
Can Local Geographically Restricted Measurements Be Used to Recover Missing Geo-Spatial Data?


Abstract
:1. Introduction
2. Materials and Methods
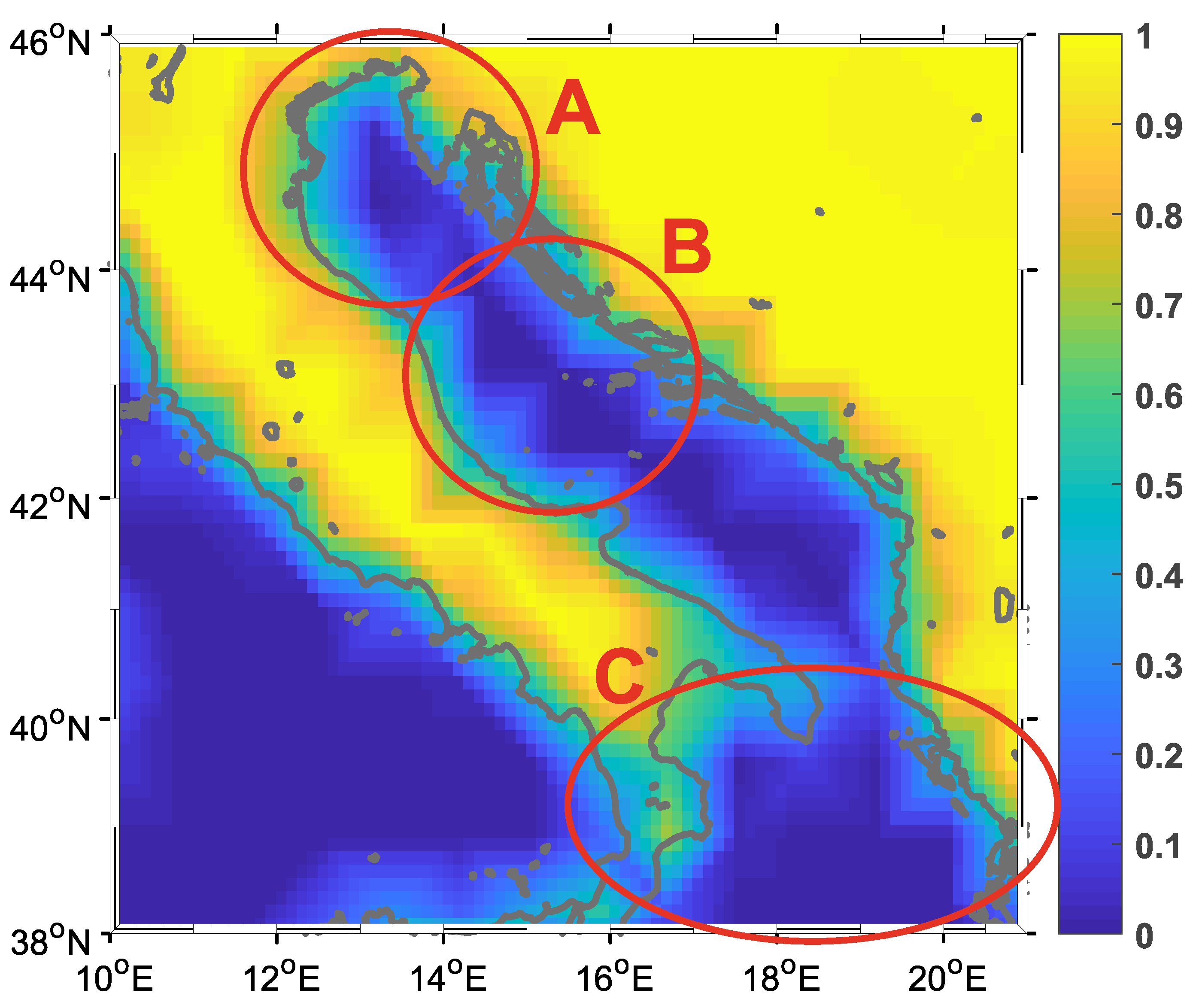
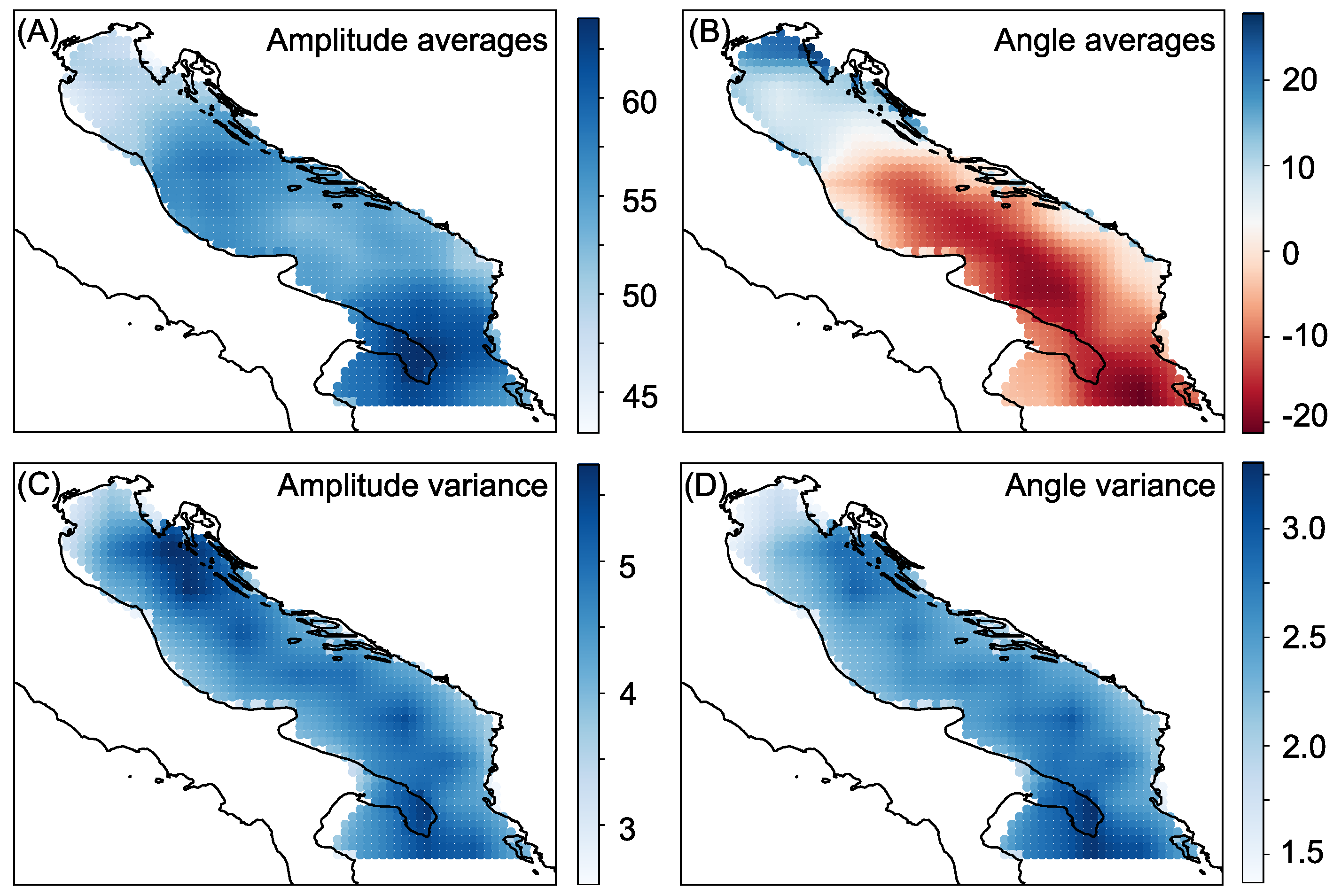
2.1. Data
2.2. Linear Regression
2.3. K-Nearest Neighbors
2.4. Extra Trees
2.5. Neural Networks
2.6. K-Means
2.7. Definition of Error and Gold Standard
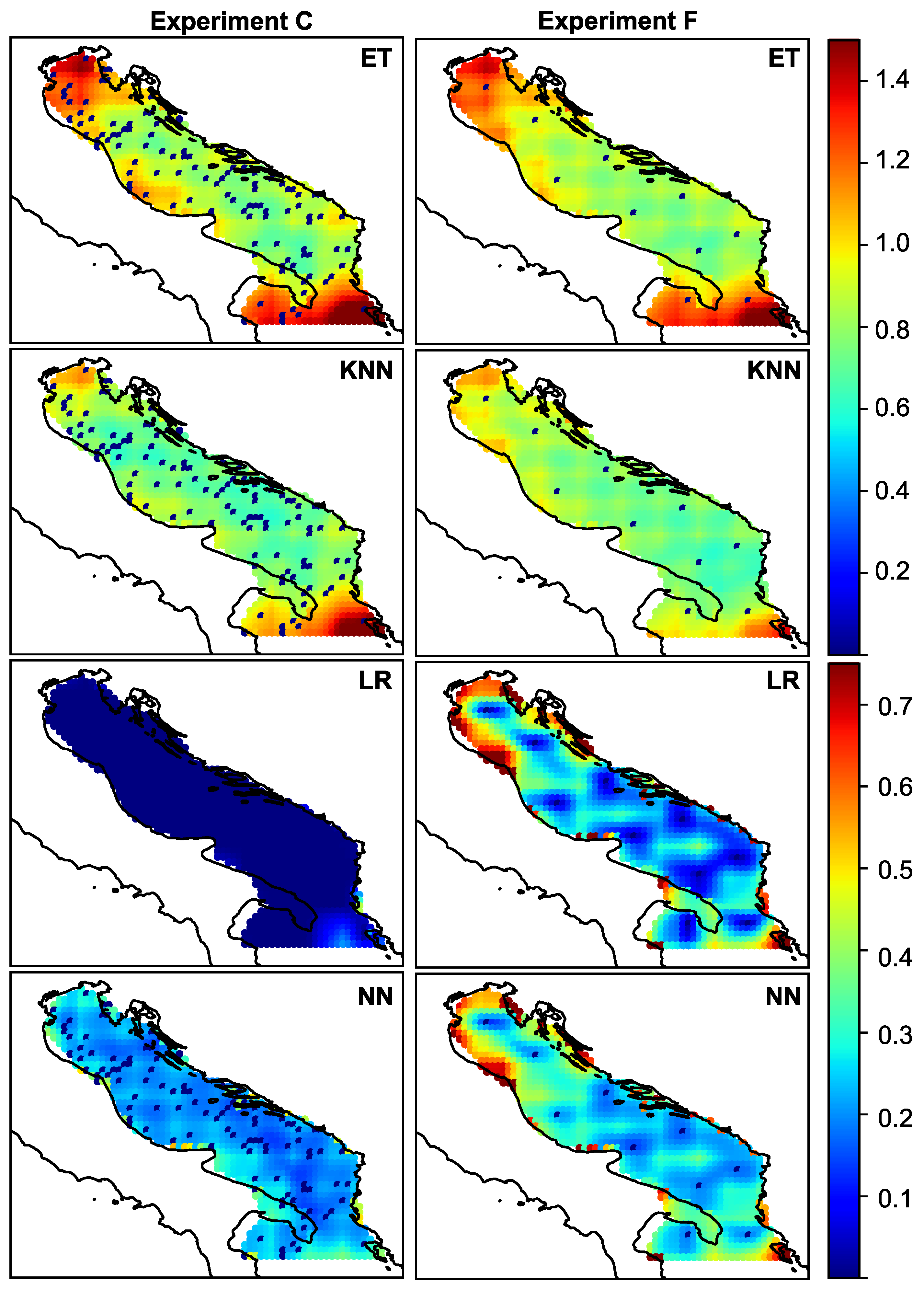
3. Results
3.1. Experimental Setup
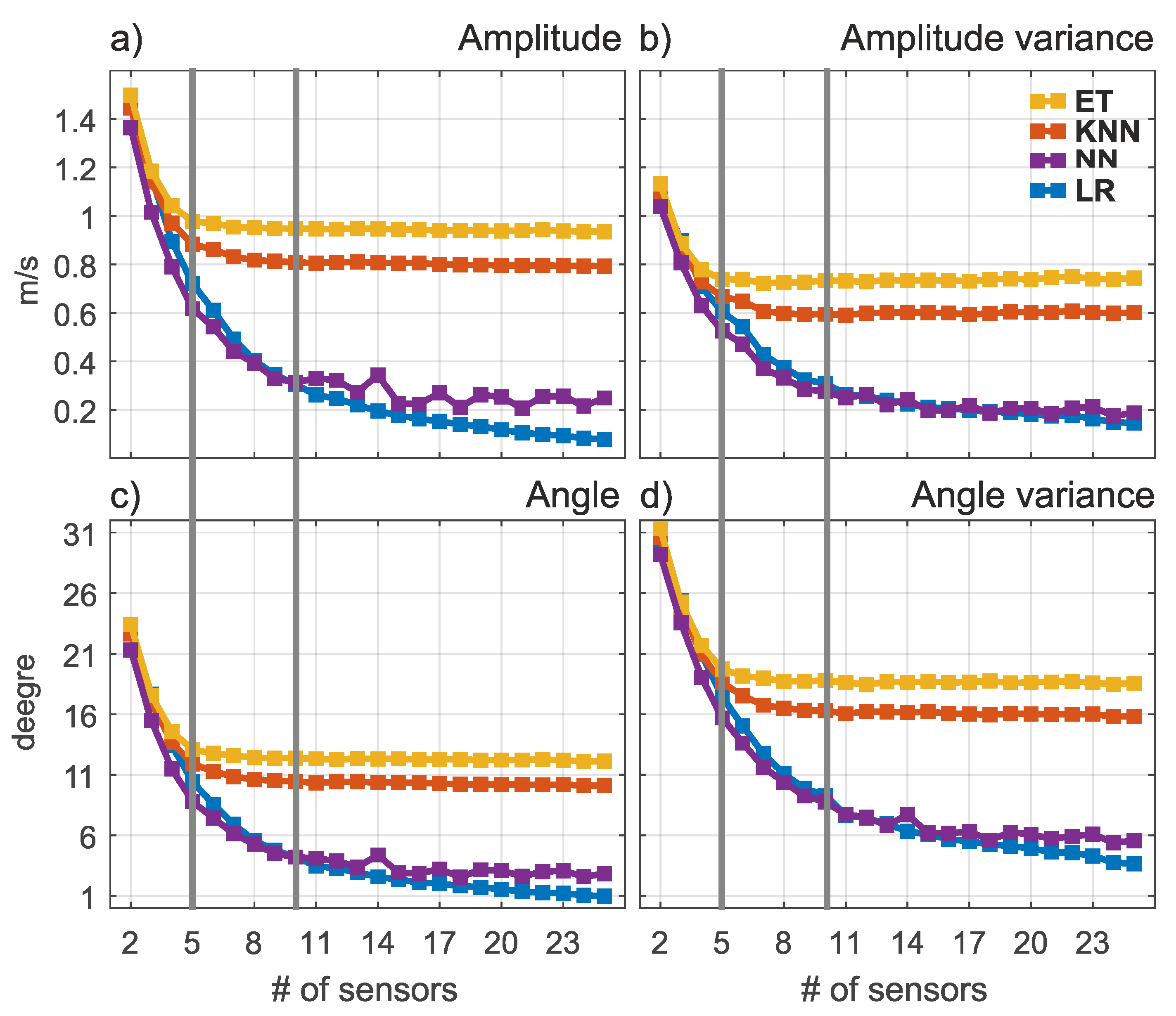
3.2. Experimenal Results
4. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| LR | linear regression |
| KNN | K-nearest neighbours |
| ET | extra trees |
| NN | neural network |
| PCA | Proncipal Component Analysis |
| ECMWF | European Center for Medium-range Weather Forecasts |
References
- Kovač, Ž.; Platt, T.; Ninčević Gladan, Ž.; Morović, M.; Sathyendranath, S.; Raitsos, D.E.; Grbec, B.; Matić, F.; VeŽa, J. A 55-Year Time Series Station for Primary Production in the Adriatic Sea: Data Correction, Extraction of Photosynthesis Parameters and Regime Shifts. Remote Sens. 2018, 10, 1460. [Google Scholar] [CrossRef] [Green Version]
- Benway, H.M.; Lorenzoni, L.; White, A.E.; Fiedler, B.; Levine, N.M.; Nicholson, D.P.; DeGrandpre, M.D.; Sosik, H.M.; Church, M.J.; O’Brien, T.D.; et al. Ocean Time Series Observations of Changing Marine Ecosystems: An Era of Integration, Synthesis, and Societal Applications. Front. Mar. Sci. 2019, 6, 393. [Google Scholar] [CrossRef] [Green Version]
- Steinberg, D.K.; Carlson, C.A.; Bates, N.R.; Johnson, R.J.; Michaels, A.F.; Knap, A.H. Overview of the US JGOFS Bermuda Atlantic Time-series Study (BATS): A decade-scale look at ocean biology and biogeochemistry. Deep Sea Res. Part II Top. Stud. Oceanogr. 2001, 48, 1405–1447. [Google Scholar] [CrossRef]
- Karl, D.M.; Lukas, R. The Hawaii Ocean Time-series (HOT) program: Background, rationale and field implementation. Deep Sea Res. Part II Top. Stud. Oceanogr. 1996, 43, 129–156. [Google Scholar] [CrossRef]
- Friendly, M.; Dray, S.; Wickham, H.; Hanley, J.; Murphy, D.; Li, P. HistData: Data Sets from the History of Statistics and Data Visualization, R Package Version 0.8-7; 2021. Available online: https://cran.r-project.org/web/packages/HistData (accessed on 14 March 2021).
- Tufte, E.R. The Visual Display of Quantitative Information; Graphics Press: Cheshire, CT, USA, 1986. [Google Scholar]
- Li, J.; Roy, D. A Global Analysis of Sentinel-2A, Sentinel-2B and Landsat-8 Data Revisit Intervals and Implications for Terrestrial Monitoring. Remote Sens. 2017, 9, 902. [Google Scholar]
- Vilibić, I.; Šepić, J.; Mihanović, H.; Kalinić, H.; Cosoli, S.; Janeković, I.; Žagar, N.; Jesenko, B.; Tudor, M.; Dadić, V.; et al. Self-Organizing Maps-based ocean currents forecasting system. Sci. Rep. 2016, 6, 22924. [Google Scholar] [CrossRef] [PubMed]
- Ćatipović, L.; Udovičić, D.; Džoić, T.; Matić, F.; Kalinić, H.; Juretić, T.; Tičina, V. Adriatic Mix Layer Depth Changes in September in the Recent Years. In Proceedings of the EGU General Assembly 2021, EGU21-2410, Online, 19–30 April 2021. [Google Scholar] [CrossRef]
- Hu, Q.; Li, Z.; Wang, L.; Huang, Y.; Wang, Y.; Li, L. Rainfall Spatial Estimations: A Review from Spatial Interpolation to Multi-Source Data Merging. Water 2019, 11, 579. [Google Scholar] [CrossRef] [Green Version]
- Simolo, C.; Brunetti, M.; Maugeri, M.; Nanni, T. Improving estimation of missing values in daily precipitation series by a probability density function-preserving approach. Int. J. Climatol. 2009, 30, 1564–1576. [Google Scholar] [CrossRef]
- Kasam, A.; Lee, B.; Paredis, C. Statistical methods for interpolating missing meteorological data for use in building simulation. Build. Simul. 2014, 7. [Google Scholar] [CrossRef]
- Xu, C.D.; Wang, J.F.; Hu, M.G.; Li, Q.X. Interpolation of Missing Temperature Data at Meteorological Stations Using P-BSHADE. J. Clim. 2013, 26, 7452–7463. [Google Scholar] [CrossRef]
- Li, J.; Heap, A.D. A review of comparative studies of spatial interpolation methods in environmental sciences: Performance and impact factors. Ecol. Inform. 2011, 6, 228–241. [Google Scholar] [CrossRef]
- Grilli, F.; Accoroni, S.; Acri, F.; Bernardi Aubry, F.; Bergami, C.; Cabrini, M.; Campanelli, A.; Giani, M.; Guicciardi, S.; Marini, M.; et al. Seasonal and Interannual Trends of Oceanographic Parameters over 40 Years in the Northern Adriatic Sea in Relation to Nutrient Loadings Using the EMODnet Chemistry Data Portal. Water 2020, 12, 2280. [Google Scholar] [CrossRef]
- Matić, F.; Kalinić, H.; Vilibić, I.; Grbec, B.; MoroŽin, K. Adriatic-Ionian air temperature and precipitation patterns derived from self-organizing maps: Relation to hemispheric indices. Clim. Res. 2019, 78, 149–163. [Google Scholar] [CrossRef]
- Grbec, B.; Matić, F.; Beg Paklar, G.; Morović, M.; Popović, R.; Vilibić, I. Long-Term Trends, Variability and Extremes of In Situ Sea Surface Temperature Measured Along the Eastern Adriatic Coast and its Relationship to Hemispheric Processes. Pure Appl. Geophys. 2018, 175, 4031–4046. [Google Scholar] [CrossRef]
- Kalinić, H.; Mihanović, H.; Cosoli, S.; Tudor, M.; Vilibić, I. Predicting ocean surface currents using numerical weather prediction model and Kohonen neural network: A northern Adriatic study. Neural Comput. Appl. 2017, 28, 611–620. [Google Scholar] [CrossRef]
- Li, W.; Chen, C.; Zhang, M.; Li, H.; Du, Q. Data Augmentation for Hyperspectral Image Classification with Deep CNN. IEEE Geosci. Remote Sens. Lett. 2018, 16, 593–597. [Google Scholar] [CrossRef]
- Wu, P.; Yin, Z.; Yang, H.; Wu, Y.; Ma, X. Reconstructing Geostationary Satellite Land Surface Temperature Imagery Based on a Multiscale Feature Connected Convolutional Neural Network. Remote Sens. 2019, 11, 300. [Google Scholar] [CrossRef] [Green Version]
- Zeng, C.; Shen, H.; Zhong, M.; Zhang, L.; Penghai, W. Reconstructing MODIS LST Based on Multitemporal Classification and Robust Regression. Geosci. Remote Sens. Lett. IEEE 2015, 12, 512–516. [Google Scholar] [CrossRef]
- Ji, T.Y.; Yokoya, N.; Zhu, X.X.; Huang, T.Z. Nonlocal Tensor Completion for Multitemporal Remotely Sensed Images’ Inpainting. IEEE Trans. Geosci. Remote Sens. 2018, 56, 3047–3061. [Google Scholar] [CrossRef]
- Addesso, P.; Mura, M.; Condat, L.; Restaino, R.; Vivone, G.; Picone, D.; Chanussot, J. Hyperspectral image inpainting based on collaborative total variation. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017. [Google Scholar]
- Campbell, J.; Wynne, R. History and Scope of Remote Sensing. In Introduction to Remote Sensing, 5th ed.; Guilford Publications: New York, NY, USA, 2011; pp. 3–30. [Google Scholar]
- Turk, F.; Hawkins, J.; Smith, E.; Marzano, F.; Mugnai, A.; Levizzani, V.S. TRMM and Infrared Geostationary Satellite Data in a Near-Realtime Fashion for Rapid Precipitation Updates: Advantages and Limitations. In Proceedings of the 2000 EUMETSAT Meteorological Satellite Data Users, Bologna, Italy, 29 May–2 June 2000; Volume 2, pp. 705–707. [Google Scholar]
- Donoho, D. Compressed sensing. IEEE Trans. Inform. Theory 2006, 52, 12891306. [Google Scholar] [CrossRef]
- Candès, E.; Wakin, M. An Introduction to Compressive Sampling. IEEE Signal Process. Mag. 2008, 28, 21–30. [Google Scholar] [CrossRef]
- Pham, D.S.; Venkatesh, S. Efficient algorithms for robust recovery of images from compressed data. IEEE Trans. Image Process. 2013, 22, 4724–4737. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bora, A.; Jalal, A.; Price, E.; Dimakis, A. Compressed Sensing using Generative Models. arXiv 2017, arXiv:1703.03208. [Google Scholar]
- Aghazadeh, A.; Golbabaee, M.; Lan, A.; Baraniuk, R. Insense: Incoherent sensor selection for sparse signals. Signal Process. 2018, 150, 57–65. [Google Scholar] [CrossRef] [Green Version]
- Rao, S.; Chepuri, S.P.; Leus, G. Greedy Sensor Selection for Non-Linear Models. In Proceedings of the 2015 IEEE 6th International Workshop on Computational Advances in Multi-Sensor Adaptive Processing (CAMSAP), Cancun, Mexico, 13–16 December 2015; pp. 241–244. [Google Scholar]
- Ranieri, J.; Chebira, A.; Vetterli, M. Near-Optimal Sensor Placement for Linear Inverse Problems. IEEE Trans. Signal Process. 2014, 62, 1135–1146. [Google Scholar] [CrossRef] [Green Version]
- Jaimes, A.; Tweedie, C.; Magoč, T.; Kreinovich, V.; Ceberio, M. Optimal Sensor Placement in Environmental Research: Designing a Sensor Network under Uncertainty. In Proceedings of the 4th International Workshop on Reliable Engineering Computing REC’2010, Singapore, 3–5 March 2010; pp. 255–267. [Google Scholar]
- Guestrin, C.; Krause, A.; Singh, A.P. Near-optimal sensor placements in gaussian processes. In Proceedings of the 22nd international conference on Machine learning, ICML’05, Bonn, Germany, 7–11 August 2005. [Google Scholar]
- C3S. Copernicus Climate Change Service: ERA5: Fifth Genera-Tion of ECMWF Atmospheric Reanalyses of the Global Climate, Copernicus Climate Change Service Climate Data Store (CDS). 2017. Available online: https://cds.climate.copernicus.eu/cdsapp#!/dataset/reanalysis-era5-single-levels?tab=overview (accessed on 14 March 2021).
- Cushman-Roisin, B.; Gacic, M.; Poulain, P.M.; Artegiani, A. Physical Oceanography of the Adriatic Sea: Past, Present and Future; Springer: Heidelberg, Germany, 2001. [Google Scholar] [CrossRef]
- Boldrin, A.; Carniel, S.; Giani, M.; Marini, M.; Bernardi Aubry, F.; Campanelli, A.; Grilli, F.; Russo, A. Effects of bora wind on physical and biogeochemical properties of stratified waters in the northern Adriatic. J. Geophys. Res. Ocean. 2009, 114. [Google Scholar] [CrossRef]
- Pandžić, K.; Likso, T. Eastern Adriatic typical wind field patterns and large-scale atmospheric conditions. Int. J. Climatol. 2005, 25, 81–98. [Google Scholar] [CrossRef]
- Duda, R.O.; Hart, P.E.; Stork, D.G. Pattern Classification, 2nd ed.; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2001. [Google Scholar]
- Geurts, P.; Ernst, D.; Wehenkel, L. Extremely randomized trees. Mach. Learn. 2006, 63, 3–42. [Google Scholar] [CrossRef] [Green Version]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
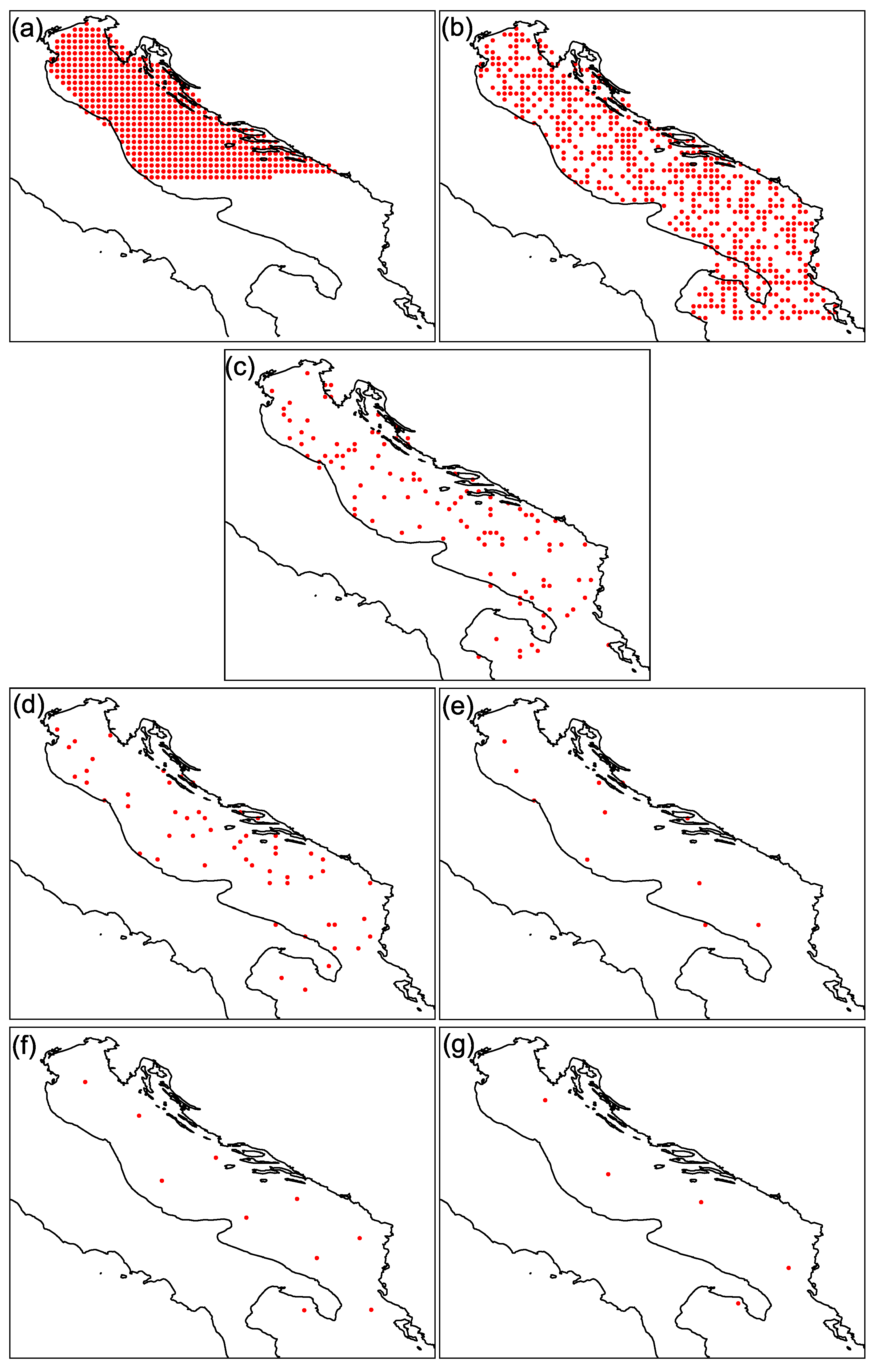
| Experiment | Sampling Model | # of Sensors |
|---|---|---|
| (a) | pre order | 50% (1105 sensors) |
| (b) | random | 50% (1105 sensors) |
| (c) | random | 10% (110 sensors) |
| (d) | random | 5% (55 sensors) |
| (e) | random | 1% (10 sensors) |
| (f) | k-means | - 10 sensors |
| (g) | k-means | - 5 sensors |
| Experiment | Linear | KNN | Extra | Neural | |||||
|---|---|---|---|---|---|---|---|---|---|
| Regression | Trees | Network | |||||||
| (a) | Amplitude | 0.52 | 1.00 | 0.91 | 1.42 | 0.76 | 1.23 | 0.73 | 1.17 |
| Angle | 6.28 | 17.03 | 11.43 | 24.40 | 9.49 | 21.34 | 8.79 | 19.88 | |
| (b) | Amplitude | 0.00 | 0.00 | 0.40 | 0.58 | 0.48 | 0.71 | 0.17 | 0.25 |
| Angle | 0.00 | 0.00 | 5.16 | 12.33 | 6.24 | 14.63 | 2.00 | 5.12 | |
| (c) | Amplitude | 0.00 | 0.03 | 0.74 | 0.64 | 0.87 | 0.77 | 0.20 | 0.16 |
| Angle | 0.09 | 0.89 | 9.50 | 15.80 | 11.34 | 18.29 | 2.63 | 5.08 | |
| (d) | Amplitude | 0.03 | 0.14 | 0.79 | 0.66 | 0.92 | 0.76 | 0.27 | 0.24 |
| Angle | 0.40 | 2.72 | 10.20 | 16.47 | 11.89 | 18.55 | 3.17 | 6.32 | |
| (e) | Amplitude | 0.52 | 0.68 | 0.94 | 0.81 | 1.02 | 0.84 | 0.55 | 0.59 |
| Angle | 6.61 | 13.86 | 12.08 | 18.93 | 13.47 | 20.25 | 6.88 | 13.07 | |
| (f) | Amplitude | 0.30 | 0.30 | 0.80 | 0.59 | 0.94 | 0.73 | 0.32 | 0.28 |
| Angle | 4.20 | 9.30 | 10.44 | 16.29 | 12.37 | 18.76 | 4.31 | 8.95 | |
| (g) | Amplitude | 0.72 | 0.60 | 0.88 | 0.66 | 0.97 | 0.73 | 0.61 | 0.52 |
| Angle | 10.42 | 17.44 | 11.89 | 18.61 | 13.07 | 19.74 | 8.75 | 15.65 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kalinić, H.; Bilokapić, Z.; Matić, F. Can Local Geographically Restricted Measurements Be Used to Recover Missing Geo-Spatial Data? Sensors 2021, 21, 3507. https://doi.org/10.3390/s21103507
Kalinić H, Bilokapić Z, Matić F. Can Local Geographically Restricted Measurements Be Used to Recover Missing Geo-Spatial Data? Sensors. 2021; 21(10):3507. https://doi.org/10.3390/s21103507
Chicago/Turabian StyleKalinić, Hrvoje, Zvonimir Bilokapić, and Frano Matić. 2021. "Can Local Geographically Restricted Measurements Be Used to Recover Missing Geo-Spatial Data?" Sensors 21, no. 10: 3507. https://doi.org/10.3390/s21103507
APA StyleKalinić, H., Bilokapić, Z., & Matić, F. (2021). Can Local Geographically Restricted Measurements Be Used to Recover Missing Geo-Spatial Data? Sensors, 21(10), 3507. https://doi.org/10.3390/s21103507