
A Robust Fire Detection Model via Convolution Neural Networks for Intelligent Robot Vision Sensing



Abstract
:1. Introduction
- (1)
- The K-mean++ algorithm is proposed to optimize anchor box clustering and significantly reduce the rate of error of the classification results.
- (2)
- Dynamic convolution is introduced in the convolution layer of YOLOv5 based on the determination of the candidate region box by K-means++.
- (3)
- The network heads of YOLOv5’s neck and head are pruned to improve detection speed and further achieve the objective of real-time detection while ensuring accuracy.
2. Related Work
2.1. Conventional Image-Based Methods
2.2. Deep-Learning-Based Methods
3. Proposed Method
3.1. Determination of Anchor Box Based on K-Means++
- (1)
- A sample is randomly selected as the first clustering center.
- (2)
- The distance between each sample and the nearest cluster center is calculated, and Equation (1) is used to calculate the probability of each sample being selected as the next cluster center:
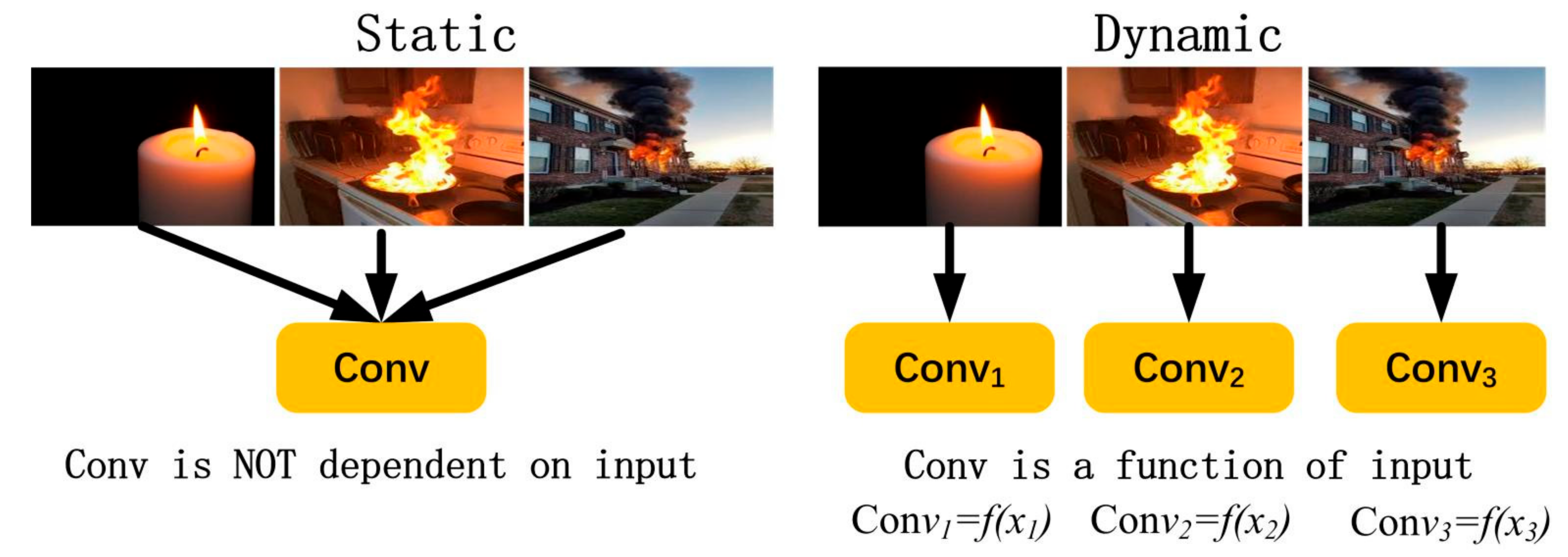
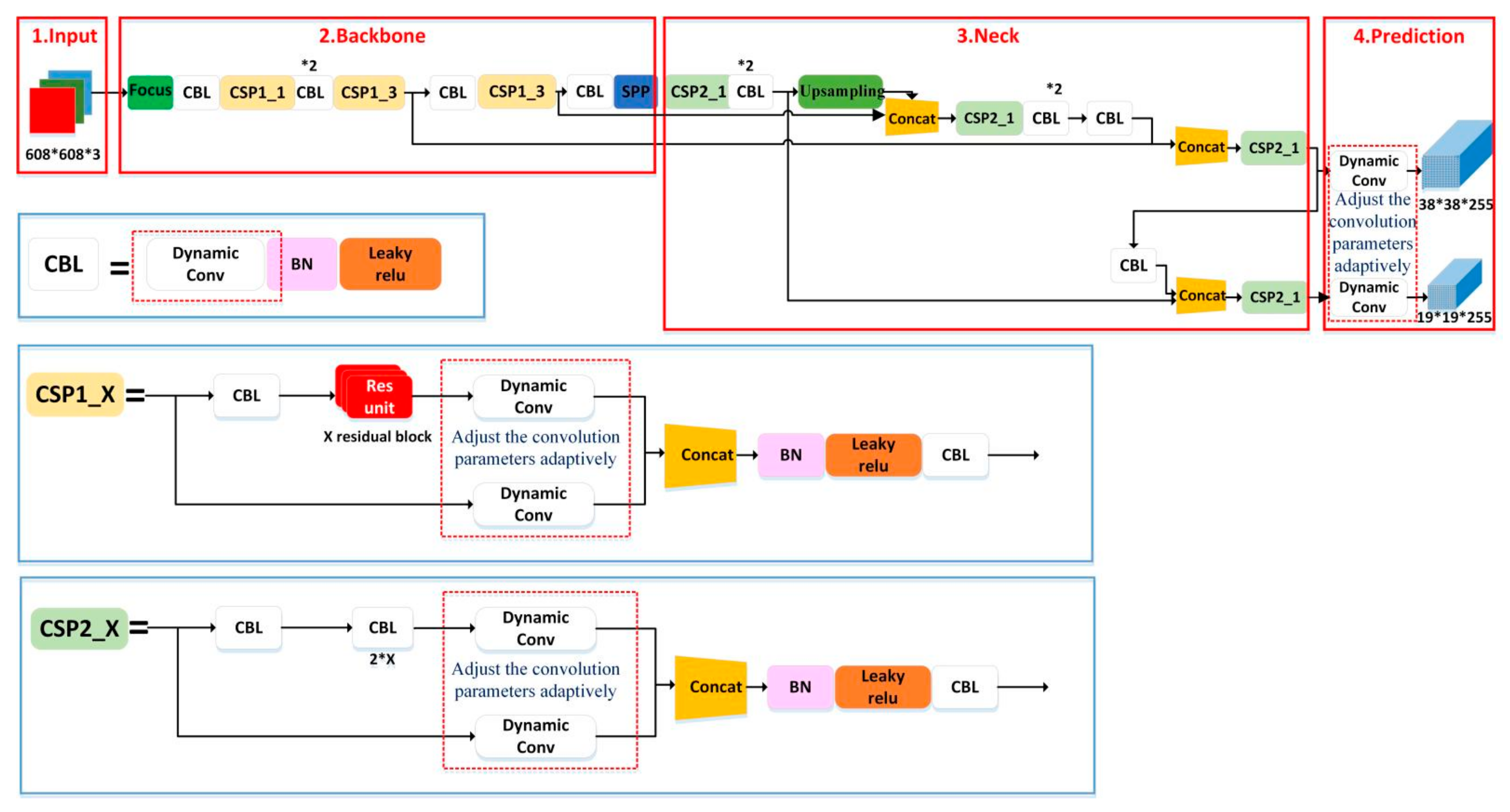
3.2. Dynamic Convolution YOLOv5
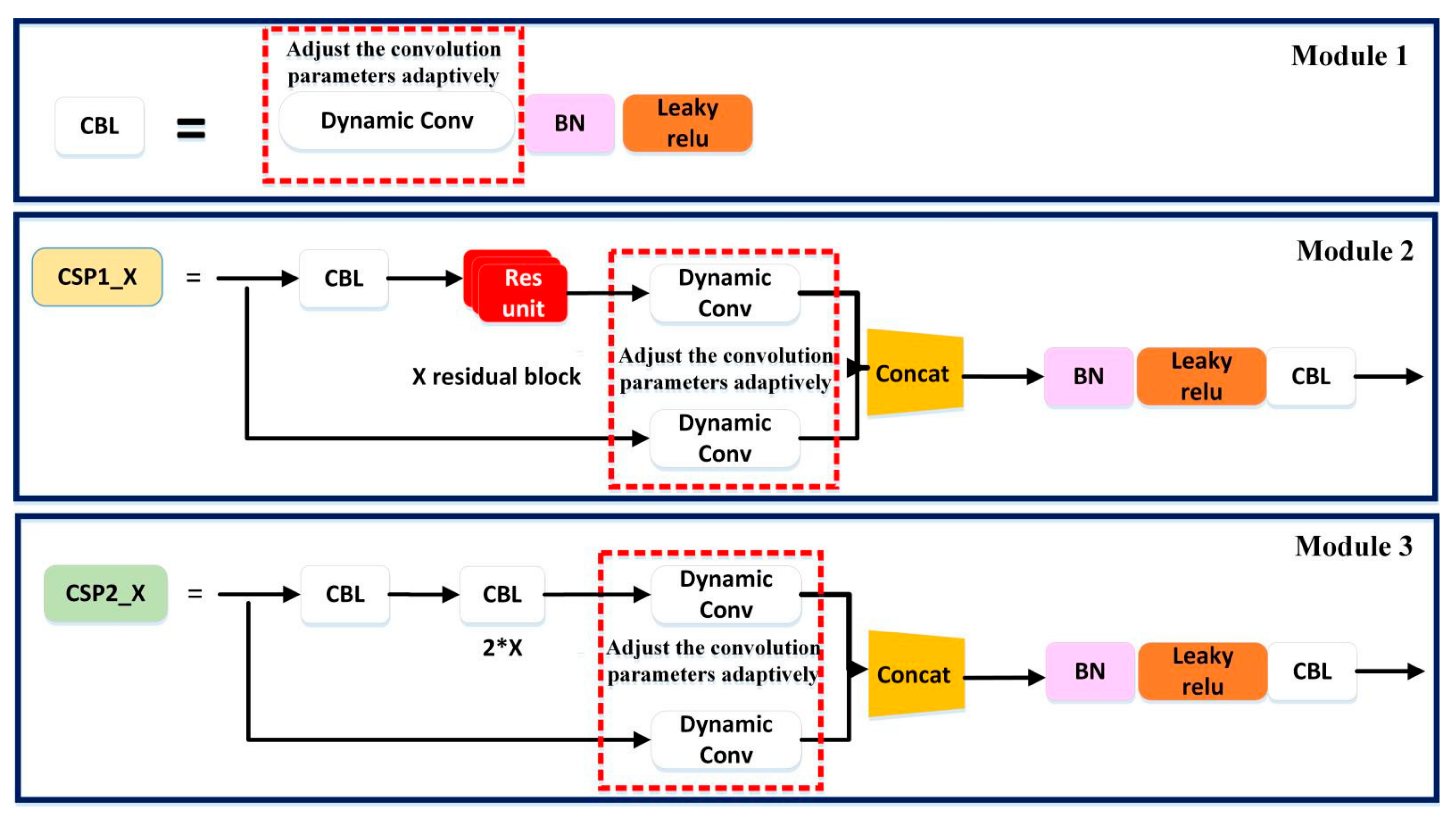
- (1)
- Module 1 is the CBL module, which is the smallest component in the YOLOv5 network structure. The CBL module consists of the Conv + BN + Leaky_relu activation functions, which are replaced by the Dynamic Conv + BN + Leaky_relu activation functions, as shown in Module 1 of Figure 2. The role of the CBL module is that it uses the activation function for convolution.
- (2)
- Module 2 is the CSP1_X module. It is used in the backbone network, which can increase the residual structure, thus increasing the gradient value of backpropagation between layers. Thus, the loss of gradient due to deepening is avoided, and finer-grained features can be extracted. The CSP1_X module consists of a CBL module, a RES unint module, a Conv and a Concat module, which are replaced by a CBLmodule, a Res unint module and a dynamic Conv and Concat, as shown in Module 2 of Figure 2.
- (3)
- Module 3 is the CSP2_X module. It is located in the neck layer of the network structure. It consists of Conv and X Res unint modules and Concat, which are replaced by dynamic Conv and X Res unint modules and Concat, as shown in Module 3 of Figure 2.
3.3. Optimization of Network Structure Based on Structure Pruning
4. Results and Discussion
4.1. Experimental Setup
- (1)
- Experiment details: The experimental hardware is a server equipped with an Intel (R) Celeron (R) CPU N2840 @ 2.16 GHz, 4.00 GB RAM, and a 1080Ti graphics card that has 4 GB on-chip memory. The improved YOLOV5 network model is trained on the Pytorch deep learning framework.
- (2)
- Datasets: the experimental dataset consists of three parts, namely a training, a verification and a test dataset, as shown in Table 1.
4.2. Evaluation Metrics
4.3. Ablation Experiments
4.3.1. Dynamic Convolution Ablation Experiment
4.3.2. Pruning Experiment
4.4. Performance Comparison
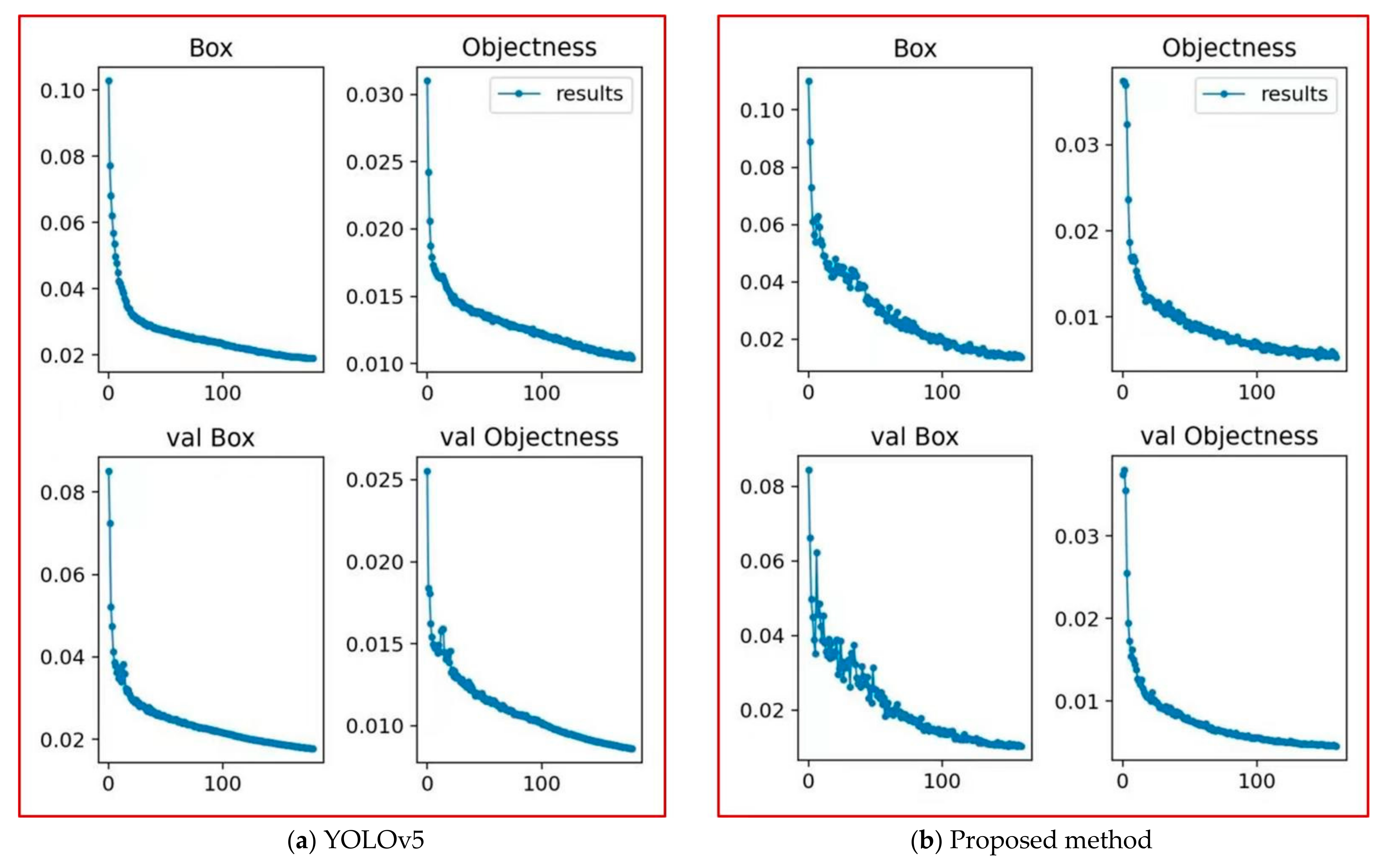
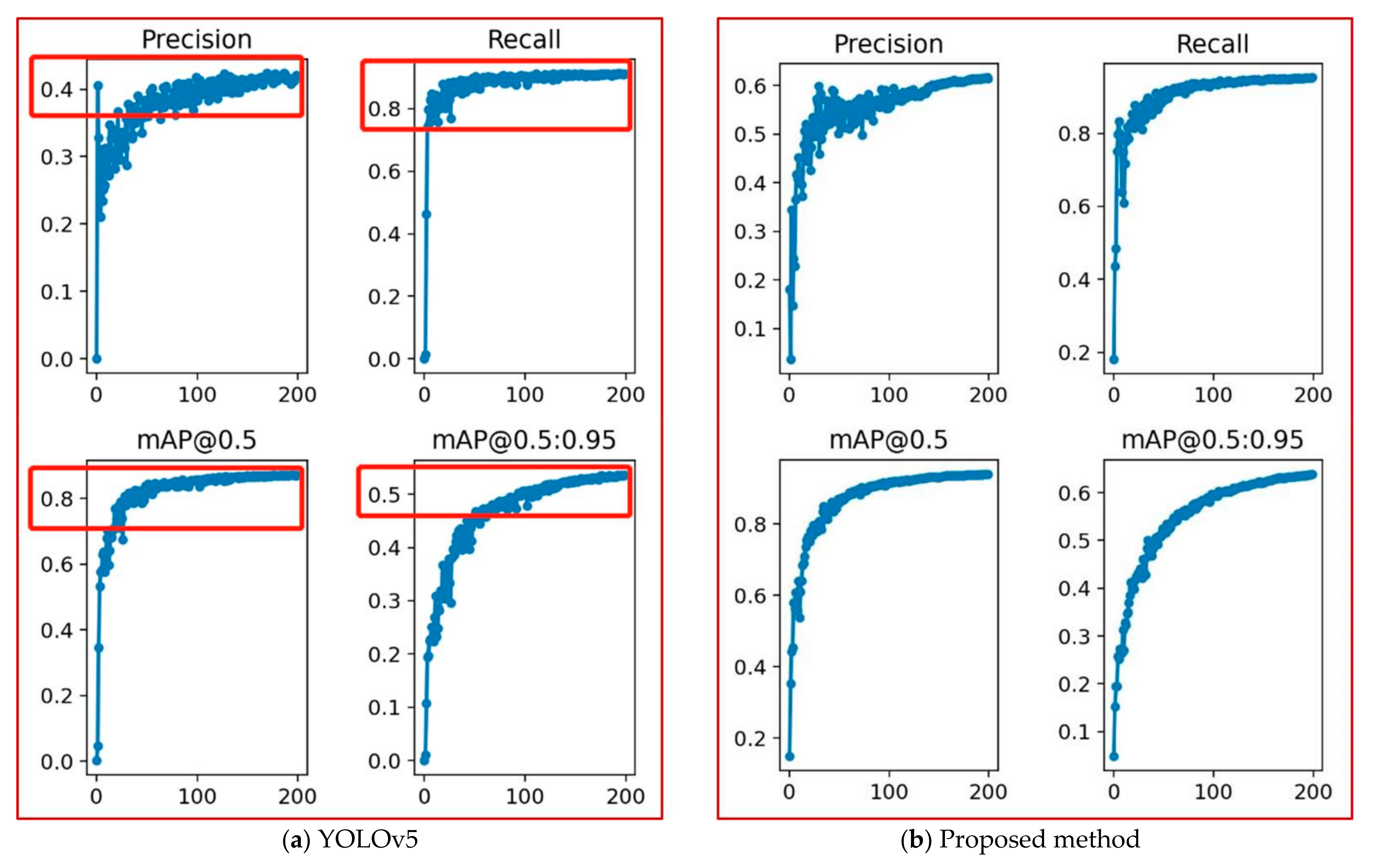
4.4.1. Comparison of Training Results
4.4.2. Comparison in Different Scenarios Based on the Visualization
- (1)
- Comparison of Different Methods in Outdoor and Indoor Scenarios
- (2)
- Comparison of Different Methods for Different Distances
- (3)
- Comparison of Different Methods in the Field of Multi-Objective Detection
- (4)
- Comparison of Different Methods in Different Weather Conditions
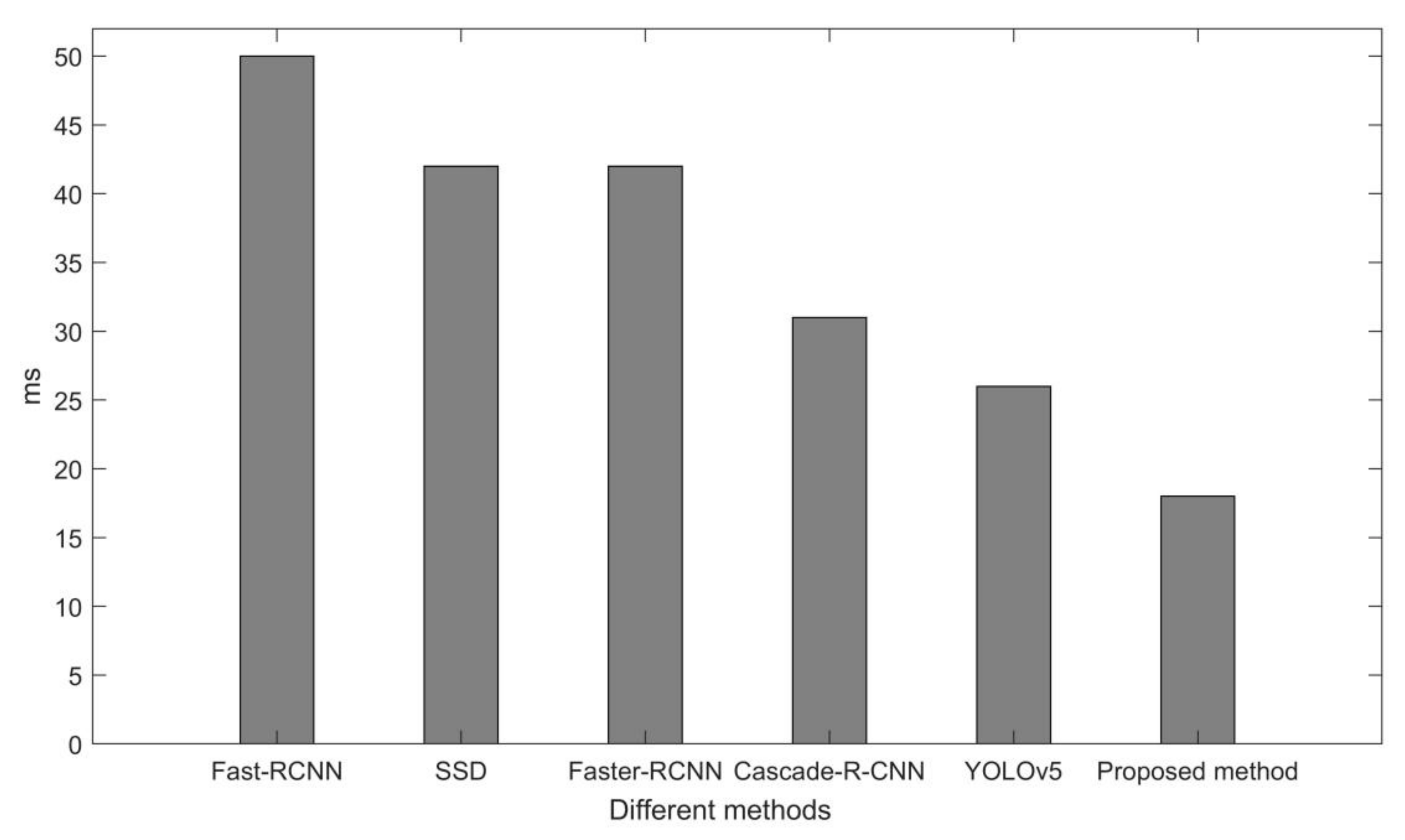
4.4.3. Comparison of Different Methods Based on Quantitative Evaluation
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Liu, H.; Liu, T.; Zhang, Z.; Sangaiah, A.K.; Yang, B.; Li, Y. ARHPE: Asymmetric Relation-Aware Representation Learning for Head Pose Estimation in Industrial Human-Computer Interaction. IEEE Trans. Ind. Inf. 2022, 32, 1–12. [Google Scholar] [CrossRef]
- Kim, J. Obstacle information aided target tracking algorithms for angle-only tracking of a highly maneuverable target in three dimensions. IET Radar Sonar Navig. 2019, 13, 1074–1080. [Google Scholar] [CrossRef]
- An, Q.; Chen, X.; Wang, H.; Yang, H.; Yang, Y. Segmentation of concrete cracks by using fractal dimension and UHK-net. Fractal Fract. 2022, 6, 95. [Google Scholar] [CrossRef]
- Kumar, M.; Jindal, S.R. Fusion of RGB and HSV colour space for foggy image quality enhancement. Multimed. Tools Appl. 2019, 78, 9791–9799. [Google Scholar] [CrossRef]
- Zhang, Y.; Dong, Z.; Zhang, K.; Shu, S.; Lu, F.; Chen, J. Illumination variation-resistant video-based heart rate monitoring using LAB color space. Opt. Lasers Eng. 2021, 136, 1–18. [Google Scholar] [CrossRef]
- Gao, G.; Lai, H.; Liu, Y.; Wang, L.; Jia, Z. Sandstorm image enhancement based on YUV space. Optik 2021, 226, 1–17. [Google Scholar] [CrossRef]
- Abbadi, E.L.; Saleem, E. Gray Image Colorization Based on General Singular Value Decomposition and YCbCr Color Space. Kuwait J. Sci. 2019, 46, 47–57. [Google Scholar]
- Luo, Y.; Zhao, L.; Liu, P.; Huang, D. Fire smoke detection algorithm based on motion characteristic and convolutional neural networks. Multimed. Tools Appl. 2018, 77, 15075–15092. [Google Scholar] [CrossRef]
- Pan, H.; Badawi, D.; Zhang, X.; Cetin, A.E. Additive neural network for forest fire detection. Signal Image Video Process. 2019, 14, 675–682. [Google Scholar] [CrossRef]
- Liu, H.; Fang, S.; Zhang, Z.; Li, D.; Lin, K.; Wang, J. MFDNet: Collaborative Poses Perception and Matrix Fisher Distribution for Head Pose Estimation. IEEE Trans. Multimed. 2022, 24, 1–13. [Google Scholar] [CrossRef]
- Liu, H.; Zheng, C.; Li, D.; Shen, X.; Lin, K.; Wang, J.; Zhang, Z.; Zhang, Z.; Xiong, N.N. EDMF: Efficient Deep Matrix Factorization with Review Feature Learning for Industrial Recommender System. IEEE Trans. Ind. Inf. 2022, 1–11. [Google Scholar] [CrossRef]
- Son, G.Y.; Park, J.S. A Study of Kernel Characteristics of CNN Deep Learning for Effective Fire Detection Based on Video. J. Korea Inst. Electron. Commun. Sci. 2018, 13, 1257–1262. [Google Scholar]
- Park, M.; Ko, B.C. Two-step real-time night-time fire detection in an urban environment using Static ELASTIC-YOLOv3 and Temporal Fire-Tube. Sensors 2020, 20, 2202. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, H.; Zheng, C.; Li, D.; Zhang, Z.; Lin, K.; Shen, X.; Xiong, N.N.; Wang, J. Multi-perspective social recommendation method with graph representation learning. Neurocomputing 2022, 468, 469–481. [Google Scholar] [CrossRef]
- Li, Z.; Liu, H.; Zhang, Z.; Liu, T.; Xiong, N. Learning Knowledge Graph Embedding with Heterogeneous Relation Attention Networks. IEEE Trans. Neural Netw. Learn. Syst. 2022, 17, 1–13. [Google Scholar] [CrossRef]
- Liu, H.; Nie, H.; Zhang, Z.; Li, Y.-F. Anisotropic angle distribution learning for head pose estimation and attention understanding in human-computer interaction. Neurocomputing 2021, 433, 310–322. [Google Scholar] [CrossRef]
- Liu, T.; Liu, H.; Li, Y.; Chen, Z.; Zhang, Z.; Liu, S. Flexible FTIR Spectral Imaging Enhancement for Industrial Robot Infrared Vision Sensing. IEEE Trans. Ind. Inf. 2020, 16, 544–554. [Google Scholar] [CrossRef]
- Gomes, P.; Santana, P.; Barata, J. A Vision-Based Approach to Fire Detection. Int. J. Adv. Robot. Syst. 2014, 11, 149. [Google Scholar] [CrossRef]
- Calderara, S.; Piccinini, P.; Cucchiara, R. Vision based smoke detection system using image energy and color information. Mach. Vis. Appl. 2011, 22, 705–719. [Google Scholar] [CrossRef]
- Yuan, F. A double mapping framework for extraction of shape-invariant features based on multi-scale partitions with AdaBoost for video smoke detection. Pattern Recognit. 2012, 45, 4326–4336. [Google Scholar] [CrossRef]
- Appana, D.K.; Islam, M.R.; Kim, J.M. A video-based smoke detection using smoke flow pattern and spatial-temporal energy analyses for alarm systems. Inf. Sci. 2017, 418–419, 91–101. [Google Scholar] [CrossRef]
- Xuehui, W.; Xiaobo, L.; Leung, H. A video based fire smoke detection using Robust AdaBoost. Sensors 2018, 8, 1–22. [Google Scholar]
- Zhao, Y.; Zhou, Z.; Xu, M. Forest fire smoke detection using spatiotemporal and dynamic texture features. J. Electr. Comput. Eng. 2015, 2015, 706187. [Google Scholar] [CrossRef] [Green Version]
- Ye, W.; Zhao, J.; Wang, S.; Wang, Y.; Zhang, D.; Yuan, Z. Dynamic texture based smoke detection using surfacelet transform and HMT model. Fire Saf. J. 2015, 73, 91–101. [Google Scholar] [CrossRef]
- Ye, S.; Bai, Z.; Chen, H.; Bohush, R.; Ablameyko, S. An effective algorithm to detect both smoke and flame using color and wavelet analysis. Pattern Recognit. Image Anal. 2017, 27, 131–138. [Google Scholar] [CrossRef]
- Islam, M.R.; Amiruzzaman, M.; Nasim, S.; Shin, J. Smoke Object Segmentation and the Dynamic Growth Feature Model for Video-Based Smoke Detection Systems. Symmetry 2020, 12, 1075. [Google Scholar] [CrossRef]
- Foggia, P.; Saggese, A.; Vento, M. Real-time fire detection for video-surveillance applications using a combination of experts based on color, shape, and motion. IEEE Trans. Circuits Syst Video Technol. 2015, 25, 1545–1556. [Google Scholar] [CrossRef]
- Premal, C.E.; Vinsley, S. Image processing based forest fire detection using ycbcr color model. In Proceedings of the 2014 International Conference on Circuits, Power and Computing Technologies (ICCPCT), Nagercoil, India, 20–21 March 2014; pp. 1229–1237. [Google Scholar]
- Prema, C.E.; Vinsley, S.; Suresh, S. Efficient flame detection based on static and dynamic texture analysis in forest fifire detection. Fire Technol. 2018, 54, 255–288. [Google Scholar] [CrossRef]
- Han, X.F.; Jin, J.S.; Wang, M.J.; Jiang, W.; Gao, L.; Xiao, L.P. Video fire detection based on Gaussian mixture model and multi-color features. Signal Image Video Process. 2017, 11, 1419–1425. [Google Scholar] [CrossRef]
- Khalil, A.; Rahman, S.U.; Alam, F.; Ahmad, I.; Khalil, I. Fire Detection Using Multi Color Space and Background Modeling. Fire Technol. 2020, 57, 1221–1239. [Google Scholar] [CrossRef]
- Zhao, Y.; Ma, J.; Li, X.; Zhang, J. Saliency detection and deep learning-based wildfire identification in UAV imagery. Sensors 2018, 18, 712. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, Q.; Xu, J.; Xu, L.; Guo, H. Deep convolutional neural networks for forest fire detection. In Proceedings of the 2016 International Forum on Management, Education and Information Technology Application, Guangzhou, China, 30–31 January 2016; Atlantis Press: Paris, France, 2016. [Google Scholar]
- Maksymiv, O.; Rak, T.; Peleshko, D. Real-time fire detection method combining AdaBoost, LBP and convolutional neural network in video sequence. In Proceedings of the 2017 14th International Conference the Experience of Designing and Application of CAD Systems in Microelectronics (CADSM), Lviv, Ukraine, 21–25 February 2017; pp. 351–353. [Google Scholar]
- Muhammad, K.; Ahmad, J.; Mehmood, I.; Rho, S.; Baik, S.W. Convolutional neural networks based fire detection in surveillance videos. IEEE Access. 2018, 6, 18174–18183. [Google Scholar] [CrossRef]
- Mao, W.; Wang, W.; Dou, Z.; Li, Y. Fire recognition based on multi-channel convolutional neural network. Fire Technol. 2018, 54, 531–554. [Google Scholar] [CrossRef]
- Muhammad, K.; Ahmad, J.; Baik, S.W. Early fire detection using convolutional neural networks during surveillance for effective disaster management. Neurocomputing 2018, 288, 30–42. [Google Scholar] [CrossRef]
- Dunnings, A.J.; Breckon, T.P. Experimentally defined convolutional neural network architecture variants for non-temporal real-time fire detection. In Proceedings of the 2018 25th IEEE International conference on image processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 1558–1562. [Google Scholar]
- Jadon, A.; Omama, M.; Varshney, A.; Ansari, M.S.; Sharma, R. Firenet: A specialized lightweight fire & smoke detection model for real-time IoT applications. arXiv 2019, arXiv:1905.11922. [Google Scholar]
- Saeed, F.; Paul, A.; Gaikumar, P.; Nayyar, A. Convolutional neural network based early fire detection. Multimed. Tools Appl. 2019, 79, 9083–9099. [Google Scholar] [CrossRef]
- Muhammad, K.; Khan, S.; Elhoseny, M.; Ahmed, S.H.; Baik, S.W. Efficient fire detection for uncertain surveillance environment. IEEE Trans. Ind Inf. 2019, 15, 3113–3122. [Google Scholar] [CrossRef]
- Zhang, G.; Wang, M.; Liu, K. Forest fire susceptibility modeling using a convolutional neural network for Yunnan province of China. Int J. Disaster Risk Sci. 2019, 10, 386–403. [Google Scholar] [CrossRef] [Green Version]
- Ross, G.; Jeff, D.; Trevor, D.; Jitendra, M. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Li, P.; Zhao, W. Image fire detection algorithms based on convolutional neural networks. Case Stud. Therm. Eng. 2020, 19, 100625. [Google Scholar] [CrossRef]
- Li, S.; Yan, Q.; Liu, P. An efficient fire detection method based on multiscale feature extraction, implicit deep supervision and channel attention mechanism. IEEE Trans. Image Process. 2020, 29, 8467–8475. [Google Scholar] [CrossRef]
- Pan, H.; Badawi, D.; Cetin, A.E. Computationally Efficient Wildfire Detection Method Using a Deep Convolutional Network Pruned via Fourier Analysis. Sensors 2020, 20, 2891. [Google Scholar] [CrossRef] [PubMed]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H. YOLOv4: Optimal Speed and Accuracy of Object Detection [EB/OL]. Available online: https://arxiv.org/abs/2004.10934.pdf (accessed on 23 April 2020).
- Chen, Y.; Dai, X.; Liu, M.; Chen, D.; Yuan, L.; Liu, Z. Dynamic Convolution: Attention Over Convolution Kernels. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11030–11039. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Fire Images | Non-Fire Images | Total |
|---|---|---|---|
| Train set | 8054 | 6046 | 14,100 |
| Validation set | 2033 | 1521 | 3554 |
| Test set | 5150 | 3130 | 8280 |
| Total | 15,237 | 10,697 | 25,934 |
| Negative | Positive | |
|---|---|---|
| False | False Negative (FN) | False Positive (FP) |
| True | True Negative (TN) | True Positive (TP) |
| P | R | Acc | F1-Score | Detection Time (ms) | |
|---|---|---|---|---|---|
| YOLOv5 | 89.7% | 97.4% | 91.5% | 46.7% | 26 |
| Dynamic convolution YOLOv5 | 96.4% | 99% | 96.8% | 49.3% | 29 |
| P | R | Acc | F1-Score | Model Size | Detection Time (ms) | |
|---|---|---|---|---|---|---|
| YOLOv5 | 89.7% | 97.4% | 91.5% | 46.7% | 13.7 | 26 |
| YOLOv5 (after pruning) | 88.2% | 96.6% | 89.7% | 44.3% | 10.8 | 13 |
| Different Methods | TP | TN | FP | FN |
|---|---|---|---|---|
| Fast-RCNN | 4314 | 2290 | 840 | 836 |
| SSD | 4501 | 2391 | 739 | 649 |
| Faster-RCNN | 4972 | 2417 | 713 | 178 |
| Cascade R-CNN | 5003 | 2447 | 683 | 147 |
| YOLOv5 | 5020 | 2554 | 576 | 130 |
| Proposed Method | 5100 | 2873 | 257 | 50 |
| Different Methods | P (%) | R (%) | Acc (%) | F1-Score (%) |
|---|---|---|---|---|
| Fast-RCNN | 83.7 | 83.8 | 79.8 | 41.9 |
| SSD | 85.9 | 87.3 | 83.2 | 43.3 |
| Faster-RCNN | 87.5 | 96.5 | 89.2 | 44.8 |
| Cascade R-CNN | 88.1 | 97.1 | 90.1 | 45.6 |
| YOLOv5 | 89.7 | 97.4 | 91.5 | 46.7 |
| Proposed method | 95.2 | 99 | 96.3 | 48.5 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
An, Q.; Chen, X.; Zhang, J.; Shi, R.; Yang, Y.; Huang, W. A Robust Fire Detection Model via Convolution Neural Networks for Intelligent Robot Vision Sensing. Sensors 2022, 22, 2929. https://doi.org/10.3390/s22082929
An Q, Chen X, Zhang J, Shi R, Yang Y, Huang W. A Robust Fire Detection Model via Convolution Neural Networks for Intelligent Robot Vision Sensing. Sensors. 2022; 22(8):2929. https://doi.org/10.3390/s22082929
Chicago/Turabian StyleAn, Qing, Xijiang Chen, Junqian Zhang, Ruizhe Shi, Yuanjun Yang, and Wei Huang. 2022. "A Robust Fire Detection Model via Convolution Neural Networks for Intelligent Robot Vision Sensing" Sensors 22, no. 8: 2929. https://doi.org/10.3390/s22082929
APA StyleAn, Q., Chen, X., Zhang, J., Shi, R., Yang, Y., & Huang, W. (2022). A Robust Fire Detection Model via Convolution Neural Networks for Intelligent Robot Vision Sensing. Sensors, 22(8), 2929. https://doi.org/10.3390/s22082929