1. Introduction
Human physical activity recognition (HPAR) has emerged as a crucial area of research with diverse applications in surveillance systems [
1], health care systems [
2,
3], gyms [
4], gaming [
5], etc. Additional applications of PAR include assisting older people to live freely and safely in the community while utilizing the improved healthcare system. Moreover, vision-based human activity recognition for human–computer interaction (HCI) has attracted the interest of many researchers in recent times. For example, the invention of Kinect enables real-time HCI by recognizing user gestures and body motions to control a character or for gameplay features. However, despite advancements in vision-based HCI, the major obstacle is the automatic recognition of gesture, action, and behavioral context, which is still an open and challenging topic to tackle. Therefore, several researchers utilized Kinect for the evaluation of indoor HPAR for full body tracking and gesture-based detection by an intelligent HCI system [
5,
6]. Human activity recognition is an essential domain that involves analyzing the gestures and actions that humans perform throughout their daily lives. Researchers use many data modalities to understand and identify these activities, with each modality providing distinct insights into patterns of human motion [
7,
8,
9,
10]. RGB video data are one of the modalities that collect visual information by using the colors red, green, and blue and provide a comprehensive perspective of the activities performed by humans [
11,
12]. They offer a comprehensive depiction of applications’ objects and motions, allowing for meticulous examination using image processing and computer vision methodologies. Although RGB data provide extensive visual information, they often pose difficulties in processing caused by variables such as variations in lighting, obstructions, and distracting background elements, all of which may impact the accuracy of identification. On the other hand, skeletal data offer a different and often more sophisticated method for recognizing activities [
13]. They simplify human postures into essential joint coordinates, providing an organized depiction of physical motions [
14]. This data type offers a streamlined and concentrated perspective, highlighting the fundamental characteristics necessary for identifying actions. Skeleton data provide a stable and robust representation by recording body joint spatial connections and configurations throughout motions [
15]. They are less influenced by external variables like lighting conditions or background clutter. By concentrating on the fundamental elements of joint positions and motions, this abstraction simplifies the recognition process, allowing for a more efficient and precise study of human activities. The advantage of skeletal data over RGB data in certain situations stems from their capacity to condense intricate motions into essential joint locations and trajectories, resulting in a more distinct and less distorted depiction of human activities. The simplified representation of skeletal data allows for more efficient analysis and identification, making them a preferred method in situations where exact activity detection is essential, such as in gesture recognition [
16], sports analytics [
17], or healthcare applications [
18] that need precise movement monitoring. While RGB data provide a wider contextual perspective, skeletal data’s concentrated representation is frequently more appropriate and resilient for the recognition and categorization of human physical activity.
Recently, artificial intelligence-based methods, especially deep learning, have achieved outstanding breakthroughs in human activity recognition. Accurate and real-time recognition of human activities provides valuable insights into understanding human behavior, promoting fitness, and enhancing quality of life. Furthermore, advancements in sensor technology and the availability of large-scale annotated datasets have fueled the development of sophisticated activity recognition systems. Among the various modalities used for PAR, skeleton data have gained significant attention due to their effectiveness, low computational cost, and robustness to occlusions and noise. Skeleton data represent human body movements as a series of 2D or 3D joint positions over time, which can be captured using depth sensors, such as Microsoft Kinect, or through pose estimation techniques [
19] from 2D images or videos. The inherent spatiotemporal representation of skeleton data enables a concise yet informative representation of human actions, making them an ideal input for activity recognition models.
Deep learning-based methods have demonstrated remarkable performance for HPAR. However, several challenges are associated with the current literature. The baseline methods utilize CNN or recurrent neural network (RNN) variants for HPAR. However, these methods can only extract spatial or temporal patterns from the data, while HPAR data have spatiotemporal dependencies. To overcome this challenge, the recent literature has developed hybrid models; however, these methods utilize stacked layer phenomena, which extract spatial patterns followed by temporal patterns or vice versa. Furthermore, the output of these methods is directly inputted into fully connected layers for classification. To overcome these challenges, we developed a PAR-Net that extracts both spatial and temporal features simultaneously. The PAR-Net integrates a CNN for spatial patterns and an ESN for temporal dependencies for extraction. The output of both streams is then concatenated, followed by a self-attention mechanism for optimal feature selection. Additionally, we investigate the network’s interpretability, providing insights into how it learns to recognize specific activities from the skeleton data. The main contributions of this research are as follows:
The PAR-Net introduces a novel dual-stream paradigm tailored for HPAR, which involves the integration of two distinct streams within the network architecture. The first stream utilized a CNN, which is adept at capturing spatial patterns inherent in the data. Simultaneously, the second stream incorporates an ESN, which is uniquely designed to capture temporal dependencies embedded within the activity sequences. By operating these streams in parallel, the PAR-Net inherently preserves both spatial and temporal characteristics crucial for accurate activity recognition, thereby overcoming the limitations posed by prior models that could only capture spatial or temporal aspects separately or in stacked layer phenomena.
The PAR-Net incorporates a crucial self-attention mechanism. This mechanism dynamically highlights relevant spatiotemporal features while suppressing noise and irrelevant information. By allowing the network to focus on critical aspects of the data selectively, the self-attention mechanism significantly enhances the discriminative capabilities of the PAR-Net. This integration empowers the network to learn more salient representations, thereby contributing to improved accuracy and robustness in physical activity recognition tasks.
This research extensively examines the PAR-Net and other architectures through thorough ablation studies. Each component, including the dual-stream design, self-attention mechanism, CNN–ESN architecture, and other architecture utilization, is systematically evaluated to understand their individual impact before the PAR-Net selection.
To gauge the efficacy and superiority of the PAR-Net, comprehensive comparisons are made against the baseline methods commonly used in physical activity recognition. The evaluation encompasses various metrics, including accuracy, robustness, and computational efficiency, comparing the PAR-Net performance against baselines.
The rest of the paper is structured as follows:
Section 2 presents a review of related works in human physical activity recognition and discusses existing approaches using skeleton data.
Section 3 details the architecture and components of the PAR-Net.
Section 4 presents the experimental setup, dataset descriptions, evaluation metrics, and comparative analysis with state-of-the-art methods. Finally,
Section 5 concludes the paper and outlines potential directions for future research in this domain.
2. Literature Review
Over the past eight years, significant advancements have been made in human physical activity recognition using 2D skeleton data based on advanced neural network architectures. For instance, Shi et al. [
20] demonstrated the efficacy of CNNs for skeleton-based action recognition. The authors proposed a method to map 2D joint coordinates to heatmaps, effectively transforming the skeleton data into a format suitable for CNN input. Although lacking temporal modeling, this study laid the foundation for CNN-based approaches in the field. The authors [
21] proposed a novel LSTM network called global context-aware attention LSTM (GCA-LSTM), which mainly focuses on useful joints using a global context memory cell. They also introduced a recurrent attention mechanism to increase the attention capability of the network and combined fine-grained and coarse-grained attention in a two-stream framework. This approach achieves state-of-the-art accuracy on five different challenging datasets utilized by researchers for skeleton-based action recognition. Liu et al. [
22] proposed a skeleton visualization method for view-invariant human action recognition. The method involves a view-invariant transform based on sequences to eliminate the influence of view variations, visualizing transformed skeletons as color images, and applying visual and motion enhancement methods to enhance local patterns. A CNN-based model is then used to extract informative and discriminative features from the RGB images, and decision-level fusion is applied to generate action class scores.
Another research study [
23] provided a deep learning-inspired ConvNets-based strategy for activity identification utilizing numerous visual signals. It also presented a novel technique for producing skeletal pictures that reflect motion data. RGB, skeletal data, and depth from RGB-D sensors are employed in the method, which is subsequently trained on ConvNets and merged at the outcome level. Ghazal et al. [
24] focused on vision-based human activity recognition (HAR) using skeletal data obtained from standard cameras. The approach extracts motion features from the 2D positions of human skeleton joint data through the OpenPose library. The study used supervised machine learning with different classifiers (K-nearest neighbors (KNN), support vector machine (SVM), naive Bayes (NB), linear discriminant, and feed-forward back-propagation neural network) to recognize four activity classes: standing, walking, sitting, and falling. The experimental results showed that the K-nearest neighbors classifier performed the best among the others. This method offers device-independent HAR for various applications like video surveillance, telecare, ambient intelligence, and robot navigation. Experimental results for deep learning methods like [
25], where a CNN and long short-term memory (LSTM) have been adopted to obtain spatial-temporal information, show that the score fusion of CNN and LSTM performs better than LSTM, achieving 87.40% accuracy and ranking 1st in the Large-Scale 3D Human Activity Recognition Challenge in Depth Videos. Li et al. [
26] developed actional–structural graph convolutional networks (AS-GCNs) that integrate both actional and structural graph convolutions to capture the dynamics of actions and the spatial relationships between joints. The actional graph convolution captures the temporal dependencies between joints, while the structural graph convolution focuses on modeling the skeletal structure. The AS-GCN demonstrated superior performance on challenging action recognition tasks, emphasizing the importance of considering both spatial and temporal aspects. Another study proposed an intelligent HAR-based system [
27] that combines image processing and deep learning techniques using human skeleton information and automatically recognizes human daily activities. This approach has proven promising because of its low computation cost and high accuracy outcomes, making it suitable for embedded systems.
However, effective model training is essential for PAR systems to accurately detect human body parts and the required physical activities. Therefore, Nadeem et al. [
28] presented an integrated framework that deals with multidimensional features using a fusion of human body part models and quadratic discriminant analysis. Multilevel features are extracted as displacement parameters, representing the spatiotemporal properties of body parts over time. The recognition engine utilizes a maximum-entropy Markov model to process these characteristics. The experimental findings demonstrated that this method outperformed existing techniques in terms of accuracy for body part identification and physical activity recognition. The body part detection accuracy achieved a rate of 90.91% on the sports action dataset provided by the University of Central Florida. In contrast, the accuracy for activity recognition on UCF YouTube action dataset was found to be 89.09% and the accuracy on IM-DailyRGBEvents dataset was 88.26%, respectively. To capture spatial information and temporal variations for action classification, Tasnim et al. [
29] offered a spatio-temporal image formation (STIF) approach for 3D skeletal joints. The transfer learning technique was used by utilizing the pre-trained weights of the models, including MobileNetV2, ResNet18, and DenseNet121, and their proposed method. The method outperformed prior works using UTD-MHAD and MSR-Action3D datasets, including STIF representation, attaining performance accuracy of approximately 98.93%, 98.80%, and 99.65% on UTD-MHAD and 96.00%, 97.08%, and 98.75% on MSR-Action3D datasets for each method, respectively. A dual-stream structured graph convolution network (DS-SGCN) was proposed in [
30] to address the issue of skeleton-based action recognition. The DS-SGCN integrates the spatiotemporal joint coordinates and appearance contexts of skeletal joints, allowing for a better representation of discrete joints. The module encodes segregated body parts and dynamic interactions in a spatiotemporal sequence. Structured intra-part graphs represent distinct body parts, while inter-part graphs model dynamic interactions across different body parts. The DS-SGCN acquires intrinsic properties and dynamic interactions of human activity by learning on both inter- and intra-part graphs. After integrating spatial context and coordinate cues, a convolution-filtering process captures the temporal dynamics of human movement. The fusion of two streams of graph convolution responses predicts category information about human action end-to-end. The DS-SGCN technique achieved encouraging performance on five benchmark datasets.
Another method developed in [
31] aimed to assess the efficacy of two RNN models, namely the 2BLSTM and 3BGRU, in accurately detecting daily postures and possibly dangerous situations in a home monitoring system. The analysis was conducted using 3D skeletal data obtained from a Kinect V2 device. The RNN models were evaluated using two distinct feature sets: one composed of eight kinematic characteristics that were manually picked using a genetic algorithm, and another composed of 52 ego-centric 3D coordinates for each skeletal joint, together with the subject’s distance from the Kinect V2. In order to enhance the capacity of the 3BGRU model to make generalizations, they used a data augmentation technique to ensure a balanced training dataset and attained the highest level of accuracy of 88%. Cheng et al. [
32] proposed a system for recognizing physical exercise from video frames (extracted 3D human skeleton data using VIBE) using deep semantic features and repetitive segmentation algorithms. The system locates and segments the activity into multiple unit actions, improving recognition and time intervals. Experiments on the “NOL-18 Exercise” dataset showed an accuracy of 96.27% with a 0.23% time error. This system could be used in fitness or rehabilitation centers for patient treatment. Another study [
33] presented a human tracking model for squat exercises using open-source MediaPipe technology. The model detects and tracks vital body joints, analyzing critical joint motions for abnormal movements. Validated using a squat dataset from ten healthy individuals, the model uses double exponential smoothing to classify movements as normal or abnormal. The model accurately predicted six out of ten subjects, with a mean square error of 56.31% for normal squat and 29.78% mean square error for abnormal squat setting, respectively. This low-cost camera-based squat movement condition detection model effectively detects workout movement abnormalities. Chariar et al. [
34] introduced a method for classifying different types of squats and recommending the appropriate version for individuals. The study utilized MediaPipe and a deep learning-based approach to determine whether squatting is performed correctly or incorrectly. A stacked Bidirectional Gated Recurrent Unit (Bi-GRU) with an attention layer was used to consistently and fairly evaluate each user, categorizing squats into seven classes. The model was compared to other advanced models, both with and without the attention layer, and it outperformed the baselines. Recently, Li et al. [
35] developed a unique approach to recognizing human skeletal movement in energy-efficient smart homes by fusing several CNNs. Gray value encoding is used in this technique to encode spatiotemporal information for each 3D skeletal sequence. The CNN fusion model uses three SPI and three STSI sequences as model input for skeletal activity recognition, allowing hierarchical learning of spatiotemporal features. Experimental results were carried out on three public datasets, showing that their performance is better than that of state-of-the-art methods. To address the limitations of traditional machine learning and deep learning models for activity recognition, the authors [
36] developed a hybrid model that combines CNN and LSTM for activity recognition. They also generated a new dataset containing 12 different classes of human physical activities, collected from 20 participants using the Kinect V2 sensor. Through an extensive study, the CNN-LSTM technique achieved an accuracy of 90.89%, demonstrating its suitability for HAR applications. Furthermore, Luwe et al. [
37] presented a hybrid deep learning model called 1D-CNN-BiLSTM for recognizing human activities using data collected from wearable sensors. Using bidirectional long short-term memory (BiLSTM), the model encodes long-range relationships while transforming sensor time series data into high-level representative characteristics.
Researchers have explored various approaches, including multi-modal fusion, attention mechanisms, visualization networks, and domain adaptation, to enhance the accuracy, interpretability, and generalization capabilities of the models. These advancements contribute to human activity recognition systems for diverse real-world applications using different types of input data, which collectively contribute to developing a robust and reliable system and also provide valuable insights into building more efficient recognition systems. In summary, the literature review highlights the evolution of methodologies in human physical activity recognition using skeleton data. However, several challenges are associated with the current literature. For instance, hybrid models in HPAR often employ sequential approaches, limiting their ability to extract both spatial and temporal features concurrently. This compromises accurate recognition as it fails to preserve the intricate relationship between spatial and temporal characteristics. Furthermore, existing methods lack efficient strategies for feature selection, potentially leading to suboptimal representations and impacting recognition accuracy. To overcome these challenges, the PAR-Net introduces a dual-stream paradigm, integrating a CNN for spatial patterns and an ESN for temporal dependencies. This simultaneous extraction of spatial and temporal features preserves the essential characteristics for accurate activity recognition. Additionally, the PAR-Net incorporates a self-attention mechanism, dynamically highlighting salient spatiotemporal features, thereby enhancing discriminative capabilities. This comprehensive approach ensures optimal feature representation and addresses the limitations of prior methods, leading to superior performance in accuracy, robustness, and computational efficiency for physical activity recognition.
The existing literature predominantly focuses on solo architectures for HPAR, overlooking the challenge posed by datasets containing both spatial and temporal features. Solo models struggle to effectively extract both types of features, hindering their performance. While some hybrid models have been proposed, such as combinations of CNN and RNN variants, they often utilize a stacked layer phenomenon for feature extraction. This approach, where one model learns from the original data while the subsequent model learns from the extracted features, faces difficulties in capturing effective temporal dependencies due to the reduction in data dimensionality after each convolutional layer. Moreover, the outputs of these models, whether solo or hybrid, are directly fed to dense layers without optimal feature selection. Consequently, the accuracy attained is insufficient for real-world implementation. In response to these limitations, we developed a PAR-Net, leveraging a dual-stream architecture to extract spatial and temporal features from raw data. These features are then concatenated and subjected to a self-attention mechanism for optimal feature selection, followed by classification using dense layers. Notably, the PAR-Net achieves higher accuracy compared to baseline models, addressing the shortcomings of existing approaches.
3. Proposed Methodology
A PAR-Net was developed to address the inherent challenges in recognizing complex activities from skeleton data. It incorporates various modules, including CNN, ESN, and self-attention, to extract spatial and temporal features effectively, where the integration of the attention module plays a crucial role in feature selection. All these modules are further discussed in the subsequent sections.
3.1. Spatial Feature Extraction
The 1D CNN is an effective architecture for extracting spatial patterns from data [
38]. Unlike traditional approaches, which are reliant on handcrafted features, a 1D CNN automatically learns hierarchical representations of spatial features, making it capable of discerning complex patterns. Skeleton-based human physical activity recognition data provide a unique perspective on human movements through joints and key point configurations over time. A 1D CNN uses filters over the spatial dimension for feature extraction that gradually abstracts into high-level feature representation. A CNN layer is followed by a max-pooling layer to reduce the computational burden by focusing on the most salient information in feature maps. To finally classify the resulting features, the output is forwarded to fully connected layers. This architecture excels at learning both short-term and long-term dependencies within the data, making it well-suited for discerning nuanced patterns in activities. The processes of the
convolution operation, max pooling operation, and fully connected layer can be mathematically demonstrated below where Equation (1) can be written as:
Here,
is the bias term of the
feature map, W represents the weights,
is the filter, and
is the activation function (e.g., ReLU).
Equation (2) shows the mathematical representation of the max pooling operation, which downsamples the input by selecting the maximum value for the window. Where
is the stride and
is the size of the pooling operation.
where
is the weights,
is the activation function,
is the input data, and
is the bias term in Equation (3).
3.2. Temporal Feature Learning
The ESN is the reservoir computing architecture that has become popular for processing sequential data, which makes it useful for time series analysis and advantageous in physical activity detection compared to other RNN architectures in terms of effectiveness and efficiency. ESNs can be distinguished from the other RNNs by a fixed, randomly generated reservoir of neurons that function as a dynamic memory. The ESNs have a fixed set of parameters and only optimize the output layer weights during training; they are better suited for applications with minimal labeled data because training is less complicated. The intrinsic memory capacity of ESNs is well suited for processing skeleton data. The reservoir of the network extracts temporal features from the sequential input by identifying patterns and relationships. Due to its dynamic properties, the reservoir can accurately simulate the temporal information of human actions and can accurately identify complex activities. To employ ESNs for activity recognition with skeleton data, the input sequences, which describe the spatiotemporal dynamics of human motions, are fed into the reservoir. The input data are converted into a high-dimensional state space by the reservoir. A linear readout layer that maps the high-dimensional representations to the target activity classes is subsequently trained using the reservoir states. Particularly, the only portion of the network that is trained is this readout layer, which streamlines the optimization procedure. ESNs have the benefit of being robust against noise, capturing long-term dependencies, and providing effective training with a small amount of labeled data. Due to the intrinsic memory provided by the fixed reservoir structure, the network can recognize and make use of temporal patterns in the skeletal data. Moreover, ESN training makes it easy, especially in situations where gathering sizable, labeled datasets might be difficult.
The ESN is mainly composed of three layers (input layer, reservoir layer, and output layer), as shown in
Figure 1. The input layer and reservoir layer are generated randomly. The reservoir layer consists of
neurons and is considered fading memory, where
is the input and
combines it at time
. The state of the ESN is updated by Equation (4), as given in [
39].
The activation function utilized in reservoir neurons is represented by
, the weight matrices of the reservoir layer are represented by
, the weight matrices of the input and output feedback are represented by
, and the input bias is denoted by
. The input
at the current instant is desired. Hence,
can be combined with the
item. Equation (4) can be written as shown in Equation (5), where
can be fused into
while only connecting the output rather than connecting the input and other neurons in the reservoir layer.
Equation (6) is used to determine the target
Y at time
:
where the output weights of the ESN are denoted with
, the output bias is denoted by
, and
is fused with
according to Equation (6), which can be written as shown in Equation (7):
ESN implementation has two steps for target prediction, where the first step is specifying
,
, and states of ESN. The input weights
and
of the reservoir layer are generated randomly and kept constant. The output weights
are optimized, all states are stored in matrix
, and the targeted outputs are stored in a feature vector
. Finally, the model is connected with a linear regressor where the ridge regressor is used, which computes the regularized least-square problem using Equation (8), where
represents the L
2 regularization coefficient.
3.3. Self-Attention Mechanism
The self-attention mechanism is a key tool for improving model performance, particularly in hybrid models. Both stream outputs are combined in order to generate a single feature vector, which is then inputted into SAM to provide a representative pattern for the final prediction.
Figure 2 illustrates a visual representation of each stream output, concatenation layer, SAM, and fully connected layer. We integrate the SAM to select optimal features from the data by dynamically adjusting the importance of hidden patterns. SAM is used to identify the key patterns in the merged feature vector of the CNN and ESN streams prior to the prediction process. It also analyzes the correlation of hidden characteristics across different timestamps in each dimension. In SAM, the score of hidden features of the
time stamp in the
dimension can be calculated using Equation (9):
Here, the dimension of the hidden state on the timestamp is represented by , the weight metric is indicated by , a function implemented by fully connected layers is represented by , the number of timestamps is represented by , and the hidden feature dimension is represented by . The final layers of our proposed model are fully connected layers, which are used for activity recognition. The SAM output is flattened to a feature vector, where the number of SAM output dimensions is represented by . The output of the attention module is fed to a dense layer.
3.4. PAR-Net
We proposed a dual-stream model with an attention mechanism called PAR-Net to efficiently recognize physical activities using skeleton data. In the spatial stream, CNN layers are employed to extract spatial features from the input skeleton data. These convolutional layers apply filters to the data, capturing hierarchical spatial patterns. In the temporal stream, the ESN is integrated to model the temporal dynamics of the skeletal sequence. In the CNN stream, the data are processed by two 1D-convalutional layers with 64 and 128 filters and a kernel size of 3 and 1, respectively. This process is followed by a dense layer with 128 units and a flattened layer. Meanwhile, the ESN stream utilizes an Echo State RNN cell consisting of 32 units, which has been configured with a hyperbolic tangent (tanh) activation function. The cell is started with predetermined parameters, including decay, epsilon, and alpha, and is configured to update certain variables throughout the training process. The output of both streams is then combined by a concatenation method and forwarded to a self-attention mechanism. A self-attention mechanism is used to select more prominent features from the combined feature vector. These optimal features are then fed to a dense layer consisting of 64 units using a rectified linear unit (ReLU) activation function. Finally, a SoftMax layer consisting of 5 units (depending on the number of classes) is applied to calculate the model output probabilities for the various activity classes. The model is trained using the Adam optimizer, with a learning rate of 0.0001, and the categorical cross-entropy loss function. During the training process, the model is adjusted to the training data using a batch size of 32 for 100 epochs.
4. Experimental Results
This section delves into a detailed exploration of the evaluation metrics, datasets, and performance comparisons of different models. Specifically, we focus on assessing the efficacy of the PAR-Net in comparison to baseline models. We have used two datasets for the evaluations of our proposed model and the dataset details are given in
Table 1. Several evaluation metrics are used to assess the performance of models that aim to recognize or classify human activities based on skeletal joint data captured from devices. We used accuracy, precision, recall, and F1-score for performance and comparative analysis; the details of these metrics are given in [
36]. The experiments are conducted on a computational setup composed of a GeForce RTX 3070 GPU with 8 GB of RAM, a Core i7 processor with 32 GB of onboard memory, and the Windows 10 operating system (Nvidia Corporation, Santa Clara, CA, USA). The implementation was carried out using Python V3.7.4, employing the Keras deep learning framework built on TensorFlow.
4.1. Dataset Description
In this study, we used two datasets for the PAR-Net evaluation. The first dataset, the Physical Activity Recognition Dataset (PAR) [
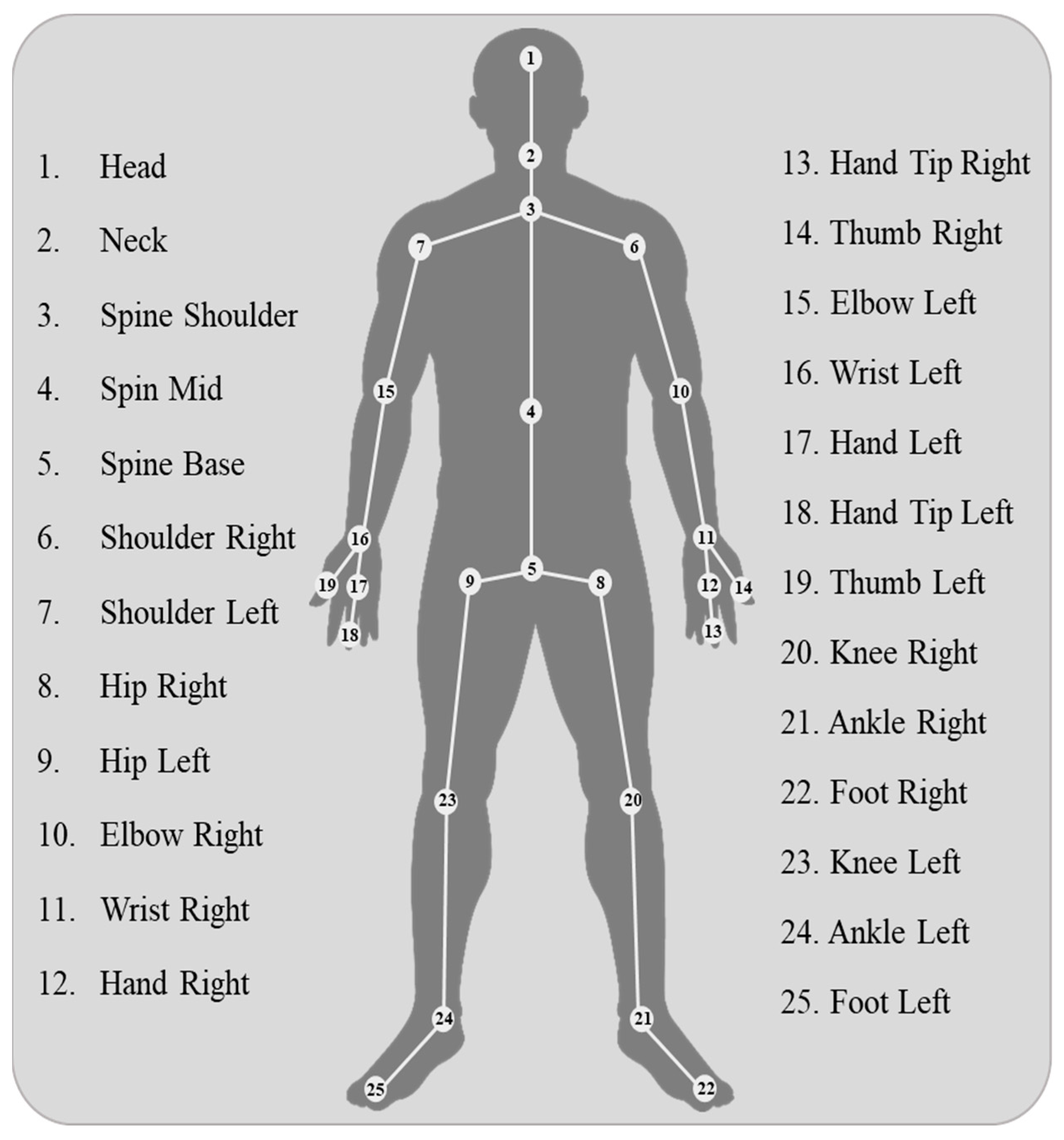
36], is composed of 12 distinct activities performed by 20 different individuals aged 25–35 years. Data collection involved the use of Microsoft’s Kinect sensor V2, which is capable of extracting 25 different joints from the human body (refer to
Figure 3). The dataset contains the x- and y-axis values of all body joints and stores them as CSV files. Each participant performed an activity for 10 s, resulting in 200 samples for each activity, with 10 repetitions per participant (totaling 120 samples per participant). The Kinect V2 sensor was employed to extract human skeleton joints using the Discrete Gestures Basics WPF SDK. Joint data were captured by the Kinect Body View script and saved as CSV files.
The data are organized in the sequence shown in
Figure 3, representing 25 body joints, labeled numerically as indicated in
Table 1. The labeled activity data files are consolidated and identified by their respective class numbers. All activity files are then merged into a single training file and transferred to the model using 5 different frame sequences, such as 30, 60, 90, 120, and 150 frame sequence data.
The second dataset used in this study is called the Physical Exercise Recognition Dataset (PER) [
40], which is composed of 10 different poses that can be used to distinguish 5 exercise activities. The exercises are jumping jacks, push-ups, sit-ups, pull-ups, and squats. The dataset is composed of 33 different landmarks representing the positions of human body parts. A sequence of poses is provided to preserve the order of frames in each record. The data is collected from 447 videos in which different people are performing exercises, and these videos are collected from the Countix dataset, which provides the YouTube links to several activity videos. The videos are downloaded and preprocessed, where the frames are extracted from the videos and stored. They used the MediaPipe framework to extract the human skeletal data from the video frames, which can efficiently predict the location of 33 landmarks on the human body and face and store it as CSV files. The labels are provided with data in separate CSV files, which contain details about the data and their specific labels. The detailed explanation of both datasets used in this research is shown in
Table 1.
4.2. Comparative Analysis of Different Models
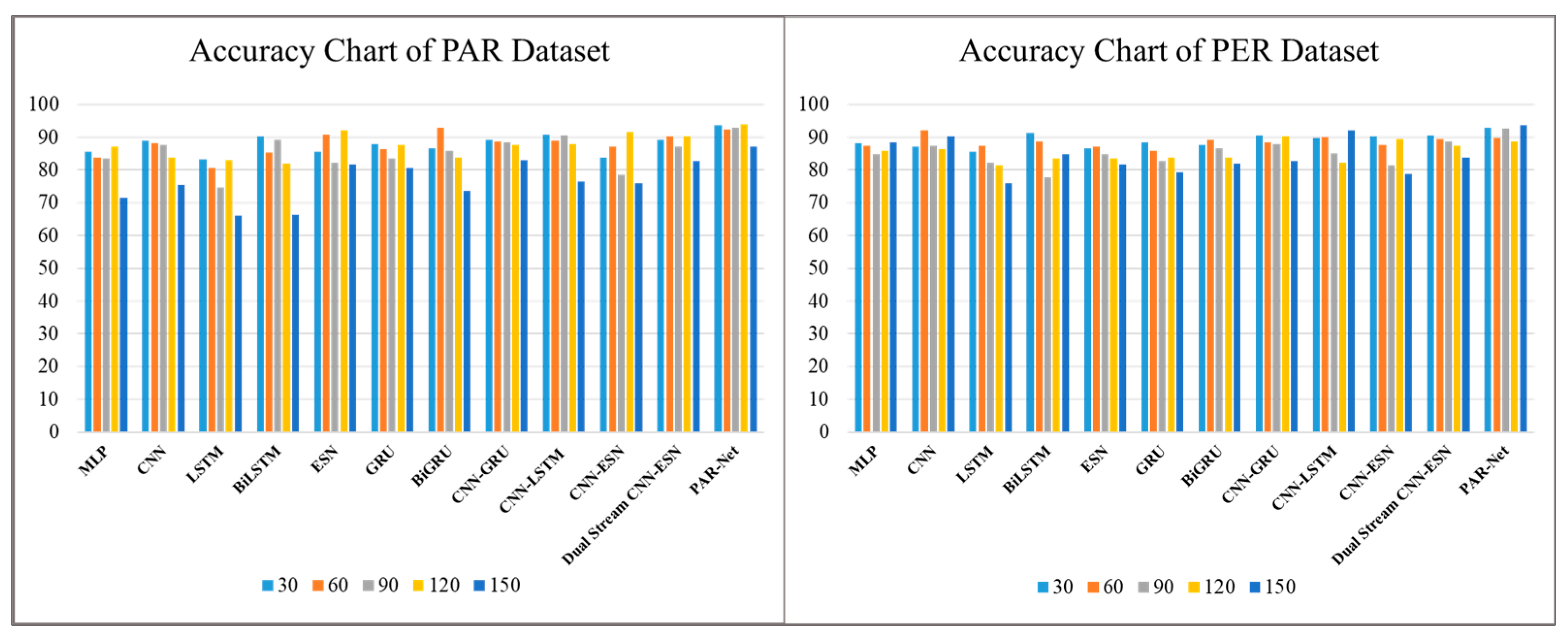
The performance of different deep learning models is evaluated for activity recognition on different frame sequences, such as 30, 60, 90, 120, and 150 frames. The data of each frame are stored row-wise in a CSV file, where the information for each frame includes the coordinates of skeletal joints and corresponding labels indicating the specific activity. Therefore, each row of data represents one frame of the activity sequence, with the activity label in the last column. The term "frames" refers to the number of consecutive frames of skeleton data passed to the model as input. For example, when we mention using 30 frames of data, it means that we fed sequences of 30 consecutive frames of data to the model. The accuracy of each model is emphasized during these intervals, offering information about how effective it is in terms of accuracy, as reported in
Table 2. The ablation results show a consistent tendency among the models evaluated, where most models show a reasonable level of accuracy at shorter intervals but are unable to sustain it as the frame intervals increase. Certain models, such as the MLP, CNN, LSTM, Bidirectional LSTM, ESN, GRU, BiGRU, CNN-GRU, CNN-LSTM, CNN–ESN, and Dual-Stream CNN–ESN without an attention mechanism, show good accuracy at certain intervals on both datasets but become less accurate at longer frames, suggesting that they are unable to capture long-term temporal dependencies. Nonetheless, the proposed dual-stream model, coupled with the attention mechanism, consistently obtains the best results comparatively.
Figure 4 shows the accuracy of our proposed model compared to other models.
Table 3 shows the precision scores generated by various deep-learning models used to recognize activities at different intervals of time: 30, 60, 90, 120, and 150 frames. These models include the MLP, CNN, LSTM, Bidirectional LSTM, ESN, GRU, BiGRU, CNN-GRU, CNN-LSTM, CNN–ESN, and Dual-Stream CNN–ESN without an attention mechanism. However, when the frame intervals increase, they show a reduction in accuracy, suggesting that greater periods cannot be reliably predicted. On the other hand, the PAR-Net consistently performs well with higher precision scores through all frame intervals and also maintains an impressive level of precision, peaking at 94.41% at 120 frames on the PAR dataset, while the peak precision score is 94.88% on the physical exercise recognition dataset. Such high performance highlights the PAR-Net's ability to reliably anticipate a wide range of actions, demonstrating its advantage over other models during evaluation across varying time intervals, as shown in
Figure 5. The recall and F1-score metrics are also used to evaluate the performance of different models with diverse frame sequences, as shown in
Table 4 and
Table 5 respectively. The performance of these models decreases when the sequence increases. However, the PAR-Net performs well at longer intervals, peaking at 120 sequences with a recall value of 94.02% and a 94% F1-score on the physical activity recognition dataset, while the recall score and F1-score on the physical exercise dataset are 94.02% and 93.5%, respectively, as given in
Figure 6 and
Figure 7.
Overall, the PAR-Net performed better in all evaluated measures (accuracy, precision, recall, and F1-score), demonstrating its ability to capture complex temporal correlations and make accurate predictions over extended periods. Although some models demonstrate proficiency within particular temporal domains, they are unable to preserve stability and uniformity, particularly as the input sequences of the model increase. Therefore, the empirical results emphasize the PAR-Net as an optimal solution among the assessed models, supported by its dual-stream design and integrated attention mechanism. The ability of the PAR-Net to interpret activities over a range of time intervals highlights an optimal solution for activity recognition tasks, providing a thorough understanding of temporal and spatial dynamics in input data.
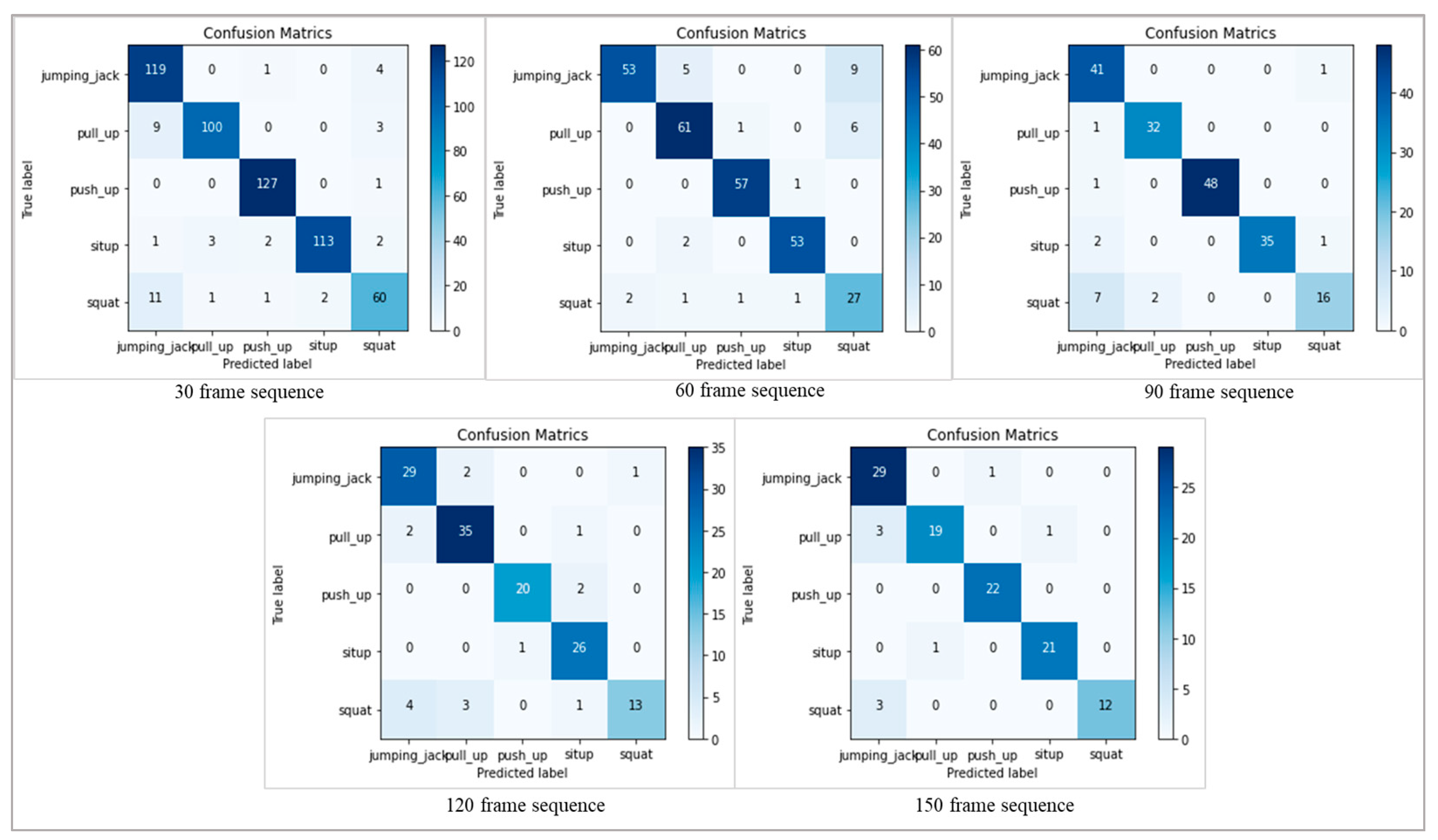
In order to provide a thorough study of the model’s performance, we have included confusion matrices for both datasets at different frame sequences (30, 60, 90, 120, and 150). The confusion matrices, which provide the counts of true positive, true negative, false positive, and false negative predictions for each activity class, provide insightful information about the classification results.
Figure 8 shows the confusion metrics of different frame sequences on the PAR dataset, where the activities in the confusion metrics are represented by the number sequences mentioned in
Table 1.
Figure 9 represents the confusion metrics of the PER dataset on various frame sequences.
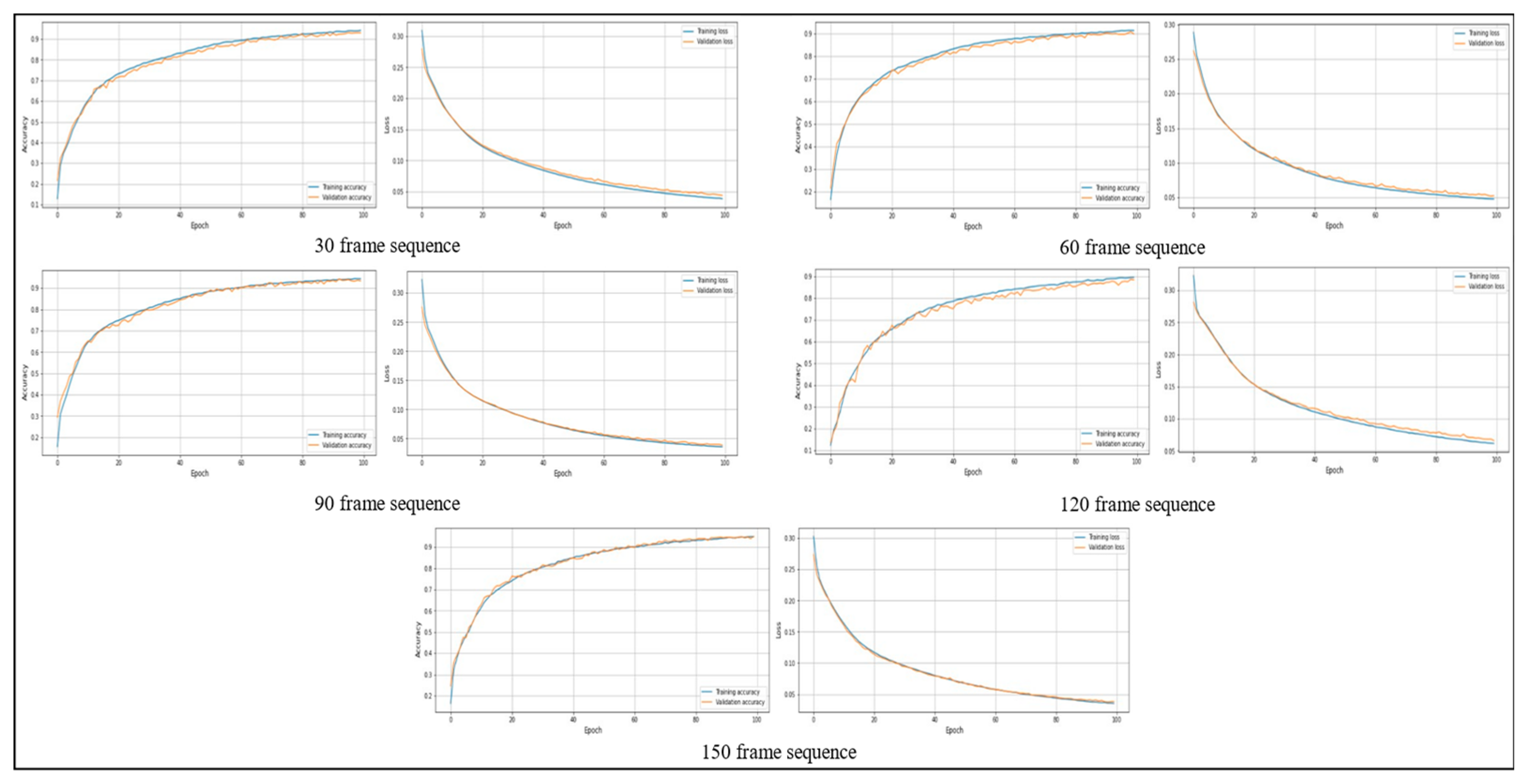
4.3. Stability Analysis Test
Stability analysis involves examining a model’s behavior and performance throughout many training iterations and epochs to determine its consistency and dependability. This research evaluates many aspects of the model’s learning dynamics, with a specific emphasis on its capacity to reach an optimum solution without experiencing overfitting or underfitting. Stability analysis involves examining the consistency and convergence of accuracy trends over consecutive epochs while analyzing the training and validation accuracy graphs. Both training and validation accuracy should ideally show consistent improvement and stability, indicating successful learning without affecting generalization. When analyzing the training and validation loss graphs, stability analysis entails observing the decreasing trend of loss values over epochs to verify that the model is efficiently reducing errors. An important part of stability analysis is recognizing the convergence of validation loss, which signals that the model has achieved its optimum performance on the validation set.
Figure 10 and
Figure 11 show the training and validation accuracy and loss on the PAR and PER datasets, respectively.
4.4. Statistical Significance Tests
Statistical significance tests, or
t-tests, are used in our research to evaluate and guarantee the suggested model’s capacity for generalization. It is a systematic process used in statistical analysis to determine whether the results of the experiment provide strong enough evidence to reject a null hypothesis against an alternative hypothesis. This test aims to determine whether any differences or impacts in the data are statistically significant or just due to random variation. The procedure usually starts by creating two opposing hypotheses: the null hypothesis (H0), stating no impact or difference, and the alternative hypothesis (H1), proposing the existence of an effect. We chose a significance level (α) of 0.05 to determine the threshold of significance for approving or disapproving the null hypothesis. The significance test uses an appropriate test statistic, t-statistics, to produce either the
p-value or critical value. The
p-value indicates the likelihood of observing the data or more extreme data if the null hypothesis is true, but the critical value indicates the threshold at which the null hypothesis is rejected. The null hypothesis is determined by comparing the estimated
p-value to the specified significance level or determining whether the test statistic is inside the rejection zone. When the
p-value is less than α or when the test statistic exceeds the critical value, the null hypothesis is rejected, suggesting a statistically significant difference. If the
p-value is greater than α or if the test statistic is within the non-rejection zone, the null hypothesis is not rejected since there is not enough evidence to support its rejection. The model is considered accurate if the t-statistic value is low, and the
p-value is acquired through the comparison of the PAR-Net with another baseline model. The significance test provides a structured method to make meaningful inferences from data, facilitating informed decision-making and inference in scientific studies.
Table 6 shows the significant test results comparison of the PAR-Net with other baseline models.
The PAR-Net holds significant potential for real-world applications, particularly in healthcare, sports training, and smart home systems. In healthcare, it enables remote monitoring and customized therapies by tracking patients’ physical activity levels, which is especially beneficial for long-term health issues and rehabilitation. Athletes can benefit from improved training and performance monitoring through insights into movement patterns and workload management, reducing the risk of injuries. Integrating the model into smart home devices enhances comfort and energy efficiency by adjusting environmental parameters based on inhabitants’ activities and preferences. However, challenges arise from reliance on precise data collection devices and fluctuations in data integrity and external circumstances, necessitating improvements in data collection methods, noise handling, and validation through longitudinal studies. Investigating hybrid methodologies combining skeletal data with other modalities may enhance adaptability in various scenarios.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}