1. Introduction
The three-dimensional (3D) spatial context is becoming an integral part of 3D user interfaces in everyday life, such as modeling applications, virtual and augmented reality, and gaming systems. The 3D user interfaces are all characterized by a user input that involves 3D position (x, y, z) or orientation (yaw, pitch, roll), and 3D tracking is a key technology to recovering the 3D position and orientation of an object relative to the camera or, equivalently, the 3D position and orientation of the camera relative to the object in physical 3D space. Recovering the position and orientation of an object from images is becoming an important task in the fields of computer vision and photogrammetry. A necessity has arisen for users in both fields to know more about the differences in, and behavior of, the approaches developed by the computer vision and photogrammetry communities. In both fields, mathematical motion models are expressed with an epipolar constraint under perspective geometry. Linear approaches have mainly been developed by the computer vision community, while the photogrammetric community has generally considered non-linear solutions to recover 3D motion parameters.
Especially in computer vision, determining the 3D motion of an object from image sequences starts from image matching, as the establishment of point correspondences extracted from two or more images. The automatic relative orientation of image sequences, with assumptions of calibrated or uncalibrated cameras (unknown intrinsic parameters), has been widely investigated. An essential matrix is defined as the set of linear homogeneous equations found by establishing eight point correspondences. By decomposing the essential matrix, the relative pose parameters of the two perspective views were computed [
1,
2,
3]. Pose estimations based on decomposition of the essential matrix using fewer than eight point correspondences were developed for various applications, such as visual servoing and robot control [
4,
5,
6,
7]. Moreover, the pose parameters of the camera relative to a planar object can be estimated by decomposing a homography matrix through point correspondences. Numerical and analytical methods for pose estimation based on homography decomposition were introduced, in detail, in [
8]. Other authors introduced non-linear and linear solutions for determining the pose parameters based on the decomposition of a homography matrix in augmented reality and robot control applications [
9,
10,
11,
12,
13,
14].
In photogrammetry, the determination of 3D pose from a set of 3D points was originally known as resectioning. To determine the position and orientation (extrinsic parameters) of the right image, relative to the left image, from a sufficient set of tie-points is well known as a relative orientation process. In this photogrammetric task, the intrinsic parameters are assumed to be known, instead the analysis of the images, to discover the corresponding points between the images, but no ground truth is assumed. Mathematically, relative orientation parameters, as pose parameters between frames in a sequence, can be determined by collinearity or coplanarity equations [
15,
16,
17,
18,
19].
Various solutions for pose estimation from the point correspondences have been published, introducing their accuracy to image noise and their computation speed against state-of-the-art methods for both simulated and real image data. The non-linear and the linear approaches to solve the perspective-n-point (PnP) problem for determining the position and orientation of the camera based on the 3D reference points and their 2D projections have been developed for various applications, and quantitative comparisons of their results with the state-of-the-art approaches were carried out. The authors in [
20] developed an algorithm to solve the PnP problem using the 3D collinearity model. The experimental results on simulated and real data were compared with the efficient PnP (EPnP) algorithm [
21], the orthogonal iterative (OI) approach [
22], and a non-linear solution to relative position estimation [
23]. An algebraic method was developed, in [
24], to solve the perspective-three-point (P3P) problem of computing the rotation and position of a camera. The experimental results demonstrated that the accuracy and precision of the method was comparable to the existing state-of-the-art methods, such as the first complete analytical solution to the P3P problem [
25], the perspective similar triangle (PST) method [
26], and the closed-form solution to the P3P problem [
27]. The authors in [
28] proposed a method for the PnP problem, for determining the position and orientation of a calibrated camera from known reference points. The authors investigated the performance of the proposed method and compared the accuracy with the leading PnP methods, such as the non-linear least-squares solution [
29], the efficient PnP (EPnP) algorithm [
21], the robust non-iterative method (RPnP) [
26], the direct least-squares (DLS) method [
30], and the optimal solution (OPnP) [
31]. A novel set of linear solutions to the pose estimation problem from an image of
n points and
n lines was presented in [
32]. Their results were compared to other recent linear algorithms, such as the non-linear least-squares solutions [
29,
33], the direct recovery and decomposition of the full projection matrix [
34], and the
n point linear algorithms [
35,
36]. Combining two fields, a evaluation of epipolar resampling methods developed for image sequences with an intension of stereo applications was reported in [
37]. A theoretical comparison of the 3D metric reconstruction in the cultural heritage field and its accuracy assessment with the results from commercial software were discussed in [
38]. The relationship between photogrammetry and computer vision was examined in [
39]. However, the evaluations, comparisons, and the differences in the theoretical and practical perspectives of pose estimation methods based on the epipolar constraint developed in each field, using a common dataset, are missing. On the other hand, even if the processing steps for the two techniques seem to be different approaches, some computer vision techniques were implemented for increasing the workflow automation of the photogrammetric techniques. Moreover, an additional investigation of the automatic techniques that regulate the processing steps is needed.
The aim of this paper is to investigate the approaches to determining the 3D motion of a moving object in real-time image sequences taken by a monocular camera. First, we determined a novel automatic technique to perform motion estimations with a single camera. Common processing steps were implemented in the estimations. We try to use a web camera instead of other specialized devices, such as accelerometers, gyroscopes, and global positioning systems (GPS), to sense 3D motion, as the web camera is cheap and widely available. Furthermore, we believe a single camera is more suitable for real-time computation, because we can maintain one processing chain. Second, we analyzed and compared the linear approaches with the non-linear approaches. We used four estimation methods for recovering the 3D motion parameters, based on tracked point correspondences. Two of them were developed with linear solutions in computer vision, and two of them were developed with non-linear solutions in photogrammetry. We argue that most previous investigations for pose estimations have not thoroughly compared the methods developed in both fields. It is, at present, difficult to define the border between the two methodologies. Moreover, a number of applications have recently been developed by linking the techniques developed in both fields. It is, thus, important to show the differences in the methods and to confirm which one is the most suitable technique to be used, based on the needs of the given application. We aim to identify the differences and better understand how those differences may influence outcomes. First, we review general principles and mathematical formulations for motion models in linear and non-linear solutions. Next, we explain the implementation steps of pose estimations, regarding image sequences from a single camera. Third, we point out the practical differences at the experimental level, with the test datasets, and analyze the results. This paper is organized as follows. Mathematical models of the proposed methods in computer vision and photogrammetry are described in
Section 2. Processing techniques to implement pose estimations in both fields, with test datasets, are presented in
Section 3. The comparison results are discussed in
Section 4. The conclusions are presented in
Section 5.
2. General Motion Model
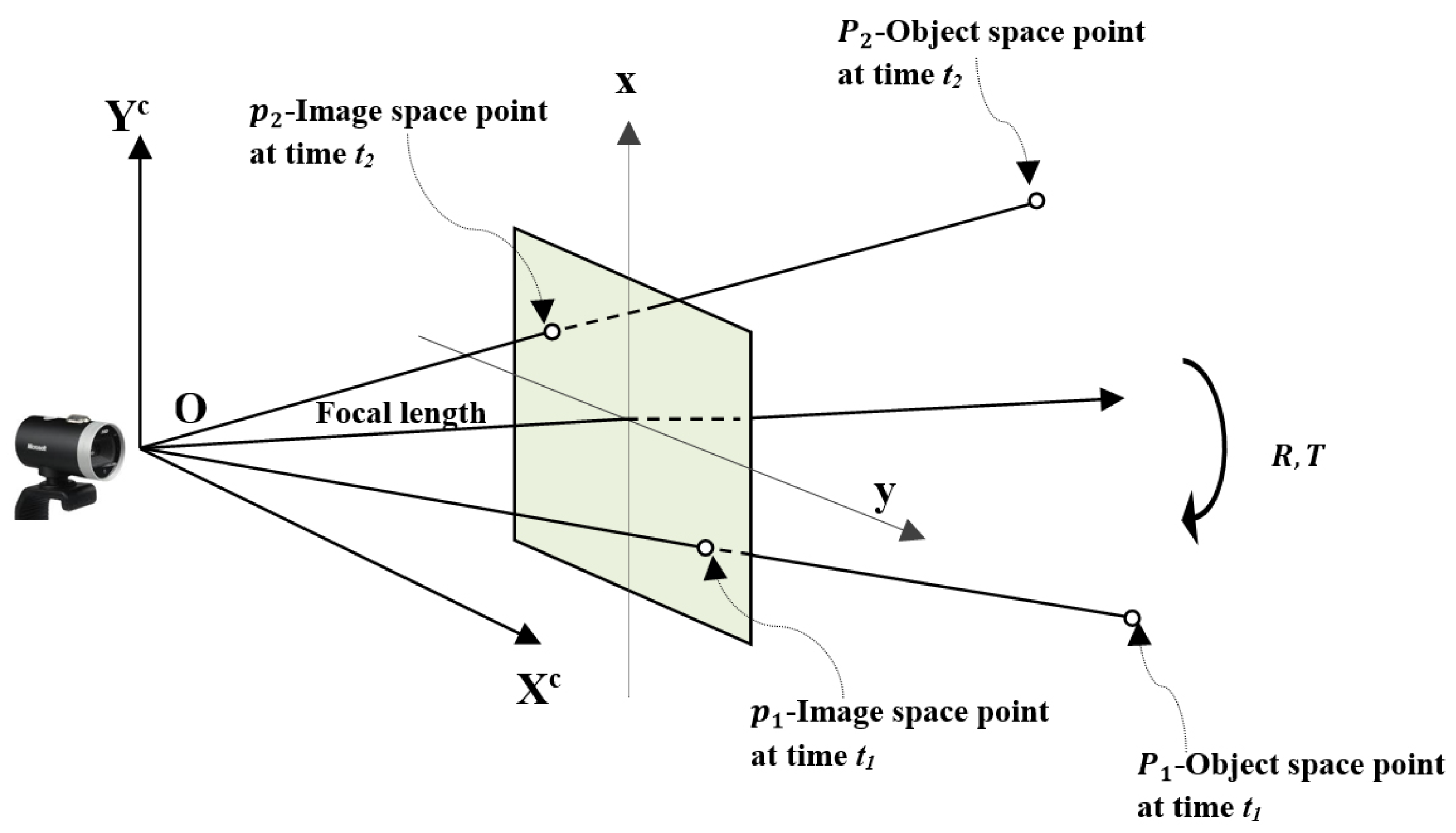
We reviewed the basic geometry of the proposed motion models to determine the relative pose of a moving object in image sequences, once the correspondence points have been established. We assumed that a stationary camera has taken an image sequence of the moving object through its field of view. The camera coordinate system is fixed with its origin, O, at the optical center. The z axis is pointing in the direction of the view, coinciding with the optical axis. The image plane is located at a distance equal to the focal length, which is considered to be unity.
Consider point
on a rigid object at time
moving to point
on a rigid object at time
, with respect to the camera coordinate system (as shown in
Figure 1). Point
is projected at point
on the image plane under perspective projection. Similarly, point
is projected at point
on the image plane. The object-space coordinates of point
are
, and the image-space coordinates are defined as
. The object-space coordinates of point
are
, and the image-space coordinates are defined as
.
To summarize, our problem is as follows:
Given two image views with correspondences , find 3D rotations and 3D translations.
We have that
and
are related by the rotation matrix
R and translational vector
T, due to the rigidity constraint of the object motion:
It is obvious, from the geometry of
Figure 1, that
,
, and
T are coplanar, which can be written in matrix form as
This is called coplanarity, or an epipolar constraint, written in a triple product of vectors.
2.1. Recovering Motion Parameters from an Essential Matrix
We can reformulate Equation (
2) as follows:
where
Equation (
3) is linear and homogeneous in the nine unknowns. Given
N point correspondences, we can write Equation (
3) in the form:
The relative pose between two views can be found from matrix Equation (
3), encoded by a well-known essential matrix. Due to the theorem in [
40],
E has singular value decomposition (SVD), defined as:
where
U,
V, and
are chosen such that
,
, and
. Furthermore, the following formulas give the two distinct solutions for the rotation and translation vectors from, the essential matrix.
One of the four possible solutions corresponds to the true solution for Equation (
6). The correct solution can be chosen by enforcing a constraint called the cheirality test [
41]. The cheirality test basically means that the triangulated scene points should have positive depth, and scene points should be in front of the camera.
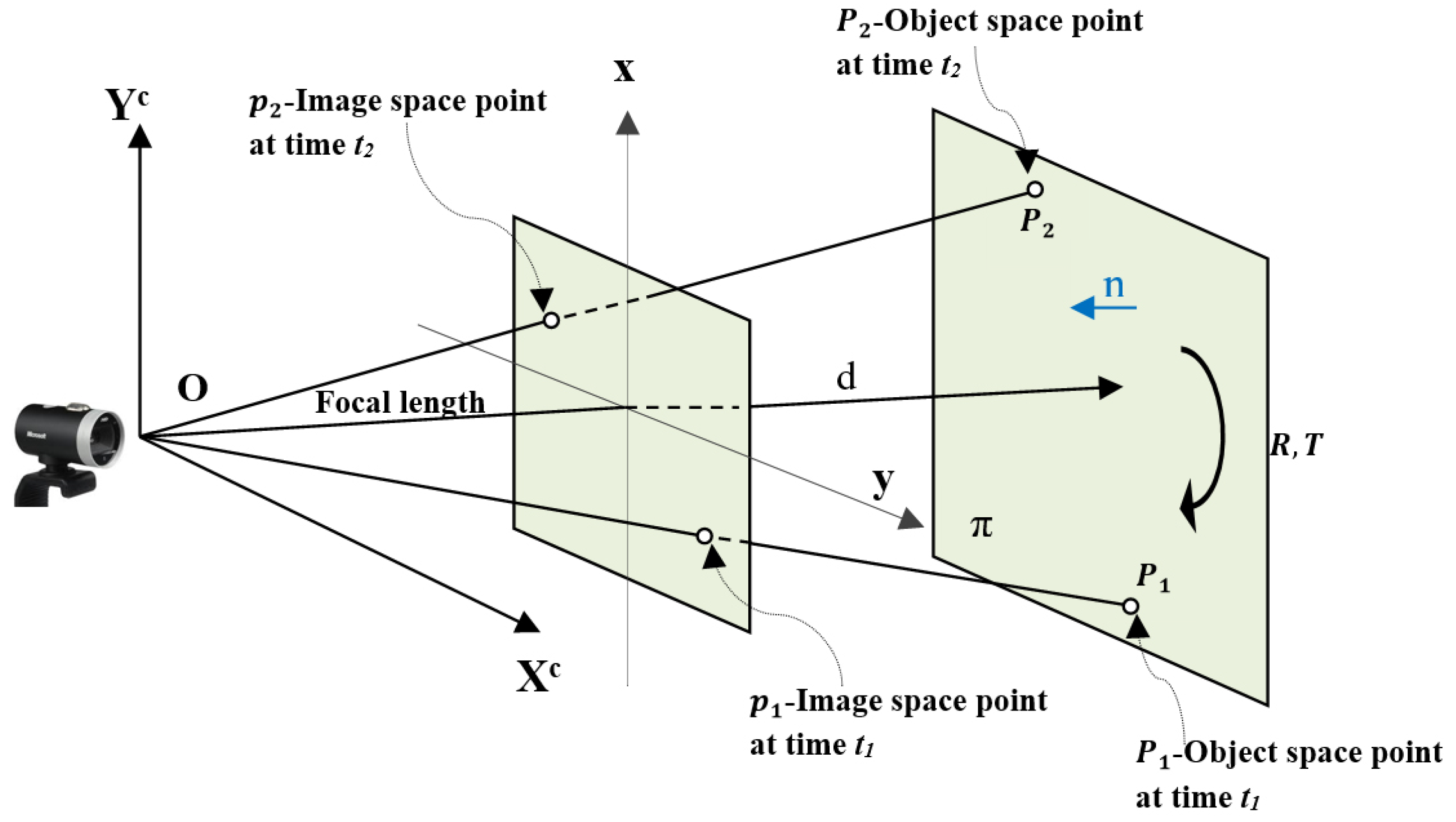
2.2. Recovering Motion Parameters from a Homography Matrix
Consider the points
to be on a 2D plane,
, in 3D space. The plane
has unit normal vector
, and
denotes the distance from plane
to the optical center of the camera. Suppose the optical center of the camera never passes through plane
, as shown in
Figure 2.
Then, we formulate the following equation, normalizing the translational vector
T by the plane depth
d from Equation (
1):
We call the matrix H a planar homography matrix, as it depends on motion parameters
and structure parameters
. We have a homography mapping induced by the plane
, since it denotes a linear transformation from
to
, due to the scale ambiguity in the term
in Equation (
7):
Equation (
8) is linear and homogeneous in the nine unknowns. Given
N point correspondences, we can write Equation (
8) in the form:
After we have recovered the
H matrix, using at least four point correspondences, we can decompose the matrix into its motion and structure parameters by SVD ([
8,
42,
43,
44]):
where
U and
V are orthogonal matrices, and
is a diagonal matrix which contains a singular value for
H. Then, we also obtain four solutions: Two completely different solutions, and their opposites for decomposing the
H matrix. In order to reduce the number of physically possible solutions, we impose a positive depth constraint, having
, as the camera can see only points in front of it.
2.3. Recovering Motion Parameters from Relative Orientation
In photogrammetry, determining the relative position and orientation of the first view of the frame, with respect to the next view of the frame in a sequence, is well-known as a relative orientation process. In general, the geometric relationship between a ground point
P and its corresponding image points,
and
, at two time instants, is formulated by the coplanarity constraint from Equation (
2). As shown in Equation (
2), the essential matrix determined in computer vision is mathematically identical to a coplanarity condition equation in photogrammetry, which has been well-confirmed [
19,
37].
By equivalently reformulating the non-linear equations of the coplanarity condition in [
17] into Equation (
2), we have the following:
where
Then, the triple-scalar product of the three vectors is as follows:
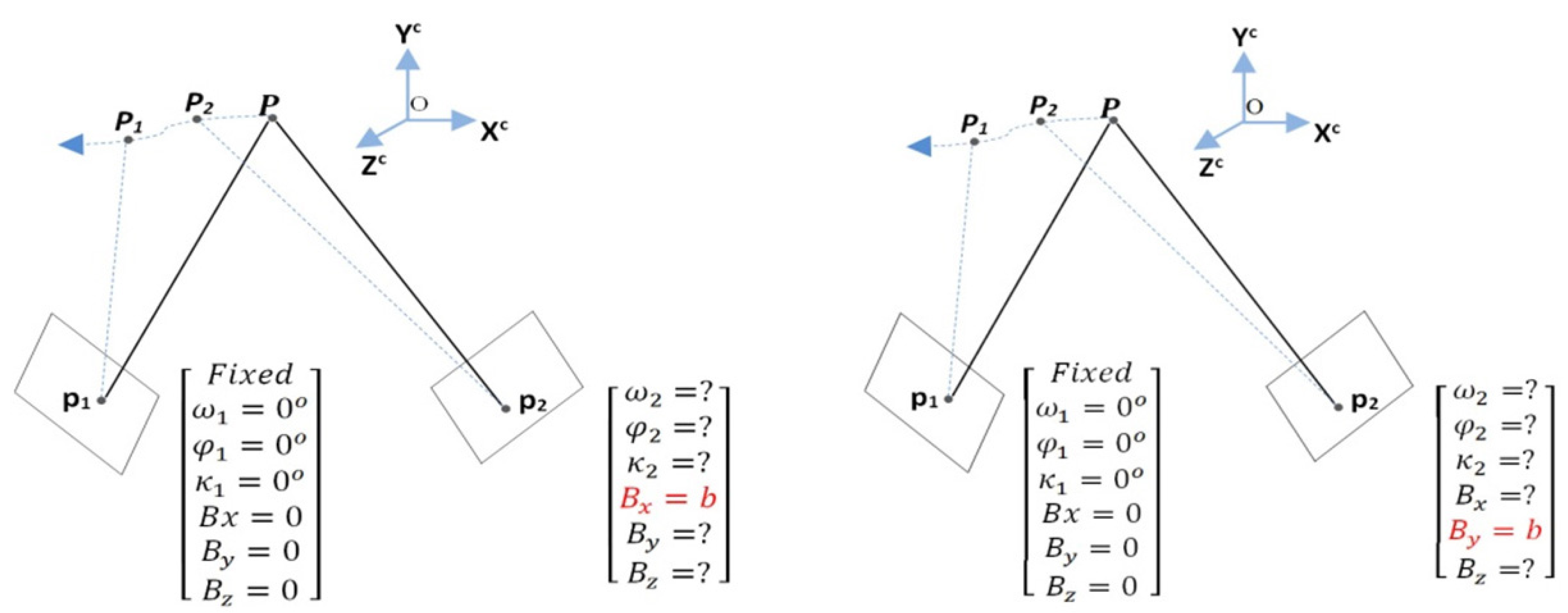
From this non-linear equation, the unknowns can be obtained by Taylor’s linearization in a least-squares solution. The three parameters of the rotation matrix
R, and two components of the base vector, are estimated. In
Figure 3,
,
, and
are rotations about the
x,
y, and
z axes, respectively; and
,
, and
are translations about the
x,
y, and
z axes, respectively. The iterative method for solving a non-linear equation requires an initial estimate for each unknown parameter for convergence to the correct answer. We set the position and orientation angles of the first-view by making all six variables equal to zero (
), because we considered no movement of the object in the first-view. The second-view orientation is set as
, by assuming a constant fixed value for
or
based on simple parallax differences between the two views, as is illustrated in
Figure 3.
2.4. Recovering Motion Parameters from Homography-Based Relative Orientation
By reformulating matrix Equation (
8), we can obtain the motion and structure parameters from the following non-linear equation, as mapping from the first to the next image is given by homography:
The seven unknown parameters of this equation can be described as five parameters (
,
,
,
or
, and
) for the relative orientation, and two parameters
for the plane normal in object-space. Similarly, this equation can be solved by Taylor’s linearization in a least-squares solution, with an a priori fixed value for
or
, as illustrated in
Figure 3. We set the initial value for the variable
as 1.
2.5. Summary of Approaches
We have reviewed estimations for determining the motion of a rigid body from 2D to 2D point correspondences. If the rank of
in Equation (
4) is 8,
E can be determined uniquely, within a scale factor, and with an eight point correspondence. Once
E is determined,
R and
T can be determined uniquely. If the rank of
is less than 8, then either we have a pure rotation case or the surface assumption of eight points is violated. However, the surface assumption (position) of the given eight points is very important. It can be easily shown that, if these points form a degenerate configuration, the estimation will fail [
44]. This approach is sensitive to noise. Pure rotation of the object in the images generates numerical ill-conditioning, so enough translation in the motion of the object is needed in the images for the estimation (given in
Section 2.1) to operate correctly. With a four point correspondence, the rank of
in Equation (
9) is 8 when the 3D points lie on a plane [
45]. In this case, a pure rotation can be handled by the planar approach. Then, we have a unique solution for
H, within a scale factor. Once
H is determined,
R and
T can be determined uniquely. If the rank of
is more than 8, it is considered that the 3D points do not lie on a plane. As both
E and
H give four possible solutions to (
), the depths of the 3D points being observed by the camera are all positive. Therefore, one of the four solutions will be chosen, based on the positive depth constraint. To find a least-squares solution of the non-linear equations in (12) and (13), using the iterative method is not computationally expensive; however, we need a good initial value for its convergence to the correct solution. We set the initial values for
or
differently, depending on the experimental settings. However, we expect that the solution for non-linear approaches is generally unique with six or more point correspondences for the five motion parameters.
4. Performance of 3D Motion Estimation
4.1. Performance Analysis for Estimations with a Real Dataset
After estimating the motion parameters, we analyzed the accuracy of the proposed four estimations in
Section 2. We renamed the estimation methods to simplify the notation in the experimental results. Decomposition of the essential matrix is notated as (CV_E). Decomposition of the homography matrix is notated as (CV_H). Relative orientation is notated as (PM_RO). Homography-based relative orientation is notated as (PM_H).
First, we estimated the motion parameters for the real dataset in two different cases. We checked the accuracy of the estimated rotation parameters by comparing them with true (known) rotation parameters. For a true reference value, we manually measured the corresponding points between the template and the next consecutive frames of the object. Using the measured corresponding points, the precise 3D motion was estimated for each frame. In the first case, the object in the image sequences was rotated along only one of the x, y, or z axes separately, and translated along one of the axes. In the second case, we estimated the motion parameters of an object from image sequences rotated by a combination of rotations around the x, y, and z axes, and translated along an x, y, or z axis differently. For example, the object was rotated around the y axis by , and simultaneously rotated around the z axis by up to .
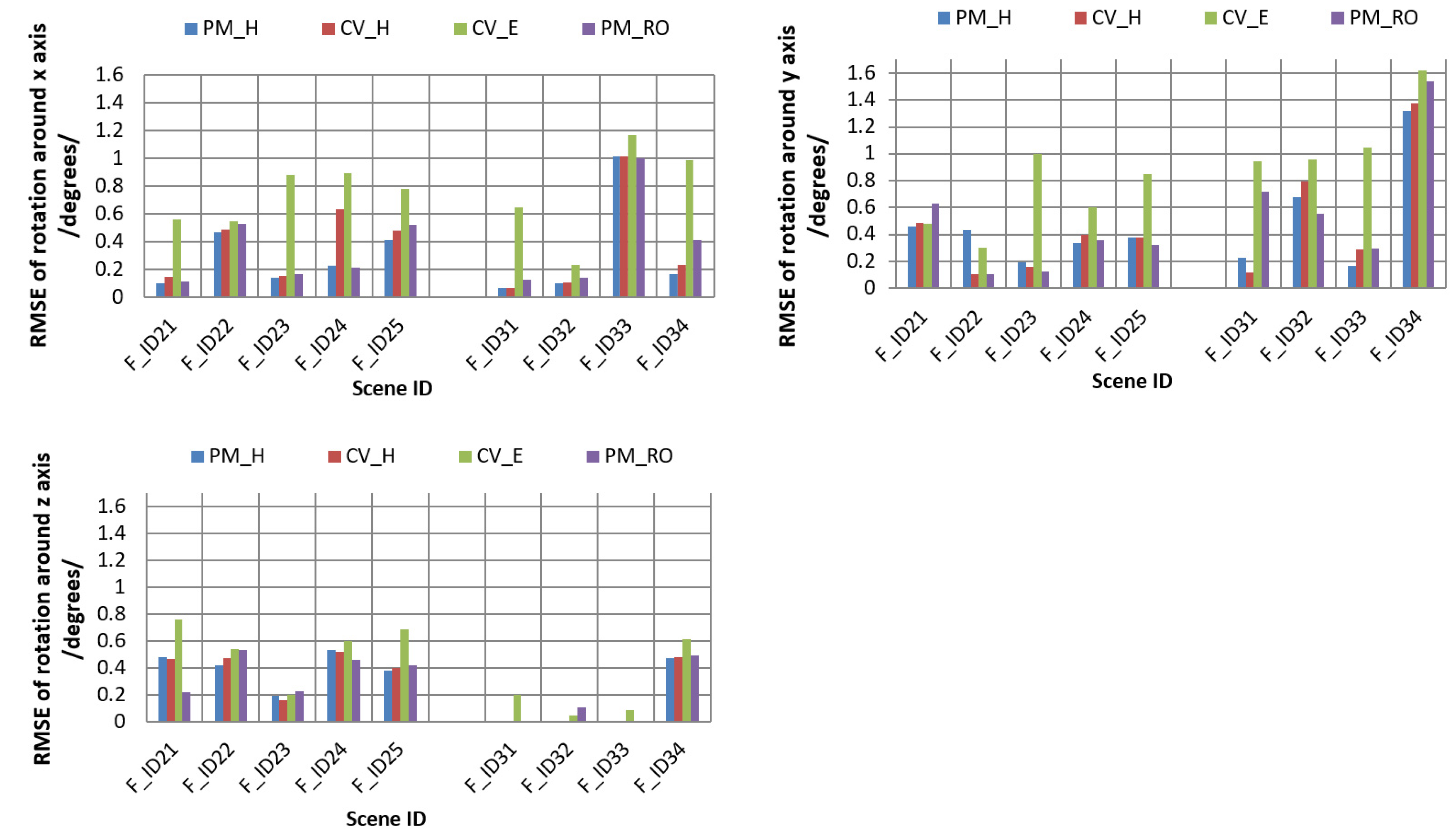
For both cases, we analyzed the mean, maximum (Max), and minimum (Min) errors for the four estimations, as summarized in
Table 2. We also checked the accuracy of the estimated rotation parameters around each of the three axes by comparing them with true (known) rotation parameters and analyzing the root mean square error (RMSE). The RMSEs for rotation around the
x,
y, and
z axes are shown in
Table 3,
Table 4 and
Table 5, respectively; which are summarized for each dataset used in the experiments. A graphical representation of the comparisons is shown in
Figure 5.
As we can see, from
Table 2,
Table 3,
Table 4 and
Table 5, the RMSEs were small, and the rotation results were accurate for each of the four approaches in both of the test cases. In particular, the homography-based methods PM_H and CV_H produced more accurate results for image sequences of the moving planar object, since the planar pattern is dominant in the test datasets F_ID31 to F_ID34. On the other hand, PM_H and CV_H produced more negligible and comparable errors, among the four methods with noisy correspondences for the datasets of both 3D and planar objects. Among them, the motion parameters from PM_H estimations are especially accurate. We observe that the estimation errors for the motion parameters slightly increased in the dataset for cases F_ID33 in
Table 3 and F_ID34 in
Table 4, due to noisy feature correspondences. For these datasets, the object was translated close to the camera along the z axis and was rotated around the x or y axis to a large degree. Object rotation around the x or y axis at large degrees creates the side-effect of scaling. In this case, matched feature correspondences are noisy and unstable in their matched positions. Generally, we can see that the CV_E estimation method was sensitive to noisy measurements in feature correspondences, as is seen in most of the results in
Table 2,
Table 3,
Table 4 and
Table 5. Another interesting result is that the motion parameters estimated by PM_RO were the most accurate, compared to the other three approaches for the 3D object datasets F_ID21 to F_ID25.
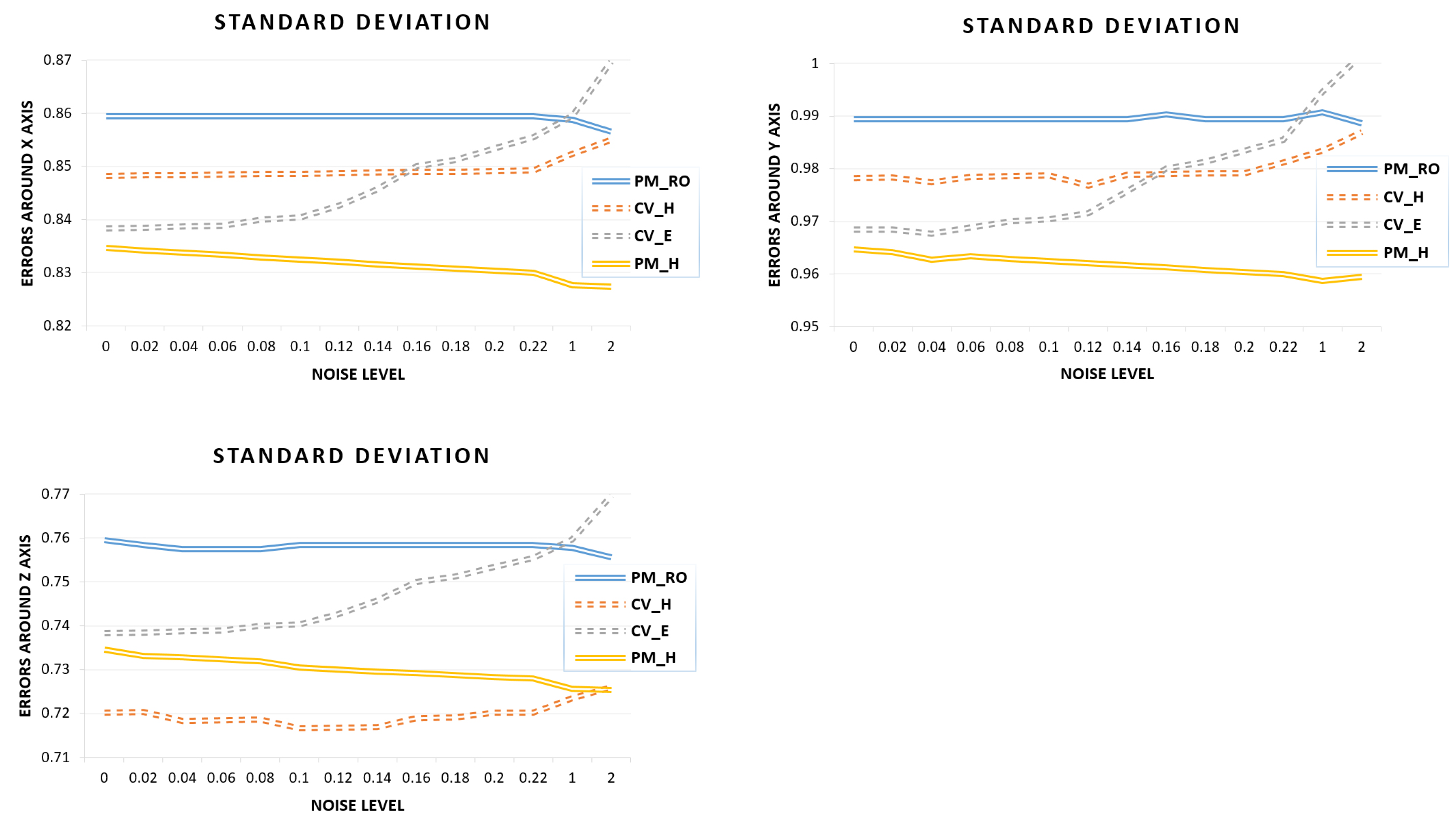
Stability Analysis for Estimations with Varying Noises
This experiment examines the stability of the all estimations with the real dataset. We chose
random point correspondences as noise, nearing each of the six numbers:
,
, and computed the rotations around the
x,
y, and
z axes. The experimental results, as illustrated in
Figure 6, give the standard deviation of the rotation errors around the
x,
y, and
z axes. From
Figure 6, we observe that the non-linear approaches (PM_H and PM_RO) were more stable with increasing noises, as compared to the linear approaches (CV_H and CV_E). We see that the linear approaches were critical and showed accuracy degradation with increasing noise. The experimental results strongly support the fact that the linear approaches are very sensitive to noise. The computation of CV_E became unstable when reaching the middle of the noise level range. We also observed that the errors from the computation of CV_H were stable at the low noise levels but, as the noise level increased, the stability decreased.
4.2. Performance Analysis for Estimations with a Simulated Dataset
We checked the accuracy of the estimated motion parameters for simulated datasets in two different test cases. We checked the accuracy of the estimated rotation parameters by comparing them with true (known) rotation parameters. For a true reference value, we created synthetic corresponding points between the template and the next consecutive frames of the 3D object. Using the created corresponding points, a precise 3D motion was estimated for each frame. In the first case, the 3D object in the simulated sequences was rotated along one of the x, y, or z axes separately, and translated along an x, y, or z axis. In the second case, the 3D object was rotated by a combination of rotation degrees around the x, y, and z axes, and translated by 15 units along one of the x, y, or z axes.
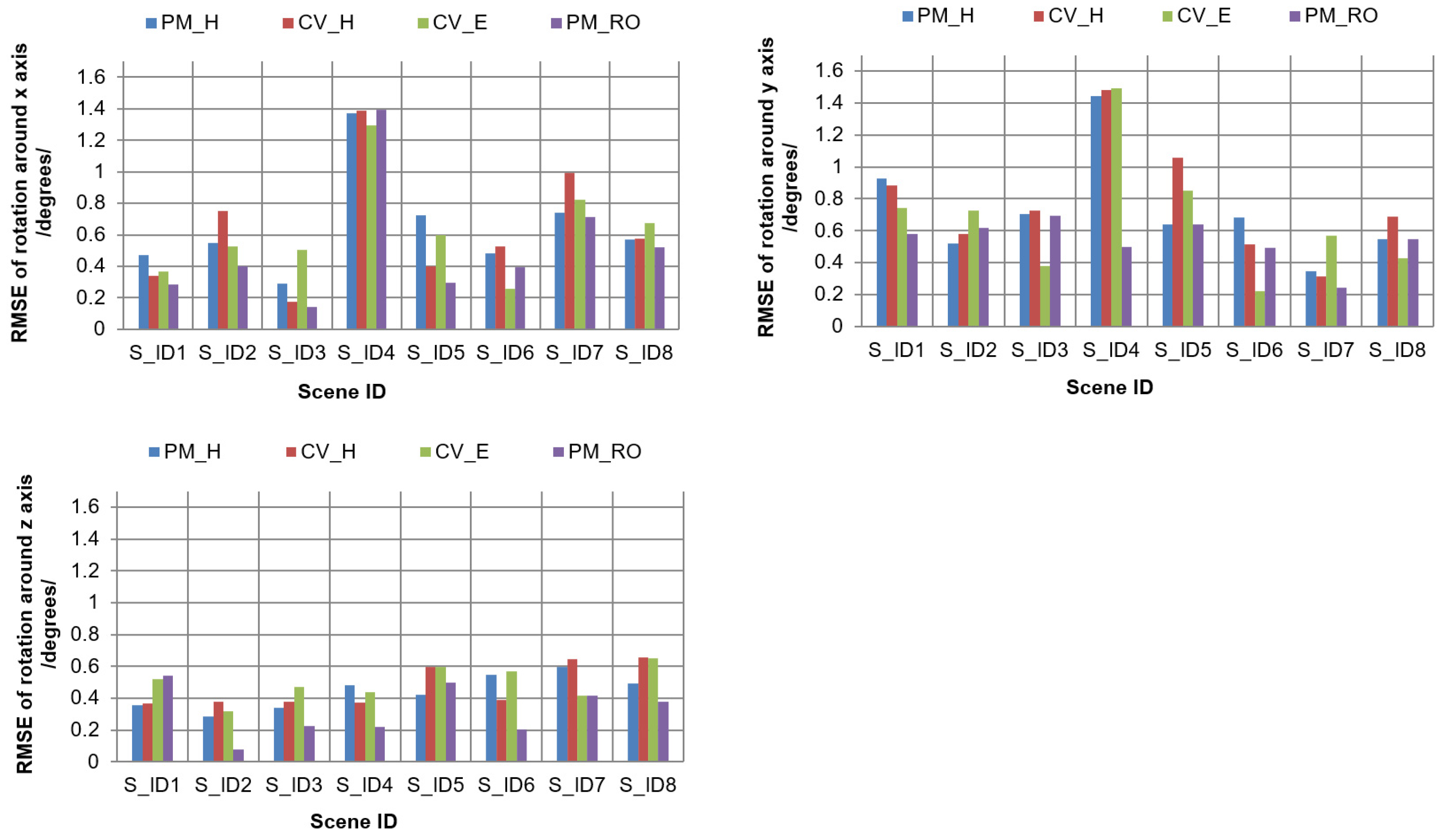
For both cases, we checked the accuracy of the estimated rotation parameters through motion estimations. To check the performance of the four estimations, we compared the estimated rotation parameters with the known rotation parameters. We analyzed the mean, Max, and Min errors in the results of the estimations and summarize them in
Table 6. We also computed the RMSEs of the estimated rotation results by comparing them against the true rotation parameters for each of the four estimations. The dataset summaries of RMSEs for rotations around the
x,
y, and
z axes are given in
Table 7,
Table 8 and
Table 9, respectively. A graphical representation of the comparisons is shown in
Figure 7.
As we see in
Table 6,
Table 7,
Table 8 and
Table 9, the four estimations in photogrammetry and computer vision produced small errors in both test cases of the simulated datasets. The success rates of the estimations stayed within the range for large motions in the moving 3D object; this means that large perspective changes did not affect estimation accuracy. Moreover, this implies that all four estimations worked successfully when favorable corresponding points were provided. Specifically, the motion parameters obtained by PM_RO were the most accurate, compared to the other three approaches. It is confirmed, again, that PM_RO outperformed the other three approaches for datasets of 3D objects.
Generally, relative orientation-based approaches are formulated in non-linear problems, requiring an initial guess for each unknown parameter; however, these approaches are more robust to unique solutions for motion parameters with noisy point correspondences. Moreover, these approaches do not require additional computation to choose a correct solution for the motion parameters and estimate the rotation and translation parameters directly, compared with the linear approaches. Combining the two cases of test datasets, we observed that the PM_H approach produced more accurate results for planar objects in real-image sequences, and the PM_RO approach produced more accurate results for 3D objects in real and simulated sequences. On the other hand, the results with a real dataset are very interesting. Regardless of linear or non-linear approaches, homography-based methods outperformed other (essential matrix or relative orientation-based) methods under noisy situations. In particular, we observed that the homography-based non-linear approach worked better than the relative orientation-based non-linear approach. In other words, the homography-based non-linear approach supports the motivation for linking the techniques developed in photogrammetry and computer vision.
4.3. Qualification of Fast Processing
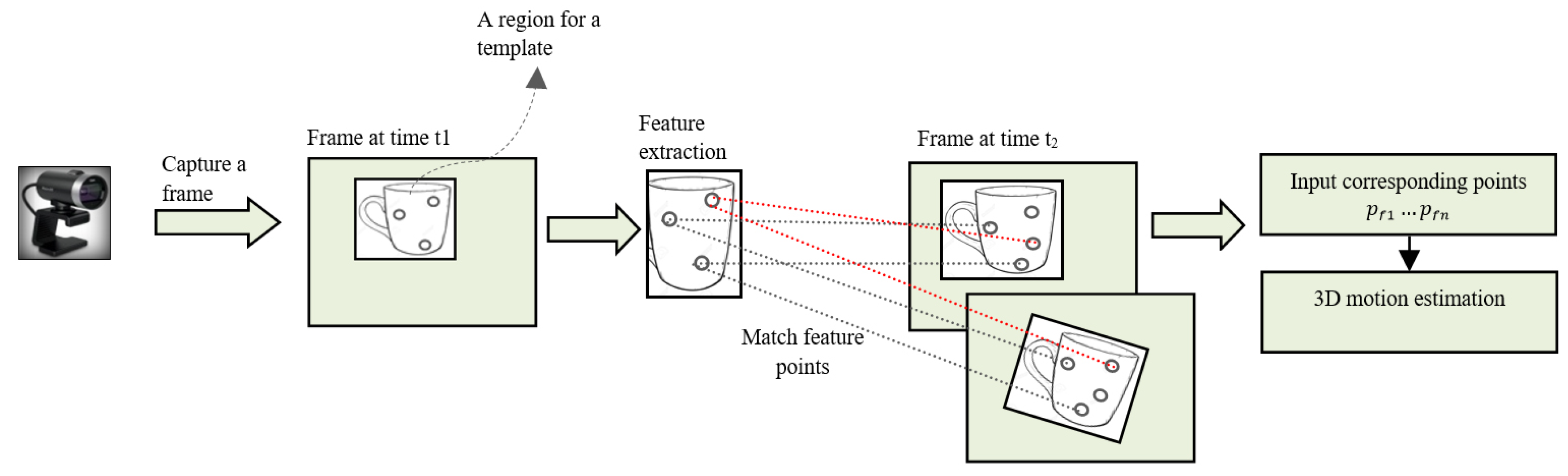
Once we define the template region in the initial frame, real-time processing is started with all computational steps. We extracted feature points by CPU-based or GPU-based parallel processing with a GeForce GTX 550 Ti graphics card.
To assess real-time performance, we measured the processing time for SIFT feature extraction with different numbers of extracted feature points. The speed of feature extraction was almost independent of the number of feature points, due to parallel processing. The processing time in SIFT feature extraction speeds up with a large number of feature points, by 0.2 s. Moreover, processing time can speed up with more powerful CPUs and graphics cards.
We also measured the processing time of four motion estimations, by including RANSAC-based elimination of outliers for different numbers of correspondences. For this, the comparison results are summarized in
Table 10.
As we can see in
Table 10, the processing times of all four methods were very fast with large numbers of feature correspondences. Generally, the processing speed of the PM_H estimation method is slower than the other three methods, due to its non-linear estimation. The processing speeds of the PM_RO and CV_H functions are the fastest. The total processing time could be defined as the sum of processing times for feature extraction and estimation of motion parameters.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}








