
Electricity Price Forecasting by Averaging Dynamic Factor Models †



Abstract
:
1. Introduction
- this is a strategic sector of the economy;
- there are financial implications due to the trading of forwards and options;
- forecasts help optimize and plan consumption and production.
2. Fundamentals
2.1. Dynamic Factor Model (DFM)
2.2. Forecast Combination
2.2.1. Classical Techniques for Forecast Combination
2.2.2. Bayesian Techniques for Forecast Combination (BMA)
3. Methodology

Forecast Combinations and Accuracy Metrics
- Forecast resulting from the benchmark model (the ‘BIC-selected model’). This is the best model according to the BIC (has the lowest BIC). Selecting only one model is equivalent to assigning it a weight (Equation (3); superscript has been eliminated because weights will not be adaptive to the forecasting horizons, and subscript t has also been omitted to avoid confusion with time-varying weights), and for all other models.
- Forecast calculated as the median of the forecasts of all of the models (the “median-based combination”). This is also a case of weights , for the model with the median forecast, and for all other models.
- Forecast equal to the mean of all forecasts (“mean-based combination”). In this case, Equation (3)’s weights are all equal , where K is the total number of models in the analysis.
- Forecast obtained using BIC-based weights as in Equation (6) (“BIC-based combination”). This approach involves equal a priori probabilities. Other sensible sets of a priori probabilities were considered, and similar results were obtained. For the sake of concreteness, those results are not presented hereby, but are available upon request to the authors.
- Forecast obtained with BIC-based weights for the top 50% models (“BIC-50% combination”). In other words, half of the models are included according to their BIC criterion of Equation (6), and for the half that has the largest BIC values, . Let us recall that the BIC evaluates the fit of the model, not how accurate it is when used to forecast.
- Forecast calculated as the mean of the forecasts of the top 50% models (“mean BIC-based combination”). Only half of the models are included (the “best” half of the models depending on their BIC), and the forecast combination is simply their average. In other words, the 50% of models with the lowest BIC are assigned weights , and the 50% of models with the greatest BIC are assigned weights .
4. Results
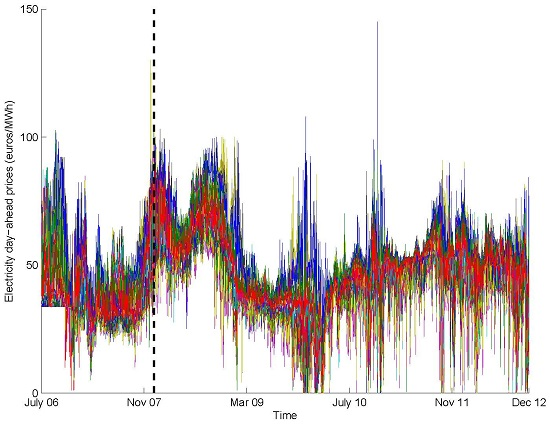
4.1. Data
4.2. ANOVA for a Comparison of Alternatives for Modeling
- Whether to use prices or the logarithm of prices (factor “LOG” or logarithm, with two levels, zero and one, when not taking logarithm or when doing so, respectively).
- The length of historical data for the rolling windows (44 weeks [12] or years).
- Are common factors best fit by auto-regressive (AR) or auto-regressive-moving-average (ARMA)? The factor “MA” has two levels, zero (not including MA component) and one (including the MA component).
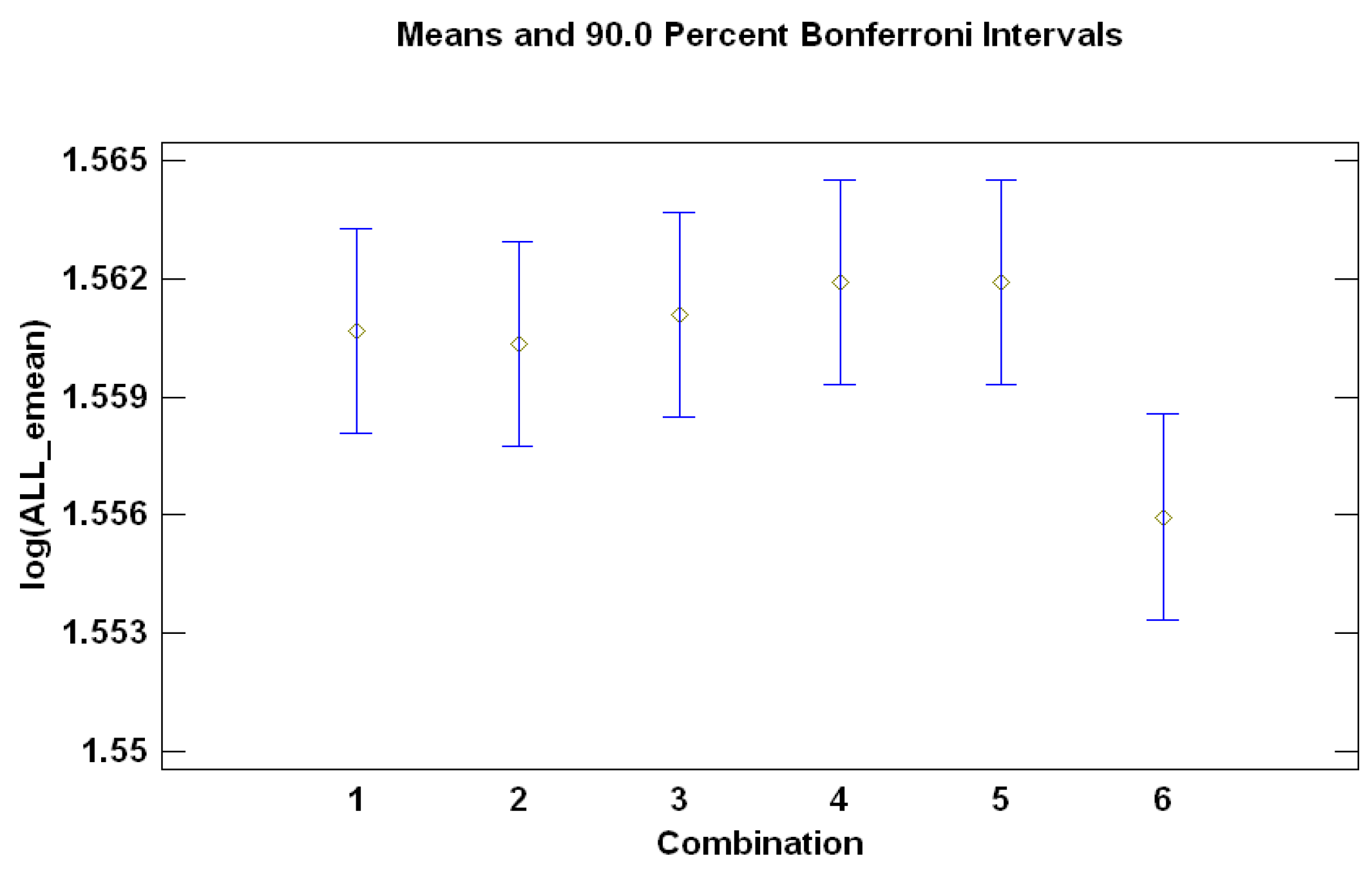
- Are there statistically-significant differences between the six possible forecasts combinations?
Summarizing the Conclusions from the ANOVAs
4.3. Electricity Price Forecasting
4.3.1. Illustration for a Single Forecasting Window
4.3.2. Forecasting Results
5. Conclusions and Further Lines of Research
Acknowledgments
Author Contributions
Conflicts of Interest
Appendix A
Appendix A.1. Details of ANOVA for the Comparison of Alternatives for Modeling
Appendix A.1.1. Minimizing Forecasting Error for One-Day-Ahead Forecasts (h = 1)


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Source | Sum of Squares | DF | Mean Square | F-Ratio | p-Value |
|---|---|---|---|---|---|
| A: day to predict | 22167.4 | 1766 | 12.5523 | 478.47 | 0.0000 |
| B: combination | 0.352927 | 5 | 0.0705854 | 2.69 | 0.0195 |
| C: MA | 111.204 | 1 | 111.204 | 4238.87 | 0.0000 |
| D: length history | 1.55697 | 1 | 1.55697 | 59.35 | 0.0000 |
| E: logarithm | 0.0176442 | 1 | 0.0176442 | 0.67 | 0.4122 |
| Residual | 2178.52 | 83,041 | 0.0262343 | - | - |
| Total (corrected) | 24,459.1 | 84,815 | - | - | - |


Appendix A.1.2. Minimizing Forecasting Error for Seven-Day-Ahead Forecasts (h = 7)

| Source | Sum of Squares | DF | Mean Square | F-Ratio | p-Value |
|---|---|---|---|---|---|
| A: day to predict | 25,361.8 | 1766 | 14.3612 | 550.56 | 0.0000 |
| B: combination | 8.36877 | 5 | 1.67375 | 64.17 | 0.0000 |
| C: MA | 7.70108 | 1 | 7.70108 | 295.23 | 0.0000 |
| D: length history | 0.60067 | 1 | 0.60067 | 23.03 | 0.0000 |
| E: logarithm | 0.0699315 | 1 | 0.0699315 | 2.68 | 0.1016 |
| Residual | 2166.11 | 83,041 | 0.0260848 | - | - |
| Total (corrected) | 27,544.7 | 84,815 | - | - | - |
Appendix A.1.3. Minimizing Forecasting Error for One-Month-Ahead Forecasts (h = 30)

| Source | Sum of Squares | DF | Mean Square | F-Ratio | p-Value |
|---|---|---|---|---|---|
| A: day to predict | 24,319.1 | 1766 | 13.7707 | 317.31 | 0.0000 |
| B: combination | 11.3659 | 5 | 2.27317 | 52.38 | 0.0000 |
| C: MA | 10.3354 | 1 | 10.3354 | 238.15 | 0.0000 |
| D: length history | 19.8807 | 1 | 19.8807 | 458.10 | 0.0000 |
| E: logarithm | 0.0147844 | 1 | 0.0147844 | 0.34 | 0.5594 |
| Residual | 3603.82 | 83,041 | 0.0433981 | - | - |
| Total (corrected) | 27,964.5 | 84,815 | - | - | - |
Appendix A.1.4. Minimizing Forecasting Error for Two-Months-Ahead Forecasts (h = 60)
| Source | Sum of Squares | DF | Mean Square | F-Ratio | p-Value |
|---|---|---|---|---|---|
| A: day to predict | 25,659.5 | 1766 | 14.52970 | 269.97 | 0.0000 |
| B: combination | 20.8166 | 5 | 4.16332 | 77.36 | 0.0000 |
| C: MA | 6.73218 | 1 | 6.73218 | 125.09 | 0.0000 |
| D: length history | 126.922 | 1 | 126.922 | 2358.28 | 0.0000 |
| E: logarithm | 0.0075782 | 1 | 0.0075782 | 0.14 | 0.7075 |
| Residual | 4669.23 | 83,041 | 0.0538196 | - | - |
| Total (corrected) | 30,283.2 | 84,815 | - | - | - |

References
- Weron, R. Electricity price forecasting: A review of the state-of-the-art with a look into the future. Int. J. Forecast. 2014, 30, 1030–1081. [Google Scholar] [CrossRef]
- Huisman, R.; Huurman, C.; Mahieu, R. Hourly electricity prices in day-ahead markets. Energy Econ. 2007, 29, 240–248. [Google Scholar] [CrossRef]
- Panagiotelis, A.; Smith, M. Bayesian Density Forecasting of intraday electricity prices using multivariate skewed t distributions. Int. J. Forecast. 2008, 24, 710–727. [Google Scholar] [CrossRef]
- García-Martos, C.; Rodríguez, J.; Sánchez, M. Mixed Models for Short-Run Forecasting of Electricity Prices: Application for the Spanish Market. IEEE Trans. Power Syst. 2007, 22, 544–552. [Google Scholar] [CrossRef]
- Alonso, A.; García-Martos, C.; Rodríguez, J.; Sánchez, M. Seasonal Dynamic Factor Analysis and Bootstrap Inference: Application to Electricity Market Forecasting. Technometrics 2011, 53, 137–151. [Google Scholar] [CrossRef] [Green Version]
- Sargent, T.; Sims, C. Business Cycle Modelling Without Pretending to Have Too Much a Priori Economic Theory, New Methods in Business Cycle Research; Federal Reserve Bank of Minneapolis: Minneapolis, MN, USA, 1977; Volume 55. [Google Scholar]
- Geweke, J. The Dynamic Factor Analysis of Economic Time Series. Latent Variables in Socio-Economic Models; North-Holland: Amsterdam, The Netherlands, 1977. [Google Scholar]
- Lee, R.; Carter, L. Modelling and forecasting U.S. mortality. J. Am. Stat. Assoc. 1992, 87, 659–671. [Google Scholar]
- Stock, J.; Watson, M. Forecasting using principal components from a large number of predictors. J. Am. Stat. Assoc. 2002, 97, 1167–1179. [Google Scholar] [CrossRef]
- Peña, D.; Poncela, P. Forecasting with Nonstationary Dynamic Factor Models. J. Econom. 2004, 119, 291–321. [Google Scholar] [CrossRef]
- Peña, D.; Poncela, P. Nonstationary dynamic factor analysis. J. Stat. Plan. Inference 2006, 136, 1237–1257. [Google Scholar] [CrossRef]
- García-Martos, C.; Rodríguez, J.; Sánchez, M. Forecasting electricity prices by extracting dynamic common factors: Application to the Iberian market. IET Gener. Transm. Distrib. 2012, 6, 11–20. [Google Scholar] [CrossRef]
- Peña, D.; Box, G. Identifying a simplifying structure in time series. J. Am. Stat. Assoc. 1987, 82, 836–843. [Google Scholar] [CrossRef]
- Maciejowska, K.; Weron, R. Forecasting of daily electricity prices with factor models: Utilizing intra-day and inter-zone relationships. Comput. Stat. 2015, 30, 805–819. [Google Scholar] [CrossRef]
- Clemen, R. Combining forecasts: A review and annotated bibliography. Int. J. Forecast. 1989, 5, 559–583. [Google Scholar] [CrossRef]
- Sánchez, I. Short-term prediction of wind energy production. Int. J. Forecast. 2006, 22, 43–56. [Google Scholar] [CrossRef]
- Bjørnland, H.; Gerdrup, K.; Jore, A.; Smith, C.; Thorsrud, L. Does forecast combination improve Norges Bank inflation forecasts? Oxford Bull. Econ. Stat. 2012, 74, 163–179. [Google Scholar] [CrossRef]
- Bordignon, S.; Bunn, D.; Lisi, F.; Nan, F. Combining day-ahead forecasts for British electricity prices. Energy Econ. 2013, 35, 88–103. [Google Scholar] [CrossRef]
- Nowotarskia, J.; Raviv, E.; Trückc, S.; Werona, R. An empirical comparison of alternate schemes for combining electricity spot price forecasts. Energy Econ. 2014, 46, 395–412. [Google Scholar] [CrossRef]
- Raviv, E.; Bouwman, K.; Van Dijk, D. Forecasting day-ahead electricity prices: Utilizing hourly prices. Energy Econ. 2015, 50, 227–239. [Google Scholar] [CrossRef]
- Monteiro, C.; Fernandez-Jimenez, L.; Ramirez-Rosado, I. Explanatory Information Analysis for Day-Ahead Price Forecasting in the Iberian Electricity Market. Energies 2015, 8, 10464–10486. [Google Scholar] [CrossRef]
- García-Martos, C.; Caro, E.; Sánchez, M. Electricity price forecasting accounting for renewable energies: Optimal combined forecasts. J. Oper. Res. Soc. 2015, 66, 871–884. [Google Scholar] [CrossRef]
- Poncela, P.; Rodriguez, J.; Sánchez-Mangas, R.; Senra, E. Forecast combination through dimension reduction techniques. J. Forecast. 2011, 27, 224–237. [Google Scholar] [CrossRef]
- Kuzin, V.; Marcellino, M.; Schumacher, C. Pooling versus model selection for nowcasting GDP with many predictors: Empirical evidence for six industrialized countries. J. Appl. Econom. 2012, 28, 32–411. [Google Scholar] [CrossRef]
- Martínez-Álvarez, F.; Troncoso, A.; Asencio-Cortés, G.; Riquelme, J. A Survey on Data Mining Techniques Applied to Electricity-Related Time Series Forecasting. Energies 2015, 8, 13162–13193. [Google Scholar] [CrossRef]
- Stock, J.; Watson, M. Combination forecasts of output growth in a seven country dataset. J. Forecast. 2004, 23, 405–430. [Google Scholar] [CrossRef]
- Yang, Y. Combining forecasting procedures: some theoretical results. Econom. Theory 2004, 20, 176–222. [Google Scholar] [CrossRef]
- Elliott, G.; Granger, C.; Timmermann, A. Handbook of Economic Forecasting; North-Holland: Oxford, UK, 2006; Volume 1. [Google Scholar]
- Swanson, N.; Zeng, T. Choosing Among Competing Econometric Forecasts: Regression-Based Forecast Combination Using Model Selection. J. Forecast. 2001, 20, 425–440. [Google Scholar] [CrossRef]
- Schwarz, G. Estimating the dimension of a model. Ann. Stat. 1978, 6, 461–464. [Google Scholar] [CrossRef]
- Wright, J. Bayesian Model Averaging and exchange rate forecasts. J. Econom. 2008, 146, 329–341. [Google Scholar] [CrossRef]
- Leamer, E. Specification Searches: Ad Hoc Inference with Nonexperimental Data; John Wiley & Sons: New York, NY, USA, 1978. [Google Scholar]
- Raftery, A. Bayesian Model Selection in Social Research. Sociol. Methodol. 1995, 25, 111–163. [Google Scholar] [CrossRef]
- Raftery, A.; Madigan, D.; Hoeting, J. Bayesian model averaging for linear regression models. J. Am. Stat. Assoc. 1997, 92, 179–191. [Google Scholar] [CrossRef]
- Chipman, H.; George, E.; McCulloch, R. The practical implementation of Bayesian model selection. IMS Lect. Notes 2001, 38, 70–134. [Google Scholar]
- Koop, G.; Potter, S. Forecasting in Large Macroeconomic Panels Using Bayesian Model Averaging; Federal Reserve Bank of New York: New York, NY, USA, 2003; Volume 163. [Google Scholar]
- Cremers, K. Stock return predictability: A Bayesian model selection perspective. Rev. Financ. Stud. 2002, 15, 1223–1249. [Google Scholar] [CrossRef]
- Billio, M.; Casarin, R.; Ravazzolo, F.; Van Dijk, H. Combining Predictive Densities using Nonlinear Filtering with Applications to US Economics Data. Tinbergen Institute Discussion Paper. 2011. Available online: http://papers.ssrn.com/sol3/papers.cfm?abstract_id=1967435 (accessed on 18 July 2016).
- Conejo, A.; Contreras, J.; Espínola, R.; Plazas, M. Forecasting electricity prices for a day-ahead poll-based electric energy market. Int. J. Forecast. 2005, 21, 435–462. [Google Scholar] [CrossRef]
- Hyndman, R.; Koehler, A. Another look at measures of accuracy. Int. J. Forecast. 2006, 22, 679–688. [Google Scholar] [CrossRef]
- Bello, A.; Reneses, J.; Muñoz, A. Medium-Term Probabilistic Forecasting of Extremely Low Prices in Electricity Markets: Application to the Spanish Case. Energies 2016, 9, 193–219. [Google Scholar] [CrossRef]
- Montgomery, D.C. Design and Analysis of Experiments; Wiley: New York, NY, USA, 1984. [Google Scholar]



| BIC-Selected | Median-Based | Mean-Based | BIC-Based | BIC 50% | Mean BIC-Based | |
|---|---|---|---|---|---|---|
| Model | Combination | Combination | Combination | Combination | Combination | |
| Weekly | ||||||
| MAE | 5.9455 | 5.8690 | 5.8965 | 5.9384 | 5.9384 | 5.8397 |
| MedAE | 5.3515 | 5.2433 | 5.2677 | 5.3444 | 5.3444 | 5.2275 |
| Monthly | ||||||
| MAE | 6.9069 | 6.6952 | 6.7097 | 6.8934 | 6.8934 | 6.6526 |
| MedAE | 6.3635 | 6.1179 | 6.1367 | 6.3484 | 6.3484 | 6.0882 |
| Bi-Monthly | ||||||
| MAE | 7.8184 | 7.5456 | 7.5512 | 7.8014 | 7.8014 | 7.4867 |
| MedAE | 7.3047 | 7.0081 | 7.0157 | 7.2844 | 7.2844 | 6.9539 |
| BIC-Selected | Median-Based | Mean-Based | BIC-Based | BIC 50% | Mean BIC-Based | ||
|---|---|---|---|---|---|---|---|
| Model | Combination | Combination | Combination | Combination | Combination | ||
| January | MAE | 5.9914 | 6.7577 | 6.8780 | 6.0130 | 6.0130 | 6.4687 |
| 2012 | MedAE | 5.3622 | 6.4678 | 6.7260 | 5.2593 | 5.2593 | 6.0601 |
| February | MAE | 6.4675 | 7.2435 | 7.4060 | 6.4906 | 6.4906 | 6.9594 |
| 2012 | MedAE | 6.5416 | 7.4396 | 7.5021 | 6.6464 | 6.6464 | 7.2376 |
| March | MAE | 6.9734 | 6.1102 | 6.0922 | 6.8243 | 6.8243 | 6.1867 |
| 2012 | MedAE | 6.0546 | 5.3264 | 5.256 | 6.0065 | 6.0065 | 5.2017 |
| April | MAE | 13.5490 | 12.4104 | 12.2801 | 13.3762 | 13.3762 | 12.5287 |
| 2012 | MedAE | 13.2217 | 10.7761 | 10.0235 | 13.1850 | 13.1850 | 11.2624 |
| May | MAE | 10.8668 | 9.3332 | 9.1965 | 10.6543 | 10.6543 | 9.5498 |
| 2012 | MedAE | 9.3751 | 7.5543 | 7.4841 | 9.1088 | 9.1088 | 7.7359 |
| June | MAE | 6.0767 | 6.3919 | 6.6578 | 6.1280 | 6.1280 | 6.2612 |
| 2012 | MedAE | 5.5188 | 5.8455 | 6.3053 | 5.5588 | 5.5588 | 5.8795 |
| July | MAE | 5.9894 | 5.5998 | 5.7148 | 5.9188 | 5.9188 | 5.5693 |
| 2012 | MedAE | 5.8066 | 5.6251 | 5.7086 | 5.8096 | 5.8096 | 5.4504 |
| August | MAE | 6.3186 | 5.6453 | 5.7619 | 6.2278 | 6.2278 | 5.7026 |
| 2012 | MedAE | 5.9970 | 5.4338 | 5.6871 | 5.8635 | 5.8635 | 5.0984 |
| September | MAE | 8.1682 | 7.4471 | 7.4487 | 8.0259 | 8.0259 | 7.4593 |
| 2012 | MedAE | 6.9071 | 6.3828 | 6.9140 | 6.8746 | 6.8746 | 6.3112 |
| October | MAE | 9.1325 | 7.9165 | 7.8303 | 8.9732 | 8.9732 | 8.1128 |
| 2012 | MedAE | 6.6286 | 6.2065 | 6.4013 | 6.4605 | 6.4605 | 5.3778 |
| November | MAE | 11.4100 | 9.7935 | 9.5407 | 11.1893 | 11.1893 | 10.1087 |
| 2012 | MedAE | 9.2314 | 6.9678 | 6.3402 | 9.1100 | 9.1100 | 7.6911 |
| December | MAE | 13.1200 | 12.2841 | 12.1081 | 12.9827 | 12.9827 | 12.3144 |
| 2012 | MedAE | 9.3700 | 9.9895 | 9.2326 | 9.7346 | 9.7346 | 9.7757 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alonso, A.M.; Bastos, G.; García-Martos, C. Electricity Price Forecasting by Averaging Dynamic Factor Models. Energies 2016, 9, 600. https://doi.org/10.3390/en9080600
Alonso AM, Bastos G, García-Martos C. Electricity Price Forecasting by Averaging Dynamic Factor Models. Energies. 2016; 9(8):600. https://doi.org/10.3390/en9080600
Chicago/Turabian StyleAlonso, Andrés M., Guadalupe Bastos, and Carolina García-Martos. 2016. "Electricity Price Forecasting by Averaging Dynamic Factor Models" Energies 9, no. 8: 600. https://doi.org/10.3390/en9080600
APA StyleAlonso, A. M., Bastos, G., & García-Martos, C. (2016). Electricity Price Forecasting by Averaging Dynamic Factor Models. Energies, 9(8), 600. https://doi.org/10.3390/en9080600