Comparing Person-Specific and Independent Models on Subject-Dependent and Independent Human Activity Recognition Performance †


Abstract
:1. Introduction
2. Related Work
3. Methods
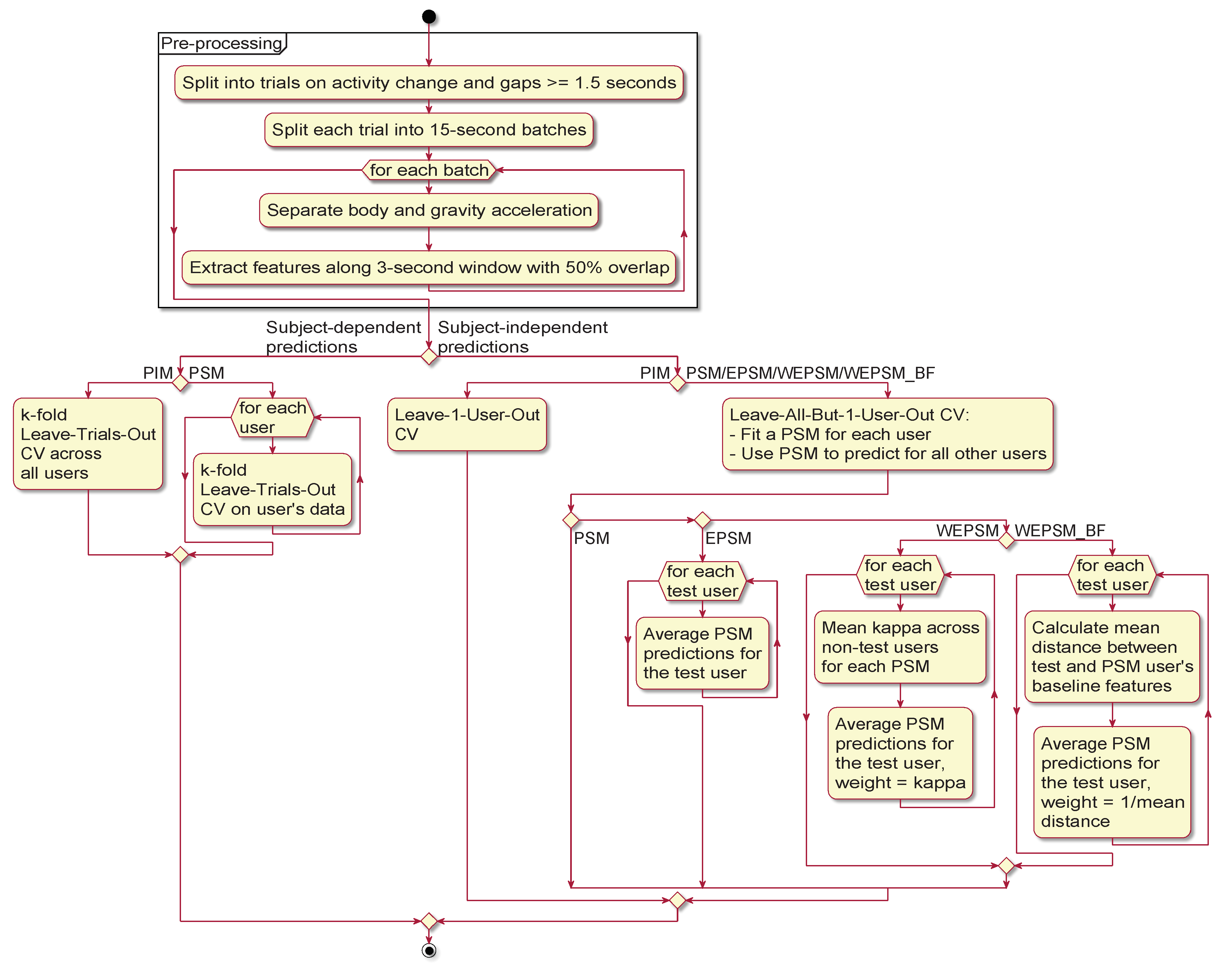
3.1. Pre-Processing, Segmentation, and Feature Extraction
3.2. Activity Inference and Evaluation
4. Results and Analysis
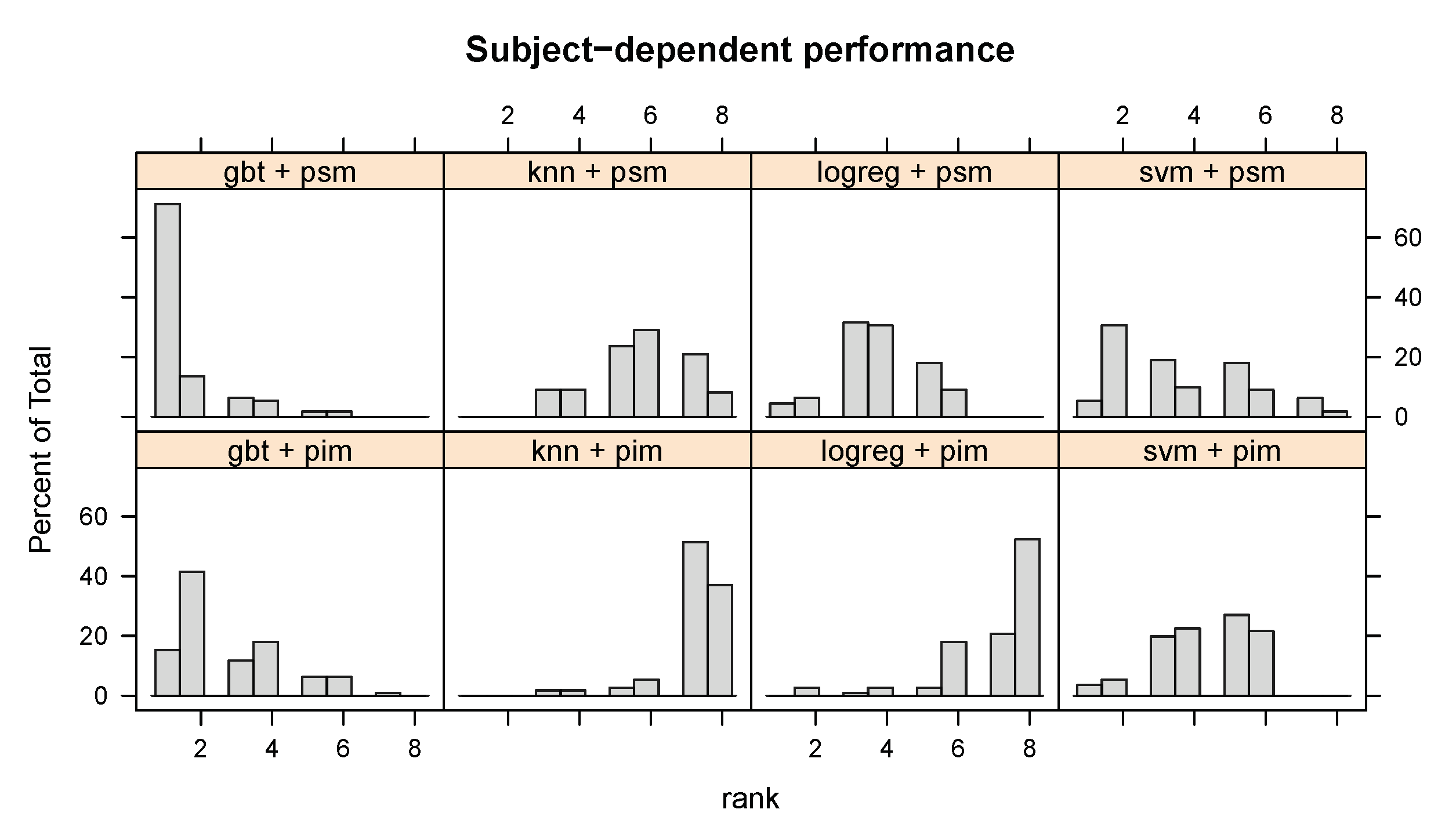
4.1. Analysis of the Subject-Dependent Performance
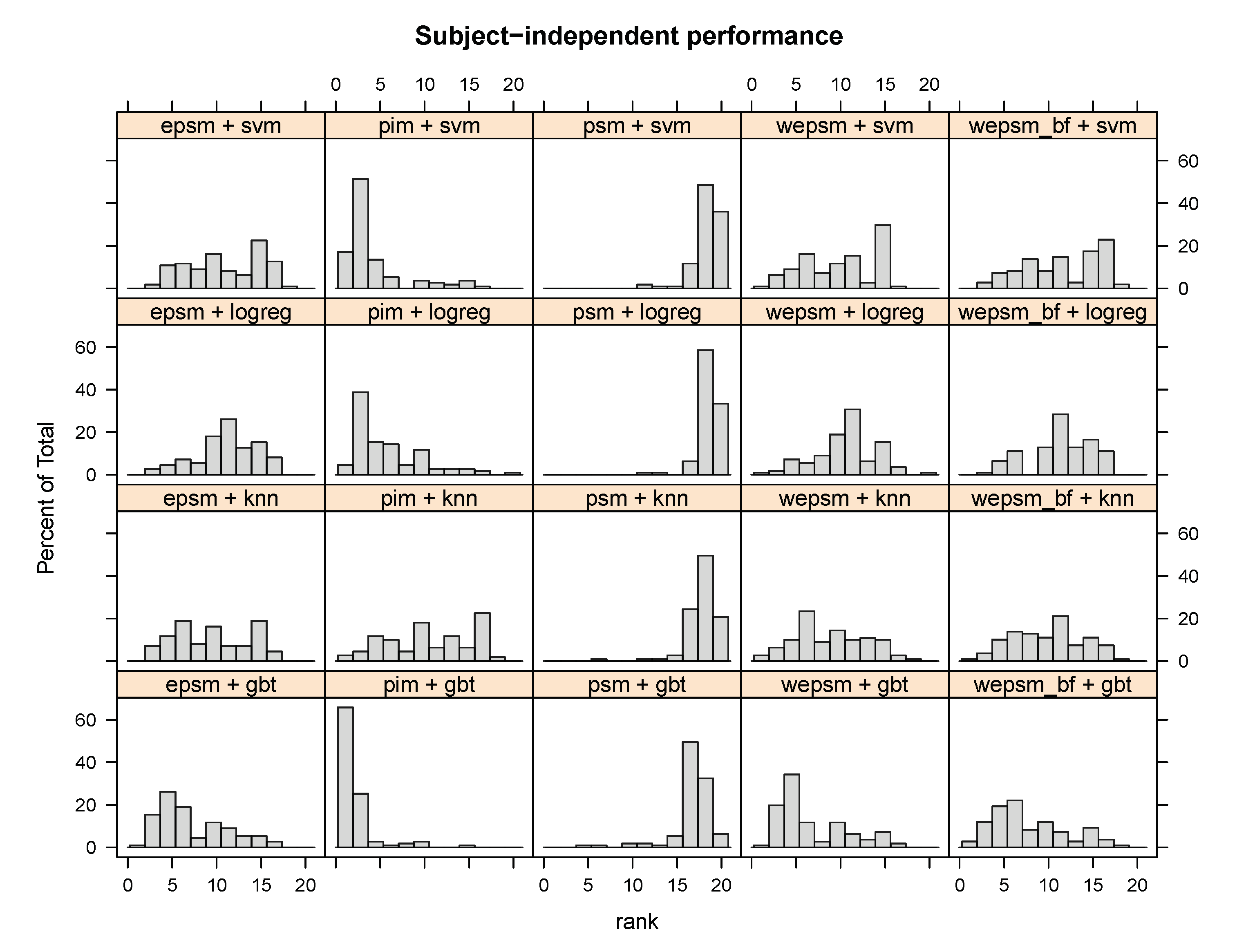
4.2. Analysis of the Subject-Independent Performance
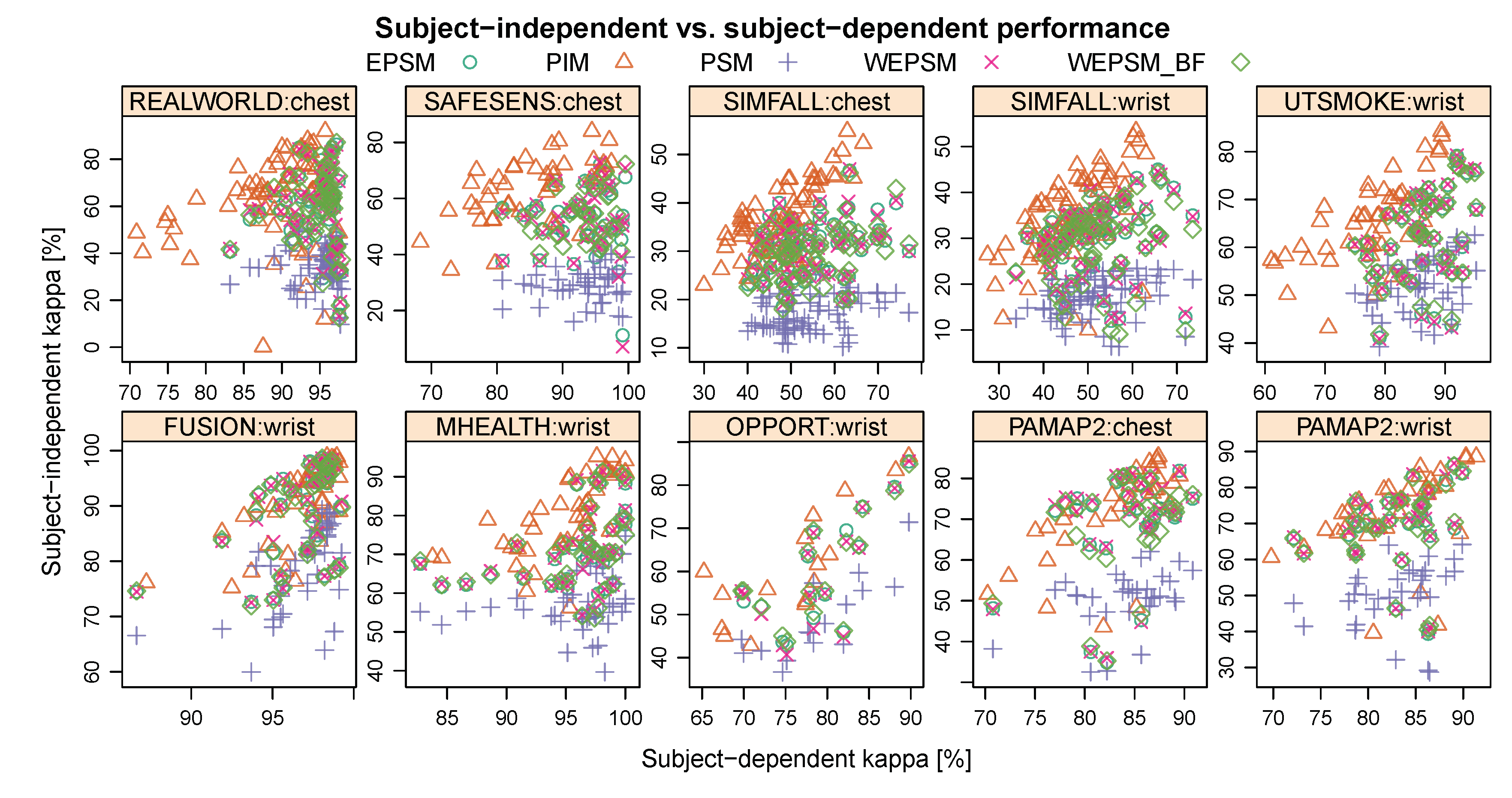
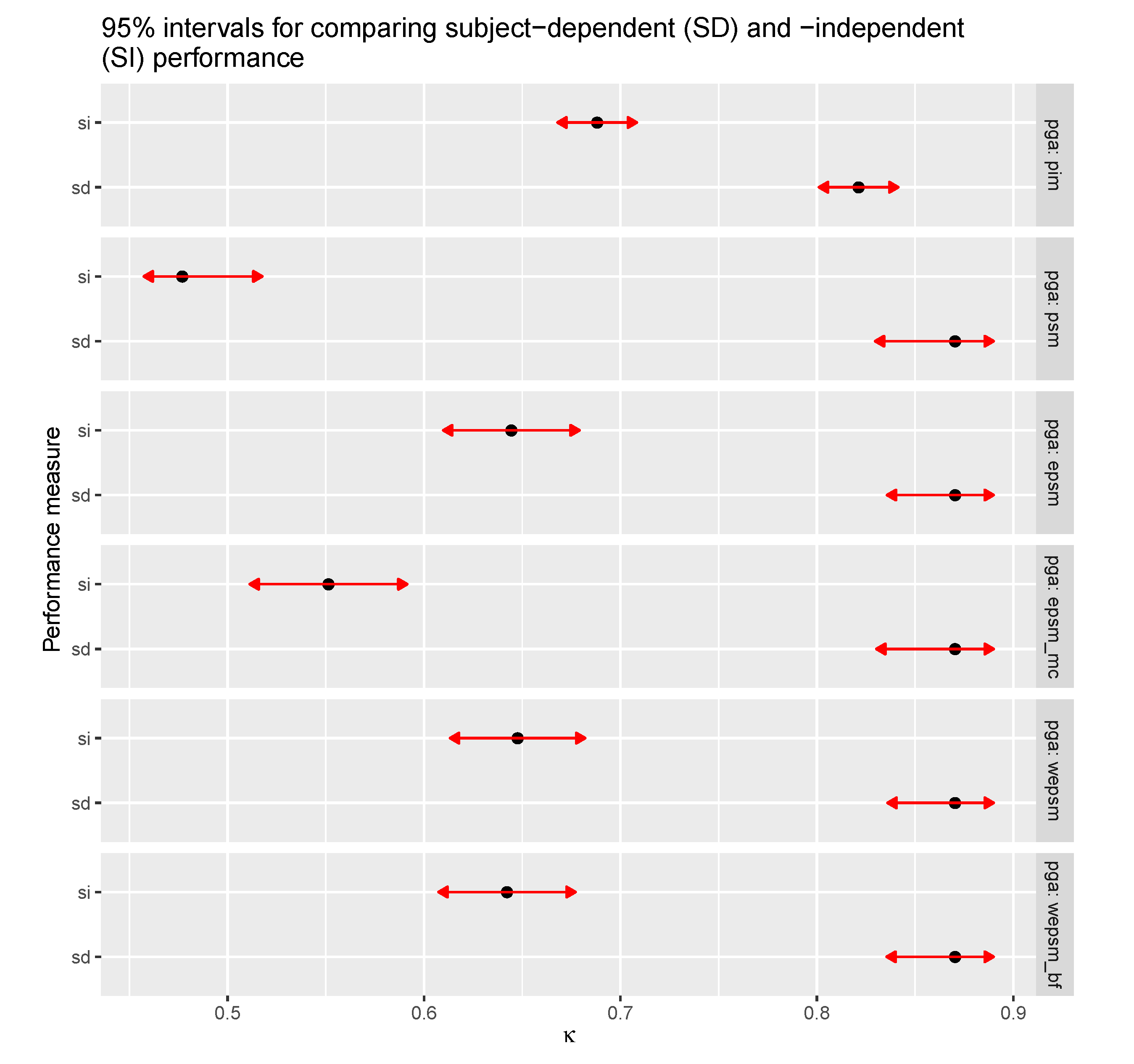
4.3. Comparison of Subject-Dependent and Independent Performance
5. Discussion
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A. Alternative Performance Metrics

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Subject-Dependent | Subject-Independent | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Dataset | Sensor | mla | PIM | (E)PSM | PIM | PSM | EPSM | WEPSM | WEPSM |
| FUSION | wrist | gbt | 98.3 ± 0.3 | 98.0 ± 0.3 | 93.5 ± 1.8 | 84.1 ± 1.8 | 91.9 ± 2.2 | 92.1 ± 2.2 | 91.7 ± 2.2 |
| knn | 94.9 ± 0.8 | 95.0 ± 0.9 | 87.9 ± 1.7 | 78.5 ± 2.2 | 89.3 ± 2.4 | 89.3 ± 2.4 | 89.1 ± 2.4 | ||
| logreg | 97.2 ± 0.5 | 97.8 ± 0.3 | 93.0 ± 1.8 | 82.3 ± 2.3 | 91.0 ± 2.4 | 91.0 ± 2.4 | 90.6 ± 2.3 | ||
| svm | 98.2 ± 0.3 | 98.1 ± 0.3 | 92.2 ± 1.8 | 82.9 ± 2.0 | 91.7 ± 2.3 | 91.8 ± 2.3 | 91.4 ± 2.3 | ||
| MHEALTH | wrist | gbt | 97.8 ± 0.7 | 97.5 ± 1.1 | 84.0 ± 3.3 | 63.2 ± 2.1 | 74.7 ± 3.2 | 74.9 ± 3.1 | 74.2 ± 3.2 |
| knn | 93.6 ± 1.2 | 94.3 ± 1.3 | 78.3 ± 2.8 | 60.0 ± 1.9 | 74.0 ± 2.3 | 74.2 ± 2.4 | 75.3 ± 2.3 | ||
| logreg | 93.8 ± 1.2 | 96.1 ± 1.3 | 80.9 ± 3.0 | 58.3 ± 2.2 | 72.8 ± 2.6 | 72.9 ± 2.6 | 73.4 ± 2.6 | ||
| svm | 95.9 ± 0.9 | 97.0 ± 0.9 | 83.6 ± 2.4 | 61.8 ± 1.9 | 74.5 ± 3.6 | 74.7 ± 3.6 | 74.1 ± 3.6 | ||
| OPPORT | wrist | gbt | 87.8 ± 1.9 | 89.1 ± 1.5 | 79.8 ± 4.6 | 72.4 ± 3.4 | 78.7 ± 4.9 | 78.5 ± 5.0 | 78.7 ± 4.8 |
| knn | 80.7 ± 1.8 | 83.2 ± 1.8 | 67.7 ± 2.7 | 61.6 ± 2.2 | 70.0 ± 3.4 | 69.5 ± 3.1 | 70.1 ± 2.8 | ||
| logreg | 81.5 ± 2.5 | 84.6 ± 1.9 | 73.8 ± 4.3 | 63.9 ± 2.1 | 72.0 ± 4.0 | 71.8 ± 4.2 | 72.2 ± 3.8 | ||
| svm | 87.0 ± 1.7 | 87.4 ± 1.6 | 77.4 ± 4.3 | 65.6 ± 1.8 | 75.3 ± 4.0 | 75.1 ± 4.1 | 75.6 ± 3.7 | ||
| PAMAP2 | chest | gbt | 88.8 ± 0.4 | 88.9 ± 0.6 | 79.6 ± 3.9 | 59.2 ± 2.7 | 75.2 ± 3.8 | 75.6 ± 3.9 | 74.8 ± 3.5 |
| knn | 78.0 ± 0.9 | 80.6 ± 1.1 | 67.3 ± 2.3 | 54.1 ± 1.7 | 71.0 ± 3.0 | 71.4 ± 3.1 | 69.8 ± 2.8 | ||
| logreg | 84.3 ± 1.0 | 86.9 ± 0.8 | 75.0 ± 3.4 | 53.9 ± 2.2 | 72.4 ± 4.4 | 72.4 ± 4.5 | 71.7 ± 4.4 | ||
| svm | 87.4 ± 0.7 | 86.6 ± 0.7 | 76.3 ± 4.1 | 54.6 ± 2.5 | 72.4 ± 4.7 | 72.9 ± 4.7 | 71.6 ± 4.7 | ||
| PAMAP2 | wrist | gbt | 88.1 ± 1.0 | 87.4 ± 0.8 | 80.6 ± 2.6 | 61.1 ± 2.2 | 74.6 ± 2.4 | 75.0 ± 2.4 | 74.8 ± 2.6 |
| knn | 79.7 ± 1.3 | 81.1 ± 1.4 | 68.7 ± 3.7 | 52.6 ± 2.5 | 71.4 ± 3.5 | 71.7 ± 3.6 | 70.9 ± 3.4 | ||
| logreg | 84.2 ± 1.6 | 85.2 ± 1.2 | 77.2 ± 3.7 | 54.8 ± 3.3 | 72.0 ± 4.5 | 72.4 ± 4.5 | 72.1 ± 4.4 | ||
| svm | 86.5 ± 1.1 | 85.0 ± 1.1 | 75.6 ± 4.8 | 51.6 ± 2.8 | 71.5 ± 4.1 | 72.0 ± 4.1 | 71.3 ± 3.9 | ||
| REALWORLD | chest | gbt | 94.5 ± 0.5 | 96.9 ± 0.3 | 76.4 ± 3.7 | 47.1 ± 1.7 | 68.7 ± 3.4 | 69.9 ± 3.3 | 69.2 ± 3.4 |
| knn | 88.1 ± 1.1 | 92.9 ± 0.8 | 66.1 ± 2.9 | 47.2 ± 2.1 | 68.3 ± 3.2 | 69.2 ± 3.1 | 68.5 ± 3.3 | ||
| logreg | 86.8 ± 1.4 | 96.3 ± 0.4 | 66.4 ± 5.5 | 40.7 ± 2.0 | 64.0 ± 3.8 | 65.3 ± 3.8 | 64.0 ± 4.0 | ||
| svm | 93.6 ± 0.6 | 96.4 ± 0.4 | 68.1 ± 4.6 | 40.6 ± 2.0 | 62.0 ± 4.2 | 63.3 ± 4.0 | 62.2 ± 4.3 | ||
| SAFESENS | chest | gbt | 94.7 ± 0.7 | 97.3 ± 0.8 | 71.2 ± 2.6 | 33.3 ± 1.9 | 53.1 ± 4.5 | 52.7 ± 5.3 | 57.9 ± 3.1 |
| knn | 83.0 ± 1.8 | 89.0 ± 1.4 | 59.9 ± 3.6 | 35.8 ± 1.8 | 58.9 ± 3.3 | 58.9 ± 3.4 | 58.0 ± 2.5 | ||
| logreg | 80.9 ± 1.6 | 93.7 ± 1.0 | 67.7 ± 2.8 | 33.1 ± 1.7 | 58.6 ± 2.5 | 58.0 ± 2.4 | 58.0 ± 2.6 | ||
| svm | 89.2 ± 1.2 | 95.7 ± 0.8 | 70.2 ± 2.6 | 35.8 ± 1.8 | 56.7 ± 2.4 | 57.8 ± 2.3 | 56.1 ± 2.8 | ||
| SIMFALL | chest | gbt | 60.0 ± 1.1 | 68.1 ± 1.2 | 47.5 ± 1.5 | 24.6 ± 0.6 | 37.8 ± 1.4 | 37.8 ± 1.4 | 37.0 ± 1.4 |
| knn | 48.6 ± 0.9 | 52.8 ± 1.2 | 34.8 ± 0.7 | 25.0 ± 0.6 | 37.7 ± 1.0 | 37.5 ± 1.0 | 36.5 ± 0.9 | ||
| logreg | 42.3 ± 0.8 | 55.4 ± 1.1 | 38.8 ± 1.1 | 20.0 ± 0.4 | 33.6 ± 0.9 | 33.6 ± 0.9 | 32.7 ± 0.9 | ||
| svm | 53.4 ± 0.7 | 52.8 ± 1.5 | 42.2 ± 1.3 | 19.7 ± 0.4 | 30.7 ± 0.9 | 31.0 ± 0.9 | 29.6 ± 0.9 | ||
| SIMFALL | wrist | gbt | 58.3 ± 1.4 | 65.1 ± 1.4 | 44.6 ± 2.2 | 24.4 ± 0.9 | 37.3 ± 2.0 | 37.4 ± 2.0 | 36.4 ± 2.1 |
| knn | 48.2 ± 1.1 | 52.1 ± 1.1 | 33.8 ± 1.4 | 24.4 ± 0.9 | 36.2 ± 1.5 | 36.3 ± 1.5 | 35.4 ± 1.6 | ||
| logreg | 41.3 ± 1.3 | 52.9 ± 1.2 | 37.0 ± 1.9 | 21.5 ± 0.8 | 32.3 ± 1.6 | 32.8 ± 1.6 | 32.1 ± 1.7 | ||
| svm | 51.5 ± 1.2 | 49.4 ± 1.4 | 40.1 ± 2.2 | 19.2 ± 0.7 | 31.6 ± 1.4 | 31.9 ± 1.5 | 31.1 ± 1.6 | ||
| UTSMOKE | wrist | gbt | 83.6 ± 1.3 | 92.1 ± 0.8 | 73.2 ± 2.5 | 61.3 ± 1.6 | 70.3 ± 2.8 | 70.4 ± 2.8 | 70.2 ± 2.7 |
| knn | 79.7 ± 1.1 | 83.9 ± 1.0 | 67.1 ± 2.1 | 57.8 ± 1.5 | 66.3 ± 2.4 | 66.4 ± 2.5 | 66.1 ± 2.3 | ||
| logreg | 73.3 ± 1.8 | 86.4 ± 1.0 | 68.5 ± 2.2 | 57.6 ± 1.4 | 65.1 ± 2.1 | 65.2 ± 2.2 | 65.3 ± 2.0 | ||
| svm | 86.0 ± 1.1 | 90.7 ± 0.8 | 73.6 ± 2.3 | 59.6 ± 1.6 | 68.8 ± 2.5 | 68.9 ± 2.5 | 69.0 ± 2.3 | ||
| Subject-Dependent | Subject-Independent | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Dataset | Sensor | mla | PIM | (E)PSM | PIM | PSM | EPSM | WEPSM | WEPSM |
| FUSION | wrist | gbt | 1.8 ± 0.3 | 2.0 ± 0.3 | 92.7 ± 2.3 | 82.3 ± 2.1 | 90.6 ± 2.8 | 90.8 ± 2.8 | 90.4 ± 2.8 |
| knn | 5.1 ± 0.8 | 5.0 ± 0.9 | 87.7 ± 1.8 | 77.4 ± 2.5 | 88.2 ± 2.9 | 88.4 ± 2.9 | 88.2 ± 2.9 | ||
| logreg | 2.8 ± 0.5 | 2.2 ± 0.3 | 92.5 ± 2.2 | 80.7 ± 2.5 | 89.8 ± 2.9 | 89.9 ± 2.9 | 89.4 ± 2.9 | ||
| svm | 1.8 ± 0.3 | 1.9 ± 0.3 | 91.6 ± 2.1 | 81.2 ± 2.3 | 90.4 ± 2.9 | 90.5 ± 3.0 | 90.1 ± 2.9 | ||
| MHEALTH | wrist | gbt | 2.2 ± 0.7 | 2.5 ± 1.1 | 81.9 ± 4.0 | 58.3 ± 2.2 | 69.8 ± 3.6 | 70.1 ± 3.5 | 69.2 ± 3.6 |
| knn | 6.4 ± 1.2 | 5.7 ± 1.3 | 76.6 ± 2.8 | 56.3 ± 1.9 | 70.9 ± 2.7 | 71.2 ± 2.7 | 72.6 ± 2.6 | ||
| logreg | 6.2 ± 1.2 | 3.9 ± 1.3 | 78.9 ± 3.3 | 53.0 ± 2.1 | 67.6 ± 3.2 | 67.8 ± 3.2 | 68.2 ± 3.2 | ||
| svm | 4.1 ± 0.9 | 3.0 ± 0.9 | 81.9 ± 2.7 | 56.6 ± 2.0 | 70.0 ± 4.1 | 70.2 ± 4.1 | 69.3 ± 4.1 | ||
| OPPORT | wrist | gbt | 12.2 ± 1.9 | 10.9 ± 1.5 | 79.3 ± 5.0 | 71.4 ± 4.2 | 77.3 ± 5.7 | 77.0 ± 5.8 | 77.4 ± 5.5 |
| knn | 19.3 ± 1.8 | 16.9 ± 1.8 | 67.2 ± 2.9 | 61.1 ± 2.3 | 69.2 ± 3.6 | 68.7 ± 3.4 | 69.5 ± 3.0 | ||
| logreg | 18.5 ± 2.5 | 15.5 ± 1.9 | 72.7 ± 4.9 | 63.0 ± 2.6 | 70.3 ± 4.7 | 70.2 ± 4.9 | 70.8 ± 4.5 | ||
| svm | 13.0 ± 1.7 | 12.6 ± 1.6 | 76.6 ± 4.8 | 64.5 ± 2.2 | 73.9 ± 4.7 | 73.6 ± 5.0 | 74.4 ± 4.4 | ||
| PAMAP2 | chest | gbt | 11.2 ± 0.4 | 11.1 ± 0.6 | 79.2 ± 4.6 | 56.2 ± 3.3 | 74.3 ± 4.5 | 74.8 ± 4.6 | 73.9 ± 4.2 |
| knn | 21.9 ± 0.9 | 19.4 ± 1.1 | 67.7 ± 2.5 | 52.4 ± 2.1 | 70.9 ± 3.4 | 71.3 ± 3.5 | 69.5 ± 3.2 | ||
| logreg | 15.7 ± 1.0 | 13.1 ± 0.8 | 74.1 ± 4.1 | 50.4 ± 2.7 | 71.4 ± 5.1 | 71.4 ± 5.2 | 70.4 ± 5.1 | ||
| svm | 12.6 ± 0.7 | 13.4 ± 0.7 | 75.9 ± 4.6 | 51.5 ± 3.0 | 71.2 ± 5.6 | 71.7 ± 5.5 | 70.3 ± 5.5 | ||
| PAMAP2 | wrist | gbt | 11.9 ± 1.0 | 12.6 ± 0.8 | 79.9 ± 3.0 | 58.2 ± 2.4 | 73.1 ± 2.6 | 73.5 ± 2.6 | 73.3 ± 2.8 |
| knn | 20.3 ± 1.3 | 18.9 ± 1.4 | 68.2 ± 4.1 | 50.5 ± 2.8 | 70.3 ± 3.9 | 70.7 ± 3.9 | 69.5 ± 3.8 | ||
| logreg | 15.8 ± 1.6 | 14.8 ± 1.2 | 76.5 ± 4.2 | 51.5 ± 3.7 | 70.0 ± 5.3 | 70.6 ± 5.2 | 70.1 ± 5.2 | ||
| svm | 13.6 ± 1.1 | 14.9 ± 1.1 | 75.0 ± 5.3 | 48.3 ± 3.3 | 69.7 ± 4.8 | 70.3 ± 4.8 | 69.4 ± 4.7 | ||
| REALWORLD | chest | gbt | 5.5 ± 0.5 | 3.1 ± 0.3 | 76.5 ± 3.6 | 43.4 ± 1.6 | 68.4 ± 3.4 | 70.0 ± 3.2 | 68.7 ± 3.2 |
| knn | 11.9 ± 1.1 | 7.1 ± 0.8 | 67.5 ± 2.9 | 45.3 ± 2.1 | 67.9 ± 3.5 | 69.0 ± 3.3 | 68.4 ± 3.4 | ||
| logreg | 13.2 ± 1.4 | 3.7 ± 0.4 | 66.3 ± 5.6 | 37.2 ± 2.2 | 62.0 ± 3.9 | 63.8 ± 3.9 | 62.1 ± 3.9 | ||
| svm | 6.4 ± 0.6 | 3.6 ± 0.4 | 67.8 ± 4.9 | 36.9 ± 2.0 | 59.4 ± 4.4 | 61.5 ± 4.2 | 59.8 ± 4.4 | ||
| SAFESENS | chest | gbt | 5.3 ± 0.7 | 2.7 ± 0.8 | 70.8 ± 2.6 | 29.0 ± 1.7 | 52.5 ± 3.9 | 51.3 ± 4.8 | 55.1 ± 3.6 |
| knn | 17.0 ± 1.8 | 11.0 ± 1.4 | 61.0 ± 4.0 | 33.3 ± 2.2 | 59.7 ± 3.9 | 59.6 ± 4.0 | 57.1 ± 3.1 | ||
| logreg | 19.1 ± 1.6 | 6.3 ± 1.0 | 67.7 ± 3.0 | 29.9 ± 2.1 | 58.1 ± 2.8 | 57.6 ± 2.9 | 56.3 ± 3.1 | ||
| svm | 10.8 ± 1.2 | 4.3 ± 0.8 | 70.5 ± 3.0 | 31.8 ± 2.2 | 56.8 ± 2.9 | 57.7 ± 3.0 | 54.0 ± 3.3 | ||
| SIMFALL | chest | gbt | 40.0 ± 1.1 | 31.9 ± 1.2 | 46.9 ± 1.5 | 22.4 ± 0.6 | 34.7 ± 1.5 | 34.9 ± 1.5 | 33.9 ± 1.5 |
| knn | 51.4 ± 0.9 | 47.2 ± 1.2 | 34.6 ± 0.7 | 23.7 ± 0.6 | 36.0 ± 1.0 | 36.1 ± 1.1 | 34.9 ± 0.9 | ||
| logreg | 57.7 ± 0.8 | 44.6 ± 1.1 | 38.2 ± 1.1 | 17.7 ± 0.5 | 31.0 ± 1.0 | 31.1 ± 1.0 | 30.0 ± 1.0 | ||
| svm | 46.6 ± 0.7 | 47.2 ± 1.5 | 41.8 ± 1.3 | 17.4 ± 0.4 | 27.8 ± 1.1 | 28.3 ± 1.0 | 26.4 ± 1.1 | ||
| SIMFALL | wrist | gbt | 41.7 ± 1.4 | 34.9 ± 1.4 | 44.2 ± 2.1 | 22.1 ± 0.9 | 35.7 ± 1.9 | 35.9 ± 1.9 | 34.7 ± 1.9 |
| knn | 51.8 ± 1.1 | 47.9 ± 1.1 | 33.5 ± 1.4 | 23.5 ± 0.9 | 35.5 ± 1.5 | 35.7 ± 1.5 | 34.5 ± 1.6 | ||
| logreg | 58.7 ± 1.3 | 47.1 ± 1.2 | 36.5 ± 1.9 | 19.6 ± 0.8 | 30.8 ± 1.5 | 31.3 ± 1.6 | 29.9 ± 1.6 | ||
| svm | 48.5 ± 1.2 | 50.6 ± 1.4 | 39.8 ± 2.2 | 17.3 ± 0.6 | 29.1 ± 1.2 | 29.5 ± 1.3 | 28.2 ± 1.4 | ||
| UTSMOKE | wrist | gbt | 16.4 ± 1.3 | 7.9 ± 0.8 | 72.3 ± 2.6 | 59.2 ± 1.6 | 69.1 ± 2.8 | 69.1 ± 2.8 | 69.0 ± 2.7 |
| knn | 20.3 ± 1.1 | 16.1 ± 1.0 | 66.6 ± 2.1 | 55.6 ± 1.5 | 64.0 ± 2.5 | 64.1 ± 2.5 | 63.7 ± 2.4 | ||
| logreg | 26.7 ± 1.8 | 13.6 ± 1.0 | 67.2 ± 2.2 | 54.7 ± 1.4 | 62.7 ± 2.2 | 62.8 ± 2.2 | 63.0 ± 2.2 | ||
| svm | 14.0 ± 1.1 | 9.3 ± 0.8 | 73.0 ± 2.3 | 57.1 ± 1.6 | 67.0 ± 2.5 | 67.1 ± 2.6 | 67.2 ± 2.4 | ||
| Subject-Dependent | Subject-Independent | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Dataset | Sensor | mla | PIM | (E)PSM | PIM | PSM | EPSM | WEPSM | WEPSM |
| FUSION | wrist | gbt | 98.2 ± 0.3 | 98.0 ± 0.3 | 92.7 ± 2.3 | 82.3 ± 2.1 | 90.6 ± 2.8 | 90.8 ± 2.8 | 90.4 ± 2.8 |
| knn | 94.9 ± 0.8 | 95.0 ± 0.9 | 87.7 ± 1.8 | 77.4 ± 2.5 | 88.2 ± 2.9 | 88.4 ± 2.9 | 88.2 ± 2.9 | ||
| logreg | 97.2 ± 0.5 | 97.8 ± 0.3 | 92.5 ± 2.2 | 80.7 ± 2.5 | 89.8 ± 2.9 | 89.9 ± 2.9 | 89.4 ± 2.9 | ||
| svm | 98.2 ± 0.3 | 98.1 ± 0.3 | 91.6 ± 2.1 | 81.2 ± 2.3 | 90.4 ± 2.9 | 90.5 ± 3.0 | 90.1 ± 2.9 | ||
| MHEALTH | wrist | gbt | 97.7 ± 0.7 | 97.5 ± 1.1 | 81.9 ± 4.0 | 58.3 ± 2.2 | 69.8 ± 3.6 | 70.1 ± 3.5 | 69.2 ± 3.6 |
| knn | 93.5 ± 1.2 | 94.1 ± 1.3 | 76.6 ± 2.8 | 56.3 ± 1.9 | 70.9 ± 2.7 | 71.2 ± 2.7 | 72.6 ± 2.6 | ||
| logreg | 93.7 ± 1.3 | 96.1 ± 1.3 | 78.9 ± 3.3 | 53.0 ± 2.1 | 67.6 ± 3.2 | 67.8 ± 3.2 | 68.2 ± 3.2 | ||
| svm | 95.9 ± 0.9 | 97.0 ± 0.9 | 81.9 ± 2.7 | 56.6 ± 2.0 | 70.0 ± 4.1 | 70.2 ± 4.1 | 69.3 ± 4.1 | ||
| OPPORT | wrist | gbt | 87.8 ± 1.9 | 89.1 ± 1.5 | 79.3 ± 5.0 | 71.4 ± 4.2 | 77.3 ± 5.7 | 77.0 ± 5.8 | 77.4 ± 5.5 |
| knn | 80.7 ± 1.8 | 83.2 ± 1.8 | 67.2 ± 2.9 | 61.1 ± 2.3 | 69.2 ± 3.6 | 68.7 ± 3.4 | 69.5 ± 3.0 | ||
| logreg | 81.3 ± 2.4 | 84.5 ± 1.9 | 72.7 ± 4.9 | 63.0 ± 2.6 | 70.3 ± 4.7 | 70.2 ± 4.9 | 70.8 ± 4.5 | ||
| svm | 87.0 ± 1.8 | 87.4 ± 1.6 | 76.6 ± 4.8 | 64.5 ± 2.2 | 73.9 ± 4.7 | 73.6 ± 5.0 | 74.4 ± 4.4 | ||
| PAMAP2 | chest | gbt | 89.0 ± 0.4 | 89.1 ± 0.6 | 79.2 ± 4.6 | 56.2 ± 3.3 | 74.3 ± 4.5 | 74.8 ± 4.6 | 73.9 ± 4.2 |
| knn | 78.2 ± 1.0 | 80.6 ± 1.1 | 67.7 ± 2.5 | 52.4 ± 2.1 | 70.9 ± 3.4 | 71.3 ± 3.5 | 69.5 ± 3.2 | ||
| logreg | 84.3 ± 1.1 | 87.0 ± 0.8 | 74.1 ± 4.1 | 50.4 ± 2.7 | 71.4 ± 5.1 | 71.4 ± 5.2 | 70.4 ± 5.1 | ||
| svm | 87.6 ± 0.7 | 86.6 ± 0.7 | 75.9 ± 4.6 | 51.5 ± 3.0 | 71.2 ± 5.6 | 71.7 ± 5.5 | 70.3 ± 5.5 | ||
| PAMAP2 | wrist | gbt | 88.3 ± 1.0 | 87.6 ± 0.8 | 79.9 ± 3.0 | 58.2 ± 2.4 | 73.1 ± 2.6 | 73.5 ± 2.6 | 73.3 ± 2.8 |
| knn | 79.7 ± 1.3 | 81.0 ± 1.4 | 68.2 ± 4.1 | 50.5 ± 2.8 | 70.3 ± 3.9 | 70.7 ± 3.9 | 69.5 ± 3.8 | ||
| logreg | 84.2 ± 1.6 | 85.3 ± 1.2 | 76.5 ± 4.2 | 51.5 ± 3.7 | 70.0 ± 5.3 | 70.6 ± 5.2 | 70.1 ± 5.2 | ||
| svm | 86.6 ± 1.1 | 85.1 ± 1.1 | 75.0 ± 5.3 | 48.3 ± 3.3 | 69.7 ± 4.8 | 70.3 ± 4.8 | 69.4 ± 4.7 | ||
| REALWORLD | chest | gbt | 94.7 ± 0.5 | 96.8 ± 0.3 | 76.5 ± 3.6 | 43.4 ± 1.6 | 68.4 ± 3.4 | 70.0 ± 3.2 | 68.7 ± 3.2 |
| knn | 88.8 ± 1.0 | 92.9 ± 0.8 | 67.5 ± 2.9 | 45.3 ± 2.1 | 67.9 ± 3.5 | 69.0 ± 3.3 | 68.4 ± 3.4 | ||
| logreg | 87.5 ± 1.4 | 96.2 ± 0.4 | 66.3 ± 5.6 | 37.2 ± 2.2 | 62.0 ± 3.9 | 63.8 ± 3.9 | 62.1 ± 3.9 | ||
| svm | 93.9 ± 0.5 | 96.3 ± 0.4 | 67.8 ± 4.9 | 36.9 ± 2.0 | 59.4 ± 4.4 | 61.5 ± 4.2 | 59.8 ± 4.4 | ||
| SAFESENS | chest | gbt | 95.1 ± 0.7 | 97.3 ± 0.8 | 70.8 ± 2.6 | 29.0 ± 1.7 | 52.5 ± 3.9 | 51.3 ± 4.8 | 55.1 ± 3.6 |
| knn | 83.5 ± 1.9 | 88.9 ± 1.4 | 61.0 ± 4.0 | 33.3 ± 2.2 | 59.7 ± 3.9 | 59.6 ± 4.0 | 57.1 ± 3.1 | ||
| logreg | 81.4 ± 1.8 | 93.6 ± 1.0 | 67.7 ± 3.0 | 29.9 ± 2.1 | 58.1 ± 2.8 | 57.6 ± 2.9 | 56.3 ± 3.1 | ||
| svm | 89.6 ± 1.2 | 95.6 ± 0.8 | 70.5 ± 3.0 | 31.8 ± 2.2 | 56.8 ± 2.9 | 57.7 ± 3.0 | 54.0 ± 3.3 | ||
| SIMFALL | chest | gbt | 59.8 ± 1.1 | 68.3 ± 1.2 | 46.9 ± 1.5 | 22.4 ± 0.6 | 34.7 ± 1.5 | 34.9 ± 1.5 | 33.9 ± 1.5 |
| knn | 48.7 ± 0.9 | 52.9 ± 1.2 | 34.6 ± 0.7 | 23.7 ± 0.6 | 36.0 ± 1.0 | 36.1 ± 1.1 | 34.9 ± 0.9 | ||
| logreg | 41.9 ± 0.9 | 55.3 ± 1.2 | 38.2 ± 1.1 | 17.7 ± 0.5 | 31.0 ± 1.0 | 31.1 ± 1.0 | 30.0 ± 1.0 | ||
| svm | 53.6 ± 0.7 | 52.7 ± 1.5 | 41.8 ± 1.3 | 17.4 ± 0.4 | 27.8 ± 1.1 | 28.3 ± 1.0 | 26.4 ± 1.1 | ||
| SIMFALL | wrist | gbt | 58.2 ± 1.4 | 65.2 ± 1.4 | 44.2 ± 2.1 | 22.1 ± 0.9 | 35.7 ± 1.9 | 35.9 ± 1.9 | 34.7 ± 1.9 |
| knn | 48.2 ± 1.1 | 52.2 ± 1.1 | 33.5 ± 1.4 | 23.5 ± 0.9 | 35.5 ± 1.5 | 35.7 ± 1.5 | 34.5 ± 1.6 | ||
| logreg | 41.0 ± 1.3 | 52.8 ± 1.2 | 36.5 ± 1.9 | 19.6 ± 0.8 | 30.8 ± 1.5 | 31.3 ± 1.6 | 29.9 ± 1.6 | ||
| svm | 51.8 ± 1.2 | 49.4 ± 1.4 | 39.8 ± 2.2 | 17.3 ± 0.6 | 29.1 ± 1.2 | 29.5 ± 1.3 | 28.2 ± 1.4 | ||
| UTSMOKE | wrist | gbt | 83.3 ± 1.3 | 92.2 ± 0.8 | 72.3 ± 2.6 | 59.2 ± 1.6 | 69.1 ± 2.8 | 69.1 ± 2.8 | 69.0 ± 2.7 |
| knn | 79.5 ± 1.2 | 83.8 ± 1.0 | 66.6 ± 2.1 | 55.6 ± 1.5 | 64.0 ± 2.5 | 64.1 ± 2.5 | 63.7 ± 2.4 | ||
| logreg | 72.4 ± 1.9 | 86.2 ± 1.1 | 67.2 ± 2.2 | 54.7 ± 1.4 | 62.7 ± 2.2 | 62.8 ± 2.2 | 63.0 ± 2.2 | ||
| svm | 85.9 ± 1.1 | 90.7 ± 0.8 | 73.0 ± 2.3 | 57.1 ± 1.6 | 67.0 ± 2.5 | 67.1 ± 2.6 | 67.2 ± 2.4 | ||
References
- Scheurer, S.; Tedesco, S.; Brown, K.N.; O’Flynn, B. Subject-dependent and-independent human activity recognition with person-specific and-independent models. In Proceedings of the 6th international Workshop on Sensor-based Activity Recognition and Interaction, Rostock, Germany, 16–17 September 2019; pp. 1–7. [Google Scholar]
- Wang, J.; Chen, Y.; Hao, S.; Peng, X.; Hu, L. Deep learning for sensor-based activity recognition: A survey. Pattern Recognit. Lett. 2019, 119, 3–11. [Google Scholar] [CrossRef] [Green Version]
- Chavarriaga, R.; Sagha, H.; Calatroni, A.; Digumarti, S.T.; Tröster, G.; Millán, J.d.R.; Roggen, D. The Opportunity challenge: A benchmark database for on-body sensor-based activity recognition. Pattern Recognit. Lett. 2013, 34. [Google Scholar] [CrossRef] [Green Version]
- Jiang, W.; Yin, Z. Human Activity Recognition Using Wearable Sensors by Deep Convolutional Neural Networks. In Proceedings of the 23rd ACM International Conference on Multimedia, New York, NY, USA, October 2015; pp. 1307–1310. [Google Scholar] [CrossRef]
- Zhang, L.; Wu, X.; Luo, D. Recognizing Human Activities from Raw Accelerometer Data Using Deep Neural Networks. In Proceedings of the 2015 IEEE 14th International Conference on Machine Learning and Applications (ICMLA), Miami, FL, USA, 9–11 December 2015; pp. 865–870. [Google Scholar] [CrossRef]
- Ordóñez, F.J.; Roggen, D. Deep Convolutional and LSTM Recurrent Neural Networks for Multimodal Wearable Activity Recognition. Sensors 2016, 16. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hammerla, N.Y.; Halloran, S.; Plötz, T. Deep, Convolutional, and Recurrent Models for Human Activity Recognition Using Wearables. arXiv 2016, arXiv:1604.08880. [Google Scholar]
- Shoaib, M.; Bosch, S.; Incel, O.D.; Scholten, H.; Havinga, P.J.M. Fusion of Smartphone Motion Sensors for Physical Activity Recognition. Sensors 2014, 14. [Google Scholar] [CrossRef] [PubMed]
- Reiss, A.; Stricker, D. Introducing a New Benchmarked Dataset for Activity Monitoring. In Proceedings of the 2012 16th International Symposium on Wearable Computers, Newcastle, UK, 18–22 June 2012. [Google Scholar] [CrossRef]
- Jordao, A.; Nazare, A.C., Jr.; Sena, J.; Schwartz, W.R. Human Activity Recognition Based on Wearable Sensor Data: A Standardization of the State-of-the-Art. arXiv 2019, arXiv:1806.05226. [Google Scholar]
- Banos, O.; Garcia, R.; Holgado-Terriza, J.A.; Damas, M.; Pomares, H.; Rojas, I.; Saez, A.; Villalonga, C. mHealthDroid: A Novel Framework for Agile Development of Mobile Health Applications. In International Workshop on Ambient Assisted Living; Pecchia, L., Chen, L.L., Nugent, C., Bravo, J., Eds.; Springer: Cham, Switzerland, 2014. [Google Scholar] [CrossRef]
- Catal, C.; Tufekci, S.; Pirmit, E.; Kocabag, G. On the Use of Ensemble of Classifiers for Accelerometer-Based Activity Recognition. Appl. Soft Comput. 2015, 37, 1018–1022. [Google Scholar] [CrossRef]
- Chen, Y.; Xue, Y. A Deep Learning Approach to Human Activity Recognition Based on Single Accelerometer. In Proceedings of the 2015 IEEE International Conference on Systems, Kowloon, China, 9–12 October 2015; pp. 1488–1492. [Google Scholar] [CrossRef]
- Abdu-Aguye, M.G.; Gomaa, W. Competitive Feature Extraction for Activity Recognition based on Wavelet Transforms and Adaptive Pooling. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; pp. 1–8. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sztyler, T.; Stuckenschmidt, H. On-body localization of wearable devices: An investigation of position-aware activity recognition. In Proceedings of the 2016 IEEE International Conference on Pervasive Computing and Communications (PerCom), Sydney, Australia, 14–19 March 2016. [Google Scholar] [CrossRef]
- Vakili, M.; Ghamsari, M.; Rezaei, M. Performance Analysis and Comparison of Machine and Deep Learning Algorithms for IoT Data Classification. arXiv 2020, arXiv:2001.09636. [Google Scholar]
- Özdemir, A.T.; Barshan, B. Detecting Falls with Wearable Sensors Using Machine Learning Techniques. Sensors 2014, 14. [Google Scholar] [CrossRef] [PubMed]
- Alharbi, F.; Farrahi, K. A Convolutional Neural Network for Smoking Activity Recognition. In Proceedings of the 2018 IEEE 20th International Conference on e-Health Networking, Applications and Services (Healthcom), Ostrava, Czech Republic, 17–20 September 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Shoaib, M.; Scholten, H.; Havinga, P.J.M.; Incel, O.D. A hierarchical lazy smoking detection algorithm using smartwatch sensors. In Proceedings of the 2016 IEEE 18th International Conference on e-Health Networking, Applications and Services (Healthcom), Munich, Germany, 14–16 September 2016. [Google Scholar] [CrossRef]
- Bao, L.; Intille, S.S. Activity Recognition from User-Annotated Acceleration Data. In International Conference on Pervasive Computing; Springer: Berlin/Heidelberg, Germany, 2004; pp. 1–17. [Google Scholar] [CrossRef]
- Weiss, G.M.; Lockhart, J.W. The Impact of Personalization on Smartphone-Based Activity Recognition. In Workshops at the Twenty-Sixth AAAI Conference on Artificial Intelligence; AAAI: Palo Alto, CA, USA, 2012. [Google Scholar]
- Bulling, A.; Blanke, U.; Schiele, B. A Tutorial on Human Activity Recognition Using Body-worn Inertial. Sensors 2014, 46. [Google Scholar] [CrossRef]
- Scheurer, S.; Tedesco, S.; Brown, K.N.; O’Flynn, B. Human Activity Recognition for Emergency First Responders via Body-Worn Inertial Sensors. In Proceedings of the 2017 IEEE 14th International Conference on Wearable and Implantable Body Sensor Networks (BSN), Eindhoven, The Netherlands, 9–12 May 2017; pp. 5–8. [Google Scholar]
- Jones, E.; Oliphant, T.; Peterson, P. SciPy: Open Source Scientific Tools for Python. Available online: https://www.scipy.org (accessed on 27 May 2020).
- Van der Walt, S.; Colbert, S.C.; Varoquaux, G. The NumPy Array: A Structure for Efficient Numerical Computation. Comput. Sci. Eng. 2011, 13, 22–30. [Google Scholar] [CrossRef] [Green Version]
- McKinney, W. Data Structures for Statistical Computing in Python. In Proceedings of the 9th Python in Science Conference, Austin, TX, USA, June 28–July 2010; pp. 51–56. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Tange, O. GNU Parallel—The Command-Line Power Tool. Login Usenix Mag. 2011, 36, 42–47. [Google Scholar]
- R Core Team. R: A Language and Environment for Statistical Computing. Available online: https://www.r-project.org (accessed on 20 May 2020).
- Bates, D.; Mächler, M.; Bolker, B.; Walker, S. Fitting Linear Mixed-Effects Models Using lme4. J. Stat. Softw. 2015, 67. [Google Scholar] [CrossRef]
- Lenth, R. emmeans: Estimated Marginal Means, aka Least-Squares Means. 2019. Available online: https://cran.r-project.org/package=emmeans (accessed on 10 May 2020).
- Karantonis, D.M.; Narayanan, M.R.; Mathie, M.; Lovell, N.H.; Celler, B.G. Implementation of a real-time human movement classifier using a triaxial accelerometer for ambulatory monitoring. IEEE Trans. Inf. Technol. Biomed. 2006, 10, 156–167. [Google Scholar] [CrossRef] [PubMed]
- Gelman, A.; Hill, J. Data Analysis Using Regression and Multilevel/Hierarchical Models; Cambridge University Press: Cambridge, MA, USA, 2006. [Google Scholar]







| Dataset | Act | Ind | Trials/Act | Hz | |
|---|---|---|---|---|---|
| [8] | FUSION | 7 | 10 | 90 ± 0 | 50 |
| [11] | MHEALTH | 11 | 10 | 38 ± 0 | 50 |
| [3] | OPPORT | 4 | 4 | 590 ± 258 | 30 |
| [9] | PAMAP2 | 12 | 9 | 81 ± 8 | 100 |
| [16] | REALWORLD | 8 | 15 | 318 ± 42 | 50 |
| [24] | SAFESENS | 17 | 11 | 91 ± 13 | 33 |
| [18] | SIMFALL | 16 | 17 | 128 ± 8 | 25 |
| [20] | UTSMOKE | 7 | 11 | 859 ± 7 | 50 |
| Subject-Dependent | Subject-Independent | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Dataset | Sensor | mla | PIM | (E)PSM | PIM | PSM | EPSM | WEPSM | WEPSM |
| FUSION | wrist | gbt | 97.9 ± 0.3 | 97.6 ± 0.4 | 92.4 ± 2.2 | 81.4 ± 2.1 | 90.6 ± 2.6 | 90.7 ± 2.5 | 90.2 ± 2.6 |
| knn | 94.0 ± 0.9 | 94.2 ± 1.0 | 85.9 ± 2.0 | 74.9 ± 2.6 | 87.5 ± 2.8 | 87.5 ± 2.8 | 87.3 ± 2.8 | ||
| logreg | 96.7 ± 0.6 | 97.4 ± 0.4 | 91.9 ± 2.1 | 79.4 ± 2.7 | 89.5 ± 2.8 | 89.5 ± 2.8 | 89.0 ± 2.7 | ||
| svm | 98.0 ± 0.3 | 97.8 ± 0.4 | 90.9 ± 2.1 | 80.0 ± 2.3 | 90.3 ± 2.7 | 90.4 ± 2.7 | 90.0 ± 2.6 | ||
| MHEALTH | wrist | gbt | 97.5 ± 0.8 | 97.2 ± 1.2 | 82.4 ± 3.6 | 59.5 ± 2.3 | 72.2 ± 3.5 | 72.4 ± 3.4 | 71.5 ± 3.5 |
| knn | 92.9 ± 1.3 | 93.7 ± 1.4 | 76.1 ± 3.1 | 56.0 ± 2.1 | 71.4 ± 2.6 | 71.6 ± 2.6 | 72.8 ± 2.5 | ||
| logreg | 93.2 ± 1.4 | 95.8 ± 1.4 | 78.9 ± 3.3 | 54.1 ± 2.4 | 70.0 ± 2.9 | 70.2 ± 2.9 | 70.8 ± 2.9 | ||
| svm | 95.5 ± 1.0 | 96.8 ± 1.0 | 82.0 ± 2.6 | 58.0 ± 2.1 | 72.0 ± 3.9 | 72.1 ± 3.9 | 71.4 ± 4.0 | ||
| OPPORT | wrist | gbt | 81.5 ± 2.8 | 83.5 ± 2.4 | 69.0 ± 7.2 | 57.9 ± 5.8 | 66.5 ± 8.1 | 66.2 ± 8.4 | 66.7 ± 7.9 |
| knn | 71.1 ± 2.7 | 74.8 ± 2.7 | 51.4 ± 4.2 | 42.9 ± 3.3 | 54.5 ± 5.4 | 53.6 ± 5.1 | 54.8 ± 4.6 | ||
| logreg | 71.9 ± 3.7 | 76.7 ± 3.0 | 59.9 ± 7.0 | 46.2 ± 3.4 | 56.7 ± 6.7 | 56.4 ± 7.0 | 57.2 ± 6.4 | ||
| svm | 80.3 ± 2.6 | 81.0 ± 2.4 | 65.4 ± 6.7 | 48.4 ± 2.8 | 61.7 ± 6.6 | 61.3 ± 7.0 | 62.3 ± 6.2 | ||
| PAMAP2 | chest | gbt | 87.5 ± 0.5 | 87.7 ± 0.6 | 77.4 ± 4.3 | 54.7 ± 2.9 | 72.4 ± 4.1 | 72.9 ± 4.2 | 72.0 ± 3.8 |
| knn | 75.5 ± 1.0 | 78.4 ± 1.2 | 63.7 ± 2.5 | 49.0 ± 1.8 | 67.7 ± 3.2 | 68.2 ± 3.4 | 66.3 ± 3.1 | ||
| logreg | 82.5 ± 1.0 | 85.4 ± 0.9 | 72.2 ± 3.8 | 48.8 ± 2.4 | 69.4 ± 4.9 | 69.4 ± 4.9 | 68.6 ± 4.8 | ||
| svm | 86.0 ± 0.7 | 85.1 ± 0.8 | 73.7 ± 4.5 | 49.7 ± 2.6 | 69.4 ± 5.1 | 70.0 ± 5.1 | 68.5 ± 5.1 | ||
| PAMAP2 | wrist | gbt | 86.8 ± 1.1 | 86.0 ± 0.9 | 78.5 ± 2.8 | 56.8 ± 2.3 | 71.7 ± 2.7 | 72.2 ± 2.6 | 72.0 ± 2.8 |
| knn | 77.4 ± 1.5 | 78.9 ± 1.6 | 65.2 ± 4.1 | 47.5 ± 2.7 | 68.1 ± 3.9 | 68.5 ± 4.0 | 67.6 ± 3.8 | ||
| logreg | 82.4 ± 1.7 | 83.5 ± 1.3 | 74.7 ± 4.1 | 49.9 ± 3.5 | 68.8 ± 4.9 | 69.3 ± 4.9 | 69.0 ± 4.8 | ||
| svm | 84.9 ± 1.3 | 83.3 ± 1.3 | 73.1 ± 5.1 | 46.6 ± 3.0 | 68.3 ± 4.5 | 68.8 ± 4.5 | 68.2 ± 4.3 | ||
| REALWORLD | chest | gbt | 93.3 ± 0.6 | 96.1 ± 0.4 | 71.7 ± 4.4 | 37.5 ± 1.9 | 62.7 ± 4.0 | 64.1 ± 3.8 | 63.2 ± 3.9 |
| knn | 85.3 ± 1.5 | 91.3 ± 1.0 | 59.3 ± 3.4 | 37.9 ± 2.4 | 61.8 ± 3.7 | 62.8 ± 3.6 | 62.0 ± 3.8 | ||
| logreg | 83.8 ± 1.8 | 95.4 ± 0.5 | 60.6 ± 5.8 | 30.3 ± 2.1 | 57.1 ± 4.2 | 58.7 ± 4.2 | 57.1 ± 4.3 | ||
| svm | 92.0 ± 0.7 | 95.5 ± 0.4 | 62.2 ± 5.1 | 30.4 ± 2.1 | 54.8 ± 4.5 | 56.5 ± 4.3 | 55.0 ± 4.7 | ||
| SAFESENS | chest | gbt | 93.9 ± 0.9 | 97.0 ± 0.8 | 67.6 ± 3.3 | 27.9 ± 2.0 | 48.9 ± 4.8 | 48.7 ± 5.4 | 53.9 ± 3.3 |
| knn | 81.3 ± 1.9 | 87.8 ± 1.5 | 55.7 ± 3.5 | 30.2 ± 1.7 | 54.7 ± 3.2 | 54.6 ± 3.3 | 54.2 ± 2.7 | ||
| logreg | 78.7 ± 1.6 | 93.1 ± 1.0 | 64.1 ± 3.0 | 27.4 ± 1.8 | 54.0 ± 2.7 | 53.3 ± 2.7 | 54.1 ± 2.8 | ||
| svm | 88.1 ± 1.2 | 95.2 ± 0.8 | 66.9 ± 2.7 | 29.9 ± 1.8 | 51.9 ± 2.6 | 53.0 ± 2.4 | 51.9 ± 2.9 | ||
| SIMFALL | chest | gbt | 57.2 ± 1.2 | 65.9 ± 1.3 | 43.9 ± 1.6 | 19.3 ± 0.7 | 33.5 ± 1.6 | 33.5 ± 1.6 | 32.6 ± 1.5 |
| knn | 45.0 ± 0.9 | 49.5 ± 1.2 | 30.3 ± 0.7 | 19.8 ± 0.6 | 33.3 ± 1.0 | 33.2 ± 1.1 | 32.2 ± 0.9 | ||
| logreg | 38.3 ± 0.9 | 52.3 ± 1.2 | 34.5 ± 1.1 | 14.5 ± 0.5 | 29.1 ± 1.0 | 29.1 ± 1.0 | 28.2 ± 1.0 | ||
| svm | 50.1 ± 0.7 | 49.5 ± 1.6 | 38.2 ± 1.4 | 14.1 ± 0.4 | 25.9 ± 1.0 | 26.2 ± 0.9 | 24.8 ± 1.0 | ||
| SIMFALL | wrist | gbt | 55.4 ± 1.5 | 62.7 ± 1.5 | 40.8 ± 2.3 | 19.1 ± 1.0 | 32.9 ± 2.2 | 33.0 ± 2.2 | 32.0 ± 2.2 |
| knn | 44.6 ± 1.2 | 48.8 ± 1.2 | 29.2 ± 1.5 | 19.2 ± 1.0 | 31.8 ± 1.6 | 31.9 ± 1.6 | 31.0 ± 1.6 | ||
| logreg | 37.3 ± 1.4 | 49.6 ± 1.3 | 32.7 ± 2.1 | 16.2 ± 0.9 | 27.9 ± 1.7 | 28.4 ± 1.7 | 27.6 ± 1.8 | ||
| svm | 48.2 ± 1.3 | 45.9 ± 1.5 | 36.0 ± 2.3 | 13.7 ± 0.7 | 27.1 ± 1.5 | 27.3 ± 1.6 | 26.5 ± 1.7 | ||
| UTSMOKE | wrist | gbt | 80.9 ± 1.5 | 90.8 ± 0.9 | 68.7 ± 2.9 | 54.8 ± 1.8 | 65.4 ± 3.2 | 65.4 ± 3.3 | 65.3 ± 3.1 |
| knn | 76.3 ± 1.3 | 81.2 ± 1.2 | 61.6 ± 2.4 | 50.8 ± 1.7 | 60.7 ± 2.8 | 60.8 ± 2.9 | 60.5 ± 2.7 | ||
| logreg | 68.9 ± 2.1 | 84.1 ± 1.2 | 63.2 ± 2.5 | 50.5 ± 1.6 | 59.4 ± 2.5 | 59.4 ± 2.5 | 59.6 ± 2.4 | ||
| svm | 83.6 ± 1.3 | 89.1 ± 0.9 | 69.2 ± 2.7 | 52.9 ± 1.8 | 63.6 ± 2.9 | 63.8 ± 3.0 | 63.8 ± 2.7 | ||
| Coefficient | 2.5% | β | 97.5% | p |
|---|---|---|---|---|
| (Intercept) | 1.425 | 2.129 | 2.833 | 3.1 × 10−9 |
| kNN | −0.628 | −0.616 | −0.604 | <2.0 × 10−16 |
| logreg | −0.620 | −0.608 | −0.596 | <2.0 × 10−16 |
| SVM | −0.229 | −0.217 | −0.204 | <2.0 × 10−16 |
| PSM | 0.155 | 0.361 | 0.566 | 5.78 × 10−4 |
| Coefficient | 2.5% | β | 97.5% | p |
|---|---|---|---|---|
| (Intercept) | 0.367 | 0.907 | 1.448 | 1.00 × 10−3 |
| kNN | −0.231 | −0.225 | −0.219 | <2.0 × 10−16 |
| logreg | −0.251 | −0.245 | −0.239 | <2.0 × 10−16 |
| SVM | −0.178 | −0.172 | −0.166 | <2.0 × 10−16 |
| PSM | −0.825 | −0.818 | −0.812 | <2.0 × 10−16 |
| EPSM | −0.199 | −0.193 | −0.186 | <2.0 × 10−16 |
| WEPSM | −0.186 | −0.179 | −0.172 | <2.0 × 10−16 |
| WEPSM | −0.210 | −0.203 | −0.196 | <2.0 × 10−16 |
| Coefficient | 2.5% | β | 97.5% | p |
|---|---|---|---|---|
| (Intercept) | 0.930 | 1.530 | 2.130 | 5.83 × 10−7 |
| PSM/(E)PSM | 0.371 | 0.379 | 0.387 | <2.0 × 10−16 |
| SI | −0.739 | −0.732 | −0.725 | <2.0 × 10−16 |
| SI + EPSM | −0.586 | −0.575 | −0.564 | <2.0 × 10−16 |
| SI + PSM | −1.272 | −1.261 | −1.250 | <2.0 × 10−16 |
| SI + WEPSM | −0.572 | −0.561 | −0.551 | <2.0 × 10−16 |
| SI + WEPSM | −0.595 | −0.584 | −0.574 | <2.0 × 10−16 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Scheurer, S.; Tedesco, S.; O’Flynn, B.; Brown, K.N. Comparing Person-Specific and Independent Models on Subject-Dependent and Independent Human Activity Recognition Performance. Sensors 2020, 20, 3647. https://doi.org/10.3390/s20133647
Scheurer S, Tedesco S, O’Flynn B, Brown KN. Comparing Person-Specific and Independent Models on Subject-Dependent and Independent Human Activity Recognition Performance. Sensors. 2020; 20(13):3647. https://doi.org/10.3390/s20133647
Chicago/Turabian StyleScheurer, Sebastian, Salvatore Tedesco, Brendan O’Flynn, and Kenneth N. Brown. 2020. "Comparing Person-Specific and Independent Models on Subject-Dependent and Independent Human Activity Recognition Performance" Sensors 20, no. 13: 3647. https://doi.org/10.3390/s20133647
APA StyleScheurer, S., Tedesco, S., O’Flynn, B., & Brown, K. N. (2020). Comparing Person-Specific and Independent Models on Subject-Dependent and Independent Human Activity Recognition Performance. Sensors, 20(13), 3647. https://doi.org/10.3390/s20133647