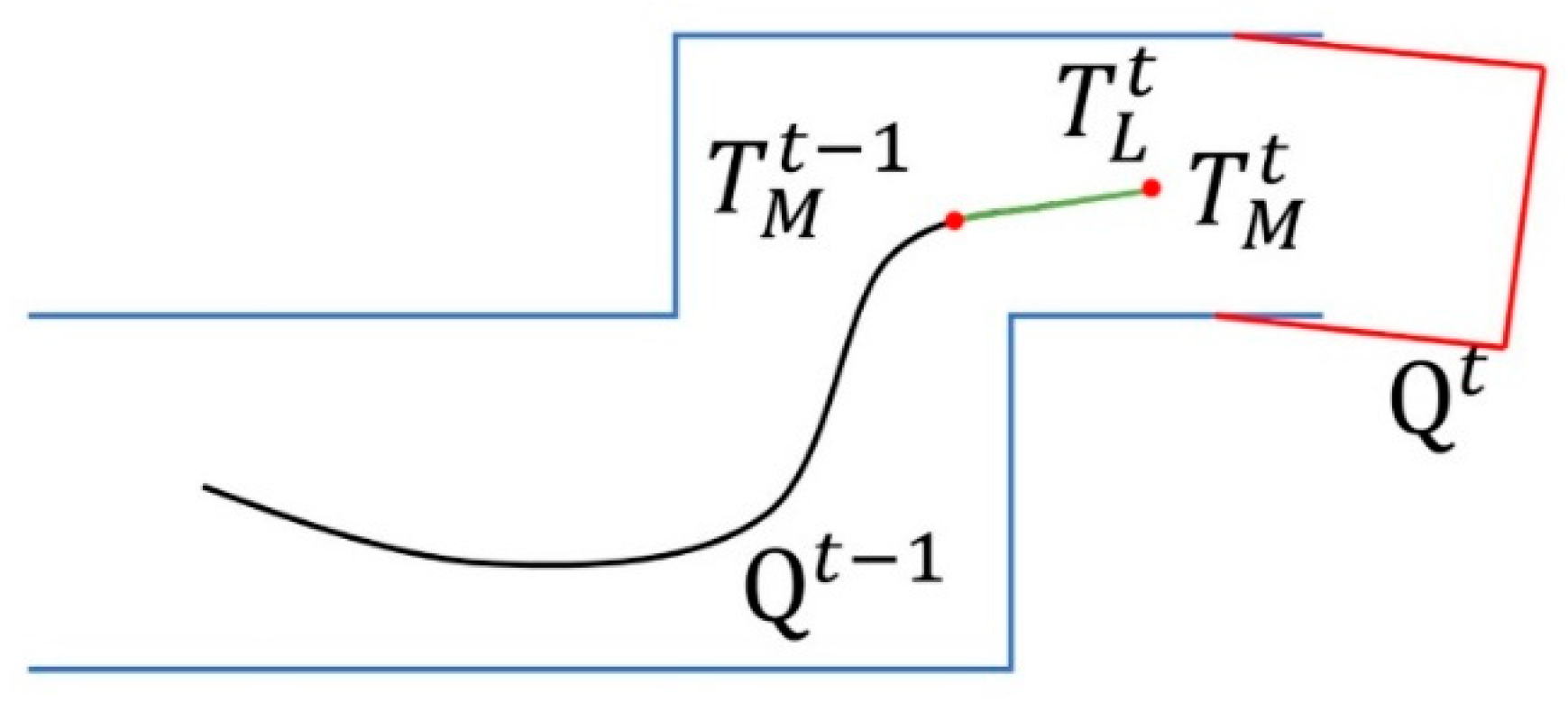
3.5.2. Global Optimization
4. Experiment
4.1. Tests
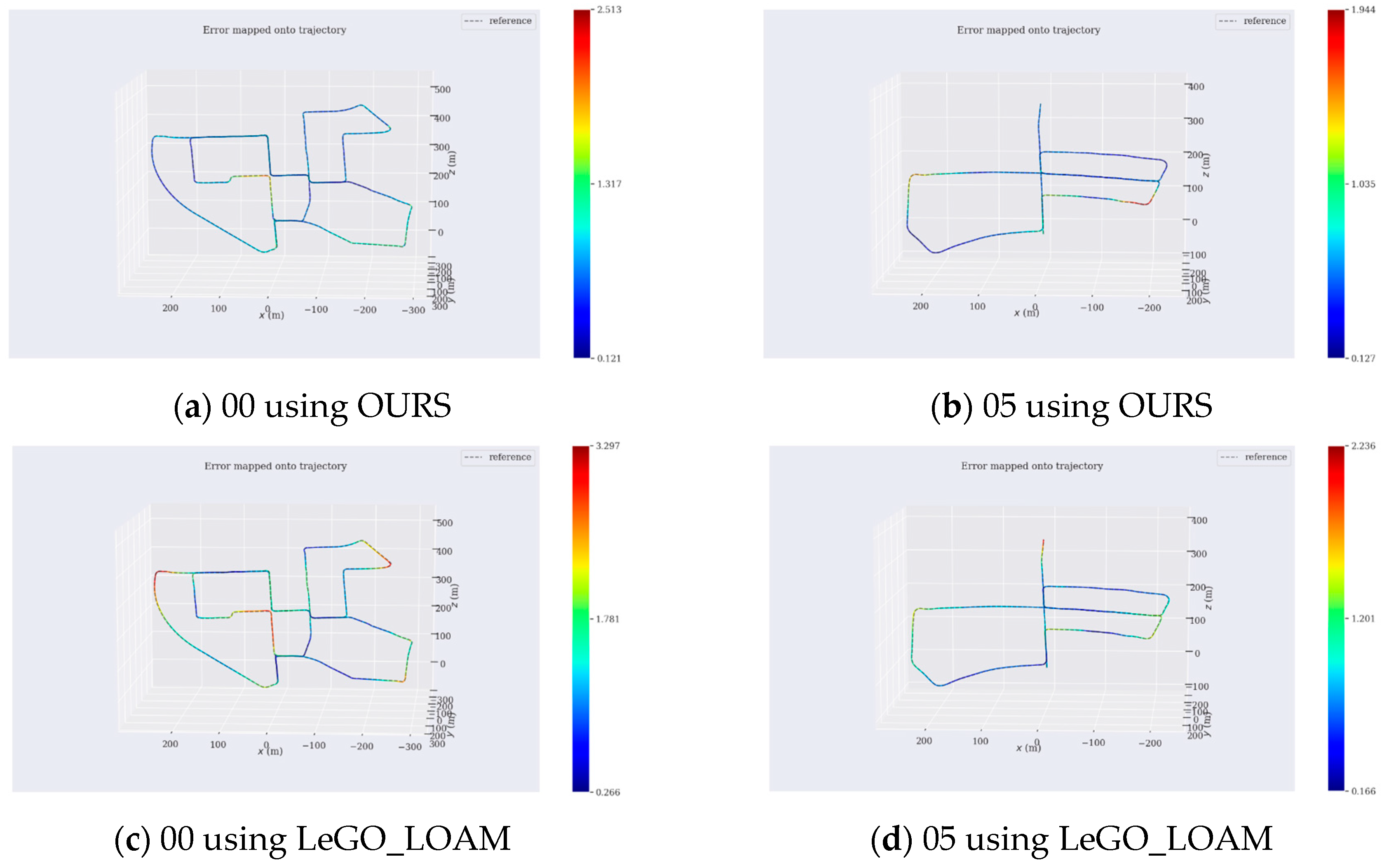
4.1.1. Tests with KITTI Dataset
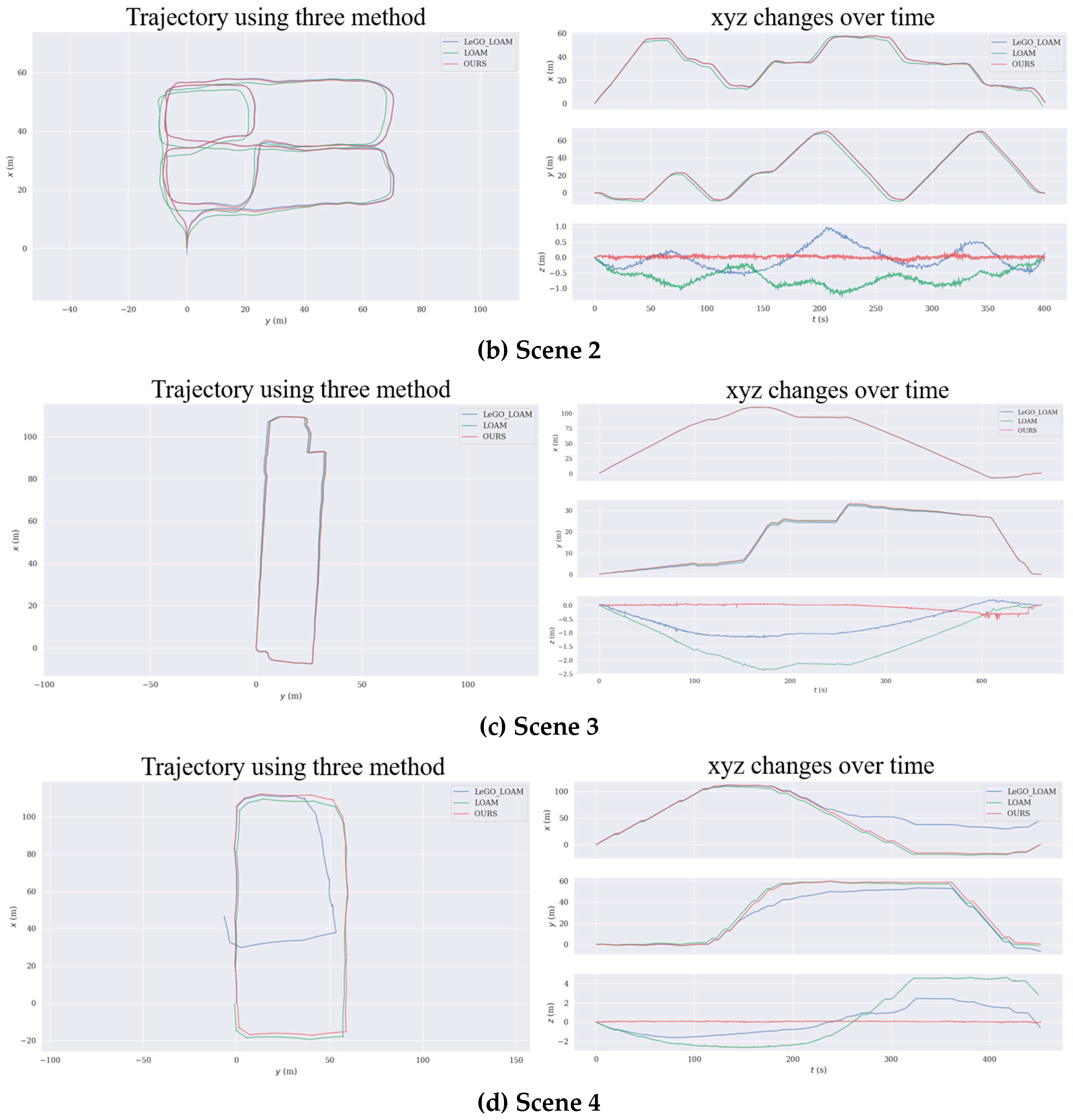
4.1.2. Tests with Our Dataset
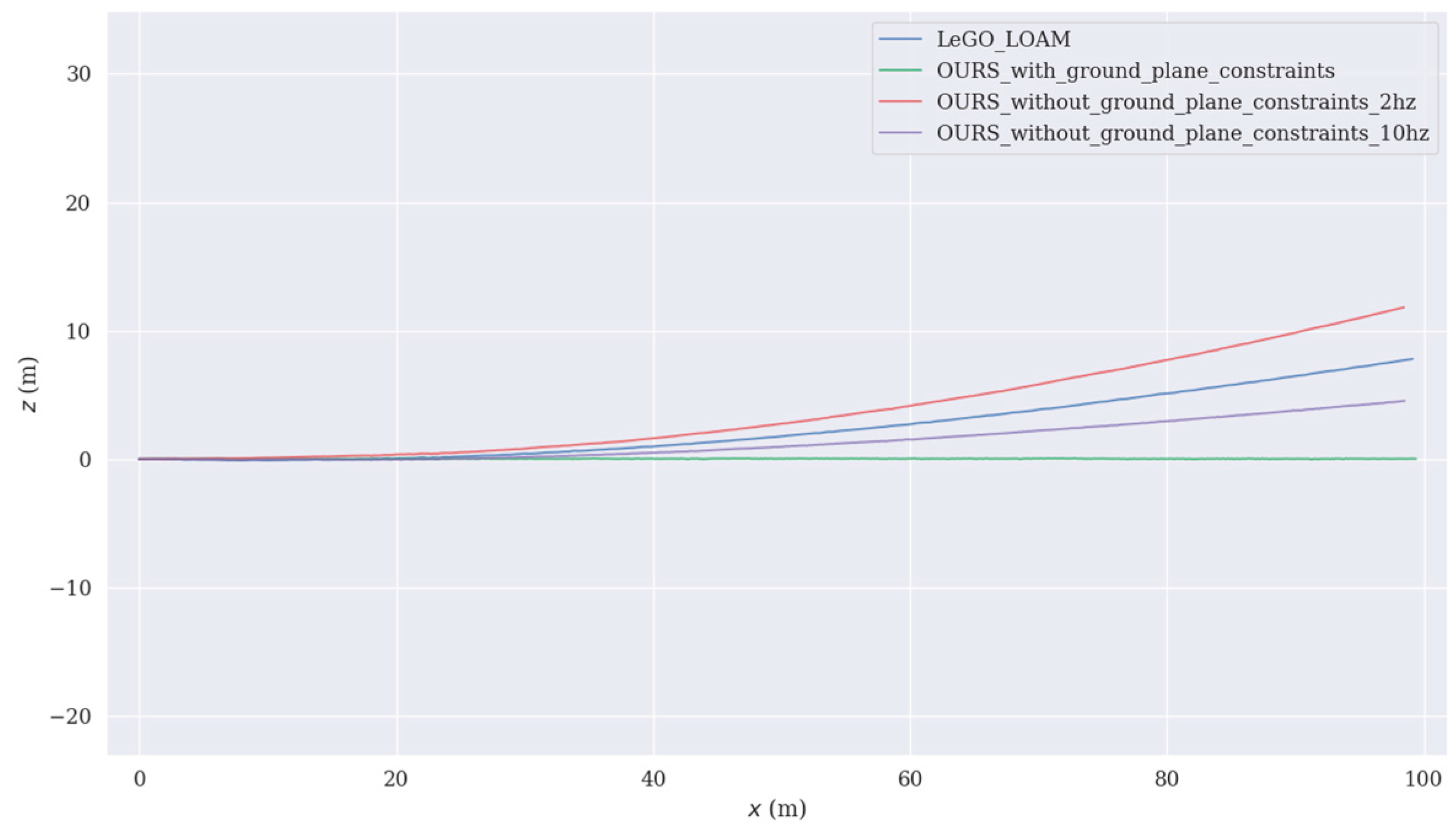
4.2. Discussion of Tests
4.2.1. Influence of Ground Plane Constraints
4.2.2. Impact of Loop Closure
4.2.3. Runtime Analysis
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Zhang, J.; Singh, S. LOAM: Lidar Odometry and Mapping in Real-time. In Proceedings of the Robotics: Science and Systems, Berkeley, CA, USA, 12–16 July 2014. [Google Scholar]
- Dubé, R.; Dugas, D.; Stumm, E.; Nieto, J.; Siegwart, R.; Cadena, C. SegMatch: Segment based place recognition in 3D point clouds. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 5266–5272. [Google Scholar]
- Schnabel, R.; Wahl, R.; Klein, R. Efficient RANSAC for Point-Cloud Shape Detection. Comput. Graph. Forum 2007, 26, 214–226. [Google Scholar] [CrossRef]
- Besl, P.J.; McKay, N.D. A Method for Registration of 3D Shapes. IEEE Trans. Pattern Anal. Mach. Intell. 1992, 14, 239–256. [Google Scholar] [CrossRef]
- Magnusson, M.; Andreasson, H.; Lilienthal, A.J.; Nuchter, A. Appearance-based loop detection from 3D laser data using the normal distributions transform. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Kobe, Japan, 12–17 May 2009; pp. 23–28. [Google Scholar]
- Bosse, M.; Zlot, R. Keypoint Design and Evaluation for Place Recognition in 2D Lidar Maps. Robot. Auton. Syst. 2009, 57, 1211–1224. [Google Scholar] [CrossRef]
- Zlot, R.; Bosse, M. Efficient Large-scale 3D Mobile Mapping and Surface Reconstruction of an Underground Mine. In Proceedings of the 8th International Conference on Field and Service Robotics, Matsushima, Japan, 16–18 July 2012. [Google Scholar]
- Grant, W.S.; Voorhies, R.C.; Itti, L. Finding Planes in LiDAR Point Clouds for Real-time Registration. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, Tokyo, Japan, 3–7 July 2013; pp. 4347–4354. [Google Scholar]
- Zhang, J.; Singh, S. Low-drift and real-time lidar odometry and mapping. Auton. Robot. 2017, 41, 401–416. [Google Scholar] [CrossRef]
- Geiger, A.; Lenz, P.; Urtasun, R. Are We Ready for Autonomous Driving? The KITTI Vision Benchmark Suite. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Steder, B.; Ruhnke, M.; Grzonka, S.; Burgard, W. Place recognition in 3D scans using a combination of bag of words and point feature based relative pose estimation. In Proceedings of the 2011 IEEE/RSJ International Conference on Intelligent Robots and Systems, San Francisco, CA, USA, 25–30 September 2011; pp. 1249–1255. [Google Scholar]
- Zhong, Y. Intrinsic shape signatures: A shape descriptor for 3D object recognition. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision Workshops, ICCV Workshops, Kyoto, Japan, 27 September–4 October 2009; pp. 689–696. [Google Scholar]
- Sipiran, I.; Bustos, B. A Robust 3D Interest Points Detector Based on Harris Operator. In Eurographics Workshop on 3D Object Retrieval; Daoudi, M., Schreck, T., Eds.; The Eurographics Association: Norrköping, Sweden, 2010; pp. 7–14. [Google Scholar]
- Scovanner, P.; Ali, S.; Shah, M. A 3-Dimensional Sift Descriptor and Its Application to Action Recognition. In Proceedings of the MULTIMEDIA ’07 15th International Conference on Multimedia, Augsburg, Germany, 25–29 September 2007; ACM: New York, NY, USA, 2007; pp. 357–360. [Google Scholar]
- Steder, B.; Rusu, R.B.; Konolige, K.; Burgard, W. NARF: 3D Range Image Features for Object Recognition. In Proceedings of the Workshop on Defining and Solving Realistic Perception Problems in Personal Robotics at the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Taipei, Taiwan, 8 October 2010. [Google Scholar]
- Johnson, A. Spin-Images: A Representation for 3-D Surface Matching. Ph.D. Thesis, Carnegie Mellon University, Pittsburgh, PA, USA, 1997. [Google Scholar]
- Salti, S.; Tombari, F.; di Stefano, L. SHOT: Unique signatures of histograms for surface and texture description. Comput. Vis. Image Underst. 2014, 125, 251–264. [Google Scholar] [CrossRef]
- Rusu, R.B.; Marton, Z.C.; Blodow, N.; Beetz, M. Learning Informative Point Classes for the Acquisition of Object Model Maps. In Proceedings of the IEEE International Conference on Control, Automation, Robotics and Vision, Hanoi, Vietnam, 17–20 December 2008; pp. 643–650. [Google Scholar]
- Rusu, R.B.; Bradski, G.; Thibaux, R.; Hsu, J. Fast 3D Recognition and Pose Using the Viewpoint Feature Histogram. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, Taipei, Taiwan, 8 October 2010; pp. 2155–2162. [Google Scholar]
- Dewan, A.; Caselitz, T.; Burgard, W. Learning a Local Feature Descriptor for 3D LiDAR Scans. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 4774–4780. [Google Scholar]
- Zeng, A.; Song, S.; Nießner, M.; Fisher, M.; Xiao, J.; Funkhouser, T. 3DMatch: Learning Local Geometric Descriptors from RGB-D Reconstructions. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Fernández-Moral, E.; Mayol-Cuevas, W.; Arévalo, V.; González-Jiménez, J. Fast place recognition with plane-based maps. In Proceedings of the 2013 IEEE International Conference on Robotics and Automation, Karlsruhe, Germany, 6–10 May 2013; pp. 2719–2724. [Google Scholar]
- Shan, T.; Englot, B. LeGO-LOAM: Lightweight and Ground-Optimized Lidar Odometry and Mapping on Variable Terrain. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 4758–4765. [Google Scholar]
- Deschaud, J. IMLS-SLAM: Scan-to-Model Matching Based on 3D Data. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, QLD, Australia, 21–25 May 2018; pp. 2480–2485. [Google Scholar] [CrossRef] [Green Version]
- Cho, Y.; Kim, G.; Kim, A. DeepLO: Geometry-Aware Deep LiDAR Odometry. arXiv 2019, arXiv:1902.10562. [Google Scholar]
- Li, Q.; Chen, S.; Wang, C.; Li, X.; Wen, C.; Cheng, M.; Li, J. LO-Net: Deep Real-Time Lidar Odometry. arXiv 2019, arXiv:1904.08242. [Google Scholar]
- Behley, J.; Stachniss, C. Efficient Surfel-Based SLAM using 3D Laser Range Data in Urban Environments. In Proceedings of the Robotics: Science and Systems (RSS), Pittsburgh, PA, USA, 26–30 June 2018. [Google Scholar]
- Agarwal, S.; Mierle, K. Ceres Solver. Available online: http://ceres-solver.org (accessed on 22 August 2018).
- Dubé, R.; Cramariuc, A.; Dugas, D.; Nieto, J.; Siegwart, R.; Cadena, C. SegMap: 3D Segment Mapping using Data-Driven Descriptors. In Proceedings of the Robotics: Science and Systems, Pittsburgh, PA, USA, 26–30 June 2018. [Google Scholar]
- Dubé, R.; Gawel, A.; Sommer, H.; Nieto, J.; Siegwart, R.; Cadena, C. An online multi-robot SLAM system for 3D LiDARs. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 1004–1011. [Google Scholar]
- Douillard, B.; Underwood, J.; Kuntz, N.; Vlaskine, V.; Quadros, A.; Morton, P.; Frenkel, A. On the segmentation of 3D LIDAR point clouds. In Proceedings of the 2011 IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011. [Google Scholar]
- Weinmann, M.; Jutzi, B.; Mallet, C. Semantic 3D scene interpretation: A framework combining optimal neighborhood size selection with relevant features. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2014, 2, 181. [Google Scholar] [CrossRef] [Green Version]
- Kaess, M.; Johannsson, H.; Roberts, R.; Ila, V.; Leonard, J.J.; Dellaert, F. iSAM2: Incremental smoothing and mapping using the Bayes tree. Int. J. Robot. Res. 2012, 31, 216–235. [Google Scholar] [CrossRef]
- Dellaert, F.; Kaess, M. Square Root SAM: Simultaneous localization and mapping viasquare root information smoothing. Int. J. Robot. Res. 2006, 25, 1181–1203. [Google Scholar] [CrossRef] [Green Version]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sequence | Method | Max (m) | Min (m) | Mean (m) | Rmse 1 (m) |
|---|---|---|---|---|---|
| 00 | OURS | 2.51 | 0.12 | 0.75 | 0.82 |
| LeGO_LOAM | 3.29 | 0.26 | 1.45 | 1.61 | |
| 05 | OURS | 1.94 | 0.12 | 0.67 | 0.76 |
| LeGO_LOAM | 2.24 | 0.17 | 0.83 | 0.89 |
| Scene | Method | Roll | Pitch | Yaw | Total Rot.2 (deg) | X | Y | Z | Total Trans.3 (m) |
|---|---|---|---|---|---|---|---|---|---|
| 1 | OURS | −0.52 | 0.48 | −179.74 | 179.74 | −0.08 | −0.05 | −0.01 | 0.08 |
| LOAM | −1.51 | −0.33 | −179.88 | 179.88 | −0.18 | −0.05 | 0.03 | 0.19 | |
| LeGO_LOAM | −0.81 | −0.4 | −179.59 | 179.6 | −0.12 | −0.06 | 0.02 | 0.13 | |
| 2 | OURS | 4.34 | 0.01 | 179.75 | 179.8 | 0.47 | −0.19 | 0.01 | 0.51 |
| LOAM | 2.71 | 0.8 | 174.69 | 174.72 | −2.06 | −0.02 | 0.03 | 2.06 | |
| LeGO_LOAM | 1.27 | −0.72 | 177.93 | 177.93 | 1.22 | −0.13 | 0.16 | 1.24 | |
| 3 | OURS | −1.49 | 0.44 | 0.94 | 1.83 | −0.05 | 0.01 | −0.01 | 0.04 |
| LOAM | 0.43 | −0.61 | −6.4 | 6.44 | −0.16 | 0.09 | −0.09 | 0.21 | |
| LeGO_LOAM | −0.83 | 0.87 | 0.3 | 1.24 | −0.15 | 0.02 | −0.01 | 0.15 | |
| 4 | OURS LOAM LeGO_LOAM | 2.57 −3.31 | −1.98 −1.58 | −8.13 −9.52 | 8.76 10.2 | −0.01 −0.51 fail | 0.11 −1.19 | 0.04 2.82 | 0.11 3.11 |
| Modules | Average Time (ms) |
|---|---|
| Scan preprocessing | 50 |
| Lidar odometry | 65 |
| Point cloud map construction | 80 |
| Loop closure | 220 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, X.; Zhang, L.; Qin, S.; Tian, D.; Ouyang, S.; Chen, C. Optimized LOAM Using Ground Plane Constraints and SegMatch-Based Loop Detection. Sensors 2019, 19, 5419. https://doi.org/10.3390/s19245419
Liu X, Zhang L, Qin S, Tian D, Ouyang S, Chen C. Optimized LOAM Using Ground Plane Constraints and SegMatch-Based Loop Detection. Sensors. 2019; 19(24):5419. https://doi.org/10.3390/s19245419
Chicago/Turabian StyleLiu, Xiao, Lei Zhang, Shengran Qin, Daji Tian, Shihan Ouyang, and Chu Chen. 2019. "Optimized LOAM Using Ground Plane Constraints and SegMatch-Based Loop Detection" Sensors 19, no. 24: 5419. https://doi.org/10.3390/s19245419
APA StyleLiu, X., Zhang, L., Qin, S., Tian, D., Ouyang, S., & Chen, C. (2019). Optimized LOAM Using Ground Plane Constraints and SegMatch-Based Loop Detection. Sensors, 19(24), 5419. https://doi.org/10.3390/s19245419