
Hybrid Imitation Learning Framework for Robotic Manipulation Tasks



Abstract
:1. Introduction
- The proposed HIL framework combines BC and SC to enhance the efficiency of robotic manipulation learning by providing the synergistic effect of their respective advantages, i.e., high learning efficiency and high policy flexibility.
- The framework efficiently combines BC and SC losses using the adaptive loss mixing weight, which is automatically adjusted according to the degree of policy convergence.
- The framework efficiently implements SC learning using a pretrained dynamics network that predicts the next state from the result of the implemented action in association with the policy network within the HIL framework.
- The framework performs stochastic state recovery while performing SC to ensure a stable training of the policy network.
- This paper presents the process for and results of a series of object manipulation experiments using a 9-DOF (degree of freedom) Jaco robotic hand, demonstrating the high learning efficiency and policy flexibility of the proposed HIL framework.
2. Related Work
3. Methodology
3.1. Problem Description
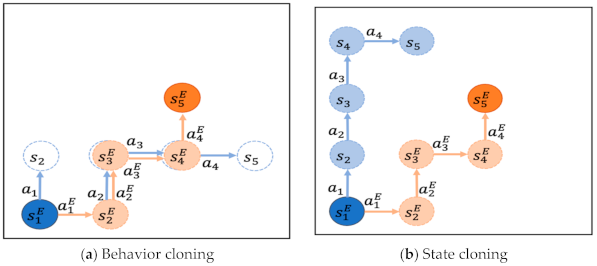
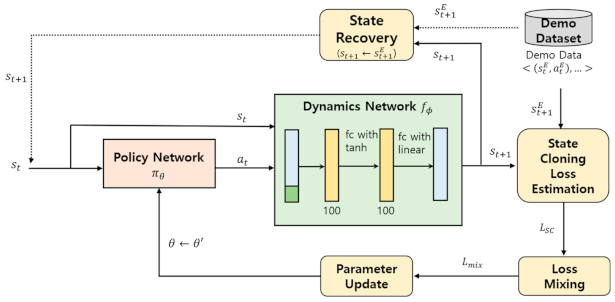
3.2. Hybrid Imitation Learning (HIL) Framework
| Algorithm 1. Hybrid imitation learning framework. |
| Function HIL(D, )
/* the demo dataset , the state recovery probability */ Initialize the policy network and the dynamics network = Pretrain_Dynamics_Network( , ) for e = 0,…, E epochs do for I = 0,…,|D| do Sample from Behavior_Cloning(, ) State_Cloning(, , ) Loss_Mixing(, ) Update the policy network parameters by gradient descent end for end for return |
| Algorithm 2. Behavior cloning. |
| Function Behavior_Cloning(, )
/* the policy network the demo data */ Initialize the episodic buffer to be empty for t = 1,…, timesteps do Sample an action end for Estimate the BC loss Calculate the degree of cloning return |
3.3. State Cloning with Dynamics Network
| Algorithm 3. State cloning. |
| Function State_Cloning(, , )
/* the policy network the pretrained dynamics network , the demo data the state recovery probability */ Initialize the episodic buffer to be empty for t = 1,…, timesteps do Sample an action B B{( //append each pair of states to B end for Estimate the SC loss return |
3.4. Pretraining the Dynamics Network
| Algorithm 4. Pretraining the dynamics network. |
| Function Pretrain_Dynamics_Network ( )
/* the dynamics network , the demo dataset */ for e = 0,…,E epochs do for i = 0,…,|D| do Initialize the episodic buffer to be empty Sample from Initialize the environment to initial state for t = 1,…. timesteps do Execute an action and perceive the next state B B{//append each state transition to B end for Update the dynamics network parameters by gradient descent end for end for return |
4. Implementation and Evaluation
4.1. Manipulation Tasks
4.2. Model Training
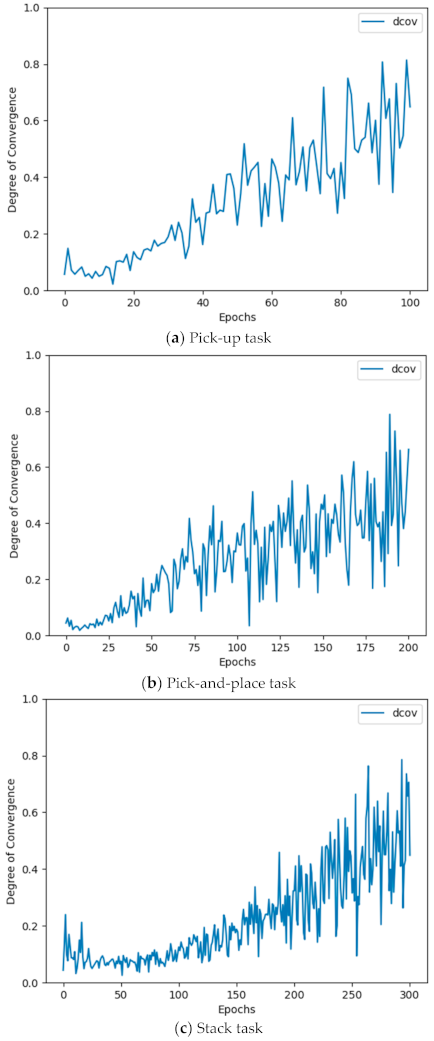
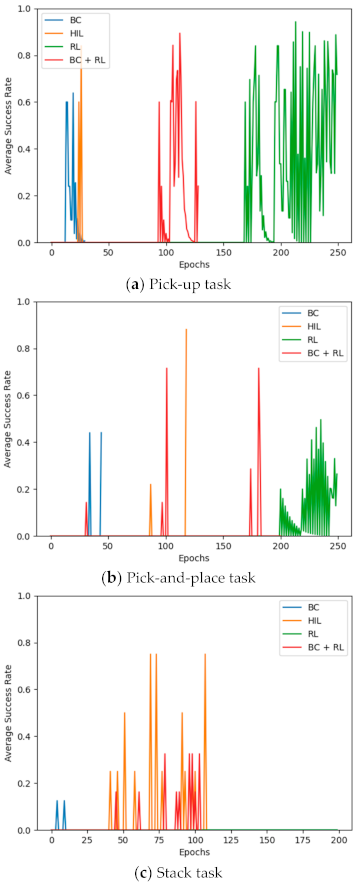
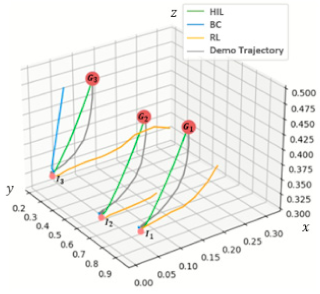
4.3. Experiments in Simulated Envirionment
- Pick-up:
- A reward of +0.01 is awarded when the robotic hand approaches the object, +0.1 when it grasps it, and +1 when it lifts it to or above a certain height.
- Pick-and-Place:
- A reward of +0.01 is awarded when the robotic hand approaches the object, +0.1 when it grasps it, and +10 when it lifts and moves it to or above a certain height.
- Stack:
- A reward of +0.01 is awarded when the robotic hand approaches the object, +0.1 when it grasps it, +1 when it lifts it to or above a certain height, and +10 when it stacks it onto another object.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Billard, A.; Kragic, D. Trends and Challenges in Robot Manipulation. Science 2019, 364. [Google Scholar] [CrossRef] [PubMed]
- Tang, S.H.; Khaksar, W.; Ismail, N.; Ariffin, M. A Review on Robot Motion Planning Approaches. Pertanika J. Sci. Technol. 2012, 20, 15–29. [Google Scholar]
- Karaman, S.; Frazzoli, E. Sampling-based Algorithms for Optimal Motion Planning. Int. J. Robot. Res. 2011, 30, 846–894. [Google Scholar] [CrossRef]
- Maeda, Y.; Nakamura, T.; Arai, T. Motion Planning of Robot Fingertips for Graspless Manipulation. In Proceedings of the 2004 IEEE International Conference on Robotics and Automation, New Orleans, LA, USA, 26 April–1 May 2004; pp. 2951–2956. [Google Scholar]
- Cohen, B.J.; Subramania, G.; Chitta, S.; Likhachev, M. Planning for Manipulation with Adaptive Motion Primitives. In Proceedings of the 2011 IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011; pp. 5478–5485. [Google Scholar]
- Jain, A.; Niekum, S. Efficient Hierarchical Robot Motion Planning under Uncertainty and Hybrid Dynamics. arXiv 2018, arXiv:1802.04205. [Google Scholar]
- Ebert, F.; Dasari, S.; Lee, A.X.; Levine, S.; Finn, C. Robustness via Retrying: Closed-loop Robotic Manipulation with Self-supervised Learning. arXiv 2018, arXiv:1810.03043. [Google Scholar]
- Arulkumaran, K.; Deisenroth, M.P.; Brundage, M.; Bharath, A.A. A Brief Survey of Deep Reinforcement Learning. IEEE Signal Process. Mag. 2017, 34, 26–38. [Google Scholar] [CrossRef] [Green Version]
- Alibeigi, M.; Ahmadabadi, M.N.; Araabi, B.N. A Fast, Robust, and Incremental Model for Learning High-level Concepts from Human Motions by Imitation. IEEE Trans. Robot. 2016, 33, 153–168. [Google Scholar] [CrossRef]
- Zhang, T.; McCarthy, Z.; Jow, O.; Lee, D.; Chen, X.; Goldberg, K.; Abbeel, P. Deep Imitation Learning for Complex Manipulation Tasks from Virtual Reality Teleoperation. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation, Brisbane, Australia, 21–26 May 2018; pp. 1–8. [Google Scholar]
- Giusti, A.; Guzzi, J.; Cireşan, D.C.; He, F.L.; Rodríguez, J.P.; Fontana, F.; Fassler, M.; Forster, C.; Schmidhuber, J.; Di, C.G.; et al. A Machine Learning Approach to Visual Perception of Forest Trails for Mobile Robots. IEEE Robot. Autom. Lett. 2015, 1, 661–667. [Google Scholar] [CrossRef] [Green Version]
- Ross, S.; Gordon, G.; Bagnell, D. A Reduction of Imitation Learning and Structured Prediction to No-regret Online Learning. In Proceedings of the International Conference on Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 11–13 April 2011; pp. 627–635. [Google Scholar]
- Ross, S.; Bagnell, D. Efficient Reductions for Imitation Learning. In Proceedings of the International Conference on Artificial Intelligence and Statistics, Sardinia, Italy, 13–15 May 2010; pp. 661–668. [Google Scholar]
- Wu, A.; Piergiovanni, A.J.; Ryoo, M. Model-based Behavioral Cloning with Future Image Similarity Learning. In Proceedings of the Conference on Robot Learning, Cambridge, MA, USA, 16–18 November 2020; pp. 1062–1077. [Google Scholar]
- Liu, F.; Ling, Z.; Mu, T.; Su, H. State Alignment-based Imitation Learning. arXiv 2019, arXiv:1911.10947. [Google Scholar]
- Englert, P.; Paraschos, A.; Deisenroth, M.P.; Peters, J. Probabilistic Model-based Imitation Learning. Adapt. Behav. 2013, 21, 388–403. [Google Scholar] [CrossRef]
- Jena, R.; Liu, C.; Sycara, K. Augmenting Gail with BC for Sample Efficient Imitation Learning. arXiv 2020, arXiv:2001.07798. [Google Scholar]
- Nair, A.; McGrew, B.; Andrychowicz, M.; Zaremba, W.; Abbeel, P. Overcoming Exploration in Reinforcement Learning with Demonstrations. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation, Brisbane, Australia, 21–26 May 2018; pp. 6292–6299. [Google Scholar]
- Peng, X.B.; Abbeel, P.; Levine, S.; van de Panne, M. Deepmimic: Example-guided Deep Reinforcement Learning of Physics-based Character Skills. ACM Trans. Graph. 2018, 37, 1–14. [Google Scholar] [CrossRef] [Green Version]
- Goecks, V.G.; Gremillion, G.M.; Lawhern, V.J.; Valasek, J.; Waytowich, N.R. Integrating Behavior Cloning and Reinforcement Learning for Improved Performance in Dense and Sparse Reward Environments. In Proceedings of the International Conference on Autonomous Agents and Multi-Agent Systems, Auckland, New Zealand, 9–13 May 2020; pp. 465–473. [Google Scholar]
- Hussein, A.; Gaber, M.M.; Elyan, E.; Jayne, C. Imitation Learning: A Survey of Learning Methods. ACM Comput. Surv. 2017, 50, 1–35. [Google Scholar] [CrossRef]
- Di Palo, N.; Johns, E. Safari: Safe and Active Robot Imitation Learning with Imagination. arXiv 2020, arXiv:2011.09586. [Google Scholar]
- Ziebart, B.D.; Maas, A.L.; Bagnell, J.A.; Dey, A.K. Maximum Entropy Inverse Reinforcement Learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 22–26 July 2007; pp. 1433–1438. [Google Scholar]
- Ng, A.Y.; Russell, S.J. Algorithms for Inverse Reinforcement Learning. In Proceedings of the International Conference on Machine Learning, Stanford, CA, USA, 29 June–2 July 2000; p. 2. [Google Scholar]
- Ho, J.; Ermon, S. Generative Adversarial Imitation Learning. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 4565–4573. [Google Scholar]
- Laskey, M.; Lee, J.; Fox, R.; Dragan, A.; Goldberg, K. Dart: Noise Injection for Robust Imitation Learning. In Proceedings of the Conference on Robot Learning PMLR, Boston, MA, USA, 24–25 October 2017; pp. 143–156. [Google Scholar]
- Lee, Y.; Hu, E.S.; Yang, Z.; Lim, J.J. To Follow or not to Follow: Selective Imitation Learning from Observations. arXiv 2019, arXiv:1912.07670. [Google Scholar]
- Wang, X.; Xiong, W.; Wang, H.; Yang, W.W. Look before You Leap: Bridging Model-free and Model-based Reinforcement Learning for Planned-ahead Vision-and-Language Navigation. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 37–53. [Google Scholar]
- Kurutach, T.; Clavera, I.; Duan, Y.; Tamar, A.; Abbeel, P. Model-ensemble Trust-region Policy Optimization. arXiv 2018, arXiv:1802.10592. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal Policy Optimization Algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Description |
|---|---|
| Demo state | |
| Demo action | |
| Task state | |
| Task action | |
| State space | |
| A | Action space |
| Stochastic state transition probability | |
| Assigned robotic task | |
| Initial state condition | |
| Goal state condition | |
| Stochastic policy network | |
| Demo task trajectory | |
| Demo dataset | |
| Length of each demo task trajectory | |
| Behavior cloning (BC) loss | |
| State cloning (SC) loss | |
| Mixed loss | |
| Degree of policy convergence | |
| Dynamics network | |
| Loss mixing weight | |
| State recovery probability |
| Task | Pick-Up | Pick-and-Place | Stack | ||||
|---|---|---|---|---|---|---|---|
| Loss Mixing | Success Rate | Time (min) | Success Rate | Time (min) | Success Rate | Time (min) | |
| 0.58 | 112 | 0.48 | 128 | 0.16 | 135 | ||
| 0.75 | 293 | 0.52 | 422 | 0.46 | 414 | ||
| 0.72 | 393 | 0.78 | 456 | 0.72 | 545 | ||
| 0.64 | 460 | 0.76 | 625 | 0.66 | 724 | ||
| 0.75 | 119 | 0.84 | 156 | 0.78 | 181 | ||
| Task | Pick-Up | Pick-and-Place | Stack | |
|---|---|---|---|---|
| Recovery | ||||
| = 1.0 | 0.64 | 0.46 | 0.52 | |
| = 0.6 | 0.75 | 0.84 | 0.78 | |
| = 0.3 | 0.816 | 0.75 | 0.76 | |
| = 0 | ||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jung, E.; Kim, I. Hybrid Imitation Learning Framework for Robotic Manipulation Tasks. Sensors 2021, 21, 3409. https://doi.org/10.3390/s21103409
Jung E, Kim I. Hybrid Imitation Learning Framework for Robotic Manipulation Tasks. Sensors. 2021; 21(10):3409. https://doi.org/10.3390/s21103409
Chicago/Turabian StyleJung, Eunjin, and Incheol Kim. 2021. "Hybrid Imitation Learning Framework for Robotic Manipulation Tasks" Sensors 21, no. 10: 3409. https://doi.org/10.3390/s21103409
APA StyleJung, E., & Kim, I. (2021). Hybrid Imitation Learning Framework for Robotic Manipulation Tasks. Sensors, 21(10), 3409. https://doi.org/10.3390/s21103409