A Review on Automatic Facial Expression Recognition Systems Assisted by Multimodal Sensor Data

 ,
,
Abstract
:1. Introduction
- We introduce a variety of sensors that may provide extra information and help the FER systems to detect emotions and focus on studying using multimodal sensors to improve the accuracy and reliability of an expression recognition system.
- We comprehensively discuss three significant challenges in the unconstrained real-world environments, such as illumination variation, head pose, and subject-dependence and explore the role of multimodal sensors combining with FER systems to tackle the challenges. We comparatively review the most prominent multimodal emotional expression recognition approaches as well as discussing the advantages and limitations of used sensors. In this way, it can be useful for other researchers to find a road map in this area.
- We briefly introduce the public datasets related to FER systems for each category of sensors.
- We design a reliable and robust expression recognition system by integrating the three categories of sensors to image/video analysis, especially for use in the extreme wild environment, and point out the future directions of FER systems.
2. Motivation
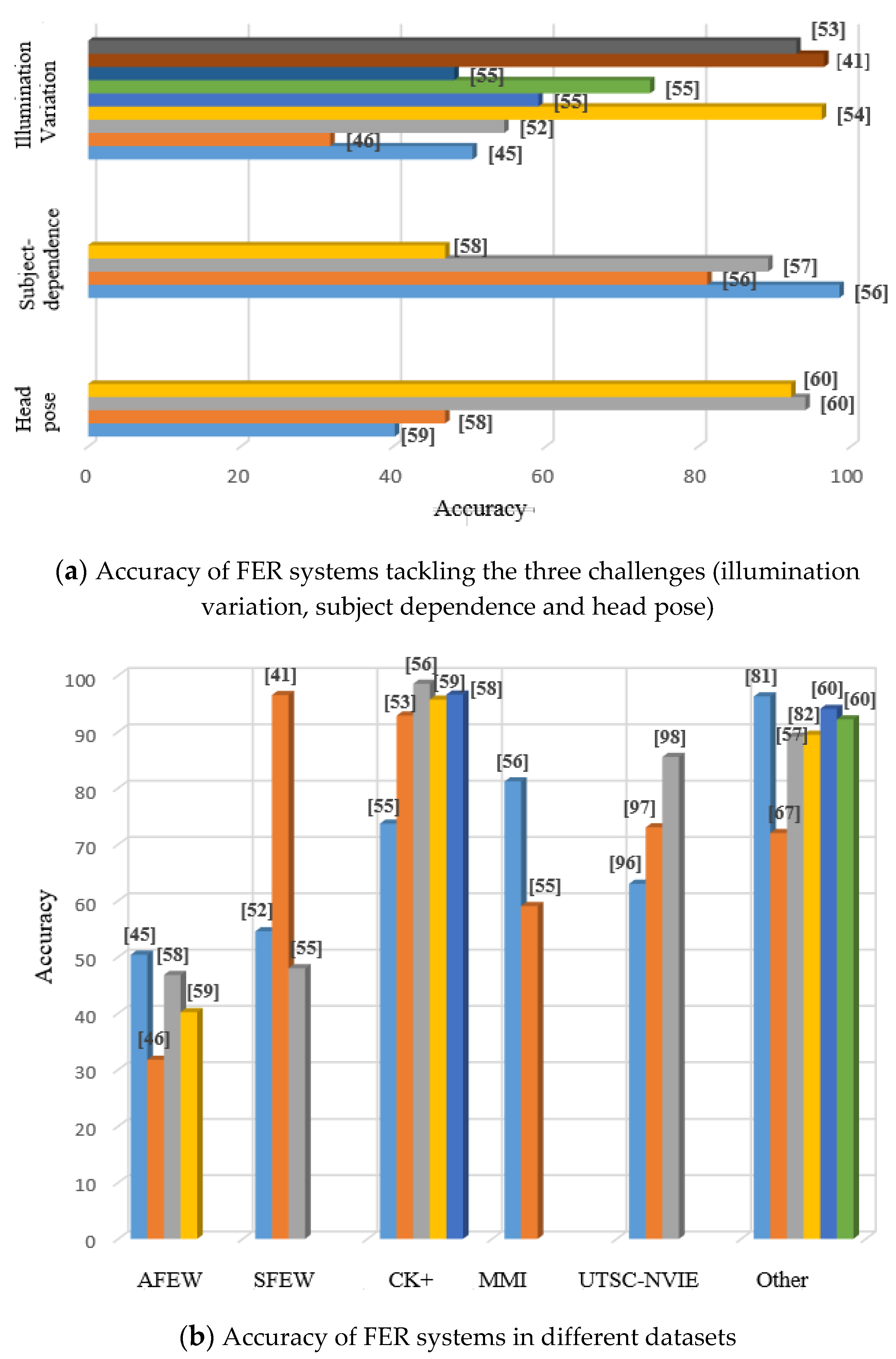
2.1. Illumination Variation
2.2. Subject-Dependence
2.3. Head Pose
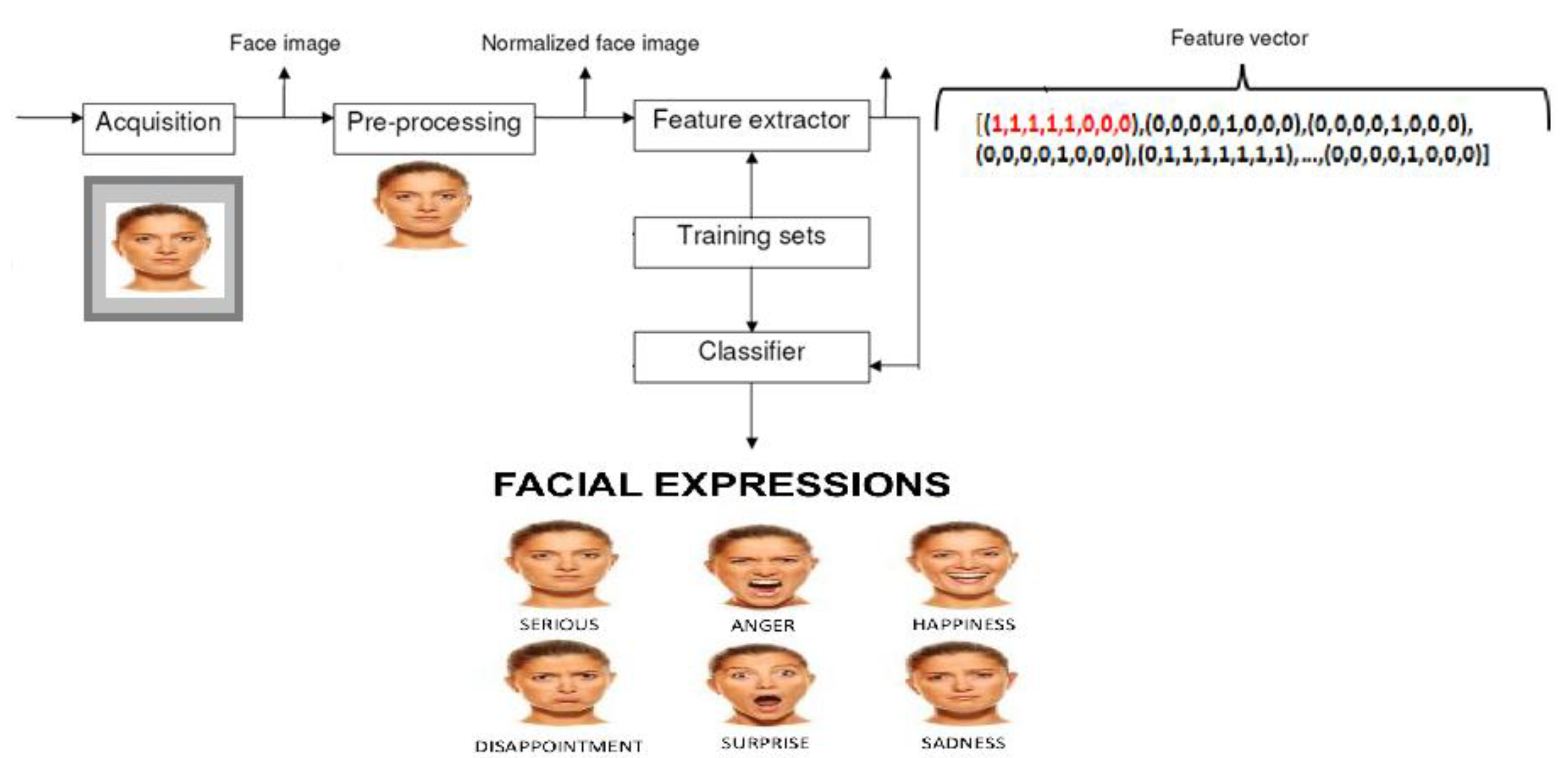
3. Multimodal Sensors
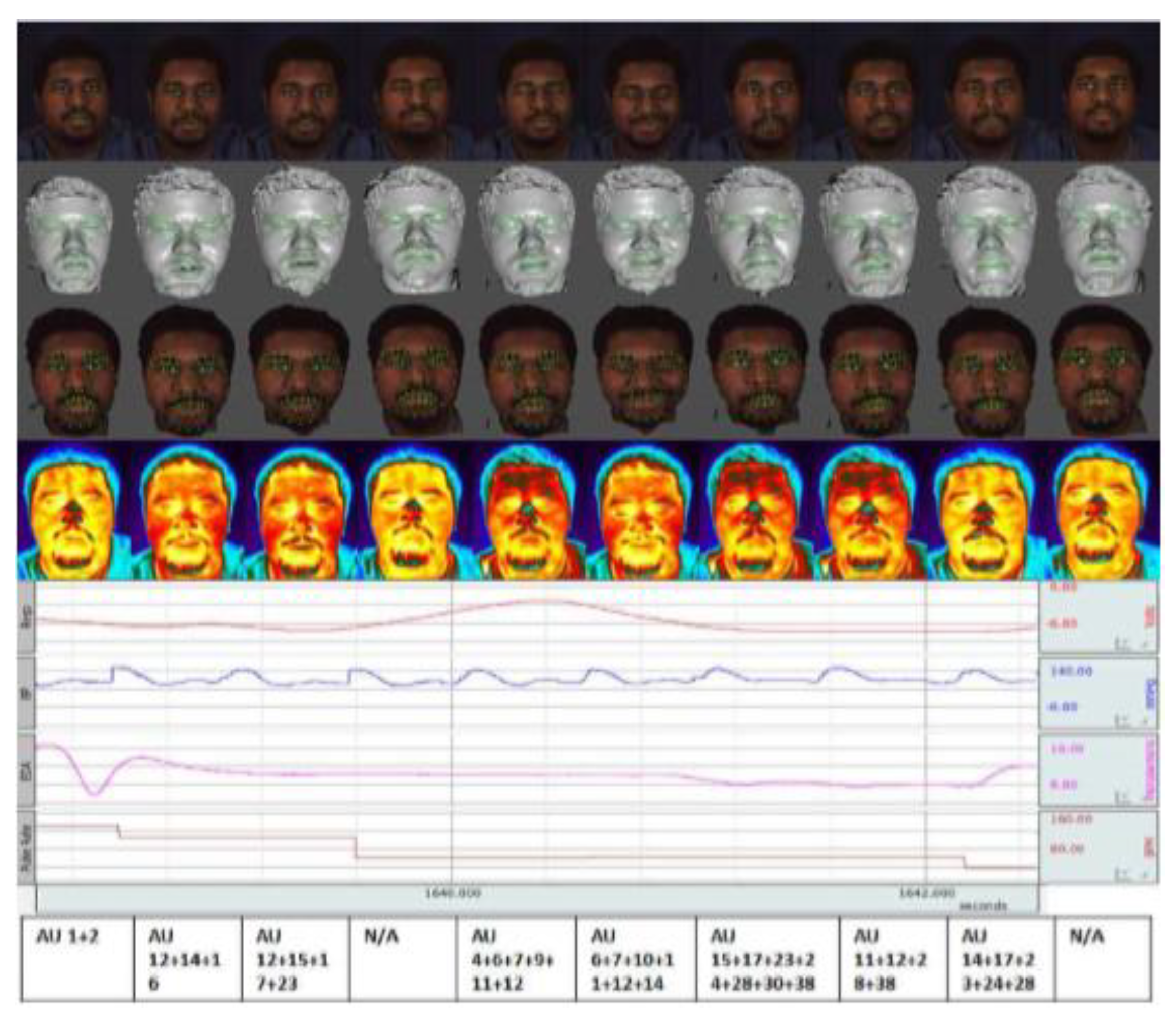
3.1. Detailed-Face Sensors
3.2. Non-Visual Sensors
3.2.1. Audio
3.2.2. ECG and EEG Sensors
3.2.3. Depth Camera
3.3. Target-Focused Sensors
4. Datasets
4.1. Camera-Based Datasets
4.1.1. Chinese Academy of Sciences Macro-Expressions and Micro-Expressions (CAS (ME)2)
4.1.2. Acted Facial Expression in Wild (AFEW) 4.0
4.1.3. Static Facial Expressions in the Wild (SFEW)
4.1.4. Extended Cohn–Kanade (CK+)
4.1.5. CMU Multi-PIE
4.1.6. Florentine Dataset
4.1.7. Autoencoder Dataset
4.1.8. Web-Based Database (MMI)
4.1.9. Affectiva-MIT Facial Expression Dataset (AM-FED)
4.1.10. CAS-PEAL
4.2. Non-Visual Datasets
The Vera Am Mittag German Audio-Visual Emotional Speech Database (VAMGS)
4.3. Target-Focused Datasets
4.3.1. Natural Visible and Infrared Facial EXPRESSIONS (UTSC-NVIE)
4.3.2. Spontaneous vs. Posed (SPOS)
4.4. Multimodal Spontaneous Emotion Database (MMSE)
5. Discussion and Comparison of the Existing Real-World, Multimodal FER Systems
6. Multimodal Sensors Assisting in Automatic Facial Expression Recognition
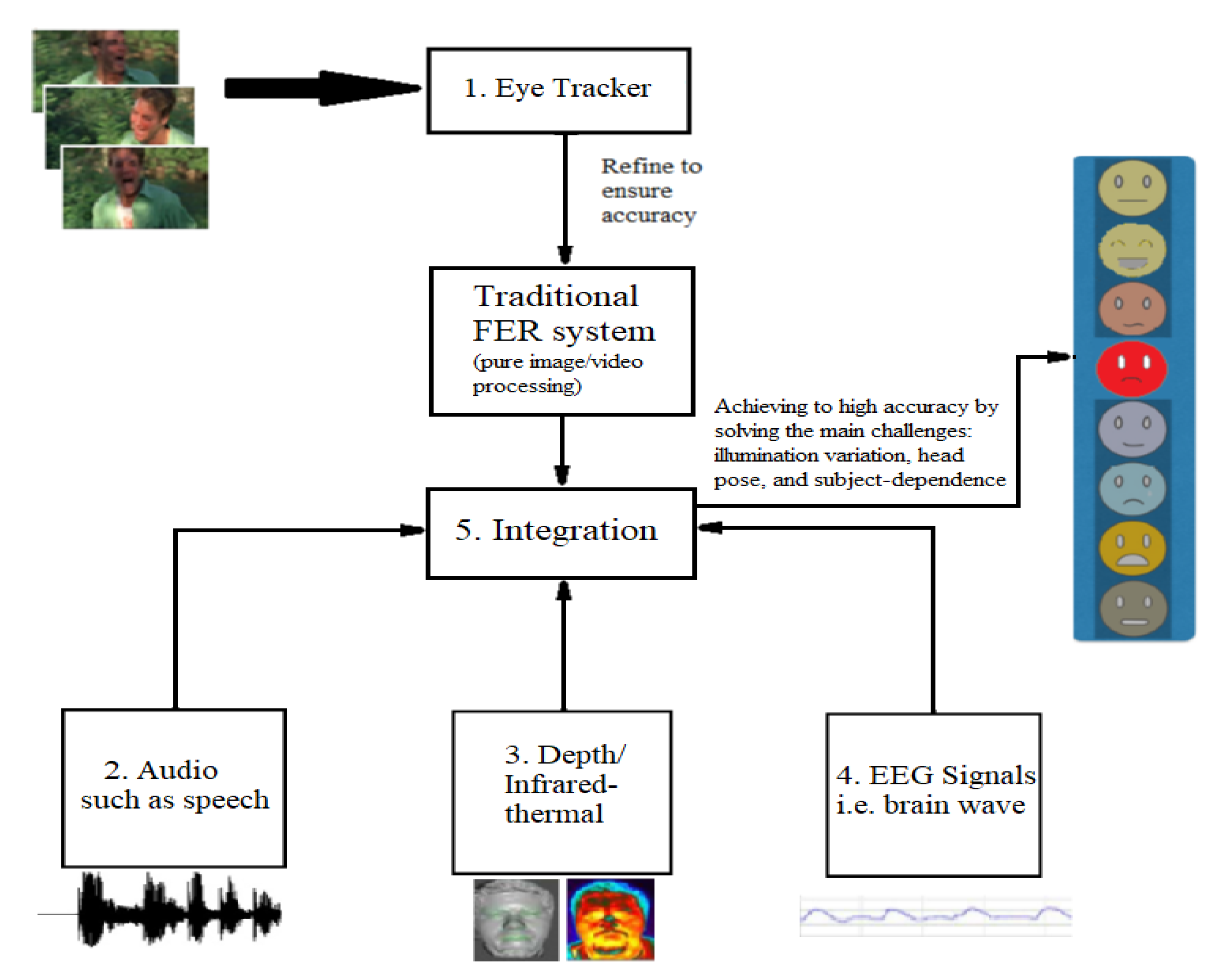
6.1. The Proposed Method and Future Direction
- (1)
- Module 1: We use data extracted from detailed-face sensors to improve the performance of the FER system and test the system using real-world background changes, for instance, from indoor to outdoor situations. As an eye tracker can reduce a large amount of face image processing [62], we can use it to efficiently do a coarse detection and thus, image/video processing for detecting and tracking face from other wild background environment is only required to refine the results when confidence is low. This module can improve the efficiency of the proposed method.
- (2)
- Module 2: We collect the audio data along with RGB videos. By adding an audio dimension to the conventional FER system, it is possible to tackle the head pose issue. Works [58,59] have recorded audio and appended several audio features to the feature vector. Accuracy improvement rather than other works in real-world situations demonstrates the usefulness of the new dimension.
- (3)
- Module 3: It is necessary to tackle the most common challenges: illumination variation and subject-dependence. We need to capture depth or infrared-thermal data to add to the usual feature vector. As the works [54,57,87,96,97,98] have focused on extracting depth maps and thermal-infrared information and could achieve to a higher accuracy than other state-of-the-art FER systems in the wild, the results illustrate that appending depth or thermal information to a feature vector can lead the FER system to overcome the mentioned challenges.
- (4)
- Module 4: We record the EEG and ECG data in another module for the situations which the previous modules could not address or could not recognize similar such as disgust and anger. In these positions, using the EEG and ECG signals is helpful due to wave shape variations when people express different emotions. As known, the EEG and ECG signals are unique per individual and can be used as an appropriate feature vector to recognize the emotions [76].
- (5)
- Module 5: We integrate multimodal sensor data with the traditional FER system to classify the expressions with high accuracy.
6.2. Open Problems
7. Conclusions and Future Work
Funding
Conflicts of Interest
References
- Cowie, R.; Douglas-Cowie, E.; Tsapatsoulis, N.; Votsis, G.; Kollias, S.; Fellenz, W.; Taylor, J.G. Emotional expression recognition in human–computer interaction. IEEE Signal Process. Mag. 2001, 18, 32–80. [Google Scholar] [CrossRef]
- Zhang, Z.; Luo, P.; Loy, C.-C.; Tang, X. Learning social relation traits from face images. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 13–16 December 2015; pp. 3631–3639. [Google Scholar]
- Baxter, P.; Trafton, J.G. Cognitive architectures for human–robot interaction. In Proceedings of the 2014 ACM/IEEE International Conference on Human–Robot Interaction, Bielefeld, Germany, 3–6 March 2016; pp. 504–505. [Google Scholar]
- Tadeusz, S. Application of vision information to planning trajectories of Adept Six-300 robot. In Proceedings of the International Conference on Advanced Robotics and Mechatronics (ICARM), Miedzyzdroje, Poland, 29 August–1 September 2016; pp. 88–94. [Google Scholar]
- Mehrabian, A. Communication without words. IOJT 2008, 193–200. [Google Scholar]
- McClure, E.B.; Pope, K.; Hoberman, A.J.; Pine, D.S.; Leibenluft, E. Facial expression recognition in adolescents with mood and anxiety disorders. Am. J. Psychiatry 2003, 160, 1172–1174. [Google Scholar] [CrossRef]
- Wallace, S.; Coleman, M.; Bailey, A. An investigation of basic facial expression recognition in autism spectrum disorders. Cogn. Emot. 2008, 22, 1353–1380. [Google Scholar] [CrossRef]
- Liu, M.; Li, S.; Shan, S.; Wang, R.; Chen, X. Deeply learning deformable facial action parts model for dynamic expression analysis. In Proceedings of the Asian Conference on Computer Vision, Singapore, 1–5 November 2014; pp. 143–157. [Google Scholar]
- Hickson, S.; Dufour, N.; Sud, A.; Kwatra, V.; Essa, I. Eyemotion: Classifying facial expressions in VR using eye-tracking cameras. arXiv 2017, arXiv:1707.07204. [Google Scholar]
- Chen, C.-H.; Lee, I.-J.; Lin, L.-Y. Augmented reality-based self-facial modeling to promote the emotional expression and social skills of adolescents with autism spectrum disorders. Res. Dev. Disabil. 2015, 36, 396–403. [Google Scholar] [CrossRef]
- Ekman, P.; Friesen, W.V.; Ellsworth, P. Emotion in the Human Face: Guide-Lines for Research and an Integration of Findings: Guidelines for Research and an Integration of Findings; Pergamon: Berlin, Germany, 1972. [Google Scholar]
- Gan, Q.; Wu, C.; Wang, S.; Ji, Q. Posed and spontaneous facial expression differentiation using deep Boltzmann machines. In Proceedings of the 2015 International Conference on Affective Computing and Intelligent Interaction (ACII), Xi’an, China, 21–24 September 2015; pp. 643–648. [Google Scholar]
- Schmidt, K.L.; Cohn, J.F. Human facial expressions as adaptations: Evolutionary questions in facial expression research. Am. J. Phys. Anthropol. 2001, 116, 3–24. [Google Scholar] [CrossRef] [PubMed]
- Ekman, P.; Friesen, W.V. Nonverbal leakage and clues to deception. Psychiatry 1969, 32, 88–106. [Google Scholar] [CrossRef]
- Ekman, P. Telling Lies: Clues to Deceit in the Marketplace, Politics, and Marriage (Revised Edition); WW Norton & Company: New York, NY, USA, 2009. [Google Scholar]
- Datcu, D.; Rothkrantz, L. Facial expression recognition in still pictures and videos using active appearance models: A comparison approach. In Proceedings of the 2007 International Conference on Computer Systems and Technologies, Rousse, Bulgaria, 14–15 June 2007; p. 112. [Google Scholar]
- Corneanu, C.A.; Simón, M.O.; Cohn, J.F.; Guerrero, S.E. Survey on RGB, 3D, Thermal, and Multimodal Approaches for Facial Expression Recognition: History, Trends, and Affect-Related Applications. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 1548–1568. [Google Scholar] [CrossRef] [PubMed]
- Revina, I.M.; Emmanuel, W.R.S. A Survey on Human Face Expression Recognition Techniques. J. King Saud Univ. Comput. Inf. Sci. 2018. [Google Scholar] [CrossRef]
- Kumar, Y.; Sharma, S. A systematic survey of facial expression recognition techniques. In Proceedings of the 2017 International Conference on Computing Methodologies and Communication (ICCMC), Erode, India, 18–19 July 2017; pp. 1074–1079. [Google Scholar]
- Salah, A.A.; Sebe, N.; Gevers, T. Communication and automatic interpretation of affect from facial expressions. In Affective Computing and Interaction: Psychological, Cognitive and Neuroscientific Perspectives; IGI Global: Hershey, PA, USA, 2010; pp. 157–183. [Google Scholar]
- Ko, B. A Brief Review of Facial Emotional expression recognition Based on Visual Information. Sensors 2018, 18, 401. [Google Scholar] [CrossRef]
- Mehta, D.; Siddiqui, M.F.H.; Javaid, A.Y. Facial Emotional expression recognition: A Survey and Real-World User Experiences in Mixed Reality. Sensors 2018, 18, 416. [Google Scholar] [CrossRef] [PubMed]
- Sariyanidi, E.; Gunes, H.; Cavallaro, A. Automatic analysis of facial affect: A survey of registration, representation, and recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1113–1133. [Google Scholar] [CrossRef] [PubMed]
- Salih, H.; Kulkarni, L. Study of video based facial expression and emotions recognition methods. In Proceedings of the 2017 International Conference on I-SMAC (IoT in Social, Mobile, Analytics and Cloud) (I-SMAC), Coimbatore, India, 10–11 February 2017; pp. 692–696. [Google Scholar]
- Salah, A.A.; Kaya, H.; Gürpınar, F. Chapter 17—Video-based emotional expression recognition in the wild. In Multimodal Behavior Analysis in the Wild; Alameda-Pineda, X., Ricci, E., Sebe, N., Eds.; Academic Press: Cambridge, MA, USA, 2019; pp. 369–386. [Google Scholar]
- Sandbach, G.; Zafeiriou, S.; Pantic, M.; Yin, L. Static and dynamic 3D facial expression recognition: A comprehensive survey. Image Vis. Comput. 2012, 30, 683–697. [Google Scholar] [CrossRef]
- Deshmukh, S.; Patwardhan, M.; Mahajan, A. Survey on real-time facial expression recognition techniques. IET Biom. 2016, 5, 155–163. [Google Scholar] [CrossRef]
- Tian, Y.-I.; Kanade, T.; Cohn, J.F. Recognizing action units for facial expression analysis. IEEE Trans. Pattern Anal. Mach. Intell. 2001, 23, 97–115. [Google Scholar] [CrossRef] [PubMed]
- Calvo, R.A.; D’Mello, S. Affect detection: An interdisciplinary review of models, methods, and their applications. IEEE Trans. Affect. Comput. 2010, 1, 18–37. [Google Scholar] [CrossRef]
- Zeng, Z.; Pantic, M.; Roisman, G.I.; Huang, T.S. A survey of affect recognition methods: Audio, visual, and spontaneous expressions. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 39–58. [Google Scholar] [CrossRef]
- Yan, H.; Ang, M.H.; Poo, A.N. A survey on perception methods for human–robot interaction in social robots. Int. J. Soc. Robot. 2014, 6, 85–119. [Google Scholar] [CrossRef]
- Yan, H.; Lu, J.; Zhou, X. Prototype-based discriminative feature learning for kinship verification. IEEE Trans. Cybern. 2015, 45, 2535–2545. [Google Scholar] [CrossRef] [PubMed]
- Yan, H. Transfer subspace learning for cross-dataset facial expression recognition. Neurocomputing 2016, 208, 165–173. [Google Scholar] [CrossRef]
- Yan, H. Biased subspace learning for misalignment-robust facial expression recognition. Neurocomputing 2016, 208, 202–209. [Google Scholar] [CrossRef]
- Wang, N.; Gao, X.; Tao, D.; Yang, H.; Li, X. Facial feature point detection: A comprehensive survey. Neurocomputing 2018, 275, 50–65. [Google Scholar] [CrossRef]
- Saha, A.; Pradhan, S.N. Facial expression recognition based on eigenspaces and principle component analysis. Int. J. Comput. Vis. Robot. 2018, 8, 190–200. [Google Scholar] [CrossRef]
- Naik, S.; Jagannath, R.P.K. GCV-Based Regularized Extreme Learning Machine for Facial Expression Recognition. In Advances in Machine Learning and Data Science; Springer: Singapore, 2018; pp. 129–138. [Google Scholar]
- Benini, S.; Khan, K.; Leonardi, R.; Mauro, M.; Migliorati, P. Face analysis through semantic face segmentation. Signal Process. Image Commun. 2019, 74, 21–31. [Google Scholar] [CrossRef]
- Chengeta, K.; Viriri, S. A survey on facial recognition based on local directional and local binary patterns. In Proceedings of the 2018 Conference on Information Communications Technology and Society (ICTAS), Durban, South Africa, 8–9 March 2018; pp. 1–6. [Google Scholar]
- Verma, V.K.; Srivastava, S.; Jain, T.; Jain, A. Local Invariant Feature-Based Gender Recognition from Facial Images. In Soft Computing for Problem Solving; Springer: Berlin/Heidelberg, Germany, 2019; pp. 869–878. [Google Scholar]
- Munir, A.; Hussain, A.; Khan, S.A.; Nadeem, M.; Arshid, S. Illumination invariant facial expression recognition using selected merged binary patterns for real world images. Optik 2018, 158, 1016–1025. [Google Scholar] [CrossRef]
- Khan, S.A.; Hussain, A.; Usman, M. Reliable facial expression recognition for multi-scale images using weber local binary image based cosine transform features. Multimed. Tools Appl. 2018, 77, 1133–1165. [Google Scholar] [CrossRef]
- García-Ramírez, J.; Olvera-López, J.A.; Olmos-Pineda, I.; Martín-Ortíz, M. Mouth and eyebrow segmentation for emotional expression recognition using interpolated polynomials. J. Intell. Fuzzy Syst. 2018, 34, 1–13. [Google Scholar] [CrossRef]
- Rahul, M.; Mamoria, P.; Kohli, N.; Agrawal, R. An Efficient Technique for Facial Expression Recognition Using Multistage Hidden Markov Model. In Soft Computing: Theories and Applications (SoCTA 2017); Springer: Singapore, 2017; pp. 33–43. [Google Scholar]
- Zeng, N.; Zhang, H.; Song, B.; Liu, W.; Li, Y.; Dobaie, A.M. Facial expression recognition via learning deep sparse autoencoders. Neurocomputing 2018, 273, 643–649. [Google Scholar] [CrossRef]
- Liu, M.; Wang, R.; Li, S.; Shan, S.; Huang, Z.; Chen, X. Combining Multiple Kernel Methods on Riemannian Manifold for Emotional expression recognition in the Wild. In Proceedings of the 16th International Conference on Multimodal Interaction, Istanbul, Turkey, 12–16 November 2014; pp. 494–501. [Google Scholar]
- Liu, M.; Shan, S.; Wang, R.; Chen, X. Learning Expressionlets on Spatio-temporal Manifold for Dynamic Facial Expression Recognition. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2014; pp. 1749–1756. [Google Scholar]
- Zhang, D.; Ding, D.; Li, J.; Liu, Q. Pca based extracting feature using fast fourier transform for facial expression recognition. In Transactions on Engineering Technologies; Springer: Berlin/Heidelberg, Germany, 2015; pp. 413–424. [Google Scholar]
- Patil, M.N.; Iyer, B.; Arya, R. Performance Evaluation of PCA and ICA Algorithm for Facial Expression Recognition Application. In Proceedings of the Fifth International Conference on Soft Computing for Problem Solving, Uttarakhand, India, 15 March 2016; pp. 965–976. [Google Scholar]
- Garg, A.; Bajaj, R. Facial expression recognition & classification using hybridization of ica, ga, and neural network for human–computer interaction. J. Netw. Commun. Emerg. Technol. 2015, 2, 49–57. [Google Scholar]
- Chao, W.-L.; Ding, J.-J.; Liu, J.-Z. Facial expression recognition based on improved local binary pattern and class-regularized locality preserving projection. Signal Process. 2015, 117, 1–10. [Google Scholar] [CrossRef]
- Levi, G.; Hassner, T. Emotional expression recognition in the Wild via Convolutional Neural Networks and Mapped Binary Patterns. In Proceedings of the 2015 ACM on International Conference on Multimodal Interaction, Seattle, WA, USA, 9–13 November 2015; pp. 503–510. [Google Scholar]
- Ding, Y.; Zhao, Q.; Li, B.; Yuan, X. Facial expression recognition from image sequence based on lbp and taylor expansion. IEEE Access 2017, 5, 19409–19419. [Google Scholar] [CrossRef]
- Uddin, M.Z.; Hassan, M.M.; Almogren, A.; Zuair, M.; Fortino, G.; Torresen, J. A facial expression recognition system using robust face features from depth videos and deep learning. Comput. Elect. Eng. 2017, 63, 114–125. [Google Scholar] [CrossRef]
- Gupta, O.; Raviv, D.; Raskar, R. Illumination invariants in deep video expression recognition. Pattern Recognit. 2018, 76, 25–35. [Google Scholar] [CrossRef]
- Zhang, K.; Huang, Y.; Du, Y.; Wang, L. Facial expression recognition based on deep evolutional spatial-temporal networks. IEEE Trans. Image Procss. 2017, 26, 4193–4203. [Google Scholar] [CrossRef]
- Uddin, M.Z.; Hassan, M.M.; Almogren, A.; Alamri, A.; Alrubaian, M.; Fortino, G. Facial expression recognition utilizing local direction-based robust features and deep belief network. IEEE Access 2017, 5, 4525–4536. [Google Scholar] [CrossRef]
- Chen, J.; Chen, Z.; Chi, Z.; Fu, H. Facial expression recognition in video with multiple feature fusion. IEEE Trans. Affect. Comput. 2018, 9, 38–50. [Google Scholar] [CrossRef]
- Yan, H. Collaborative discriminative multi-metric learning for facial expression recognition in video. Pattern Recognit. 2018, 75, 33–40. [Google Scholar] [CrossRef]
- Liu, L.; Gui, W.; Zhang, L.; Chen, J. Real-time pose invariant spontaneous smile detection using conditional random regression forests. Optik 2019, 182, 647–657. [Google Scholar] [CrossRef]
- Huang, G.B.; Mattar, M.; Berg, T.; Learned-Miller, E. Labeled faces in the wild: A database forstudying face recognition in unconstrained environments. In Proceedings of the Workshop on Faces in ‘Real-Life’ Images: Detection, Alignment, and Recognition, Marseille, France, 17–20 October 2008. [Google Scholar]
- Hupont, I.; Baldassarri, S.; Cerezo, E.; Del-Hoyo, R. The Emotracker: Visualizing Contents, Gaze and Emotions at a Glance. In Proceedings of the 2013 Humaine Association Conference on Affective Computing and Intelligent Interaction (ACII), Geneva, Switzerland, 2–5 September 2013; pp. 751–756. [Google Scholar]
- T60, T. Available online: http://www.tobii.com/en/eye-trackingresearch/global/products/hardware/tobii-t60t120-eye-tracker/ (accessed on 12 April 2019).
- Den Uyl, M.; Van Kuilenburg, H. The FaceReader: Online facial expression recognition. In Proceedings of the Measuring Behavior, Wageningen, The Netherlands, 27–29 August 2005; pp. 589–590. [Google Scholar]
- Valstar, M.; Pantic, M.; Patras, I. Motion history for facial action detection in video. In Proceedings of the 2004 IEEE International Conference on Systems, Man and Cybernetics, The Hague, The Netherlands, 10–13 October 2004; pp. 635–640. [Google Scholar]
- Ekman, P.; Rosenberg, E.L. What the Face Reveals: Basic and Applied Studies of Spontaneous Expression Using the Facial Action Coding System (FACS); Oxford University Press: New York City, NY, USA, 1997. [Google Scholar]
- Silva, L.C.D.; Pei Chi, N. Bimodal emotional expression recognition. In Proceedings of the Fourth IEEE International Conference on Automatic Face and Gesture Recognition (Cat. No. PR00580), Grenoble, France, 28–30 March 2000; pp. 332–335. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2005), San Diego, CA, USA, 20–25 June 2005; pp. 886–893. [Google Scholar]
- Reilly, R.B.; Lee, T.C. Electrograms (ecg, eeg, emg, eog). Technol. Health Care 2010, 18, 443–458. [Google Scholar] [PubMed]
- Bulling, A.; Roggen, D.; Tröster, G.J.; Environments, S. Wearable EOG goggles: Seamless sensing and context-awareness in everyday environments. J. Ambient Intell. Smart Environ. 2009, 1, 157–171. [Google Scholar]
- Brás, S.; Ferreira, J.H.; Soares, S.C.; Pinho, A.J. Biometric and emotion identification: An ECG compression based method. Front. Psychol. 2018, 9, 467. [Google Scholar] [CrossRef]
- Kaji, H.; Iizuka, H.; Sugiyama, M. ECG-Based Concentration Recognition With Multi-Task Regression. IEEE Trans. Biomed. Eng. 2019, 66, 101–110. [Google Scholar] [CrossRef]
- Munoz, R.; Olivares, R.; Taramasco, C.; Villarroel, R.; Soto, R.; Barcelos, T.S.; Merino, E.; Alonso-Sánchez, M.F. Using Black Hole Algorithm to Improve EEG-Based Emotional expression recognition. Comput. Intell. Neurosci. 2018, 2018, 1–21. [Google Scholar] [CrossRef] [PubMed]
- Pandey, P.; Seeja, K. Emotional state recognition with eeg signals using subject independent approach. In Data Science and Big Data Analytic; Springer: Berlin/Heidelberg, Germany, 2019; pp. 117–124. [Google Scholar]
- Nakisa, B.; Rastgoo, M.N.; Tjondronegoro, D.; Chandran, V. Evolutionary computation algorithms for feature selection of EEG-based emotional expression recognition using mobile sensors. Expert Syst. Appl. 2018, 93, 143–155. [Google Scholar] [CrossRef]
- Hassan, M.M.; Alam, M.G.R.; Uddin, M.Z.; Huda, S.; Almogren, A.; Fortino, G. Human emotional expression recognition using deep belief network architecture. Inf. Fusion 2019, 51, 10–18. [Google Scholar] [CrossRef]
- Kanjo, E.; Younis, E.M.; Sherkat, N. Towards unravelling the relationship between on-body, environmental and emotion data using sensor information fusion approach. Inf. Fusion 2018, 40, 18–31. [Google Scholar] [CrossRef]
- Lee, G.; Kwon, M.; Sri, S.K.; Lee, M. Emotional expression recognition based on 3D fuzzy visual and EEG features in movie clips. Neurocomputing 2014, 144, 560–568. [Google Scholar] [CrossRef]
- Bilalpur, M.; Kia, S.M.; Chawla, M.; Chua, T.-S.; Subramanian, R. Gender and emotional expression recognition with implicit user signals. In Proceedings of the 19th ACM International Conference on Multimodal Interaction, Glasgow, UK, 13–17 November 2017; pp. 379–387. [Google Scholar]
- Koelstra, S.; Patras, I. Fusion of facial expressions and EEG for implicit affective tagging. Image Vis. Comput. 2013, 31, 164–174. [Google Scholar] [CrossRef]
- Park, B.-K.D.; Jones, M.; Miller, C.; Hallman, J.; Sherony, R.; Reed, M. In-Vehicle Occupant Head Tracking Using aLow-Cost Depth Camera; SAE Technical Paper 0148-7191; SAE International: Troy, MI, USA, 2018. [Google Scholar]
- Kong, J.; Zan, B.; Jiang, M. Human action recognition using depth motion maps pyramid and discriminative collaborative representation classifier. J. Electron. Imaging 2018, 27, 033027. [Google Scholar] [CrossRef]
- Tian, L.; Li, M.; Hao, Y.; Liu, J.; Zhang, G.; Chen, Y.Q. Robust 3D Human Detection in Complex Environments with Depth Camera. IEEE Trans. Multimedia 2018, 20, 2249–2261. [Google Scholar] [CrossRef]
- Zhang, S.; Yu, H.; Wang, T.; Qi, L.; Dong, J.; Liu, H. Dense 3D facial reconstruction from a single depth image in unconstrained environment. Virtual Real. 2018, 22, 37–46. [Google Scholar] [CrossRef]
- Raghavendra, R.; Raja, K.B.; Busch, C. Presentation attack detection for face recognition using light field camera. IEEE Trans. Image Process. 2015, 24, 1060–1075. [Google Scholar] [CrossRef]
- Uddin, M.Z. Facial expression recognition using depth information and spatiotemporal features. In Proceedings of the 2016 18th International Conference on Advanced Communication Technology (ICACT), Pyeongchang, Korea, 31 January–31 February 2016; pp. 726–731. [Google Scholar]
- Cai, L.; Xu, H.; Yang, Y.; Yu, J. Robust facial expression recognition using RGB-D images and multichannel features. Multimed. Tools Appl. 2018, 1–17. [Google Scholar] [CrossRef]
- Pavlidis, I.; Levine, J. Thermal image analysis for polygraph testing. IEEE Eng. Med. Biol. Mag. 2002, 21, 56–64. [Google Scholar] [CrossRef]
- Puri, C.; Olson, L.; Pavlidis, I.; Levine, J.; Starren, J. StressCam: Non-contact measurement of users’ emotional states through thermal imaging. In Proceedings of the CHI’05 Extended Abstracts on Human Factors in Computing Systems, Portland, OR, USA, 2–7 April 2005; pp. 1725–1728. [Google Scholar]
- Hernández, B.; Olague, G.; Hammoud, R.; Trujillo, L.; Romero, E. Visual learning of texture descriptors for facial expression recognition in thermal imagery. Comput. Vis. Image Underst. 2007, 106, 258–269. [Google Scholar] [CrossRef]
- Trujillo, L.; Olague, G.; Hammoud, R.; Hernandez, B. Automatic feature localization in thermal images for facial expression recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition-Workshops, San Diego, CA, USA, 21–23 September 2005; p. 14. [Google Scholar]
- Khan, M.M.; Ingleby, M.; Ward, R.D. Automated facial expression classification and affect interpretation using infrared measurement of facial skin temperature variations. ACM Trans. Auton. Adapt. Syst. 2006, 1, 91–113. [Google Scholar] [CrossRef]
- Krzywicki, A.T.; He, G.; O’Kane, B.L. Analysis of facial thermal variations in response to emotion: Eliciting film clips. In Proceedings of the Independent Component Analyses, Wavelets, Neural Networks, Biosystems, and Nanoengineering VII, Orlando, FL, USA, 22 April 2009; p. 734312. [Google Scholar]
- Khan, M.M.; Ward, R.D.; Ingleby, M. Classifying pretended and evoked facial expressions of positive and negative affective states using infrared measurement of skin temperature. ACM Trans. Appl. Percept. 2009, 6, 6. [Google Scholar] [CrossRef]
- Yoshitomi, Y. Facial expression recognition for speaker using thermal image processing and speech recognition system. In Proceedings of the 10th WSEAS international conference on Applied Computer Science, Moscow, Russia, 27 September–2 October 2009; pp. 182–186. [Google Scholar]
- Wang, S.; He, S. Spontaneous facial expression recognition by fusing thermal infrared and visible images. In Intelligent Autonomous Systems 12; Springer: Berlin/Heidelberg, Germany, 2013; pp. 263–272. [Google Scholar]
- Shen, P.; Wang, S.; Liu, Z. Facial expression recognition from infrared thermal videos. In Intelligent Autonomous Systems 12; Springer: Berlin/Heidelberg, Germany, 2013; pp. 323–333. [Google Scholar]
- Wang, S.; Wu, C.; He, M.; Wang, J.; Ji, Q. Posed and spontaneous expression recognition through modeling their spatial patterns. Mach. Vis. Appl. 2015, 26, 219–231. [Google Scholar] [CrossRef]
- Chrysos, G.G.; Antonakos, E.; Zafeiriou, S.; Snape, P. Offline deformable face tracking in arbitrary videos. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Santiago, Chile, 7–13 December 2015; pp. 1–9. [Google Scholar]
- Shen, J.; Zafeiriou, S.; Chrysos, G.G.; Kossaifi, J.; Tzimiropoulos, G.; Pantic, M. The first facial landmark tracking in-the-wild challenge: Benchmark and results. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Santiago, Chile, 7–13 December 2015; pp. 50–58. [Google Scholar]
- Huang, G.B.; Learned-Miller, E. Labeled Faces in the Wild: Updates and New Reporting Procedures; University of Massachusetts Amherst: Amherst, MA, USA, 2014. [Google Scholar]
- Belhumeur, P.N.; Jacobs, D.W.; Kriegman, D.J.; Kumar, N. Localizing parts of faces using a consensus of exemplars. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 2930–2940. [Google Scholar] [CrossRef] [PubMed]
- Qu, F.; Wang, S.; Yan, W.; Li, H.; Wu, S.; Fu, X. CAS(ME)2: A Database for Spontaneous Macro-Expression and Micro-Expression Spotting and Recognition. IEEE Trans. Affect. Comput. 2018, 9, 424–436. [Google Scholar] [CrossRef]
- Dhall, A.; Goecke, R.; Lucey, S.; Gedeon, T. Collecting Large, Richly Annotated Facial-Expression Databases from Movies. IEEE Multimed. 2012, 19, 34–41. [Google Scholar] [CrossRef]
- Dhall, A.; Goecke, R.; Lucey, S.; Gedeon, T. Static facial expression analysis in tough conditions: Data, evaluation protocol and benchmark. In Proceedings of the 2011 IEEE International Conference on Computer Vision Workshops (ICCV Workshops), Barcelona, Spain, 6–13 November 2011; pp. 2106–2112. [Google Scholar]
- Lucey, P.; Cohn, J.F.; Kanade, T.; Saragih, J.; Ambadar, Z.; Matthews, I. The extended cohn–Kanade dataset (ck+): A complete dataset for action unit and emotion-specified expression. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition-Workshops, San Francisco, CA, USA, 13–18 June 2010; pp. 94–101. [Google Scholar]
- Gross, R.; Matthews, I.; Cohn, J.; Kanade, T.; Baker, S. Multi-PIE. Image Vis. Comput. 2010, 28, 807–813. [Google Scholar] [CrossRef]
- Sim, T.; Baker, S.; Bsat, M. The CMU Pose, Illumination, and Expression (PIE) Database. In Proceedings of the Fifth IEEE International Conference on Automatic Face and Gesture Recognition, Washington, DC, USA, 20–21 May 2002; p. 53. [Google Scholar]
- Gupta, O.; Raviv, D.; Raskar, R. Multi-velocity neural networks for facial expression recognition in videos. IEEE Trans. Affect. Comput. 2018. [Google Scholar] [CrossRef]
- Pantic, M.; Valstar, M.; Rademaker, R.; Maat, L. Web-based database for facial expression analysis. In Proceedings of the 2005 IEEE International Conference on Multimedia and Expo, Amsterdam, The Netherlands, 6–8 July 2005; p. 5. [Google Scholar]
- McDuff, D.; Kaliouby, R.; Senechal, T.; Amr, M.; Cohn, J.F.; Picard, R. Affectiva-MIT Facial Expression Dataset (AM-FED): Naturalistic and Spontaneous Facial Expressions Collected “In-the-Wild”. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition Workshops, Portland, OR, USA, 23–28 June 2013; pp. 881–888. [Google Scholar]
- Gao, W.; Cao, B.; Shan, S.; Chen, X.; Zhou, D.; Zhang, X.; Zhao, D. The CAS-PEAL Large-Scale Chinese Face Database and Baseline Evaluations. IEEE Trans. Syst. Man Cybern. Part A Syst. Hum. 2008, 38, 149–161. [Google Scholar] [CrossRef]
- Grimm, M.; Kroschel, K.; Narayanan, S. The Vera am Mittag German audio-visual emotional speech database. In Proceedings of the 2008 IEEE International Conference on Multimedia and Expo, Hannover, Germany, 23–26 June 2008; pp. 865–868. [Google Scholar]
- Wang, S.; Liu, Z.; Lv, S.; Lv, Y.; Wu, G.; Peng, P.; Chen, F.; Wang, X. A Natural Visible and Infrared Facial Expression Database for Expression Recognition and Emotion Inference. IEEE Trans. Multimed. 2010, 12, 682–691. [Google Scholar] [CrossRef]
- Pfister, T.; Li, X.; Zhao, G.; Pietikäinen, M. Differentiating spontaneous from posed facial expressions within a generic facial expression recognition framework. In Proceedings of the 2011 IEEE International Conference on Computer Vision Workshops (ICCV Workshops), Barcelona, Spain, 6–13 November 2011; pp. 868–875. [Google Scholar]
- Zhang, Z.; Girard, J.M.; Wu, Y.; Zhang, X.; Liu, P.; Ciftci, U.; Canavan, S.; Reale, M.; Horowitz, A.; Yang, H.; et al. Multimodal Spontaneous Emotion Corpus for Human Behavior Analysis. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Washington, DC, USA, 27–30 June 2016; pp. 3438–3446. [Google Scholar]
- Gehrig, T.; Ekenel, H.K. Why is facial expression analysis in the wild challenging? In Proceedings of the 2013 on Emotional expression recognition in the wild challenge and workshop, Sydney, Australia, 9 December 2013; pp. 9–16. [Google Scholar]
- Dhall, A.; Joshi, J.; Sikka, K.; Goecke, R.; Sebe, N. The more the merrier: Analysing the affect of a group of people in images. In Proceedings of the 2015 11th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition (FG), Ljubljana, Slovenia, 4–8 May 2015; pp. 1–8. [Google Scholar]
- Islam, M.R.; Sobhan, M.A. Feature Fusion Based Audio-Visual Speaker Identification Using Hidden Markov Model under Different Lighting Variations. J. Appl. Comput. Intell. Soft Comput. 2014, 2014, 1–7. [Google Scholar] [CrossRef]
- Lu, H.-C.; Huang, Y.-J.; Chen, Y.-W.; Yang, D.-I. Real-time facial expression recognition based on pixel-pattern-based texture feature. Electron. Lett. 2007, 43, 916–918. [Google Scholar] [CrossRef]
- Azazi, A.; Lebai Lutfi, S.; Venkat, I.; Fernández-Martínez, F. Towards a robust affect recognition: Automatic facial expression recognition in 3D faces. Expert Syst. Appl. 2015, 42, 3056–3066. [Google Scholar] [CrossRef]
- Masai, K.; Sugiura, Y.; Ogata, M.; Suzuki, K.; Nakamura, F.; Shimamura, S.; Kunze, K.; Inami, M.; Sugimoto, M. AffectiveWear: Toward recognizing facial expression. In Proceedings of the ACM SIGGRAPH 2015 Emerging Technologies, Los Angeles, CA, USA, 9–13 August 2015; p. 4. [Google Scholar]
- Cha, J.; Kim, J.; Kim, S. An IR-based facial expression tracking sensor for head-mounted displays. In Proceedings of the 2016 IEEE SENSORS, Orlando, FL, USA, 30 October–3 November 2016; pp. 1–3. [Google Scholar]
- Emotiv/Epoc. Available online: https://www.emotiv.com/epoc/ (accessed on 12 April 2019).
- Caps, W. Available online: https://www.ant-neuro.com/products/waveguard_caps (accessed on 12 April 2019).
- Hu, S.; Short, N.J.; Riggan, B.S.; Gordon, C.; Gurton, K.P.; Thielke, M.; Gurram, P.; Chan, A.L. A Polarimetric Thermal Database for Face Recognition Research. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 187–194. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Classifier | Work | Method | Sensor Type | Dataset | Average Accuracy % |
|---|---|---|---|---|---|
| SVM | [46], 2014 | HOG, dense SIFT features kernel SVM, logistic regression, partial least squares | RGB Video Audio | AFEW 4.0 (real-world) | 50.4 |
| [47], 2014 | STM, UMM features Multi-class linear SVM | RGB Video | AFEW 4.0 (real world) | 31.73 | |
| Deep Network | [52], 2015 | LBP features Convolutional neural network (CNN) | RGB Image | SWEF (real-world) | 54.56 |
| [54], 2017 | MLDP-GDA features Deep Belief Network (DBN) | Depth Video | 40 videos taken from 10 subjects (Lab-controlled) | 96.2 | |
| [55], 2018 | Spatio-temporal convolutional neural network | RGB Video | MMI CK+ Florentine (real-world) | 59.03 73.68 48 | |
| KNN | [41], 2018 | FFT-CLAHE, MBPC features KNN, MLP, simple logistic, SMO, J48 | RGB Image | SEWF (real-world) | 96.5 |
| [53], 2017 | Logarithm-laplace (LL) domain in DLBP Taylor expansion theorem | RGB Video | CK+ (lab-controlled) | 92.86 |
| Classifier | Work | Method | Sensor Type | Dataset | Average Accuracy % |
|---|---|---|---|---|---|
| Deep Network | [56], 2017 | Deep spatial-temporal networks | RGB Video | CK+ MMI (Lab-controlled) | 98.5 81.18 |
| [57], 2017 | MLDP-GDA features Deep Belief Network (DBN) | Depth Video | 40 videos taken from 10 subjects (Lab-controlled) | 89.16 | |
| CD-MM Learning | [59], 2018 | 3D-HOG, geometric warp, audio features | RGB Video Audio | AFEW 4.0 (real-world) | 46.8 |
| Classifier | Work | Method | Sensor Type | Dataset | Average Accuracy % |
|---|---|---|---|---|---|
| SVM | [58], 2018 | HOG-TOP and geometric features | RGB Video Audio | AFEW 4.0 (real-world) | 40.2 |
| CD-MM | [59], 2018 | 3D-HOG, geometric warp, audio features | RGB Video Audio | AFEW 4.0 (real-world) | 46.8 |
| Regression forest | [60], 2019 | Multiple-label dataset augmentation, non-informative patch | RGB Image | LFW CCNU-Class | 94.05 92.17 |
| Work | Method | Sensor Type | Fusion Technology | Dataset | Average Accuracy % |
|---|---|---|---|---|---|
| [67], 2000 | Statistical features, KNN, Hidden Markov Model (HMM) | RGB Video Audio | Rule-based methodology | 144 videos from two subjects | 72 |
| [46], 2014 | HOG, dense SIFT features kernel SVM, logistic regression, partial least squares | Audio RGB Video | Equal-weighted linear fusion technique | AFEW 4.0 | 50.4 |
| [86], 2016 | MLDP-GDA Deep Belief Network (DBN) | Depth Video | No fusion | 40 videos included ten frames | 96.25 |
| [57], 2017 | LDPP, GDA, PCA Deep Belief Network (DBN) | Depth Video | No fusion | 40 videos included ten frames | 89.16 |
| [79], 2017 | ERP, fixation distribution patterns Naive-Bayes (NB), LSVM, RSVM | Eye movements EEG signals | procedure [80] | Radboud Faces Database (RaFD) | AUC > 0.6 |
| [58], 2018 | HOG-TOP, geometric features SVM | Audio RGB Video | Multi-kernel SVM | CK+ AFEW | 95.7 40.2 |
| [59], 2018 | Collaborative discriminative multi-metric learning | RGB Video Audio | PCA | AFEW 4.0 CK+ | 46.8 96.6 |
| [87], 2018 | HOG, AMM GS-SVM | RGB Image Depth Image | Multichannel feature vector | A merged dataset of three public datasets | 89.46 |
| Work | Method | Sensor Type | Fusion Technology | Dataset | Average Accuracy % |
|---|---|---|---|---|---|
| [96], 2013 | Head motion, AAM, thermal statistical parameters KNN | RGB Image Infrared-thermal Image | Multiple genetic algorithms-based fusion method | USTC-NVIE | 63 |
| [97], 2013 | Sequence features AdaBoost, KNN | RGB Image Infrared thermal video | No fusion | USTC-NVIE | 73 |
| [98], 2015 | Geometric features Bayesian networks (BN) | Infrared thermal Image | No fusion | USTC-NVIE SPOS | 85.51 74.79 |
| Dataset | Main Feature | Capacity | Emotions | Environment | Link |
|---|---|---|---|---|---|
| CAS(ME)2 | Both spontaneous micro and macro-expressions | 87 images of micro and macro-expressions 57 micro-expressions | Four | Lab controlled | http://fu.psych.ac.cn/CASME/cas(me)2-en.php |
| AFEW 4.0 | Videos from real world scenarios | 1268 videos | Seven | Real-world | https://cs.anu.edu.au/few/AFEW.html |
| SFEW | Images from real world scenarios | 700 images | Seven | Real-world | https://cs.anu.edu.au/few/AFEW.html |
| CK+ | The most common lab-controlled dataset | 593 videos | Seven | Lab controlled | http://www.consortium.ri.cmu.edu/ckagree/ |
| CMU Multi-PIE | Simulation of 19 various lighting conditions | 755,370 images | Six | Lab controlled in different illumination variations | http://www.multipie.org/ |
| Florentine | Many participants for collecting videos | 2777 video clips | Seven | Lab controlled in different illumination variations | Not still public |
| Autoencoder | The largest introduced dataset in real world | 6.5 million video clips | Seven | Real world | Not still public |
| MMI | Dual view in an image | 1520 videos of Posed expressions | Six | Lab-controlled trying poor illumination conditions | https://mmifacedb.eu/accounts/register/ |
| AM-FED | Webcam videos from online viewers | 242 videos spontaneous expressions | Smile | Real-world | http://www.affectiva.com/facialexpression-dataset-am-fed/ |
| CAS-PEAL | Simulation of various backgrounds in the lab | images of posed expressions | Five | Lab-controlled in various illumination conditions | http://www.jdl.ac.cn/peal/home.htm |
| Dataset | Main Feature | Capacity | Number of Emotions | Environment | Link |
|---|---|---|---|---|---|
| UTSC-NVIE (target-focused) | The biggest thermal-infrared dataset | Videos of posed and spontaneous expressions | Six | Lab controlled | http://nvie.ustc.edu.cn |
| SPOS (target-focused) | Subjects with different accessories | 231 images of spontaneous, and posed expressions | Six | Lab controlled | https://www.oulu.fi/cmvs/node/41317 |
| VAMGS (non-visual) | Visual-audio real world dataset | 1867 images of spontaneous expression 1018 emotional voices | Six | Real-world | http://emotion-research.net |
| MMSE | A multimodal dataset | 10 GB data per subject | Ten | Lab controlled | http://www.cs.binghamton.edu/~lijun/Research/3DFE/3DFE_Analysis.html |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Samadiani, N.; Huang, G.; Cai, B.; Luo, W.; Chi, C.-H.; Xiang, Y.; He, J. A Review on Automatic Facial Expression Recognition Systems Assisted by Multimodal Sensor Data. Sensors 2019, 19, 1863. https://doi.org/10.3390/s19081863
Samadiani N, Huang G, Cai B, Luo W, Chi C-H, Xiang Y, He J. A Review on Automatic Facial Expression Recognition Systems Assisted by Multimodal Sensor Data. Sensors. 2019; 19(8):1863. https://doi.org/10.3390/s19081863
Chicago/Turabian StyleSamadiani, Najmeh, Guangyan Huang, Borui Cai, Wei Luo, Chi-Hung Chi, Yong Xiang, and Jing He. 2019. "A Review on Automatic Facial Expression Recognition Systems Assisted by Multimodal Sensor Data" Sensors 19, no. 8: 1863. https://doi.org/10.3390/s19081863
APA StyleSamadiani, N., Huang, G., Cai, B., Luo, W., Chi, C. -H., Xiang, Y., & He, J. (2019). A Review on Automatic Facial Expression Recognition Systems Assisted by Multimodal Sensor Data. Sensors, 19(8), 1863. https://doi.org/10.3390/s19081863