1. Introduction
Forests have received a lot of attention from researchers and policymakers as a nature-based solution to climate change mitigation. Plantations account for approximately 7% of the world’s forest area (about 294 million hectares) and play a key role in supplying wood products and absorbing carbon dioxide. Many countries and regions around the world have made major declarations to achieve carbon peak and carbon neutrality, and forest carbon sequestration has become a hotspot of CCER with huge market potential [
1,
2]. Forest abatement schemes typically convert stock into biomass and, combined with expansion factors, into carbon stocks again [
3]. Plantation forests provide a growing forest stock that is directly linked to existing renewable wood resources and biomass energy under intensive management practices [
4]. Forest stock is the total volume of a stand or growing population per unit area, which is an important index to calculate the economic value of forests, and can directly reflect the quantity and quality of forest resources [
5]. Therefore, the establishment of effective methods and technical means to accurately estimate the stock of plantation is crucial for forest managers to find a balance between plantation timber production and carbon sink trading [
6,
7].
Existing forest stock estimation methods usually rely on labor-intensive field measurements to obtain the necessary parameters, such as DBH and tree height obtained through field surveys after sampling the target forest, which can incur expensive human resources and economic costs [
8,
9]. The sites selected may not accurately represent the entire project area [
10,
11]. Low-frequency estimation may lead to delays in detecting changes in forest growth conditions [
12]. Therefore, the previous estimation methods have some limitations, such as time and effort, limited investigation area, etc. [
13,
14]. In the context of carbon neutrality, people urgently need a more efficient and intelligent method to timely and accurately quantify forest stock and better balance the relationship between the economic value of renewable plantation and the value of carbon sink [
15,
16].
With the increasing maturity of ML, unmanned aerial vehicle and satellite remote sensing technology, its intelligent and high spatiotemporal resolution characteristics provide a new technology for forest stock estimation. At present, Light Detection and Ranging (LiDAR) is considered as an effective means to acquire forest 3D structure information at a regional or landscape scale [
17,
18]. Zeng Weisheng built a stock estimation model based on airborne LiDAR point clouds with a multiple regression method, which demonstrated the effectiveness of the forest stock multiple regression model based on point clouds [
19]. Dalla established four machine learning methods based on LiDAR to estimate forest parameters, among which the support vector regression algorithm performed best [
20]. Jiang Diexuan built a machine learning model based on the height and density of airborne point clouds in two periods to achieve dynamic storage estimation. Airborne LiDAR, unmanned aerial vehicles and satellite remote sensing technologies can provide high spatio-temporal resolution data, but obtaining these data is often costly and limited by weather conditions and geographical location. This can result in limited time and space coverage for data acquisition [
21]. Remote sensing technology solves the problem of stock estimation at the stand or regional scale, and stock estimation at the forest farm, provincial or national scale requires satellite remote sensing [
22,
23]. Remarkable progress has been made in forest stock estimation based on satellite remote sensing, and forest parameters are constructed to estimate stock by extracting spectral and texture features [
24]. By developing or improving data preprocessing methods and machine learning methods, people try to integrate multiple data sources to improve the estimation accuracy [
25,
26]. While machine learning models perform well on specific data sets, their ability to generalize remains a challenge. The data sets on which the model is trained are often geographically limited, and the prediction accuracy of the model may decline when applied to different regions or different forest types. Naik conducted generalized linear modeling based on Sentinel-2, Rapid Eye and other multi-spectral data to evaluate the impact of time, spectrum and spatial capabilities of multi-spectral satellites on forest stock prediction, and the results showed that the model built based on multi-temporal data was more effective than the single temporal model [
27].
To improve the precision and spatial scale of forest resource estimation, more and more attention has been paid to research methods such as the combination of unmanned aerial vehicle and satellite remote sensing, LiDAR feature fusion and spectral feature fusion [
28,
29]. Using Sentinel-2 multispectral, Resource-3 stereo imaging and airborne LiDAR data, Wenke Lin studied the ability of multi-source remote sensing to estimate forest stock in the north subtropical region, and pointed out the advantages of the Bayesian model in forest stock estimation in the case of small samples [
30]. Campbell combined airborne point clouds and multi-spectral images to jointly retrieve forest biomass, and pointed out that combined multi-data sources are conducive to large-scale forest parameter estimation [
31]. Yu proposed a method that combined multi-spectral satellite images and airborne laser scanning data to estimate the forest stock of larch in China, and used the random forest model for estimation, which proved that the method had certain applicability and high accuracy. In addition, the fusion of hyperspectral remote sensing and other data sources has also achieved some results in forest stock estimation [
32]. Gao combined airborne point clouds and hyperspectral data, adopted a random forest screening method and constructed multiple stepwise regression to estimate forest above-ground biomass, and the results showed that the fusion of multi-source data could significantly improve the estimation accuracy of the model [
33]. The RF model was used to estimate the forest stock, and the verification showed that the method had certain applicability and high accuracy [
34,
35]. Although multi-source data fusion has been proved to improve the estimation accuracy of the model, the fusion processing between different data sources is a complex process, which needs to solve the problems of spatial, temporal and spectral resolution mismatch. In future studies, addressing these limitations will be the key to improving the accuracy and reliability of forest stock estimation [
36]. There is a need to further explore more cost-effective data acquisition methods, improve model generalization, simplify and optimize multi-source data fusion processes, enhance model transparency and interpretability, and develop model training strategies for limited sample sizes.
Data sources and types, modeling methods and forest types affect the accuracy and stability of stock estimation [
37,
38]. This paper proposes an accurate forest stock estimation method based on “ML + LiDAR + satellite”, and a research experiment of “sky and ground integration” was carried out at the site of a national plantation emission reduction project in southern China [
39]. The results show that the ML method combined with multi-source remote sensing can enhance the modeling of forest stock resources [
40]. The research objectives of this paper are as follows: (1) a high-precision estimation method of eucalyptus plantation stock based on airborne point clouds combined with Landsat 8 images was proposed. This method aims to enhance the accuracy of eucalyptus stock estimation beyond the capabilities of existing techniques. (2) The estimation parameters and non-parametric models of eucalyptus plantation stock at the forest farm scale were established. These models are expected to provide a robust framework for accurate stock estimation, facilitating better forest management and resource allocation. (3) A scheme for estimating the stock of eucalyptus plantation with multi-source data is provided. This scheme is intended to leverage the complementary strengths of various data sources, thereby improving the reliability and precision of the stock estimation process.
3. Results
According to the results of the stepwise screening method (SS) and random forest screening method (RFFS), the parameters of stepwise regression (SS), partial least squares regression (PLSR), random forest regression (RFR) and support vector regression (SVR) were optimized, and the leave-one method was used for cross-validation. The results of accumulation modeling under multi-data sources and multi-modeling methods were evaluated comprehensively by comparing the sample survey data with the model prediction.
3.1. Point Clouds Model Evaluation and Analysis
The results are shown in
Figure 3 and
Figure 4. The solid line is the fitting line between the real value and the predicted value, and the dotted line is the 1:1 auxiliary judgment line. The blue line is the fitting line.
To comprehensively evaluate the model, R
2, RMSE and MAE were used to comprehensively evaluate the above eight models; the results are shown in
Table 1.
Based on the evaluation results of the above model, the following conclusions can be drawn:
- (1)
The fitting accuracy of COLL2 optimized using random forest screening is generally better than that of COLL1 with stepwise regression. In addition to the stepwise regression method, other modeling methods can achieve better prediction results when using the random forest screening method. Among them, partial least squares regression, random forest regression and support vector regression can achieve better prediction results when using the random forest screening method. Compared with the stepwise screening method, R2 increased by 0.01~0.07, RMSE decreased by 1.88~6.11 m3·hm−2, MAE decreased by 2.04~7.25 m3·hm−2, and the SVR model had the most significant reduction in prediction error. R2 increased by 0.04, RMSE decreased by 6.11 m3·hm−2, MAE decreased by 7.25 m3·hm−2, and the stepwise regression method was more suitable for the COLL1 selected using the stepwise screening method.
- (2)
The fitting effect of the non-parametric method is better than that of the parametric method. In this chapter, two non-parametric methods, random forest regression and support vector regression, constructed based on laser point clouds, have R2 values greater than or close to 0.9, and their RMSE and MAE evaluation indexes are small. In contrast, both partial least squares regression and stepwise regression in the parametric method have R2 values lower than 0.8, while the optimal parametric method model has an R2 values of only 0.83, and the corresponding RMSE and MAE indexes are relatively high.
It can be seen that when constructing a forest stock estimation model based on airborne LiDAR point clouds, using a random forest screening method and a constructing non-parametric method has the best model effect compared with other methods.
3.2. Evaluation and Analysis of Optical Remote Sensing Models
Figure 5 and
Figure 6 show image-based forest stock modeling; the solid line is the fitting line between the true value and the predicted value, and the dashed line is the 1:1 auxiliary judgment line.
Table 2 shows the comprehensive evaluation of the eight models.
The specific model construction is as follows: support vector regression algorithms constructed based on different screening methods have high fitting accuracy, with the R2 reaching 0.62 and 0.67, respectively, but RMSE and MAE are also relatively high, with values of 60.86 m3·hm−2 and 46.20 m3·hm−2 and 54.64 m3·hm−2 and 32.63 m3·hm−2, respectively. Among the parametric methods, the model estimation error of the stepwise regression algorithm based on the COLL3 variable combination is the smallest, with an R2 of 0.66, RMSE of 35.76 m3·hm−2 and MAE of 29.01 m3·hm−2.
From the perspective of screening methods, when the COLL4 variable combination selected using the random forest screening method is used in the four modeling methods, compared with the COLL3 variable combination selected by the stepwise screening method, the model fitting accuracy is improved to a certain extent. The R2 increased by 0.03~0.27, RMSE decreased by 6.22~13.77 m3·hm−2, and MAE decreased by 1.17~13.57 m3·hm−2, among which the stepwise regression algorithm improved the best fit. It can be seen that the selection of random forest as a remote sensing feature variable is more reliable.
From the perspective of modeling methods, when the COLL3 variable combination is used as the model modeling factor, the fitting accuracy of parametric methods (stepwise regression and partial least squares regression) is smaller than that of non-parametric methods (support vector regression and random forest regression), and the R2 of the optimal performance model PLSR is only 0.4, while that of non-parametric methods reaches at least 0.53. When the COLL4 variable combination is used as the model modeling factor, the fitting accuracies of the parametric method and non-parametric method only slightly differ, but SVR is still the model with the highest fitting accuracy. It can be seen that the non-parametric method (machine learning method) has certain advantages when constructing the storage estimation model based on remote sensing sources.
3.3. Model Evaluation and Analysis of Combined Point Clouds and Optical Remote Sensing
Forest stock modeling of point clouds combined with images is shown in
Figure 7 and
Figure 8.
- (1)
According to the accuracy evaluation indexes of each model, it can be seen that the support vector regression model constructed based on the COLL6 variable combination of random forest screening method has the best prediction performance, with an R2 of 0.94, RMSE of 24.14 m3·hm−2 and MAE of 17.74 m3·hm−2. The results show that the combination of point clouds and optical remote sensing for forest stock inversion is feasible and can obtain better prediction results.
- (2)
The modeling results based on the random forest screening method are better than the those obtained using the stepwise regression method. By comparing the model evaluation results when variable combination COLL5 and variable combination COLL6 were used in each modeling method, we can see that when variable combination COLL6 with the random forest screening method is used as the modeling factor, the overall prediction accuracy of each model is higher than that when COLL5 is used as the modeling factor, and the partial least squares model has the most significant improvement. The R2 increased by 0.08, the RMSE was 4.49 m3·hm−2, and the MAE was 2.69 m3·hm−2. Combined with the model evaluation results, it can be seen that when constructing forest stock estimation models based on single or multiple data sources, the random forest screening method is more reliable than the stepwise screening method as the feature variable screening method, and the combination of selected variables can better reflect the forest parameter information. The interpretation rate of the model after modeling can be improved more effectively.
- (3)
The accuracy of non-parametric models (random forest regression and support vector regression) is better than that of parametric methods (stepwise regression and the partial least squares method). As can be seen from
Table 3, among the eight models constructed by combining point clouds and optical remote sensing, the accuracy ranking of the models based on the combination of variables COLL5 and COLL6 is in the order of support vector regression, random forest regression, stepwise regression and partial least squares, and the top two are non-parametric methods. The fitting degree R
2 values of the non-parametric methods established in this section are all greater than 0.91, while the best fitting result of the parametric methods is stepwise regression, whose fitting degree R
2 is only 0.85, which is relatively low. According to the evaluation results of the model in
Section 3.1 and
Section 3.2, considering that the prediction of forest stock usually has certain nonlinear characteristics, the non-parametric method can capture these nonlinear relationships more flexibly, thus improving the prediction accuracy of the model. On the other hand, non-parametric methods can better deal with high-dimensional data and missing data problems. In the face of high dimensional data, non-parametric methods such as random forest regression can reduce the complexity of the model by constructing multiple decision trees, and at the same time have a good ability to deal with missing data. Therefore, the non-parametric method for retrieving forest stock has certain advantages over the parametric method.
- (4)
Compared with the previous model using only a single data source, the prediction accuracy of the model combined with multiple data sources has been significantly improved. From the perspective of the dimensional evaluation model accuracy of the same screening method and the same modeling method, compared with only using point clouds, the model fit R2 increased by 0.01~0.09, RMSE decreased by 0.47~6.41 m3·hm−2, MAE decreased by 0.15~6.09 m3·hm−2, and the model accuracy improved more significantly than that using only optical remote sensing. The fit R2 increased by 0.19~0.46, RMSE decreased by 12.15~33.39 m3·hm−2, and MAE decreased by 10.55~26.34 m3·hm−2. According to the experimental results, combining multi-source data to build a forest stock model for forest stock inversion can significantly improve the prediction accuracy of the model. Under sufficient conditions, multi-data sources will be the first choice for modeling data sources.
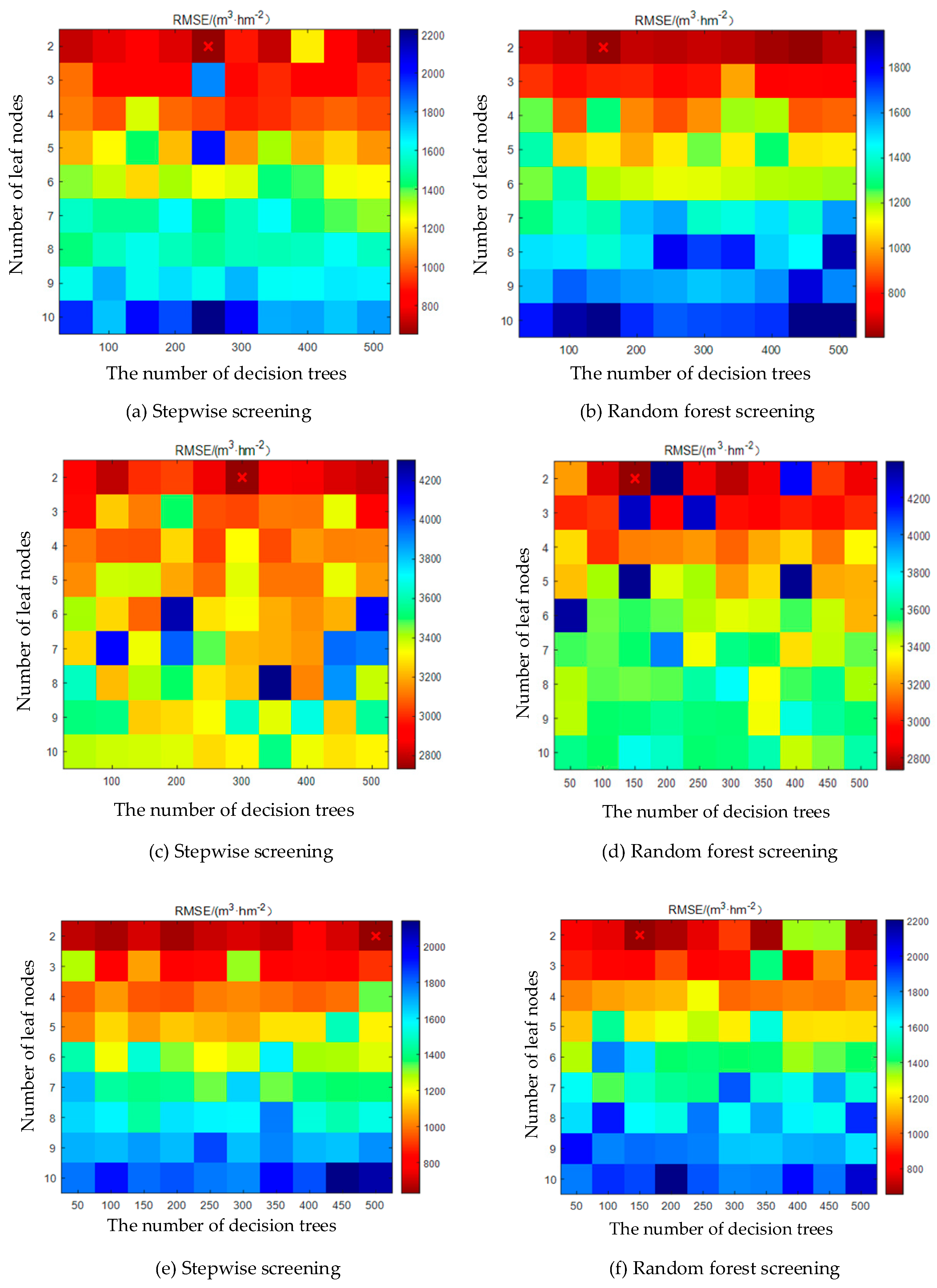
When the parameter combination corresponding to the minimum MSE of the out-of-pocket error is obtained during the optimization process, the value of the parameter combination is output to ensure the optimal prediction performance of the RF regression model. The model based on different data sources is cross-validated using the leave-one method. The results based on the combination of point clouds variables COLL1 and COLL2 are shown in
Figure 9a,b. The optimal parameter combination is 2 and 250 and 2 and 150 as input parameters for modeling, respectively. The combination of spectral characteristic variables COLL3 and COLL4 is shown in
Figure 9c,d, and the optimal parameter combination is 2 and 300 and 2 and 150, respectively. The modeling results of COLL5 and COLL6 are shown in
Figure 9e,f, and the optimal parameter combinations are 2 and 500 and 2 and 150, respectively.


 ,
, 

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}











