1. Introduction
According to an estimate by Cisco Global Cloud Index, the data produced by the Internet of Things (IoT) will soon exceed 800 zettabytes. For efficient treatment of such huge volumes of data, the edge-computing paradigm has been suggested. In this paradigm, most of the data is processed close to, or at the edge of, the network. Some functions of the network core are delegated to the network edges, where the connected entities produce the data directly. The corresponding computing platforms and system resources can fortify these facilities. Edge computing offloads the computation and communication load of the network core, and by processing data near the data sources, it provides a better quality of service (QoS) for delay-sensitive applications and efficient structural support for user privacy, and it prevents and mitigates some types of DDoS attacks [
1].
The ratio of enterprise-generated data, which is processed outside of a conventional centralized data center or cloud, is expected to reach 75%. ResearchAndMarkets.com estimates that the total edge computing market will increase to USD 9.0 billion by 2024, at a compound annual growth rate of 26.5%. According to an alternative forecast provided by Gartner, this market will reach USD 13 billion by 2022. Worldwide, the financial industry is one of the largest beneficiaries of edge computing. The increased adoption of digital and mobile banking initiatives, advanced technologies such as blockchain, and payments through smart mobile devices is fueling the demand for modern edge computing solutions. The Asia-Pacific region is destined to become one of the main markets because companies and governmental organizations there show a greater inclination toward storing and processing data locally.
However, an increase in the number of data processing locations will increase the attack surface proportionately [
2]. Edge devices are generally used with limited resources [
3], and the limited resources of the IoT poses a serious security threat as energy exhaustion and flood attacks, as well as various types of related intrusions have been described [
4,
5,
6,
7,
8,
9]. In addition, limited computing power and storage size and low battery capacity prevent IoT devices from executing conventional actions to support network security [
10]. Storing large amounts of data and executing a highly complex algorithm for intrusion detection are unreasonable. Considering the security challenges, leading academic researchers and experts from for-profit companies concluded that the current situation with IoT and edge computing security is far from satisfactory and essential efforts are required to overcome weaknesses and vulnerabilities. Thus, edge-computing security is rightfully recognized as an important area for future research [
11,
12,
13].
A lightweight and secure data analytics technique can increase its potential adoption, which is a major benefit because ensuring that the resource consumption of security systems does not harm the performance of IoT devices is important [
14]. Efficiency becomes a crucial issue in secure edge computing, particularly for applications with high real-time requirements. A few recent papers on the theme of intrusion detection systems (IDSs) for edge computing have been published. Some authors offered various IDS mechanisms, but they ignored quantitative analysis [
15]. Other researchers focused only on the quality of detection method [
16,
17,
18], but edge node slowdowns from intrusion detection activities were usually ignored. An edge node usually has extremely limited computational resources and the gateways/endpoints may have the same problem. Hence, it is necessary to take into account the effect of the corresponding additional computational operations. If it is possible to delegate some of the calculations to a central server then heavy ML-based methods like Convolutional Neural Networks, Recurrent Neural Networks can be used. An experimental review of the corresponding methods can be found in [
19]. However, we should pay attention to the following circumstance: an intrusion, such as a flood of spoofed requests (packets, tasks) can be very effective against an edge node, regardless of whether the node processes the packet itself or sends it to the cloud.
As shown in a recent survey [
20], previous works have mainly focused on the trade-off between IDS performance and resource consumption (energy). There are no quantitative methods in the literature to form a proper holistic view of a defense system and receive requirements for the efficiency of the underlying intrusion detection algorithms. This paper intends to fill this gap partially by describing a novel IDS approach. To the best of our knowledge, this is a first attempt to combine IDS quality, the system performance degradation due to IDS operations, and workload specificity into the unified quantitative criterion.
This paper is an extended version of a report [
21] published in the proceedings of the 20th International Conference on Computational Science and Applications (ICCSA 2020, Cagliari, Italy) and differs from it in significant ways. In particular, this paper considers novel mathematical problems concerning the strategies for deploying intrusion detection systems, corresponding inverse problems, and provides closed-form solutions for a few previously unsolved problems.
The remainder of this paper is organized as follows.
Section 2 introduces the related concepts in which the types of losses that should rely on an IDS are considered, and the corresponding formalism is provided.
Section 3 presents an analysis of IDS deployment applicability using additional assumptions.
Section 4 outlines the criteria for IDS deployment on the IoT edge nodes.
Section 5 presents the performance analysis, and
Section 6 concludes the paper.
2. System Model and Problem Statement
A signature-based intrusion detection approach usually begins with an understanding of the attack patterns, and a detection algorithm is then implemented to find the signatures for the situation in question, assuming that the signature represented the attack accurately. Failing to recognize a new attack is a serious limitation. In contrast, an anomaly-based intrusion detection approach is designed to enable security systems to learn from data without any explicit deterministic rules. The training dataset contains the input samples and the corresponding output. The detection algorithm is trained until the difference between its predicted outputs and real outputs becomes negligible. It is assumed that the trained algorithm can predict intrusions missing from the training dataset. Therefore, the anomaly-based intrusion detection approach applies to a variety of attacks. On the other hand, some detection errors need to be allowed. There is no guarantee that an IDS would be able to protect against all threats even if it were theoretically possible. Even the best intrusion detection algorithm is unlikely to be 100% accurate. Thus, the detection error tolerance is an inherent feature of an IDS. This means that its protection mechanisms are not suitable for all scenarios. Therefore, the deployment of an IDS must be justified for suitability and throughput.
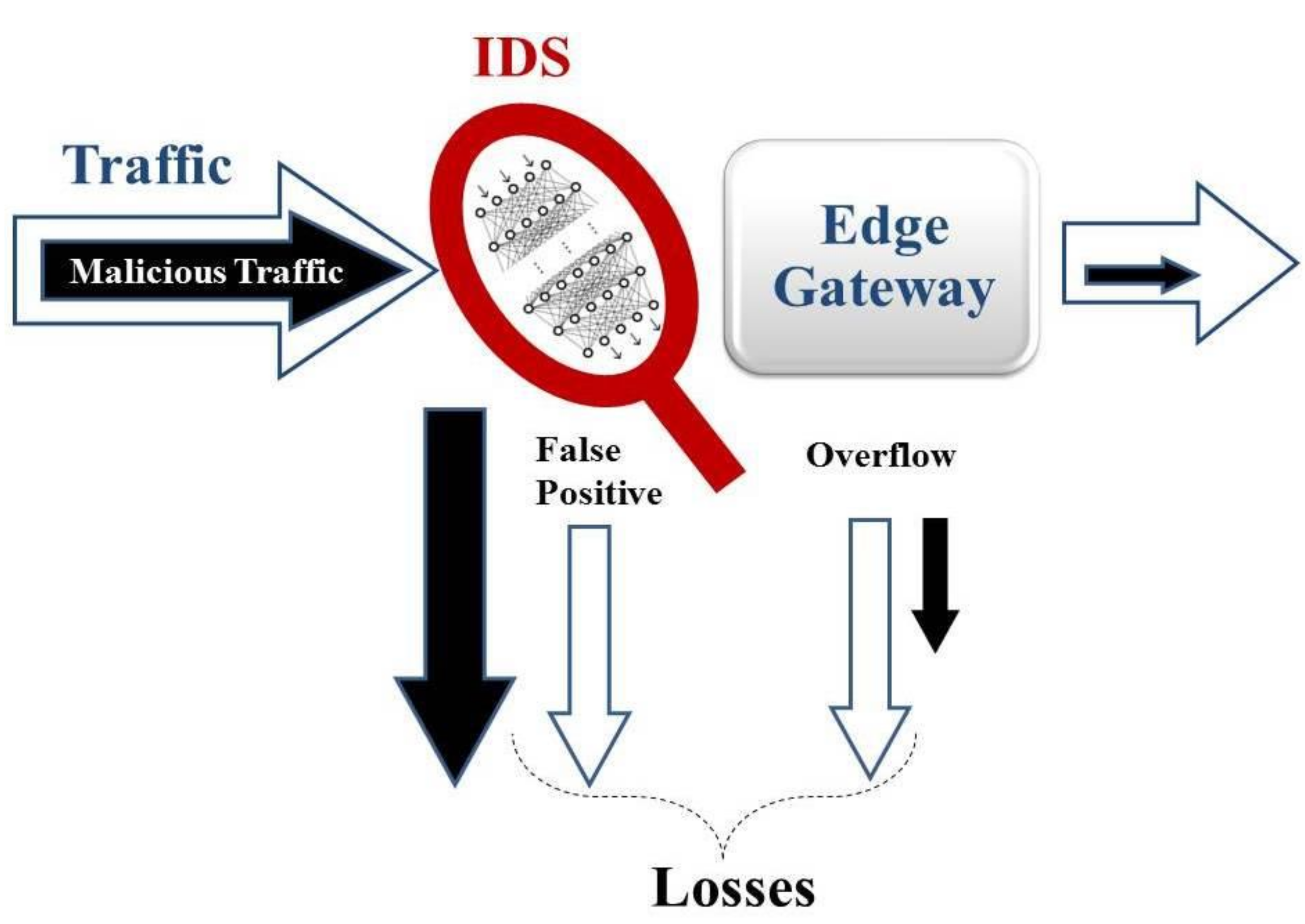
This paper addresses a criterion for IDS deployment on IoT edge nodes and focuses on DDoS attacks such as flooding, which impedes legitimate users and quickly drains the batteries of the mobile edge nodes [
4]. An IDS can filter out some of the malicious traffic, but the following losses to legal users are possible.
A false positive error, known as a false alarm, occurs when an IDS identifies a legal packet as malicious.
An IDS consumes system resources, which reduces the system throughput, and causes possible packet losses due to buffer overflow.
Therefore, the benefits of using an IDS can be offset by the mentioned losses. Hence, it is necessary to choose a scenario (with or without an IDS) with minimal losses.
Figure 1 presents these concepts.
The following two maps can be defined by introducing the corresponding formalism:
where
is a set of edge network environmental parameters; the functional
is the loss metrics in the case of the non-use of the IDS;
is a set of IDS indicators; and the functional
is the losses metric in the case of IDS deployment.
Thus, the general goal is to solve the following problem:
In other words, this paper addressed the following issue: is it advisable to deploy an IDS with given parameters in a given environment?
This study also considered various problem statements related to (3). For example, if there is an opportunity to affect the environment, then it is reasonable to consider the following problem:
Here,
is a subset of
, depending on resource limits and service-level agreements. An alternative problem can be formulated as follows: This is example 1 of an equation:
where the function
describes the cost of recourses used, and
is the level of admissible losses.
The effective functioning of an IDS entails an increase in resource consumption. Therefore, the overall throughput of the system will be reduced if an IDS is actively used. The problem of IDS deployment is reduced to determining the set:
Taking tight budget constraints for IDS implementation into account, the problem can be formulated as follows:
where the function
provides a cost of IDS implementation, and
is the maximum allowable cost.
The choice of loss metrics mentioned above can be influenced by the system architecture, the service agreement, the goal of the researcher, the nature of the losses and how they are interpreted by the participants, and the details of the application. If we obtain a convex optimization problem, then the Lagrange multiplier method, which finds the local optima, can be used to find the global minimum of our problem. In general, we deal with non-convex optimization problems (see, for example, [
22]); that is, we often need to study the problem of minimizing a loss function over nonconvex sets. Moreover, the domain of a loss function can contain discrete subsets (the number of servers, the memory chip sizes, the number of features used for classification tasks). In these cases, stochastic optimization methods (simulated annealing, swarm algorithms, evolution strategies) can be preferable. Fortunately, in some practical cases, the loss metric is strictly monotonic and continuous. Thus, as will be seen below, a simple consequence of the Weierstrass extreme value theorem allows for the finding the optimal solution and derivation of a criterion, formulated in closed form, for IDS deployment.
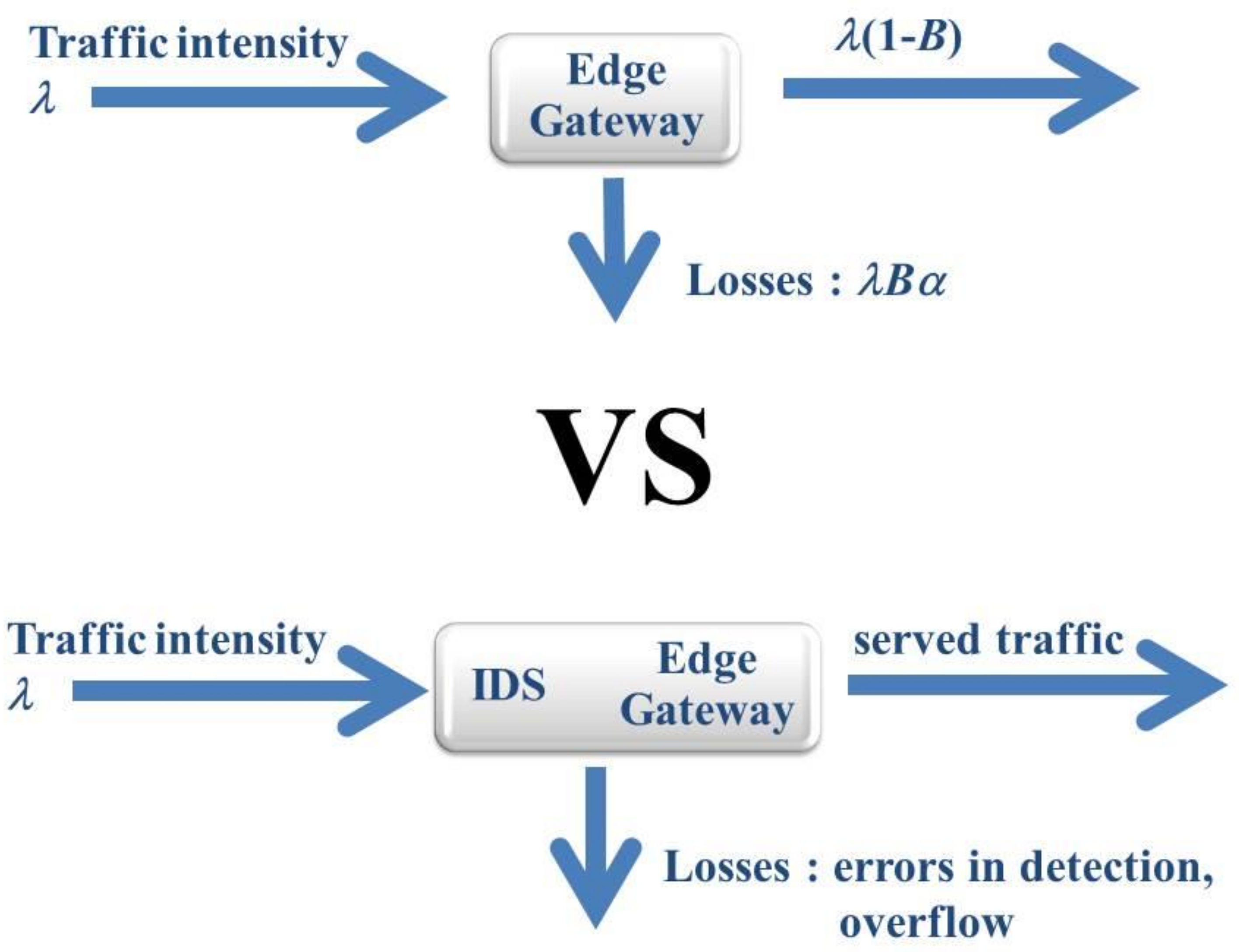
Consider some particular implementations of problem (3) using the features typical of wireless communications. In these assumptions, a set of IoT edge nodes serves a user-generated workload. The set includes traffic, which needs to be treated and retransmitted. Let us use the following designations:
λ: the traffic intensity;
μ: the intensity of the request treatment;
α: the percentage of the workload of legal users, which can be estimated using an observable sample or an auxiliary model; and
: the probability of packet/request rejection––the blocking probability.
Here, a situation with two types of users is considered. Legitimate users generate traffic with intensity
Therefore, malicious users generate traffic with the following intensity:
. Owing to limited resources of edge nodes, a part of the traffic does not receive service and is rejected. Generally, the blocking probability (
) is a function of
and
μ, (the losses rate) is
and the served workload rate is
Note that not all packets are useful. The actual loss rate of legal users is
Consider the edge nodes equipped by an IDS. It is reasonable to assume that part of the malicious requests will be rejected and the novel workload intensity
will be reduced (
On the other hand, it does not guarantee that the system throughput will improve. IoT devices need to perform additional operations for intrusion detection, system maintenance, and malicious request filtering. Therefore, the performance of the request treatment needs to be reduced, i.e., the novel intensity of the request treatment becomes
, and
A signature-based IDS can be used if the security system is designed to counteract a limited set of known attacks. In this case, the IDS uses a set of rules (signatures) that can detect the presence of an attack pattern. This provides a high level of accuracy for well-known intrusions. A signature-based IDS is usually characterized by low computational cost (
The same effect can be reached using a small number of secret bits for requests verification. On the other hand, this situation is not typical for IoT environments. Hands-on experience has shown that attackers often change their hacking tactics and develop new intrusion approaches and instruments. Signature-based detection does not detect slightly modified attacks; much less, it does not detect unknown attacks. Hence, advanced intrusion detection methods must be applied. Furthermore,
is not typical for the IoT considering the edge devices level [
23]. Low resources render heavy computation algorithms, such as deep learning, ineffective. Therefore, it is reasonable to assume that the performance of a requested treatment did not increase drastically. Moreover, some legitimate requests are mistakenly recognized as illegal and are filtered by an IDS.
The following section examines the cases where IDS deployment makes sense. These cases are formulated, and condition (6) is specified using mathematical modeling.
4. Criterion
A closed-form solution can be obtained for the inequality (18) in the case of a heavy workload.
Proposition. The IDS is justified if the following inequality is true: This inequality can be used to estimate and select the intrusion detection algorithms. For convenience, the inequality (39) can be rewritten as a ratio of the request treatment intensities:
It is often (but not always) expected that a way to improve the false-positive parameter entails the consequences of the proportional degradation of the false-negative parameter and vice versa. This is specific to IDS design. On the other hand, if the IDS quality is good enough, both
and
are small enough. Consider the following ratio:
If the IDS is of poor quality, the values of and will be in the vicinity of 1. Therefore, the ratio becomes large. If the IDS quality is good enough, then the ratio is around zero. Despite some uncertain intermedia cases, the ratio indicates the IDS quality. Thus, let us define the ratio in (41) as the “IDS Performance Index (IDS-PI)”. Generally, packets are processed individually by the IDS; hence, this value does not depend on the legal users’ packet proportion.
Consider a situation when the efficiency of applied intrusion detection algorithms is very high:
In this case, the criterion for the appropriateness of an IDS takes a simple form:
Please note that it is natural to accept that , hence .
The decision to deploy an IDS (or provide requirements for one) can be based on profitability analysis. Therefore, a criterion can take a set of various forms, such as “the IDS should improve the loss rate
k times”:
where
k is a desired constant. In this case, the inequality (18) takes the form
An alternative criterion could be: “An effect of IDS implementation is that it has to provide the desired loss threshold
h″:
Here, the requirements for system throughput are
The approximation above allows a closed-form solution for various similar cases of system profitability analysis. In addition, various solutions can be obtained for inverse problems. For example, if the system performance degradation (
due to IDS deployment is given, and it is necessary to define the conditions for one of the other parameters of IDS/environment, then
5. Performance Evaluation
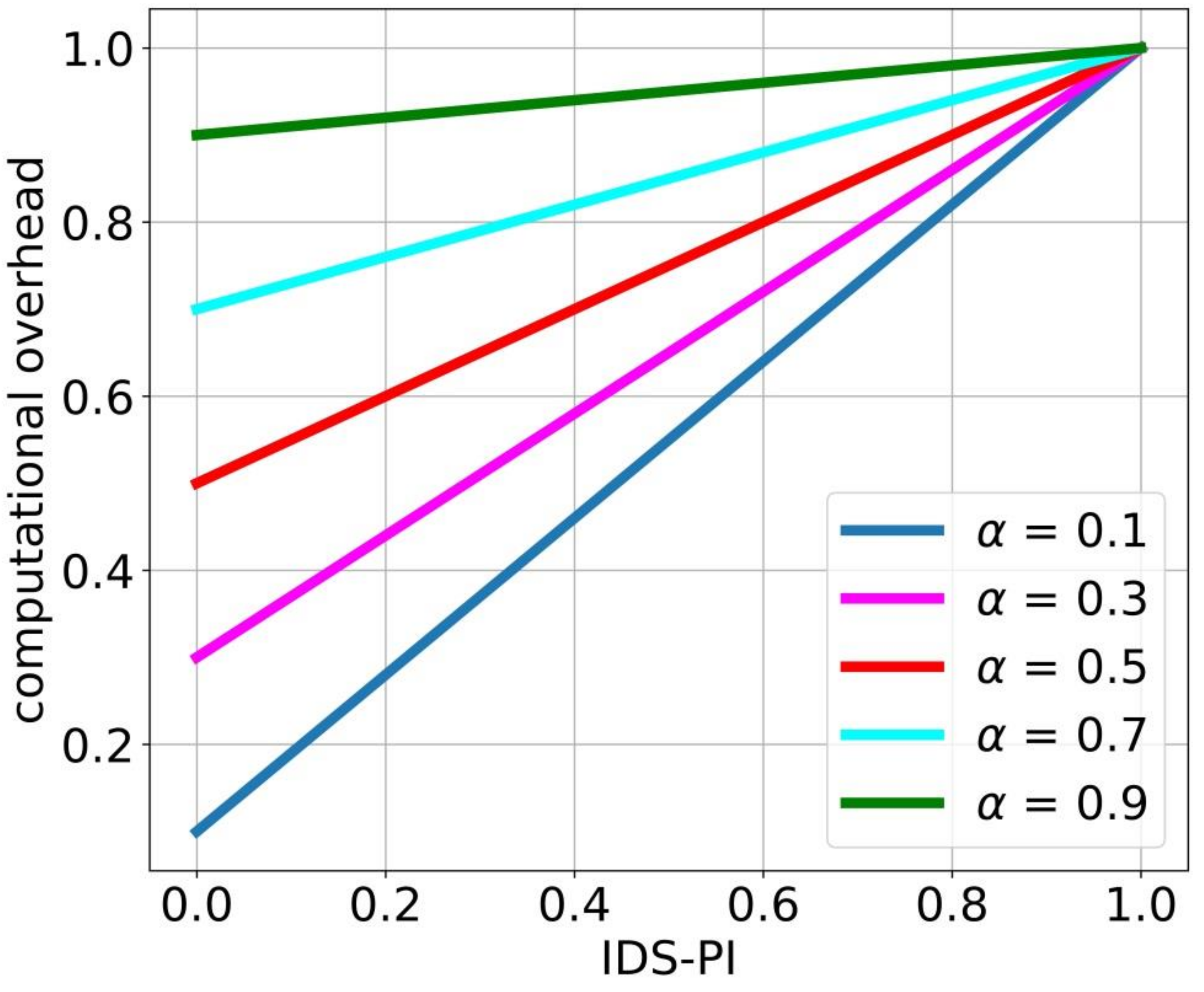
In this consideration, it can be assumed that IDS-PI varied in the range (0; 1). Actually, there was no reason for using intrusion detection algorithms with
or
. The following function can be useful for determining the trade-off between the admissible computational overhead and intrusion detection efficiency:
The function
provides a critical line separating the acceptable deceleration from the unacceptable one.
Figure 3 presents critical lines change according to the IDS throughput efficiency for
. In accordance with inequality (40), the IDS is justified if
Using this plot, we also obtained the IDS quality requirements.
Figure 3.
The computational overhead is acceptable if its value lies above the corresponding line.
Figure 3.
The computational overhead is acceptable if its value lies above the corresponding line.
If the alpha is high enough, the IDS mostly handles legitimate traffic and wastes resources. A small proportion of spoofed packets does not have a significant impact on the network node. In this situation, using such an IDS was justified because it did not slow down the operation of the node and detected almost all spoofed packets. The effect of a mediocre IDS is more like a DDoS attack. It is intuitively clear and shown in
Figure 3.
If the portion of legitimate requests is approximately 10 percent, and the IDS leads to a 50 percent decrease in node performance, an IDS-PI of about 0.3 is allowed. This is a very mediocre IDS. In the next example, if the portion of legitimate requests is approximately 90 percent and there is only 15 percent degradation of node throughput, then there are no reasons to use even an ideal ID with no mistakes in algorithm detection (zero false positives and false negatives).
The suitability of α as a threshold for degradation in node performance was previously noted. Taking into account the inequality (43), we concluded that the throughput of the edge node equipped with IDS could be reduced by less than
times; that is,
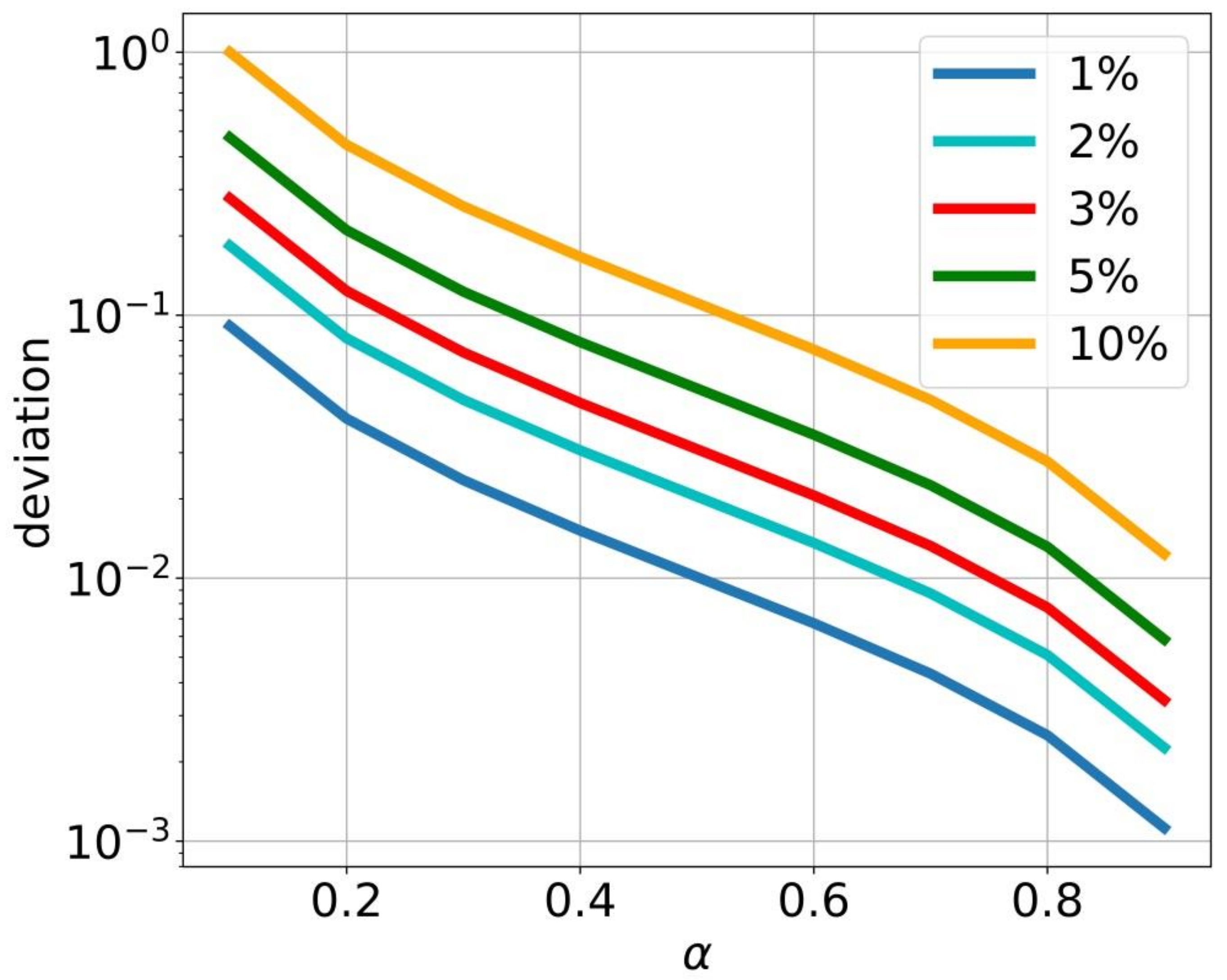
This threshold needed to be applied carefully and in a balanced manner. The quality of this approach depends on the quality of the intrusion detection algorithm used. Let us illustrate this proposition. Consider the following value:
Assume that the false positive and false negative values are small enough. Here, without a loss of generality, .
If the quality of the intrusion detection algorithm used is very high (the error is approximately one percent or less), then
α can be taken as a threshold for reducing the node performance due to the IDS operation. This would not be true if the values
and
exceeded 2 percent, even though this would still be a good enough intrusion detection algorithm. As the quality of intrusion detection algorithms decreases, the second term in formula (51) becomes comparable to
.
Figure 4 illustrates this point.
As a final remark, the false positive and false negative values of recently presented energy-efficient IDS reached 5% (see, for example, [
28]). Assume that the admissible system performance degradation is limited to 10%. It would be advisable to activate the IDS if the proportion of spoofed packages exceeded 15%; otherwise it would be inappropriate.



{kind=link}
{kind=link}
{kind=link}
{kind=link}



