1. Introduction
Under very mild conditions, there exists a scalar stochastic discount factor (SDF) process that generates moment restrictions on the returns (or cash flows) of traded securities. Knowledge of the SDF process allows one to check if a particular security is priced consistently with other traded assets, and it allows the valuation of uncertain future cash flows regarding nontraded assets as far as one is confident the pricing implications extend appropriately. In the literature, there are a plethora of methods either to nonparametrically extract the SDF process from historical data or to evaluate particular theories on the SDF process such as long-run risk models or habit models.
One issue associated with such approaches concerns the ex post implied level of real interest rates. Extant procedures use moment conditions based on asset returns, and the return horizons typically range from monthly to annual. The returns series are like first differenced asset prices and thus nearly white-noise processes; information on the levels of asset prices, and bond prices in particular, is negligible, leaving interest rates ill determined. Left on its own, an extracted SDF can give rise to somewhat implausible levels of real interest rates. As an example, for a recent long-run risk application,
Christensen (
2017) reports the long-term interest rate as a rather high at 7 percent per year; in additional computations using this author’s code, we found that the entire yield curve from one year on out is essentially flat at just over 7 percent. Poorly determined real yield curves were encountered using the extraction procedure of this paper, where absent prior knowledge implied that yield curves shifted and bent in implausible configurations. As just noted, the moment conditions contain little, if any, level information, and external information from other sources needs to be imposed to discipline the SDF extraction.
An agreed upon fact is that U.S. real interest rates are very low. According to
Campbell (
2003, p. 812), the average short-term U.S. real rate was
percent over the period 1947–1998, and few would have argued for higher real short-term rates since then. As for longer-term real rates, Figure 2 of
Tesar and Obstfeld (
2015, p. 8) indicates that the 10-year real rate of interest over the period 1930–2014 was often negative, generally fluctuated between 0 and 2.5 percent per year, and only briefly bumped 5 percent during the interwar era and again during the disinflation period of the early 1980s. Additional information from Treasury Inflation Protected Securities (TIPS) real yields is seen in
Table 1, which are remarkably low.
In what follows, we implemented a Bayesian SDF extraction procedure subject to a prior that enforces these known low values for U.S. real interest rates. The method’s mathematical foundation requires a prior to ensure all the random variables are actually defined on a proper probability space, and here, we elected to use the yield curve prior in place of a specific model of the SDF. Specifically, the prior centers the one-year yield at
percent with a standard deviation of
percent, and it centers the 30-year yield at
percent with a standard deviation of
percent. The prior generally accommodates both the levels and fluctuations in real rates suggested in the above discussion and by
Table 1. This prior was maintained throughout the entire sample period, although it would be relatively easy to impose a time-varying prior with possibly higher yields in the earlier parts of the sample if reliable real rates were available to inform the development of such a prior.
Post-extraction, we used the dynamics of the SDF and related variables in a standard log-Gaussian pricing framework to value various cash flows, with a focus on the risk premiums on stripped cash flows, often termed dividend strips in the literature. The concept is simple: if, from the perspective of period 0, an investment pays off the uncertain stream
into the indefinite future, then the stripped cash flow is the asset that pays just
in period
and zero in all other periods. Recently, researchers have been investigating the term structure of the equity risk premiums on stripped cash flows to better understand the relationship between risk and reward at short- and long-term horizons. Asset-pricing models (
van Binsbergen et al. 2012;
Giglio et al. 2015) suggest that the term structure of risk premiums is upward sloping, with more distant cash flows earning higher risk premiums due to a long-run risk (
Bansal and Yaron 2004) mechanism that makes investors fearful of volatility in the distant future. This prediction seems at odds with common sense intuition, but theory alone is not powerful enough to make an unambiguous prediction on the slope of the equity risk premium term structure.
Backus et al. (
2016) show how a wide range of levels and shapes of the term structures of claims can be achieved by modifying the dynamics of the pricing kernel, the cash flow growth, and their interaction. Empirically, discussions about the true average slope of the equity return term structure have not yet been settled (
Cochrane 2017;
Bansal et al. 2017;
van Binsbergen et al. 2017), and reconciling asset-pricing models with the possible slopes of the term structure of equity returns has recently become a very active area of research. Of particular interest here is
Croce et al. (
2015), who developed a bounded rationality model with long-run risk that appears to explain our findings below.
2. Ex Post Stochastic Discount Factor
The ex post-realized values of
were extracted annually for 1930–2015 using the methodology developed in
Gallant and Hong (
2007). The differences are threefold: the dataset is longer due to the passage of time, all of the Fama–French portfolios (
Fama and French 1992,
1993) can be used because a missing data problem has been resolved, and the prior tilts values toward a specified yield curve instead of toward long-run risk dynamics (
Bansal and Yaron 2004). In brief, the ideas are as follows.
For time , where corresponds to 1930 and corresponds to 2015, denote the real gross returns on the 25 Fama–French 5 × 5 size and value portfolios with the vector , denote the real gross annual return on the thirty-day T-bill with , denote the real per capita consumption growth with , and denote the per capita labor income growth with . Let be a vector of length 28 containing these variables. Let x be an array with as columns; x has the dimensions 28 by . Let denote the stochastic discount factor and set .
The vector is random and endogenous, so determining a likelihood for Bayesian analysis requires some care. The likelihood construction proceeds as follows.
We presume the existence of, but not knowledge of, a general equilibrium model with a financial sector. The general equilibrium model determines a joint probability space on which all the random variables that enter the model live and, hence, a marginal probability space on which the random variables live. The marginal probability space determines a conditional distribution of x given . We presume that this conditional distribution has the density . Ours is a partial equilibrium analysis, so any general equilibrium parameters that might be involved in an expression for , were they known, do not affect our analysis and can be ignored or, to be pedantic, are fixed and calibrated by nature.
Let denote the prior we intend to use for a partial equilibrium Bayesian analysis. The analysis will be with reference to the probability space , where has the density .
Denote the vector of the (conditional) moment-equation errors with
where 1 denotes a vector of 1’s of length twenty-six. Define the instruments
where
denotes 1 subtracted from each element of
. Consider the moment conditions
where ⊗ denotes the Kronecker product, and their sample average
The length of the vector
is
, so the number of overidentifying restrictions on
is 669. Note that
is not yet identified because
does not appear in (
3); it is identified by the prior as discussed later in this subsection.
Following
Gallant and Hong (
2007), we assume that
has a factor structure. There is one error common to all the elements of
and twenty-six idiosyncratic errors, one for each element of
. Denote this matrix with
(or with
if one wants to allow for heterogeneity, which makes no difference in what follows). A set of orthogonal eigenvectors
for
is easy to construct (
Gallant and Hong 2007, p. 535) and can be used to diagonalize
. Similarly,
and
for
can be determined. Let
with elements
. Diagonalization implies that we can estimate the variance of
by a diagonal matrix
with the elements
Let denote this matrix with the diagonal elements replaced by their square roots.
The extraction of the ex post realization of the SDF is based on the random variable
with a range
defined on the aforementioned probability space
.
is the normalized sum of transformed draws
and is asymptotically multivariate normal with a zero mean and identity variance under plausible regularity conditions on
. Note, specifically, that
is random and jointly distributed with
, so issues of uniformity in
do not arise. Thus, it is reasonable to assume that
Z follows the standard normal distribution
with a density of
.
The assumption that
has a density of
induces a probability space
where
is the
-algebra of preimages
and
. Define
to be the smallest
-algebra that contains all the sets in
plus all the sets of the form
, where
B is a Borel subset of
. Under a semipivotal assumption for (
4), ( Which is that
is not empty for any choice of
in the parameter space
and range space
; a sufficient condition is that each element of
Z is continuous in
when some element
of
is replaced by
for all
t and is unbounded from above and below in
.) there is an extension of
to a space
on which the conditional density of
x given
is
(
Gallant 2016a). This density is termed the “method of moments representation” of the likelihood and may be used for Bayesian inference in connection with the prior
(
Gallant 2016a,
2016b). (Missing in (
5) is a multiplicative Jacobian term that experience indicates has a negligible impact on computations when omitted (
Gallant 2020)).
In short, the Bayesian method used in
Gallant and Hong (
2007) and here uses the moment conditions
given by (
4), takes
as the likelihood, and proceeds directly to Bayesian inference using a prior
.
Next, we describe the prior.
Let
, where
growth is observed for
. GDP is not involved in the SDF extraction up to this point. It is now included as prior information regarding past business-cycle conditions. Consider the recursion
where the
are independent and bivariate normal with a zero mean and variance
. Markov chain Monte Carlo (MCMC) (
Gamerman and Lopes 2006) is used in the
Gallant and Hong (
2007) method which means that the proposed
is available to compute
before the prior and likelihood need to be computed. From the
the parameters of (
7) can be determined by the least squares. With the least-squares values replacing parameters in (
7), a yield curve for maturities one year through thirty years can be computed analytically from (
7) conditional on a specified initial condition
; see Equations (
12), (
13) and (
15) of
Section 3. In particular, the one-year and 30-year yields,
and
, can be computed successively for
,
. Our prior is
Note, in particular, that the prior identifies .
With likelihood (
5) and prior (
8) in hand, Bayesian inference can be carried out using MCMC in the usual way; see, for exaxmple,
Gamerman and Lopes (
2006). After the transients died out, we ran an MCMC chain of length 8,000,000. The
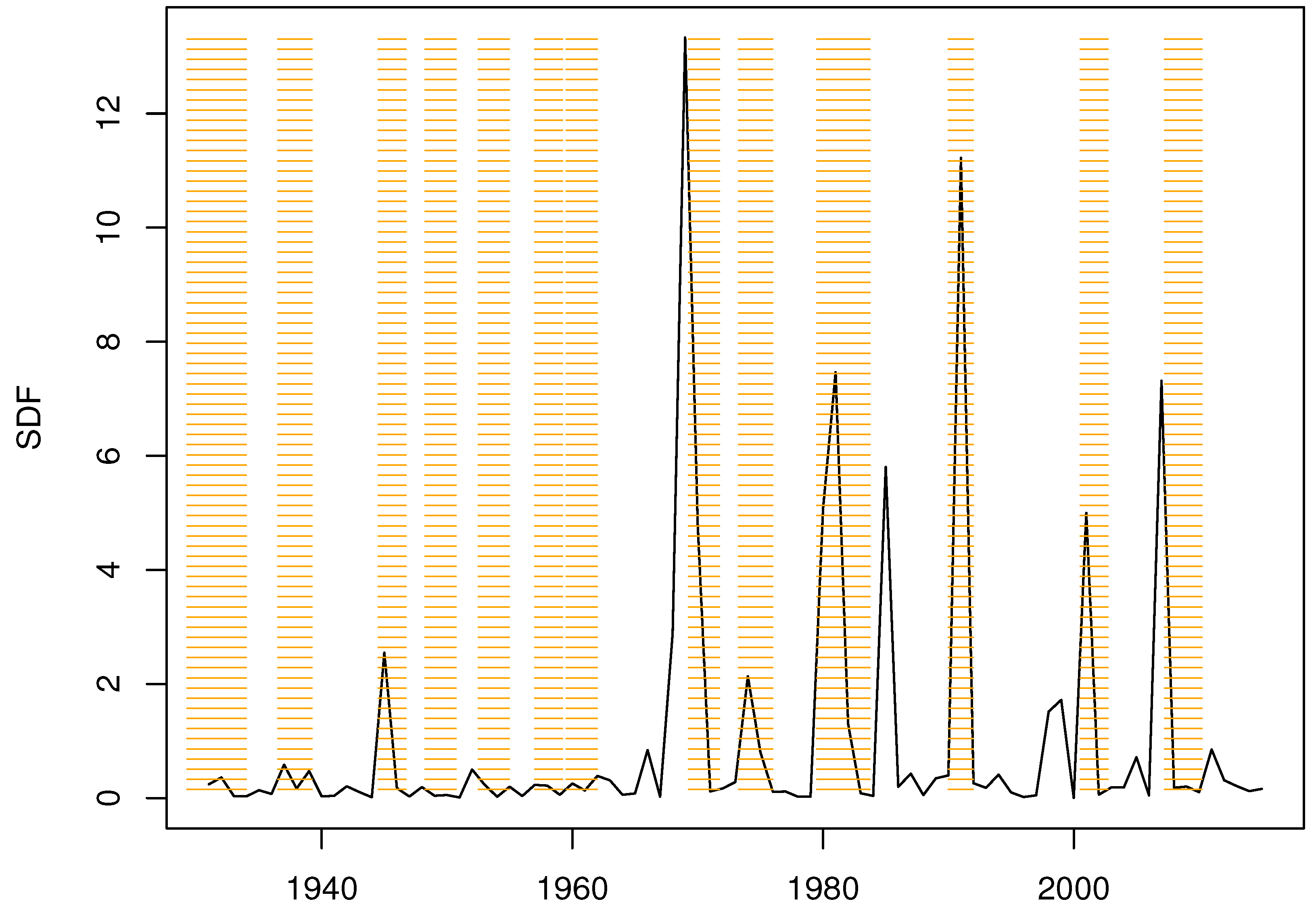
in the chain with the highest value of the posterior was selected as the estimate
of the ex post SDFs for the years 1930 through 2015. The estimate is plotted as
Figure 1. The shaded areas are NBE R recessions.
3. Discounted Cash Flow Estimation
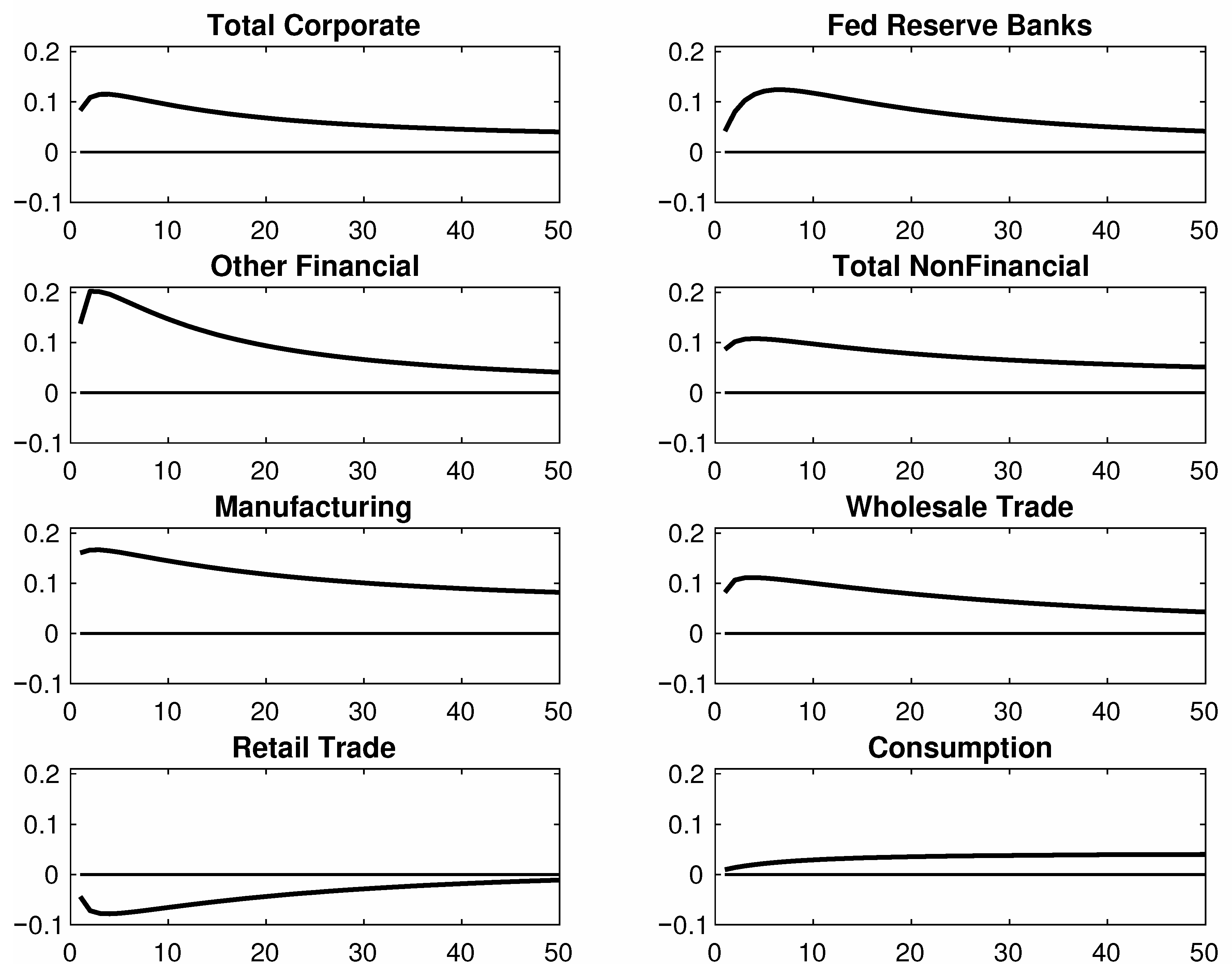
We now used the extracted SDF series to value cash flows for assets outside the span of returns used in the extraction step. For this part, we used annual data on corporate profits from various large sectors of the U.S. economy. We assembled annual data for seven sectors but for the shorter period 1959–2015, as data limitations precluded going any farther back. We also treated consumption as a cash flow, making a total of eight under consideration. These data were concatenated with the extracted SDF data and various macroaggregates for this shorter time span.
For the valuation step, consider the trivariate series
where
denotes a cash flow payoff at time
t, such as the annual corporate profits in year t;
denotes the gross domestic product; and
denotes the extracted stochastic discount factor
of
Section 2. Note that the second variable in the autoregression,
, plays no direct role in subsequent pricing, but it is included because it conveys information on future cash flows. The specification presumes co-integration between GDP and CF, which is discussed more fully in
Section 4 below.
The time zero present value of the cash flow
is
where
denotes the time 0 information set. (Note that in (
10), the time zero value of the
must be unity; the time zero value of
is irrelevant because we work in terms of ratios—see (
19) below—and therefore, we will normalize it to be unity.) (In (
10), the expectation
refers to the probability space
defined in
Section 2. In (
14)–(
16) and thereafter,
refers to the VAR (
11).) For a risk-free payoff of one real dollar at time
t, the time zero present value is
, where
. The corresponding yield is
.
Let
where the
are independent and trivariate normal with a zero mean and variance
. The sum
where
,
,
, etc., has moments
One can use (
12) and (
13) to evaluate
where
refers to expectation with respect to the VAR (
11). Note that in the above, the time zero value of the
must be unity; the time zero value of
is irrelevant because we work in terms of ratios—see, for example, (
19)—therefore, we normalize it to be unity.
We now describe the imposition of a yield curve prior on the estimation of the
,
B, and
that appear in the VAR (
11). Consider a state-space representation of VAR (
11)
The estimation of (
17) subject to the indicated parameter restrictions gives the same estimates
, and
,
as does the unconstrained estimation of (
11). Let
and note that the fourth and fifth elements of
are
and
. An implication is that we can insert the parameters
,
, and
of
into Equations (
12), (
13), and (
15) to compute the one-year yield,
, and 30-year yield,
, with
set to
successively for
, and impose the prior (
8).
The computational procedure is, within an MCMC loop, for the proposed
,
B, and
, to evaluate the likelihood implied by VAR (
11); compute
,
, and
as indicated by expression (
18) from the proposed
,
B, and
; evaluate the prior (
8); and use the likelihood and prior so computed to make the accept/reject decision of the MCMC loop.
Serendipitously, the state-space complications can be avoided because it turns out that the yields
and
obtained by applying Equations (
12), (
13) and (
15) directly to the
,
B, and
of VAR (
11) are identical to those computed from the
,
, and
of VAR (
18). Apparently, the reason is that the only difference between the distributions of
and
is the location parameter of their fifth element, and the location parameter of the fifth element is not involved in Equation (
12), (
13) or (
15). For ourselves, we are more comfortable relying on having performed the computations using both (
11) and (
18) and and obtaining identical results than relying on the distributional argument.
5. Robustness
The objective of the paper was to adapt a Bayesian methodology (
Gallant and Hong 2007) to a completely model-free data-only setting and then value important nontraded cash flows for the economic analysis of risk premiums. It only considers this specific objective and reaches interesting economic conclusions, but it is not exhaustive.
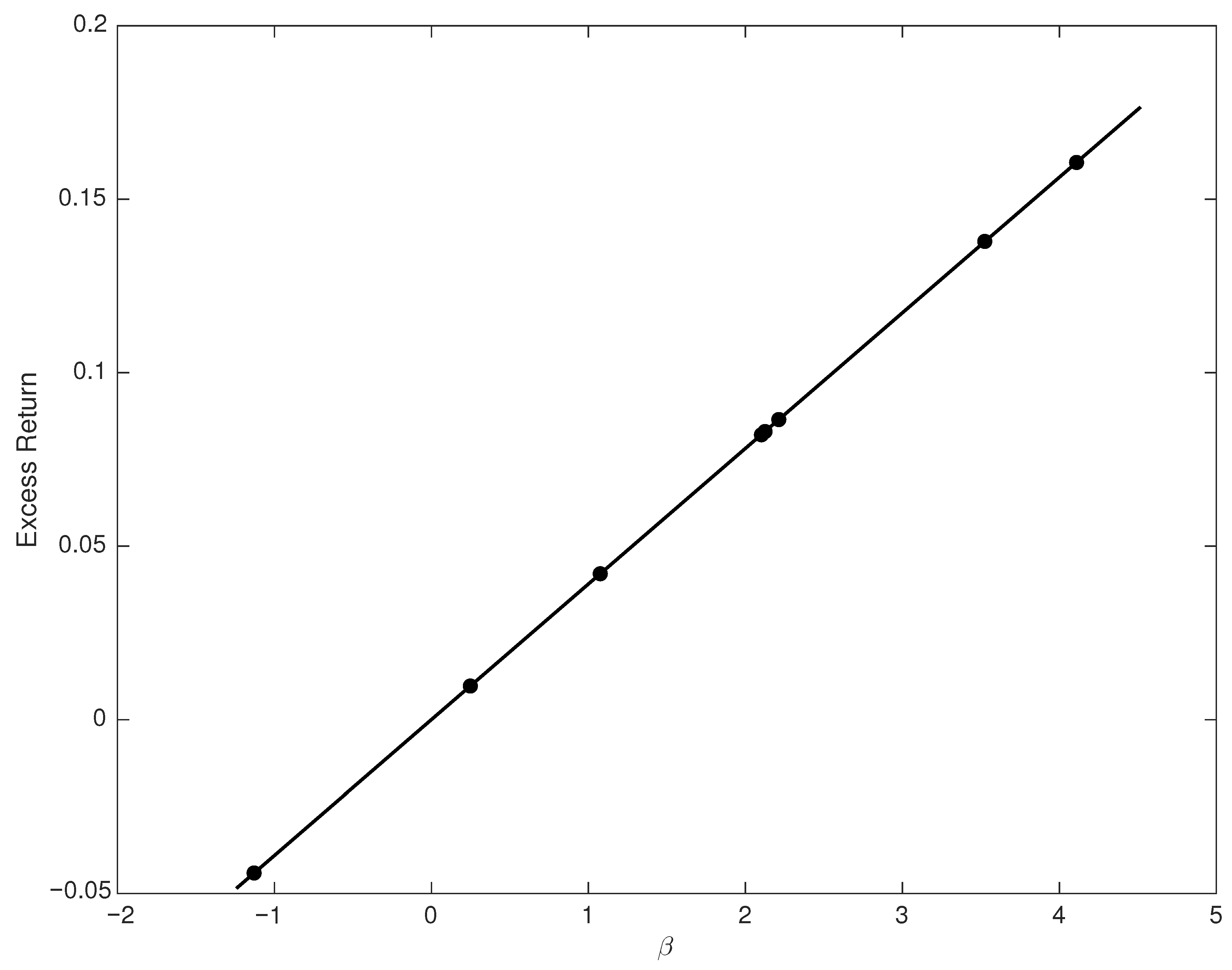
There are two issues regarding robustness that should be remarked upon: Is the methodology sensitive to the choice of assets? Is the methodology sensitive to the choice of prior?
As regards the assets, the methodology extracts the ex post SDF from the asset-pricing errors on 754 dynamic portfolio returns induced by instrumenting a smaller core set of asset returns. The core set, described in the
Appendix A, is representative of those used for evaluating asset-pricing models; see, for example, the review by
Bryzgalova et al. (
2020, p. 3). The methods for the extraction of an SDF can be dependent on the assets used for the extraction, e.g.,
Nieto and Rubio (
2014). However, our surmise is confidence that the large set of portfolio returns spans the factors on which all assets load, especially upon taking into account that the portfolios are dynamic and include instrumental variables such as consumption and labor income growth. Rather than the assets, it is the prior to which the
Gallant and Hong (
2007) methodology is sensitive. This issue we have examined, as reported above.
A referee suggests other references that a reader might consider.
Lewellen et al. (
2010) and
Ghosh et al. (
2017) discuss other methods for the extraction of the SDF, rather than the valuation of nontraded cash flows, though it would be interesting to extend these studies to our application. That step is beyond the scope of this paper. Additionally,
Gormsen (
2020);
Bansal et al. (
2019); and
Giglio et al. (
2020) further examine evidence on the slope of the term structure of equity returns without consensus. Our main finding regards the contrast between the term structure of the risk premiums on consumption versus that of those on the industrial cash flows we considered.







{kind=link}
{kind=link}
{kind=link}
{kind=link}