
Prediction of Work-Related Risk Factors among Bus Drivers Using Machine Learning



Abstract
:1. Introduction
- In bus drivers, work-related factors appear to be significant determinants of WMSDs.
- Model to predict the risk factors contributing to WMSDs among bus drivers.
2. Methods
2.1. Data Set
2.2. Feature Extraction from the Data
2.3. Machine Learning Techniques for Risk Factor Prediction
2.3.1. Decision Tree
- The classifier builds a leaf node by offering obvious categorization if all of the sectors in the combination belong to the same class.
- If none of the characteristics add any new information, the algorithm makes a “decisive node”.
- If the difference in entropy between all characteristics is zero, the algorithm creates a decisive node based on the predicted identity of the class.
2.3.2. Random Forest
2.3.3. Naïve Bayes Classifier
2.4. Feature Selection
- The cost of calculation will increase.
- The training procedure could be misled by the irrelevant input characteristics.
2.5. Pruning
3. Data Analysis
4. Result
4.1. Data Extracted from the Questionnaire
Prevalence of WMSDs from the Previous 7 Days
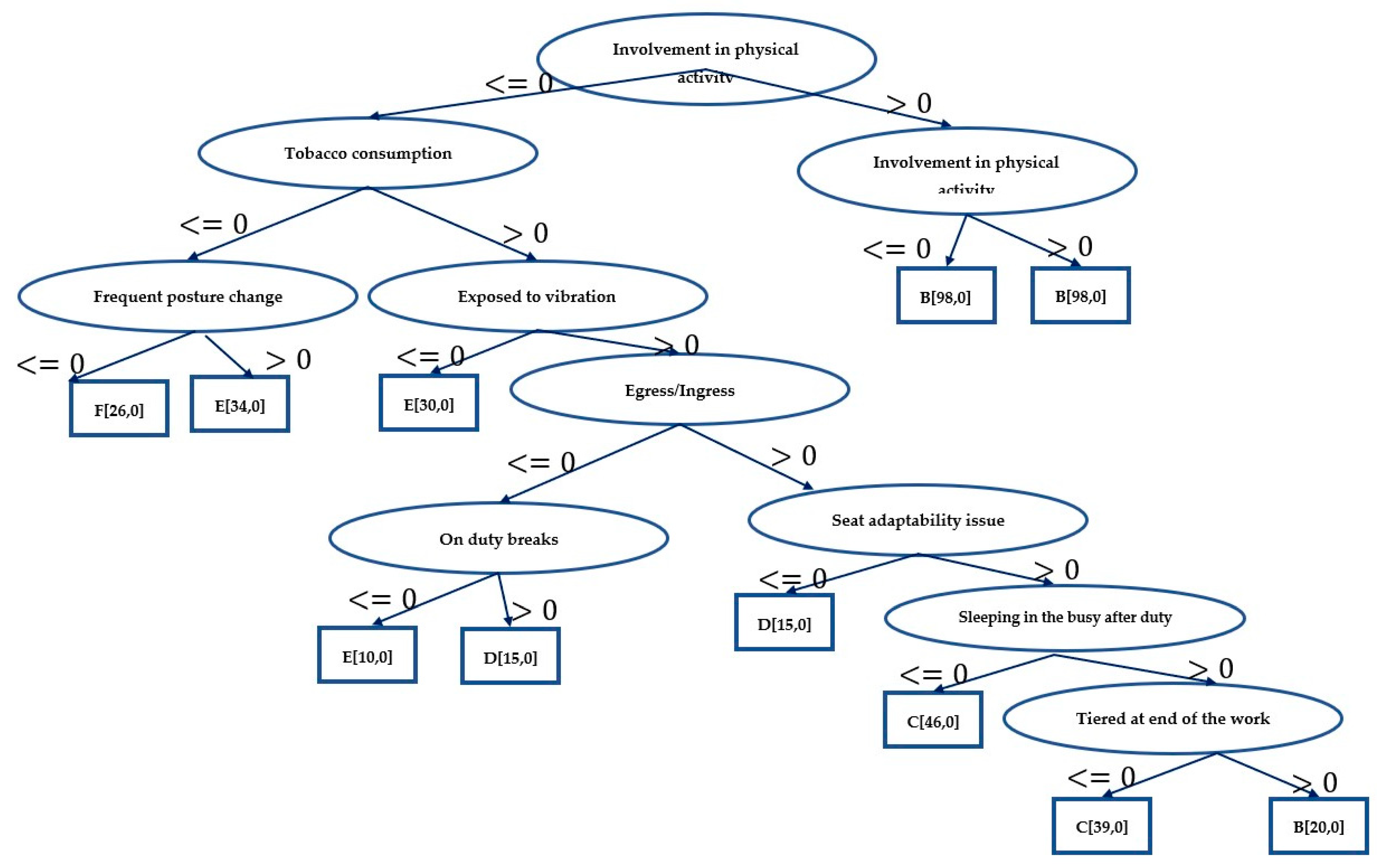
4.2. Classification Using Decision Tree
- Involvement in physical activities.
- Tobacco consumption.
- Frequent posture change.
- Egress/ingress.
- Exposure to vibration.
- On duty breaks.
- Seat adaptability issues.
- Tired at end of the work.
- Sleeping in the bus (after duty).
4.3. Classification Using Random Forest
4.4. Classification Using Random Forest
4.5. Comparative Analysis
- Pre-pruning.
- Post-pruning.
- Acquire more training data.
- Remove irrelevant attributes.
- Cross validation.
- 1.
- Pre-Pruning
- 2.
- Post-Pruning
- 3.
- Removal of features
- 4.
- Increasing the trained data set
- 5.
- Stratified cross validation
- Reduce tree depth.
- Reduce number of variables sampled in each split.
- Acquire more training set.
- K-fold cross validation test.
Independent Variables Validation
5. Discussion
6. Limitations
- The current study relied solely on drivers’ self-reported responses; no clinical data were collected.
- Since most of the driver’s replies to the physical risk factors were binary, future research on this topic may include gathering data based on the frequency, seriousness, and intensity of the risk factors.
- The study’s participants were all male drivers.
7. Conclusions and Recommendation
8. Future Scope of the Study
- (a)
- To verify the effectiveness of the model, other techniques such as KNN (K-closest neighbors), SVM (support vector machine), logistic regression, and ensembled techniques such as boosting and bagging classifiers can be utilized.
- (b)
- To assess the effectiveness of the model and confirm how the model works for the provided data set, deep learning techniques such as CNN may be employed.
- (c)
- Since the number of replies in our situation is constrained, a vast data set can be employed as a training model.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
| Reported MSDs | Statistics | ||||||||
| Risk Factors | n | (%) | Yes (%) (n = 247) | No (%) (n = 123) | χ2 | df | pa | ||
| Socio-demographic | |||||||||
| Age (years) | |||||||||
| 24–28 | 38 | 10 | 4.86 | 18 | 5.4 | 20 | 9.9 | 2 | <0.05 |
| 29–39 | 187 | 51 | 33 | 122 | 18 | 65 | |||
| ≥40 | 145 | 39 | 29 | 107 | 10 | 38 | |||
| Work related | |||||||||
| Seat adaptability issue | |||||||||
| Yes | 286 | 77 | 48 | 177 | 29 | 109 | 13 | 1 | <0.05 |
| No | 84 | 23 | 19 | 70 | 4 | 14 | |||
| Prolong sitting | |||||||||
| Yes | 270 | 73 | 42 | 156 | 31 | 115 | 39 | 1 | <0.05 |
| No | 100 | 27 | 25 | 91 | 2 | 8 | |||
| Periodic postural changes | |||||||||
| Yes | 276 | 75 | 44 | 161 | 31 | 115 | 35 | 1 | <0.05 |
| No | 94 | 25 | 23 | 86 | 2 | 8 | |||
| On duty breaks | |||||||||
| Yes | 189 | 51 | 48 | 177 | 29 | 109 | 13 | 1 | <0.05 |
| No | 181 | 49 | 19 | 70 | 4 | 14 | |||
| Egress/ingress | |||||||||
| Yes | 272 | 74 | 41 | 152 | 10 | 37 | 33 | 1 | <0.05 |
| No | 98 | 26 | 26 | 95 | 23 | 86 | |||
| Participation in some form of physical activity | |||||||||
| Yes | 122 | 33 | 1 | 2 | 32 | 120 | 348 | 1 | <0.05 |
| No | 248 | 67 | 66 | 245 | 1 | 3 | |||
| Posture training | |||||||||
| Yes | 177 | 48 | 28 | 103 | 20 | 74 | 11 | 1 | <0.05 |
| No | 193 | 52 | 39 | 144 | 13 | 49 | |||
| Reachable in-vehicle controls | |||||||||
| Yes | 291 | 79 | 54 | 198 | 25 | 93 | 1 | 1 | >0.05 |
| No | 79 | 21 | 13 | 49 | 8 | 30 | |||
| Reliance on outside food | |||||||||
| Yes | 323 | 87 | 62 | 230 | 25 | 93 | 23 | 1 | <0.05 |
| No | 47 | 13 | 5 | 17 | 11 | 30 | |||
| Exposed to vibration while working | |||||||||
| Low magnitude | 69 | 19 | 2 | 9 | 16 | 60 | 110 | 1 | <0.05 |
| High magnitude | 301 | 81 | 64 | 238 | 17 | 63 | |||
| Stress at work | |||||||||
| Yes | 313 | 85 | 62 | 230 | 22 | 83 | 41 | 1 | <0.05 |
| No | 57 | 15 | 5 | 17 | 11 | 40 | |||
| Access to potable water and bathrooms while on duty | |||||||||
| Yes | 104 | 28 | 9 | 32 | 19 | 72 | 84 | 1 | <0.05 |
| No | 266 | 72 | 58 | 215 | 14 | 51 | |||
| Work satisfaction (personally) | |||||||||
| Yes | 262 | 71 | 13 | 49 | 15 | 55 | 25 | 1 | <0.05 |
| No | 108 | 29 | 54 | 198 | 18 | 68 | |||
| sufficient breaks at work | |||||||||
| Yes | 97 | 26 | 20 | 75 | 6 | 22 | 6.6 | 1 | <0.05 |
| No | 273 | 74 | 46 | 172 | 27 | 101 | |||
| Thermal distress in the cabin | |||||||||
| Yes | 213 | 56 | 50 | 186 | 7 | 27 | 96 | 1 | <0.05 |
| No | 157 | 42 | 16 | 61 | 26 | 96 | |||
| Shift timings | |||||||||
| First | 157 | 42 | 26 | 96 | 16 | 61 | 14 | 1 | <0.05 |
| Second | 100 | 27 | 1 | 60 | 11 | 40 | |||
| General | 113 | 31 | 25 | 91 | 6 | 22 | |||
| Cabin surroundings | |||||||||
| Yes | 242 | 65 | 58 | 213 | 7 | 29 | 142 | 1 | <0.05 |
| No | 128 | 35 | 9 | 34 | 25 | 94 | |||
| Bending over to reach side mirrors | |||||||||
| Yes | 198 | 54 | 42 | 155 | 12 | 43 | 37 | 1 | <0.05 |
| No | 172 | 46 | 22 | 82 | 24 | 90 | |||
| On-the-job exposure to air pollution | |||||||||
| Yes | 309 | 84 | 65 | 240 | 19 | 69 | 101 | 1 | <0.05 |
| No | 61 | 16 | 1 | 7 | 14 | 54 | |||
| Hazardous driving job | |||||||||
| Yes | 237 | 64 | 57 | 210 | 7 | 27 | 142 | 1 | <0.05 |
| No | 133 | 36 | 10 | 37 | 26 | 96 | |||
| A proclivity towards risky driving | |||||||||
| Yes | 78 | 21 | 12 | 45 | 9 | 33 | 3.7 | 1 | >0.05 |
| No | 292 | 79 | 55 | 202 | 24 | 90 | |||
| Participated in traffic violence | |||||||||
| Yes | 121 | 33 | 10 | 36 | 23 | 85 | 111 | 1 | <0.05 |
| No | 249 | 67 | 57 | 211 | 10 | 38 | |||
| Reacting to other drivers | |||||||||
| Yes | 189 | 51 | 40 | 147 | 11 | 42 | 21 | 1 | <0.05 |
| No | 181 | 49 | 27 | 100 | 22 | 81 | |||
| Daily route road conditions | |||||||||
| Average/good | 110 | 30 | 10 | 37 | 20 | 73 | 77 | 1 | <0.05 |
| Bad/worst | 260 | 70 | 57 | 210 | 13 | 50 | |||
| Shutting off ignition at signals | |||||||||
| Yes | 288 | 78 | 58 | 214 | 20 | 74 | 33 | 1 | <0.05 |
| No | 92 | 25 | 9 | 33 | 16 | 49 | |||
| Maintenance department’s daily/weekly inquiries about bus condition were promptly resolved | |||||||||
| Delayed | 257 | 69 | 54 | 200 | 15 | 57 | 46 | 1 | <0.05 |
| Sometimes on time | 113 | 31 | 13 | 47 | 18 | 66 | |||
| Manhole protrusion on daily routes | |||||||||
| Yes | 101 | 27 | 9 | 32 | 18 | 69 | 77 | 1 | <0.05 |
| No | 269 | 73 | 58 | 215 | 15 | 54 | |||
| Sleeping in bus after duty | |||||||||
| Yes | 226 | 61 | 54 | 199 | 7 | 27 | 119 | 1 | <0.05 |
| No | 144 | 39 | 13 | 48 | 26 | 96 | |||
| Health related | |||||||||
| Body mass index | |||||||||
| Under weight | 22 | 6 | 5 | 20 | 1 | 2 | 8 | 3 | <0.05 |
| Normal weight | 300 | 81 | 51 | 192 | 30 | 108 | |||
| Overweight | 42 | 11 | 8 | 30 | 3 | 12 | |||
| Obese | 6 | 2 | 1 | 5 | 1 | 1 | |||
| Current state of health | |||||||||
| Good | 83 | 22 | 18 | 68 | 4 | 15 | 21 | 2 | <0.05 |
| Average | 153 | 41 | 22 | 81 | 22 | 82 | |||
| Bad/very bad | 134 | 36 | 21 | 78 | 12 | 46 | |||
| Experiencing fatigue after work | |||||||||
| Yes | 233 | 63 | 57 | 210 | 6 | 23 | 155 | 1 | <0.05 |
| No | 137 | 37 | 10 | 37 | 27 | 100 | |||
| Lack of strength | |||||||||
| yes | 230 | 6 | 42 | 155 | 9 | 35 | 24 | 1 | <0.05 |
| no | 140 | 38 | 14 | 52 | 24 | 88 | |||
| Surgical history | |||||||||
| Yes | 72 | 19 | 13 | 47 | 6 | 25 | 0.8 | 1 | >0.05 |
| No | 298 | 81 | 54 | 200 | 27 | 98 | |||
| Muscle exhaustion during working hours | |||||||||
| Yes | 276 | 75 | 64 | 236 | 11 | 40 | 172 | 1 | <0.05 |
| No | 94 | 25 | 3 | 11 | 22 | 83 | |||
| Training on health and safety | |||||||||
| regularly | 136 | 37 | 26 | 97 | 11 | 39 | 2 | 1 | >0.05 |
| sometimes | 234 | 63 | 40 | 150 | 23 | 84 | |||
| Pain relief by self-medication | |||||||||
| yes | 98 | 26 | 14 | 51 | 12 | 47 | 13 | 1 | <0.05 |
| no | 272 | 74 | 53 | 196 | 21 | 76 | |||
References
- Weale, V.; Stuckey, R.; Kinsman, N.; Oakman, J. Workplace musculoskeletal disorders: A systematic review and key stakeholder interviews on the use of comprehensive risk management approaches. Int. J. Ind. Ergon. 2022, 91, 103338. [Google Scholar] [CrossRef]
- Murtoja, S.A.; Mandal, B.B.; Mangalavalli, S.M. Causative and risk factors of musculoskeletal disorders among mine workers: A systematic review and meta-analysis. Saf. Sci. 2022, 15, 105868. [Google Scholar] [CrossRef]
- Kubat, M. An Introduction to Machine Learning; Springer International Publishing: Cham, Switzerland, 2017; Volume 2, pp. 321–329. [Google Scholar]
- Reme, S.E.; Shaw, W.S.; Steenstra, I.A.; Woiszwillo, M.J.; Pransky, G.; Linton, S.J. Distressed, immobilized, or lacking employer support? A sub-classification of acute work-related low back pain. J. Occup. Rehabil. 2012, 22, 541–542. [Google Scholar] [CrossRef] [PubMed]
- Ruddy, J.D.; Cormack, S.; Whiteley, R.; Williams, M.D.; Timmins, R.; Opar, D. Modeling the risk of team sport injuries: A narrative review of different statistical approaches. Front. Physiol. 2019, 10, 829. [Google Scholar] [CrossRef]
- Gilseung, A.; Hur, S.; Jung, M. Bayesian network model to diagnose WMSDs with working characteristics. Int. J. Occup. Saf. Ergon. 2018, 26, 336–347. [Google Scholar] [CrossRef]
- Gross, D.P.; Steenstra, I.A.; Harrell, F.E.; Bellinger, C.; Zaïane, O. Machine Learning for Work Disability Prevention: Introduction to the Special Series. J. Occup. Rehabil. 2020, 30, 303–307. [Google Scholar] [CrossRef]
- Lee, S.; Liu, L.; Radwin, R.; Li, J. Machine learning in manufacturing ergonomics: Recent advances, challenges, and opportunities. IEEE Robot. Autom. Lett. 2021, 6, 5745–5752. [Google Scholar] [CrossRef]
- Friedenberg, R.; Kalichman, L.; Ezra, D.; Wacht, O.; Alperovitch-Najenson, D. Work-related musculoskeletal disorders and injuries among emergency medical technicians and paramedics: A comprehensive narrative review. Arch. Environ. Occup. Health 2022, 77, 9–17. [Google Scholar] [CrossRef]
- Indumathi, N.; Ramalakshmi, R. An Evaluation of Work Posture and Musculoskeletal Disorder Risk Level Identification for the Fireworks Industry Worker’s. In Proceedings of the 9th International Conference on Reliability, Infocom Technologies and Optimization (Trends and Future Directions) (ICRITO), Noida, India, 3–4 September 2021. [Google Scholar]
- Maynard, S.; Filtness, A.; Miller, K.; Pilkington-Cheney, F. Bus driver fatigue: A qualitative study of drivers in London. Appl. Ergon. 2021, 92, 103309. [Google Scholar] [CrossRef]
- Golinko, V.; Cheberyachko, S.; Deryugin, O.; Tretyak, O.; Dusmatova, O. Assessment of the risks of occupational diseases of the passenger bus drivers. Saf. Health Work. 2020, 11, 543–549. [Google Scholar] [CrossRef]
- Frank, L.; Giles-Corti, B.; Ewing, R. The influence of the built environment on transport and health. J. Transp. Health 2016, 3, 423–425. [Google Scholar] [CrossRef]
- McAtamney, L.; Corlett, E.N. RULA: A survey method for the investigation of work-related upper limb disorders. Appl. Ergon. 1993, 24, 91–99. [Google Scholar] [CrossRef]
- Massaccesi, M.; Pagnotta, A.; Soccetti, A.; Masali, M.; Masiero, C.; Greco, F. Investigation of work-related disorders in truck drivers using RULA method. Appl. Ergon. 2003, 34, 303–307. [Google Scholar] [CrossRef]
- Burström, L.; Nilsson, T.; Wahlström, J. Whole-body vibration and the risk of low back pain and sciatica: A systematic review and meta-analysis. Int. Arch. Occup. Environ. Health 2015, 88, 403–418. [Google Scholar] [CrossRef] [PubMed]
- Anderson, R. The back pain of bus drivers. Prevalence in an urban area of California. Spine 1992, 17, 1481–1488. [Google Scholar] [CrossRef]
- Griffin, M.J. Discomfort from feeling vehicle vibration. Veh. Syst. Dyn. 2007, 45, 679–698. [Google Scholar] [CrossRef] [Green Version]
- Griffin, M.J. Evaluation of vibration with respect to human response. SAE Trans. 1986, 18, 323–346. [Google Scholar] [CrossRef]
- Lis, A.M.; Black, K.M.; Korn, H.; Nordin, M. Association between sitting and occupational LBP. Eur. Spine J. 2007, 16, 283–298. [Google Scholar] [CrossRef] [Green Version]
- Hulshof, C.T.J.; Verbeek, J.H.A.M.; Braam, I.T.J.; Bovenzi, M.; Van Dijk, F.J.H. Evaluation of an occupational health intervention programme on whole-body vibration in forklift truck drivers: A controlled trial. Occup. Environ. Med. 2006, 63, 461–468. [Google Scholar] [CrossRef] [PubMed]
- Reid, C.R.; Bush, P.M.; Karwowski, W.; Durrani, S.K. Occupational postural activity and lower extremity discomfort: A review. Int. J. Ind. Ergon. 2010, 40, 247–256. [Google Scholar] [CrossRef]
- Gama, T.M.S.; Ferreira, W.N.; Ramos, R.A.R. Factors Associated with Musculoskeletal and Postural Discomfort of Bus Drivers. J. Transp. Health 2021, 22, 101223. [Google Scholar] [CrossRef]
- Wang, X.; Wang, K.; Huang, K.; Wu, X.; Huang, W.; Yang, L. The association between demographic characteristics, personality, and mental health of bus drivers in China: A structural equation model. Physiol. Behav. 2020, 229, 113247. [Google Scholar] [CrossRef] [PubMed]
- Laal, F.; Madvari, R.F.; Balarak, D.; Mohammadi, M.; Dortaj, E.; Khammar, A.; Adineh, H.A. Relationship between musculoskeletal disorders and anthropometric indices among bus drivers in Zahedan city. Int. J. Occup. Saf. Ergon. 2017, 24, 431–437. [Google Scholar] [CrossRef] [PubMed]
- Cardoso, A.M.; Matos, L. The prevalence of work-related musculoskeletal disorders in professional bus drivers—A systematic review. In Occupational Safety and Hygiene V; CRC Press: Boca Raton, FL, USA, 2017; pp. 211–214. [Google Scholar]
- Lau, N. Machine Learning and Human Factors: Status, Applications, and Future Directions. In Proceedings of the Human Factors and Ergonomics Society Annual Meeting, Los Angeles, CA, USA, 25 September 2018. [Google Scholar]
- Kadir, B.A.; Broberg, O.; da Conceição, C.S. Current research and future perspectives on human factors and ergonomics in Industry 4.0. Comput. Ind. Eng. 2019, 137, 106004. [Google Scholar] [CrossRef]
- Neumann, W.P.; Winkelhaus, S.; Grosse, E.H.; Glock, C.H. Industry 4.0 and the human factor–A systems framework and analysis methodology for successful development. Int. J. Prod. Econ. 2021, 233, 107992. [Google Scholar] [CrossRef]
- Hakim, S.; Mohsen, A. Work-related and ergonomic risk factors associated with low back pain among bus drivers. J. Egypt. Public Health Assoc. 2017, 92, 195–201. [Google Scholar] [CrossRef] [PubMed]
- Hanumegowda, P.K.; Gnanasekaran, S.; Subramaniam, S.; Honnappa, A. Occupational physical risk factors and prevalence of musculoskeletal disorders among the traditional lacquerware toy makers of South India. Work 2021, 70, 405–418. [Google Scholar] [CrossRef]
- Dickinson, C.; Campion, K.; Foster, A.; Newman, S.; O’Rourke, A.; Thomas, P. Questionnaire development: An examination of the Nordic Musculoskeletal questionnaire. Appl. Ergon. 1992, 23, 197–201. [Google Scholar] [CrossRef]
- Kuorinka, I.; Jonsson, B.; Kilbom, A.; Vinterberg, H.; Biering-Sørensen, F.; Andersson, G.; Jørgensen, K. Standardised Nordic questionnaires for the analysis of musculoskeletal symptoms. Appl. Ergon. 1987, 18, 233–237. [Google Scholar] [CrossRef]
- Lee, G.Y.; Alzamil, L.; Doskenov, B.; Termehchy, A. A Survey on Data Cleaning Methods for Improved Machine Learning Model Performance. arXiv 2021, arXiv:2109.07127. [Google Scholar] [CrossRef]
- Paris, C.; Battat, R. Machine learning models and over-fitting considerations. World J. Gastroenterol. 2022, 28, 605. [Google Scholar]
- Masahiro, K.; Nakaji, K.; Yamamoto, N. Overfitting in quantum machine learning and entangling dropout. arXiv 2022, arXiv:2205.11446, preprint. [Google Scholar]
- Amro, A.; Al-Akhras, M.; El Hindi, K.; Habib, M.; Abu Shawar, B. Instance reduction for avoiding overfitting in decision trees. J. Intell. Syst. 2021, 30, 438–459. [Google Scholar] [CrossRef]
- Shaeke, S.; Liu, X. Overfitting mechanism and avoidance in deep neural networks. arXiv 2019, arXiv:1901.06566. [Google Scholar]
- Jabbar, H.; Khan, R.Z. Methods to avoid over-fitting and under-fitting in supervised machine learning (comparative study). Comput. Sci. Commun. Instrum. Devices 2015. Available online: http://rpsonline.com.sg/proceedings/9789810952471/html/017.xml (accessed on 28 December 2020).
- Rafał, K.; Smusz, S.; Bojarski, A.J. The influence of negative training set size on machine learning-based virtual screening. J. Cheminformatics 2014, 6, 32. [Google Scholar]
- Sashikanta, P.; Patnaik, S.; Dash, S.K. SKCV: Stratified K-fold cross-validation on ML classifiers for predicting cervical cancer. Front. Nanotechnol. 2022, 4, 972421. [Google Scholar]
- Kernbach, J.M.; Staartjes, V.E. Foundations of Machine Learning-Based Clinical Prediction Modeling: Part II—Generalization and Overfitting. Mach. Learn. Clin. Neurosci. 2022, 134, 15–21. [Google Scholar]
- Wen, Y.; Kalander, M.; Su, C.; Pan, L. An Ensemble Noise-Robust K-fold Cross-Validation Selection Method for Noisy Labels. arXiv 2021, arXiv:2107.02347. [Google Scholar]
- Moore, A.W. Cross-Validation for Detecting and Preventing Overfitting. Ph.D. Thesis, School of Computer Science Carneigie Mellon University, Pittsburgh, PA, USA, 2001. [Google Scholar]
- Akinpelu, A.O.; Oyewole, O.O.; Odole, A.C.; Olukoya, R.O. Prevalence of musculoskeletal pain and health seeking behaviour among occupational drivers in Ibadan, Nigeria. Afr. J. Biomed. Res. 2011, 14, 89–94. [Google Scholar]
- Dagne, D.; Abebe, S.M.; Getachew, A. Work-related musculoskeletal disorders and associated factors among bank workers in Addis Ababa, Ethiopia: A cross-sectional study. Environ. Health Prev. Med. 2020, 25, 33. [Google Scholar] [CrossRef] [PubMed]
- Tamrin, S.B.M.; Yokoyama, K.; Jalaludin, J.; Aziz, N.A.; Jemoin, N.; Nordin, R.; Naing, A.L.; Abdullah, Y.; Abdullah, M. The association between risk factors and low back pain among commercial vehicle drivers in peninsular Malaysia: A preliminary result. Ind. Health 2007, 45, 268–278. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jadhav, A.V. Comparative cross-sectional study for understanding the burden of low back pain among public bus transport drivers. Indian J. Occup. Environ. Med. 2016, 20, 26. [Google Scholar] [CrossRef] [PubMed]
- Szeto, G.P.Y.; Lam, P. Work-related musculoskeletal disorders in urban bus drivers of Hong Kong. J. Occup. Rehabil. 2007, 17, 181–198. [Google Scholar] [CrossRef]
- Jaiswal, A. Low back pain and work-related risk factors among drivers of Pondicherry. Int. J. Sci. Footpr. 2013, 1, 7–16. [Google Scholar]
- Torregroza-Vargas, N.M.; Bocarejo, J.P.; Ramos-Bonilla, J.P. Fatigue and crashes: The case of freight transport in Colombia. Accid. Anal. Prev. 2014, 72, 440–448. [Google Scholar] [CrossRef]
- Safiyeh, G.; Pirzadeh, A. Effectiveness of educational physical activity intervention for preventive of musculoskeletal disorders in bus drivers. Int. J. Prev. Med. 2019, 10, 132. [Google Scholar]
- Durkin, J.L.; Harvey, A.; Hughson, R.L.; Callaghan, J.P. The effects of lumbar massage on muscle fatigue, muscle oxygenation, low back discomfort, and driver performance during prolonged driving. Ergonomics 2006, 49, 28–44. [Google Scholar] [CrossRef]
- Hendi, O.M.; Abdulaziz, A.A.; Althaqafi, A.M.; Hindi, A.M.; Khan, S.A.; Atalla, A.A. Prevalence of musculoskeletal disorders and its correlation to physical activity among health specialty students. Int. J. Prev. Med. 2019, 10, 48. [Google Scholar] [CrossRef]
- Tu, H.; Liao, X.; Schuller, K.; Cook, A.; Fan, S.; Lan, G.; Lu, Y.; Yuan, Z.; Moore, J.B.; Maddock, J.E. Insights from an observational assessment of park-based physical activity in Nanchang, China. Prev. Med. Rep. 2015, 2, 930–934. [Google Scholar] [CrossRef] [Green Version]
- World Health Organization. Global Action Plan on Physical Activity 2018–2030: More Active People for a Healthier World; World Health Organization: Geneva, Switzerland, 2019. [Google Scholar]
- Evans, G.W.; Johansson, G.; Rydstedt, L. Hassles on the job: A study of a job intervention with urban bus drivers. J. Organ. Behav. Int. J. Ind. Occup. Organ. Psychol. Behav. 1999, 20, 199–208. [Google Scholar] [CrossRef]
- Hanumegowda, G. Risk factors and prevalence of work-related musculoskeletal disorders in metropolitan bus drivers: An assessment of whole body and hand-arm transmitted vibration. Work 2022, 71, 951–973. [Google Scholar] [CrossRef] [PubMed]
- Jonsson, P.M.; Rynell, P.W.; Hagberg, M.; Johnson, P.W. Comparison of whole-body vibration exposures in buses: Effects and interactions of bus and seat design. Ergonomics 2015, 58, 1133–1142. [Google Scholar] [CrossRef]
- Ning, D.; Sun, S.; Du, H.; Li, W.; Zhang, N.; Zheng, M.; Luo, L. An electromagnetic variable inertance device for seat suspension vibration control. Mech. Syst. Signal Process. 2019, 133, 106259. [Google Scholar] [CrossRef]
- Sekulić, D.; Rusov, S.; Dedović, V.; Šalinić, S.; Mladenović, D.; Ivković, I. Analysis of bus users’ vibration exposure time. Int. J. Ind. Ergon. 2018, 65, 26–35. [Google Scholar] [CrossRef]
- Rai, R.; Tiwari, M.K.; Ivanov, D.; Dolgui, A. Machine learning in manufacturing and industry 4.0 applications. Int. J. Prod. Res. 2021, 59, 4773–4778. [Google Scholar] [CrossRef]
- Prakash, C.; Kumar, R.; Mittal, N. Recent developments in human gait research: Parameters, approaches, applications, machine learning techniques, datasets and challenges. Artif. Intell. Rev. 2016, 49, 1–40. [Google Scholar] [CrossRef]
- Jacob, S.; Menon, V.G.; Al-Turjman, F.; Vinoj, P.G.; Mostarda, L. Artificial muscle intelligence system with deep learning for post-stroke assistance and rehabilitation. IEEE Access 2019, 7, 133463–133473. [Google Scholar] [CrossRef]


{kind=link}
| Classification | |
| Number of samples trained | 357 |
| Accurately classified samples | 357 |
| Classification accuracy | 100% |
| Wrongly classified samples | 0 |
| Misclassification | 0 |
| Inter-rater agreement using Cohen’s kappa | 1 |
| Errors | |
| Root relative square (RRSE) | 0 |
| Relative absolute (RAE) | 0 |
| Mean absolute (MAE) | 0 |
| Root mean square (RMSE) | 0 |
| Class | Very Often | Often | Sometimes | Rarely | Never |
|---|---|---|---|---|---|
| Very Often | 50 | 0 | 0 | 0 | 0 |
| Often | 0 | 118 | 0 | 0 | 0 |
| Sometimes | 0 | 0 | 85 | 0 | 0 |
| Rarely | 0 | 0 | 0 | 30 | 0 |
| Never | 0 | 0 | 0 | 0 | 74 |
| Classification | |
| Number of samples trained | 357 |
| Accurately classified samples | 357 |
| Classification accuracy | 100% |
| Wrongly classified samples | 0 |
| Misclassification | 0 |
| Inter-rater agreement using Cohen’s kappa | 1 |
| Errors | |
| Root relative square (RRSE) | 1.90% |
| Relative absolute (RAE) | 0.11% |
| Mean absolute (MAE) | 0.0003 |
| Root mean square (RMSE) | 0.0068 |
| Class | Very Often | Often | Sometimes | Rarely | Never |
|---|---|---|---|---|---|
| Very Often | 50 | 0 | 0 | 0 | 0 |
| Often | 0 | 118 | 0 | 0 | 0 |
| Sometimes | 0 | 0 | 85 | 0 | 0 |
| Rarely | 0 | 0 | 0 | 30 | 0 |
| Never | 0 | 0 | 0 | 0 | 74 |
| Classification | |
| Number of samples trained | 357 |
| Accurately classified samples | 333 |
| Classification accuracy | 93.28% |
| Wrongly classified samples | 24 |
| Misclassification | 6.72% |
| Inter-rater agreement using Cohen’s kappa | 0.9138 |
| Errors | |
| Root relative square (RRSE) | 0.1371 |
| Relative absolute (RAE) | 12.12% |
| Mean absolute (MAE) | 0.0313 |
| Root mean square (RMSE) | 38.16% |
| Class | Very Often | Often | Sometimes | Rarely | Never |
|---|---|---|---|---|---|
| Very Often | 50 | 0 | 0 | 0 | 0 |
| Often | 0 | 104 | 14 | 0 | 0 |
| Sometimes | 0 | 0 | 78 | 7 | 0 |
| Rarely | 0 | 0 | 3 | 27 | 0 |
| Never | 0 | 0 | 0 | 0 | 74 |
| Classification | |
| Number of samples trained | 357 |
| Accurately classified samples | 342 |
| Classification accuracy | 95.79% |
| Wrongly classified samples | 15 |
| Misclassification | 4.21% |
| Inter-rater agreement using Cohen’s kappa | 0.9118 |
| Errors | |
| Root relative square (RRSE) | 0.1261 |
| Relative absolute (RAE) | 10.12% |
| Mean absolute (MAE) | 0.0313 |
| Root mean square (RMSE) | 35.16% |
| Class | Very Often | Often | Sometimes | Rarely | Never |
|---|---|---|---|---|---|
| Very Often | 50 | 0 | 0 | 0 | 0 |
| Often | 0 | 104 | 15 | 0 | 0 |
| Sometimes | 0 | 0 | 84 | 0 | 0 |
| Rarely | 0 | 0 | 0 | 30 | 0 |
| Never | 0 | 0 | 0 | 0 | 74 |
| Techniques to Prevent Overfitting in Decision Tree | Accuracy % |
|---|---|
| Pre-Pruning | 92 |
| Post-Pruning | 91 |
| Acquire more training set | 95 |
| Remove irrelevant attributes | 92 |
| K-fold cross validation test | 96 |
| Techniques to Prevent Overfitting in Random Forest | Accuracy % |
|---|---|
| Reduce tree depth | 96 |
| Reduce number of variables sampled in each split | 91 |
| Acquire more training set | 94 |
| K-fold cross validation test | 93 |
| % of Trained Data— % Test Data | Accuracy % | |
|---|---|---|
| Decision Tree | Random Forest | |
| 70–30 | 100 | 100 |
| 80–20 | 96 | 94 |
| 90–10 | 98 | 95 |
| 60–40 | 89 | 86 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hanumegowda, P.K.; Gnanasekaran, S. Prediction of Work-Related Risk Factors among Bus Drivers Using Machine Learning. Int. J. Environ. Res. Public Health 2022, 19, 15179. https://doi.org/10.3390/ijerph192215179
Hanumegowda PK, Gnanasekaran S. Prediction of Work-Related Risk Factors among Bus Drivers Using Machine Learning. International Journal of Environmental Research and Public Health. 2022; 19(22):15179. https://doi.org/10.3390/ijerph192215179
Chicago/Turabian StyleHanumegowda, Pradeep Kumar, and Sakthivel Gnanasekaran. 2022. "Prediction of Work-Related Risk Factors among Bus Drivers Using Machine Learning" International Journal of Environmental Research and Public Health 19, no. 22: 15179. https://doi.org/10.3390/ijerph192215179
APA StyleHanumegowda, P. K., & Gnanasekaran, S. (2022). Prediction of Work-Related Risk Factors among Bus Drivers Using Machine Learning. International Journal of Environmental Research and Public Health, 19(22), 15179. https://doi.org/10.3390/ijerph192215179