3.2.1. Sensor Placement
- a.
POD results
From the POD analysis, 2249 modes were obtained.
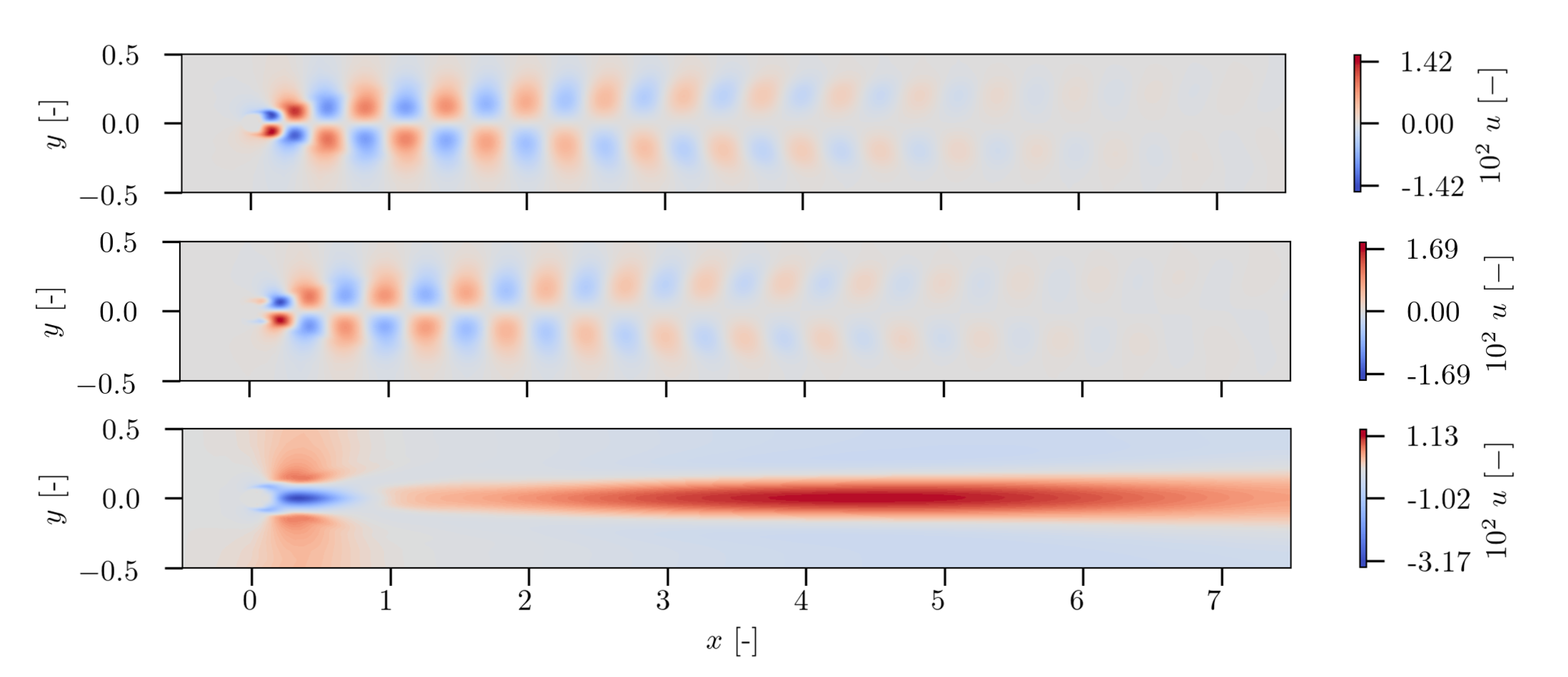
Figure 19 shows the flow characteristics governed by three distinct POD modes: mode 1, mode 5 and mode 15. The lower POD modes capture the large scale flow structures. The higher the POD modes, the smaller the scale of the flow structures. The 1st POD mode captures the large flow dynamics at the beginning of the wake recovery at
. This POD mode also indicates the development of vortex structures due to ground interactions of the flow at
. POD mode 5 shows more detailed patterns. The flow dynamics of detached vortices near the ground at
is clearly shown. More downstream, a clearly visible mixing of the flow is present. The presence of the bade tip vortices as well as the wake of the wind turbine hub are slightly visible in POD mode 15. In the near ground region, the interaction of the blade tip vortices with the ground boundary layer and the sheared inflow, respectively, can be seen. It can be noticed that the vortex structures in the ground area increase more downstream. The beginning of the wake recovery at
is also captured. Higher POD modes, corresponding to low eigenvalues, only capture some small scale dynamics. At POD mode 500, for instance, high resolution correlation structures in the turbine hub wake and in the upper region of the wake recovery are present.
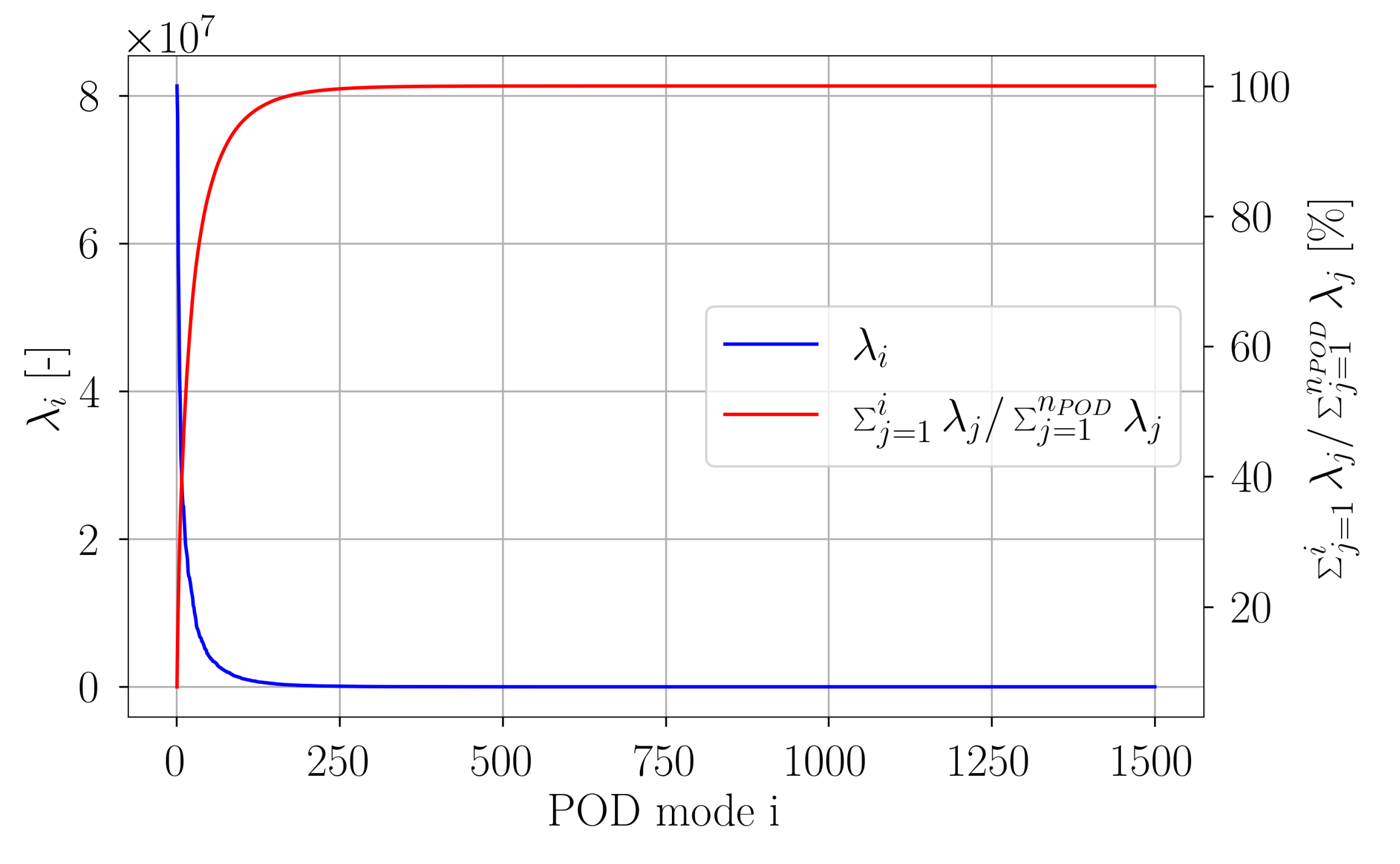
In
Figure 20, the value of each eigenvalue is depicted. The accumulated fluctuation kinetic energy portion of the first
i POD modes relative to the total fluctuating kinetic energy is shown. It can be clearly seen that the main portion of the fluctuation kinetic energy of the flow is captured by only approximately 10% of the POD modes. More detailed, around 90% of the fluctuation kinetic energy is captured by the first 22 POD modes, around 99% is captured by the first 198 POD modes. As observed in the case of the flow around a cylinder, the higher POD modes contribute no significant amount of fluctuation kinetic energy to the total amount.
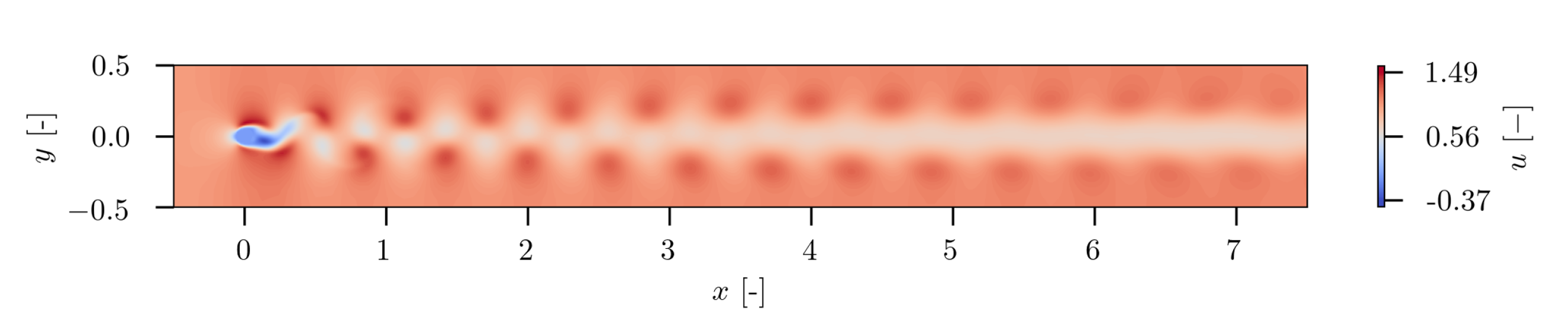
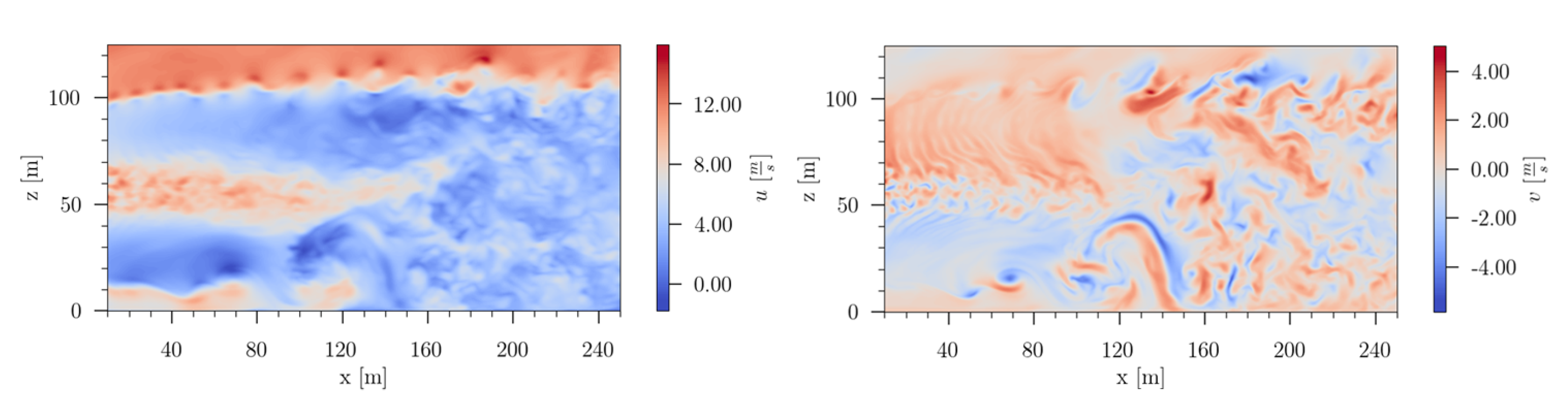
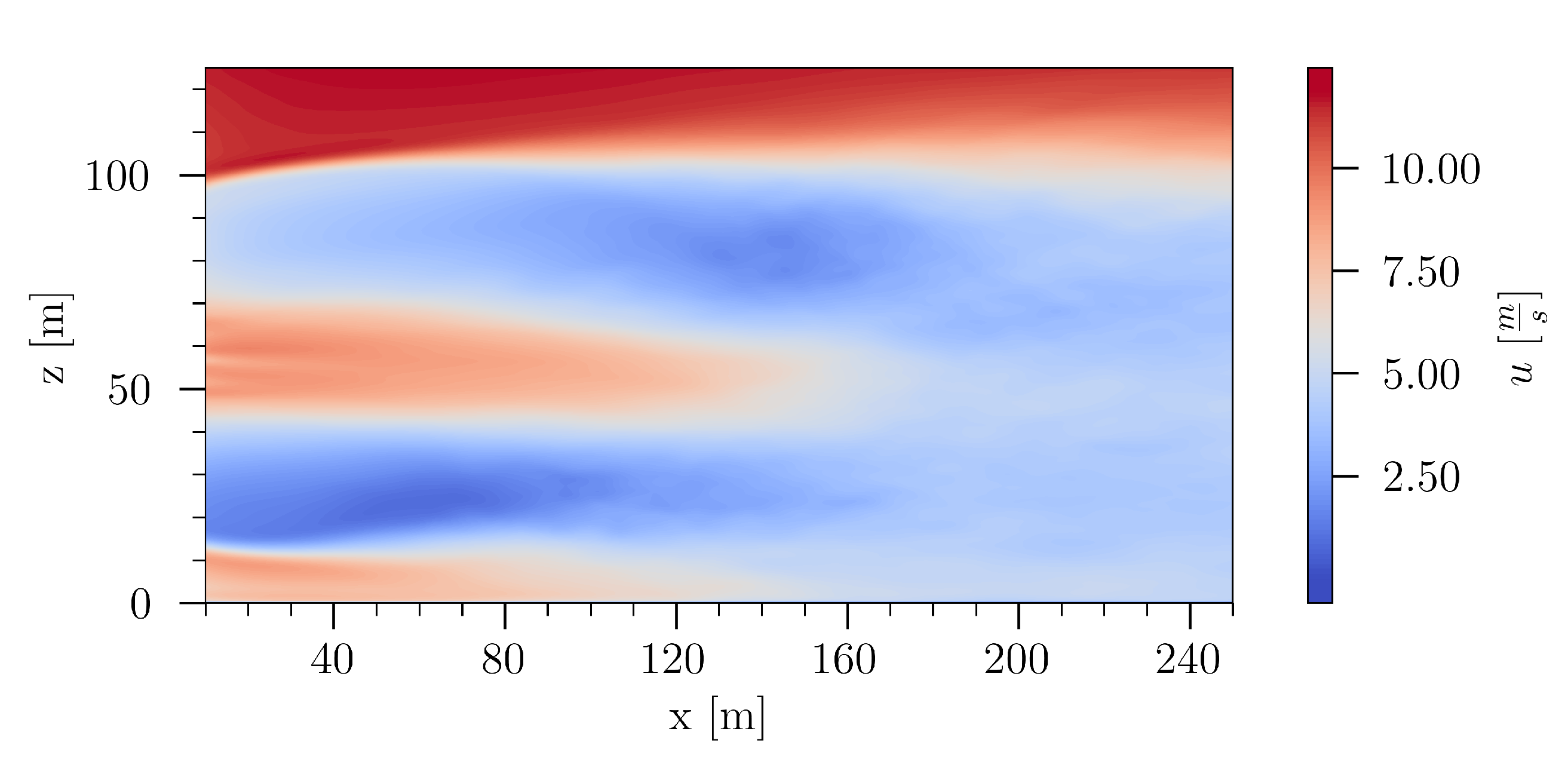
Considering the mean velocity field in
Figure 21, some time averaged properties of the wake are revealed. The contour plot of
u shows a clear delimitation between the unperturbed flow and the wake of the wind turbine. A distinct velocity deficit of the flow, which interacts with the rotor blades, is present. The wake of the turbine hub reduces more downstream and vanishes in the wake recovery region. In the lower region of the wake, the interaction of the blade tip vortices with the sheared velocity profile leads to instabilities more upstream than in the upper region of the wake, where the blade tip vortices evolve in a more delimited area. Approximately one rotor diameter downstream the wind turbine, the wake recovery is clearly visible. Highly turbulent structures lead to a significant mixing of the flow.
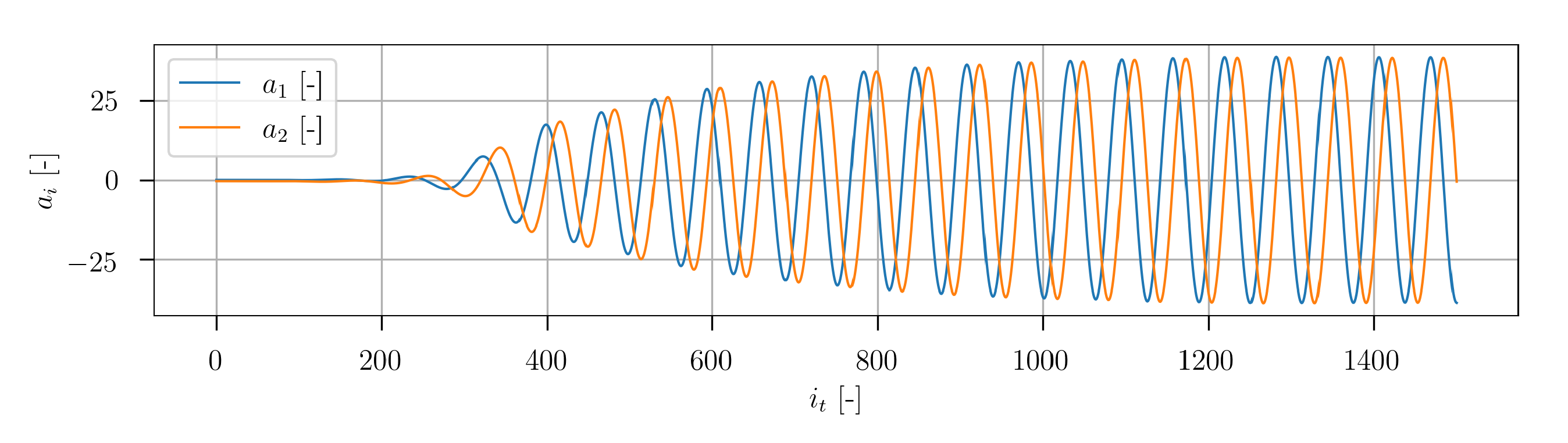
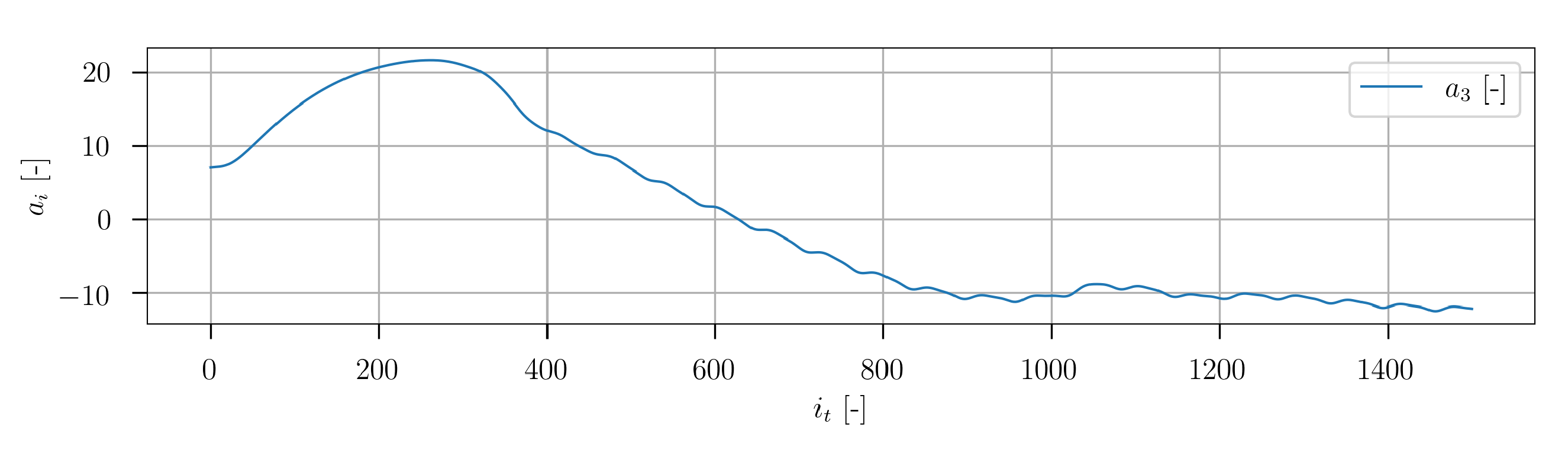
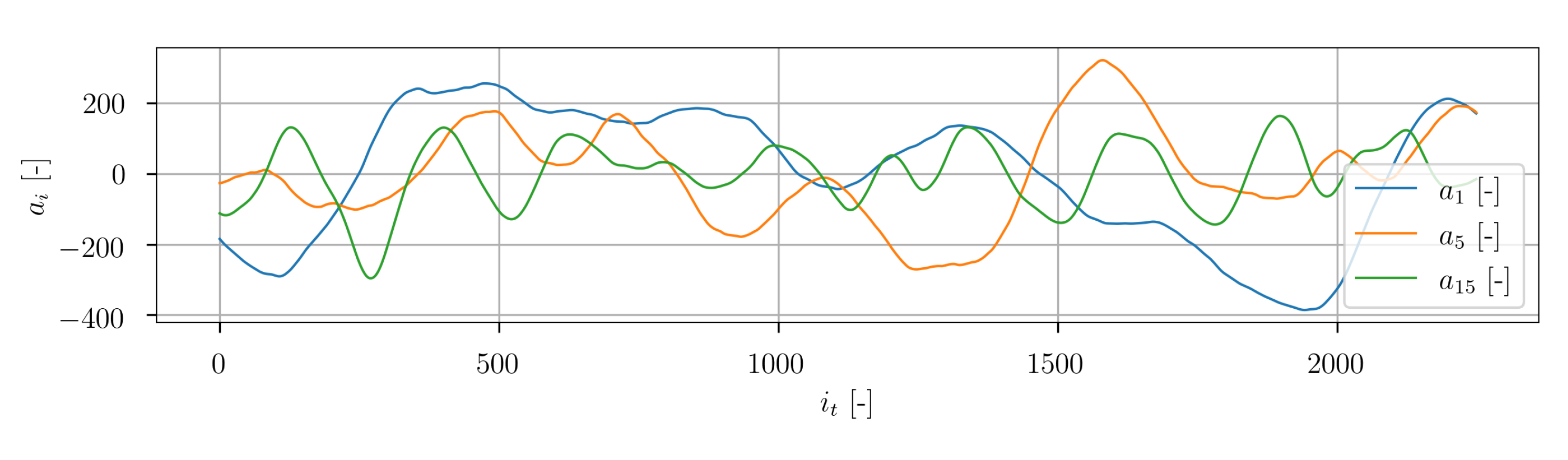
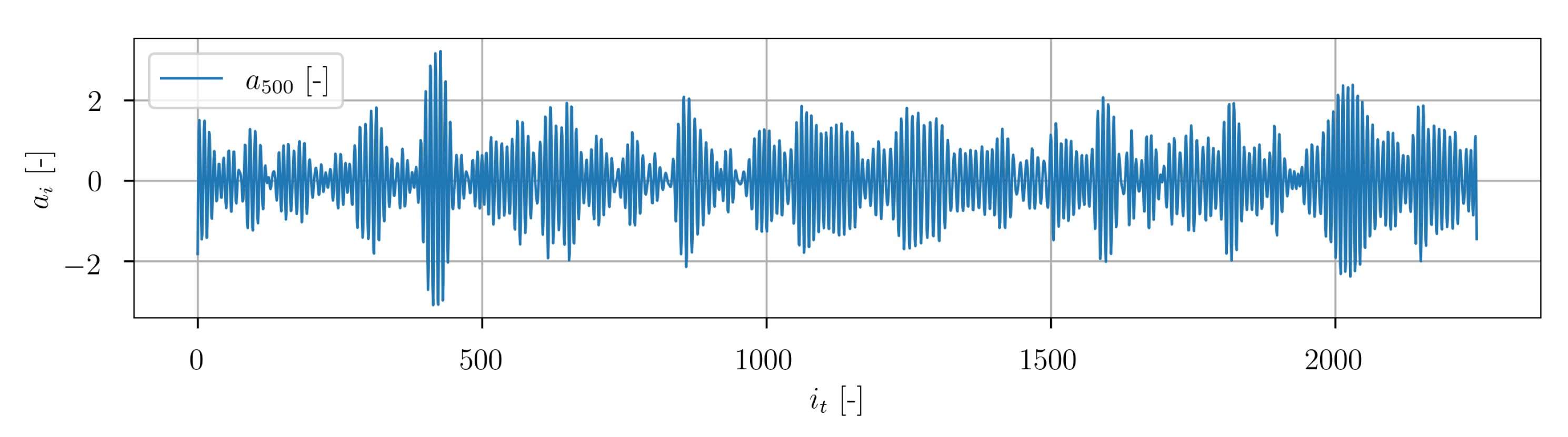
In
Figure 22 the temporal developments of the POD coefficients of mode 1, 5 and 15 are depicted. A very transient character is clearly visible. The representative of higher POD modes is plotted in
Figure 23. The signal exhibits significantly higher frequencies. In general, the temporal progression of the POD coefficients shows no obvious regular macroscopic patterns.
The results obtained from the POD reveal a significantly higher complexity of the dataset compared to the cylinder flow dataset. Different POD modes capture flow characteristics over a wide range of spatial resolution. This corresponds to the different turbulence length scales of the high resolution turbulent flow data. The temporal POD coefficients show no obvious regular patterns in their temporal progressions.
- b.
Clustering and reduced order modeling
- b.1
Based on k-means clustering
In this section, sparse sensor placement results based on the classification approach are presented. The adopted approach is similar to what has been done for the cylinder case in
Section 3.1.1. Four different settings were tested according to
Table 2.
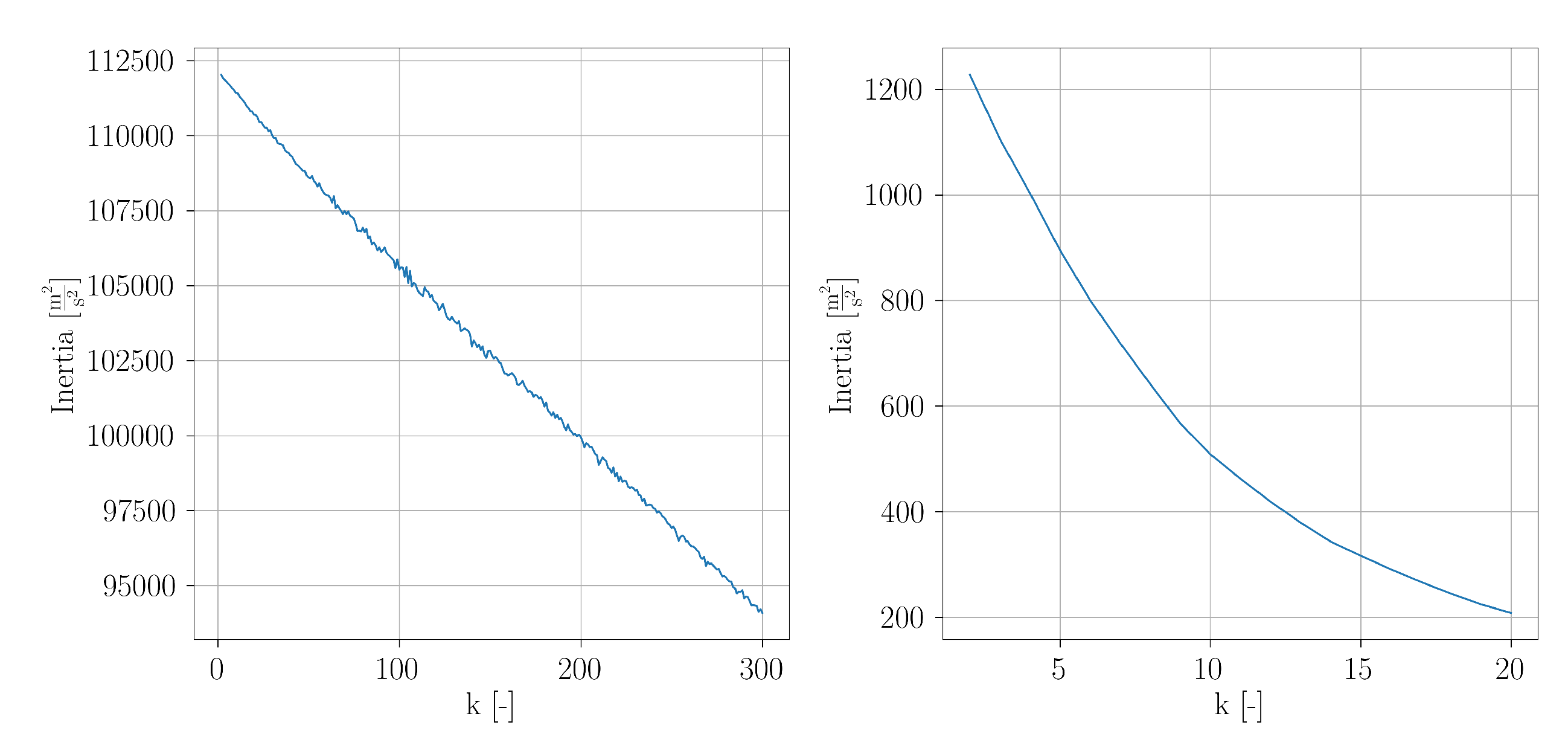
For setup 1, the inertia values obtained from
k-means clustering are shown in
Figure 24. It is clearly visible, that the curve exhibits no ‘elbow’. This can be caused by several reasons. The POD was conducted in the 2249-dimensional POD subspace and it is possible that the dimensionality is too high so that the distance metric of the
k-means clustering becomes ineffective. This problem can be related to the curse of dimensionality (firstly introduced by Bellman [
55]). It is also possible that an appropriate clustering can be achieved for a very high value of
k, but it seems unlikely. A further possibility is the lack of enough snapshot data, i.e., not enough statistical information are available. Since, in this context a small
k is desired, for setup 1, no reasonable results are obtained.
For setup 2, the plot of inertia over
k is shown in
Figure 24. With increasing
k, it can be seen that the slope of the curve flattens. A slight elbow can be seen. In
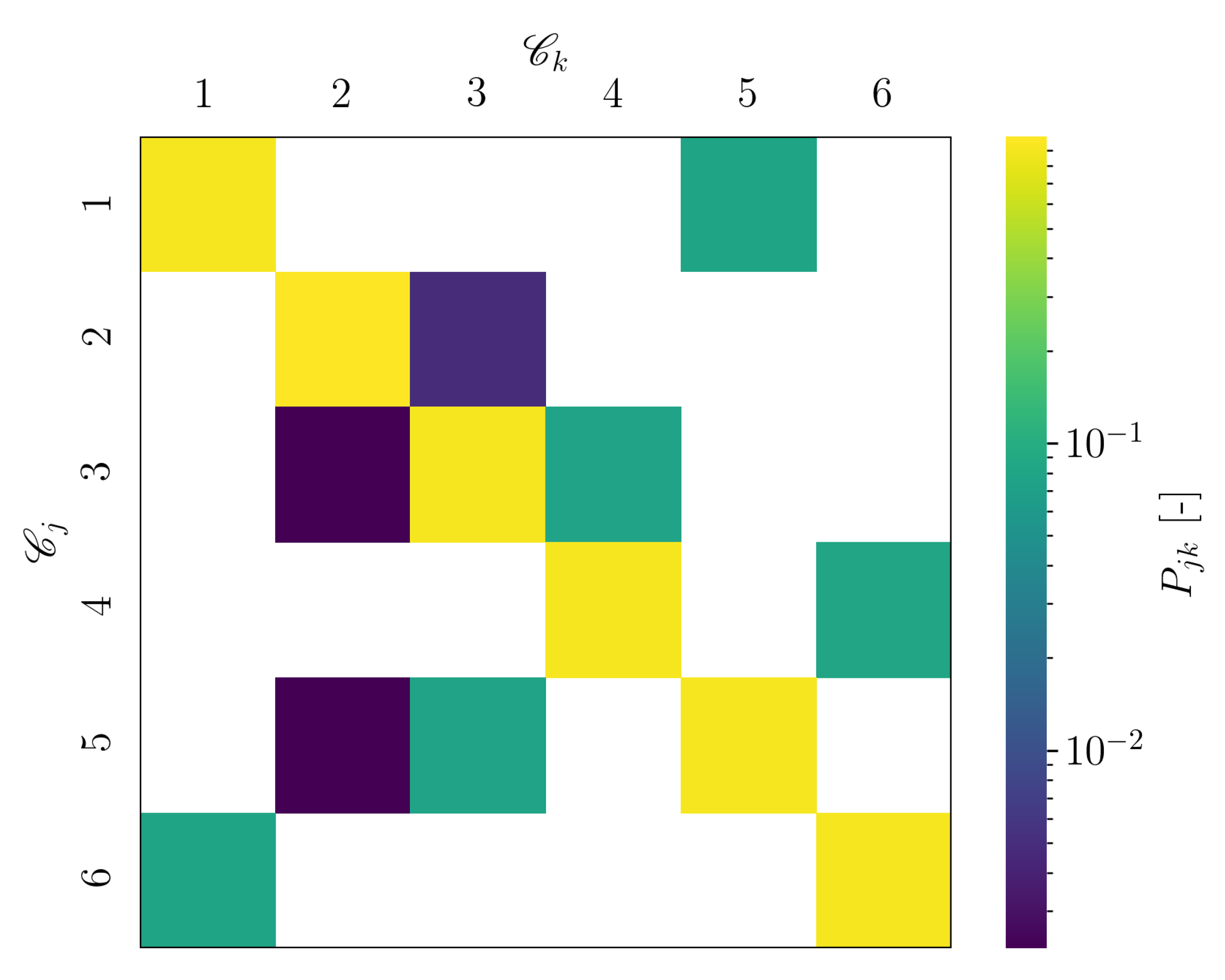
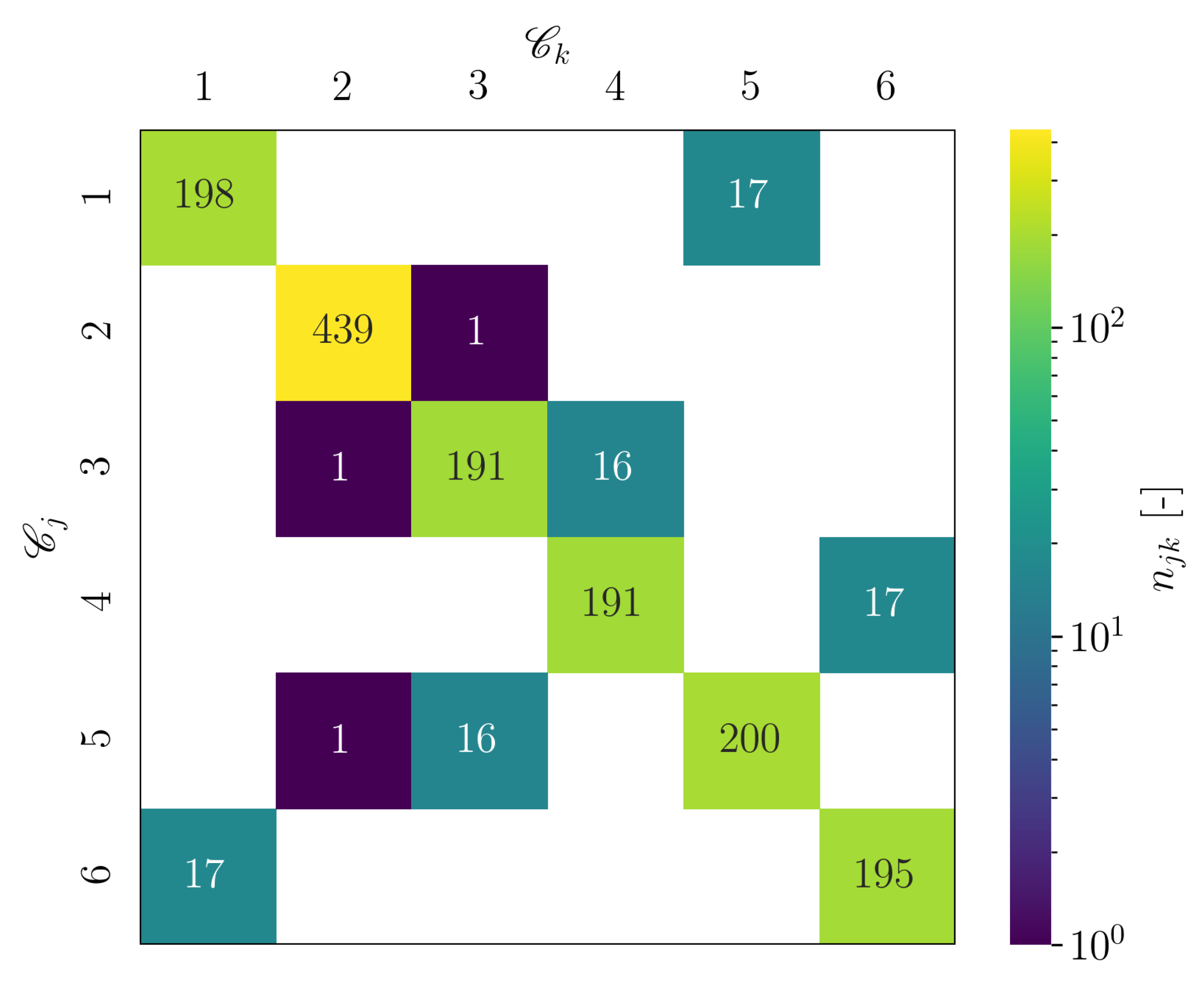
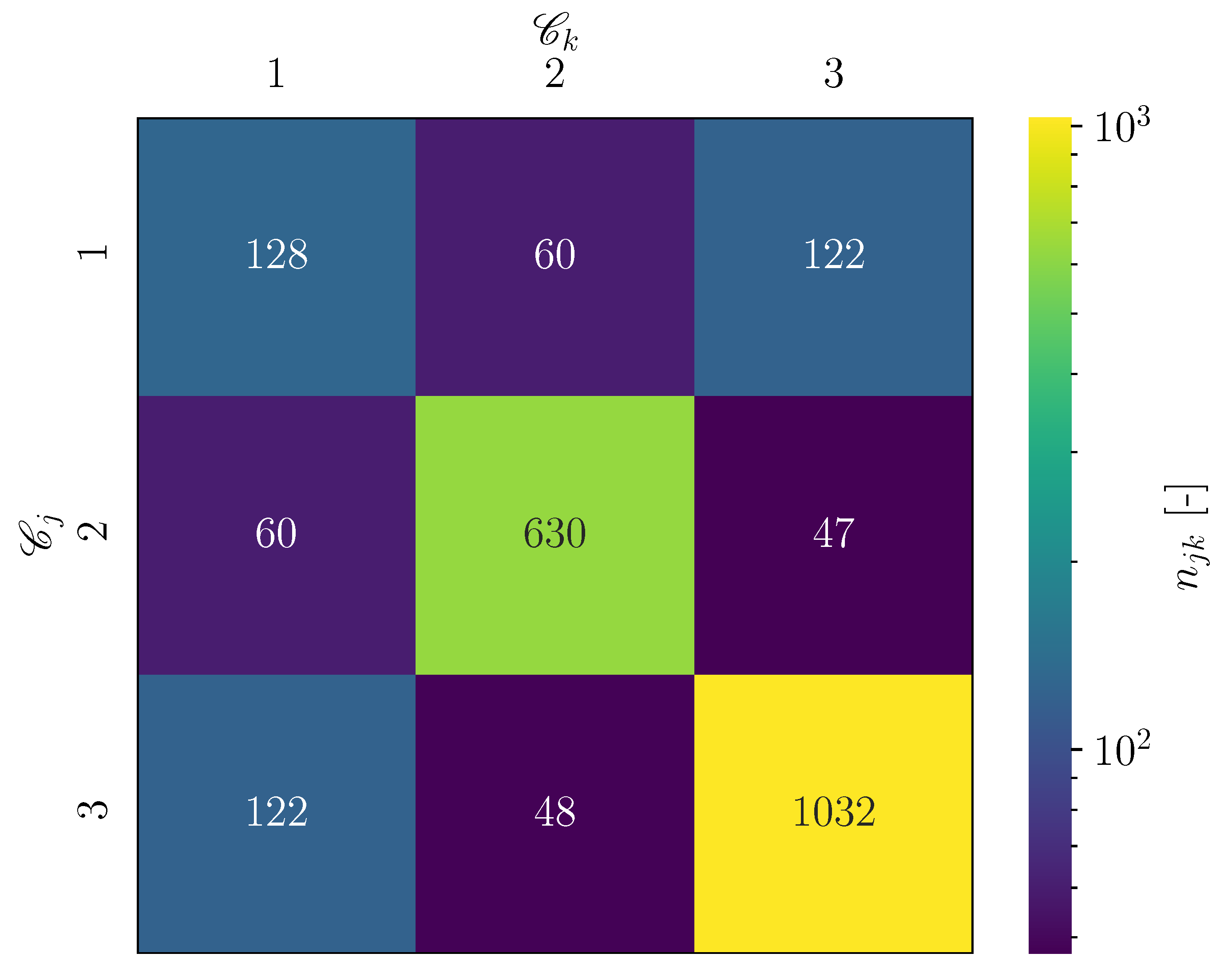
Figure 25, a visualization of the number of cluster transitions is given. The main diagonal entries show the number of transitions, for which the assigned cluster remains the same. The off-diagonal entries show the number of transitions, which occur between two different clusters. It can be seen that each transition between two different clusters only occurred once and twice, respectively. In contrast to the estimated dynamical system for the cylinder flow dataset, the estimated dynamical model of the wind turbine case corresponds rather to a chain. Hence, considering the complexity of the flow, the obtained reduced order model is likely not suitable for a subsequent application of SSPOC.
The inertia over k plots for setup 3 and setup 4 also indicate the presence of elbow (not presented in this paper). Similar to what has been observed for setup 2, all off-diagonal entries unequal zero showed solely the value one for the counted cluster transitions. Hence, again the dynamical models are rather similar to a transition chain. In this sense, the estimated reduced order models are also not suitable for a subsequent application of SSPOC.
A reasonable clustering of the snapshot data is necessary as a preliminary step before applying SSPOC since this technique requires labeled snapshot data. For setup 1 which considers all POD modes, the corresponding curve of the inertia over
k shows no elbow. Based on the assumption that the
k-means metric possibly will be more effective in case of a lower dimensionality of the POD subspace, only the first
r POD modes were considered in setup 2–4 (and consequently only a part of the total fluctuating kinetic energy) in
Table 2 to investigate the influence of the POD subspace dimensionality on the clustering results. Since no improvements were achieved for these setups, it can be depicted that considering even more POD modes (and consequently an even higher amount of fluctuating kinetic energy) will not lead to better results because this further increases the dimensionality of the corresponding POD subspace.
Furthermore, it was also attempted to reduce the dimensionality of the state space by means of spatial subsampling. For different values of subsampling factor, further evaluation was applied to the snapshot dataset. The POD was applied to the reduced dataset and subsequently k-means clustering was conducted for different values of k. The obtained plots of inertia over k indicate a constant descend of the curve for each subsampling factor. Hence, it was not possible to estimate a reasonable value of k.
- b.2
Based on hierarchical agglomerative clustering
Since the standard
k-means clustering is not suitable for the complex wind turbine case, the suitability of the hierarchical agglomerative clustering (HAC) was also tested. For each
, a HAC and subsequent estimation of the silhouette coefficients was evaluated. For this, the
AgglomerativeClustering and
silhouette_score implementation by
scikit-learn [
43] were chosen. The Euclidean distance was used for computing the linkage distance. A minimization of merged clusters variance was adopted as the linkage criterion.
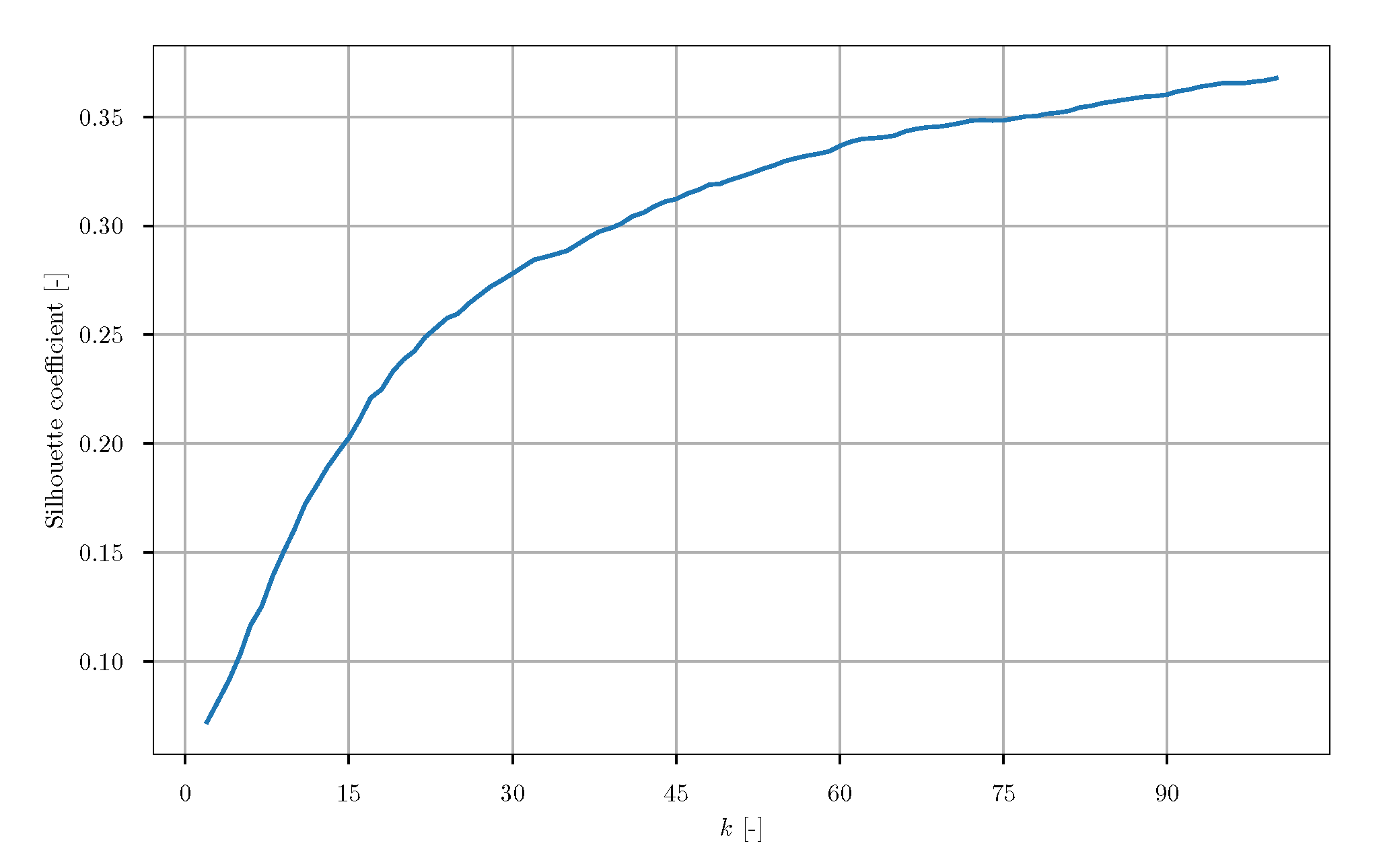
For increasing values of
k, the silhouette coefficients (also known as overall average silhouette width) were estimated (
Figure 26). It seems like the curve converges against an asymptotic value. Either a local maximum is located at a higher value of
k or the maximum silhouette coefficient occurs at
, i.e., each snapshot is estimated as separate cluster comprising only one observation. In case of an optimal clustering, it is expected that the obtained curve exhibits a local maximum. However, this is not observed here. Instead, the silhouette plots of each
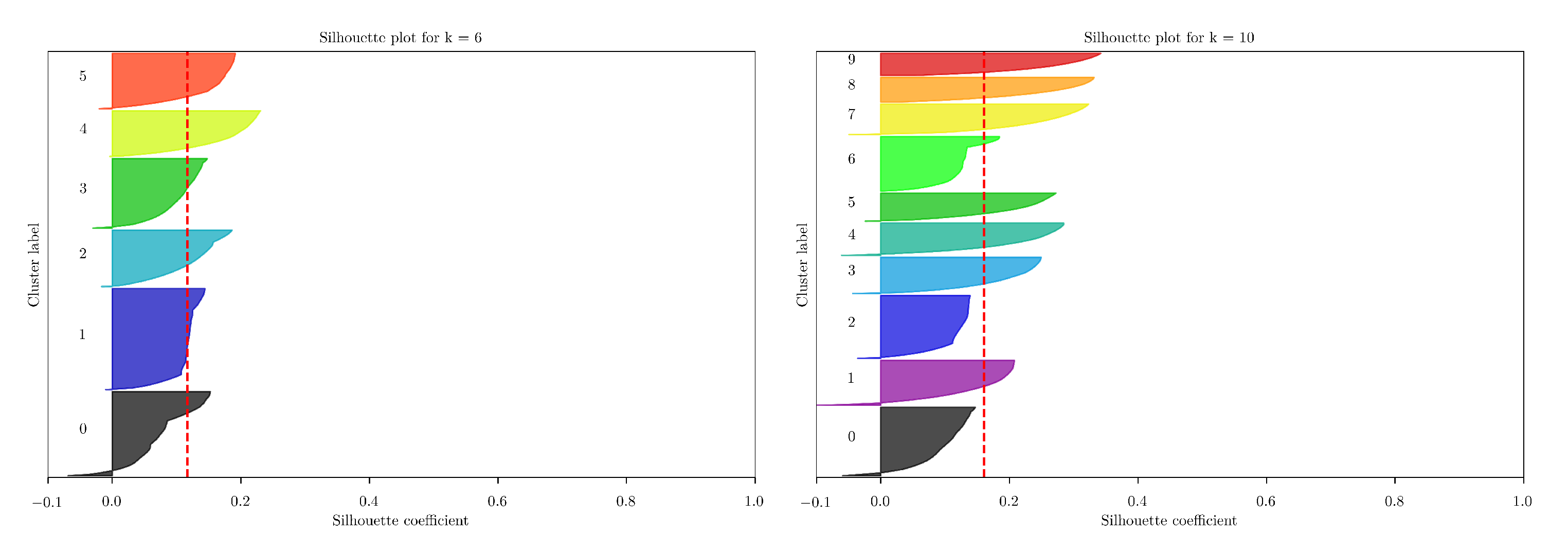
k are visually evaluated. For example, in
Figure 27 the silhouette plot for
is shown. Each silhouette shows a narrow contour. This shows that in each cluster only a part of the points is clustered appropriately. It can be further seen that the silhouette coefficients do not exceed a value of around
. Ideally, the values are close to one. The red line denotes the overall averaged silhouette width. The given contour plot shows that no reasonable clustering of the snapshots can be estimated. Similar observations can be made for
as depicted in
Figure 27. The silhouette plots for the remaining values of
k are of similar patterns. Hence, no reasonable results were obtained. Therefore, this method is not suggested for further evaluating the complex wind turbine case.
- b.3
Based on Gaussian mixture model
The main weaknesses of
k-means are the necessity of circular clusters and the lack of probabilistic cluster assignment [
56]. To overcome these issues, the Gaussian mixture model (GMM) was considered. Different settings were considered as listed in
Table 8. Three different numbers of considered POD modes were used:
POD modes (no truncation),
POD modes and
POD modes, which correspond to
, ≈90.0% and ≈99.0% captured fluctuation kinetic energy, respectively. For each
r, both cases of raw and normalized snapshot data were taken into account.
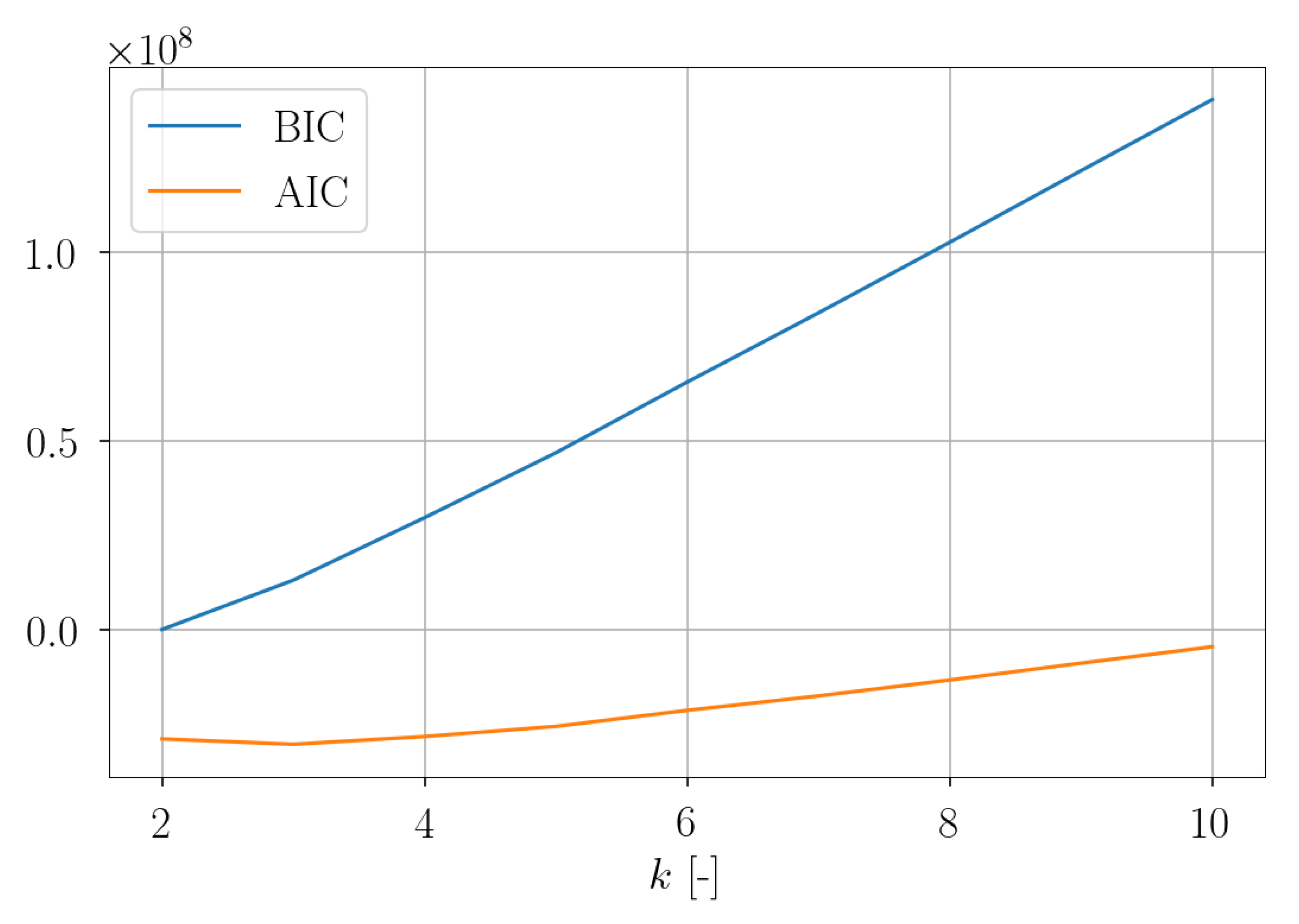
For the 1st setup, the obtained values for the Akaike information criterion (AIC) and the Bayesian information criterion (BIC) are shown in
Figure 28. It can be seen that both raise for increasing values of the number of clusters
k. To be exact, in the context of GMMs
k denotes the number of used Gaussian probability distributions in the POD subspace, not the number of clusters. It is desired to minimize the AIC and BIC. For the AIC, a local minimum was estimated for
. Here again, the number of transitions from cluster
to cluster
were estimated. The corresponding heatmap (not shown here) indicates the off-diagonal entries only values of zero, one and two. Hence, as argued for the
k-means clustering, no suitable dynamic model was also obtained here. The inertia over
k has a monotone decreasing progression. Consequently, it is not suitable for applying the elbow method.
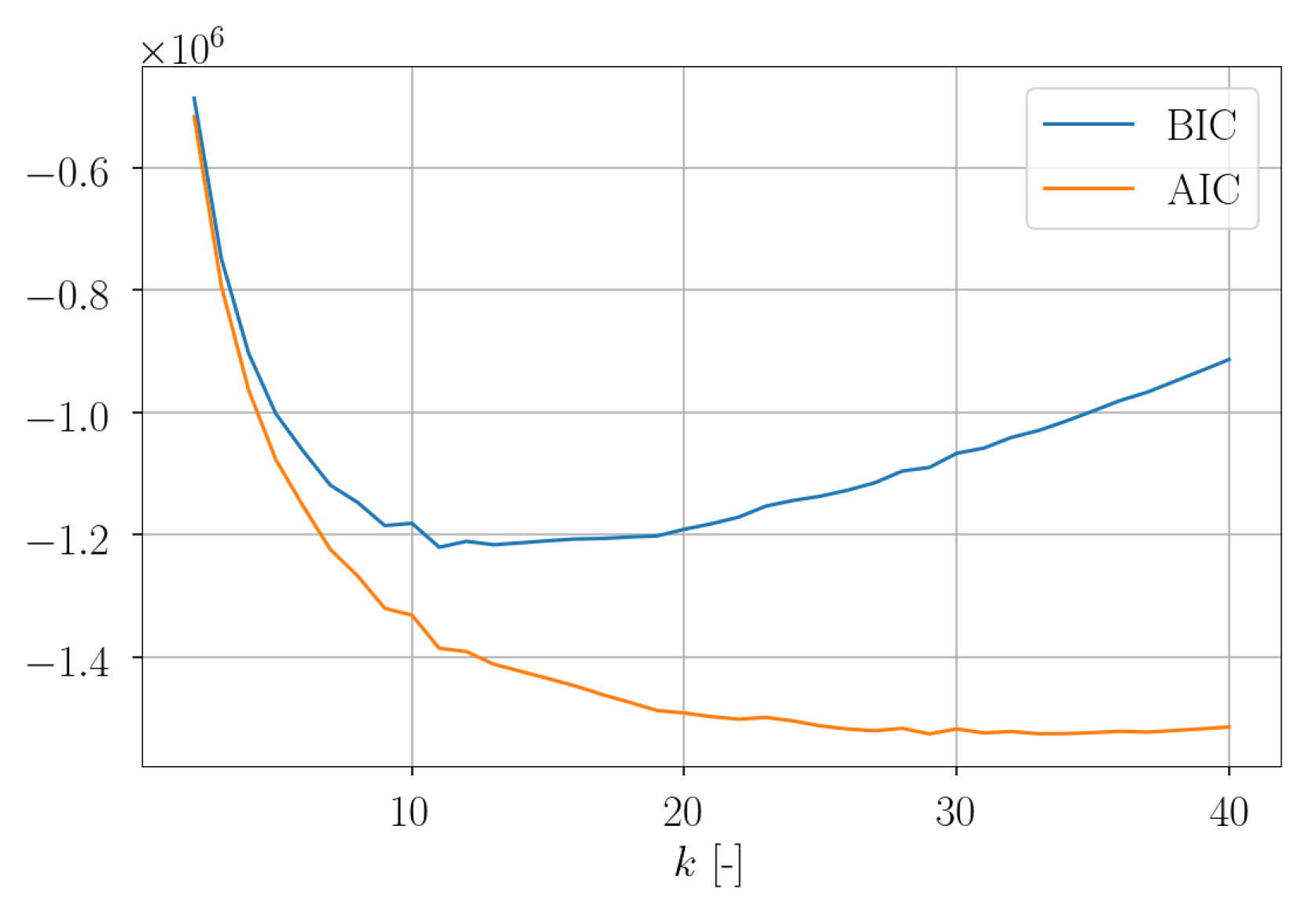
For the 2nd setup, the plot of the AIC and BIC over
k show a similar progression. Also here, for the AIC a local minimum was estimated for
. Interestingly, the estimated CTM was not sparse. In
Figure 29, an equivalent visualization of the number of transitions from cluster
to cluster
is given. For a further evaluation of the obtained results, the progression of the assigned cluster over
was considered. As can be seen in
Figure 30, the temporal progression shows a rather random character, indicating that the clustering leads to no reasonable partition of the POD subspace. Furthermore, it seems unlikely that the highly complex flow around a wind turbine can be properly represented by means of a reduced order model containing only three states.
Since no reasonable results were obtained also for the remaining setups (3–6), in the following only the relevant information is summarized. For the 3rd setup, a local minimum of the BIC at
was estimated. The obtained CTM shows the same structure as for setup 1. As depicted in
Figure 31, a local minimum of the BIC was estimated at
. Again, the CROM approach led to no useful results. In the case of setup 5 and 6, a local minimum of the BIC was estimated at
and
, respectively. However, no meaningful reduced order model of the snapshot data was obtained.
In summary, for the wind turbine data set, the pursued approaches of CROM in combination with SSPOC provide to no reasonable results. It can be seen that the high complexity of the wind turbine data set makes it is very difficult to estimate a low-order model representation of the flow field without significant loss of information. These findings coincide with the studies of D’Agostino et al. [
24] for a four-bladed propeller wake. They applied
k-means clustering to the phase-locked vorticity snapshots of a four-bladed propeller wake. Considering the entire wake (near- and far-wake), reasonable clustering results were achieved. Taking only the very near wake into account, no reasonable clustering results were obtained, which means that a single cluster was estimated as optimum snapshot partitioning. The results of the present work are inline with the results obtained in [
24]. This indicates that clustering of snapshot flow data is in general only reasonable for macroscopic flow structures.
- c.
Sensor placement based on reconstruction
- c.1
Variation of number of basis modes
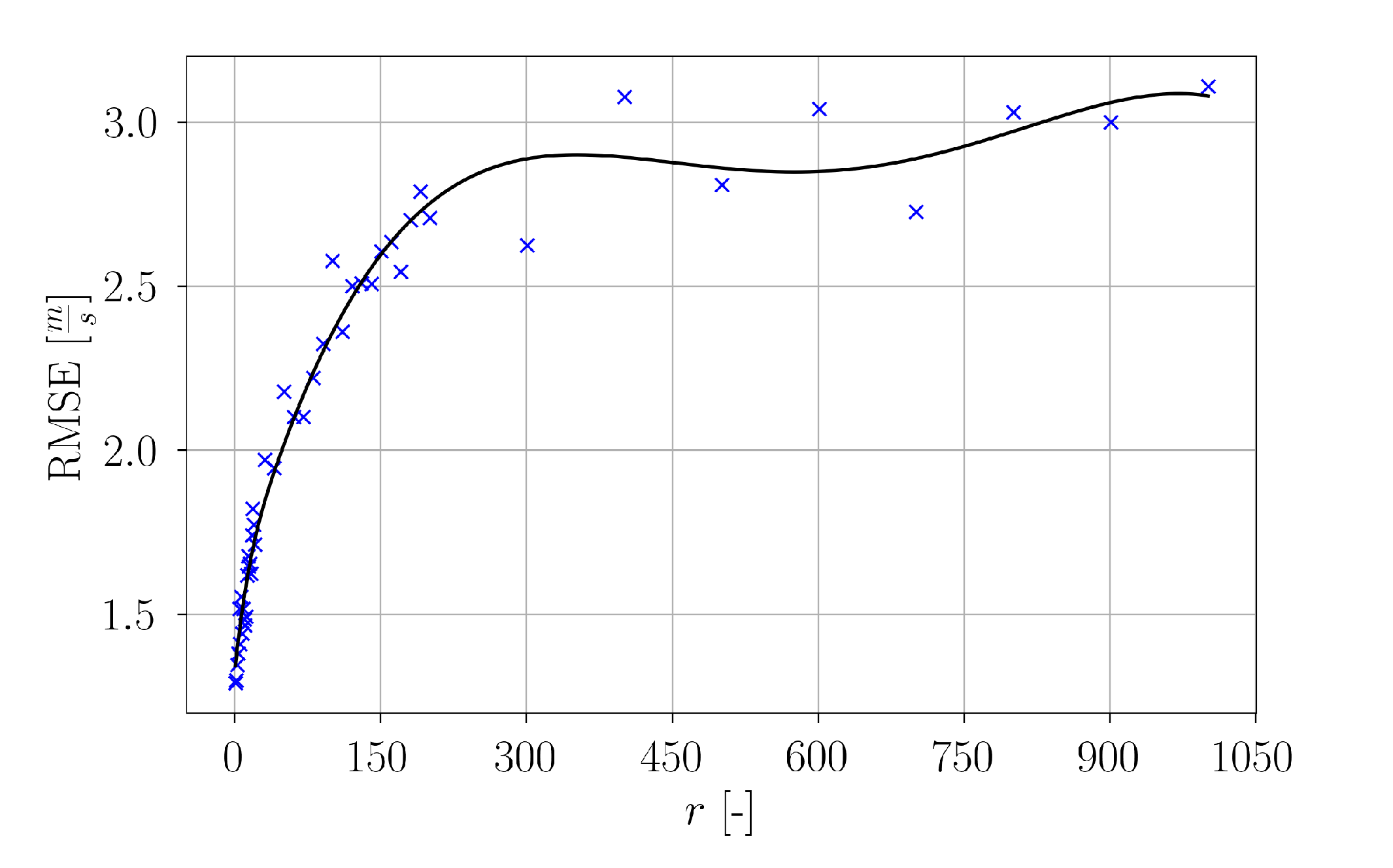
The estimated reconstruction errors of all setups are summarized in
Figure 32. The computed reconstruction error values for each
r are depicted as blue crosses. The data points were interpolated by means of a spline of fourth order. In the range of
, a steep increase of the reconstruction error can be observed. However, for higher values of
r the curve flattens. One might assume that the reconstruction error for low values of
r will be higher, since fewer flow characteristics will be captured and consequently the reconstruction will be less accurate. Consequently, the reconstruction error will decrease for higher
r. However, here the opposite is observed. By increasing the number of basis modes for snapshot representation, the reconstruction error rises and seems to approach an asymptotic value for very high
r. This is caused by the fact that for low
r, the small scale flow structures are not captured for reconstruction. Consequently, the true values fluctuate around a rather steady progression of the predicted values. In the case of higher
r, also small scale flow structures are reconstructed. Hence, both the true and the predicted signal exhibit a higher degree of fluctuation, which partially increases the difference between true signals and predictions. As mentioned in the POD analysis, around 99% of the fluctuation kinetic energy is captured by the first
POD modes. This value coincides with the range of
r in which the curve flattens. Therefore, for 198 employed sensors, reconstructions of the snapshot data can be made without a significant loss of information.
- c.2
Estimation of the smallest possible set of sensors
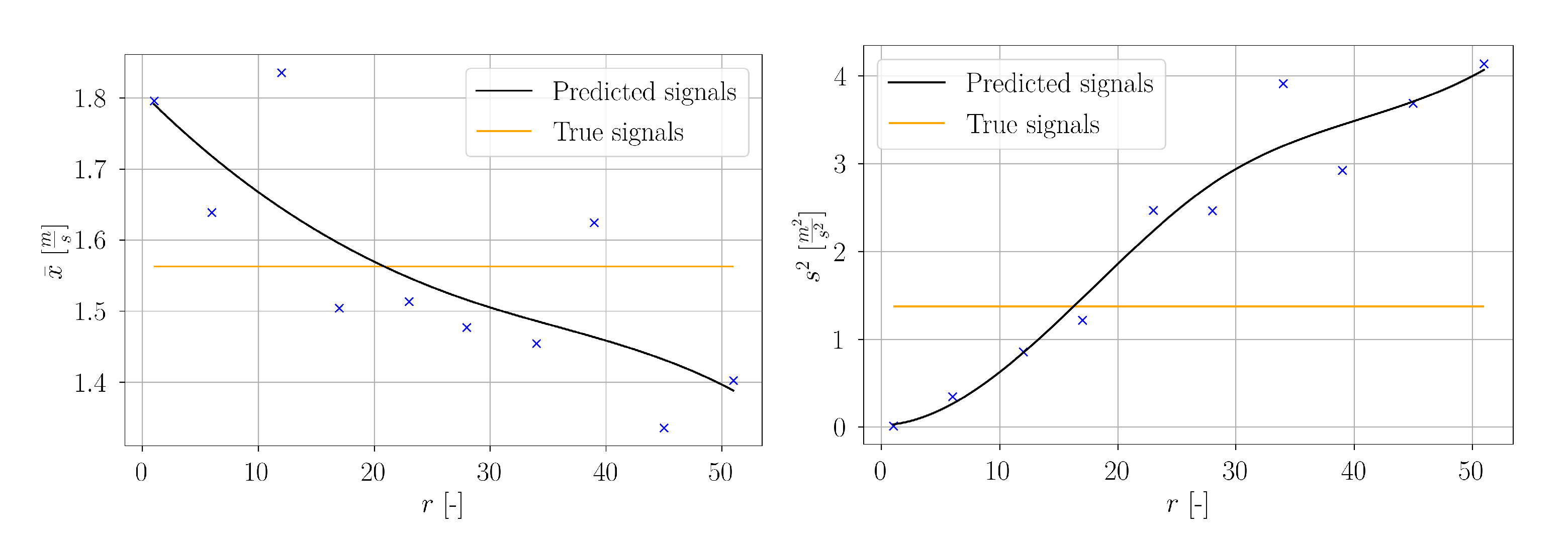
In the context of this work, a minimum number of sensors is desired. Consequently, is considered as too high. For estimation of an appropriate value of , in the following, another approach was pursued. At discrete spatial locations, predicted and true signals were evaluated for different values of r to achieve a maximum possible agreement of the statistical properties with the true signals.
At first, the signal mean averaged over all measurement points and all velocity components according to Equations (
11) and (
17) for true and predicted signals, respectively, were considered. In
Figure 33, the estimated values are denoted as blue crosses. An interpolation curve was estimated by means of a cubic spline. For low values of
r, the total mean of the predictions is higher than for the true signals. At around
they are equal and for higher
r the prediction mean is lower than the true one. Furthermore, the signal variance averaged over all measurement points and all velocity components according to Equations (
14) and (
20) for true and predicted signals, respectively, were also considered. It is clearly visible that an increase of
r goes hand in hand with a higher variance of the predictions. At
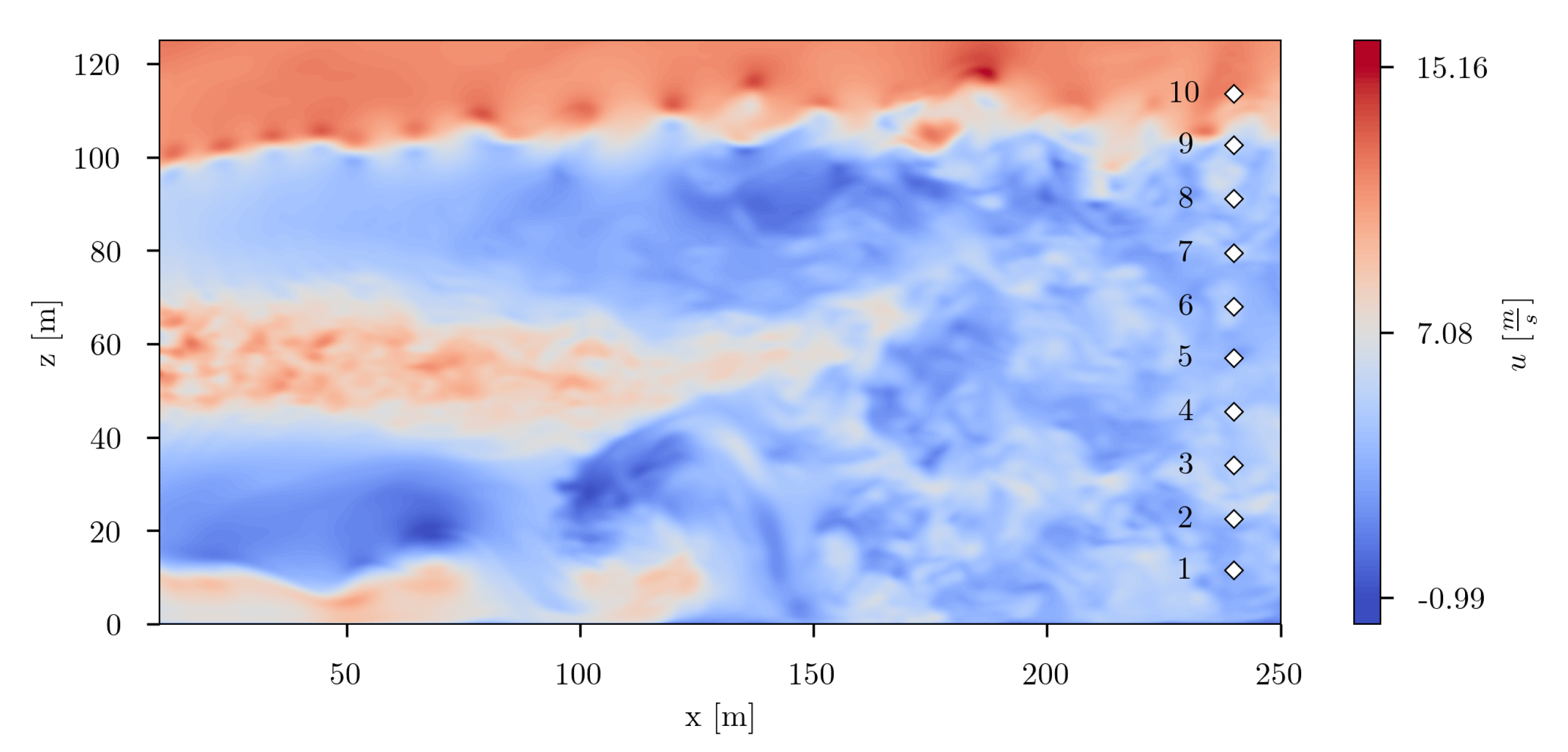
the overall variance of the predictions equals the true test data variance. From this basis, a number of 20 sensors was selected as an appropriate value. The estimated sensor locations were used for further studies.
- c.3
Final sensor placement
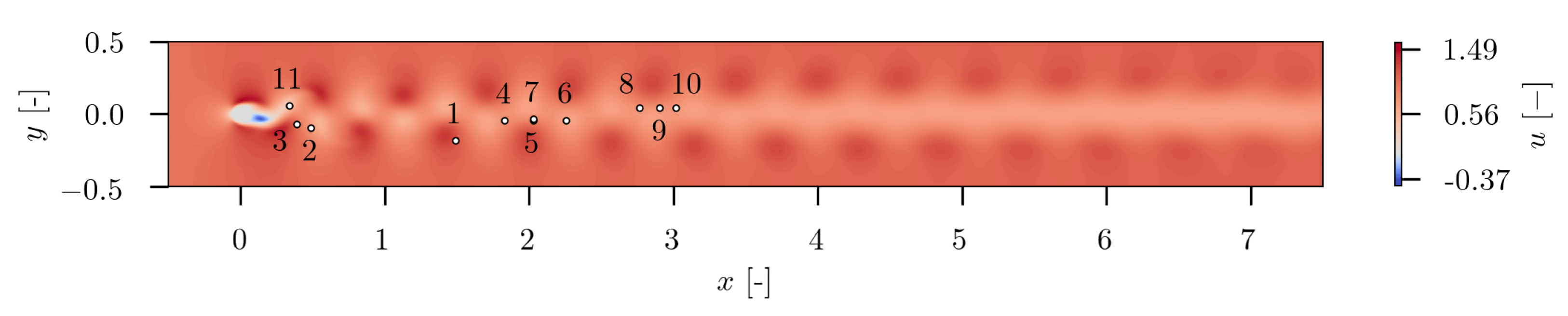
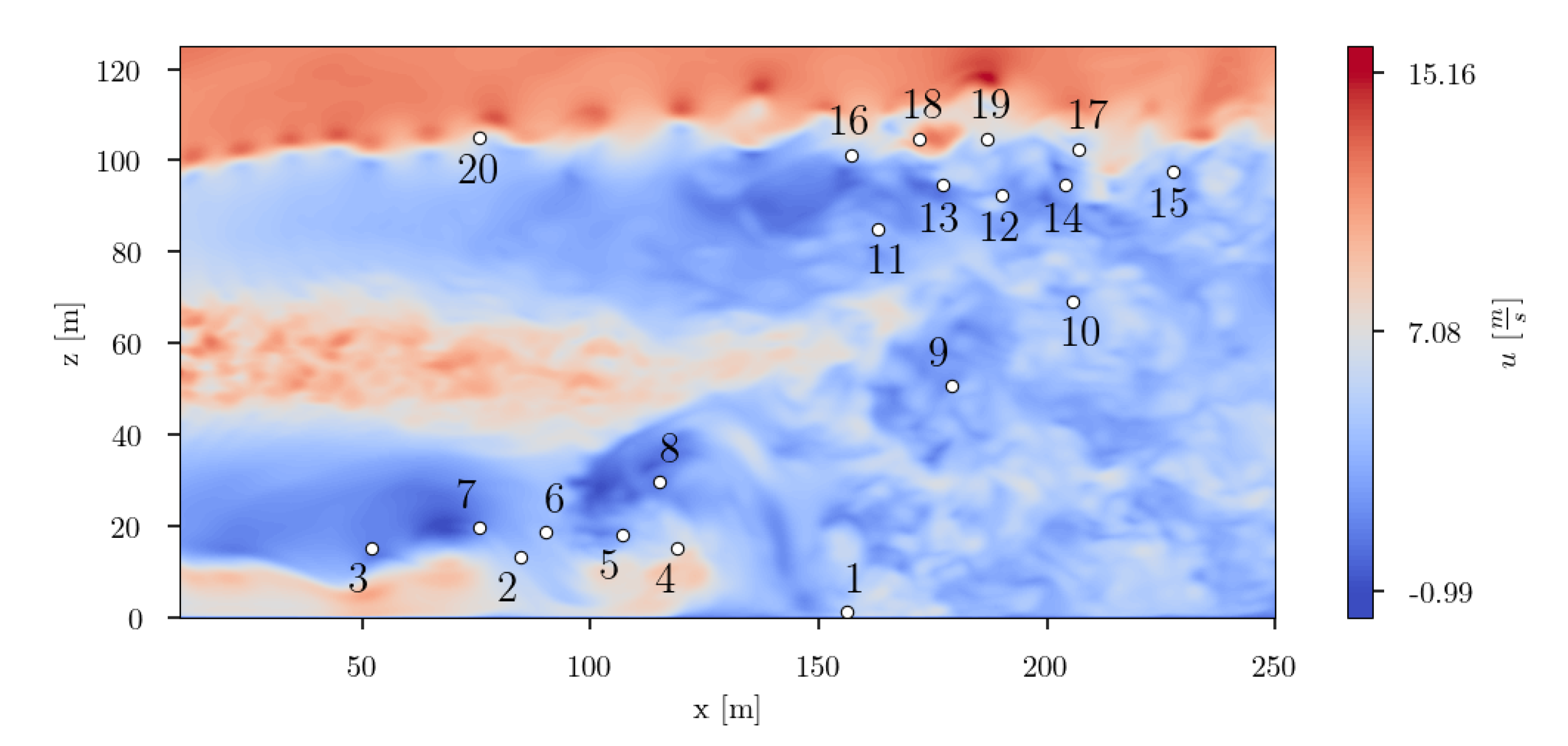
In
Figure 34, the twenty finally estimated sensors are depicted. Taking a look at the spatial distribution of the sensors, it can be clearly seen that the sensors are not equally distributed. They are agglomerated in two distinct regions, and a single sensor is placed in a third region. The sensors in the lower part of the flow field domain are located in the area, where distinct large scale vortex structures evolve. By means of SSPOR the transition area in the near ground region was estimated as one of the most informative location for sensors. The second cluster of sensors is located in the region in the upper right of the flow domain. In this region, the transition area of the wind turbine wake can be identified, where wake recovery begins. This region seems also to be most informative. Additionally, in the upper left of the flow domain one single sensor is placed. This one could possibly indicate the region where the pairing of tip vortices occurs.
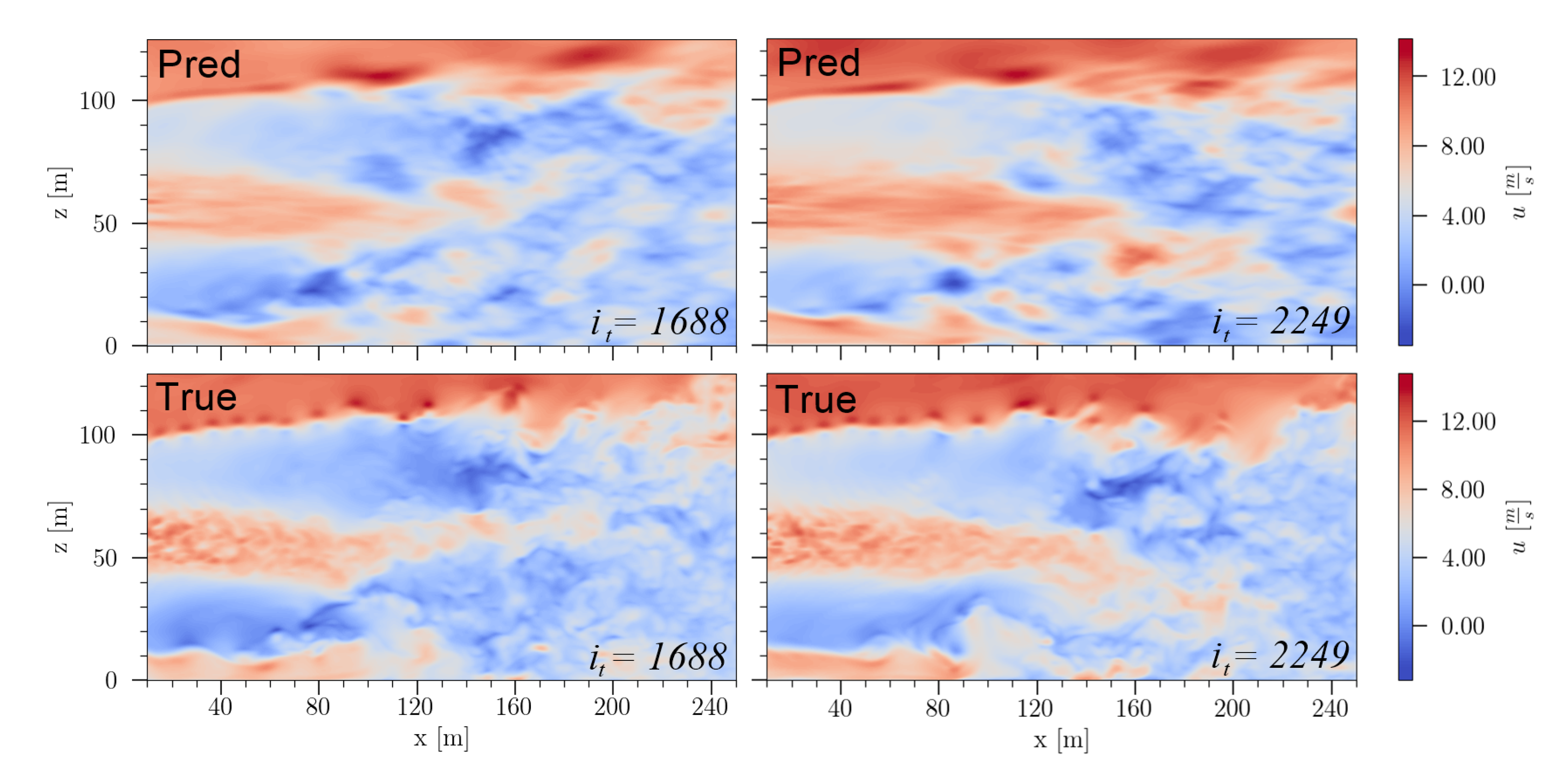
In
Figure 35, the reconstructed velocity field based on the sensor measurements for two different time instances is presented. It is apparent, that the predicted velocity fields contain less small scale turbulent structures. However, the main characteristics of the flow field are preserved: the wake area of the wind turbine hub, the large vortex structures in the ground area at
, the distinct velocity deficit of the near-wake, the clear distinction to the unperturbed flow and the beginning of the wake recovery. The fact that the predicted flow field snapshots show less small scale turbulent structures is because the POD modes used as basis modes for SSPOR do not capture these very small scale flow structures. Note that increasing the number of the employed modes increase the computational effort and the number of data and sensors, and is counter productive for real applications.
3.2.2. Wake Prediction
- a.
Standard setup
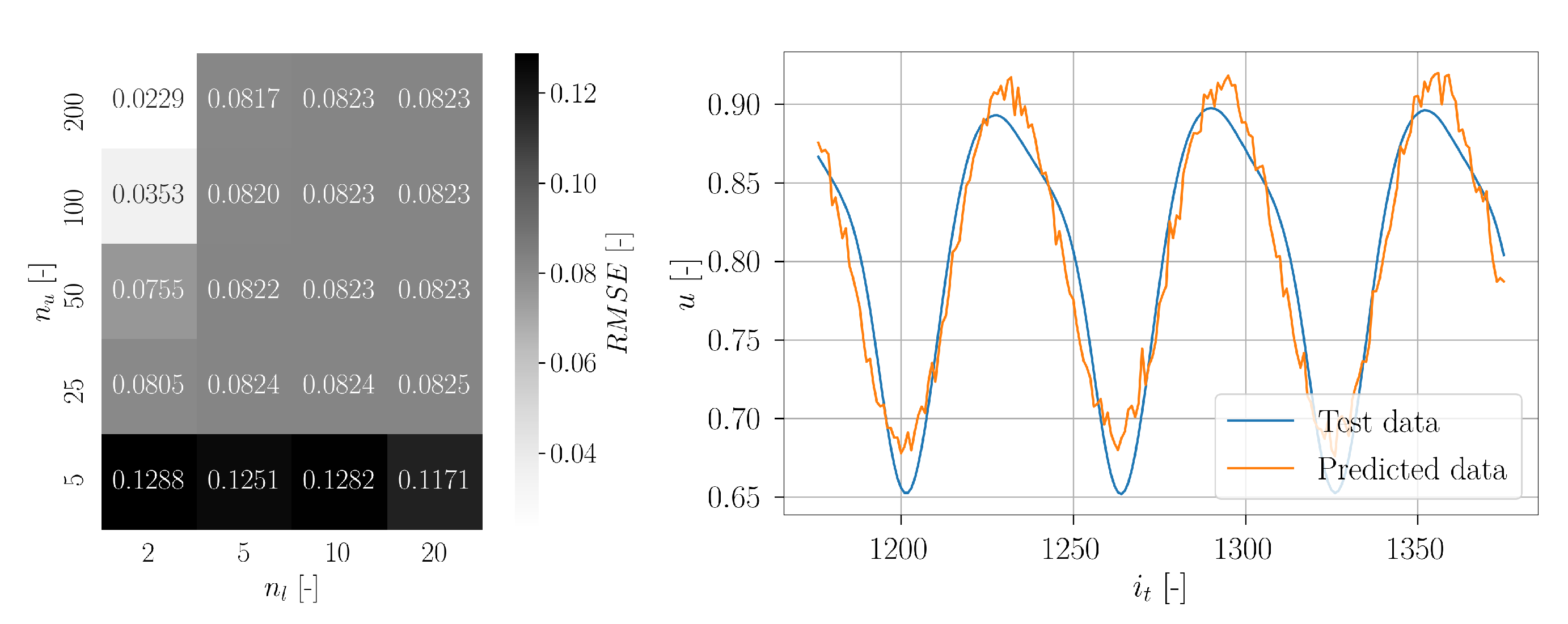
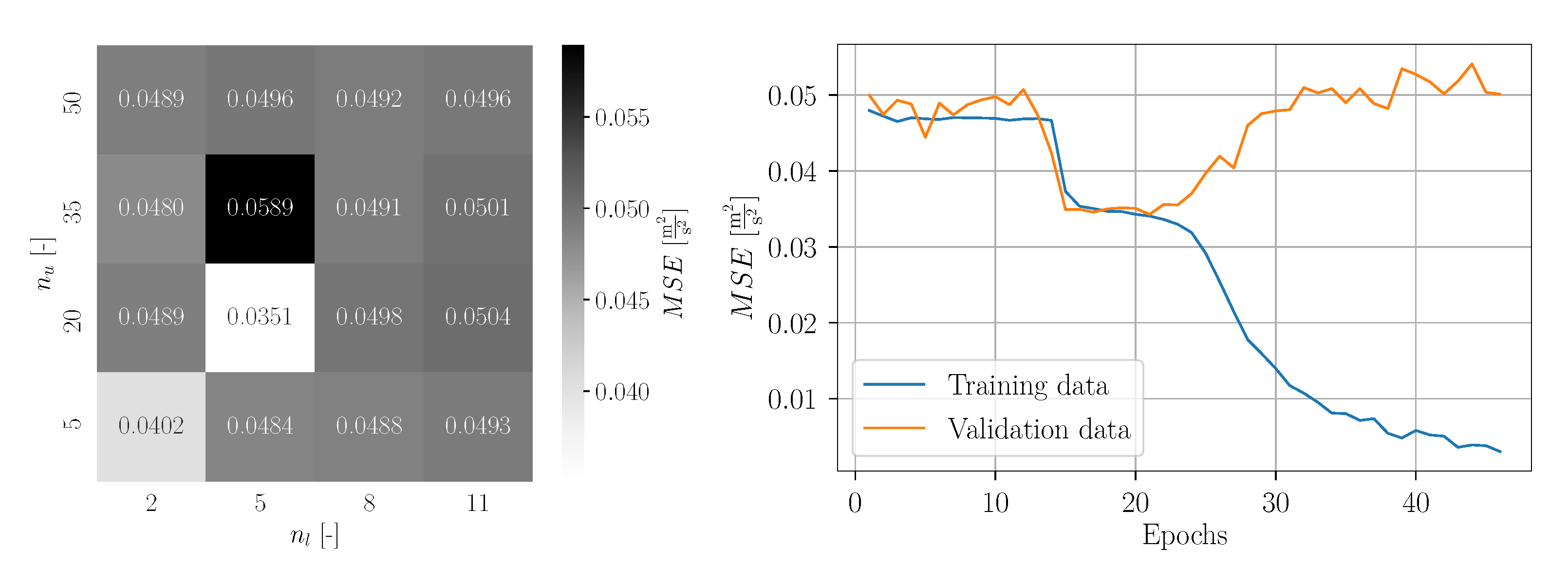
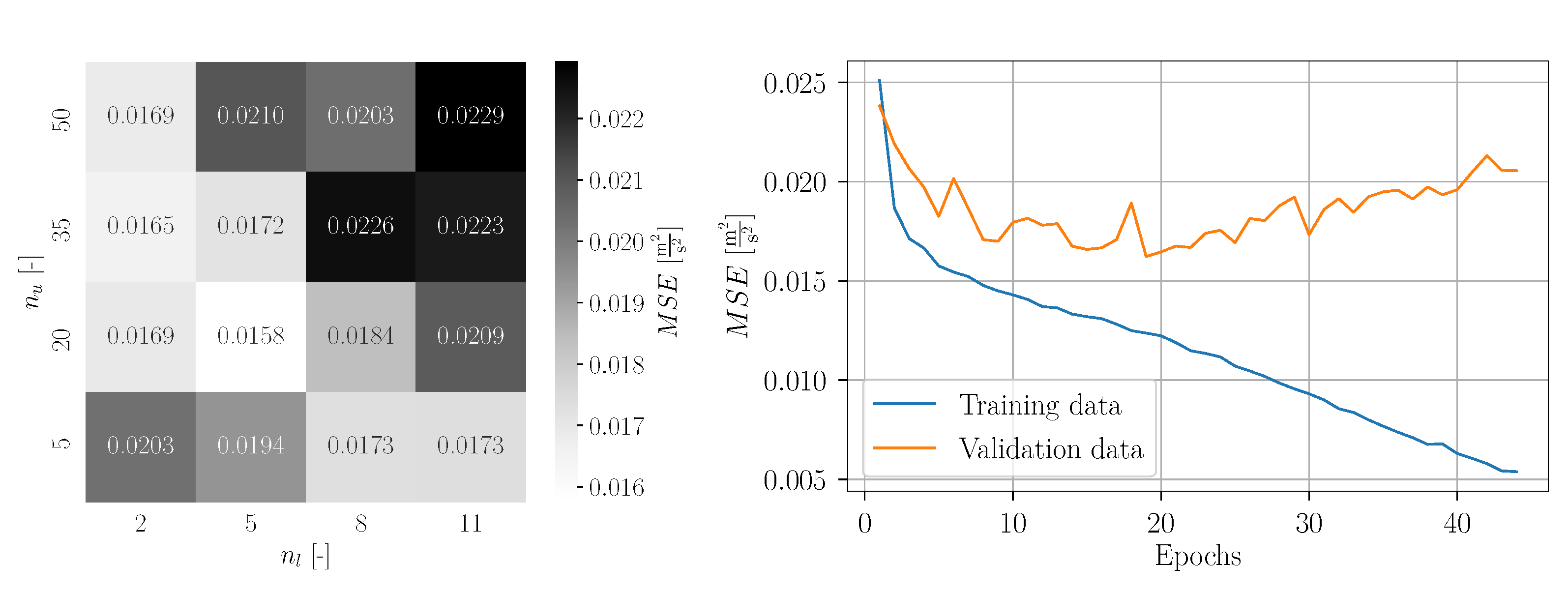
The obtained validation loss values for each parameter grid point are visualized in
Figure 36. It should be noted that the MSE was computed for the normalized data, which explains the perceived really low values. The best result was estimated for
Bi-LSTM layers and
units per layer. Interestingly, for
and
the maximum MSE was obtained. The remaining values of the parameter grid reveal no regular pattern and slightly vary around a moderate value.
With the estimated optimum hyperparameters, a subsequent training was conducted. The corresponding learning curve is depicted also in
Figure 36. It can be seen that no significant learning progress is achieved for the first twelve epochs. However, around epoch 15, the training and the validation loss drops significantly. For epoch 21, the global minimum of the validation loss was estimated and the corresponding Bi-LSTM network was saved as final model. For further epochs, the training loss decreases further and the validation loss increases, which shows an indication of overfitting. The relatively constant development of the loss values for the first epochs demonstrates that the training algorithm has some difficulties to find a reasonable direction for the gradient descent. This is caused by the unsuitable window size of the time series for the standard setup, challenging the Bi-LSTM to learn the data. For training of the Bi-LSTM networks, the Adam algorithm was applied enabling adaptive learning rates. This explains the smaller number of epochs compared to regular Stochastic Gradient Descent. Using the network weights corresponding to epoch 21 with the minimum validation loss—not the weights for the last epoch—ensures an optimal trained network without overfitting. The limited number of available snapshot data results in a limited learning success of the Bi-LSTM networks. This explains the remaining difference between training and validation loss for epoch 21, as well as the limited prediction accuracy. The CFD datasets were obtained from computationally expensive DDES simulations, even less than 10 min physical time for the complete statistics. The wind turbine is exposed to complex turbulent flow in combination with shear and yaw [
10]. Furthermore, the rotor operates at a relatively large induction factor [
10]. Thus, the prediction becomes very challenging. However, this is actually what the reality is in wind turbine operation, especially for fast-controller actions due to incoming wind, e.g., pitch response control. To account for this drawback, a modification in the method was made by adopting an adjusted window size based on the autocorrelation approach. This way, the prediction accuracy can be improved significantly but still maintaining a reasonable computational cost.
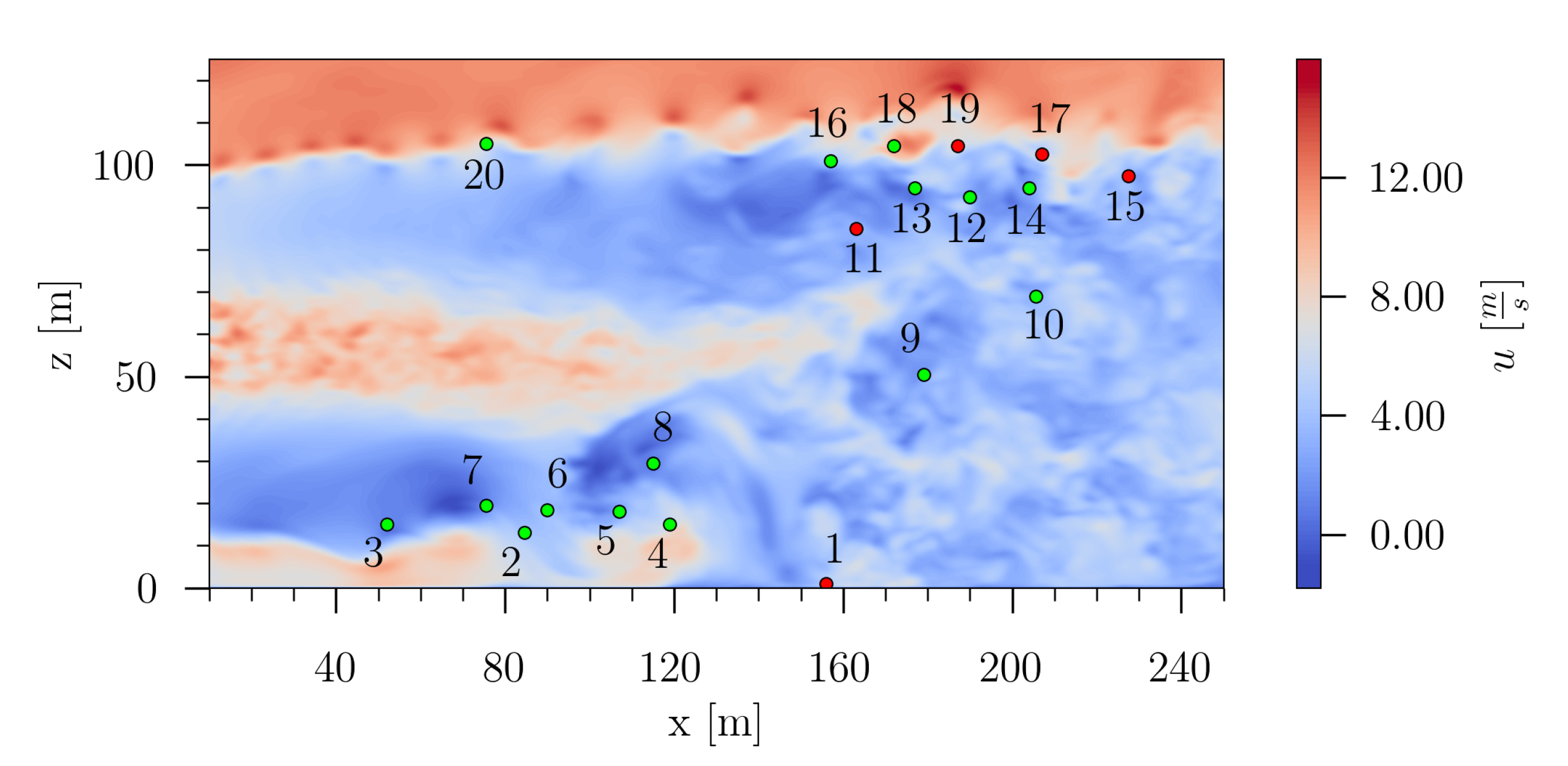
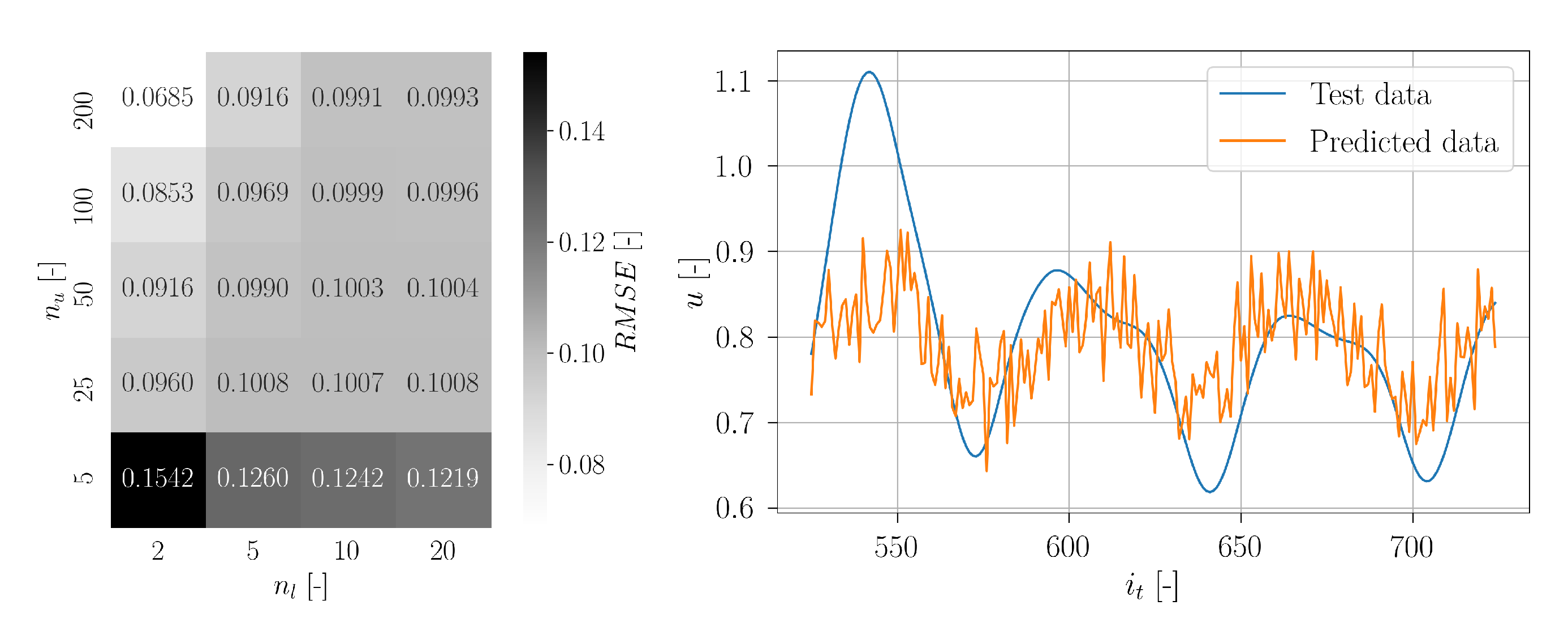
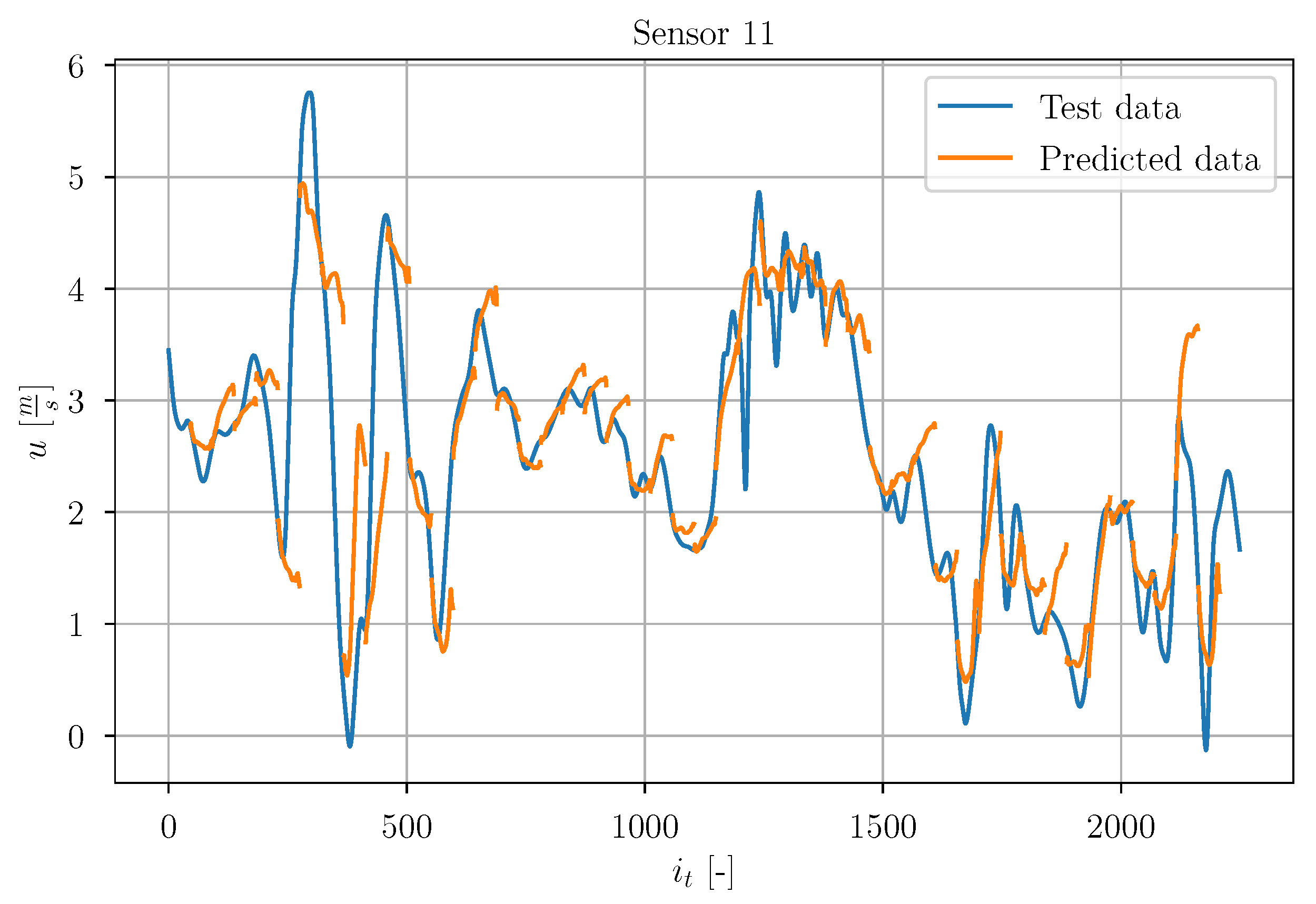
With the final model, predictions of the test data timeseries
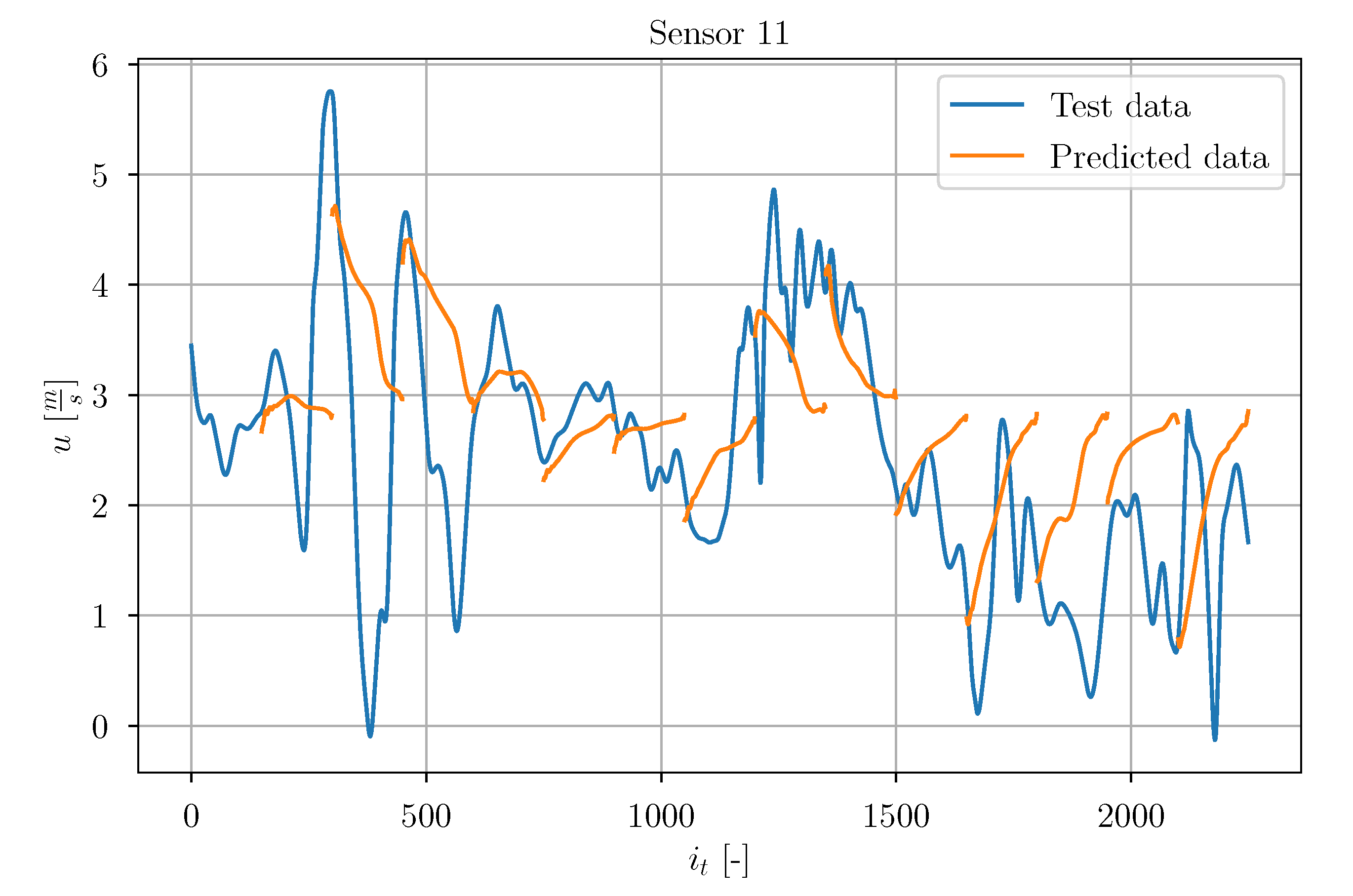
were made. As an example of the prediction, in the following the obtained results are discussed for sensor 11 (randomly chosen among other sensors). In
Figure 37, the true test data signal is depicted together with a set of chronologically consecutive predicted timeseries. On a first sight, the predictions show no significant accuracy. It is noticeable that most of the predicted timeseries seem to strive towards
m/s. Some of the predictions seem to forecast some trend of the true signal, but there are also predictions which do not coincide with the true timeseries.
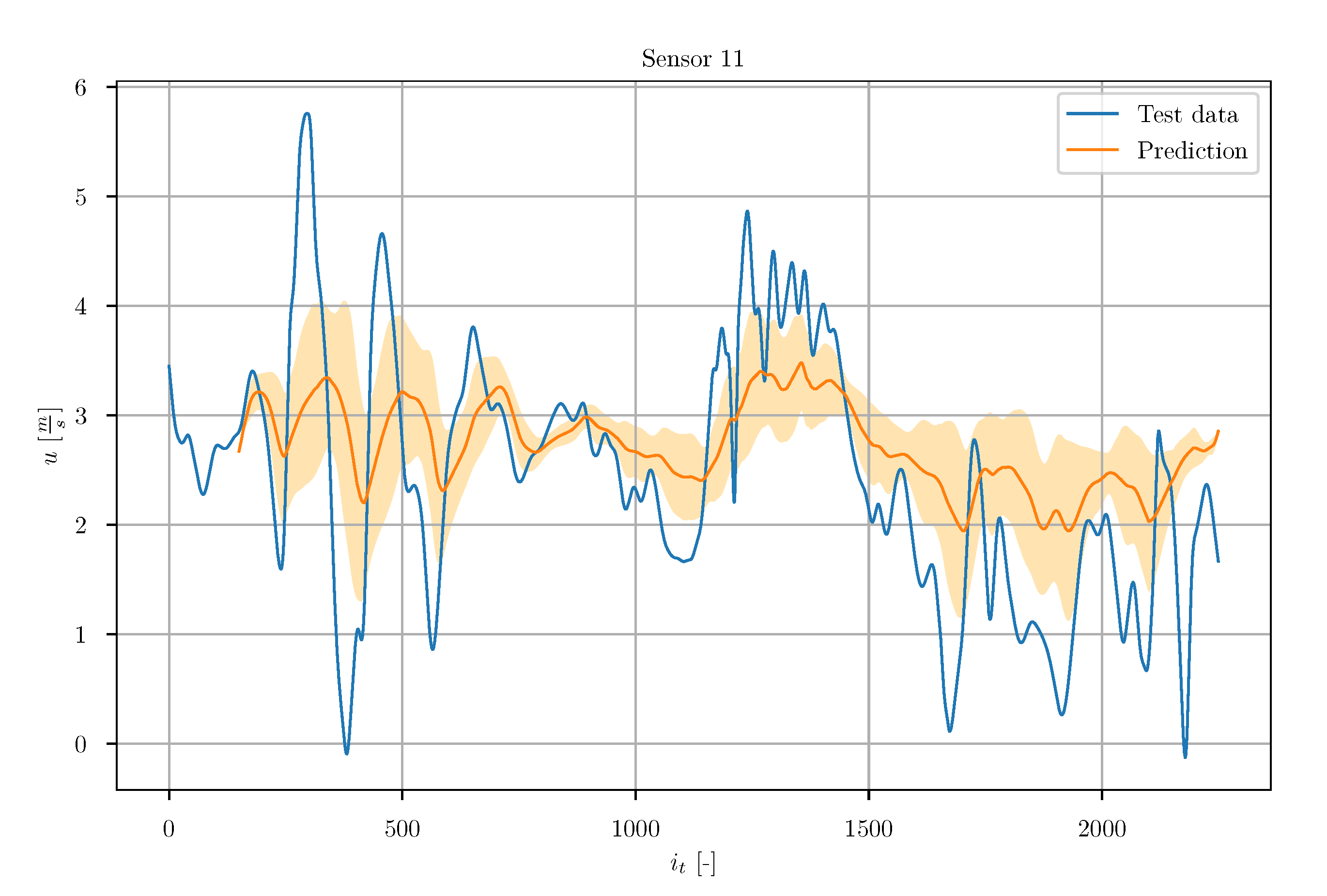
Furthermore, for a general impression of the prediction accuracy and consistency, all predicted test data timeseries were averaged. This means, for each instant, the mean of all available predicted observations from different timeseries was calculated. Additionally, the corresponding standard deviation was computed. In
Figure 38, the averaged timeseries (orange) are shown together with the true signal of sensor 11. The transparent orange band indicates the standard deviation. The predictions show a large uncertainty. It can be seen that the predictions capture some tendencies of the true signal, but the overall averaged prediction is not performing well against the true signal. Furthermore, the uncertainty is relatively high.
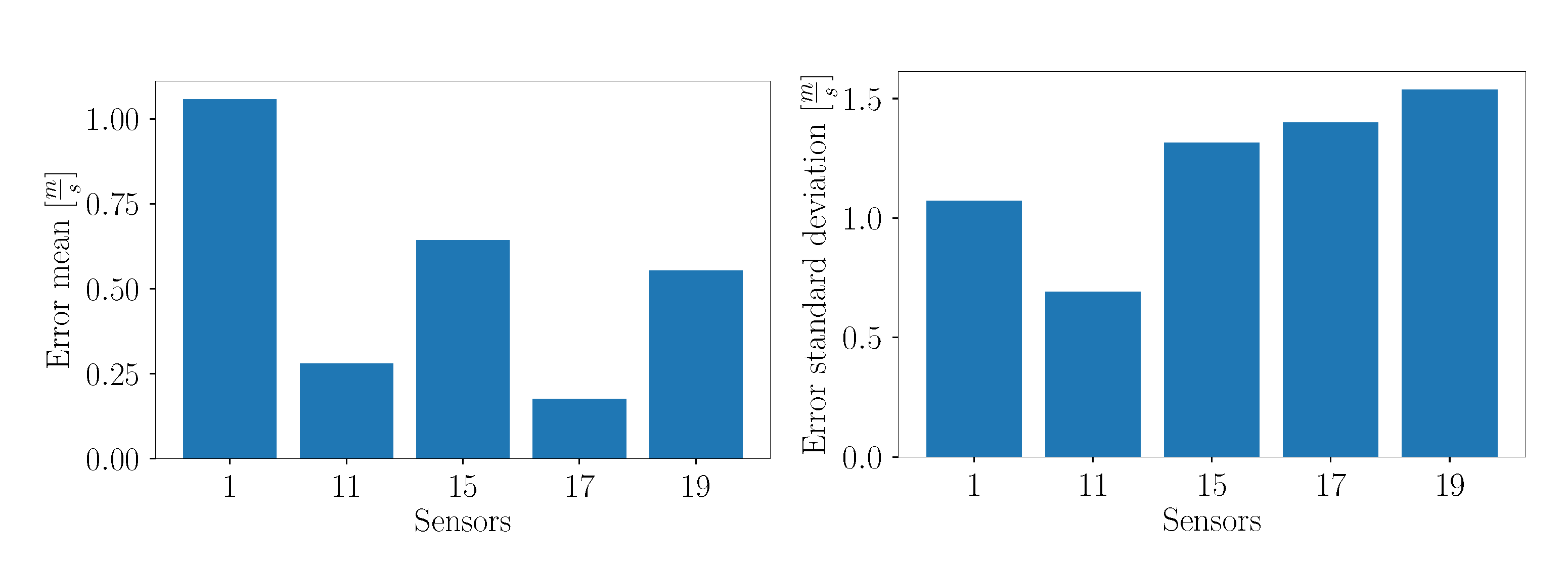
Considering the overall error mean of each test sensor in
Figure 39, it can be seen that sensor 1 exhibits the largest error. This can be explained by its location in the flow field. In contrast to the other test sensors, sensor 1 is located relatively far away from other training sensors, whereas sensors 11, 15, 17 and 19 are located in the cluster of sensors in the upper right part of the flow domain. It can be concluded that the measurements of closely placed sensors are more similar due to coherent structures of the flow, and hence it is easier to make predictions at locations which lie nearby training sensors. Interestingly, the values of the error standard deviation of sensors 15, 17 and 19 are higher than for sensor 1, although sensor 1 is more distant to the training sensors. This could be explained by the fact that sensor 1 is located nearly to the ground, where no large fluctuations are expected. The other sensors are placed in the wake recovery region, where highly turbulent structures are present. Sensor 11 exhibits the smallest error standard deviation, as depicted in
Figure 39.
- b.
Adjusted window size
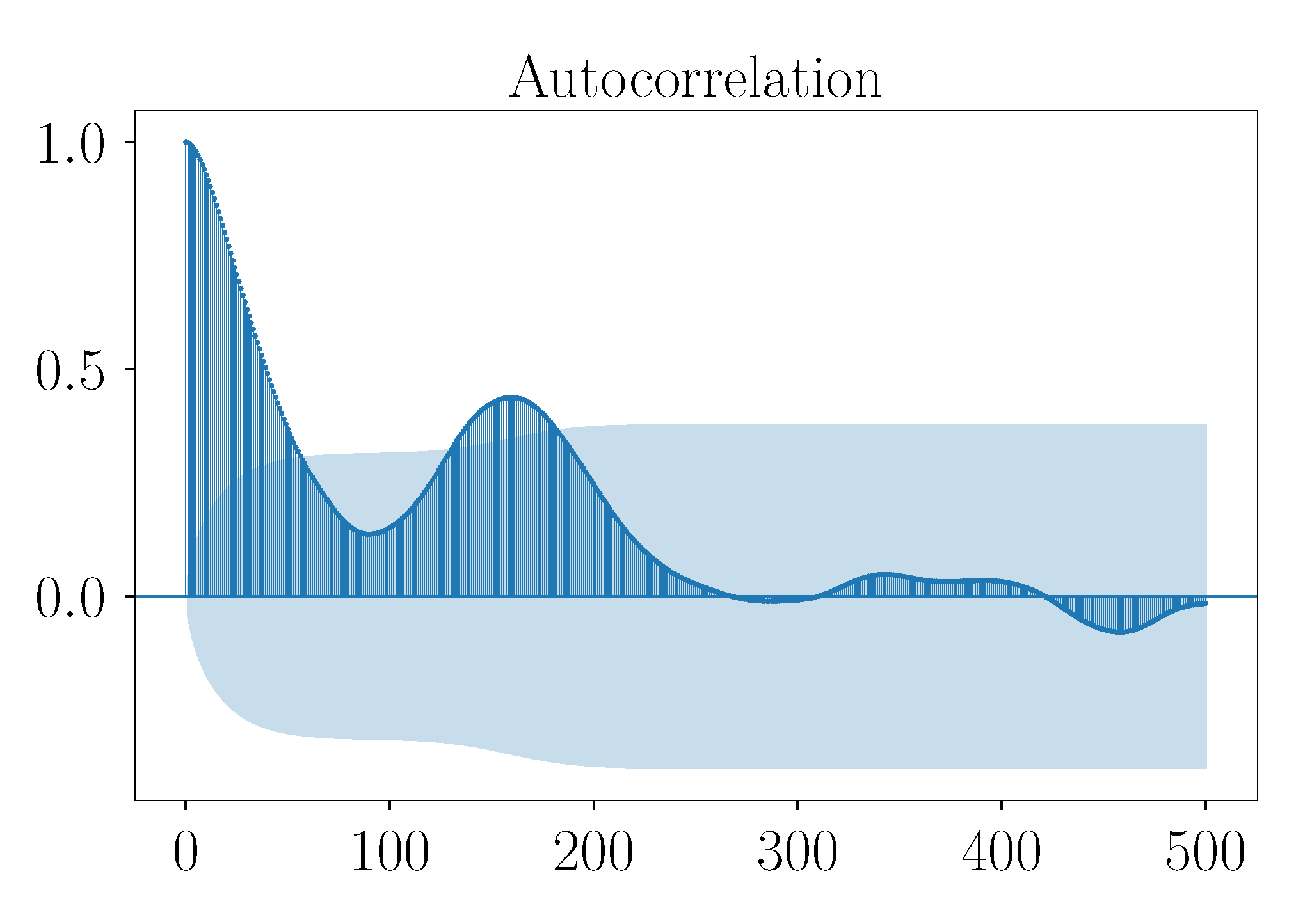
As a brief example, in
Figure 40, the autocorrelation function (ACF) of the measured velocity component in
x-direction at sensor 11 is depicted. The dark blue contour represents the autocorrelation values over the number of lags, and the light blue area represents the confidence interval. Correlation values inside the light blue area are regarded as not statistically significant. It can be seen that for low lag values the correlation values are high and decrease slowly for higher lag values. Furthermore, fluctuations are present. This progression of the ACF indicates a non-stationary timeseries showing a certain seasonality and also a trend. The frequency of the seasonal pattern can be approximated by the distance between two local maxima [
57]. However, for higher lag values the seasonality pattern vanishes. It can be seen that the ACF exhibits no strict periodic patterns. This is in accordance with the fact that the underlying set of snapshots show a highly turbulent flow characteristic. Furthermore, despite the presence of some seasonality patterns, for high lag values the correlation values lie within the blue area, i.e., the correlation is not statistically significant. Similar observations were also made for the ACF of the other sensor locations.
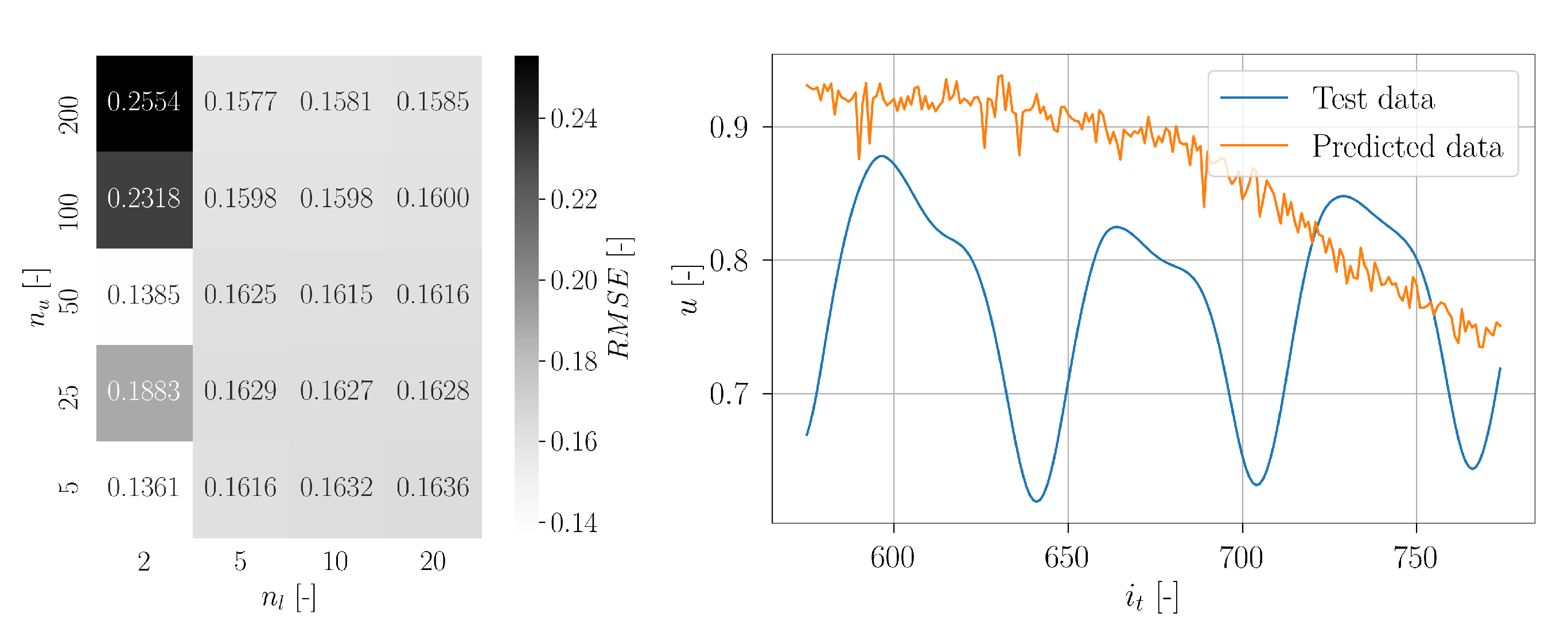
The obtained validation loss values of the grid search with adjusted
and
are visualized in
Figure 41. A relation can be seen between the number of layers and the resulting prediction accuracy. A high number of Bi-LSTM layers are rather disadvantageous regarding the prediction error. However, too few layers are also not appropriate. A similar dependency is also present regarding the number of Bi-LSTM units per layer. Higher
delivers higher prediction errors. Hence, the optimum is located at
and
. Interestingly, these are the same hyperparameters as obtained for the standard setup.
For the subsequent training with
and
, the corresponding learning curve is depicted in
Figure 41. In contrast to the learning curve of the standard setup, the curve of the training loss is always decreasing, indicating a constant learning progress. The validation loss curve exhibits some noise, but, nonetheless, it can be seen that the validation loss decreases for the first epochs. Around epoch 20, it can be seen that the validation loss begins to increase. The minimum validation loss is obtained at epoch 19. The corresponding Bi-LSTM weights were then saved as the final model. This methodology was chosen to prevent overfitting in the setup.
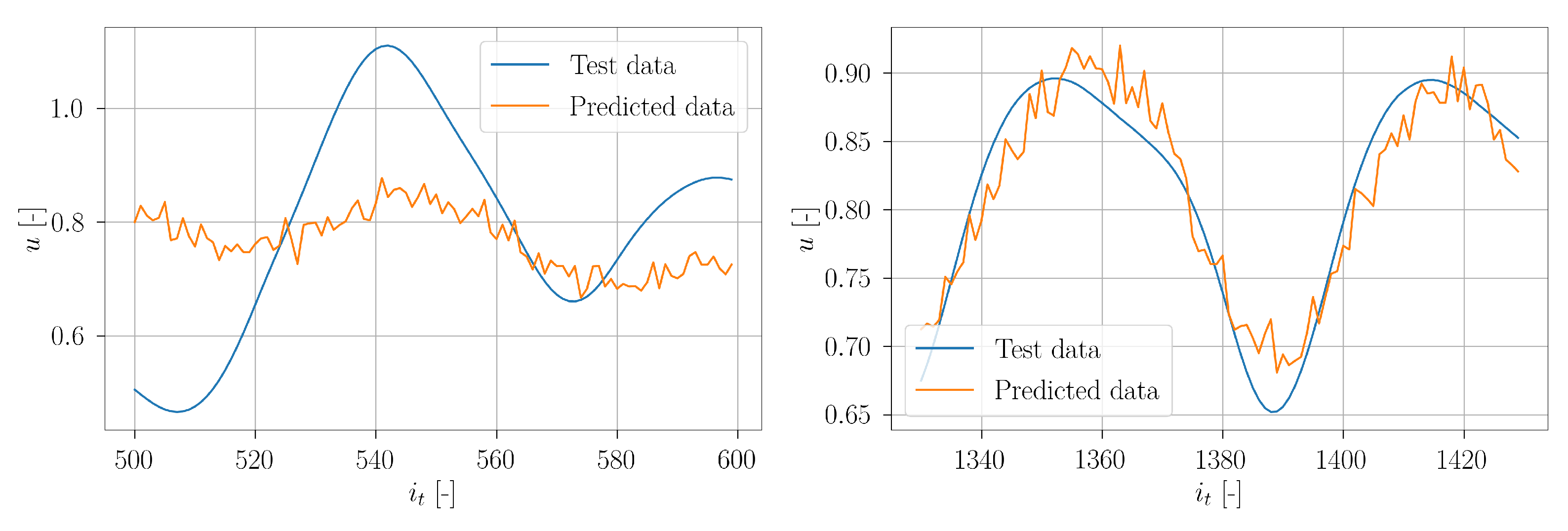
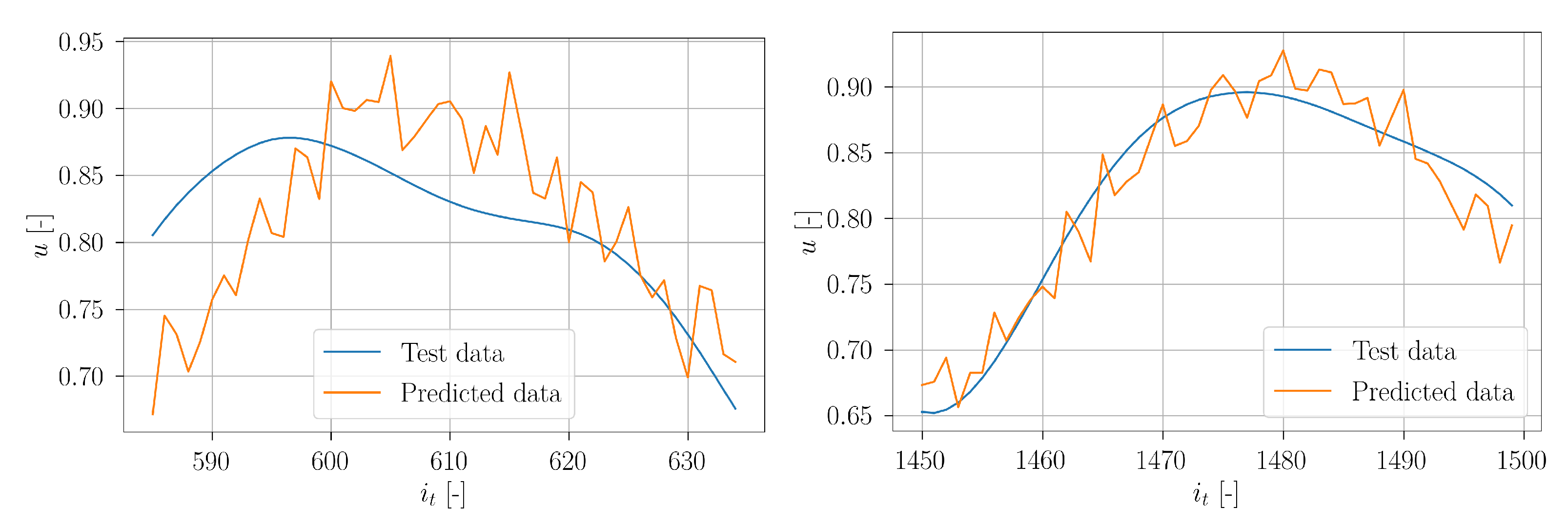
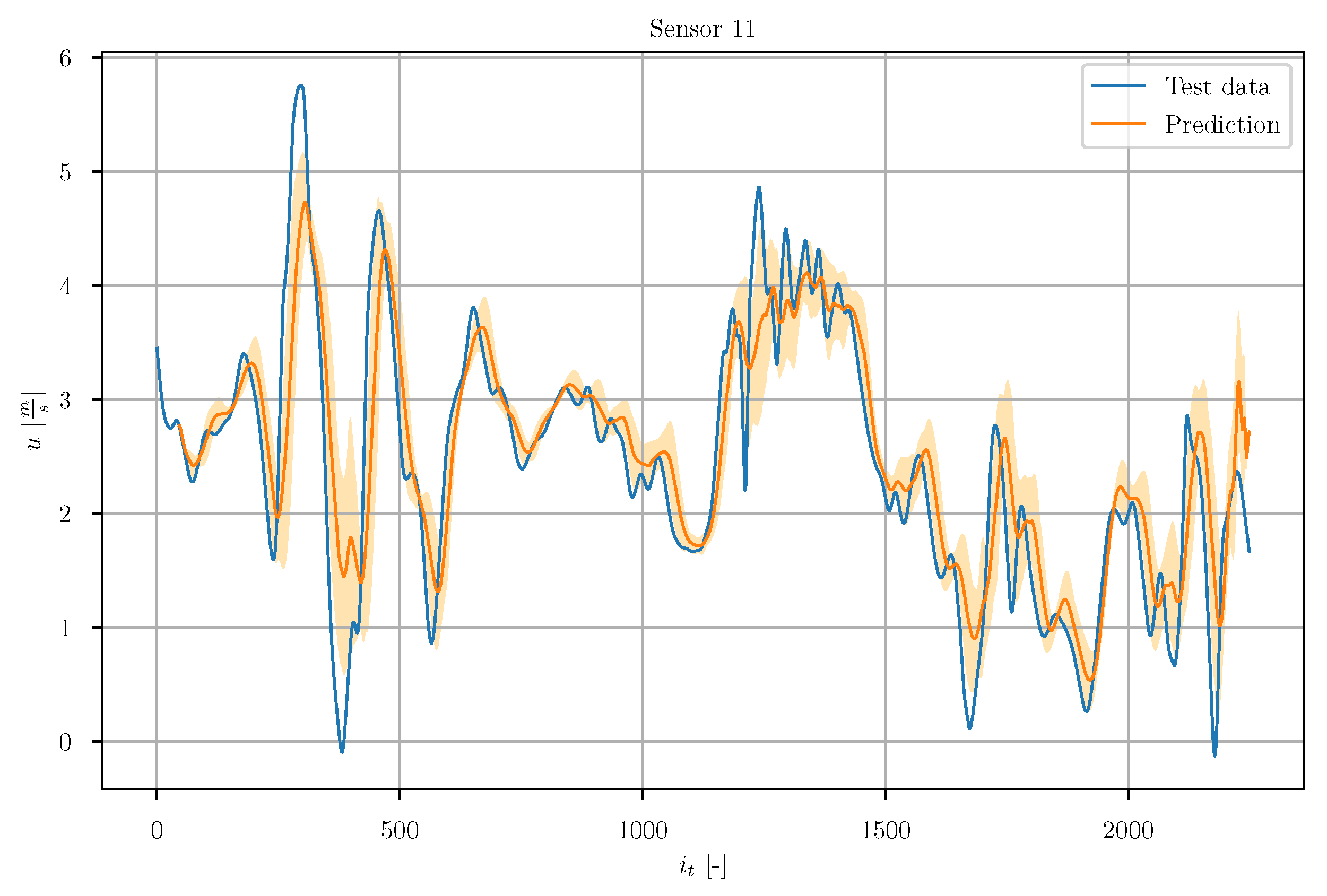
In
Figure 42, a set of chronologically consecutive predicted timeseries are depicted together with the true test timeseries of sensor 11. The visualization of these exemplary predictions shows the adjustment of the window width based on the autocorrelation algorithm. It can be seen that the overall accuracy has increased compared to the standard setup. In contrast to the standard setup, here the predicted timeseries do not strive towards a common value. Instead, they coincide rather with the progression of the true signal.
In
Figure 43, the averaged timeseries are shown. The prediction results are significantly better compared to the standard setup. The predicted signal shows a significantly better agreement with the true signal. It can be seen that the uncertainty of the prediction, indicated by the orange area around the prediction curve, significantly decreases compared to the standard setup.
The distribution of the mean error and error standard deviation of each test sensor in
Figure 44 shows a similar relation between the sensors as observed for the standard setup. However, for this setup, the mean error of sensor 1 is similar to the values of sensor 15 and 19. Furthermore, the absolute values of the error mean and standard deviation are in general smaller compared to the standard setup, indicating an improvement of the prediction accuracy and a successful prediction of the timeseries.



















































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
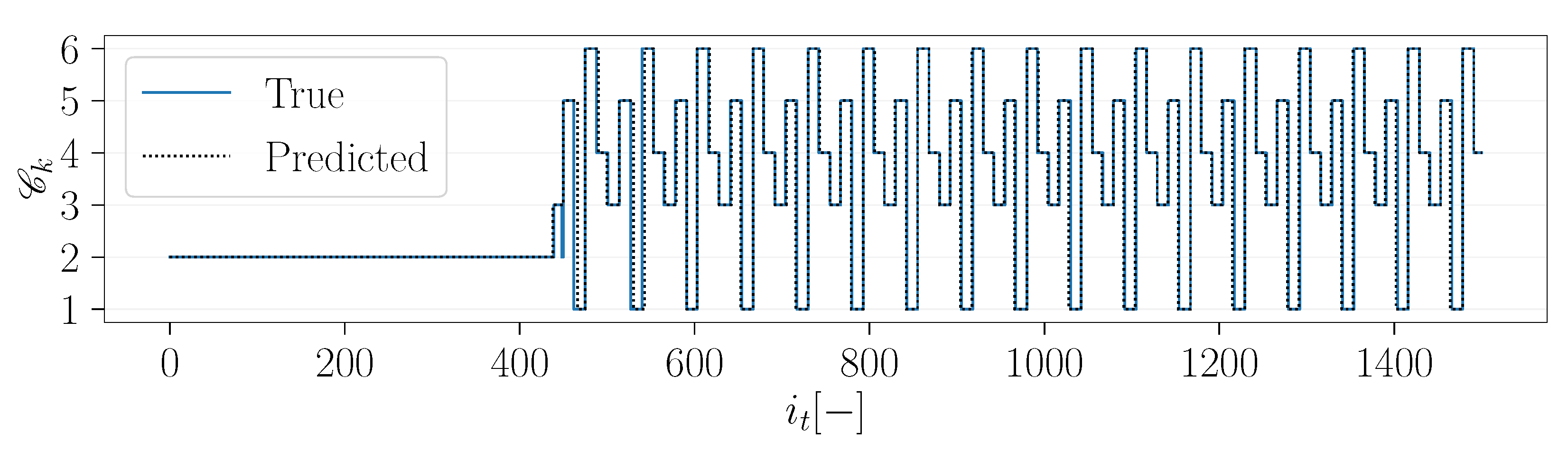{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
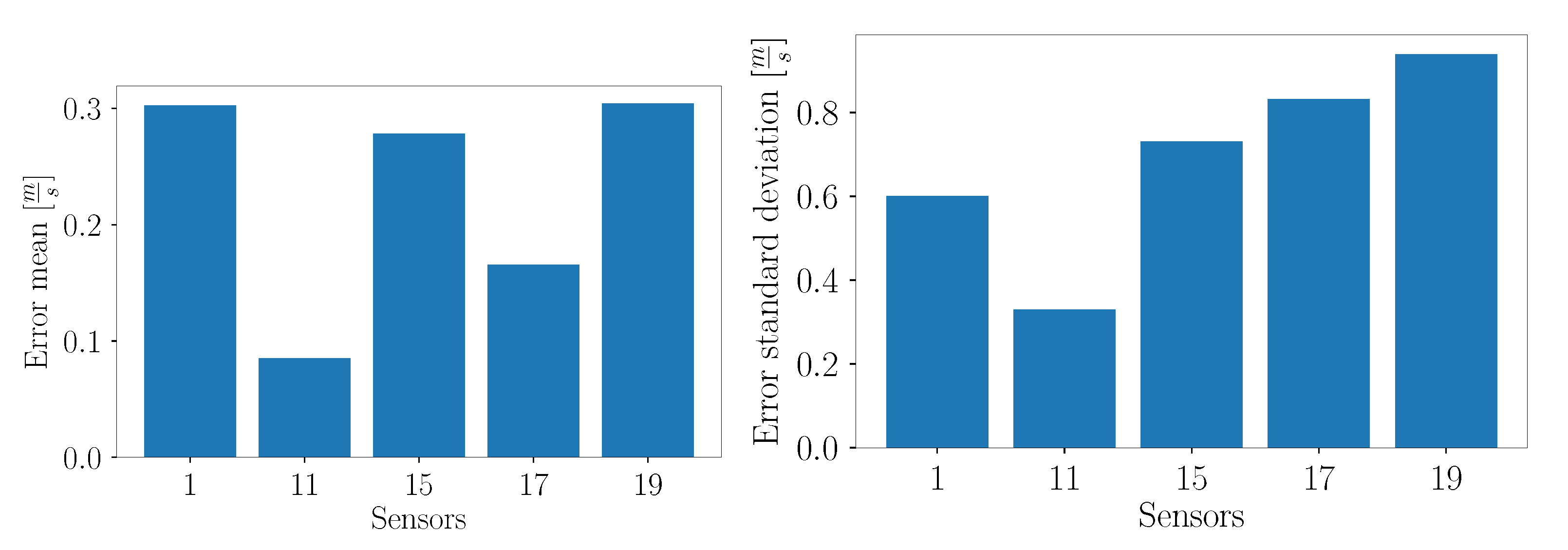{kind=link}