Dear Colleagues,
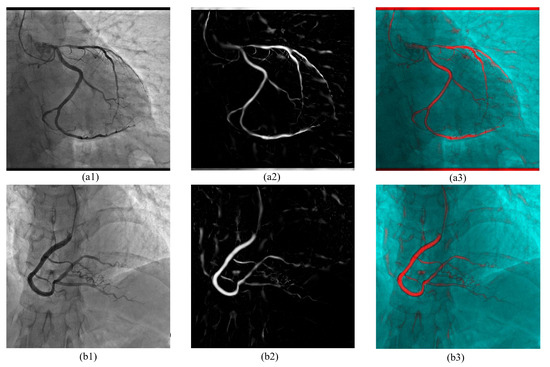
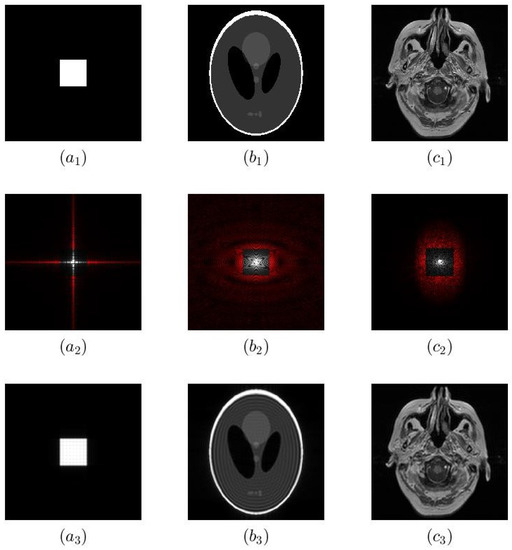
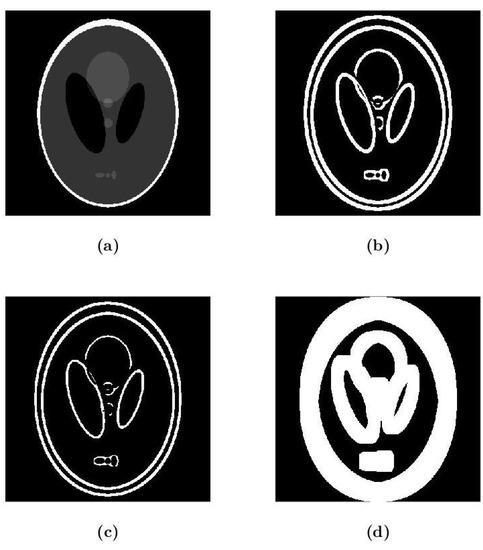
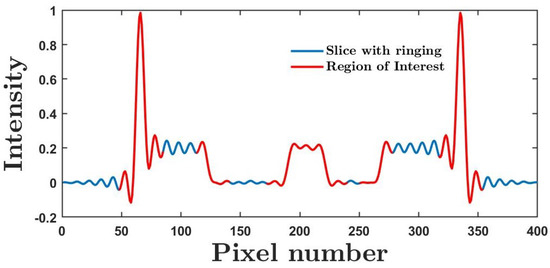
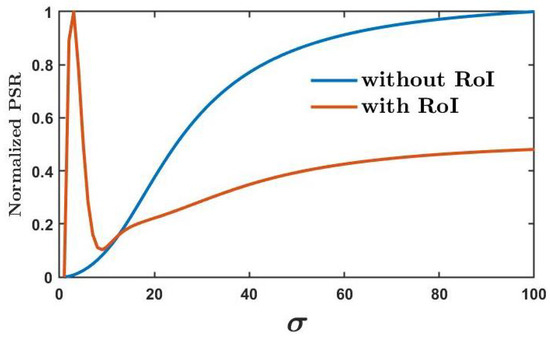
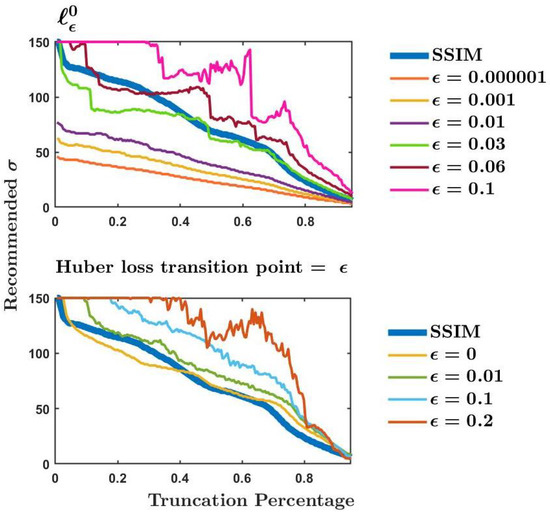
Imaging problems, including image restoration, inpainting, etc., are usually modelled as inverse problems; analytical methods, such as regularization, have been widely used as a classical approach to the solution. Even image segmentation can be formulated as an ill-posed problem, and several models include a priori information as a sort of regularization approach.
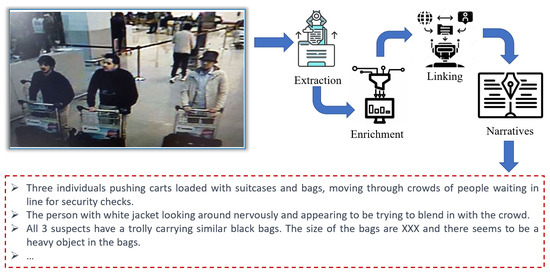
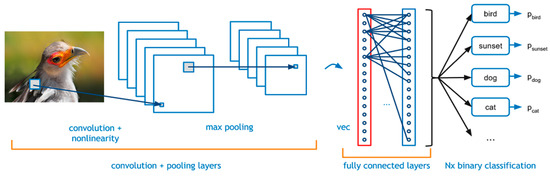
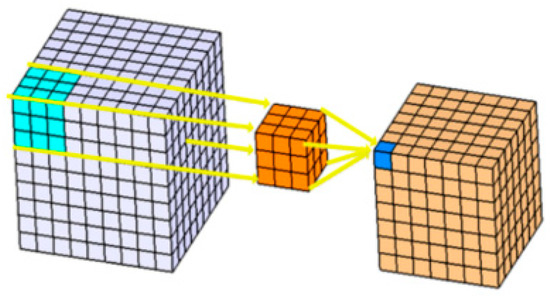
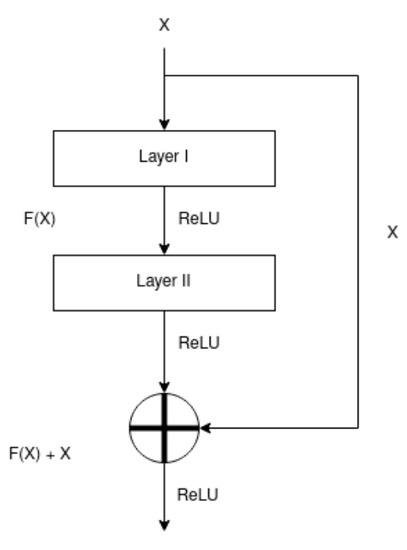
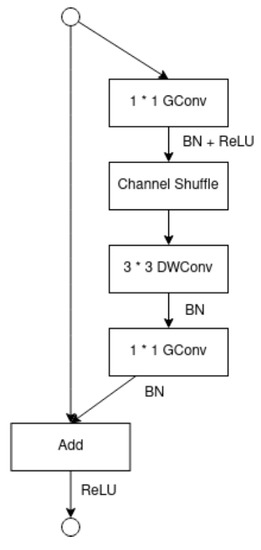
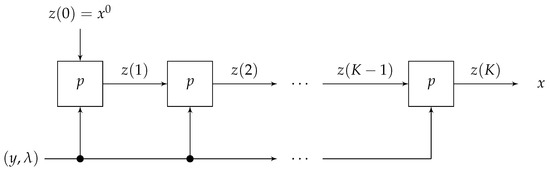
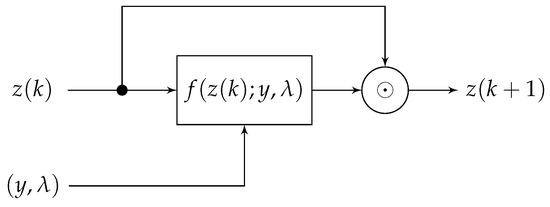
Recently, machine and deep learning methods have been widely used to solve such imaging problems, often outperforming classical approaches. Classical and learning methods aim to achieve the solution through different means; classical methods are carefully designed to carry out a specific solution using domain knowledge, whereas learning approaches do not benefit from such prior knowledge but take advantage of large datasets to "learn", i.e., extract information on the unknown solution to the imaging problem. However, the two approaches can be combined by integrating prior domain-based knowledge into the machine (and deep) learning framework.
The proposed Topical Collection aims to gather original research articles and reviews on these two approaches to solving imaging problems, including combined methods aiming to provide a better solution. We welcome papers presenting results from theory to experimental practice in various application fields, especially those promoting critical comparisons between traditional and learning methods, revealing their strength and weakness.
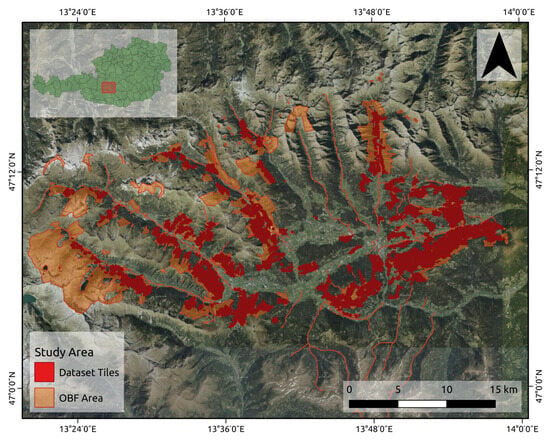
Submissions may cover different application fields, such as biomedical imaging, microscopy imaging, remote sensing, etc., with potential topics of interest including but not being limited to:
- Image deblurring;
- Image denoising;
- Image reconstruction from projections;
- Image inpainting;
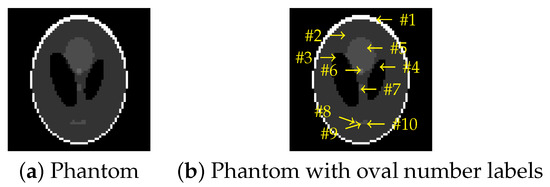
- Image segmentation;
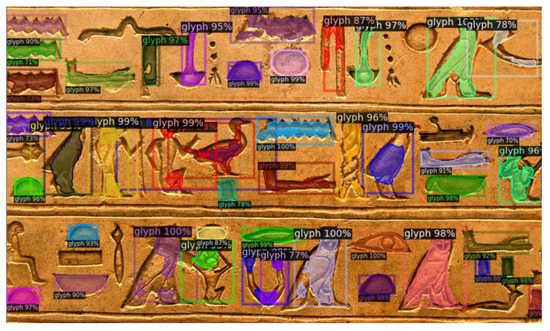
- Image classification;
- object detection;
- Application in biomedical imaging;
- Application in super-resolution microscopy;
- Application in healthcare;
- Application in (your field of research!);
- Other related areas.
Dr. Laura Antonelli
Dr. Lucia Maddalena
Guest Editors
Manuscript Submission Information
Manuscripts should be submitted online at www.mdpi.com by registering and logging in to this website. Once you are registered, click here to go to the submission form. Manuscripts can be submitted until the deadline. All submissions that pass pre-check are peer-reviewed. Accepted papers will be published continuously in the journal (as soon as accepted) and will be listed together on the collection website. Research articles, review articles as well as short communications are invited. For planned papers, a title and short abstract (about 100 words) can be sent to the Editorial Office for announcement on this website.
Submitted manuscripts should not have been published previously, nor be under consideration for publication elsewhere (except conference proceedings papers). All manuscripts are thoroughly refereed through a single-blind peer-review process. A guide for authors and other relevant information for submission of manuscripts is available on the Instructions for Authors page. Algorithms is an international peer-reviewed open access monthly journal published by MDPI.
Please visit the Instructions for Authors page before submitting a manuscript.
The Article Processing Charge (APC) for publication in this open access journal is 1600 CHF (Swiss Francs).
Submitted papers should be well formatted and use good English. Authors may use MDPI's
English editing service prior to publication or during author revisions.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
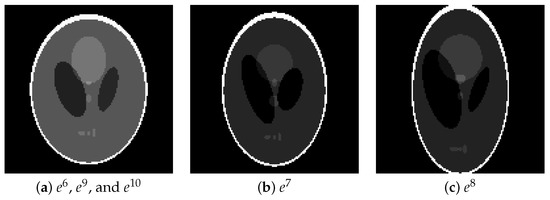{kind=link}
{kind=link}
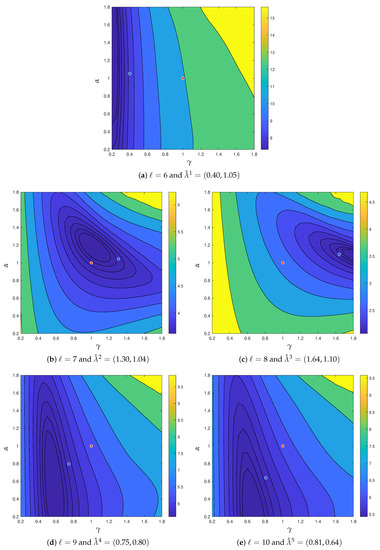{kind=link}
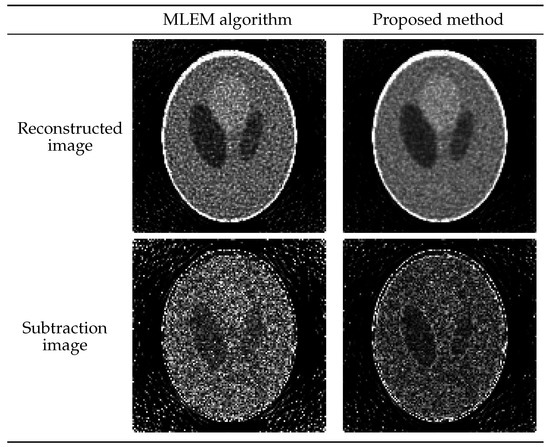{kind=link}
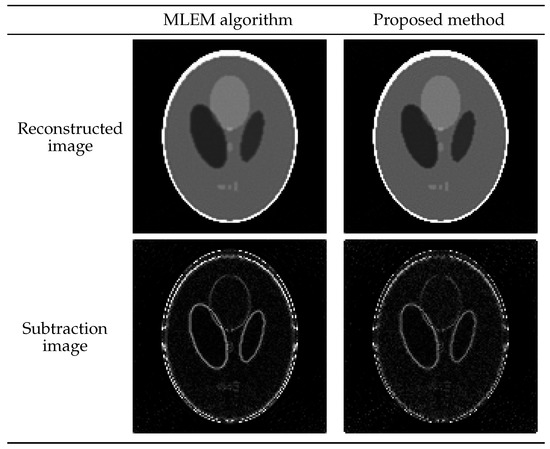{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}