Classification Algorithm for Person Identification and Gesture Recognition Based on Hand Gestures with Small Training Sets


Abstract
:1. Introduction
2. Mathematical Model
- V—number of variables
- v—variable index
- D—number of observations in a sample
- i—observation index in a sample
- J—number of all samples in the data set
- j—sample index in data set
- —the value of the ith observation of vth variable and jth sample.
- C—number of classes
- —label of the class the jth sample belongs to
2.1. Data Definition
2.2. Data Sets
3. New Algorithm
3.1. Training
3.2. Prediction
3.3. Parameter Optimization
3.4. Time Complexity
4. Experiments
4.1. Gestures Data Set
4.2. Experiment Design
4.3. Data Preprocessing
4.4. Methods Evaluation
5. Results
5.1. Parameter Selection
5.2. Efficiency Results
5.3. Performance Results
6. Discussion
7. Conclusions
Supplementary Materials
Funding
Acknowledgments
Conflicts of Interest
References
- Murphy, K.P. Machine Learning: A Probabilistic Perspective, 1st ed.; Adaptive Computation and Machine Learning; The MIT Press: Cambridge, MA, USA, 2012. [Google Scholar]
- Rutkowski, L. Computational Intelligence: Methods and Techniques, 1st ed.; Springer: New York, NY, USA, 2008. [Google Scholar]
- James, G.; Witten, D.; Hastie, T.; Tibshirani, R. An Introduction to Statistical Learning: With Applications in R; Springer: New York, NY, USA, 2014. [Google Scholar]
- Altman, N.S. An introduction to kernel and nearest-neighbor nonparametric regression. Am. Stat. 1992, 46, 175–185. [Google Scholar]
- Specht, D.F. Probabilistic neural networks. Neural Netw. 1990, 3, 109–118. [Google Scholar] [CrossRef]
- Hinton, G.E. Connectionist Learning Procedures. Artif. Intell. 1989, 40, 185–234. [Google Scholar] [CrossRef] [Green Version]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Rasmussen, C.E.; Williams, C.K.I. Gaussian Processes for Machine Learning; Adaptive Computation and Machine Learning; The MIT Press: Cambridge, MA, USA, 2005. [Google Scholar]
- Sugeno, M. Industrial Applications of Fuzzy Control; Elsevier Science Pub. Co.: Amsterdam, The Netherlands, 1985. [Google Scholar]
- Broomhead, D.S.; Lowe, D. Radial Basis Functions, Multi-Variable Functional Interpolation and Adaptive Networks. Complex Syst. 1988, 2, 321–355. [Google Scholar]
- Bromley, J.; Guyon, I.; LeCun, Y.; Säckinger, E.; Shah, R. Signature Verification Using a “Siamese” Time Delay Neural Network. In NIPS’93: Proceedings of the 6th International Conference on Neural Information Processing Systems; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 1993; pp. 737–744. [Google Scholar]
- El-Abed, M.; Giot, R.; Hemery, B.; Rosenberger, C. A study of users’ acceptance and satisfaction of biometric systems. In Proceedings of the 44th Annual 2010 IEEE International Carnahan Conference on Security Technology, San Jose, CA, USA, 5–8 October 2010; pp. 170–178. [Google Scholar] [CrossRef] [Green Version]
- Oh, U.; Findlater, L. The Challenges and Potential of End-User Gesture Customization. In CHI’13: Proceedings of the SIGCHI Conference on Human Factors in Computing Systems; Association for Computing Machinery: New York, NY, USA, 2013; pp. 1129–1138. [Google Scholar] [CrossRef]
- Han, Z.; Ban, X.; Wang, X.; Wu, D. Robust and customized methods for real-time hand gesture recognition under object-occlusion. arXiv 2018, arXiv:1809.05911. [Google Scholar]
- Sriram Krishna, N.S. Gestop: Customizable Gesture Control of Computer Systems. arXiv 2020, arXiv:2010.13197. [Google Scholar]
- Morgado, L. Cultural Awareness and Personal Customization of Gestural Commands Using a Shamanic Interface. Procedia Comput. Sci. 2014, 27, 449–459. [Google Scholar] [CrossRef] [Green Version]
- Ascari, R.E.O.S.; Silva, L.; Pereira, R. Personalized Interactive Gesture Recognition Assistive Technology. In Proceedings of the 18th Brazilian Symposium on Human Factors in Computing Systems, IHC ’19, Vitoria, Brazil, 22–25 October 2019; Association for Computing Machinery: New York, NY, USA, 2019. [Google Scholar] [CrossRef]
- Muralidhar, P.; Saha, A.; Sateesh, P. Customizable Dynamic Hand Gesture recognition System for Motor Impaired people using Siamese neural network. In Proceedings of the 2019 International Conference of Artificial Intelligence and Information Technology (ICAIIT), Yogyakarta, Indonesia, 13–15 March 2019; pp. 354–358. [Google Scholar] [CrossRef]
- Mezari, A.; Maglogiannis, I. An Easily Customized Gesture Recognizer for Assisted Living Using Commodity Mobile Devices. J. Healthc. Eng. 2018, 2018, 3180652. [Google Scholar] [CrossRef] [Green Version]
- Gyöngyössy, N.M.; Domonkos, M.; Botzheim, J.; Korondi, P. Supervised Learning with Small Training Set for Gesture Recognition by Spiking Neural Networks. In Proceedings of the 2019 IEEE Symposium Series on Computational Intelligence (SSCI), Xiamen, China, 6–9 December 2019; pp. 2201–2206. [Google Scholar] [CrossRef]
- Kurakin, A.; Zhang, Z.; Liu, Z. A real time system for dynamic hand gesture recognition with a depth sensor. In Proceedings of the 2012 Proceedings of the 20th European Signal Processing Conference (EUSIPCO), Bucharest, Romania, 27–31 August 2012; pp. 1975–1979. [Google Scholar]
- Cha, S.H. Comprehensive Survey on Distance/Similarity Measures between Probability Density Functions. Int. J. Math. Model. Methods Appl. Sci. 2007, 1, 300–307. [Google Scholar]
- Pławiak, P.; Sośnicki, T.; Niedźwiecki, M.; Tabor, Z.; Rzecki, K. Hand Body Language Gesture Recognition Based on Signals From Specialized Glove and Machine Learning Algorithms. IEEE Trans. Ind. Inform. 2016, 12, 1104–1113. [Google Scholar] [CrossRef]
- Wahid, M.F.; Tafreshi, R.; Al-Sowaidi, M.; Langari, R. An efficient approach to recognize hand gestures using machine-learning algorithms. In Proceedings of the 2018 IEEE 4th Middle East Conference on Biomedical Engineering (MECBME), Tunis, Tunisia, 28–30 March 2018; pp. 171–176. [Google Scholar] [CrossRef]
- Baran, M. Closest paths in graph drawings under an elastic metric. Int. J. Appl. Math. Comput. Sci. 2018, 28, 387–397. [Google Scholar] [CrossRef] [Green Version]
- Baran, M.; Siwik, L.; Rzecki, K. Application of Elastic Principal Component Analysis to Person Recognition Based on Screen Gestures. In Artificial Intelligence and Soft Computing; Rutkowski, L., Scherer, R., Korytkowski, M., Pedrycz, W., Tadeusiewicz, R., Zurada, J.M., Eds.; Springer: Cham, Switzerland, 2019; pp. 553–560. [Google Scholar]
- Rzecki, K.; Siwik, L.; Baran, M. The Elastic k-Nearest Neighbours Classifier for Touch Screen Gestures. In Artificial Intelligence and Soft Computing; Rutkowski, L., Scherer, R., Korytkowski, M., Pedrycz, W., Tadeusiewicz, R., Zurada, J.M., Eds.; Springer: Cham, Switzerland, 2019; pp. 608–615. [Google Scholar]
- Przybyło, J.; Kańtoch, E.; Augustyniak, P. Eyetracking-based assessment of affect-related decay of human performance in visual tasks. Future Gener. Comput. Syst. 2019, 92, 504–515. [Google Scholar] [CrossRef]
- Schramm, R.; Jung, C.R.; Miranda, E.R. Dynamic Time Warping for Music Conducting Gestures Evaluation. IEEE Trans. Multimed. 2015, 17, 243–255. [Google Scholar] [CrossRef]
- Zabatani, A.; Surazhsky, V.; Sperling, E.; Ben Moshe, S.; Menashe, O.; Silver, D.H.; Karni, T.; Bronstein, A.M.; Bronstein, M.M.; Kimmel, R. Intel® RealSense™ SR300 Coded light depth Camera. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 2333–2345. [Google Scholar] [CrossRef]
- Rzecki, K.; Pławiak, P.; Niedźwiecki, M.; Sośnicki, T.; Leśkow, J.; Ciesielski, M. Person recognition based on touch screen gestures using computational intelligence methods. Inf. Sci. 2017, 415–416, 70–84. [Google Scholar] [CrossRef]
- Wu, Y.; Jiang, D.; Liu, X.; Bayford, R.; Demosthenous, A. A Human-Machine Interface Using Electrical Impedance Tomography for Hand Prosthesis Control. IEEE Trans. Biomed. Circuits Syst. 2018, 12, 1322–1333. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Y.; Harrison, C. Tomo: Wearable, Low-Cost Electrical Impedance Tomography for Hand Gesture Recognition. In Proceedings of the 28th Annual ACM Symposium on User Interface Software and Technology, UIST ’15, Charlotte, NC, USA, 8–11 November 2015; ACM: New York, NY, USA, 2015; pp. 167–173. [Google Scholar] [CrossRef]
- Kim, Y.; Toomajian, B. Hand Gesture Recognition Using Micro-Doppler Signatures With Convolutional Neural Network. IEEE Access 2016, 4, 7125–7130. [Google Scholar] [CrossRef]
- Ren, Z.; Yuan, J.; Meng, J.; Zhang, Z. Robust Part-Based Hand Gesture Recognition Using Kinect Sensor. IEEE Trans. Multimed. 2013, 15, 1110–1120. [Google Scholar] [CrossRef]
- Lu, W.; Tong, Z.; Chu, J. Dynamic Hand Gesture Recognition with Leap Motion Controller. IEEE Signal Process. Lett. 2016, 23, 1188–1192. [Google Scholar] [CrossRef]
- Marin, G.; Dominio, F.; Zanuttigh, P. Hand gesture recognition with jointly calibrated Leap Motion and depth sensor. Multimed. Tools Appl. 2016, 75, 14991–15015. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
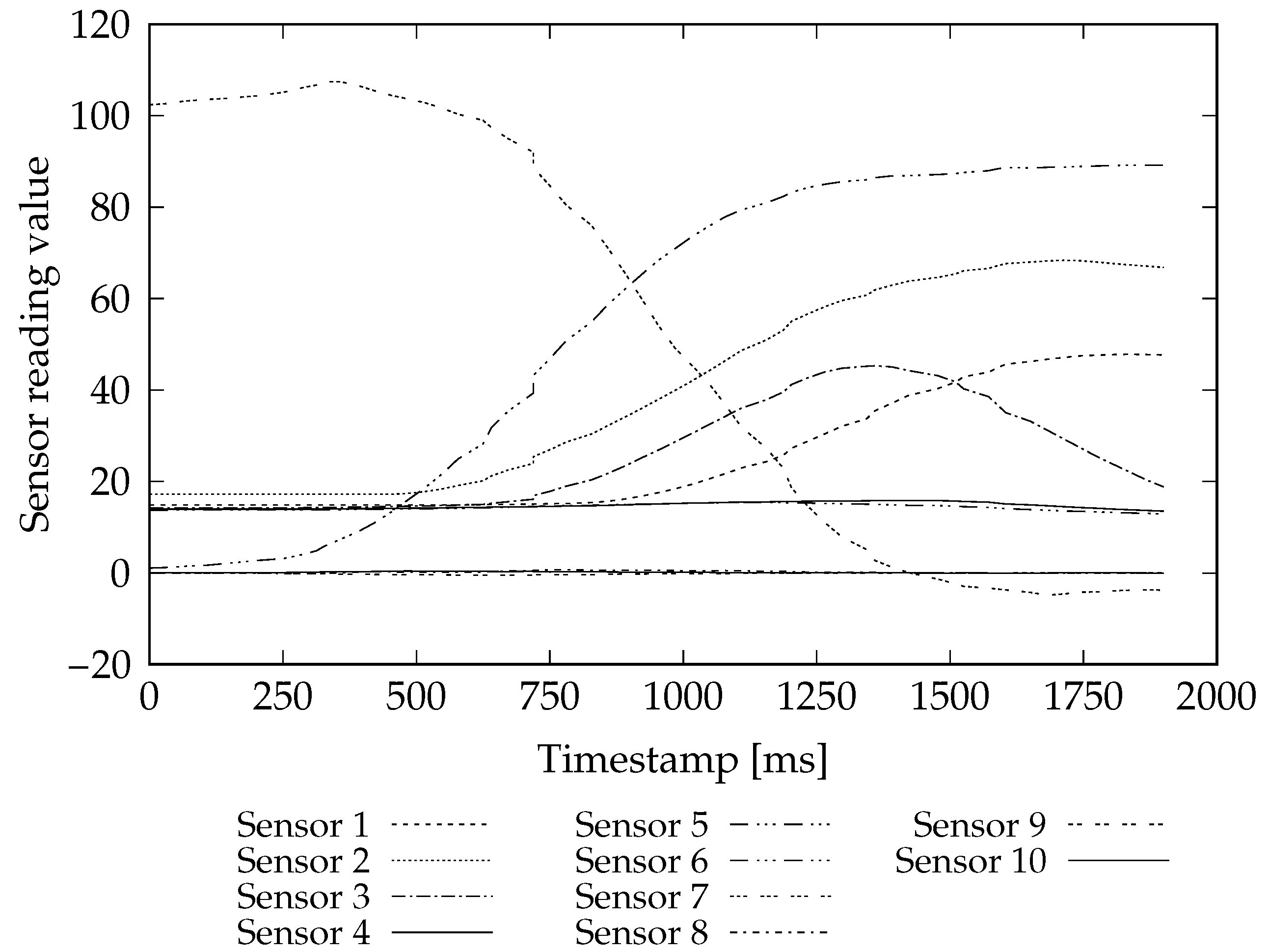
| Variables | ||||||
|---|---|---|---|---|---|---|
| Timestamp | Sensor 1 | Sensor 2 | Sensor 3 | … | Sensor 10 | |
| Observations | 0 | 14.8438 | 17.1875 | 14.2725 | … | 0.0343 |
| 47 | 14.8438 | 17.1875 | 14.2529 | … | 0.0467 | |
| 63 | 14.8438 | 17.1875 | 14.2432 | … | 0.0513 | |
| … | … | … | … | … | … | |
| 1869 | 47.7539 | 67.0801 | 20.3076 | … | −0.0044 | |
| 1900 | 47.6465 | 66.8164 | 18.8184 | … | 0.0010 | |
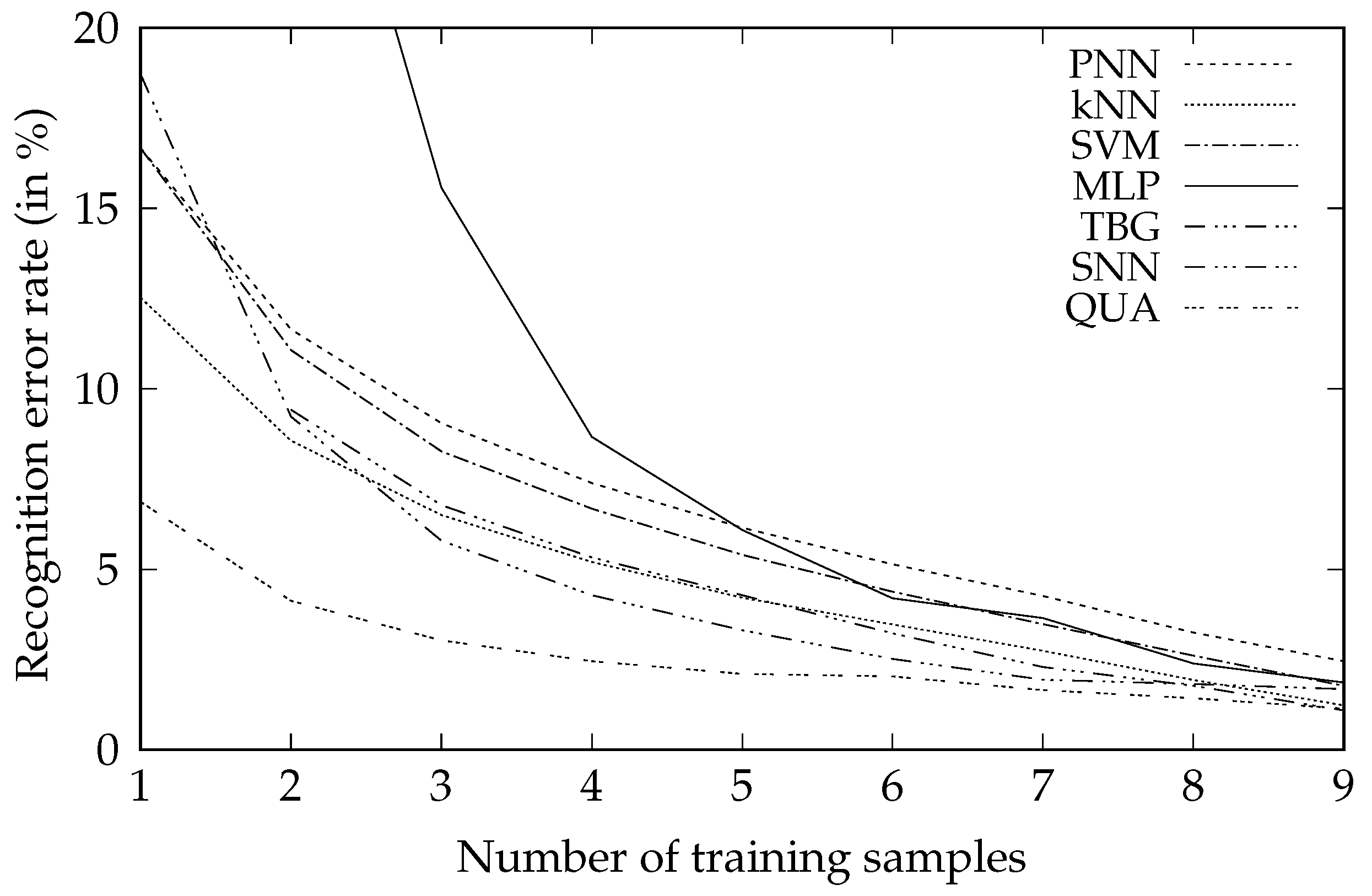
| n | PNN | kNN | SVM | MLP | TBG | SNN | QUA |
|---|---|---|---|---|---|---|---|
| 1 | 16.67% | 12.53% | 16.67% | 77.24% | 18.72% | — | 6.87% |
| 2 | 11.65% | 8.56% | 11.07% | 29.95% | 9.23% | 9.42% | 4.13% |
| 3 | 9.05% | 6.50% | 8.27% | 15.57% | 5.79% | 6.78% | 3.03% |
| 4 | 7.39% | 5.20% | 6.68% | 8.67% | 4.28% | 5.33% | 2.45% |
| 5 | 6.15% | 4.21% | 5.40% | 6.09% | 3.31% | 4.28% | 2.10% |
| 6 | 5.14% | 3.47% | 4.38% | 4.20% | 2.52% | 3.23% | 2.03% |
| 7 | 4.26% | 2.74% | 3.48% | 3.65% | 1.94% | 2.29% | 1.65% |
| 8 | 3.25% | 1.93% | 2.61% | 2.39% | 1.82% | 1.77% | 1.43% |
| 9 | 2.45% | 1.23% | 1.77% | 1.86% | 1.68% | 1.09% | 1.14% |
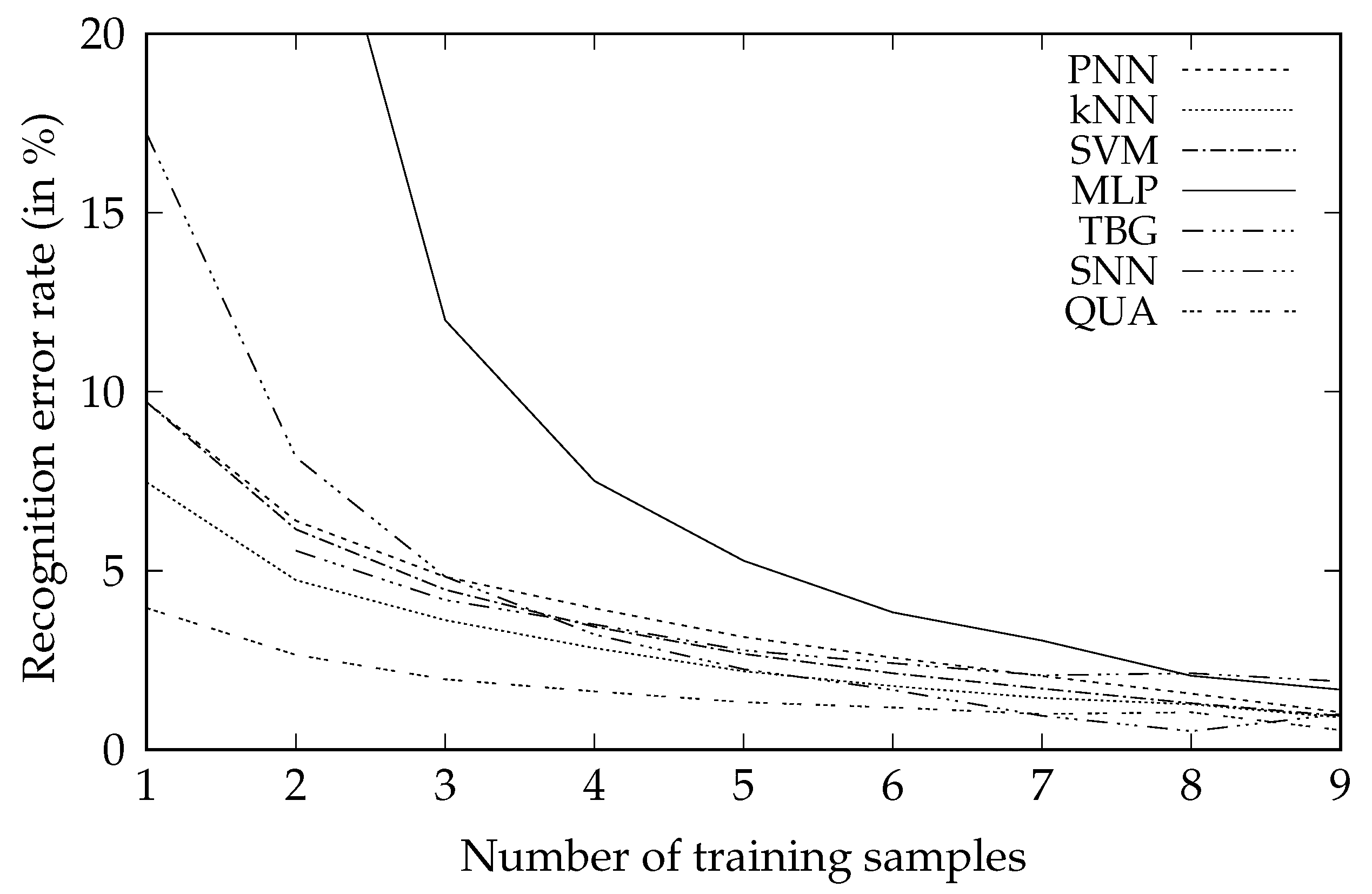
| n | PNN | kNN | SVM | MLP | TBG | SNN | QUA |
|---|---|---|---|---|---|---|---|
| 1 | 9.71% | 7.47% | 9.71% | 79.23% | 17.21% | — | 3.96% |
| 2 | 6.40% | 4.74% | 6.16% | 27.26% | 8.17% | 5.56 % | 2.65% |
| 3 | 4.83% | 3.62% | 4.47% | 12.00% | 4.84% | 4.18 % | 1.97% |
| 4 | 3.95% | 2.84% | 3.44% | 7.51% | 3.22% | 3.50 % | 1.63% |
| 5 | 3.15% | 2.19% | 2.68% | 5.28% | 2.25% | 2.78 % | 1.33% |
| 6 | 2.57% | 1.78% | 2.14% | 3.84% | 1.67% | 2.42 % | 1.18% |
| 7 | 2.06% | 1.45% | 1.71% | 3.05% | 0.95% | 2.08 % | 1.00% |
| 8 | 1.57% | 1.27% | 1.30% | 2.07% | 0.52% | 2.14 % | 1.05% |
| 9 | 1.05% | 0.91% | 0.95% | 1.68% | 1.00% | 1.91 % | 0.55% |
| PNN | kNN | SVM | MLP | TBG | SNN | QUA | |
|---|---|---|---|---|---|---|---|
| training | 12.75 | 3.17 | 0.42 | 92.20 | 57.55 | 59.16 s | 11.87 |
| classification | 0.0514 | 0.4819 | <0.1 μs | 0.0574 | 0.4290 | 151.84 | 10.3926 |
| PNN | kNN | SVM | MLP | TBG | SNN | QUA | |
|---|---|---|---|---|---|---|---|
| training | 15.71 | 4.00 | 1.92 | 95.77 | 61.76 | 60.74 s | 14.93 |
| classification | 0.0376 | 0.5081 | <0.1 μs | 0.0289 | 0.2638 | 104.32 | 11.50 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rzecki, K. Classification Algorithm for Person Identification and Gesture Recognition Based on Hand Gestures with Small Training Sets. Sensors 2020, 20, 7279. https://doi.org/10.3390/s20247279
Rzecki K. Classification Algorithm for Person Identification and Gesture Recognition Based on Hand Gestures with Small Training Sets. Sensors. 2020; 20(24):7279. https://doi.org/10.3390/s20247279
Chicago/Turabian StyleRzecki, Krzysztof. 2020. "Classification Algorithm for Person Identification and Gesture Recognition Based on Hand Gestures with Small Training Sets" Sensors 20, no. 24: 7279. https://doi.org/10.3390/s20247279
APA StyleRzecki, K. (2020). Classification Algorithm for Person Identification and Gesture Recognition Based on Hand Gestures with Small Training Sets. Sensors, 20(24), 7279. https://doi.org/10.3390/s20247279