1. Introduction
Sparse image matching is one of the most critical steps in many computer vision applications, including structure from motion (SfM) and robotic navigation. In contrast to dense image matching, where image correspondences are established at nearly each pixel, sparse matching establishes the correspondences at salient image points only. Recent research works apply sparse matching to address a variety of problems including simultaneous localization and mapping [
1,
2], feature tracking [
3] and real-time mosaicking [
4,
5]. The results of sparse matching are usually contaminated with false correspondences. Given the recent advancements in the fields of low-altitude, oblique and ultra-high resolution imagery, the rate of contamination has increased, and detecting the correct correspondences with high accuracy has become more challenging [
6]. This is due to several factors, which include noisy measurements, the inefficiency of local descriptors, the lack of texture diversity and the existence of repeated and similar patterns that cause matching ambiguity [
7,
8,
9]. Therefore, outlier detection should be substantially integrated into sparse matching. From now on, the term putative correspondence is used for referring to the raw results of sparse matching. The term inlier applies to true matches among the putative correspondences, and the term outlier refers to false matches. Besides, the terms correspondence and match have the same meanings throughout this paper. The problem of outlier detection implies the detection of inliers by eliminating outliers from putative correspondences given no prior information about the parameters of relative orientation or intrinsic camera calibration assuming straight line-preserving perspective camera models.
Outlier detection techniques are based on the fact that inliers have some spatial characteristics in common. The correspondences that are not consistent with such spatial characteristics can be classified as outliers. The idea of using epipolar geometry as a spatial constraint to detect inliers/outliers has been proposed in several studies. In this regard, the outlier detection problem turns into two problems of (i) robust estimation of epipolar geometry given the putative correspondences and (ii) detecting all of the inliers and outliers using the estimated model. In this paper, the term model refers to the two-view epipolar geometry, which is described here by the fundamental matrix. In particular cases where approximations can be made on the perspective camera model or assumptions can be formulated about the planarity of the scene, the model can refer to affine transformations and homographies, as well.
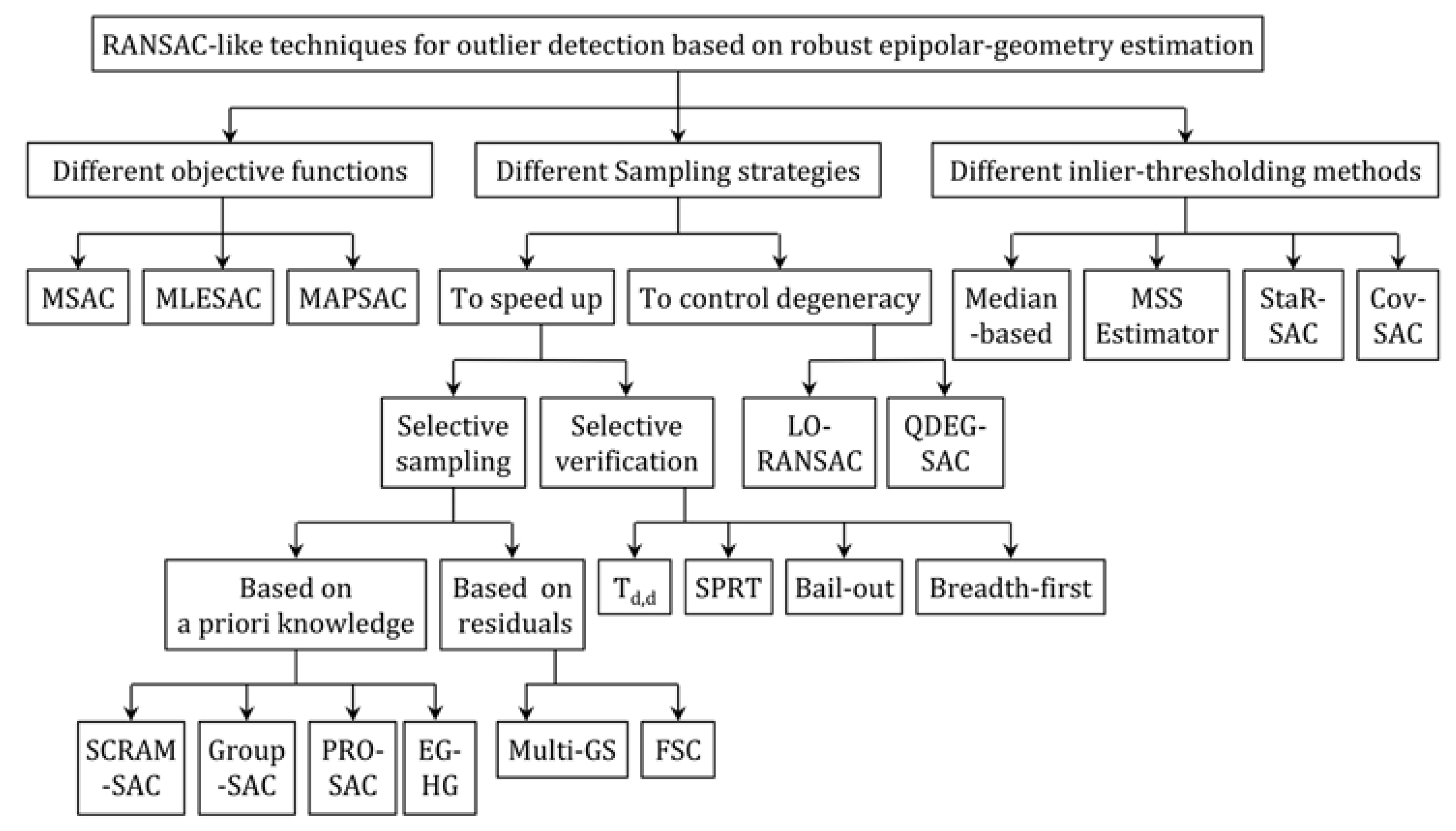
Figure 1 presents the summary of the outlier detection techniques that are discussed in
Section 2. In addition to the techniques using epipolar geometry, several methods are based on other spatial criteria, such as the distribution of parallax values [
10,
11], spatial patterns of outliers [
12], orientations of the lines connecting inliers [
13] and two-way spatial order differences [
14]. However, such methods use spatial consistency measures that are less general and valid for specific imaging configurations.
In this paper, we also focus on the problem of outlier detection based on the robust estimation of epipolar geometry. To this end, we use the integer-coded genetic algorithm (GA) followed by an adaptive inlier-classification method. The proposed technique can be considered as an extension and generalization of RANSAC-like methods for handling a high percentage of outliers, varying amounts of noise and degenerate configurations. This technique has the following distinctive characteristics. First, random sampling is replaced with an evolutionary search. The evolutionary search brings a significant advantage: new sample sets are generated considering the feedback information obtained by evaluating previous sample sets. Second, a guided sampling scheme based on the spatial distribution of the correspondences is proposed and applied to the evolutionary search. This sampling scheme increases the robustness of the solutions against degenerate configurations and local optima without requiring additional computation or prior information about the matches. Third, the objective function of robust estimation is not defined based on the support cardinality, but the robust least trimmed sum of squared residuals is used instead. Therefore, there is no need to successively set a threshold at any iteration for detecting the support of the estimated model or to assume any specific probability distribution for outlier/inlier residuals. Finally, to identify all of the inliers, a detection method based on adaptive thresholding is proposed, as opposed to using a fixed threshold. In this approach, the uncertainty of the estimated model is taken into account to identify all of the inliers correctly.
The rest of the paper is organized as follows. In
Section 2, a review of the techniques of robust epipolar-geometry estimation is presented. The main problem of simultaneous inlier detection and epipolar-geometry estimation is formulated in
Section 3.
Section 4 describes the solution using the genetic algorithm, which is followed by the method of detecting all of the inliers. The experimental results are discussed in
Section 5, and the conclusion is presented in
Section 6.
2. Related Works
Random sample consensus (RANSAC) techniques are popular approaches in fields of robust estimation [
15]. RANSAC is a method to estimate the parameters of a mathematical model from a set of observations that contain outliers, assuming that the quality of the model and the observations are inter-dependent. More precisely, RANSAC aims at determining the optimal model from an outlier-free sample set of correspondences by maximizing the support size of the model. The inliers that support the model are detected as correspondences whose residuals from the estimated model are less than a given threshold. To find an outlier-free sample set, successive random sampling is performed. To ensure, with probability
p, that at least one outlier-free set of
m correspondences is drawn from a dataset containing
percent of inliers, at least
k sample sets should be drawn such that
. This also means that within RANSAC, approximately,
good models are generated before the confidence
p is achieved.
By this definition, six major questions are involved in RANSAC-like techniques. (i) Is maximizing the support cardinality a robust objective function when no information about the rate of the outliers is available? (ii) How does one handle a large number of required samples in cases where is very small? (iii) Why does the algorithm not take advantage of the probability of generating good hypotheses before reaching the termination criterion; i.e., why not include the feedback of previous samples in the sampling procedure? (iv) How can the robustness of the estimated model be ensured against the influence of noise since it is relying on a minimal (just enough) subset of inliers? (v) How does one control the effect of degenerate sample sets, which naturally maximize the support cardinality? (vi) Does the threshold used to detect the inliers reflect the uncertainty of the estimated model as well? Some of these questions are answered by different variants of RANSAC, which are discussed here.
Unlike the standard RANSAC, there are improved variants, which use robust objective functions to determine the support cardinality. In m-estimator sample consensus (MSAC), inliers are scored based on their fitness, and outliers are scored with a non-zero constant penalty [
16]. Maximum likelihood estimation sample consensus (MLESAC) maximizes the log-likelihood of the solution via the RANSAC process by assuming that outliers are distributed uniformly and residuals distribute a Gaussian function over inliers [
17]. Maximum a posterior estimation sample consensus (MAPSAC) is also a refined version of MLESAC with Bayesian parameter estimation [
18]. These objective functions make models with similar inlier scores more distinguishable. However, they make certain assumptions about the distribution of the residuals either for inliers or outliers. Besides, they still score the models and detect the final inliers by applying a hard threshold to the residuals. Generally, this threshold is determined from the standard deviation of the residuals themselves. Assuming that the noise in data points follows a Gaussian distribution
and that the residuals are expressed as point-model distances, then the residuals follow a Chi-square distribution. Therefore, the threshold can be expressed as
, where
is the cumulative Chi-square distribution with one degree-of-freedom at probability
p as the fraction of the inliers to be captured (e.g.,
). However, this assumption is valid when ignoring the uncertainty of the model itself. Besides, estimating the standard deviation
at any RANSAC iteration is another problem. One of the most common methods is to estimate this variable from the median of the residuals on the potential inliers that support the best tentative model. Therefore, it might not be robust against outliers [
19]. Another method is to determine a Gaussian distribution fitting to the smallest residuals in the dataset (modified selective statistical estimator (MSSE) by [
20]). While this method is more robust against outliers, it is sensitive to the distinction of inliers from outliers. One strategy to eliminate the requirement of a fixed threshold is to run RANSAC several times using a range of pre-determined thresholds (the stable random sample consensus (StaRSAC) method by [
21]). However, depending on the range of the thresholds to be tested and the number of RANSAC executions, this strategy can be computationally exhaustive. In the RANSAC with uncertainty estimation (Cov-RANSAC) algorithm, the uncertainty of the model estimated from the minimal sample set is used to determine a subset of potential inliers, to which the ordinary RANSAC is applied afterwards [
22]. However, the uncertainty of the estimated model highly depends on the uncertainty of the configuration of the points appearing in the minimal sample set.
The sampling strategy in RANSAC is also an important factor, as it influences the algorithm efficiency with respect to both the number of RANSAC iterations and degeneracy (Degeneracy in robust epipolar-geometry estimation occurs when one or more degenerate configurations exist in the scene. This usually happens when the majority of the correspondences belong to a dominant plane in the scene and the rest of the correspondences are not on the plane (planar degeneracy), or when the correspondences belong to a very small region of an image (ill-configuration).) of the estimated model. There are several methods to control each of these two factors. The main contributions in this regard are discussed here. To control the speed of the algorithm, two strategies can be applied. The first strategy is to enforce an initial consistency check to filter the putative correspondences. This consistency can be measured as the fraction of neighbouring features in a region around a point in one image whose correspondences fall into the similar region in the other image (Spatially Consistent Random Sample Consensus (SCRAMSAC) method by [
23]). This strategy is sensitive to the region size and the threshold used to define the spatial consistency. Alternatively, sampling can be guided by keypoint matching scores (Progressive Sample Consensus (PROSAC) method [
24], Efficient Guided Hypothesis Generation (EGHG) method by [
25]). However, such a strategy is not effective when foreground motion happens. In addition, the scenes with repetitive textures may result in many false matches with high matching scores. Another example of such strategies is to assume that correspondences have a natural grouping structure, in which some of the groups have higher inlier probability than others (the GroupSAC method by [
26]). However, finding a meaningful and efficient grouping among the correspondences is itself a concerning challenge in different applications.
The strategies mentioned so far mostly require supplementary information about the scene or the matches. Comparatively, guided sampling based on the information from sorted residuals can be used to accelerate the hypothesis generation while avoiding any application-specific ordering or grouping technique (Multi-Structure Hypothesis Generation (Multi-GS) by [
27]). In this method, sampling is guided towards selecting the points that are rising from the same structure. This strategy speeds up the procedure to reach an outlier-free sample set. However, this method causes more computational complexity, since every point in the hypothesized sample set should be compared against all of the other points in the dataset in order to determine its intersection (in terms of structure) with them. The fast consensus sampling (FCS) method based on the residuals is developed by [
28]. In this method, proposal probabilities are calculated for the correspondences based on their normalized residuals and a concentration score. Although this method accelerates the sampling, it is still sensitive to degeneracy, image noise and uncertainty of the model estimation. This is due to the fact that it reduces the number of potential inliers by thresholding the proposal probabilities that are, themselves, dependent on the robust estimation of normalized residuals. Several studies have attempted to apply evolutionary algorithms instead of the random search [
29,
30]. Although promising results were achieved, several limitations were not addressed yet. For instance, their objective functions still require a hard threshold to distinguish outliers from inliers; the two-dimensional spatial configuration of the correspondences is ignored; the uncertainties of the estimated model are not taken into account; and the experiments are limited to small datasets. Genetic Algorithm Sample Consensus (GASAC) is also another technique that is, to the best of the authors’ knowledge, the most similar technique to the one proposed in our study. The difference of GASAC from typical RANSAC is that the random sampling is replaced with evolutionary search based on classic genetic algorithms (genetic algorithms are meta-heuristics inspired by biological evolution, which are used for solving optimization problems by relying on evolutionary search operators) [
31]. This study shows that the computational cost could be sped up 13-times by applying the evolutionary search instead of the random one. However, according to their report, the technique is applicable to small datasets with less than 50% outliers; the objective function is still based on support cardinality; and it introduces no solution to avoid local optima (such as degeneracy). The second strategy proposed in the literature in order to speed up RANSAC is to reduce the solution space by only verifying the hypotheses with a higher probability of being optimal. These highly probable hypotheses can be selected by a
test [
32], a bail-out test [
33] or a sequential probability ratio test (SPRT) [
34,
35]. In addition, the hypothesis verification can be performed preemptively in a breadth-first manner only for a fixed number of sample sets [
36]. These techniques may increase the number of required hypotheses, as good models may wrongly be rejected by not being verified completely.
It has been observed that, in the case of degenerate configurations, RANSAC-like algorithms result in a model with a very large support, while it is completely incorrect. This behaviour can be explained by the fact that a high inlier support can be obtained even if the sample set includes some outliers and at least five inliers that belong to a dominant plane or to a very small area of the image. This large support causes the termination of RANSAC before a non-degenerate outlier-free sample set can be picked up [
37]. The main strategy to control the degeneracy of solutions is to re-investigate the support of the best tentative model either locally or globally. For instance, the support of the best model can be re-sampled, and the model estimated from those subsamples can be compared to the best one to find out the degenerate models (the Locally Optimized Random Sample Consensus (LO -RANSAC) method by [
38]). Another example of such strategies is the Quasi Degenerate Sample Consensus (QDEGSAC) (proposed by [
39]), where a hierarchical RANSAC is performed by changing the number of the parameters in the model and verifying it over the entire dataset. The main issue concerning these techniques is that they cause additional operations, as a separate mechanism is added to the original RANSAC; i.e., they do not directly handle degeneracy in the sampling process. Universal RANSAC (USAC) is also a modular fusion of some of the mentioned RANSAC algorithms, including PROSAC sampling, SPRT verification and LO-RANSAC local optimization [
40]. In general, its performance is better than any of the single modules integrated into the universal implementation. However, it does not improve any of the modules individually.
To conclude, in most variants of RANSAC, the termination criterion is decided based on the size of the maximum consensus set found, which itself depends on the methods of threshold selection. These methods usually ignore the effect of the uncertainties of the estimated models caused by noisy image observations and spatial configurations of the matches in the minimal sample sets. Most RANSAC algorithms require extra operations or validations to increase the robustness of the results against degenerate configurations, and finally, they do not provide an explicit solution to maximize the accuracy of inlier detection.
5. Experimental Results and Discussion
To demonstrate the efficiency of our algorithm and its individual components, we performed several experiments on simulated and real data. The variables that are tested with these experiments include: (i) the performance of our sampling scheme; (ii) the accuracy of our adaptive thresholding method for inlier classification; (iii) the effect of GA population size on the performance of the algorithm and (iv) the performance of the overall algorithm under different levels of noise, outliers and degeneracy.
Table 1 summarizes the criteria used to assess these variables.
The experimental results obtained from the proposed technique are compared with those of the following state-of-the-art techniques: RANSAC, MSAC, MLESAC, LO-RANSAC (Lebeda et al., 2012), StaRSAC, Cov-RANSAC, Multi-GS-RANSAC and least median of squares (LMedS). Note that for implementing these techniques, the programs were prepared by the authors of this manuscript except for the following ones. The MATLAB built-in computer-vision toolbox was used for LMedS. For measuring the uncertainty of the fundamental matrix in Cov-RANSAC, the code was provided by the original authors [
54]. The code for Multi-GS sampling was also provided by the authors [
27].
5.1. Experiments on Synthetic Data
Several synthetic datasets were used to evaluate the performance of our algorithm. Using the synthetic data allowed us to control the imaging geometry, the fraction of outliers and the image noise. Besides, it let us assess the accuracy of inlier detection and model estimation in comparison with the ground-truth. Instead of creating random correspondences without having any particular geometric or physical form, real 3D point clouds were used to generate synthetic images. The synthetic outliers were produced in a relatively small range of error because large gross errors can be easily detected by statistical tests. Thus, we are interested in testing the performance of the proposed method in dealing with medium ranges of errors (smaller than 40 pixels). The synthetic datasets are described in
Table 2. Different scenarios were chosen to cover diverse real-world cases including close-range and aerial photography, narrow and wide baselines and degenerate configurations. The following paragraphs briefly explain the reasons for which each dataset was selected for these performance tests.
The Table dataset: This is mainly generated to simulate a degenerate configuration, where a large number of correspondences is located on a planar object. Therefore, the performance of the sampling technique under degeneracies (
Section 5.2.1) was tested on this dataset.
The Church dataset: This does not have any degenerate configurations. This close-range stereo-pair contains a small number of correspondences, which allows the application of the Multi-GS-RANSAC method. Furthermore, a low level of noise is simulated, which is usually the case of close-range images with static imaging platforms. The relative orientation of two cameras is quite challenging from the photogrammetric point of view (a narrow baseline and large relative rotations). Therefore, the performance of the sampling technique under varying outlier ratios (
Section 5.2.2), the stability and the effect of GA population size were tested on this dataset.
The Urban dataset: This represents the case of aerial imagery, where the level of image noise is considerably higher compared to close-range imagery. The lower spatial resolution of the images and the motion blur caused by movements of an airborne platform are the main reasons to make such an assumption. Therefore, this dataset was used to test the performance under various noise levels.
The Multiview dataset: This dataset was designed to be unbiased and representative of general photogrammetric applications. This dataset includes stereo images with short, long and moderate base-lines. There is no specific degenerate configuration or any particular structuring pattern in the scene. Some of the images are simulated at very low altitudes (similar to close-range imagery), while the others are at higher altitudes (similar to aerial imagery); this also causes high variations of scale across the images. Therefore, the performance under various outlier ratios (
Section 5.4) was tested on this dataset. The results obtained from the StaRSAC method were not represented in the graphs of
Section 5.4 since they were not as good as the results of the other methods, and their representation would have caused mis-scaling of the graphs. The Multi-GS-RANSAC was not tested on this dataset since most stereo pairs contained thousands of correspondences, the processing of which with Multi-GS would have been too time consuming.
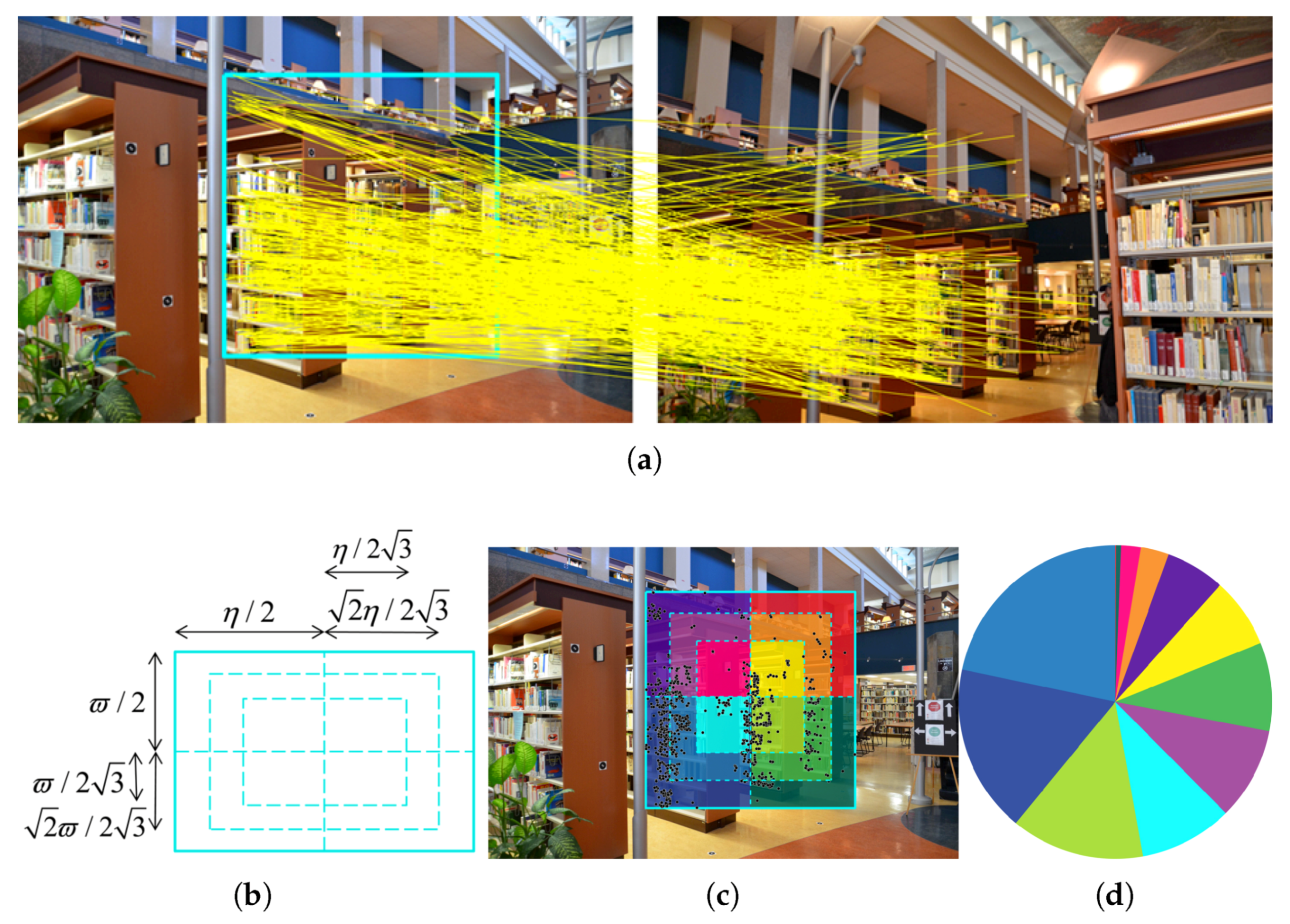
Furthermore, a stereo pair from this dataset with a large number of matches (4510 matches) and a low level of noise was used to test the performance of inlier classification (
Section 5.3). There is no specific structuring pattern in this stereo pair. Furthermore, there is no challenge or complexity regarding the relative poses of the cameras; i.e., the baseline is neither too short, nor too long, and the relative rotation between images includes yaw differences only.
5.2. Performance of the Guided Sampling Technique
5.2.1. Performance under Degeneracies
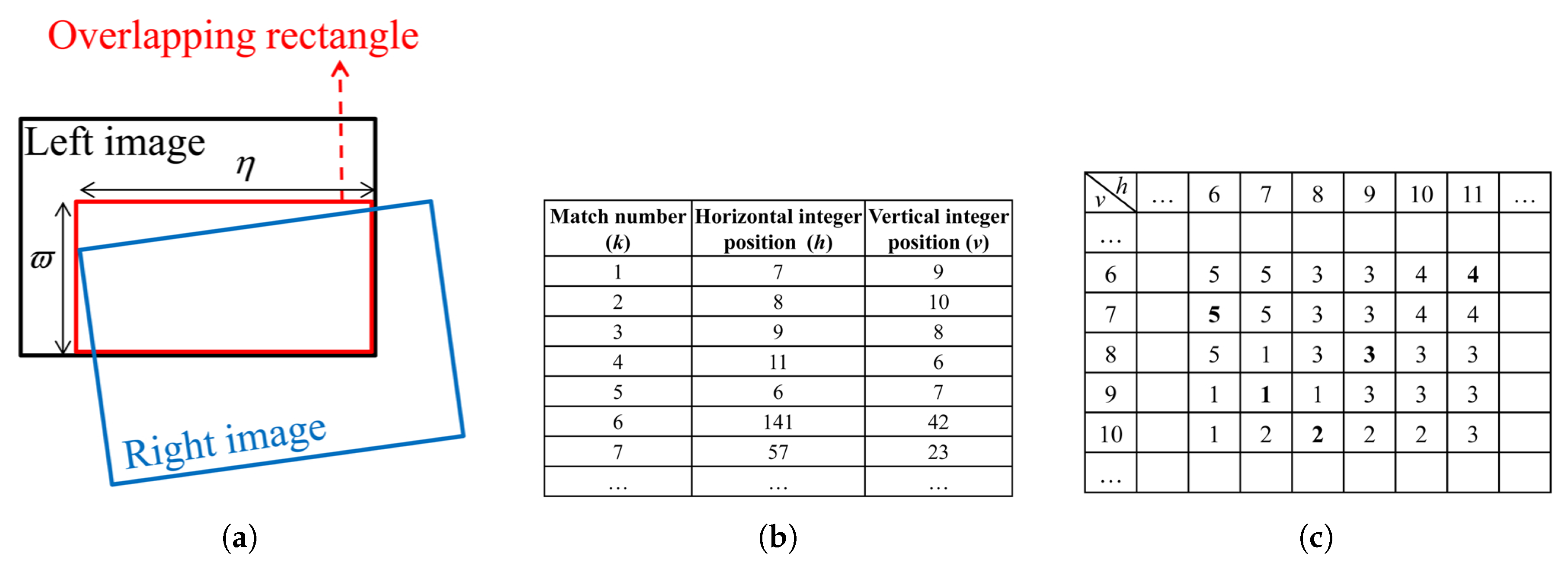
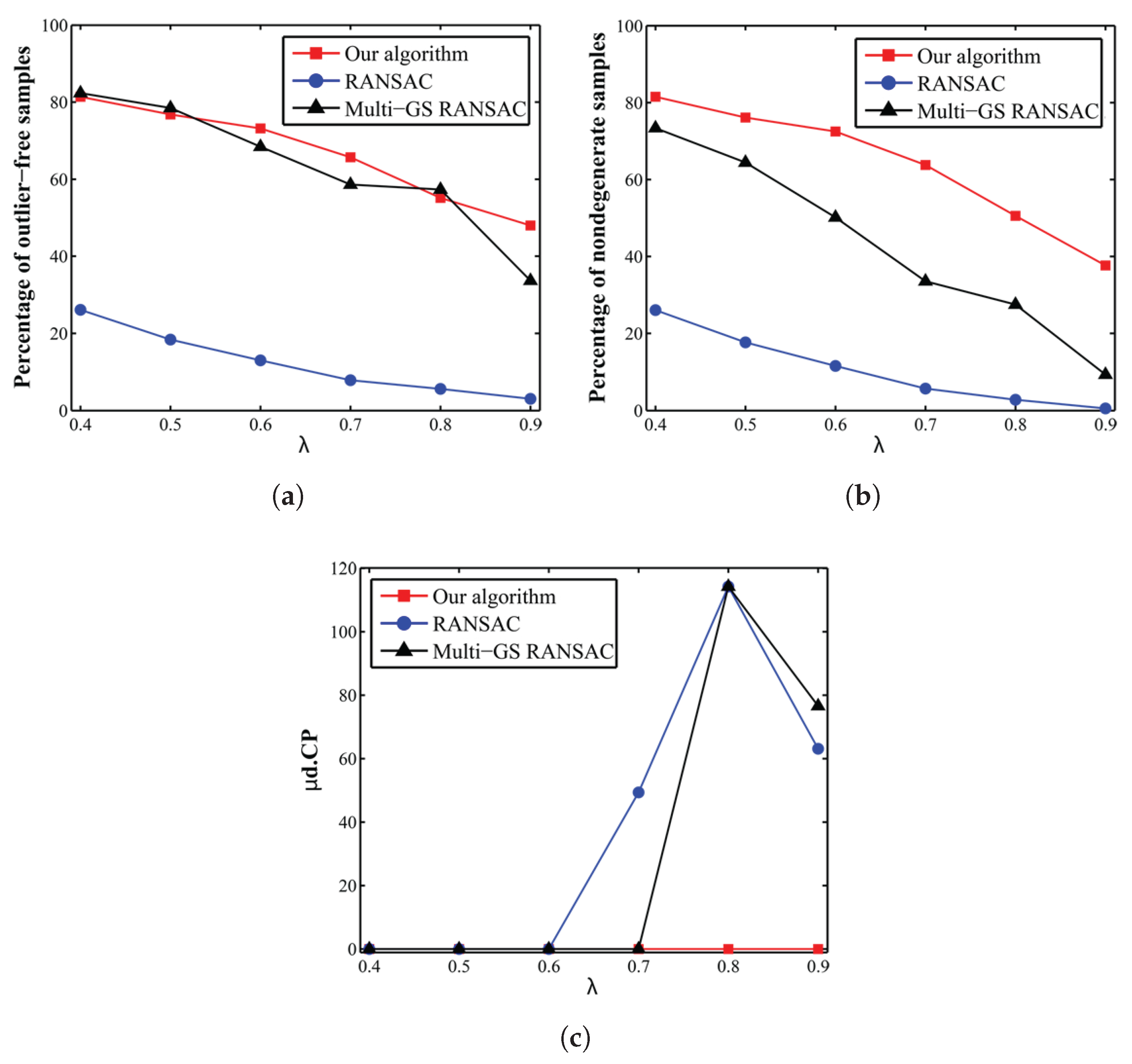
To verify the efficiency of our sampling algorithm to avoid planar degeneracy, the Table dataset was used. In each instance of these data, 258 synthesized correspondences were placed on the surface of the monitor, and the number of matches from other objects of the scene was varied to get the ratio
. For instance, at
, the total number of correspondences was 645, from which 258 correspondences were located on the monitor plane. It should be noted that synthetic images were captured so that all of the objects of the scene were visible in the images, and the monitor plane only occupied a small area in each image. For any instance of the dataset at different ratios
, we limited the total number of hypotheses to 1000 and compared the results of our method with those of RANSAC and Multi-GS-RANSAC. That is, each algorithm was stopped when exactly 1000 sample sets were drawn. This limited number of sample sets is approximately six-times more than the theoretical number of sample sets for achieving 95% probability of drawing at least one outlier-free random sample set from the data containing 40% outliers, which is the maximum outlier ratio in the dataset instances. The performance criteria used for this experiment were (i) the percentage of outlier-free (an outlier-free sample set is a set of matches where all of the matches are inlier) sample sets among the 1000 sample sets; (ii) the percentage of non-degenerate (a degenerate sample set (due to planar degeneracy) has more than five points from the dominant plane (in this example, the monitor plane); see
Section 2) and outlier-free sample sets among the 1000 sample sets that we denote as non-degenerate sample sets for simplicity and (iii) estimation accuracy (
). The medians of the results obtained after five trials are represented in
Figure 4.
The proposed algorithm drew up to 75-times more outlier-free sample sets in comparison with RANSAC within a limited budget of 1000 sample sets (
Figure 4a). The percentages of outlier-free samples for our algorithm and Multi-GS-RANSAC were very close. This showed that the Multi-GS sampling strategy performed well in the absence of degeneracy. However, Multi-GS sampling failed to draw non-degenerate sample sets as the ratio
increased (
Figure 4b). For ratios higher than
, both RANSAC and Multi-GS-RANSAC failed to estimate the model correctly (
Figure 4c), while the proposed algorithm estimated the model robustly even in the presence of serious degeneracy (
).
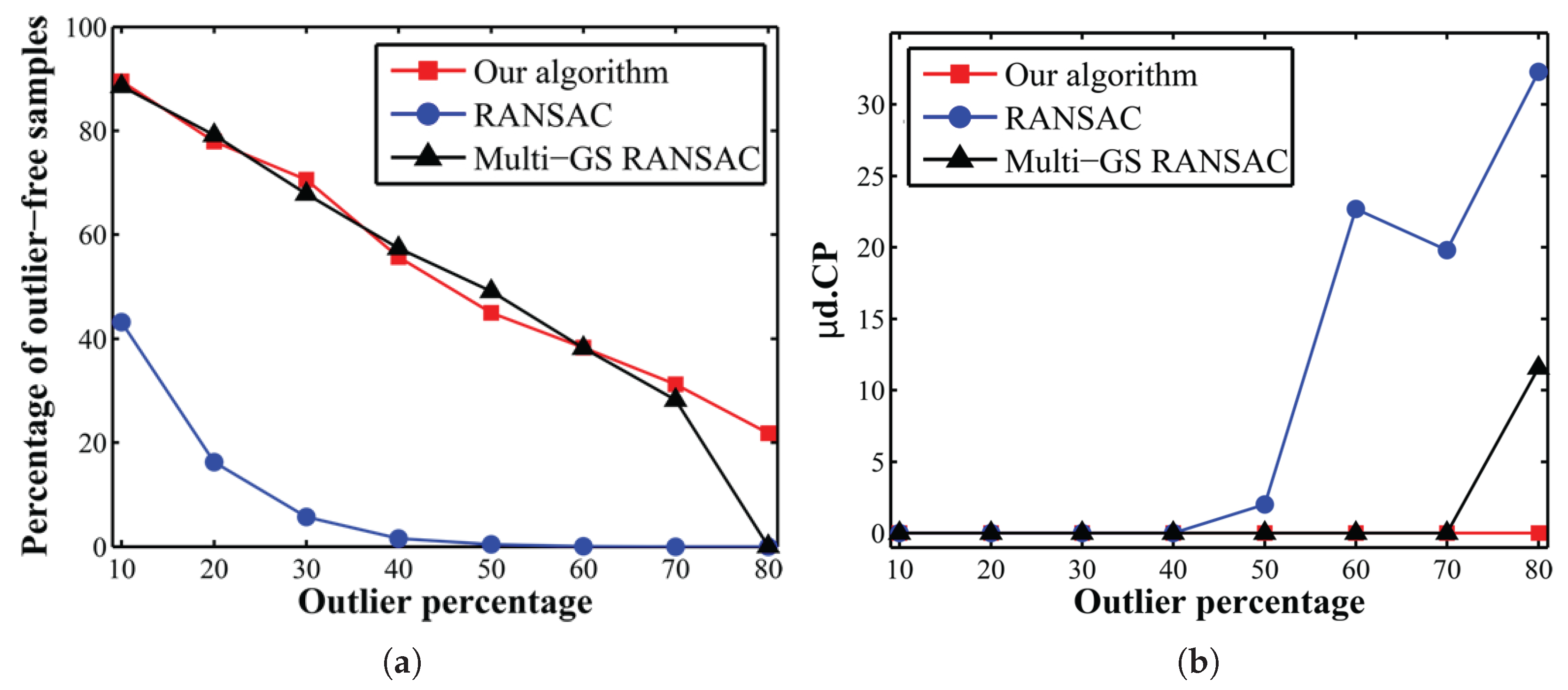
5.2.2. Performance under Varying Outlier Ratios
A similar test was performed to assess the performance of the sampling algorithm under various ratios of outliers. To this end, the Church dataset was used. The limited sampling budget was set to 1000 and 5000 sample sets for outlier rates less than or equal to 50% and higher than 50%, respectively. The percentage of outlier-free sample sets among the budgeted sample sets (either 1000 or 5000) and the estimation accuracy (
) are presented in
Figure 5.
For most of the outlier ratios, the outlier-free sampling rates of the proposed algorithm and those of Multi-GS were very close. RANSAC drew quite less outlier-free sample sets in comparison with the other two methods. For outlier ratios higher than 50%, RANSAC completely failed to detect outlier-free sample sets and to estimate the model correctly. For an outlier ratio of 80%, only the proposed algorithm kept good performance by drawing at least 22% outlier-free sample sets, given the limited sampling budget. As a conclusion, the sampling strategy based on the spatial distribution of correspondences along with the evolutionary search not only increased the speed of reaching an outlier-free sample set, but also decreased the probability of ending up with a degenerate solution.
5.3. Performance of Inlier Classification with Adaptive Thresholding
In order to verify the performance of the proposed thresholding method for inlier classification (
Section 4.4), a stereo pair from the Multiview dataset at the baseline of 20 m was used. To eliminate the effect of other components of the algorithm, such as sampling and the objective function, no outlier was introduced to the images; i.e., the dataset was outlier-free. The results from our method were compared with those of the median-based and covariance-based algorithms. To this end, each algorithm was applied 500 times. In any trial, a minimal sample set of eight points was randomly drawn, and the fundamental matrix was estimated with the normalized eight-point algorithm. For our algorithm, the technique of
Section 4.4 was applied to determine the inlier thresholds. For the median-based algorithm, the robust standard deviation of residuals was defined as
. Since the dataset was outlier-free,
n was equal to the total number of matches, and
was the residual of any correspondence with respect to the estimated fundamental matrix. Then, the inlier threshold was calculated as
. For the covariance-based algorithm, which is the core component of Cov-RANSAC, first, the uncertainty of the estimated model was used to narrow down the total set of matches to the set of potential inliers. Then, the median-based algorithm was applied to the potential inliers for determining the inlier threshold.
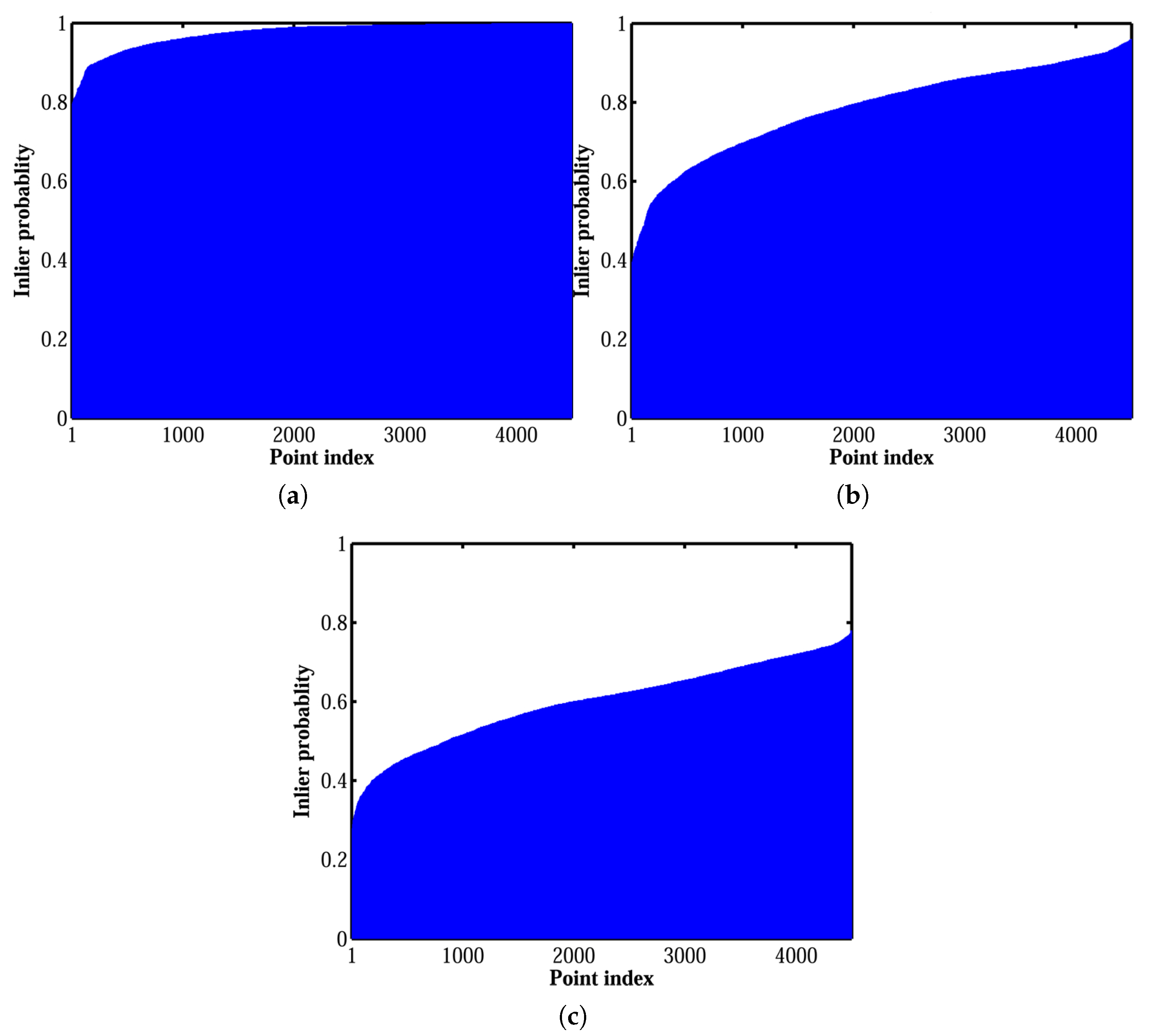
In order to evaluate the performance of these algorithms, the fraction of runs (from a total of 500 runs) in which a correspondence was classified as inlier was calculated, namely the inlier probability of that match. The inlier probabilities (sorted in ascending order) are shown in
Figure 6. Knowing that the dataset was outlier-free, the inlier probability for all of the points was ideally one. Our thresholding algorithm resulted in the most stable and robust solutions. That is, for 92% of the points, the inlier probability was higher than
. For the median-based algorithm, this percentage was only 15%. The covariance-based algorithm had poor performance in comparison with both of the other methods. Our algorithm resulted in inlier ratios higher than 90% for more than 88% of the runs. However, the median-based and covariance-based algorithms yielded inlier ratios greater than 90% at only 32% and 15% of the runs, respectively.
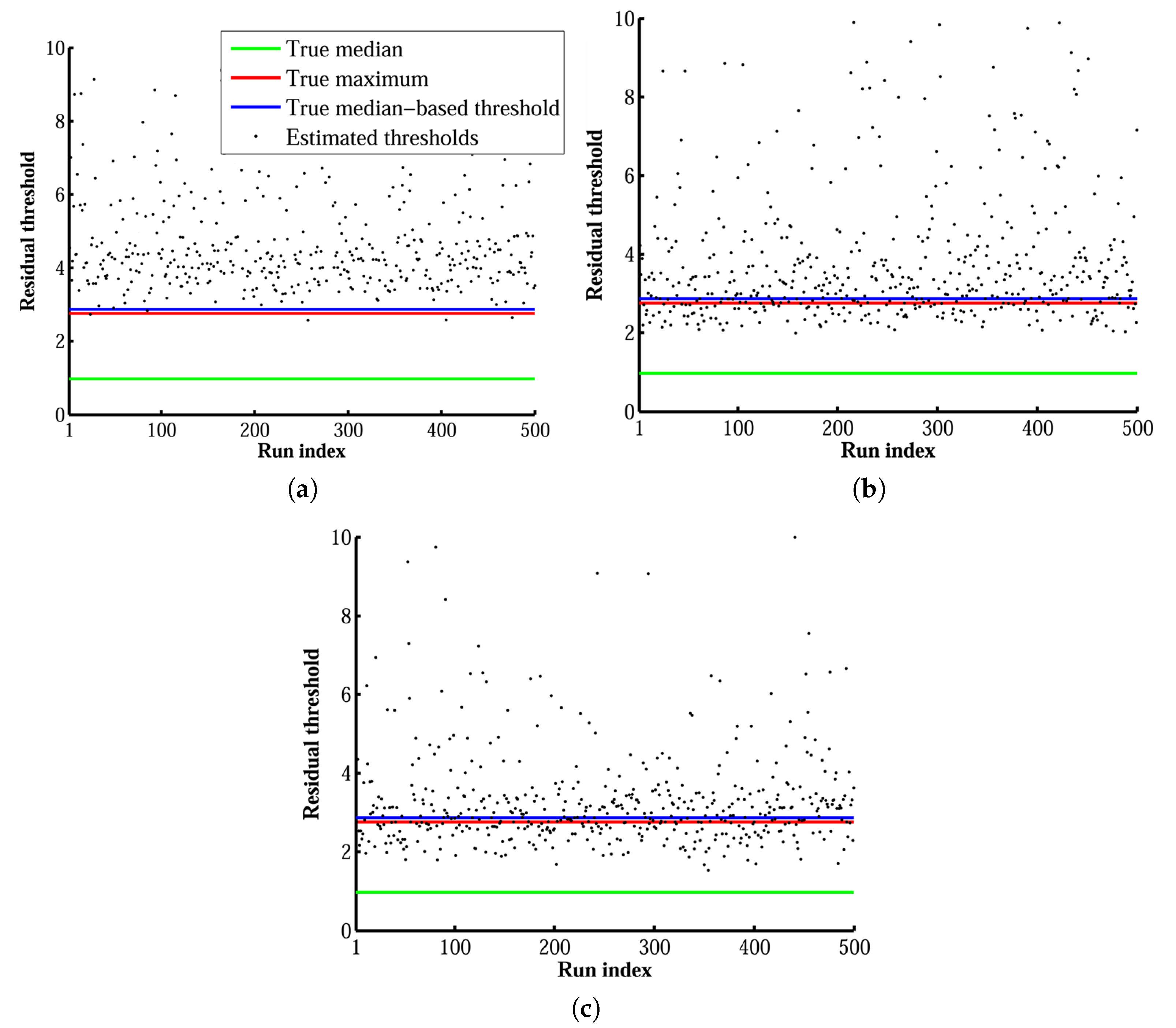
To investigate the reason behind the performance of each algorithm, the threshold values determined at each run are illustrated versus the run index as black points in
Figure 7. Then, the true residuals, which are residuals of the matches from the true fundamental matrix, were calculated. Note that the true fundamental matrix is the one based on which the matches are synthesized. The maximum and the median of the true residuals are shown in
Figure 7 as the red and green lines, respectively. Then, the parameter
using true residuals was used to calculate the true median-based threshold. The blue line illustrates this value in
Figure 7.
The true median-based threshold was slightly higher than the true maximum residual, and it would be an ideal choice of threshold only if the fundamental matrix were perfect. However, in these tests, the fundamental matrix was calculated from a minimal sample set of eight correspondences, which had different values of noise and did not necessarily have an ideal spatial configuration either. Because of the uncertainty of the fundamental matrix and the noise value of the points participating in the estimation of the fundamental matrix, the threshold value should be larger than the ideal one to detect all of the inliers correctly. Although the covariance-based method tried to consider this effect, it underestimated the potential inliers. The main reason was that the uncertainty of the fundamental matrix was estimated only from the minimal sample set. As shown in
Figure 7, our algorithm calculated the threshold adaptively. Frequently, the estimated threshold value was slightly higher than the ideal median-based threshold. This was reasonable since the calculated fundamental matrix, although determined from an outlier-free sample set, was not necessarily perfect. However, for the other two methods, the threshold values were approximately around the true median-based threshold, which could be suitable threshold values only if the estimated fundamental matrices were as accurate as the true one.
5.4. Performance under Various Outlier Ratios
To assess the performance of the overall algorithm under different ratios of outliers, the Multiview dataset was used. In the following experiments, the stall generation of the GA was set to 60. The upper bound to the standard deviation of image noise (
) was set to three pixels. The GA population size was set to 27. The parameter
was set to
in all of our experiments. The algorithm was implemented in the MATLAB environment directly without using its optimization toolbox. The average of the results over all of the stereo pairs versus the outlier ratios are presented in
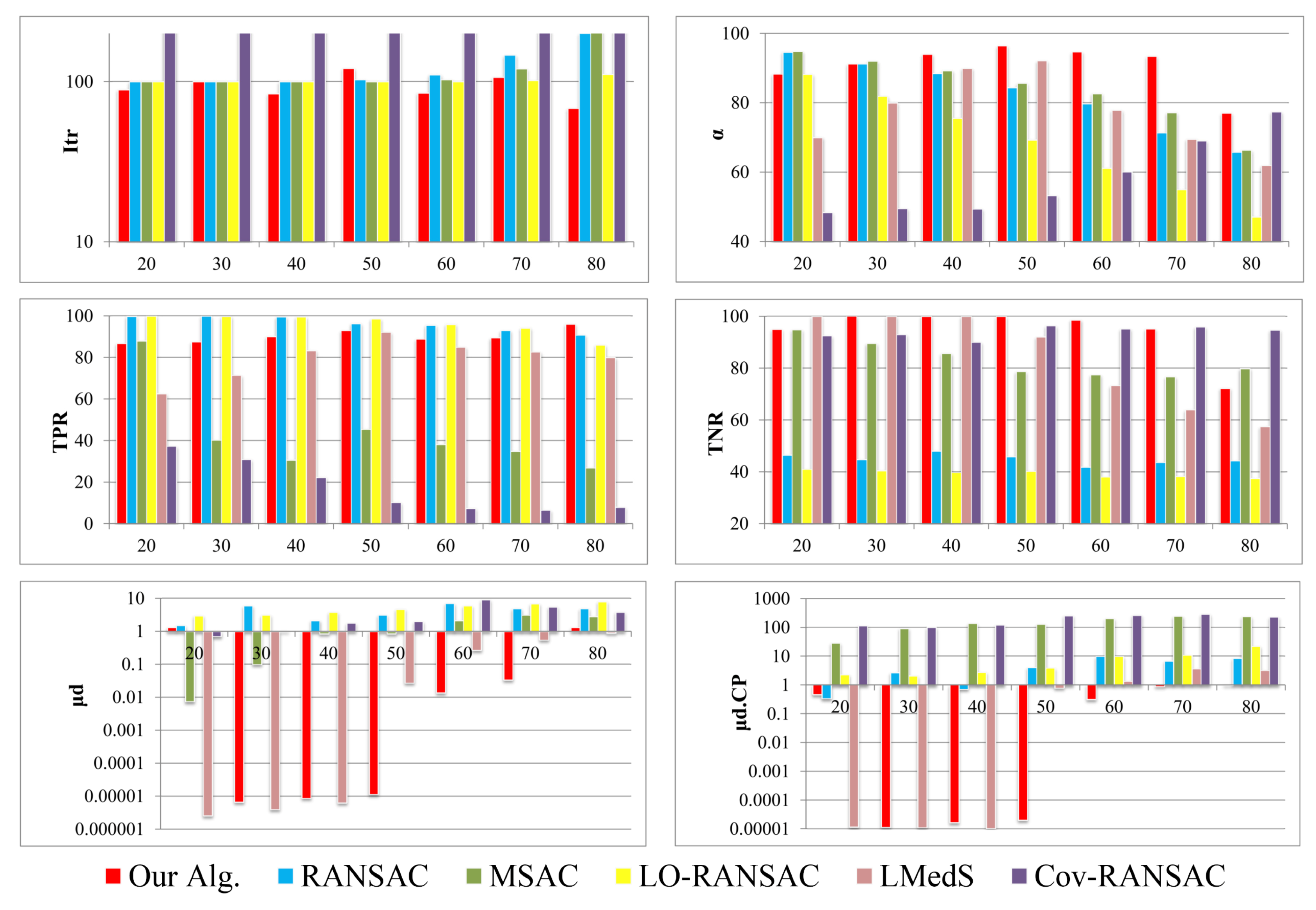
Figure 8.
The results can clearly illustrate the performance of the proposed algorithm. For instance, to reach 95% accuracy in inlier detection from a dataset with 70% outliers, at least 45,658 sample sets must be drawn in random sample consensus. However, the proposed algorithm reached 95% accuracy by drawing only 2100 sample sets. Similarly, our algorithm achieved 78% accuracy over the 80% contaminated dataset with only 1440 hypotheses, while 591,455 random sample sets would be theoretically required to reach that accuracy. There was a combination of reasons caused by the evolutionary search and the sampling strategy that boosted this improvement. Furthermore, for all of the outlier ratios, the number of GA iterations was lower than other algorithms (average
Itr of 93). However, it should be noted that any iteration of GA corresponds to the maximum of 27 hypothesis generation. In the case of data with a low percentage of outliers, there are many correct solutions that each can be slightly fitter; such slightly fitter solutions may violate the termination criterion mentioned in
Section 4.3. Therefore, an additional condition based on the rate of improvement achieved by the new elites must be considered to avoid unnecessary iterations. One can use the following method; whenever the elite solutions of two generations have fitness values within 10% of one another, then the fitter solution should duplicate itself, and the less fit solution should be removed to ensure a low standard deviation over the stall generations.
From the accuracy point of view, the proposed algorithm was more robust to outliers in comparison with other algorithms, especially when the outlier percentage grew over 40%. On average, the proposed technique achieved 91% ± 6% accuracy for inlier detection. The considerably high estimation accuracy (average
of
) confirmed this, as well. The improvement obtained by the proposed algorithm was also evident regarding the true negative rate (average
TNR of 94%), which showed the efficiency of the algorithm to distinguish outliers from inliers.
Figure 8 also indicates that LMedS performs robustly for outlier ratios less than 50%. However, model estimation and, particularly, inlier detection for higher outlier rates is the bottleneck of this algorithm. The Cov-RANSAC resulted in better
TNR compared to our algorithm. However, the spatial configuration and the level of noise in the sampled points are ignored in this method. As a result, the estimation of model uncertainty becomes impractically too large or too small. Consequently, the number of inliers is usually over- or under-estimated. That is why this technique resulted in very low
TPR. .
5.5. Performance Stability
Another variable that should be tested under various outlier ratios is the stability of the results obtained by running the algorithm multiple times. To this end, the Church dataset was used. The algorithm was repeated 50 times for each instance of the data. For outlier ratios ranging from 10 to 70%, the variations of accuracy was not considerable ( = 99% 2%). However, at an 80% outlier rate, the average accuracy decreased to 92% ± 8%. Although this was a noticeable change in the performance of the algorithm, the median of the accuracies was yet reasonably high (95%). Regarding the number of models hypothesized before termination, a large range of changes was observed at lower outlier ratios. As explained earlier, this happened due to the stopping criterion in GA. However, this was itself an advantage for large outlier ratios (more than 50% outliers).
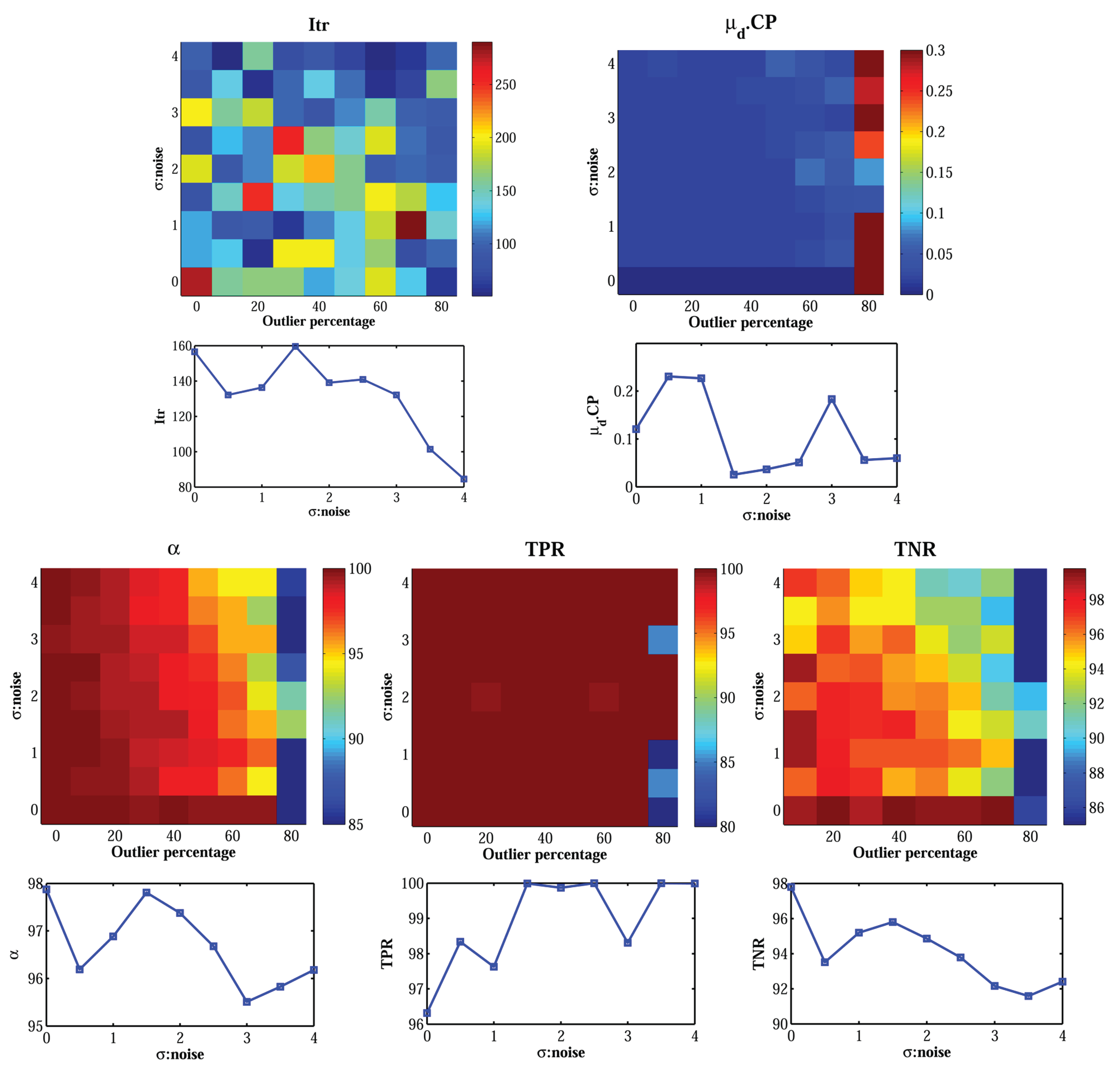
5.6. Performance under Various Noise Levels
The Urban dataset was used to evaluate the robustness of the proposed algorithm against noisy image observations. To this end, the effects of image noise along with varying percentages of outliers were tested using 81 instances of the Urban dataset. The results are illustrated in
Figure 9.
From the accuracy point of view, the accuracy of estimation (described by ) did not decrease by increasing the noise level. The different noise synthesized on putative matches varies between zero and four pixels. The robustness of the algorithm to noise means that the sample sets whose points have a lower level of noise can be recognized through the LTS-based objective function. Thus, the estimation of the fundamental matrix would be based on the least-noisy correspondences of the dataset. Regarding the accuracy of inlier detection, the true positive rate was not affected by the noise. However, the true negative rate decreased slightly by increasing the noise level. Since the outliers were synthesized by adding gross errors as low as 10 pixels to correspondences, distinguishing real outliers from noisy inliers at higher noise levels became a more difficult task, and the false positive rate increased. In terms of convergence speed, increasing the magnitude of image noise decreased the number of iterations. The total number of iterations required to find the final solution changed only from 80 to 250 as the ratio of outliers increased to 80% and the level of noise increased to four pixels. This shows the high computational efficiency of the overall algorithm in the presence of high ratios of outliers and noise.
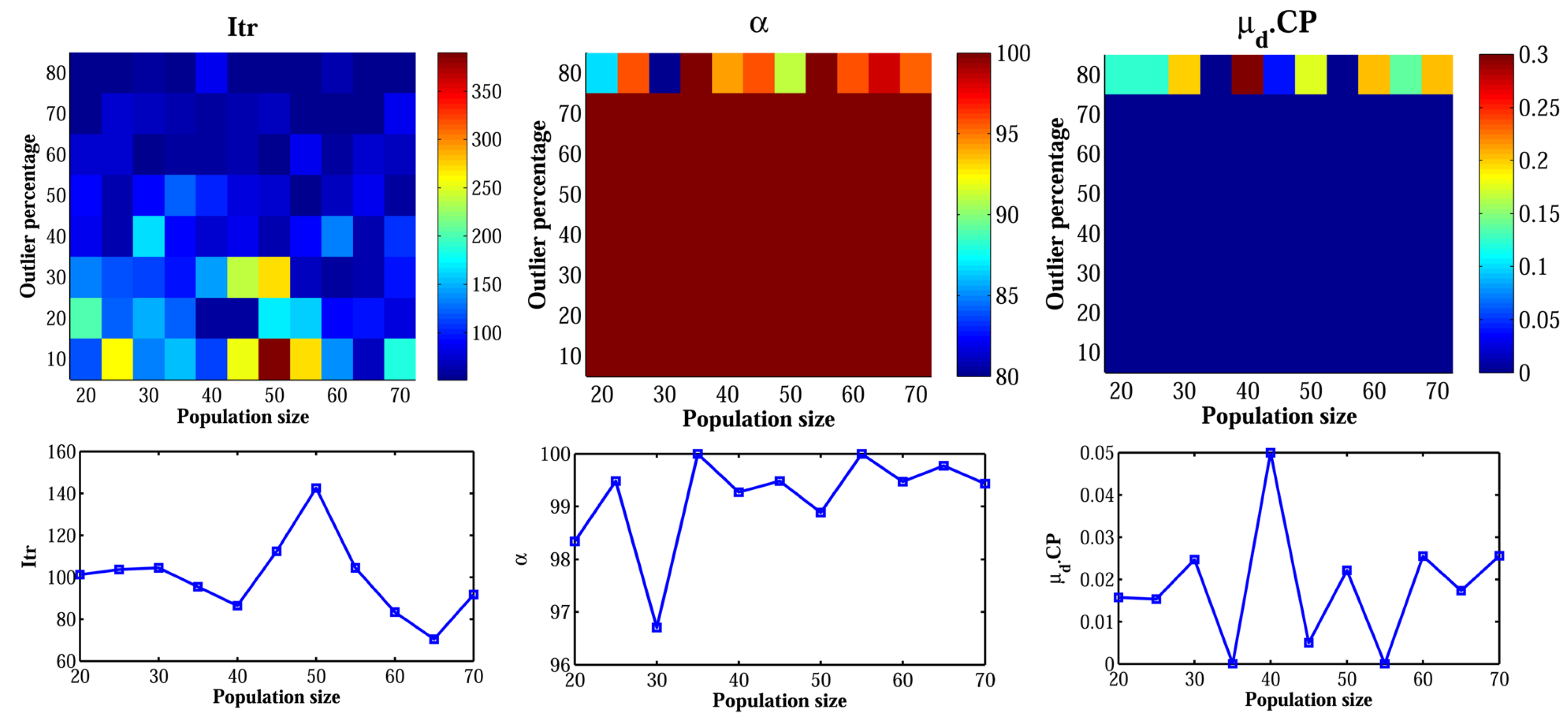
5.7. Effect of the GA Population Size
To evaluate the effect of GA population size on the performance of the algorithm, the Church dataset was applied. The GA population size was varied from 20 to 70 by steps of five individuals, and the performance of the algorithm was assessed under various outlier ratios. The results obtained from this experiment are illustrated in
Figure 10.
There was no considerable correlation between the accuracy and the size of the population. The average accuracy of inlier-detection () with different population sizes was % with a standard deviation of only %. The accuracy of estimation () also remained below , which confirmed the stable accuracy of model estimation. The number of iterations before termination (Itr) seemed to be more dependent on the outlier percentage rather than the population size. The average number of iterations at outlier ratios less than 50% was 122, while it was only 62 at higher outlier ratios. The number of generated hypotheses () increased by either decreasing the outlier ratio or increasing the GA population size, since it depended both on the population size and the number of iterations. Showing that the accuracy does not have any distinct correlation with the population size, the moderate size of the population is suggested to both avoid the unnecessary generation of hypotheses and to keep the number of iterations small.
5.8. Experiments on Real Data
The proposed algorithm of robust estimation and inlier detection was compared with other RANSAC-like techniques for 15 stereo pairs (
Table 3). These examples were chosen to cover various cases, such as close-range and aerial photography, narrow and wide baselines, degenerate configurations, scale variation, multi-platform photography and highly contaminated data. The first seven pairs and their putative matches were gathered from [
40]. For these data, the percentages of true inliers in the dataset (
) were manually determined in the reference article. For the 8th, the 9th and the 10th stereo pairs, we used signalized targets to provide ground control data when acquiring the images. The reference fundamental matrices were calculated from these control points. The 11th stereo pair belongs to the ISPRS datasets for urban classification
www2.isprs.org/commissions/comm3/wg4/detection-and-reconstruction.html. The 14th stereo pair belongs to the ISPRS benchmark for multi-platform photogrammetry
http://www2.isprs.org/commissions/comm1/icwg15b/benchmark_main.html [
55]. For these last two pairs, the exterior and interior orientation parameters provided by ISPRS were used as reference values for evaluation. For the last five stereo pairs, SIFT key points were detected and matched using the VlFeat
www.vlfeat.org feature-based matching library. For the second and the 12th stereo pairs, we could not apply Multi-GS, since the low inlier ratio and a high number of correspondences made that algorithm too slow to be executable.
It can be noticed from the results that our algorithm generally yielded solutions that were compatible with the ground-truth in terms of either inlier-detection accuracy or estimation accuracy. For the eight and the ninth images, a dominant plane existed in the scene. Therefore, most of the algorithms ended up with a degenerate solution. However, the degeneracy could be avoided quite efficiently by our algorithm. This was mainly due to the guided sampling based on the spatial distribution of matches. Finally, it was noticed that the algorithm had good performance in challenging cases such as multi-platform photography.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}



























