
Forest Tree Species Classification Based on Sentinel-2 Images and Auxiliary Data

Abstract
:1. Introduction
2. Study Area and Data
2.1. Study Area
2.2. Data
2.2.1. Sentinel-2 Data
2.2.2. Auxiliary Data
2.2.3. Field Survey Data
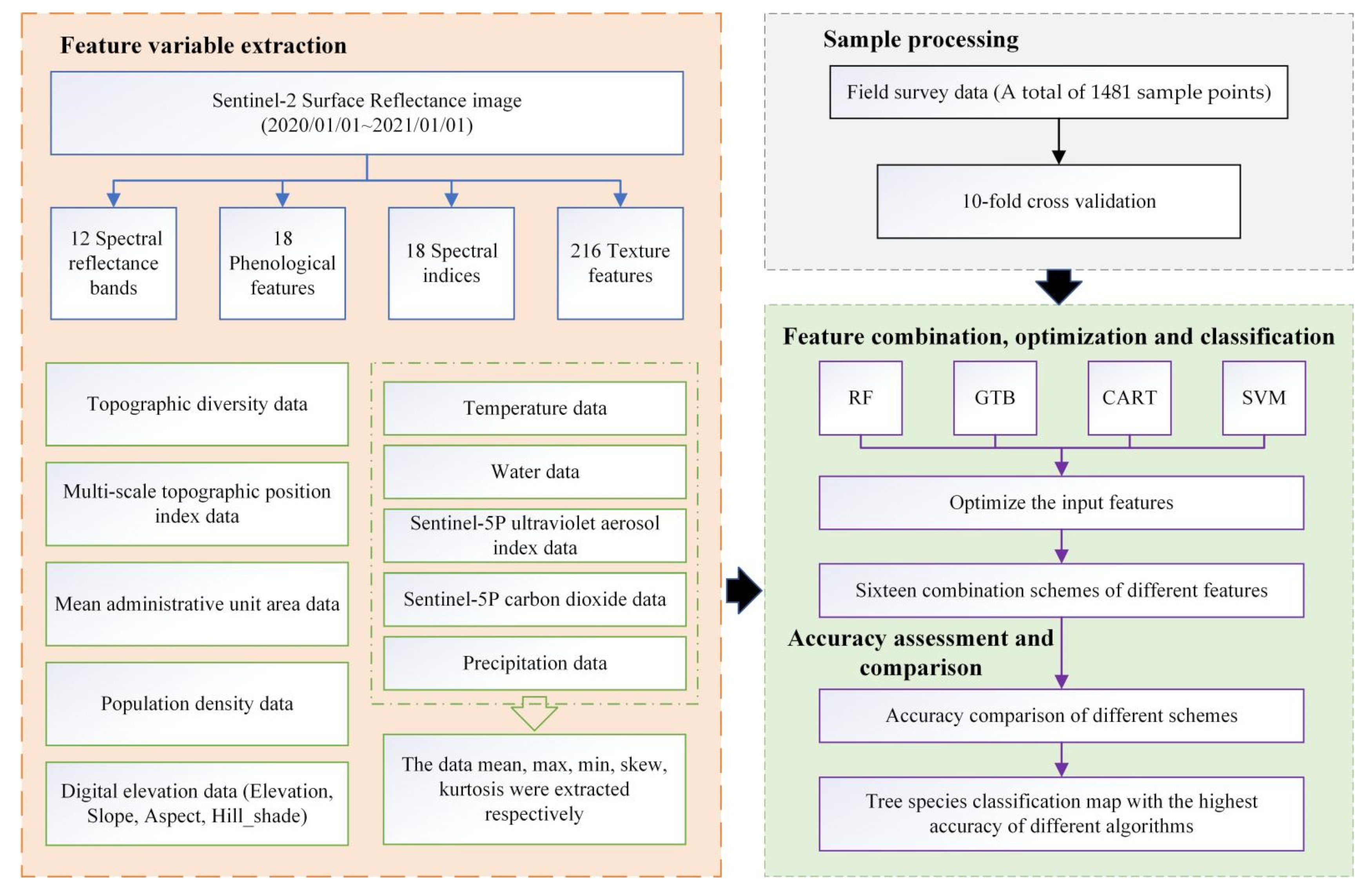
3. Methods
3.1. Feature Combination Scheme
3.2. Feature Variable Extraction
3.3. Classification Algorithm
3.4. Accuracy Assessment
4. Results
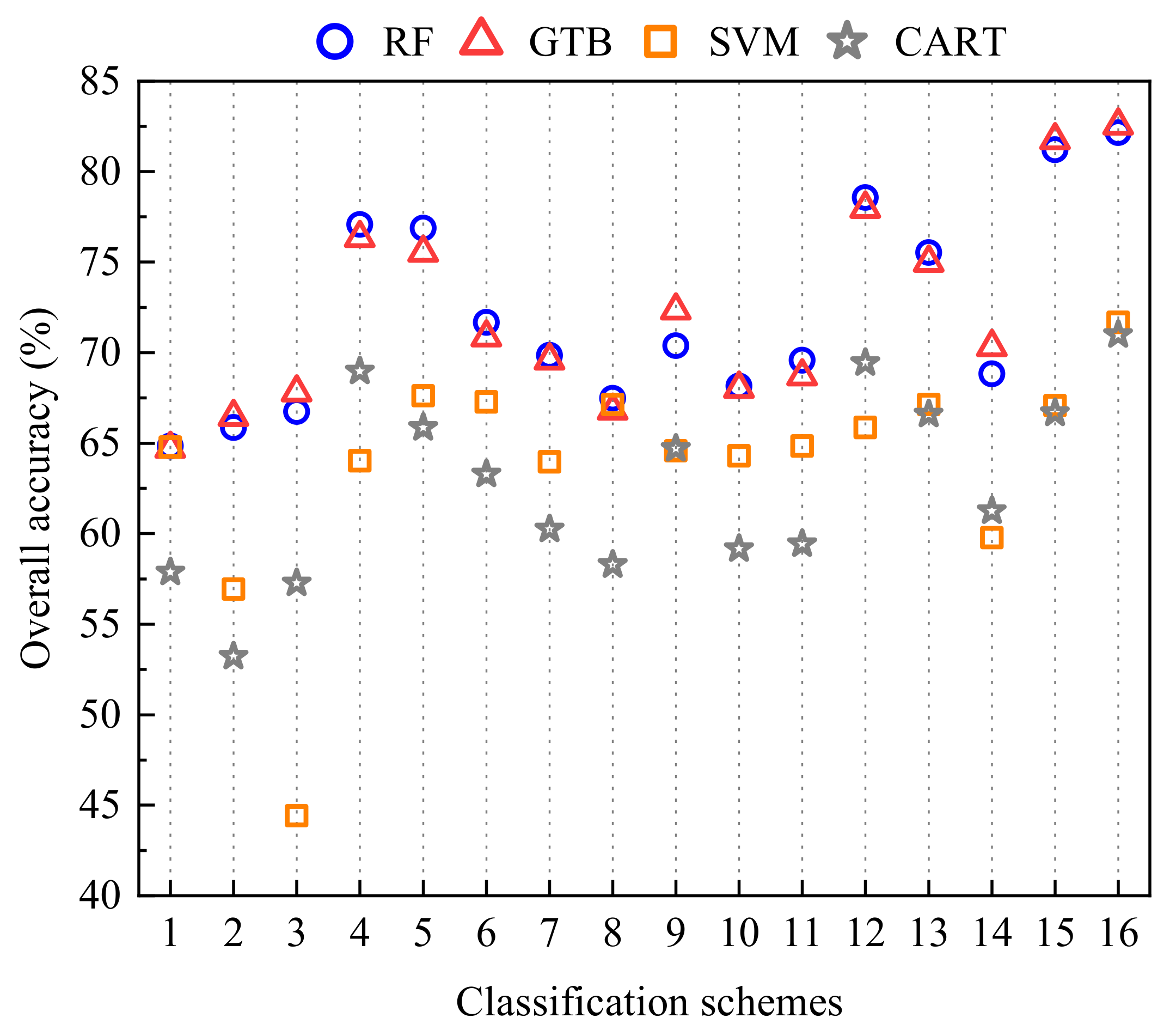
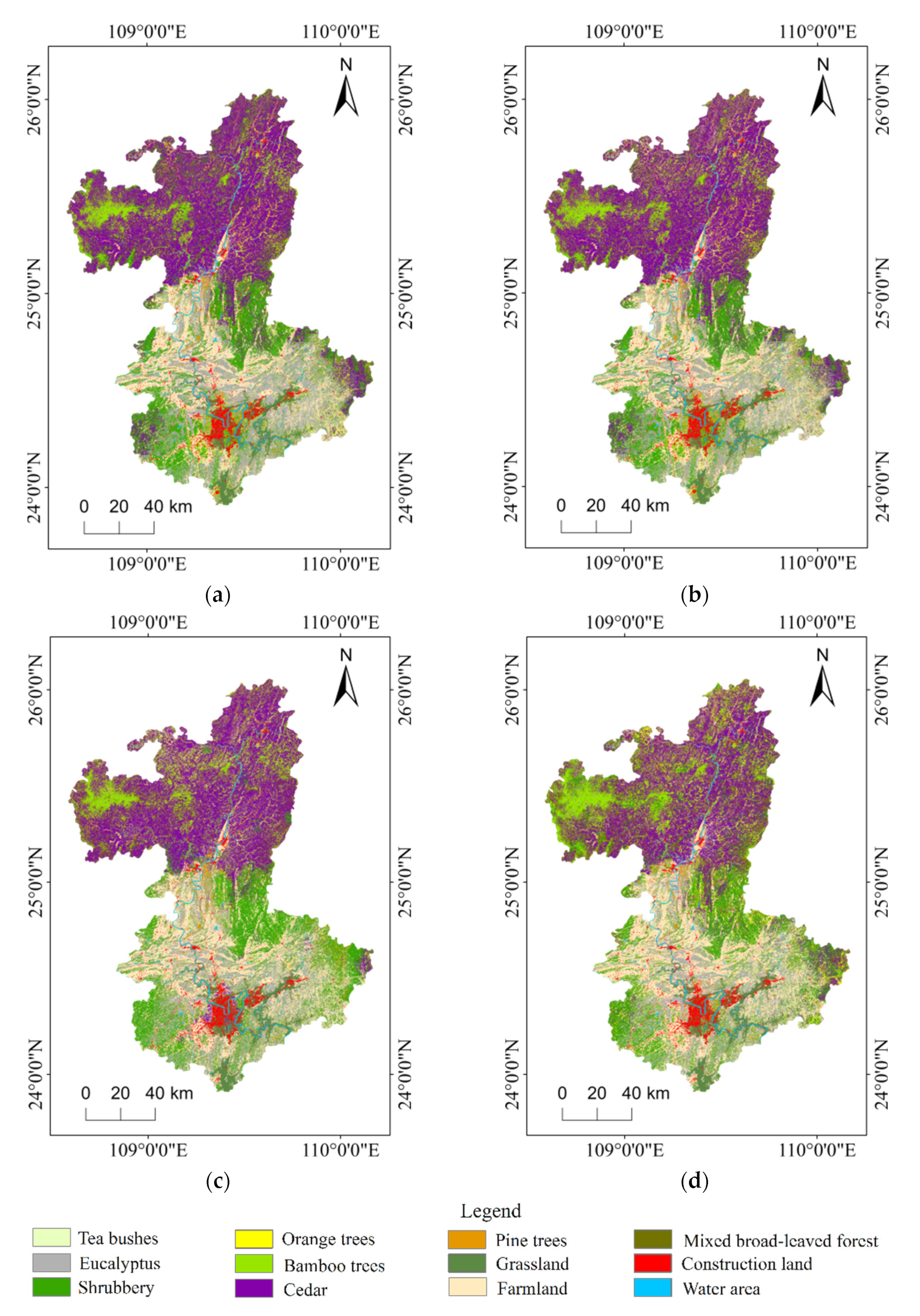
4.1. Classification Results with Different Feature Combination Schemes
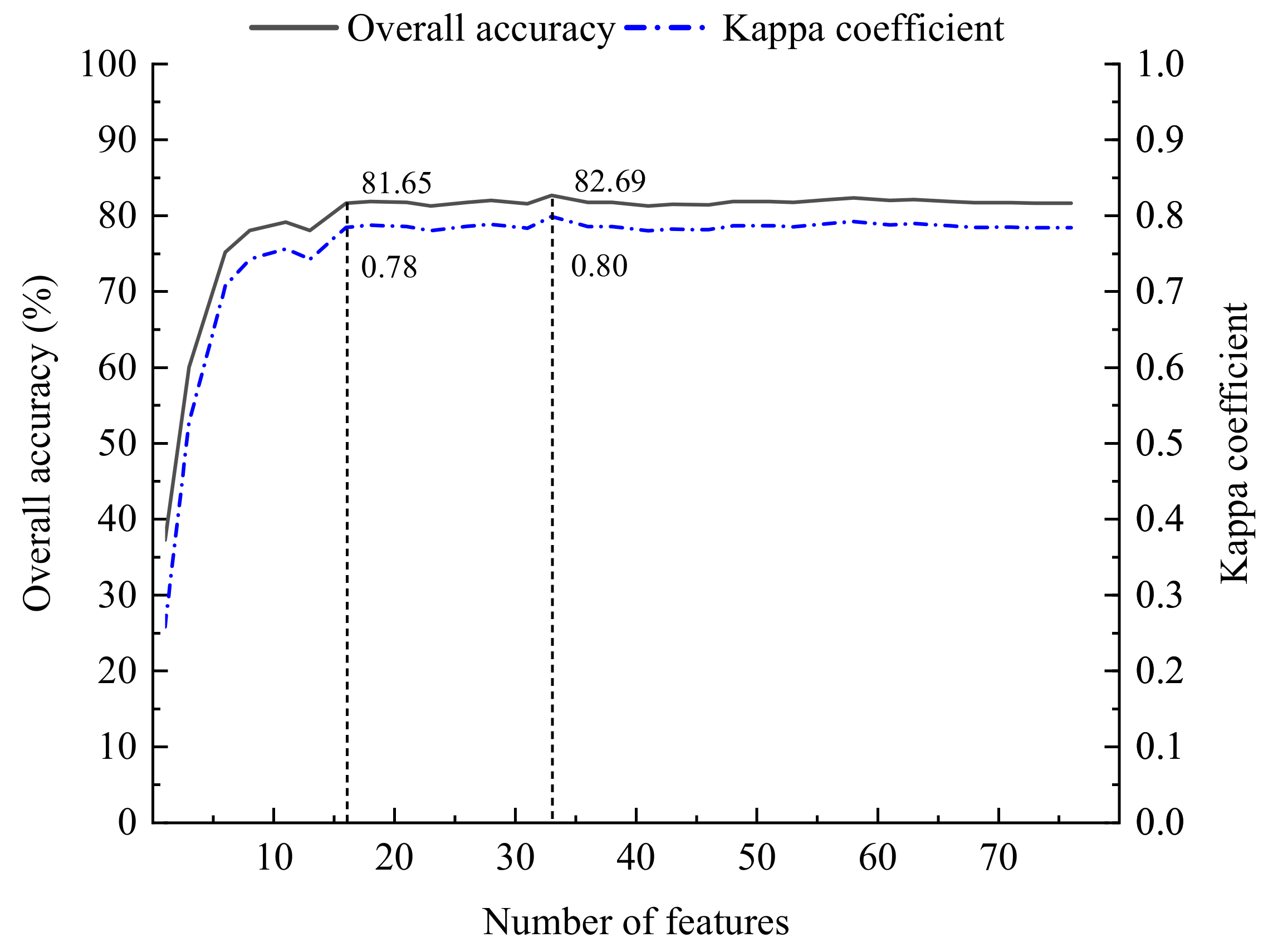
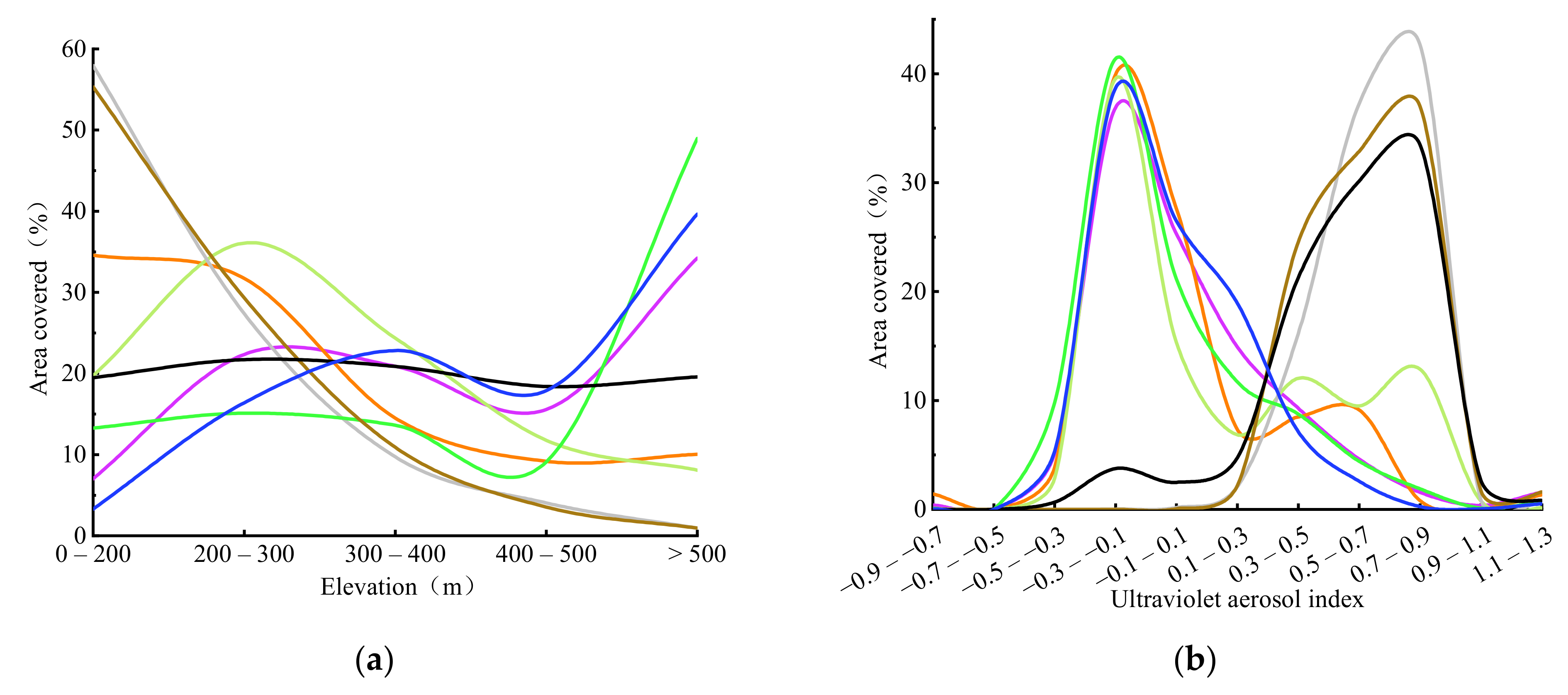
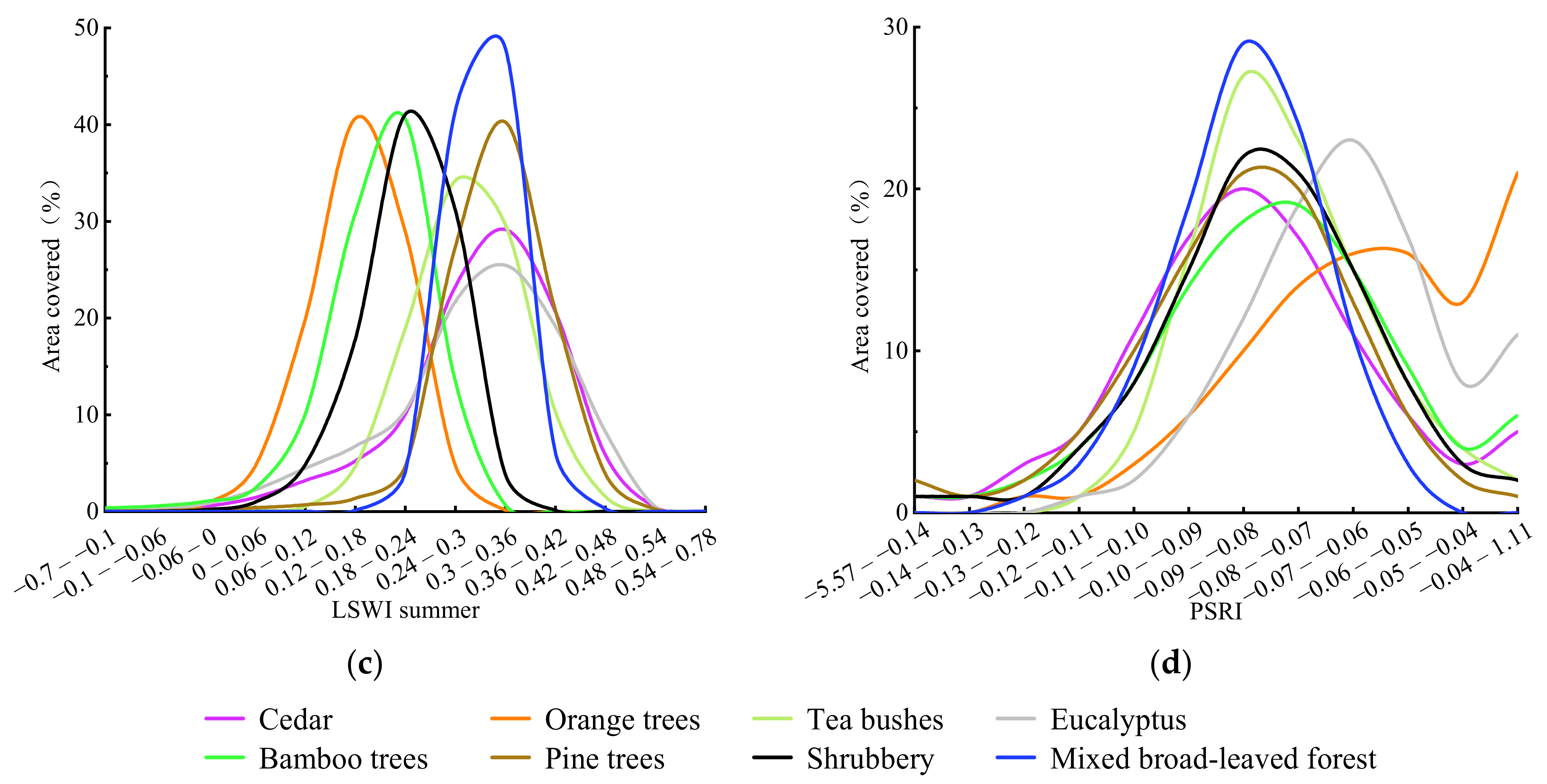
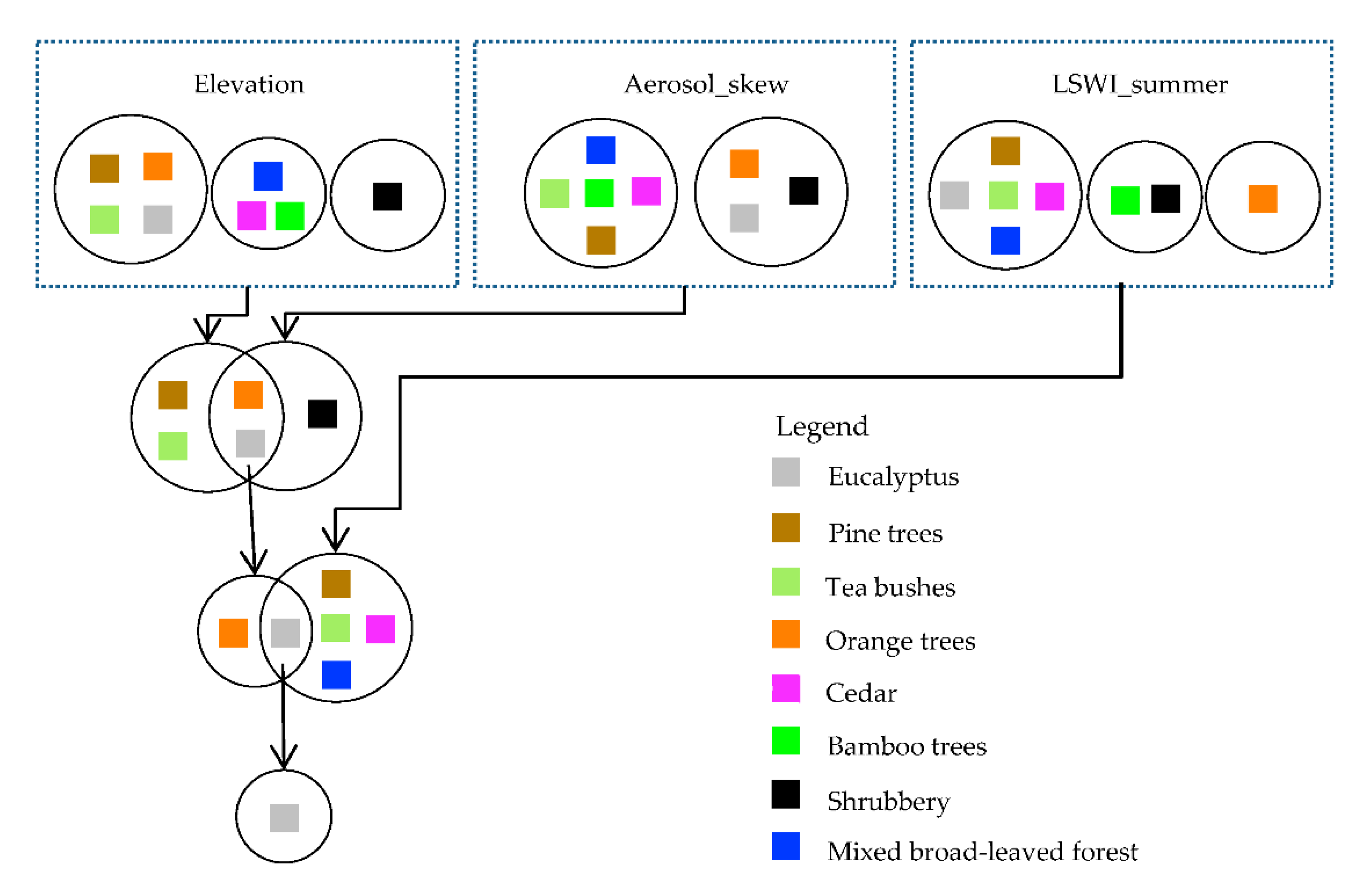
4.2. Analysis of Feature Variable Optimization Results
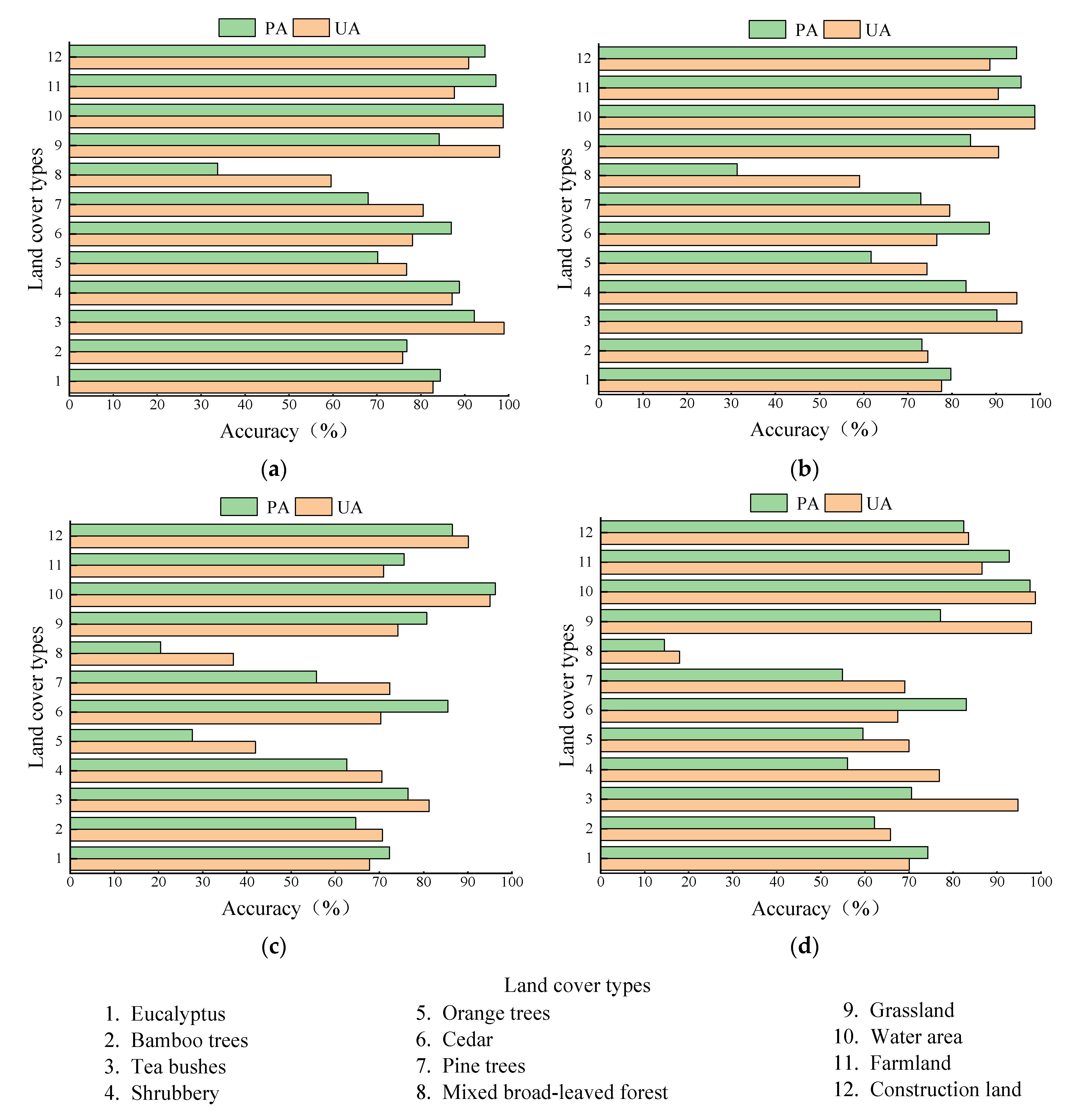
4.3. Comparison of the Classification Results of Different Algorithms Based on the Optimal Feature Variables
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Kurz, W.A.; Dymond, C.C.; Stinson, G.; Rampley, G.J.; Neilson, E.T.; Carroll, A.L.; Ebata, T.; Safranyik, L. Mountain pine beetle and forest carbon feedback to climate change. Nature 2008, 452, 987–990. [Google Scholar] [CrossRef]
- Dale, V.H.; Joyce, L.A.; Mcnulty, S.; Neilson, R.P.; Ayres, M.P.; Flaningan, M.D.; Hanson, P.J.; Irland, L.C.; Lugo, A.E.; Peterson, C.J.; et al. Climate Change and Forest Disturbances. Bioscience 2001, 51, 723–734. [Google Scholar] [CrossRef]
- Fassnacht, F.E.; Latifi, H.; Stereńczak, K.; Modzelewska, A.; Lefsky, M.; Waser, L.T.; Straub, C.; Ghosh, A. Review of studies on tree species classification from remotely sensed data. Remote Sens. Environ. 2016, 186, 64–87. [Google Scholar] [CrossRef]
- Jia, K.; Li, Q.; Tian, Y.; Wu, B.; Zhang, F.; Meng, J. Crop classification using multi-configuration SAR data in the North China Plain. Int. J. Remote Sens. 2011, 33, 170–183. [Google Scholar] [CrossRef]
- Huang, J.W.; Li, Z.Y.; Chen, E.X.; Zhao, L.; Mo, P. Classification of plantation types based on WFV multispectral imagery of the GF-6 satellite. J. Remote Sens. 2021, 25, 539–548. [Google Scholar]
- Zhao, L.; Zhang, X.L.; Wu, Y.S.; Zhang, B. Subtropical Forest Tree Species Classification Based on 3D-CNN for Airborne Hyperspectral Data. Sci. Silvae Sin. 2020, 56, 97–107. [Google Scholar]
- Immitzer, M.; Neuwirth, M.; Böck, S.; Brenner, H.; Vuolo, F.; Atzberger, C. Optimal Input Features for Tree Species Classification in Central Europe Based on Multi-Temporal Sentinel-2 Data. Remote Sens. 2019, 11, 2599. [Google Scholar] [CrossRef]
- Zhao, Q.Z.; Jiang, P.; Wang, X.W.; Zhang, L.H.; Zhang, J.X. Classification of Protection Forest Tree Species Based on UAV Hyperspectral Data. Trans. Chin. Soc. Agric. Mach. 2021, 52, 190–199. [Google Scholar]
- Hościło, A.; Lewandowska, A. Mapping Forest Type and Tree Species on a Regional Scale Using Multi-Temporal Sentinel-2 Data. Remote Sens. 2019, 11, 929. [Google Scholar] [CrossRef]
- Ma, M.F.; Liu, J.H.; Liu, M.X.; Zeng, J.C.; Li, Y.H. Tree Species Classification Based on Sentinel-2 Imagery and Random Forest Classifier in the Eastern Regions of the Qilian Mountains. Forests 2021, 12, 1736. [Google Scholar] [CrossRef]
- Cai, L.F.; Wu, D.S.; Fang, L.M.; Deng, X.Y. Tree Species Identification Using XGBoost Based on GF-2 Images. For. Resour. Manag. 2019, 44–51. [Google Scholar] [CrossRef]
- Tran, A.T.; Nguyen, K.A.; Liou, Y.A.; Le, M.H.; Vu, V.T.; Nguyen, D.D. Classification and Observed Seasonal Phenology of Broadleaf Deciduous Forests in a Tropical Region by Using Multitemporal Sentinel-1A and Landsat 8 Data. Forests 2021, 12, 235. [Google Scholar] [CrossRef]
- Hologa, R.; Scheffczyk, K.; Dreiser, C.; Gärtner, S. Tree Species Classification in a Temperate Mixed Mountain Forest Landscape Using Random Forest and Multiple Datasets. Remote Sens. 2021, 13, 4657. [Google Scholar] [CrossRef]
- Hu, B.; Li, Q.; Hall, G.B. A decision-level fusion approach to tree species classification from multi-source remotely sensed data. ISPRS Open J. Photogramm. Remote Sens. 2021, 1, 100002. [Google Scholar] [CrossRef]
- Chen, L.P.; Sun, Y.J. Comparison of object-oriented remote sensing image classification based on different decision trees in forest area. Chin. J. Appl. Ecol. 2018, 29, 3995–4003. [Google Scholar]
- Koyasu, S.; Nishio, M.; Isoda, H.; Nakamoto, Y.; Togashi, K. Usefulness of gradient tree boosting for predicting histological subtype and EGFR mutation status of non-small cell lung cancer on 18F FDG-PET/CT. Ann. Nucl. Med. 2019, 34, 49–57. [Google Scholar] [CrossRef]
- Ehrentraut, C.; Ekholm, M.; Tanushi, H.; Tiedemann, J.; Dalianis, H. Detecting hospital-acquired infections: A document classification approach using support vector machines and gradient tree boosting. Health Inform. J. 2016, 24, 24–42. [Google Scholar] [CrossRef]
- Luo, Y.; Ye, W.; Zhao, X.; Pan, X.; Cao, Y. Classification of Data from Electronic Nose Using Gradient Tree Boosting Algorithm. Sensors 2017, 17, 2376. [Google Scholar] [CrossRef]
- Liu, H.Q.; Huete, A. A Feedback Based Modification of the Ndvi to Minimize Canopy Background and Atmospheric Noise. IEEE Trans. Geosci. Remote Sens. 1995, 33, 814. [Google Scholar] [CrossRef]
- Broge, N.H.; Mortensen, J.V. Deriving green crop area index and canopy chlorophyll density of winter wheat from spectral reflectance data. Remote Sens. Environ. 2002, 81, 45–57. [Google Scholar] [CrossRef]
- Dash, J.; Curran, P.J. The MERIS terrestrial chlorophyll index. Int. J. Remote Sens. 2004, 25, 5403–5413. [Google Scholar] [CrossRef]
- Frampton, W.J.; Dash, J.; Watmough, G.; Milton, E.J. Evaluating the capabilities of Sentinel-2 for quantitative estimation of biophysical variables in vegetation. ISPRS J. Photogramm. Remote Sens. 2013, 82, 83–92. [Google Scholar] [CrossRef]
- Merzlyak, M.N.; Gitelson, A.A.; Chivkunova, O.B.; Rakitin, V.Y. Non-destructive optical detection of pigment changes during leaf senescence and fruit ripening. Physiol. Plant. 1999, 106, 135–141. [Google Scholar] [CrossRef]
- Haboudane, D.; Miller, J.R.; Tremblay, N.; Zarco-Tejada, P.J.; Dextraze, L. Integrated narrow-band vegetation indices for prediction of crop chlorophyll content for application to precision agriculture. Remote Sens. Environ. 2002, 81, 416–426. [Google Scholar] [CrossRef]
- McFeeters, S.K. The use of the Normalized Difference Water Index (NDWI) in the delineation of open water features. Int. J. Remote Sens. 1996, 17, 1425–1432. [Google Scholar] [CrossRef]
- Daughtry, C.S.T.; Walthall, C.L.; Kim, M.S.; De Colstoun, E.B.; McMurtrey, J.E., III. Estimating Corn Leaf Chlorophyll Concentration from Leaf and Canopy Reflectance. Remote Sens. Environ. 2000, 74, 229–239. [Google Scholar] [CrossRef]
- Huete, A.; Justice, C.; Liu, H. Development of vegetation and soil indices for MODIS-EOS. Remote Sens. Environ. 1994, 49, 224–234. [Google Scholar] [CrossRef]
- Broge, N.H.; Leblanc, E. Comparing prediction power and stability of broadband and hyperspectral vegetation indices for estimation of green leaf area index and canopy chlorophyll density. Remote Sens. Environ. 2001, 76, 156–172. [Google Scholar] [CrossRef]
- Bolyn, C.; Michez, A.; Gaucher, P.; Lejeune, P.; Bonnet, S. Forest mapping and species composition using supervised per pixel classification of Sentinel-2 imagery. Biotechnol. Agron. Soc. Environ. 2018, 22, 172–187. [Google Scholar] [CrossRef]
- Bridhikitti, A.; Overcamp, T.J. Estimation of Southeast Asian rice paddy areas with different ecosystems from moderate-resolution satellite imagery. Agric. Ecosyst. Environ. 2012, 146, 113–120. [Google Scholar] [CrossRef]
- Gamon, J.A.; Surfus, J.S. Assessing leaf pigment content and activity with a reflectometer. New Phytol. 1999, 143, 105–117. [Google Scholar] [CrossRef]
- Le Maire, G.; François, C.; Dufrêne, E. Towards universal broad leaf chlorophyll indices using PROSPECT simulated database and hyperspectral reflectance measurements. Remote Sens. Environ. 2004, 89, 1–28. [Google Scholar] [CrossRef]
- Fourty, T.; Baret, F.; Jacquemoud, S.; Schmuck, G.; Verdebout, J. Leaf optical properties with explicit description of its bio-chemical composition: Direct and inverse problems. Remote Sens. Environ. 1996, 57, 185. [Google Scholar]
- Gitelson, A.A.; Gritz, Y.; Merzlyak, M.N. Relationships between leaf chlorophyll content and spectral reflectance and algorithms for non-destructive chlorophyll assessment in higher plant leaves. J. Plant. Physiol. 2003, 160, 271–282. [Google Scholar] [CrossRef]
- Pal, M. Random forest classifier for remote sensing classification. Int. J. Remote Sens. 2005, 26, 217–222. [Google Scholar] [CrossRef]
- Vu, Q.-V.; Truong, V.-H.; Thai, H.-T. Machine learning-based prediction of CFST columns using gradient tree boosting algorithm. Compos. Struct. 2020, 259, 113505. [Google Scholar] [CrossRef]
- Tu, Y.; Lang, W.; Yu, L.; Li, Y.; Xu, B. Improved Mapping Results of 10 m Resolution Land Cover Classification in Guang-dong, China Using Multisource Remote Sensing Data With Google Earth Engine. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 5384–5397. [Google Scholar] [CrossRef]
- Pal, M.; Mather, P.M. Support vector machines for classification in remote sensing. Int. J. Remote Sens. 2005, 26, 1007–1011. [Google Scholar] [CrossRef]
- Bellman, R. Dynamic Programming. Science 1966, 153, 34–37. [Google Scholar] [CrossRef]
- Wang, X.; Hu, B.; Han, Z.M.; Jian, Y.F.; Liang, J.; Zhou, H.; Zhou, J.J.; Dian, Y.Y. Dominant Tree Species Specific Classified by GF-2 Imagery. Hubei For. Sci. Technol. 2020, 49, 1–7, 76. [Google Scholar]
- Katoh, M. Classifying tree species in a northern mixed forest using high-resolution IKONOS data. J. For. Res. 2004, 9, 7–14. [Google Scholar] [CrossRef]
- Pippuri, I.; Suvanto, A.; Maltamo, M.; Korhonen, K.T.; Pitkänen, J.; Packalen, P. Classification of forest land attributes using multi-source remotely sensed data. Int. J. Appl. Earth Obs. Geoinf. ITC J. 2016, 44, 11–22. [Google Scholar] [CrossRef]
- Chong, R.; Ju, H.; Zhang, H.; Huang, J. Forest land type precise classification based on SPOT5 and GF-1 images. In Proceedings of the IGARSS 2016—2016 IEEE International Geoscience and Remote Sensing Symposium, Beijing, China, 10–15 July 2016. [Google Scholar]
- Chiang, S.-H.; Valdez, M. Tree Species Classification by Integrating Satellite Imagery and Topographic Variables Using Maximum Entropy Method in a Mongolian Forest. Forests 2019, 10, 961. [Google Scholar] [CrossRef]
- Kollert, A.; Bremer, M.; Löw, M.; Rutzinger, M. Exploring the potential of land surface phenology and seasonal cloud free composites of one year of Sentinel-2 imagery for tree species mapping in a mountainous region. Int. J. Appl. Earth Obs. Geoinf. ITC J. 2020, 94, 102208. [Google Scholar] [CrossRef]
- Deur, M.; Gašparović, M.; Balenović, I. Tree Species Classification in Mixed Deciduous Forests Using Very High Spatial Resolution Satellite Imagery and Machine Learning Methods. Remote Sens. 2020, 12, 3926. [Google Scholar] [CrossRef]
- Gini, R.; Sona, G.; Ronchetti, G.; Passoni, D.; Pinto, L. Improving Tree Species Classification Using UAS Multispectral Images and Texture Measures. ISPRS Int. J. Geo-Inf. 2018, 7, 315. [Google Scholar] [CrossRef] [Green Version]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | GEE ID | Dataset Provider | Period | Spatial Resolution |
|---|---|---|---|---|
| Emissivity 8-Day Global 1 km SRTM Digital Elevation Data (digital elevation data) | USGS/SRTMGL1_003 | NASA/USGS/JPL-Caltech | 2000 | 30 m |
| CHIRPS Daily: Climate Hazards Group InfraRed Precipitation with Station Data (V 2) (precipitation data) | UCSB-CHG/CHIRPS/DAILY | UCSB/CHG | 1 January 1981–30 June 2022 | 5566 m |
| GCOM-C/SGLI L3 Land Surface Temperature (V2) (temperature data) | JAXA/GCOM-C/L3/LAND/LST/V2 | Global Change Observation Mission | 1 January 2018–28 November 2021 | 4638.3 m |
| JRC Monthly Water History, v1.3 (water data) | JRC/GSW1_3/MonthlyHistory | EC JRC/Google | 16 March 1984–1 January 2021 | 30 m |
| Sentinel-5P NRTI AER AI: Near Real-Time UV Aerosol Index (Sentinel-5P ultraviolet aerosol index data) | COPERNICUS/S5P/NRTI/L3_AER_AI | European Union/ESA/Copernicus | 10 July 2018–15 August 2022 | 1113.2 m |
| Global ALOS mTPI (multi-scale topographic position index data) | CSP/ERGo/1_0/Global/ALOS_mTPI | Conservation Science Partners | 24 January 2006–13 May 2011 | 270 m |
| Global ALOS Topographic Diversity (topographic diversity data) | CSP/ERGo/1_0/Global/ALOS_topoDiversity | Conservation Science Partners | 24 January 2006–13 May 2011 | 270 m |
| GPWv411: Population Density (V 4) (population density data) | CIESIN/GPWv411/GPW_Population_Density | NASA SEDAC at the Center for International Earth Science Information Network | 1 January 2000–1 January 2020 | 927.67 m |
| Sentinel-5P OFFL NO2: Offline Nitrogen Dioxide (Sentinel-5P carbon dioxide data) | COPERNICUS/S5P/OFFL/L3_NO2 | European Union/ESA/Copernicus | 28 June 2018–6 August 2022 | 1113.2 m |
| GPWv411: Mean Administrative Unit Area (V 4) (mean administrative unit area data) | CIESIN/GPWv411/GPW_Mean_Administrative_Unit_Area | NASA SEDAC at the Center for International Earth Science Information Network | 1 January 2000–1 January 2020 | 927.67 m |
| Type | Category of Sample Points | Quantity of Sample Points |
|---|---|---|
| Forest land | Eucalyptus | 148 |
| Bamboo trees | 164 | |
| Pine trees | 122 | |
| Cedar | 407 | |
| Orange trees | 51 | |
| Tea bushes | 47 | |
| Brushwood | 107 | |
| Mixed broad-leaved forest | 85 | |
| Non-forest land | Water area | 80 |
| Farmland | 139 | |
| Construction land | 74 | |
| Grassland | 57 |
| Scheme | Feature Combination |
|---|---|
| 1 | Spectral features |
| 2 | Spectral features + spectral indices |
| 3 | Spectral features + texture features |
| 4 | Spectral features + temperature features |
| 5 | Spectral features + precipitation features |
| 6 | Spectral features + terrain features |
| 7 | Spectral features + phenological features |
| 8 | Spectral features + water features |
| 9 | Spectral features + population density feature |
| 10 | Spectral features + topographic diversity feature |
| 11 | Spectral features + multi-scale topographic position index |
| 12 | Spectral features + ultraviolet aerosol indices |
| 13 | Spectral features + NO2 concentration features |
| 14 | Spectral features + administrative unit area feature |
| 15 | Spectral features + all of the above features |
| 16 | Preference features |
| Features | Number | Feature Variable |
|---|---|---|
| Spectral features | 12 | B1, B2, B3, B4, B5, B6, B7, B8, B8A, B9, B11, B12 |
| Spectral indices | 18 | EVI, NDVI, NDVIA, MTCI, IRECI, PSRI, TCARI, NDWI, MCARI, RDVI, TVI, SAVI, MSI, LSWI, NDVIred_edge, mNDVIred_edge, MSRred_edge, CIred_edge |
| Texture features | 216 | The texture metric was calculated from the gray level co-occurrence matrix around each pixel in each band. Each band yielded 18 texture feature variables. There were a total of 216 feature variables |
| Temperature features | 5 | Temp_mean, Temp_max, Temp_min, Temp_skew, Temp_kurtosis |
| Precipitation features | 5 | Precipitation_mean, Precipitation_max, Precipitation_min, Precipitation_skew, Precipitation_kurtosis |
| Terrain features | 4 | Elevation, Slope, Aspect, Hill_shade |
| Phenological features | 18 | NDVI_winter, NDVI_summer, NDVI_spring, NDVI_fall, EVI_winter, EVI_summer, EVI_spring, EVI_fall, LSWI_winter, LSWI_summer, LSWI_spring, LSWI_fall, NDVI_summer_winter, NDVI_fall_spring, EVI_summer_winter, EVI_fall_spring, LSWI_summer_winter, LSWI_fall_spring |
| Water features | 5 | Water_mean, Water_max, Water_min, Water_skew, Water_kurtosis |
| Population density feature | 1 | PD |
| Topographic diversity feature | 1 | TD |
| Multi-scale topographic position index | 1 | MSTPI |
| Ultraviolet aerosol indices | 5 | Aerosol_mean, Aerosol_max, Aerosol_min, Aerosol_skew, Aerosol_kurtosis |
| NO2 concentration features | 5 | NO2_mean, NO2_max, NO2_min, NO2_skew, NO2_kurtosis |
| Administrative unit area feature | 1 | MAUA |
| Spectral Indices | Formula | Reference |
|---|---|---|
| Enhanced vegetation index (EVI) | 2.5 × (B8 − B4)/(B8 + 6 × B4 − 7.5 × B2 + 1) | Liu et al. [19] |
| Normalized difference vegetation index (NDVI) | (B8 − B4)/(B8 + B4) | Broge et al. [20] |
| Normalized difference vegetation index (NDVIA) | (B8A − B4)/(B8A + B4) | Broge et al. [20] |
| MERIS terrestrial chlorophyll index (MTCI) | (B6 − B5)/(B5 − B4) | Dash et al. [21] |
| Inverted red-edge chlorophyll index (IRECI) | (B7 − B4)/(B5/B6) | Frampton et al. [22] |
| Plant senescence reflectance index (PSRI) | (B4 − B3)/B6) | Merzlyak et al. [23] |
| Transformed chlorophyll absorption in reflectance index (TCARI) | 3 × ((B8 − B4) − 0.2 × (B8 − B3)) × (B8/B4) | Haboudane et al. [24] |
| Normalized difference water index (NDWI) | (B3 − B8)/(B8 + B3) | Mcfeeters et al. [25] |
| Modified chlorophyll absorption in reflectance index (MCARI) | (B8 − B4) − 0.2 × (B8 − B3)) × (B8/B4) | Daughtry et al. [26] |
| Ratio difference vegetation index (RDVI) | (B8 − B4)/pow (B8 − B4,0.5) | Huete et al. [27] |
| Triangular vegetation index (TVI) | 0.5 × (120 × (B8 − B3)/200 × (B4 − B3)) | Broge et al. [28] |
| Soil adjusted vegetation index (SAVI) | (1 + 0.2) × float (B8 − B4)/(B8 + B4 + 0.2) | Bolyn et al. [29] |
| Moisture stress index (MSI) | B8/B3 | Bolyn et al. [29] |
| Land surface water index (LSWI) | (B8 − B11)/(B8 + B11) | Bridhikitti et al. [30] |
| Normalized difference red-edge vegetation index (NDVIred_edge) | (B6 − B5)/(B6 + B5) | Gamon et al. [31] |
| Modified normalized difference red-edge vegetation index (mNDVIred_edge) | (B6 − B5)/(B6 + B5 – 2 × B1) | Le Maire et al. [32] |
| Modified specific ratio red-edge vegetation index (MSRred_edge) | (B6 − B1)/(B5 + B1) | Fourty et al. [33] |
| Chlorophyll red-edge index (CIred_edge) | (B6 − 800/B5 − 725) − 1 | Gitelson et al. [34] |
| Number | Feature Variable | Score | Number | Feature Variable | Score | Number | Feature Variable | Score |
|---|---|---|---|---|---|---|---|---|
| 1 | Elevation | 70.96 | 28 | B11 | 55.96 | 55 | MCARI | 49.62 |
| 2 | Aerosol_skew | 67.77 | 29 | NO2_min | 55.83 | 56 | B3 | 49.37 |
| 3 | LSWI_summer | 65.69 | 30 | NO2_max | 55.38 | 57 | Precipitation_kurtosis | 49.13 |
| 4 | Aerosol_mean | 65.53 | 31 | MSTPI | 55.09 | 58 | MSI | 48.85 |
| 5 | Aerosol_kurtosis | 63.85 | 32 | NDVI_summer | 54.72 | 59 | Aerosol_min | 48.43 |
| 6 | PSRI | 63.06 | 33 | NDVIred_edge | 54.58 | 60 | MAUA | 48.26 |
| 7 | NO2_mean | 62.58 | 34 | EVI_fall | 54.53 | 61 | NDVI | 48.16 |
| 8 | LSWI_fall | 61.76 | 35 | NDVIA | 54.11 | 62 | Hill_shade | 48.06 |
| 9 | B5 | 61.34 | 36 | CIred_edge | 53.94 | 63 | B4 | 47.87 |
| 10 | B9 | 61.22 | 37 | PD | 53.72 | 64 | B7 | 47.27 |
| 11 | Temp_mean | 60.71 | 38 | NDWI | 53.67 | 65 | Temp_kurtosis | 46.34 |
| 12 | Precipitation_mean | 60.31 | 39 | LSWI_winter | 53.39 | 66 | NO2_skew | 45.75 |
| 13 | EVI_spring | 59.76 | 40 | NO2_kurtosis | 53.23 | 67 | SAVI | 45.62 |
| 14 | B12 | 58.92 | 41 | NDVI_winter | 53.06 | 68 | IRECI | 45.24 |
| 15 | MTCI | 58.28 | 42 | B8 | 52.94 | 69 | TCARI | 45.09 |
| 16 | B6 | 57.69 | 43 | LSWI | 52.92 | 70 | Temp_skew | 45.09 |
| 17 | B2 | 57.63 | 44 | Slope | 52.85 | 71 | EVI | 44.50 |
| 18 | TD | 57.23 | 45 | NDVI_summer_winter | 52.57 | 72 | Precipitation_max | 44.48 |
| 19 | B1 | 57.21 | 46 | Precipitation_skew | 52.30 | 73 | B8A | 44.36 |
| 20 | RDVI | 57.09 | 47 | MSRred_edge | 52.25 | 74 | EVI_fall_spring | 44.04 |
| 21 | LSWI_spring | 57.01 | 48 | NDVI_fall_spring | 51.65 | 75 | Temp_min | 38.54 |
| 22 | mNDVIred_edge | 56.92 | 49 | Aerosol_max | 51.54 | 76 | Water_skew | 32.71 |
| 23 | LSWI_summer_winter | 56.90 | 50 | EVI_summer_winter | 51.41 | 77 | Water_mean | 29.75 |
| 24 | LSWI_fall_spring | 56.71 | 51 | Aspect | 51.26 | 78 | Water_kurtosis | 26.95 |
| 25 | NDVI_spring | 56.47 | 52 | EVI_winter | 51.18 | 79 | Water_max | 1.99 |
| 26 | EVI_summer | 56.27 | 53 | TVI | 49.93 | |||
| 27 | Temp_max | 56.05 | 54 | NDVI_fall | 49.86 |
| Number | RF | SVM | CART | GTB |
|---|---|---|---|---|
| Feature Variables | ||||
| 1 | Elevation | TD | B1 | B11 |
| 2 | Aerosol_skew | LSWI_fall_spring | Elevation | B1 |
| 3 | LSWI_summer | Temp_skew | B9 | NO2_mean |
| 4 | Aerosol_mean | NDVI_fall | MTCI | MAUA |
| 5 | Aerosol_kurtosis | B8 | MSRred_edge | Elevation |
| 6 | PSRI | NDVI_fall_spring | B2 | B9 |
| 7 | NO2_mean | B7 | PSRI | Slope |
| 8 | LSWI_fall | B8A | LSWI | LSWI_summer |
| 9 | B5 | B11 | Slope | mNDVIred_edge |
| 10 | B9 | NDVI_summer_winter | NDVI | B12 |
| 11 | Temp_mean | LSWI_summer_winter | EVI_fall | NDVI_winter |
| 12 | Precipitation_mean | mNDVIred_edge | EVI | AVE |
| 13 | EVI_spring | LSWI | EVI_winter | Aerosol_kurtosis |
| 14 | B12 | MSRred_edge | mNDVIred_edge | NO2_max |
| 15 | MTCI | B12 | PD | Aerosol_mean |
| RF | GTB | SVM | CART | |
|---|---|---|---|---|
| Overall accuracy | 82.69% | 82.55% | 71.67% | 70.99% |
| Kappa coefficient | 0.80 | 0.80 | 0.67 | 0.66 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
You, H.; Huang, Y.; Qin, Z.; Chen, J.; Liu, Y. Forest Tree Species Classification Based on Sentinel-2 Images and Auxiliary Data. Forests 2022, 13, 1416. https://doi.org/10.3390/f13091416
You H, Huang Y, Qin Z, Chen J, Liu Y. Forest Tree Species Classification Based on Sentinel-2 Images and Auxiliary Data. Forests. 2022; 13(9):1416. https://doi.org/10.3390/f13091416
Chicago/Turabian StyleYou, Haotian, Yuanwei Huang, Zhigang Qin, Jianjun Chen, and Yao Liu. 2022. "Forest Tree Species Classification Based on Sentinel-2 Images and Auxiliary Data" Forests 13, no. 9: 1416. https://doi.org/10.3390/f13091416
APA StyleYou, H., Huang, Y., Qin, Z., Chen, J., & Liu, Y. (2022). Forest Tree Species Classification Based on Sentinel-2 Images and Auxiliary Data. Forests, 13(9), 1416. https://doi.org/10.3390/f13091416