Few-Shot Rolling Bearing Fault Diagnosis with Metric-Based Meta Learning

Abstract
:1. Introduction
- (1)
- Based on signal processing and conventional machine learning methods, a large number of manual feature extraction operations are required, which cannot adapt well to the complex dynamic system of bearing vibration signals;
- (2)
- Conventional machine learning methods cannot learn the nonlinear relationships in the system;
- (3)
- Artificial feature extractor and expert systems cannot extract fault features well against changing scenario data, and sufficient expert knowledge of signal processing is usually required, which is not convenient for industrial applications.
- Propose a metric-based few-shot meta learning method for bearing fault diagnosis;
- Label smoothing is adopted to alleviate over-fitting and improve generalization in few-shot learning;
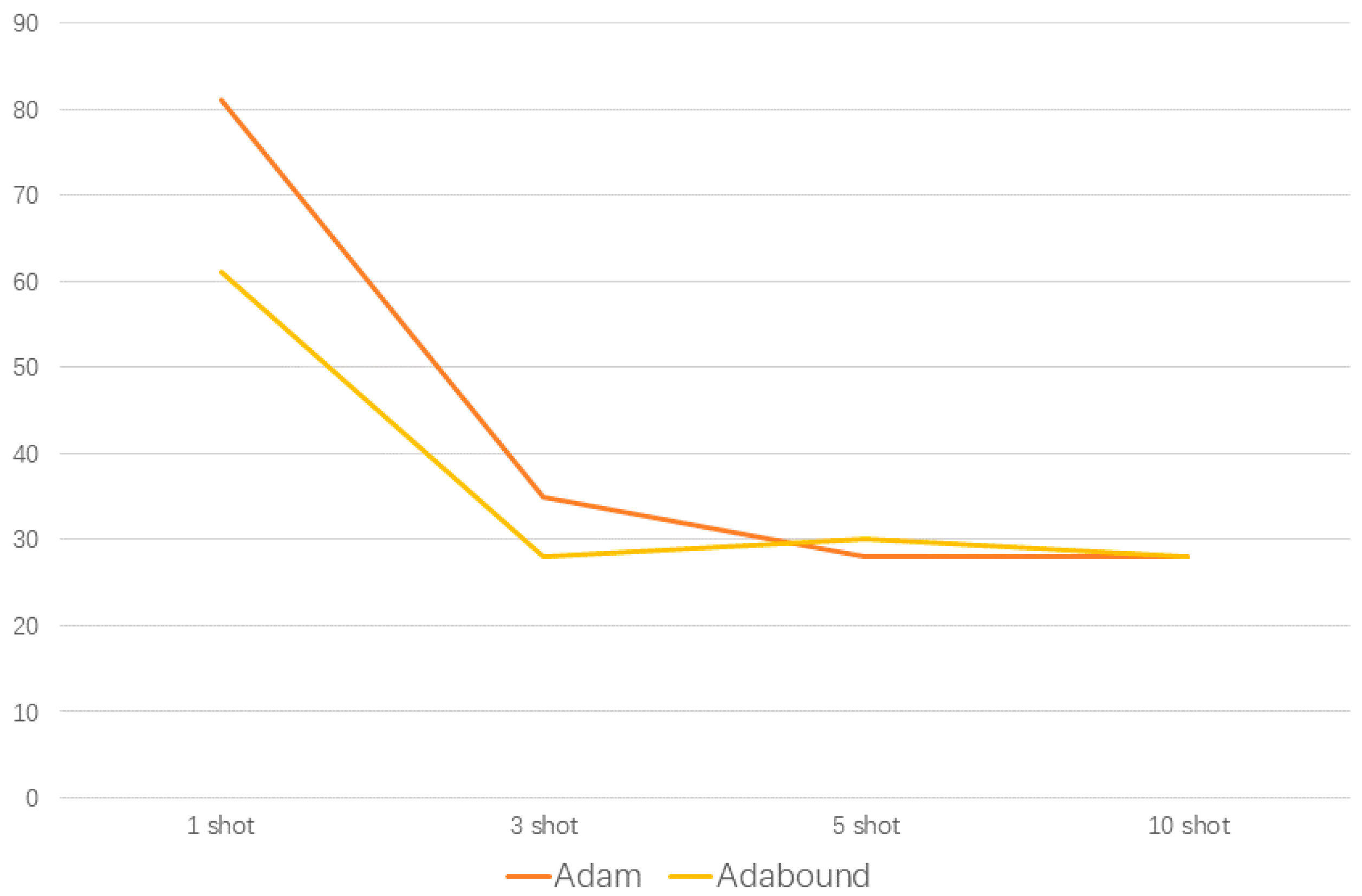
- Adabound is first introduced in fault diagnosis, which can converge faster and obtain higher accuracy.
2. Background
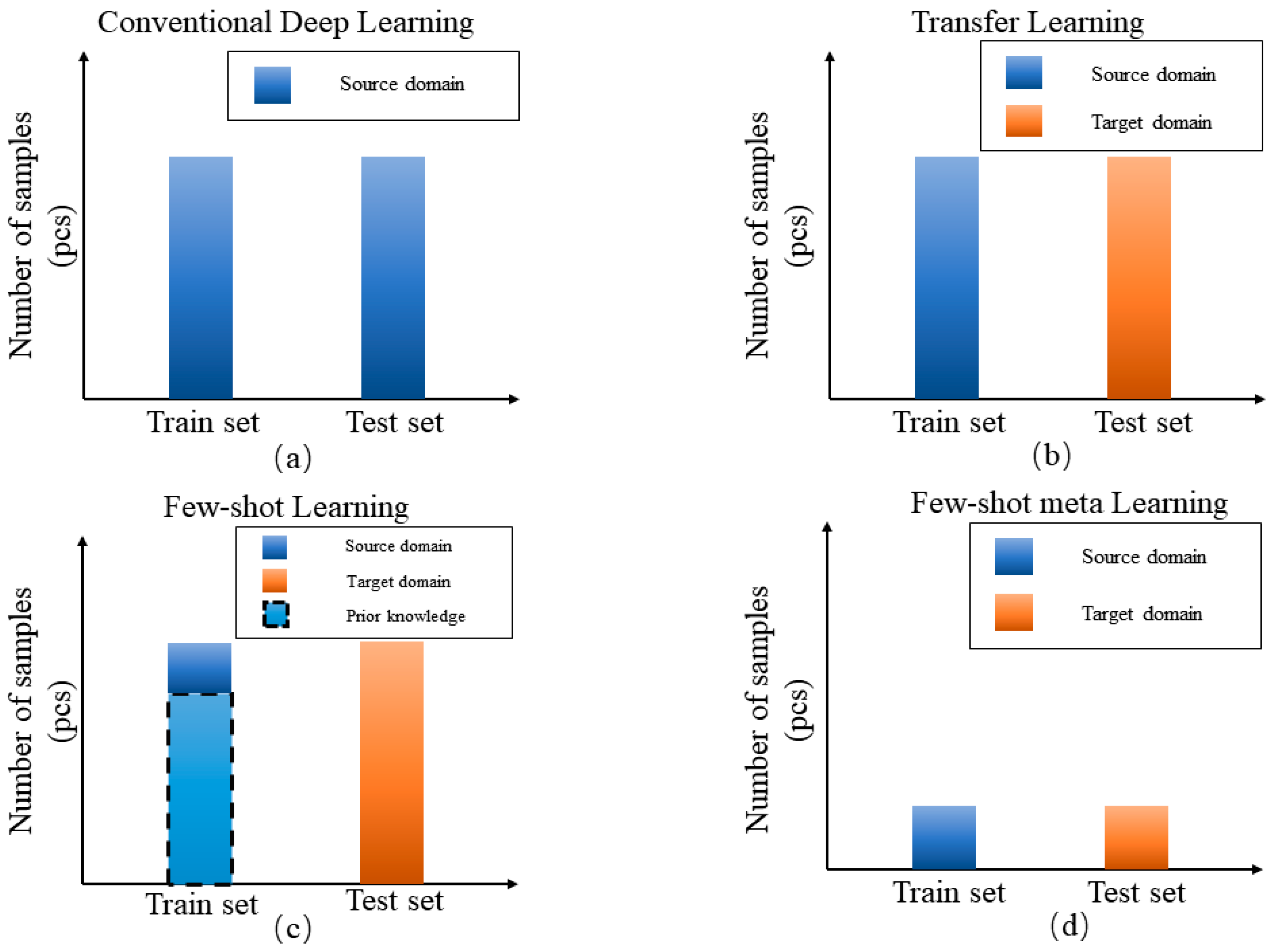
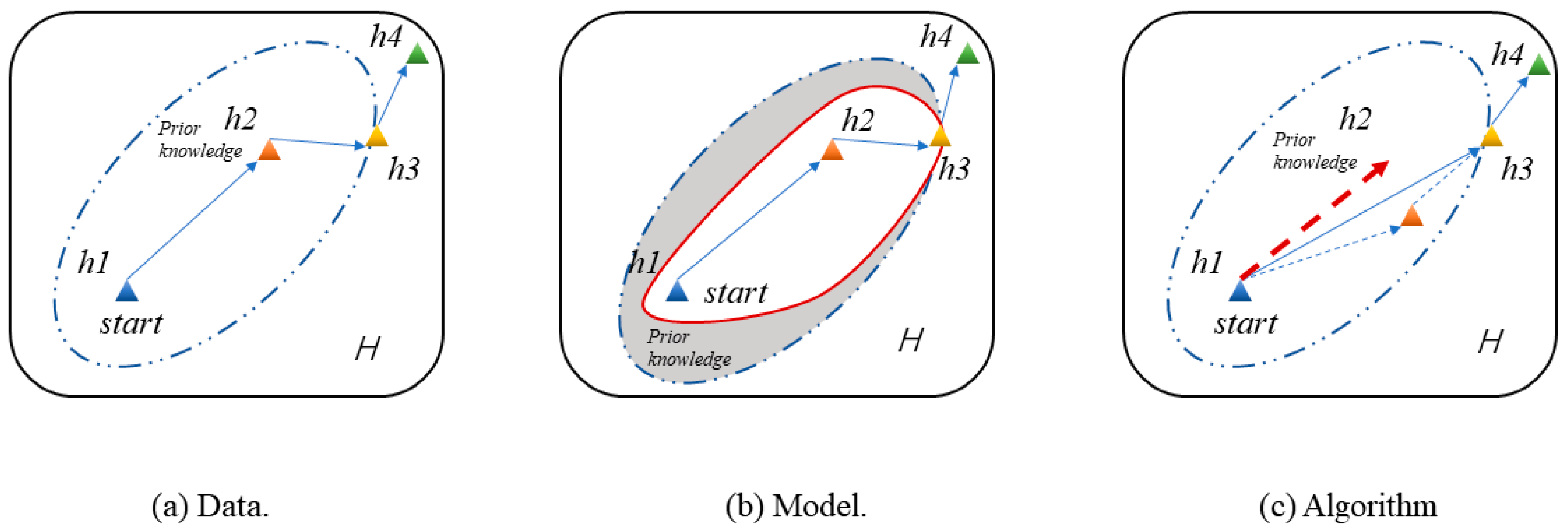
2.1. Few-Shot Learning
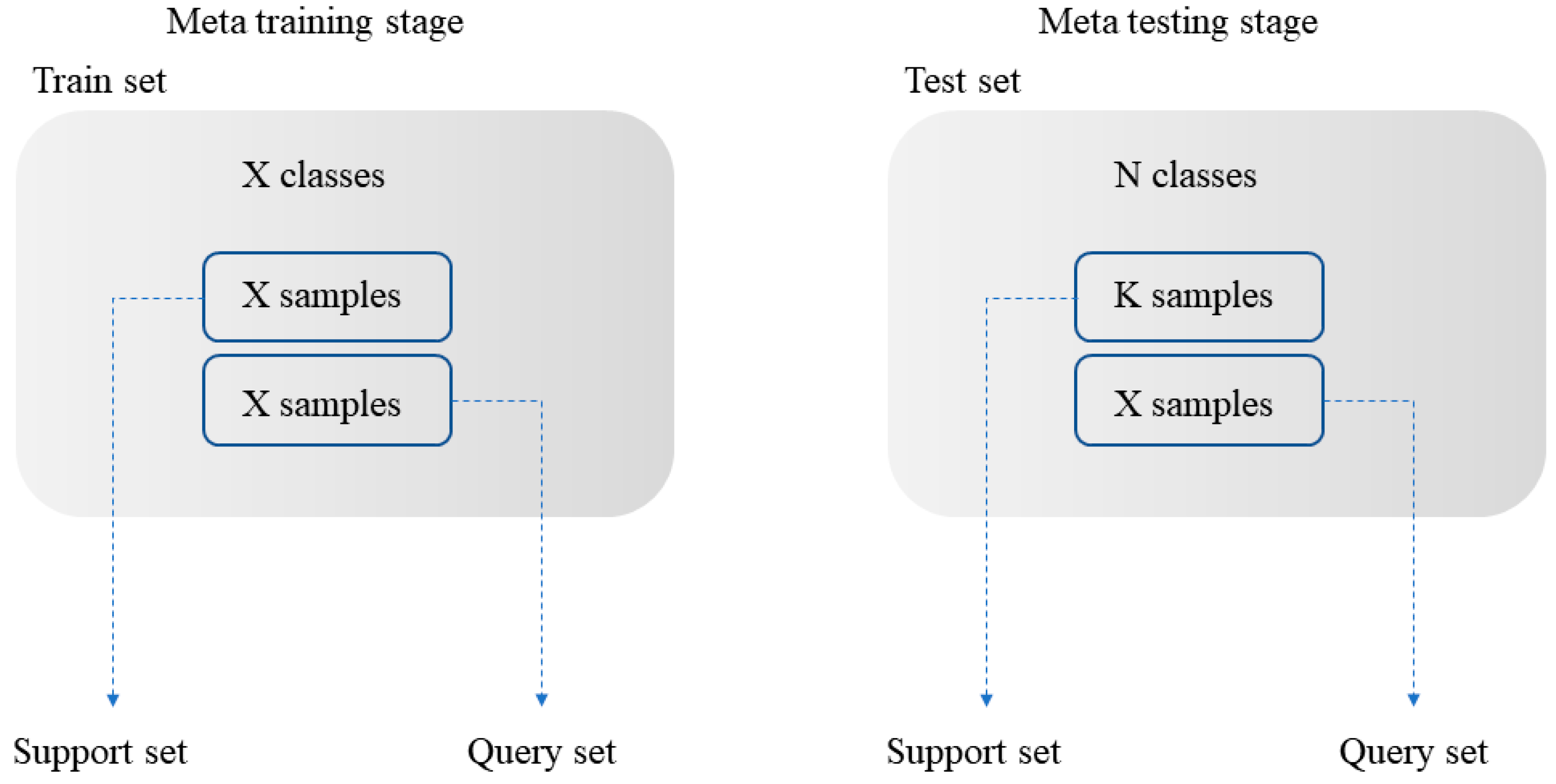
2.2. Few-Shot Meta Learning
3. Model Framework
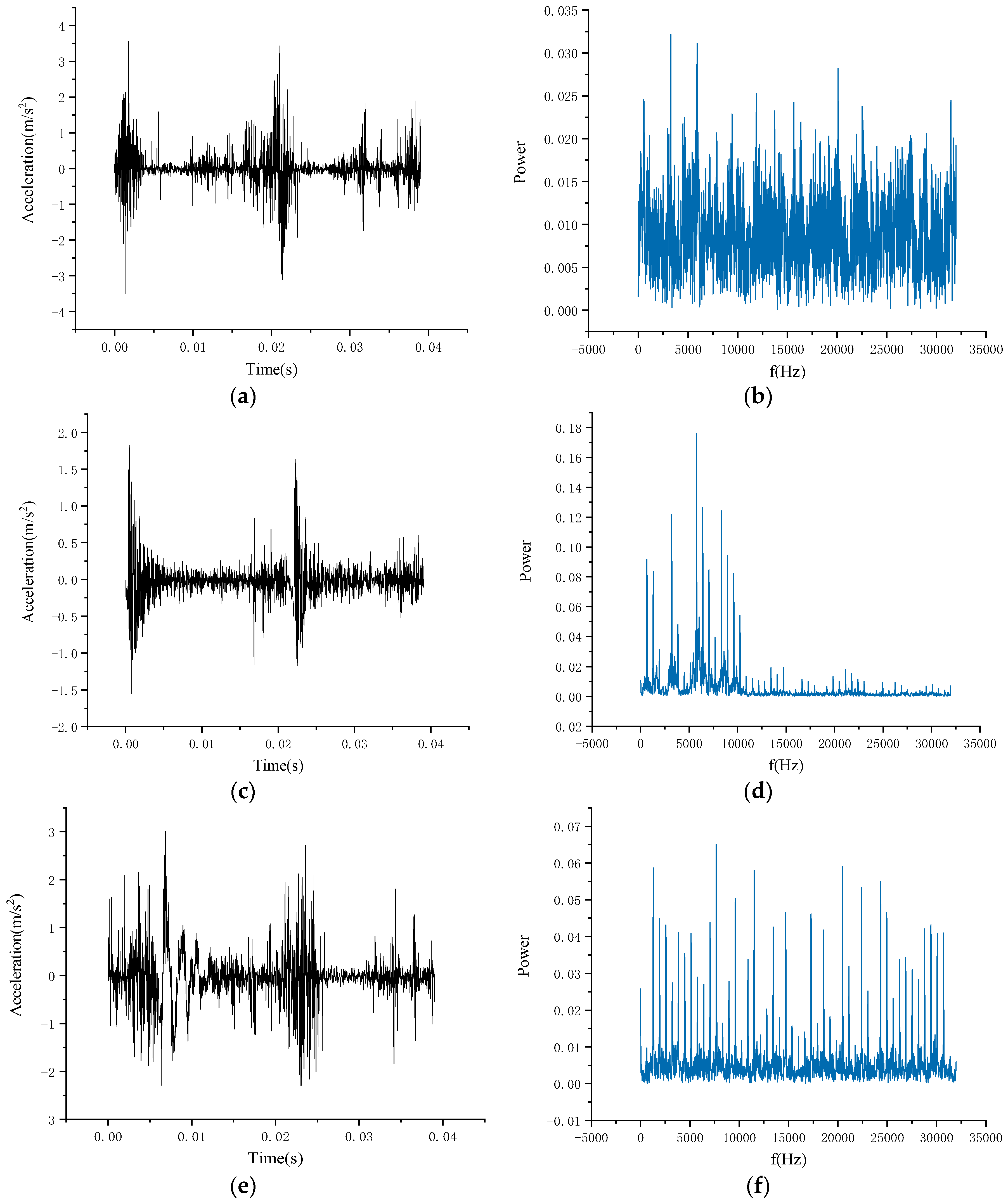
3.1. Data Preprocessing
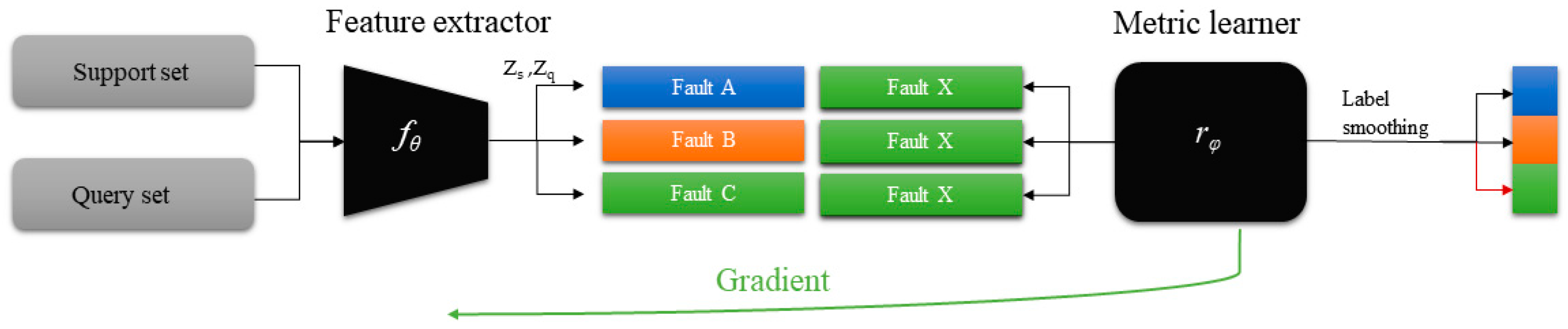
3.2. Network Structure
3.3. Methods
3.3.1. Transfer Learning
3.3.2. Few-Shot Meta-Learning
4. Label Smoothing and Adabound
4.1. Label Smoothing
4.2. Adabound
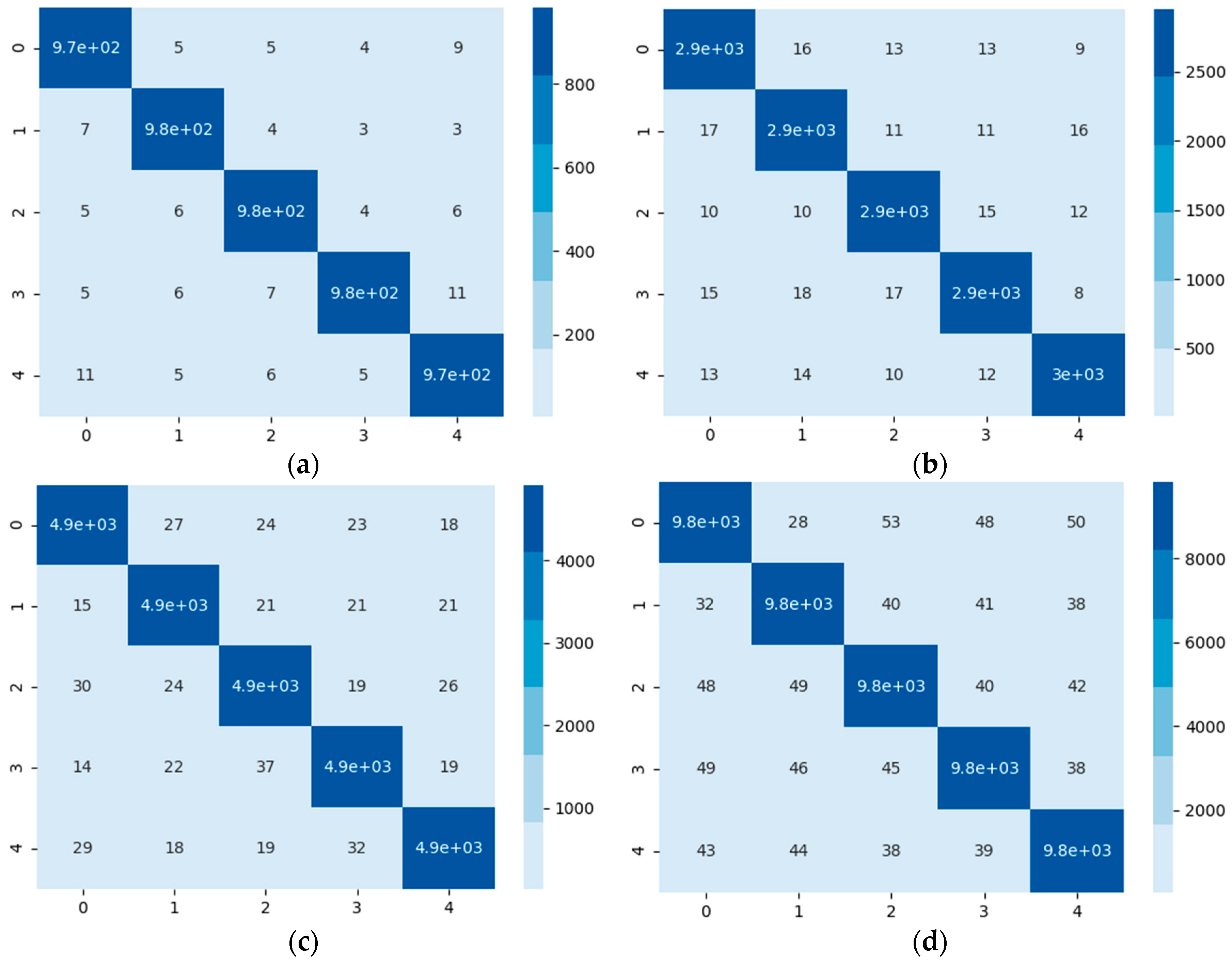
5. Case Study
6. Conclusions
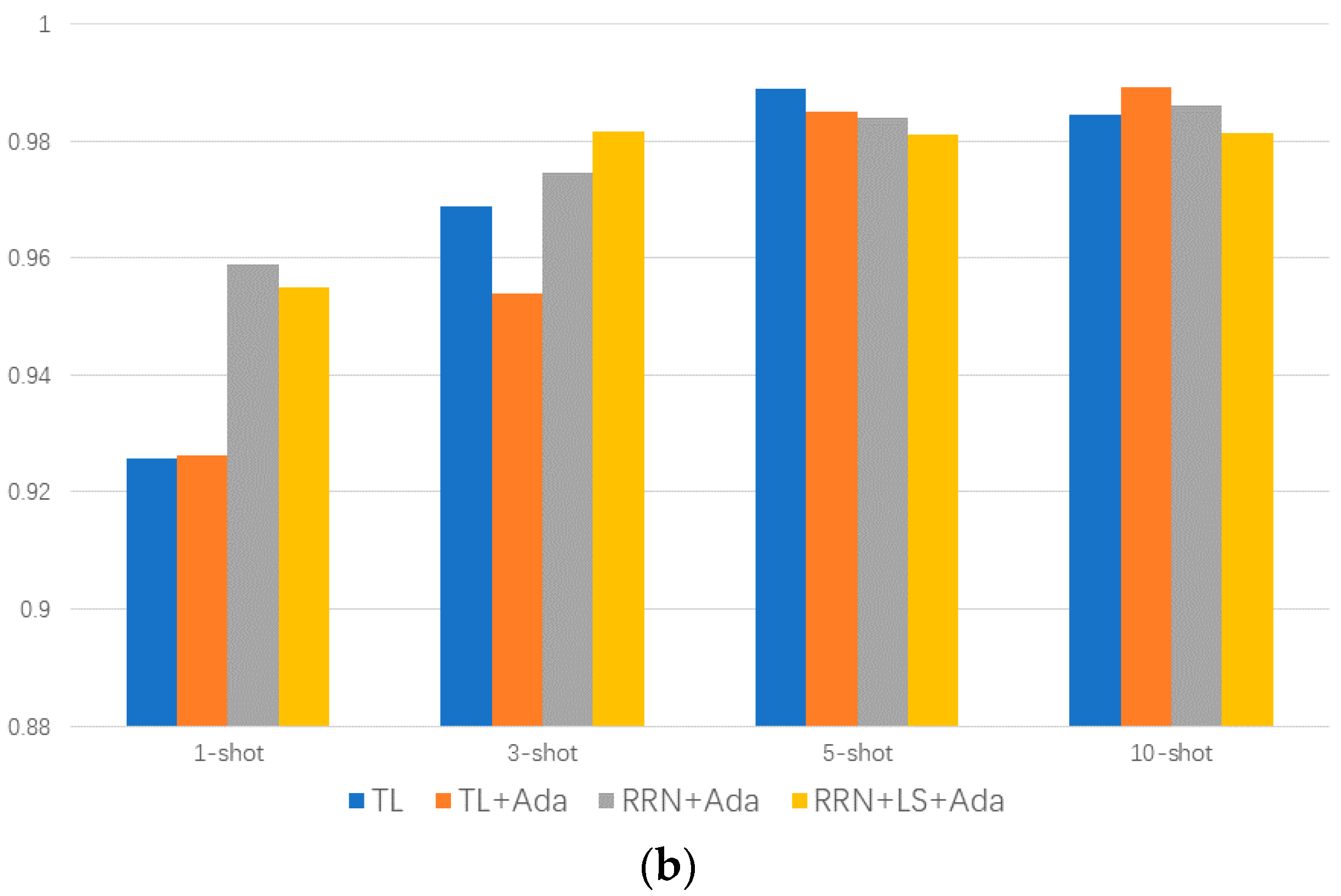
- A metric-based, few-shot, meta-learning framework is designed for bearing fault diagnosis, which is more suitable for a few-shot transfer scenario from the experimental situation to the actual working situation;
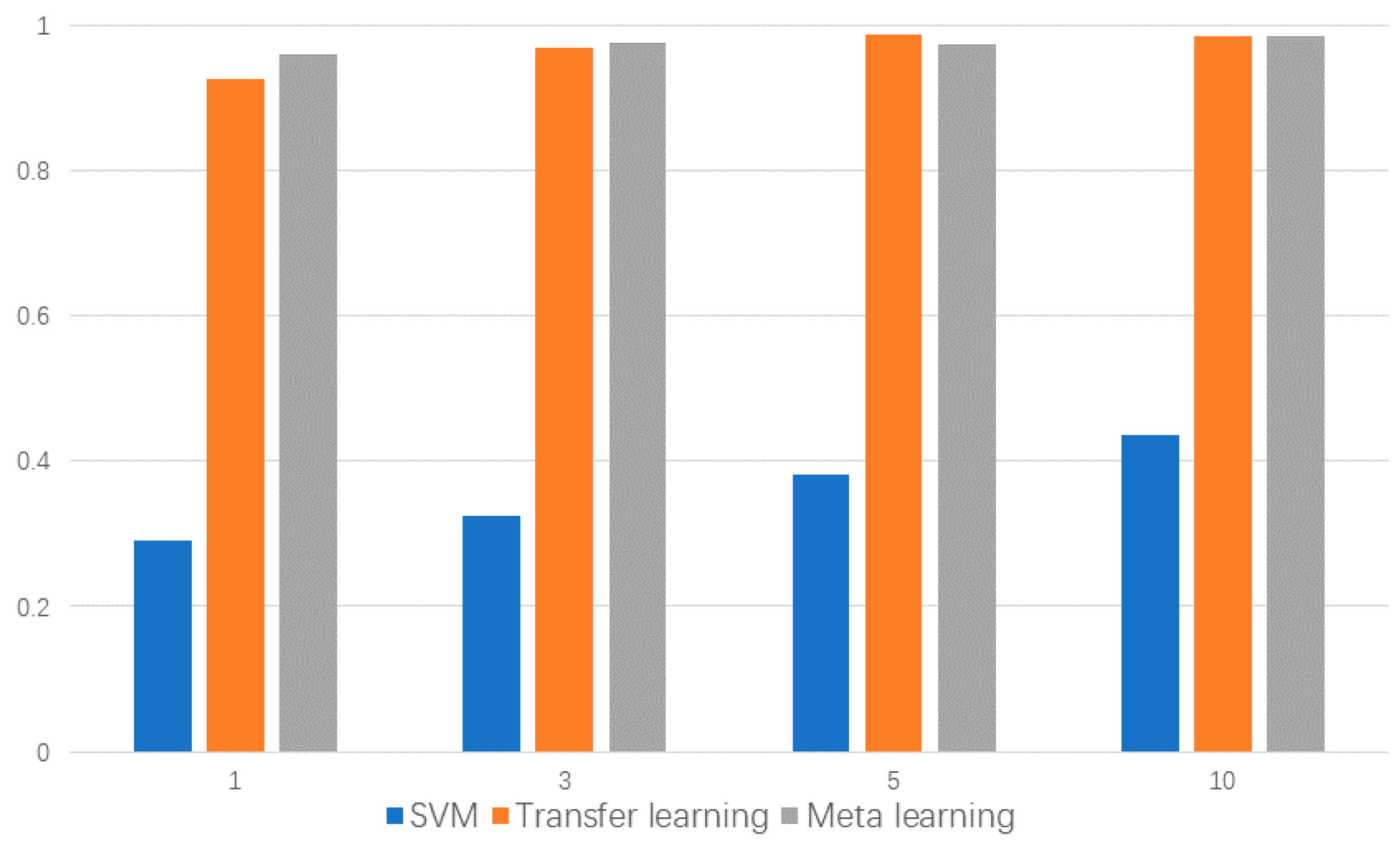
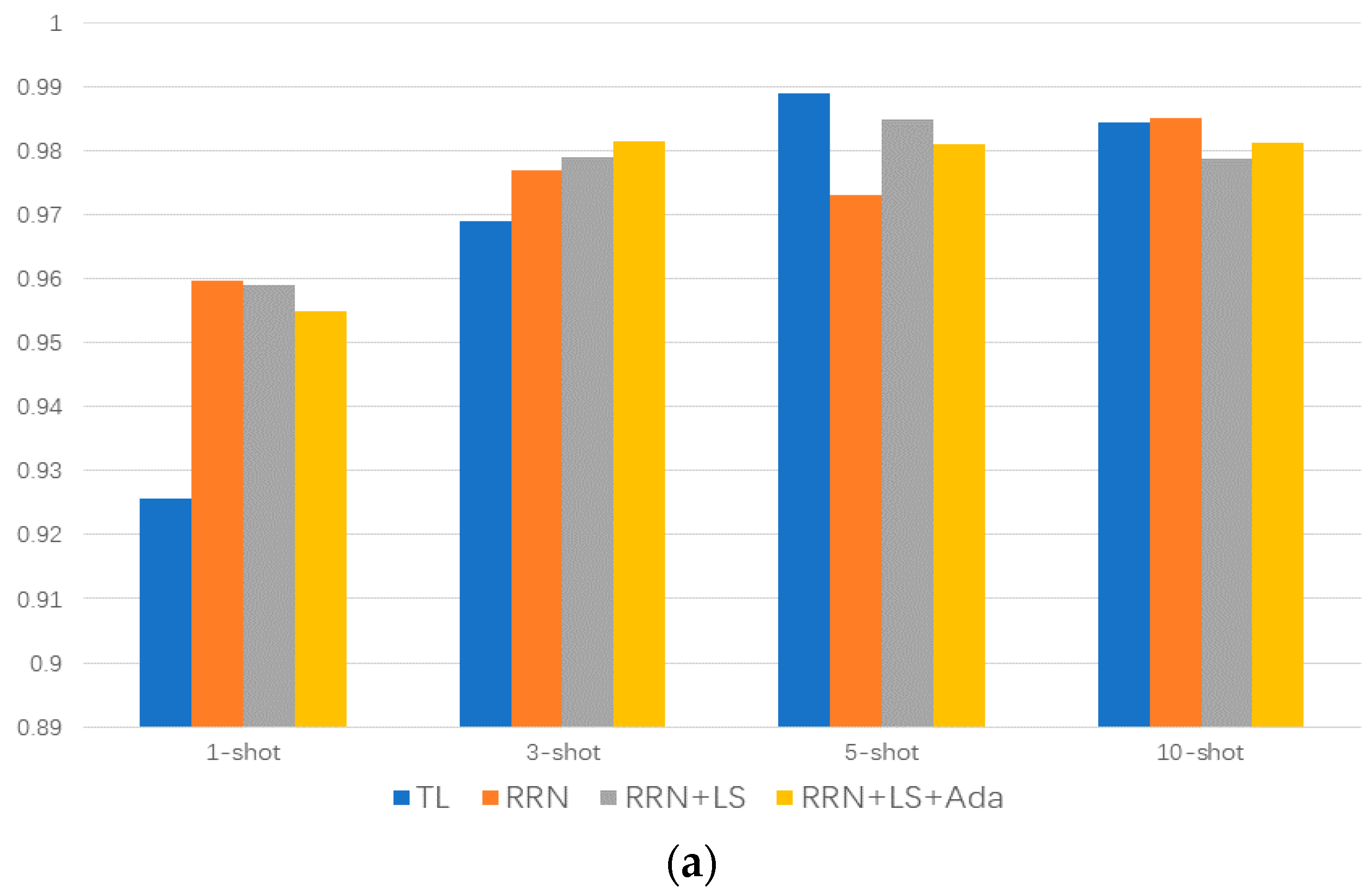
- Comparison analysis among the designed few-shot meta-learning method and fine-tuning-based transfer-learning method is performed, showing that the proposed method has a better performance in the case of extreme data absence. The proposed method is 5% more accurate than the conventional transfer learning method and 65% higher than the conventional statistical method in extremely few-shot scenarios;
- The label smoothing regularization method and Adabound optimizer can inhibit the overfitting in the learning process of small sample elements. The Adabound optimizer can help the model learn the data feature more quickly, and reduce mode training by up to 20 episodes.
Author Contributions
Funding
Conflicts of Interest
References
- Yu, Y.; Junsheng, C. A roller bearing fault diagnosis method based on EMD energy entropy and ANN. J. Sound Vib. 2006, 294, 269–277. [Google Scholar] [CrossRef]
- Ni, J.; Zhang, C.; Yang, S.X. An Adaptive Approach Based on KPCA and SVM for Real-Time Fault Diagnosis of HVCBs. IEEE Trans. Power Deliv. 2011, 26, 1960–1971. [Google Scholar] [CrossRef]
- Malhi, A.; Gao, R.X. PCA-based feature selection scheme for machine defect classification. IEEE Trans. Instrum. Meas. 2004, 53, 1517–1525. [Google Scholar] [CrossRef]
- You, D.; Gao, X.; Katayama, S. Multisensor Fusion System for Monitoring High-Power Disk Laser Welding Using Support Vector Machine. IEEE Trans. Ind. Inform. 2014, 10, 1285–1295. [Google Scholar]
- Wang, D. K-nearest neighbors based methods for identification of different gear crack levels under different motor speeds and loads: Revisited. Mech. Syst. Signal Process. 2016, 70–71, 201–208. [Google Scholar] [CrossRef]
- Shevchik, S.A.; Saeidi, F.; Meylan, B.; Wasmer, K. Prediction of Failure in Lubricated Surfaces Using Acoustic Time–Frequency Features and Random Forest Algorithm. IEEE Trans. Ind. Inform. 2016, 13, 1541–1553. [Google Scholar] [CrossRef]
- Ren, Z.; Zhou, S.; Chunhui, E.; Gong, M.; Li, B.; Wen, B. Crack fault diagnosis of rotor systems using wavelet transforms. Comput. Electr. Eng. 2015, 45, 33–41. [Google Scholar] [CrossRef]
- Yan, X.; Jia, M.; Zhang, W.; Zhu, L. Fault diagnosis of rolling element bearing using a new optimal scale morphology analysis method. ISA Trans. 2018, 73, 165–180. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; Zhang, W.; Ding, Q.; Sun, J.-Q. Multi-Layer domain adaptation method for rolling bearing fault diagnosis. Signal Process. 2019, 157, 180–197. [Google Scholar] [CrossRef] [Green Version]
- Liu, H.; Zhou, J.; Zheng, Y.; Jiang, W.; Zhang, Y. Fault diagnosis of rolling bearings with recurrent neural network-based autoencoders. ISA Trans. 2018, 77, 167–178. [Google Scholar] [CrossRef]
- Hua, G.; Lia, H.; Xia, Y.; Luo, L. A deep Boltzmann machine and multi-grained scanning forest ensemble collaborative method and its application to industrial fault diagnosis. Comput. Ind. 2018, 100, 287–296. [Google Scholar] [CrossRef]
- Shao, H.; Jiang, H.; Zhao, H.; Wang, F. A novel deep autoencoder feature learning method for rotating machinery fault diagnosis. Mech. Syst. Signal Process. 2017, 95, 187–204. [Google Scholar] [CrossRef]
- Zhang, W. A deep convolutional neural network with new training methods for bearing fault diagnosis under noisy environment and different working load. Mech. Syst. Signal Process. 2018, 100, 439–453. [Google Scholar] [CrossRef]
- Janssens, O. Convolutional Neural Network Based Fault Detection for Rotating Machinery. J. Sound Vib. 2016, 377, 331–345. [Google Scholar] [CrossRef]
- Guo, X.; Chen, L.; Shen, C. Hierarchical adaptive deep convolution neural network and its application to bearing fault diagnosis. Measurement 2016, 93, 490–502. [Google Scholar] [CrossRef]
- Jing, L.; Zhao, M.; Li, P.; Xu, X. A convolutional neural network based feature learning and fault diagnosis method for the condition monitoring of gearbox. Measurement 2017, 111, 1–10. [Google Scholar] [CrossRef]
- Chen, Z.; Li, C.; Sanchez, R.-V. Gearbox Fault Identification and Classification with Convolutional Neural Networks. Shock Vib. 2015, 2015, 390134. [Google Scholar] [CrossRef] [Green Version]
- Jiang, G.; He, H.; Yan, J.; Xie, P. Multiscale Convolutional Neural Networks for Fault Diagnosis of Wind Turbine Gearbox. IEEE Trans. Ind. Electron. 2019, 66, 3196–3207. [Google Scholar] [CrossRef]
- Li, X.; Zhang, W.; Xu, N.-X.; Ding, Q. Deep Learning-Based Machinery Fault Diagnostics with Domain Adaptation across Sensors at Different Places. IEEE Trans. Ind. Electron. 2020, 67, 6785–6794. [Google Scholar] [CrossRef]
- Zhang, W.; Li, X.; Ding, Q. Deep residual learning-based fault diagnosis method for rotating machinery. ISA Trans. 2019, 95, 295–305. [Google Scholar] [CrossRef]
- Bendre, N.; Marín, H.T.; Najafirad, P. Learning from Few Samples: A Survey. arXiv 2020, arXiv:2007.15484. [Google Scholar]
- Sun, Q.; Liu, Y.; Chua, T.-S.; Schiele, B. Meta-Transfer Learning for Few-Shot Learning. arXiv 2019, arXiv:1812.02391. [Google Scholar]
- Wang, Y.; Yao, Q.; Kwok, J.; Ni, L.M. Generalizing from a Few Examples: A Survey on Few-Shot Learning. arXiv 2020, arXiv:1904.05046. [Google Scholar] [CrossRef]
- Zhang, W.; Peng, G.; Li, C.; Chen, Y.; Zhang, Z. A New Deep Learning Model for Fault Diagnosis with Good Anti-Noise and Domain Adaptation Ability on Raw Vibration Signals. Sensors 2017, 17, 425. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; Zhang, W.; Ding, Q. Cross-Domain Fault Diagnosis of Rolling Element Bearings Using Deep Generative Neural Networks. IEEE Trans. Ind. Electron. 2019, 66, 5525–5534. [Google Scholar] [CrossRef]
- Gao, Y.; Liu, X.; Huang, H.; Xiang, J. A hybrid of FEM simulations and generative adversarial networks to classify faults in rotor-bearing systems. ISA Trans. 2020. [Google Scholar] [CrossRef] [PubMed]
- Cubuk, E.D.; Zoph, B.; Mane, D.; Vasudevan, V.; Le, Q.V. AutoAugment: Learning Augmentation Strategies from Data. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–21 June 2019; pp. 113–123. [Google Scholar]
- Benaim, S.; Wolf, L. One-Shot Unsupervised Cross Domain Translation. In Proceedings of the 2018 Thirty-second Conference on Neural Information Processing Systems, Montreal, QC, Canada, 2–8 December 2018; pp. 2104–2114. [Google Scholar]
- Jia, Y.; Shelhamer, E.; Donahue, J.; Karayev, S.; Long, J.; Girshick, R.; Guadarrama, S.; Darrell, T. Caffe: Convolutional Architecture for Fast Feature Embedding. In Proceedings of the ACM International Conference on Multimedia-MM ’14, Orlando, FL, USA, 3–7 November 2014; pp. 675–678. [Google Scholar]
- Zhang, A.; Li, S.; Cui, Y.; Yang, W.; Dong, R.; Hu, J. Limited Data Rolling Bearing Fault Diagnosis With Few-Shot Learning. IEEE Access 2019, 7, 110895–110904. [Google Scholar] [CrossRef]
- Sung, F.; Yang, Y.; Zhang, L.; Xiang, T.; Torr, P.H.S.; Hospedales, T.M. Learning to Compare: Relation Network for Few-Shot Learning. arXiv 2018, arXiv:1711.06025. [Google Scholar]
- Snell, J.; Swersky, K.; Zemel, R.S. Prototypical Networks for Few-shot Learning. arXiv 2017, arXiv:1703.05175. [Google Scholar]
- Hinton, G.E.; Osindero, S.; Teh, Y.-W. A Fast Learning Algorithm for Deep Belief Nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef]
- Zhang, S.; Ye, F.; Wang, B.; Habetler, T.G. Few-Shot Bearing Anomaly Detection Based on Model-Agnostic Meta-Learning. arXiv 2020, arXiv:2007.12851. [Google Scholar]
- Nichol, A.; Achiam, J.; Schulman, J. On First-Order Meta-Learning Algorithms. arXiv 2018, arXiv:1803.02999. [Google Scholar]
- Fei, N.; Lu, Z.; Gao, Y.; Tian, J.; Xiang, T.; Wen, J.-R. Meta-Learning across Meta-Tasks for Few-Shot Learning. arXiv 2020, arXiv:2002.04274. [Google Scholar]
- Li, Z.; Zhou, F.; Chen, F.; Li, H. Meta-SGD: Learning to Learn Quickly for Few-Shot Learning. arXiv 2017, arXiv:1707.09835. [Google Scholar]
- Ravi, S.; Larochelle, H. Optimization as a model for few-shot learning. In Proceedings of the 2017 5th International Conference on Learning Representations, Toulon, France, 24–26 April 2017; pp. 1–11. [Google Scholar]
- Peng, D.; Wang, H.; Liu, Z.; Zhang, W.; Zuo, M.J.; Chen, J. Multibranch and Multiscale CNN for Fault Diagnosis of Wheelset Bearings under Strong Noise and Variable Load Condition. IEEE Trans. Ind. Inf. 2020, 16, 4949–4960. [Google Scholar] [CrossRef]
- Liu, Y.; Jiang, Z.; Xiang, J. An Adaptive Cross-Validation Thresholding De-Noising Algorithm for Fault Diagnosis of Rolling Element Bearings Under Variable and Transients Conditions. IEEE Access 2020, 8, 67501–67518. [Google Scholar] [CrossRef]
- Wu, J.; Zhao, Z.; Sun, C.; Yan, R.; Chen, X. Few-shot transfer learning for intelligent fault diagnosis of machine. Measurement 2020, 166, 108202. [Google Scholar] [CrossRef]
- Chen, W.-Y.; Liu, Y.-C.; Kira, Z.; Wang, Y.-C.F.; Huang, J.-B. A Closer Look at Few-shot Classification. arXiv 2020, arXiv:1904.04232. [Google Scholar]
- Müller, R.; Kornblith, S.; Hinton, G. When Does Label Smoothing Help? arXiv 2020, arXiv:1906.02629. [Google Scholar]
- Luo, L.; Xiong, Y.; Liu, Y.; Sun, X. Adaptive gradient methods with dynamic bound of learning rate. In Proceedings of the 2019 7th International Conference for Learning Representations, New Orleans, LA, USA, 6–9 May 2019; p. 21. [Google Scholar]
- Lessmeier, C.; Kimotho, J.K.; Zimmer, D.; Sextro, W. Condition Monitoring of Bearing Damage in Electromechanical Drive Systems by Using Motor Current Signals of Electric Motors: A Benchmark Data Set for Data-Driven Classification. In Proceedings of the European Conference of the Prognostics and Health Management Society, Bilbao, Spain, 5–8 July 2016; p. 17. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Bearing Name | Fault Location | Damage | Severity |
|---|---|---|---|
| K001 | Healthy | Healthy | Healthy |
| KA01 | OR | EDM | 1 |
| KA03 | OR | EE | 2 |
| KA05 | OR | EE | 1 |
| KA07 | OR | Drilling | 1 |
| KA08 | OR | Drilling | 2 |
| KI01 | IR | EDM | 1 |
| KI03 | IR | EE | 1 |
| KI07 | IR | EE | 2 |
| KA04 | OR | pitting | 1 |
| KB23 | OR + IR | pitting | 2 |
| KB27 | OR + IR | plastic deform | 1 |
| KI04 | IR | pitting | 1 |
| OR: outer ring | IR: inner ring | ||
| EMD: Electrical discharge machining | |||
| EE: Electric engraver | |||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, S.; Wang, D.; Kong, D.; Wang, J.; Li, W.; Zhou, S. Few-Shot Rolling Bearing Fault Diagnosis with Metric-Based Meta Learning. Sensors 2020, 20, 6437. https://doi.org/10.3390/s20226437
Wang S, Wang D, Kong D, Wang J, Li W, Zhou S. Few-Shot Rolling Bearing Fault Diagnosis with Metric-Based Meta Learning. Sensors. 2020; 20(22):6437. https://doi.org/10.3390/s20226437
Chicago/Turabian StyleWang, Sihan, Dazhi Wang, Deshan Kong, Jiaxing Wang, Wenhui Li, and Shuai Zhou. 2020. "Few-Shot Rolling Bearing Fault Diagnosis with Metric-Based Meta Learning" Sensors 20, no. 22: 6437. https://doi.org/10.3390/s20226437
APA StyleWang, S., Wang, D., Kong, D., Wang, J., Li, W., & Zhou, S. (2020). Few-Shot Rolling Bearing Fault Diagnosis with Metric-Based Meta Learning. Sensors, 20(22), 6437. https://doi.org/10.3390/s20226437