
Cascade and Fusion: A Deep Learning Approach for Camouflaged Object Sensing


Abstract
:1. Introduction
- New framework: We propose CODCEF, a new framework for camouflaged object detection. With the cascaded structure and the Feedback Partial Decoders, CODCEF is endowed with superior noise suppression capabilities required for camouflaged target detection, even on a shallow backbone network (ResNet-50).
- Efficient loss function: We propose a new loss function, namely the Pixel Perception Fusion (PPF) loss, to train the model. The PPF loss fits the characteristics of the cascaded structure, makes the model pay further attention to the high-frequency local pixels and facilitates the training of the model.
- Experimental evaluation: On an Nvidia Jetson Nano, we compare CODCEF with 10 state-of-the-art COD or SOD models on three datasets, including COD10K, CAMO, and CHAMELEON. The experimental results show that CODCEF demonstrates stable and accurate camouflage target recognition capabilities. Simultaneously, with the use of additional cameras and portable power supplies, we proved the feasibility of the model on portable edge devices in a real environment. The source code will be publicly available at https://github.com/HHHKKKHHH/CODCEF (accessed on 20 May 2021).
2. Related Work
2.1. Generic Object Detection (GOD)
2.2. Salient Object Detection (SOD)
2.3. Camouflaged Object Detection (COD)
2.3.1. Datasets
2.3.2. Methods
3. Materials and Methods
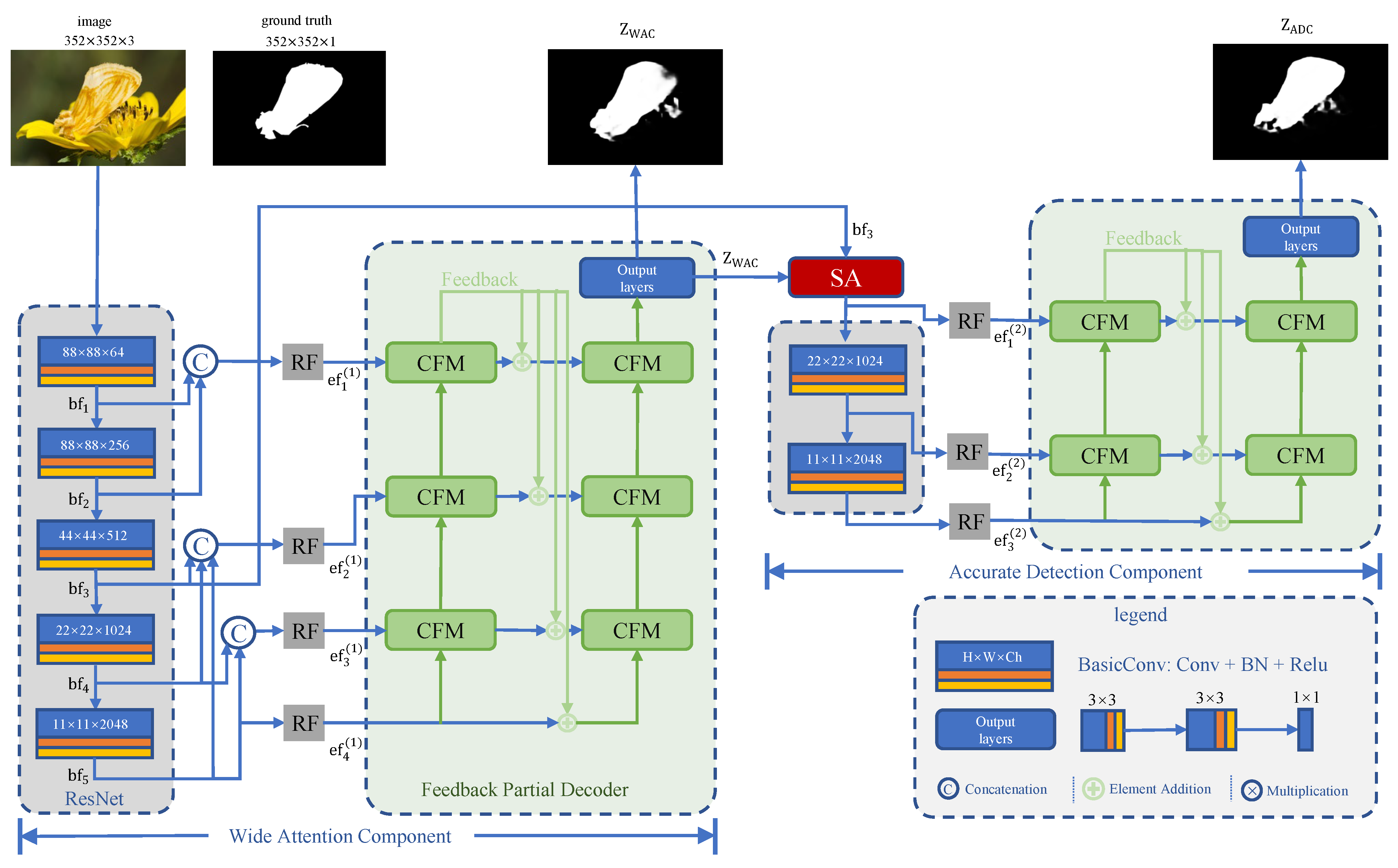
3.1. Overview
3.2. Wide Attention Component
3.3. Accurate Detection Component
3.4. Feedback Partial Decoder
| Algorithm 1: Feedback partial decoder. |
 |
3.5. Pixel Perception Fusion Loss
4. Evaluation
4.1. Datasets
4.2. Evaluation Metrics
4.3. Implementation Details
4.3.1. Training Implementation
4.3.2. Testing Implementation
4.4. Results and Analysis
4.4.1. Overview
4.4.2. Performance on COD10K
4.4.3. Performance on CAMO
4.4.4. Performance on CHAMELEON
4.5. Ablation Study
4.5.1. Structure Ablation
- ADC ablation: The removal of an ADC is equivalent to abandoning the cascading structure, which directly leads to the lack of boundary refinement in the prediction results. The experimental results demonstrated a significant image degradation after removing the ADC, , which was more sensitive to the details of the results. In other words, the depth of the model introduced by the ADC did not produce a significant degradation in the prediction accuracy. Compared with F3Net, our structure can accommodate more sub-decoders to provide more visual perception capabilities.
- RF ablation: Our motivation for using RF was to reduce the dependence on deep backbone networks. After replacing RF with a common convolutional layer, ResNet50 could not extract the basic features of the available level, which led to the rapid degradation of the prediction results. This shows that the introduction of RF effectively enhanced the features extracted by the encoder.
- FPD ablation: Compared with the traditional decoder [25] used in SINet, FPD had a stronger ability to improve the signal-to-noise ratio, which is extremely important for COD tasks. The experimental results demonstrated the excellent performance of FPD.
4.5.2. Loss Function Ablation
5. Real Environment Experiment
5.1. Experiment Implement
5.2. Result and Analysis
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Hyperparameter Selection

References
- Zhu, C.; Li, T.H.; Li, G. Towards automatic wild animal detection in low quality camera-trap images using two-channeled perceiving residual pyramid networks. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2017; pp. 2860–2864. [Google Scholar]
- Tydén, A.; Olsson, S. Edge Machine Learning for Animal Detection, Classification, and Tracking. 2020. Available online: http://liu.diva-portal.org/smash/record.jsf?pid=diva2%3A1443352&dswid=-8721 (accessed on 10 January 2021).
- Stevens, M.; Merilaita, S. Animal camouflage: Current issues and new perspectives. Philos. Trans. R. Soc. B Biol. Sci. 2009, 364, 423–427. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rida, I. Feature extraction for temporal signal recognition: An overview. arXiv 2018, arXiv:1812.01780. [Google Scholar]
- Zhang, X.; Zhu, C.; Wang, S.; Liu, Y.; Ye, M. A Bayesian approach to camouflaged moving object detection. IEEE Trans. Circuits Syst. Video Technol. 2016, 27, 2001–2013. [Google Scholar] [CrossRef]
- Li, S.; Florencio, D.; Zhao, Y.; Cook, C.; Li, W. Foreground detection in camouflaged scenes. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 4247–4251. [Google Scholar] [CrossRef] [Green Version]
- Pike, T.W. Quantifying camouflage and conspicuousness using visual salience. Methods Ecol. Evol. 2018, 9, 1883–1895. [Google Scholar] [CrossRef] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Lowe, D.G. Distinctive Image Features from Scale-Invariant Keypoints; Springer: Berlin/Heidelberg, Germany, 2004; Volume 60, pp. 91–110. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Deng, Y.; Teng, S.; Fei, L.; Zhang, W.; Rida, I. A Multifeature Learning and Fusion Network for Facial Age Estimation. Sensors 2021, 21, 4597. [Google Scholar] [CrossRef] [PubMed]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-fcn: Object detection via region-based fully convolutional networks. In Proceedings of the 30th Annual Conference on Neural Information Processing Systems 2016, Barcelona, Spain, 5–10 December 2016. [Google Scholar]
- Zhao, Z.Q.; Zheng, P.; Xu, S.t.; Wu, X. Object detection with deep learning: A review. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3212–3232. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cheng, M.M.; Zhang, Z.; Lin, W.Y.; Torr, P. BING: Binarized normed gradients for objectness estimation at 300 fps. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 3286–3293. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Le, T.N.; Nguyen, T.V.; Nie, Z.; Tran, M.T.; Sugimoto, A. Anabranch network for camouflaged object segmentation. Comput. Vis. Image Underst. 2019, 184, 45–56. [Google Scholar] [CrossRef]
- Lv, Y.; Zhang, J.; Dai, Y.; Li, A.; Liu, B.; Barnes, N.; Fan, D.P. Simultaneously localize, segment and rank the camouflaged objects. arXiv 2021, arXiv:2103.04011. [Google Scholar]
- Fan, D.P.; Ji, G.P.; Sun, G.; Cheng, M.M.; Shen, J.; Shao, L. Camouflaged object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2777–2787. [Google Scholar]
- Wang, T.; Borji, A.; Zhang, L.; Zhang, P.; Lu, H. A stagewise refinement model for detecting salient objects in images. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4019–4028. [Google Scholar]
- Zhao, T.; Wu, X. Pyramid feature attention network for saliency detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3085–3094. [Google Scholar]
- Merilaita, S.; Scott-Samuel, N.E.; Cuthill, I.C. How Camouflage Works; The Royal Society: Cambridge, UK, 2017; Volume 372, p. 20160341. [Google Scholar]
- Rida, I.; Al-Maadeed, N.; Al-Maadeed, S.; Bakshi, S. A comprehensive overview of feature representation for biometric recognition. Multimed. Tools Appl. 2020, 79, 4867–4890. [Google Scholar] [CrossRef]
- Wu, Z.; Su, L.; Huang, Q. Cascaded partial decoder for fast and accurate salient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3907–3916. [Google Scholar]
- Qin, X.; Zhang, Z.; Huang, C.; Gao, C.; Dehghan, M.; Jagersand, M. Basnet: Boundary-aware salient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7479–7489. [Google Scholar]
- Wei, J.; Wang, S.; Huang, Q. F3Net: Fusion, Feedback and Focus for Salient Object Detection. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12321–12328. [Google Scholar]
- Rahman, M.A.; Wang, Y. Optimizing intersection-over-union in deep neural networks for image segmentation. In International Symposium on Visual Computing; Springer: Berlin/Heidelberg, Germany, 2016; pp. 234–244. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition; IEEE: Washington, DC, USA, 2015; Volume 37, pp. 1904–1916. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. arXiv 2015, arXiv:1506.01497. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2961–2969. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Zhu, W.; Liang, S.; Wei, Y.; Sun, J. Saliency optimization from robust background detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 23–28 June 2014; pp. 2814–2821. [Google Scholar]
- Yang, C.; Zhang, L.; Lu, H.; Ruan, X.; Yang, M.H. Saliency detection via graph-based manifold ranking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 3166–3173. [Google Scholar]
- Cheng, M.M.; Mitra, N.J.; Huang, X.; Torr, P.H.; Hu, S.M. Global Contrast Based Salient Region Detection; IEEE: Washington, DC, USA, 2014; Volume 37, pp. 569–582. [Google Scholar]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3213–3223. [Google Scholar]
- Wang, W.; Shen, J.; Dong, X.; Borji, A. Salient object detection driven by fixation prediction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1711–1720. [Google Scholar]
- Kümmerer, M.; Theis, L.; Bethge, M. Deep gaze i: Boosting saliency prediction with feature maps trained on imagenet. arxv 2014, arXiv:1411.1045. [Google Scholar]
- Huang, X.; Shen, C.; Boix, X.; Zhao, Q. Salicon: Reducing the semantic gap in saliency prediction by adapting deep neural networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 262–270. [Google Scholar]
- Liu, S.; Huang, D. Receptive field block net for accurate and fast object detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 385–400. [Google Scholar]
- Zhao, J.X.; Liu, J.J.; Fan, D.P.; Cao, Y.; Yang, J.; Cheng, M.M. EGNet: Edge guidance network for salient object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 8779–8788. [Google Scholar]
- Pang, Y.; Zhao, X.; Zhang, L.; Lu, H. Multi-scale interactive network for salient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 9413–9422. [Google Scholar]
- Skurowski, P.; Abdulameer, H.; Baszczyk, J.; Depta, T.; Kornacki, A.; Kozie, P. Animal Camouflage Analysis: Chameleon Database. Unpublished manuscript, 2018. [Google Scholar]
- Zhai, Q.; Li, X.; Yang, F.; Chen, C.; Cheng, H.; Fan, D.P. Mutual Graph Learning for Camouflaged Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Montreal, Canada, 11–17 October 2021; pp. 12997–13007. [Google Scholar]
- Gao, S.H.; Tan, Y.Q.; Cheng, M.M.; Lu, C.; Chen, Y.; Yan, S. Highly efficient salient object detection with 100k parameters. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2020; pp. 702–721. [Google Scholar]
- Borji, A.; Cheng, M.M.; Jiang, H.; Li, J. Salient object detection: A benchmark. IEEE Trans. Image Process. 2015, 24, 5706–5722. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fan, D.P.; Cheng, M.M.; Liu, Y.; Li, T.; Borji, A. Structure-measure: A new way to evaluate foreground maps. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4548–4557. [Google Scholar]
- Margolin, R.; Zelnik-Manor, L.; Tal, A. How to evaluate foreground maps? In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 23–28 June 2014; pp. 248–255. [Google Scholar]
- Fan, D.P.; Gong, C.; Cao, Y.; Ren, B.; Cheng, M.M.; Borji, A. Enhanced-alignment measure for binary foreground map evaluation. arXiv 2018, arXiv:1805.10421. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Models | CHAMELEON [49] | COD10K [20] | CAMO [18] | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| FPN [34] | 0.075 | 0.794 | 0.590 | 0.783 | 0.075 | 0.697 | 0.411 | 0.691 | 0.131 | 0.684 | 0.483 | 0.677 |
| BASNet [26] | 0.118 | 0.687 | 0.474 | 0.721 | 0.105 | 0.634 | 0.365 | 0.678 | 0.159 | 0.618 | 0.413 | 0.661 |
| PFANet [22] | 0.144 | 0.679 | 0.378 | 0.648 | 0.128 | 0.636 | 0.286 | 0.618 | 0.172 | 0.659 | 0.391 | 0.622 |
| CPD [25] | 0.052 | 0.853 | 0.706 | 0.866 | 0.059 | 0.747 | 0.508 | 0.770 | 0.115 | 0.726 | 0.550 | 0.729 |
| CSNet [51] | 0.051 | 0.819 | 0.759 | 0.859 | 0.048 | 0.745 | 0.615 | 0.808 | 0.106 | 0.704 | 0.633 | 0.753 |
| F3Net [27] | 0.047 | 0.848 | 0.770 | 0.894 | 0.051 | 0.739 | 0.593 | 0.795 | 0.109 | 0.711 | 0.616 | 0.741 |
| ANet [18] | - | - | - | - | - | - | - | - | 0.126 | 0.682 | 0.484 | 0.685 |
| SINet [20] | 0.044 | 0.869 | 0.740 | 0.891 | 0.051 | 0.771 | 0.551 | 0.806 | 0.100 | 0.751 | 0.606 | 0.771 |
| RankNet [19] | 0.046 | 0.842 | 0.794 | 0.896 | 0.045 | 0.760 | 0.658 | 0.831 | 0.105 | 0.708 | 0.645 | 0.755 |
| R-MGL [50] | 0.030 | 0.893 | 0.813 | 0.923 | 0.035 | 0.814 | 0.666 | 0.865 | 0.088 | 0.775 | 0.673 | 0.847 |
| CODCEF(Ours) | 0.030 | 0.875 | 0.825 | 0.932 | 0.043 | 0.766 | 0.667 | 0.854 | 0.092 | 0.736 | 0.685 | 0.797 |
| Model | Params | Infer Time | CHAMELEON | COD10K | CAMO | |||
|---|---|---|---|---|---|---|---|---|
| SINet | 198M | 32 ms | 0.891 | 0.740 | 0.806 | 0.551 | 0.771 | 0.606 |
| R-MGL | 444M | 48 ms | 0.923 | 0.813 | 0.865 | 0.666 | 0.847 | 0.673 |
| CODCEF | 212M | 37 ms | 0.932 | 0.825 | 0.854 | 0.667 | 0.802 | 0.685 |
| Structure | COD10K | ||||||
|---|---|---|---|---|---|---|---|
| WAC | ADC | RF | FPD | ||||
| ✓ | ✓ | ✓ | 0.048 | 0.747 | 0.573 | 0.845 | |
| ✓ | ✓ | ✓ | 0.301 | 0.446 | 0.195 | 0.428 | |
| ✓ | ✓ | ✓ | 0.085 | 0.649 | 0.542 | 0.799 | |
| ✓ | ✓ | ✓ | ✓ | 0.043 | 0.766 | 0.667 | 0.854 |
| Loss | COD10K | |||
|---|---|---|---|---|
| PPF (ours) | 0.043 | 0.766 | 0.667 | 0.854 |
| BCE | 0.049 | 0.749 | 0.558 | 0.824 |
| drop (%) | 8.8 | 2.8 | 9.2 | 3.5 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, K.; Li, C.; Zhang, J.; Wang, B. Cascade and Fusion: A Deep Learning Approach for Camouflaged Object Sensing. Sensors 2021, 21, 5455. https://doi.org/10.3390/s21165455
Huang K, Li C, Zhang J, Wang B. Cascade and Fusion: A Deep Learning Approach for Camouflaged Object Sensing. Sensors. 2021; 21(16):5455. https://doi.org/10.3390/s21165455
Chicago/Turabian StyleHuang, Kaihong, Chunshu Li, Jiaqi Zhang, and Beilun Wang. 2021. "Cascade and Fusion: A Deep Learning Approach for Camouflaged Object Sensing" Sensors 21, no. 16: 5455. https://doi.org/10.3390/s21165455
APA StyleHuang, K., Li, C., Zhang, J., & Wang, B. (2021). Cascade and Fusion: A Deep Learning Approach for Camouflaged Object Sensing. Sensors, 21(16), 5455. https://doi.org/10.3390/s21165455