_Sun.png)


Denoising of BOTDR Dynamic Strain Measurement Using Convolutional Neural Networks


Abstract
:1. Introduction
2. Materials and Methods
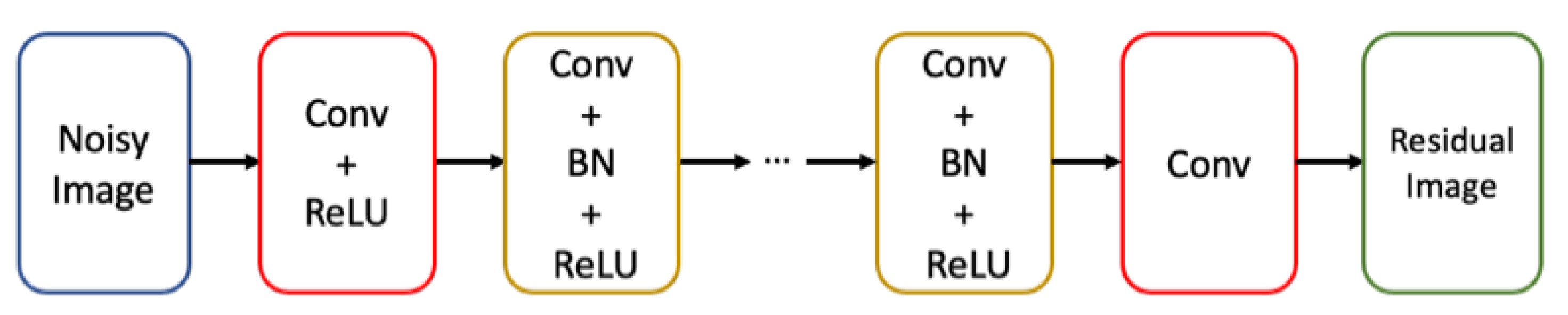
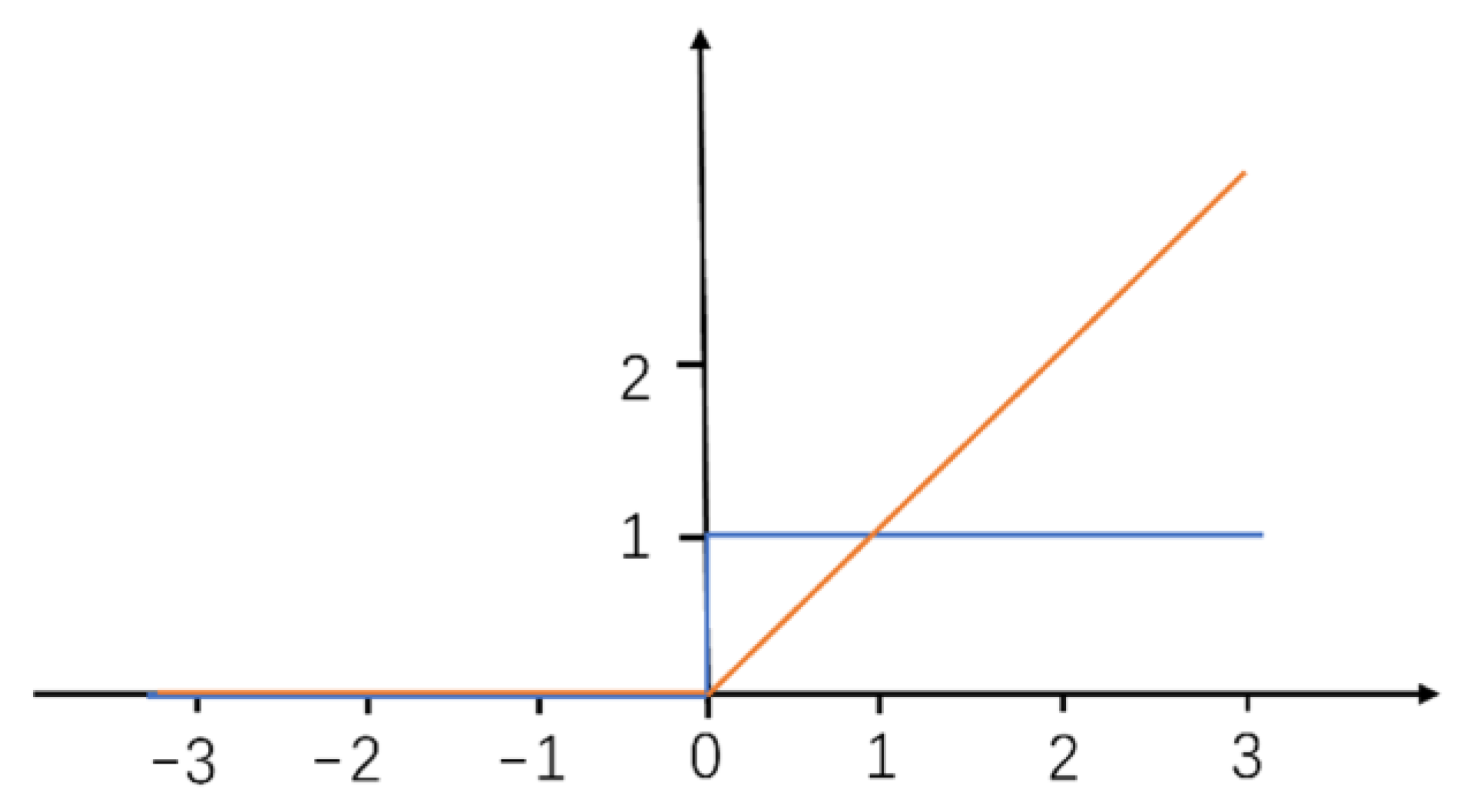
2.1. DnCNN Architecture
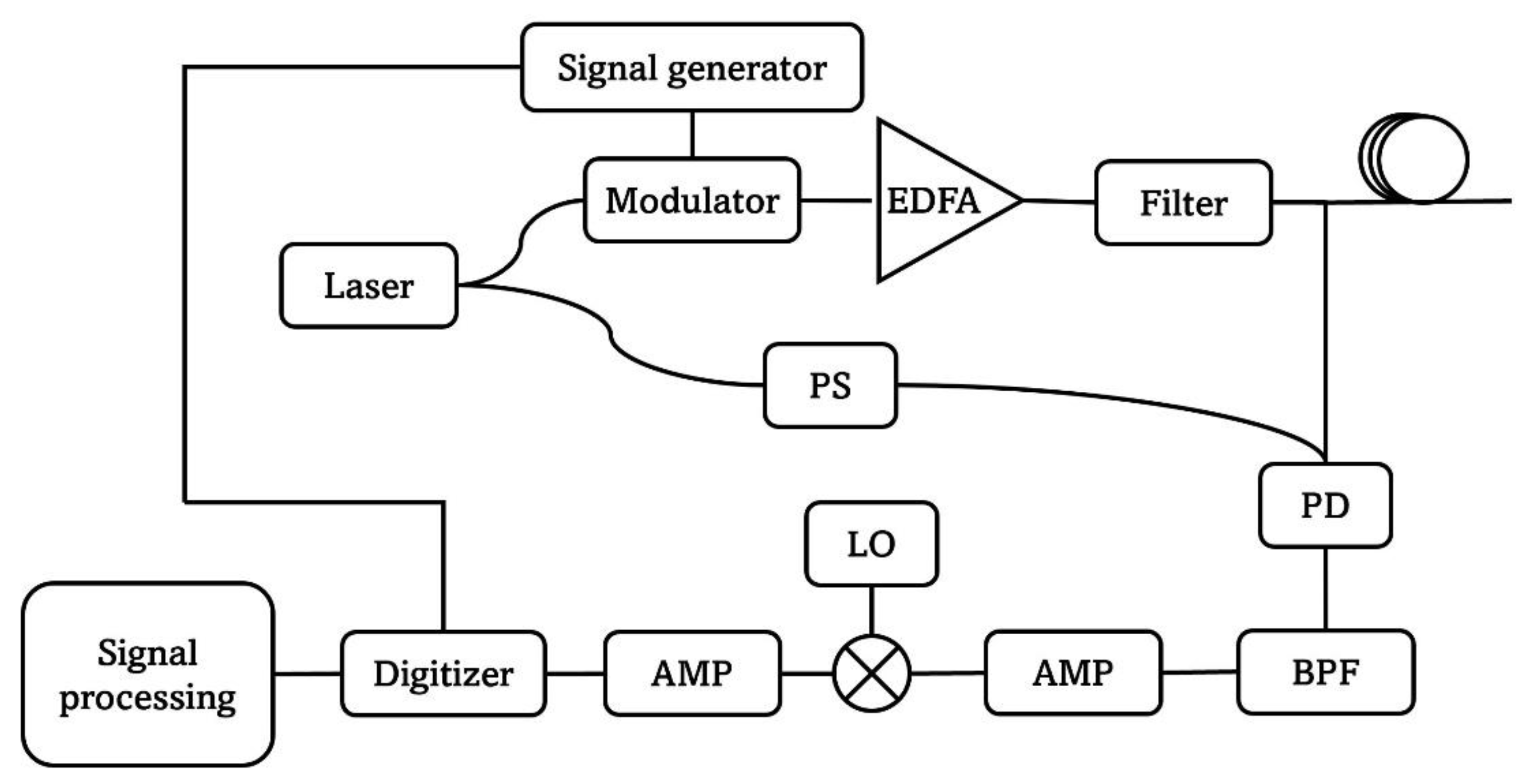
2.2. BOTDR Setup
2.3. Training Setup
3. Results and Discussion
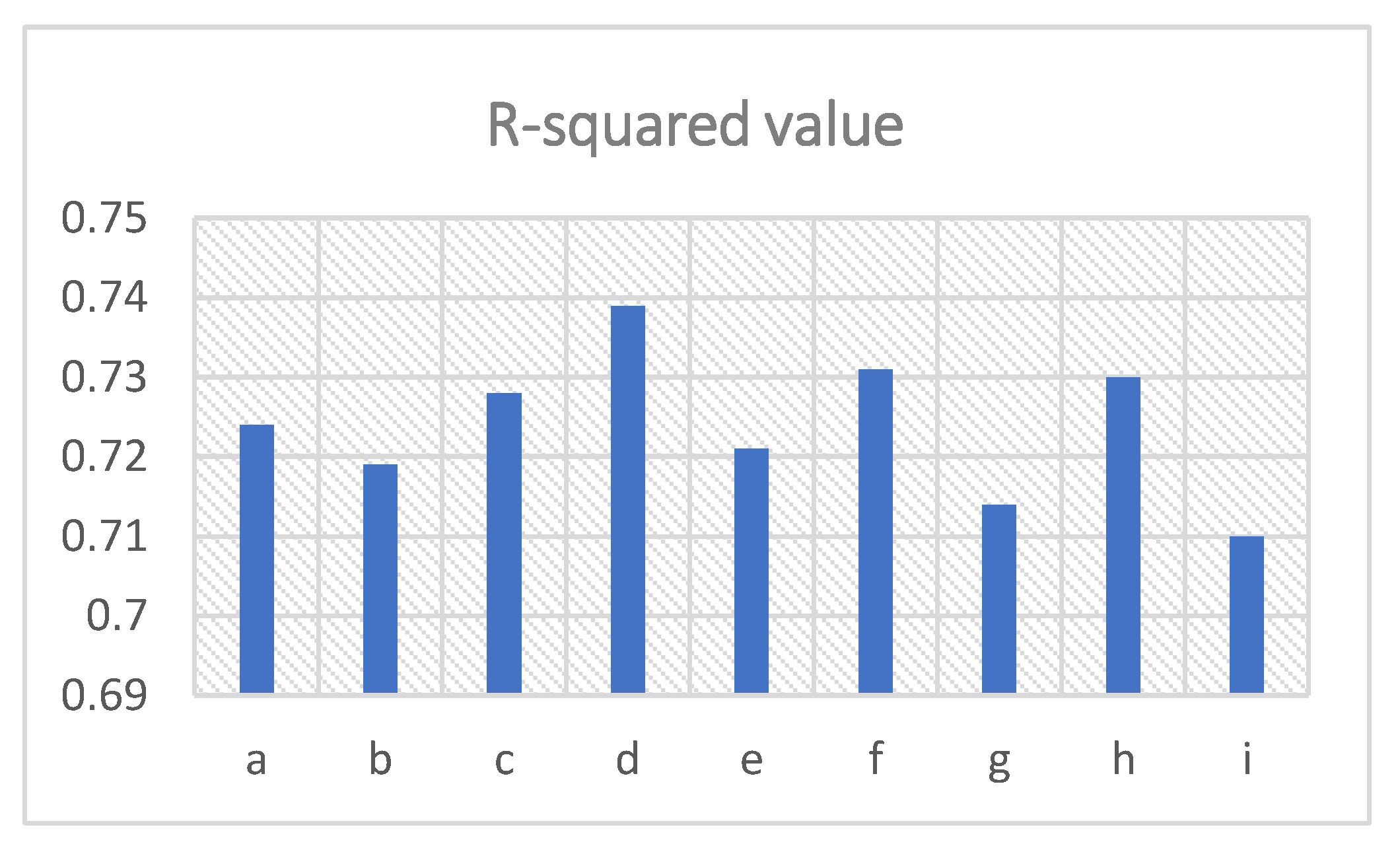
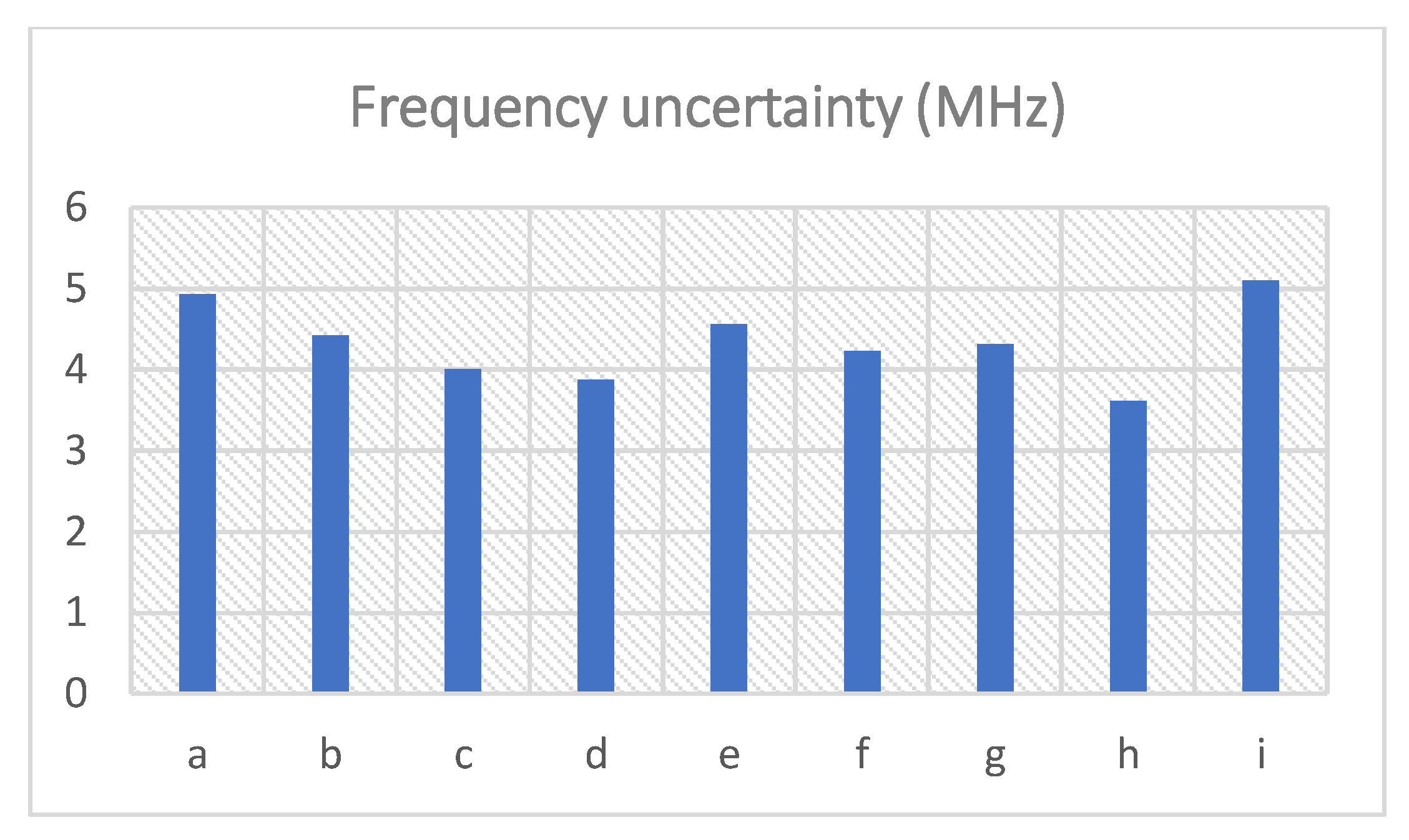
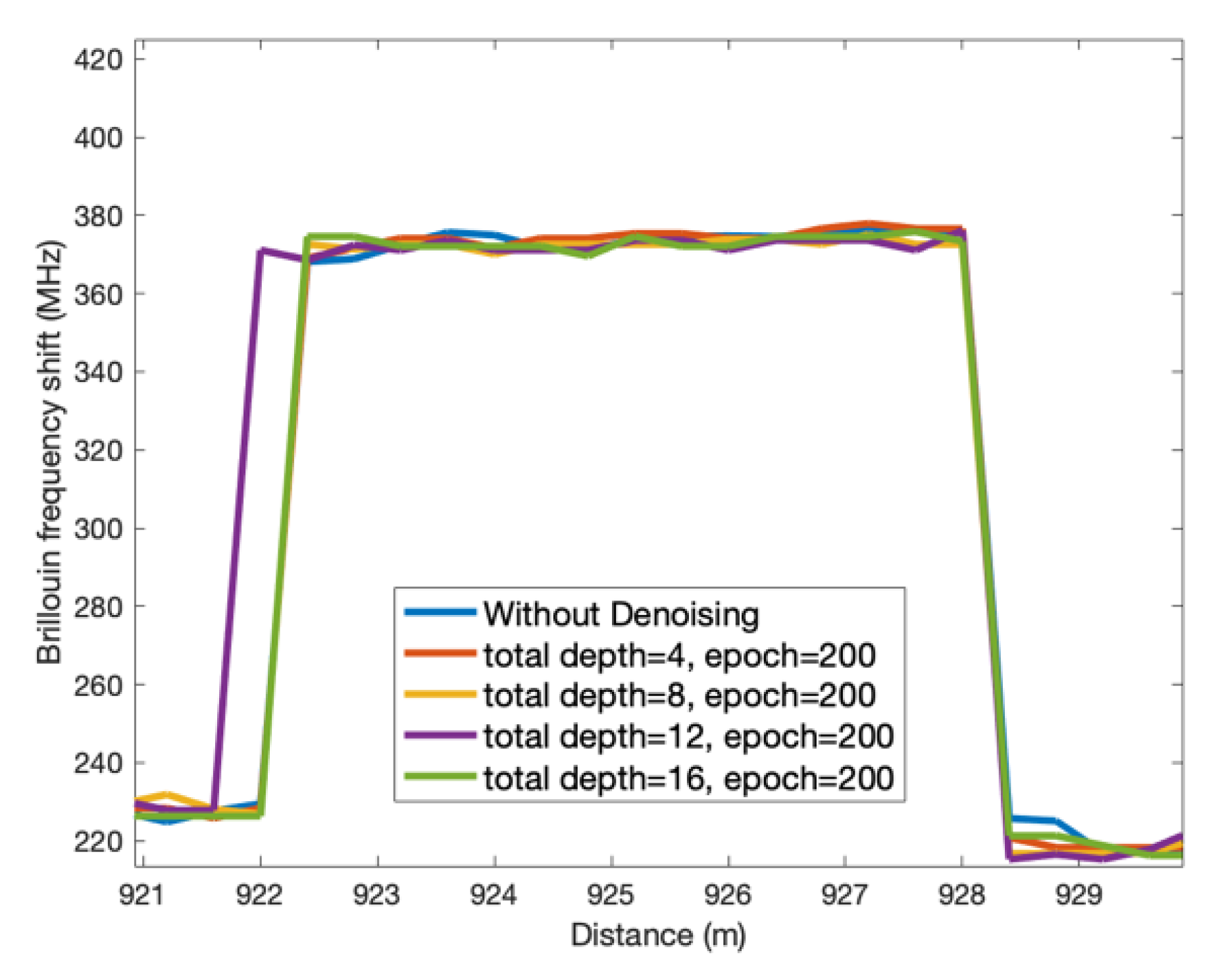
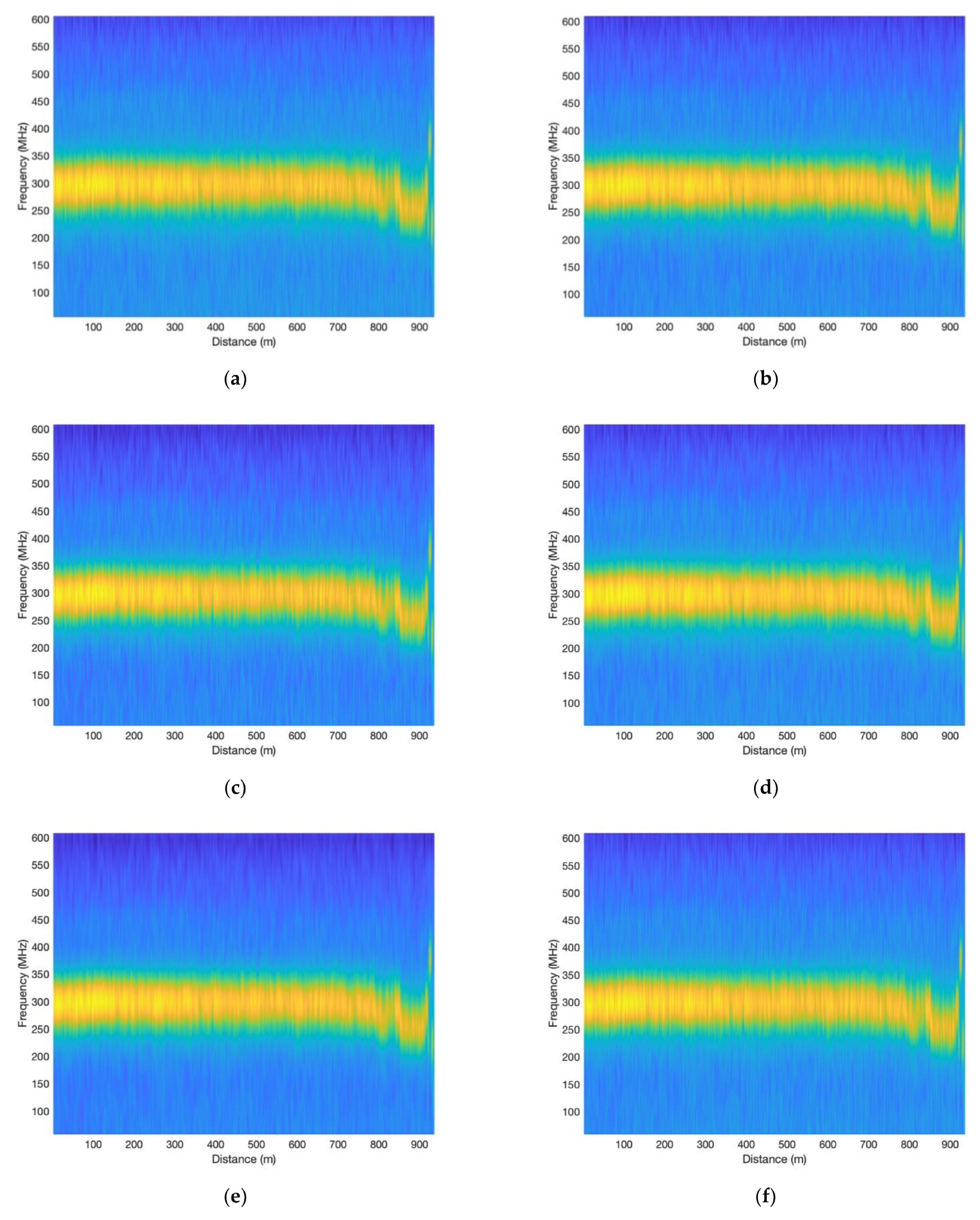
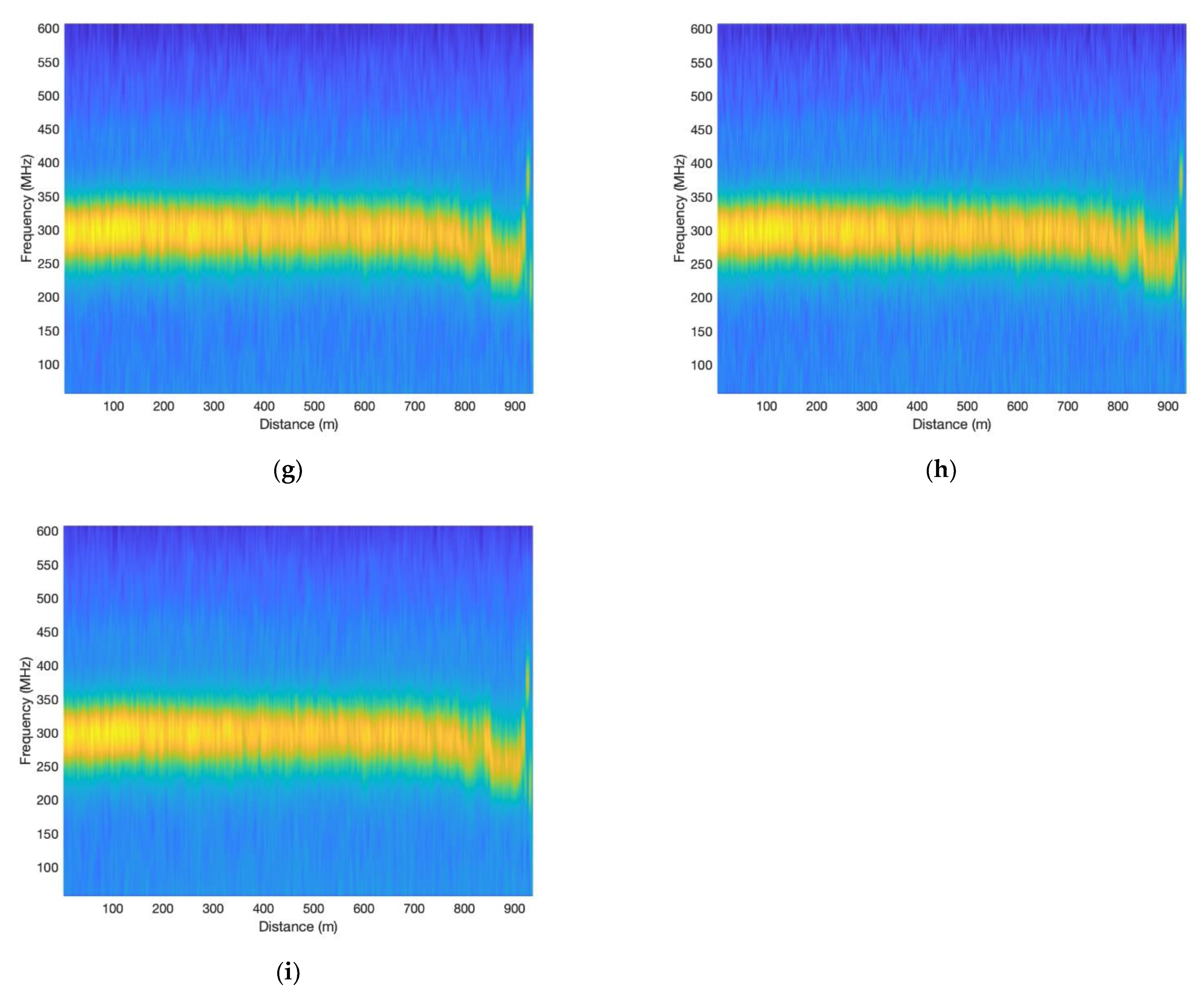
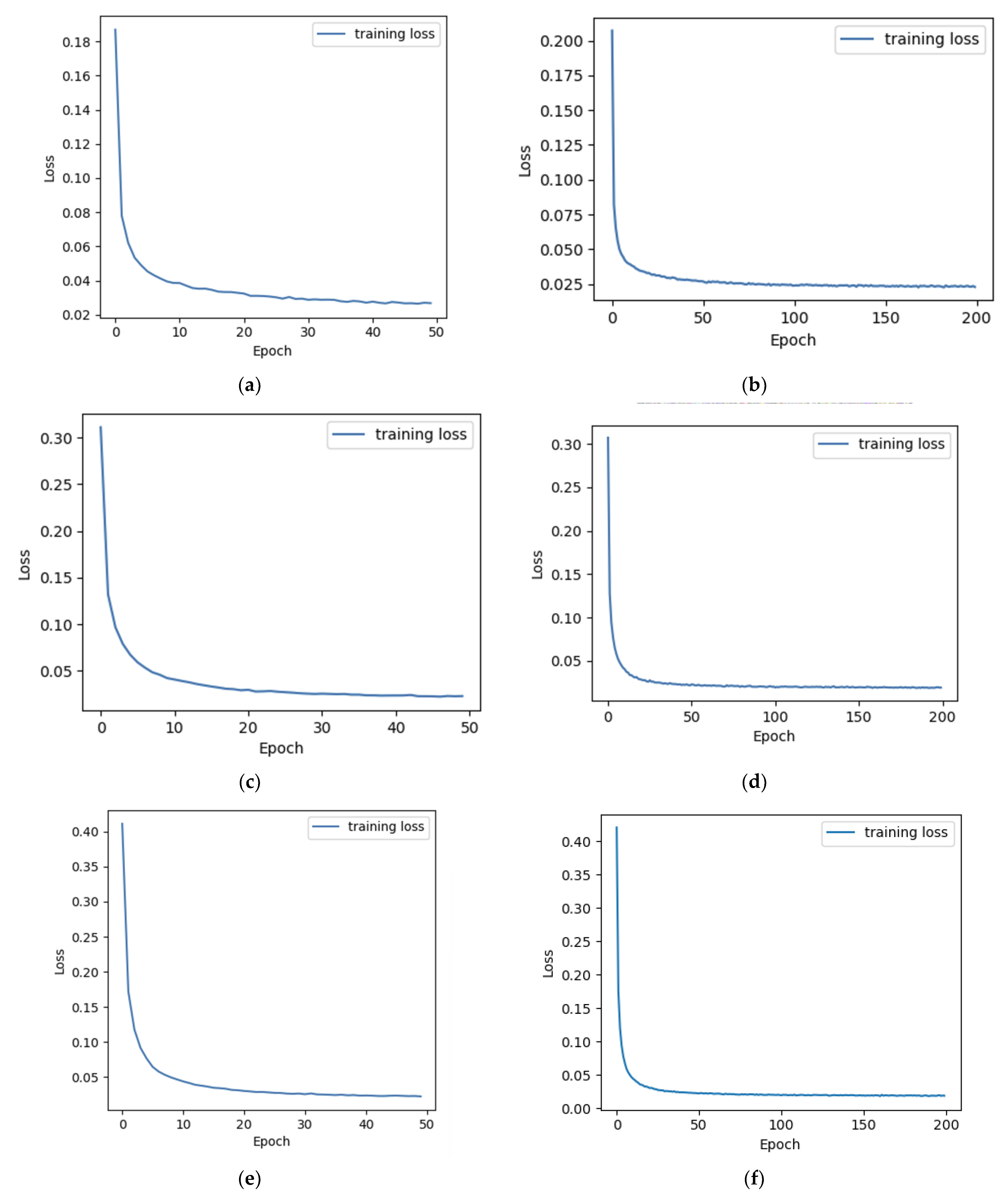
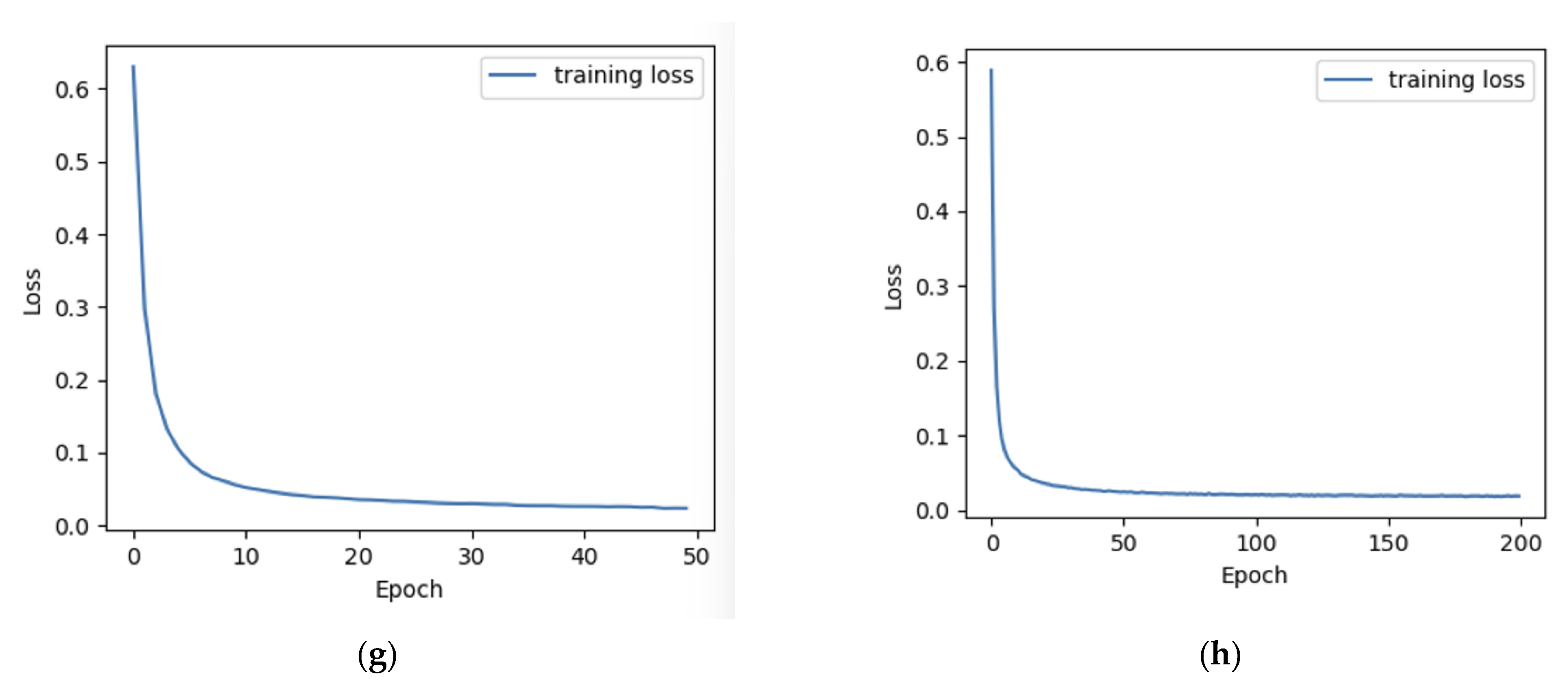
3.1. Experiments with Different Total Depths and Epochs
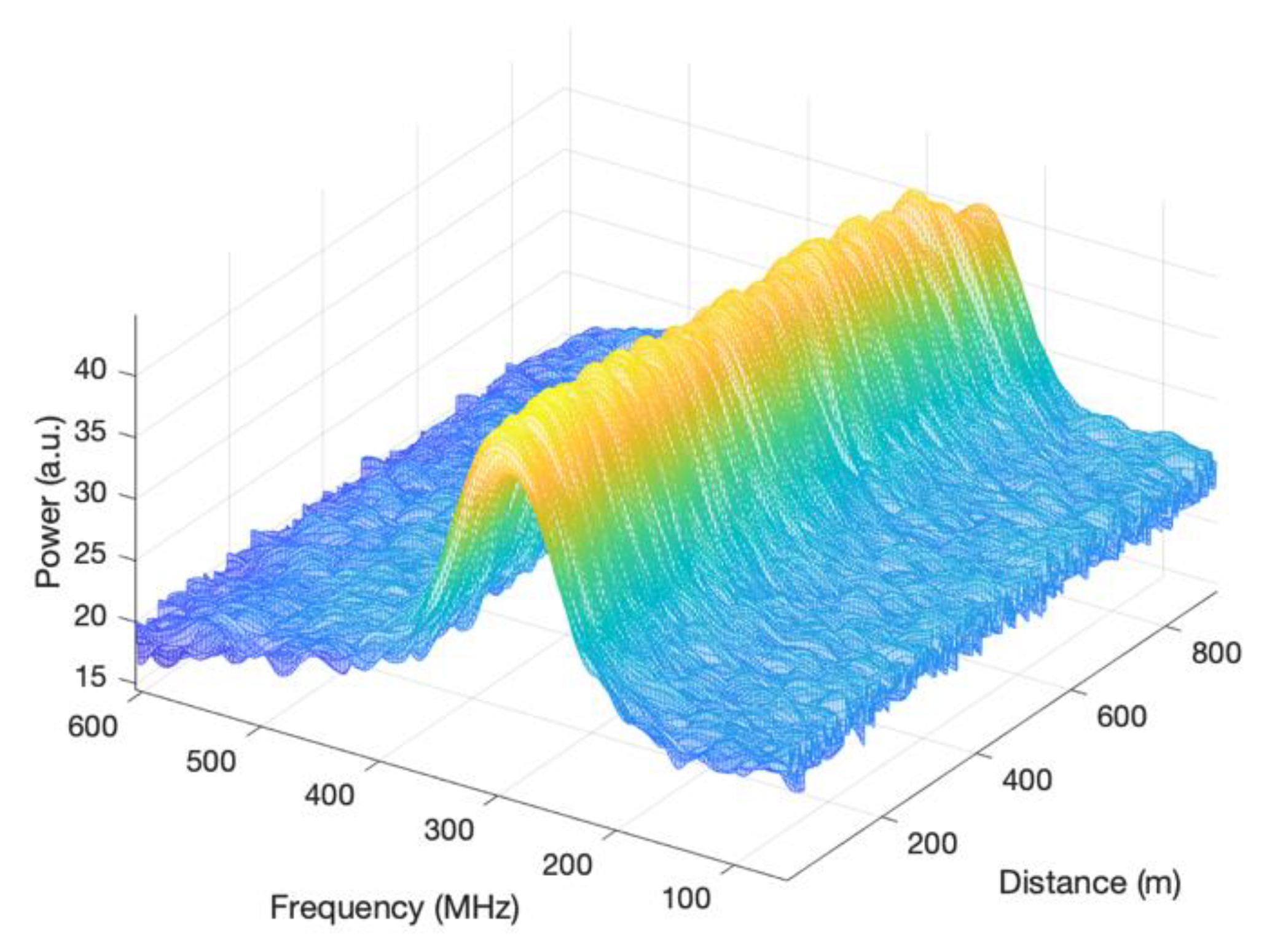
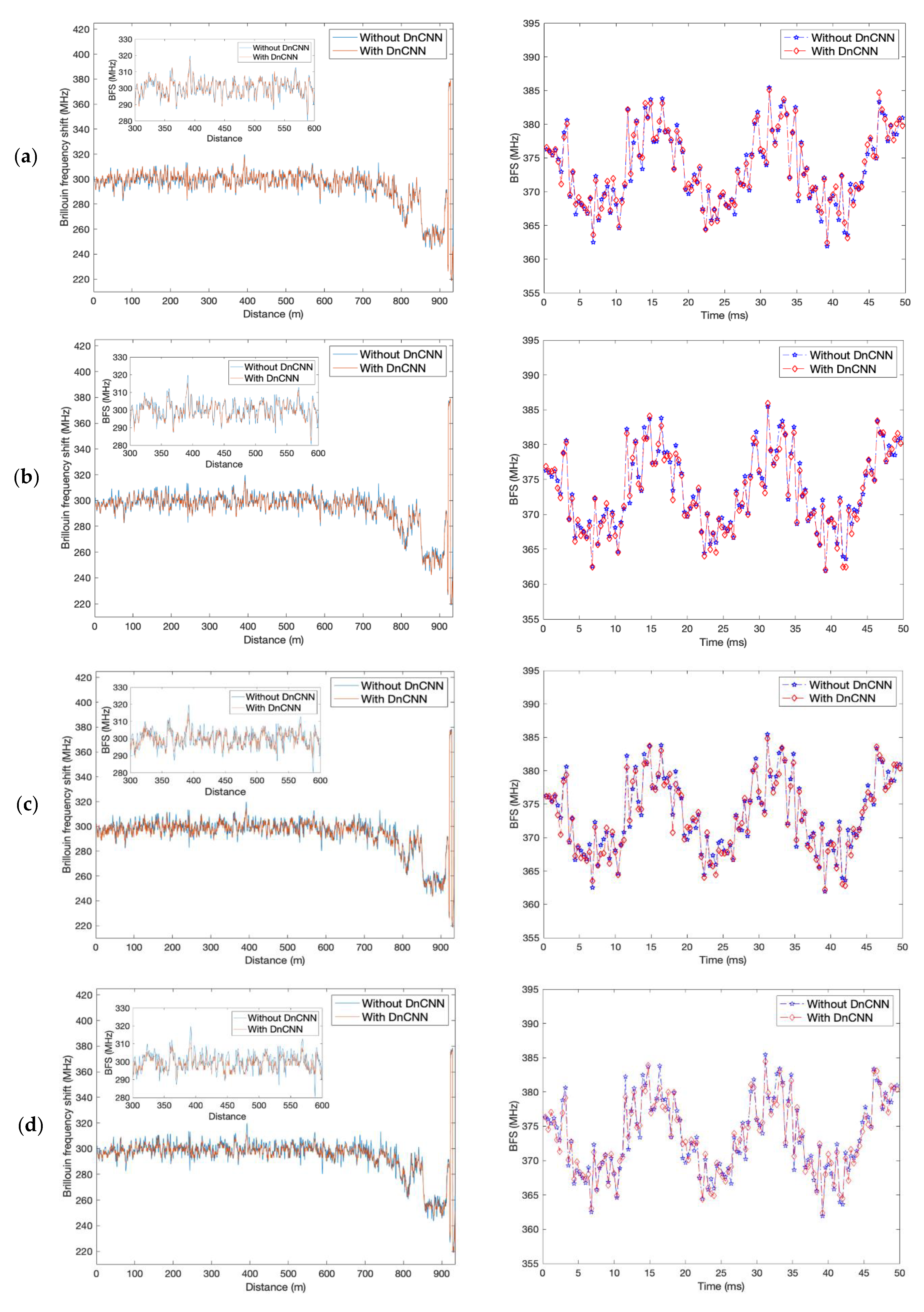
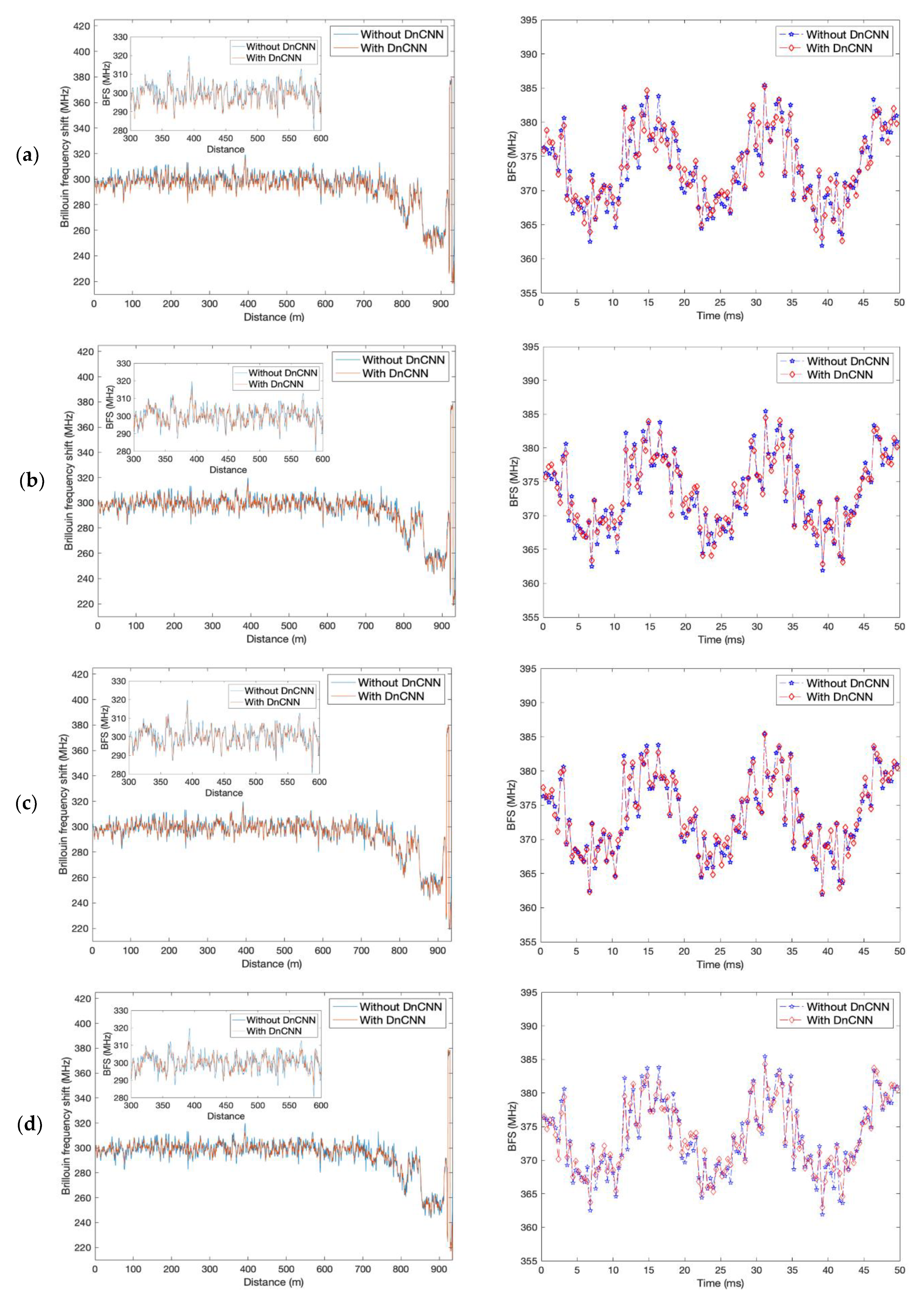
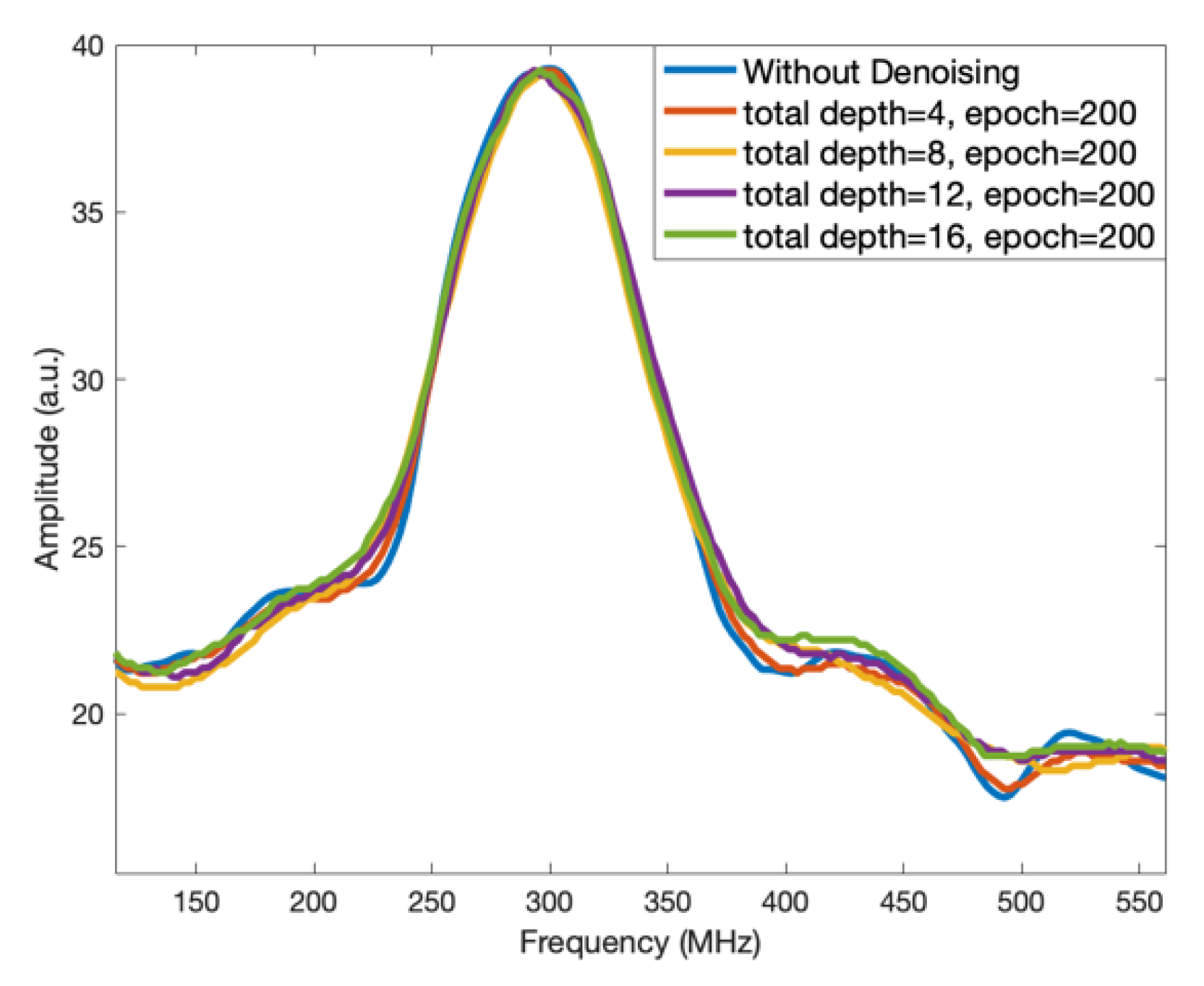
3.2. Spatial Performance and the Brillouin Gain Spectra
3.3. Comparison with Some Known Methods
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A


Appendix B


References
- Wu, H.; Wang, L.; Zhao, Z.; Guo, N.; Shu, C.; Lu, C. Brillouin optical time domain analyzer sensors assisted by advanced image denoising techniques. Opt. Express 2018, 26, 5126–5139. [Google Scholar] [CrossRef] [PubMed]
- Guo, N.; Wang, L.; Wu, H.; Jin, C.; Tam, H.; Lu, C. Enhanced coherent BOTDA System without trace averaging. J. Light. Technol. 2018, 36, 871–878. [Google Scholar] [CrossRef]
- Soto, M.A.; Ramírez, J.A.; Thévenaz, L. Optimizing image denoising for long-range brillouin distributed fibre sensing. J. Light. Technol. 2018, 36, 1168–1177. [Google Scholar] [CrossRef]
- Bai, Q.; Wang, Q.; Wang, D.; Wang, Y.; Gao, Y.; Zhang, H.; Zhang, M.; Jin, B. Recent advances in brillouin optical time domain reflectometry. Sensors 2019, 19, 1862. [Google Scholar] [CrossRef] [PubMed]
- Soto, M.A.; Ramírez, J.A.; Thévenaz, L. Intensifying the response of distributed optical fibre sensors using 2D and 3D image restoration. Nat. Commun. 2016, 7, 10870. [Google Scholar] [CrossRef] [PubMed]
- Soto, M.A.; Yang, Z.; Ramírez, J.A.; Zaslawski, S.; Thévenaz, L. Evaluating measurement uncertainty in Brillouin distributed optical fibre sensors using image denoising. Nat. Commun. 2021, 12, 4901. [Google Scholar] [CrossRef]
- Zaslawski, S.; Yang, Z.; Thévenaz, L. On the 2D post-processing of Brillouin optical time-domain analysis. J. Light. Technol. 2020, 38, 3723–3736. [Google Scholar] [CrossRef]
- Yang, G.; Wang, B.; Wang, L.; Cheng, Z.; Yu, C.; Chan, C.C.; Li, L.; Tang, M.; Liu, D. Optimization of 2D-BM3D denoising for long-range Brillouin optical time domain analysis. In Proceedings of the 2020 ACP and International Conference on IPOC, Beijing, China, 24–27 October 2020. [Google Scholar]
- Wu, H.; Wan, Y.; Tang, M.; Chen, Y.; Zhao, C.; Liao, R.; Chang, Y.; Fu, S.; Shum, P.P.; Liu, D. Real-Time denoising of brillouin optical time domain analyzer with high data fidelity using convolutional neural networks. J. Light. Technol. 2019, 37, 2648–2653. [Google Scholar] [CrossRef]
- Chiang, Y.; Sullivan, B.J. Multi-frame image restoration using a neural network. In Proceedings of the 32nd Midwest Symposium on Circuits and Systems, Champaign, IL, USA, 14–16 August 1989; Volume 2, pp. 744–747. [Google Scholar]
- Cruz, C.; Foi, A.; Katkovnik, V.; Egiazarian, K. Nonlocality-reinforced convolutional neural networks for image denoising. IEEE Signal Process. Lett. 2018, 25, 1216. [Google Scholar] [CrossRef]
- Cho, S.I.; Kang, S. Gradient prior-aided CNN denoiser with separable convolution-based optimization of feature dimension. IEEE Trans. Multimed. 2019, 21, 484–493. [Google Scholar] [CrossRef]
- Cui, J.; Gong, K.; Guo, N.; Wu, C.; Meng, X.; Kim, K.; Zheng, K.; Wu, Z.; Fu, L.; Xu, B.; et al. PET image denoising using unsupervised deep learning. Eur. J. Nucl. Med. Mol. Imaging 2019, 46, 2780–2789. [Google Scholar] [CrossRef]
- Tian, C.; Fei, L.; Zheng, W.; Xu, Y.; Zuo, W.; Lin, C.W. Deep learning on image denoising: An overview. Neural Netw. 2020, 131, 251–275. [Google Scholar] [CrossRef]
- Lucas, A.; Iliadis, M.; Molina, R.; Katsaggelos, A.K. Using deep neural networks for inverse problems in imaging: Beyond analytical methods. IEEE Signal Process. Mag. 2018, 35, 20–36. [Google Scholar] [CrossRef]
- Schmidhuber, J. Deep Learning in neural networks: An overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef]
- Franm, E.; Zhen, Y.; Han, F.; Shailesh, T.; Matthias, D. An introductory review of deep learning for prediction models with big data. Front. Artif. Intell. 2020, 3, 4. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Tian, C.; Xu, Y.; Zuo, W. Image denoising using deep CNN with batch renormalization. Neural Netw. 2020, 121, 461–473. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the 3rd International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015; pp. 1–14. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. In Proceedings of the 26th Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; Volume 25, pp. 1097–1105. [Google Scholar]
- Zhang, K.; Zuo, W.; Chen, Y.; Meng, D.; Zhang, L. Beyond a Gaussian denoiser: Residual learning of deep CNN for image denoising. IEEE Trans. Image Process. 2017, 26, 3142–3155. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating deep network training by reducing internal covariate shift. Proc. Mach. Learn. Res. 2015, 37, 448–456. [Google Scholar]
- Wang, J.; Yang, Y.; Mao, J.; Huang, Z.; Huang, C.; Xu, W. CNN-RNN: A unified framework for multi-label image classification. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition (CVPTR), Honolulu, HI, USA, 21–26 July 2016; pp. 2285–2294. [Google Scholar]
- Dumoulin, V.; Visin, F. A guide to convolution arithmetic for deep learning. arXiv 2016, arXiv:1603.07285. [Google Scholar]
- Li, X.; Li, F.; Fern, X.; Raich, R. Filter shaping for convolutional neural networks. In Proceedings of the 5th International Conference on Learning Representations, Toulon, France, 24–26 April 2017; pp. 1–7. [Google Scholar]
- Li, B.; Luo, L.; Yu, Y.; Soga, K.; Yan, J. Dynamic strain measurement using small gain stimulated Brillouin scattering in STFT-BOTDR. IEEE Sensors J. 2017, 17, 2718–2724. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar]
- Lihi, S.; Giryes, R. Introduction to deep learning. arXiv 2020, arXiv:2003.03253. [Google Scholar]
- Yu, Y.; Luo, L.; Li, B.; Guo, L.; Yan, J.; Soga, K. Double peak-induced distance error in short-time-Fourier-transform-Brillouin optical time domain reflectometers event detection and the recovery method. Appl. Opt. 2015, 54, E196. [Google Scholar] [CrossRef] [PubMed]
- Shan, L.; Xi, L.; Zhang, Y.; Yuan, X.; Wang, C.; Zhang, X.; Xiao, Z.; Li, X. Enhancing the Frequency Resolution of BOTDR based on the combination of Quadratic Time-Frequency Transform and Wavelet denoising technique. In Proceedings of the Asia Communications and Photonics Conference, Beijing China, 24–27 October 2020. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Depth | Epoch | R-Squared | Frequency Uncertainty (MHz) |
|---|---|---|---|---|
| a | 4 | 50 | 0.724 | 4.93 |
| b | 4 | 200 | 0.719 | 4.42 |
| c | 8 | 50 | 0.728 | 4.01 |
| d | 8 | 200 | 0.739 | 3.88 |
| e | 12 | 50 | 0.721 | 4.56 |
| f | 12 | 200 | 0.731 | 4.23 |
| g | 16 | 50 | 0.714 | 4.31 |
| h | 16 | 200 | 0.730 | 3.62 |
| i | - | - | 0.710 | 5.10 |
| Method | Setup | BFS Uncertainty/Accuracy | Original BFS Uncertainty | Spatial Resolution | Fibre Length | Averaging Number | BGS Acquisition | Fast Measurement Sampling Rate | Fibre Vibration Speed |
|---|---|---|---|---|---|---|---|---|---|
| NLM [1] | BOTDA | 0.57 °C/13.32 °C 1 | - | 2 m/4.42 m 2 | 62.3 km | 16 | Frequency scanning | - | - |
| WD [1] | BOTDA | 0.55 °C/8.81 °C 1 | - | 2 m/5.5 m 2 | 62.3 km | 16 | Frequency scanning | - | - |
| BM3D [1] | BOTDA | 0.55 °C/2.17 °C 1 | - | 2 m/3.86 m 2 | 62.3 km | 16 | Frequency scanning | - | - |
| NLM [2] | BOTDA | 0.843 MHz | 1.473 MHz | 4 m | 40.63 km | 1 | Frequency scanning | - | - |
| NLM [3] | BOTDA | 0.77 MHz | - | 2 m | 100 km | 2000 | Frequency scanning | - | - |
| NLM [5,6] | BOTDA | 1.2 MHz | 4.5 MHz | 2 m | 50 km | 4 | Frequency scanning | - | - |
| WD [5,6] | BOTDA | 1.3 MHz | 4.5 MHz | 2 m | 50 km | 4 | Frequency scanning | - | - |
| BM3D [8] | BOTDA | 2.1 °C | 8.8 °C | 2.5 m | 100.8 km | 2000 | Frequency scanning | - | - |
| STFT and WD [31] | BOTDR | 1.27 MHz | 1.57 MHz | 20 m | 12.5 km | 400 | STFT | - | - |
| This work | BOTDR | 3.88 MHz | 5.1 MHz | 4 m | 935 m | 25 | STFT | 2.5 kHz | 60 Hz |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, B.; Jiang, N.; Han, X. Denoising of BOTDR Dynamic Strain Measurement Using Convolutional Neural Networks. Sensors 2023, 23, 1764. https://doi.org/10.3390/s23041764
Li B, Jiang N, Han X. Denoising of BOTDR Dynamic Strain Measurement Using Convolutional Neural Networks. Sensors. 2023; 23(4):1764. https://doi.org/10.3390/s23041764
Chicago/Turabian StyleLi, Bo, Ningjun Jiang, and Xiaole Han. 2023. "Denoising of BOTDR Dynamic Strain Measurement Using Convolutional Neural Networks" Sensors 23, no. 4: 1764. https://doi.org/10.3390/s23041764
APA StyleLi, B., Jiang, N., & Han, X. (2023). Denoising of BOTDR Dynamic Strain Measurement Using Convolutional Neural Networks. Sensors, 23(4), 1764. https://doi.org/10.3390/s23041764