
Crossroads in Liver Transplantation: Is Artificial Intelligence the Key to Donor–Recipient Matching?
 ,
,
Abstract
:1. Introduction
2. What Is the Starting Point? The Achilles’ Heel of Traditional D–R Matching Models
- a.
- They assume a linear relationship between variables. Most health sciences relationships are non-linear, so this statistical methodology is not accurate.
- b.
- The models exclude variables considered non-significant when all variables contribute to a clinical outcome to a greater or lesser degree.
- c.
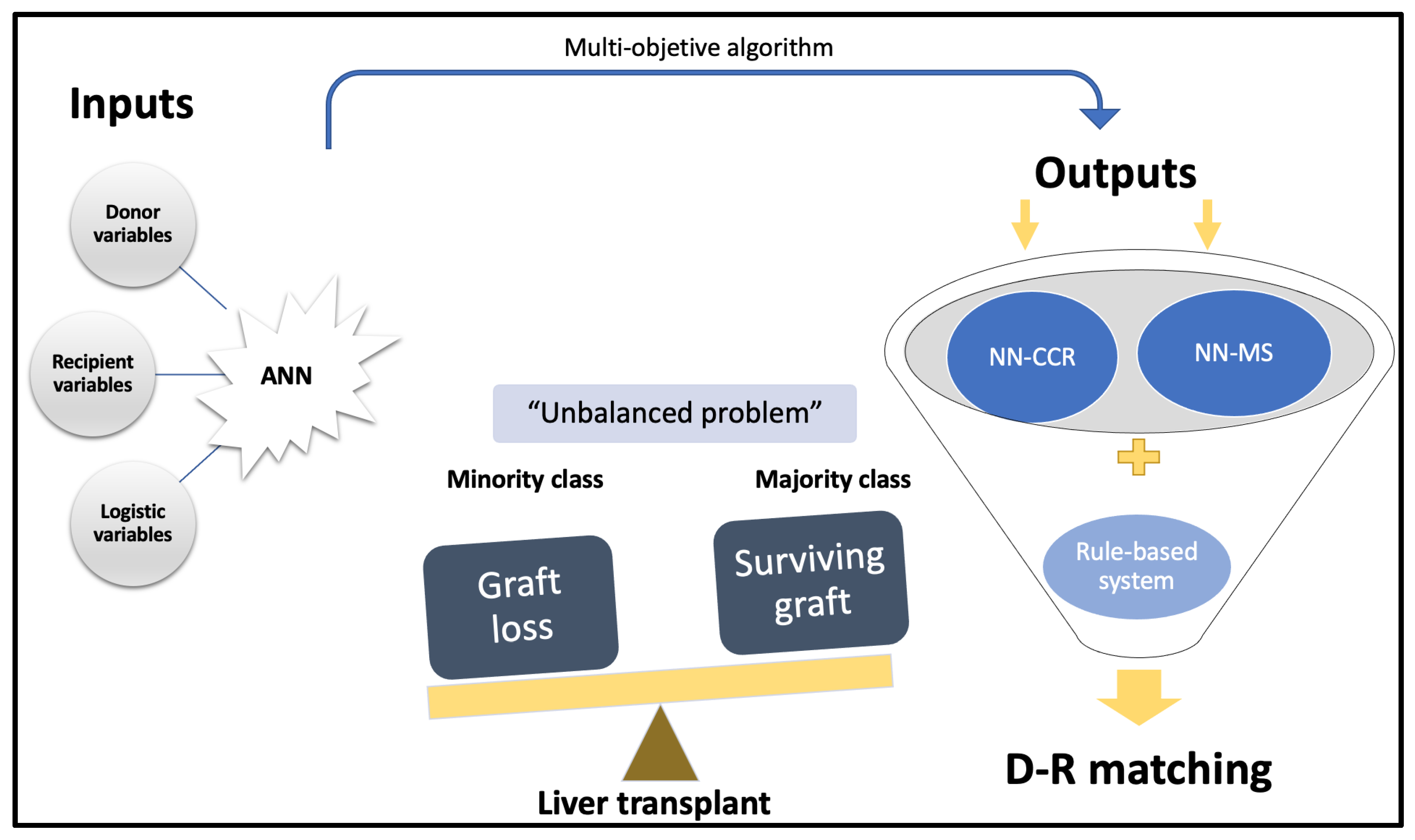
- In unbalanced problems such as liver transplantation, where deceased patients are rare, and most of them survive, logistic regression does not have an adequate predictive capacity. This is because modern biostatistics are not able to predict unbalanced phenomena, and the most common solution is to use large cohorts of patients to increase the number of infrequent events.
3. What Is Artificial Intelligence, and Are Machine Learning and Deep Learning the Same Concept?
4. The Role of Deep Learning in Liver Transplantation
4.1. Artificial Neural Networks
Strengths and Weaknesses
4.2. Random Forests
Strengths and Weaknesses
4.3. Study Limitations
5. Conclusions: What Is on the Horizon?
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kwong, A.; Kim, W.R.; Lake, J.R.; Smith, J.M.; Schladt, D.P.; Skeans, M.A.; Noreen, S.M.; Foutz, J.; Miller, E.; Snyder, J.J.; et al. OPTN/SRTR 2018 Annual Data Report: Liver. Am. J. Transplant. 2020, 20 (Suppl. S1), 193–299. [Google Scholar] [CrossRef] [PubMed]
- Neuberger, J. Liver transplantation in the United Kingdom. Liver Transpl. 2016, 22, 1129–1135. [Google Scholar] [CrossRef]
- MacConmara, M.; Hanish, S.I.; Hwang, C.S.; De Gregorio, L.; Desai, D.M.; Feizpour, C.A.; Tanriover, B.; Markmann, J.F.; Zeh, H., III; Vagefi, P.A. Making Every Liver Count: Increased Transplant Yield of Donor Livers Through Normothermic Machine Perfusion. Ann. Surg. 2020, 272, 397–401. [Google Scholar] [CrossRef]
- Briceno, J.; Ciria, R.; de la Mata, M. Donor-recipient matching: Myths and realities. J. Hepatol. 2013, 58, 811–820. [Google Scholar] [CrossRef] [PubMed]
- Schlegel, A.; Linecker, M.; Kron, P.; Gyori, G.; De Oliveira, M.L.; Mullhaupt, B.; Clavien, P.A.; Dutkowski, P. Risk Assessment in High- and Low-MELD Liver Transplantation. Am. J. Transplant. 2017, 17, 1050–1063. [Google Scholar] [CrossRef] [PubMed]
- Lai, J.C. Defining the threshold for too sick for transplant. Curr. Opin. Organ Transplant. 2016, 21, 127–132. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hann, A.; Lembach, H.; Nutu, A.; Dassanayake, B.; Tillakaratne, S.; McKay, S.C.; Boteon, A.P.C.S.; Boteon, Y.L.; Mergental, H.; Murphy, N.; et al. Outcomes of normothermic machine perfusion of liver grafts in repeat liver transplantation (NAPLES initiative). Br. J. Surg. 2022, 109, 372–380. [Google Scholar] [CrossRef]
- Veerankutty, F.H.; Jayan, G.; Yadav, M.K.; Manoj, K.S.; Yadav, A.; Nair, S.R.S.; Shabeerali, T.U.; Yeldho, V.; Sasidharan, M.; Rather, S.A. Artificial Intelligence in hepatology, liver surgery and transplantation: Emerging applications and frontiers of research. World J. Hepatol. 2021, 13, 1977–1990. [Google Scholar] [CrossRef]
- Doyle, H.R.; Dvorchik, I.; Mitchell, S.; Marino, I.R.; Ebert, F.H.; McMichael, J.; Fung, J.J. Predicting outcomes after liver transplantation. A connectionist approach. Ann. Surg. 1994, 219, 408–415. [Google Scholar] [CrossRef]
- Lewsey, J.D.; Dawwas, M.; Copley, L.P.; Gimson, A.; Van der Meulen, J.H. Developing a prognostic model for 90-day mortality after liver transplantation based on pretransplant recipient factors. Transplantation 2006, 82, 898–907. [Google Scholar] [CrossRef]
- Sacleux, S.C.; Samuel, D. A Critical Review of MELD as a Reliable Tool for Transplant Prioritization. Semin. Liver Dis. 2019, 39, 403–413. [Google Scholar] [CrossRef] [PubMed]
- Dutkowski, P.; Oberkofler, C.E.; Slankamenac, K.; Puhan, M.A.; Schadde, E.; Müllhaupt, B.; Geier, A.; Clavien, P.A. Are there better guidelines for allocation in liver transplantation? A novel score targeting justice and utility in the model for end-stage liver disease era. Ann Surg. 2011, 254, 745–753. [Google Scholar] [CrossRef] [PubMed]
- Rana, A.; Hardy, M.A.; Halazun, K.J.; Woodland, D.C.; Ratner, L.E.; Samstein, B.; Guarrera, J.V.; Brown, R.S., Jr.; Emond, J.C. Survival outcomes following liver transplantation (SOFT) score: A novel method to predict patient survival following liver transplantation. Am. J. Transplant. 2008, 8, 2537–2546. [Google Scholar] [CrossRef] [PubMed]
- Boecker, J.; Czigany, Z.; Bednarsch, J.; Amygdalos, I.; Meister, F.; Santana, D.A.M.; Liu, W.J.; Strnad, P.; Neumann, U.P.; Lurje, G. Potential value and limitations of different clinical scoring systems in the assessment of short- and long-term outcome following orthotopic liver transplantation. PLoS ONE 2019, 14, e0214221. [Google Scholar] [CrossRef] [Green Version]
- Briceño, J.; Calleja, R.; Hervás, C. Artificial intelligence and liver transplantation: Looking for the best donor-recipient pairing. Hepatobiliary Pancreat. Dis. Int. 2022, 21, 347–353. [Google Scholar] [CrossRef]
- Deo, R.C. Machine learning in medicine. Circulation 2015, 132, 1920–1930. [Google Scholar] [CrossRef] [Green Version]
- Fernández-Delgado, M.; Cernadas, E.; Barro, S.; Amorim, D. Do we need hundreds of classifiers to solve real world classification problems? J. Mach. Learn Res. 2014, 15, 3133–3181. [Google Scholar]
- Bertsimas, D.; Kung, J.; Trichakis, N.; Wang, Y.; Hirose, R.; Vagefi, P.A. Development and validation of an optimized prediction of mortality for candidates awaiting liver transplantation. Am. J. Transplant. 2019, 19, 1109–1118. [Google Scholar] [CrossRef]
- Lee, H.C.; Yoon, S.B.; Yang, S.M.; Kim, W.H.; Ryu, H.G.; Jung, C.W.; Suh, K.S.; Lee, K.H. Prediction of Acute Kidney Injury after Liver Transplantation: Machine Learning Approaches vs. Logistic Regression Model. J. Clin. Med. 2018, 7, 428. [Google Scholar] [CrossRef] [Green Version]
- Briceño, J.; Cruz-Ramírez, M.; Prieto, M.; Navasa, M.; Ortiz de Urbina, J.; Orti, R.; Gómez-Bravo, M.Á.; Otero, A.; Varo, E.; Tomé, S.; et al. Use of artificial intelligence as an innovative donor-recipient matching model for liver transplantation: Results from a multicenter Spanish study. J. Hepatol. 2014, 61, 1020–1028. [Google Scholar] [CrossRef]
- Ayllón, M.D.; Ciria, R.; Cruz-Ramírez, M.; Pérez-Ortiz, M.; Gómez, I.; Valente, R.; O’Grady, J.; de la Mata, M.; Hervás-Martínez, C.; Heaton, N.D.; et al. Validation of artificial neural networks as a methodology for donor-recipient matching for liver transplantation. Liver Transpl. 2018, 24, 192–203. [Google Scholar] [CrossRef] [PubMed]
- Guijo-Rubio, D.; Briceño, J.; Gutiérrez, P.A.; Ayllón, M.D.; Ciria, R.; Hervás-Martínez, C. Statistical methods versus machine learning techniques for donor-recipient matching in liver transplantation. PLoS ONE 2021, 16, e0252068. [Google Scholar] [CrossRef] [PubMed]
- Kelly, C.J.; Karthikesalingam, A.; Suleyman, M.; Corrado, G.; King, D. Key challenges for delivering clinical impact with artificial intelligence. BMC Med. 2019, 17, 195–204. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ruffle, J.K.; Farmer, A.D.; Aziz, Q. Artificial intelligence-assisted gastroenterology promises and pitfalls. Am. J. Gastroenterol. 2019, 114, 422–428. [Google Scholar] [CrossRef] [PubMed]
- Thrall, J.H.; Li, X.; Li, Q.; Cruz, C.; Do, S.; Dreyer, K.; Brink, J. Artificial intelligence and machine learning in radiology opportunities, challenges, pitfalls, and criteria for success. J. Am. Coll. Radiol. 2018, 15, 504–508. [Google Scholar] [CrossRef] [PubMed]
- Lau, L.; Kankanige, Y.; Rubinstein, B.; Jones, R.; Christophi, C.; Muralidharan, V.; Bailey, J. Machine-Learning Algorithms Predict Graft Failure After Liver Transplantation. Transplantation 2017, 101, e125–e132. [Google Scholar] [CrossRef]
- Sapir-Pichhadze, R.; Kaplan, B. Seeing the Forest for the Trees: Random Forest Models for Predicting Survival in Kidney Transplant Recipients. Transplantation 2020, 104, 905–906. [Google Scholar] [CrossRef]
- Wingfield, L.R.; Ceresa, C.; Thorogood, S.; Fleuriot, J.; Knight, S. Using Artificial Intelligence for Predicting Survival of Individual Grafts in Liver Transplantation: A Systematic Review. Liver Transplant. 2020, 26, 922–934. [Google Scholar] [CrossRef]
- Spann, A.; Yasodhara, A.; Kang, J.; Watt, K.; Wang, B.; Goldenberg, A.; Bhat, M. Applying machine learning in liver disease & transplantation: A comprehensive review. Hepatology 2020, 71, 1093–1105. [Google Scholar]
- Sucher, R.; Sucher, E. Artificial intelligence is poised to revolutionize human liver allocation and decrease medical costs associated with liver transplantation. Hepatobiliary Surg. Nutr. 2020, 9, 679–681. [Google Scholar] [CrossRef]
- Nitski, O.; Azhie, A.; Qazi-Arisar, F.A.; Wang, X.; Ma, S.; Lilly, L.; Watt, K.D.; Levitsky, J.; Asrani, S.K.; Lee, D.S.; et al. Long-term mortality risk stratification of liver transplant recipients: Real-time application of deep learning algorithms on longitudinal data. Lancet Digit Health 2021, 3, e295–e305. [Google Scholar] [CrossRef] [PubMed]
- Park, R.; Lee, S.; Sung, Y.; Yoon, J.; Suk, H.I.; Kim, H.; Choi, S. Accuracy and Efficiency of Right-Lobe Graft Weight Estimation Using Deep-Learning-Assisted CT Volumetry for Living-Donor Liver Transplantation. Diagnostics 2022, 12, 590. [Google Scholar] [CrossRef] [PubMed]
- Liu, Z.; Liu, Y.; Zhang, W.; Hong, Y.; Meng, J.; Wang, J.; Zheng, S.; Xu, X. Deep learning for prediction of hepatocellular carcinoma recurrence after resection or liver transplantation: A discovery and validation study. Hepatol. Int. 2022, 16, 577–589. [Google Scholar] [CrossRef] [PubMed]
- Lim, J.; Han, S.; Lee, D.; Shim, J.H.; Kim, K.M.; Lim, Y.S.; Lee, H.C.; Jung, D.H.; Lee, S.G.; Kim, K.H.; et al. Identification of hepatic steatosis in living liver donors by machine learning models. Hepatol. Commun. 2022, 6, 1689–1698. [Google Scholar] [CrossRef] [PubMed]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Artificial Neural Networks. Strengths and Weaknesses |
|---|
Strengths
|
Weaknesses
|
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Calleja Lozano, R.; Hervás Martínez, C.; Briceño Delgado, F.J. Crossroads in Liver Transplantation: Is Artificial Intelligence the Key to Donor–Recipient Matching? Medicina 2022, 58, 1743. https://doi.org/10.3390/medicina58121743
Calleja Lozano R, Hervás Martínez C, Briceño Delgado FJ. Crossroads in Liver Transplantation: Is Artificial Intelligence the Key to Donor–Recipient Matching? Medicina. 2022; 58(12):1743. https://doi.org/10.3390/medicina58121743
Chicago/Turabian StyleCalleja Lozano, Rafael, César Hervás Martínez, and Francisco Javier Briceño Delgado. 2022. "Crossroads in Liver Transplantation: Is Artificial Intelligence the Key to Donor–Recipient Matching?" Medicina 58, no. 12: 1743. https://doi.org/10.3390/medicina58121743
APA StyleCalleja Lozano, R., Hervás Martínez, C., & Briceño Delgado, F. J. (2022). Crossroads in Liver Transplantation: Is Artificial Intelligence the Key to Donor–Recipient Matching? Medicina, 58(12), 1743. https://doi.org/10.3390/medicina58121743