
BERT-Based Approaches to Identifying Malicious URLs

Abstract
:1. Introduction
2. Related Research
- Utilization of BERT-based model with public datasets: The proposed system leverages three public datasets to demonstrate the effectiveness of the BERT-based model in detecting malicious URLs.
- Feature-based detection: Even when provided with only URL features rather than the URL strings, the proposed method works well, highlighting the versatility of the approach in different scenarios.
- Extensibility: The proposed method has the potential for extension to identify attacks in other environments, such as the Internet of Things (IoT) and Domain Name System over HTTPS (DoH), not solely limited to malicious URL detection.
- Real-time detection: The proposed system is designed for real-time deployment, allowing it to swiftly detect malicious URLs as they appear, enhancing online security measures.
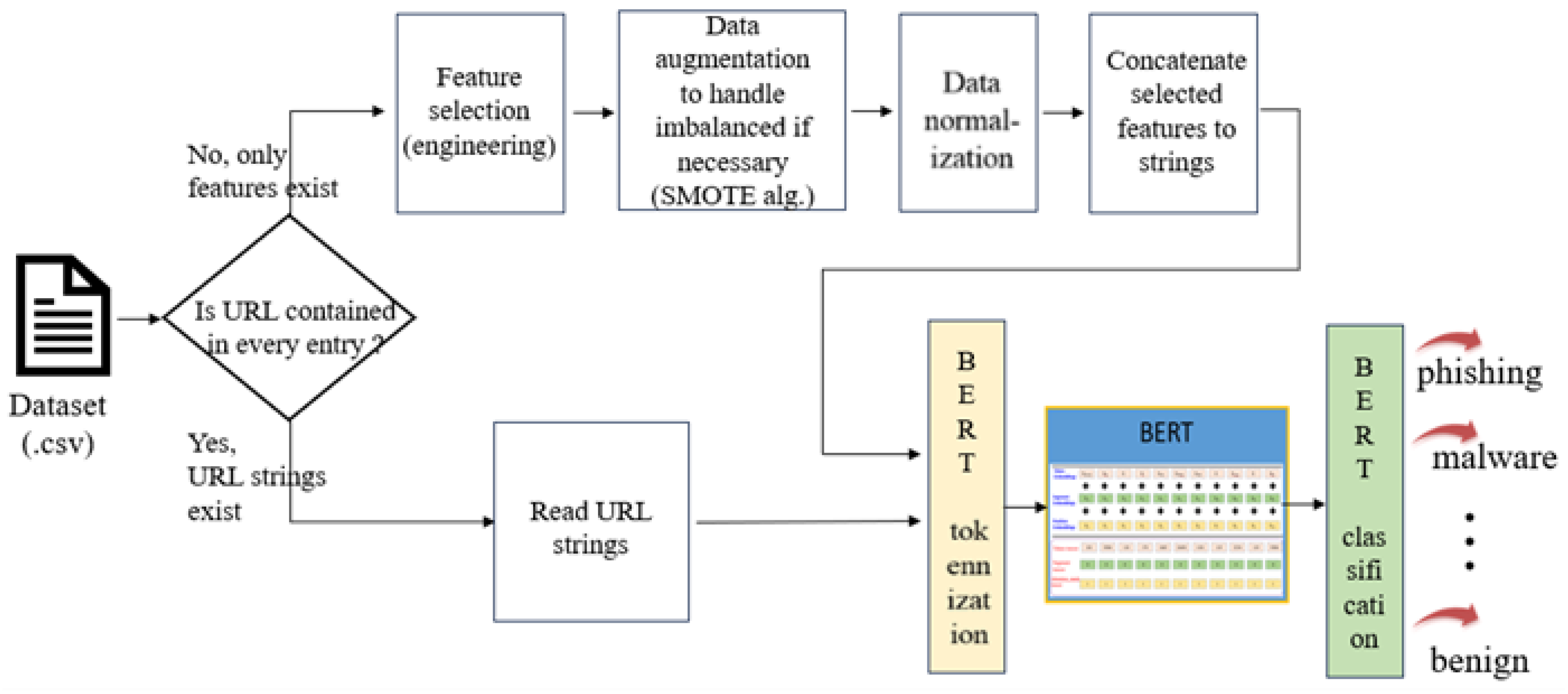
3. The Proposed Methodology
| Algorithm 1: URL Classification |
| Input: A dataset of labeled URLs or features, divided into 80% training and 20% testing. Output: Confusion matrix.
|
3.1. Data Pre-Processing
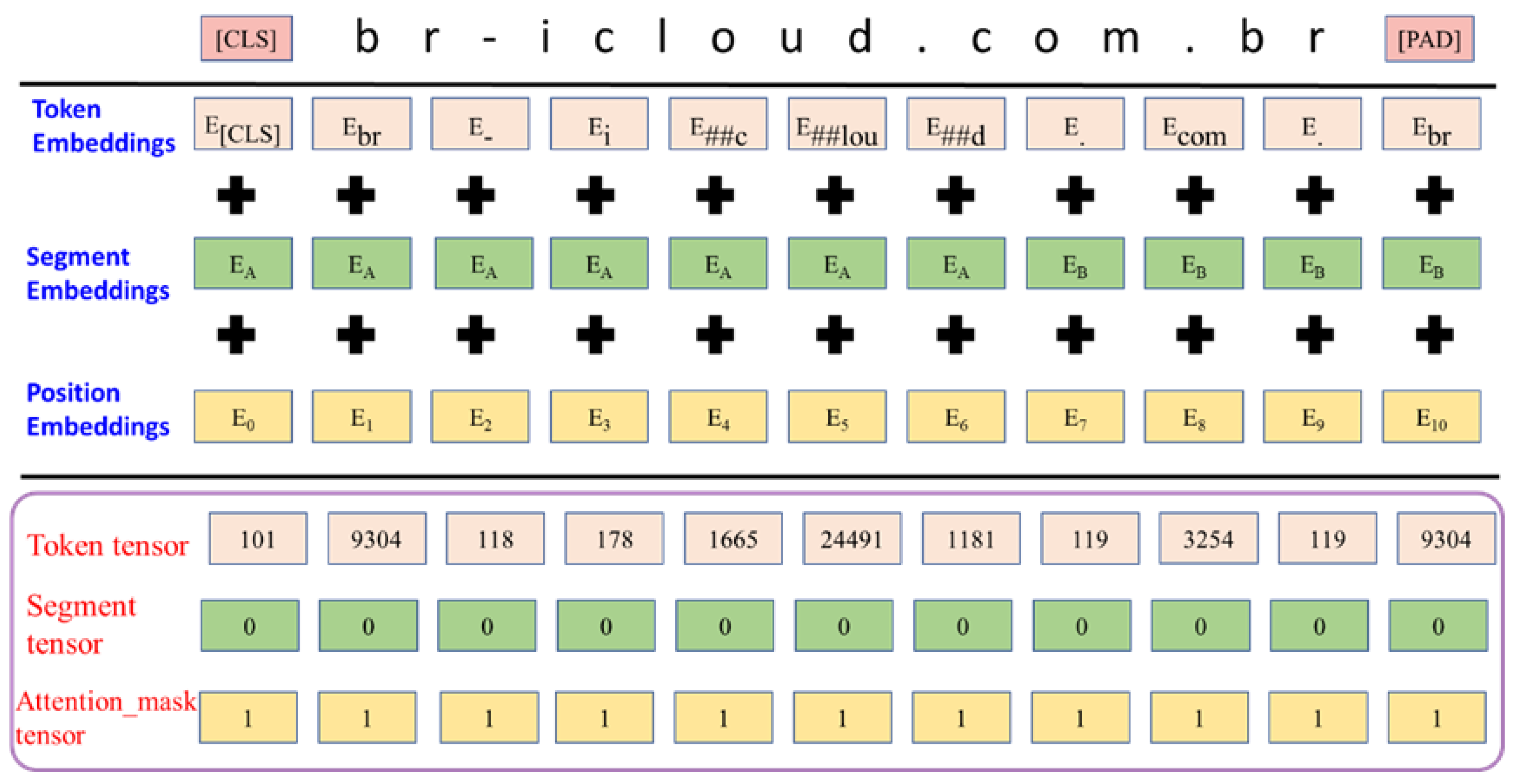
3.1.1. URL String and BERT Tokenization
3.1.2. URL Feature String and BERT Tokenization
3.2. Fine-Tuning the BERT Model
4. Experimental Results
4.1. Performance on Kaggle Dataset
4.2. Performance on GitHub Dataset
4.3. Performance on ISCX 2016 Dataset
4.4. Extending to Other Domains
4.5. URL Prediction Time
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Aaron, G.; Chapin, L.; Piscitello, D.; Strutt, C. Phishing Landscape 2022: An Annual Study of the Scope and Distribution of Phishing; Interisle Consulting Group, LLC: Boston, MA, USA, 2022; pp. 1–65. Available online: https://interisle.net/PhishingLandscape2022.pdf (accessed on 26 August 2023).
- Trend Micro 2021 Annual Cybersecurity Report: Navigating New Frontiers, 17 March 2022; pp. 1–42. Available online: https://documents.trendmicro.com/assets/rpt/rpt-navigating-new-frontiers-trend-micro-2021-annual-cybersecurity-report.pdf (accessed on 26 August 2023).
- Kumar, R.; Zhang, X.; Tariq, H.A.; Khan, R.U. Malicious URL Detection Using Multi-Layer Filtering Model. In Proceedings of the 14th IEEE International Computer Conference on Wavelet Active Media Technology and Information Processing (ICCWAMTIP), Chengdu, China, 15–17 December 2017; pp. 97–100. [Google Scholar]
- Ahammad, S.H.; Kale, S.D.; Upadhye, G.D.; Pande, S.D.; Babu, E.V.; Dhumane, A.V.; Bahadur, D.K.J. Phishing URL detection using machine learning methods. Adv. Eng. Softw. 2022, 173, 103288. [Google Scholar] [CrossRef]
- Gupta, B.B.; Yadav, K.; Razzak, I.; Psannis, K.; Castiglione, A.; Chang, X. A novel approach for phishing URLs detection using lexical based machine learning in a real-time environment. Comput. Commun. 2021, 175, 47–57. [Google Scholar] [CrossRef]
- Saleem, R.A.; Vinodini, R.; Kavitha, A. Lexical features based malicious URL detection using machine learning techniques. Mater. Today Proc. 2021, 47, 163–166. [Google Scholar] [CrossRef]
- Li, T.; Kou, G.; Peng, Y. Improving malicious URLs detection via feature engineering: Linear and nonlinear space transformation methods. Inf. Syst. 2020, 91, 101494. [Google Scholar] [CrossRef]
- Mondal, D.K.; Singh, B.C.; Hu, H.; Biswas, S.; Alom, Z.; Azim, M.A. SeizeMaliciousURL: A novel learning approach to detect malicious URLs. J. Inf. Secur. Appl. 2021, 62, 102967. [Google Scholar] [CrossRef]
- Srinivasan, S.; Ravi, V.; Arunachalam, A.; Alazab, M.; Soman, K.P. DURLD: Malicious URL Detection Using Deep Learning-Based Character Level Representations. In Malware Analysis Using Artificial Intelligence and Deep Learning; Springer: Berlin/Heidelberg, Germany, 2021; pp. 535–554. [Google Scholar]
- Bozkir, A.S.; Dalgic, F.C.; Aydos, M. GramBeddings: A New Neural Network for URL Based Identification of Phishing Web Pages Through N-gram Embeddings. Comput. Secur. 2023, 124, 102964. [Google Scholar] [CrossRef]
- Alshehri, M.; Abugabah, A.; Algarni, A.; Almotairi, S. Character-level word encoding deep learning model for combating cyber threats in phishing URL detection. Comput. Electr. Eng. 2022, 100, 107868. [Google Scholar] [CrossRef]
- Zheng, F.; Yan, Q.; Leung, V.C.M.; Yu, F.R.; Ming, Z. HDP-CNN: Highway deep pyramid convolution neural network combining word-level and character-level representations for phishing website detection. Comput. Secur. 2022, 114, 102584. [Google Scholar] [CrossRef]
- Hussain, M.; Cheng, C.; Xu, R.; Afzal, M. CNN-Fusion: An effective and lightweight phishing detection method based on multi-variant ConvNet. Inf. Sci. 2023, 631, 328–345. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Piñeiro, J.J.M.L.; Portillo, L.R.W. Web architecture for URL-based phishing detection based on Random Forest, Classification Trees, and Support Vector Machine. Intel. Artif. 2022, 25, 107–121. [Google Scholar] [CrossRef]
- Kalabarige, L.R.; Rao, R.S.; Abraham, A.; Gabralla, L.A. Multilayer Stacked Ensemble Learning Model to Detect Phishing Websites. IEEE Access 2022, 10, 79543–79552. [Google Scholar] [CrossRef]
- Somesha, M.; Alwyn, R.P. Classification of Phishing Email Using Word Embedding and Machine Learning Techniques. J. Cyber Secur. Mobil. 2022, 11, 279–320. [Google Scholar]
- Li, Q.; Cheng, M.; Wang, J.; Su, B. LSTM Based Phishing Detection for Big Email Data. IEEE Trans. Big Data 2022, 8, 278–288. [Google Scholar] [CrossRef]
- Singh, S.; Singh, M.P.; Pandey, R. Phishing Detection from URLs Using Deep Learning Approach. In Proceedings of the 5th IEEE International Conference on Computing, Communication and Security (ICCCS), Patna, Bihar, India, 14–16 October 2020; pp. 1–4. [Google Scholar]
- Ariyadasa, S.; Fernando, S.; Fernando, S. Combining Long-Term Recurrent Convolutional and Graph Convolutional Networks to Detect Phishing Sites Using URL and HTML. IEEE Access 2022, 10, 82355–82375. [Google Scholar] [CrossRef]
- Alsaedi, M.; Ghaleb, F.A.; Saeed, F.; Ahmad, J.; Alasli, M. Cyber Threat Intelligence-Based Malicious URL Detection Model Using Ensemble Learning. Sensors 2022, 22, 3373. [Google Scholar] [CrossRef]
- Remmide, M.A.; Boumahdi, F.; Boustia, N.; Feknous, C.L.; Della, R. Detection of Phishing URLs Using Temporal Convolutional Network. Procedia Comput. Sci. 2022, 212, 74–82. [Google Scholar] [CrossRef]
- Wang, C.; Chen, Y. TCURL: Exploring hybrid transformer and convolutional neural network on phishing URL detection. Knowl.-Based Syst. 2022, 258, 109955. [Google Scholar] [CrossRef]
- Maneriker, P.; Stokes, J.W.; Lazo, E.G. URLTran: Improving Phishing URL Detection Using Transformers. In Proceedings of the IEEE Military Communications Conference (MILCOM), San Diego, CA, USA, 29 November–2 December 2021; pp. 197–204. [Google Scholar]
- Ullah, F.; Alsirhani, A.; Alshahrani, M.M.; Alomari, A.; Naeem, H.; Shah, S.A. Explainable Malware Detection System Using Transformers-Based Transfer Learning and Multi-Model Visual Representation. Sensors 2022, 22, 6766. [Google Scholar] [CrossRef]
- Lin, X.; Xiong, G.; Gou, G.; Li, Z.; Shi, J.; Yu, J. ET-BERT: A Contextualized Datagram Representation with Pre-training Transformers for Encrypted Traffic Classification. In Proceedings of the ACM Web Conference, Lyon, France, 25–29 April 2022; pp. 633–642. [Google Scholar]
- Shi, Z.; Luktarhan, N.; Song, Y.; Yin, H. TSFN: A Novel Malicious Traffic Classification Method Using BERT and LSTM. Sensors 2023, 25, 821. [Google Scholar] [CrossRef]
- Malicious URLs Dataset. Available online: https://www.kaggle.com/datasets/sid321axn/malicious-urls-dataset (accessed on 26 August 2023).
- Vrbančič, G.; Fister, I., Jr.; Podgorelec, V. Datasets for Phishing Websites Detection. Data Brief 2020, 33, 1–7. Available online: https://github.com/GregaVrbancic/Phishing-Dataset (accessed on 26 August 2023). [CrossRef] [PubMed]
- ISCX-URL 2016 Dataset. Available online: https://www.unb.ca/cic/datasets/url-2016.html (accessed on 26 August 2023).
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic Minority Over-sampling Technique. arXiv 2011, arXiv:1106.1813. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł. Attention Is All You Need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Canadian Institute for Cybersecurity. Available online: https://www.unb.ca/cic/datasets/ (accessed on 26 August 2023).














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| attention probs dropout prob | hidden act | hidden dropout prob | initializer range | intermediate size | type vocab size | max seq length | BERT model | num train epochs |
| 0.1 | gelu | 0.1 | 0.02 | 3072 | 2 | 128 | bert-base-cased | 10/20/30 |
| max position embeddings | hidden size | num attention heads | layer norm eps | num hidden layers | learning rate | train batch size | vocab size | |
| 512 | 768 | 12 | 1 × 10−12 | 12 | 1 × 10−5 | 16 | 28,996 |
| Samples for Each Category | #URLs | Accuracy (%) | Precision (%) | Recall (%) |
|---|---|---|---|---|
| 10,000 | 40,000 | 96.70 | 96.74 | 97.73 |
| Min {100,000, actual entry number} | about 320,000 | 98.02 | 97.71 | 97.96 |
| All | 646,083 | 98.78 | 99.12 | 98.02 |
| Research | Approach | Binary/Multi Classification | Accuracy (%) |
|---|---|---|---|
| Alsaedi et al. [21] (2022) | Ensemble features + Classifiers (DT) | Binary | 95.70 |
| Ensemble features + Classifiers (RF) | Binary | 96.80 | |
| Ensemble features + Classifiers (CNN) | Binary | 94.70 | |
| Ensemble features + Classifiers (RF with feature selection) | Binary | 96.80 | |
| Ensemble features + Classifiers (RF with feature selection and grid search best-found hyperparameters) | Binary | 97.25 | |
| This study | Fine-tuning BERT + Classifier | Multi | 98.78 |
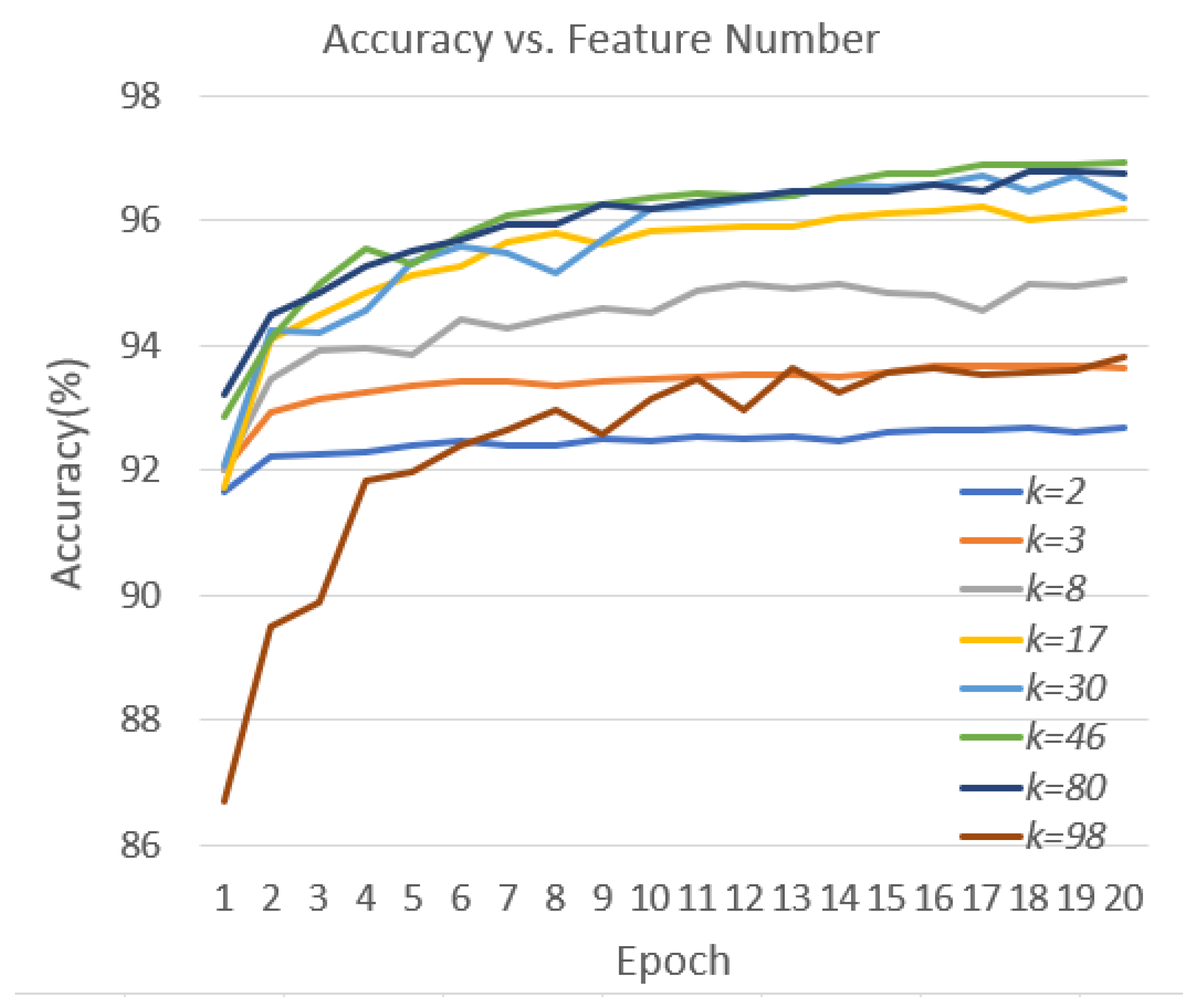
| k (#Features) | Accuracy (%) | Precision (%) | Recall (%) |
|---|---|---|---|
| 2 | 92.64 | 91.33 | 92.99 |
| 3 | 93.36 | 92.38 | 93.09 |
| 8 | 94.69 | 94.44 | 93.76 |
| 17 | 95.84 | 95.64 | 95.14 |
| 30 | 95.93 | 95.83 | 95.14 |
| 46 | 96.71 | 96.25 | 96.50 |
| 80 | 96.53 | 96.17 | 96.15 |
| 86 | 96.42 | 96.48 | 95.70 |
| Research | Binary/Multi-Classification | Accuracy (%) | Approach |
|---|---|---|---|
| Saleem et al. [6] (2021) | Binary | 99 | Feature extraction + RF |
| Gupta et al. [5] (2021) | Binary (phish only) | 99.57 | Feature extraction + RF |
| Bozkir et al. [10] (2023) | Binary (phish only) | 99.82 | n-gram + CNN_BiLSTM + Attention |
| Wang and Chen [23] (2022) | Binary (phish only) | 99.77 | CNN1D + Transformer |
| Binary (phish only) | 98.67 | CNN-MHSA | |
| Binary (phish only) | 99.57 | BiLSTM | |
| This study | Binary | 99.98 | Fine-tunned BERT + Classifier |
| Multi | 99.78 |
| Dataset | Accuracy (%) | Precision (%) | Recall (%) | |
|---|---|---|---|---|
| IoT Attack Dataset 2023 | original | 93.62 | 89.29 | 87.75 |
| augmented by SMOTE [31] | 93.71 | 93.77 | 93.71 | |
| DoHBrw 2020 (original) | 99.56 | 97.57 | 98.04 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Su, M.-Y.; Su, K.-L. BERT-Based Approaches to Identifying Malicious URLs. Sensors 2023, 23, 8499. https://doi.org/10.3390/s23208499
Su M-Y, Su K-L. BERT-Based Approaches to Identifying Malicious URLs. Sensors. 2023; 23(20):8499. https://doi.org/10.3390/s23208499
Chicago/Turabian StyleSu, Ming-Yang, and Kuan-Lin Su. 2023. "BERT-Based Approaches to Identifying Malicious URLs" Sensors 23, no. 20: 8499. https://doi.org/10.3390/s23208499
APA StyleSu, M. -Y., & Su, K. -L. (2023). BERT-Based Approaches to Identifying Malicious URLs. Sensors, 23(20), 8499. https://doi.org/10.3390/s23208499