Automatic and Robust Infrared-Visible Image Sequence Registration via Spatio-Temporal Association

Abstract
:1. Introduction
- (1)
- We propose a spatio-temporal associated registration algorithm for infrared-visible image sequences, which combines temporal motion information and intra-frame feature matching scheme, achieving low registration overlapping errors.
- (2)
- We create MVD descriptors of foreground contours for coarse registration without feature extraction. Thus, foreground targets can be roughly aligned to eliminate the impact of inaccurate positioning of feature points.
- (3)
- We propose a description of feature points based on the spatial location distribution of connected blob contours, and perform feature matching using bidirectional optimal maximum strategy. A robust reservoir updated by BIWO strategy is proposed to improve the accuracy of the final global transformation matrix.
2. Related Work
3. Methodology
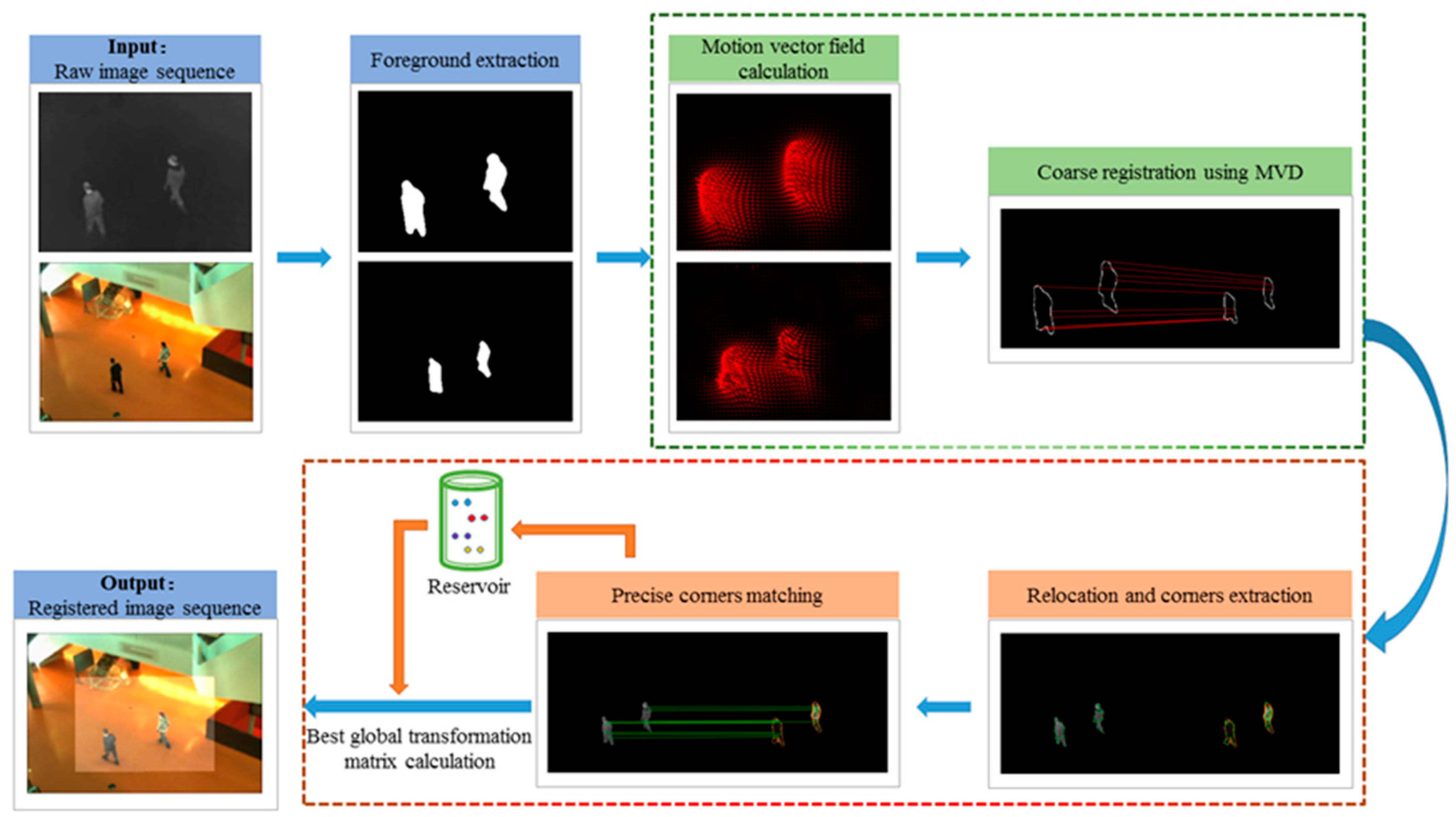
3.1. Overview of the Proposed Algorithm
3.2. Foreground Extraction
3.3. Coarse Registration
3.3.1. Image Preprocessing
- The lighting condition may change when sensors capture images, which will greatly affect the accuracy of the motion vector field. For an image sequence with a resolution of M × N, the gray value of the pixels in the next frame will be rectified to the previous frame by:
- Noise removal is necessary. We use a Gaussian filter (5 × 5 size, standard deviation of 3) to smooth each frame of the image sequence.
3.3.2. Motion Vector Field Calculation
3.3.3. Motion Vector Field Filtering and Re-Projection
- Motion vector that belongs to the background is set to zero. Because only the motion vector of the foreground is sufficiently distinguishable for registering foreground contours.
- Motion vector near the image boundaries tends to be inaccurate and is not conducive to the establishment of subsequent MVD descriptors. We remove the motion vector near the boundaries with a threshold of 20 pixels.
- For a pixel with location , gray value , and calculated motion vector , the offset of the gray value relative to the pixel in the next frame can be obtained by re-projection (bilinear interpolation method):
3.3.4. Creation of Motion Vector Distribution Descriptor and Contour Matching
3.4. Precise Registration
3.4.1. Relocation and Feature Point Extraction
3.4.2. Feature Points Description
- Position of the feature point: .
- Location of the feature point relative to the centroid of the connected foreground blob to which it belongs, calculated by:where is the position of the centroid.
- The shape context descriptor [18] of the feature point. It reflects the spatial location distribution of neighbored points around the center. Contour points of the connected foreground blob to which the feature point belongs form the descriptor. In our algorithm, log-polar coordinate is used to divide the distance into 5 bins and the angle into 8 bins. The shape context descriptor (40-dimensional) of the feature point is established by:where is the distribution statistical histogram of joint distance and angle.
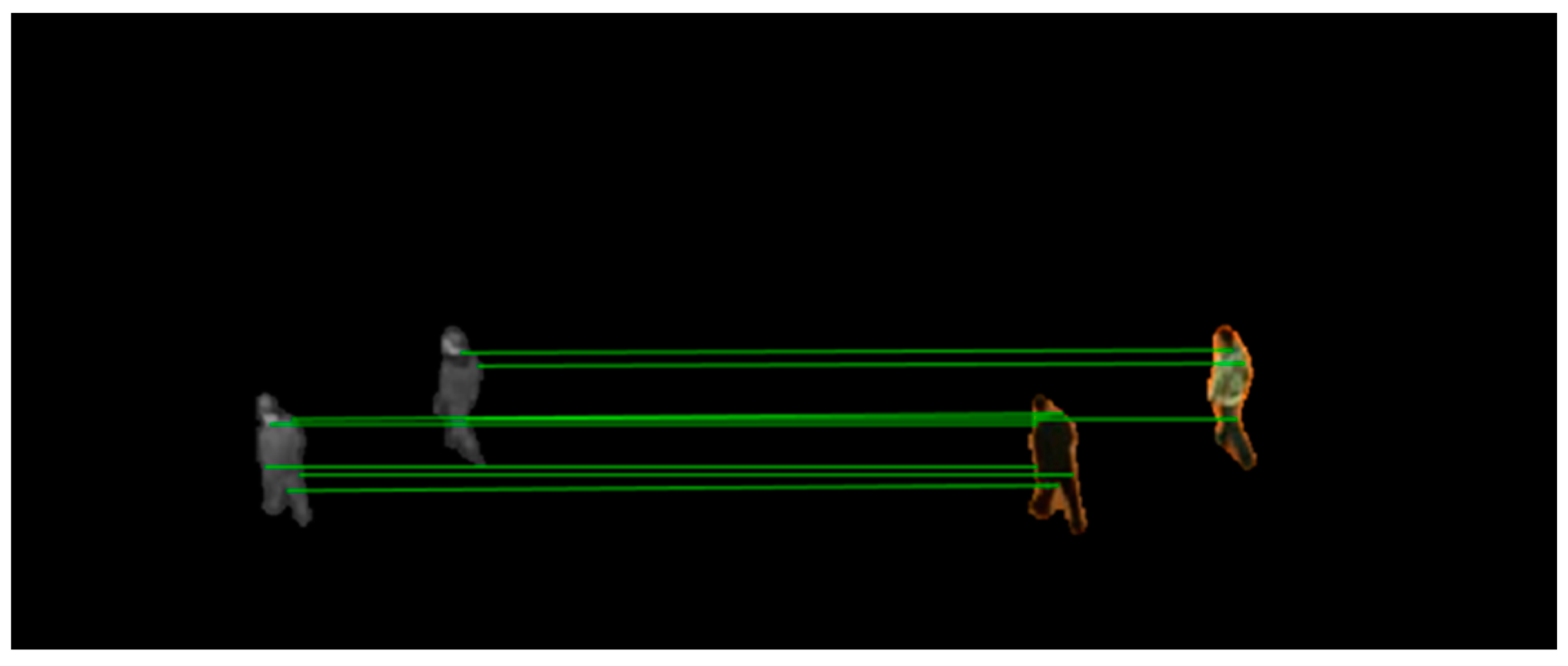
3.4.3. Matching
- Euclidean distance between positions of the two feature points:
- Euclidean distance between locations of the two feature points relative to the centroids:
- Chi-square test statistic between two shape context descriptors:
| Algorithm 1: Bidirectional Optimal Maximum Matching Strategy |
| Input: Point sets and ; descriptions , , and , , . |
| Output: Matched point set . |
| For each point in |
| Foreach |
| If ( in our algorithm) & ( in our algorithm) |
| Calculate using Equation (13); get the minimun and sub-minimum |
| If ( in our algorithm) |
| Point with is regarded as the matched point |
| End if |
| End if |
| End if |
| For each point in , adopt the same matching strategy |
| Preserve bidirectionally matched point pairs in |
3.4.4. Reservoir Construction and Optimal Transformation Matrix Calculation
| Algorithm 2: Reservoir updated by BIWO strategy |
| Input: Reservoir ; new point pair and its |
| similarity metrics , and . |
| Output: Updated reservoir . |
| If |
| Calculate the means of and of |
| If and are smaller than the means & is smaller than the maximum |
| Abandon the point pair with maximal and replace it with the new |
| End if |
| End if |
| Obtain the updated reservoir |
4. Experiments and Analysis
4.1. Dataset
4.2. Qualitative Results and Analysis
4.3. Quantitative Results and Analysis
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Sappa, A.; Carvajal, J.; Aguilera, C.; Oliveira, M.; Romero, D.; Vintimilla, B. Wavelet-based visible and infrared image fusion: A comparative study. Sensors 2016, 16, 861. [Google Scholar] [CrossRef] [PubMed]
- Du, Q.; Xu, H.; Ma, Y.; Huang, J.; Fan, F. Fusing infrared and visible images of different resolutions via total variation model. Sensors 2018, 18, 3827. [Google Scholar] [CrossRef] [PubMed]
- Zhou, Z.; Bo, W.; Sun, L.; Dong, M. Perceptual fusion of infrared and visible images through a hybrid multi-scale decomposition with gaussian and bilateral filters. Inf. Fus. 2016, 30, 15–26. [Google Scholar] [CrossRef]
- Zambotti-Villela, L.; Yamasaki, S.C.; Villarroel, J.S.; Alponti, R.F.; Silveira, P.F. Novel fusion method for visible light and infrared images based on nsst-sf-pcnn. Infrared Phys. Technol. 2014, 65, 103–112. [Google Scholar]
- Xiao, G.; Yun, X.; Wu, J. A multi-cue mean-shift target tracking approach based on fuzzified region dynamic image fusion. Sci. China Inf. Sci. 2012, 55, 577–589. [Google Scholar] [CrossRef]
- Singh, R.; Vatsa, M.; Noore, A. Integrated multilevel image fusion and match score fusion of visible and infrared face images for robust face recognition. Pattern Recognit. 2008, 41, 880–893. [Google Scholar] [CrossRef]
- Tsagaris, V.; Anastassopoulos, V. Fusion of visible and infrared imagery for night color vision. Displays 2005, 26, 191–196. [Google Scholar] [CrossRef]
- Sonn, S.; Bilodeau, G.-A.; Galinier, P. Fast and accurate registration of visible and infrared videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Portland, OR, USA, 23–28 June 2013; pp. 308–313. [Google Scholar]
- Aguilera, C.; Barrera, F.; Lumbreras, F.; Sappa, A.D.; Toledo, R. Multispectral image feature points. Sensors 2012, 12, 12661–12672. [Google Scholar] [CrossRef]
- Rui, T.; Zhang, S.-a.; Zhou, Y.; Jianchun, X.; Jian, D. Registration of infrared and visible images based on improved sift. In Proceedings of the 4th International Conference on Internet Multimedia Computing and Service, Wuhan, China, 9–11 September 2012; pp. 144–147. [Google Scholar]
- Zhang, Y.; Zhang, X.; Maybank, S.J.; Yu, R. An ir and visible image sequence automatic registration method based on optical flow. Mach. Vis. Appl. 2013, 24, 947–958. [Google Scholar] [CrossRef]
- Caspi, Y.; Simakov, D.; Irani, M. Feature-based sequence-to-sequence matching. Int. J. Comput. Vis. 2006, 68, 53–64. [Google Scholar] [CrossRef]
- Bilodeau, G.-A.; Torabi, A.; Morin, F. Visible and infrared image registration using trajectories and composite foreground images. Image Vis. Comput. 2011, 29, 41–50. [Google Scholar] [CrossRef]
- St-Charles, P.-L.; Bilodeau, G.-A.; Bergevin, R. Online multimodal video registration based on shape matching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Boston, MA, USA, 7–12 June 2015; pp. 26–34. [Google Scholar]
- Sun, X.; Xu, T.; Zhang, J.; Li, X. A hierarchical framework combining motion and feature information for infrared-visible video registration. Sensors 2017, 17, 384. [Google Scholar] [CrossRef] [PubMed]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–25 June 2005; pp. 886–893. [Google Scholar]
- Rosten, E.; Porter, R.; Drummond, T. Faster and better: A machine learning approach to corner detection. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 105–119. [Google Scholar] [CrossRef] [PubMed]
- Belongie, S.; Malik, J.; Puzicha, J. Shape matching and object recognition using shape contexts. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 509–522. [Google Scholar] [CrossRef] [Green Version]
- Chi, K.C.; Tsui, H.T.; Tong, L. Surface registration using a dynamic genetic algorithm. Pattern Recognit. 2004, 37, 105–117. [Google Scholar]
- Rezaei, H.; Shakeri, M.; Azadi, S.; Jaferzade, K. Multimodality image registration utilizing ant colony algorithm. In Proceedings of the 2009 2nd International Conference on Machine Vision, Dubai, UAE, 28–30 December 2009; pp. 49–53. [Google Scholar]
- Thévenaz, P.; Unser, M. Optimization of mutual information for multiresolution image registration. IEEE Trans. Image Process. 2000, 9, 2083–2099. [Google Scholar] [PubMed] [Green Version]
- Kim, J.; Fessler, J.A. Intensity-based image registration using robust correlation coefficients. IEEE Trans. Med. Imaging 2004, 23, 1430–1444. [Google Scholar] [CrossRef] [PubMed]
- Pluim, J.P.; Maintz, J.A.; Viergever, M.A. Mutual-information-based registration of medical images: A survey. IEEE Trans. Med. Imaging 2003, 22, 986–1004. [Google Scholar] [CrossRef] [PubMed]
- Foroosh, H.; Zerubia, J.B.; Berthod, M. Extension of phase correlation to subpixel registration. IEEE Trans. Image Process. 2002, 11, 188–200. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jang, J.; Yoo, Y.; Kim, J.; Paik, J. Sensor-based auto-focusing system using multi-scale feature extraction and phase correlation matching. Sensors 2015, 15, 5747–5762. [Google Scholar] [CrossRef] [PubMed]
- Kim, Y.S.; Lee, J.H.; Ra, J.B. Multi-sensor image registration based on intensity and edge orientation information. Pattern Recognit. 2008, 41, 3356–3365. [Google Scholar] [CrossRef]
- St-Charles, P.-L.; Bilodeau, G.-A.; Bergevin, R. A self-adjusting approach to change detection based on background word consensus. In Proceedings of the 2015 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 5–9 January 2015; pp. 990–997. [Google Scholar]
- Horn, B.K.; Schunck, B.G. Determining optical flow. Artif. Intell. 1981, 17, 185–203. [Google Scholar] [CrossRef] [Green Version]
- Bouguet, J.-Y. Pyramidal implementation of the affine lucas kanade feature tracker description of the algorithm. Intel Corp. 2001, 5, 4. [Google Scholar]
- Liu, T.; Shen, L. Fluid flow and optical flow. J. Fluid Mech. 2008, 614, 253–291. [Google Scholar] [CrossRef]
- Fischler, M.A.; Bolles, R.C. Random sample consensus: A paradigm for model fitting with applications to image analysis and automated cartography. Commun. ACM 1981, 24, 381–395. [Google Scholar] [CrossRef]
- Torabi, A.; Massé, G.; Bilodeau, G.-A. An iterative integrated framework for thermal–visible image registration, sensor fusion, and people tracking for video surveillance applications. Comput. Vis. Image Understand. 2012, 116, 210–221. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sequence Pair | Ground-Truth | Ours | Sun et al. | Charles et al. |
|---|---|---|---|---|
| LITIV-1 | 0.1498 | 0.1297 | 0.1348 | 0.1868 |
| LITIV-2 | 0.0777 | 0.0917 | 0.0825 | 0.1058 |
| LITIV-3 | 0.0803 | 0.0886 | 0.1011 | 0.1083 |
| LITIV-4 | 0.2213 | 0.0987 | 0.1094 | 0.1184 |
| LITIV-5 | 0.1500 | 0.0956 | 0.1020 | 0.1721 |
| LITIV-6 | 0.0875 | 0.0823 | 0.0831 | 0.0689 |
| LITIV-7 | 0.1360 | 0.0448 | 0.0523 | 0.0909 |
| LITIV-8 | 0.2596 | 0.1848 | 0.1763 | 0.1367 |
| LITIV-9 | 0.1343 | 0.0954 | 0.0932 | 0.0950 |
| Sequence Pair | Ground-Truth | Ours | Sun et al. | Charles et al. |
|---|---|---|---|---|
| LITIV-1 | 0.1498 | 0.1933 | 0.2264 | 0.2657 |
| LITIV-2 | 0.0777 | 0.1474 | 0.1617 | 0.2049 |
| LITIV-3 | 0.0803 | 0.1667 | 0.1872 | 0.1932 |
| LITIV-4 | 0.2213 | 0.2454 | 0.1981 | 0.3116 |
| LITIV-5 | 0.1500 | 0.1339 | 0.1512 | 0.2671 |
| LITIV-6 | 0.0875 | 0.1543 | 0.1902 | 0.4125 |
| LITIV-7 | 0.1360 | 0.1191 | 0.1358 | 0.2573 |
| LITIV-8 | 0.2596 | 0.2213 | 0.2366 | 0.2038 |
| LITIV-9 | 0.1343 | 0.1503 | 0.1726 | 0.1850 |
| Sequence Pair | LITIV-1 | LITIV-2 | LITIV-3 | LITIV-4 | LITIV-5 | LITIV-6 | LITIV-7 | LITIV-8 | LITIV-9 |
|---|---|---|---|---|---|---|---|---|---|
| Time(s) | 0.0615 | 0.1028 | 0.0638 | 0.0925 | 0.0781 | 0.0699 | 0.0633 | 0.0764 | 0.0733 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, B.; Xu, T.; Chen, Y.; Li, T.; Sun, X. Automatic and Robust Infrared-Visible Image Sequence Registration via Spatio-Temporal Association. Sensors 2019, 19, 997. https://doi.org/10.3390/s19050997
Zhao B, Xu T, Chen Y, Li T, Sun X. Automatic and Robust Infrared-Visible Image Sequence Registration via Spatio-Temporal Association. Sensors. 2019; 19(5):997. https://doi.org/10.3390/s19050997
Chicago/Turabian StyleZhao, Bingqing, Tingfa Xu, Yiwen Chen, Tianhao Li, and Xueyuan Sun. 2019. "Automatic and Robust Infrared-Visible Image Sequence Registration via Spatio-Temporal Association" Sensors 19, no. 5: 997. https://doi.org/10.3390/s19050997
APA StyleZhao, B., Xu, T., Chen, Y., Li, T., & Sun, X. (2019). Automatic and Robust Infrared-Visible Image Sequence Registration via Spatio-Temporal Association. Sensors, 19(5), 997. https://doi.org/10.3390/s19050997