1. Introduction
Among the fundamental technologies in intelligent transportation systems (ITS), the Internet of Vehicles (IoV) serves as a platform for information transmission, facilitating the creation of a vast network for the exchange and sharing of information among vehicle-to-everything (V2X) entities. Through real-time sensing and collaboration among various functional entities, such as people, vehicles, roads, and clouds, IoV has become a crucial tool, reducing traffic congestion, enhancing operational efficiency, and promoting safe and eco-friendly travel in modern cities [
1,
2,
3].
With the advent of the 5G era, the number of IoV users and services is expected to increase substantially. In-vehicle mobile terminal communication devices will be required to not only process massive volumes of service data but also ensure the quality requirements of differentiated and diverse services. Networked technologies are essential to realize L3 level conditional autonomous driving and L4 advanced autonomous driving [
4], compensating for the limited sensing capability of local sensors and enabling the fusion decision making of global sensing information in complex environments.
L3 and L4 level autonomous driving systems impose significant demands for quality of service (QoS). However, several challenges exist in ensuring QoS through resource allocation. On one hand, autonomous driving relies on immediate and reliable traffic information, requiring 99.999% reliability and ultra-low latency of less than 5 ms end-to-end [
5]. Hence, it is crucial to allocate limited network resources appropriately to guarantee QoS for users. On the other hand, the proliferation of IoV applications and the densification of communication node deployments have led to a substantial increase in the variety and volume of services in next-generation traffic information networks. The exponential growth of data further exacerbates resource constraints. Wireless resource allocation methods for IoV can be categorized into three types: those based on traditional convex optimization theory, game theory, and machine learning-based approaches.
Resource allocation optimization is a challenging problem, commonly formulated as a mixed-integer nonlinear programming model, known for its nonconvexity and NP-hardness [
6]. Previous studies [
7,
8,
9] have primarily addressed resource allocation using traditional convex optimization principles. In [
7], a mixed-integer nonlinear programming problem is formulated to maximize the sum ergodic capacity of vehicle-to-infrastructure (V2I) links while ensuring a specified probability of delayed outages in vehicle-to-vehicle (V2V) links. The problem is decomposed into two subproblems: power allocation and spectrum allocation. For dynamic resource allocation [
8], a two-stage algorithm named DRA and DRA-Pre is introduced, which utilizes a multi-valued discrete particle swarm optimization technique to solve the resource allocation problem in the first stage, while dividing the precoding design problem into rate maximization and total power consumption minimization subproblems in the second stage. In [
9], whale optimization algorithms are applied to address resource allocation problems in wireless networks. This involves power allocation strategies to achieve a balance between energy and spectral efficiency, power allocation to maximize throughput, and mobile edge computing shunting. Alternatively, certain studies [
10,
11,
12] treat the resource allocation problem as a game and utilize game theory techniques to solve it.
One study [
10] proposes an innovative auction-matching-based spectrum allocation scheme that considers interference constraints and user satisfaction. This approach effectively improves the spectrum efficiency for users, addressing the limitations of traditional mechanisms. In a different study [
11], the resource allocation problem is modeled as a multi-user game, and the existence of Nash equilibrium is proven through a potential game. To optimize the computational and communication resources and maximize the system utility, a multi-user offloading algorithm based on better response is proposed. In yet another study [
12], a resource allocation scheme is designed for unmanned aerial vehicle (UAV)-assisted vehicle communication scenarios. The study introduces a two-stage resource allocation algorithm based on Stackelberg game principles. In the first stage, a clustering algorithm matches users with different blocks of spectrum resources. Subsequently, in the second stage, the Stackelberg game is employed to solve the power optimization problem for each cluster, achieving the dual objectives of maximizing the sum rate of V2I users while ensuring the reliability of V2V users.
Deep learning has emerged as a powerful data-driven approach addressing resource allocation challenges by learning efficient data representations with multiple levels of abstraction from unstructured sources [
13]. In [
14], a deep learning-based damped 3D messaging algorithm is proposed, considering tradeoffs between energy efficiency and spectral efficiency as the optimization objective. This algorithm takes into account quality of service, power consumption, and data rate constraints. In [
15], a binarized neural network is utilized for resource allocation. The primary objective of this scheme is to maximize the classification accuracy at the server while adhering to a total transmit power constraint. Another study [
16] introduces a distributed resource allocation mechanism where agents, such as V2V links or vehicles, can make decisions without waiting for global state information. Each agent efficiently learns to satisfy strict delay constraints on V2V links while minimizing interference with V2I communication. Considering the bandwidth and low latency requirements in vehicular communication applications, one study [
17] proposes a framework and optimization scheme for the slicing pf networks based on device-to-device communication. The slicing resource allocation problem is modeled as a Markov decision process, and a deep reinforcement learning (RL) algorithm is employed to solve the problem, leading to improved resource utilization, slice satisfaction, and throughput gain. In the integration of communication mode selection and resource allocation, one study [
18] formulates a Markov decision process problem and solves it using a deep deterministic policy gradient algorithm. This approach effectively improves the long-term energy efficiency. For joint computation offloading and resource allocation decisions, another study [
19] proposes two distinct methods: a value iteration-based RL method and a double deep Q-network (DDQN)-based method. These methods aim to optimize resource allocation decisions while considering computation offloading. Additionally, in [
20], a novel fuzzy-logic-assisted Q-learning model (FAQ) is proposed, leveraging the advantages of the centralized allocation mode. The FAQ model aims to maximize network throughput while minimizing interference caused by concurrent transmissions during resource allocation.
Additionally, 5G New Radio V2X (NR V2X) [
21] is considered a promising technology after LTE V2X, proposing new goals for air interface selection, interface enhancement, and quality management to support advanced V2X applications with varying levels of latency, reliability, and throughput requirements. The application of network slicing technology [
22] provides a novel idea for telematics resource allocation. V2I and V2V communication aim to facilitate information exchange, promoting enhanced mobile broadband and ultra-reliable low-latency communication for widespread usage. Activities such as cloud access, video streaming, and in-vehicle social networking entail large data exchanges, necessitating frequent access to wireless access points and core web servers, requiring high-speed communication links for efficient data transmission. Similarly, safety-critical information, such as collaboration-aware content, dispersed environmental notification information, and autonomous driving data in vehicle networks, demand exceptionally stringent ultra-low latency and high reliability. Consequently, V2V communication needs to offer communication services with improved spectrum and energy efficiency and higher communication rates and meet more stringent reliability and latency requirements by accessing ultra-reliable and low-latency communications (URLLC) slices.
Traditional resource allocation methods can no longer meet the delay and reliability demands of V2V communication. In recent years, with the development of artificial intelligence, researchers have found reinforcement learning [
23] to be effective for decision making in situations with uncertainty conditions. It provides a robust and principled approach to making a series of decisions in dynamically changing environments, making it a considerable approach to address specific highly dynamic problems in vehicular networking.
Hence, studying the V2V resource allocation problem with the ultra-low latency and high reliability constraints of V2V communication holds significant research significance. The main work and innovations of this paper are as follows.
We explore the application of mixed spectrum access for V2V links and V2I links under the 5G New Radio V2X standard and network slicing technology. To maximize the spectrum–energy efficiency (SEE) of the network, we incorporate the reliable transmission and delay constraints of URLLC slicing into the optimization problem.
We use the multi-agent deep Q-network (MDQN) to handle the resource allocation problem by setting up state, action, and reward functions rationally.
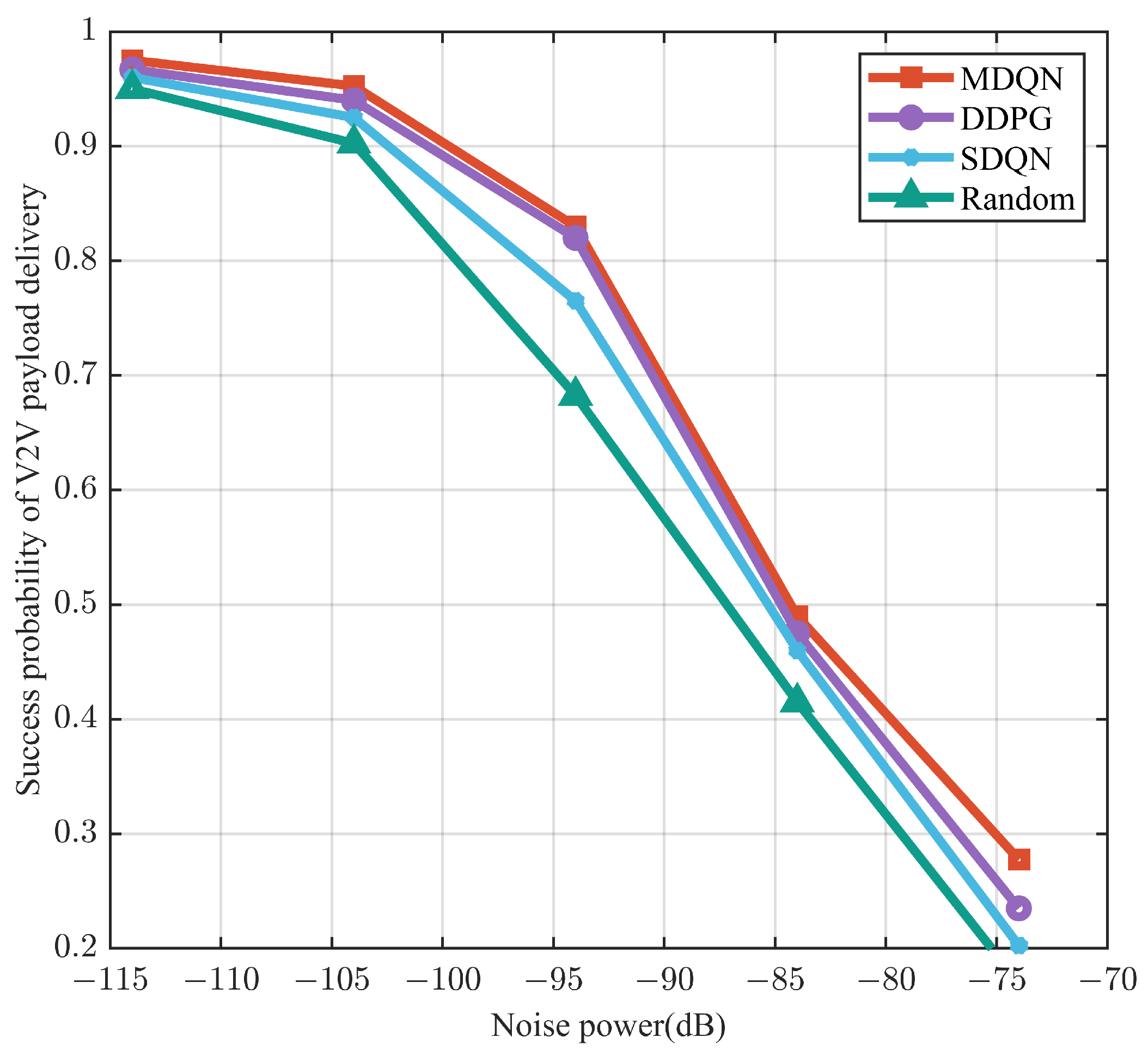
Simulation results demonstrate that the proposed algorithm improves the SEE of the network while guaranteeing the success rate of V2V link load transmission. When compared to three other resource allocation schemes, the MDQN algorithm allows for distributed resource allocation in response to environmental variations, promoting collaboration among V2V links to achieve global optimization.
2. System Model
Based on 5G NR V2X, in order to improve the network transmission rate and enhance the spectrum utilization at the same time, a hybrid spectrum access technology is proposed to be used for transmission, i.e., the PC5 interface and the Uu interface share spectrum resources. Vehicles can be divided into two types: cellular users (CUEs), who communicate with the base station for V2I and access the vehicular network through the Uu interface to request high-speed communication services from the base station, and V2V users (VUEs), who communicate with adjacent vehicles for side-chain communication and access the vehicular network through the PC5 interface to achieve low latency and high reliability. To cater to diverse vehicle requirements, we establish two logical slices within a shared infrastructure: the eMBB slice and the URLLC slice. Within the 5G network, vehicles have the option to access either the eMBB slice or the URLLC slice. The eMBB slice is designed for regular internet access and remote server connectivity, involving substantial data exchange. It serves CUEs that require frequent and reliable internet access. On the other hand, the URLLC slice is intended for the transmission of safety-critical information and is primarily utilized by VUEs.
Since V2V and V2I communications utilize different slices, the resource allocation for V2V links must be independent of the resource allocation for V2I links.
Figure 1 illustrates a V2X communications scenario based on the 5G network, where
K pairs of V2V links are present. For V2V links, we assume that there is an authorized bandwidth of
B, which is evenly divided into
M subchannels. Denote the subchannel set and the V2V link set as
and
, respectively. At the same time, the channel transmission in the model uses Orthogonal Frequency Division Multiplexing (OFDM) technology, and the subchannels are orthogonal to each other without interference, but the same subchannel can be shared by more than one user and interference will occur between the VUEs sharing the same subchannel, thus affecting the channel capacity.
The signal to interference plus noise ratio (SINR) of the
kth V2V link at the
mth subchannel can be expressed as
where
represents the channel gain of the
kth V2V link at the
mth subchannel; it comprises two components: the large-scale fading component and the small-scale component. Additionally, the large-scale fading component includes two factors, namely shadowing and path loss. The channel capacity of the
kth V2V link on the
mth subchannel can be expressed as
Among them,
is the total interference power of all V2V links sharing the same subchannel.
denotes the transmit power of the
kth VUE.
denotes the noise power, and
is the interference gain of the
th V2V link to the
kth V2V link.
indicates the subchannel allocation indicator, and
indicates that the
kth V2V link occupies the subchannel
m; otherwise,
. It is specified that each V2V link can select only one subchannel for transmission at the same moment, i.e.,
.
In addition, the reliability requirement of V2V communication is expressed by the following equation.
where
is the signal-to-noise ratio threshold for the VUE receiver on the
kth V2V link.
Assume that the packet arrival process of the
kth V2V link is independently and identically distributed and obeys a Poisson distribution with an arrival rate of
.
denotes the size of the first
n packets and obeys an exponential distribution with an average packet size of
, and
is the number of packets cached by the
kth V2V link in the time slot
t. Moreover,
is the packet waiting time in the cache to be served, and
denotes the packet transmission time, so the time delay of the
xth packet in the V2V user’s
k cache is
The packet of the
kth V2V link must be guaranteed to be transmitted within a finite time,
denotes the maximum tolerable delay in packet transmission,
is the maximum violation probability, and the delay interruption probability of V2V communication is bounded by
The constraints on the physical layer metrics of V2V include the spectral efficiency and energy efficiency, defined as the channel capacity that can be obtained per unit frequency and per unit energy consumption. Thus, the spectrum–energy efficiency (SEE) of V2V links can be expressed as
where
is the circuit power.
The objective of V2V resource allocation is to allocate the V2V link transmission power and subchannels to maximize the SEE of the V2V links while satisfying the delay and reliability constraints. Therefore, the following objective function and constraints can be established.
where the objective function is to maximize the SEE of the V2V links, constraints C1 and C2 are reliability and delay constraints on the V2V links, constraint C3 states that the transmission power is within the reachable maximum transmission power, and constraints C4 and C5 imply that each V2V link can be assigned to only one subchannel, but the same subchannel can access multiple V2V links.
3. Resource Allocation Algorithm
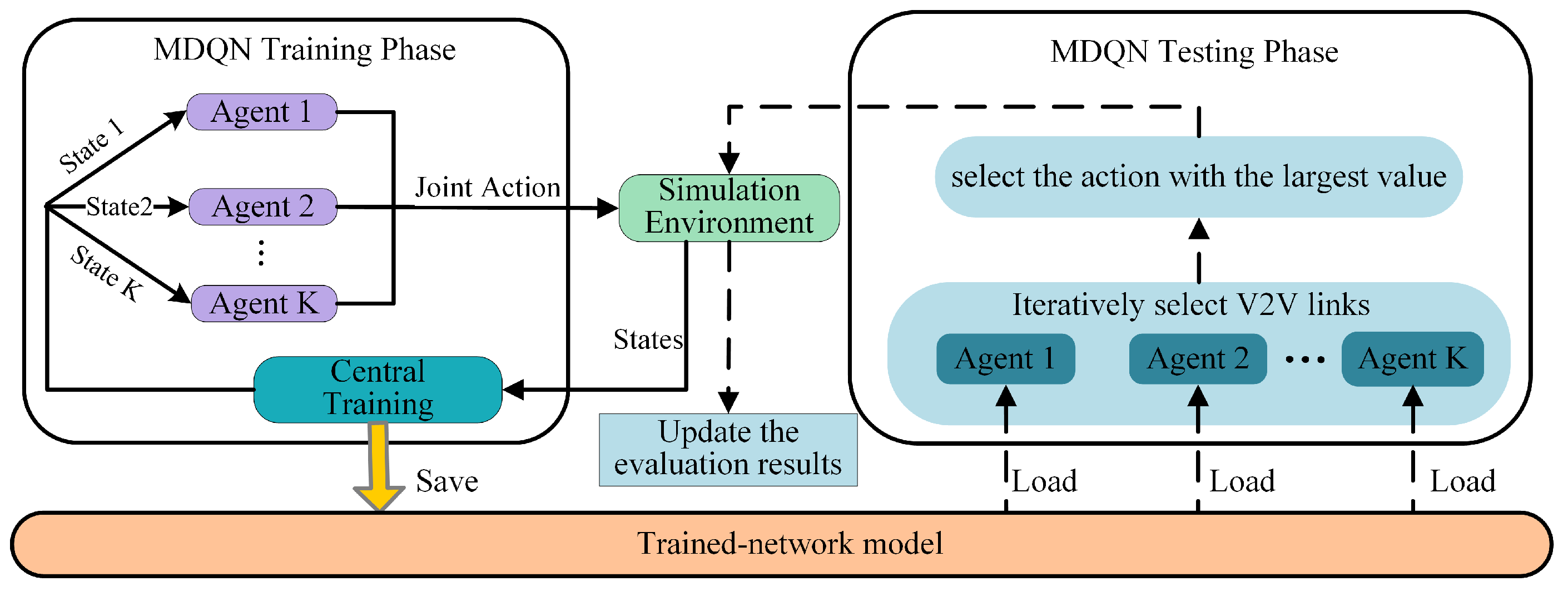
Reinforcement learning is a powerful technique that can be used to solve optimization problems. In the field of resource management for V2V communication, the conventional Q-learning approach has been observed to encounter difficulties in achieving convergence of the Q-function due to the limited accessibility of states and infrequent updates of corresponding Q-values. This limitation has led to the development of a more efficient method known as the deep Q-network (DQN), which combines the Q-learning algorithm with deep neural networks. We leverage DQN to train the multiple V2V agents, namely multi-agent DQN (MDQN). Motivated by the literature [
24], the MDQN algorithm comprises two distinct phases: the MDQN training phase and the MDQN testing phase, as depicted in
Figure 2. During the training phase, each V2V link operates as an independent agent, engaging in interactions with the simulation environment to obtain rewards. In order to ensure consistency in network performance, all agents are assigned the same reward. Moreover, the reward and subsequent state are solely dependent on the current state and the joint actions taken by all agents [
25]. This information, which is introduced as follows, encompassing the current state, action, reward, and subsequent state, is then utilized to update the network of each agent. In the MDQN testing phase, each V2V agent receives local observations of the environment and, based on its trained network model, selects an action to execute.
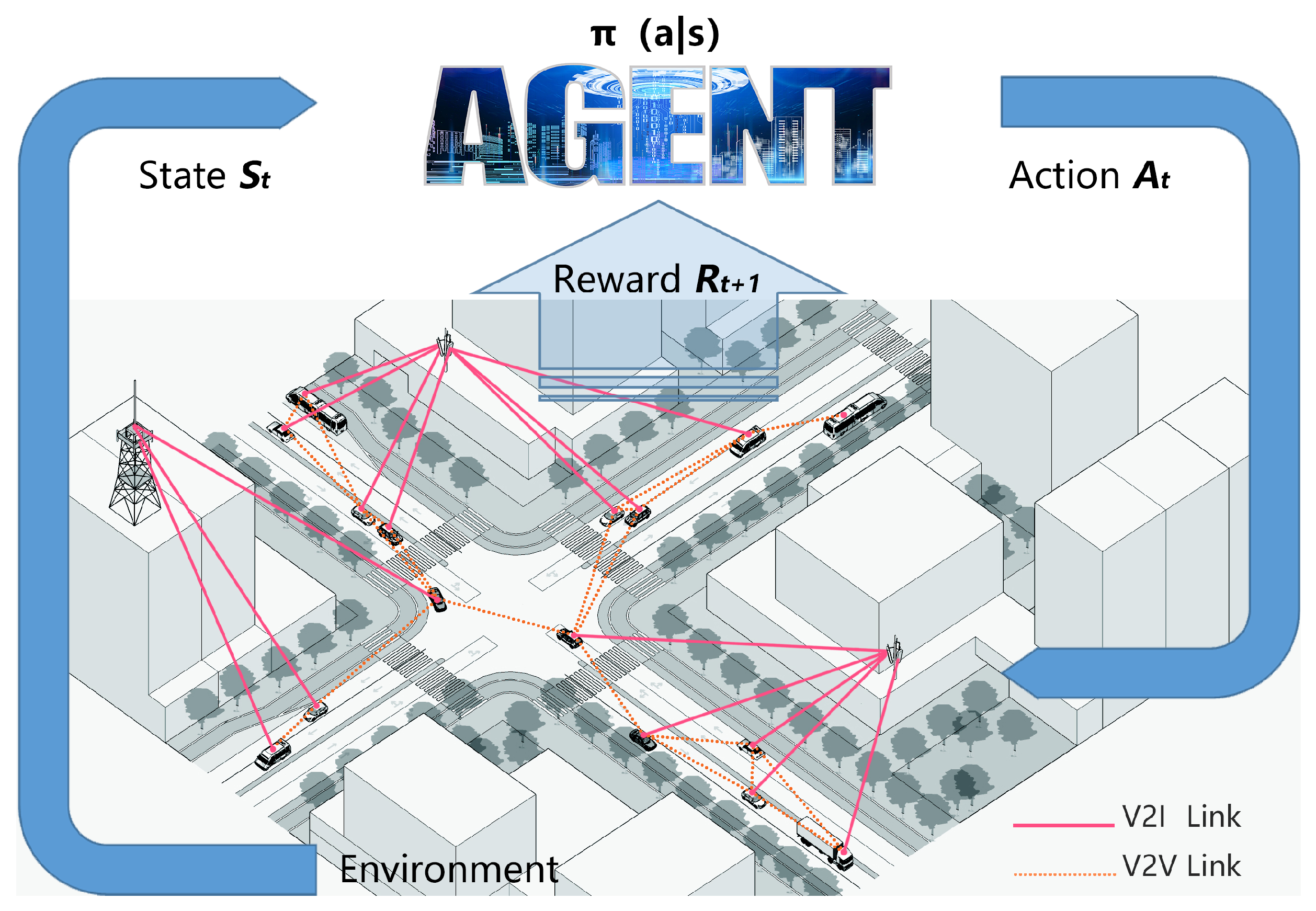
3.1. Status, Action, Reward
The high mobility of vehicles can result in incomplete access to channel state information for the central controller, which necessitates the use of a distributed resource allocation scheme. This framework considers each V2V link as an agent, with all other V2V links being regarded as the environment. At any given moment
t, the state of an agent is represented by the information that it senses, denoted as
. Agents interact with the environment by selecting subchannels and transmission power based on their local observations. This interaction results in the agent receiving a reward
and a new state
, as shown in
Figure 3.
State information
includes the local instantaneous channel information of the subchannel
m, denoted as
, the remaining V2V payload
, and the remaining time budget
.
where
is the channel power gain of the
kth V2V link, and
is the interference of the
th V2V link with the
kth V2V link.
Action space A includes the selection subchannel and the transmit power, and the selection subchannel is denoted by . denotes the kth V2V link using the mth channel. In existing resource allocation schemes, most of the transmission power is set to a continuous reading value, but considering the model training and actual vehicle limitations, the transmission power is set to [23,18,10,5,−100] dBm, and when the V2V link selection transmission power level is −100 dBm, it indicates that the V2V link transmission power level is 0. Thus, the action space dimension is , and each action corresponds to a particular combination of subchannel and power selection.
The flexibility of the reward function is a key strength of deep reinforcement learning, as it enables the agent to learn and adapt its behavior by receiving feedback in the form of rewards from its environment. This process of learning through trial and error can lead to significant improvements in performance, as the agent becomes better equipped to achieve its objectives.
The objective of V2V resource allocation is to maximize the SEE of the network while ensuring that the V2V link load is transmitted within the maximum tolerable delay and considering the SINR threshold value of the link. Therefore, the design of the reward function needs to consider these three components and the expression is as follows.
Among them,
where
is a fixed large constant,
is also a constant, and
and
are weights, both of which are empirically adjusted hyperparameters.
3.2. MDQN Algorithm
The Q-value, denoted by
, represents the expected long-term reward for taking an action
a in a given state
s. The classical Q-learning approach involves constructing a table of state–action pairs to store the Q-values and selecting actions based on these values to obtain larger gains. The algorithm works by initializing a table of values, setting the initial state, selecting the current state action with the highest reward based on the table, executing the action
a, and observing the resulting return
r and next state
. The algorithm then updates the Q-value table for each step by calculating
and storing it in the table. The Q-value can be considered as the expectation of the long-term payoff and the update formula can be expressed as
where
is the learning rate that controls the step size of the updates and
is the discount factor that determines the importance of future rewards.
DQN leverages the approximation of the optimal Q-values by the network with parameters denoted by
through the following equation.
In training neural networks, DQN proposes two unique mechanisms.
Experience replay is a technique whereby the agent stores its experiences in a replay buffer, which is a data structure that contains a collection of transitions . The agent then samples a batch of transitions from the replay buffer and uses them to update its Q-network. This approach leads to a reduction in the correlations between successive updates, allowing for the more efficient use of data and improving the stability.
The target network involves using a separate network to estimate the target Q-values, i.e., the DQN uses two neural networks with different parameters but the same structure, as shown in
Figure 4. This helps to stabilize the learning process by reducing the variance in the target values used to update the Q-network.
3.2.1. MDQN Training Phase
The MDQN training process in this paper involves the interaction between the agent and the environment simulator, which generates training data. A double network structure is employed, consisting of a Q-network and a target Q-network with identical initial parameters. The agent generates experience by taking actions in the environment and storing the resulting state, action, reward, and next state in a memory pool. To train the neural network, a small batch of data is randomly selected from the experience pool, and a small batch gradient descent method is used to optimize the loss function. This method is less volatile than the random gradient method, reduces variance, and ensures stability. Additionally, small batch training has faster learning speeds and consumes less memory. In this paper, small batches of 50 data points are extracted for training.
The loss function is defined as the deviation of the target network from the current output as follows, which is optimized during training.
The DQN algorithm uses a target Q-value network that is separate from the Q-value network. The target network is kept fixed for a certain number of iterations, while the primary Q-value network is updated using backpropagation. Every C iterations, the weights of the primary network are then copied over to the target network, which is used to compute the Q-value targets for the next batch of experiences. This delayed update strategy helps to reduce the risk of oscillations and divergence in the learning process.
The specific training phase is shown in Algorithm 1.
| Algorithm 1: MDQN training phase for V2V resource allocation |
- 1:
Input: V2V link settings and for all - 2:
Output: Trained Q-value function and target Q-value network - 3:
Activate environmental simulator and generate vehicles - 4:
For each V2V link : - 5:
For each step: - 6:
Select subchannels and transmit power based on policy - 7:
Receive feedback on status and rewards of actions from ambient simulators - 8:
Collect and store data quadruplet state, reward, action, previous state in memory bank - 9:
Select a small batch of data from experience pool to train neural network - 10:
Perform gradient descent according to Equation (20) - 11:
If step is a multiple of C: - 12:
Copy Q-value network weights to target Q-value network - 13:
End For - 14:
End For - 15:
Return: Trained Q-value function and target Q-value network
|
3.2.2. MDQN Testing Phase
In the testing phase, the trained neural network model is loaded. Then, the algorithm’s performance is evaluated by changing the load or noise power of the V2V link in an environmental simulator, which generates vehicles and V2V links.
Each V2V link is selected as an agent, and the action with the largest Q-value is chosen by the agent. The environment is updated according to the chosen action, which results in a change in the state information provided by the environment simulator. The simulator returns a reward value to the agent, and the evaluation results, including the total transmission rate of V2V and the V2V link load transmission success rate, are provided by the environment simulator.
Since the agents select actions independently based on local information, simultaneous action updates can cause the agents to be unaware of the actions taken by other V2V links. This means that the state observed by each V2V link may not fully capture the environment. To address this issue, the agents update their actions asynchronously, meaning that only one or a small fraction of the V2V agents update their actions at each time period. This allows the changes in the environment caused by the actions of other agents to be observed. The specific MDQN testing phase is shown in Algorithm 2.
| Algorithm 2: MDQN testing phase for V2V resource allocation |
- 1:
Load the trained network model. - 2:
Activate the environmental simulator and generate vehicles. - 3:
Iteratively select V2V links in the system. - 4:
for each V2V link : - 5:
select the action with the largest value. - 6:
Update the environment simulator based on the selected action. - 7:
Update the evaluation results, including the total transmission rate of V2V and the V2V link load transmission success rate. - 8:
Return the evaluation results.
|













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}