Global-and-Local Context Network for Semantic Segmentation of Street View Images




Abstract
:
1. Introduction
2. Related Work
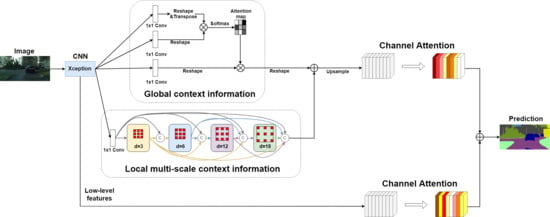
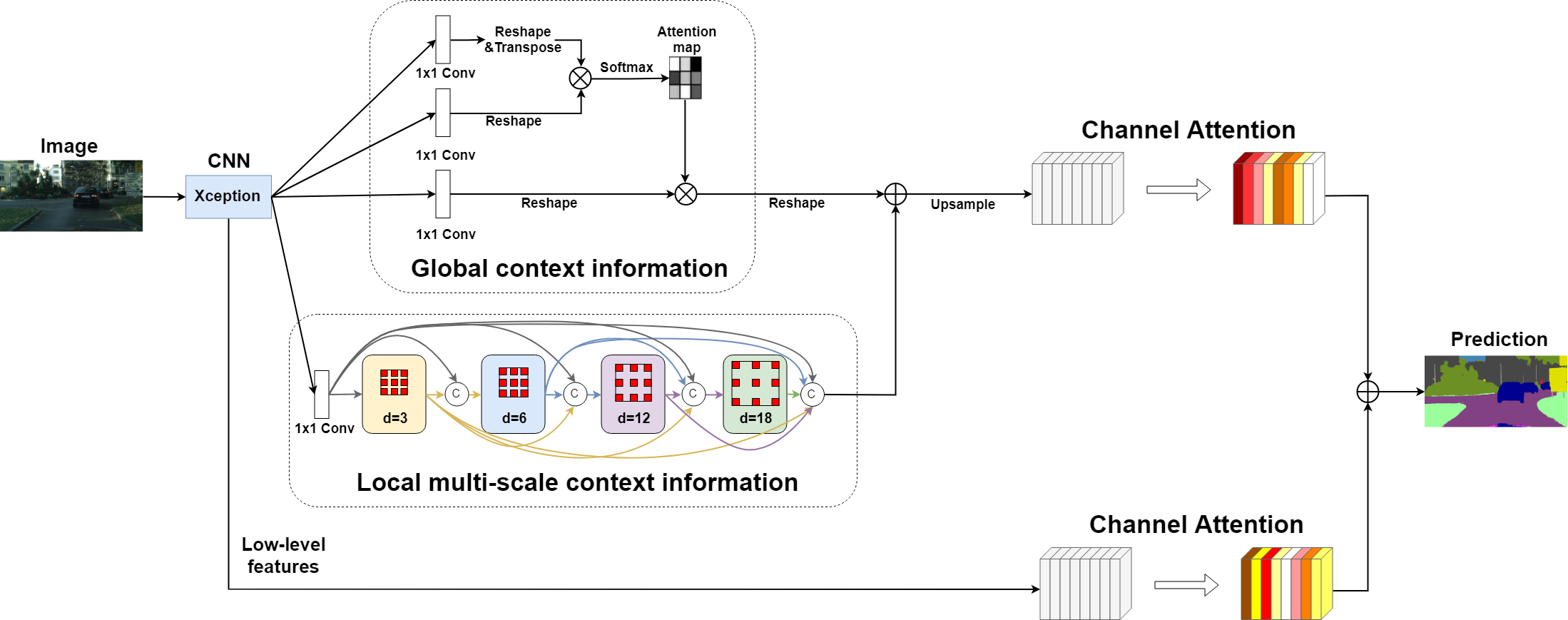
3. Method
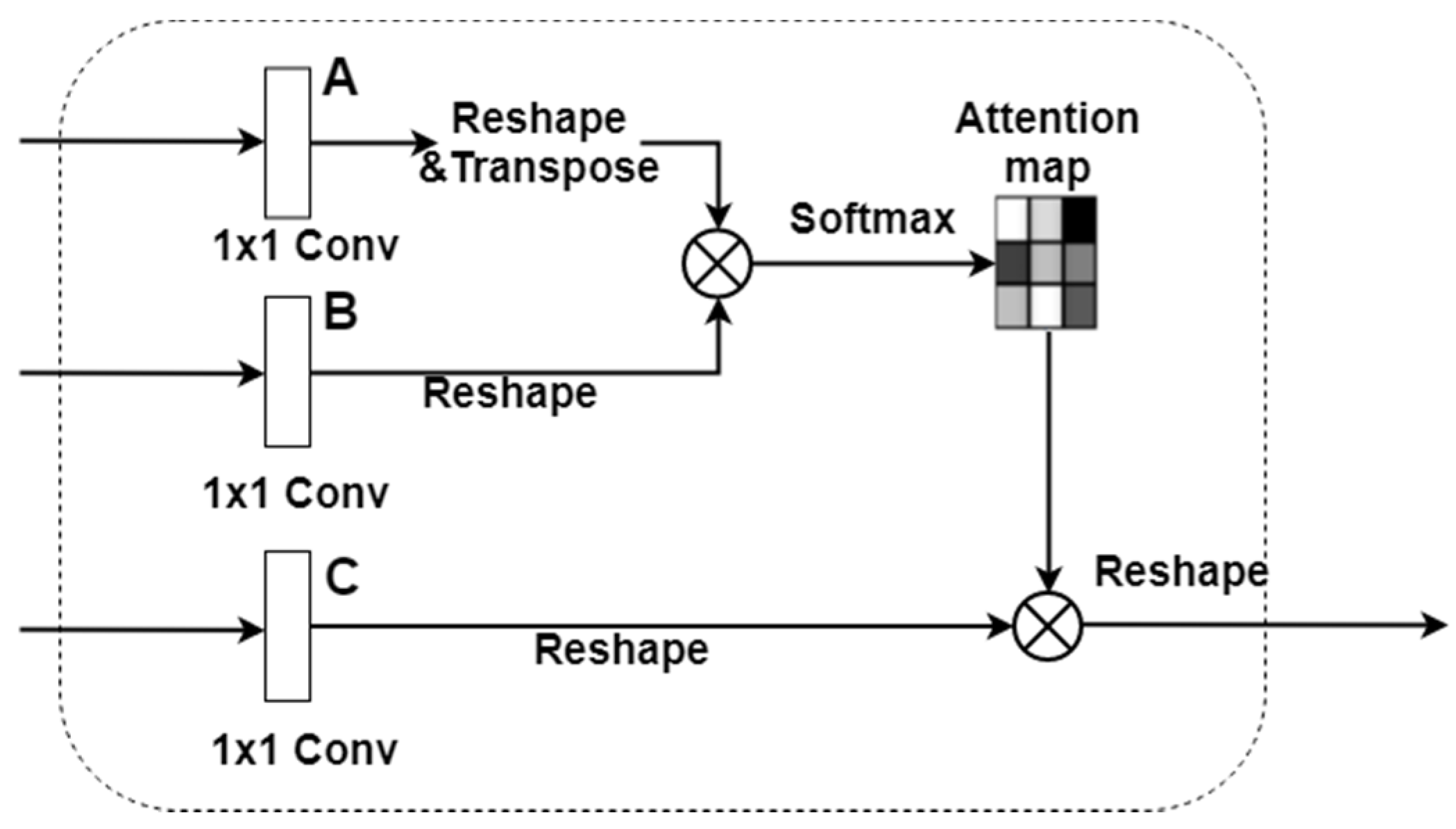
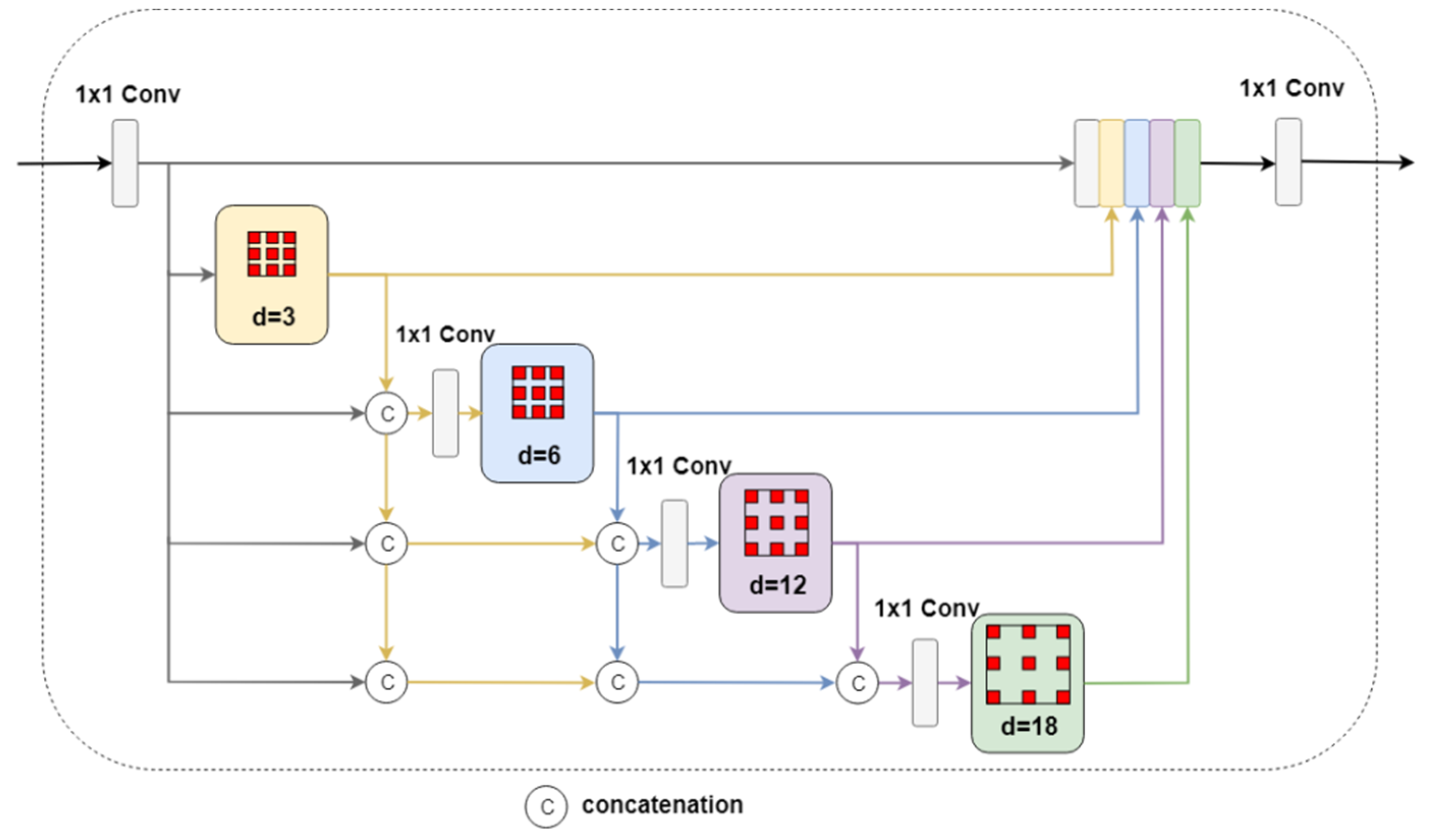
3.1. Global Module
3.2. Local Module
3.3. Channel Attention Module
4. Experiments
4.1. Implementation Details
4.2. Ablation Study
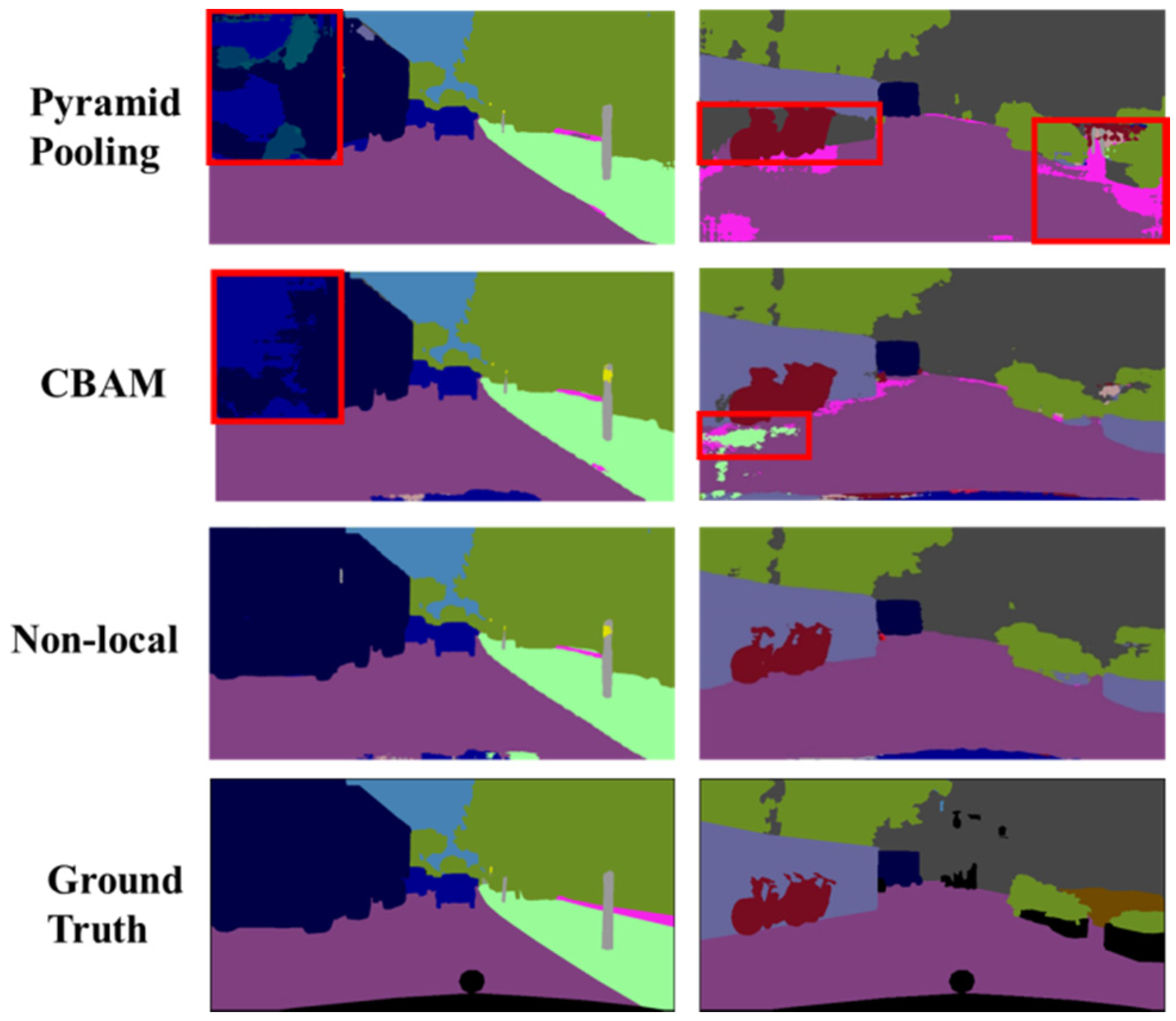
4.2.1. Effect of Global Context Information
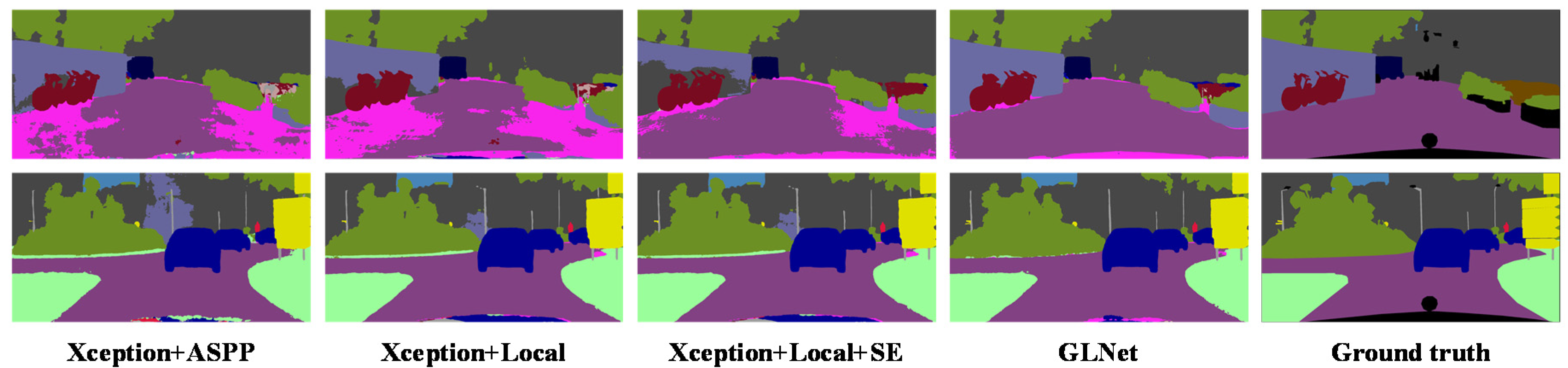
4.2.2. GLNet Modules
4.2.3. Global Module
4.2.4. Fusion vs. Concatenation
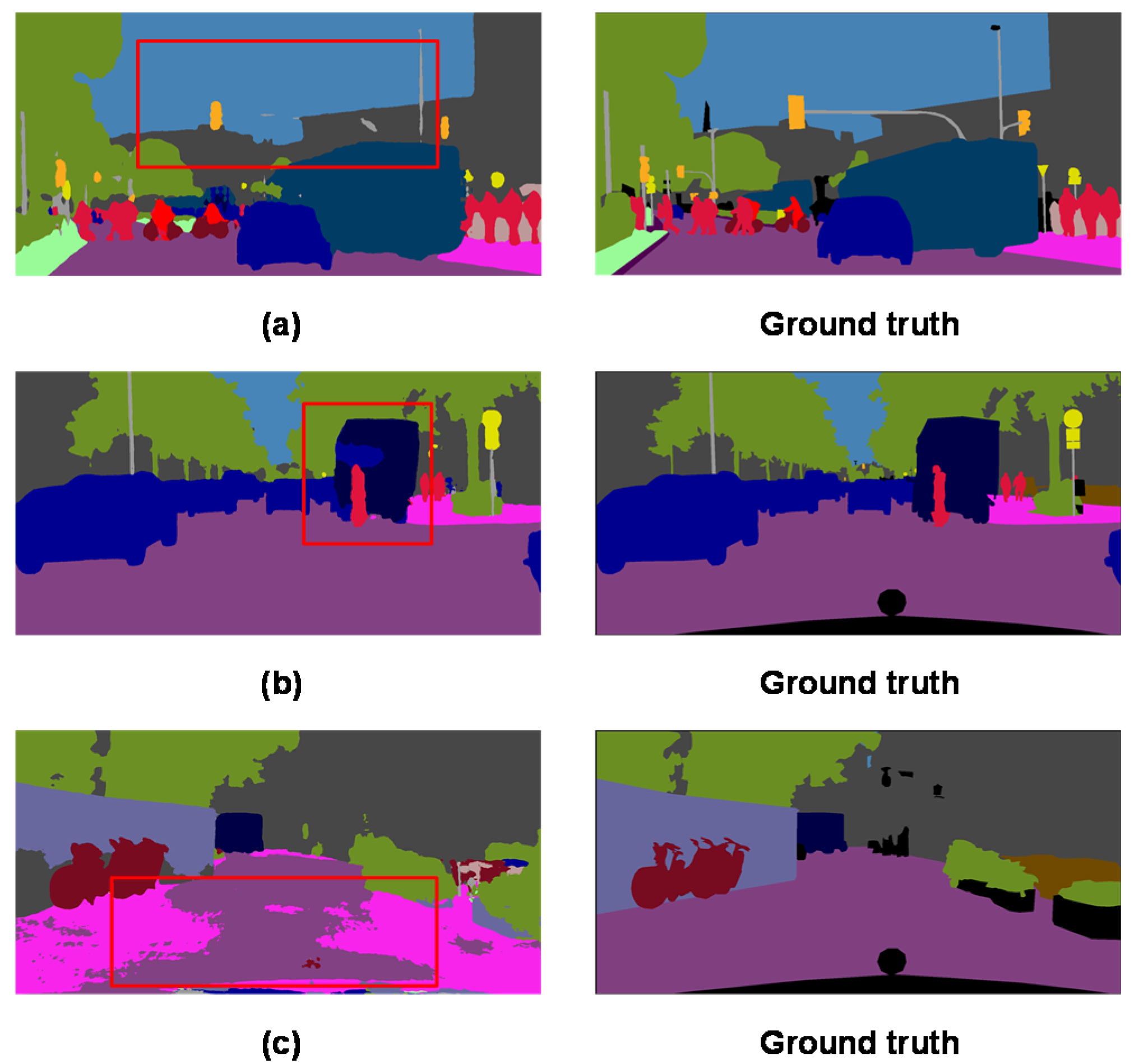
4.3. Performance Comparison
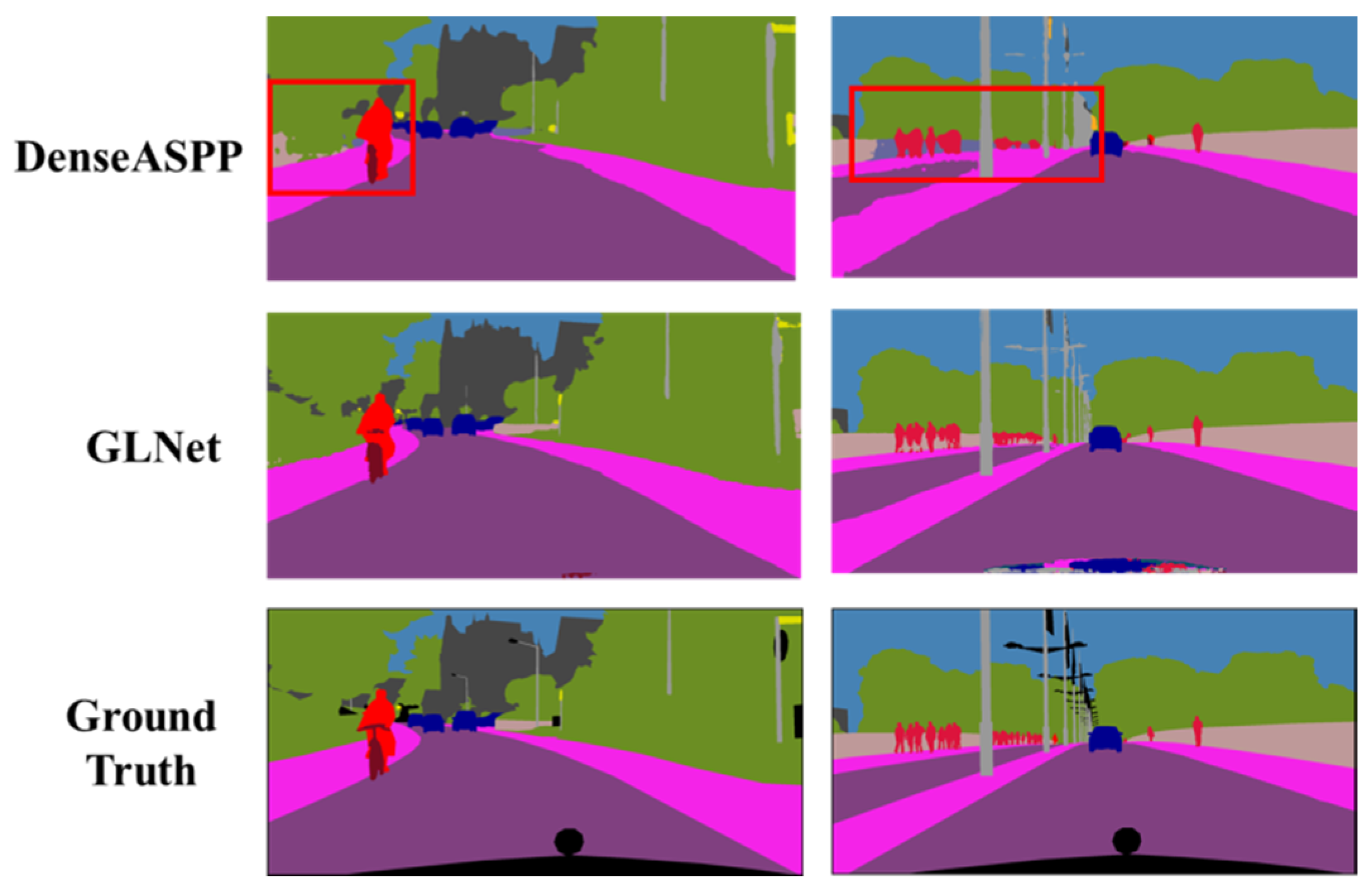
4.3.1. Performance on Cityscapes Dataset
4.3.2. Network Size and Inference Speed
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Sharma, S.; Ball, J.; Tang, B.; Carruth, D.; Doude, M.; Islam, M.A. Semantic Segmentation with Transfer Learning for Off-Road Autonomous Driving. Sensors 2019, 19, 2577. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sáez, Á.; Bergasa, L.M.; López-Guillén, E.; Romera, E.; Tradacete, M.; Gómez-Huélamo, C.; Del Egido, J. Real-Time Semantic Segmentation for Fisheye Urban Driving Images Based on ERFNet †. Sensors 2019, 19, 503. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Noh, H.; Hong, S.; Han, B. Learning deconvolution network for semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015; pp. 1520–1528. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic image segmentation with deep convolutional nets and fully connected crfs. arXiv 2014, arXiv:1412.7062. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Yu, F.; Koltun, V. Multi-scale context aggregation by dilated convolutions. arXiv 2015, arXiv:1511.07122. [Google Scholar]
- Chen, L.-C.; Yang, Y.; Wang, J.; Xu, W.; Yuille, A.L. Attention to scale: Scale-aware semantic image segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 3640–3649. [Google Scholar]
- Eigen, D.; Fergus, R. Predicting depth, surface normals and semantic labels with a common multi-scale convolutional architecture. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015; pp. 2650–2658. [Google Scholar]
- Zhao, H.; Qi, X.; Shen, X.; Shi, J.; Jia, J. ICNeT for real-time semantic segmentation on high-resolution images. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 405–420. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.0558. [Google Scholar]
- Yang, M.; Yu, K.; Zhang, C.; Li, Z.; Yang, K. DenseASPP for semantic segmentation in street scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3684–3692. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–8 December 2012; pp. 1097–1105. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7794–7803. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-assisted Intervention (MICCAI), Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Zhou, Q.; Yang, W.; Gao, G.; Ou, W.; Lu, H.; Chen, J.; Latecki, L. Multi-scale deep context convolutional neural networks for semantic segmentation. World Wide Web 2019, 22, 555–570. [Google Scholar] [CrossRef]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 3146–3154. [Google Scholar]
- Zhang, H.; Zhang, H.; Wang, C.; Xie, J. Co-occurrent features in semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 548–557. [Google Scholar]
- Yuan, Y.; Wang, J. OCNet: Object context network for scene parsing. arXiv 2018, arXiv:1809.00916. [Google Scholar]
- Hu, X.; Yang, K.; Fei, L.; Wang, K. ACNET: Attention based network to exploit complementary features for rgbd semantic segmentation. In Proceedings of the IEEE Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 1440–1444. [Google Scholar]
- Yang, K.; Wang, K.; Bergasa, L.M.; Romera, E.; Hu, W.; Sun, D.; Sun, J.; Cheng, R.; Chen, T.; López, E. Unifying terrain awareness for the visually impaired through real-time semantic segmentation. Sensors 2018, 18, 1506. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Zhang, H.; Dana, K.; Shi, J.; Zhang, Z.; Wang, X.; Tyagi, A.; Agrawal, A. Context encoding for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7151–7160. [Google Scholar]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 3213–3223. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Lin, G.; Milan, A.; Shen, C.; Reid, I. Refinenet: Multi-path refinement networks for high-resolution semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1925–1934. [Google Scholar]
- Wang, P.; Chen, P.; Yuan, Y.; Liu, D.; Huang, Z.; Hou, X.; Cottrell, G. Understanding convolution for semantic segmentation. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Lake Tahoe, NV, USA, 12–15 March 2018; pp. 1451–1460. [Google Scholar]
- Wu, Z.; Shen, C.; Van Den Hengel, A. Wider or deeper: Revisiting the resnet model for visual recognition. Pattern Recog. 2019, 90, 119–133. [Google Scholar] [CrossRef] [Green Version]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| BaseNet | ASPP | Local | Global | SE | Mean IoU% |
|---|---|---|---|---|---|
| Xception-65 | ✓ | 77.1% | |||
| Xception-65 | ✓ | 77.6% | |||
| Xception-65 | ✓ | ✓ | 78.4% | ||
| Xception-65 | ✓ | ✓ | ✓ | 80.1% |
| BaseNet | Non-Local | CBAM | Pyramid Pooling | Mean IoU% |
|---|---|---|---|---|
| Xception-65 | ✓ | 70.3% | ||
| Xception-65 | ✓ | 78.9% | ||
| Xception-65 | ✓ | 80.1% |
| BaseNet | Concatenation | Fusion | Mean IoU% |
|---|---|---|---|
| Xception-65 | ✓ | 79.9% | |
| Xception-65 | ✓ | 80.1% |
| Method | Mean IoU | Road | Sidewalk | Building | Wall | Fence | Pole | Traffic light | Traffic sign | Vegetation | Terrain | Sky | Person | Rider | Car | Truck | Bus | Train | Motorcycle | Bicycle |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| FCN-8s [3] | 65.3 | 97.4 | 78.4 | 89.2 | 34.9 | 44.2 | 47.4 | 60.1 | 65.0 | 91.4 | 69.3 | 93.7 | 77.1 | 51.4 | 92.6 | 35.3 | 48.6 | 46.5 | 51.6 | 66.8 |
| DeepLab-v2 [6] | 70.4 | 97.9 | 81.3 | 90.3 | 48.8 | 47.4 | 49.6 | 57.9 | 67.3 | 91.9 | 69.4 | 94.2 | 79.8 | 59.8 | 93.7 | 56.5 | 67.5 | 57.5 | 57.7 | 68.8 |
| RefineNet [32] | 73.6 | 98.2 | 83.3 | 91.3 | 47.8 | 50.4 | 56.1 | 66.9 | 71.3 | 92.3 | 70.3 | 94.8 | 80.9 | 63.3 | 94.5 | 64.6 | 76.1 | 64.3 | 62.2 | 70 |
| DUC [33] | 77.6 | 98.5 | 85.5 | 92.8 | 58.6 | 55.5 | 65 | 73.5 | 77.9 | 93.3 | 72 | 95.2 | 84.8 | 68.5 | 95.4 | 70.9 | 78.8 | 68.7 | 65.9 | 73.8 |
| ResNet-38 [34] | 78.4 | 98.5 | 85.7 | 93.1 | 55.5 | 59.1 | 67.1 | 74.8 | 78.7 | 93.7 | 72.6 | 95.5 | 86.6 | 69.2 | 95.7 | 64.5 | 78.8 | 74.1 | 69 | 76.7 |
| PSPNet [18] | 78.4 | 98.6 | 86.2 | 92.9 | 50.8 | 58.8 | 64.0 | 75.6 | 79.0 | 93.4 | 72.3 | 95.4 | 86.5 | 71.3 | 95.9 | 68.2 | 79.5 | 73.8 | 69.5 | 77.2 |
| DenseASPP [12] | 80.6 | 98.7 | 87.1 | 93.4 | 60.7 | 62.7 | 65.6 | 74.6 | 78.5 | 93.6 | 72.5 | 95.4 | 86.2 | 71.9 | 96.0 | 78.0 | 90.3 | 80.7 | 69.7 | 76.8 |
| GLNet | 80.8 | 98.7 | 86.7 | 93.4 | 56.9 | 60.5 | 68.3 | 75.5 | 79.8 | 93.7 | 72.6 | 95.9 | 87.0 | 71.6 | 96.0 | 73.5 | 90.5 | 85.7 | 71.1 | 77.3 |
| Method | Mean IoU | Road | Sidewalk | Building | Wall | Fence | Pole | Traffic light | Traffic sign | Vegetation | Terrain | Sky | Person | Rider | Car | Truck | Bus | Train | Motorcycle | Bicycle |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| FCN-8s [3] | 57.3 | 93.5 | 75.7 | 87.2 | 33.7 | 41.7 | 36.4 | 40.5 | 57.1 | 89.0 | 52.7 | 91.8 | 64.3 | 29.9 | 89.2 | 34.2 | 56.4 | 34.0 | 19.7 | 62.2 |
| ICNet [10] | 67.2 | 97.3 | 79.3 | 89.5 | 49.1 | 52.3 | 46.3 | 48.2 | 61.0 | 90.3 | 58.4 | 93.5 | 69.9 | 43.5 | 91.3 | 64.3 | 75.3 | 58.6 | 43.7 | 65.2 |
| DeepLab-v2 [6] | 69.0 | 96.7 | 76.7 | 89.4 | 46.2 | 49.3 | 43.6 | 55.0 | 64.8 | 89.5 | 56.0 | 91.6 | 73.3 | 53.2 | 90.8 | 62.3 | 79.6 | 65.8 | 58.0 | 70.2 |
| PSPNet [18] | 76.5 | 98.0 | 84.4 | 91.7 | 57.8 | 62.0 | 54.6 | 67.4 | 75.2 | 91.4 | 63.2 | 93.4 | 79.1 | 60.6 | 94.4 | 77.2 | 84.6 | 79.4 | 63.3 | 75.1 |
| DeepLab-v3+ [19] | 77.1 | 98.2 | 85.1 | 92.6 | 56.4 | 61.9 | 65.5 | 68.6 | 78.8 | 92.5 | 61.9 | 95.1 | 81.8 | 61.9 | 94.9 | 72.6 | 84.6 | 71.3 | 64.0 | 77.1 |
| DenseASPP [12] | 79.5 | 98.6 | 87.0 | 93.2 | 59.9 | 63.3 | 64.2 | 71.4 | 80.4 | 93.1 | 64.6 | 94.9 | 81.8 | 63.8 | 95.6 | 84.0 | 90.8 | 79.9 | 66.4 | 78.1 |
| GLNet | 80.1 | 98.4 | 86.7 | 93.1 | 59.5 | 62.7 | 68.4 | 73.0 | 81.7 | 92.9 | 64.4 | 95.3 | 84.0 | 65.4 | 95.3 | 82.6 | 90.6 | 81.0 | 67.9 | 79.7 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, C.-Y.; Chiu, Y.-C.; Ng, H.-F.; Shih, T.K.; Lin, K.-H. Global-and-Local Context Network for Semantic Segmentation of Street View Images. Sensors 2020, 20, 2907. https://doi.org/10.3390/s20102907
Lin C-Y, Chiu Y-C, Ng H-F, Shih TK, Lin K-H. Global-and-Local Context Network for Semantic Segmentation of Street View Images. Sensors. 2020; 20(10):2907. https://doi.org/10.3390/s20102907
Chicago/Turabian StyleLin, Chih-Yang, Yi-Cheng Chiu, Hui-Fuang Ng, Timothy K. Shih, and Kuan-Hung Lin. 2020. "Global-and-Local Context Network for Semantic Segmentation of Street View Images" Sensors 20, no. 10: 2907. https://doi.org/10.3390/s20102907
APA StyleLin, C. -Y., Chiu, Y. -C., Ng, H. -F., Shih, T. K., & Lin, K. -H. (2020). Global-and-Local Context Network for Semantic Segmentation of Street View Images. Sensors, 20(10), 2907. https://doi.org/10.3390/s20102907