
Content-Aware SLIC Super-Pixels for Semi-Dark Images (SLIC++)

 , , ,
, , ,
Abstract
:1. Introduction
- Super-pixels abstraction potentially decreases the overhead of processing each pixel at a time.
- Gray-level or color images can be processed by a single algorithm implementation.
- Integrated user control provided for performance tuning.
- Absence of classification of state-of-the-art methods based on low level manipulations.
- Inherited discontinuity in super-pixel segmentation due to inconsistent manipulations.
- Unknown pixel grouping criteria in terms of distance measure to retain fine grained details.
- Unknown effect of semi-dark images on final super-pixel segmentations.
- Classification of Literary Studies w.r.t Singular Pixel Manipulation Strategies:
- 2.
- Investigation of Appropriate Pixel Grouping Scheme:
- 3.
- Novel Hybrid Content-Aware Extension of SLIC—SLIC++:
- 4.
- Comprehensive Perceptual Results focusing Semi-dark Images:
Paper Organization
2. Literature Review
2.1. Limited Semi-Dark Image Centric Research Focusing Gradient-Ascent Methods
2.2. Critical Analysis of Gradient-Ascent Super-Pixel Creation Algorithms Based on Manipulation Strategy
Key Takeaways
2.3. Exclusiveness of SLIC++ w.r.t Recent Developments
2.4. Summary and Critiques
3. Materials and Methods
3.1. The Semi-Dark Dataset
3.2. Desiderata of Accurate Super-Pixels
- 1.
- Boundary Adherence
- 2.
- Efficiency with Less Complexity
- 3.
- Controllable Number of Super-Pixels
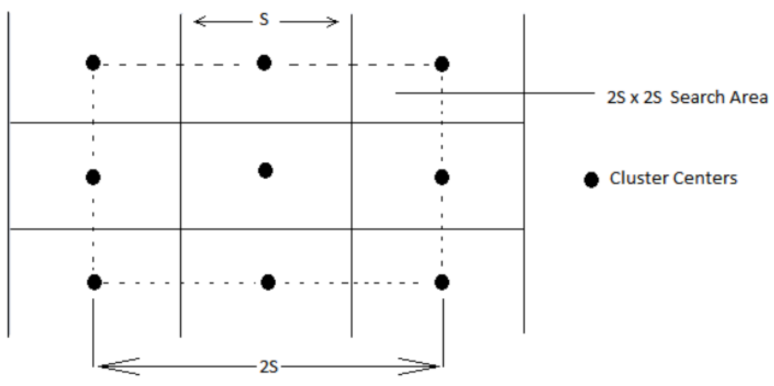
3.3. SLIC Preliminaries
3.4. The Extension Hypothesis—Fusion Similarity Measure
- Chessboard: This measure calculates the maximum distance between vectors. This can be referred to measuring path between the pixels based on eight connected neighborhood whose edges are one unit apart. The chessboard distance along any co-ordinate is given by identifying maximum, as presented in Equation (4).Rationale of Consideration: Since the problem with existing similarity measures is loss of information, chessboard is one of the alternate to be incorporated in super-pixel creation base. This measure is considered as it takes into account information of eight connected neighbors of pixels under consideration. However, it might add computational overhead due to the same.
- Cosine: This measure calculates distance based on the angle between two vectors. The cosine angular dimensions counteract the problem of high dimensionality. The inner angular product between the vectors turns out to be one if vectors were previously normalized. Cosine distance is based on cosine similarity which is then plugged-in distance equation. Equations (5) and (6) shows calculation of cosine distance between pixels.Rationale of Consideration: One of the aspects of content aware similarity measure is to retain the angular information thus we attempted to incorporate this measure. The resulting super-pixels are expected to retain the content relevant boundaries. However, this measure does not consider magnitude of the vectors/pixels due to which boundary performance might fall.
- Minkowski: This measure is a bit more intricate. It can be used for normed vector spaces, where distance is represented as vector having some length. The measure multiplies a positive weight value which changes the length whilst keeping its direction. Equation (7) presents distance formulation of Minkowski similarity measure.Here is the weight, if its value is set to 1 the resultant measure corresponds to Manhattan distance measure. , refers to euclidean and , refers to chessboard or Chebyshev distance measure.Rationale of Consideration: As user-control in respective application is desired, Minkowski similarity provides the functionality by replacing merely one parameter which changes the entire operationality without changing the core equations. However, here we still have problems relating to the retainment of angular information.
- Geodesic: This measure considers geometric movements along the pixel path in image space. This distance presents locally shortest path in the image plane. Geodesic distance computes distance between two pixels which results in surface segmentation with minimum distortion. Efficient numerical implementation of geodesic distance is achieved using first order approximation. For approximation parametric surfaces are considered with number of points on the surface. Given an image mask, geodesic distance for image pixels can be calculated using Equation (8).where is connected path between pixel , provided t = 0,1. The density function increments the distance and can be computed using Equation (9).where is scaling factor, is edge measurement also provides normalization of gradient magnitude of image . is the Gaussian function with its standard deviation being . minimizes the effect of weak intensity boundaries over density function. D(x) always produces constant distance, for homogeneous appearing regions if E(x) is zero D(x) becomes one.Rationale of Consideration: For shape analysis by computing distances geodesic has been the natural choice. However, computing geodesic distance is computationally expensive and is susceptible to noise [44]. Therefore, to overcome effect of noise geodesic distance should be used in amalgamation of Euclidean properties to retain maximum possible information in terms of minimum distance among pixels and their relevant angles.
3.5. SLIC++ Proposal
3.5.1. Euclidean Geodesic—Content-Aware Similarity Measure
3.5.2. Proposal of Content-Aware Feature Infusion in SLIC
| Algorithm 1. SLIC++ Algorithm |
| 1: Initialize cluster center with seed defined at regular intervals 2: Move cluster centers in pixel neighborhood to lowest gradient 3: Repeat 4: each cluster center do 5: Assign the pixel from in a square window or CVT using distance measure given by Equation (3). 6: Assign the pixel from in a square window or CVT using distance measure given by Equation (10). 7: End for 8: Compute new cluster centers and residual error (distance between previous centers and recomputed centers). 9: <= threshold 10: Enforce connectivity. |
- Initialization and Termination
- b.
- Algorithm Complexity
4. Validation of the Proposed Algorithm
4.1. Experimental Setup and Implementation Details
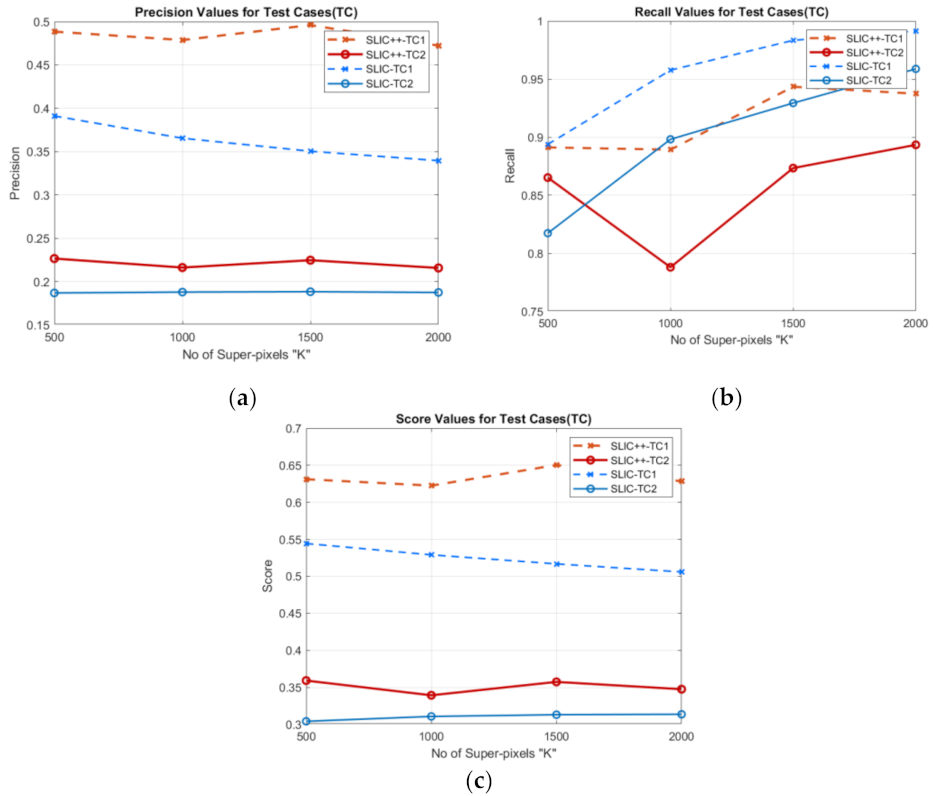
4.2. Parameter Selection
4.3. Performance Analysis
4.3.1. Numeric Analysis of SLIC Extension with Different Distance Measures
4.3.2. Comparative Analysis with State-of-the-Art
4.3.3. Boundary Precision Visualization against Ground-Truth
4.3.4. Visualizing Super-Pixels on Images
Key Takeaways
5. Limitations of Content-Aware SLIC++ Super-Pixels
6. Emerging Successes and Practical Implications
7. Conclusions and Future Work
7.1. Conclusions
7.2. Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Al-Huda, Z.; Peng, B.; Yang, Y.; Algburi, R.N. Object Scale Selection of Hierarchical Image Segmentation with Deep Seeds. Int. J. Pattern Recogn. Artif. Intell. 2021, 35, 2154026. [Google Scholar] [CrossRef]
- Riera, L.; Ozcan, K.; Merickel, J.; Rizzo, M.; Sarkar, S.; Sharma, A. Detecting and Tracking Unsafe Lane Departure Events for Predicting Driver Safety in Challenging Naturalistic Driving Data. In Proceedings of the 2020 IEEE Intelligent Vehicles Symposium (IV), Las Vegas, NV, USA, 19 October–13 November 2020; pp. 238–245. [Google Scholar]
- Nadeem, A.; Jalal, A.; Kim, K. Automatic human posture estimation for sport activity recognition with robust body parts detection and entropy markov model. Multimed. Tools Appl. 2021, 80, 21465–21498. [Google Scholar] [CrossRef]
- Rashid, M.; Khan, M.A.; Alhaisoni, M.; Wang, S.-H.; Naqvi, S.R.; Rehman, A.; Saba, T. A sustainable deep learning framework for object recognition using multi-layers deep features fusion and selection. Sustainability 2020, 12, 5037. [Google Scholar] [CrossRef]
- Jaffari, R.; Hashmani, M.A.; Reyes-Aldasoro, C.C. A Novel Focal Phi Loss for Power Line Segmentation with Auxiliary Classifier U-Net. Sensors 2021, 21, 2803. [Google Scholar] [CrossRef] [PubMed]
- Memon, M.M.; Hashmani, M.A.; Rizvi, S.S.H. Novel Content Aware Pixel Abstraction for Image Semantic Segmentation. J. Hunan Univ. Nat. Sci. 2020, 47, 9. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H. Conditional convolutions for instance segmentation. In Proceedings of the Computer Vision–ECCV 2020 16th European Conference, Glasgow, UK, 23–28 August 2020; Part I 16; pp. 282–298. [Google Scholar]
- Junejo, A.Z.; Memon, S.A.; Memon, I.Z.; Talpur, S. Brain Tumor Segmentation Using 3D Magnetic Resonance Imaging Scans. In Proceedings of the 2018 1st International Conference on Advanced Research in Engineering Sciences (ARES), Dubai, United Arab Emirates, 15 June 2018; pp. 1–6. [Google Scholar]
- Hamadi, A.B. Interactive Automation of COVID-19 Classification through X-Ray Images using Machine Learning. J. Indep. Stud. Res. Comput. 2021, 18. [Google Scholar] [CrossRef]
- Zhao, L.; Li, Z.; Men, C.; Liu, Y. Superpixels extracted via region fusion with boundary constraint. J. Vis. Commun. Image Represent. 2020, 66, 102743. [Google Scholar] [CrossRef]
- Achanta, R.; Shaji, A.; Smith, K.; Lucchi, A.; Fua, P.; Süsstrunk, S. Slic Superpixels; EPFL Technical Report 149300; School of Computer and Communication Sciences, Ecole Polytechnique Fedrale de Lausanne: Lausanne, Switzerland, 2010; pp. 1–15. [Google Scholar]
- Kim, K.-S.; Zhang, D.; Kang, M.-C.; Ko, S.-J. Improved simple linear iterative clustering superpixels. In Proceedings of the 2013 IEEE International Symposium on Consumer Electronics (ISCE), Hsinchu, Taiwan, 3–6 June 2013; pp. 259–260. [Google Scholar]
- Wang, M.; Liu, X.; Gao, Y.; Ma, X.; Soomro, N.Q. Superpixel segmentation: A benchmark. Signal Process. Image Commun. 2017, 56, 28–39. [Google Scholar] [CrossRef]
- Achanta, R.; Shaji, A.; Smith, K.; Lucchi, A.; Fua, P.; Süsstrunk, S. SLIC superpixels compared to state-of-the-art superpixel methods. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 2274–2282. [Google Scholar] [CrossRef] [Green Version]
- Liu, Y.-J.; Yu, C.-C.; Yu, M.-J.; He, Y. Manifold SLIC: A fast method to compute content-sensitive superpixels. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 651–659. [Google Scholar]
- Wang, P.; Zeng, G.; Gan, R.; Wang, J.; Zha, H. Structure-sensitive superpixels via geodesic distance. Int. J. Comput. Vis. 2013, 103, 1–21. [Google Scholar] [CrossRef] [Green Version]
- Comaniciu, D.; Meer, P. Mean shift: A robust approach toward feature space analysis. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 603–619. [Google Scholar] [CrossRef] [Green Version]
- Sheikh, Y.A.; Khan, E.A.; Kanade, T. Mode-seeking by medoidshifts. In Proceedings of the 2007 IEEE 11th International Conference on Computer Vision, Rio de Janeiro, Brazil, 14–21 October 2017; pp. 1–8. [Google Scholar]
- Vedaldi, A.; Soatto, S. Quick shift and kernel methods for mode seeking. In Proceedings of the European Conference on Computer Vision; ECCV 2008; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2008; Volume 5305. [Google Scholar] [CrossRef] [Green Version]
- Levinshtein, A.; Stere, A.; Kutulakos, K.N.; Fleet, D.J.; Dickinson, S.J.; Siddiqi, K. Turbopixels: Fast superpixels using geometric flows. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 2290–2297. [Google Scholar] [CrossRef] [Green Version]
- Moore, A.P.; Prince, S.J.; Warrell, J.; Mohammed, U.; Jones, G. Scene shape priors for superpixel segmentation. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 771–778. [Google Scholar]
- Veksler, O.; Boykov, Y.; Mehrani, P. Superpixels and supervoxels in an energy optimization framework. In Proceedings of the European Conference on Computer Vision; ECCV 2010; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2010; Volume 6315. [Google Scholar] [CrossRef] [Green Version]
- Van den Bergh, M.; Boix, X.; Roig, G.; de Capitani, B.; Van Gool, L. Seeds: Superpixels extracted via energy-driven sampling. Int. J. Comput. Vis. 2012, 111, 298–314. [Google Scholar] [CrossRef]
- Weikersdorfer, D.; Schick, A.; Cremers, D. Depth-adaptive supervoxels for RGB-D video segmentation. In Proceedings of the 2013 IEEE International Conference on Image Processing, Melbourne, Australia, 15–18 September 2013; pp. 2708–2712. [Google Scholar]
- Conrad, C.; Mertz, M.; Mester, R. Contour-relaxed superpixels. In Proceedings of the International Workshop on Energy Minimization Methods in Computer Vision and Pattern Recognition; EMMCVPR 2013; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany; Germany, 2013; Volume 8081. [Google Scholar] [CrossRef]
- Xu, L.; Zeng, L.; Wang, Z. Saliency-based superpixels. Signal Image Video Process. 2014, 8, 181–190. [Google Scholar] [CrossRef]
- Li, Z.; Chen, J. Superpixel segmentation using linear spectral clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 12 June 2015; pp. 1356–1363. [Google Scholar]
- Rubio, A.; Yu, L.; Simo-Serra, E.; Moreno-Noguer, F. BASS: Boundary-aware superpixel segmentation. In Proceedings of the 2016 23rd International Conference on Pattern Recognition (ICPR), Cancun, Mexico, 4–8 December 2016; pp. 2824–2829. [Google Scholar]
- Wang, H.; Peng, X.; Xiao, X.; Liu, Y. BSLIC: Slic superpixels based on boundary term. Symmetry 2017, 9, 31. [Google Scholar] [CrossRef] [Green Version]
- Liu, Y.-J.; Yu, M.; Li, B.-J.; He, Y. Intrinsic manifold SLIC: A simple and efficient method for computing content-sensitive superpixels. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 653–666. [Google Scholar] [CrossRef]
- Akyilmaz, E.; Leloglu, U.M. Similarity ratio based adaptive Mahalanobis distance algorithm to generate SAR superpixels. Can. J. Remote Sens. 2017, 43, 569–581. [Google Scholar] [CrossRef]
- Lowekamp, B.C.; Chen, D.T.; Yaniv, Z.; Yoo, T.S. Scalable Simple Linear Iterative Clustering (SSLIC) Using a Generic and Parallel Approach. arXiv 2018, arXiv:1806.08741. [Google Scholar]
- Chuchvara, A.; Gotchev, A. Content-Adaptive Superpixel Segmentation Via Image Transformation. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 1505–1509. [Google Scholar]
- Uziel, R.; Ronen, M.; Freifeld, O. Bayesian adaptive superpixel segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 8470–8479. [Google Scholar] [CrossRef]
- Yang, F.; Sun, Q.; Jin, H.; Zhou, Z. Superpixel Segmentation With Fully Convolutional Networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 13961–13970. [Google Scholar]
- Wu, J.; Liu, C.; Li, B. Texture-aware and structure-preserving superpixel segmentation. Comput. Graph. 2021, 94, 152–163. [Google Scholar] [CrossRef]
- Chuchvara, A.; Gotchev, A. Efficient Image-Warping Framework for Content-Adaptive Superpixels Generation. IEEE Signal Process. Lett. 2021, 28, 1948–1952. [Google Scholar] [CrossRef]
- Yu, Y.; Yang, Y.; Liu, K. Edge-Aware Superpixel Segmentation with Unsupervised Convolutional Neural Networks. In Proceedings of the 2021 IEEE International Conference on Image Processing (ICIP), Anchorage, AK, USA, 19–22 September 2021; pp. 1504–1508. [Google Scholar]
- Arbelaez, P.; Maire, M.; Fowlkes, C.; Malik, J. Contour detection and hierarchical image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 898–916. [Google Scholar] [CrossRef] [Green Version]
- Memon, M.M.; Hashmani, M.A.; Junejo, A.Z.; Rizvi, S.S.; Arain, A.A. A Novel Luminance-Based Algorithm for Classification of Semi-Dark Images. Appl. Sci. 2021, 11, 8694. [Google Scholar] [CrossRef]
- Stutz, D.; Hermans, A.; Leibe, B. Superpixels: An evaluation of the state-of-the-art. Comput. Vis. Image Underst. 2018, 166, 1–27. [Google Scholar] [CrossRef] [Green Version]
- Neubert, P.; Protzel, P. Superpixel benchmark and comparison. J. Comput. Phys. 1983, 51, 191–207. [Google Scholar]
- Tanemura, M.; Ogawa, T.; Ogita, N. A new algorithm for three-dimensional Voronoi tessellation. J. Comput. Phys. 1983, 51, 191–207. [Google Scholar] [CrossRef]
- Yu, J.; Kim, S.B. Density-based geodesic distance for identifying the noisy and nonlinear clusters. Inf. Sci. 2016, 360, 231–243. [Google Scholar] [CrossRef]
- Monteiro, F.C.; Campilho, A.C. Performance evaluation of image segmentation. In Image Analysis and Recognition. ICIAR 2006; Lecture Notes in Computer Science; Campilho, A., Kamel, M.S., Eds.; Springer: Berlin/Heidelberg, Germany, 2006; Volume 4141. [Google Scholar] [CrossRef] [Green Version]
- Gauriau, R. Shape-Based Approaches for Fast Multi-Organ Localization and Segmentation in 3D Medical Images; Telecom ParisTech: Paris, France, 2015. [Google Scholar]
- Dai, W.; Dong, N.; Wang, Z.; Liang, X.; Zhang, H.; Xing, E.P. Scan: Structure correcting adversarial network for organ segmentation in chest x-rays. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support; Springer: Berlin/Heidelberg, Germany, 2018; pp. 263–273. [Google Scholar]
- Khan, A.; Mineo, C.; Dobie, G.; Macleod, C.; Pierce, G. Vision guided robotic inspection for parts in manufacturing and remanufacturing industry. J. Remanuf. 2021, 11, 49–70. [Google Scholar] [CrossRef]
- Fedorov, A.; Nikolskaia, K.; Ivanov, S.; Shepelev, V.; Minbaleev, A. Traffic flow estimation with data from a video surveillance camera. J. Big Data 2019, 6, 1–15. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Complexity | Pixel Manipulation Strategy | Distance Measure | Dataset | Semi-Dark Image Mentions | Year | Ref. |
|---|---|---|---|---|---|---|---|
| Meanshift | Mode seeking to locate local maxima | Euclidean | Not mentioned | ✘ | 2002 | [17] | |
| Medoidshift | Approximates local gradient using weighted estimates of medoids. | Euclidean | Not mentioned | ✘ | 2007 | [18] | |
| Quickshift | Parzen’s density estimation for pixel values | Non-Euclidean | Caltech-4 | ✘ | 2008 | [19] | |
| TurboPixel | Geometric flows for limited pixels | Gradient calculation for boundary pixels only | Berkeley Dataset | ✘ | 2009 | [20] | |
| Scene Shape Super-pixel (SSP) | Shortest path manipulation with prior information of boundary. | Probabilistic modeling plus Euclidean space manipulation | Dynamic road scenes. No explicit mentions of semi-dark images but we suspect presence of semi | ✓ | 2009 | [21] | |
| Compact Super-pixels (CS) | - | Approximation of distance between pixels and further optimization with graph cut methods | Euclidean | 3D images | ✘ | 2010 | [22] |
| Compact Intensity Super-pixels | - | Same as CS, With added color constant information. | Euclidean | 3D images | ✘ | 2010 | [22] |
| SLIC | Gradient optimization after every iteration | Euclidean | Berkeley Dataset | ✘ | 2012 | [11] | |
| SEEDS | - | Energy optimization for super-pixel is based on hill-climbing. | Euclidean | Berkeley Dataset | ✘ | 2012 | [23] |
| Structure Sensitive Super-pixels | Super-pixel densities are checked, and energy minimization is conformed. | Geodesic | Berkeley Dataset | ✘ | 2013 | [16] | |
| Depth-adaptive super-pixels | Super-pixel density identification, followed by sampling and finally k-means to create final clusters | Euclidean | RGB-D dataset consisting of 11 images | ✘ | 2013 | [24] | |
| Contour Relaxed Super-pixels | Uses pre-segmentation technique to create homogeneity constraint | Not mentioned | Not mentioned | ✘ | 2013 | [25] | |
| Saliency-based super-pixel | Super-pixel creation followed by merging operator based on saliency. | Euclidean | Not mentioned | ✘ | 2014 | [26] | |
| Linear Spectral Clustering | Two-fold pixel manipulation strategy of optimization based on graph and clustering based algorithms. | Euclidean | Berkeley Dataset | ✘ | 2015 | [27] | |
| Manifold SLIC | Same as SLIC but with mapping over manifold. | Euclidean | Berkeley Dataset (Random) | ✘ | 2016 | [15] | |
| BASS (Boundary-Aware Super-pixel Segmentation) | Extension of SLIC initially creates boundary then uses SLIC with different distance measures, along with optimization of initialization parameters. | Euclidean + Geodesic | Fashionista, Berkeley Segmentation Dataset (BSD), HorseSeg, DogSeg, MSRA Salient Object Database, Complex Scene Saliency Dataset (CSSD) and Extended CSSD (ECSSD) | ✓ | 2016 | [28] | |
| BSLIC | Extension of SLIC initializes seed within a hexagonal space rather than square | Euclidean | Berkeley Dataset | ✘ | 2017 | [29] | |
| Intrinsic Manifold SLIC | Extension of Manifold SLIC with geodesic distance measure | Geodesic | Berkeley Dataset (Random) | ✘ | 2017 | [30] | |
| Similarity Ratio based Super-pixels | Extension of SLIC. Proposes automatic scaling of coordinate axes. | Mahanlanobis | SAR Image dataset | ✓ | 2017 | [31] | |
| Scalable SLIC | Optimized initialization parameters such as ‘n’ number of super-pixels, focused research to parallelization of sequential implementation. | Euclidean | cyrosection Visible Human Male dataset | ✘ | 2018 | [32] | |
| Content adaptive super-pixel segmentation | Work on prior transformation of image with highlighted edges created by edge filters | Euclidean (with graph-based transformation) | Berkeley Dataset | ✘ | 2019 | [33] | |
| BASS (Bayesian Adaptive Super-Pixel Segmentation) | Uses probabilistic methods to intelligently initialize the super-pixel seeds. | Euclidean | Berkeley Dataset | ✘ | 2019 | [34] | |
| Super-pixel segmentation with fully convolutional networks | Attempts to use neural networks for automatic seed initialization over grid. | Euclidean | Berkeley Dataset, SceneFlow Dataset | ✘ | 2020 | [35] | |
| Texture-aware and structure preserving Super-pixels | The seed initialization takes place in circular grid. | Three different distance measure (without explicit details) | Berkeley Dataset | ✘ | 2021 | [36] | |
| Efficient Image-Warping Framework for Content-Adaptive Super-pixels Generation | Warping transform is used along with SLIC for creation of adaptive super-pixels. | Euclidean | Berkeley Dataset | ✘ | 2021 | [37] | |
| Edge aware super-pixel segmentation with unsupervised CNN | Edges are detected using unsupervised convolutional neural networks then passed to super-pixel segmentation algorithms | Entropy based clustering | Berkeley Dataset | ✘ | 2021 | [38] |
| Row | Ratio | (Euclidean) | (Geodesic) | Precision | Recall | Score |
|---|---|---|---|---|---|---|
| Test Case 1 (Image ID = 14037): | ||||||
| 1 | 10:90 | 0.1123 | 0.8877 | 0.47882 | 0.88930 | 0.62248 |
| 2 | 70:30 | 0.6825 | 0.3175 | 0.38850 | 0.92210 | 0.54660 |
| 3 | 50:50 | 0.4863 | 0.5137 | 0.37780 | 0.93040 | 0.53740 |
| 4 | 30:70 | 0.3175 | 0.6825 | 0.48854 | 0.89124 | 0.63113 |
| 5 | 90:10 | 0.8877 | 0.1123 | 0.38840 | 0.87340 | 0.53770 |
| Test Case 2 (Image ID = 26031): | ||||||
| 6 | 10:90 | 0.1123 | 0.8877 | 0.21623 | 0.78808 | 0.33935 |
| 7 | 70:30 | 0.6825 | 0.3175 | 0.18370 | 0.82790 | 0.30070 |
| 8 | 50:50 | 0.4863 | 0.5137 | 0.18910 | 0.85000 | 0.31000 |
| 9 | 30:70 | 0.3175 | 0.6825 | 0.22661 | 0.86520 | 0.35920 |
| 10 | 90:10 | 0.8877 | 0.1123 | 0.18650 | 0.79000 | 0.30220 |
| Test Case 3 (Image ID = 108082): | ||||||
| 11 | 10:90 | 0.1123 | 0.8877 | 0.27023 | 0.89832 | 0.41548 |
| 12 | 70:30 | 0.6825 | 0.3175 | 0.21840 | 0.82160 | 0.34510 |
| 13 | 50:50 | 0.4863 | 0.5137 | 0.22640 | 0.86800 | 0.35920 |
| 14 | 30:70 | 0.3175 | 0.6825 | 0.28547 | 0.91629 | 0.43532 |
| 15 | 90:10 | 0.8877 | 0.1123 | 0.22360 | 0.79470 | 0.34900 |
| Row | K | m | n | Parameters | Score | Precision | Recall | Distance Measure | |
|---|---|---|---|---|---|---|---|---|---|
| Test Case 1 (Image ID = 14037): | |||||||||
| 1 | 500 | 10 | 10 | 0.54430 | 0.39120 | 0.89390 | Euclidean—SLIC | ||
| 2 | 500 | 10 | 10 | 0.61234 | 0.46563 | 0.89406 | Chessboard—SLIC+ | ||
| 3 | 500 | 10 | 10 | 0.59713 | 0.44407 | 0.91118 | Cosine—SLIC+ | ||
| 4 | 500 | 10 | 10 | 0.62792 | 0.47345 | 0.93199 | Min4—SLIC+ | ||
| 5 | 500 | 10 | 10 | 0.56128 | 0.43777 | 0.78186 | Geodesic—SLIC+ | ||
| 6 | 500 | 10 | 10 | 0.63113 | 0.48854 | 0.89124 | Euclidean Geodesic—SLIC++ | ||
| Test Case 2 (Image ID = 26031): | |||||||||
| 7 | 500 | 10 | 10 | 0.30420 | 0.18690 | 0.81740 | Euclidean—SLIC | ||
| 8 | 500 | 10 | 10 | 0.35454 | 0.22098 | 0.89623 | Chessboard—SLIC+ | ||
| 9 | 500 | 10 | 10 | 0.35698 | 0.22329 | 0.88957 | Cosine—SLIC+ | ||
| 10 | 500 | 10 | 10 | 0.34057 | 0.20959 | 0.90798 | Min4—SLIC+ | ||
| 11 | 500 | 10 | 10 | 0.33715 | 0.21369 | 0.79842 | Geodesic—SLIC+ | ||
| 12 | 500 | 10 | 10 | 0.3592 | 0.22661 | 0.86525 | Euclidean Geodesic—SLIC++ | ||
| Test Case 3 (Image ID = 108082): | |||||||||
| 13 | 500 | 10 | 10 | 0.35410 | 0.22720 | 0.80260 | Euclidean—SLIC | ||
| 14 | 500 | 10 | 10 | 0.42099 | 0.27720 | 0.87476 | Chessboard—SLIC+ | ||
| 15 | 500 | 10 | 10 | 0.38368 | 0.24251 | 0.91811 | Cosine—SLIC+ | ||
| 16 | 500 | 10 | 10 | 0.42465 | 0.27694 | 0.91004 | Min4—SLIC+ | ||
| 17 | 500 | 10 | 10 | 0.40382 | 0.26764 | 0.82216 | Geodesic—SLIC+ | ||
| 18 | 500 | 10 | 10 | 0.43532 | 0.28547 | 0.91629 | Euclidean Geodesic—SLIC++ | ||
| Algorithm | Score | Precision | Recall |
|---|---|---|---|
| SLIC | 0.47020 | 0.31604 | 0.97719 |
| SLIC++ | 0.54799 | 0.39776 | 0.93470 |
| Meanshift-32 | 0.55705 | 0.57573 | 0.68416 |
| Row ID | Image | Groundtruth Image | Prediction | Prediction Map Compared with Groundtruth |
|---|---|---|---|---|
| Test Case 1: | ||||
| 1 |  |  |  |  |
| 2 |  |  |  |  |
| 3 |  |  |  |  |
| Test Case 2: | ||||
| 4 |  |  |  |  |
| 5 |  |  |  |  |
| 6 |  |  |  |  |
| Test Case 3: | ||||
| 7 |  |  |  |  |
| 8 |  |  |  |  |
| 9 |  |  |  |  |
| Number of Super-Pixels/Algorithm | 500 | 1000 | 1500 | 2000 |
|---|---|---|---|---|
| SLIC |  |  |  |  |
| SLIC++ |  |  |  |  |
| Bandwidth/ Meanshift | 16 | 32 | ||
 |  | |||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hashmani, M.A.; Memon, M.M.; Raza, K.; Adil, S.H.; Rizvi, S.S.; Umair, M. Content-Aware SLIC Super-Pixels for Semi-Dark Images (SLIC++). Sensors 2022, 22, 906. https://doi.org/10.3390/s22030906
Hashmani MA, Memon MM, Raza K, Adil SH, Rizvi SS, Umair M. Content-Aware SLIC Super-Pixels for Semi-Dark Images (SLIC++). Sensors. 2022; 22(3):906. https://doi.org/10.3390/s22030906
Chicago/Turabian StyleHashmani, Manzoor Ahmed, Mehak Maqbool Memon, Kamran Raza, Syed Hasan Adil, Syed Sajjad Rizvi, and Muhammad Umair. 2022. "Content-Aware SLIC Super-Pixels for Semi-Dark Images (SLIC++)" Sensors 22, no. 3: 906. https://doi.org/10.3390/s22030906
APA StyleHashmani, M. A., Memon, M. M., Raza, K., Adil, S. H., Rizvi, S. S., & Umair, M. (2022). Content-Aware SLIC Super-Pixels for Semi-Dark Images (SLIC++). Sensors, 22(3), 906. https://doi.org/10.3390/s22030906