1. Introduction
Nowadays, power grids face many challenges. New technology enables the grid integration of different renewable energy sources (RESs), which has led to bi-direction power flow and voltage overshoot [
1]. The injection of intermittent power into the traditional distribution network has resulted in many problems, and new approaches, including ones that address the allocation strategy, control system, and power grid structure, are needed [
2]. Optimization-based power dispatch and battery energy storage systems (BSSs) are frequently used to overcome the poor power quality caused by RESs. However, such approaches may not be efficient in the areas where the output of discrete generators (DGs) cannot be greatly changed and the surplus power generated by the RESs is large. Under such conditions, the optimization of power grid structure can be a promising choice due to its relatively low cost, high flexibility, and efficiency.
Research related to the structure of the power grid can be divided into two types according to the problem being solved. Algorithms for network reconfiguration have been proposed to solve the bi-direction power flow and reduce the power loss in networks [
3,
4,
5,
6,
7,
8,
9]. In this approach, a network with loops is designed and switches are used to reconfigure the network so that different radial network is obtained in the running process to re-direct the power flow. The aim of a network reconfiguration is to reduce the total power losses and different optimization algorithms that are applied, including the Particle Swarm Optimization (PSO), Invasive Weeds Optimization (IWO), and Cuckoo Search Algorithm (CSA) [
3,
4,
5]. To address the issue of power losses, the network survivability index was introduced as a measurement of the redundancy, and the Ant Colony Algorithm (ACA) was used to optimize the survivability index and power losses [
6]. To achieve a better convergence property, the Big Bang-Big Crunch (BB-BC) [
7] algorithm was used, and a mutation step was added to the Big Crunch process. The optimal power losses can be obtained with the modified BB-BC algorithm [
8]. In one study [
9], a distributed approach was proposed to reconfigure the network based on open shortest path first (OSPF) routing protocol. In that research, the physical architecture was proposed, and the Dijkstra Algorithm was used to obtain the optimal radial configuration.
Algorithms for the network partition were proposed to solve the computational complexity caused by the expansion of the network [
10,
11,
12,
13,
14,
15,
16,
17]. A large network is partitioned into several clusters in which the supply and demand is balanced, cohesiveness is high, and inter-connection is low so that the control strategy can be applied to each cluster in parallel. Network partitioning requires a distance matrix indicating the dependency of any two nodes. Commonly the differential of the voltage as a function of the power was used as the distance matrix, and the traditional k-means algorithm was applied to achieve the clusters [
10]. In one study [
11], the usage of the spectral clustering in a power grid was analyzed, and several weight matrixes were proposed and compared. With the normalized Laplacian matrix and its eigenvalues, the first k eigenvectors were chosen to perform the k-means analysis. Similarly, spectral analysis has been applied to address this issue [
12], where both the active and reactive matrixes were considered. Instead of using k-means, the Self-Organizing Map (SOM) algorithm was used so that the number of clusters could be learned from the data. A modified community detection algorithm was used to optimize the network partition. An unbiased performance index was proposed with the knowledge of structure and power supply condition in each cluster to determine the quality of the algorithm so that auto-termination of the algorithm was ensured [
13]. The sensitivity matrix was used as the distance matrix and different cluster algorithms were compared using four different performance indexes; it was found that intelligence algorithms were superior to classical clustering algorithms [
14].
Both the network reconfiguration and network partition help improve the power quality of the modern power grid. However, they need a well predesigned network, which is unrealistic in most rural areas. In underdeveloped areas far from the city center, it is difficult to supply enough energy from the transmission lines, resulting in the exploitation of local resources, such as hydro energy, to compensate for the load demand. However, with the development of renewable energy generators and photovoltaic (PV) poverty alleviation programs, particularly in China, a large number of RESs have been installed in such places, leading to surplus power energy. Such surplus energy is mainly provided by the large hydro station at the end of the grid, which may lead to poor power quality and a voltage overshoot. It is challenging to solve these problems because mainly runoff hydropower stations are installed in such remote areas, and the citizens are not willing to shut down their PVs. To solve the unbalanced power energy at the end of grid, a practical method that has been employed in many places in China is to add transmission lines. By doing so, a power grid is divided into several separated radial grids which are separately connected to a national grid so that the surplus energy can be directly transmitted to the national grid without causing any voltage overshoot. However, research on how to separate a particular network is limited, and the practical operation is based on subjective judgment. Instead of dividing a grid into several inter-connected clusters in the network partition, this problem requires the separation of the unbalanced part of the grid. This paper proposes a power-mileage-based network optimization algorithm to provide a guideline for how to add transmission lines. The main contributions of our work have been illustrated in the following:
- (1)
To save the time consumed by calculation, a performance index which denotes voltage profile is deduced and used. It has a linear relationship with the input power condition so that it can be calculated with linear algebra easily.
- (2)
A network optimization algorithm is proposed to guide how to divide a power grid and achieve the optimal voltage condition. The algorithms automatically decide the number of clusters and when to stop the iteration.
The rest of the paper is organized as follows. The problem is formulated in
Section 2. In
Section 3, related concepts, including the power mileage value, are introduced and a simple algorithm to calculate the mileage matrix is also presented.
Section 4 elucidates the power-mileage-based algorithm, and two cases are used to illustrate the algorithm’s effectiveness.
Section 5 provides another case study, and
Section 6 gives our conclusions.
2. Problem Formulation
In rural areas which are far from the city center, there are always some local hydro power stations to provide the local power consumption. However, with the exploitation of RESs and the photovoltaic poverty alleviation program (PPAP), on a large number of windfarms, PVs were installed. Such RESs are often installed locally and the surplus energy provided by the hydro stations could only be transmitted to the national grid, resulting in the voltage overshoot and poor power quality. It is difficult to solve these problems with traditional methods, such as a battery energy storage system (BESS), hydrogen storage system [
18] and network reconfiguration, largely because the surplus energy is of the order of 100 MW·h and the structure of the network is already defined. Thus, adding transmission lines can be a promising approach because once an ending large hydro station directly connects to the national grid, the power quality of the grid increases significantly. However, such an intuitive judgment cannot be used as a guideline for real life practice, and a mathematical model is needed to help decide the number of added lines and where to add transmission lines.
Unlike traditional network clustering, which aims to find the best partition of the network with the highest inter-cluster cohesiveness and loosest intra-cluster coupling, network optimization separates the sub-grid, which is far from the national grid and unbalanced in regard to the energy supply and demand. Suppose a grid is divided into
and
, and
is the relatively balanced grid originally connected to the national grid. Before the separation, a large amount of power from unbalanced
should be transmitted to
, leading to the voltage overshoot in the ending node of
. Once an effective separation is made, the power flow through
decreases significantly, and a better power quality is achieved. In the meanwhile, the voltage of the first node in
will be exactly 1 p.u., instead of the much worse condition before the separation, which also improves the power quality in
. As a result, an effective separation should offer an improvement of the power quality for all of the sub-grids. The following model of network optimization can be formulated using the above discussion. Suppose that the level of the power quality of a grid
can be quantified with
, where a smaller value means a better quality, and graph
is separated into
graphs. The following model can be formulated:
Because only the connected graph without loops is considered, its sub-graph is also a connected graph without loops, which ensures the basic property of a grid. The second and third equations are mutually exclusive and exhaustive of all of the separations; the first equation ensures the power quality of all of the sub-grids to achieve the best conditions. During the flow, a metric power mileage was deduced to quantify the quality of a power grid, and then an algorithm was proposed to perform the separation.
3. Preliminary Work
The graph theory [
19] was used to represent a grid. A power grid can be seen as a radial graph where the loads and generators in one position make up the node. The transmission line between two nodes is the branch. The node number is sorted by preorder traversal and the branch order equals the larger one of the two neighboring node numbers. The national grid is node 0 and is not counted. Throughout the whole manuscript, the terms grid, network, and graph have the same meaning and will be used interchangeably.
The definition and calculation of the power mileage are given below.
3.1. Nomenclatures
The terms will be used in the paper will be listed in
Table 1 for a better illustration in the algorithm part.
3.2. Power Mileage
To determine the power quality of a power grid, many different performance indexes have been proposed [
20,
21,
22,
23]. In the adding lines problem, we needed a metric to indicate the voltage profile. Because our algorithm will iterate many times, a linear index with input is a reasonable choice. We defined the performance index and power mileage from the voltage drop equation.
The definition of power mileage was deduced from the following:
where
is the voltage drop in a branch,
is the normal voltage,
and
are the active and reactive power flow through the branch, and
and
are the resistance and reactance of the line.
For a distribution network in a microgrid, the material and per kilometer’s parameters for the main line typically keep constant due to its relatively small size. To simplify the equation further, the resistance and reactance can be replaced by the resistance and reactance per kilometer (
and
) multiplied by the length of a branch (
) so that the voltage drop between node
and node 0 can be written as
where branch
is in the path from node 0 to node
.
Even if the resistance and reactance per kilometer are not constant in same networks, we can choose one as the base value and then modify the length of other branches to achieve the simplification in Equation (3).
In a particular transmission line, the voltage drop in node
is a linear combination of
and
so we called them the active power mileage and reactive power mileage. We calculated the active and reactive power mileage of the whole grid (
and
) with the method proposed in
Section 3.3. Then, the performance index power mileage
was defined:
where τ is the weight denotes the relationship between resistance and reactance.
As shown in the formulas, the power mileage has a linear relationship with the power condition so that it can be calculated with matrix. This formula indicates the voltage profile of a power grid and it can be used to optimize.
3.3. Calculation of Power Mileage
We first introduced a mileage matrix , which describes the structure of the power grid to help the calculation. is the number of nodes and equals the length of branch if branch is part of the path from node 0 to node . Otherwise, is 0.
Column of is the route that arrives at node from node 0 and the row of means the nodes whose power will transmit through branch . If the power demand of each node is multiplied by the row of the mileage matrix, we can obtain the power mileage in each branch.
Suppose we have an active power condition matrix
, where its element
is the power needed in node
at time
. As a result, the total active power mileage can be calculated with the following formula (5). In the formula, the row
of
means the nodes whose power will transmit through branch
(otherwise it will be 0) and the column of
means the power needed, thus the element
of
means the active power mileage through branch
at time
.
The reactive power mileage can be obtained in exactly same way.
3.4. Algorithm to Calculate Mileage Matrix
For the calculation of the mileage matrix , we needed to decide whether a branch lies in the path between two nodes, which is a time-consuming process. A simple algorithm is discussed here for calculating the mileage matrix from the edge weight matrix of a graph.
Suppose that is the edge weight matrix, and its element is the length of the branch between node and node if it exists. Otherwise, is 0. The pseudocode for algorithm is shown in Algorithm 1.
The effectiveness of this algorithm is briefly explained here. Because this graph is a connected graph without a loop, there exists only one route from node 0 to any node. If is not 0 (line 4), there is a branch connecting node and node . The route to node can be separated into the route to node plus the branch , and also the route to the node is a column of the mileage matrix, so line 5 and line 6 can be performed to construct a mileage matrix.
| Algorithm 1: Calculation of the mileage matrix |
Input: edge weight matrix W
Output: mileage matrix Mn = number of columns in W fori = 1:n for j = 1:n endfor endfor endfor
|
4. Power-mileage-based Network Optimization
The main task of network optimization is to separate the sub-graph that is far from the national grid and whose power is imbalanced. As we illustrated in
Section 2, this means the optimal overall voltage profile, or, minimum power mileage. So, the object of the network optimization algorithms is to find the specific separation of a grid
satisfy:
where
means the total power mileage of
.
To implement such an idea, an iterative power-mileage-based method is proposed. In each turn, the algorithm only divides the grid into two sub-grids, and thus it works greedily in each turn to find the best separation which satisfies Equation (6) (which is discussed in
Section 4.1). In the process of network optimization, there were two issues that needed to be considered: how to choose the best partition and when to stop the iteration. We used an effective indicator in our algorithm, which is explained in
Section 4.2.
4.1. Network Optimization Algorithm
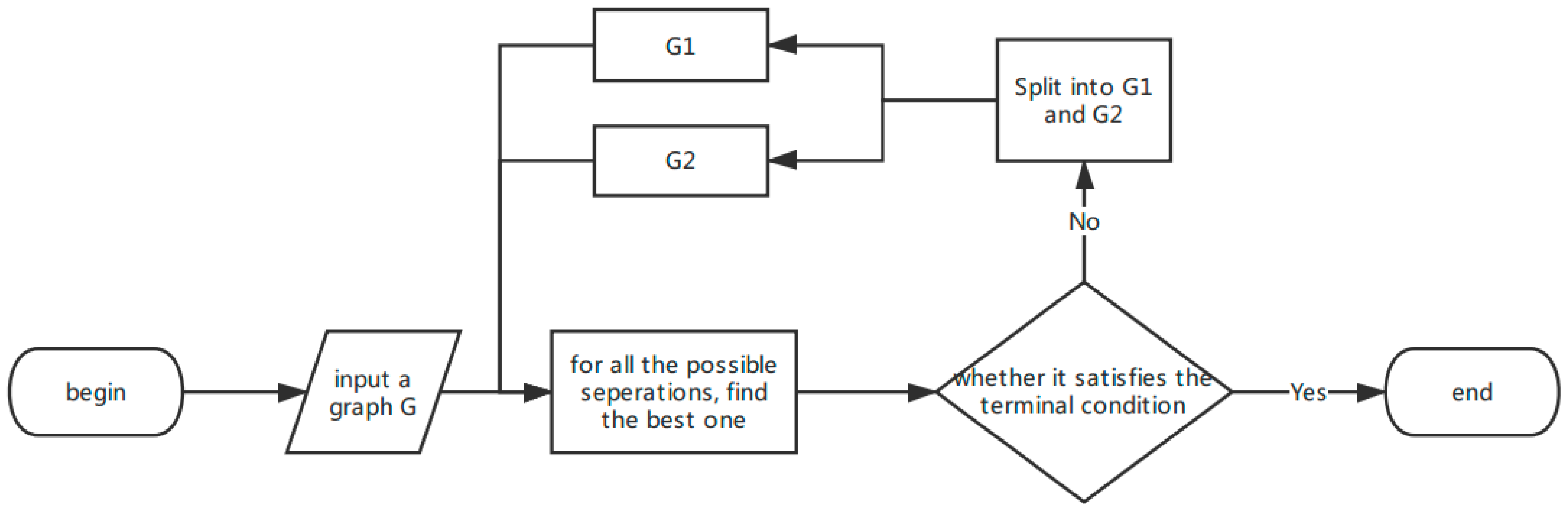
The scheme of the algorithm is shown as follows.
Step 1: For a given graph , each possible candidate for the partition is examined and the best partition is chosen. In this process, , and their power mileage , are obtained.
Step 2: Check whether the best partition satisfies the terminal condition. If so, graph is returned. If not, repeat Steps 1 and 2 in graphs and separately.
With the iterative operation and terminal condition, the algorithm can automatically choose the number of clusters and stops when the terminal condition is satisfied. Also, in each iteration, the objective function in Equation (6) is achieved, thus the algorithm greedily finds the optimal separation of the whole grid.
The aim of this algorithm is to separate the sub-graph, which is imbalanced in power and far from the national grid. If the best partition in Step 1 does not satisfy these two purposes, the algorithm should stop. We wanted the power mileage per branch in
to be larger than that in
so that the imbalance in power is satisfied. We also did not want the voltage profile in the sub-graph to be worse than the original one, so
. should be smaller than
. In addition, the number of clusters should not be too large, and the sub-graph should not be too small. In other words, we did not want the algorithm to iterate too many times. As a result, a punishment was added to the second terminal condition. The terminal conditions are not satisfied when both of the following formulas are met.
where
means the number of nodes in
and
means the length of the sub-graph over the length of the original graph.
Equation (7) ensures the imbalance property of the separated graph and Equation (8) ensures the quality of the separation. The existence of punishes the algorithm for splitting the graph too many times. In each iteration, is the length of the graph to be partitioned over the length of the original graph, which is a constant. equals 1 for the first iteration and keeps decreasing in the running process, leading to a heavier punishment.
The flow chart of the algorithm is shown in
Figure 1.
4.2. Effectiveness of Terminal Condition
In this part, two cases are used to explain the effectiveness of Equations (7) and (8). For easy calculation, instead of using a discrete load like that found in real life, we used the continuous load, which is distributed evenly in the line. The punishment shown in Equation (6) is not discussed here.
First, a transmission line with evenly distributed loads is discussed (
Figure 2).
Figure 2 is a model of a traditional distribution network, and it should not be partitioned by our algorithms because the separated grid is exactly the same as the original one. Once a partition is made, the iteration will continue until the end. If we cut the grid at the point that is
km from the end point, the resulting power mileage is calculated as shown in
Table 2.
From the power mileage calculation, we can see that when , the summation of and reaches the minimum and both and equal . As we discussed earlier, the graph should not be separated by our algorithm, so this is the reason why we set the terminal condition as Equation (7). When we cut the graph at , two parts of the graph are exactly same, so that is not more imbalanced than ; thus, the division is 1. The above outcome proves the utility of Equation (6).
A network that needs to be partitioned is discussed here. Unlike a pure load system, a large distributed generator (DG) was installed at the end of the grid. The power of the DG was exactly the total load, as shown in
Figure 3.
When we cut the line at the same position as the first case, the result in
Table 3 can be achieved.
The summation of and does not change because the absolute value of the power flow through the sub-graph is exactly the same as that of the original one. The only difference is that the flow in the first sub-graph is in the opposite direction compared with that of the original grid. In this graph, our algorithm will cut the line at the point where both and equal . This result is much more reasonable because the power flow through the line in the second sub-graph is much larger, so to reach a better global voltage improvement, the cut point should be closer to the DG. Also, the division is always larger than 1, which means the existence of the DG leads to the imbalance of the second sub-graph.
6. Conclusions
In this paper, the problem of adding transmission lines is first discussed. Unlike a well-designed power grid in a big city, power grids in remote areas always include large power stations that supply the demand of local loads. However, with the development of REs and national poverty alleviation programs, these areas usually have a large number of RESs. Without good planning, voltage overshoot and bad voltage quality become the norm. It is difficult to use traditional methods to overcome such problems due to the large amount of energy being managed. However, adding transmission lines is a promising method. In our study, a network optimization algorithm is proposed to present a guideline for adding transmission lines. In this process, the sub-graph that is far from the national grid and imbalanced between the power supply and demand is separated and connected to the national grid directly. To measure the quality of a network partition and facilitate the calculation, the power mileage value is deduced from the voltage drop equation. It has a linear relationship with the power flow and can indicate the voltage quality of a power grid. Then, an iterative algorithm is proposed to perform the network optimization. The algorithm can automatically choose the number of sub-graphs, and the effectiveness of the terminal conditions were verified by several case studies. We evaluated the algorithm using a real grid with 17 nodes and the IEEE 123-bus grid. Our results show a great improvement in the voltage profile for both cases and proves the utility of the power mileage value.













{kind=link}
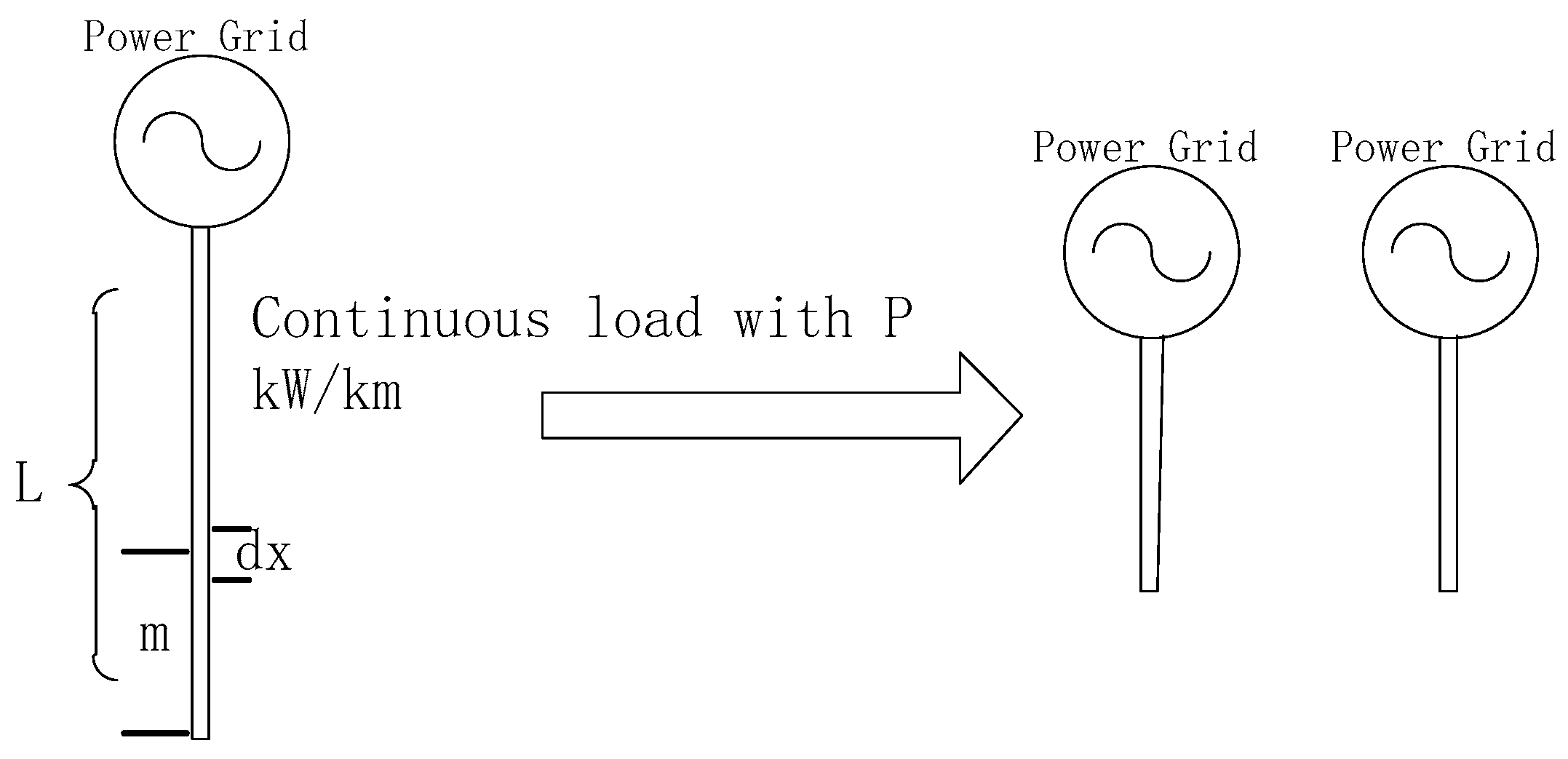{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}