
LiDAR-to-Radar Translation Based on Voxel Feature Extraction Module for Radar Data Augmentation

Abstract
:1. Introduction
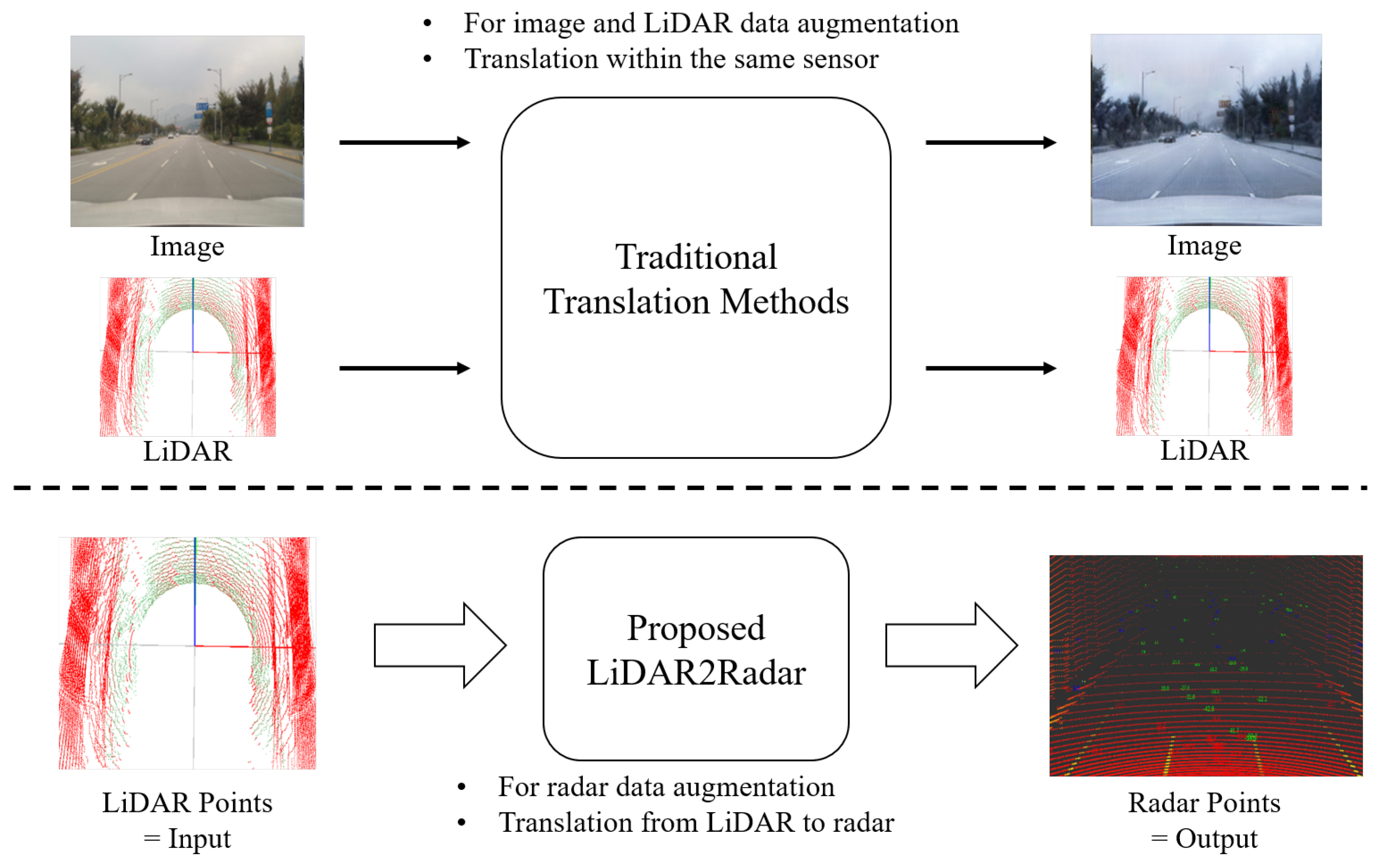
- We introduce the first, innovative, deep-learning-based LiDAR-to-Radar translation method that preserves 3D point information.
- We make a significant contribution to radar data augmentation, which, in turn, greatly advances the development of deep-learning-based algorithms that utilize radar data.
- The proposed method utilizes LiDAR and radar data acquired in the same environment for training and quantitative evaluation. The experimental results demonstrate that it is possible to successfully generate radar data with less noise from reliable LiDAR data, compared to actual radar data.
2. Related Work
2.1. General Image Translation
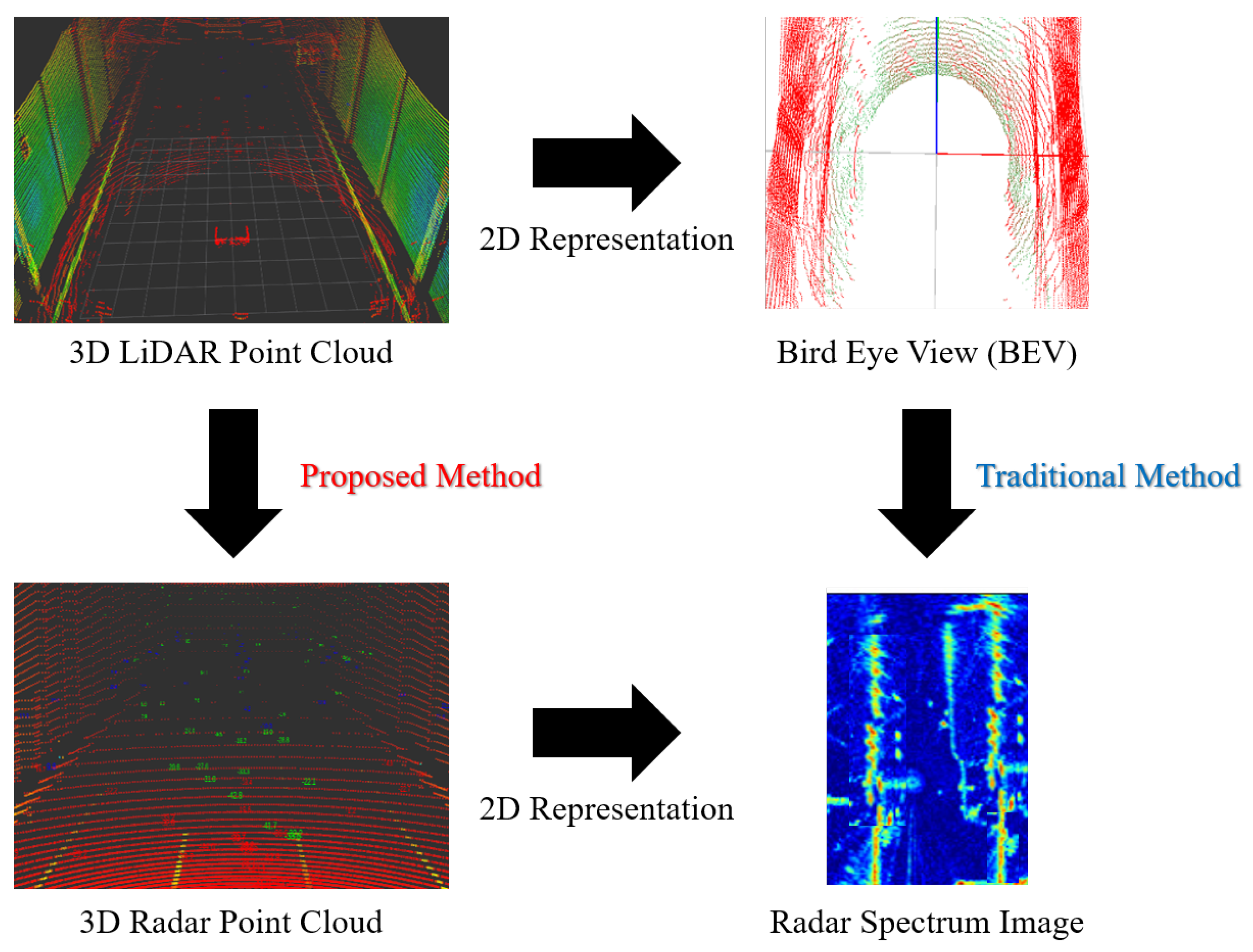
2.2. LiDAR and Radar Translation within Same Sensor Domain
2.3. LiDAR-to-Radar Translation for Radar Data Augmentation
3. Proposed Method
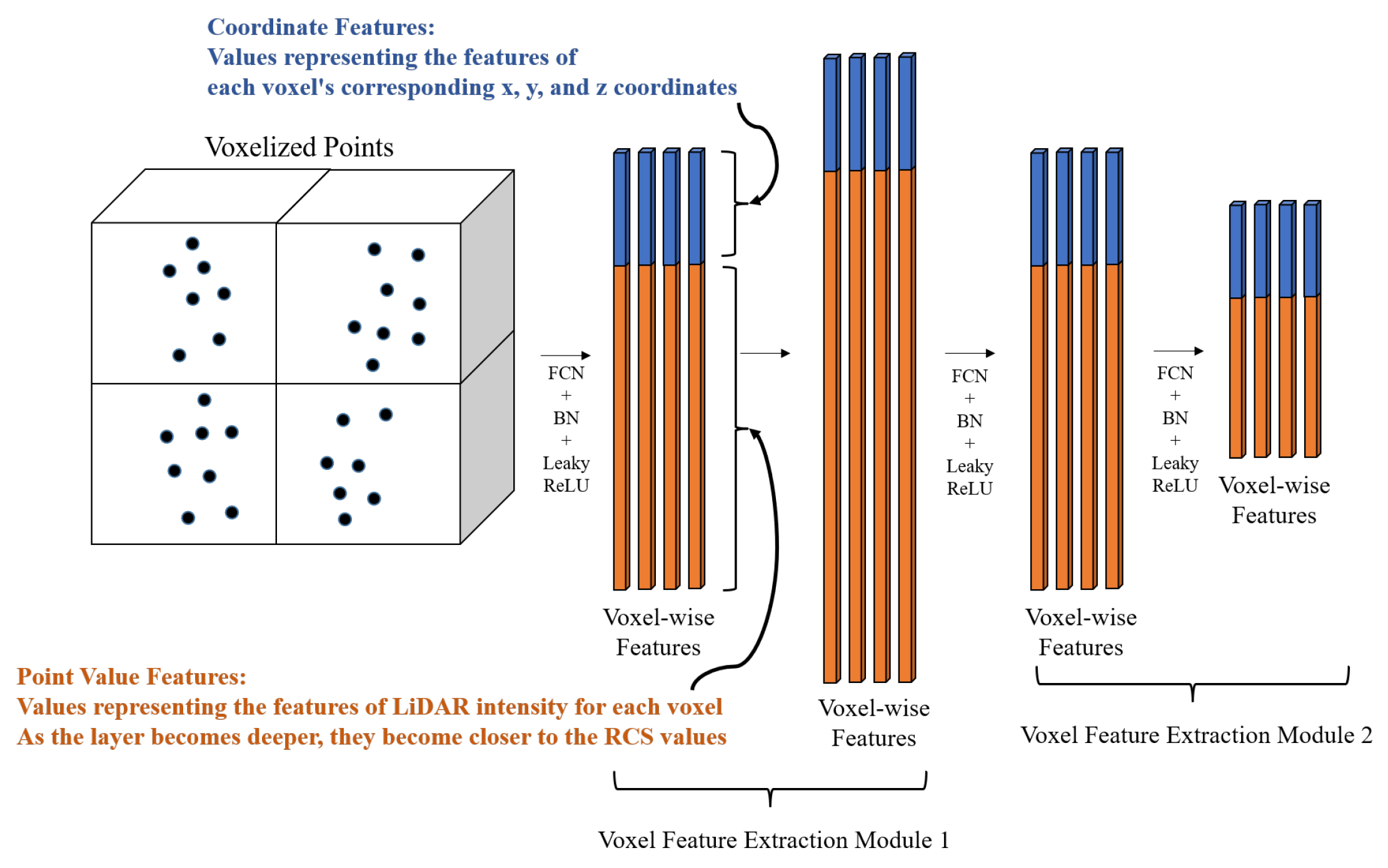
3.1. Voxel Feature Extraction Module
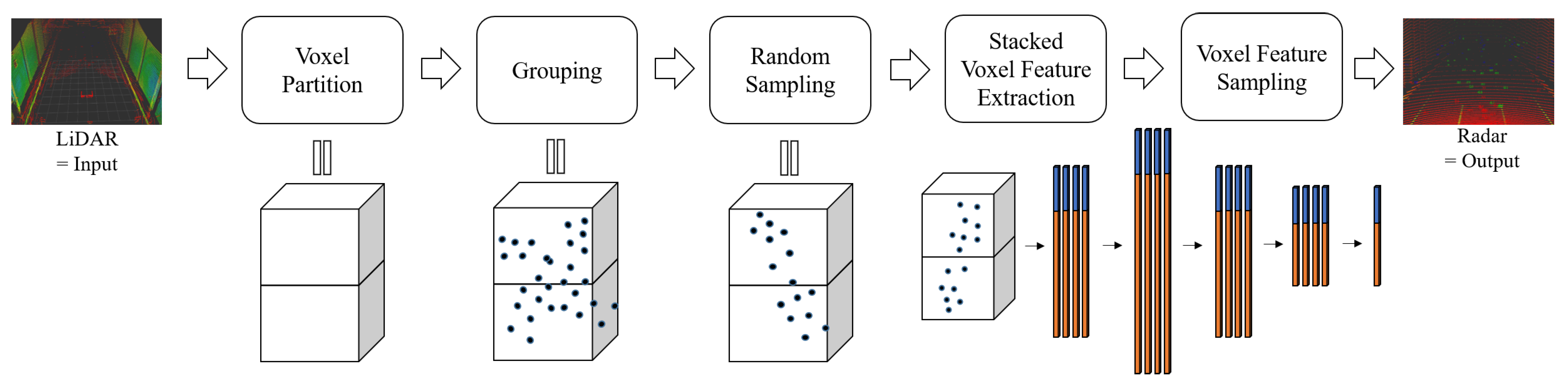
3.2. Pipeline
3.2.1. Voxel Partition
3.2.2. Grouping
3.2.3. Random Sampling
3.2.4. Stacked Voxel Feature Extraction
3.2.5. Voxel Feature Sampling
3.3. Training
4. Experimental Results
4.1. Data Set
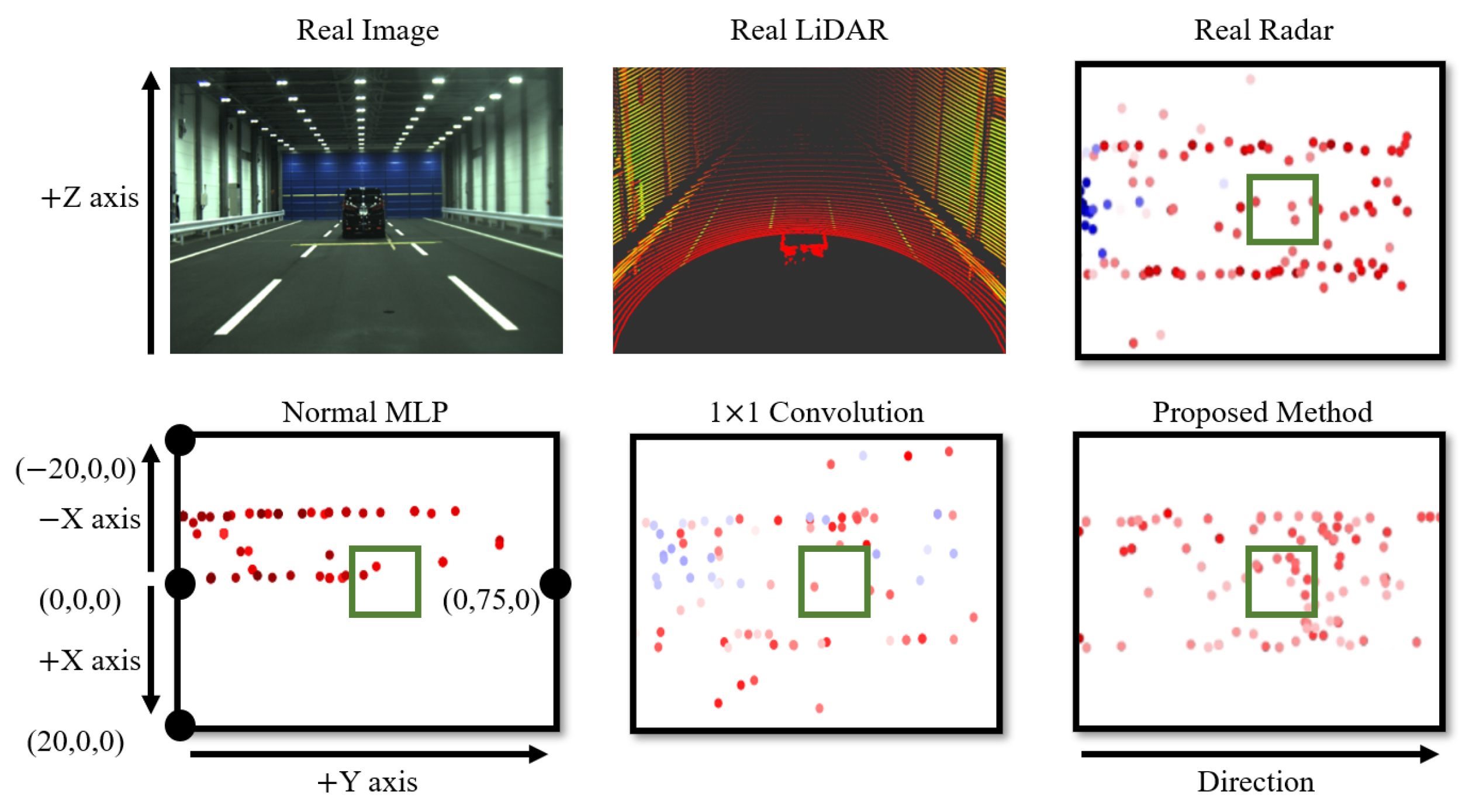
4.2. Experiment 1: The Most Optimal Architecture
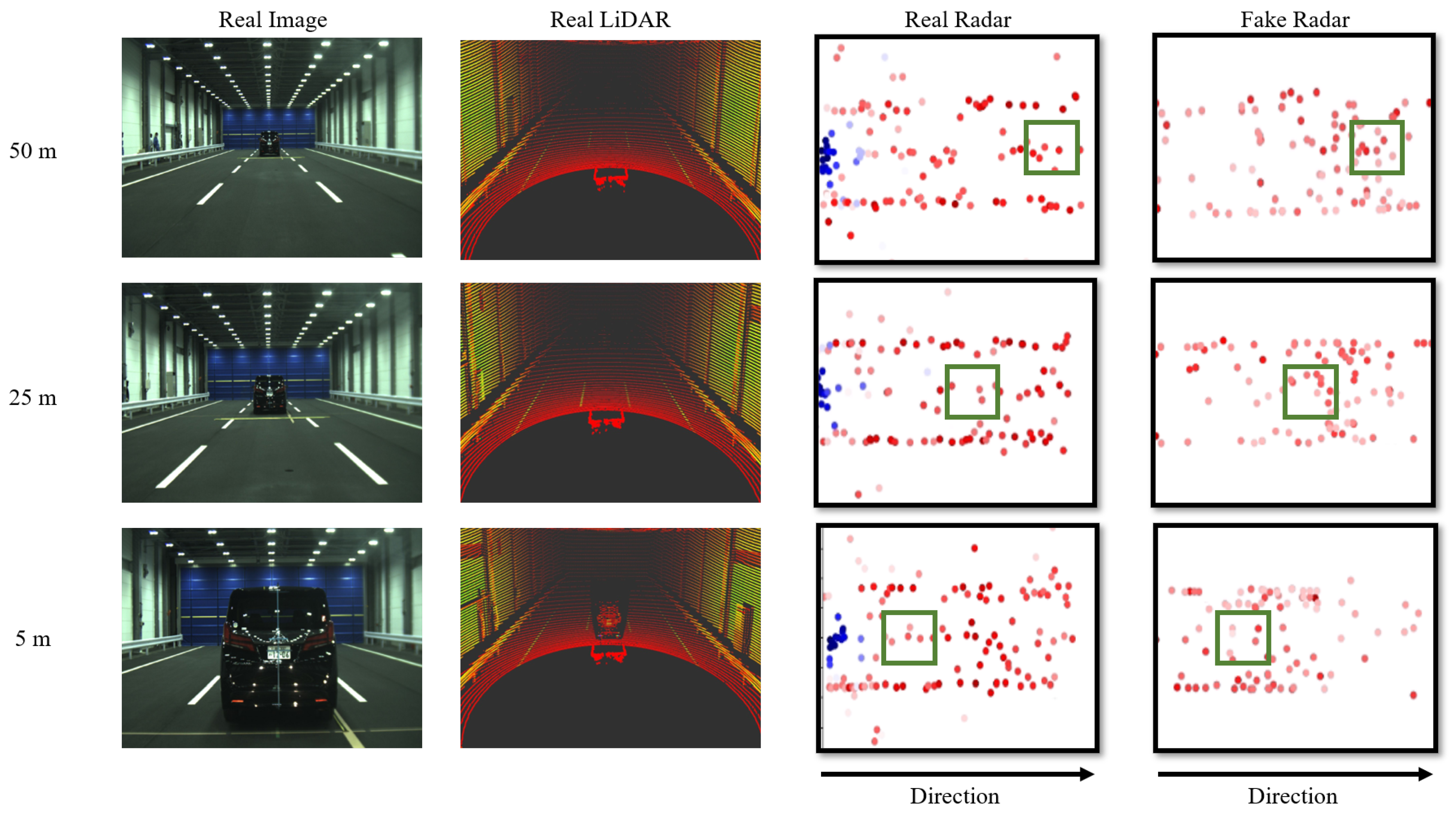
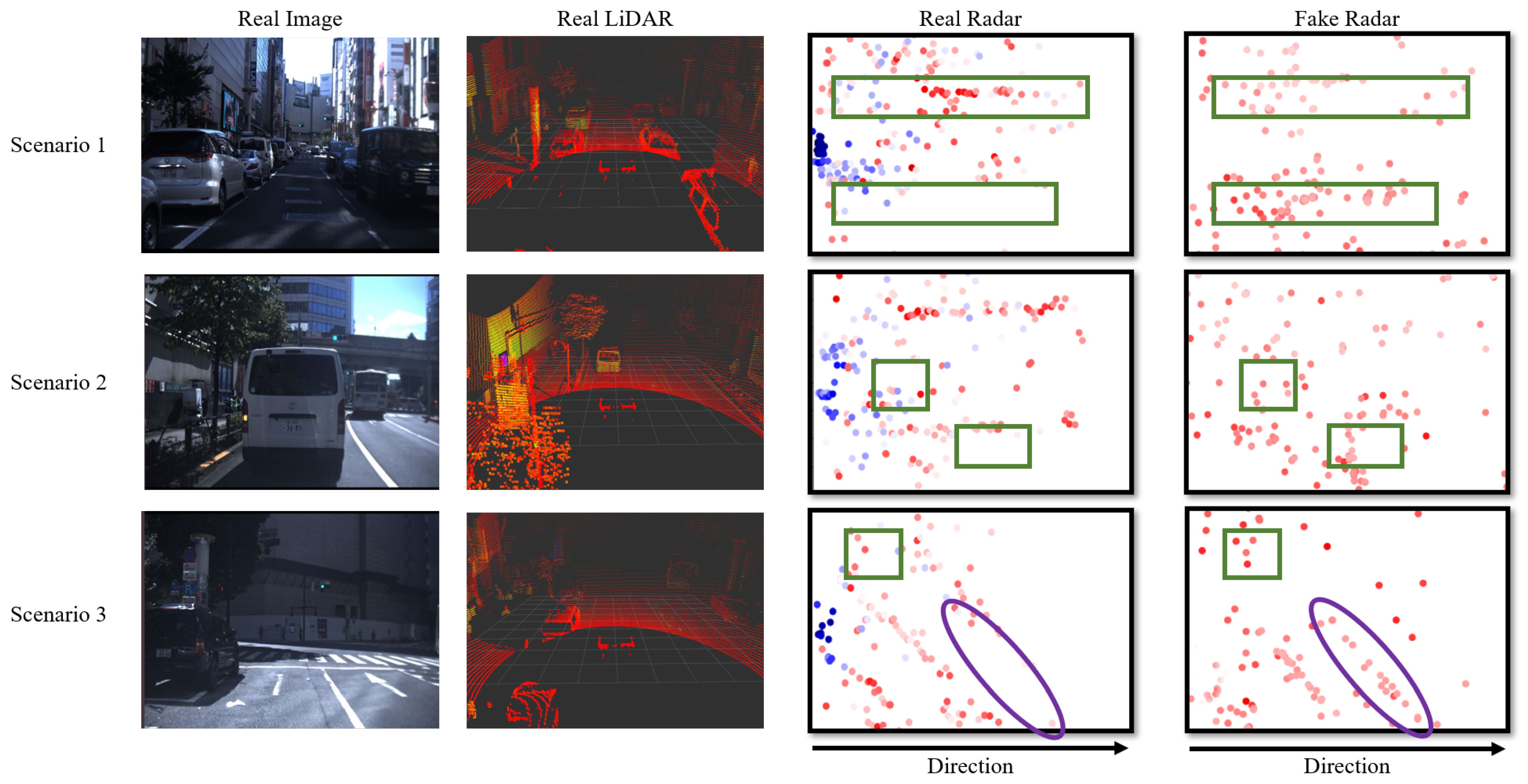
4.3. Experiment 2: Qualitative Evaluation of LiDAR-to-Radar Translation
4.4. Experiment 3: Quantitative Evaluation of LiDAR-to-Radar Translation
4.5. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Xie, E.; Ding, J.; Wang, W.; Zhan, X.; Xu, H.; Sun, P.; Luo, P. Detco: Unsupervised contrastive learning for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Nashville, TN, USA, 20–25 June 2021; pp. 8392–8401. [Google Scholar]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Wei, X. YOLOv6: A single-stage object detection framework for industrial applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Yadav, S.S.; Jadhav, S.M. Deep convolutional neural network based medical image classification for disease diagnosis. J. Big Data 2019, 6, 1–18. [Google Scholar] [CrossRef]
- Yadav, S.; Chand, S. Automated food image classification using deep learning approach. In Proceedings of the 2021 7th International Conference on Advanced Computing and Communication Systems (ICACCS), Coimbatore, India, 19–20 March 2021; Volume 1, pp. 542–545. [Google Scholar]
- Ferdous, H.; Siraj, T.; Setu, S.J.; Anwar, M.M.; Rahman, M.A. Machine learning approach towards satellite image classification. In Proceedings of the International Conference on Trends in Computational and Cognitive Engineering: Proceedings of TCCE 2020, Dhaka, Bangladesh, 17–18 December 2020; pp. 627–637. [Google Scholar]
- Strudel, R.; Garcia, R.; Laptev, I.; Schmid, C. Segmenter: Transformer for semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Nashville, TN, USA, 20–25 June 2021; pp. 7262–7272. [Google Scholar]
- Fan, M.; Lai, S.; Huang, J.; Wei, X.; Chai, Z.; Luo, J.; Wei, X. Rethinking bisenet for real-time semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 9716–9725. [Google Scholar]
- Cheng, B.; Schwing, A.; Kirillov, A. Per-pixel classification is not all you need for semantic segmentation. Adv. Neural Inf. Process. Syst. 2021, 34, 17864–17875. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 27, 139–144. [Google Scholar]
- Mirza, M.; Osindero, S. Conditional generative adversarial nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv 2015, arXiv:1511.06434. [Google Scholar]
- Mao, X.; Li, Q.; Xie, H.; Lau, R.Y.; Wang, Z.; Paul Smolley, S. Least squares generative adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2794–2802. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- El Sallab, A.; Sobh, I.; Zahran, M.; Essam, N. LiDAR sensor modeling and data augmentation with GANs for autonomous driving. arXiv 2019, arXiv:1905.07290. [Google Scholar]
- Lee, J.; Shiotsuka, D.; Nishimori, T.; Nakao, K.; Kamijo, S. GAN-Based LiDAR Translation between Sunny and Adverse Weather for Autonomous Driving and Driving Simulation. Sensors 2022, 22, 5287. [Google Scholar] [CrossRef] [PubMed]
- Lee, J.; Shiotsuka, D.; Nishimori, T.; Nakao, K.; Kamijo, S. LiDAR Translation Based on Empirical Approach between Sunny and Foggy for Driving Simulation. In Proceedings of the 2022 25th International Symposium on Wireless Personal Multimedia Communications (WPMC), Herning, Denmark, 30 October–2 November 2022; pp. 430–435. [Google Scholar]
- Zhou, Y.; Tuzel, O. Voxelnet: End-to-end learning for point cloud based 3d object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4490–4499. [Google Scholar]
- Karacan, L.; Akata, Z.; Erdem, A.; Erdem, E. Learning to generate images of outdoor scenes from attributes and semantic layouts. arXiv 2016, arXiv:1612.00215. [Google Scholar]
- Sangkloy, P.; Lu, J.; Fang, C.; Yu, F.; Hays, J. Scribbler: Controlling deep image synthesis with sketch and color. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5400–5409. [Google Scholar]
- Yi, Z.; Zhang, H.; Tan, P.; Gong, M. Dualgan: Unsupervised dual learning for image-to-image translation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2849–2857. [Google Scholar]
- Liu, M.Y.; Tuzel, O. Coupled generative adversarial networks. Adv. Neural Inf. Process. Syst. 2016, 29, 469–477. [Google Scholar]
- Anoosheh, A.; Agustsson, E.; Timofte, R.; Van Gool, L. Combogan: Unrestrained scalability for image domain translation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–23 June 2018; pp. 783–790. [Google Scholar]
- Yang, X.; Xie, D.; Wang, X. Crossing-domain generative adversarial networks for unsupervised multi-domain image-to-image translation. In Proceedings of the 26th ACM International Conference on Multimedia, Seoul, Republic of Korea, 22–26 October 2018; pp. 374–382. [Google Scholar]
- Ding, J.; Chen, B.; Liu, H.; Huang, M. Convolutional neural network with data augmentation for SAR target recognition. IEEE Geosci. Remote. Sens. Lett. 2016, 13, 364–368. [Google Scholar] [CrossRef]
- Sheeny, M.; Wallace, A.; Wang, S. Radio: Parameterized generative radar data augmentation for small datasets. Appl. Sci. 2020, 10, 3861. [Google Scholar] [CrossRef]
- Wang, L.; Goldluecke, B.; Anklam, C. L2R GAN: LiDAR-to-radar translation. In Proceedings of the Asian Conference on Computer Vision, Virtual, 30 November–4 December 2020. [Google Scholar]
- Sindagi, V.A.; Zhou, Y.; Tuzel, O. Mvx-net: Multimodal voxelnet for 3d object detection. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 7276–7282. [Google Scholar]
- Xie, J.; Zheng, Z.; Gao, R.; Wang, W.; Zhu, S.C.; Wu, Y.N. Generative VoxelNet: Learning energy-based models for 3D shape synthesis and analysis. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 2468–2484. [Google Scholar] [CrossRef]
- Dou, J.; Xue, J.; Fang, J. SEG-VoxelNet for 3D vehicle detection from RGB and LiDAR data. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 4362–4368. [Google Scholar]
- Maturana, D.; Scherer, S. Voxnet: A 3d convolutional neural network for real-time object recognition. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Habmburg, Germany, 28 September–2 October 2015; pp. 922–928. [Google Scholar]
- Ji, S.; Xu, W.; Yang, M.; Yu, K. 3D convolutional neural networks for human action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 221–231. [Google Scholar] [CrossRef] [PubMed]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Li, B.; Yan, J.; Wu, W.; Zhu, Z.; Hu, X. High performance visual tracking with siamese region proposal network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8971–8980. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Van Erven, T.; Harremos, P. Rényi divergence and Kullback-Leibler divergence. IEEE Trans. Inf. Theory 2014, 60, 3797–3820. [Google Scholar] [CrossRef]
- Moreno, P.; Ho, P.; Vasconcelos, N. A Kullback-Leibler divergence based kernel for SVM classification in multimedia applications. Adv. Neural Inf. Process. Syst. 2003, 16, 1385–1392. [Google Scholar]
- Hashemi, M. Enlarging smaller images before inputting into convolutional neural network: Zero-padding vs. interpolation. J. Big Data 2019, 6, 1–13. [Google Scholar] [CrossRef]
- Dubey, A.K.; Jain, V. Comparative study of convolution neural network’s relu and leaky-relu activation functions. In Applications of Computing, Automation and Wireless Systems in Electrical Engineering: Proceedings of MARC 2018; Springer: Berlin/Heidelberg, Germany, 2019; pp. 873–880. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted boltzmann machines. In Proceedings of the 27th International Conference on Machine Learning (ICML-10), Haifa, Israel, 21–24 June 2010; pp. 807–814. [Google Scholar]
- Popescu, M.C.; Balas, V.E.; Perescu-Popescu, L.; Mastorakis, N. Multilayer perceptron and neural networks. WSEAS Trans. Circuits Syst. 2009, 8, 579–588. [Google Scholar]
- Ruck, D.W.; Rogers, S.K.; Kabrisky, M. Feature selection using a multilayer perceptron. J. Neural Netw. Comput. 1990, 2, 40–48. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Piotrowski, A.P.; Napiorkowski, J.J. A comparison of methods to avoid overfitting in neural networks training in the case of catchment runoff modelling. J. Hydrol. 2013, 476, 97–111. [Google Scholar] [CrossRef]
- Lin, M.; Chen, Q.; Yan, S. Network in network. arXiv 2013, arXiv:1312.4400. [Google Scholar]
- Caesar, H.; Bankiti, V.; Lang, A.H.; Vora, S.; Liong, V.E.; Xu, Q.; Beijbom, O. Nuscenes: A Multimodal Dataset for Autonomous Driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11621–11631. [Google Scholar]
- Thomas, H.; Qi, C.R.; Deschaud, J.E.; Marcotegui, B.; Goulette, F.; Guibas, L.J. Kpconv: Flexible and deformable convolution for point clouds. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6411–6420. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature Extraction Methods | Original MLP | 1 × 1 Convolution | Proposed Method |
|---|---|---|---|
| Coordinate Errors | 28.711 | 11.492 | 7.931 |
| RCS Errors | 12.775 | 20.389 | 10.356 |
| Voxel Feature Extraction Module | X Coordinate Error [cm] | Y Coordinate Error [cm] | Z Coordinate Error [cm] | RCS Error |
|---|---|---|---|---|
| Not-Segregated Module | 10.759 | 25.512 | 0.016 | 12.217 |
| Segregated Module | 3.044 | 7.324 | 0.021 | 10.356 |
| Voxel Feature Extraction Module | X Coordinate Error [cm] | Y Coordinate Error [cm] | Z Coordinate Error [cm] | RCS Error |
|---|---|---|---|---|
| Not-segregated Module | 13.116 | 24.735 | 0.031 | 17.947 |
| Segregated Module | 5.948 | 6.881 | 0.017 | 9.744 |
| Total Radar Points | Noise Radar Points | Object Radar Points | |
|---|---|---|---|
| JARI (Real) | 137 | 39 | 4 |
| JARI (Generated) | 135 | 2 | 9 |
| Tokyo (Real) | 201 | 54 | 31 |
| Tokyo (Generated) | 200 | 3 | 47 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, J.; Bang, G.; Shimizu, T.; Iehara, M.; Kamijo, S. LiDAR-to-Radar Translation Based on Voxel Feature Extraction Module for Radar Data Augmentation. Sensors 2024, 24, 559. https://doi.org/10.3390/s24020559
Lee J, Bang G, Shimizu T, Iehara M, Kamijo S. LiDAR-to-Radar Translation Based on Voxel Feature Extraction Module for Radar Data Augmentation. Sensors. 2024; 24(2):559. https://doi.org/10.3390/s24020559
Chicago/Turabian StyleLee, Jinho, Geonkyu Bang, Takaya Shimizu, Masato Iehara, and Shunsuke Kamijo. 2024. "LiDAR-to-Radar Translation Based on Voxel Feature Extraction Module for Radar Data Augmentation" Sensors 24, no. 2: 559. https://doi.org/10.3390/s24020559
APA StyleLee, J., Bang, G., Shimizu, T., Iehara, M., & Kamijo, S. (2024). LiDAR-to-Radar Translation Based on Voxel Feature Extraction Module for Radar Data Augmentation. Sensors, 24(2), 559. https://doi.org/10.3390/s24020559