A Survey on Reinforcement Learning for Reconfigurable Intelligent Surfaces in Wireless Communications


Abstract
:1. Introduction
1.1. Related Work
1.2. Scope and Contributions
- In the beginning, we give brief insights into RIS technology and RL. We provide a comprehensive introduction to RIS technology, including the types of RISs in terms of reflector types and phase-shift coefficient values.
- We provide a mathematical explanation of the RL algorithms presented in the literature. We categorize the different RL algorithms as DQN, DDPG, TD3, and PPO. We conduct a comprehensive review of the peculiarities, including the implementation of each RL algorithm in RIS technologies mentioned.
- We carry out an extensive analysis of the role of RL in empowering the use of this RIS integration by optimizing several parameters to solve various types of problems in several emerging technologies and application scenarios. The problems found in RIS technologies that can be solved by implementing RL algorithms are described as the energy efficiency, spectral efficiency, network capacity, security, and age of information.
- In the end, we discuss several existing and potential challenges while providing possible solutions as future research opportunities for overcoming the issues and honing the research work dedicated to this promising integration of RISs and RL algorithms.
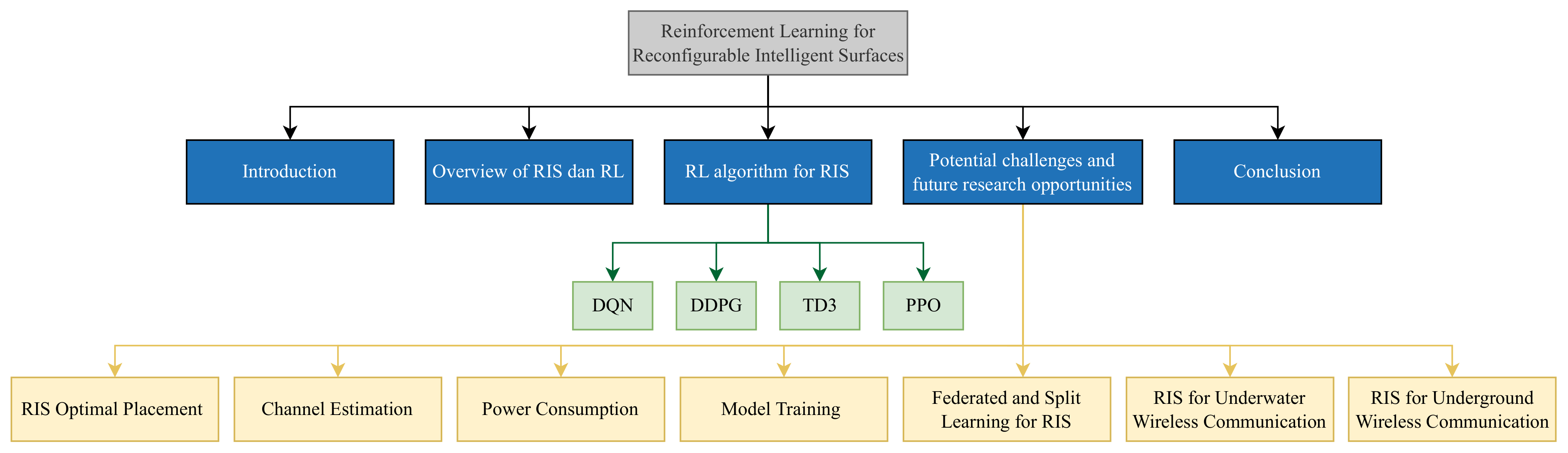
1.3. Organization of the Paper
2. An Overview of RISs and RL
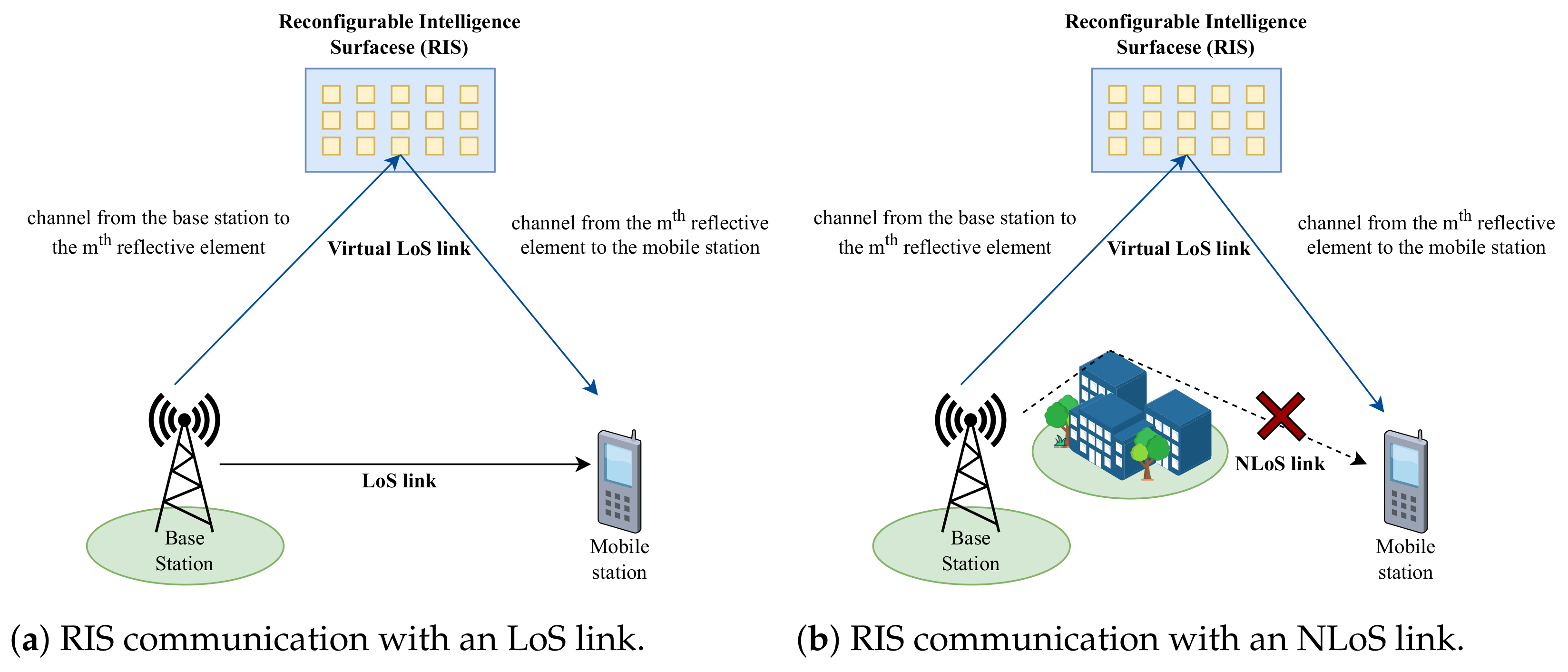
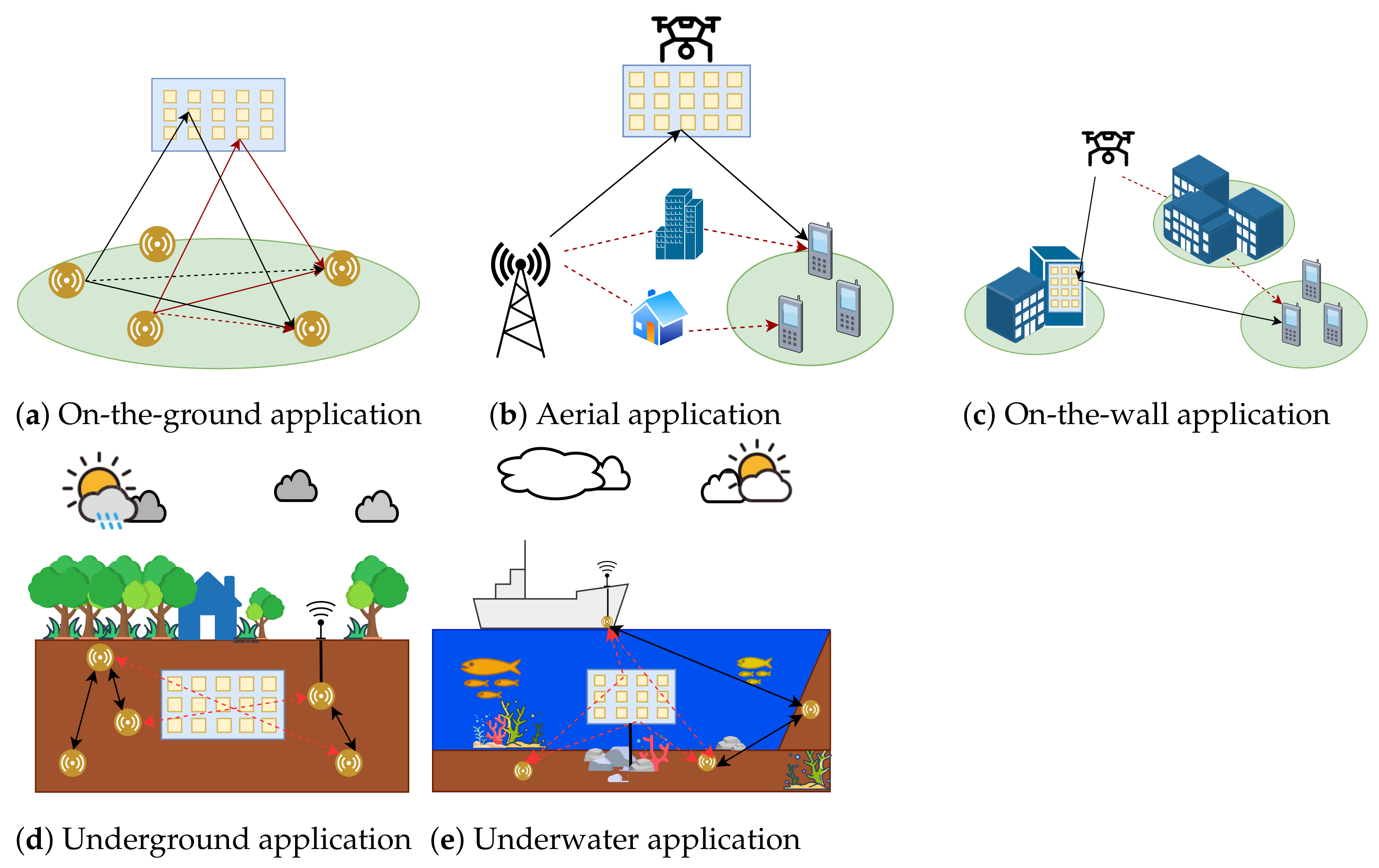
2.1. RIS Technology
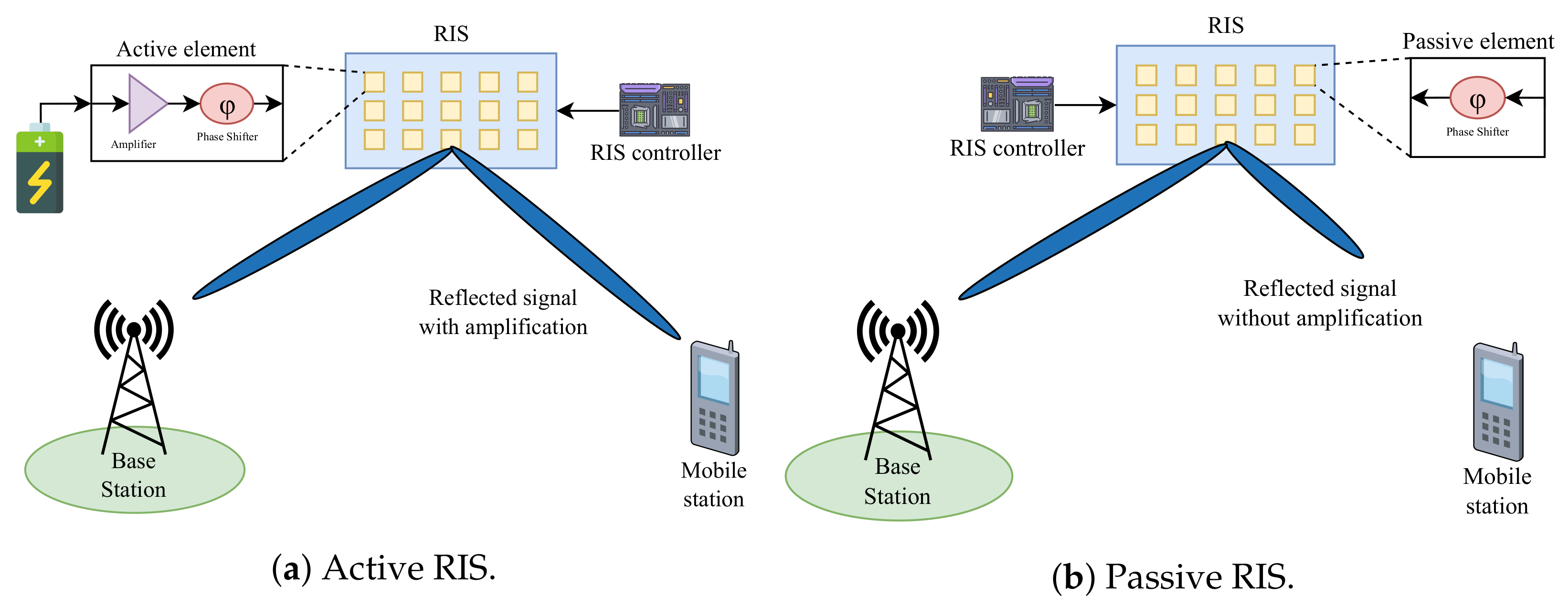
2.1.1. Active and Passive RISs
2.1.2. Continuous and Discrete RISs
2.2. RL Algorithm
- State: a collection of the environment’s characteristics (S) sent by the environment to the agent. The input is the initial state , and denotes the environment at the time step t.
- Action: a collection of actions that are the response of the agent (A) to the received environmental characteristics. Every time the agent gives the action at time instant t, the environment will send the agent the latest environment characteristics or what is called the next state .
- Reward: a collection of feedback from the environment to the action sent by the agent (R). For every at time instant t, the environment will reward the agent when the results obtained are better than the results that were previously achieved. On the other hand, the environment will carry out a punishment when the results obtained are worse than before.
- Q-value function: a state–action value function that measures the cumulative reward value received by agent . Q-value indicates how good the action taken for the given state was.
3. RL Algorithm for RISs
3.1. Deep Q-Network (DQN)
3.2. Deep Deterministic Policy Gradient (DDPG)

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| References | Problem | Optimized Parameters | Implemented RL Algorithm | RIS Installation |
|---|---|---|---|---|
| [59] | Maximizing the energy efficiency of a UAV | 1. UAV trajectory 2. RIS phase shift | DQN and DDPG | Attached to a building |
| [60] | Maximizing the data rate and reducing the loss of accuracy | 1. Continuous UAV trajectory 2. Continuous GT scheduling | DDQN and DDPG | Aerial RIS |
| [62] | Maximizing sum rate capacity | 1. Transmit beamforming 2. RIS phase shift | DDPG | Attached to a building |
| [63] | Maximizing the capacity with interference | 1. RIS phase shift | DDPG | Attached to a moving vehicle |
| [64] | Maximizing the user’s data rate | 1. Transmit beamforming 2. RIS phase shift | DDPG | On the ground |
| [65] | Maximizing the downlink user’s data rate | 1. BS power allocation 2. RIS phase shift 3. UAV horizontal position | DDPG | Aerial RIS |
| [66] | Maximizing the long-term average of users | 1. RIS phase shift | DDPG | On the ground |
| [67] | Maximizing the sum secrecy rate | 1. UAV active and passive beamforming 2. RIS reflecting beamforming | TDDRL | Attached to a building |
3.3. Twin Delayed DDPG (TD3)
| References | Problem | Optimized Parameters | Implemented RL Algorithm | RIS Installation |
|---|---|---|---|---|
| [68] | Maximizing the total achievable finite block length rate | 1. RIS phase shift | TD3 | On the ground |
| [69] | Maximizing the energy ratio | 1. RIS phase shift | TD3 | On the ground |
| [70] | Maximizing the sum rate | 1. RIS phase shift 2. Precoding at transmitter | TD3 | On top of building |
3.4. Proximal Policy Optimization (PPO)
4. Potential Challenges and Future Research Opportunities
4.1. Optimal RIS Placement
4.2. Channel Estimation
4.3. Power Consumption
4.4. Model Training
4.5. Federated and Split Learning for RISs
4.6. RISs for Underwater Wireless Communication
4.7. RISs for Underground Wireless Communication
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| Adagrad | Adaptive Gradient |
| AI | Artificial Intelligence |
| AmBC | Ambient Backscatter Communication |
| BS | Base Station |
| CSI | Channel State Information |
| DC | Direct Current |
| DDPG | Deep Deterministic Policy Gradient |
| DNN | Deep Neural Networks |
| DDQN | Double Deep Q-Network |
| DQN | Deep Q-Network |
| DRL | Deep Reinforcement Learning |
| EM | Electromagnetic |
| FL | Federated Learning |
| GT | Ground Terminal |
| IoUgT | Internet of Underground Things |
| IoUwT | Internet of Underwater Things |
| IRS | Intelligent Reflecting Surface |
| LoS | Line of Sight |
| MDP | Markov Decision Process |
| MIMO | Multiple Input Multiple Output |
| ML | Machine Learning |
| NLoS | Non-Line of Sight |
| NOMA | Non-Orthogonal Multiple Access |
| PPO | Proximal Policy Optimization |
| RE | Reflecting Elements |
| RF | Radio Frequency |
| RIS | Reconfigurable Intelligent Surface |
| RL | Reinforcement Learning |
| RMSprop | Root Mean Square Propagation |
| RProp | Resilient Propagation |
| SGD | Scholastic Gradient Descent |
| SL | Split Learning |
| SNR | Signal-to-Noise Ratio |
| TD3 | Twin Delayed DDPG |
| TDDRL | Twin-DDPG Deep Reinforcement Learning |
| UAV | Unmanned Aerial Vehicle |
| UWOC | Underwater Wireless Optical Communication |
References
- Elhattab, M.; Arfaoui, M.A.; Assi, C.; Ghrayeb, A. Reconfigurable Intelligent Surface Assisted Coordinated Multipoint in Downlink NOMA Networks. IEEE Commun. Lett. 2021, 25, 632–636. [Google Scholar] [CrossRef]
- Nguyen, K.K.; Masaracchia, A.; Sharma, V.; Poor, H.V.; Duong, T.Q. RIS-Assisted UAV Communications for IoT With Wireless Power Transfer Using Deep Reinforcement Learning. IEEE J. Sel. Top. Signal Process. 2022, 16, 1086–1096. [Google Scholar] [CrossRef]
- Le, A.T.; Ha, N.D.X.; Do, D.T.; Silva, A.; Yadav, S. Enabling User Grouping and Fixed Power Allocation Scheme for Reconfigurable Intelligent Surfaces-Aided Wireless Systems. IEEE Access 2021, 9, 92263–92275. [Google Scholar] [CrossRef]
- Le, C.B.; Do, D.T.; Li, X.; Huang, Y.F.; Chen, H.C.; Voznak, M. Enabling NOMA in Backscatter Reconfigurable Intelligent Surfaces-Aided Systems. IEEE Access 2021, 9, 33782–33795. [Google Scholar] [CrossRef]
- Zhang, S.; Zhang, R. Capacity Characterization for Intelligent Reflecting Surface Aided MIMO Communication. IEEE J. Sel. Areas Commun. 2020, 38, 1823–1838. [Google Scholar] [CrossRef]
- Khalili, A.; Monfared, E.M.; Zargari, S.; Javan, M.R.; Yamchi, N.M.; Jorswieck, E.A. Resource Management for Transmit Power Minimization in UAV-Assisted RIS HetNets Supported by Dual Connectivity. IEEE Trans. Wirel. Commun. 2022, 21, 1806–1822. [Google Scholar] [CrossRef]
- Jiao, S.; Fang, F.; Zhou, X.; Zhang, H. Joint Beamforming and Phase Shift Design in Downlink UAV Networks with IRS-Assisted NOMA. J. Commun. Inf. Netw. 2020, 5, 138–149. [Google Scholar] [CrossRef]
- Afzali, N.; Omidi, M.J.; Navaie, K.; Moayedian, N.S. Low Complexity Multi-User Indoor Localization Using Reconfigurable Intelligent Surface. In Proceedings of the 2022 30th International Conference on Electrical Engineering (ICEE), Tehran, Iran, 17–19 May 2022; pp. 731–736. [Google Scholar] [CrossRef]
- Ranjha, A.; Kaddoum, G. URLLC Facilitated by Mobile UAV Relay and RIS: A Joint Design of Passive Beamforming, Blocklength, and UAV Positioning. IEEE Internet Things J. 2021, 8, 4618–4627. [Google Scholar] [CrossRef]
- Yang, L.; Meng, F.; Zhang, J.; Hasna, M.O.; Renzo, M.D. On the Performance of RIS-Assisted Dual-Hop UAV Communication Systems. IEEE Trans. Veh. Technol. 2020, 69, 10385–10390. [Google Scholar] [CrossRef]
- Michailidis, E.T.; Miridakis, N.I.; Michalas, A.; Skondras, E.; Vergados, D.J. Energy Optimization in Dual-RIS UAV-Aided MEC-Enabled Internet of Vehicles. Sensors 2021, 21, 4392. [Google Scholar] [CrossRef]
- Ren, S.; Shen, K.; Zhang, Y.; Li, X.; Chen, X.; Luo, Z.Q. Configuring Intelligent Reflecting Surface with Performance Guarantees: Blind Beamforming. IEEE Trans. Wirel. Commun. 2022. [Google Scholar] [CrossRef]
- Elsayed, M.; Samir, A.; El-Banna, A.A.; Khan, W.U.; Chatzinotas, S.; ElHalawany, B.M. Mixed RIS-Relay NOMA-Based RF-UOWC Systems. In Proceedings of the 2022 IEEE 95th Vehicular Technology Conference: (VTC2022-Spring), Helsinki, Finland, 19–22 June 2022; pp. 1–6. [Google Scholar] [CrossRef]
- Li, S.; Yang, L.; Costa, D.B.d.; Renzo, M.D.; Alouini, M.S. On the Performance of RIS-Assisted Dual-Hop Mixed RF-UWOC Systems. IEEE Trans. Cogn. Commun. Netw. 2021, 7, 340–353. [Google Scholar] [CrossRef]
- Agrawal, N.; Bansal, A.; Singh, K.; Li, C.P.; Mumtaz, S. Finite Block Length Analysis of RIS-Assisted UAV-Based Multiuser IoT Communication System With Non-Linear EH. IEEE Trans. Commun. 2022, 70, 3542–3557. [Google Scholar] [CrossRef]
- Fan, X.; Liu, M.; Chen, Y.; Sun, S.; Li, Z. RIS-Assisted UAV for Fresh Data Collection in 3D Urban Environments: A Deep Reinforcement Learning Approach. IEEE Trans. Vehicular Technol. 2022, 1–15. [Google Scholar] [CrossRef]
- Fernández, S.; Gregorio, F.; Chalise, B.K.; Cousseau, J. Wireless Information and power transfer assisted by reconfigurable intelligent surfaces: Invited Paper. In Proceedings of the 2021 Argentine Conference on Electronics (CAE), Bahia Blanca, Argentina, 11–12 March 2021; pp. 73–77. [Google Scholar] [CrossRef]
- Lin, J.; Zou, Y.; Dong, X.; Gong, S.; Hoang, D.T.; Niyato, D.T. Deep Reinforcement Learning for Robust Beamforming in IRS-assisted Wireless Communications. In Proceedings of the GLOBECOM 2020—2020 IEEE Global Communications Conference, Taipei, Taiwan, 7–11 December 2020; pp. 1–6. [Google Scholar]
- Mohamed, Z.; Aïssa, S. Resource Allocation for Energy-Efficient Cellular Communications via Aerial IRS. In Proceedings of the 2021 IEEE Wireless Communications and Networking Conference (WCNC), Nanjing, China, 29 March–1 April 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Wang, T.; Fang, F.; Ding, Z. An SCA and Relaxation Based Energy Efficiency Optimization for Multi-User RIS-Assisted NOMA Networks. IEEE Trans. Veh. Technol. 2022, 71, 6843–6847. [Google Scholar] [CrossRef]
- Kisseleff, S.; Chatzinotas, S.; Ottersten, B. Reconfigurable Intelligent Surfaces in Challenging Environments: Underwater, Underground, Industrial and Disaster. IEEE Access 2021, 9, 150214–150233. [Google Scholar] [CrossRef]
- Sharma, T.; Chehri, A.; Fortier, P. Reconfigurable Intelligent Surfaces for 5G and beyond Wireless Communications: A Comprehensive Survey. Energies 2021, 14, 8219. [Google Scholar] [CrossRef]
- Mohsan, S.A.H.; Khan, M.A.; Alsharif, M.H.; Uthansakul, P.; Solyman, A.A.A. Intelligent Reflecting Surfaces Assisted UAV Communications for Massive Networks: Current Trends, Challenges, and Research Directions. Sensors 2022, 22, 5278. [Google Scholar] [CrossRef]
- Park, K.W.; Kim, H.M.; Shin, O.S. A Survey on Intelligent-Reflecting-Surface-Assisted UAV Communications. Energies 2022, 15, 5143. [Google Scholar] [CrossRef]
- Pogaku, A.C.; Do, D.T.; Lee, B.M.; Nguyen, N.D. UAV-Assisted RIS for Future Wireless Communications: A Survey on Optimization and Performance Analysis. IEEE Access 2022, 10, 16320–16336. [Google Scholar] [CrossRef]
- Sejan, M.A.S.; Rahman, M.H.; Shin, B.S.; Oh, J.H.; You, Y.H.; Song, H.K. Machine Learning for Intelligent-Reflecting-Surface-Based Wireless Communication towards 6G: A Review. Sensors 2022, 22, 5405. [Google Scholar] [CrossRef] [PubMed]
- Li, Z.; Wang, S.; Lin, Q.; Li, Y.; Wen, M.; Wu, Y.C.; Poor, H.V. Phase Shift Design in RIS Empowered Wireless Networks: From Optimization to AI-Based Methods. Network 2022, 2, 398–418. [Google Scholar] [CrossRef]
- Cao, X.; Yang, B.; Huang, C.; Alexandropoulos, G.C.; Yuen, C.; Han, Z.; Poor, H.V.; Hanzo, L. Massive Access of Static and Mobile Users via Reconfigurable Intelligent Surfaces: Protocol Design and Performance Analysis. IEEE J. Sel. Areas Commun. 2022, 40, 1253–1269. [Google Scholar] [CrossRef]
- Zhi, K.; Pan, C.; Ren, H.; Wang, K. Power Scaling Law Analysis and Phase Shift Optimization of RIS-Aided Massive MIMO Systems With Statistical CSI. IEEE Trans. Commun. 2022, 70, 3558–3574. [Google Scholar] [CrossRef]
- Zeng, P.; Qiao, D.; Wu, Q.; Wu, Y. Throughput Maximization for Active Intelligent Reflecting Surface-Aided Wireless Powered Communications. IEEE Wirel. Commun. 2022, 11, 992–996. [Google Scholar] [CrossRef]
- Liu, K.; Zhang, Z.; Dai, L.; Xu, S.; Yang, F. Active Reconfigurable Intelligent Surface: Fully-Connected or Sub-Connected? IEEE Commun. Lett. 2022, 26, 167–171. [Google Scholar] [CrossRef]
- Pang, X.; Sheng, M.; Zhao, N.; Tang, J.; Niyato, D.; Wong, K.K. When UAV Meets IRS: Expanding Air-Ground Networks via Passive Reflection. IEEE Wirel. Commun. 2021, 28, 164–170. [Google Scholar] [CrossRef]
- Huang, A.; Guo, L.; Mu, X.; Dong, C. Integrated Passive Reconfigurable Intelligent Surface and Active Relay Assisted NOMA Systems. In Proceedings of the ICC 2022—IEEE International Conference on Communications, Seoul, Republic of Korea, 16–20 May 2022; pp. 3918–3923. [Google Scholar] [CrossRef]
- Khaleel, A.; Basar, E. Phase Shift-Free Passive Beamforming for Reconfigurable Intelligent Surfaces. IEEE Trans. Commun. 2022, 70, 6966–6976. [Google Scholar] [CrossRef]
- Di, B.; Zhang, H.; Song, L.; Li, Y.; Han, Z.; Poor, H.V. Hybrid Beamforming for Reconfigurable Intelligent Surface based Multi-User Communications: Achievable Rates With Limited Discrete Phase Shifts. IEEE J. Sel. Areas Commun. 2020, 38, 1809–1822. [Google Scholar] [CrossRef]
- Obeed, M.; Chaaban, A. Joint Beamforming Design for Multiuser MISO Downlink Aided by a Reconfigurable Intelligent Surface and a Relay. IEEE Trans. Wirel. Commun. 2022, 21, 8216–8229. [Google Scholar] [CrossRef]
- Lv, Y.; He, Z.; Rong, Y. Multiuser Uplink MIMO Communications Assisted by Multiple Reconfigurable Intelligent Surfaces. IEEE Commun. Lett. 2021, 25, 3975–3979. [Google Scholar] [CrossRef]
- Wu, Q.; Zhang, R. Beamforming Optimization for Intelligent Reflecting Surface with Discrete Phase Shifts. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 7830–7833. [Google Scholar] [CrossRef] [Green Version]
- Zhi, K.; Pan, C.; Ren, H.; Chai, K.K.; Elkashlan, M. Active RIS Versus Passive RIS: Which is Superior With the Same Power Budget? IEEE Commun. Lett. 2022, 26, 1150–1154. [Google Scholar] [CrossRef]
- Xu, D.; Yu, X.; Kwan Ng, D.W.; Schober, R. Resource Allocation for Active IRS-Assisted Multiuser Communication Systems. In Proceedings of the 2021 55th Asilomar Conference on Signals, Systems, and Computers, Pacific Grove, CA, USA, 31 October–3 November 2021; pp. 113–119. [Google Scholar] [CrossRef]
- Nguyen, N.T.; Nguyen, V.D.; Wu, Q.; Tölli, A.; Chatzinotas, S.; Juntti, M. Hybrid Active-Passive Reconfigurable Intelligent Surface-Assisted Multi-User MISO Systems. In Proceedings of the 2022 IEEE 23rd International Workshop on Signal Processing Advances in Wireless Communication (SPAWC), Oulu, Finland, 4–6 July 2022; pp. 1–5. [Google Scholar] [CrossRef]
- Guo, H.; Liang, Y.C.; Chen, J.; Larsson, E.G. Weighted Sum-Rate Maximization for Intelligent Reflecting Surface Enhanced Wireless Networks. In Proceedings of the 2019 IEEE Global Communications Conference (GLOBECOM), Waikoloa, HI, USA, 9–13 December 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Jiang, W.; Chen, B.; Zhao, J.; Xiong, Z.; Ding, Z. Joint Active and Passive Beamforming Design for the IRS-Assisted MIMOME-OFDM Secure Communications. IEEE Trans. Veh. Technol. 2021, 70, 10369–10381. [Google Scholar] [CrossRef]
- You, L.; Xiong, J.; Ng, D.W.K.; Yuen, C.; Wang, W.; Gao, X. Energy Efficiency and Spectral Efficiency Tradeoff in RIS-Aided Multiuser MIMO Uplink Transmission. IEEE Trans. Signal Process. 2021, 69, 1407–1421. [Google Scholar] [CrossRef]
- Xiu, Y.; Zhao, J.; Sun, W.; Renzo, M.D.; Gui, G.; Zhang, Z.; Wei, N. Reconfigurable Intelligent Surfaces Aided mmWave NOMA: Joint Power Allocation, Phase Shifts, and Hybrid Beamforming Optimization. IEEE Trans. Wirel. Commun. 2021, 20, 8393–8409. [Google Scholar] [CrossRef]
- Li, Q.; El-Hajjar, M.; Hemadeh, I.; Shojaeifard, A.; Mourad, A.A.M.; Clerckx, B.; Hanzo, L. Reconfigurable Intelligent Surfaces Relying on Non-Diagonal Phase Shift Matrices. IEEE Trans. Veh. Technol. 2022, 71, 6367–6383. [Google Scholar] [CrossRef]
- Wang, J.; Liang, Y.C.; Joung, J.; Yuan, X.; Wang, X. Joint Beamforming and Reconfigurable Intelligent Surface Design for Two-Way Relay Networks. IEEE Trans. Commun. 2021, 69, 5620–5633. [Google Scholar] [CrossRef]
- Zhang, H.; Zhang, H.; Di, B.; Bian, K.; Han, Z.; Song, L. MetaLocalization: Reconfigurable Intelligent Surface Aided Multi-User Wireless Indoor Localization. IEEE Trans. Wirel. Commun. 2021, 20, 7743–7757. [Google Scholar] [CrossRef]
- Huang, C.; Zappone, A.; Alexandropoulos, G.C.; Debbah, M.; Yuen, C. Reconfigurable Intelligent Surfaces for Energy Efficiency in Wireless Communication. IEEE Trans. Wirel. Commun. 2019, 18, 4157–4170. [Google Scholar] [CrossRef] [Green Version]
- Do, T.N.; Kaddoum, G.; Nguyen, T.L.; da Costa, D.B.; Haas, Z.J. Aerial Reconfigurable Intelligent Surface-Aided Wireless Communication Systems. In Proceedings of the 2021 IEEE 32nd Annual International Symposium on Personal, Indoor and Mobile Radio Communications (PIMRC), Helsinki, Finland, 13–16 September 2021; pp. 525–530. [Google Scholar] [CrossRef]
- Ernst, D.; Glavic, M.; Wehenkel, L. Power systems stability control: Reinforcement learning framework. IEEE Trans. Power Syst. 2004, 19, 427–435. [Google Scholar] [CrossRef] [Green Version]
- Liu, Y.; Zhang, D.; Gooi, H.B. Optimization strategy based on deep reinforcement learning for home energy management. CSEE J. Power Energy Syst. 2020, 6, 572–582. [Google Scholar] [CrossRef]
- DiGiovanna, J.; Mahmoudi, B.; Fortes, J.; Principe, J.C.; Sanchez, J.C. Coadaptive Brain–Machine Interface via Reinforcement Learning. IEEE Trans. Biomed. Eng. 2009, 56, 54–64. [Google Scholar] [CrossRef] [PubMed]
- Saleem, R.; Ni, W.; Ikram, M.; Jamalipour, A. Deep Reinforcement Learning-Driven Secrecy Design for Intelligent Reflecting Surface-Based 6G-IoT Networks. IEEE Internet Things J. 2022. [Google Scholar] [CrossRef]
- Du, Y.; Zandi, H.; Kotevska, O.; Kurte, K.; Munk, J.; Amasyali, K.; Mckee, E.; Li, F. Intelligent multi-zone residential HVAC control strategy based on deep reinforcement learning. Appl. Energy 2021, 281, 116117. [Google Scholar] [CrossRef]
- Tang, X.; Zhang, J.; Pi, D.; Lin, X.; Grzesiak, L.M.; Hu, X. Battery Health-Aware and Deep Reinforcement Learning-Based Energy Management for Naturalistic Data-Driven Driving Scenarios. IEEE Trans. Transp. Electrif. 2022, 8, 948–964. [Google Scholar] [CrossRef]
- Wan, K.; Gao, X.; Hu, Z.; Wu, G. Robust Motion Control for UAV in Dynamic Uncertain Environments Using Deep Reinforcement Learning. Remote Sens. 2020, 12, 640. [Google Scholar] [CrossRef] [Green Version]
- Fu, Q.; Li, K.; Chen, J.; Wang, J.; Lu, Y.; Wang, Y. Building Energy Consumption Prediction Using a Deep-Forest-Based DQN Method. Buildings 2022, 12, 131. [Google Scholar] [CrossRef]
- Wang, L.; Wang, K.; Pan, C.; Aslam, N. Joint Trajectory and Passive Beamforming Design for Intelligent Reflecting Surface-Aided UAV Communications: A Deep Reinforcement Learning Approach. IEEE Trans. Mobile Comput. 2022. [Google Scholar] [CrossRef]
- Mei, H.; Yang, K.; Liu, Q.; Wang, K. 3D-Trajectory and Phase-Shift Design for RIS-Assisted UAV Systems Using Deep Reinforcement Learning. IEEE Trans. Veh. Technol. 2022, 71, 3020–3029. [Google Scholar] [CrossRef]
- Wang, W.; Zhang, W. Intelligent Reflecting Surface Configurations for Smart Radio Using Deep Reinforcement Learning. IEEE J. Sel. Areas Commun. 2022, 40, 2335–2346. [Google Scholar] [CrossRef]
- Huang, C.; Mo, R.; Yuen, C. Reconfigurable Intelligent Surface Assisted Multiuser MISO Systems Exploiting Deep Reinforcement Learning. IEEE J. Sel. Areas Commun. 2020, 38, 1839–1850. [Google Scholar] [CrossRef]
- Xu, J.; Ai, B.; Quek, T.Q.S.; Liuc, Y. Deep Reinforcement Learning for Interference Suppression in RIS-Aided High-Speed Railway Networks. In Proceedings of the 2022 IEEE International Conference on Communications Workshops (ICC Workshops), Seoul, Republic of Korea, 16–20 May 2022; pp. 337–342. [Google Scholar] [CrossRef]
- Ma, W.; Zhuo, L.; Li, L.; Liu, Y.; Ren, H. Deep Reinforcement Learning for RIS-Aided Multiuser MISO System with Hardware Impairments. Appl. Sci. 2022, 12, 7236. [Google Scholar] [CrossRef]
- Jiao, S.; Xie, X.; Ding, Z. Deep Reinforcement Learning-Based Optimization for RIS-Based UAV-NOMA Downlink Networks (Invited Paper). Front. Signal Process. 2022, 2. [Google Scholar] [CrossRef]
- Shehab, M.; Ciftler, B.S.; Khattab, T.; Abdallah, M.M.; Trinchero, D. Deep Reinforcement Learning Powered IRS-Assisted Downlink NOMA. IEEE Open J. Commun. Soc. 2022, 3, 729–739. [Google Scholar] [CrossRef]
- Guo, X.; Chen, Y.; Wang, Y. Learning-Based Robust and Secure Transmission for Reconfigurable Intelligent Surface Aided Millimeter Wave UAV Communications. IEEE Wirel. Commun. Lett. 2021, 10, 1795–1799. [Google Scholar] [CrossRef]
- Hashemi, R.; Ali, S.; Taghavi, E.M.; Mahmood, N.H.; Latva-Aho, M. Deep Reinforcement Learning for Practical Phase Shift Optimization in RIS-assisted Networks over Short Packet Communications. In Proceedings of the 2022 Joint European Conference on Networks and Communications & 6G Summit (EuCNC/6G Summit), Grenoble, France, 7–10 June 2022; pp. 518–523. [Google Scholar] [CrossRef]
- Jing, F.; Zhang, H.; Gao, M.; Xue, B.; Cao, K. RIS-Assisted Multi-Antenna AmBC Signal Detection Using Deep Reinforcement Learning. Sensors 2022, 22, 6137. [Google Scholar] [CrossRef]
- Pereira-Ruisánchez, D.; Fresnedo, Ó.; Pérez-Adán, D.; Castedo, L. Joint Optimization of IRS-assisted MU-MIMO Communication Systems through a DRL-based Twin Delayed DDPG Approach. In Proceedings of the 2022 IEEE International Symposium on Broadband Multimedia Systems and Broadcasting (BMSB), Bilbao, Spain, 15–17 June 2022; pp. 1–6. [Google Scholar] [CrossRef]
- Nguyen, K.K.; Khosravirad, S.R.; da Costa, D.B.; Nguyen, L.D.; Duong, T.Q. Reconfigurable Intelligent Surface-Assisted Multi-UAV Networks: Efficient Resource Allocation With Deep Reinforcement Learning. IEEE J. Sel. Top. Signal Process. 2022, 16, 358–368. [Google Scholar] [CrossRef]
- Samir, M.; Elhattab, M.; Assi, C.; Sharafeddine, S.; Ghrayeb, A. Optimizing Age of Information Through Aerial Reconfigurable Intelligent Surfaces: A Deep Reinforcement Learning Approach. IEEE Trans. Veh. Technol. 2021, 70, 3978–3983. [Google Scholar] [CrossRef]
- Huang, C.; Chen, G.; Tang, J.; Xiao, P.; Han, Z. Machine-Learning-Empowered Passive Beamforming and Routing Design for Multi-RIS-Assisted Multihop Networks. IEEE Internet Things J. 2022, 9, 25673–25684. [Google Scholar] [CrossRef]
- Perović, N.S.; Tran, L.N.; Di Renzo, M.; Flanagan, M.F. Achievable Rate Optimization for MIMO Systems With Reconfigurable Intelligent Surfaces. IEEE Trans. Wirel. Commun. 2021, 20, 3865–3882. [Google Scholar] [CrossRef]
- Atapattu, S.; Fan, R.; Dharmawansa, P.; Wang, G.; Evans, J.; Tsiftsis, T.A. Reconfigurable Intelligent Surface Assisted Two–Way Communications: Performance Analysis and Optimization. IEEE Trans. Commun. 2020, 68, 6552–6567. [Google Scholar] [CrossRef]
- Hashida, H.; Kawamoto, Y.; Kato, N. Intelligent Reflecting Surface Placement Optimization in Air-Ground Communication Networks Toward 6G. IEEE Wirel. Commun. 2020, 27, 146–151. [Google Scholar] [CrossRef]
- Zhang, J.; Du, H.; Sun, Q.; Ai, B.; Ng, D.W.K. Physical Layer Security Enhancement With Reconfigurable Intelligent Surface-Aided Networks. IEEE Trans. Inf. Forensics Secur. 2021, 16, 3480–3495. [Google Scholar] [CrossRef]
- Jung, M.; Saad, W.; Jang, Y.; Kong, G.; Choi, S. Performance Analysis of Large Intelligent Surfaces (LISs): Asymptotic Data Rate and Channel Hardening Effects. IEEE Trans. Wirel. Commun. 2020, 19, 2052–2065. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Lu, H.; Sun, H. Channel Estimation in IRS-Enhanced mmWave System With Super-Resolution Network. IEEE Commun. Lett. 2021, 25, 2599–2603. [Google Scholar] [CrossRef]
- Chen, Y.; Wang, Y.; Wang, Z.; Zhang, P. Robust Beamforming for Active Reconfigurable Intelligent Omni-Surface in Vehicular Communications. IEEE J. Sel. Areas Commun. 2022, 40, 3086–3103. [Google Scholar] [CrossRef]
- Tasci, R.A.; Kilinc, F.; Basar, E.; Alexandropoulos, G.C. A New RIS Architecture With a Single Power Amplifier: Energy Efficiency and Error Performance Analysis. IEEE Access 2022, 10, 44804–44815. [Google Scholar] [CrossRef]
- Long, R.; Liang, Y.C.; Pei, Y.; Larsson, E.G. Active Reconfigurable Intelligent Surface-Aided Wireless Communications. IEEE Trans. Wirel. Commun. 2021, 20, 4962–4975. [Google Scholar] [CrossRef]
- Da Silva, L.M.D.; Torquato, M.F.; Fernandes, M.A.C. Parallel Implementation of Reinforcement Learning Q-Learning Technique for FPGA. IEEE Access 2019, 7, 2782–2798. [Google Scholar] [CrossRef]
- Ji, Z.; Qin, Z.; Parini, C.G. Reconfigurable Intelligent Surface Aided Cellular Networks With Device-to-Device Users. IEEE Trans. Commun. 2022, 70, 1808–1819. [Google Scholar] [CrossRef]
- Huang, C.; Alexandropoulos, G.C.; Yuen, C.; Debbah, M. Indoor Signal Focusing with Deep Learning Designed Reconfigurable Intelligent Surfaces. In Proceedings of the 2019 IEEE 20th International Workshop on Signal Processing Advances in Wireless Communications (SPAWC), Cannes, France, 2–5 July 2019; pp. 1–5. [Google Scholar] [CrossRef] [Green Version]
- Gupta, K.D.; Nigam, R.; Sharma, D.K.; Dhurandher, S.K. LSTM-Based Energy-Efficient Wireless Communication With Reconfigurable Intelligent Surfaces. IEEE Trans. Green Commun. Netw. 2022, 6, 704–712. [Google Scholar] [CrossRef]
- Zhang, S.; Zhang, S.; Gao, F.; Ma, J.; Dobre, O.A. Deep Learning Optimized Sparse Antenna Activation for Reconfigurable Intelligent Surface Assisted Communication. IEEE Trans. Commun. 2021, 69, 6691–6705. [Google Scholar] [CrossRef]
- Zeng, T.; Semiari, O.; Mozaffari, M.; Chen, M.; Saad, W.; Bennis, M. Federated Learning in the Sky: Joint Power Allocation and Scheduling with UAV Swarms. In Proceedings of the ICC 2020—2020 IEEE International Conference on Communications (ICC), Dublin, Ireland, 7–11 June 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Jamali, M.V.; Chizari, A.; Salehi, J.A. Performance Analysis of Multi-Hop Underwater Wireless Optical Communication Systems. IEEE Photonics Technol. Lett. 2017, 29, 462–465. [Google Scholar] [CrossRef]
- Zedini, E.; Oubei, H.M.; Kammoun, A.; Hamdi, M.; Ooi, B.S.; Alouini, M.S. Unified Statistical Channel Model for Turbulence-Induced Fading in Underwater Wireless Optical Communication Systems. IEEE Trans. Commun. 2019, 67, 2893–2907. [Google Scholar] [CrossRef] [Green Version]
- Chen, C.; Pan, C. Blocking Probability in Obstructed Tunnels With Reconfigurable Intelligent Surface. IEEE Commun. Lett. 2022, 26, 458–462. [Google Scholar] [CrossRef]





| References | Year | Thoroughly Explained Scope of the Architecture | Limitations and Contributions | ||||
|---|---|---|---|---|---|---|---|
| General Knowledge of RL | DQN | DDPG | TD3 | PPO | |||
| [21] | 2021 | ✔ | x | x | x | x | RIS deployment and system design |
| [22] | 2021 | ✔ | x | x | x | x | RIS hardware and system design |
| [23] | 2022 | ✔ | x | x | x | x | IRS-assisted UAV for massive networks in ground and airborne scenarios |
| [24] | 2022 | ✔ | x | x | x | x | IRS-assisted UAV for non-terrestrial networks |
| [25] | 2022 | ✔ | x | x | x | x | Optimization and performance analysis for UAV-assisted RIS communication |
| [26] | 2022 | ✔ | x | x | x | x | Channel estimation and RIS based on ML applications |
| [27] | 2022 | ✔ | x | x | x | x | Signal processing and AI methods for RIS phase-shift optimization |
| Our work | 2023 | ✔ | ✔ | ✔ | ✔ | ✔ | RL algorithms implementation for RISs |
| References | Problem | Optimized Parameters | Implemented RL Algorithm | RIS Installation |
|---|---|---|---|---|
| [59] | Maximizing the energy efficiency of the UAV | 1. UAV trajectory 2. RIS phase shift | DQN and DDPG | Attached to a building |
| [60] | Maximizing the data rate | 1. UAV trajectory 2. RIS passive phase shift 3. GT scheduling | DDQN and DDPG | Aerial RIS |
| [61] | Mitigating over-estimation and maximizing average sum rate | 1. RIS passive phase shift | DDQN | On the ground |
| References | Problem | Optimized Parameters | Implemented RL Algorithm | RIS Installation |
|---|---|---|---|---|
| [71] | Maximizing the energy efficiency | 1. UAV power allocation 2. RIS phase shift | PPO | Attached to a building |
| [72] | Minimizing the information age | 1. UAV altitude 2. Communication schedule 3. RIS phase shift | PPO | Aerial RIS |
| [73] | Maximizing the minimum end-to-end data rate | 1. RIS phase shift 2. User’s power allocation 3. Next transmission route node | PPO | On the ground |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Puspitasari, A.A.; Lee, B.M. A Survey on Reinforcement Learning for Reconfigurable Intelligent Surfaces in Wireless Communications. Sensors 2023, 23, 2554. https://doi.org/10.3390/s23052554
Puspitasari AA, Lee BM. A Survey on Reinforcement Learning for Reconfigurable Intelligent Surfaces in Wireless Communications. Sensors. 2023; 23(5):2554. https://doi.org/10.3390/s23052554
Chicago/Turabian StylePuspitasari, Annisa Anggun, and Byung Moo Lee. 2023. "A Survey on Reinforcement Learning for Reconfigurable Intelligent Surfaces in Wireless Communications" Sensors 23, no. 5: 2554. https://doi.org/10.3390/s23052554
APA StylePuspitasari, A. A., & Lee, B. M. (2023). A Survey on Reinforcement Learning for Reconfigurable Intelligent Surfaces in Wireless Communications. Sensors, 23(5), 2554. https://doi.org/10.3390/s23052554