1. Introduction
Maintaining a healthy, stable forest to produce valuable wood requires fostering the forest. An essential technique to accomplish this is a silvicultural operation called thinning [
1]. The main objective of thinning is to regulate the vertical space of trees, thus steering the allocation of the available resources (e.g., sunlight, water, and nutrients) into the stems of remaining higher-quality trees [
2]. Although the primary objective of thinning is to prepare the forest stand for a final harvest, it also provides forest owners with the opportunity to obtain additional income by selling the removed trees [
3,
4,
5,
6].
Determining if a forest stand needs thinning is a complex task since it depends on many factors, such as soil quality and the composition of trees regarding age and species [
7]. This makes assessing a forest stand for the necessity of thinning a non-trivial task, and this is why the job is still mainly conducted by specialized forest personnel. Sending personnel into the field is often very expensive. Hence, thinning assessments are either not performed at all, as in the case of small forest owners, or carried out at long time intervals. Long time intervals might be sufficient for slowly growing sites; however, vital areas with high mean annual increments are often overlooked, which results in the sub-optimal timing of thinning in these stands.
Recently, the proliferation of the amount of and improvement in the quality of remote sensing data have made it possible to acquire uniform and detailed aerial information over large areas [
8]. Furthermore, with recent advances in sensor technology as well as computing power, there has been increased interest in applying algorithms for the automated extraction of forest parameters from remotely sensed spectral information [
9]. Aerial forestry data coupled with recent increases in computing power allow machine learning (ML) algorithms to be deployed for applications such as detecting changes in forests [
10,
11], classifying tree species [
12,
13,
14,
15], and estimating stand volume [
16,
17,
18].
Despite the high level of importance of the timely planning of forest operations, few studies have been conducted to predict the necessity of thinning from remote sensing data. There are only two known studies that addressed this challenge. First, ref. [
19] tried to predict forest operations at the stand level using Landsat satellite imagery with moderate success. Then, ref. [
20] employed ALS data-derived features to predict thinning maturity at the stand level. This study showed much better results, with classification accuracy ranging from 79% to 83% when predicting the timing of the subsequent thinning. Another approach to predicting the need for thinning is to utilize key forest parameters acquired through remote sensing, together with additional inventory data, to create statistical models [
21]. Nevertheless, ALS data are still expensive to obtain, and only a few countries acquire it systematically.
We used semantic segmentation to extract information about the need for thinning from widespread areal images as this method was successfully used for many remote sensing tasks [
22]. Semantic segmentation is a computer vision task where the algorithm labels each pixel or patch of an image according to a predefined range of classes. The utilization of end-to-end DCNNs for the task of semantic segmentation has increased greatly and was accelerated via the first end-to-end fully convolutional network (FCN) [
23]. Since the invention of this network type, many different architectures have been proposed and adapted to remote sensing applications [
24,
25,
26]. The main advantage of using DCNNs for semantic segmentation is their effectiveness in extracting complex features from wide receptive fields. Nonetheless, this capability comes with the price of not being able to maintain a high spatial resolution and results in inaccurate and blurred boundaries between the classes. To counteract this, newer DCNNs use more pronounced or distinct encoder–decoder architectures with skip connections. For example, UNet applies such skip connections in its symmetrical encoder–decoder architecture [
27], where the features extracted in the encoder are directly coupled to the corresponding decoder layers. The outstanding performance of this architecture, together with its simplicity, has ensured its widespread adoption in the remote sensing research community for a variety of applications, such as ship detection [
28], road extraction [
29], and land cover classification [
30].
Deeper DCNNs with more stacked layers were created to obtain models that can learn more complex input representations. However, these deeper DCNNs often resulted in worse-performing models than their more shallow predecessors due to the degradation problem [
31]. This issue was resolved using deep residual networks (e.g., ResNet) that employed residual blocks, which added an identity shortcut connection and overcame the degradation problem [
32]. The further development of DCNNs resulted in the creation of a network architecture called DenseNet, which utilizes dense blocks that introduce direct connections from any layer to all subsequent layers to further improve the flow of information between layers [
33]. Jegou et al. [
34] adopted the DenseNet connection structure for semantic segmentation by applying dense blocks to a UNet-like symmetric encoder–decoder structure. This merge resulted in a DCNN called FC-DenseNet, which required fewer input parameters while performing better on various semantic segmentation challenges.
Another compelling approach to resolving the trade-off between high-context extraction with heavy downsampling and accurate boundary prediction is the use of dilated or atrous convolutions. Atrous convolutions utilize a convolution filter that is spaced apart, thus allowing them to attain a wider field of view while retaining their spatial dimensions. Ref. [
35] proposed a DCNN architecture called DeepLabv1 that incorporates atrous convolutions into a VGG-16 architecture to address the trade-off between high-context extraction and heavy downsampling. Several revisions to this architecture occurred, including, among other things, the incorporation of the spatial pyramidal pooling method that was introduced in SPPNet [
36] and adopted by [
37] to create the atrous spatial pyramid pooling (ASPP) method used in DeepLabv2. The current network architecture, DeepLabv3+ [
38], provides some of the best results for semantic segmentation challenges. Furthermore, its use in remote sensing applications is auspicious. For example, ref. [
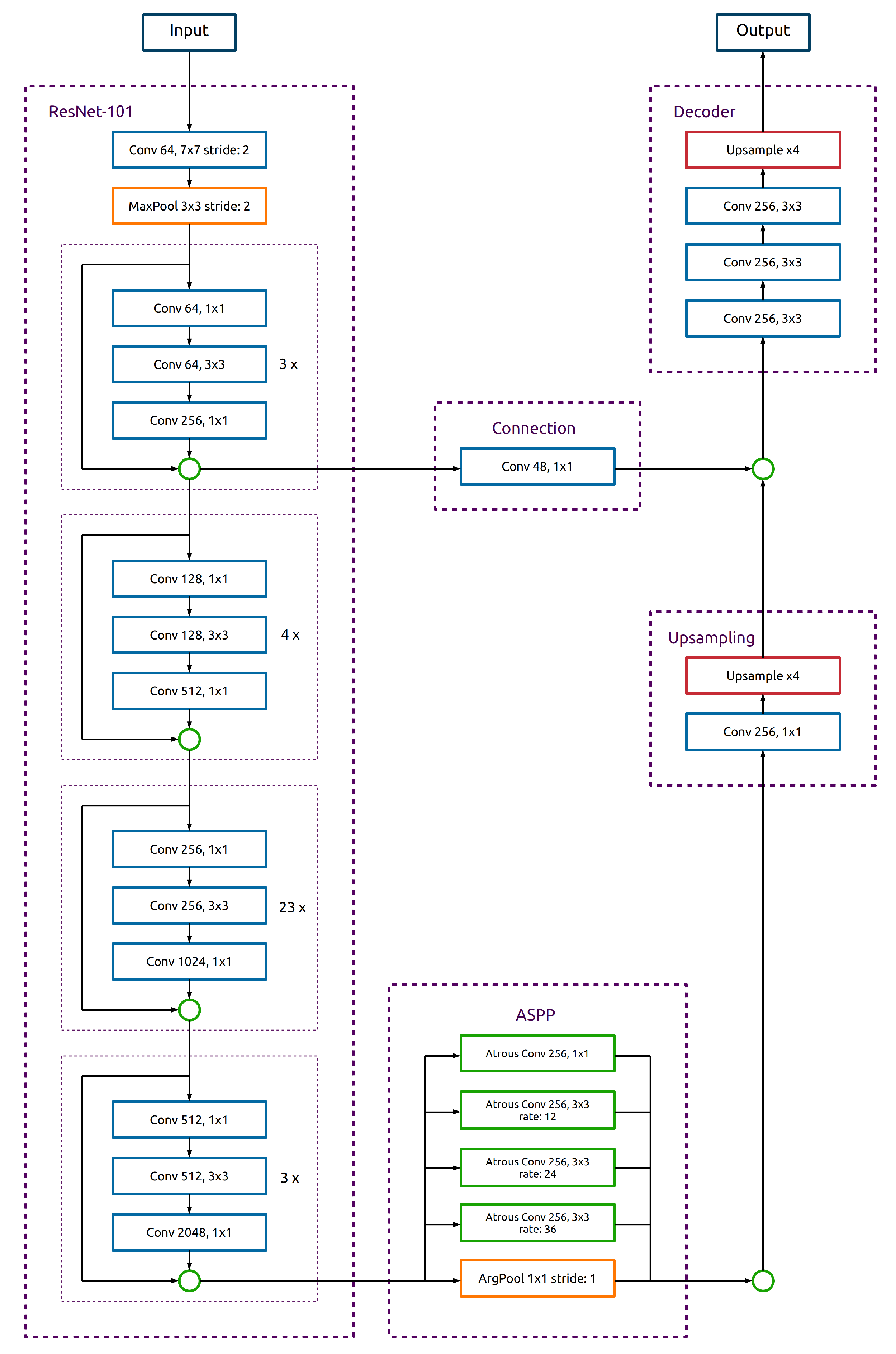
39] showed the DeepLabv3+ network’s excellent performance in classifying marsh vegetation in China. Accordingly, DeepLabv3+ is the network used in
Section 3.2 to classify regions in need of tree thinning.
Nevertheless, little research has been performed to detect the necessity of thinning solely with remote sensing data. This paper presents a model capable of achieving this task.
In this study, we tested a deep learning approach to determine if remote sensing data alone could be used to detect the need for thinning. The two factors investigated were whether the approach could
Detect if thinning is needed, based on deep convolutional neural networks (DCNNs) trained on very high spatial resolution imagery;
Differentiate between thinnings with different urgencies (i.e., timescales).
An accurate prediction of thinnings from remote sensing data has the potential to deliver information for vast or remote forest areas promptly, thus improving the stability and wood quality of forests.
5. Discussion
Timely planning and execution of thinnings are crucial for maintaining a healthy forest, but minimal research has been performed to derive the need for thinning directly from remote sensing data. Compared with detecting the necessity of thinnings, the estimation of inventory data [
16,
17,
18] or the classification tree species [
12,
13,
14,
15] has received much more attention. Accordingly, this study demonstrates the potential of predicting the necessity of thinning with state-of-the-art deep learning architectures solely from high-altitude remote sensing data.
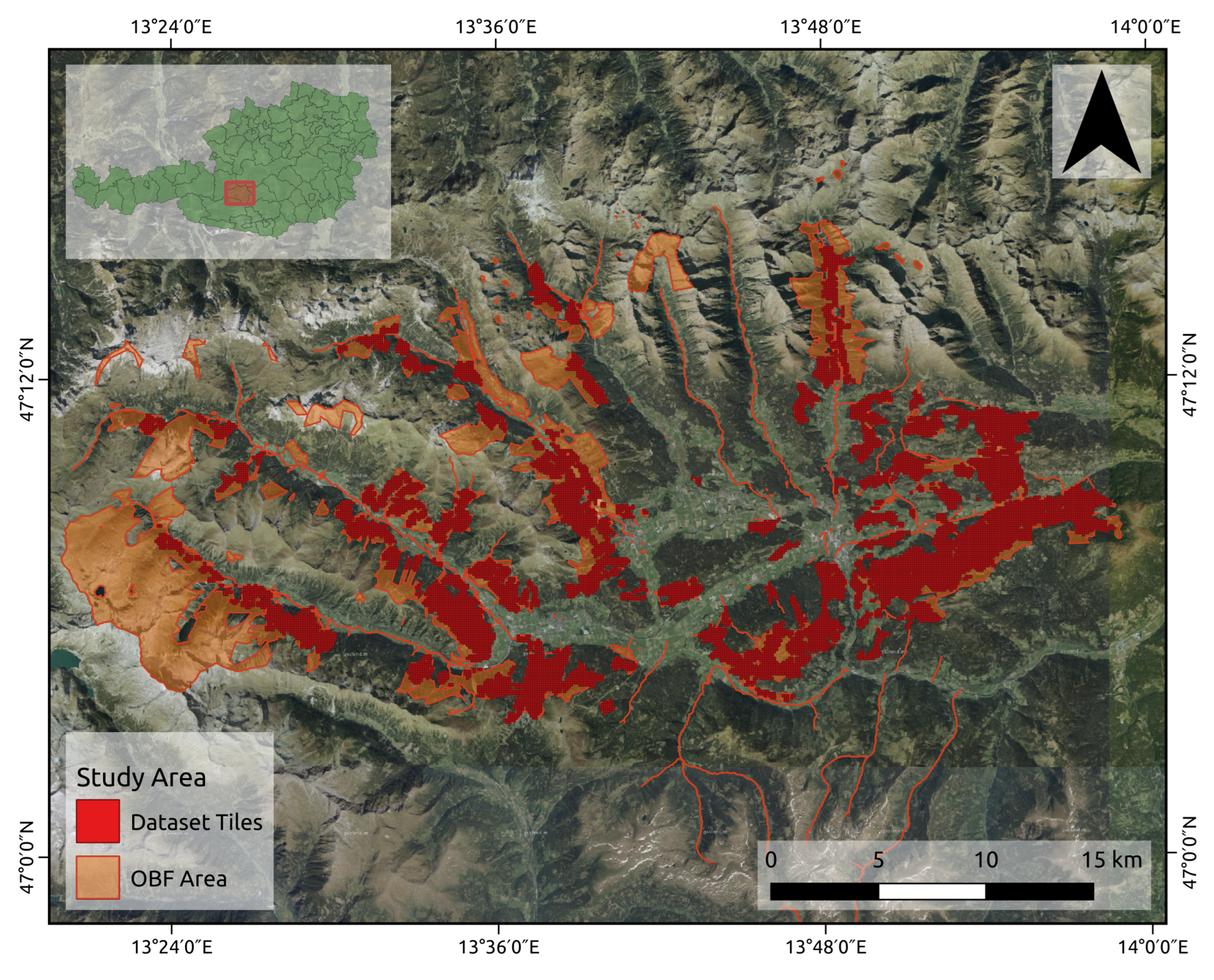
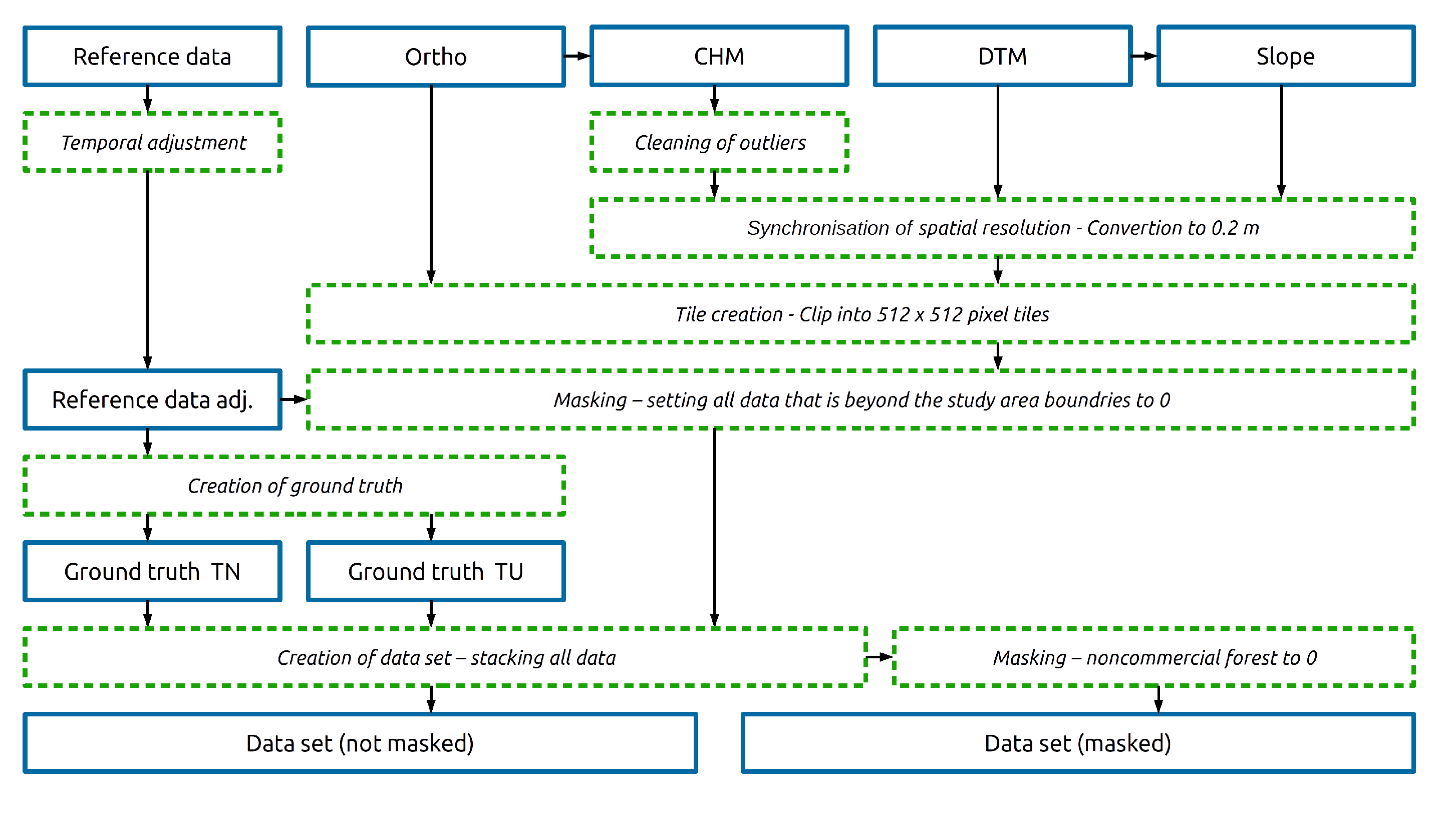
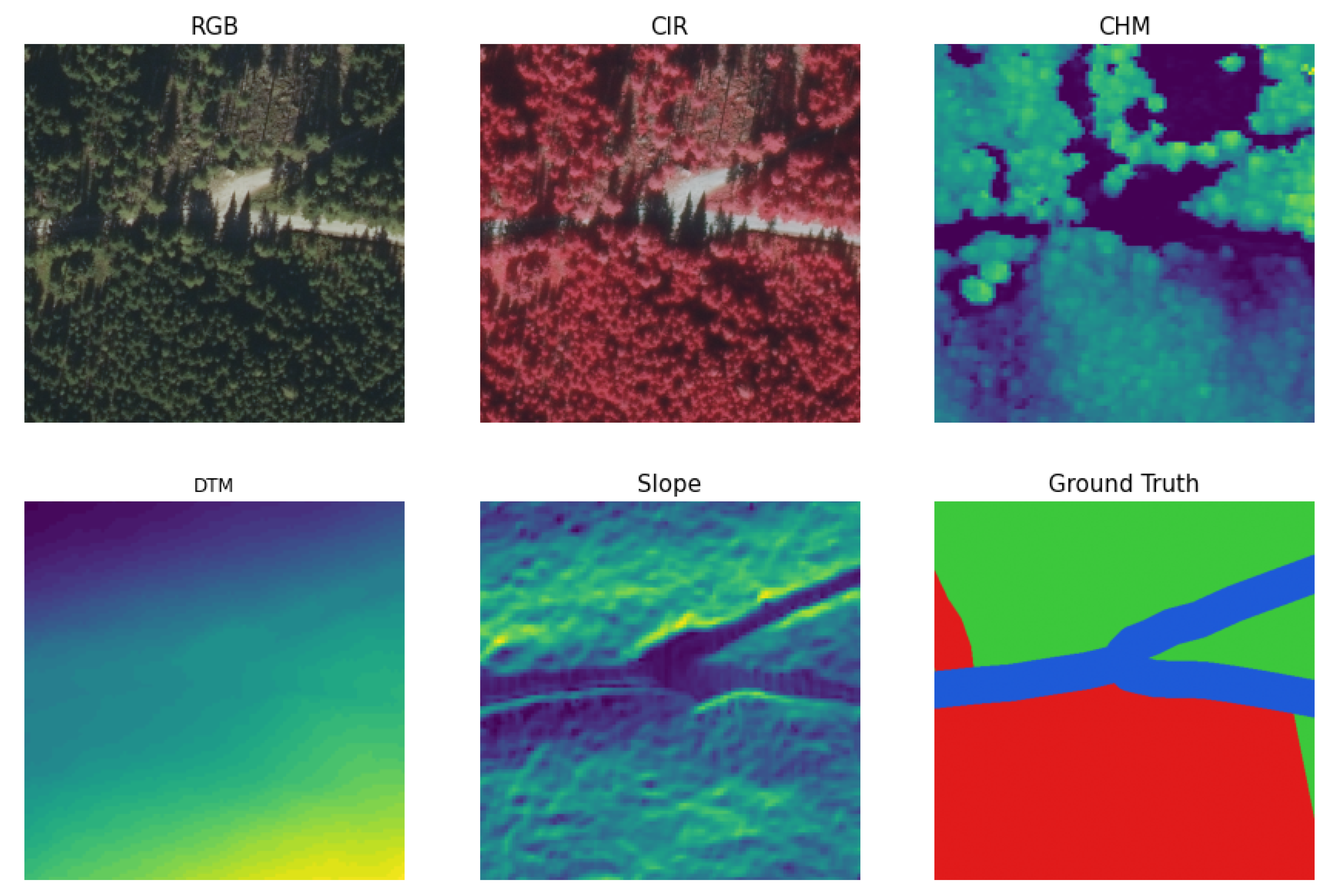
Using multispectral orthophotos, canopy height data (CHM), a digital terrain model (DTM), slope, and the reference data collected in the field by experts, two datasets were created to investigate the research question: can the necessity for thinning be reliably predicted? Using the DeepLabv3+ DCNN architecture for semantic segmentation, we achieved an score of 82.2% and demonstrated that deep learning algorithms can be applied to accurately detect forests in need of thinning. Additionally, by employing the masked dataset to restrict the analysis to exclusively the commercial forest, the approach improved the score to 85.3%.
From these results, one can conclude that the DCNN was able to extract critical information about the density of the forest from the remote sensing data and thus to assess the need for thinning. In comparison, Hyvönen [
19] used machine learning algorithms on satellite imagery to find forest stands needing thinning within the next 10 years and achieved an overall accuracy of 64.1%. However, their achievements are based on Landsat TM satellite imagery with a lower spatial resolution of 30 m compared with 0.2 m and a standwise classification of forest operations in contrast to semantic segmentation. Thus, the results are hardly comparable with those in this study. Another study from [
20] used exclusively ALS data to predict the necessity of thinnings, with an overall accuracy of 79%. There too, the necessity of thinnings was determined through a stand-wise classification of forest operations.
The necessity for thinning is determined mainly by two criteria: tree height and the standing density (basal area) of a forest stand, and the tree heights are already part of the input data. Thus, it appears that the model was capable of inferring the crown density and not the actual basal area. Therefore, the crown density is sufficient for the target thinning type, which is crown thinning. For other thinning types, such as low thinning, the DCNN might struggle to produce comparably good results. The model might provide moderate performance since only suppressed and sub-dominant trees are removed in low thinning, which have no impact on the canopy.
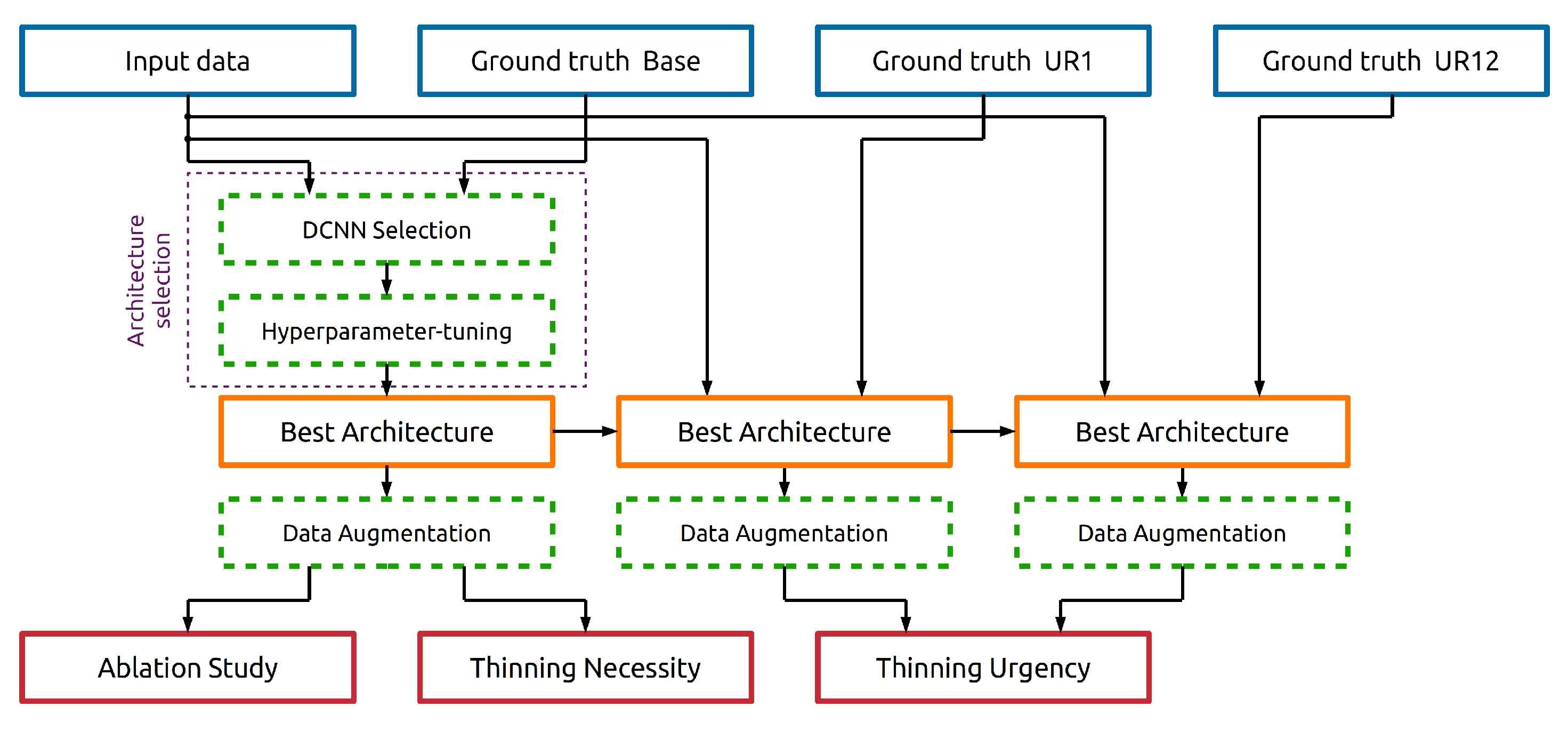
Besides creating a model that detects forests in need of thinning, we additionally explored predicting the urgency of thinning. In this case, the trained models struggled to distinguish between urgent (51.48%) and not urgent (49.57%) thinning even though we focused just on the commercially utilized forests. (see
Table 10). The poorer performance is possibly due to inconsistency in the data and missing crucial information that is not contained in the input data. Consequently, adding additional data such as yield class or age could improve the results.
An ablation study explored the importance of the individual input features, showing that orthophotos contain the most critical information for the model that assesses thinning. Adding the CHM further improved the performance of predicting thinning. On the other hand, the input features DTM and slope seem not to contain any additional helpful information.
The proposed model can be seen as a cost-efficient and scalable solution for reducing the costs of creating new forest management plans. With this approach, the necessity of sending expensive forestry personnel into the field can be greatly reduced. Thus, with the reduced costs, the frequency with which forests are planned can be shortened, thereby greatly improving the robustness of the stand against natural disturbances, increasing the quality of the wood, and optimizing the revenue.
As stated earlier, the proposed model is specifically trained to detect the need for selective crown thinnings in spruce-dominated forest stands in the study area. Consequently, further research could examine the feasibility of employing DCNNs for other thinning types, additional tree species, and other geographical areas. The training of a comparable model for deciduous forests might be challenging because of the greater diversity of tree species and the more difficult task of segmenting deciduous tree crowns.
The performance of assigning the urgency of thinning was unsatisfying in this study. Hence, one could conduct further research on this objective by providing additional valuable data such as age or yield class. Another potential direction of research could be the prediction of the volume of harvested wood for sales planning. Applicable to both small forest owners with limited funds and large forest management companies as a quick means of providing help, this approach provides the ability to infer critical information about the forest promptly.
Final remarks: Through the fusion of several types of remote sensing data and a suitable deepnet classifier, this paper presented a method to detect the necessity of thinning in spruce forests (c. 85% F1 score for identifying if forest stands need thinning). The approach was less accurate (c. 63% F1 score) when distinguishing between urgent and less urgent thinning needs. Although the resulting model needs further tuning for production use, this paper showed the potential of using remote sensing data to plan thinning cost-effectively.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}