
AI-Based Multi Sensor Fusion for Smart Decision Making: A Bi-Functional System for Single Sensor Evaluation in a Classification Task



Abstract
:1. Introduction
2. Methodology
2.1. Prototype-Based Classification
2.2. Sensors Evaluation in Fusion Systems
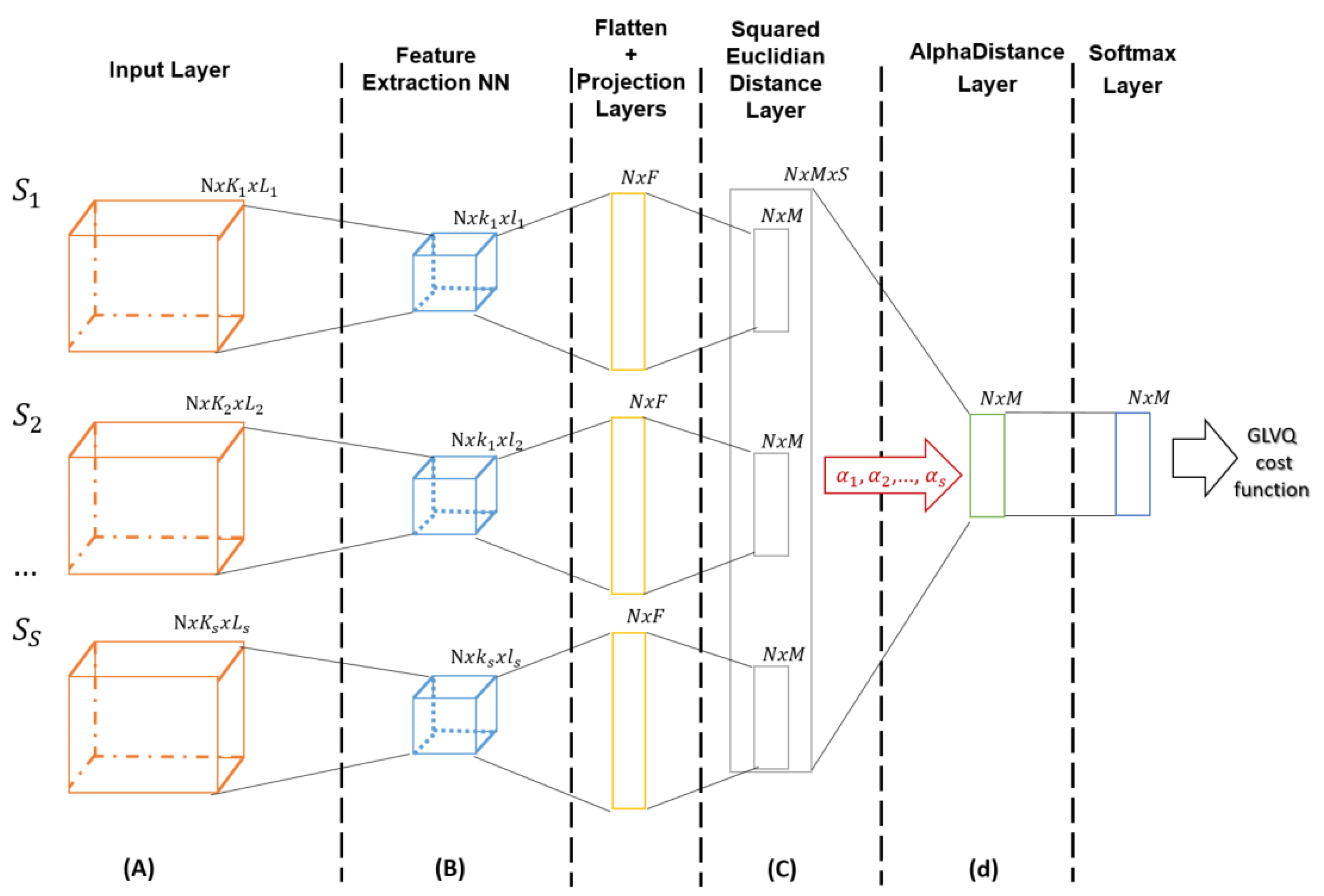
2.2.1. Sensors Contribution in Classification Problems
- (A)
- Data preparation: data sets creation for each of the considered sensors
- (B)
- Feature extraction: relevant patterns extraction out of the training data points used for prototypes training
- (C)
- Prototype-based classification: training parameters definition corresponding to the distance layer
- (D)
- Sensors contribution: Sensor’s data weighting depending on each sensor contribution in the classification task
Data Preparation
Feature Extraction
Prototype-Based Classification
Sensors Contribution
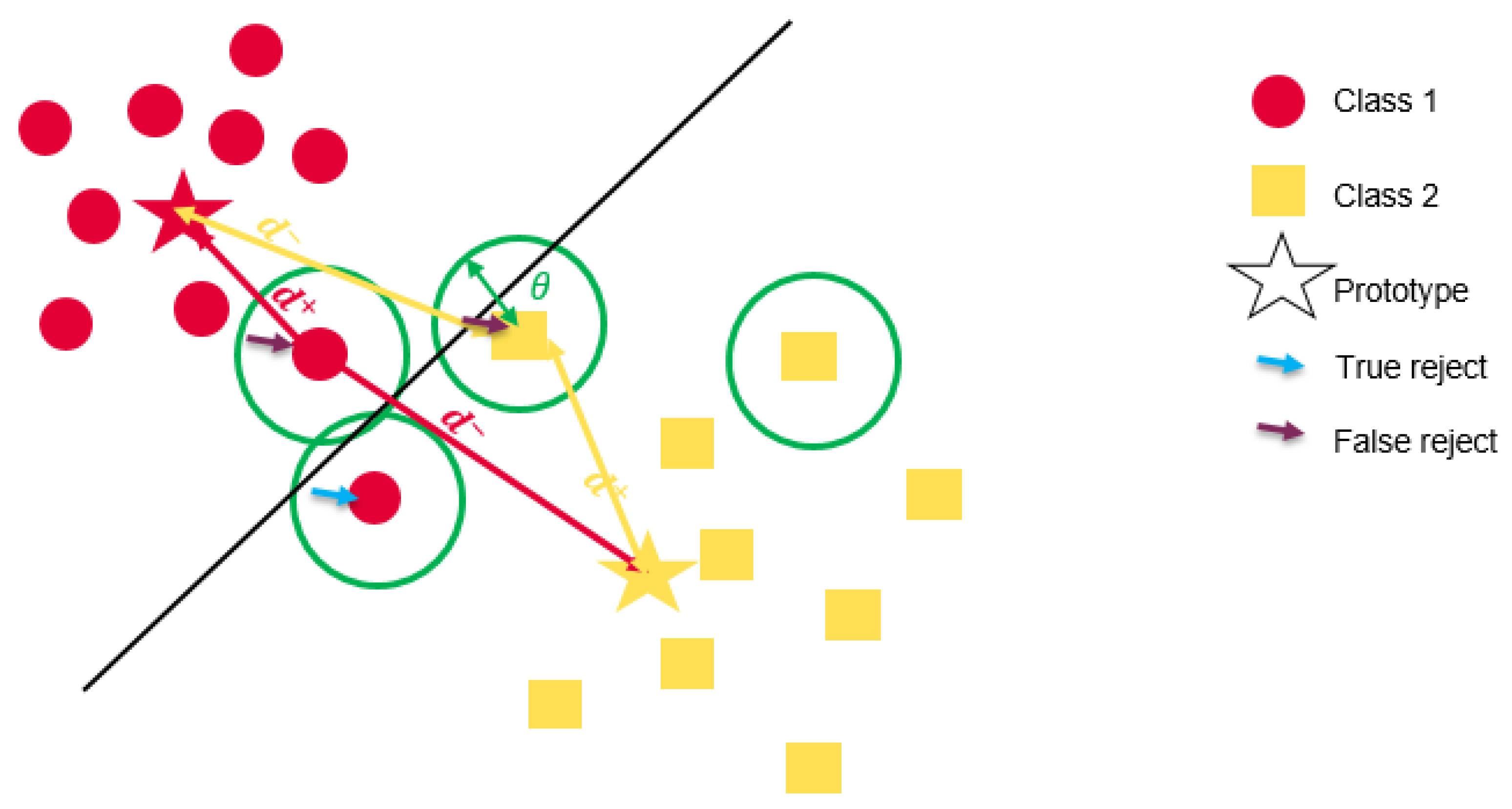
2.2.2. Sensors Robustness under Different Conditions
Classification with Reject Option
- Ambiguity: The classification is uncertain because the data point falls in an overlapping region between classes. So, the decision is unclear and confusing for the classifier.
- Outliers: The data point is defined by new features that have not been seen before by the classifier. It can belong to another strange class for the classifier.
3. Experimental Results and Discussion
3.1. Dynamic Evaluation of Fusion System
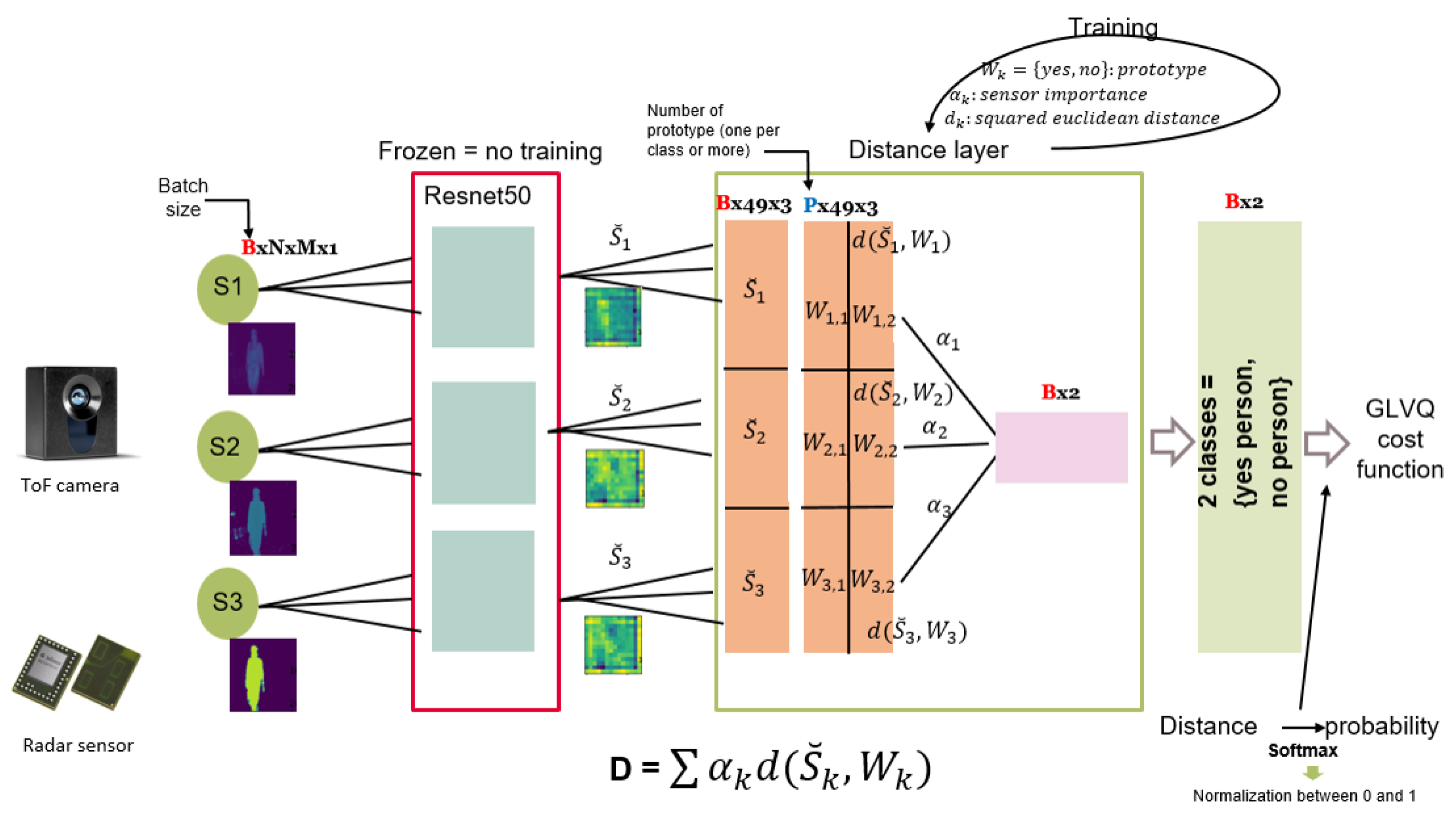
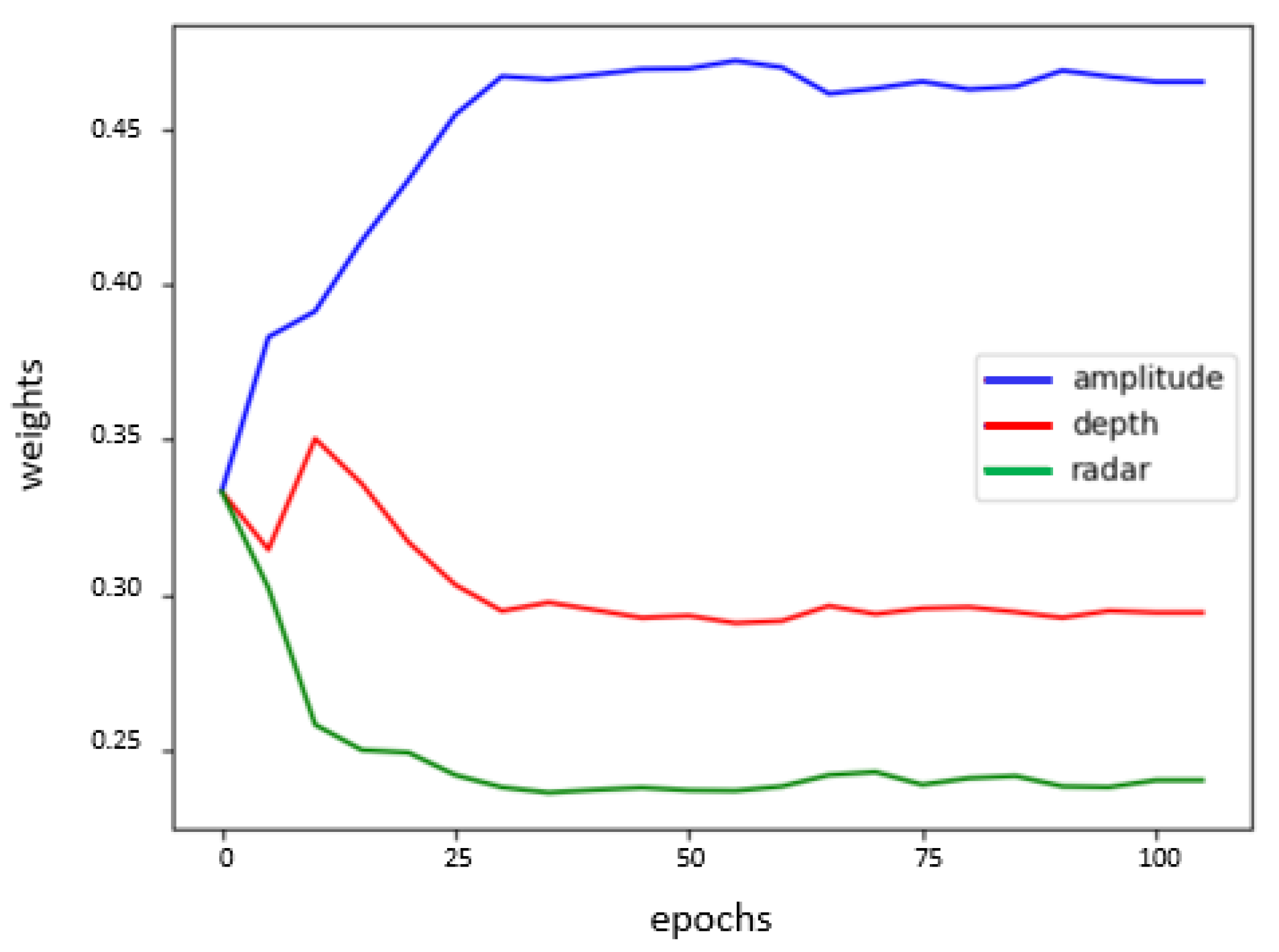
3.1.1. Tof/Radar Fusion System
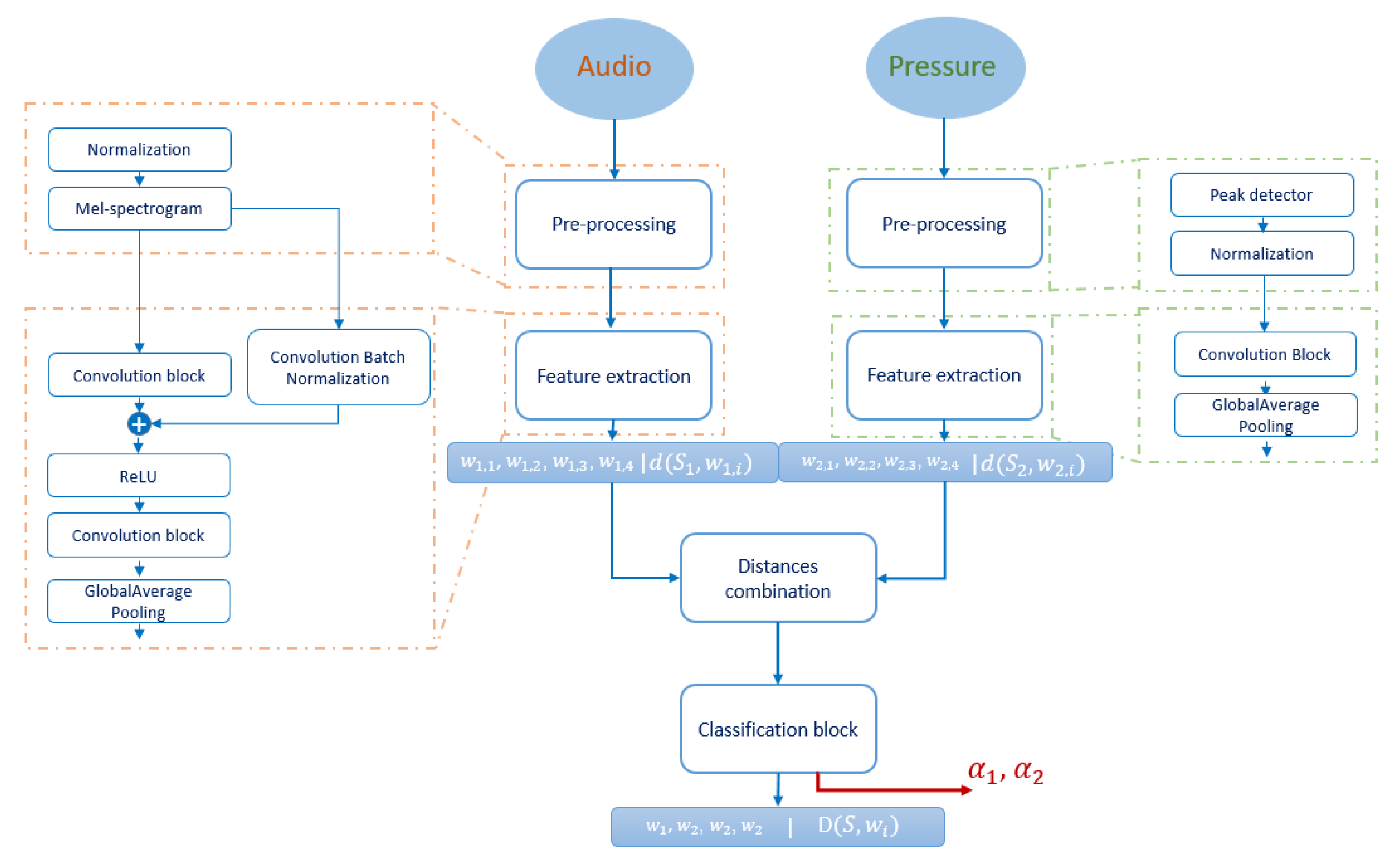
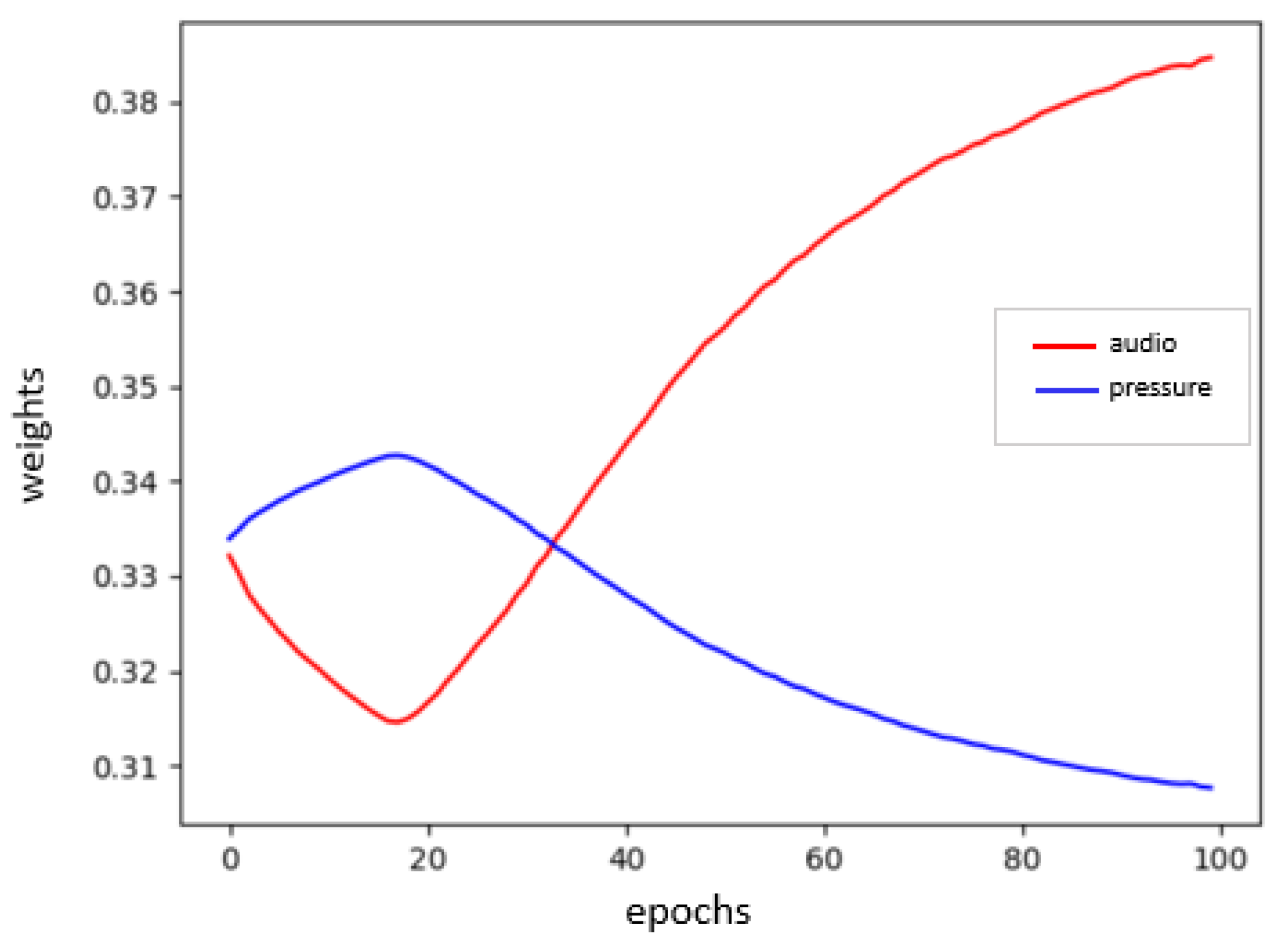
3.1.2. Audio/Pressure Fusion System
3.1.3. Sensors Contribution Evaluation
- For the ToF/radar fusion system, amplitude information is more contributing to the classification task with , then the depth information with and finally in the last place the radar information with .
- For the audio/pressure fusion system, the audio features are slightly more contributing to the events’ classification, being around more than the pressure features.
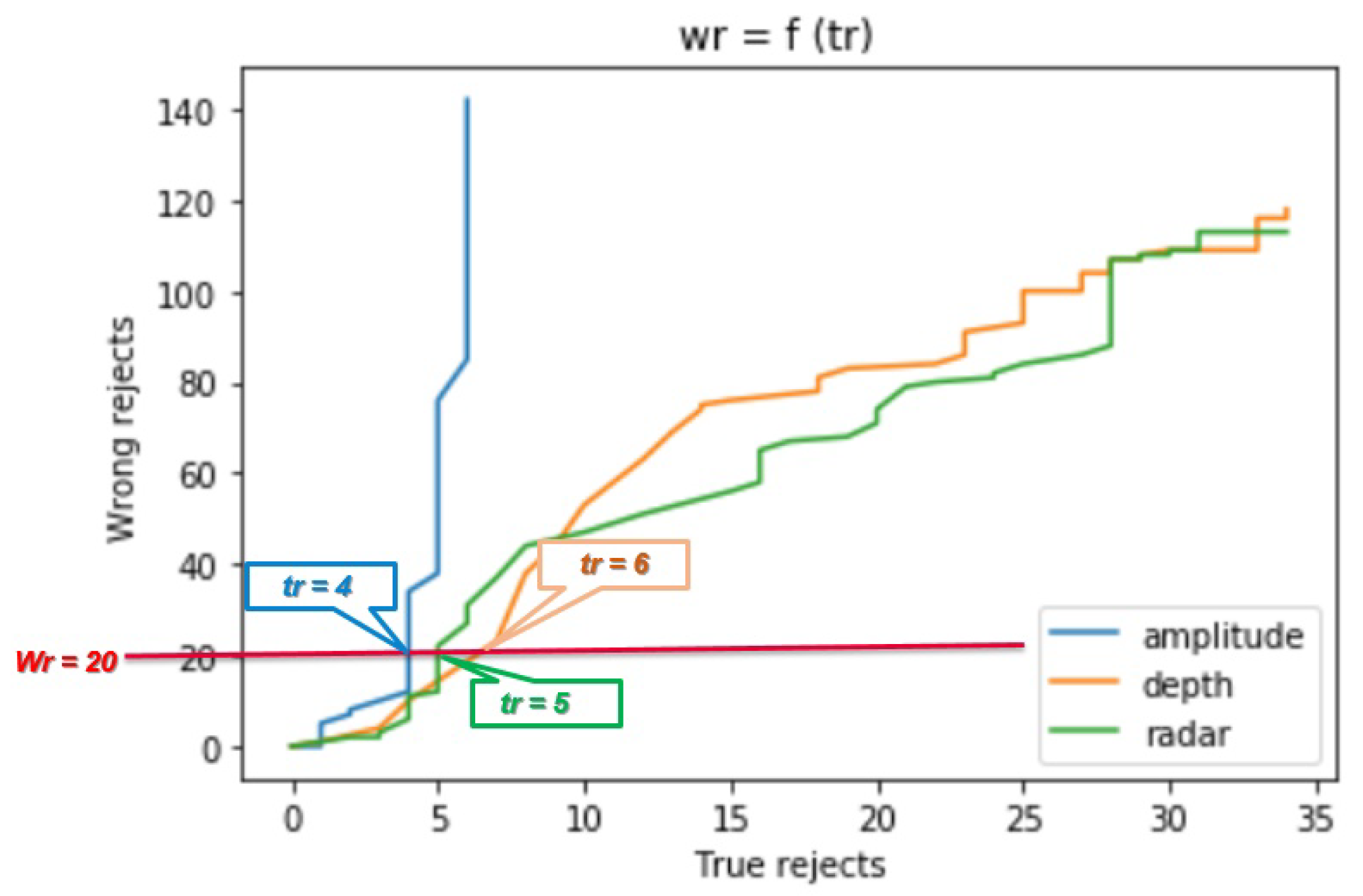
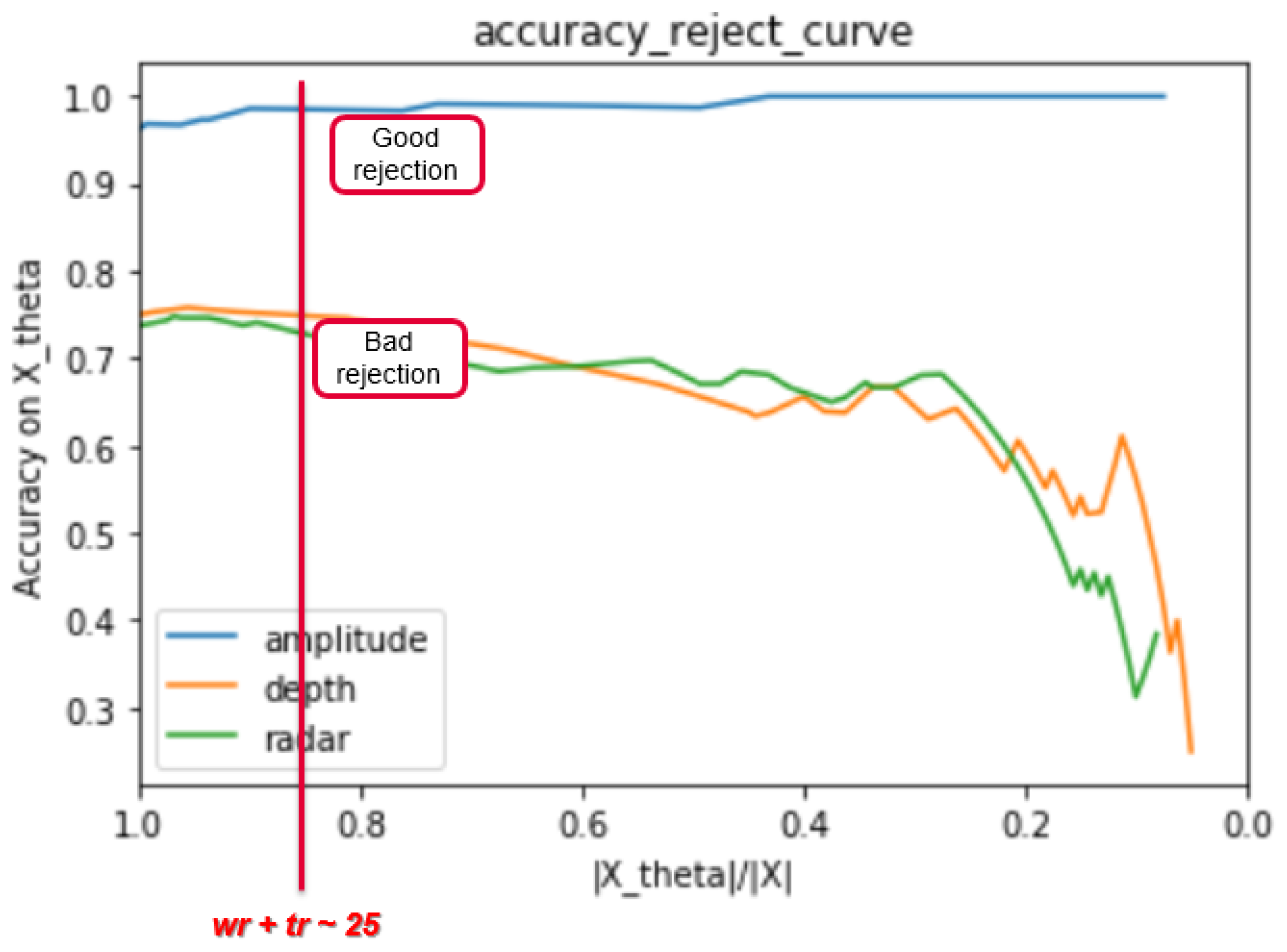
3.2. Static Evaluation of Fusion System
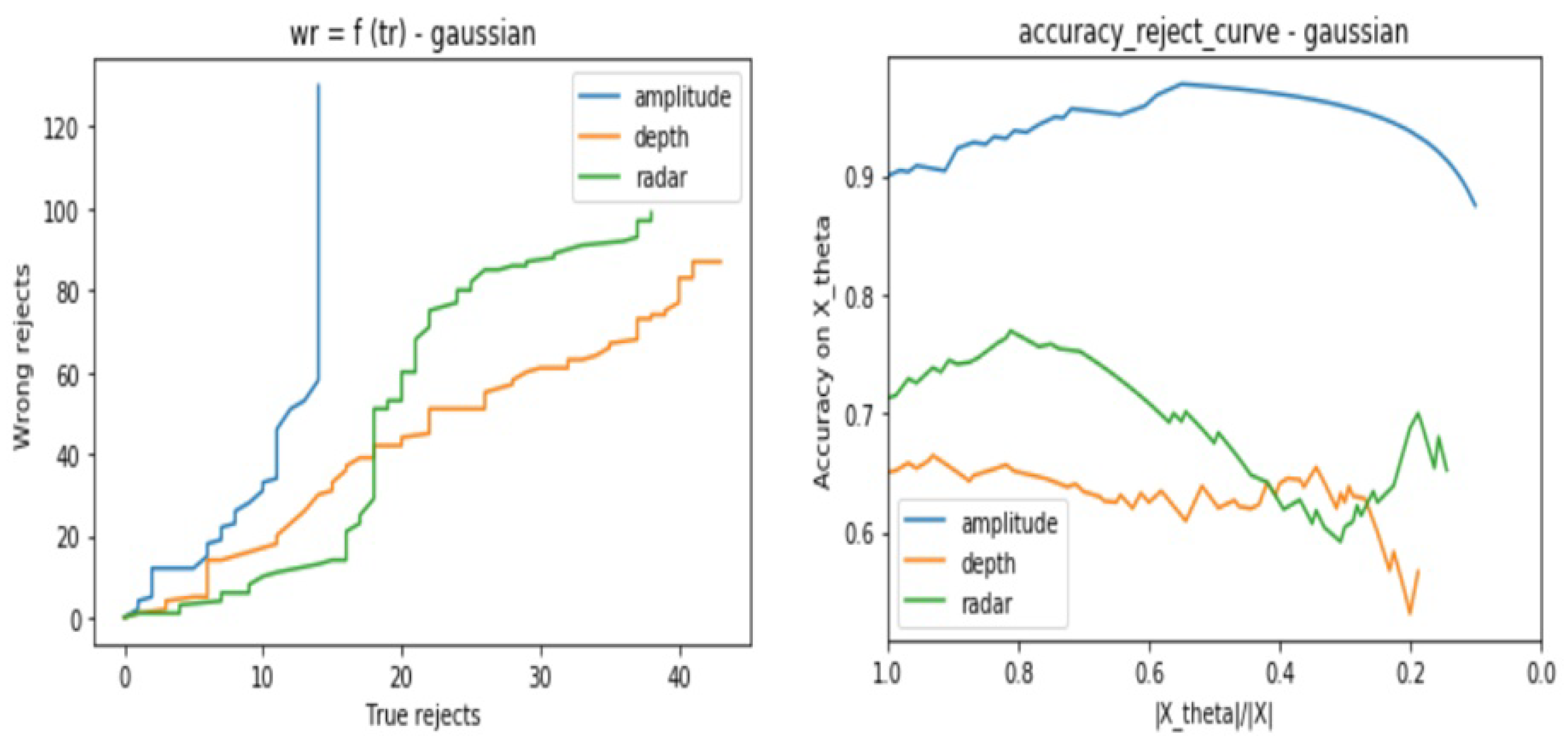
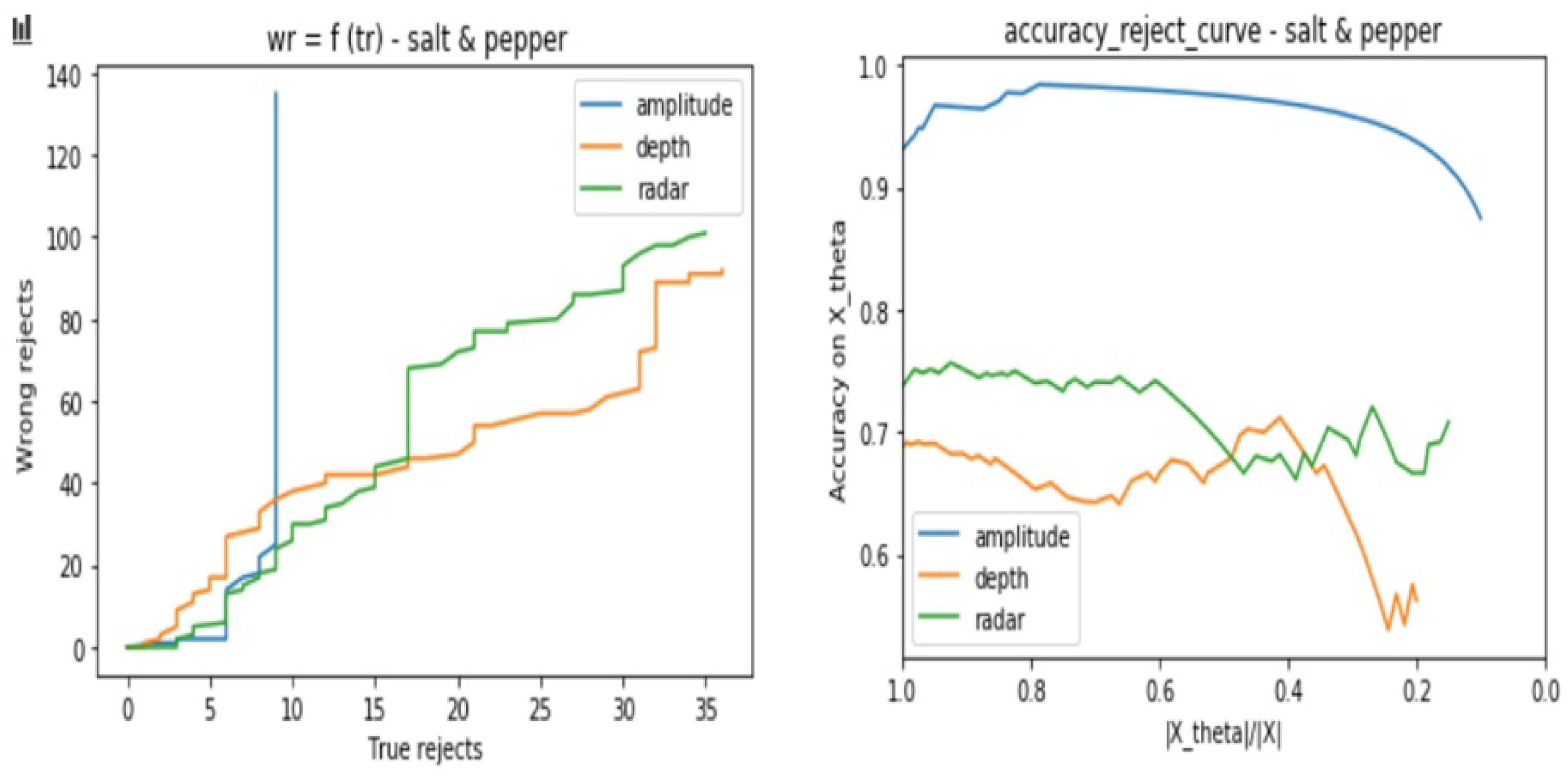
- The number of wrongly rejected data points depending on the number of correctly rejected data points .
- The accuracy reject curve (), which presents the accuracy of the classifier depending on the ratio of remaining data points from the initial set after each rejection step.
3.2.1. Predictive Power
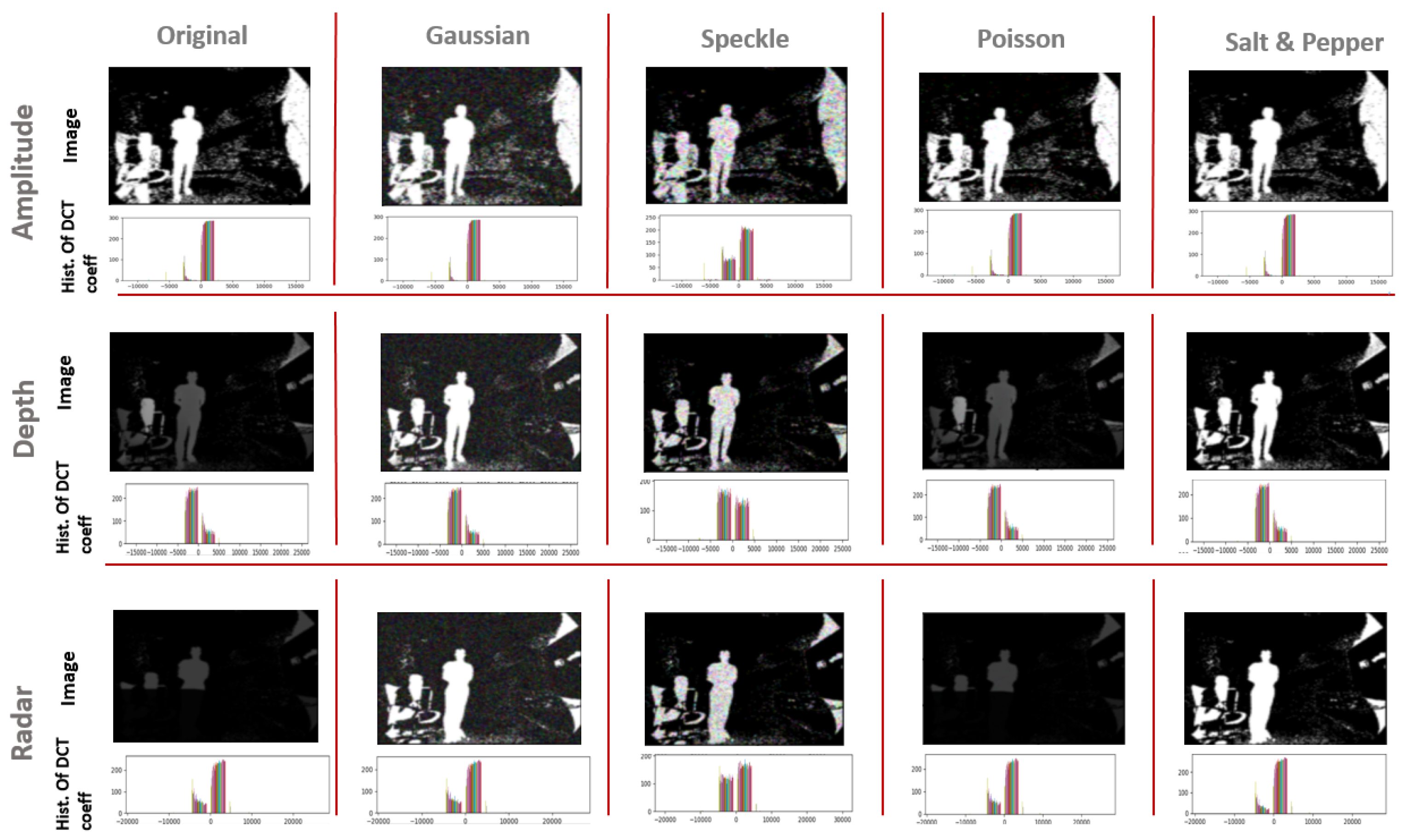
3.2.2. Robustness
- Gaussian noise or white noise
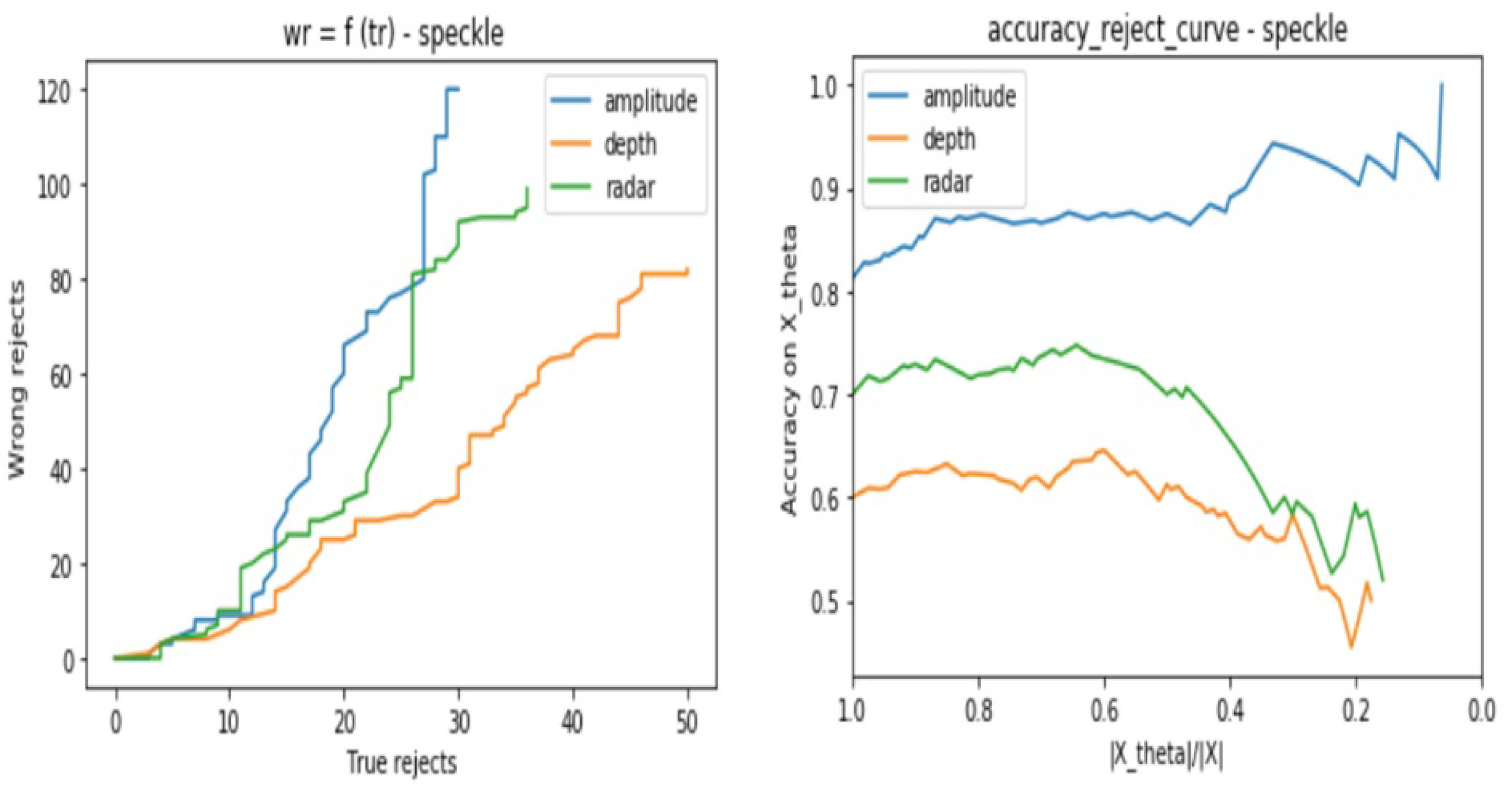
- Speckle noise
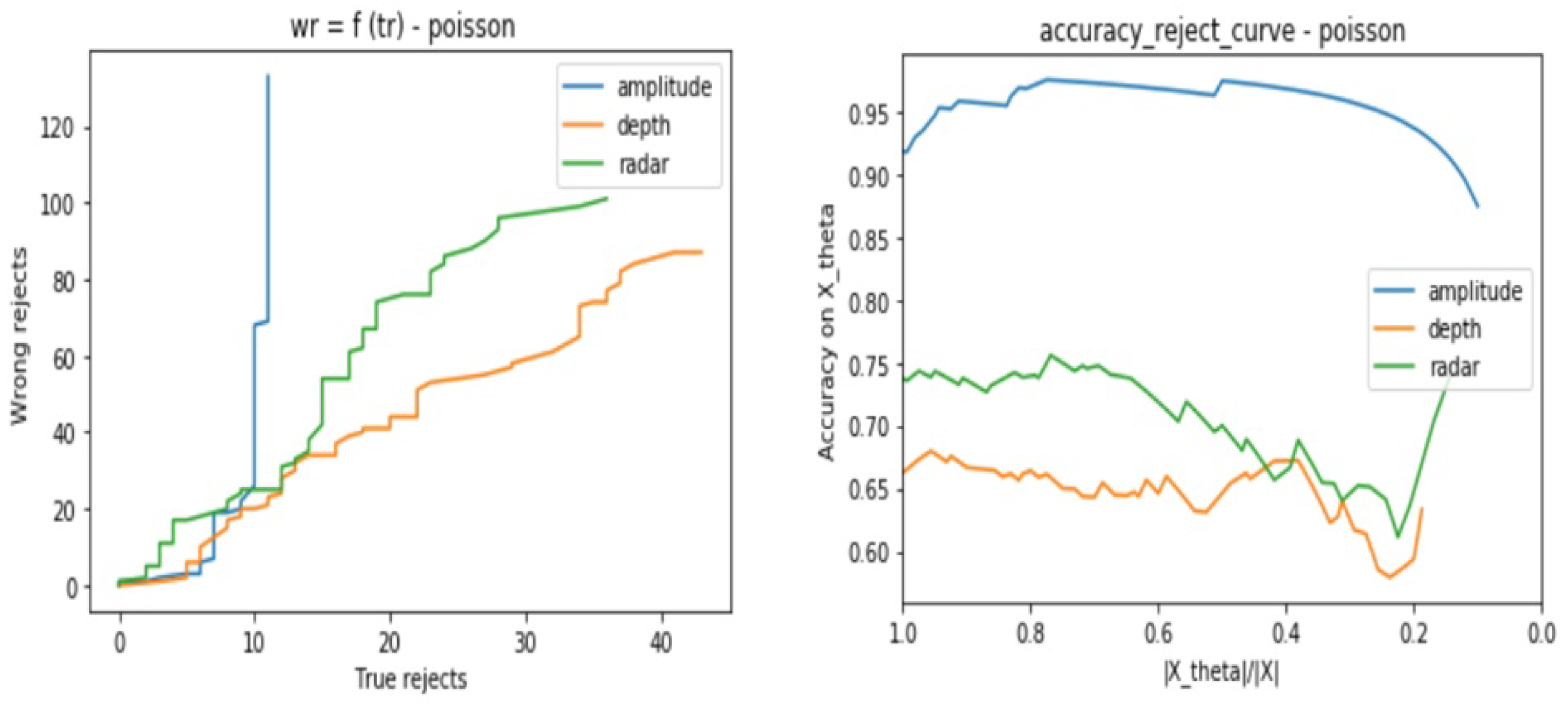
- Poisson noise or photon shot noise
- Salt and Pepper noise
- Consider the same testing sets as in Section 3.2.1 for the three sensor types.
- Apply one by one the cited above noises to all the samples and store the result samples into new data sets
- Use the same trained model for each sensor from Section 3.2 to predict the class of the test samples with consideration of the reject option.
- Track for different values the models certainties when considering the reject option in the classification process.
- Amplitude model is not stable against Gaussian, Poisson, and Salt and Pepper noises especially when there are no more possible correctly rejected data points (in case of saturation), whereas, it presents good stability against the Speckle noise.
- Depth is not stable to Salt and Pepper noise, but relatively stable to Gaussian, Poisson, and Speckle noises
- Radar is stable to all of the considered noises.
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| SVM | Support Vector Machine |
| DNN | Deep Neural Network |
| WTA | Winner Takes All |
| LVQ | Learning Vector Quantization |
| GLVQ | Generalized Learning Vector Quantization |
| ToF | Time of Flight |
| DP | Dynamic Programming |
References
- Rojko, A. Industry 4.0 concept: Background and overview. Int. J. Interact. Mob. Technol. 2017, 11, 77–90. [Google Scholar] [CrossRef] [Green Version]
- Schütze, A.; Helwig, N.; Schneider, T. Sensors 4.0—Smart sensors and measurement technology enable Industry 4.0. J. Sens. Sens. Syst. 2018, 7, 359–371. [Google Scholar] [CrossRef]
- Teh, H.Y.; Kempa-Liehr, A.W.; Kevin, I.; Wang, K. Sensor data quality: A systematic review. J. Big Data 2020, 7, 11. [Google Scholar] [CrossRef] [Green Version]
- KDnuggets—Applying Deep Learning to Real-World Problems. Available online: https://www.kdnuggets.com/2017/06/applying-deep-learning-real-world-problems.html (accessed on 3 November 2020).
- Xiong, Y.; Zuo, R. Effects of misclassification costs on mapping mineral prospectivity. Ore Geol. Rev. 2017, 82, 1–9. [Google Scholar] [CrossRef]
- Wossen, T.; Abdoulaye, T.; Alene, A.; Nguimkeu, P.; Feleke, S.; Rabbi, I.Y.; Manyong, V. Estimating the productivity impacts of technology adoption in the presence of misclassification. Am. J. Agric. Econ. 2019, 101, 1–16. [Google Scholar] [CrossRef]
- Li, Z.; Jing, X.Y.; Wu, F.; Zhu, X.; Xu, B.; Ying, S. Cost-sensitive transfer kernel canonical correlation analysis for heterogeneous defect prediction. Autom. Softw. Eng. 2018, 25, 201–245. [Google Scholar] [CrossRef]
- Xu, Z.; Liu, J.; Luo, X.; Yang, Z.; Zhang, Y.; Yuan, P.; Zhang, T. Software defect prediction based on kernel PCA and weighted extreme learning machine. Inf. Softw. Technol. 2019, 106, 182–200. [Google Scholar] [CrossRef]
- Wu, F.; Jing, X.Y.; Sun, Y.; Sun, J.; Huang, L.; Cui, F.; Sun, Y. Cross-project and within-project semi supervised software defect prediction: A unified approach. IEEE Trans. Reliab. 2018, 67, 581–597. [Google Scholar] [CrossRef]
- Doshi, A.A.; Sevugan, P.; Swarnalatha, P. Modified Support Vector Machine Algorithm to Reduce Misclassification and Optimizing Time Complexity. Big Data Anal. Satell. Image Process. Remote Sens. 2018, 34–56. [Google Scholar] [CrossRef]
- Song, Y.; Wang, X.; Zhu, J.; Lei, L. Sensor dynamic reliability evaluation based on evidence theory and intuitionistic fuzzy sets. Appl. Intell. 2018, 48, 3950–3962. [Google Scholar] [CrossRef]
- Schneider, P.; Biehl, M.; Hammer, B. Adaptive relevance matrices in learning vector quantization. Neural Comput. 2009, 21, 3532–3561. [Google Scholar] [CrossRef] [Green Version]
- Kohonen, T. Self-Organizing Maps, 3rd ed.; Springer: Berlin/Heidelberg, Germany, 2001; Volume 30, pp. 245–261. [Google Scholar]
- Salajew, S.; Holdijk, L.; Rees, M.; Villmann, T. Prototype based neural network layers: Incorporating vector quantization. arXiv 2018, arXiv:1812.01214. [Google Scholar]
- Zoghlami, F.; Kaden, M.; Villmann, T.; Heinrich, H.; Schneider, G.; Villmann, T. Sensors data fusion for smart decisions making: A novel bi-functional system for the evaluation of sensors contribution in classification problems. In Proceedings of the 22nd IEEE International Conference on Industrial Technology, Valencia, Spain, 10–12 March 2021. (accepted and presented). [Google Scholar]
- Fischer, L.; Hammer, B.; Wersing, H. Efficient Rejection Strategies for Prototype-based Classification. Neurocomputing 2015, 169, 334–342. [Google Scholar] [CrossRef] [Green Version]
- Fischer, L.; Hammer, B.; Wersing, H. Optimal local rejection for classifiers. Neurocomputing 2016, 214, 445–457. [Google Scholar] [CrossRef]
- Sato, A.; Yamada, K. Generalized learning vector quantization. Neural Inf. Process. Syst. (NIPS) 1995, 95, 423–429. [Google Scholar]
- Crammer, K.; Gilad-Bachrach, R.; Navot, A.; Tishby, A. Margin analysis of the LVQ algorithm. Adv. Neural Inf. Process. Syst. 2002, 2, 462–469. [Google Scholar]
- Paul, E. Black (17 December 2004). Manhattan Distance. Dictionary of Algorithms and Data Structures. Available online: https://xlinux.nist.gov/dads/HTML/euclidndstnc.html (accessed on 12 January 2021).
- Kafka, P.; Österreicher, F.; Vincze, I. On powers of f-divergences defining a distance. Studia Sci. Math. Hunga 1991, 26, 415–422. [Google Scholar]
- Phillips, J.M.; Venkatasubramanian, S. A gentle introduction to the kernel distance. arXiv 2011, arXiv:1103.1625. [Google Scholar]
- González, A.I.; Grana, M.; D’Anjou, A. An analysis of the GLVQ algorithm. IEEE Trans. Neural Netw. 1956, 6, 1012–1016. [Google Scholar] [CrossRef] [PubMed]
- Vailaya, A.; Jain, A. Reject option for lvq-based Bayesian classification. In Proceedings of the IEEE Proceedings 15th International Conference on Pattern Recognition, Barcelona, Spain, 3–7 September 2000; Volume 2, pp. 48–51. [Google Scholar]
- Chow, C.K. On optimum recognition error and reject tradeoff. IEEE Trans. Inf. Theory. 1970, 16, 41–46. [Google Scholar] [CrossRef] [Green Version]
- Grandvalet, Y.; Rakotomamonjy, A.; Keshet, J.; Canu, S. Support vector machines with a reject option. Neural Inf. Process. Syst. (NIPS) 2009, 21, 537–544. [Google Scholar]
- Dasarathy, B.V. Nosing around the neighborhood: A new system structure and classification rule for recognition in partially exposed environments. IEEE Trans. Pattern Anal. Mach. Intell. 1980, PAMI-2, 67–71. [Google Scholar] [CrossRef] [PubMed]
- Fischer, L.; Hammer, B.; Wersing, H. Rejection Strategies for Learning Vector Quantization; European Symposium on Artificial Neural Networks (ESANN): Bruges, Belgium, 2014; pp. 41–46. [Google Scholar]
- Fischer, L.; Nebel, D.; Villmann, T.; Hammer, B.; Wersing, H. Rejection strategies for learning vector quantization—A comparison of probabilistic and deterministic approaches. In Advances in Self-Organizing Maps and Learning Vector Quantization; Springer: Cham, Switzerland, 2014; pp. 109–118. [Google Scholar]
- Saralajew, S.; Holdijk, L.; Villmann, T. Fast Adversarial Robustness Certification of Nearest Prototype Classifiers for Arbitrary Seminorms. In Proceedings of the 34th Conference on Neural Information Processing Systems (NeurIPS), Online, 6–12 December 2020; MIT Press: Cambridge, MA, USA, 2020. [Google Scholar]
- Protoflow. Available online: https://www.protoflow.ml/en/latest/?badge=latest (accessed on 14 September 2020).
- Monstar: Picofamily. Available online: https://pmdtec.com/picofamily/monstar (accessed on 20 July 2020).
- 60 GHz—Infineon Technologies AG. Available online: https://www.infineon.com/cms/en/product/promopages/60GHz/ (accessed on 20 July 2020).
- Zoghlami, F.; Sen, O.K.; Heinrich, H.; Schneider, G.; Villmann, T. ToF/Radar Early Feature-Based Fusion System for Human Detection and Tracking. In Proceedings of the 22nd IEEE International Conference on Industrial Technology, Valencia, Spain, 10–12 March 2021. (accepted and presented). [Google Scholar]
- MEMS Microphones. Available online: https://www.infineon.com/cms/en/product/sensor/mems-microphones/ (accessed on 19 October 2020).
- DPS310. Available online: https://www.infineon.com/dgdl/Infineon-DPS310-DataSheet-v01-01-EN.pdf?fileId=5546d462576f34750157750826c42242 (accessed on 19 October 2020).
- Julli, T.; Nozick, V.; Talbot, H. Image noise and digital image forensics. In International Workshop on Digital Watermarkings; Springer: Cham, Switzerland, 2015; pp. 3–17. [Google Scholar]
- Ahmed, N.; Natarajan, T.; Rao, K.R. Discrete cosine transform. IEEE Trans. Comput. 1974, 100, 90–93. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Classifier | 1 Prototype per Class | 2 Prototypes per Class | 3 Prototypes per Class |
|---|---|---|---|
| Amplitude | 95% | 95% | 95% |
| 0.0890 | 0.0843 | 0.0838 | |
| Depth | 83.75% | 84.38% | 83.75% |
| 0.2022 | 0.1839 | 0.1856 | |
| Radar | 75.63% | 76.25% | 76.25% |
| 0.2558 | 0.2431 | 0.4115 |
| Classifier | 1 Prototype per Class | 2 Prototypes per Class | 3 Prototypes per Class |
|---|---|---|---|
| Audio | 999.5% | 95.5% | 66.7% |
| 0.0074 | 0.0390 | 0.3276 | |
| Pressure | 71.25% | 75% | 58.25% |
| 0.3082 | 0.2611 | 0.4115 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zoghlami, F.; Kaden, M.; Villmann, T.; Schneider, G.; Heinrich, H. AI-Based Multi Sensor Fusion for Smart Decision Making: A Bi-Functional System for Single Sensor Evaluation in a Classification Task. Sensors 2021, 21, 4405. https://doi.org/10.3390/s21134405
Zoghlami F, Kaden M, Villmann T, Schneider G, Heinrich H. AI-Based Multi Sensor Fusion for Smart Decision Making: A Bi-Functional System for Single Sensor Evaluation in a Classification Task. Sensors. 2021; 21(13):4405. https://doi.org/10.3390/s21134405
Chicago/Turabian StyleZoghlami, Feryel, Marika Kaden, Thomas Villmann, Germar Schneider, and Harald Heinrich. 2021. "AI-Based Multi Sensor Fusion for Smart Decision Making: A Bi-Functional System for Single Sensor Evaluation in a Classification Task" Sensors 21, no. 13: 4405. https://doi.org/10.3390/s21134405
APA StyleZoghlami, F., Kaden, M., Villmann, T., Schneider, G., & Heinrich, H. (2021). AI-Based Multi Sensor Fusion for Smart Decision Making: A Bi-Functional System for Single Sensor Evaluation in a Classification Task. Sensors, 21(13), 4405. https://doi.org/10.3390/s21134405