Open Database for Accurate Upper-Limb Intent Detection Using Electromyography and Reliable Extreme Learning Machines


Abstract
:1. Introduction
2. Materials and Methods
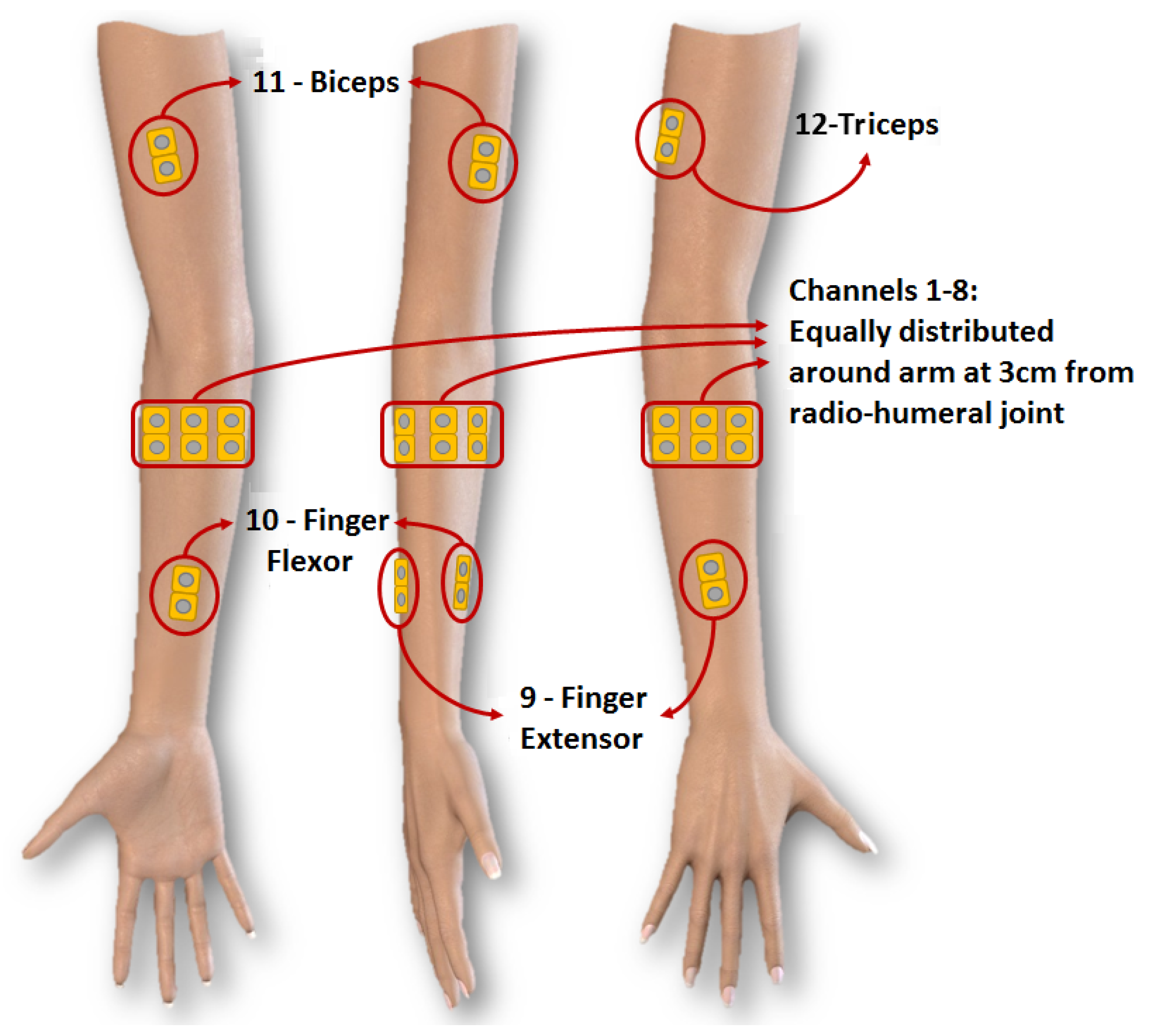
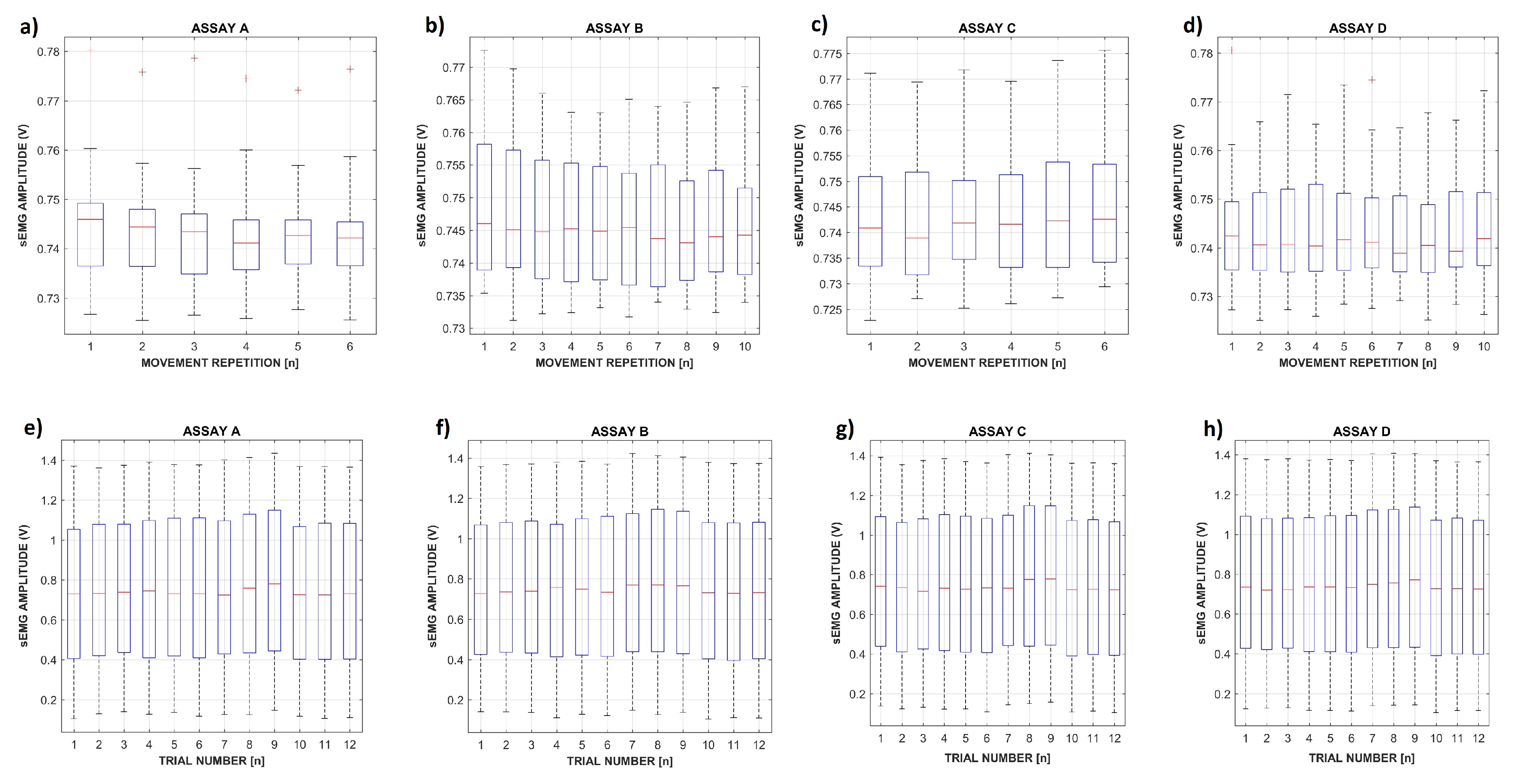
2.1. Experimental Protocol
2.2. The LabVIEW Interface
2.3. Data Relabeling
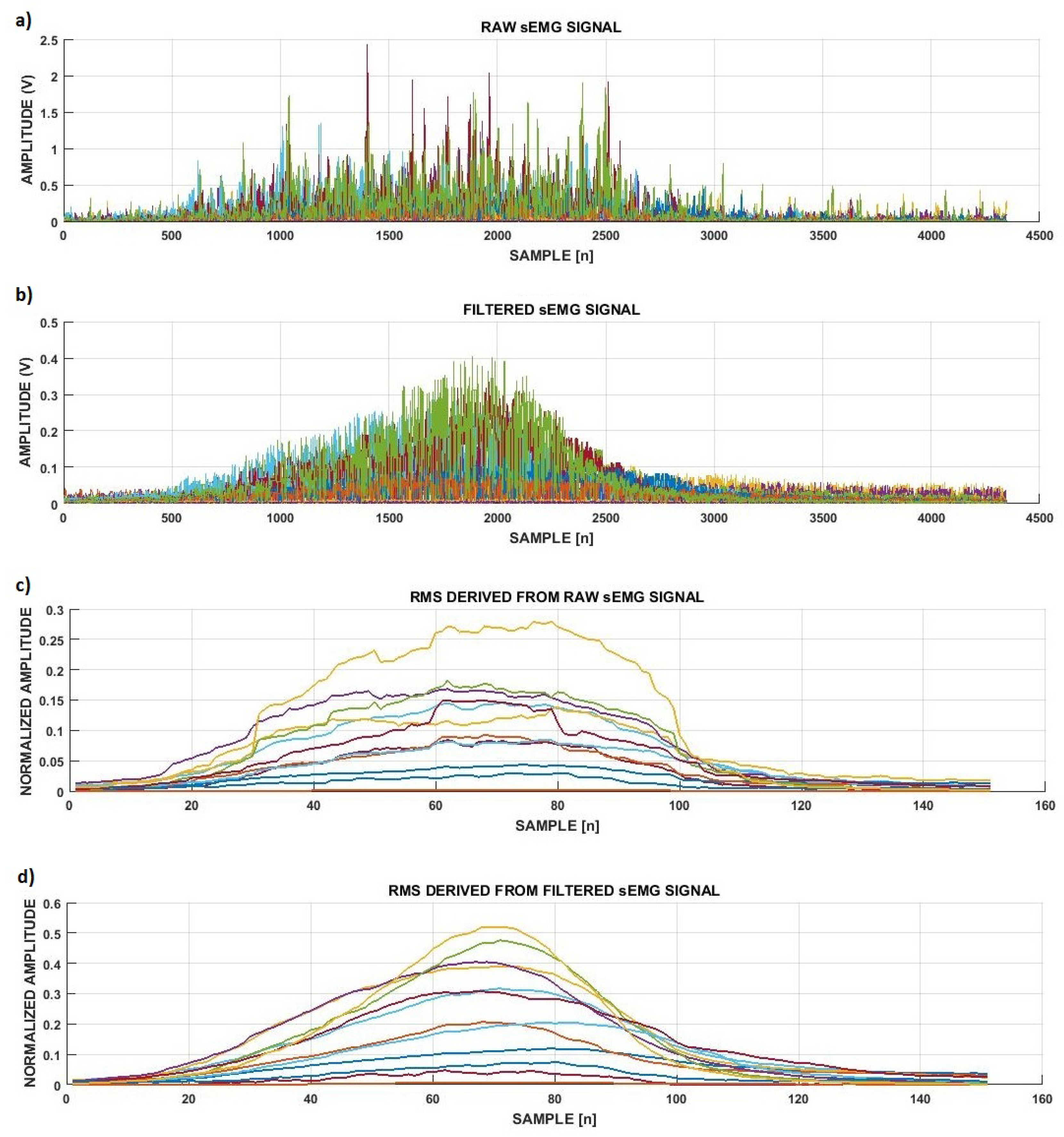
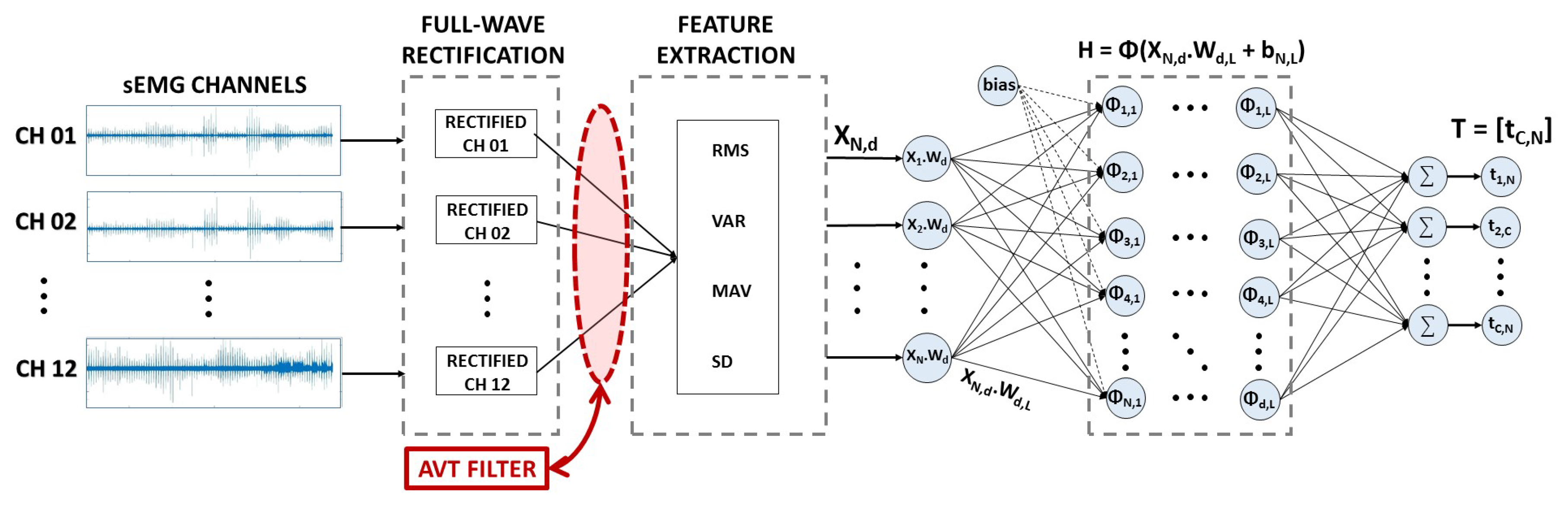
2.4. Signal Filtering
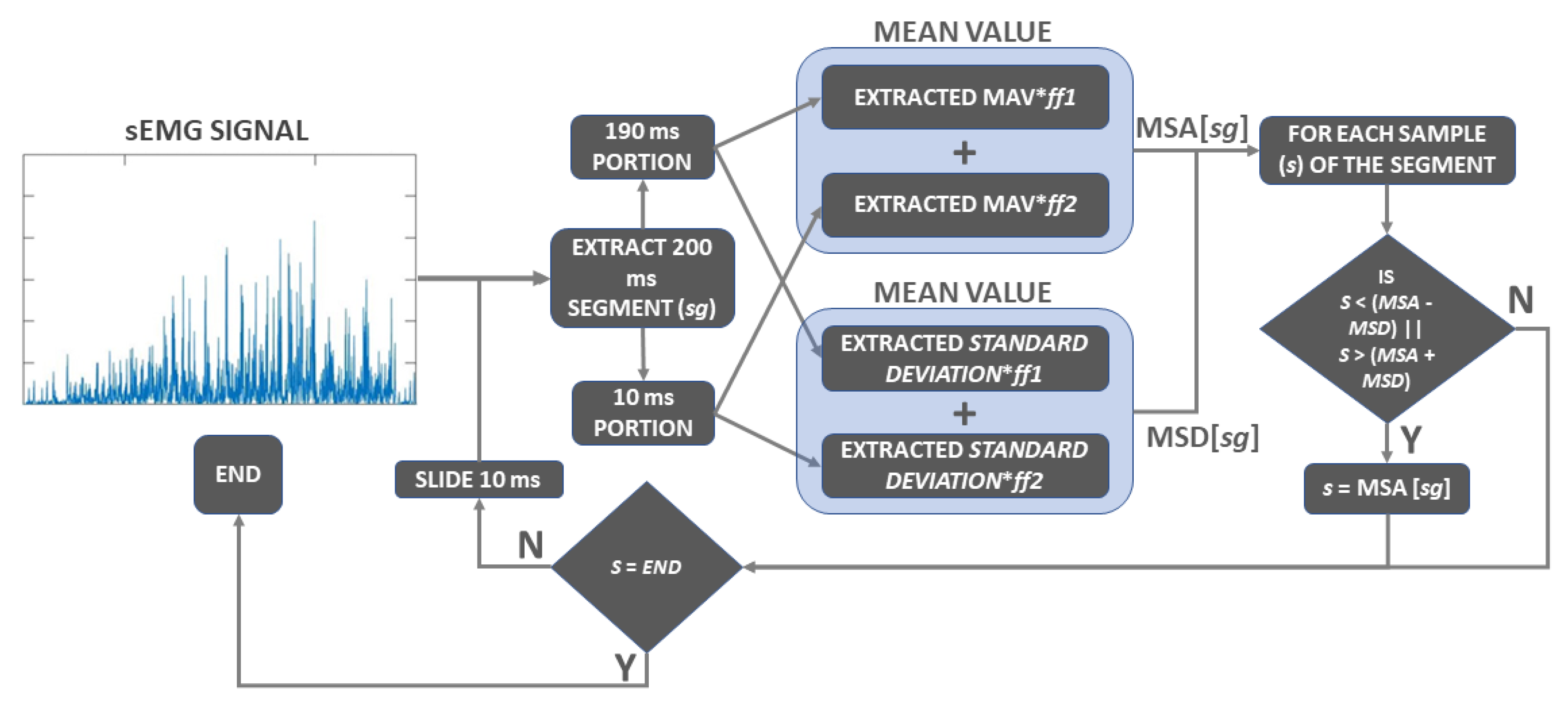
2.5. Signal Segmentation and Feature Extraction
2.6. Signal Classification
2.6.1. ELM
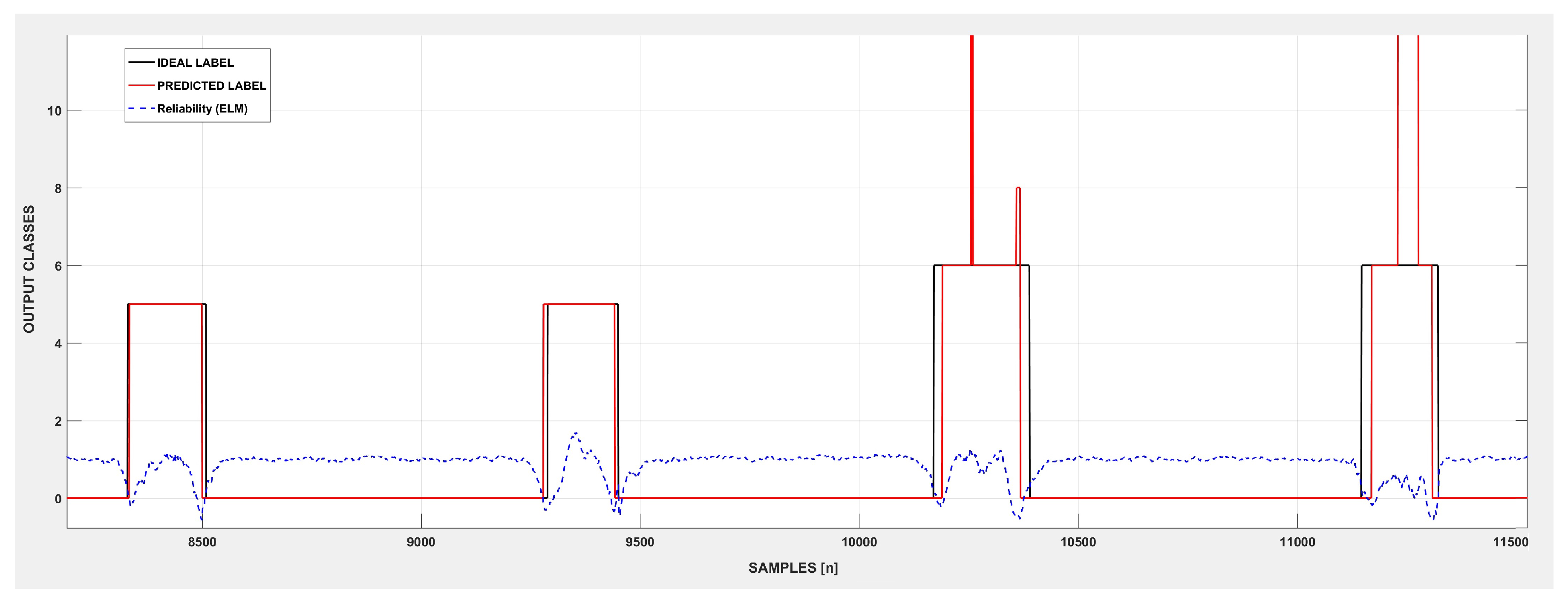
2.6.2. Reliable Signal Classification
3. Results
3.1. IEE Database Validation
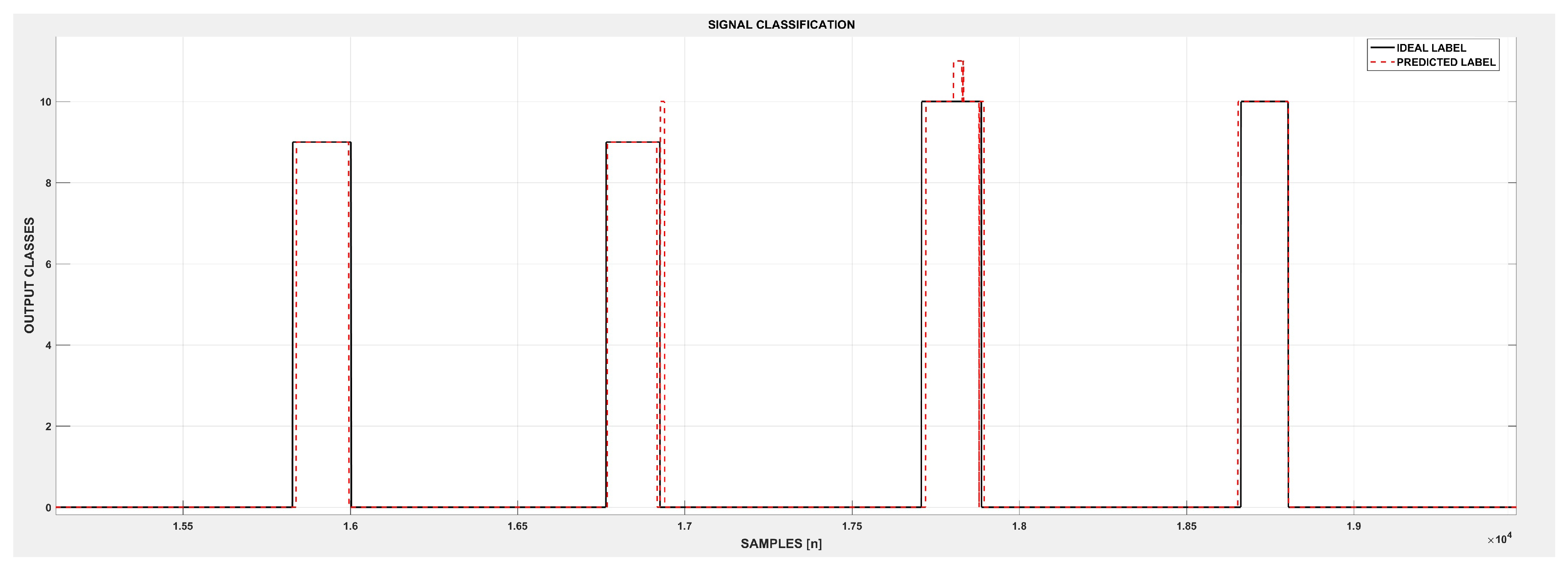
3.2. Signal Classification
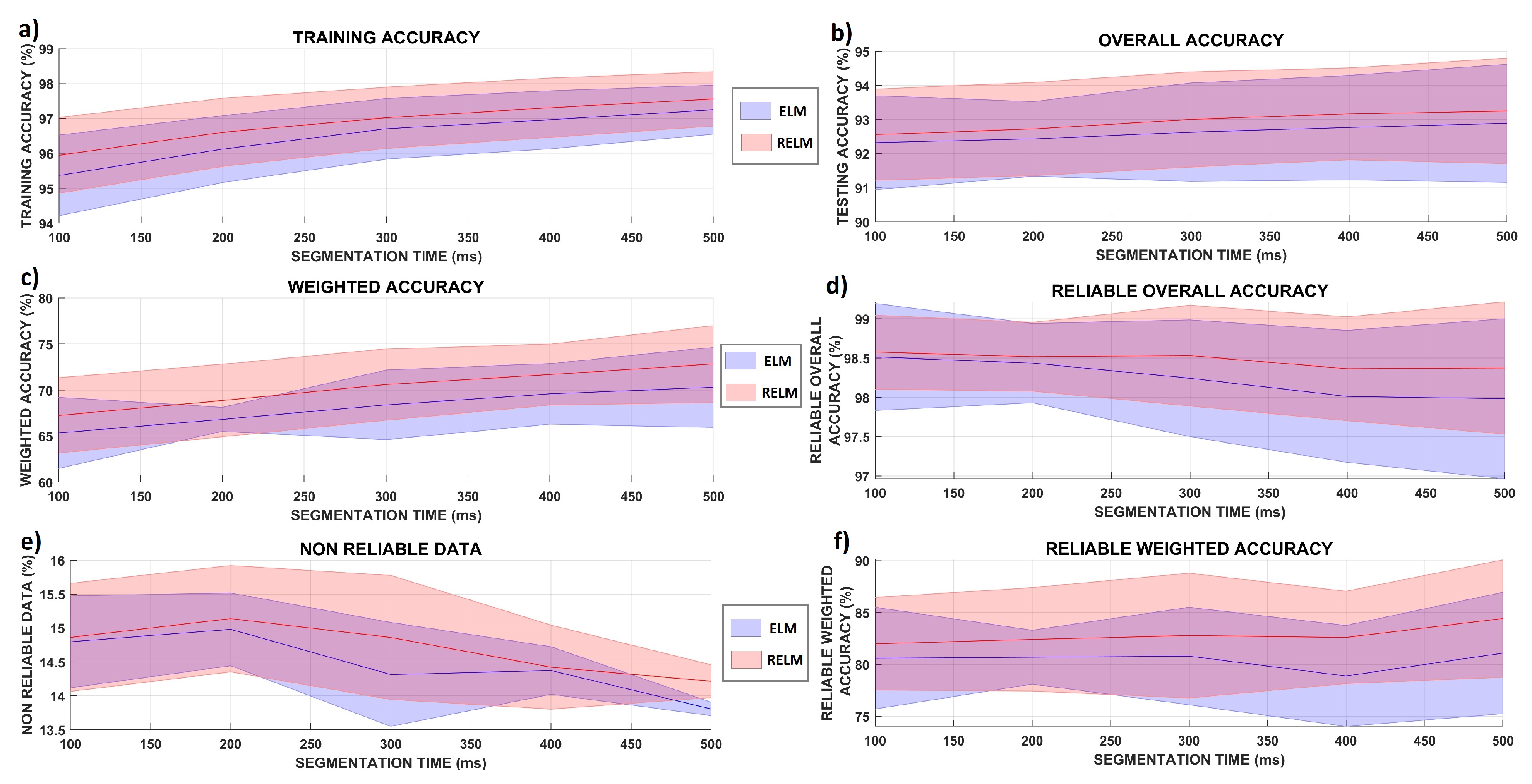
3.3. NINAPro Databases’ Classification
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Minati, L.; Yoshimura, N.; Koike, Y. Hybrid Control of a Vision-Guided Robot Arm by EOG, EMG, EEG Biosignals and Head Movement Acquired via a Consumer-Grade Wearable Device. IEEE Access 2016, 4, 9528–9541. [Google Scholar] [CrossRef]
- Tacchino, G.; Gandolla, M.; Coelli, S.; Barbieri, R.; Pedrocchi, A.; Bianchi, A.M. EEG Analysis During Active and Assisted Repetitive Movements: Evidence for Differences in Neural Engagement. IEEE Trans. Neural Syst. Rehabil. Eng. 2017, 25, 761–771. [Google Scholar] [CrossRef] [PubMed]
- Cene, V.H.; Favieiro, G.; Nedel, L.; Balbinot, A. Reever control: A biosignal controlled interface. In Proceedings of the 2017 39th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Seogwipo, Korea, 11–15 July 2017; IEEE: Jeju, Korea, 2017; pp. 706–709. [Google Scholar] [CrossRef]
- Polygerinos, P.; Wang, Z.; Galloway, K.C.; Wood, R.J.; Walsh, C.J. Soft robotic glove for combined assistance and at-home rehabilitation. Robot. Auton. Syst. 2015, 73, 135–143. [Google Scholar] [CrossRef]
- Atzori, M.; Müller, H. Control Capabilities of Myoelectric Robotic Prostheses by Hand Amputees: A Scientific Research and Market Overview. Front. Syst. Neurosci. 2015, 9, 162. [Google Scholar] [CrossRef]
- Farina, D.; Jiang, N.; Rehbaum, H.; Holobar, A.; Graimann, B.; Dietl, H.; Aszmann, O.C. The Extraction of Neural Information from the Surface EMG for the Control of Upper-Limb Prostheses: Emerging Avenues and Challenges. IEEE Trans. Neural Syst. Rehabil. Eng. 2014, 22, 797–809. [Google Scholar] [CrossRef] [PubMed]
- Phinyomark, A.; Quaine, F.; Charbonnier, S.; Serviere, C.; Tarpin-Bernard, F.; Laurillau, Y. EMG feature evaluation for improving myoelectric pattern recognition robustness. Expert Syst. Appl. 2013, 40, 4832–4840. [Google Scholar] [CrossRef]
- Young, A.J.; Smith, L.H.; Rouse, E.J.; Hargrove, L.J. Classification of Simultaneous Movements Using Surface EMG Pattern Recognition. IEEE Trans. Biomed. Eng. 2013, 60, 1250–1258. [Google Scholar] [CrossRef] [PubMed]
- Han, H.; Jo, S. Supervised Hierarchical Bayesian Model-Based Electomyographic Control and Analysis. IEEE J. Biomed. Health Inform. 2014, 18, 1214–1224. [Google Scholar] [CrossRef]
- Englehart, K.; Hudgins, B. A robust, real-time control scheme for multifunction myoelectric control. IEEE Trans. Biomed. Eng. 2003, 50, 848–854. [Google Scholar] [CrossRef]
- Micera, S.; Carpaneto, J.; Raspopovic, S. Control of Hand Prostheses Using Peripheral Information. IEEE Rev. Biomed. Eng. 2010, 3, 48–68. [Google Scholar] [CrossRef] [PubMed]
- Kuzborskij, I.; Gijsberts, A.; Caputo, B. On the challenge of classifying 52 hand movements from surface electromyography. In Proceedings of the 2012 Annual International Conference of the IEEE Engineering in Medicine and Biology Society, San Diego, CA, USA, 28 August–1 September 2012; pp. 4931–4937. [Google Scholar] [CrossRef]
- Atzori, M.; Gijsberts, A.; Castellini, C.; Caputo, B.; Hager, A.G.M.; Elsig, S.; Giatsidis, G.; Bassetto, F.; Müller, H. Electromyography data for non-invasive naturally-controlled robotic hand prostheses. Sci. Data 2014, 1. [Google Scholar] [CrossRef]
- Atzori, M.; Gijsberts, A.; Kuzborskij, I.; Elsig, S.; Mittaz Hager, A.G.; Deriaz, O.; Castellini, C.; Muller, H.; Caputo, B. Characterization of a Benchmark Database for Myoelectric Movement Classification. IEEE Trans. Neural Syst. Rehabil. Eng. 2015, 23, 73–83. [Google Scholar] [CrossRef]
- Palermo, F.; Cognolato, M.; Gijsberts, A.; Muller, H.; Caputo, B.; Atzori, M. Repeatability of grasp recognition for robotic hand prosthesis control based on sEMG data. In Proceedings of the 2017 International Conference on Rehabilitation Robotics (ICORR), London, UK, 17–20 July 2017; pp. 1154–1159. [Google Scholar] [CrossRef]
- Cene, V.H.; Balbinot, A. Using the sEMG signal representativity improvement towards upper-limb movement classification reliability. Biomed. Signal Process. Control 2018, 46, 182–191. [Google Scholar] [CrossRef]
- Cene, V.H.; Balbinot, A. Optimization of Features to Classify Upper—Limb Movements Through sEMG Signal Processing. Braz. J. Instrum. Control 2016, 4, 14–20. [Google Scholar] [CrossRef]
- Hofmann, D.; Jiang, N.; Vujaklija, I.; Farina, D. Bayesian Filtering of Surface EMG for Accurate Simultaneous and Proportional Prosthetic Control. IEEE Trans. Neural Syst. Rehabil. Eng. 2016, 24, 1333–1341. [Google Scholar] [CrossRef] [PubMed]
- Hashim, F.R.; Soraghan, J.J.; Petropoulakis, L.; Daud, N.G.N. EMG cancellation from ECG signals using modified NLMS adaptive filters. In Proceedings of the 2014 IEEE Conference on Biomedical Engineering and Sciences (IECBES), Kuala Lumpur, Malaysia, 8–10 December 2014; pp. 735–739. [Google Scholar] [CrossRef]
- Ortolan, R.; Mori, R.; Pereira, R.; Cabral, C.; Pereira, J.; Cliquet, A. Evaluation of adaptive/nonadaptive filtering and wavelet transform techniques for noise reduction in emg mobile acquisition equipment. IEEE Trans. Neural Syst. Rehabil. Eng. 2003, 11, 60–69. [Google Scholar] [CrossRef]
- Botter, A.; Vieira, T.M. Filtered Virtual Reference: A New Method for the Reduction of Power Line Interference with Minimal Distortion of Monopolar Surface EMG. IEEE Trans. Biomed. Eng. 2015, 62, 2638–2647. [Google Scholar] [CrossRef]
- Zhou, P.; Suresh, N.; Lowery, M.; Rymer, W. Nonlinear Spatial Filtering of Multichannel Surface Electromyogram Signals During Low Force Contractions. IEEE Trans. Biomed. Eng. 2009, 56, 1871–1879. [Google Scholar] [CrossRef]
- Zivanovic, M.; Gonzalez-Izal, M. Nonstationary Harmonic Modeling for ECG Removal in Surface EMG Signals. IEEE Trans. Biomed. Eng. 2012, 59, 1633–1640. [Google Scholar] [CrossRef] [PubMed]
- Farrell, T.R.; Weir, R.F. The Optimal Controller Delay for Myoelectric Prostheses. IEEE Trans. Neural Syst. Rehabil. Eng. 2007, 15, 111–118. [Google Scholar] [CrossRef]
- Akusok, A.; Miche, Y.; Lendasse, A. High-Performance Extreme Learning Machines: A Complete Toolbox for Big Data Applications. IEEE Access 2015, 3, 1011–1025. [Google Scholar] [CrossRef]
- Phinyomark, A.; Khushaba, R.N.; Scheme, E. Feature Extraction and Selection for Myoelectric Control Based on Wearable EMG Sensors. Sensors 2018, 18, 1615. [Google Scholar] [CrossRef]
- Gijsberts, A.; Atzori, M.; Castellini, C.; Muller, H.; Caputo, B. Movement Error Rate for Evaluation of Machine Learning Methods for sEMG-Based Hand Movement Classification. IEEE Trans. Neural Syst. Rehabil. Eng. 2014, 22, 735–744. [Google Scholar] [CrossRef] [PubMed]
- Castellini, C.; Ravindra, V. A wearable low-cost device based upon Force-Sensing Resistors to detect single-finger forces. In Proceedings of the 5th IEEE RAS/EMBS International Conference on Biomedical Robotics and Biomechatronics, Sao Paulo, Brazil, 12–15 August 2014; pp. 199–203. [Google Scholar] [CrossRef]
- Cene, V.H.; Balbinot, A. Upper-limb movement classification through logistic regression sEMG signal processing. In Proceedings of the 2015 Latin America Congress on Computational Intelligence (LA-CCI), Curitiba, Brazil, 13–16 October 2015; pp. 1–5. [Google Scholar] [CrossRef]
- Cene, V.H.; Favieiro, G.; Balbinot, A. Using non-iterative methods and random weight networks to classify upper-limb movements through sEMG signals. In Proceedings of the 2017 39th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Seogwipo, Korea, 11–15 July 2017; IEEE: Jeju, Korea, 2017; pp. 2047–2050. [Google Scholar] [CrossRef]
- Zhang, L.; Suganthan, P.N. A comprehensive evaluation of random vector functional link networks. Inf. Sci. 2016, 367–368, 1094–1105. [Google Scholar] [CrossRef]
- Zhang, L.; Suganthan, P. A survey of randomized algorithms for training neural networks. Inf. Sci. 2016, 364–365, 146–155. [Google Scholar] [CrossRef]
- Huang, G.B. An Insight into Extreme Learning Machines: Random Neurons, Random Features and Kernels. Cogn. Comput. 2014, 6, 376–390. [Google Scholar] [CrossRef]
- Riillo, F.; Quitadamo, L.R.; Cavrini, F.; Gruppioni, E.; Pinto, C.A.; Pasto, N.C.; Sbernini, L.; Albero, L.; Saggio, G. Optimization of EMG-based hand gesture recognition: Supervised vs. unsupervised data preprocessing on healthy subjects and transradial amputees. Biomed. Signal Process. Control 2014, 14, 117–125. [Google Scholar] [CrossRef]
- Zhai, X.; Jelfs, B.; Chan, R.H.M.; Tin, C. Short latency hand movement classification based on surface EMG spectrogram with PCA. In Proceedings of the 2016 38th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Orlando, FL, USA, 16–20 August 2016; pp. 327–330. [Google Scholar] [CrossRef]
- Zhai, X.; Jelfs, B.; Chan, R.H.M.; Tin, C. Self-Recalibrating Surface EMG Pattern Recognition for Neuroprosthesis Control Based on Convolutional Neural Network. Front. Neurosci. 2017, 11, 1–11. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| SUBJECT | LATERALITY | GENDER | AGE | HEIGHT (m) | WEIGHT (kg) | F. C. (cm) | F. L. (cm) |
|---|---|---|---|---|---|---|---|
| 1 | Right-Handed | Male | 31 | 1.87 | 78.0 | 28.3 | 25.3 |
| 2 | Right-Handed | Male | 26 | 1.80 | 70.0 | 27.0 | 24.0 |
| 3 | Right-Handed | Female | 29 | 1.64 | 60 | 25.4 | 22.7 |
| 4 | Right-Handed | Male | 34 | 1.82 | 84.0 | 27.8 | 25.7 |
| ASSAY A | ASSAY B | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| SUBJECT | METHOD | WEIGHTED ACCURACY (%) | OVERALL ACCURACY (%) | NON-RELIABLE DATA (%) | SUBJECT | METHOD | CLASS ACCURACY (%) | OVERALL ACCURACY (%) | NON-RELIABLE DATA (%) |
| 1 | ELM | 72.17 ± 10.80 | 94.00 ± 1.13 | - | 1 | ELM | 71.24 ± 12.40 | 94.22 ± 1.48 | - |
| RELM | 74.60 ± 10.82 | 94.51 ± 1.10 | - | RELM | 72.56 ± 13.07 | 94.51 ± 1.39 | - | ||
| R-ELM | 85.50 ± 16.37 | 98.80 ± 0.33 | 13.22 ± 1.76 | R-ELM | 82.63 ± 13.16 | 98.45 ± 0.60 | 11.34 ± 0.43 | ||
| R-RELM | 89.25 ± 15.38 | 99.16 ± 0.26 | 13.15 ± 1.61 | R-RELM | 85.43 ± 14.30 | 99.06 ± 0.40 | 12.27 ± 0.78 | ||
| 2 | ELM | 80.16 ± 8.70 | 95.73 ± 2.20 | - | 2 | ELM | 82.27 ± 7.62 | 96.48 ± 0.56 | - |
| RELM | 80.98 ± 8.11 | 95.86 ± 2.10 | - | RELM | 83.09 ± 7.07 | 96.67 ± 0.46 | - | ||
| R-ELM | 91.06 ± 7.82 | 98.87 ± 0.93 | 11.03 ± 1.58 | R-ELM | 92.61 ± 5.52 | 99.18 ± 0.35 | 11.10 ± 0.66 | ||
| R-RELM | 92.57 ± 6.70 | 99.17 ± 0.83 | 11.67 ± 1.21 | R-RELM | 96.00 ± 3.22 | 99.60 ± 0.29 | 11.72 ± 0.51 | ||
| 3 | ELM | 72.20 ± 11.37 | 93.65 ± 1.15 | - | 3 | ELM | 72.54 ± 11.62 | 93.74 ± 0.47 | - |
| RELM | 74.17 ± 11.10 | 94.10 ± 1.02 | - | RELM | 74.55 ± 10.86 | 94.17 ± 0.41 | - | ||
| R-ELM | 86.56 ± 10.26 | 98.76 ± 0.61 | 13.53 ± 0.20 | R-ELM | 84.82 ± 15.47 | 98.57 ± 0.26 | 12.98 ± 0.88 | ||
| R-RELM | 91.40 ± 7.29 | 99.17 ± 0.40 | 13.93 ± 0.47 | R-RELM | 88.04 ± 14.45 | 99.00 ± 0.13 | 13.28 ± 0.81 | ||
| 4 | ELM | 64.60 ± 12.10 | 93.75 ± 0.57 | - | 4 | ELM | 62.65 ± 13.12 | 93.79 ± 0.26 | - |
| RELM | 67.34 ± 12.56 | 94.23 ± 0.47 | - | RELM | 63.67 ± 12.98 | 93.98 ± 0.40 | - | ||
| R-ELM | 83.33 ± 13.26 | 98.53 ± 0.46 | 13.01 ± 0.36 | R-ELM | 74.89 ± 12.82 | 97.89 ± 1.43 | 10.57 ± 3.81 | ||
| R-RELM | 88.47 ± 11.57 | 99.02 ± 0.46 | 13.31 ± 0.35 | R-RELM | 82.83 ± 10.21 | 99.16 ± 0.13 | 13.28 ± 0.43 | ||
| 1 | ELM | 42.23 ± 18.31 | 89.25 ± 5.07 | - | 1 | ELM | 60.73 ± 16.30 | 92.97 ± 0.39 | - |
| RELM | 43.24 ± 17.91 | 89.43 ± 5.62 | - | RELM | 62.12 ± 16.18 | 93.25 ± 0.60 | - | ||
| R-ELM | 47.33 ± 23.57 | 97.62 ± 1.10 | 13.30 ± 1.76 | R-ELM | 73.26 ± 24.76 | 98.46 ± 0.38 | 14.02 ± 3.14 | ||
| R-RELM | 50.48 ± 23.40 | 97.64 ± 1.63 | 13.23 ± 1.50 | R-RELM | 77.31 ± 21.86 | 98.80 ± 0.35 | 13.53 ± 2.43 | ||
| 2 | ELM | 73.81 ± 10.34 | 94.42 ± 20.90 | - | 2 | ELM | 70.05 ± 12.22 | 94.00 ± 2.13 | - |
| RELM | 74.89 ± 10.22 | 94.70 ± 0.98 | - | RELM | 71.28 ± 11.95 | 94.27 ± 2.04 | - | ||
| R-ELM | 84.21 ± 9.88 | 97.31 ± 2.47 | 7.76 ± 6.73 | R-ELM | 83.84 ± 11.09 | 97.83 ± 2.05 | 10.28 ± 1.95 | ||
| R-RELM | 93.38 ± 6.27 | 99.28 ± 0.46 | 12.23 ± 0.28 | R-RELM | 87.92 ± 11.25 | 98.90 ± 0.95 | 12.51 ± 0.85 | ||
| 3 | ELM | 63.59 ± 13.20 | 93.12 ± 0.43 | - | 3 | ELM | 58.98 ± 14.60 | 92.67 ± 1.12 | - |
| RELM | 65.49 ± 12.40 | 93.50 ± 0.68 | - | RELM | 60.85 ± 14.22 | 93.00 ± 1.17 | - | ||
| R-ELM | 78.73 ± 14.00 | 98.00 ± 0.19 | 11.30 ± 1.02 | R-ELM | 74.50 ± 15.52 | 98.36 ± 0.68 | 11.38 ± 0.54 | ||
| R-RELM | 80.22 ± 16.68 | 98.59 ± 0.22 | 12.11 ± 0.74 | R-RELM | 79.00 ± 17.25 | 98.97 ± 0.25 | 12.03 ± 0.68 | ||
| 4 | ELM | 49.17 ± 16.70 | 91.05 ± 0.95 | - | 4 | ELM | 50.06 ± 15.20 | 91.50 ± 0.56 | - |
| RELM | 51.97 ± 17.11 | 91.56 ± 1.27 | - | RELM | 50.70 ± 15.66 | 91.59 ± 0.67 | - | ||
| R-ELM | 66.65 ± 15.34 | 97.96 ± 0.26 | 13.90 ± 1.93 | R-ELM | 71.34 ± 12.41 | 98.12 ± 0.98 | 12.57 ± 0.40 | ||
| R-RELM | 77.14 ± 17.34 | 98.54 ± 0.67 | 14.40 ± 1.10 | R-RELM | 74.38 ± 14.98 | 98.65 ± 0.43 | 13.33 ± 0.69 | ||
| PAPER | SEGMENT | DATABASE | AVERAGE ACCURACY (%) | ||||
|---|---|---|---|---|---|---|---|
| Kuzborskij et al. [12] | 400 ms + 10 ms | DB1 | 75.00 | ||||
| Zhai et al. [35] | 200 ms + 100 ms | DB2 | 77.41 | ||||
| Gijsberts et al. [27] | 400 ms + 10 ms | DB2 | 77.48 | ||||
| Atzori et al. [13] | 200 ms | DB2 | 75.27 | ||||
| Atzori et al. [14] | 400 ms + 10 ms | DB1 | 76.00 | ||||
| Zhai et al. [36] | 256/184 points (Hamming window) | DB2 | 78.71 | ||||
| Palermo et al. [15] | 200 ms + 10 ms | DB6 | CD1 | 52.43 | |||
| CD2 | 25.40 | ||||||
| ELM | RELM | R-ELM | R-RELM | ||||
| This work | 200 ms + 10 ms | DB1 | 68.77 | 71.63 | 73.13 | 75.03 | |
| DB2 | 73.67 | 74.43 | 79.33 | 79.77 | |||
| DB6 | CD1 | 64.72 | 65.21 | 68.43 | 69.83 | ||
| CD2 | 37.74 | 38.93 | 39.91 | 41.75 | |||
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cene, V.H.; Tosin, M.; Machado, J.; Balbinot, A. Open Database for Accurate Upper-Limb Intent Detection Using Electromyography and Reliable Extreme Learning Machines. Sensors 2019, 19, 1864. https://doi.org/10.3390/s19081864
Cene VH, Tosin M, Machado J, Balbinot A. Open Database for Accurate Upper-Limb Intent Detection Using Electromyography and Reliable Extreme Learning Machines. Sensors. 2019; 19(8):1864. https://doi.org/10.3390/s19081864
Chicago/Turabian StyleCene, Vinicius Horn, Mauricio Tosin, Juliano Machado, and Alexandre Balbinot. 2019. "Open Database for Accurate Upper-Limb Intent Detection Using Electromyography and Reliable Extreme Learning Machines" Sensors 19, no. 8: 1864. https://doi.org/10.3390/s19081864
APA StyleCene, V. H., Tosin, M., Machado, J., & Balbinot, A. (2019). Open Database for Accurate Upper-Limb Intent Detection Using Electromyography and Reliable Extreme Learning Machines. Sensors, 19(8), 1864. https://doi.org/10.3390/s19081864