
Video Compressive Sensing Reconstruction Using Unfolded LSTM

Abstract
:1. Introduction
- A unified end-to-end deep learning VCS reconstruction framework is proposed, including the measurement and reconstruction part, both of which consist of deep neural networks. We train the framework using a single loss function in a data-driven method, which makes the training process more efficient and faster;
- The spatial–temporal information fusion reconstruction with multiple sampling rates is accomplished by using the unfolded LSTM network, which obtains better reconstruction effects and improves the convergence performance significantly;
- Compared with the existing VCS methods, we demonstrate that the proposed network provides better reconstruction results under a wide range of measurement ratios, even under the measurement ratio as low as 0.01. We also experimentally demonstrate that the network has good convergence without pre-training and converges faster than the comparison methods.
2. Related Work
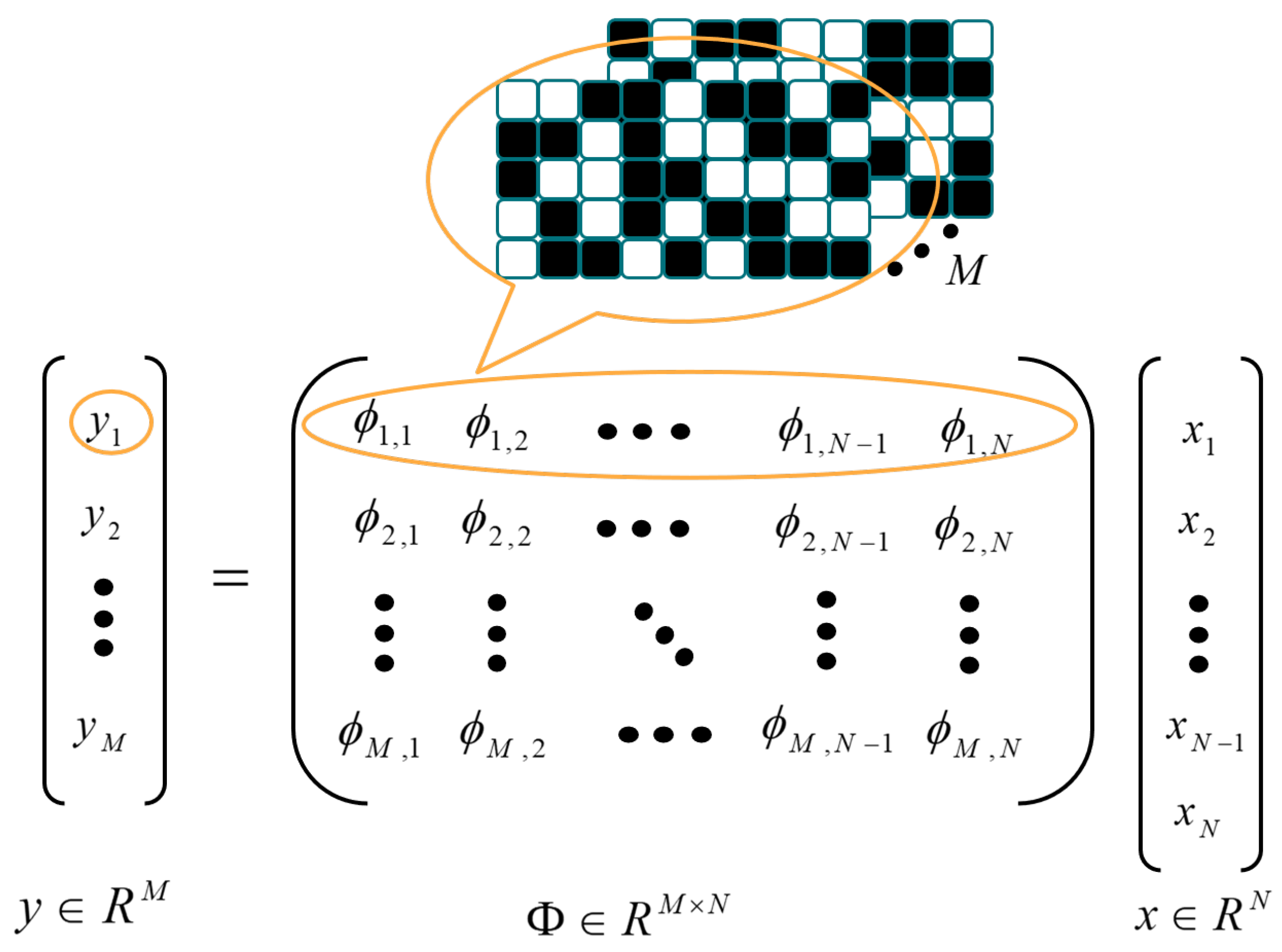
2.1. Conventional VCS Algorithm
2.2. Deep Neural Network-Based VCS Algorithms
3. Video Compressive Sensing Reconstruction Using Unfolded LSTM
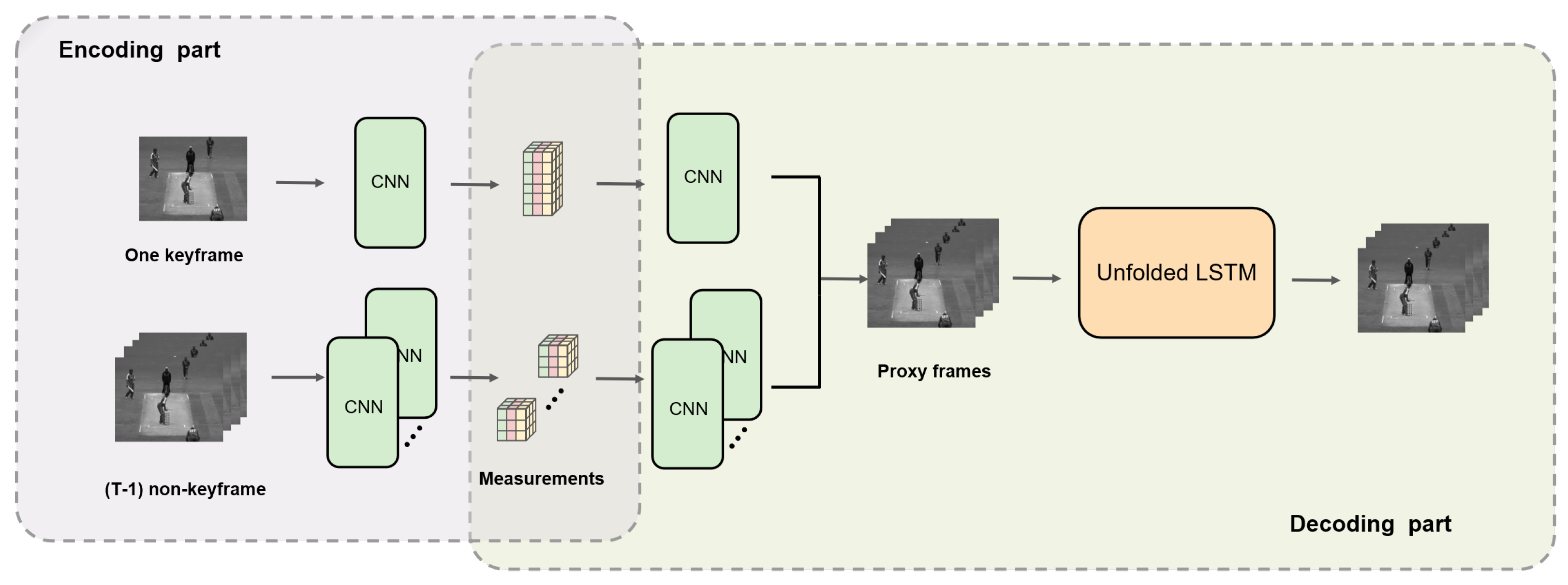
3.1. Overview of the Proposed Framework
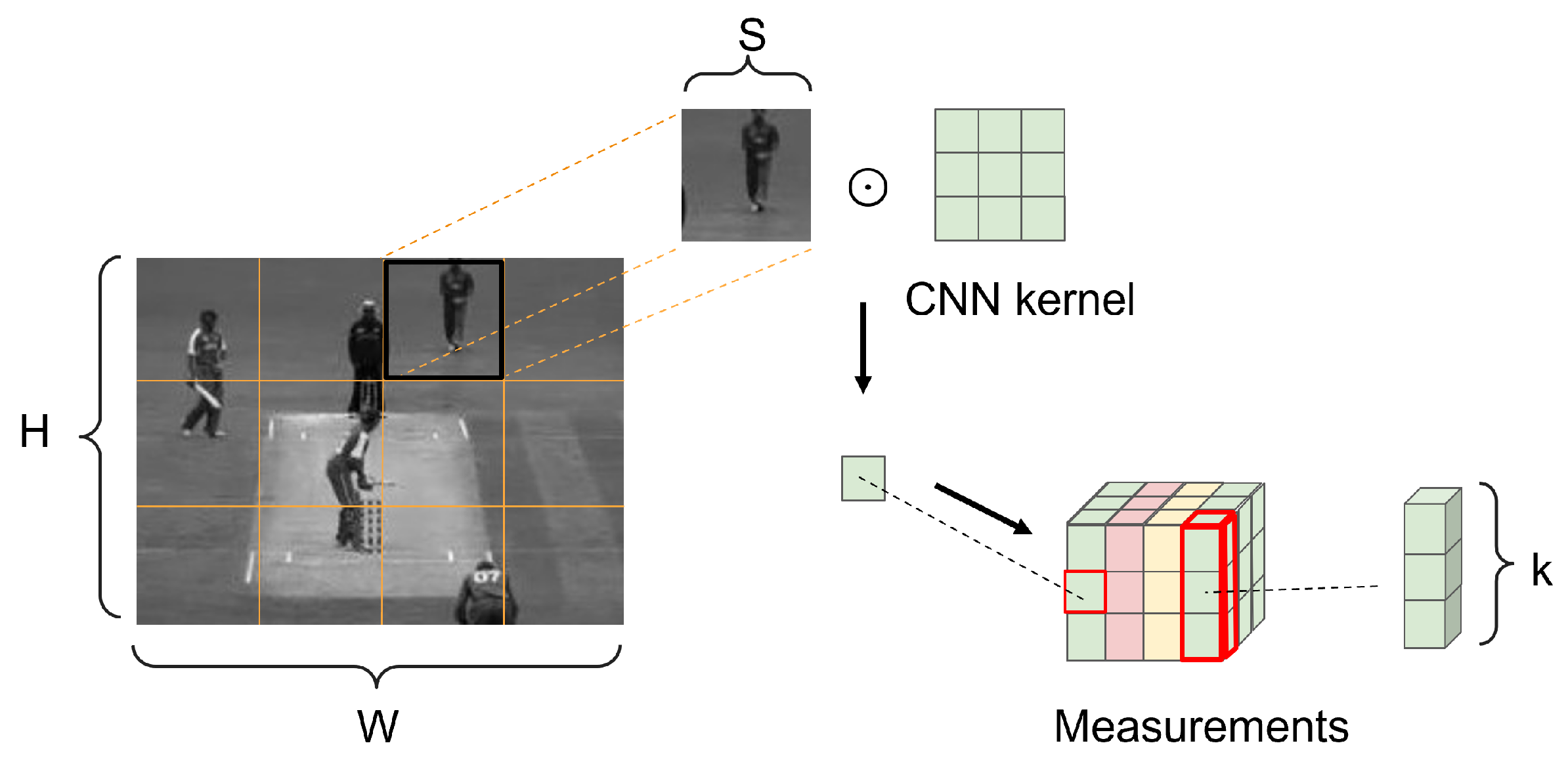
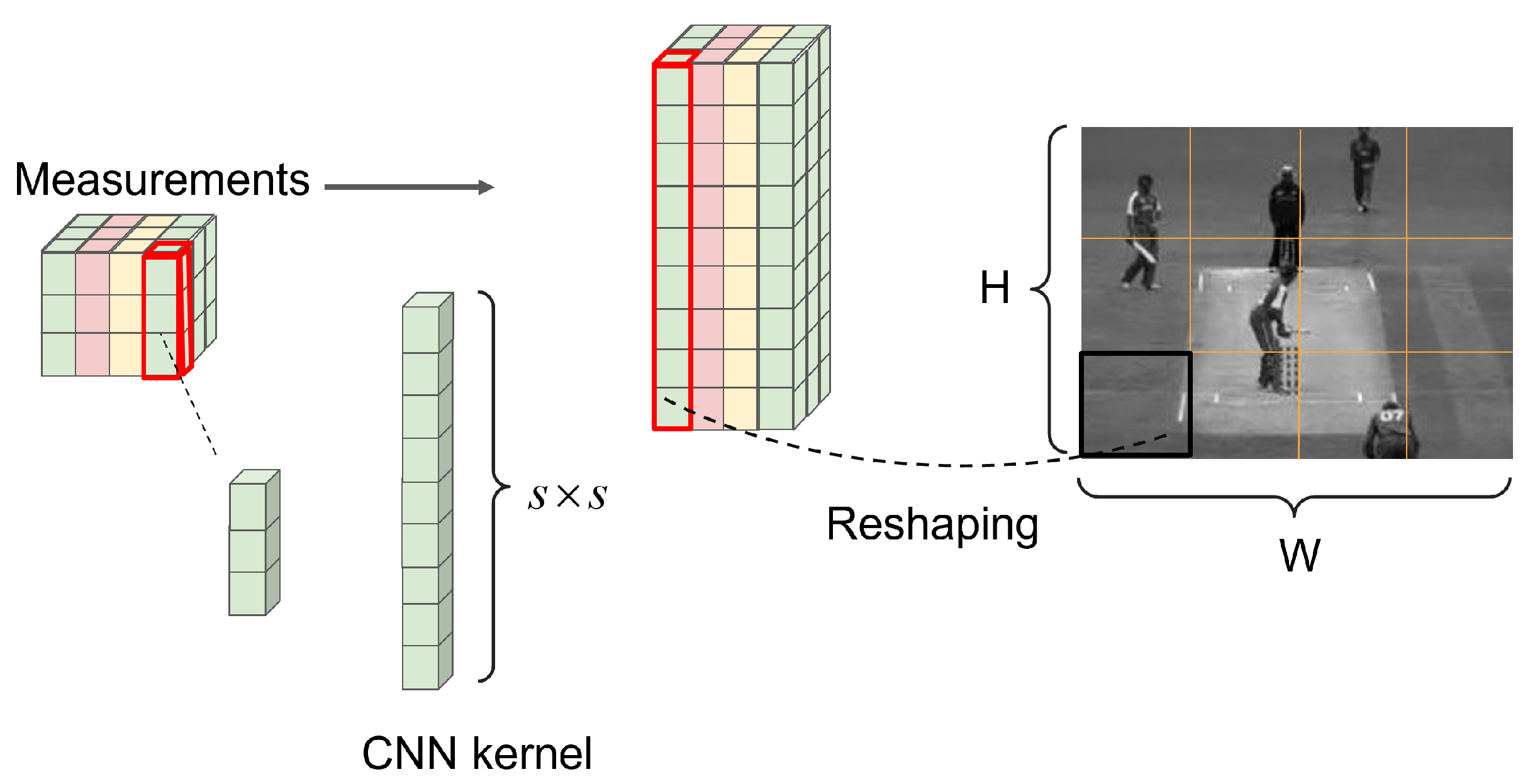
3.2. Encoding Part
3.3. Decoding Part
3.3.1. Initial Reconstruction
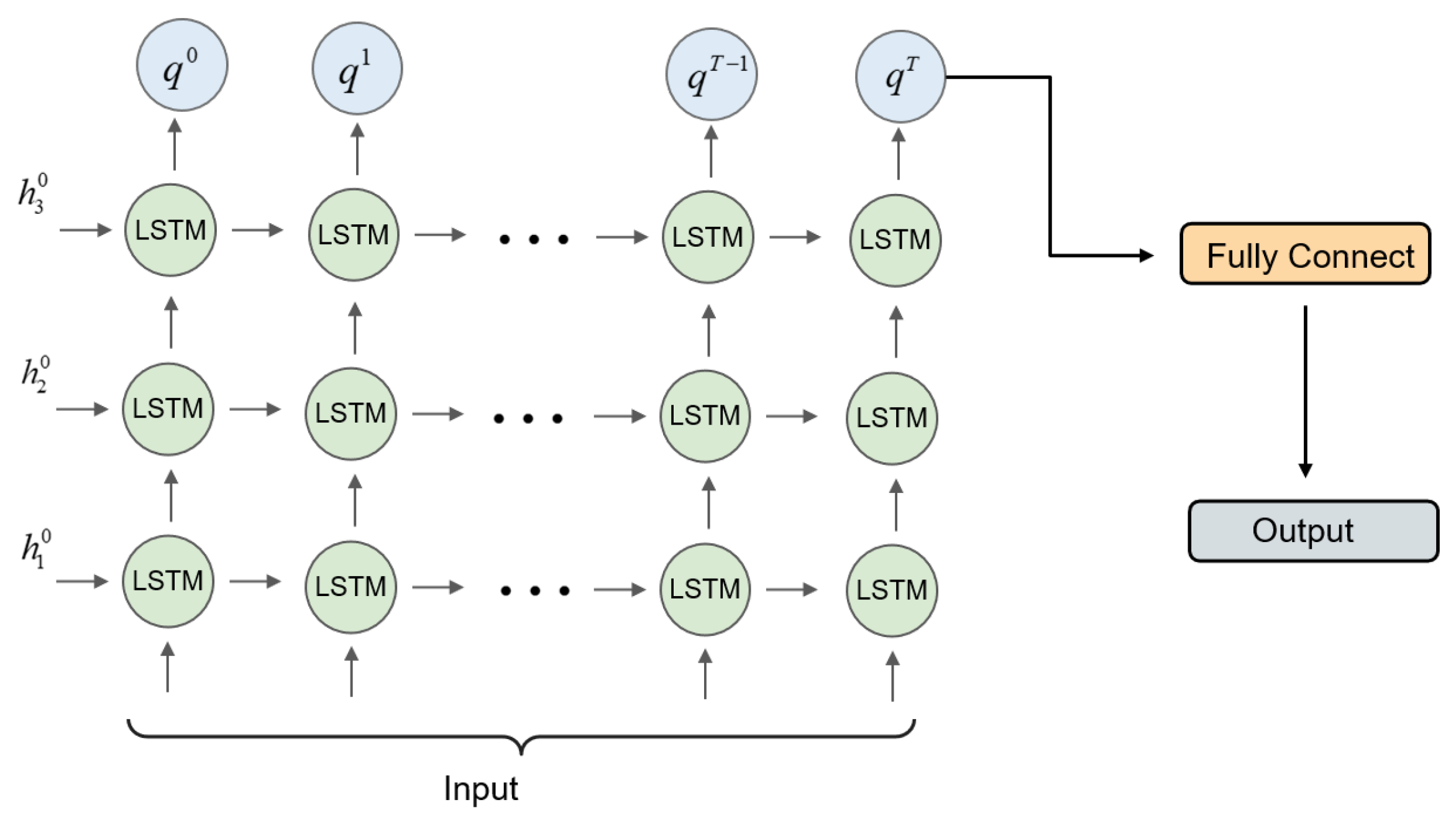
3.3.2. Deep Spatial–Temporal Information Fusion
3.4. Training
4. Experiment and Analysis
4.1. Dataset
4.2. Implementation Details
4.3. Compared with Existing VCS Algorithms
4.4. The Effectiveness of the Unfolded LSTM Structure
4.5. Optimal Measurement Ratio Allocation for Keyframes and Non-Keyframes
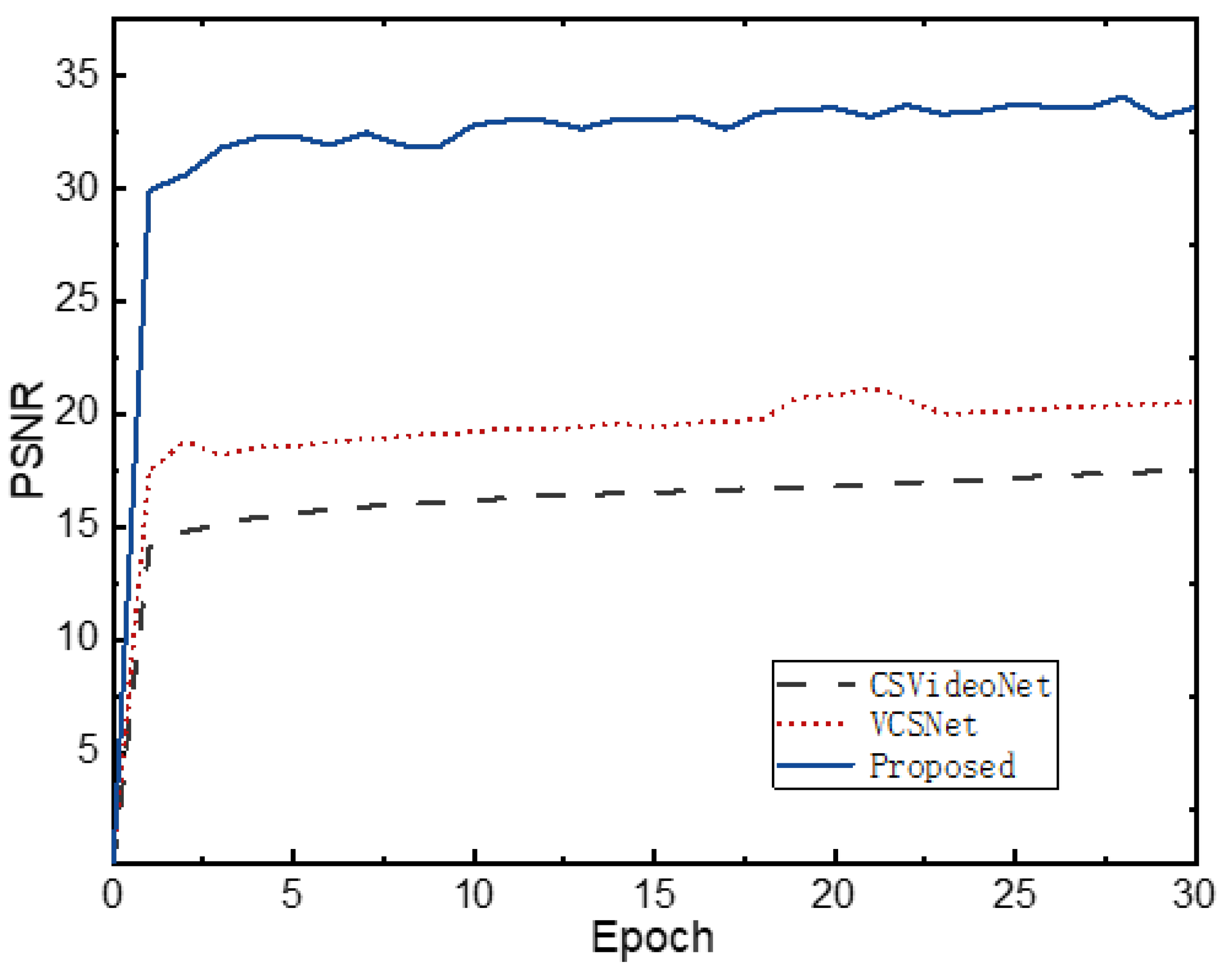
4.6. Convergence Performance and Time Complexity


5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ou, Y.F.; Liu, T.; Zhao, Z.; Ma, Z.; Wang, Y. Modeling the impact of frame rate on perceptual quality of video. In Proceedings of the 15th IEEE International Conference on Image Processing (ICIP 2008), San Diego, CA, USA, 12–15 October 2008; pp. 689–692. [Google Scholar]
- Candes, E.J.; Wakin, M.B. An introduction to compressive sampling. IEEE Signal Process. Mag. 2008, 25, 21–30. [Google Scholar] [CrossRef]
- Duarte, M.F.; Davenport, M.A.; Takhar, D.; Laska, J.N.; Sun, T.; Kelly, K.F.; Baraniuk, R.G. Single-pixel imaging via compressive sampling. IEEE Signal Process. Mag. 2008, 25, 83–91. [Google Scholar] [CrossRef]
- Hitomi, Y.; Gu, J.W.; Gupta, M.; Mitsunaga, T.; Nayar, S.K. Video from a Single Coded Exposure Photograph using a Learned Over-Complete Dictionary. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Barcelona, Spain, 6–13 November 2011; pp. 287–294. [Google Scholar]
- Veeraraghavan, A.; Reddy, D.; Raskar, R. Coded Strobing Photography: Compressive Sensing of High Speed Periodic Videos. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 671–686. [Google Scholar] [CrossRef] [PubMed]
- Yang, J.B.; Yuan, X.; Liao, X.J.; Llull, P.; Brady, D.J.; Sapiro, G.; Carin, L. Video Compressive Sensing Using Gaussian Mixture Models. IEEE Trans. Image Process. 2014, 23, 4863–4878. [Google Scholar] [CrossRef] [PubMed]
- Koller, R.; Schmid, L.; Matsuda, N.; Niederberger, T.; Spinoulas, L.; Cossairt, O.; Schuster, G.; Katsaggelos, A.K. High spatio-temporal resolution video with compressed sensing. Opt. Express 2015, 23, 15992–16007. [Google Scholar] [CrossRef]
- Yuan, X.; Sun, Y.Y.; Pang, S. Compressive video sensing with side information. Appl. Opt. 2017, 56, 2697–2704. [Google Scholar] [CrossRef]
- Iliadis, M.; Spinoulas, L.; Katsaggelos, A.K. Deep fully-connected networks for video compressive sensing. Digit. Signal Process. 2018, 72, 9–18. [Google Scholar] [CrossRef]
- Qiao, M.; Meng, Z.; Ma, J.; Yuan, X. Deep learning for video compressive sensing. Apl Photonics 2020, 5, 030801. [Google Scholar] [CrossRef]
- Zheng, J.; Jacobs, E. Video compressive sensing using spatial domain sparsity. Opt. Eng. 2009, 48, 087006. [Google Scholar] [CrossRef]
- Dong, W.S.; Shi, G.M.; Li, X.; Ma, Y.; Huang, F. Compressive Sensing via Nonlocal Low-Rank Regularization. IEEE Trans. Image Process. 2014, 23, 3618–3632. [Google Scholar] [CrossRef] [PubMed]
- Kulkarni, K.; Lohit, S.; Turaga, P.; Kerviche, R.; Ashok, A. ReconNet: Non-Iterative Reconstruction of Images from Compressively Sensed Measurements. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 449–458. [Google Scholar]
- Mousavi, A.; Dasarathy, G.; Baraniuk, R.G. DeepCodec: Adaptive Sensing and Recovery via Deep Convolutional Neural Networks. In Proceedings of the 55th Annual Allerton Conference on Communication, Control, and Computing (Allerton), Monticello, IL, USA, 3–6 October 2017; p. 744. [Google Scholar]
- Shi, W.Z.; Jiang, F.; Zhang, S.P.; Zhao, D.B. Deep networks for compressed image sensing. In Proceedings of the IEEE International Conference on Multimedia and Expo (ICME), Hong Kong, China, 10–14 July 2017; pp. 877–882. [Google Scholar]
- Xu, K.; Ren, F.B. CSVideoNet: A Real-time End-to-end Learning Framework for High-frame-rate Video Compressive Sensing. In Proceedings of the 18th IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 1680–1688. [Google Scholar]
- Chen, C.; Wu, Y.T.; Zhou, C.; Zhang, D.Y. JsrNet: A Joint Sampling-Reconstruction Framework for Distributed Compressive Video Sensing. Sensors 2020, 20, 206. [Google Scholar] [CrossRef] [PubMed]
- Zhao, Z.F.; Xie, X.M.; Liu, W.; Pan, Q.Z. A Hybrid-3D Convolutional Network for Video Compressive Sensing. IEEE Access 2020, 8, 20503–20513. [Google Scholar] [CrossRef]
- Shi, W.Z.; Liu, S.H.; Jiang, F.; Zhao, D.B. Video Compressed Sensing Using a Convolutional Neural Network. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 425–438. [Google Scholar] [CrossRef]
- He, H.; Xin, B.; Ikehata, S.; Wipf, D. From Bayesian Sparsity to Gated Recurrent Nets. In Proceedings of the Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Curran Associates Inc.: Red Hook, NY, USA, 2017; pp. 5560–5570. [Google Scholar]
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, JMLR Workshop and Conference Proceedings, Sardinia, Italy, 13–15 May 2010; pp. 249–256. [Google Scholar]
- Yuan, X. Generalized alternating projection based total variation minimization for compressive sensing. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 2539–2543. [Google Scholar]
- Iliadis, M.; Spinoulas, L.; Katsaggelos, A.K. DeepBinaryMask: Learning a binary mask for video compressive sensing. Digit. Signal Process. 2020, 96, 102591. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J.L. Adam: A method for stochastic optimization. In Proceedings of the 3rd International Conference on Learning Representations, ICLR, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Soomro, K.; Zamir, A.R.; Shah, M. UCF101: A Dataset of 101 Human Actions Classes From Videos in The Wild. arXiv 2012, arXiv:1212.0402. [Google Scholar]
- Shedligeri, P.; Anupama, S.; Mitra, K. A Unified Framework for Compressive Video Recovery from Coded Exposure Techniques. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–8 January 2021; pp. 1599–1608. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Ratio | Frame Size | GOP | PSNR | SSIM | ||
|---|---|---|---|---|---|---|---|
| VCSNet | 0.15 | 96 × 96 | 8 | 0.5 | 0.1 | 34.29 | 0.90 |
| Proposed | 96 × 96 | 8 | 0.5 | 0.1 | 36.91 | 0.96 | |
| VCSNet | 0.07 | 96 × 96 | 8 | 0.5 | 0.01 | 29.58 | 0.82 |
| Proposed | 96 × 96 | 8 | 0.5 | 0.01 | 32.66 | 0.91 |
| Name | Ratio | Frame Size | GOP | PSNR | SSIM | ||
|---|---|---|---|---|---|---|---|
| CSVideoNet | 0.04 | 160 × 160 | 10 | 0.2 | 0.022 | 26.87 | 0.81 |
| Proposed | 160 × 160 | 10 | 0.2 | 0.022 | 32.64 | 0.88 | |
| CSVideoNet | 0.02 | 160 × 160 | 10 | 0.1 | 0.011 | 25.09 | 0.77 |
| Proposed | 160 × 160 | 10 | 0.1 | 0.011 | 31.11 | 0.84 | |
| CSVideoNet | 0.01 | 160 × 160 | 10 | 0.06 | 0.004 | 24.23 | 0.74 |
| Proposed | 160 × 160 | 10 | 0.06 | 0.004 | 28.64 | 0.81 |
| Name | Ratio | Frame Size | GOP | PSNR | SSIM | ||
|---|---|---|---|---|---|---|---|
| DCF | 1/16 | 160 × 160 | 16 | - | - | 24.67 | 0.71 |
| C2B | 160 × 160 | 16 | - | - | 32.23 | 0.93 | |
| CSVideoNet | 160 × 160 | 10 | 0.2 | 0.022 | 28.08 | 0.84 | |
| VCSNet | 160 × 160 | 10 | 0.2 | 0.022 | 28.57 | 0.86 | |
| Proposed | 160 × 160 | 10 | 0.2 | 0.022 | 35.02 | 0.95 |
| Name | Ratio | Frame Size | GOP | PSNR | SSIM | ||
|---|---|---|---|---|---|---|---|
| LSTM | 0.04 | 160 × 160 | 10 | 0.2 | 0.047 | 34.11 | 0.91 |
| Proposed | 160 × 160 | 10 | 0.2 | 0.047 | 35.02 | 0.95 | |
| LSTM | 0.02 | 160 × 160 | 10 | 0.2 | 0.022 | 31.50 | 0.81 |
| Proposed | 160 × 160 | 10 | 0.2 | 0.022 | 32.64 | 0.91 | |
| LSTM | 0.01 | 160 × 160 | 10 | 0.1 | 0.011 | 30.32 | 0.77 |
| Proposed | 160 × 160 | 10 | 0.1 | 0.011 | 31.11 | 0.88 |
| Frame Size | Patch Size | GOP | PSNR | SSIM | ||||
|---|---|---|---|---|---|---|---|---|
| 96 × 96 | 32 × 32 | 10 | 0.5 | 0.014 | 512 | 14 | 31.88 | 0.81 |
| 96 × 96 | 32 × 32 | 10 | 0.4 | 0.025 | 409 | 25 | 33.59 | 0.83 |
| 96 × 96 | 32 × 32 | 10 | 0.3 | 0.036 | 307 | 37 | 34.58 | 0.86 |
| 96 × 96 | 32 × 32 | 10 | 0.2 | 0.047 | 204 | 48 | 35.02 | 0.91 |
| Model | CSVideoNet | VCSNet | Proposed |
|---|---|---|---|
| Time(s) | 587.70 | 359.61 | 194.53 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xia, K.; Pan, Z.; Mao, P. Video Compressive Sensing Reconstruction Using Unfolded LSTM. Sensors 2022, 22, 7172. https://doi.org/10.3390/s22197172
Xia K, Pan Z, Mao P. Video Compressive Sensing Reconstruction Using Unfolded LSTM. Sensors. 2022; 22(19):7172. https://doi.org/10.3390/s22197172
Chicago/Turabian StyleXia, Kaiguo, Zhisong Pan, and Pengqiang Mao. 2022. "Video Compressive Sensing Reconstruction Using Unfolded LSTM" Sensors 22, no. 19: 7172. https://doi.org/10.3390/s22197172
APA StyleXia, K., Pan, Z., & Mao, P. (2022). Video Compressive Sensing Reconstruction Using Unfolded LSTM. Sensors, 22(19), 7172. https://doi.org/10.3390/s22197172