1. Introduction
In recent years, developments within the field of Structural Health Monitoring (SHM) has focused on the integration of Artificial Intelligence (AI) techniques with visual inspection for autonomous structural maintenance [
1]. The necessity for this advancement in this field arises from the challenges of traditional human-based structural inspections. Noncontact sensing technology [
2] has shown significant promises to make SHM real-time and robust. However, extracting vision-based data from structures using cameras and other optical devices is often time-consuming and has significant economic costs [
3,
4,
5,
6,
7]. Logistical restraints of the structures themselves or health hazards posed by structures damaged by natural disaster events may restrict access, making it difficult to complete the inspection. Even once data collection is completed, there are still challenges (e.g., damage categorization and determining the level of severity) in processing a large amount of vision-based data for SHM. The data collected from the structure is not easily analyzed and is a time-consuming process for engineering firms. In addition, human-based assessments often are biased, as the analysis of the data is based on a subjective opinion of the inspector [
8,
9]. This paper explores a novel data augmentation technique to address the data scarcity issue of SHM.
The autonomous and flexible nature of AI techniques has allowed researchers to rectify the issues (e.g., prolonged inspection times and biases in damage categorization) prevalent within the SHM field. In particular, a subset of AI techniques, namely convolution-based deep-learning techniques such as Convolutional Neural Networks (CNNs) have been well researched for damage assessment of concrete structures [
10,
11,
12,
13]. Applications of these algorithms for classification of image-based [
14], region-based [
15,
16], and pixel-level [
17,
18] vision data have resulted in highly accurate and robust assessment techniques. Additionally, studies have been conducted for detection of various categories of cracks within asphalt pavement [
19,
20,
21]. Transverse pavement cracks were identified using a hybrid time-frequency enhanced CNN based on Short-Time Fourier Transform and Wavelet Transform [
19]. The inclusion of spectrograms resulted in high classification accuracies of 97.2% and 91.4%. respectively. Contrasting traditional approaches, these techniques directly learn from vision-based data and classify objects from extracted features of input data. Model parameters are updated through an iterative backpropagation method, meaning that direct human intervention to define and optimize model parameters is removed. Furthermore, they can be directly integrated with robotic platforms such as unmanned aerial vehicles, allowing for the remote inspection of structures [
19,
20], providing an economic, safe, and time-efficient method for SHM.
AI models, such as CNNs, are “Big Data” models, implying that the performance of these models is directly correlated to the amount of data available, usually >10,000 images for each class [
3,
7,
8,
9,
22,
23,
24]. However, it is often difficult to collect vision-based data from damaged structures due to logistic restraints, and subsequent damage-causing events compound this issue. Structural damages are often a result of long-term fatigue, vehicle-based impact events, or natural disasters which are rare and infrequent, resulting in a reduced amount of data available for certain damaged cases [
5,
8,
25,
26]. Therefore, the data collected from structures is often heavily imbalanced and limited, with considerably more data being available in the “undamaged” or normal class when compared to the damaged classes. Training AI models on imbalanced datasets has been demonstrated to create biases during the learning process, resulting in a model whose performance is class-dependent rather than consistent across all classes [
3,
24]. Limited datasets result in poor model robustness as the models tend to experience overfitting based on the “noisy” features from the data rather than learning the general features associated with the particular class. Moreover, the lack of publicly available datasets within the SHM domain makes it difficult to train new, and highly accurate AI models [
3].
To address these data scarcity and class imbalance issues, data augmentation has been proposed as a technique to enhance and equalize datasets used for training AI models [
27]. In SHM, simple data augmentation techniques such as rotation, shear, zoom, mirroring, flipping, and contrast changes have been predominately used to enhance image-based datasets of structural damage [
28,
29,
30]. Vertical and horizontal flipping, contrast adjustment, and rotation were applied [
28] to augment an existing dataset for the binary classification of concrete cracks using pre-trained deep learning models. Similar transformations were applied [
29] to enhance the number of segmented images of cracks of welded joints located on the gusset plates of steel bridges. The use of synthetic images during training increased the accuracy of the investigated classifier by 2–5%. An interpolation-based data augmentation technique was employed [
31] to enhance a thermal image dataset for adversarial-based classification. These synthetic samples are then used to augment the existing dataset by balancing the classes and providing increased samples for training resulting in an AI model that is more accurate and robust than would be obtained on the original data.
Recently, there has been a significant debate on the effectiveness of simple data augmentation for addressing the data scarcity and class imbalance issues in SHM [
22,
24]. Due to the limited number of samples that comprise these datasets, the diversity of the features contained within the images that relate to the given class is relatively low. Simple data augmentation techniques such as flipping, rotating, and shifting create synthetic images whose features are only slightly different than those of the original images; therefore, the overall diversity of the dataset experiences a minimal change. Training an AI algorithm with low diversity datasets, even with the inclusion of simple synthetic images, often results in poor generalization and overfitting during training, which can result in lower performance than when trained entirely on real data [
9]. To address the quality and diversity of synthetic image samples, Generative Adversarial Models (GANs) [
32] have been widely explored by researchers in various domains for data augmentation problems. The basis of these models involves competition in a “zero-sum” game between two models (1) the ‘Discriminator’ which distinguishes between real and synthetic samples and (2) the ‘generator’ which generates synthetic images from a random Gaussian vector. Since its inception, various improved GAN models have been proposed, including conditional GANs [
33], Wasserstein GANs [
34], Wasserstein GANs with Gradient Penalty [
35], and StyleGAN [
36].
In SHM, GANs have been implemented to address two types of data augmentation problems, (1) synthesizing missing data points due to damage or poor quality sensors, and (2) expanding limited or unbalanced datasets for AI algorithm training. A deep convolutional GAN was applied [
6] to reconstruct lost data from faulty bridge sensors. The experiments demonstrated that the proposed method was capable of accurately capturing the details of low- and high-frequency components of the signals with 0.5–4% error between real and synthetic samples for the first five mode shapes. However, the magnitude of the reconstruction error is heavily influenced by the number of faulty sensors used during instrumentation. Similarly, it was observed that increasing the number of faulty sensors from 5 to 15 increased the error within the simulated data from 3.7% to 9.44% when applying a traditional GAN structure for incomplete data extracted from long-term bridge monitoring [
37]. The reconstruction error was noticeably correlated with the length of the time period of the synthetic data, where longer time periods (>8 h) had higher errors. A transfer learning-based GAN-autoencoder ensemble was implemented [
38] for the detection of anomalies arising from faulty signal data for SHM applications. The signals recorded during monitoring were converted to images using a Gramian Angular Field and Cumulative Sum thresholding was applied to define the limits of the anomalies. Though this method demonstrated significant accuracy (>94%) for most signals, it was demonstrated that single-point signal anomalies may not be captured.
The more common application of GANs for data augmentation within SHM involves synthesizing images to expand existing datasets to rectify issues pertaining to limited data or imbalanced classes. Typically, the majority of SHM datasets consist of only a few hundred images with a heavy imbalance toward the normal (undamaged) state rather than the damaged cases which are more important to investigate. For instance, the original dataset implemented [
25] contained 5900 disjoint, 3000 obstacles, 2600 walls, and 6390 tree root images before data augmentation occurred. Moreover, class imbalance ratios in the original datasets ranging from 32 to 2 have been observed for binary and multiclass problems [
5,
22,
25]. Training AI algorithms using limited or unbalanced datasets results in low generalizing models that have poor accuracy and are biased to the class that has more data [
26]. The hypothesis is that by creating synthetic samples using GANs to augment these datasets, the performance of the AI-based classification should improve. For instance, as a result of an expanded dataset produced by a GAN-based implanting technique, an increase of 18% in F1 score was observed when implementing a Faster R-CNN for construction resource classification [
3]. Similar improvements were experienced [
8] when applying progressively growing GANs to improve the pixel-level segmentation and classification of cracked images. Overall, the mean intersection over union score was increased by 50% through the inclusion of synthetic images and demonstrated improved performance over traditional data augmentation techniques such as scaling, translation, and rotation. Increased network performance was also observed [
7] when applying a super-resolution GAN for road damage detection. Generally, the application of the proposed data augmentation regime improved the average classification by 1–3%. Moreover, it has been demonstrated that the addition of synthetic data has improved generalization by reducing the bias associated with the class that has the majority of the real data. This conclusion is supported by an additional study [
5] which demonstrated the proposed balanced semisupervised GAN resulted in a decreased true positive rate which provides evidence that synthetic images can be used to train a more unbiased model.
However, analogous to simple data augmentation techniques, it has not been substantially demonstrated that synthetic images generated by GANs will always improve the classification of AI algorithms. Several studies have demonstrated that GAN-based data augmentation techniques have provided no improvement or negatively impacted the performance of classification models. A recent study [
4] observed that there was no obvious correlation between the number of synthetic images and increased model performance when applying a progressively growing GAN with Poisson blending for road damage detection. Though the performance of the limited class was shown to improve using synthetic data from a Wasserstein GAN with gradient penalty [
22], it was demonstrated that the class containing only real data was negatively impacted by the inclusion of synthetic data. The F1 score of all classes was compromised when using “non-capped” features for 1D GAN generation [
26]. However, the relationship between the size of the existing real dataset and the impact on the quality of synthesized images, and the overall increase in classification accuracy has not been quantified.
To date, there have been limited studies that have investigated the performance of GANs for data augmentation within a data-compromised environment which is common within the SHM domain [
3,
5,
8,
24,
25,
26]. Though the application of DL techniques within SHM has been well explored and documented, the majority of these studies use large datasets (>10,000 images) [
3,
7,
8,
9,
22,
23,
24], contrasting the real-world availability of data within SHM. Furthermore, this trend can be extended to recent studies implementing GANs for data augmentation, focusing on their effectiveness for addressing imbalanced datasets [
3,
5,
7,
8,
22,
25] and missing data samples [
6,
35,
37], but these have not widely addressed GAN-based applications in data-scarce environments. Some evidence of this has been presented by Pei et al. [
23] who observed that the increase in model performance with the inclusion of synthesized deep convolution GAN images decreases when an increasing amount of real training data is used. However, the amount of synthetic data added to existing data is arbitrary and there have been no studies that investigate the correlation between the amount of synthetic data and the impact on overall classification accuracy.
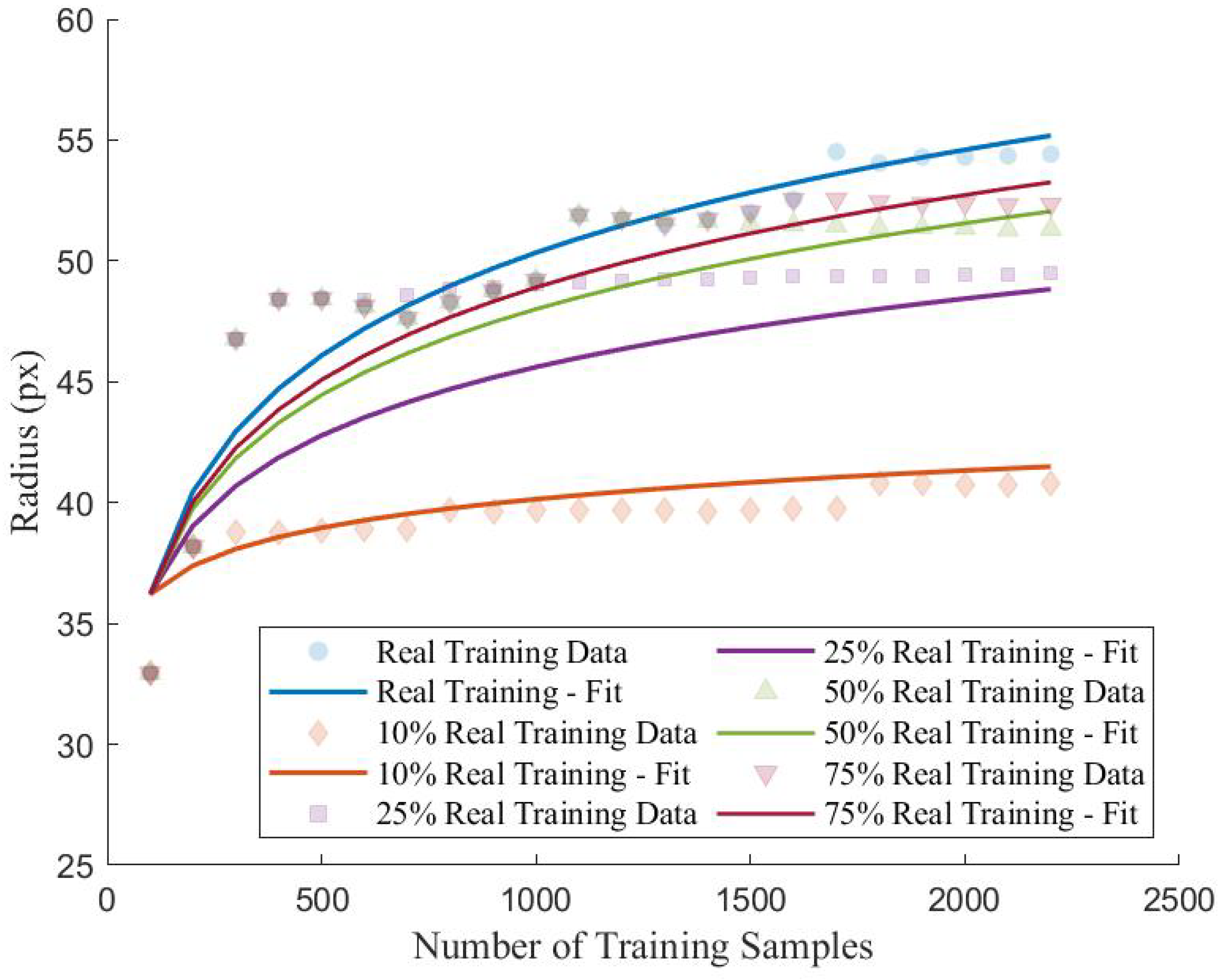
This paper presents an investigation into the effectiveness of a GAN architecture for the data augmentation of a limited multiclass dataset for the classification of surface damages on concrete structures. The impact of the size of the existing real dataset is quantified with respect to the diversity of images generated by the GAN structure. The diversity of the generated images as they relate to the real dataset is quantified using a centroidal-based dimensionality reduction approach. The radius and density of the clusters obtained from the proposed approach are used to correlate model performance with training sample diversity. Finally, the synthetic images are applied to a limited dataset to access the effect of generated samples on classification performance for various dataset sizes. This paper, for the first time, has explored synthetic data diversity and the impact it has on classification accuracy for limited datasets. The remainder of the paper is organized as follows. The proposed methodology, including a brief overview of the GAN, CNN, and centroidal-based dimensionality reduction approach used in this study, is provided in
Section 2.
Section 3 described the dataset used in this study with its implementation explained in
Section 4. The results from the parametric study are summarized in
Section 5 and the conclusion of the study is detailed in
Section 6.
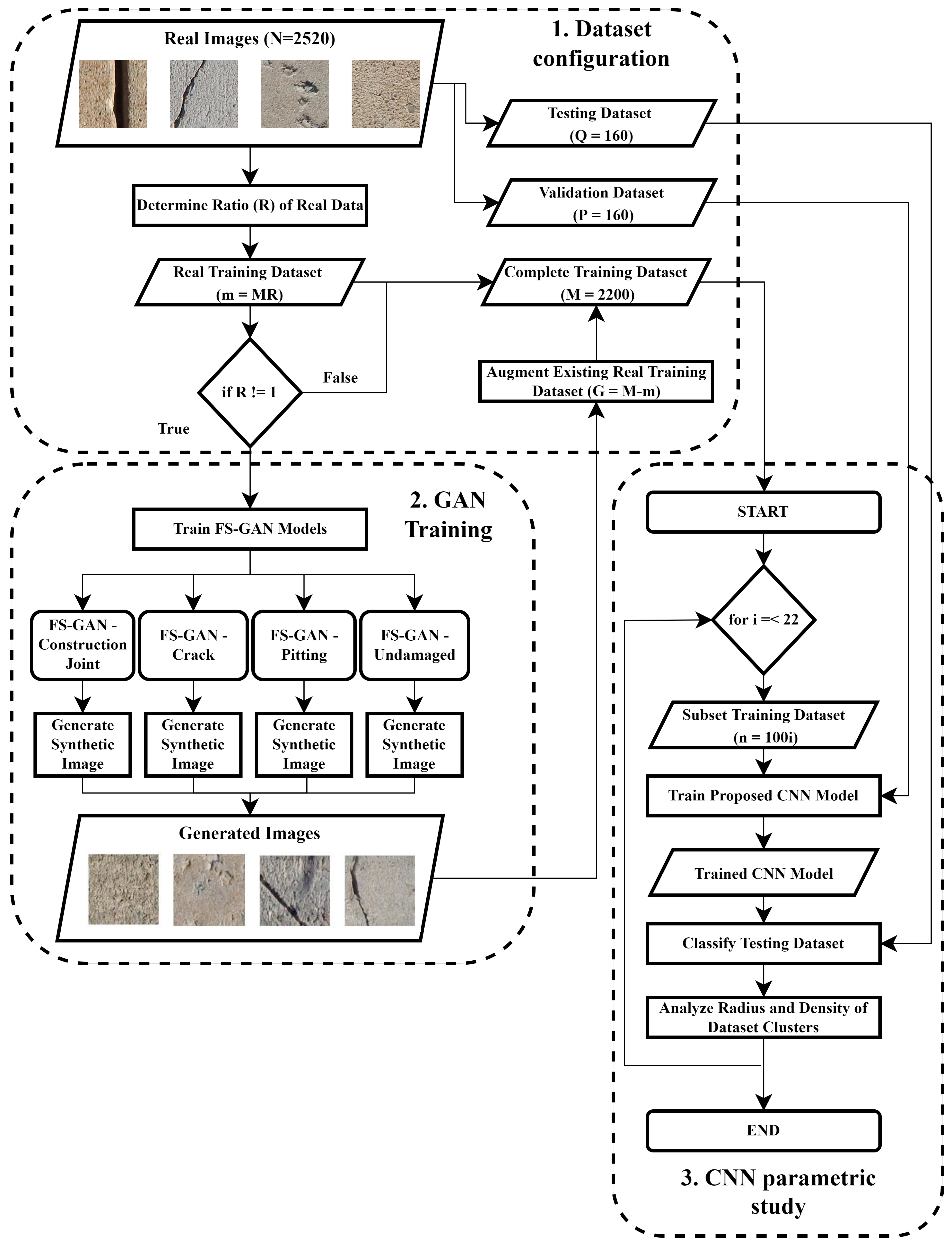
3. Proposed Framework
The proposed framework for the study of multiclass GAN to generate synthetic images with limited data is depicted in
Figure 1. The evaluation of the performance of augmented datasets is divided into three subroutines within the model pipeline, (1) dataset configuration, (2) GAN training, and (3) CNN parametric study. Through the study of synthetic data generation using limited data for data augmentation, the following relationships will be established:
- (1)
The effect of the number of samples used to train the GAN network and the overall diversity of the synthetic images generated will be characterized. Existing GAN networks for data augmentation in SHM have not quantified the effect of limited data on synthetic image diversity. Though the relative quality of synthetic images generated by GANs is often high, if the produced images are too similar to one another then they would not contribute to increasing model generalization when training a CNN.
- (2)
The effectiveness of data augmentation techniques is based on the size of the existing training dataset. It has been well established that for imbalanced datasets the addition of synthetic samples through data augmentation greatly improves the performance of the model [
3,
5,
7,
8]. However, studies [
4,
22] have shown that when the number of real training samples is sufficiently great and the classes are relatively balanced, the addition of synthetic data provides only a minimal increase in classification performance. Therefore, the relative performance increase with respect to a number of existing real training samples will be quantified for multiclass GAN-based data augmentation.
3.1. Dataset Configuration
Digital photography is a common mode of data acquisition within the SHM domain [
1,
2,
3,
4,
5,
7,
8,
9,
10,
11,
12,
13,
14,
15,
16,
17,
20,
21,
22,
23,
24,
25,
26,
27,
28,
29,
41,
42] as cameras can be readily mounted to unmanned land and aerial vehicles which are able to access damaged structures that have limited accessibility for inspectors [
2]. This study could be further extended to video as well because videos can be considered a series of frames (images) that are viewed in a sequential order. Therefore the proposed framework could be applied to each frame of the video sequence as if each frame of the video is an independent image. Given a database that contains a total of
N real image samples over four equally distributed classes (construction joint, crack, pitting, and undamaged), a significant selection of the total dataset is chosen to represent the training dataset in the analysis. The
N images are partitioned into training, validation, and testing datasets based on a 80%/10%/10% split. Therefore, the training dataset is comprised of
M images where M = 0.8 N which in this study equates to 2200 images. Similarly, the validation (
P) and testing (
Q) datasets equate to 160 images each; however, these datasets are used to validate the trained CNN architecture. The equal distribution of classes that are represented in the total dataset of size
N is also represented in the training, validation, and testing datasets to ensure that class imbalance does not impact the results of the study. However, since this study explores data augmentation for a limited dataset, a variable fraction of real image data is chosen to represent the ‘Real Training Dataset’. The amount of training samples selected is determined based on a predefined ratio
R which has a range of
where
R = 1 would represent the entire training dataset with
M samples. The ’Complete Training Dataset’ of size
M is implemented to determine the baseline performance of the model on a dataset that can be considered sufficiently large with respect to adequately training the proposed CNN network. As such, when
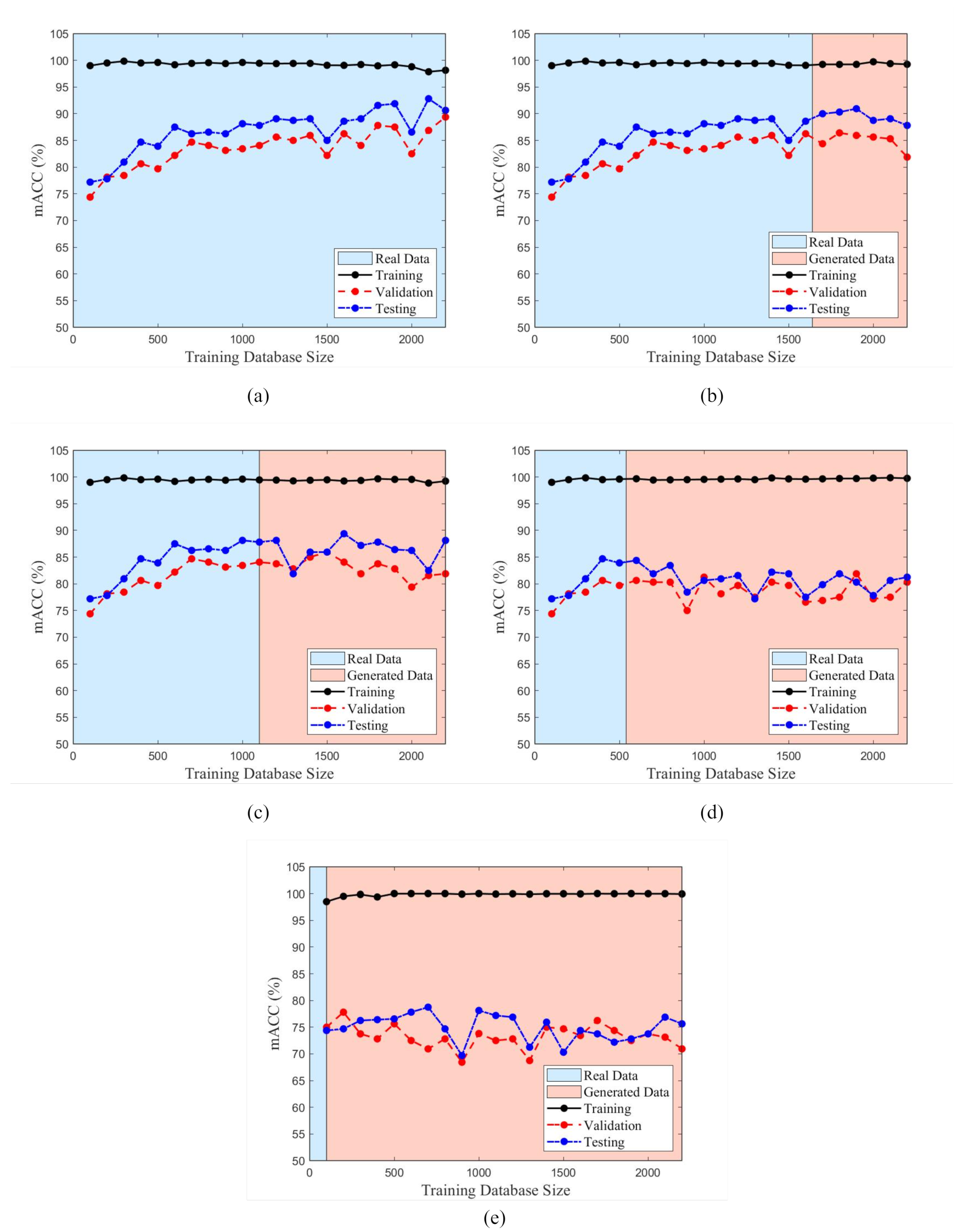
R is equal to 1, no data augmentation occurs and the existing training data are used directly to train the proposed CNN network.
Those R values not equal to 1 represent real training datasets that contain m samples where represents a small subset of all the available training data for analysis. For those R not equal to 1, the ’Real Training Dataset’ would contain m = MR samples and these are considered ‘limited datasets’ which theoretically would result in a trained CNN with reduced performance due to the limited training data being available to the network. As such, for those datasets with R < 1.00, the m samples within the ‘Real Training Dataset’ would be used to train the FS-GAN implemented in this analysis to generate new samples such that the existing ‘Real Training Dataset’ could be augmented using synthetic images. Furthermore, the range of R is exclusive of 0 because, to train the FS-GAN model, there must be real data to train the generator model to learn the characteristics of the classes within the dataset. Once the ‘Real Training Dataset’ has been used to train the FS-GAN models, the generator which represents each class can be used to generate images that augment the existing datasets. For "Real Training Datasets" with size m the number of samples that are generated by the FS-GANs is equivalent to G = M - m and these are similarly equally distributed across all four classes. These samples are used to augment the existing ‘Real Training Images’ which results in a ‘Complete Training Dataset’ of size M containing both real and synthetic images.
3.2. GAN Training
This study focuses on the generation of synthetic samples in low data environments, thus the selected GAN architecture must be capable of generating samples that have high visual quality while using a small number of samples to train the network. It is well established that though GANs possess the capabilities to generate new image samples, the training of these networks requires a significant number of images to accurately train the generator network. As such, the model implemented in the proposed research is from a study conducted in 2021 by Liu et al. [
43] in which a hybrid Few-Shot GAN (FS-GAN) was created for the generation of high-fidelity images. The model proposed by Liu et al., is capable of generating high-resolution images while only being trained on less than 100 samples, making it ideal for implementation in the current study. The authors improved upon the traditional GAN architecture by introducing skip-layer excitation modules and a multi-resolution encoder–decoder structure for the discriminator to reduce computational complexity during training while maintaining high resolution in the generated samples. More details about the discriminator and generator networks can be found in the original [
43].
An FS-GAN model is trained for each of the classes. The objective of this process is to establish a trained generator that is capable of generating synthetic images for each of the classes belonging to multiclass damage detection. Given a ‘Real Training Dataset’ of size m which is equally distributed amongst all classes, the individual classes are separated from each other and become an individual dataset for the training of the FS-GAN model. For example, in this study, there are four classes—crack, construction joint, pitting, and undamaged; each of these classes would have a homogeneous dataset that is comprised of images belonging to only that particular class. The reasoning behind separating the ‘Real Training Dataset’ and training a separate model for each class during the FS-GAN training is to ensure that the generator can properly generate the features of a particular class rather than generating features that may be a blend of all four classes. Using each dataset belonging to their classes, an FS-GAN model is trained such that a trained generator is established for each classification. The trained generator can subsequently be used to generate G synthetic images which are used to augment the existing ‘Real Training Dataset’ to establish a ‘Complete Training Dataset’ which consists of both real and synthetic images.
3.3. CNN Parametric Study
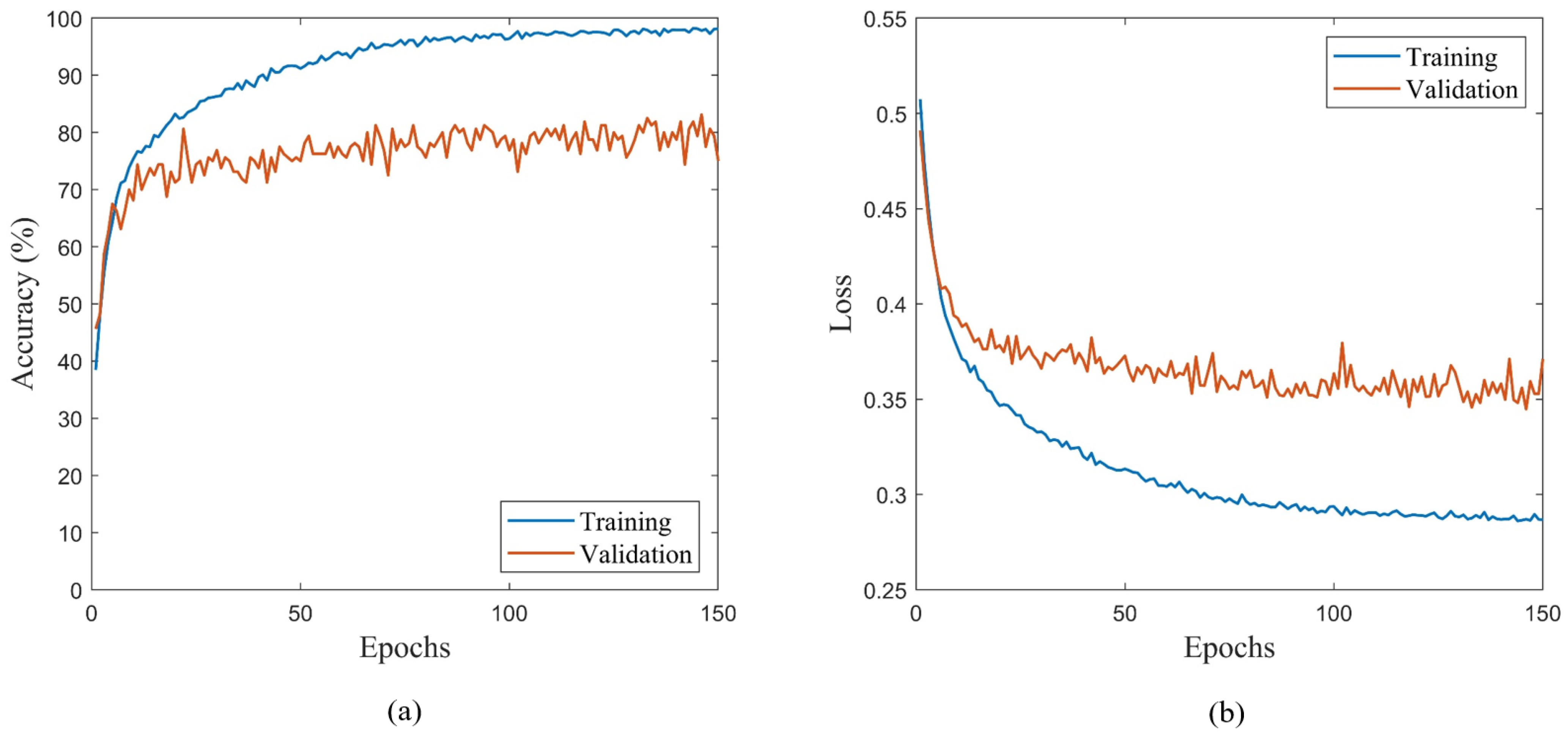
A parametric study is conducted by which the CNN model is trained with progressively increasing amounts of data each iteration. The number of iterations is relative to the number of additional training samples that must be added to each iteration originating from the ‘Complete Training Dataset’. The total number of images within the ‘Complete Training Dataset’ in this study is 2200 images and 100 images (25 images per class) per iteration are selected to comprise the ‘Subset Training Dataset’ such that there are enough data points (22 points) to observe a discernible trend in the data. Therefore, the CNN parametric study consisted of 22 iterations in which 100 new training samples are added to the ‘Subset Training Dataset’ to train the proposed CNN model. For ’Complete Training Datasets’ which are comprised of both real and synthetic image samples, the real image samples are added first to the ‘Subset Training Dataset’ followed by the synthetic images. This is to ensure that the effect of synthetic data on CNN classification can be quantified. If the training data are randomized between real and synthetic samples, it would not be possible to correlate the trend of the CNN performance to a particular data type. For example, if the ‘Complete Training Dataset’ has an R = 0.5, the first 11 iterations would have 100 real images added each iteration to the ‘Subset Training Dataset’ followed by the remaining 11 iterations which would add 100 synthetic images instead. The ’Subset Training Dataset’ is established, and it is used to train the proposed CNN network. During training, the validation dataset is used to assess the performance of the CNN model, allowing for hyperparameter tuning of variables to prevent overfitting on the training dataset. Once the proposed CNN model is trained, the trained model is applied to a testing dataset to determine the performance of the fully trained model on an unseen dataset.
3.4. Cluster and Density Analysis of Datasets
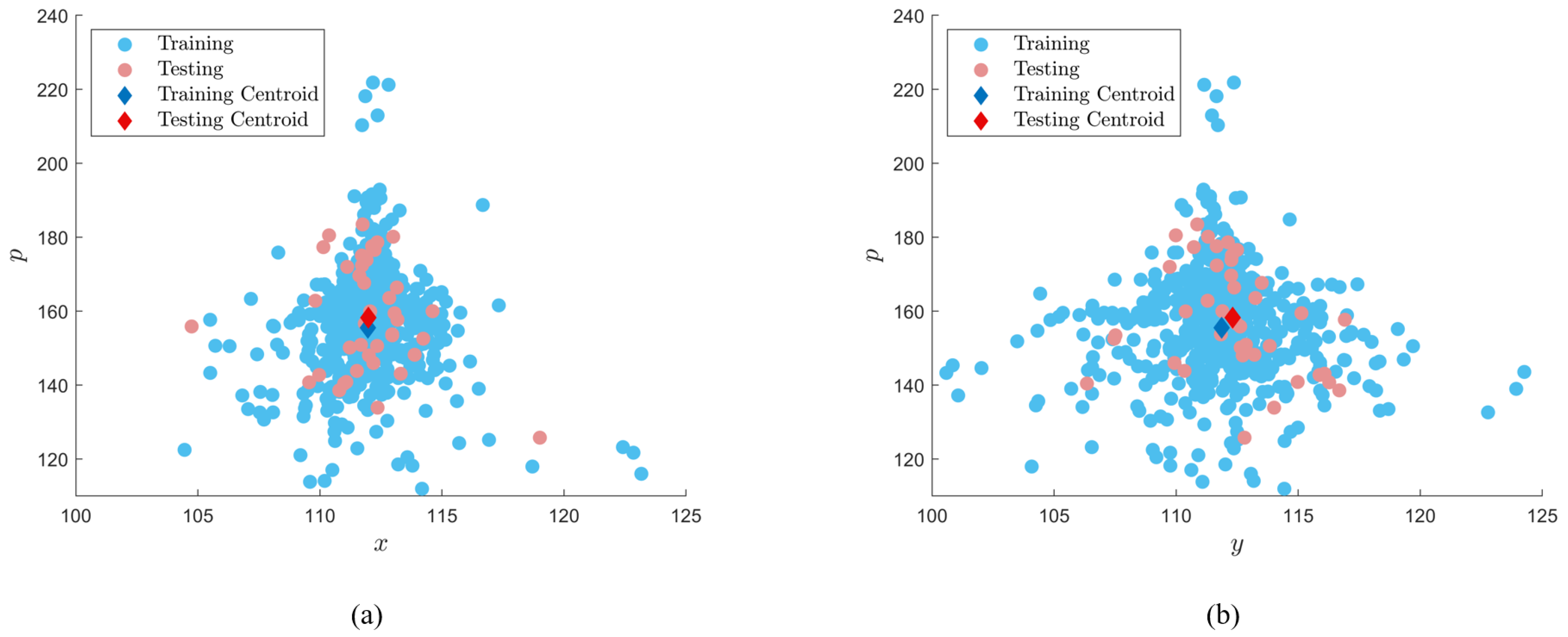
The diversity of the training dataset containing real and synthetic samples is quantified by clustering the ‘Subset Training Dataset’, validation, and testing datasets using a centroidal-based approach. The quality and diversity of synthetics samples generated by GAN architectures are important metrics to consider with respect to CNN-based classification performance. Low-quality synthetic images, when used for training, often reduce the classification performance of CNN networks as the features have a reduced detail which is more difficult to classify by the trained model. Issues with poor model generalization are often experienced too when using a training dataset with a low diversity of samples. Since the features of the dataset are similar, CNNs tend to fit the model parameters to the noisy features of the data rather than optimize based on a general understanding of the features as they relate to the definition of the classes. The result is a CNN model that performs well on the training data but has reduced performance when classifying unseen testing datasets. In SHM, models with poor generalization are detrimental to the inspection process as structural damages, such as cracks, may have a wide range of features associated with the classification and therefore perform poorly for the damage classification task. As a result, engineers may be required to retrain existing models to include additional training samples which delay the inspection process resulting in economic and social losses in the affected areas.
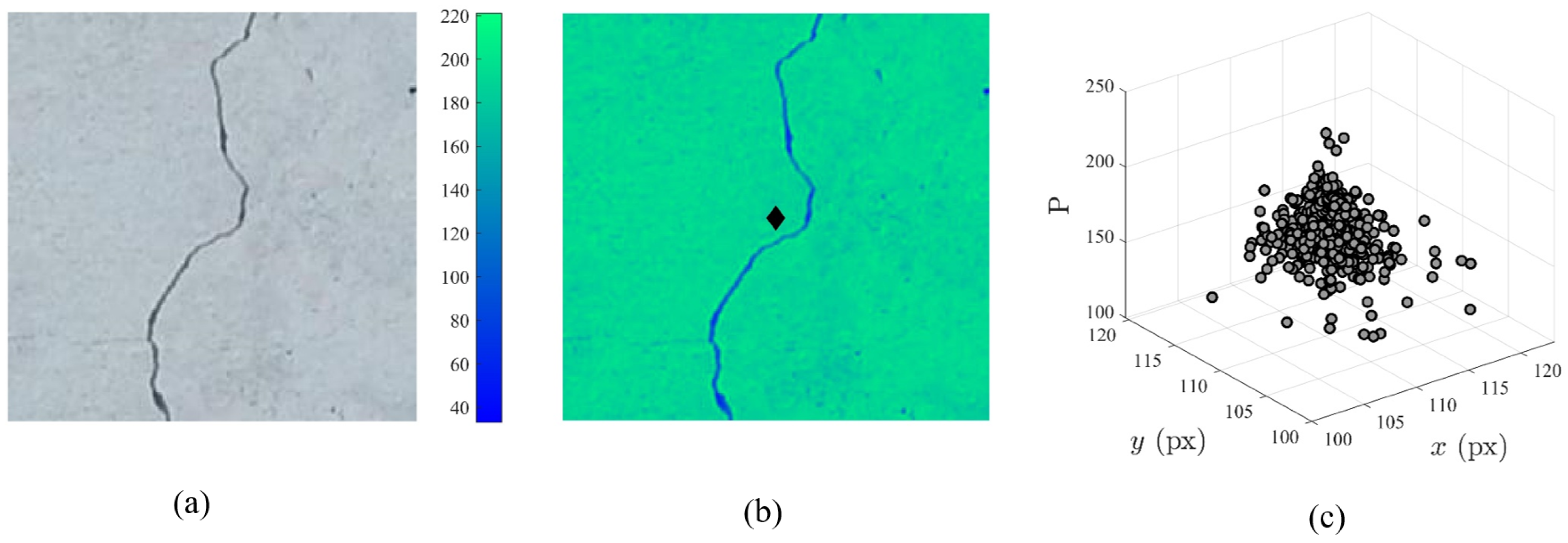
However, it is intrinsically difficult to observe the diversity of samples through clustering algorithms with respect to image-based datasets due to the high-dimensional nature of RGB images. Therefore, a centroid-based dimensionality reduction inspired by the work of Barbosh et al., 2022 [
44] is used to quantify the diversity of images within a given dataset classification as depicted in
Figure 2. The inspiration for this technique is derived from the geometric process by which a centroid of a composite shape is determined. The centroid of a composite shape can be considered the weighted sum of the centroids of all shapes where the weights given to each centroid are based on the area associated with each centroid. Similarly, an image can be considered a composite shape where the centroid of each pixel can be determined and the weight of each pixel can be represented by its pixel intensity. Given an RGB image as depicted in
Figure 2a, the number of channels is reduced by converting the RGB image to a greyscale image. As RGB images consist of a 3D matrix of size (
M,N,c) where
c is a channel associated with the red, blue, and green spectrum of the image, the image can be converted to grayscale [
44] through Equation (
6):
where
m is the integer value representing the location of the pixel along the length of the image,
n is the integer value representing the location of the pixel along the width of the image,
is the pixel intensity of the red channel at pixel location (
m,n),
is the pixel intensity of the green channel at pixel location (
m,n),
is the pixel intensity of the blue channel at pixel location (
m,n), and
is the pixel intensity of the grayscale image at pixel location (
m,n). Once the RGB image has been converted to grayscale, the centroid of the image can be determined as shown in
Figure 2b based on the pixel intensity of the image as represented by the color bar. The centroid of the grayscale image can be considered as the ‘moment’ of the image, or the point at which all pixel intensities (
) at distance (
x,y) have been balanced. Therefore, the dimensionality of the 2D grayscale image is further reduced to a 3D point which can be correlated to others within the dataset. The coordinates of the 3D point (
) can be determined using Equations (7)–(9) based on the characteristics of the grayscale image as described below:
where
is the location of the centroid along the length of the image,
is the location of the centroid along the width of the image,
is the average pixel intensity across the entire image at the centroid,
is the centroid of the pixel located at (
m,n),
is the centroid of the pixel located at (
m,n),
M is the total number of pixels along the length of the image, and
N is the total number of pixels along the length of the image. Assuming each pixel of the image has a unit length and width, the centroid of any pixel at location (
m,n) can be considered the following (
) = (
); for instance, the centroid of the pixel located at (1,1) would be (0.5,0.5). This process is repeated for all images within the dataset and a 3D cluster representing the centroids of all images with the dataset for a particular class (’crack’) can be observed as depicted in
Figure 2c. To quantify the diversity of the images within the dataset, the density of the cluster is calculated assuming the volume that encompasses the 3D points is a perfect sphere. Given a number of 3D points equal to the number of images within a particular class, the centroid of all points can be determined from Equations (10)–(12):
where (
) is the number of points represented in the cluster. Once the centroid of the cluster has been determined, the 3D Euclidean distance for each point within the cluster to the cluster center ((
),(
)…(
)) is determined using Equation (
13):
where
is the distance between the centroid of the entire cluster and the
ith point within the cluster. The radius of the sphere containing the cluster is therefore taken as the maximum of all
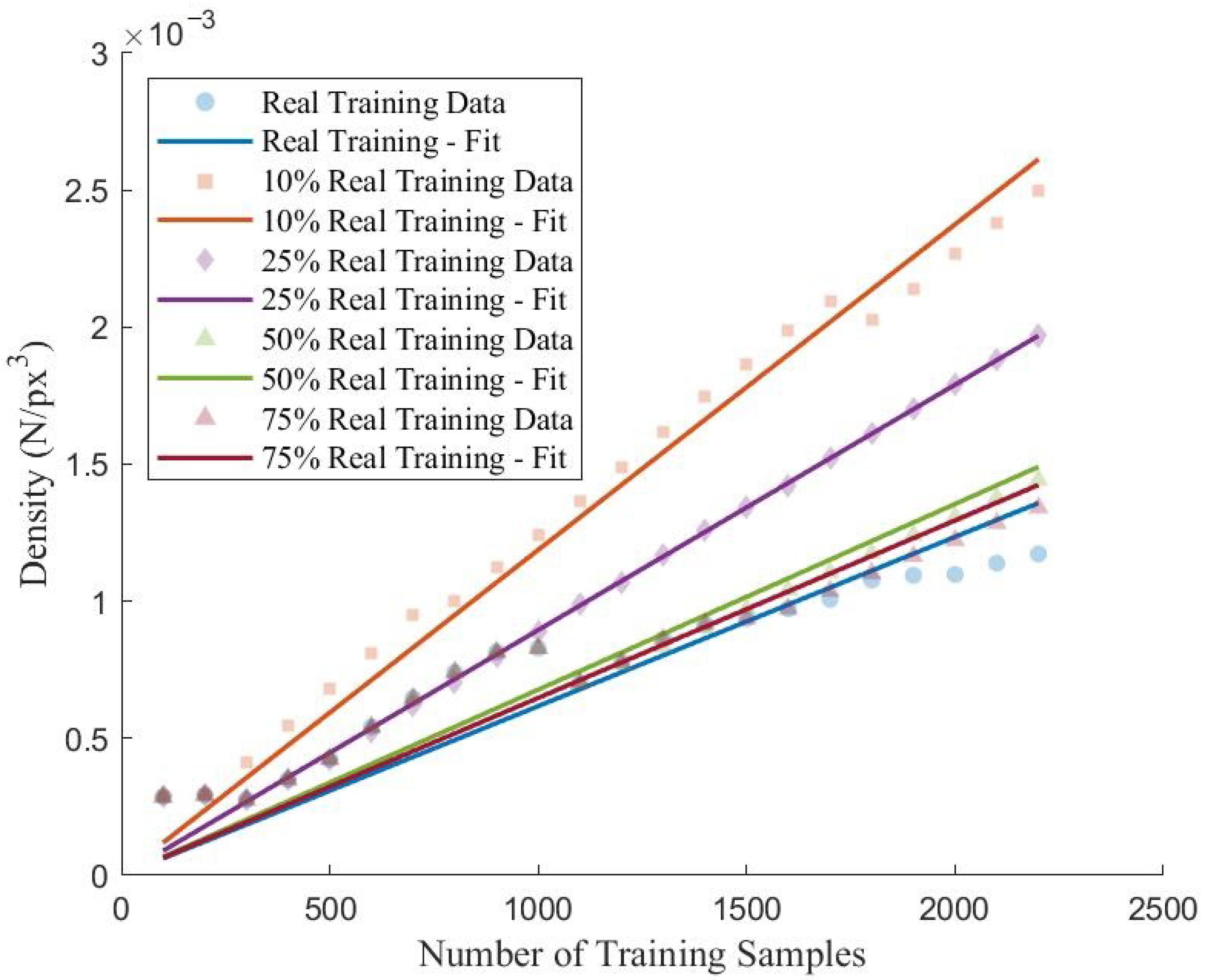
when calculating the volume of the cluster. Finally, the density of the cluster can be determined from the following equation:
where D is the density of the cluster in
,
is the volume of the cluster, and
is the maximum distance between the centroid of the entire cluster and a singular point contained within the cluster.
4. Description of Database
There exist very few benchmark datasets for training new AI algorithms in SHM. One of the most popular datasets for surface-based concrete defects of structural elements, SDNET2018 [
45] is a publicly available dataset that has been created by researchers to investigate the application of AI methods for SHM. More than 56,000 segmented images of damaged and undamaged unreinforced concrete pavement and reinforced concrete walls and bridge decks are included within this dataset. A diverse collection of defects are represented by these images including cracks of varying widths, shadows, stains, voids, surface scaling, and vegetation. A 16-MP Nikon camera at a working distance of 500 mm was used to capture 4068 × 3456 px images that were further segmented into subimages [
45]. Each segmented image is a 3D-RGB image with a size of 256 pixels in length by 256 pixels in width. Further details about the data acquisition can be found in the following study [
45].
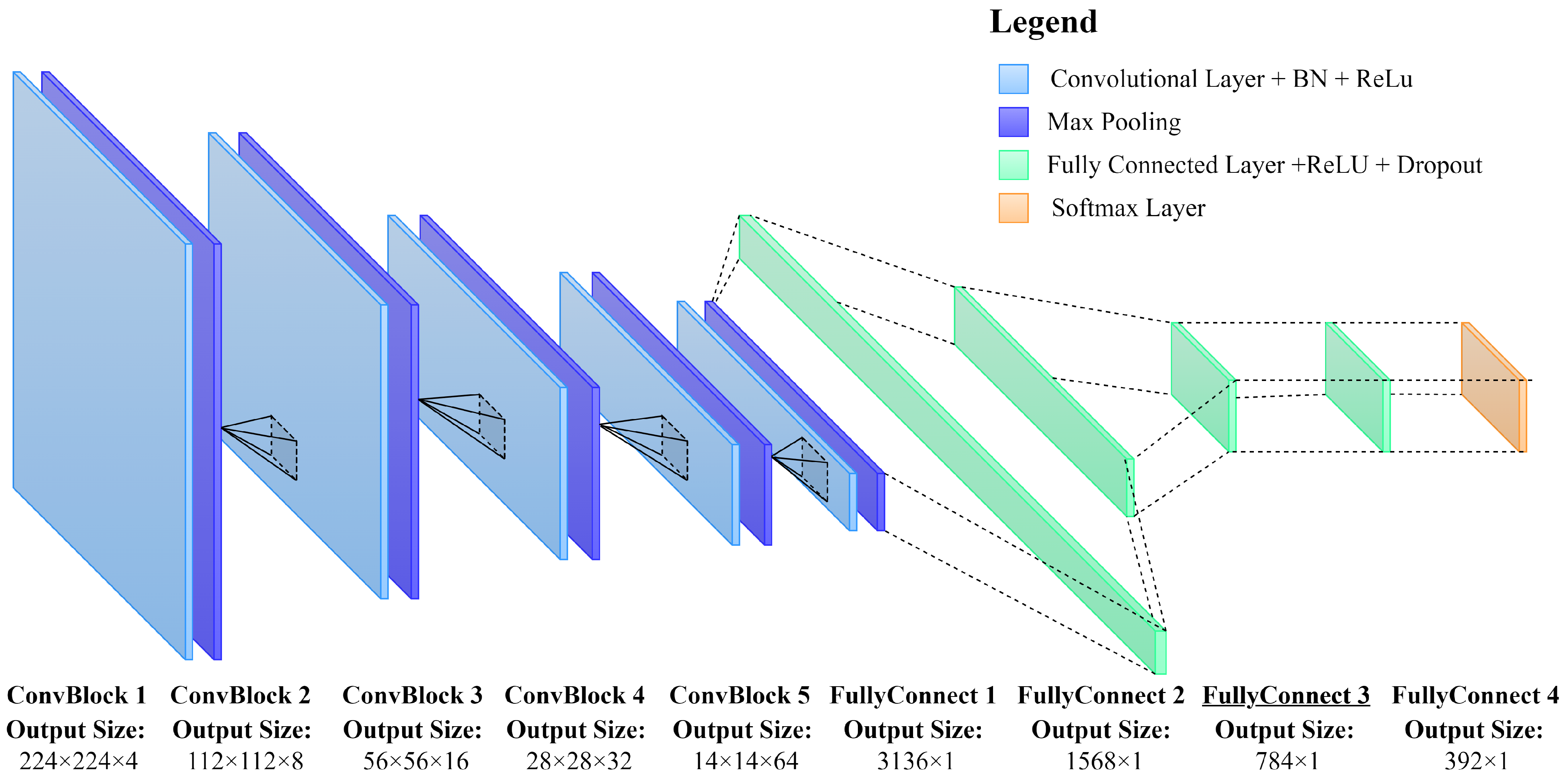
Figure 3a–d depicts the classes that are used in this study including undamaged, cracked, pitted, and concrete surfaces with construction joints. Furthermore, each selected image is resized to 224 pixels in length by 224 pixels in width to fit the desired input size of the proposed CNN model.
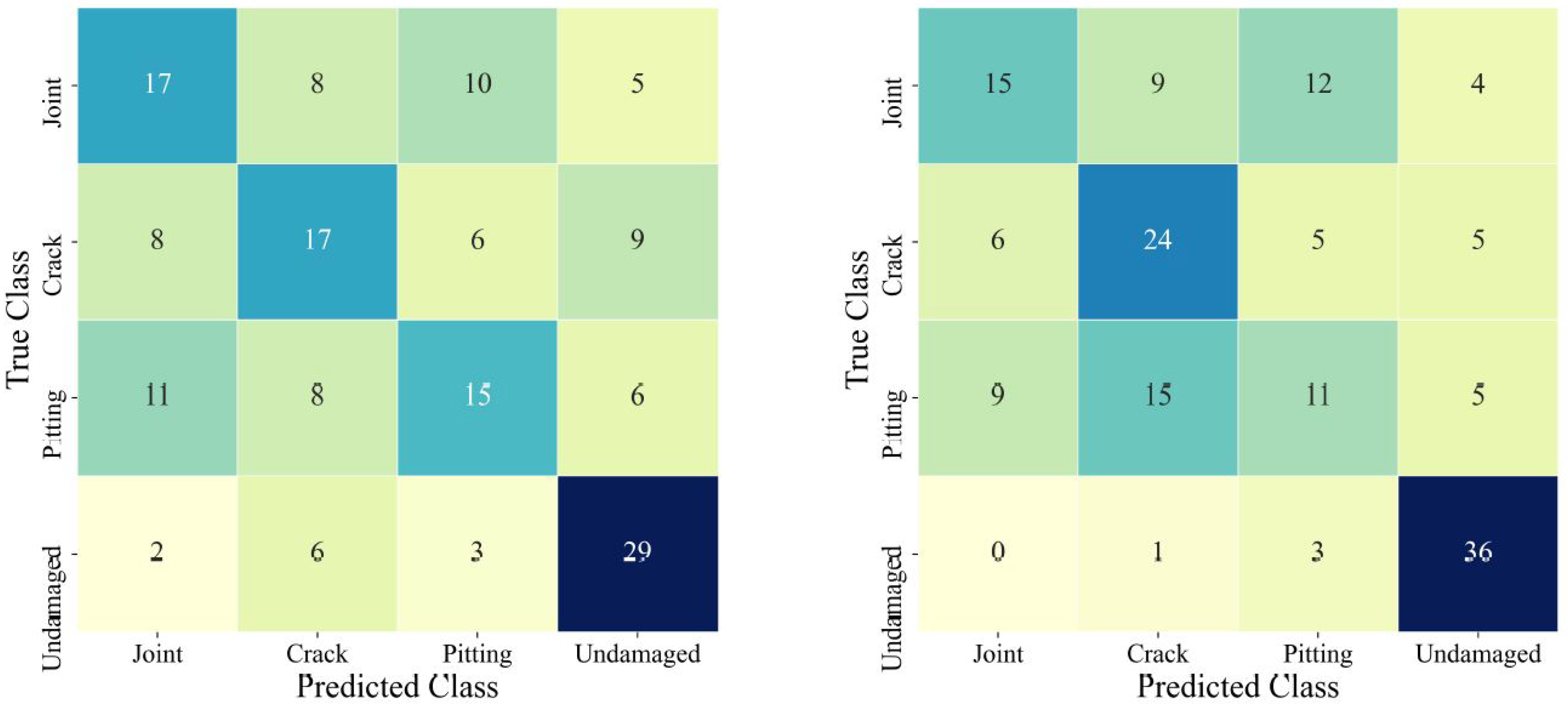
Two factors that could impact the performance of the method proposed are considered while choosing images for the creation of the dataset used in the experimentation. First, due to the low probability of observing a damaged concrete surface relative to a normal concrete surface, the number of annotated images belonging to the ‘undamaged’ class is far greater than the remaining damage-based classes. The significant difference in the number of images for each class available for training results in a biased model in which the classifier is more likely to correctly identify an image belonging to the majority class. This can be detrimental to inspection-based methods implemented in SHM as the primary objective of this analysis is to identify those images belonging to the minority class. Furthermore, the results of metrics such as accuracy lose value when quantifying the performance of classifiers and observing imbalanced data. For instance, for a binary classification problem, if the majority class is composed of 950 images compared to the minority of 50 images, correctly identifying the majority class would result in an accuracy of 95%, which is not indicative of how the model performed classifying both the major and minor class.
Secondly, many of the images contained various environmental and mechanical noises including the presence of shadows, vegetation, and blurring of various images. Similar to class imbalance, the presence of noisy images can introduce model biases during the training of a classifier. The tendency of a model is to fit the noisy features of the images (ex. background elements) rather than the features which are representative of the class itself. This may result in model overfitting, where the model performs well on the data that it has been trained on but has poor adaptation when presented with a new dataset resulting in poor performance. As such, noise-free images are chosen for the training, validation, and testing dataset as depicted in
Table 1. Each class has an equivalent number of training, validation, and testing images to address issues surrounding class imbalance. The number of training samples, (550 images) and validation, and testing samples (40 images) for each class is determined based on the size of the minority class with the lowest total images (pitting—630 images). The number of validation and testing samples for each class has been limited to 40 images in order to simulate the data scarcity issues which are prevalent in SHM. For those classes with more available images (i.e., crack, construction joint, and undamaged), a sample equal to the number of images comprising the pitting dataset is determined based on random integer selection. The validation and testing datasets consisting of 40 images per class are kept separated from the model during training to ensure these datasets remain unseen. As these datasets are not involved in the training process, the testing and training dataset can be used to determine the generalization capabilities of the model on unseen datasets as well as tuning the parameters of the model during the optimization step.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}