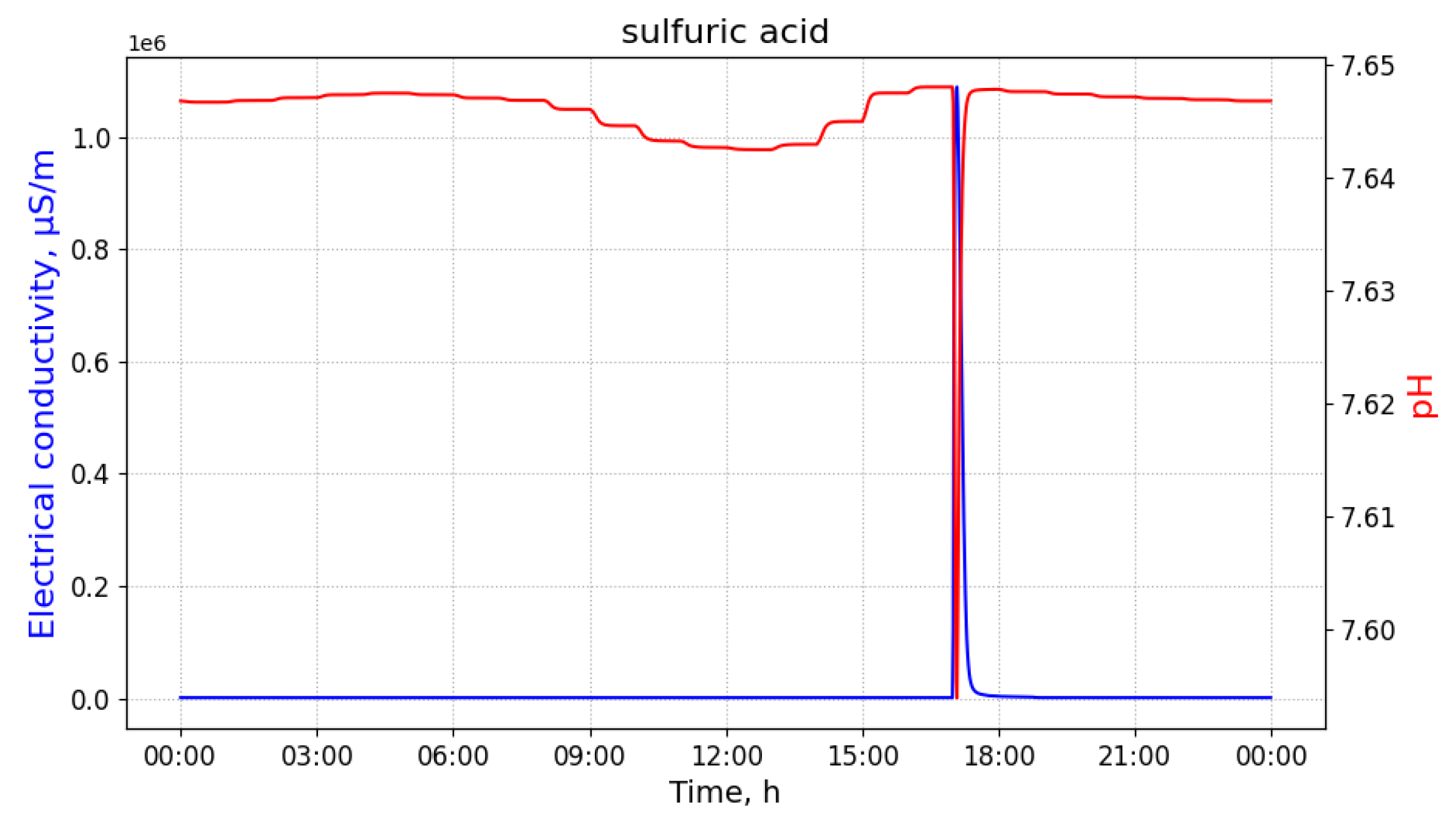
Unfortunately, not all industrial organizations carefully follow these limits, and they regularly dispose large amounts of harsh industrial waste illegally. As examples, discharges of sulfuric acid (H
2SO
4) to sewers could originate from applications, such as etching of semiconductors, accumulator acid, or the production of organic chemical substances [
2]. Sodium hydroxide (NaOH) is widely used for cleaning of surfaces in metal processing in industrial applications [
3], whereas discharges of sodium sulfate (Na
2SO
4) can be caused by the regeneration of cation exchange resins, which are used for softening of water in industrial water treatment [
4]. Illegal discharges of such dangerous harsh industrial waste into sewage networks could be harmful in the biological stage of wastewater treatment plants (WWTP), its personnel, sewer pipes, and civilians.
Not all illegal discharges of harsh industrial waste can be detected at the WWTPs, due to wastewater dilution effects in sewer pipes through the network. Therefore, monitoring as close as possible to the point of discharge is necessary for avoiding any impairment of sewer operation and protecting neighbouring infrastructure and population against odours and explosive gas compositions.
1.2. Background and Related Work
In recent years, several sensor prototypes for monitoring wastewater composition at points that are further from the WWTP [
7,
8,
9,
10,
11,
12,
13,
14,
15,
16,
17,
18,
19,
20,
21,
22,
23] have been proposed and studied. These sensors (electrochemical sensors, optical sensors, mass spectrometry, ion spectrometry, etc.) can be mounted within manholes and main sewer lines, and aim at detecting the presence or concentration of certain pollutants.
In this paper, we consider that pollution of wastewater is a rare event and, therefore, we assume that there is only a single polluting source at a time in the monitored sewer network.
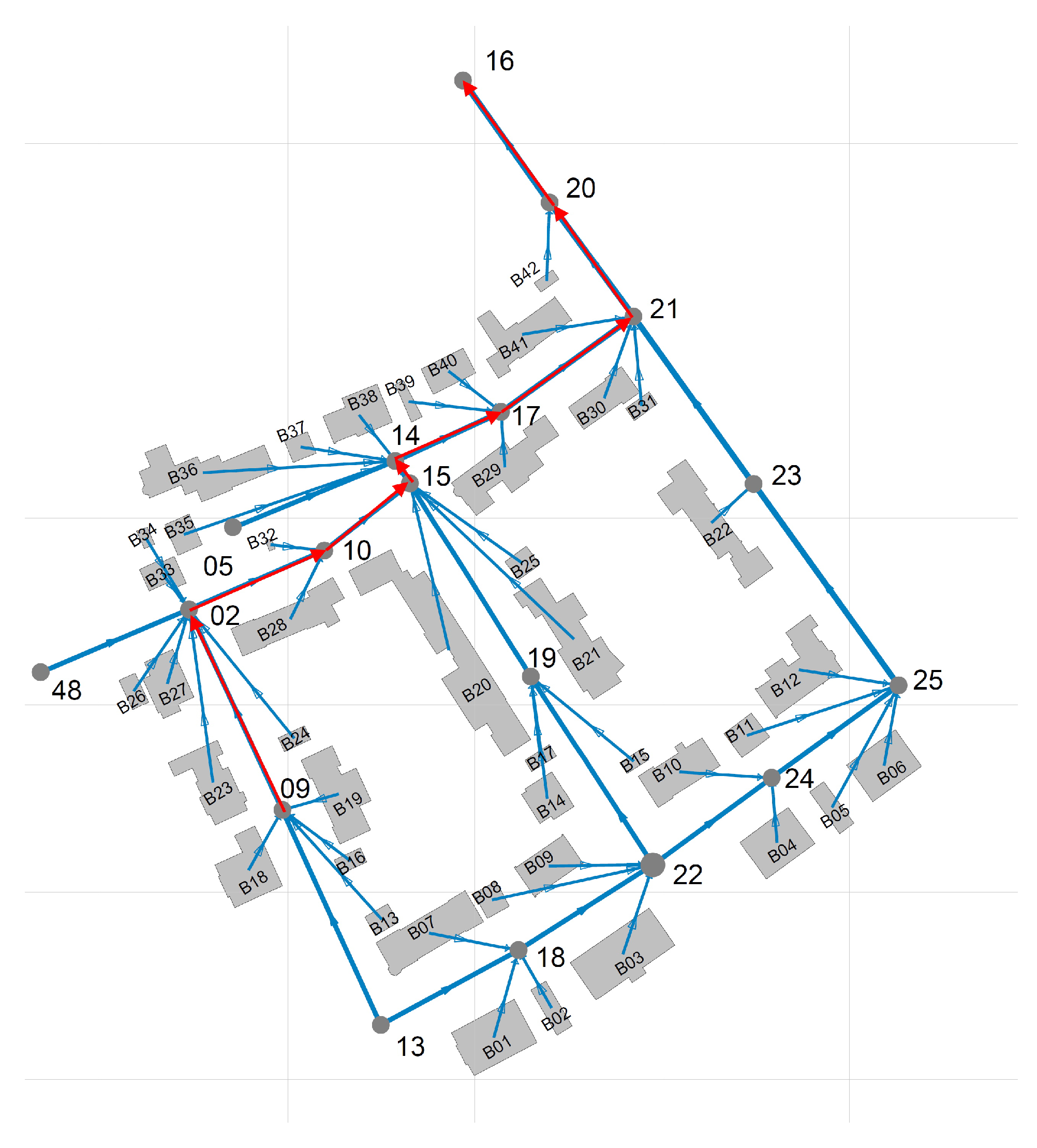
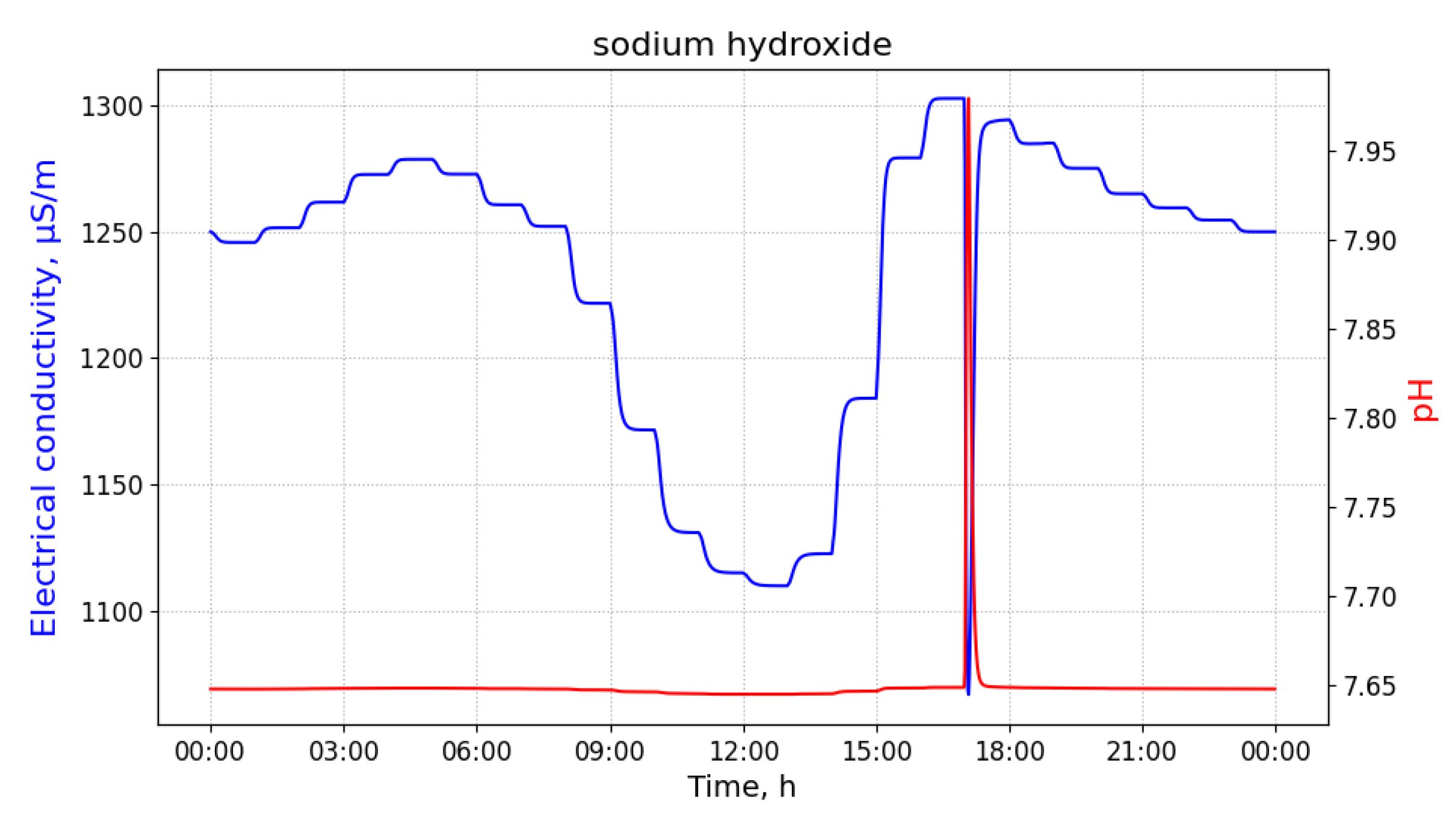
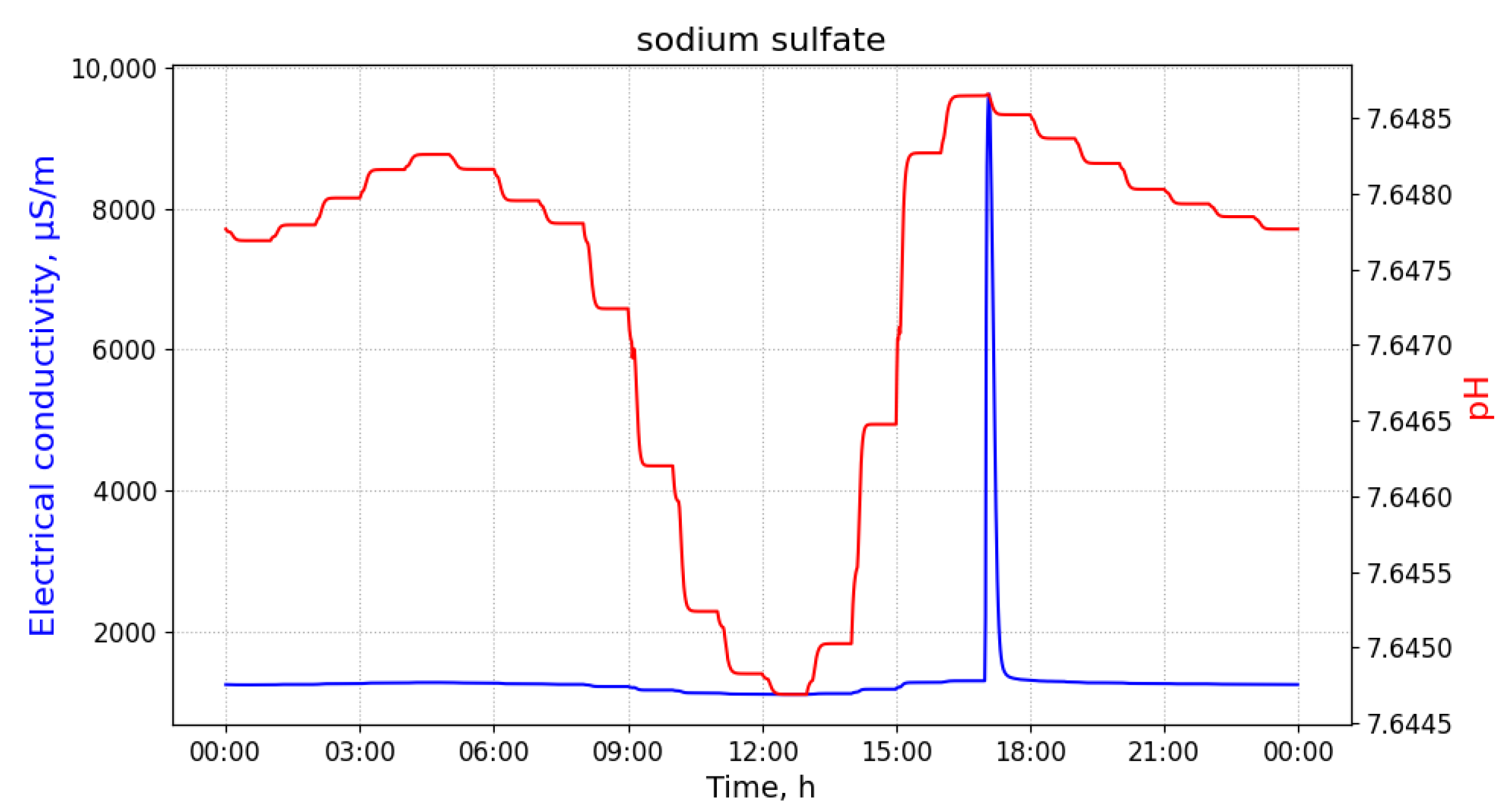
Figure 1 shows a wastewater network that corresponds to a sub-catchment area involving 42 buildings of an European city. A polluting source,
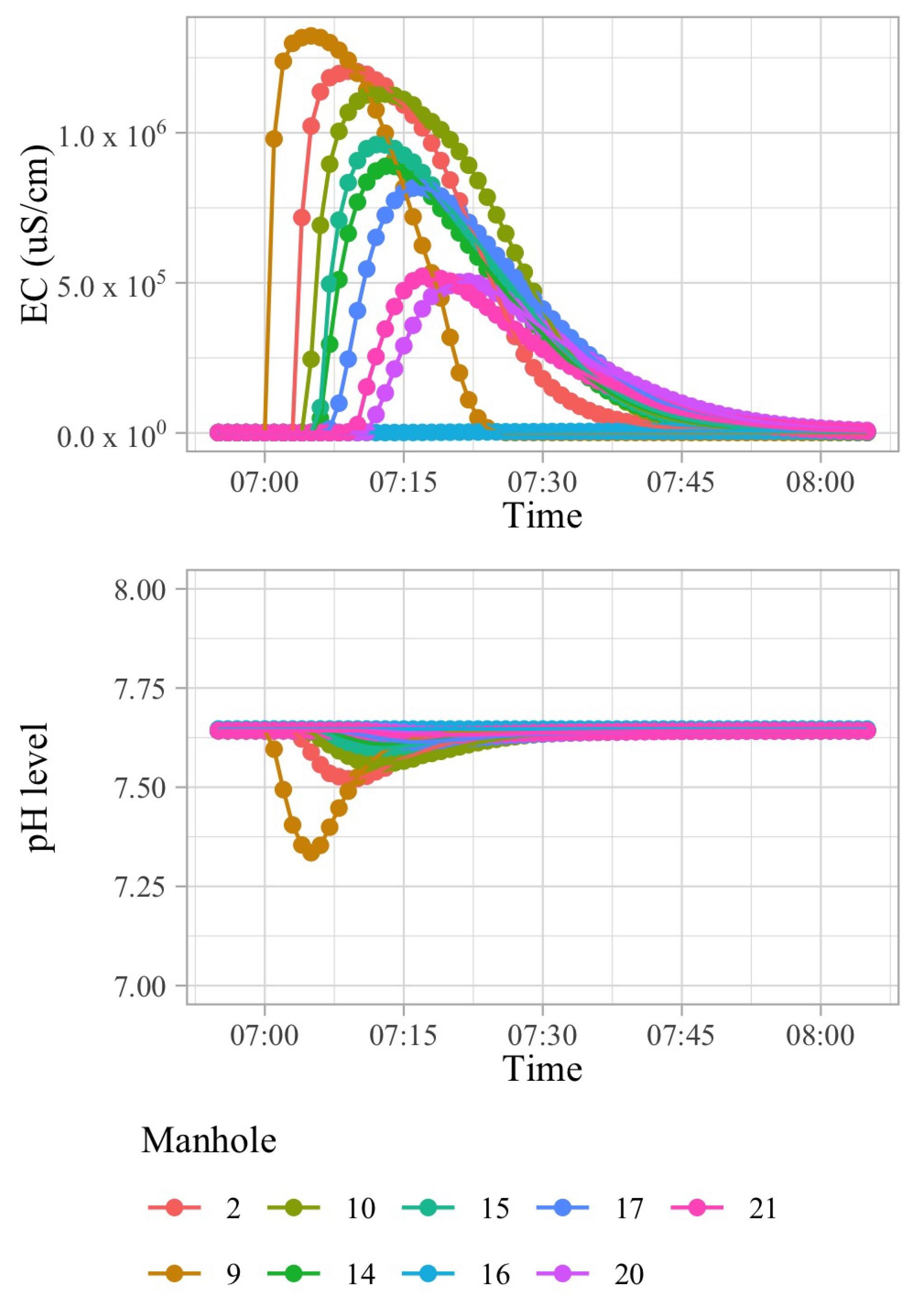
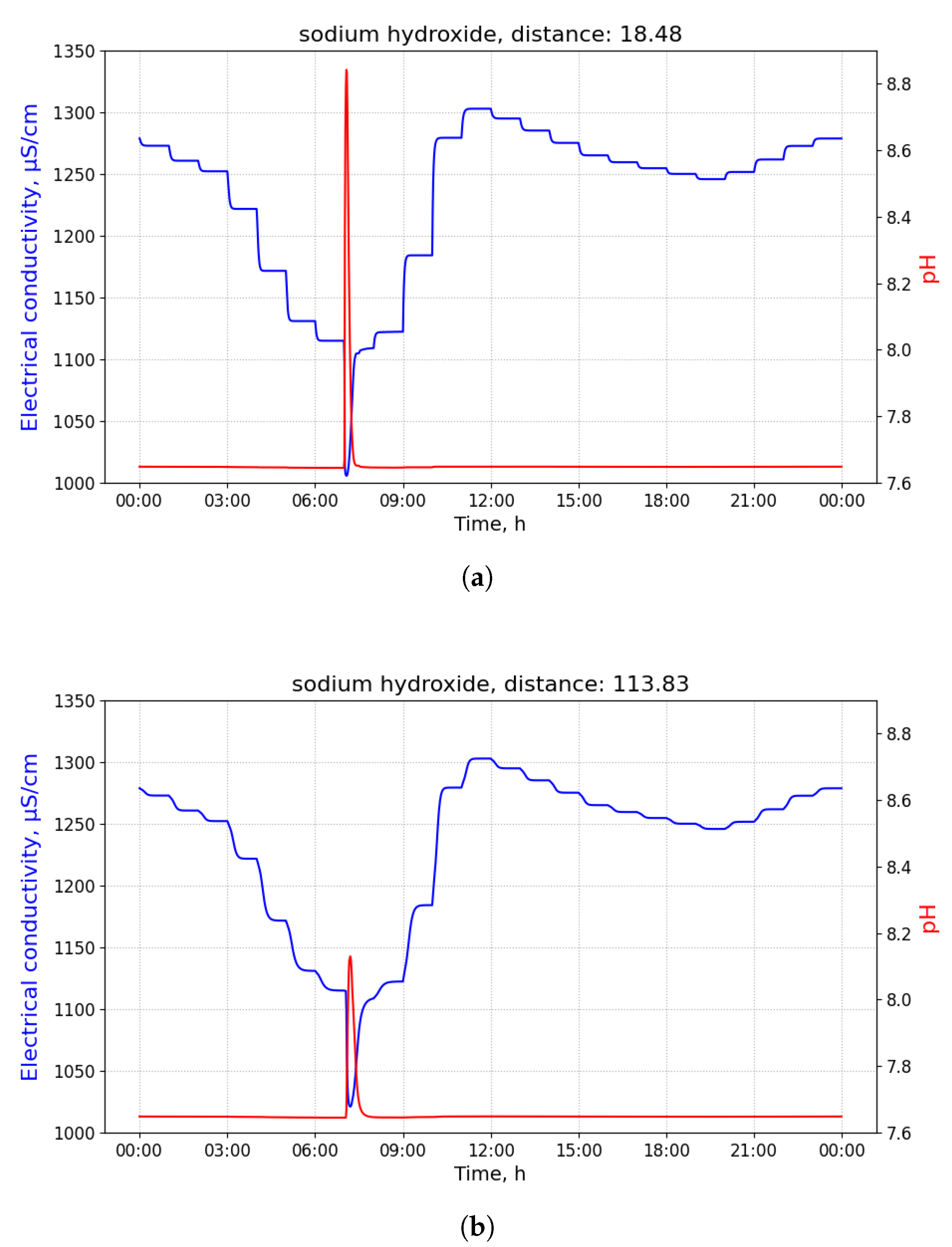
, may inject a limited amount of a pollutant into the sewage system in a short amount of time. Because of the dispersion effects in hydraulic channels, the injected pollutant can be detected in smaller concentrations in nearby pipes transporting wastewater in the direction of the WWTP. In order to illustrate this effect, consider that 100 L of sulfuric acid are discharged at building B13 of
Figure 1 at 03 h 00 min.
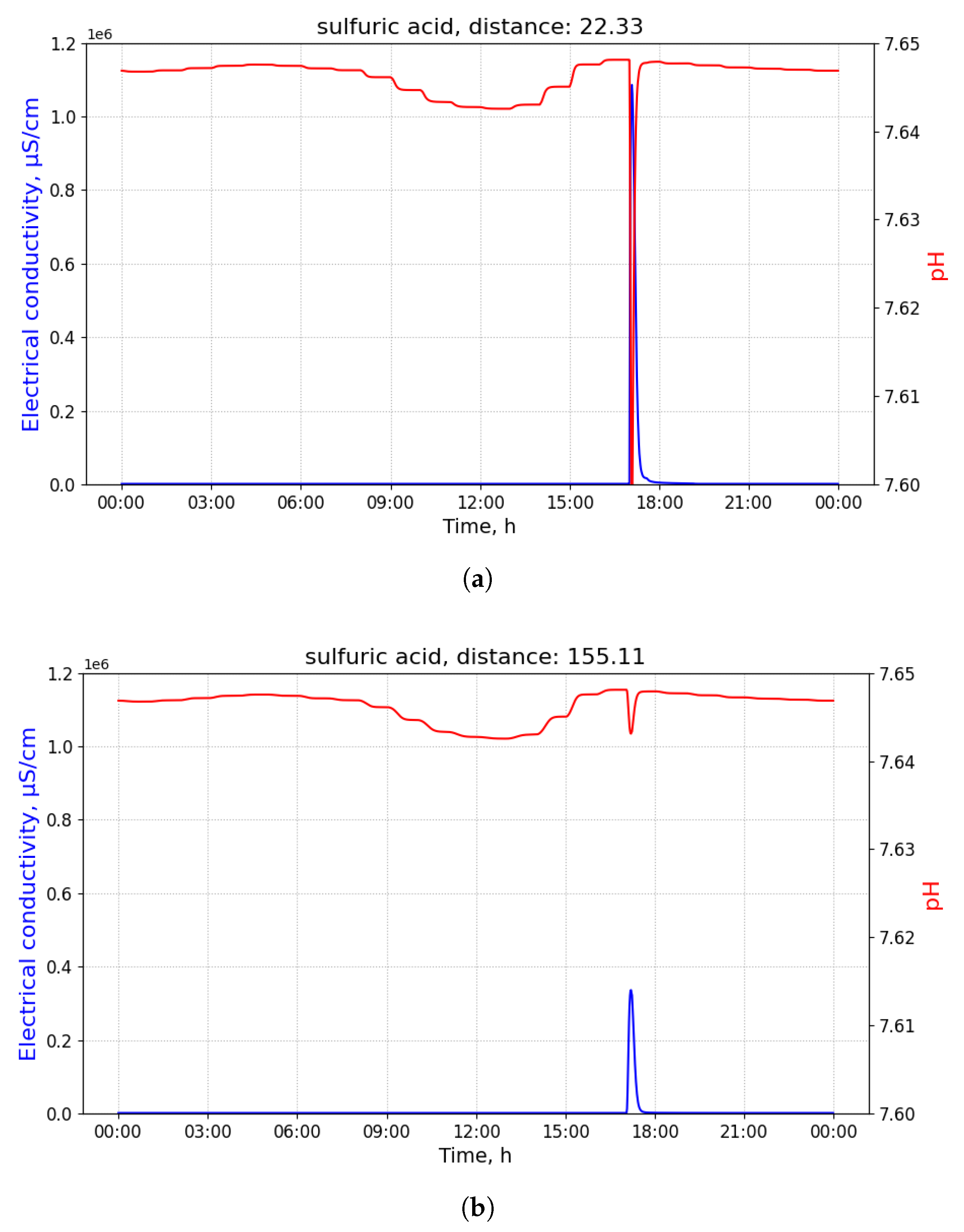
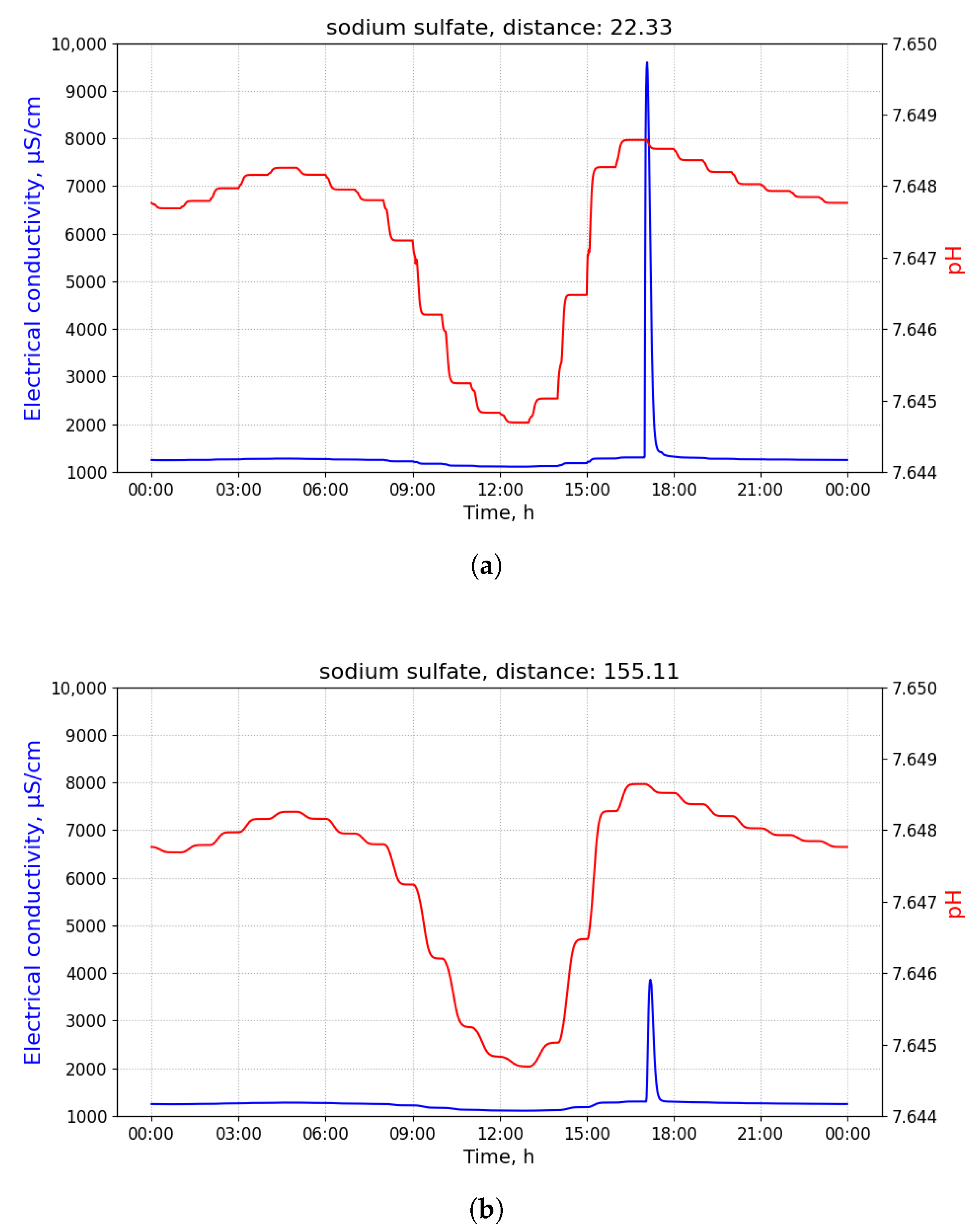
Figure 2 shows time-series of pH and electrical conductivity (EC) values measured at different manholes along the path from its source (building B13 connected to manhole 09) to the closest point to the WWTP (manhole 16).
Because of the dilution effects and limited sensitivity of the sensor devices, the pollutant can only be detected in those pipes where the diluted concentration exceeds the minimum limit of detection of the sensor. Given that the flows of wastewater are acyclic in a sewage network, the set of pipes where the pollution from a particular source can be detected form a directed acyclic sub-graph, namely , of the sewage network. It shall be noted that, given two potential polluting source and , the corresponding sub-graphs, and , where the pollutant that can be detected may have sewer pipes or edges in common. A sensor device placed in such edges is not able to discern with a single measurement whether the detected pollutant originates from either or . Therefore, most of the work that was carried out in the identification of source of pollution in water distribution systems, drainage networks, and wastewater networks related to the idea of finding a match between an input time-series of sensor measurements and a modelled (or simulated) time-series of concentration or physical parameter values for different sources. A summary of these approaches is briefly presented below.
Di Cristo et al. [
24] provide a mathematical programming formulation for finding the best match of a given input time-series of measurements to one simulated time-series of pollutant concentration values for different sources. We proceed to briefly explain their formulation. Let
be the concentration that is measured at time
t by a sensor node located at point
k in the network. Let
be the simulated contaminant concentration at time
t at point
k in the network, which is an implicit nonlinear function of its source location
j and of the input concentration magnitude
. The values of
are usually calculated through simulations that are based on modelling of the channel hydraulics. Subsequently, Di Cristo et al. [
24] propose the following fitness function
for every time
t and location
j:
A fitness function is a particular type of objective function that is used to summarise, as a single figure of merit, how close a given design solution is to achieving the set aims. Di Cristo et al. [
24] consider that the source of the pollution is the location
k with the maximum average of the fitness function over all time-instants
t. Other authors propose several other similar optimization functions in [
9,
25,
26]. In our opinion, the performance of these approaches depends on the time alignment of the values between the measured and modelled time-series.
Other approaches involve the usage of machine learning algorithms. Jalal et al. [
27] analyse the efficiency of two classification algorithms— decision trees and support-vector machines (SVM)—trained on data obtained from water treatment station (WTS) in Tunisia. For their study, Jalal et al. [
27] employ a wireless sensor network (WSN), where the sensors measure inter-alia, pH, temperature, concentration of arsenic, magnesium, and calcium. The solution based on decision trees resulted in 82% of precision and 83% of recall. For the SVM-based solution, these metrics reached 84% and 85%, respectively.
Macas et al. [
28] propose the usage of a machine learning algorithm for detecting anomalies in WTSs. Because of the insufficient amount of labelled data, Macas et al. [
28] propose an unsupervised algorithm. Macas et al. [
28] reject the usage of k-means algorithm and SVM, since they do not detect temporal patterns in the multidimensional data, thus becoming prone to false positive errors. Instead, the researchers opt for classical recurrent networks, like long-short term memory (LSTM) networks. Nevertheless, the idea was abandoned, as these structures were not producing satisfying performances with noisy data. Eventually, the researchers proposed a spatio-temporal autoencoder for anomaly detection, STAE-AD. In a nutshell, their model extracts the most important features allowing to detect the main trend in time and space from the multidimensional data using an attention-based convolutional LSTM. Based on these features, a convolutional decoder tries to recreate a statistical correlation matrix. The less similar thus obtained values are compared to the real ones. This model was trained using approximately 1,000,000 records, consisting of usual and contaminated data. The values of precision and recall of that model reached 96% and 82%, respectively.
Chachula et al. [
29] proposed a data fusion algorithm for solving the pollution source localization problem in wastewater networks. The approach does not utilize machine learning algorithms. Instead, it follows the general data fusion model of Mitchell [
30]. Data fusion parameters, such as water speed, dispersion of each substance, substance quantification, etc., have to be carefully chosen so as to match real hydraulic conditions.
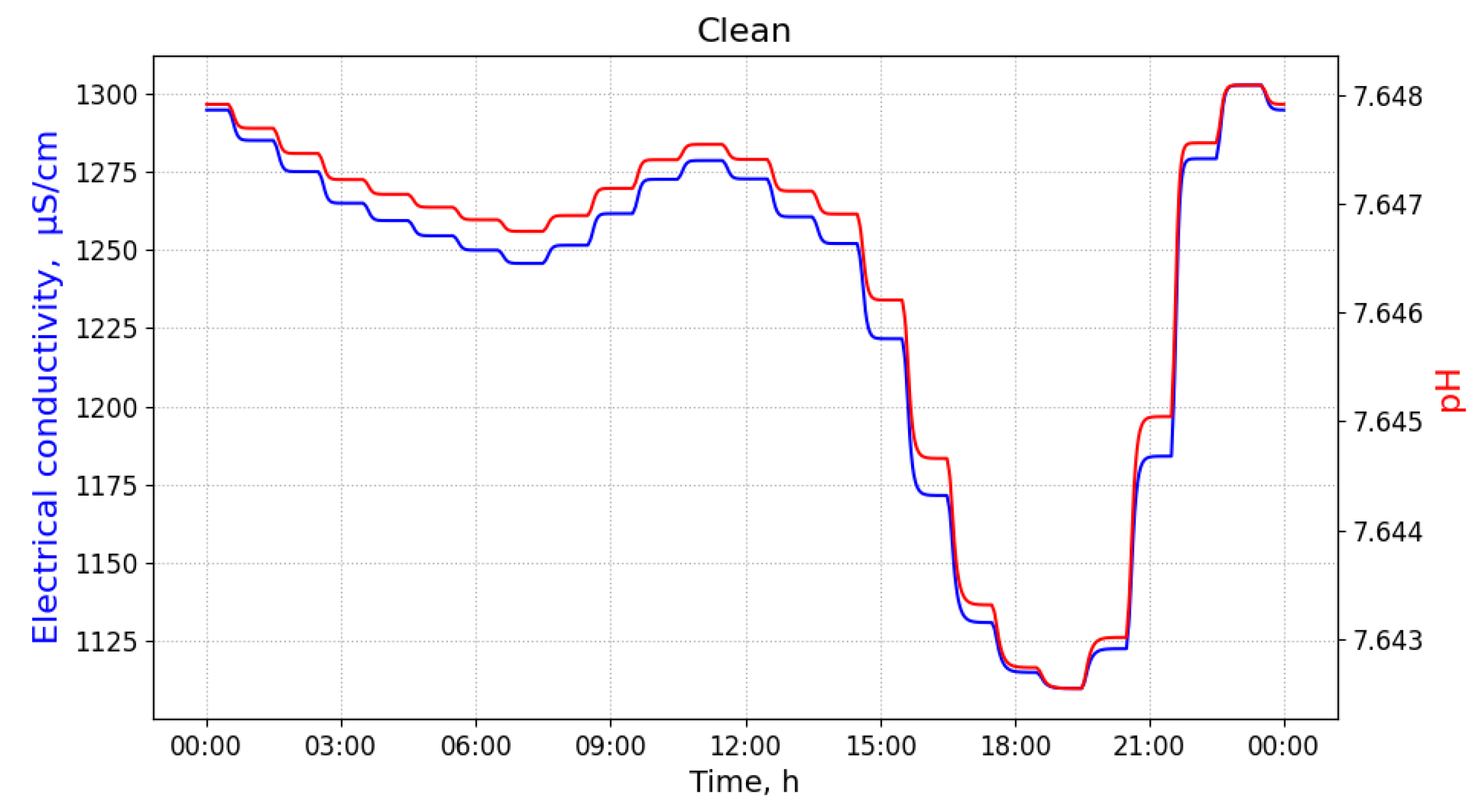
In this article, we provide a solution to the problem of detecting and identifying a wastewater pollutant, as well as estimating the distance between the source point where the pollutant was injected and its point of detection, given a time-series of observations of a monitoring device with multiple sensors. The solution approach that is presented in this article considers machine learning algorithms. As a case study, we consider that the monitoring devices are equipped with pH and EC sensors (such as those used by the Micromole device (Blue Technologies sp. z o.o., Warsaw, Poland) [
7,
8]), and that we are interested in discerning between the three major industrial pollutants of urban wastewater mentioned above.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}