
Zoning Prediction and Mapping of Three-Dimensional Forest Soil Organic Carbon: A Case Study of Subtropical Forests in Southern China

 ,
,  and
and
Abstract
:1. Introduction
2. Materials and Methods
2.1. Study Area and Soil Data
2.2. Environmental Variables
2.2.1. Model Covariates
2.2.2. Zoning Method
2.3. Prediction Technique
2.3.1. ANN Model Structure and Training
2.3.2. Screening Model
2.4. Mapping Method
2.5. Accuracy Metrics
2.6. Statistical Analysis
3. Results
3.1. Exploratory Data Analysis
3.2. Descriptive Statistics of Prediction Accuracy
3.2.1. Accuracies of Global Models
3.2.2. Accuracies of Zone Modelling
3.2.3. Accuracies of the Covariate Models
3.2.4. Independent Verification
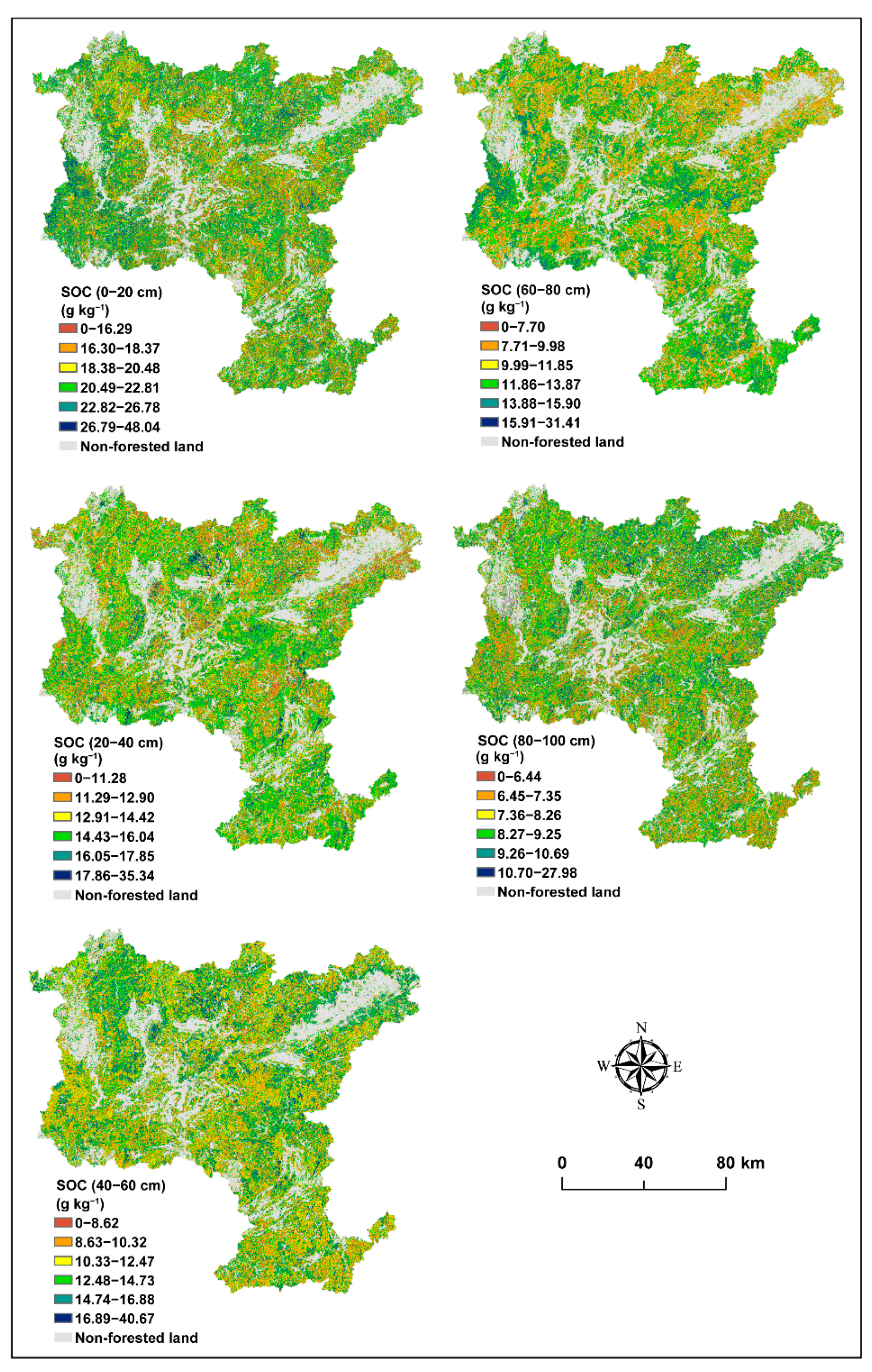
3.3. Digital Forest SOC Maps
4. Discussion
4.1. Performance of Zoning Modelling
4.2. Predicted Distribution of Forest SOC Content
4.3. Limitations
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Nitsch, P.; Kaupenjohann, M.; Wulf, M. Forest continuity, soil depth and tree species are important parameters for SOC stocks in an old forest (Templiner Buchheide, northeast Germany). Geoderma 2018, 310, 65–76. [Google Scholar] [CrossRef]
- Qiu, T.; Andrus, R.; Aravena, M.-C.; Ascoli, D.; Bergeron, Y.; Berretti, R.; Berveiller, D.; Bogdziewicz, M.; Boivin, T.; Bonal, R.; et al. Limits to reproduction and seed size-number trade-offs that shape forest dominance and future recovery. Nat. Commun. 2022, 13, 1238. [Google Scholar] [CrossRef] [PubMed]
- Mayer, M.; Rusch, S.; Didion, M.; Baltensweiler, A.; Walthert, L.; Ranft, F.; Rigling, A.; Zimmermann, S.; Hagedorn, F. Elevation dependent response of soil organic carbon stocks to forest windthrow. Sci. Total Environ. 2023, 857, 159694. [Google Scholar] [CrossRef] [PubMed]
- Jandl, R.; Rodeghiero, M.; Martinez, C.; Cotrufo, M.F.; Bampa, F.; van Wesemael, B.; Harrison, R.B.; Guerrini, I.A.; Richter, D.D.; Rustad, L.; et al. Current status, uncertainty and future needs in soil organic carbon monitoring. Sci. Total Environ. 2014, 468–469, 376–383. [Google Scholar] [CrossRef]
- Jenny, H. Factors of Soil Formation. Soil Sci. 1941, 52, 415. [Google Scholar] [CrossRef]
- Huggett, R.J. Soil landscape systems: A model of soil Genesis. Geoderma 1975, 13, 1–22. [Google Scholar] [CrossRef]
- Minasny, B.; McBratney, A. Digital soil mapping: A brief history and some lessons. Geoderma 2016, 264, 301–311. [Google Scholar] [CrossRef]
- Scull, P.; Franklin, J.; Chadwick, O.A.; McArthur, D. Predictive soil mapping: A review. Prog. Phys. Geogr. Earth Environ. 2003, 27, 171–197. [Google Scholar] [CrossRef] [Green Version]
- Chen, L.; Ren, C.; Li, L.; Wang, Y.; Zhang, B.; Wang, Z.; Li, L. A Comparative Assessment of Geostatistical, Machine Learning, and Hybrid Approaches for Mapping Topsoil Organic Carbon Content. ISPRS Int. J. Geo-Inf. 2019, 8, 174. [Google Scholar] [CrossRef] [Green Version]
- Chagas, C.D.S.; Vieira, C.A.O.; Filho, E.I.F. Comparison between artificial neural networks and maximum likelihood classification in digital soil mapping. Rev. Bras. Ciênc. Solo 2013, 37, 339–351. [Google Scholar] [CrossRef]
- Taghizadeh-Mehrjardi, R.; Nabiollahi, K.; Kerry, R. Digital mapping of soil organic carbon at multiple depths using different data mining techniques in Baneh region, Iran. Geoderma 2016, 266, 98–110. [Google Scholar] [CrossRef]
- Guevara, M.; Olmedo, G.F.; Stell, E.; Yigini, Y.; Aguilar Duarte, Y.; Arellano Hernández, C.; Arévalo, G.E.; Arroyo-Cruz, C.E.; Bolivar, A.; Bunning, S.; et al. No Silver Bullet for Digital Soil Mapping: Country-Specific Soil Organic Carbon Estimates across Latin America. Soil Methods 2018, 4, 173–193. [Google Scholar] [CrossRef] [Green Version]
- Ross, C.W.; Grunwald, S.; Vogel, J.G.; Markewitz, D.; Jokela, E.J.; Martin, T.A.; Bracho, R.; Bacon, A.R.; Brungard, C.W.; Xiong, X. Accounting for two-billion tons of stabilized soil carbon. Sci. Total Environ. 2020, 703, 134615. [Google Scholar] [CrossRef]
- Song, X.-D.; Wu, H.-Y.; Ju, B.; Liu, F.; Yang, F.; Li, D.-C.; Zhao, Y.-G.; Yang, J.-L.; Zhang, G.-L. Pedoclimatic zone-based three-dimensional soil organic carbon mapping in China. Geoderma 2020, 363, 114145. [Google Scholar] [CrossRef]
- McBratney, A.B.; Hart, G.A.; McGarry, D. The use of region partitioning to improve the representation of geo statistically mapped soil attributes. J. Soil Sci. 1991, 42, 513–532. [Google Scholar] [CrossRef]
- Hudson, B.D. The Soil Survey as Paradigm-based Science. Soil Sci. Soc. Am. J. 1992, 56, 836–841. [Google Scholar] [CrossRef]
- Mulder, V.L.; Lacoste, M.; Richer-De-Forges, A.C.; Martin, M.P.; Arrouays, D. National versus global modelling the 3D distribution of soil organic carbon in mainland France. Geoderma 2016, 263, 16–34. [Google Scholar] [CrossRef]
- Sun, X.-L.; Lai, Y.-Q.; Ding, X.; Wu, Y.-J.; Wang, H.-L.; Wu, C. Variability of soil mapping accuracy with sample sizes, modelling methods and landform types in a regional case study. Catena 2022, 213, 106217. [Google Scholar] [CrossRef]
- Peng, Y.; Xiong, X.; Adhikari, K.; Knadel, M.; Grunwald, S.; Greve, M.H. Modeling Soil Organic Carbon at Regional Scale by Combining Multi-Spectral Images with Laboratory Spectra. PLoS ONE 2015, 10, e0142295. [Google Scholar] [CrossRef] [Green Version]
- McBratney, A.B.; Mendonça Santos, M.L.; Minasny, B. On digital soil mapping. Geoderma 2003, 117, 3–52. [Google Scholar] [CrossRef]
- Ziche, D.; Grüneberg, E.; Hilbrig, L.; Höhle, J.; Kompa, T.; Liski, J.; Repo, A.; Wellbrock, N. Comparing soil inventory with modelling: Carbon balance in central European forest soils varies among forest types. Sci. Total. Environ. 2019, 647, 1573–1585. [Google Scholar] [CrossRef] [PubMed]
- Poggio, L.; Gimona, A. 3D mapping of soil texture in Scotland. Geoderma Reg. 2017, 9, 5–16. [Google Scholar] [CrossRef]
- Meersmans, J.; van Wesemael, B.; De Ridder, F.; Van Molle, M. Modelling the three-dimensional spatial distribution of soil organic carbon (SOC) at the regional scale (Flanders, Belgium). Geoderma 2009, 152, 43–52. [Google Scholar] [CrossRef]
- Wang, S.; Adhikari, K.; Zhuang, Q.; Yang, Z.; Jin, X.; Wang, Q.; Bian, Z. An improved similarity-based approach to predicting and mapping soil organic carbon and soil total nitrogen in a coastal region of northeastern China. PeerJ 2020, 8, e9126. [Google Scholar] [CrossRef] [PubMed]
- Jaeger, J.A.G. Landscape division, splitting index, and effective mesh size: New measures of landscape fragmentation. Landsc. Ecol. 2000, 15, 115–130. [Google Scholar] [CrossRef]
- Rosenbloom, N.A.; Harden, J.W.; Neff, J.C.; Schimel, D.S. Geomorphic control of landscape carbon accumulation. J. Geophys. Res. 2006, 111, G01004. [Google Scholar] [CrossRef]
- Malone, B.P.; Minasny, B.; Odgers, N.P.; McBratney, A.B. Using model averaging to combine soil property rasters from legacy soil maps and from point data. Geoderma 2014, 232–234, 34–44. [Google Scholar] [CrossRef]
- Swiderski, B.; Osowski, S.; Kruk, M.; Barhoumi, W. Aggregation of classifiers ensemble using local discriminatory power and quantiles. Expert Syst. Appl. 2016, 46, 316–323. [Google Scholar] [CrossRef]
- Li, T.; Li, M.; Ren, F.; Tian, L. Estimation and Spatio-Temporal Change Analysis of NPP in Subtropical Forests: A Case Study of Shaoguan, Guangdong, China. Remote Sens. 2022, 14, 2541. [Google Scholar] [CrossRef]
- Nóbrega, G.N.; Ferreira, T.O.; Artur, A.G.; de Mendonça, E.S.; de O. Leão, R.A.; Teixeira, A.S.; Otero, X.L. Evaluation of methods for quantifying organic carbon in mangrove soils from semi-arid region. J. Soils Sediments 2015, 15, 282–291. [Google Scholar] [CrossRef]
- Bangroo, S.A.; Najar, G.R.; Achin, E.; Truong, P.N. Application of predictor variables in spatial quantification of soil organic carbon and total nitrogen using regression kriging in the North Kashmir forest Himalayas. Catena 2020, 193, 104632. [Google Scholar] [CrossRef]
- Ding, X.; Zhao, Z.; Yang, Q.; Chen, L.; Tian, Q.; Li, X.; Meng, F.-R. Model prediction of depth-specific soil texture distributions with artificial neural network: A case study in Yunfu, a typical area of Udults Zone, South China. Comput. Electron. Agric. 2020, 169, 105217. [Google Scholar] [CrossRef]
- Zhao, Z.; Yang, Q.; Benoy, G.; Chow, T.L.; Xing, Z.; Rees, H.W.; Meng, F.-R. Using artificial neural network models to produce soil organic carbon content distribution maps across landscapes. Can. J. Soil Sci. 2010, 90, 75–87. [Google Scholar] [CrossRef]
- Mahmoudabadi, E.; Karimi, A.; Haghnia, G.H.; Sepehr, A. Digital soil mapping using remote sensing indices, terrain attributes, and vegetation features in the rangelands of northeastern Iran. Environ. Monit. Assess. 2017, 189, 500. [Google Scholar] [CrossRef]
- McGillem, C.D.; Svedlow, M. Short Papers Optimum Filter for Minimization of Image Registration Error Variance. IEEE Trans. Geosci. Electron. 1977, 15, 257–259. [Google Scholar] [CrossRef]
- Zhao, Z.; Yang, Q.; Sun, D.; Ding, X.; Meng, F.-R. Extended model prediction of high-resolution soil organic matter over a large area using limited number of field samples. Comput. Electron. Agric. 2020, 169, 105172. [Google Scholar] [CrossRef]
- Brungard, C.; Nauman, T.; Duniway, M.; Veblen, K.; Nehring, K.; White, D.; Salley, S.; Anchang, J. Regional ensemble modeling reduces uncertainty for digital soil mapping. Geoderma 2021, 397, 114998. [Google Scholar] [CrossRef]
- Zhao, Z.; Chow, T.L.; Rees, H.W.; Yang, Q.; Xing, Z.; Meng, F.-R. Predict soil texture distributions using an artificial neural network model. Comput. Electron. Agric. 2009, 65, 36–48. [Google Scholar] [CrossRef]
- Guangdong Soil Census Office. Guangdong Soil, 1st ed.; China Science Publishing: Beijing, China, 1993; p. 419. [Google Scholar]
- Lettens, S.; Van Orshoven, J.; Van Wesemael, B.; Muys, B. Soil organic and inorganic carbon contents of landscape units in Belgium derived using data from 1950 to 1970. Soil Use Manag. 2004, 20, 40–47. [Google Scholar] [CrossRef]
- Drăguţ, L.; Dornik, A. Land-surface segmentation as a method to create strata for spatial sampling and its potential for digital soil mapping. Int. J. Geogr. Inf. Sci. 2016, 30, 1359–1376. [Google Scholar] [CrossRef] [Green Version]
- Lai, Y.-Q.; Wang, H.-L.; Sun, X.-L. A comparison of importance of modelling method and sample size for mapping soil organic matter in Guangdong, China. Ecol. Indic. 2021, 126, 107618. [Google Scholar] [CrossRef]
- Fiorentini, N.; Pellegrini, D.; Losa, M. Overfitting Prevention in Accident Prediction Models: Bayesian Regularization of Artificial Neural Networks. Transp. Res. Rec. J. Transp. Res. Board 2023, 2677, 1455–1470. [Google Scholar] [CrossRef]
- Brungard, C.W.; Boettinger, J.L.; Duniway, M.C.; Wills, S.A.; Edwards, T.C. Machine learning for predicting soil classes in three semi-arid landscapes. Geoderma 2015, 239–240, 68–83. [Google Scholar] [CrossRef] [Green Version]
- Jobbágy, E.G.; Jackson, R.B. The vertical distribution of soil organic carbon and its relation to climate and vegetation. Ecol. Appl. 2000, 10, 423–436. [Google Scholar] [CrossRef]
- Fischer, G.F.; Nachtergaele, S.; Prieler, H.T.; van Velthuizen, L.; Verelst, D.W. Global Agro-Ecological Zones Assessment for Agriculture (GAEZ 2008); IIASA: Laxenburg, Austria; FAO: Rome, Italy, 2008. [Google Scholar]
- Wasson, T.; Hartemink, A.J. An ensemble model of competitive multi-factor binding of the genome. Genome Res. 2009, 19, 2101–2112. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kumar, S.; Lal, R.; Liu, D. A geographically weighted regression kriging approach for mapping soil organic carbon stock. Geoderma 2012, 189–190, 627–634. [Google Scholar] [CrossRef]
- Song, X.-D.; Brus, D.J.; Liu, F.; Li, D.-C.; Zhao, Y.-G.; Yang, J.-L.; Zhang, G.-L. Mapping soil organic carbon content by geographically weighted regression: A case study in the Heihe River Basin, China. Geoderma 2016, 261, 11–22. [Google Scholar] [CrossRef]
- Bhunia, G.S.; Kumar Shit, P.; Pourghasemi, H.R. Soil organic carbon mapping using remote sensing techniques and multivariate regression model. Geocarto Int. 2019, 34, 215–226. [Google Scholar] [CrossRef]
- Rial, M.; Martinez Cortizas, A.; Taboada, T.; Rodríguez-Lado, L. Soil organic carbon stocks in Santa Cruz Island, Galapagos, under different climate change scenarios. Catena 2017, 156, 74–81. [Google Scholar] [CrossRef]
- Wang, K.; Zhang, C.; Li, W. Predictive mapping of soil total nitrogen at a regional scale: A comparison between geographically weighted regression and cokriging. Appl. Geogr. 2013, 42, 73–85. [Google Scholar] [CrossRef]
- Xu, Y.; Smith, S.E.; Grunwald, S.; Abd-Elrahman, A.; Wani, S.P.; Nair, V.D. Estimating soil total nitrogen in smallholder farm settings using remote sensing spectral indices and regression kriging. Catena 2018, 163, 111–122. [Google Scholar] [CrossRef] [Green Version]
- Yang, L.; Qi, F.; Zhu, A.-X.; Shi, J.; An, Y. Evaluation of Integrative Hierarchical Stepwise Sampling for Digital Soil Mapping. Soil Sci. Soc. Am. J. 2016, 80, 637–651. [Google Scholar] [CrossRef]
- Zhang, Z.; Zhou, Y.; Wang, S.; Huang, X. The soil organic carbon stock and its influencing factors in a mountainous karst basin in P. R. China. Carbonates Evaporites 2019, 34, 1031–1043. [Google Scholar] [CrossRef]
- Rasel, S.M.M.; Groen, T.A.; Hussin, Y.A.; Diti, I.J. Proxies for Soil Organic Carbon Derived from Remote Sensing. Int. J. Appl. Earth Obs. Geo-Inf. 2017, 59, 157–166. [Google Scholar] [CrossRef]
- Bookhagen, B.; Thiede, R.C.; Strecker, M.R. Abnormal monsoon years and their control on erosion and sediment flux in the high, arid northwest Himalaya. Earth Planet. Sci. Lett. 2005, 231, 131–146. [Google Scholar] [CrossRef]
- Mondal, A.; Khare, D.; Kundu, S.; Mondal, S.; Mukherjee, S.; Mukhopadhyay, A. Spatial soil organic carbon (SOC) prediction by regression kriging using remote sensing data. Egypt. J. Remote Sens. Space Sci. 2017, 20, 61–70. [Google Scholar] [CrossRef] [Green Version]
- Qin, Y.; Feng, Q.; Holden, N.M.; Cao, J. Variation in soil organic carbon by slope aspect in the middle of the Qilian Mountains in the upper Heihe River Basin, China. Catena 2016, 147, 308–314. [Google Scholar] [CrossRef]
- Burke, I.C.; Yonker, C.M.; Parton, W.J.; Cole, C.V.; Flach, K.; Schimel, D.S. Texture, Climate, and Cultivation Effects on Soil Organic Matter Content in U.S. Grassland Soils. Soil Sci. Soc. Am. J. 1989, 53, 800–805. [Google Scholar] [CrossRef]
- Wynn, J.G.; Bird, M.; Vellen, L.; Grand-Clement, E.; Carter, J.; Berry, S.L. Continental-scale measurement of the soil organic carbon pool with climatic, edaphic, and biotic controls: Continental-scale soil organic carbon. Glob. Biogeochem. Cycles 2006, 20. [Google Scholar] [CrossRef]
- Thomas, M.; Clifford, D.; Bartley, R.; Philip, S.; Brough, D.; Gregory, L.; Willis, R.; Glover, M. Putting regional digital soil mapping into practice in Tropical Northern Australia. Geoderma 2015, 241–242, 145–157. [Google Scholar] [CrossRef]
- Yang, Y.; Ouyang, S.; Gessler, A.; Wang, X.; Na, R.; He, H.S.; Wu, Z.; Li, M.-H. Root Carbon Resources Determine Survival and Growth of Young Trees under Long Drought in Combination with Fertilization. Front. Plant Sci. 2022, 13, 929855. [Google Scholar] [CrossRef] [PubMed]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Covariate | Abbr. | Resolution |
|---|---|---|---|
| DEM-derived terrain factors | Slope | Slope | 12.5 m |
| Aspect | Aspect | 12.5 m | |
| Topographic position index | TPI | 12.5 m | |
| Topographic wetness index | TWI | 12.5 m | |
| Flow accumulation | FA | 12.5 m | |
| Soil terrain factor | STF | 12.5 m | |
| Stream power index | SPI | 12.5 m | |
| Sentinel-2-derived vegetation factors | Normalized difference vegetation index | NDVI | 10 m |
| Differential vegetation index | DVI | 10 m | |
| Ratio vegetation index | RVI | 10 m | |
| Reformed difference vegetation index | RDVI | 10 m | |
| Enhanced vegetation index | EVI | 10 m |
| K1 | K2 | K3 | Condition |
|---|---|---|---|
| 1 | 0 | 0 | ff outperformed both ft and fg |
| 0 | 1 | 0 | ft outperformed both ff and fg |
| 0 | 0 | 1 | fg outperformed both ff and ft |
| 1/2 | 1/2 | 0 | ff was similar to ft, and both ff and ft outperformed fg |
| 1/2 | 0 | 1/2 | ff was similar to fg, and both ff and fg outperformed ft |
| 0 | 1/2 | 1/2 | ft was similar to fg, and both ft and fg outperformed ff |
| 1/3 | 1/3 | 1/3 | all three models were similar to each other |
| Layer (cm) | Number a | RMSE (g kg−1) | R2 | ROA (%) | Optimal Variable Combinations |
|---|---|---|---|---|---|
| 0–20 | 131.81 | 0.22 | 18.34 | Slope | |
| 111.89 | 0.30 | 22.98 | Slope, NDVI | ||
| 106.26 | 0.47 | 36.25 | Slope, NDVI, SPI | ||
| 88.41 | 0.50 | 39.08 | Slope, NDVI, SPI, STF | ||
| 75.36 | 0.59 | 45.36 | Slope, NDVI, SPI, STF, Aspect | ||
| 61.05 | 0.65 | 56.52 | Slope, NDVI, SPI, STF, Aspect, EVI | ||
| 66.56 | 0.60 | 51.36 | Slope, NDVI, SPI, STF, Aspect, EVI, TWI | ||
| 20–40 | 36.26 | 0.68 | 61.16 | Aspect, Slope, STF, SPI, FA, DVI, NDVI | |
| 40–60 | 41.86 | 0.66 | 54.81 | Slope, TWI, TPI, STF, SPI, FA, DVI, RDVI, NDVI, RVI | |
| 60–80 | 40.78 | 0.64 | 56.13 | Aspect, Slope, STF, SPI, FA, EVI, DVI, NDVI | |
| 80–100 | 38.00 | 0.65 | 57.87 | Aspect, Slope, TWI, TPI, STF, SPI, EVI, RDVI, RVI |
| Forest Types | Layer (cm) | Number a | RMSE (g kg−1) | R2 | ROA (%) | Optimal Variable Combinations |
|---|---|---|---|---|---|---|
| Broad-leaved | 0–20 | 50.51 | 0.81 | 71.61 | Aspect, Slope, TWI, TPI, STF, SPI, DVI, RDVI, RVI | |
| 20–40 | 15.24 | 0.86 | 74.35 | Aspect, Slope, TPI, STF, SPI, FA, EVI, RDVI, NDVI, RVI | ||
| 40–60 | 23.51 | 0.80 | 70.51 | Aspect, Slope, TPI, STF, SPI, FA, EVI, RDVI, RVI | ||
| 60–80 | 23.46 | 0.76 | 65.66 | Aspect, Slope, TWI, TPI, SPI, EVI, DVI, NDVI, RVI | ||
| 80–100 | 22.74 | 0.78 | 68.91 | Aspect, Slope, TPI, RDVI, RVI | ||
| Coniferous | 0–20 | 37.8 | 0.83 | 75.75 | Aspect, Slope, TWI, TPI, STF, SPI, DVI, RDVI, NDVI, RVI | |
| 20–40 | 15.92 | 0.80 | 71.08 | Aspect, Slope, TWI, TPI, STF, SPI, FA, EVI, NDVI, RVI | ||
| 40–60 | 24.99 | 0.76 | 66.55 | Aspect, TWI, TPI, STF, SPI, DVI, RDVI | ||
| 60–80 | 21.26 | 0.76 | 65.44 | Aspect, STF, SPI, EVI, DVI, RDVI, NDVI | ||
| 80–100 | 23.83 | 0.75 | 67.14 | Aspect, Slope, TWI, TPI, STF, SPI, FA, EVI, RVI | ||
| Mixed forest | 0–20 | 30.50 | 0.87 | 77.15 | Slope, STF, EVI, DVI, NDVI, RVI | |
| 20–40 | 13.99 | 0.90 | 82.41 | Aspect, Slope, TPI, STF, SPI, EVI, RDVI, NDVI | ||
| 40–60 | 20.66 | 0.84 | 72.01 | Aspect, TWI, TPI, STF, SPI, FA, EVI, RDVI | ||
| 60–80 | 29.15 | 0.80 | 69.12 | Aspect, Slope, TPI, SPI, EVI, DVI, RDVI, NDVI | ||
| 80–100 | 16.07 | 0.84 | 76.34 | Slope, TPI, SPI, FA, DVI, RDVI, RVI |
| Texture Classes | Layer (cm) | Number a | RMSE (g kg−1) | R2 | ROA (%) | Optimal Variable Combinations |
|---|---|---|---|---|---|---|
| Upper texture | ||||||
| Clay | 0–20 | 41.59 | 0.82 | 73.31 | Slope, TPI, STF, SPI, FA, EVI, DVI, RDVI, NDVI, RVI | |
| 20–40 | 20.22 | 0.78 | 67.07 | Aspect, TWI, TPI, SPI, EVI, DVI, RVI | ||
| Sandy loam | 0–20 | 48.93 | 0.80 | 70.24 | Aspect, Slope, TWI, STF, EVI, RDVI, RVI | |
| 20–40 | 24.95 | 0.74 | 66.28 | Aspect, Slope, TWI, TPI, STF, SPI, FA, EVI, DVI, RVI | ||
| Deep texture | ||||||
| Clay | 40–60 | 20.72 | 0.81 | 72.55 | Aspect, Slope, TPI, STF, SPI, FA, NDVI, RVI | |
| 60–80 | 19.95 | 0.78 | 70.89 | Aspect, Slope, TWI, TPI, STF, SPI, EVI, DVI, RDVI, RVI | ||
| 80–100 | 17.08 | 0.80 | 71.95 | Aspect, Slope, TWI, TPI, STF, DVI, NDVI | ||
| Clay loam | 40–60 | 24.30 | 0.77 | 67.44 | Aspect, Slope, TWI, TPI, SPI, EVI, NDVI, RVI | |
| 60–80 | 25.94 | 0.71 | 65.14 | Aspect, TWI, TPI, STF, FA, EVI, DVI, RDVI, NDVI, RVI | ||
| 80–100 | 23.41 | 0.74 | 69.83 | Aspect, TPI, STF, SPI, FA, EVI, RDVI |
| Partition Type | Layer (cm) | Number a | RMSE (g kg−1) | R2 | ROA (%) | Optimal Variable Combinations |
|---|---|---|---|---|---|---|
| Forest type | 0–20 | 55.63 | 0.70 | 58.39 | Slope, TPI, STF, SPI, EVI, DVI, RDVI, NDVI, Forest | |
| 20–40 | 32.26 | 0.71 | 64.81 | Aspect, Slope, TWI, TPI, STF, SPI, FA, EVI, DVI, Forest | ||
| 40–60 | 38.75 | 0.70 | 57.96 | Aspect, Slope, TPI, STF, SPI, FA, EVI, DVI, NDVI, Forest | ||
| 60–80 | 37.20 | 0.67 | 57.38 | Aspect, Slope, TPI, SPI, FA, EVI, NDVI, Forest | ||
| 80–100 | 38.00 | 0.68 | 60.87 | Aspect, Slope, TWI, TPI, STF, SPI, EVI, RDVI, RVI | ||
| Texture class | 0–20 | 57.36 | 0.68 | 57.26 | Slope, TWI, TPI, STF, FA, EVI, DVI, RVI, Texture | |
| 20–40 | 34.26 | 0.69 | 62.29 | Aspect, TWI, TPI, STF, SPI, FA, EVI, DVI, RDVI, NDVI, Texture | ||
| 40–60 | 39.86 | 0.70 | 57.74 | Aspect, Slope, TWI, TPI, SPI, EVI, DVI, RDVI, NDVI, Texture | ||
| 60–80 | 40.78 | 0.64 | 56.13 | Aspect, Slope, STF, SPI, FA, EVI, DVI, NDVI | ||
| 80–100 | 34.84 | 0.68 | 59.83 | Slope, TWI, TPI, SPI, FA, DVI, RDVI, NDVI, Texture |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Y.; Zhang, Z.; Zhao, Z.; Sun, D.; Zhu, H.; Zhang, G.; Zhu, X.; Ding, X. Zoning Prediction and Mapping of Three-Dimensional Forest Soil Organic Carbon: A Case Study of Subtropical Forests in Southern China. Forests 2023, 14, 1197. https://doi.org/10.3390/f14061197
Li Y, Zhang Z, Zhao Z, Sun D, Zhu H, Zhang G, Zhu X, Ding X. Zoning Prediction and Mapping of Three-Dimensional Forest Soil Organic Carbon: A Case Study of Subtropical Forests in Southern China. Forests. 2023; 14(6):1197. https://doi.org/10.3390/f14061197
Chicago/Turabian StyleLi, Yingying, Zhongrui Zhang, Zhengyong Zhao, Dongxiao Sun, Hangyong Zhu, Geng Zhang, Xianliang Zhu, and Xiaogang Ding. 2023. "Zoning Prediction and Mapping of Three-Dimensional Forest Soil Organic Carbon: A Case Study of Subtropical Forests in Southern China" Forests 14, no. 6: 1197. https://doi.org/10.3390/f14061197
APA StyleLi, Y., Zhang, Z., Zhao, Z., Sun, D., Zhu, H., Zhang, G., Zhu, X., & Ding, X. (2023). Zoning Prediction and Mapping of Three-Dimensional Forest Soil Organic Carbon: A Case Study of Subtropical Forests in Southern China. Forests, 14(6), 1197. https://doi.org/10.3390/f14061197