
Machine-Learning Methods for Speech and Handwriting Detection Using Neural Signals: A Review

 , and
, and
Abstract
:1. Introduction
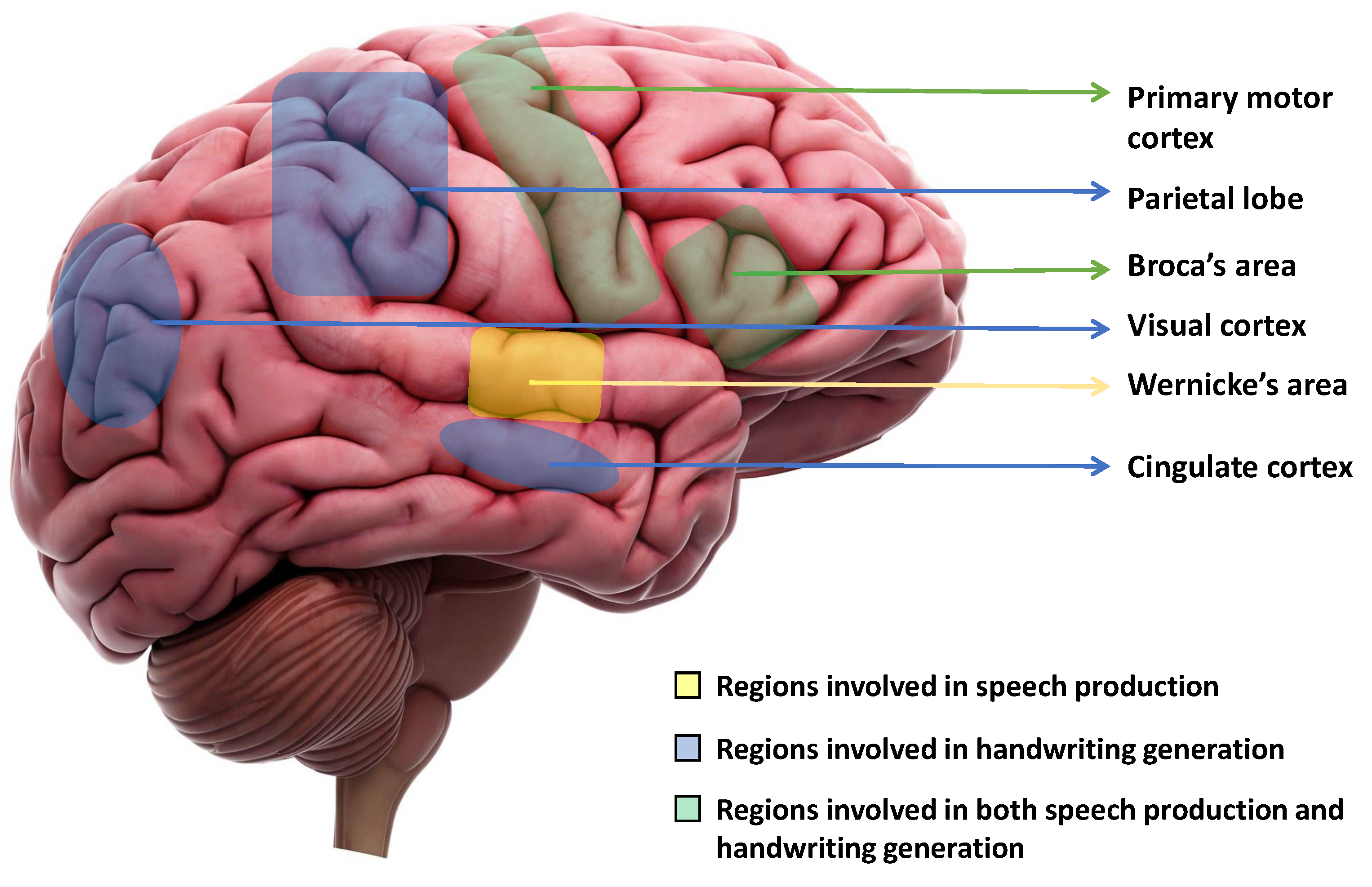
2. Regions of the Brain Responsible for Handwriting and Speech Production
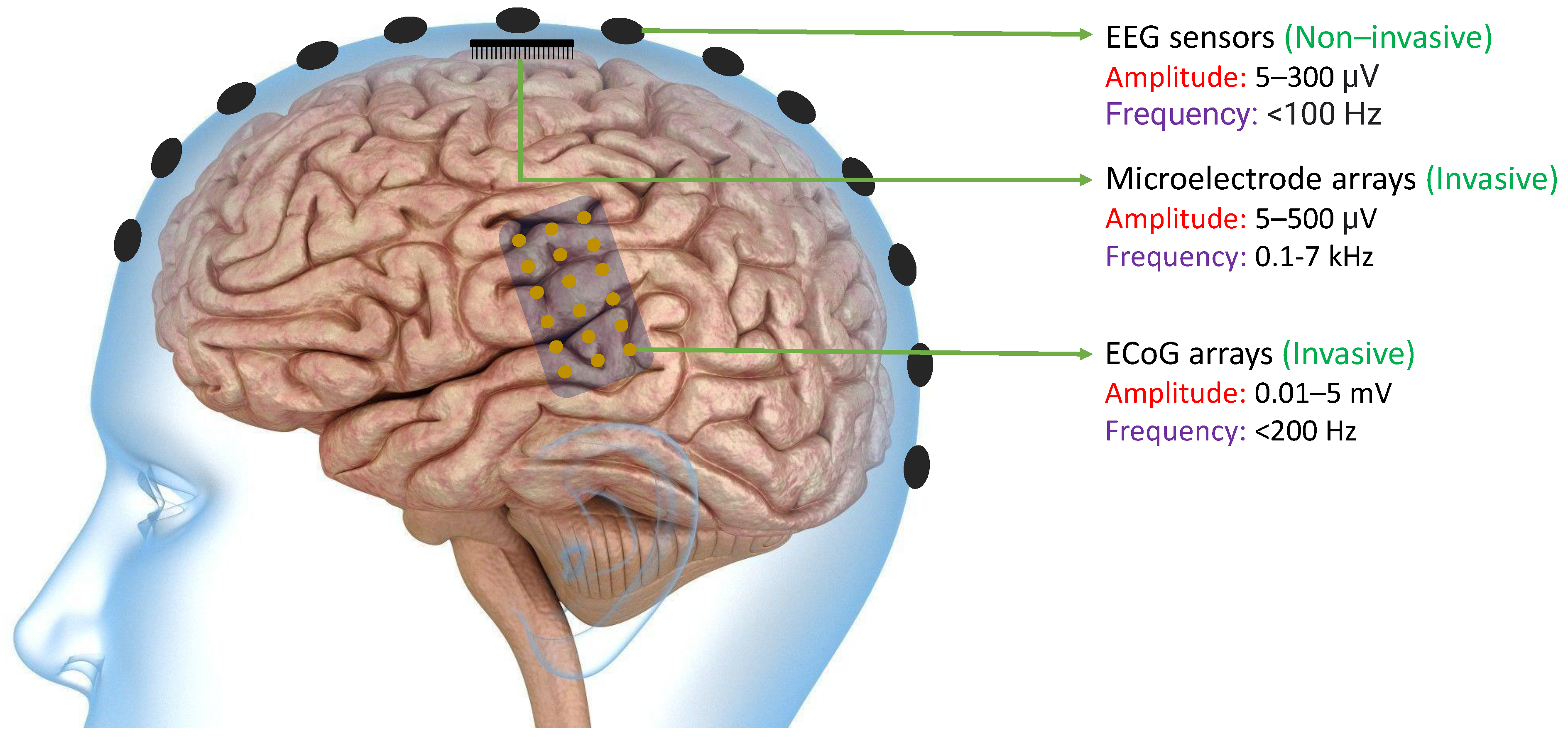
3. Methods of Collecting Data from Brain
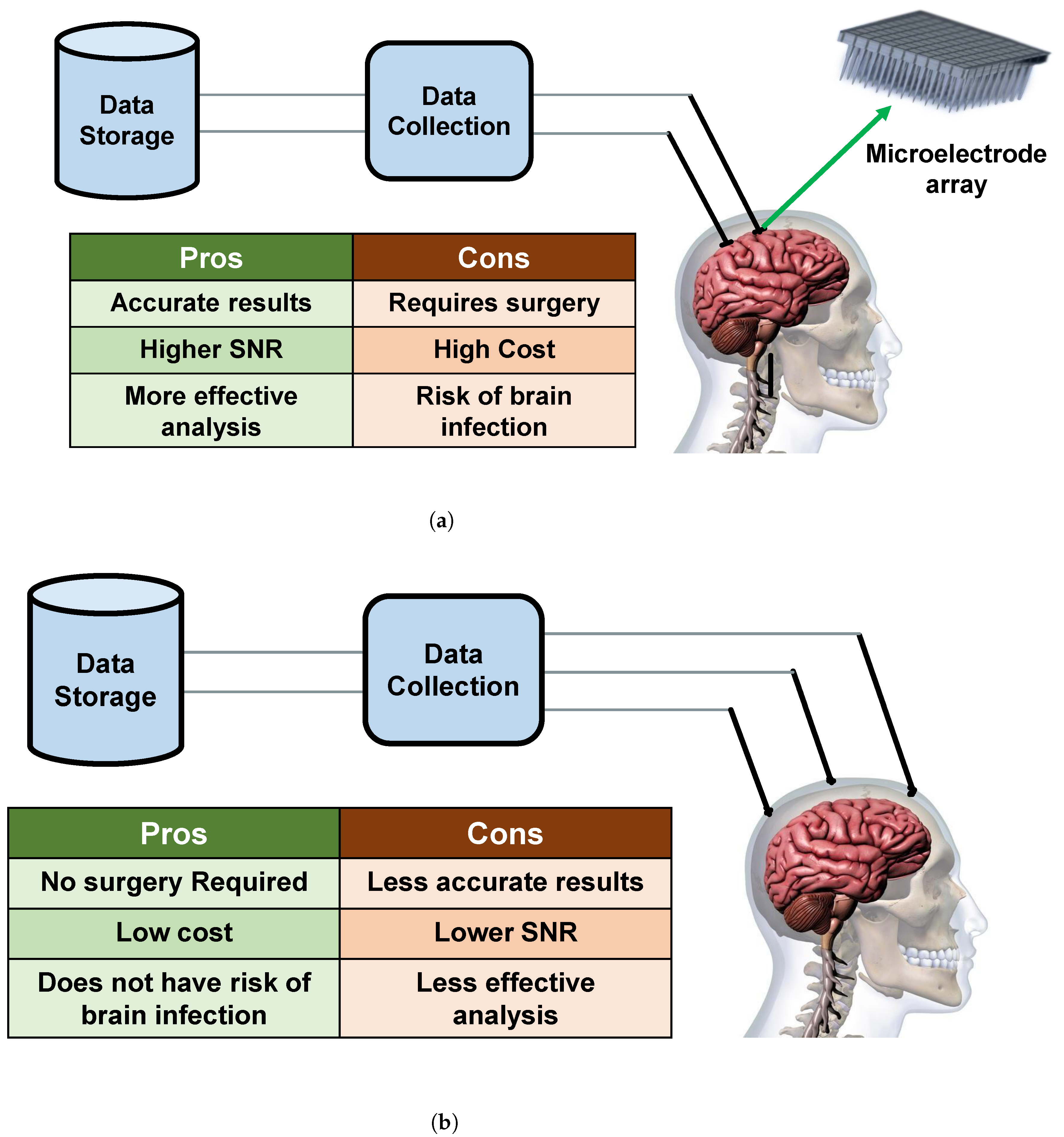
3.1. Invasive Methods
3.2. Non-Invasive Methods
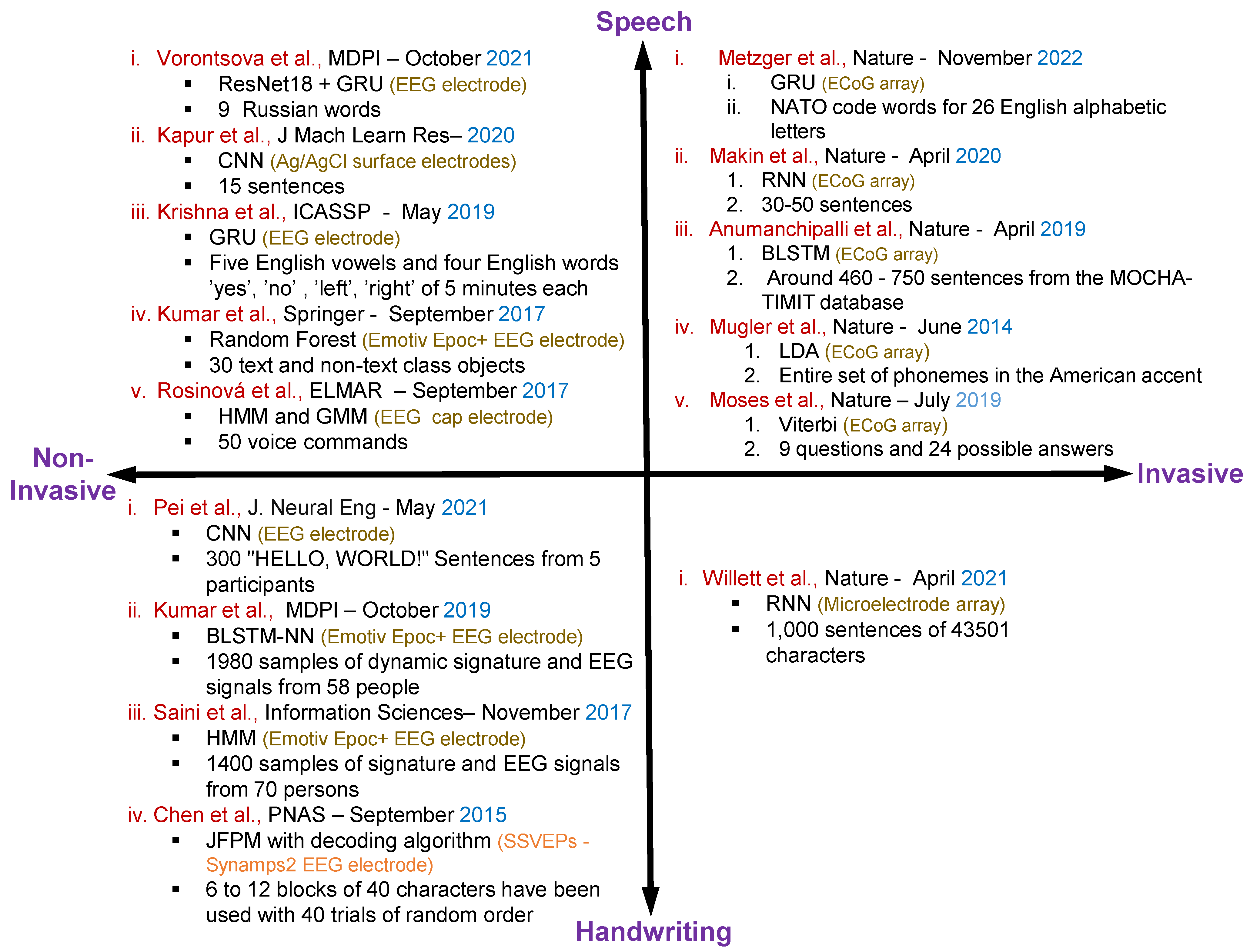
4. Articles Related to Handwriting and Speech Recognition Using Neural Signals
4.1. Speech Recognition Using Non-Invasive Neural Datasets
4.2. Speech Recognition Using Invasive Neural Datasets
4.3. Handwritten Character Recognition Using Non-Invasive Neural Datasets
4.4. Handwritten Character Recognition Using Invasive Neural Datasets
5. General Principle of Using Machine Learning Methods for Neural Signals
5.1. Prepossessing Techniques and Feature Extraction Methods
5.2. Features of the Brain Signals Used in Existing Research
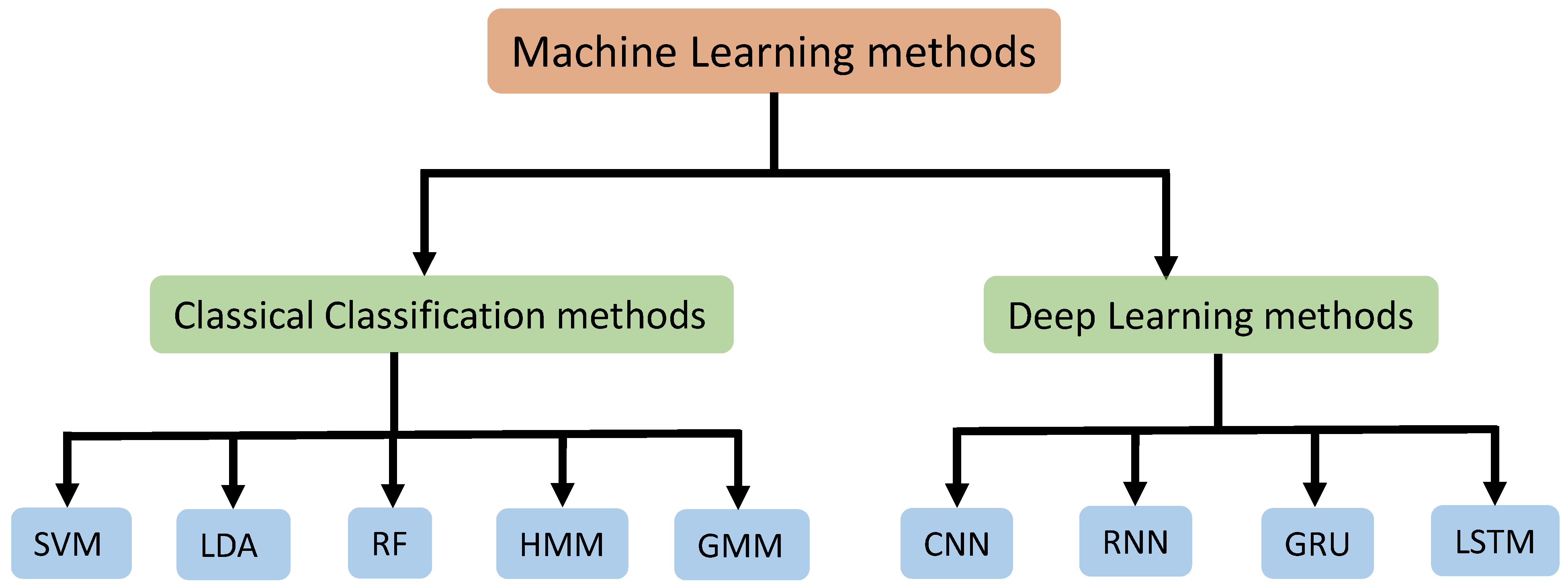
5.3. Machine Learning Methods Used for Training Neural Signals
5.3.1. Classical Classification Methods
5.3.2. Deep Learning Methods
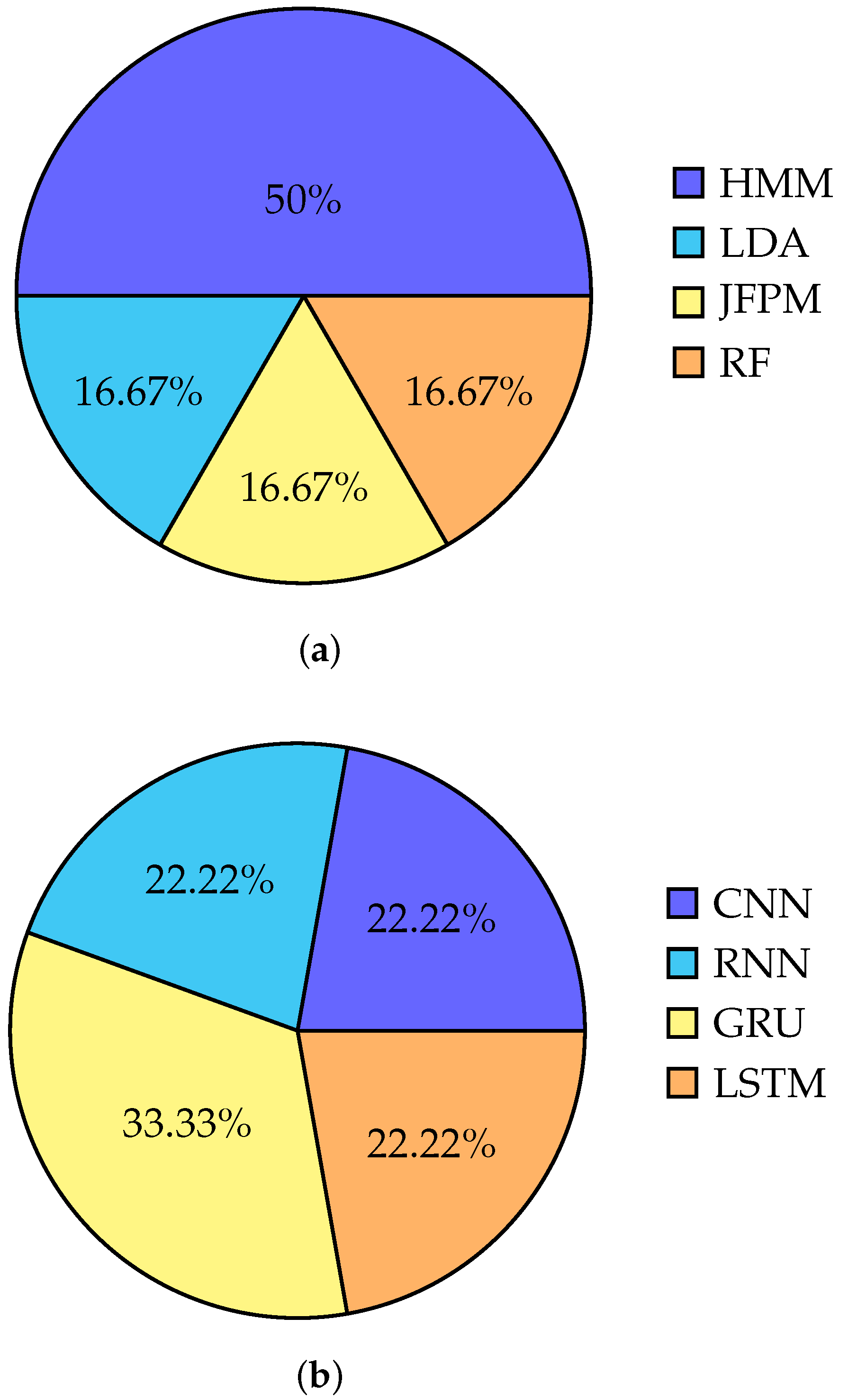
6. Chronological Analysis of Methods Used for Training Neural Signals
7. Discussion
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| MDPI | Multidisciplinary Digital Publishing Institute |
| BCI | Brain–Computer Interface |
| EEG | Electroencephalogram |
| ECoG | Electrocorticogram |
| LFP | Local Field Potential |
| CNN | Convolutional Neural Network |
| RNN | Recurrent Neural Network |
| LSTM | Long Short Term Memory |
| HMM | Hidden Markov Model |
| GMM | Gaussian Mixture Model |
| RF | Random Forest |
| LDA | Linear Discriminant Analysis |
| SSVEPs | Steady State Visual Evoked Potentials |
| GRU | Gated Recurrent Unit |
| BLSTM | Bidirectional Long Short Term Memory |
| ResNet | Residual Networks |
| EMG | Electromyography |
| sEMG | Surface Electromyography |
| IoT | Internet of Things |
| MFCC | Mel-frequency cepstral coefficient |
| BCI | Brain–Computer Interface |
| NATO | North Atlantic Treaty Organization |
| AR | Augmented Reality |
| SNR | Signal to Noise ratio |
| ANN | Artificial Neural Network |
| BMI | Brain Machine Interface |
| VR | Virtual Reality |
References
- Kübler, A.; Furdea, A.; Halder, S.; Hammer, E.M.; Nijboer, F.; Kotchoubey, B. A brain–computer interface controlled auditory event-related potential (P300) spelling system for locked-in patients. Ann. N. Y. Acad. Sci. 2009, 1157, 90–100. [Google Scholar] [CrossRef] [PubMed]
- Vorontsova, D.; Menshikov, I.; Zubov, A.; Orlov, K.; Rikunov, P.; Zvereva, E.; Flitman, L.; Lanikin, A.; Sokolova, A.; Markov, S.; et al. Silent eeg-speech recognition using convolutional and recurrent neural network with 85% accuracy of 9 words classification. Sensors 2021, 21, 6744. [Google Scholar] [CrossRef]
- Santhanam, G.; Ryu, S.I.; Yu, B.M.; Afshar, A.; Shenoy, K.V. A high-performance brain–computer interface. Nature 2006, 442, 195–198. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rusnac, A.L.; Grigore, O. CNN Architectures and Feature Extraction Methods for EEG Imaginary Speech Recognition. Sensors 2022, 22, 4679. [Google Scholar] [CrossRef]
- Herff, C.; Schultz, T. Automatic speech recognition from neural signals: A focused review. Front. Neurosci. 2016, 10, 429. [Google Scholar] [CrossRef] [Green Version]
- Horlings, R.; Datcu, D.; Rothkrantz, L.J. Emotion recognition using brain activity. In Proceedings of the 9th International Conference on Computer Systems and Technologies and Workshop for PhD Students in Computing, Gabrovo, Bulgaria, 12–13 June 2008; p. II-1. [Google Scholar]
- Patil, A.; Deshmukh, C.; Panat, A. Feature extraction of EEG for emotion recognition using Hjorth features and higher order crossings. In Proceedings of the 2016 Conference on Advances in Signal Processing (CASP), Pune, India, 9–11 June 2016; pp. 429–434. [Google Scholar]
- Lotte, F. A tutorial on EEG signal-processing techniques for mental-state recognition in brain–computer interfaces. In Guide to Brain-Computer Music Interfacing; Springer: Berlin/Heidelberg, Germany, 2014; pp. 133–161. [Google Scholar]
- Brigham, K.; Kumar, B.V. Subject identification from electroencephalogram (EEG) signals during imagined speech. In Proceedings of the 2010 Fourth IEEE International Conference on Biometrics: Theory, Applications and Systems (BTAS), Washington, DC, USA, 27–29 September 2010; pp. 1–8. [Google Scholar]
- Mirkovic, B.; Bleichner, M.G.; De Vos, M.; Debener, S. Target speaker detection with concealed EEG around the ear. Front. Neurosci. 2016, 10, 349. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Brumberg, J.S.; Nieto-Castanon, A.; Kennedy, P.R.; Guenther, F.H. Brain–computer interfaces for speech communication. Speech Commun. 2010, 52, 367–379. [Google Scholar] [CrossRef] [Green Version]
- Soman, S.; Murthy, B. Using brain computer interface for synthesized speech communication for the physically disabled. Procedia Comput. Sci. 2015, 46, 292–298. [Google Scholar] [CrossRef] [Green Version]
- Ahn, M.; Lee, M.; Choi, J.; Jun, S.C. A review of brain–computer interface games and an opinion survey from researchers, developers and users. Sensors 2014, 14, 14601–14633. [Google Scholar] [CrossRef] [Green Version]
- Sadeghi, K.; Banerjee, A.; Sohankar, J.; Gupta, S.K. Optimization of brain mobile interface applications using IoT. In Proceedings of the 2016 IEEE 23rd International Conference on High Performance Computing (HiPC), Hyderabad, India, 19–22 December 2016; pp. 32–41. [Google Scholar]
- Eleryan, A.; Vaidya, M.; Southerland, J.; Badreldin, I.S.; Balasubramanian, K.; Fagg, A.H.; Hatsopoulos, N.; Oweiss, K. Tracking single units in chronic, large scale, neural recordings for brain machine interface applications. Front. Neuroeng. 2014, 7, 23. [Google Scholar] [CrossRef] [Green Version]
- Sussillo, D.; Stavisky, S.D.; Kao, J.C.; Ryu, S.I.; Shenoy, K.V. Making brain–machine interfaces robust to future neural variability. Nat. Commun. 2016, 7, 13749. [Google Scholar] [CrossRef] [PubMed]
- Lebedev, M.A.; Nicolelis, M.A. Brain–machine interfaces: Past, present and future. Trends Neurosci. 2006, 29, 536–546. [Google Scholar] [CrossRef] [PubMed]
- Vázquez-Guardado, A.; Yang, Y.; Bandodkar, A.J.; Rogers, J.A. Recent advances in neurotechnologies with broad potential for neuroscience research. Nat. Neurosci. 2020, 23, 1522–1536. [Google Scholar] [CrossRef] [PubMed]
- Illes, J.; Moser, M.A.; McCormick, J.B.; Racine, E.; Blakeslee, S.; Caplan, A.; Hayden, E.C.; Ingram, J.; Lohwater, T.; McKnight, P.; et al. Neurotalk: Improving the communication of neuroscience research. Nat. Rev. Neurosci. 2010, 11, 61–69. [Google Scholar] [CrossRef] [Green Version]
- Koct, M.; Juh, J. Speech Activity Detection from EEG using a feed-forward neural network. In Proceedings of the 2019 10th IEEE International Conference on Cognitive Infocommunications (CogInfoCom), Naples, Italy, 23–25 October 2019; pp. 147–152. [Google Scholar]
- Koctúrová, M.; Juhár, J. A Novel approach to EEG speech activity detection with visual stimuli and mobile BCI. Appl. Sci. 2021, 11, 674. [Google Scholar] [CrossRef]
- Gannouni, S.; Aledaily, A.; Belwafi, K.; Aboalsamh, H. Emotion detection using electroencephalography signals and a zero-time windowing-based epoch estimation and relevant electrode identification. Sci. Rep. 2021, 11, 7071. [Google Scholar] [CrossRef]
- Luo, S.; Rabbani, Q.; Crone, N.E. Brain-computer interface: Applications to speech decoding and synthesis to augment communication. Neurotherapeutics 2022, 19, 263–273. [Google Scholar] [CrossRef]
- Pandarinath, C.; Nuyujukian, P.; Blabe, C.H.; Sorice, B.L.; Saab, J.; Willett, F.R.; Hochberg, L.R.; Shenoy, K.V.; Henderson, J.M. High performance communication by people with paralysis using an intracortical brain–computer interface. elife 2017, 6, e18554. [Google Scholar] [CrossRef]
- Stavisky, S.D.; Willett, F.R.; Wilson, G.H.; Murphy, B.A.; Rezaii, P.; Avansino, D.T.; Memberg, W.D.; Miller, J.P.; Kirsch, R.F.; Hochberg, L.R.; et al. Neural ensemble dynamics in dorsal motor cortex during speech in people with paralysis. elife 2019, 8, e46015. [Google Scholar] [CrossRef]
- Gorno-Tempini, M.L.; Hillis, A.E.; Weintraub, S.; Kertesz, A.; Mendez, M.; Cappa, S.F.; Ogar, J.M.; Rohrer, J.D.; Black, S.; Boeve, B.F.; et al. Classification of primary progressive aphasia and its variants. Neurology 2011, 76, 1006–1014. [Google Scholar] [CrossRef] [Green Version]
- Willett, F.R.; Murphy, B.A.; Memberg, W.D.; Blabe, C.H.; Pandarinath, C.; Walter, B.L.; Sweet, J.A.; Miller, J.P.; Henderson, J.M.; Shenoy, K.V.; et al. Signal-independent noise in intracortical brain–computer interfaces causes movement time properties inconsistent with Fitts’ law. J. Neural Eng. 2017, 14, 026010. [Google Scholar] [CrossRef] [Green Version]
- Brumberg, J.S.; Wright, E.J.; Andreasen, D.S.; Guenther, F.H.; Kennedy, P.R. Classification of intended phoneme production from chronic intracortical microelectrode recordings in speech motor cortex. Front. Neurosci. 2011, 5, 65. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rabbani, Q.; Milsap, G.; Crone, N.E. The potential for a speech brain–computer interface using chronic electrocorticography. Neurotherapeutics 2019, 16, 144–165. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yang, T.; Hakimian, S.; Schwartz, T.H. Intraoperative ElectroCorticoGraphy (ECog): Indications, techniques, and utility in epilepsy surgery. Epileptic Disord. 2014, 16, 271–279. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kirschstein, T.; Köhling, R. What is the source of the EEG? Clin. EEG Neurosci. 2009, 40, 146–149. [Google Scholar] [CrossRef] [PubMed]
- Casson, A.J.; Smith, S.; Duncan, J.S.; Rodriguez-Villegas, E. Wearable EEG: What is it, why is it needed and what does it entail? In Proceedings of the 2008 30th Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Vancouver, BC, Canada, 20–24 August 2008; pp. 5867–5870. [Google Scholar]
- Tandra, R.; Sahai, A. SNR walls for signal detection. IEEE J. Sel. Top. Signal Process. 2008, 2, 4–17. [Google Scholar] [CrossRef] [Green Version]
- Wilson, G.H.; Stavisky, S.D.; Willett, F.R.; Avansino, D.T.; Kelemen, J.N.; Hochberg, L.R.; Henderson, J.M.; Druckmann, S.; Shenoy, K.V. Decoding spoken English from intracortical electrode arrays in dorsal precentral gyrus. J. Neural Eng. 2020, 17, 066007. [Google Scholar] [CrossRef]
- Kapur, A.; Sarawgi, U.; Wadkins, E.; Wu, M.; Hollenstein, N.; Maes, P. Non-invasive silent speech recognition in multiple sclerosis with dysphonia. In Proceedings of the Machine Learning for Health Workshop. PMLR, Virtual Event, 11 December 2020; pp. 25–38. [Google Scholar]
- Müller-Putz, G.R.; Scherer, R.; Brauneis, C.; Pfurtscheller, G. Steady-state visual evoked potential (SSVEP)-based communication: Impact of harmonic frequency components. J. Neural Eng. 2005, 2, 123. [Google Scholar] [CrossRef]
- Chandler, J.A.; Van der Loos, K.I.; Boehnke, S.; Beaudry, J.S.; Buchman, D.Z.; Illes, J. Brain Computer Interfaces and Communication Disabilities: Ethical, legal, and social aspects of decoding speech from the brain. Front. Hum. Neurosci. 2022, 16, 841035. [Google Scholar] [CrossRef]
- What Part of the Brain Controls Speech? Available online: https://www.healthline.com/health/what-part-of-the-brain-controls-speech (accessed on 21 March 2023).
- The Telltale Hand. Available online: https://www.dana.org/article/the-telltale-hand/#:~:text=The%20sequence%20that%20produces%20handwriting,content%20of%20the%20motor%20sequence (accessed on 3 April 2023).
- How Does Your Brain Control Speech? Available online: https://districtspeech.com/how-does-your-brain-control-speech/ (accessed on 24 March 2023).
- Obleser, J.; Wise, R.J.; Dresner, M.A.; Scott, S.K. Functional integration across brain regions improves speech perception under adverse listening conditions. J. Neurosci. 2007, 27, 2283–2289. [Google Scholar] [CrossRef] [Green Version]
- What Part of the Brain Controls Speech? Brain Hemispheres Functions REGIONS of the Brain Brain Injury and Speech. Available online: https://psychcentral.com/health/what-part-of-the-brain-controls-speech (accessed on 21 March 2023).
- Chang, E.F.; Rieger, J.W.; Johnson, K.; Berger, M.S.; Barbaro, N.M.; Knight, R.T. Categorical speech representation in human superior temporal gyrus. Nat. Neurosci. 2010, 13, 1428–1432. [Google Scholar] [CrossRef]
- Willett, F.R.; Deo, D.R.; Avansino, D.T.; Rezaii, P.; Hochberg, L.R.; Henderson, J.M.; Shenoy, K.V. Hand knob area of premotor cortex represents the whole body in a compositional way. Cell 2020, 181, 396–409. [Google Scholar] [CrossRef]
- James, K.H.; Engelhardt, L. The effects of handwriting experience on functional brain development in pre-literate children. Trends Neurosci. Educ. 2012, 1, 32–42. [Google Scholar] [CrossRef] [Green Version]
- Palmis, S.; Danna, J.; Velay, J.L.; Longcamp, M. Motor control of handwriting in the developing brain: A review. Cogn. Neuropsychol. 2017, 34, 187–204. [Google Scholar] [CrossRef]
- Neural Prosthesis Uses Brain Activity to Decode Speech. Available online: https://medicalxpress.com/news/2023-01-neural-prosthesis-brain-decode-speech.html (accessed on 20 March 2023).
- Maas, A.I.; Harrison-Felix, C.L.; Menon, D.; Adelson, P.D.; Balkin, T.; Bullock, R.; Engel, D.C.; Gordon, W.; Langlois-Orman, J.; Lew, H.L.; et al. Standardizing data collection in traumatic brain injury. J. Neurotrauma 2011, 28, 177–187. [Google Scholar] [CrossRef] [Green Version]
- Difference between Invasive and Non-Invasive BCI|Types of BCIs. Available online: https://www.rfwireless-world.com/Terminology/Difference-between-BCI-types.html (accessed on 20 February 2023).
- What Is a Brain-Computer Interface? Everything You Need to Know about BCIs, Neural Interfaces and the Future of Mind-Reading Computers. Available online: https://www.zdnet.com/article/what-is-bci-everything-you-need-to-know-about-brain-computer-interfaces-and-the-future-of-mind-reading-computers/ (accessed on 20 February 2023).
- Downey, J.E.; Schwed, N.; Chase, S.M.; Schwartz, A.B.; Collinger, J.L. Intracortical recording stability in human brain–computer interface users. J. Neural Eng. 2018, 15, 046016. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hochberg, L.R.; Bacher, D.; Jarosiewicz, B.; Masse, N.Y.; Simeral, J.D.; Vogel, J.; Haddadin, S.; Liu, J.; Cash, S.S.; Van Der Smagt, P.; et al. Reach and grasp by people with tetraplegia using a neurally controlled robotic arm. Nature 2012, 485, 372–375. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chakrabarti, S.; Sandberg, H.M.; Brumberg, J.S.; Krusienski, D.J. Progress in speech decoding from the electrocorticogram. Biomed. Eng. Lett. 2015, 5, 10–21. [Google Scholar] [CrossRef]
- Herff, C.; Heger, D.; De Pesters, A.; Telaar, D.; Brunner, P.; Schalk, G.; Schultz, T. Brain-to-text: Decoding spoken phrases from phone representations in the brain. Front. Neurosci. 2015, 9, 217. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bouchard, K.E.; Chang, E.F. Neural decoding of spoken vowels from human sensory-motor cortex with high-density electrocorticography. In Proceedings of the 2014 36th Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Chicago, IL, USA, 26–30 August 2014; pp. 6782–6785. [Google Scholar]
- Heger, D.; Herff, C.; Pesters, A.D.; Telaar, D.; Brunner, P.; Schalk, G.; Schultz, T. Continuous speech recognition from ECOG. In Proceedings of the Sixteenth Annual Conference of the International Speech Communication Association, Dresden, Germany, 6–10 September 2015. [Google Scholar]
- Miniussi, C.; Harris, J.A.; Ruzzoli, M. Modelling non-invasive brain stimulation in cognitive neuroscience. Neurosci. Biobehav. Rev. 2013, 37, 1702–1712. [Google Scholar] [CrossRef] [Green Version]
- Data Augmentation for Brain-Computer Interface. Available online: https://towardsdatascience.com/data-augmentation-for-brain-computer-interface-35862c9beb40 (accessed on 20 February 2023).
- Grau, C.; Ginhoux, R.; Riera, A.; Nguyen, T.L.; Chauvat, H.; Berg, M.; Amengual, J.L.; Pascual-Leone, A.; Ruffini, G. Conscious brain-to-brain communication in humans using non-invasive technologies. PLoS ONE 2014, 9, e105225. [Google Scholar] [CrossRef]
- Porbadnigk, A.; Wester, M.; Calliess, J.P.; Schultz, T. EEG-based speech recognition. In Proceedings of the BIOSIGNALS 2009—International Conference on Bio-Inspired Systems and Signal Processing, Porto, Portugal, 14–17 January 2009. [Google Scholar]
- Jiménez-Guarneros, M.; Gómez-Gil, P. Standardization-refinement domain adaptation method for cross-subject EEG-based classification in imagined speech recognition. Pattern Recognit. Lett. 2021, 141, 54–60. [Google Scholar] [CrossRef]
- Kumar, P.; Scheme, E. A deep spatio-temporal model for EEG-based imagined speech recognition. In Proceedings of the ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 995–999. [Google Scholar]
- Al-Kadi, M.I.; Reaz, M.B.I.; Ali, M.A.M. Evolution of electroencephalogram signal analysis techniques during anesthesia. Sensors 2013, 13, 6605–6635. [Google Scholar] [CrossRef] [Green Version]
- Kakigi, R.; Inui, K.; Tran, D.T.; Qiu, Y.; Wang, X.; Watanabe, S.; Hoshiyama, M. Human brain processing and central mechanisms of pain as observed by electro-and magneto-encephalography. J.-Chin. Med. Assoc. 2004, 67, 377–386. [Google Scholar]
- Ogawa, S.; Menon, R.; Kim, S.G.; Ugurbil, K. On the characteristics of functional magnetic resonance imaging of the brain. Annu. Rev. Biophys. Biomol. Struct. 1998, 27, 447–474. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Brain-Computer Interfaces. Available online: https://cs181-bcis.weebly.com/non-invasive-bcis.html#:~:text=What%20is%20a%20%22non-invasive%20BCI%3F%22%20The%20term%20%E2%80%9Cnon-invasive,brain-to-computer%20stimulation%20without%20needing%20to%20penetrate%20the%20skull (accessed on 20 February 2023).
- Kumar, P.; Saini, R.; Roy, P.P.; Sahu, P.K.; Dogra, D.P. Envisioned speech recognition using EEG sensors. Pers. Ubiquitous Comput. 2018, 22, 185–199. [Google Scholar] [CrossRef]
- Rosinová, M.; Lojka, M.; Staš, J.; Juhár, J. Voice command recognition using eeg signals. In Proceedings of the 2017 International Symposium ELMAR, Zadar, Croatia, 18–20 September 2017; pp. 153–156. [Google Scholar]
- Krishna, G.; Tran, C.; Yu, J.; Tewfik, A.H. Speech recognition with no speech or with noisy speech. In Proceedings of the ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 1090–1094. [Google Scholar]
- Mugler, E.M.; Patton, J.L.; Flint, R.D.; Wright, Z.A.; Schuele, S.U.; Rosenow, J.; Shih, J.J.; Krusienski, D.J.; Slutzky, M.W. Direct classification of all American English phonemes using signals from functional speech motor cortex. J. Neural Eng. 2014, 11, 035015. [Google Scholar] [CrossRef] [Green Version]
- Moses, D.A.; Mesgarani, N.; Leonard, M.K.; Chang, E.F. Neural speech recognition: Continuous phoneme decoding using spatiotemporal representations of human cortical activity. J. Neural Eng. 2016, 13, 056004. [Google Scholar] [CrossRef] [Green Version]
- Anumanchipalli, G.K.; Chartier, J.; Chang, E.F. Speech synthesis from neural decoding of spoken sentences. Nature 2019, 568, 493–498. [Google Scholar] [CrossRef] [PubMed]
- Moses, D.A.; Leonard, M.K.; Makin, J.G.; Chang, E.F. Real-time decoding of question-and-answer speech dialogue using human cortical activity. Nat. Commun. 2019, 10, 3096. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Makin, J.G.; Moses, D.A.; Chang, E.F. Machine translation of cortical activity to text with an encoder–decoder framework. Nat. Neurosci. 2020, 23, 575–582. [Google Scholar] [CrossRef] [PubMed]
- Metzger, S.L.; Liu, J.R.; Moses, D.A.; Dougherty, M.E.; Seaton, M.P.; Littlejohn, K.T.; Chartier, J.; Anumanchipalli, G.K.; Tu-Chan, A.; Ganguly, K.; et al. Generalizable spelling using a speech neuroprosthesis in an individual with severe limb and vocal paralysis. Nat. Commun. 2022, 13, 6510. [Google Scholar] [CrossRef]
- NATO Phonetic Alphabet. Available online: https://first10em.com/quick-reference/nato-phonetic-alphabet/#:~:text=Alpha%2C%20Bravo%2C%20Charlie%2C%20Delta,%2Dray%2C%20Yankee%2C%20Zulu (accessed on 24 May 2023).
- Chen, X.; Wang, Y.; Nakanishi, M.; Gao, X.; Jung, T.P.; Gao, S. High-speed spelling with a noninvasive brain–computer interface. Proc. Natl. Acad. Sci. USA 2015, 112, E6058–E6067. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Saini, R.; Kaur, B.; Singh, P.; Kumar, P.; Roy, P.P.; Raman, B.; Singh, D. Don’t just sign use brain too: A novel multimodal approach for user identification and verification. Inf. Sci. 2018, 430, 163–178. [Google Scholar] [CrossRef]
- Kumar, P.; Saini, R.; Kaur, B.; Roy, P.P.; Scheme, E. Fusion of neuro-signals and dynamic signatures for person authentication. Sensors 2019, 19, 4641. [Google Scholar] [CrossRef] [Green Version]
- Pei, L.; Ouyang, G. Online recognition of handwritten characters from scalp-recorded brain activities during handwriting. J. Neural Eng. 2021, 18, 046070. [Google Scholar] [CrossRef]
- Willett, F.R.; Avansino, D.T.; Hochberg, L.R.; Henderson, J.M.; Shenoy, K.V. High-performance brain-to-text communication via handwriting. Nature 2021, 593, 249–254. [Google Scholar] [CrossRef]
- Saby, J.N.; Marshall, P.J. The utility of EEG band power analysis in the study of infancy and early childhood. Dev. Neuropsychol. 2012, 37, 253–273. [Google Scholar] [CrossRef] [Green Version]
- Dubey, A.; Ray, S. Comparison of tuning properties of gamma and high-gamma power in local field potential (LFP) versus electrocorticogram (ECoG) in visual cortex. Sci. Rep. 2020, 10, 5422. [Google Scholar] [CrossRef] [Green Version]
- Saeidi, M.; Karwowski, W.; Farahani, F.V.; Fiok, K.; Taiar, R.; Hancock, P.; Al-Juaid, A. Neural decoding of EEG signals with machine learning: A systematic review. Brain Sci. 2021, 11, 1525. [Google Scholar] [CrossRef]
- Agarwal, P.; Kumar, S. Electroencephalography-based imagined speech recognition using deep long short-term memory network. ETRI J. 2022, 44, 672–685. [Google Scholar] [CrossRef]
- Angrick, M.; Herff, C.; Mugler, E.; Tate, M.C.; Slutzky, M.W.; Krusienski, D.J.; Schultz, T. Speech synthesis from ECoG using densely connected 3D convolutional neural networks. J. Neural Eng. 2019, 16, 036019. [Google Scholar] [CrossRef] [PubMed]
- Hinton, G.; Deng, L.; Yu, D.; Dahl, G.E.; Mohamed, A.R.; Jaitly, N.; Senior, A.; Vanhoucke, V.; Nguyen, P.; Sainath, T.N.; et al. Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups. IEEE Signal Process. Mag. 2012, 29, 82–97. [Google Scholar] [CrossRef]
- Akar, S.A.; Kara, S.; Agambayev, S.; Bilgiç, V. Nonlinear analysis of EEG in major depression with fractal dimensions. In Proceedings of the 2015 37th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Milan, Italy, 25–29 August 2015; pp. 7410–7413. [Google Scholar]
- Nieto, N.; Peterson, V.; Rufiner, H.L.; Kamienkowski, J.E.; Spies, R. Thinking out loud, an open-access EEG-based BCI dataset for inner speech recognition. Sci. Data 2022, 9, 52. [Google Scholar] [CrossRef] [PubMed]
- Alqatawneh, A.; Alhalaseh, R.; Hassanat, A.; Abbadi, M. Statistical-hypothesis-aided tests for epilepsy classification. Computers 2019, 8, 84. [Google Scholar] [CrossRef] [Green Version]
- Chenane, K.; Touati, Y.; Boubchir, L.; Daachi, B. Neural net-based approach to EEG signal acquisition and classification in BCI applications. Computers 2019, 8, 87. [Google Scholar] [CrossRef] [Green Version]
- Borghini, G.; Aricò, P.; Di Flumeri, G.; Sciaraffa, N.; Babiloni, F. Correlation and similarity between cerebral and non-cerebral electrical activity for user’s states assessment. Sensors 2019, 19, 704. [Google Scholar] [CrossRef] [Green Version]
- Lim, J.Z.; Mountstephens, J.; Teo, J. Emotion recognition using eye-tracking: Taxonomy, review and current challenges. Sensors 2020, 20, 2384. [Google Scholar] [CrossRef] [Green Version]
- Hughes, A.; Jorda, S. Applications of Biological and Physiological Signals in Commercial Video Gaming and Game Research: A Review. Front. Comput. Sci. 2021, 3, 557608. [Google Scholar] [CrossRef]
- Li, M.; Chen, W.; Zhang, T. Classification of epilepsy EEG signals using DWT-based envelope analysis and neural network ensemble. Biomed. Signal Process. Control. 2017, 31, 357–365. [Google Scholar] [CrossRef]
- Li, X.; Samuel, O.W.; Zhang, X.; Wang, H.; Fang, P.; Li, G. A motion-classification strategy based on sEMG-EEG signal combination for upper-limb amputees. J. Neuroeng. Rehabil. 2017, 14, 1–13. [Google Scholar] [CrossRef] [Green Version]
- Yang, S.; Li, M.; Wang, J. Fusing sEMG and EEG to Increase the Robustness of Hand Motion Recognition Using Functional Connectivity and GCN. IEEE Sens. J. 2022, 22, 24309–24319. [Google Scholar] [CrossRef]
- Zhang, X.; Ma, Z.; Zheng, H.; Li, T.; Chen, K.; Wang, X.; Liu, C.; Xu, L.; Wu, X.; Lin, D.; et al. The combination of brain–computer interfaces and artificial intelligence: Applications and challenges. Ann. Transl. Med. 2020, 8, 712. [Google Scholar] [CrossRef]
- Pei, D.; Vinjamuri, R. Introductory chapter: Methods and applications of neural signal processing. In Advances in Neural Signal Processing; IntechOpen: London, UK, 2020. [Google Scholar]
- Taplin, A.M.; de Pesters, A.; Brunner, P.; Hermes, D.; Dalfino, J.C.; Adamo, M.A.; Ritaccio, A.L.; Schalk, G. Intraoperative mapping of expressive language cortex using passive real-time electrocorticography. Epilepsy Behav. Case Rep. 2016, 5, 46–51. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hill, N.J.; Gupta, D.; Brunner, P.; Gunduz, A.; Adamo, M.A.; Ritaccio, A.; Schalk, G. Recording human electrocorticographic (ECoG) signals for neuroscientific research and real-time functional cortical mapping. JoVE (J. Vis. Exp.) 2012, 26, e3993. [Google Scholar]
- Jeong, J.H.; Shim, K.H.; Kim, D.J.; Lee, S.W. Brain-controlled robotic arm system based on multi-directional CNN-BiLSTM network using EEG signals. IEEE Trans. Neural Syst. Rehabil. Eng. 2020, 28, 1226–1238. [Google Scholar] [CrossRef]
- Burwell, S.; Sample, M.; Racine, E. Ethical aspects of brain computer interfaces: A scoping review. BMC Med. Ethics 2017, 18, 1–11. [Google Scholar] [CrossRef] [Green Version]
- Glannon, W. Ethical Issues with Brain-Computer Interfaces. Front. Syst. Neurosci. 2014, 8, 13. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mridha, M.F.; Das, S.C.; Kabir, M.M.; Lima, A.A.; Islam, M.R.; Watanobe, Y. Brain-computer interface: Advancement and challenges. Sensors 2021, 21, 5746. [Google Scholar] [CrossRef] [PubMed]
- Saha, S.; Mamun, K.A.; Ahmed, K.; Mostafa, R.; Naik, G.R.; Darvishi, S.; Khandoker, A.H.; Baumert, M. Progress in brain computer interface: Challenges and opportunities. Front. Syst. Neurosci. 2021, 15, 578875. [Google Scholar] [CrossRef] [PubMed]
- Chatterjee, B.; Nath, M.; Xiao, S.; Jayant, K.; Sen, S. Bi-Phasic Quasistatic Brain Communication for Fully Untethered Connected Brain Implants. bioRxiv 2022. [Google Scholar] [CrossRef]
- Chatterjee, B.; Kumar, G.; Nath, M.; Xiao, S.; Modak, N.; Das, D.; Krishna, J.; Sen, S. A 1.15 μW 5.54 mm3 implant with a bidirectional neural sensor and stimulator SoC utilizing bi-phasic quasi-static brain communication achieving 6 kbps–10 Mbps uplink with compressive sensing and RO-PUF based collision avoidance. In Proceedings of the 2021 Symposium on VLSI Circuits, Kyoto, Japan, 13–19 June 2021; pp. 1–2. [Google Scholar]
- Chatterjee, B.; Kumar, K.G.; Xiao, S.; Barik, G.; Jayant, K.; Sen, S. A 1.8 μW 5.5 mm3 ADC-less Neural Implant SoC utilizing 13.2 pJ/Sample Time-domain Bi-phasic Quasi-static Brain Communication with Direct Analog to Time Conversion. In Proceedings of the ESSCIRC 2022-IEEE 48th European Solid State Circuits Conference (ESSCIRC), Milan, Italy, 19–22 September 2022; pp. 209–212. [Google Scholar]
- Khalifa, A.; Liu, Y.; Karimi, Y.; Wang, Q.; Eisape, A.; Stanaćević, M.; Thakor, N.; Bao, Z.; Etienne-Cummings, R. The microbead: A 0.009 mm3 implantable wireless neural stimulator. IEEE Trans. Biomed. Circuits Syst. 2019, 13, 971–985. [Google Scholar] [CrossRef] [PubMed]
- Khalifa, A.; Karimi, Y.; Wang, Q.; Montlouis, W.; Garikapati, S.; Stanaćević, M.; Thakor, N.; Etienne-Cummings, R. The microbead: A highly miniaturized wirelessly powered implantable neural stimulating system. IEEE Trans. Biomed. Circuits Syst. 2018, 12, 521–531. [Google Scholar] [CrossRef] [PubMed]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Types of Neural Signal | Regions from Which Signals Are Acquired | Features Used in the Existing Reseach |
|---|---|---|
| EEG | Non-invasively from the scalp | Standard Deviation, Root Mean Square, Sum of values, and Energy of neural signals acquired at 128 Hz using Emotiv EPOC+ headset [2,67]. Fast Fourier transform and noise filtered signal extracted at 62.5–125 Hz using 40 channels EEG headset [2]. The energy of each frame neural signal was acquired at 250 Hz using EEG head cap [68]. EEG-acoustic features [69]. Feature descriptors such as Pyramid histogram of orientation gradients extracted at 128 Hz using Emotiv EPOC+ headset [78]. Discrete Fourier Transform and dynamic signature features extracted at 128 Hz using Emotiv EPOC+ headset [79]. Independent component analysis result of neural signals acquired at 250 Hz using 32 channel EEG electrode [80]. |
| ECoG | Invasively from inside the skull. Generally from the primary motor cortex area of the brain [51] | High gamma activity (70–150 Hz) from the auditory and sensorimotor cortex [73]. High-frequency components (70–150 Hz) are recorded from the peri-Sylvian cortices [74]. Articulatory kinematic features from neural activity such as high gamma activity (70–200 Hz) and Low-frequency signal (1–30 Hz) features are recorded from ventral sensorimotor cortex [72,75]. High gamma frequency (65–250 Hz), mu frequency (7–13 Hz) and beta (15–30 Hz) frequency are recorded from cortex, frontal and temporal areas of brain [70]. Spatiotempral feature by time warping the acquired neural signal from premotor cortex [81]. |
| Article | Feature Extraction, Methods and Results | Dataset Description (Invasive/Non-Invasive | Limitations |
|---|---|---|---|
| Kumar et al. [67] | Standard Deviation, Root Mean Square, Sum of values, Energy. Fine-level classification accuracy of 57.11% was achieved using the RF classifier | 30 text and non-text class objects. 23 participants aged between 15 and 40 years. (Non-Invasive) | Fine level classification accuracy is not up to the mark |
| Rosinová et al. [68] | Feature vectors consisting of each frame’s energy. Very low accuracy using the HMM and GMM | 50 voice commands from 20 participants (Non-Invasive) | Limited recording data and low accuracy |
| Krishna et al. [69] | EEG features, acoustic features and combination of EEG-acoustic features. A high recognition accuracy of 99.38% in the presence of background noise using GRU | Four English words—“yes”, “no”, “left”, and “right” spoken by 4 different people (Non-Invasive) | Limited variations in the dataset |
| Kapur et al. [35] | 24-bit analog to digital converter sampled at 250 Hz. 81% accuracy, and information transfer rate of 203.73 bits per minute using CNN | 10 trials of 15 sentences from three multiple sclerosis patients (Non-Invasive) | Limited variations in the dataset |
| Voront-sova et al. [2] | EEG features. 85% accuracy rate for the classification using ResNet18 and GRU | Nine Russian words as silent speech from 268 healthy participants (Non-Invasive) | Out-of-sample accuracy is relatively low in this study |
| Mugler et al. [70] | Spatiotemporal features. 36% accuracy in classifying phonemes with LDA | Entire set of phonemes from American English from 4 people (Invasive) | Only 18.8% accuracy in word identification from phonemic analysis |
| Anuman-chipalli et al. [72] | Acoustic features, articulatory kinematic features, spectral features. BLSTM has been used for decoding kinematic representations of articulation | High-density ECoG signals collected from 5 individuals (Invasive) | Experimental results are not discussed briefly |
| Moses et al. [73] | High gamma activity. Viterbi decoding was used with 61% decoding accuracy for producing utterances and 76% decoding accuracy for perceiving utterances. | ECoG recordings of 9 questions and 24 possible answers collected from 3 individuals (Invasive) | Limited variations in dataset |
| Makin et al. [74] | High frequency components. RNN used for training | 30–50 sentences of data. 4 participants (Invasive) | Limited variations in dataset |
| Metzger et al. [75] | High gamma activity and Low frequency signal features. 6.13% character error rate and 29.4 characters per minute with GRU | NATO phonetic alphabet was used during spelling. 1 participant. (Invasive) | Only one participant was involved for training process |
| Chen et al. [77] | Filter bank analysis method. Spelling rate of up to 60 characters per minute with JFPM and decoding algorithm | Six blocks of 40 characters by 18 people (Non-Invasive) | Limited character sets |
| Saini et al. [78] | Pyramid histogram of orientation gradients features. 98.24%-person identification accuracy has been obtained using HMM classifiers | 1400 samples of signatures and EEG signals. 70 participants. (Non-Invasive) | User verification results have not discussed briefly |
| Kumar et al. [79] | Dynamic signature features. 98.78% accuracy has been obtained by signature-EEG fusion data using BLSTM-NN classifiers | 1980 samples of dynamic signatures and EEG signals from 58 users (Non-Invasive) | No. of samples for actual users are limited |
| Pei et al. [80] | Kinematic features. The accuracy of handwritten character recognition varied among participants, from 76.8% to 97% and cross-participant from 11.1% to 60% using CNN based classifiers | HELLO, WORLD! phrase by 5 participants (Non-Invasive) | Dataset is small and cross participant’s accuracy is low |
| Willett et al. [81] | Spatiotemporal features. 90 characters per minute decoding rate with 94.1% raw accuracy in real-time and greater than 99% accuracy offline using RNN | 1000 handwriting sentences of 43,501 characters. 1 participant. (Invasive) | Ignored capital letters and text deletion and editing is not allowed |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sen, O.; Sheehan, A.M.; Raman, P.R.; Khara, K.S.; Khalifa, A.; Chatterjee, B. Machine-Learning Methods for Speech and Handwriting Detection Using Neural Signals: A Review. Sensors 2023, 23, 5575. https://doi.org/10.3390/s23125575
Sen O, Sheehan AM, Raman PR, Khara KS, Khalifa A, Chatterjee B. Machine-Learning Methods for Speech and Handwriting Detection Using Neural Signals: A Review. Sensors. 2023; 23(12):5575. https://doi.org/10.3390/s23125575
Chicago/Turabian StyleSen, Ovishake, Anna M. Sheehan, Pranay R. Raman, Kabir S. Khara, Adam Khalifa, and Baibhab Chatterjee. 2023. "Machine-Learning Methods for Speech and Handwriting Detection Using Neural Signals: A Review" Sensors 23, no. 12: 5575. https://doi.org/10.3390/s23125575
APA StyleSen, O., Sheehan, A. M., Raman, P. R., Khara, K. S., Khalifa, A., & Chatterjee, B. (2023). Machine-Learning Methods for Speech and Handwriting Detection Using Neural Signals: A Review. Sensors, 23(12), 5575. https://doi.org/10.3390/s23125575