
Intelligent Bearing Fault Diagnosis Based on Feature Fusion of One-Dimensional Dilated CNN and Multi-Domain Signal Processing


Abstract
:1. Introduction
- (1)
- A novel feature fusion model, MD-1d-DCNN, is built using multi-domain statistical characteristics and adaptive features from one-dimensional dilated CNN. It achieves greater robustness against noise than state-of-the-art benchmark approaches.
- (2)
- Bearing condition indicators that are reflective of bearing faults from several perspectives can be effectively evaluated utilising signal processing and analysis techniques in the time, frequency, time-frequency domains.
- (3)
- By introducing dilated CNN, we can learn features more effectively over an extended field and avoid getting stuck in local feature extraction. It aids in circumventing the overfitting issue and allows for the extraction of high-quality features in a noisy environment, expanding the scope of use for this fault diagnosis model.
- (4)
- The performance of the proposed approach is assessed by adopting two rolling bearing datasets created by the Bearing Data Centre at Case Western Reserve University and the Railway Technology Research Group of the Polytechnic University of Madrid, respectively. The experimental findings show that the suggested method provides exceptional fault diagnosis accuracy and anti-noise capabilities. It is indicative of strong performance in real-world situations.
2. Fundamentals
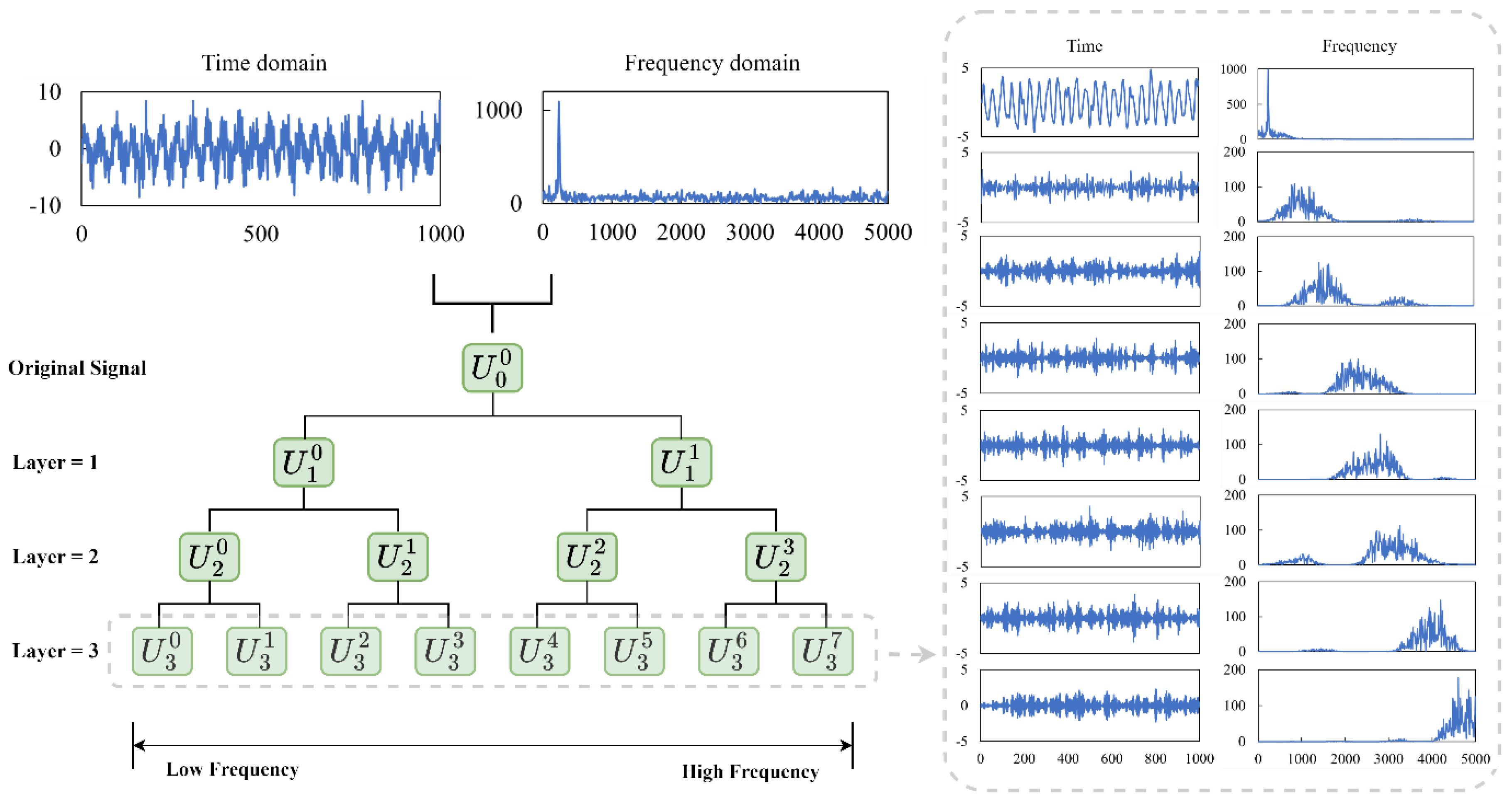
2.1. Wavelet Packet Transform
2.2. One-Dimensional Dilated Convolutional Neural Network (1d-DCNN)
2.2.1. One-Dimensional Convolutional Neural Network
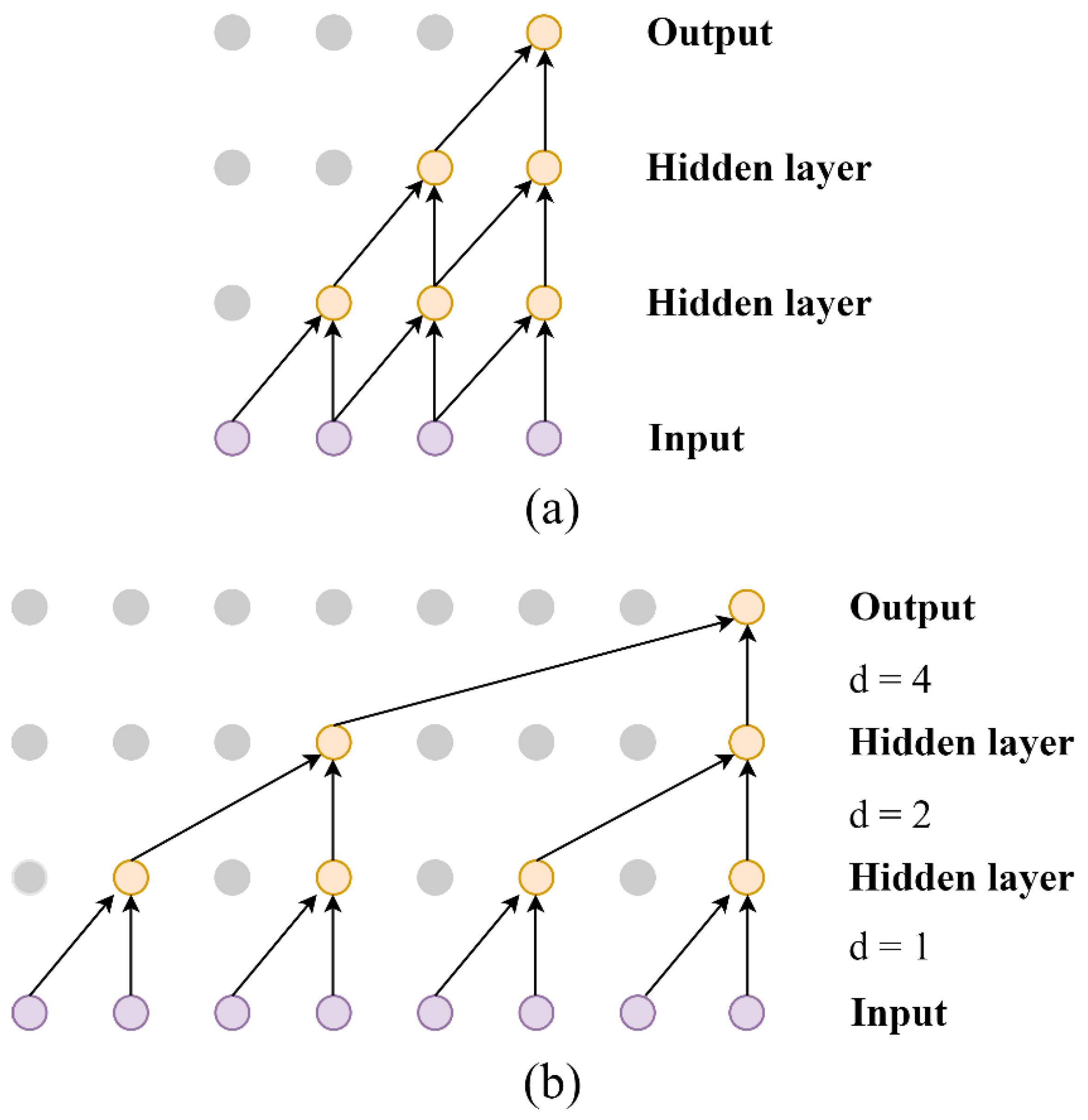
2.2.2. Dilated Convolution
3. The Proposed Method
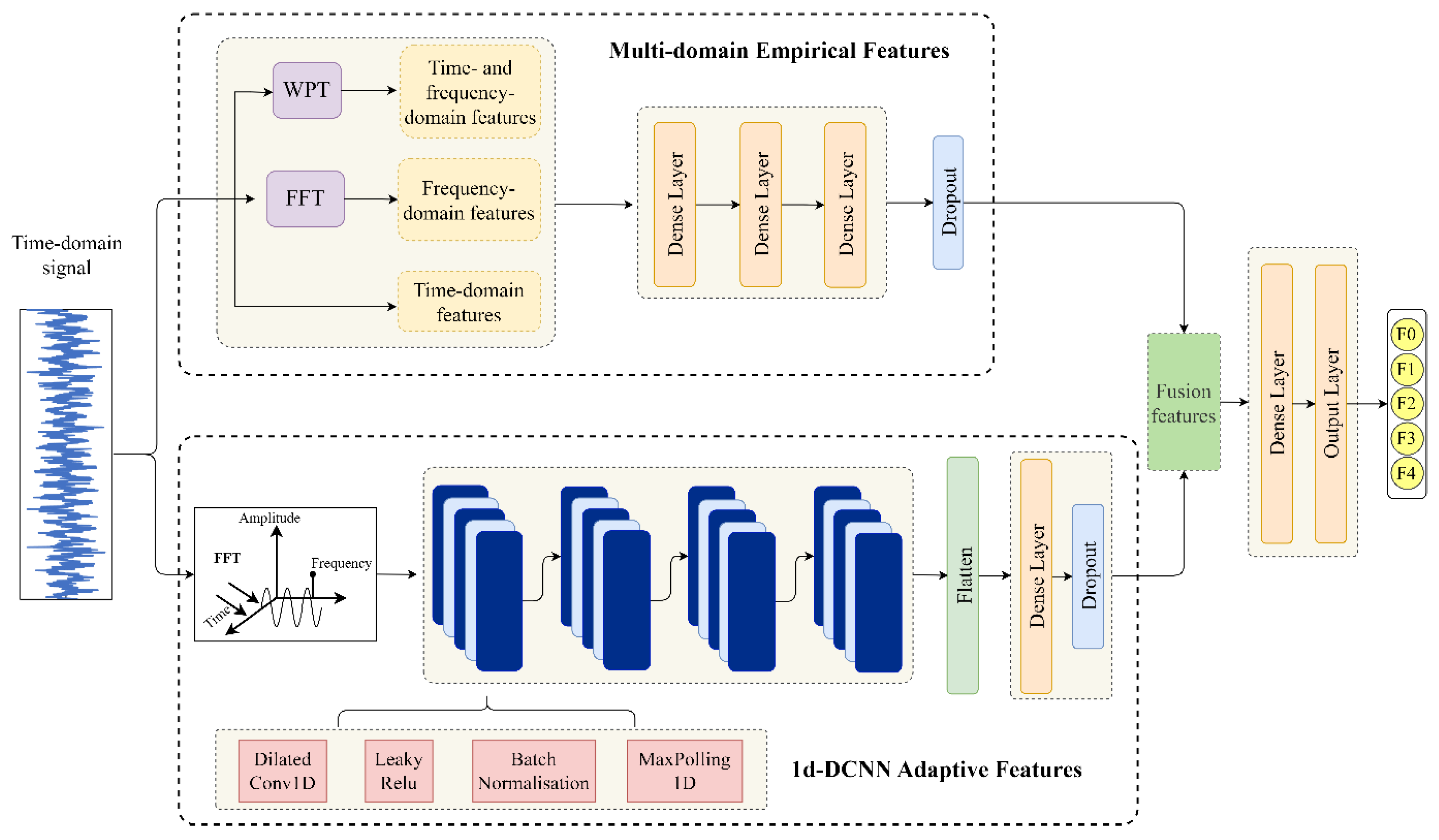
3.1. Model Structure
3.2. Feature Extraction
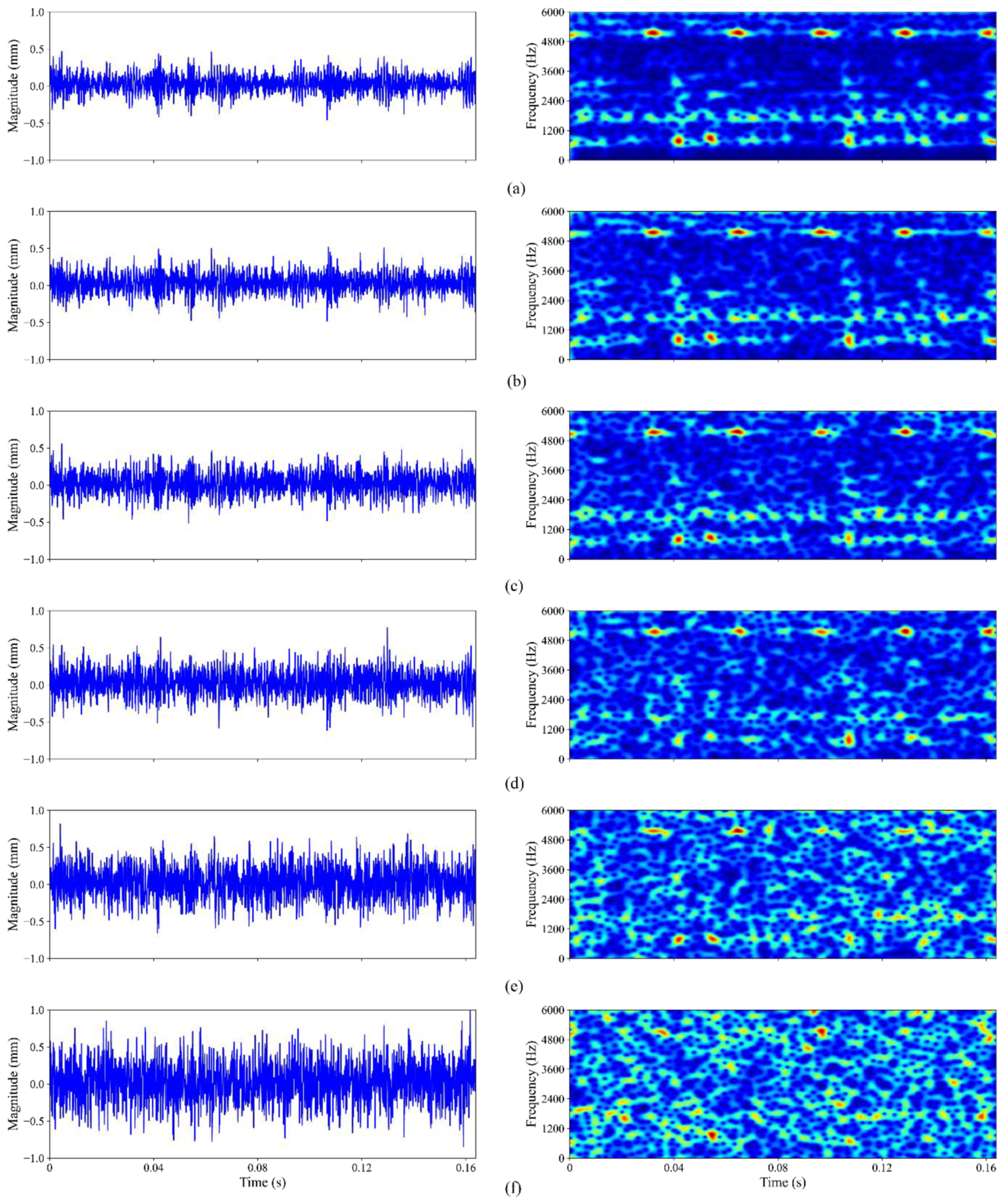
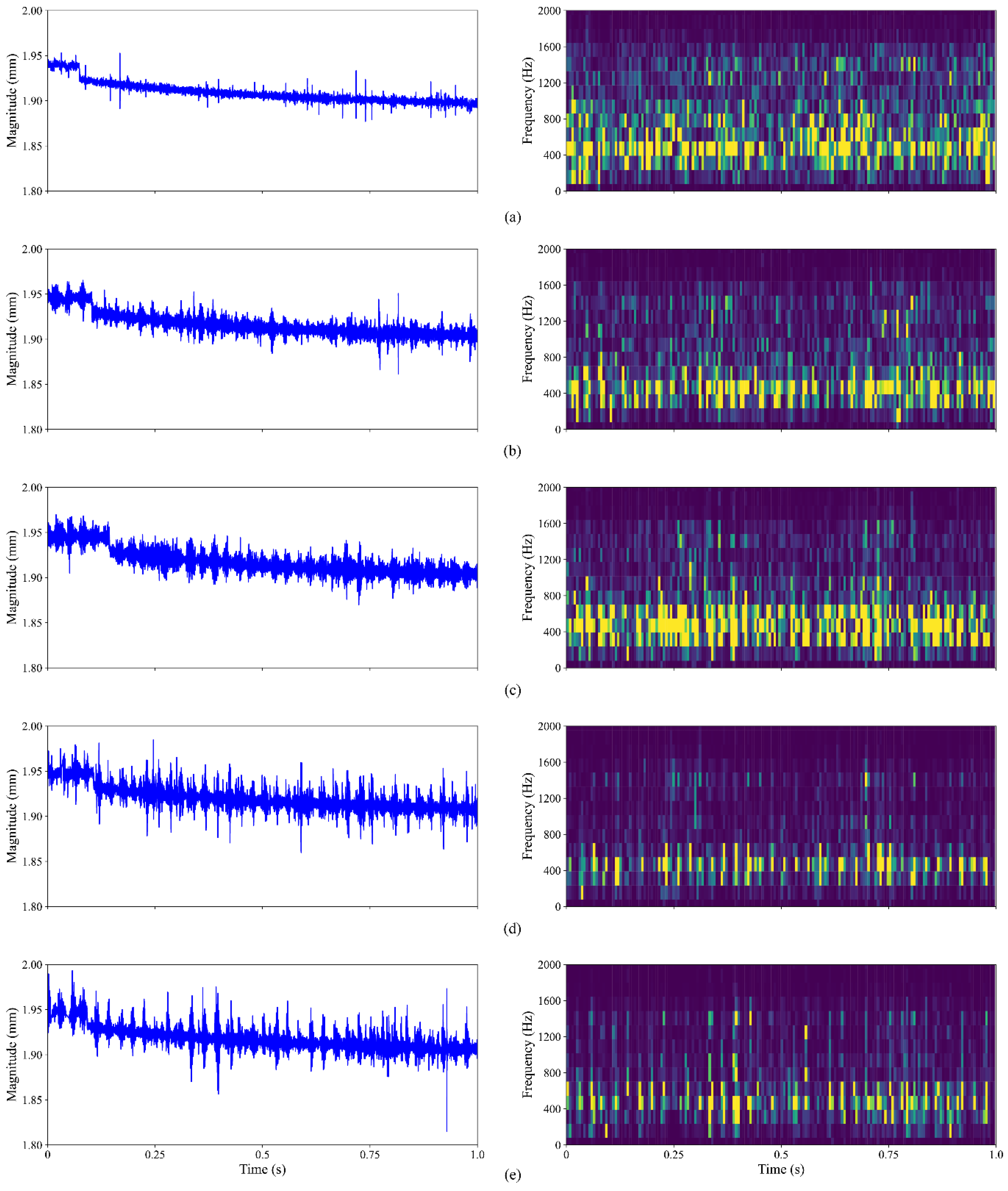
3.2.1. Data Preprocessing and Sequence Generation
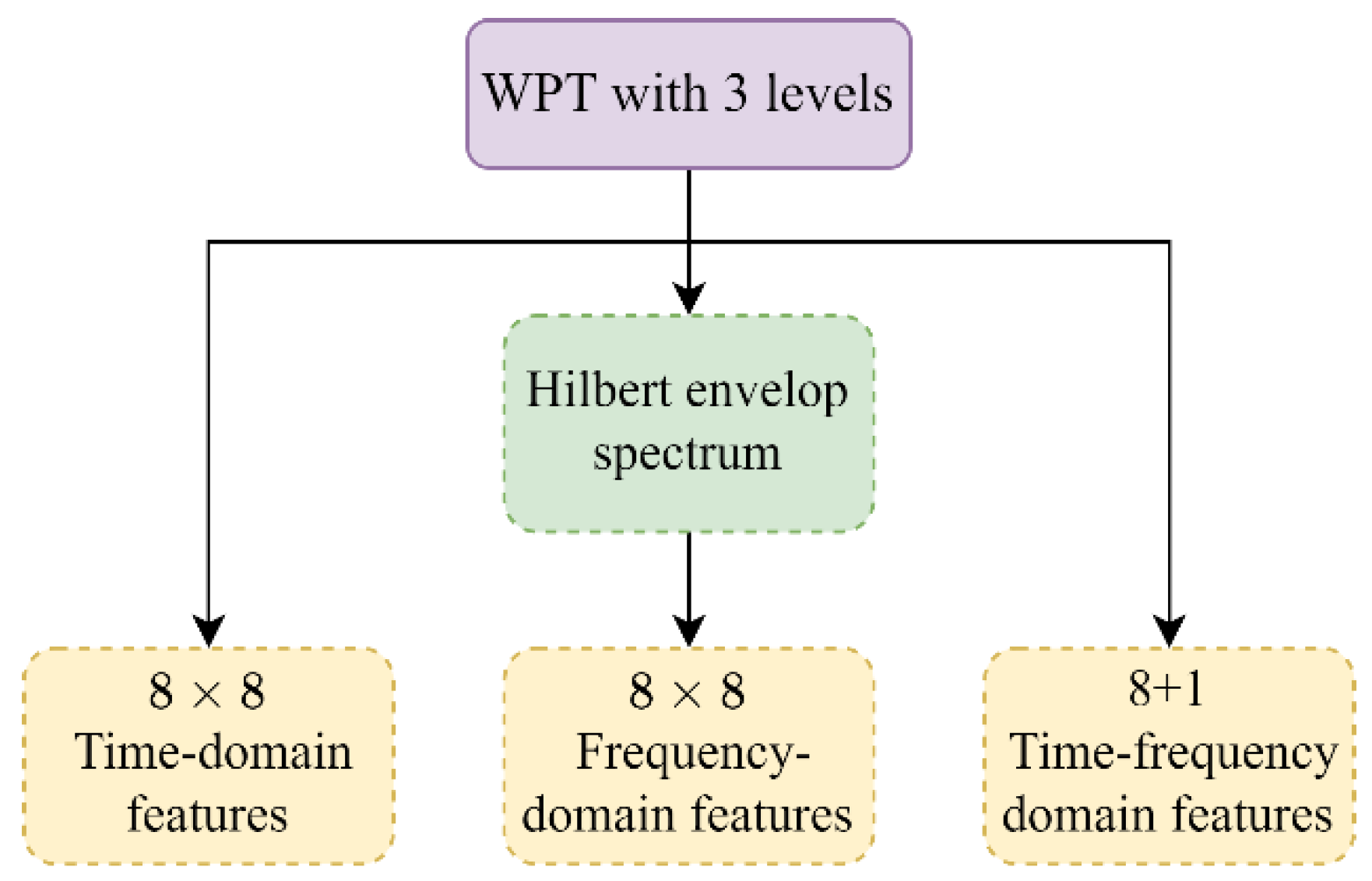
3.2.2. Multi-Domain-Based Fault Feature Extraction
3.2.3. 1d-DCNN-Based Fault Feature Extraction
3.3. Feature Fusion and Loss Function
4. Experimental Validation
4.1. Case One: The CWRU Bearing Data
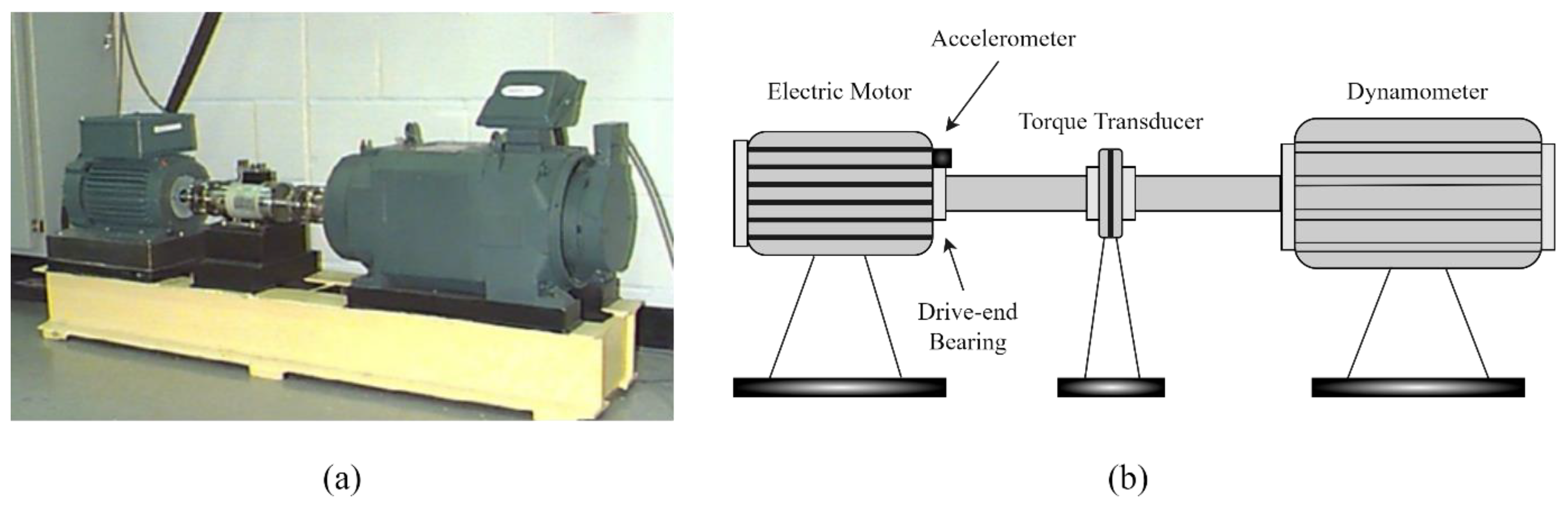
4.1.1. Experiment Setup and Data Description
4.1.2. Model Performance Metrics
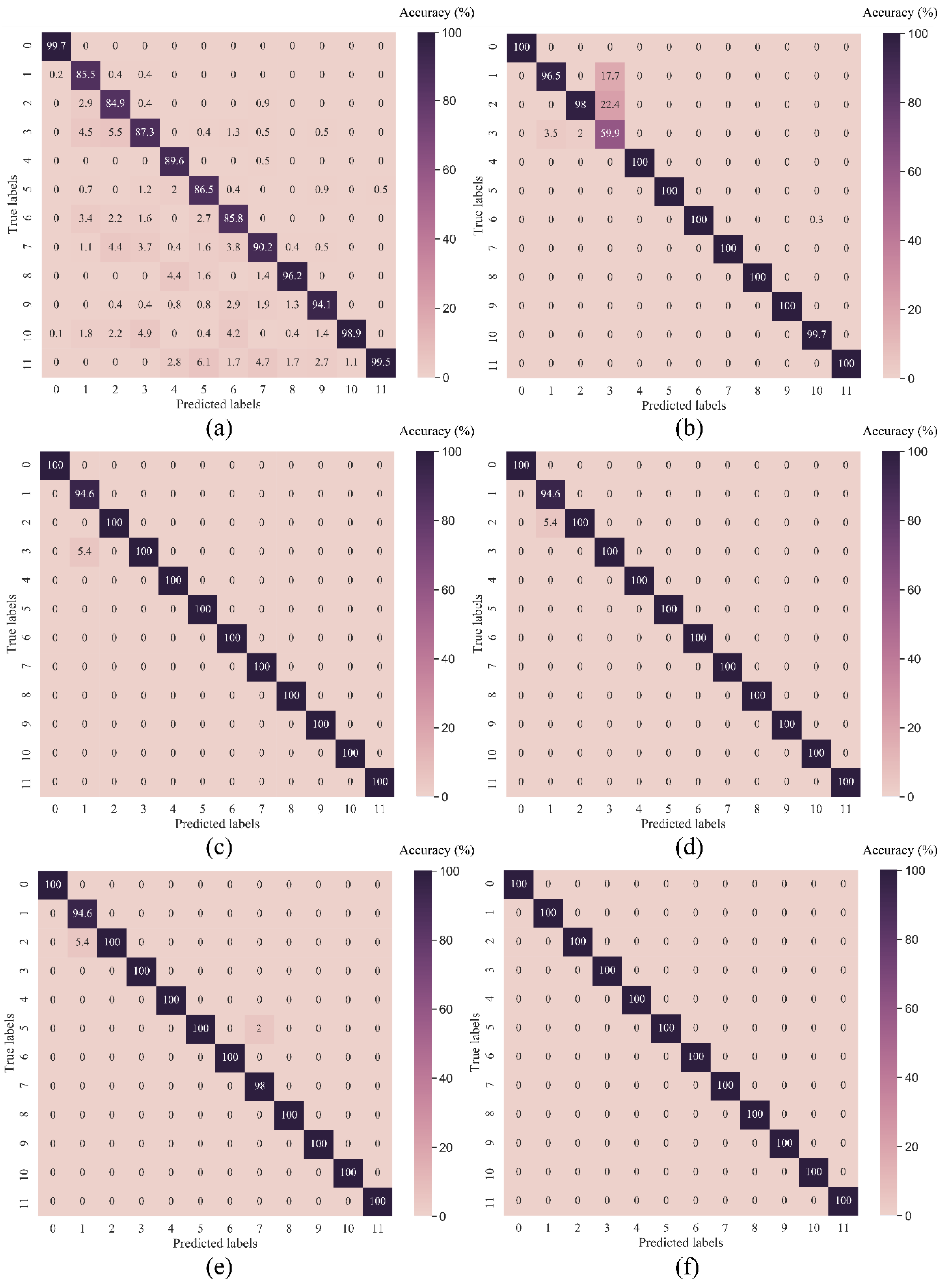
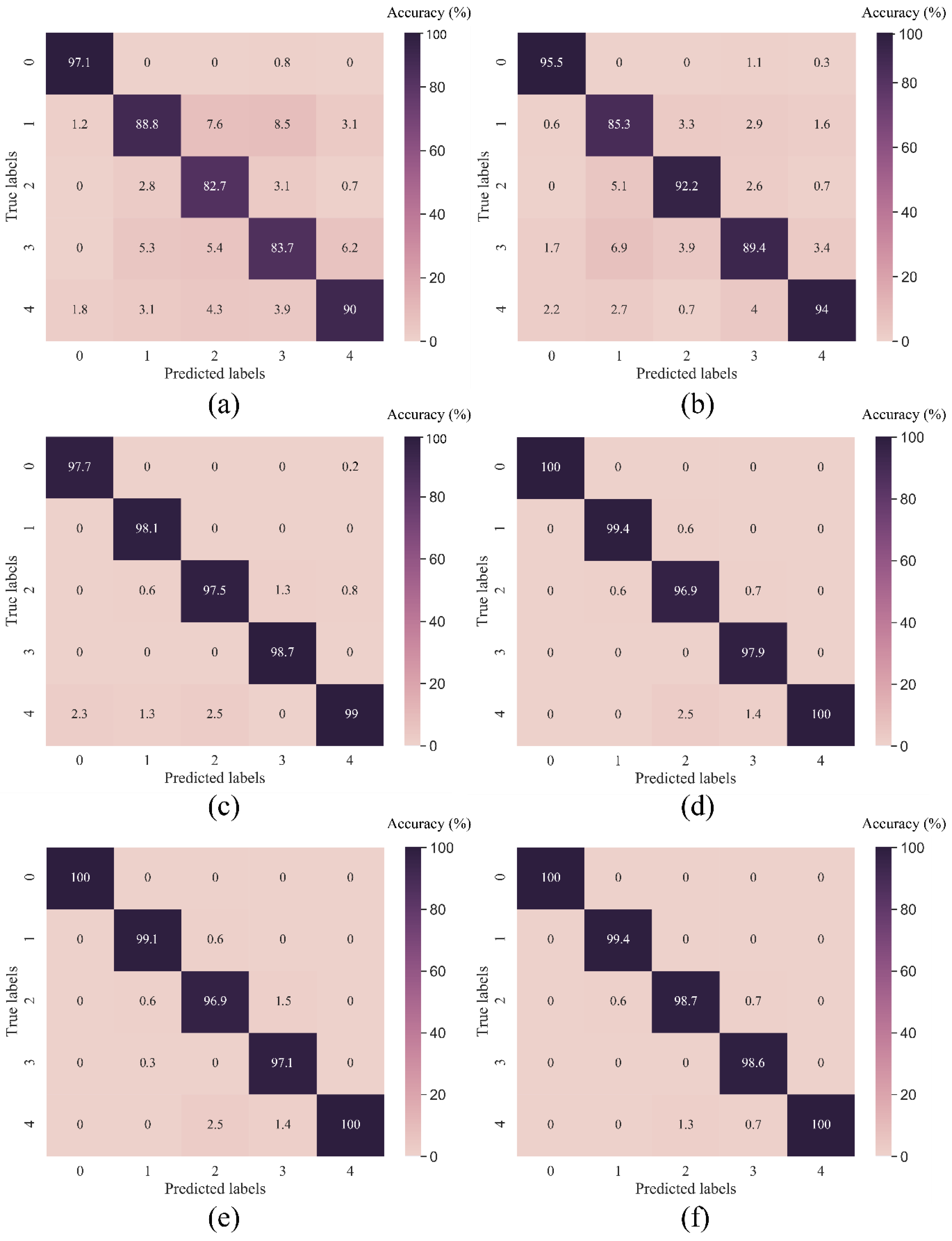
4.1.3. Model Evaluation
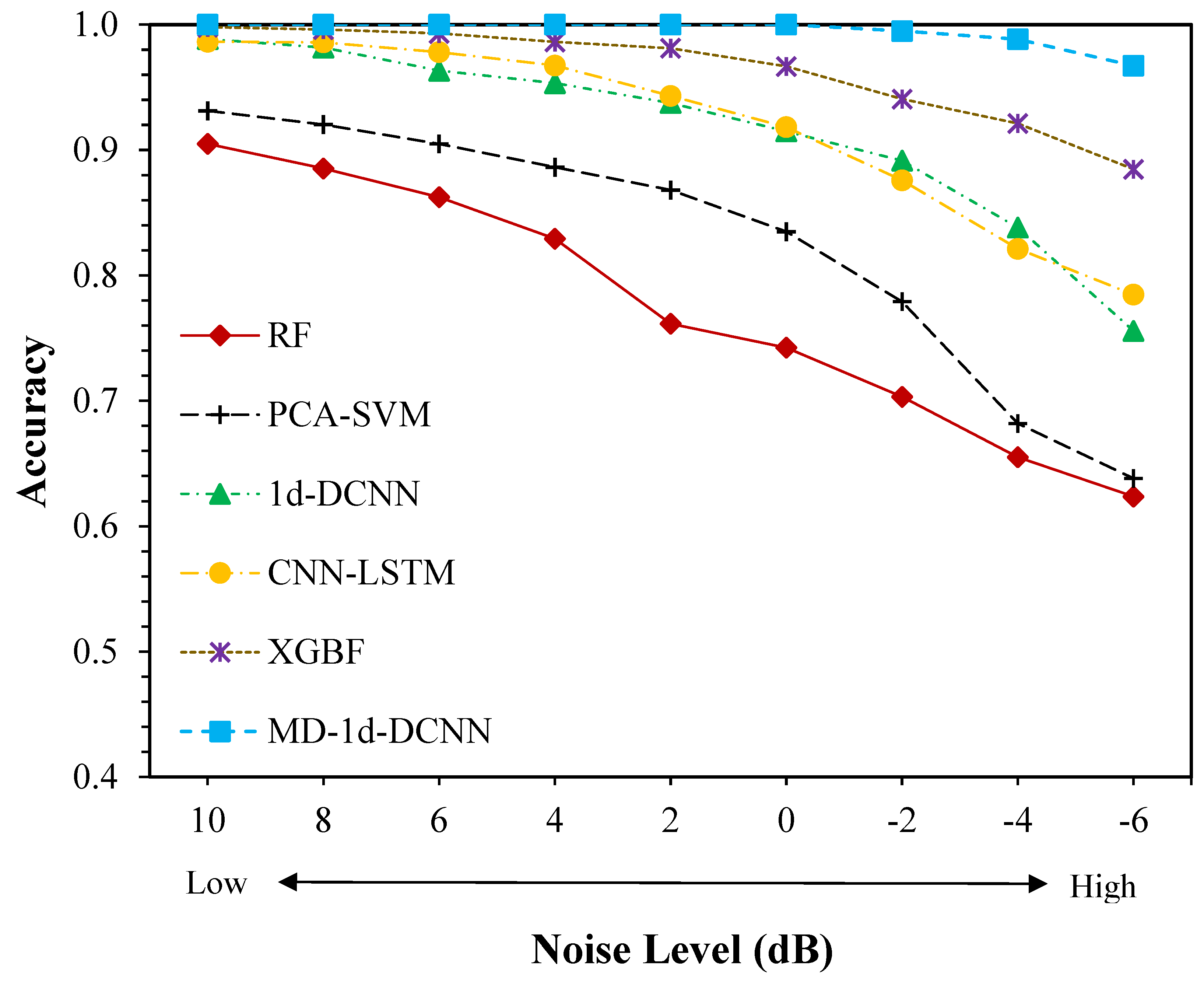
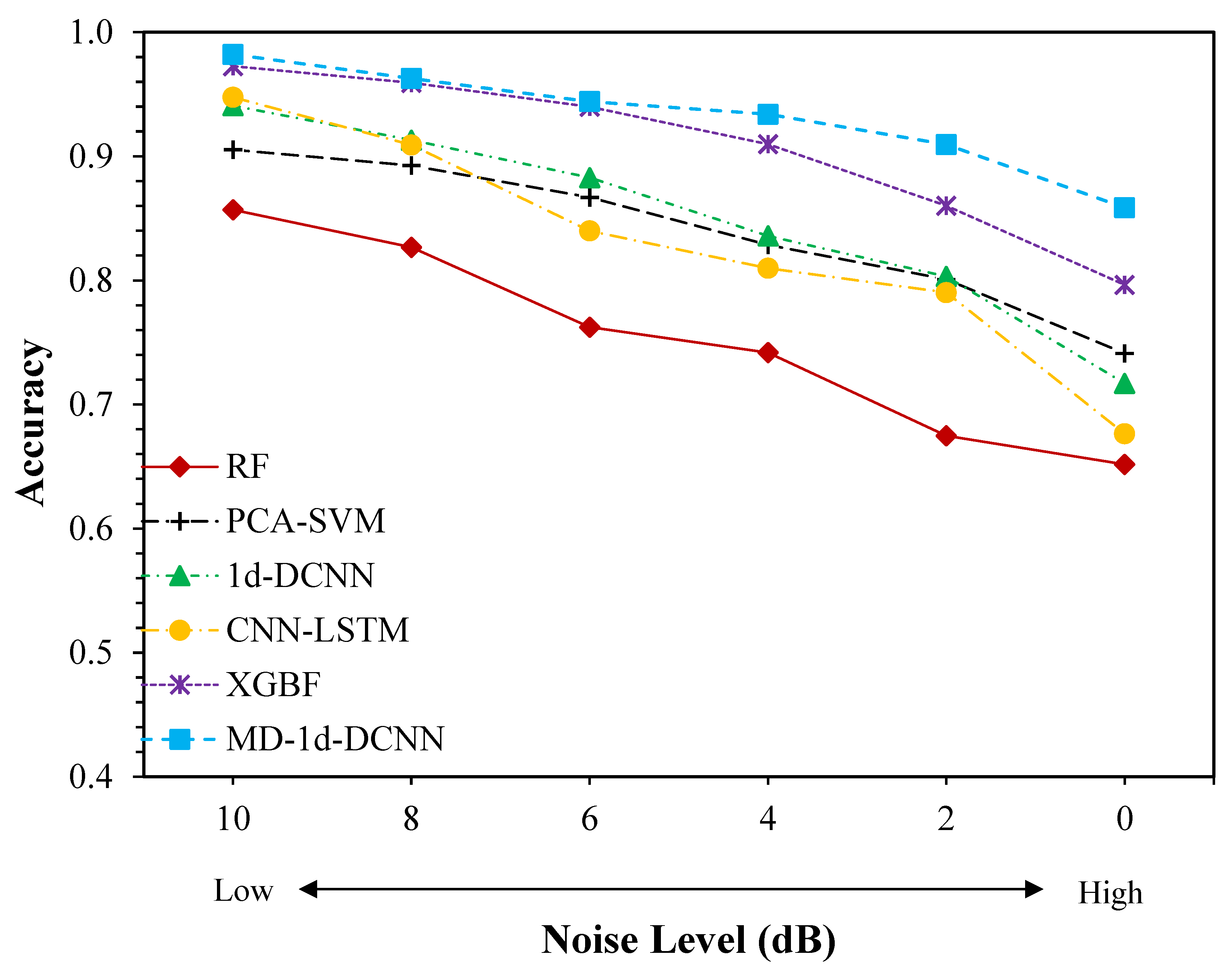
4.1.4. Model Performance under Various Noise Levels
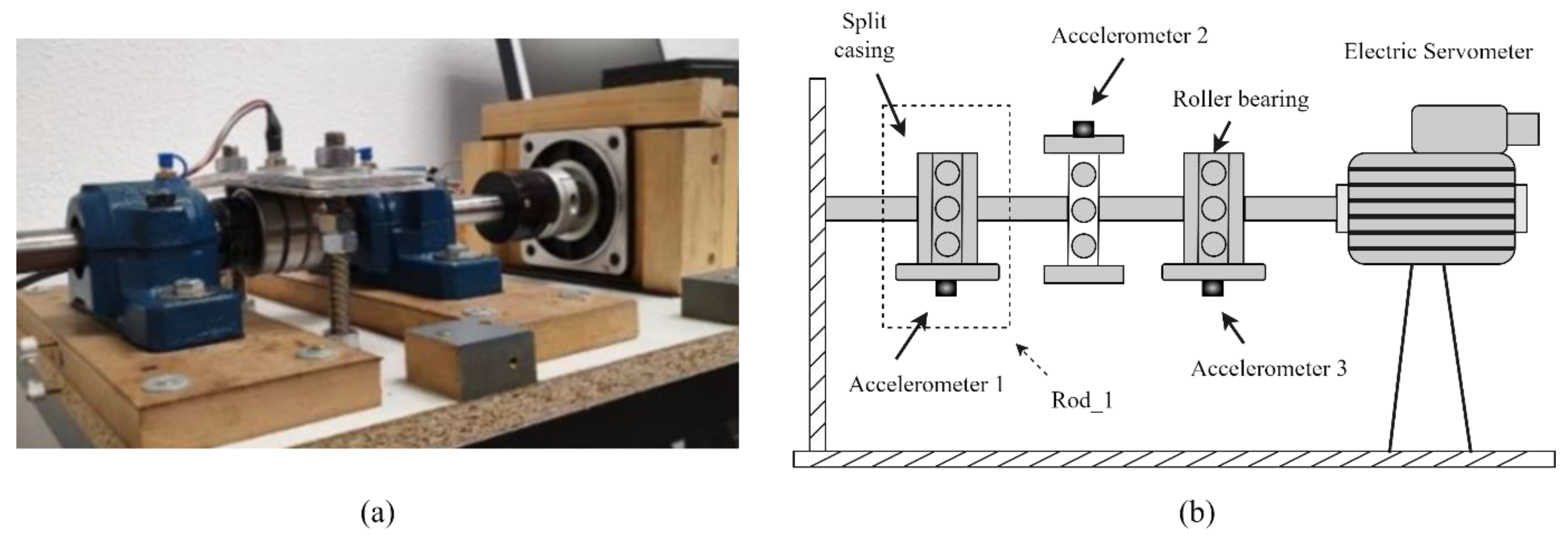
4.2. Case Two: The CITEF Bearing Data
4.2.1. Experimental Setup and Data Description
4.2.2. Model Evaluation
4.2.3. Model Performance under Various Noise Levels
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Lei, Y. Intelligent Fault Diagnosis and Remaining Useful Life Prediction of Rotating Machinery; Elsevier: Xi’an, China, 2017. [Google Scholar]
- Zhang, S.; Zhang, S.; Wang, B.; Habetler, T.G. Deep learning algorithms for bearing fault diagnostics—A comprehensive review. IEEE Access 2020, 8, 29857–29881. [Google Scholar] [CrossRef]
- AlShorman, O.; Alkahatni, F.; Masadeh, M.; Irfan, M.; Glowacz, A.; Althobiani, F.; Kozik, J.; Glowacz, W. Sounds and acoustic emission-based early fault diagnosis of induction motor: A review study. Adv. Mech. Eng. 2021, 13, 1–19. [Google Scholar] [CrossRef]
- Liu, R.; Yang, B.; Zio, E.; Chen, X. Artificial intelligence for fault diagnosis of rotating machinery: A review. Mech. Syst. Signal Process. 2018, 108, 33–47. [Google Scholar] [CrossRef]
- Mishra, R.K.; Choudhary, A.; Mohanty, A.R.; Fatima, S. Multi-domain Bearing Fault Diagnosis using Support Vector Machine. In Proceedings of the IEEE 4th International Conference on Computing, Power and Communication Technologies (GUCON), Kuala Lumpur, Malaysia, 24–26 September 2021. [Google Scholar]
- Yan, X.; Jia, M. A novel optimized SVM classification algorithm with multi-domain feature and its application to fault diagnosis of rolling bearing. Neurocomputing 2018, 313, 47–64. [Google Scholar] [CrossRef]
- Abid, A.; Khan, M.; Khan, M. Multidomain features-based GA optimized artificial immune system for bearing fault detection. IEEE Trans. Syst. Man Cybern. Syst. 2020, 50, 348–359. [Google Scholar] [CrossRef]
- Ma, Y.; Wu, X. Local-Dictionary Sparsity Discriminant Preserving Projections for Rotating Machinery Fault Diagnosis Based on Pre-Selected Multi-Domain Features. IEEE Sens. J. 2022, 22, 8781–8794. [Google Scholar] [CrossRef]
- Yu, D.; Zhu, C.; Zhang, M.; Liu, X. Experimental Study on Multi-Domain Fault Features of AUV with Weak Thruster Fault. Machines 2022, 10, 236. [Google Scholar] [CrossRef]
- Wu, Y.; Zhao, R.; Jin, W.; He, T.; Ma, S.; Shi, M. Intelligent fault diagnosis of rolling bearings using a semi-supervised convolutional neural network. Appl. Intell. 2020, 51, 2144–2160. [Google Scholar] [CrossRef]
- Zhang, J.; Sun, Y.; Guo, L.; Gao, H.; Hong, X.; Song, H. A new bearing fault diagnosis method based on modified convolutional neural networks. Chin. J. Aeronaut. 2020, 33, 439–447. [Google Scholar] [CrossRef]
- Guo, X.; Chen, L.; Shen, C. Hierarchical adaptive deep convolution neural network and its application to bearing fault diagnosis. Measurement 2016, 93, 490–502. [Google Scholar] [CrossRef]
- Jing, L.; Zhao, M.; Li, P.; Xu, X. A convolutional neural network based feature learning and fault diagnosis method for the condition monitoring of gearbox. Measurement 2017, 111, 1–10. [Google Scholar] [CrossRef]
- Abdeljaber, O.; Avci, O.; Kiranyaz, S.; Gabbouj, M.; Inman, D.J. Real-time vibration-based structural damage detection using one-dimensional convolutional neural networks. J. Sound Vib. 2017, 388, 154–170. [Google Scholar] [CrossRef]
- Peng, B.; Xia, H.; Lv, X.; Annor-Nyarko, M.; Zhu, S.; Liu, Y.; Zhang, J. An intelligent fault diagnosis method for rotating machinery based on data fusion and deep residual neural network. Appl. Intell. 2021, 52, 3051–3065. [Google Scholar] [CrossRef]
- Liang, M.; Cao, P.; Tang, J. Rolling bearing fault diagnosis based on feature fusion with parallel convolutional neural network. Int. J. Adv. Manuf. Technol. 2020, 112, 819–831. [Google Scholar] [CrossRef]
- Guo, D.; Zhong, M.; Ji, H.; Liu, Y.; Yang, R. A hybrid feature model and deep learning based fault diagnosis for unmanned aerial vehicle sensors. Neurocomputing 2018, 319, 155–163. [Google Scholar] [CrossRef]
- Xie, J.; Li, Z.; Zhou, Z.; Liu, S. A Novel Bearing Fault Classification Method Based on XGBoost: The Fusion of Deep Learning-Based Features and Empirical Features. IEEE Trans. Instrum. Meas. 2020, 70, 1–9. [Google Scholar] [CrossRef]
- Khorram, A.; Khalooei, M.; Rezghi, M. End-to-end CNN+LSTM deep learning approach for bearing fault diagnosis. Appl. Intell. 2021, 51, 736–751. [Google Scholar] [CrossRef]
- Zhang, W.; Li, C.; Peng, G.; Chen, Y.; Zhang, Z. A deep convolutional neural network with new training methods for bearing fault diagnosis under noisy environment and different working load. Mech. Syst. Signal Process. 2018, 100, 439–453. [Google Scholar] [CrossRef]
- Zhang, W.; Peng, G.; Li, C.; Chen, Y.; Zhang, Z. A New Deep Learning Model for Fault Diagnosis with Good Anti-Noise and Domain Adaptation Ability on Raw Vibration Signals. Sensors 2017, 17, 425. [Google Scholar] [CrossRef] [Green Version]
- Yao, D.; Liu, L.H.; Yang, J.; Li, X. A lightweight neural network with strong robustness for bearing fault diagnosis. Measurement 2020, 159, 107756. [Google Scholar] [CrossRef]
- Holschneider, M.; Kronland-Martinet, R.; Morlet, J.; Tchamitchian, P. A Real-Time Algorithm for Signal Analysis with the Help of the Wavelet Transform. In Wavelets; Springer: Berlin/Heidelberg, Germany, 1990. [Google Scholar]
- Chen, L.; Yang, Y.; Wang, J.; Xu, W.; Yuille, A. Attention to scale: Scale-ware semantic image segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- He, F.; Ye, Q. A Bearing Fault Diagnosis Method Based on Wavelet Packet Transform and Convolutional Neural Network Optimized by Simulated Annealing Algorithm. Sensors 2022, 22, 1410. [Google Scholar] [CrossRef]
- Huang, D.; Zhang, W.-A.; Guo, F.; Liu, W.; Shi, X. Wavelet Packet Decomposition-Based Multiscale CNN for Fault Diagnosis of Wind Turbine Gearbox. IEEE Trans. Cybern. 2021, 53, 443–453. [Google Scholar] [CrossRef] [PubMed]
- Rezamand, M.; Kordestani, M.; Carriveau, R.; Ting, D.S.-K.; Saif, M. An Integrated Feature-Based Failure Prognosis Method for Wind Turbine Bearings. IEEE/ASME Trans. Mechatron. 2020, 25, 1468–1478. [Google Scholar] [CrossRef]
- Chadha, G.; Panara, U.; Schwung, A.; Ding, S. Generalized dilation convolutional nerural networks for remaining useful lifetime estimation. Neurocomputing 2021, 452, 182–199. [Google Scholar] [CrossRef]
- Yu, F.; Koltun, V. Multi-scale context aggregation by dilated convolutions. In Proceedings of the 4th International Conference on Learning Representations, ICLR 2016, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Shensa, M. The discrete wavelet transform: Wedding the a trous and Mallat algorithms. IEEE Trans. Signal Process. 1992, 40, 2464–2482. [Google Scholar] [CrossRef] [Green Version]
- van den Oord, A.; Dieleman, S.; Zen, H.; Simonyan, K.; Vinyals, O.; Graves, A.; Kalchbrenner, N.; Senior, A.; Kavukcuoglu, K. Wavenet: A generative model for raw audio. arXiv 2016, arXiv:1609.03499. [Google Scholar]
- Tian, C.; Xu, Y.; Zup, W. Image denoising using deep CNN with batch renormalization. Neural Netw. 2020, 121, 461–473. [Google Scholar] [CrossRef]
- Fan, X.; Zuo, M.J. Gearbox fault detection using Hilbert and wavelet packet transform. Mech. Syst. Signal Process. 2006, 20, 966–982. [Google Scholar] [CrossRef]
- Yu, G. A Concentrated Time–Frequency Analysis Tool for Bearing Fault Diagnosis. IEEE Trans. Instrum. Meas. 2019, 69, 371–381. [Google Scholar] [CrossRef]
- Case Western Reserve University (CWRU) Bearing Data Centre. December 2018. Available online: https://engineering.case.edu/bearingdatacenter/welcome (accessed on 1 October 2007).
- Soto-Ocampo, C.R.; Mera, J.M.; Cano-Moreno, J.D.; Garcia-Bernardo, J.L. Low-Cost, High-Frequency, Data Acquisition System for Condition Monitoring of Rotating Machinery through Vibration Analysis-Case Study. Sensors 2020, 20, 3493. [Google Scholar] [CrossRef]
- Soto-Ocampo, C.R.; Cano-Moreno, J.D.; Mera, J.M.; Maroto, J. Bearing Severity Fault Evaluation Using Contour Maps—Case Study. Appl. Sci. 2021, 11, 6452. [Google Scholar] [CrossRef]
- Dong, J.; Li, H.; Fan, Z.; Zhao, X. Time-Frequency Sparse Reconstruction of Non-Uniform Sampling for Non-Stationary Signal. IEEE Trans. Veh. Technol. 2021, 70, 11145–11153. [Google Scholar] [CrossRef]
- Smith, W.A.; Randall, R.B. Rolling element bearing diagnostics using the Case Western Reserve University data: A benchmark study. Mech. Syst. Signal Process. 2015, 64–65, 100–131. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Time Domain | Frequency Domain | Time-Frequency Domain | |||
|---|---|---|---|---|---|
| Mean-absolute | Position change indicator | Relative energy | where energy of each frequency band, =1 | ||
| Root-mean-square | |||||
| Square-mean-root | |||||
| Peak-to-peak | Energy indicator | ||||
| Kurtosis | Energy entropy | where | |||
| Crest factor | |||||
| Shape factor | |||||
| Impulse | |||||
| Operation | Layer | Parameter |
|---|---|---|
| 1d-DCNN feature extraction | 1d-DCNN (LeakyReLU, BN, MaxPooling) | Filter: 16, kernel: 64, dilation rate: 1, pool size: 2 |
| 1d-DCNN (LeakyReLU, BN, MaxPooling) | Filter: 32, kernel: 16, dilation rate: 2, pool size: 2 | |
| 1d-DCNN (LeakyReLU, BN, MaxPooling) | Filter: 32, kernel: 16, dilation rate: 4, pool size: 2 | |
| 1d-DCNN (LeakyReLU, BN, MaxPooling) | Filter: 64, kernel: 16, dilation rate: 4, pool size: 2 | |
| Dense | Units: 16 | |
| Dropout | Dropout rate: 0.2 | |
| Multi-domain feature extraction | Dense | Units: 100 |
| Dense | Units: 50 | |
| Dense | Units: 16 | |
| Dropout | Dropout Rate: 0.5 | |
| Output layer | Dense | Units: 32 |
| Dense | Units: 12 |
| Fault Type | Fault Diameter (in) | Class Label | Sample Size |
|---|---|---|---|
| Normal (N) | - | 0 | 120 |
| Inner race (IR) | 0.007 | 1 | 120 |
| 0.014 | 2 | 120 | |
| 0.021 | 3 | 120 | |
| 0.028 | 4 | 120 | |
| Rolling element (RA) | 0.007 | 5 | 120 |
| 0.014 | 6 | 120 | |
| 0.021 | 7 | 120 | |
| 0.028 | 8 | 120 | |
| Outer race (OR) | 0.007 | 9 | 120 |
| 0.014 | 10 | 120 | |
| 0.021 | 11 | 120 |
| Methods | ||||||
|---|---|---|---|---|---|---|
| MD-1d-DCNN | XGBF | CNN-LSTM | 1d-DCNN | RF | PCA-SVM | |
| Accuracy | 100.0% | 99.70% | 99.89% | 99.89% | 91.94% | 95.32% |
| Time | 55 s | 133 s | 101 s | 36 s | 96 s | 71 s |
| Fault Type | Damage Description | Fault Class | Sample Size | ||
|---|---|---|---|---|---|
| Location | Area (mm2) | Depth (mm) | |||
| Rolling element (RE) & Outer race (OR) | RE OR | 0 0 | 0 0 | 0 | 765 |
| RE OR | 11.05 25.874 | 0.006 0.007 | 1 | 765 | |
| RE OR | 11.57 28.928 | 0.014 0.013 | 2 | 765 | |
| RE OR | 11.7 31.983 | 0.019 0.02 | 3 | 765 | |
| RE OR | 13 33.241 | 0.027 0.028 | 4 | 765 | |
| Methods | ||||||
|---|---|---|---|---|---|---|
| MD-1d-DCNN | XGBF | CNN-LSTM | 1d-DCNN | RF | PCA-SVM | |
| Accuracy | 99.35% | 98.85% | 98.95% | 98.04% | 88.27% | 91.36% |
| Time | 147 s | 546 s | 413 s | 56 s | 515 s | 394 s |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dong, K.; Lotfipoor, A. Intelligent Bearing Fault Diagnosis Based on Feature Fusion of One-Dimensional Dilated CNN and Multi-Domain Signal Processing. Sensors 2023, 23, 5607. https://doi.org/10.3390/s23125607
Dong K, Lotfipoor A. Intelligent Bearing Fault Diagnosis Based on Feature Fusion of One-Dimensional Dilated CNN and Multi-Domain Signal Processing. Sensors. 2023; 23(12):5607. https://doi.org/10.3390/s23125607
Chicago/Turabian StyleDong, Kaitai, and Ashkan Lotfipoor. 2023. "Intelligent Bearing Fault Diagnosis Based on Feature Fusion of One-Dimensional Dilated CNN and Multi-Domain Signal Processing" Sensors 23, no. 12: 5607. https://doi.org/10.3390/s23125607
APA StyleDong, K., & Lotfipoor, A. (2023). Intelligent Bearing Fault Diagnosis Based on Feature Fusion of One-Dimensional Dilated CNN and Multi-Domain Signal Processing. Sensors, 23(12), 5607. https://doi.org/10.3390/s23125607