

A Preprocessing Method for Coronary Artery Stenosis Detection Based on Deep Learning


Abstract
:1. Introduction
2. Materials and Methods
2.1. Materials
2.2. HFV Filter
2.3. Image Fusion
2.4. You Only Look Once v4
2.5. Faster Region-Convolutional Neural Network
2.6. Region-Based Fully Convolutional Networks
2.7. Mean Average Precision
- Confusion Matrix: A tool that breaks down the model’s predictions into true positives, true negatives, false positives, and false negatives, helping in the computation of other key metrics like precision and recall.
- Intersection over Union (IoU): This metric quantifies the overlap between the predicted and actual bounding boxes, providing insight into the model’s localization accuracy.
- Precision: Represents the accuracy of the model’s positive predictions, calculated as the ratio of true positives to the total of true positives and false positives.
- Recall: Measures the model’s ability to identify all relevant cases, computed as the ratio of true positives to the total of true positives and false negatives.
3. Experiments and Results
3.1. Experiments
3.1.1. Image Selection and Annotation
3.1.2. Data Preparation
3.1.3. Model Training and Evaluation
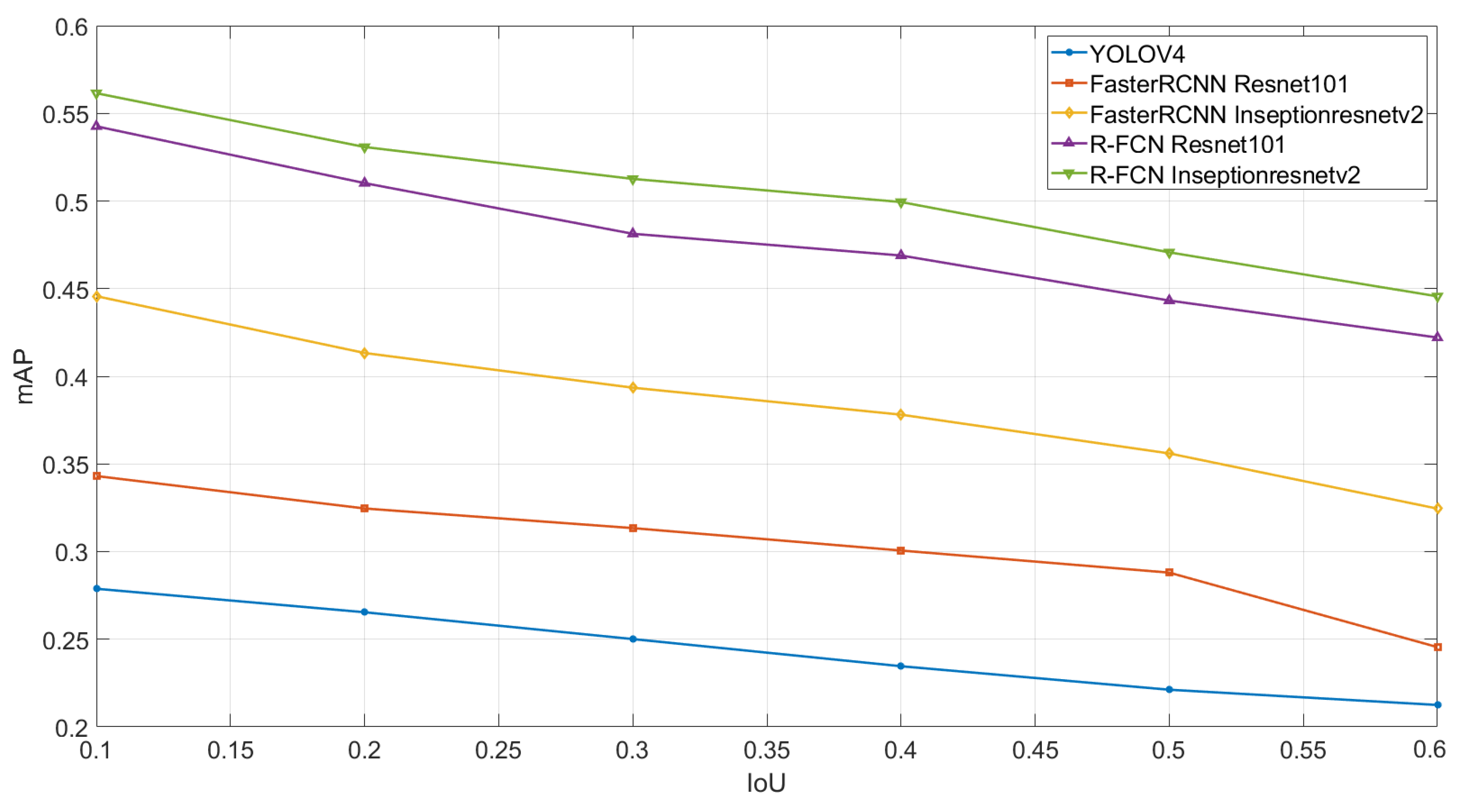
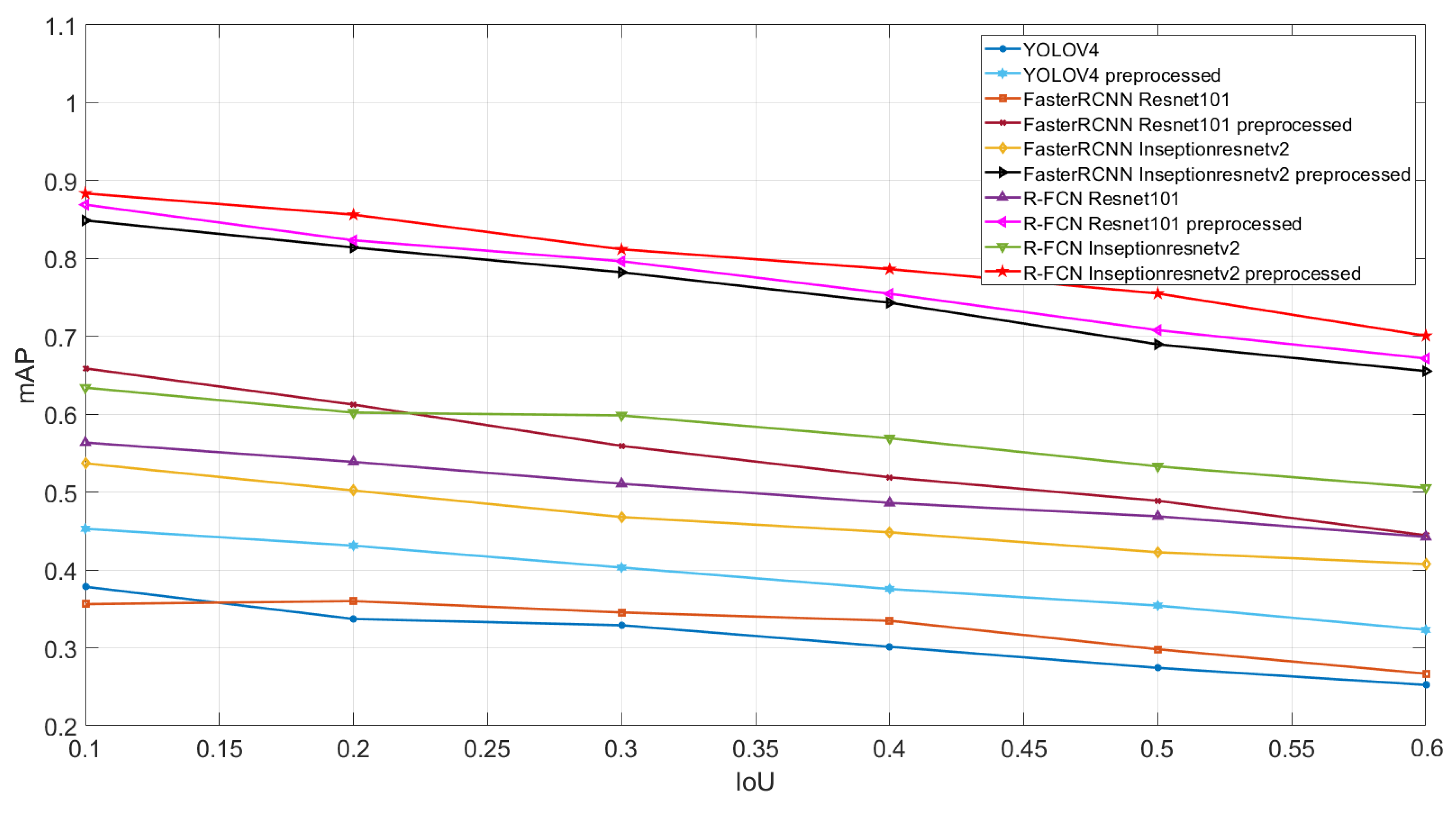
3.2. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| ICA | Invasive coronary angiography |
| CNNs | Convolutional neural networks |
| HFV | Hessian-based frangi vesselness |
| RCA | Right coronary artery |
| LCA | Left coronary artery |
| LAO | Left anterior oblique |
| RAO | Right coronary artery |
| IHS | Intensity-hue-saturation |
| RGB | Red–green–blue |
| R-FCN | Region-based fully convolutional networks |
| RPN | Region proposal network |
| ResNet | Residual network |
| RoIs | Regions of interest |
| mAP | Mean average precision |
| NMS | Non-maximum suppression |
| SPP | Spatial pyramid pooling |
| IoU | Intersection over union |
References
- Malakar, A.K.; Choudhury, D.; Halder, B.; Paul, P.; Uddin, A.; Chakraborty, S. A review on coronary artery disease, its risk factors, and therapeutics. J. Cell. Physiol. 2019, 234, 16812–16823. [Google Scholar] [CrossRef] [PubMed]
- Husmann, L.; Leschka, S.; Desbiolles, L.; Schepis, T.; Gaemperli, O.; Seifert, B.; Cattin, P.; Frauenfelder, T.; Flohr, T.G.; Marincek, B.; et al. Coronary artery motion and cardiac phases: Dependency on heart rate—Implications for CT image reconstruction. Radiology 2007, 245, 567–576. [Google Scholar] [CrossRef] [PubMed]
- Zhang, H.; Mu, L.; Hu, S.; Nallamothu, B.K.; Lansky, A.J.; Xu, B.; Bouras, G.; Cohen, D.J.; Spertus, J.A.; Masoudi, F.A.; et al. Comparison of physician visual assessment with quantitative coronary angiography in assessment of stenosis severity in China. JAMA Intern. Med. 2018, 178, 239–247. [Google Scholar] [CrossRef] [PubMed]
- Roychowdhury, S.; Koozekanani, D.D.; Parhi, K.K. Blood vessel segmentation of fundus images by major vessel extraction and subimage classification. IEEE J. Biomed. Health Inform. 2014, 19, 1118–1128. [Google Scholar]
- Chen, M.; Wang, X.; Hao, G.; Cheng, X.; Ma, C.; Guo, N.; Hu, S.; Tao, Q.; Yao, F.; Hu, C. Diagnostic performance of deep learning-based vascular extraction and stenosis detection technique for coronary artery disease. Br. J. Radiol. 2020, 93, 20191028. [Google Scholar] [CrossRef] [PubMed]
- Pijls, N.H.; Sels, J.W.E. Functional measurement of coronary stenosis. J. Am. Coll. Cardiol. 2012, 59, 1045–1057. [Google Scholar] [CrossRef] [PubMed]
- Frangi, A.F.; Niessen, W.J.; Vincken, K.L.; Viergever, M.A. Multiscale vessel enhancement filtering. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Cambridge, MA, USA, 11–13 October 1998; Springer: Berlin/Heidelberg, Germany, 1998; pp. 130–137. [Google Scholar]
- Bi, R.; Dinish, U.; Goh, C.C.; Imai, T.; Moothanchery, M.; Li, X.; Kim, J.Y.; Jeon, S.; Pu, Y.; Kim, C.; et al. In vivo label-free functional photoacoustic monitoring of ischemic reperfusion. J. Biophotonics 2019, 12, e201800454. [Google Scholar] [CrossRef] [PubMed]
- Orlova, A.; Sirotkina, M.; Smolina, E.; Elagin, V.; Kovalchuk, A.; Turchin, I.; Subochev, P. Raster-scan optoacoustic angiography of blood vessel development in colon cancer models. Photoacoustics 2019, 13, 25–32. [Google Scholar] [CrossRef] [PubMed]
- Wang, S.; Li, B.; Zhou, S. A segmentation method of coronary angiograms based on multi-scale filtering and region-growing. In Proceedings of the 2012 IEEE International Conference on Biomedical Engineering and Biotechnology, Macau, China, 28–30 May 2012; pp. 678–681. [Google Scholar]
- Zreik, M.; Van Hamersvelt, R.W.; Wolterink, J.M.; Leiner, T.; Viergever, M.A.; Išgum, I. A recurrent CNN for automatic detection and classification of coronary artery plaque and stenosis in coronary CT angiography. IEEE Trans. Med. Imaging 2018, 38, 1588–1598. [Google Scholar] [CrossRef] [PubMed]
- Ovalle-Magallanes, E.; Avina-Cervantes, J.G.; Cruz-Aceves, I.; Ruiz-Pinales, J. Transfer learning for stenosis detection in X-ray coronary angiography. Mathematics 2020, 8, 1510. [Google Scholar] [CrossRef]
- Cruz-Aceves, I.; Oloumi, F.; Rangayyan, R.M.; Aviña-Cervantes, J.G.; Hernandez-Aguirre, A. Automatic segmentation of coronary arteries using Gabor filters and thresholding based on multiobjective optimization. Biomed. Signal Process. Control 2016, 25, 76–85. [Google Scholar] [CrossRef]
- Felfelian, B.; Fazlali, H.R.; Karimi, N.; Soroushmehr, S.M.R.; Samavi, S.; Nallamothu, B.; Najarian, K. Vessel segmentation in low contrast X-ray angiogram images. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 375–379. [Google Scholar]
- Rahman, C.M.A.; Nyeem, H. Active Contour based Segmentation of ROIs in Medical Images. In Proceedings of the 2019 IEEE International Conference on Electrical, Computer and Communication Engineering (ECCE), Cox’s Bazar, Bangladesh, 7–9 February 2019; pp. 1–6. [Google Scholar]
- Banerjee, R.; Ghose, A.; Mandana, K.M. A hybrid CNN-LSTM architecture for detection of coronary artery disease from ECG. In Proceedings of the 2020 IEEE International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–8. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Kim, D.K.; Kim, B.S.; Kim, Y.J.; Kim, S.; Yoon, D.; Lee, D.K.; Jeong, J.; Jo, Y.H. Development and validation of an artificial intelligence algorithm for detecting vocal cords in video laryngoscopy. Medicine 2023, 102, e36761. [Google Scholar] [CrossRef] [PubMed]
- Das, S.; Hasan, O.; Chowdhury, A.; Aslam, S.M.; Minhaz Hossain, S.M. An Automatic Detection of Heart Block from ECG Images Using YOLOv4. In Proceedings of the International Conference on Hybrid Intelligent Systems, Online, 13–15 December 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 981–990. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; Volume 28. [Google Scholar]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-fcn: Object detection via region-based fully convolutional networks. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; Volume 29. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Angles | LCA ZERO | LCA LAO | LCA RAO | RCA ZERO | RCA LAO | RCA RAO |
|---|---|---|---|---|---|---|
| mAP | 0.7818 | 0.7462 | 0.7698 | 0.6908 | 0.6522 | 0.6474 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Y.; Yoshimura, T.; Horima, Y.; Sugimori, H. A Preprocessing Method for Coronary Artery Stenosis Detection Based on Deep Learning. Algorithms 2024, 17, 119. https://doi.org/10.3390/a17030119
Li Y, Yoshimura T, Horima Y, Sugimori H. A Preprocessing Method for Coronary Artery Stenosis Detection Based on Deep Learning. Algorithms. 2024; 17(3):119. https://doi.org/10.3390/a17030119
Chicago/Turabian StyleLi, Yanjun, Takaaki Yoshimura, Yuto Horima, and Hiroyuki Sugimori. 2024. "A Preprocessing Method for Coronary Artery Stenosis Detection Based on Deep Learning" Algorithms 17, no. 3: 119. https://doi.org/10.3390/a17030119
APA StyleLi, Y., Yoshimura, T., Horima, Y., & Sugimori, H. (2024). A Preprocessing Method for Coronary Artery Stenosis Detection Based on Deep Learning. Algorithms, 17(3), 119. https://doi.org/10.3390/a17030119