Author Contributions
Conceptualization, S.G., E.M., M.B., A.C., and L.R.Z.; methodology, S.G., E.M., M.B., A.C., M.C., D.T., and L.R.Z.; software, S.G., E.M., M.B., A.C., M.C., and D.T.; validation, S.G., E.M., A.C., M.C., and D.T.; formal analysis, S.G., E.M., and L.R.Z.; data curation, S.G., E.M., M.B., A.C., M.C., D.T., and L.R.Z.; writing—original draft preparation, S.G., E.M., and A.C.; writing—review and editing, S.G., E.M., M.B., A.C., M.C., D.T., and L.R.Z. All authors have read and agreed to the published version of the manuscript.
Figure 1.
A graphical representation of our territory and population, through a random sample of 1000 people on the territory of Florence and Sabaudia (some points may fall outside of the territory if the center of the tile to which they belong falls inside).
Figure 1.
A graphical representation of our territory and population, through a random sample of 1000 people on the territory of Florence and Sabaudia (some points may fall outside of the territory if the center of the tile to which they belong falls inside).
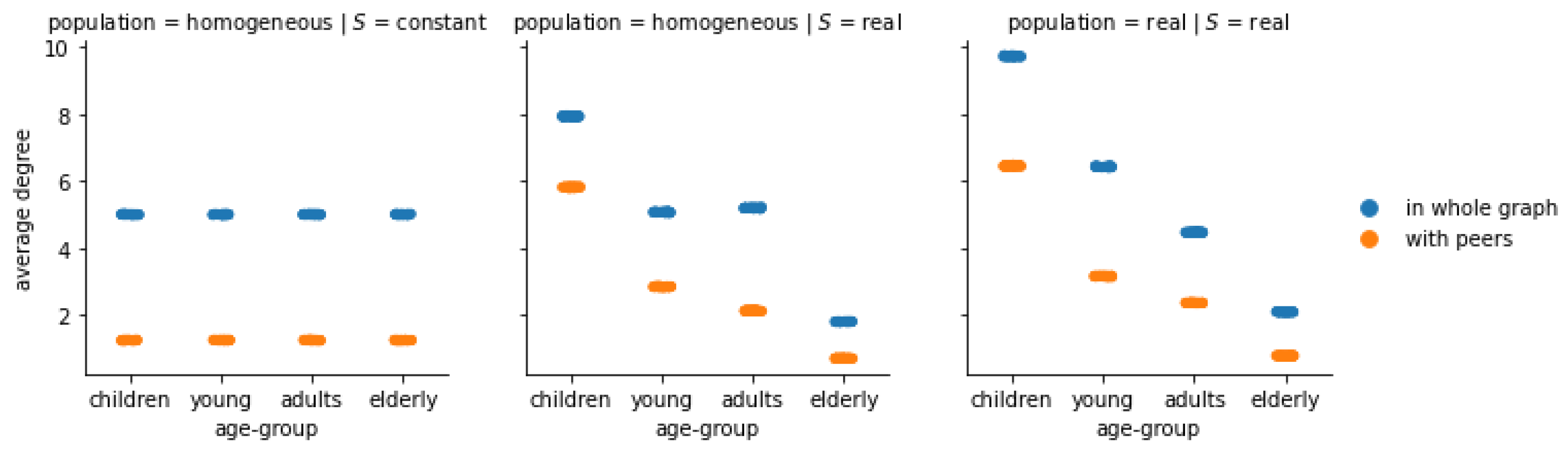
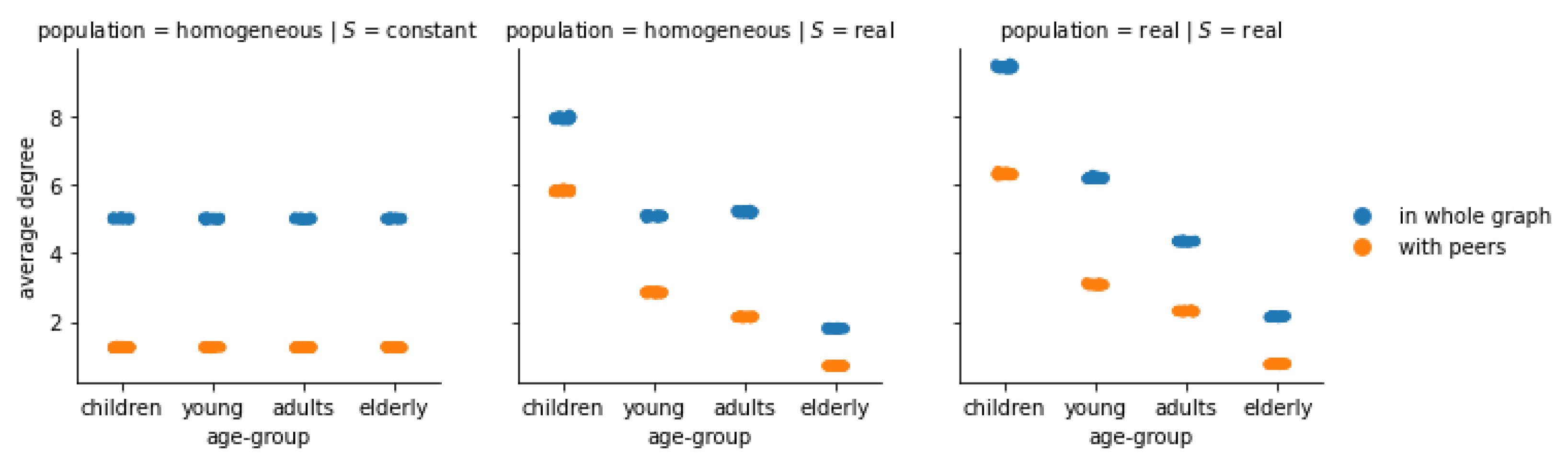
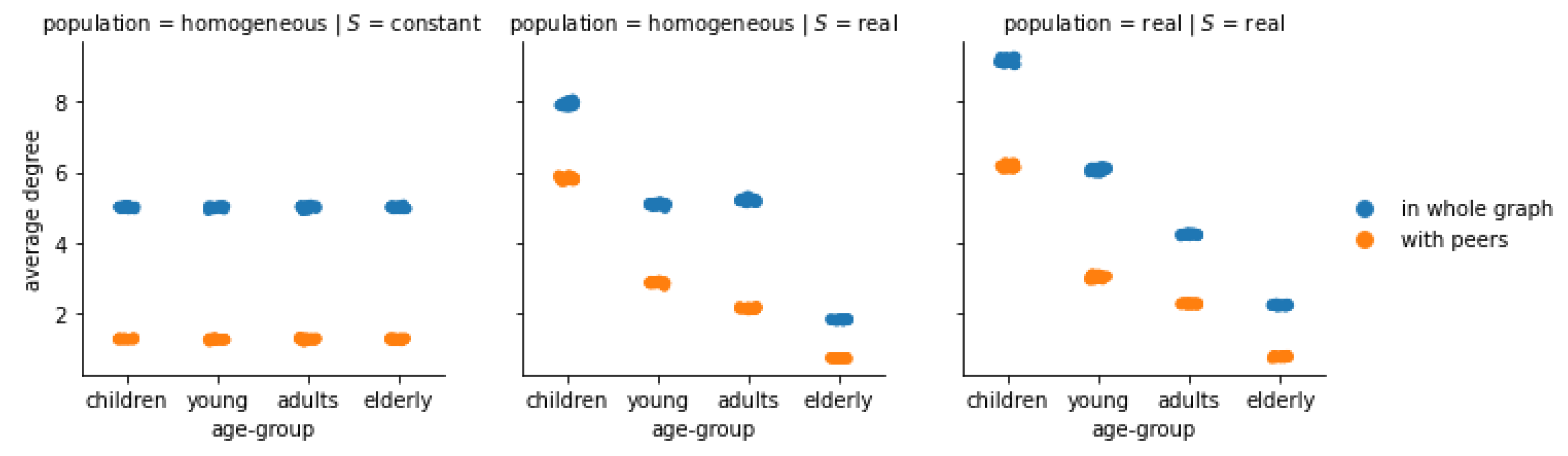
Figure 2.
(Florence) Average degree of the individuals of each age group, in the whole friendship graph and with their peers, under different configurations all with . With respect to the benchmark configuration where all age-groups are equivalent (left panel), the introduction of a data-driven S increases the internal cohesion of younger age groups, but it fails to correctly model inter-group connections (central panel), which are instead well captured if the population is also data-driven (right panel).
Figure 2.
(Florence) Average degree of the individuals of each age group, in the whole friendship graph and with their peers, under different configurations all with . With respect to the benchmark configuration where all age-groups are equivalent (left panel), the introduction of a data-driven S increases the internal cohesion of younger age groups, but it fails to correctly model inter-group connections (central panel), which are instead well captured if the population is also data-driven (right panel).
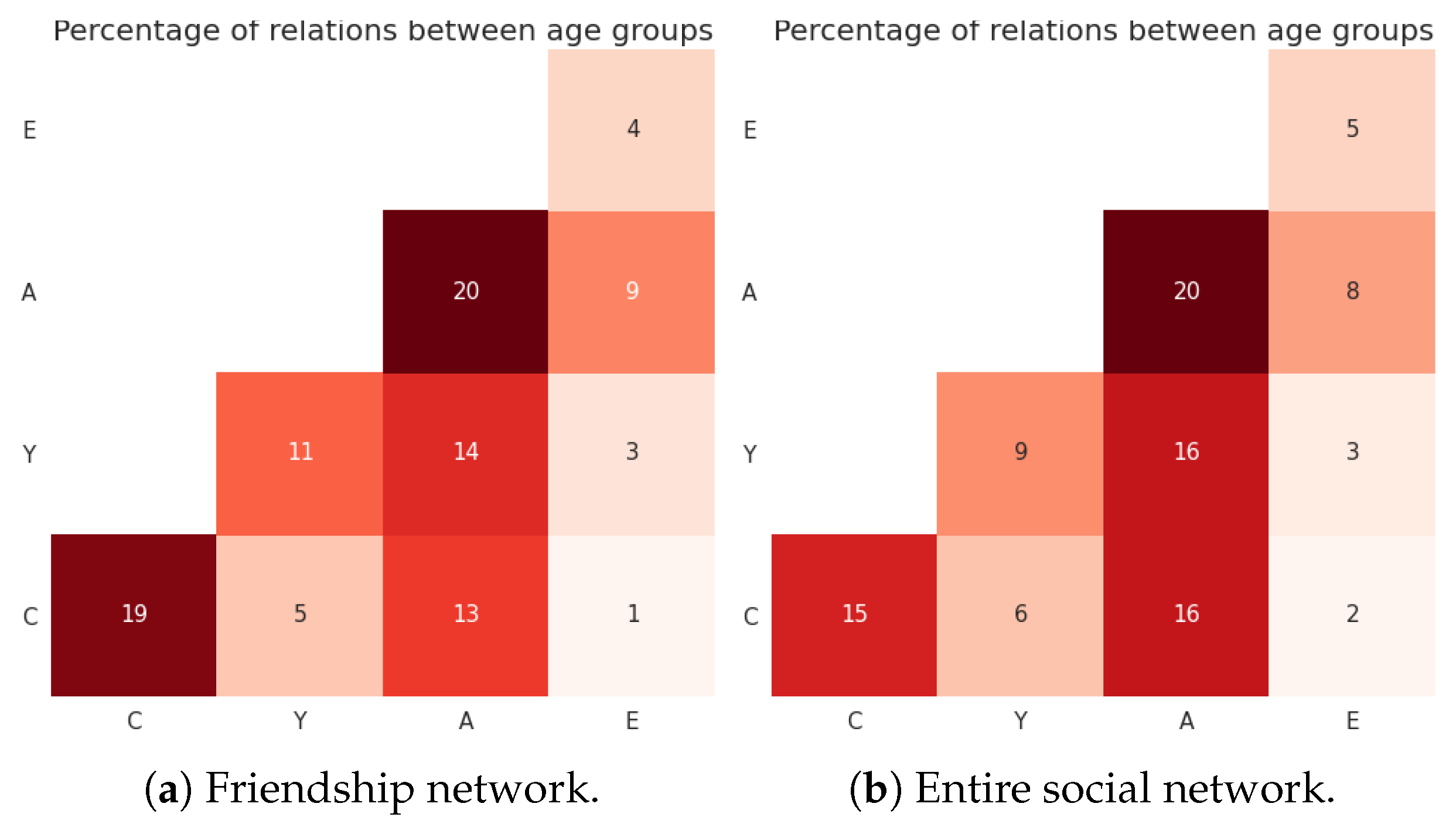
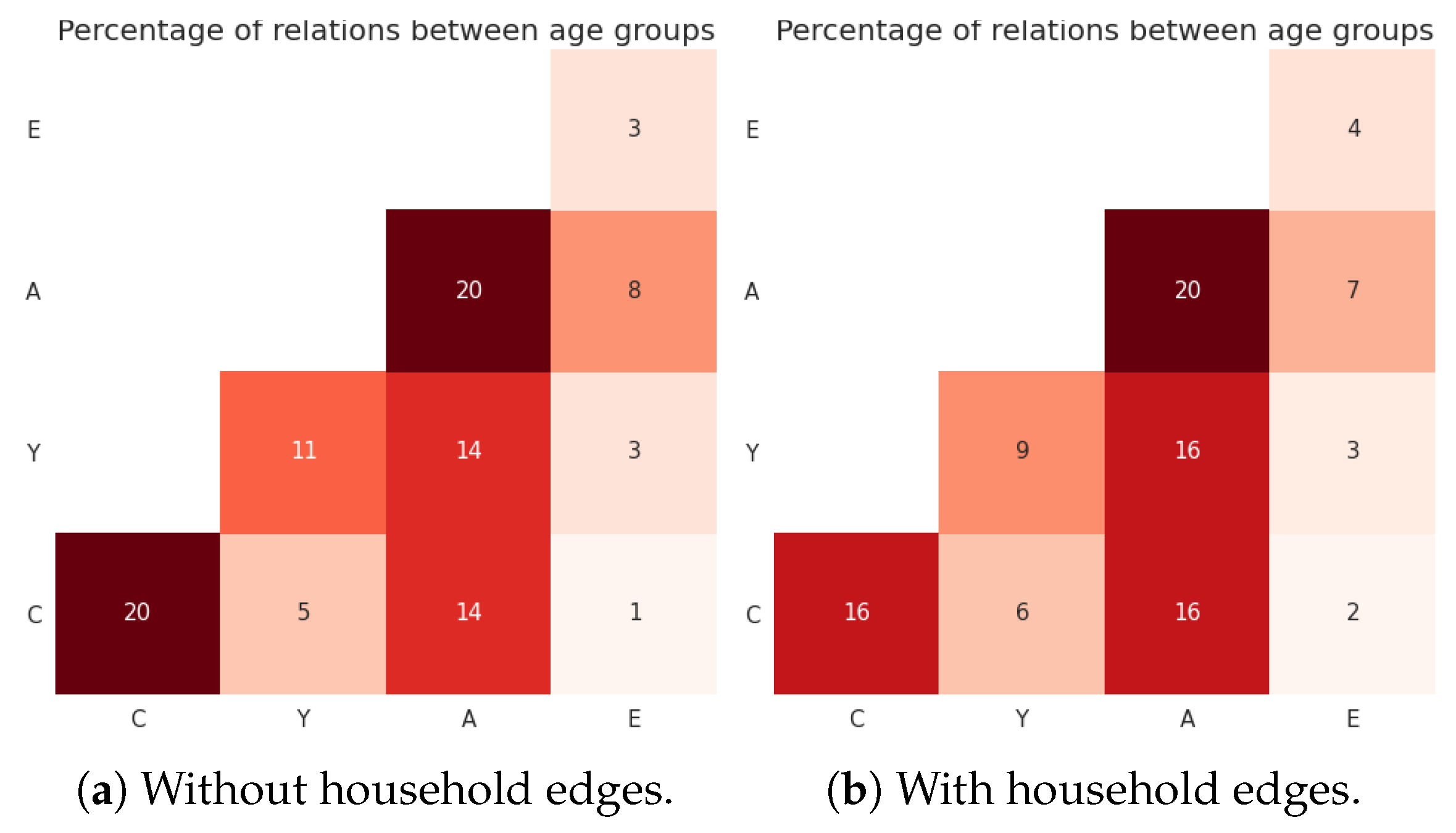
Figure 3.
(Florence) Percentage of edges between age groups in a configuration with data-driven population and age-based mixing, for , μ = 5 and . The value in cell i, j is proportional to mi,j·si,j. Adults are still involved, in total, in the majority of friendship edges, even if they have a lower average number of friends than the younger groups.
Figure 3.
(Florence) Percentage of edges between age groups in a configuration with data-driven population and age-based mixing, for , μ = 5 and . The value in cell i, j is proportional to mi,j·si,j. Adults are still involved, in total, in the majority of friendship edges, even if they have a lower average number of friends than the younger groups.
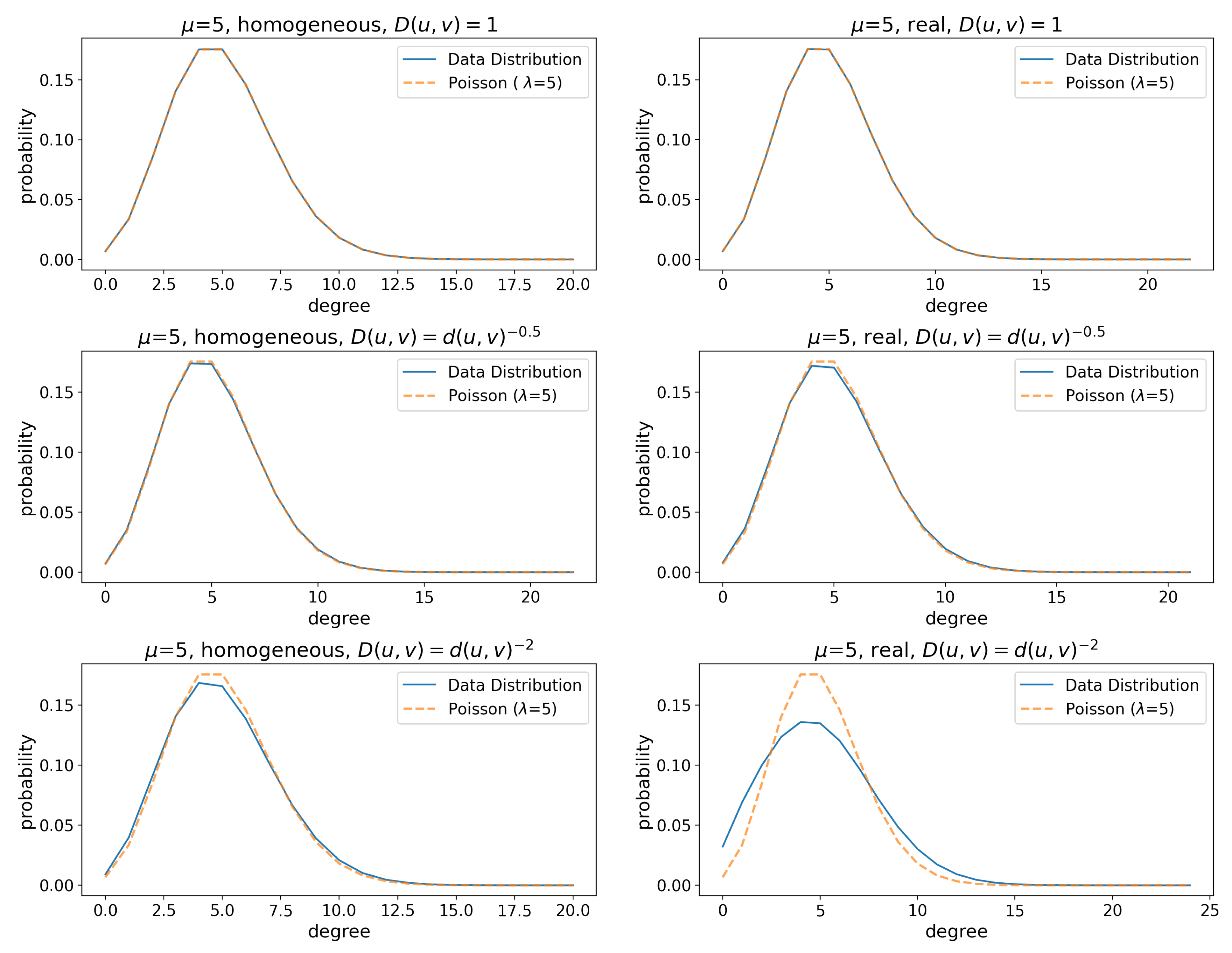
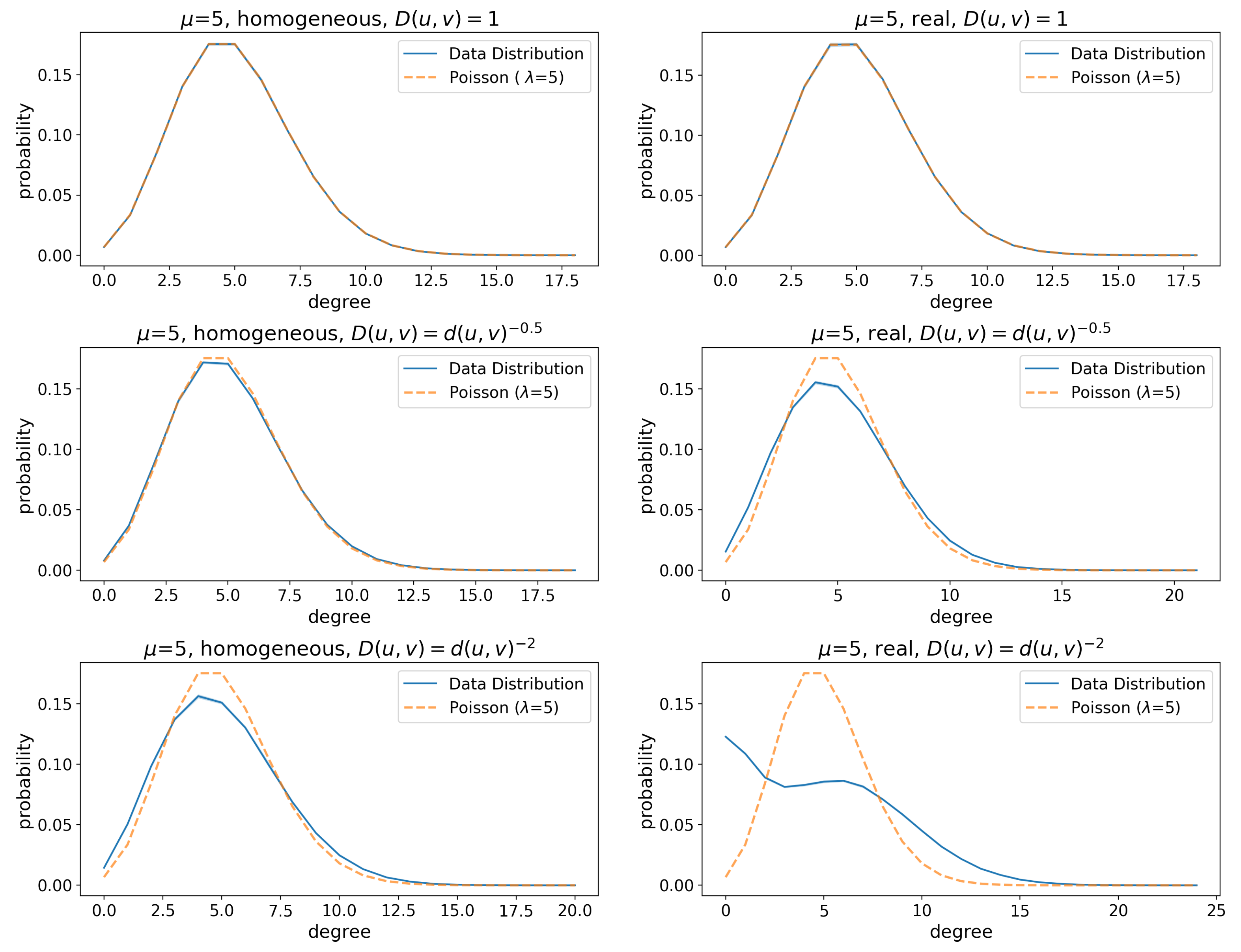
Figure 4.
(Florence) Degree distributions of friendship graphs with and corresponding Poisson distributions with . The data distribution lines show the mean, whereas the shaded areas around the lines represent the 95% confidence interval. The Kullback–Leibler divergence between the Poisson and the empirical distribution are (left to right, top to bottom): 1.6e-07, 2.87e-07, 1.1e-05, 5.2e-05, 0.0002, 0.004. The degree distribution diverges from a Poisson (which is the expected behavior in ER-like graphs) as we incorporate geographic features in the network, and the effect is especially significant when long edges are strongly penalized.
Figure 4.
(Florence) Degree distributions of friendship graphs with and corresponding Poisson distributions with . The data distribution lines show the mean, whereas the shaded areas around the lines represent the 95% confidence interval. The Kullback–Leibler divergence between the Poisson and the empirical distribution are (left to right, top to bottom): 1.6e-07, 2.87e-07, 1.1e-05, 5.2e-05, 0.0002, 0.004. The degree distribution diverges from a Poisson (which is the expected behavior in ER-like graphs) as we incorporate geographic features in the network, and the effect is especially significant when long edges are strongly penalized.
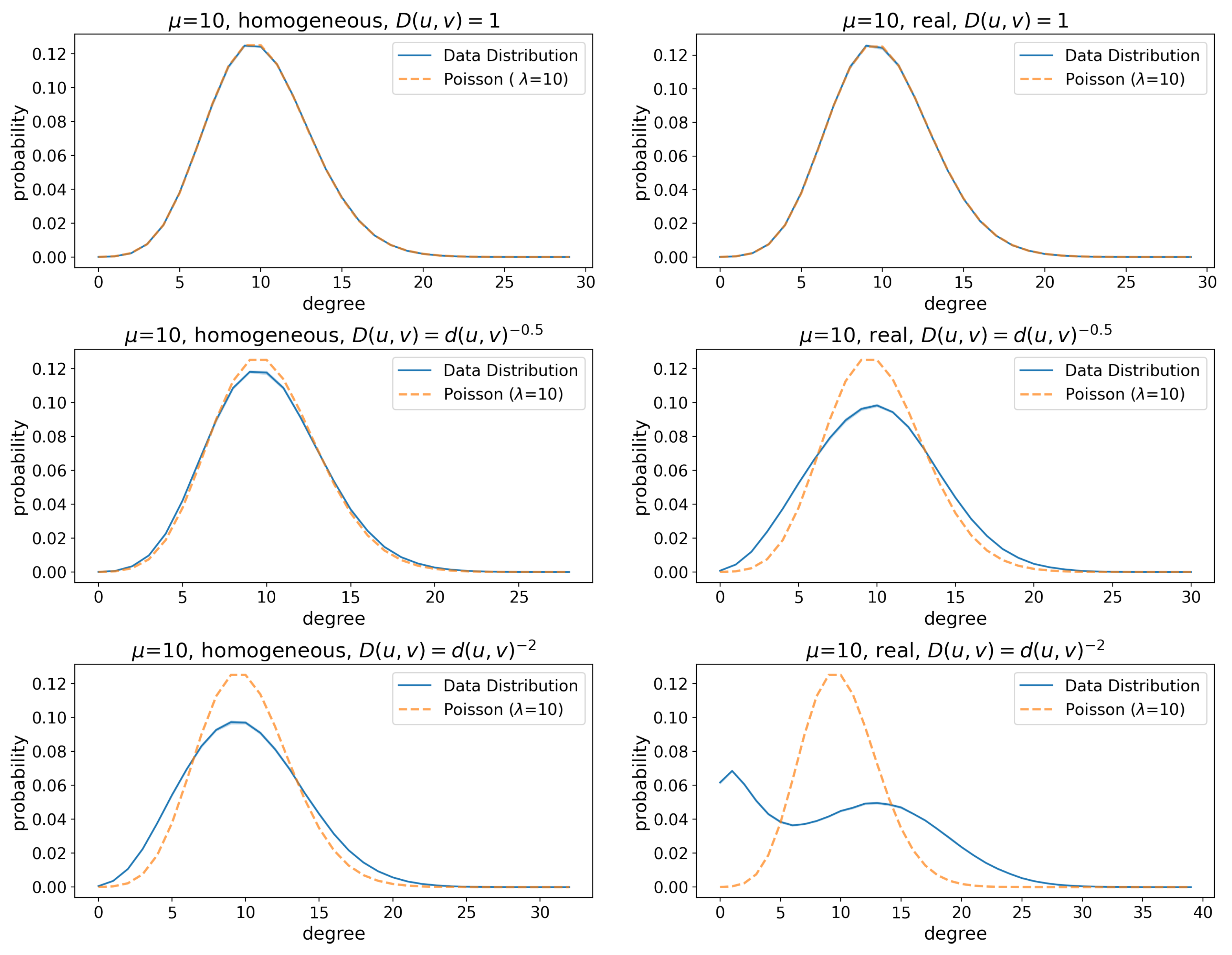
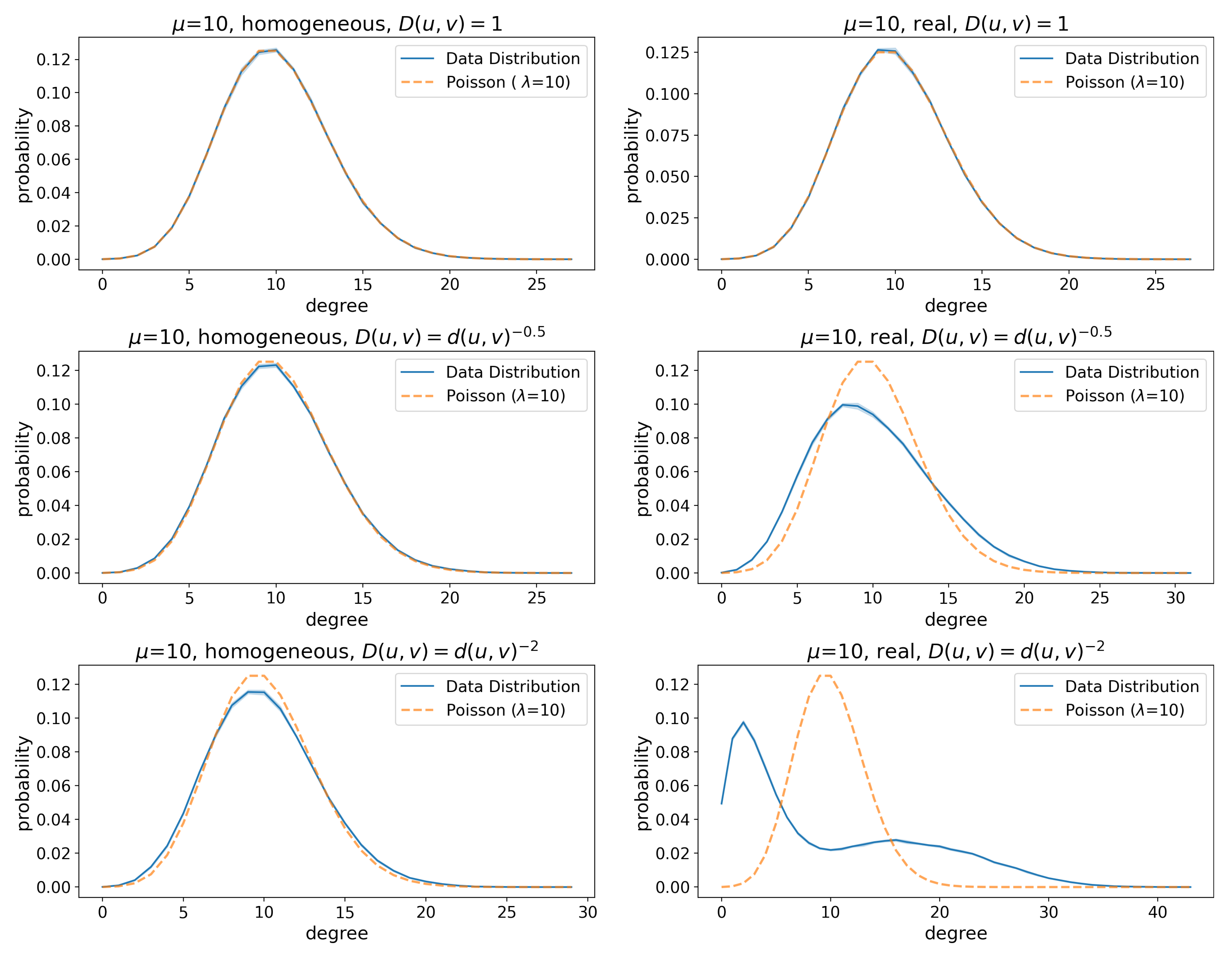
Figure 5.
(Florence) Degree distributions of friendship graphs with and corresponding Poisson distributions with . The data distribution lines show the mean, whereas the shaded areas around the lines represent the 95% confidence interval. The Kullback–Leibler divergence between the Poisson and the empirical distribution are (left to right, top to bottom): 2.5e-07, 2.01e-07, 3.2e-05, 0.0001, 0.0005, 0.009. The degree distribution diverges from a Poisson (which is the expected behavior in ER-like graphs) as we incorporate geographic features in the network, and the effect is especially significant when long edges are strongly penalized.
Figure 5.
(Florence) Degree distributions of friendship graphs with and corresponding Poisson distributions with . The data distribution lines show the mean, whereas the shaded areas around the lines represent the 95% confidence interval. The Kullback–Leibler divergence between the Poisson and the empirical distribution are (left to right, top to bottom): 2.5e-07, 2.01e-07, 3.2e-05, 0.0001, 0.0005, 0.009. The degree distribution diverges from a Poisson (which is the expected behavior in ER-like graphs) as we incorporate geographic features in the network, and the effect is especially significant when long edges are strongly penalized.
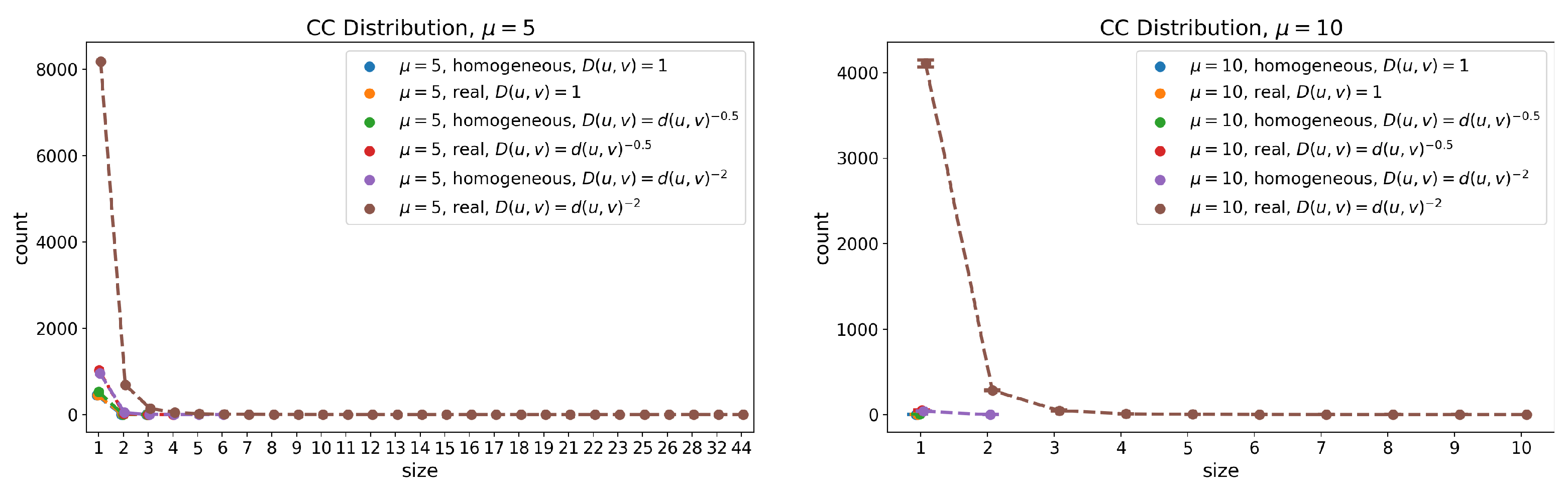
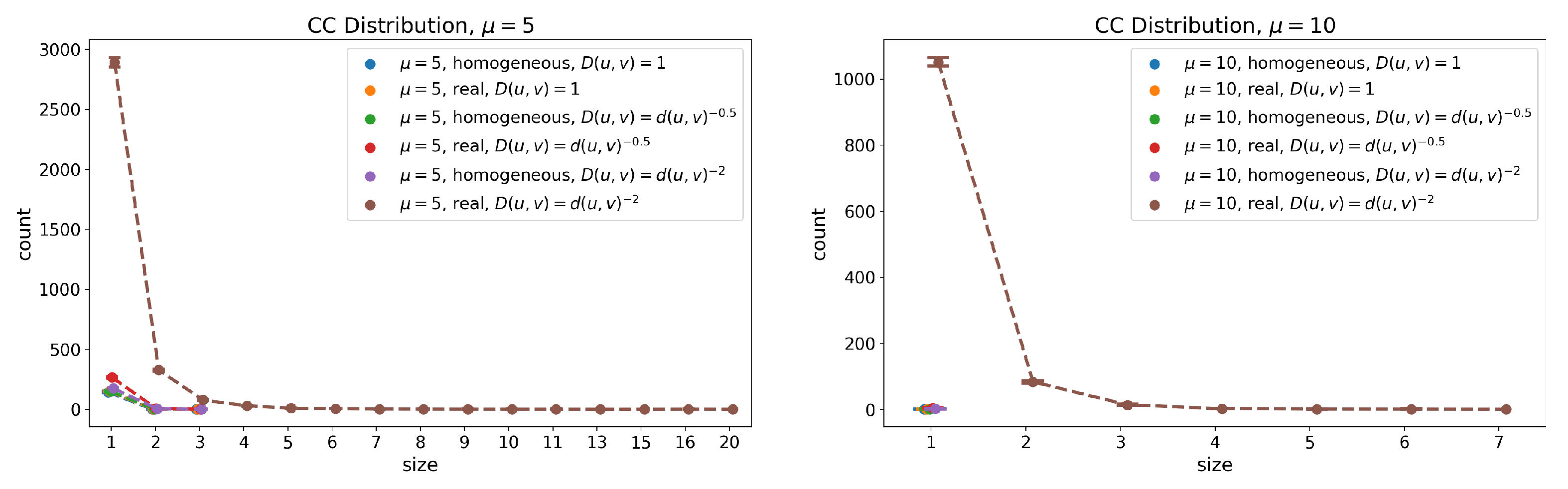
Figure 6.
(Florence) Distribution of the size of the connected components other than the giant for friendship graphs with and . The lines show the mean, whereas the error bars (with “caps”) represent the 95% confidence interval computed over each set of runs. All components other than the giant are, in general, very small, but the use of real data does favor the occurrence of a higher number of connected components.
Figure 6.
(Florence) Distribution of the size of the connected components other than the giant for friendship graphs with and . The lines show the mean, whereas the error bars (with “caps”) represent the 95% confidence interval computed over each set of runs. All components other than the giant are, in general, very small, but the use of real data does favor the occurrence of a higher number of connected components.
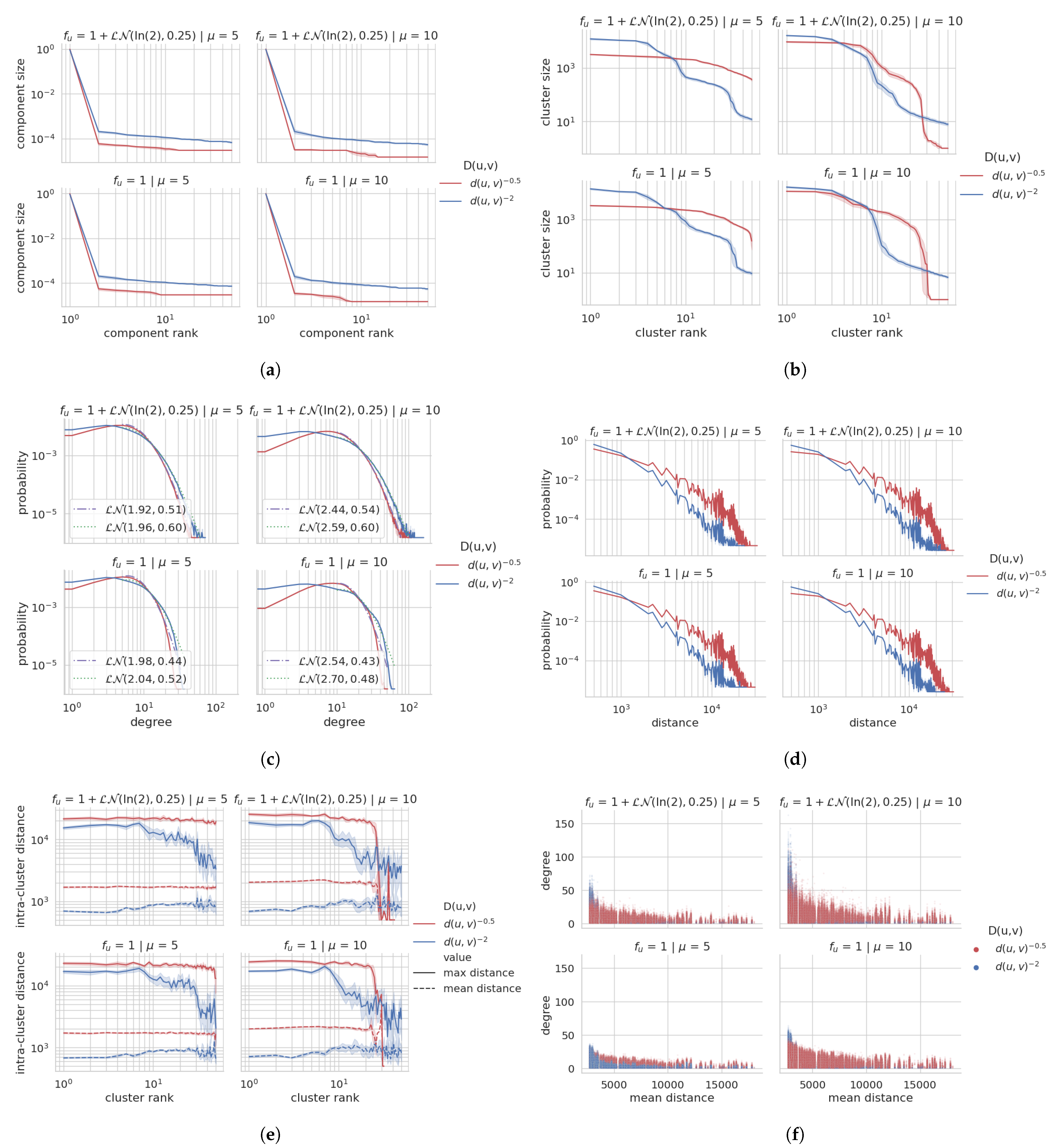
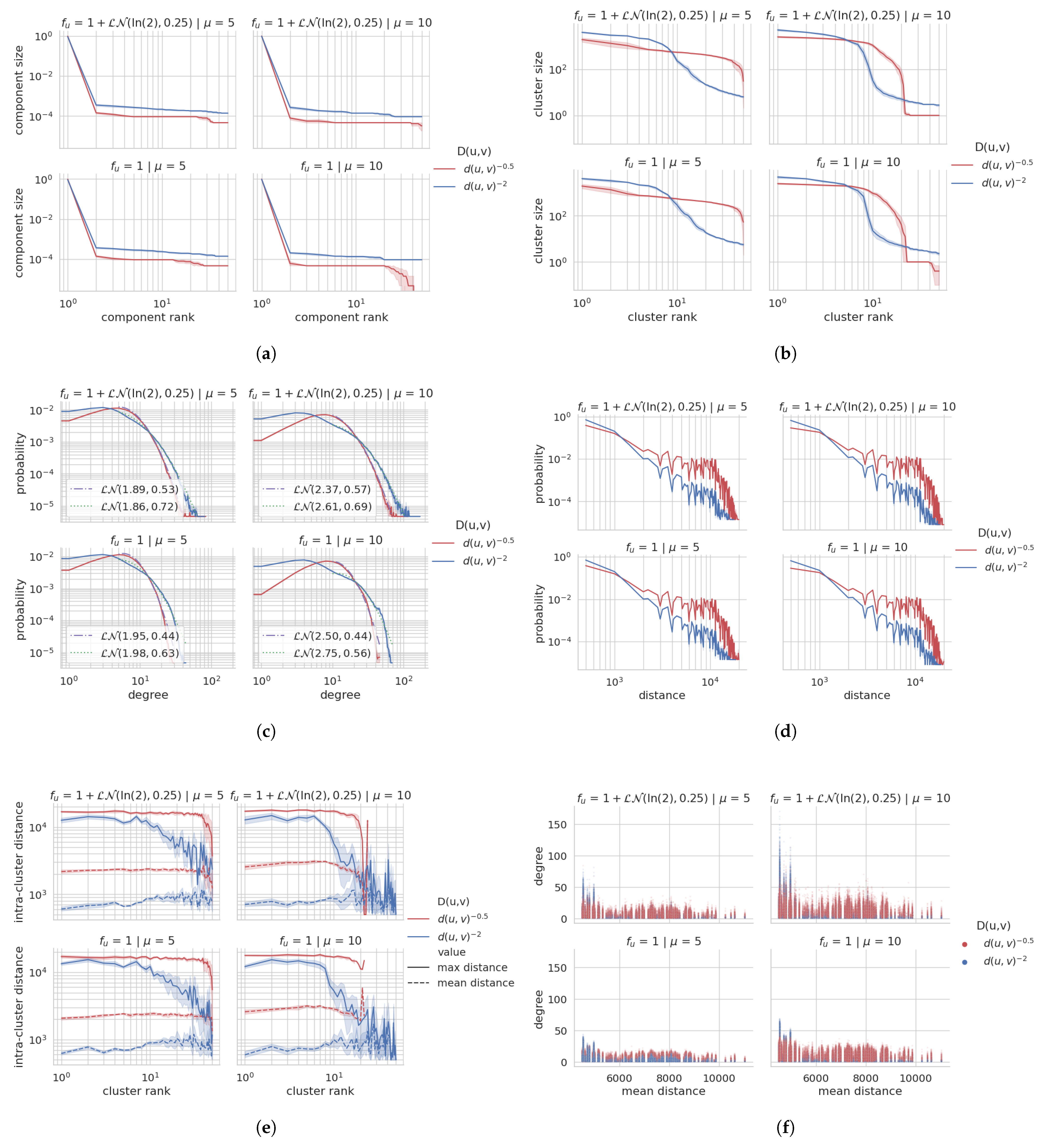
Figure 7.
(
Florence) Overview of the urban social graph. Each plot shows the average with confidence interval for 10
independent runs with the same configuration. The plots are discussed in
Section 4.2 and
Section 4.3. (
a) Size of the largest 50 connected components. (
b) Size of the largest 50 clusters (Louvain). (
c) Degree distribution with Lognormal fit. (
d) Geographical distance between adjacent vertices. (
e) Mean and max intra-cluster geographical distances. (
f) Mean distance to all other vertices vs. Degree.
Figure 7.
(
Florence) Overview of the urban social graph. Each plot shows the average with confidence interval for 10
independent runs with the same configuration. The plots are discussed in
Section 4.2 and
Section 4.3. (
a) Size of the largest 50 connected components. (
b) Size of the largest 50 clusters (Louvain). (
c) Degree distribution with Lognormal fit. (
d) Geographical distance between adjacent vertices. (
e) Mean and max intra-cluster geographical distances. (
f) Mean distance to all other vertices vs. Degree.
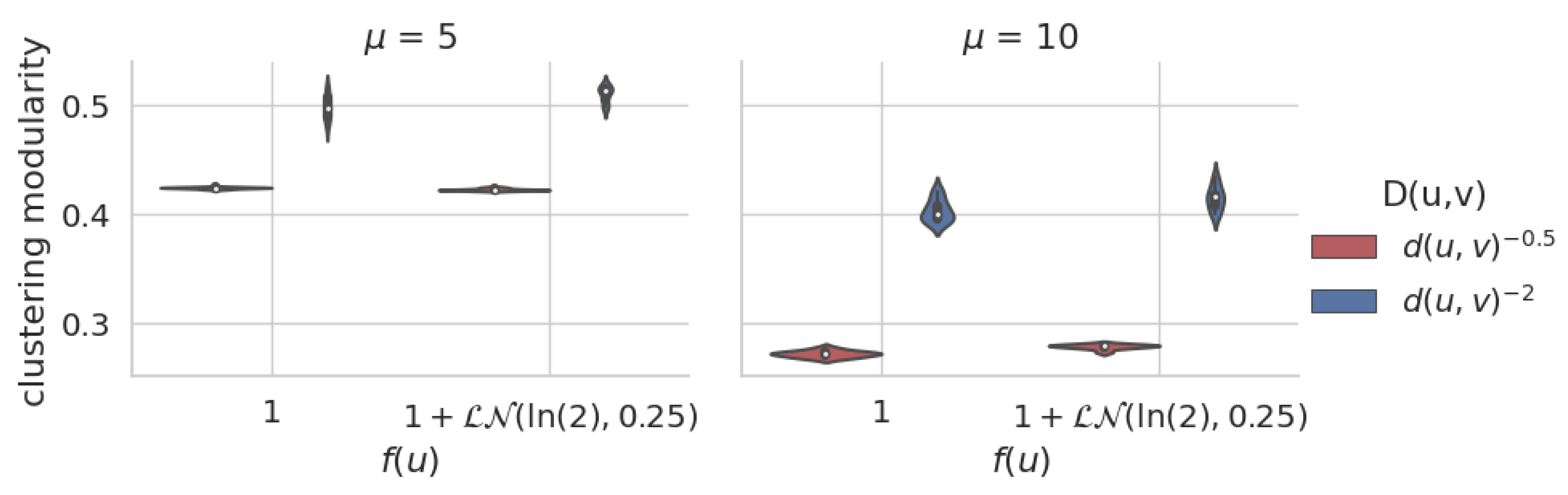
Figure 8.
(Florence) Modularity of the obtained clustering structure—distribution for 10 independent runs per configuration. The quality of the obtained partition increases for small and large , whereas it is not influenced by .
Figure 8.
(Florence) Modularity of the obtained clustering structure—distribution for 10 independent runs per configuration. The quality of the obtained partition increases for small and large , whereas it is not influenced by .
Figure 9.
(Florence) Adjacency matrix of the social graph with nodes (people) ordered by age-group. In both cases, , μ = 10 and , but β varies between the two figures. The assortativity by age is clearly visible in both cases.
Figure 9.
(Florence) Adjacency matrix of the social graph with nodes (people) ordered by age-group. In both cases, , μ = 10 and , but β varies between the two figures. The assortativity by age is clearly visible in both cases.
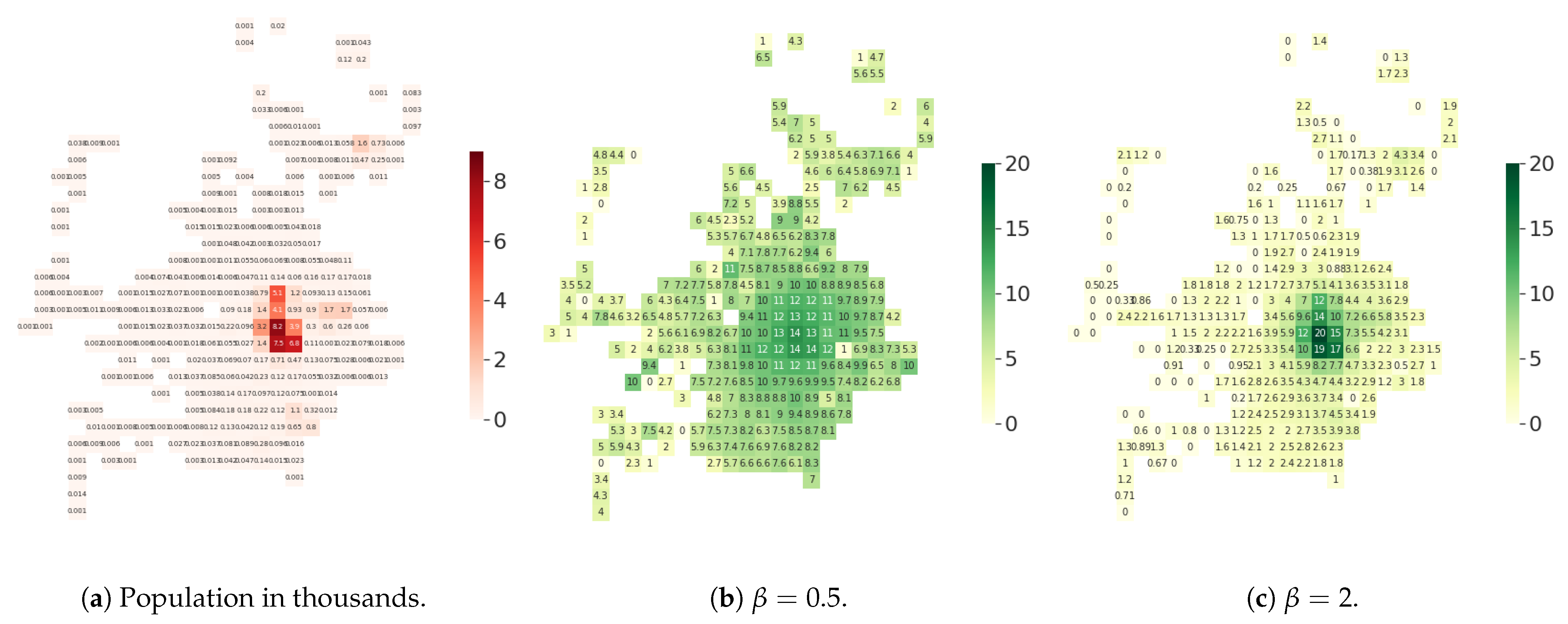
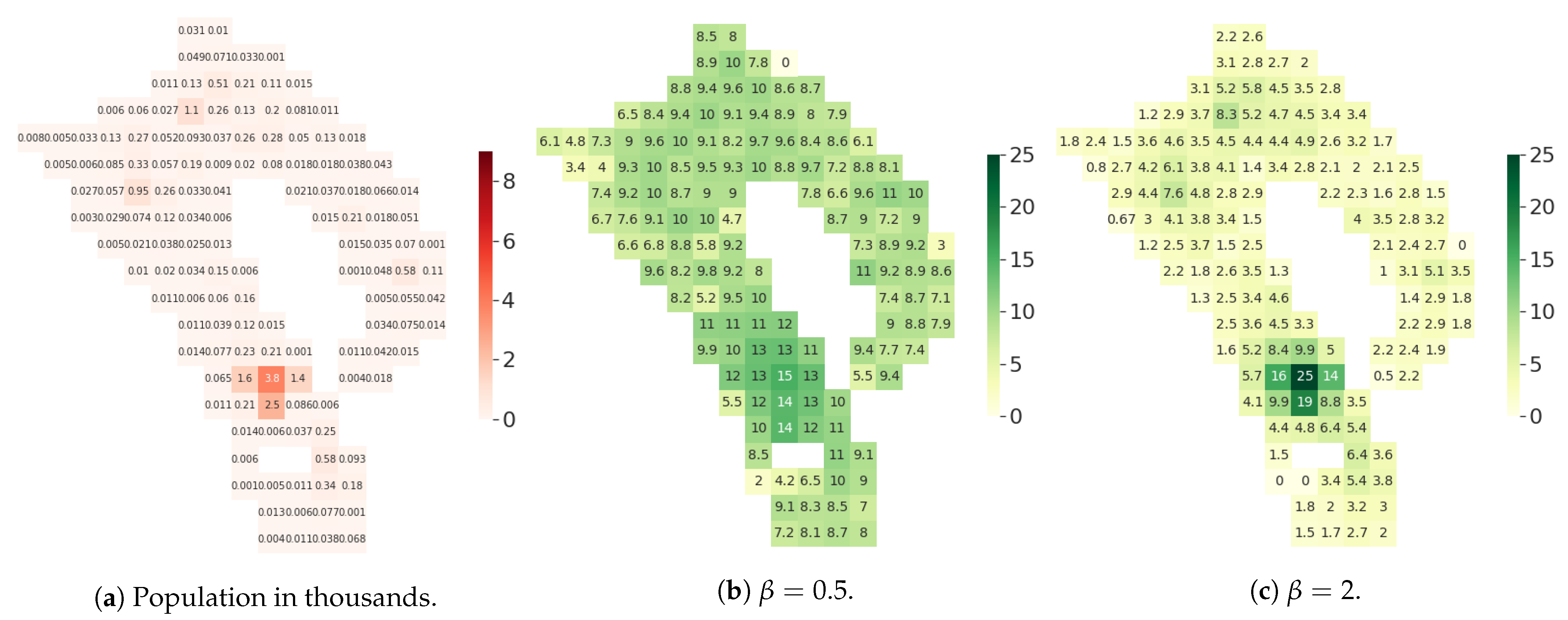
Figure 10.
(Florence) Heatmaps of the population and of the average degree per tile of the considered territory. The average degree is obtained for a graph with , μ = 10 and , for both . With (b), the mean degree is weakly correlated with the population density, contrarily to what happens when (c).
Figure 10.
(Florence) Heatmaps of the population and of the average degree per tile of the considered territory. The average degree is obtained for a graph with , μ = 10 and , for both . With (b), the mean degree is weakly correlated with the population density, contrarily to what happens when (c).
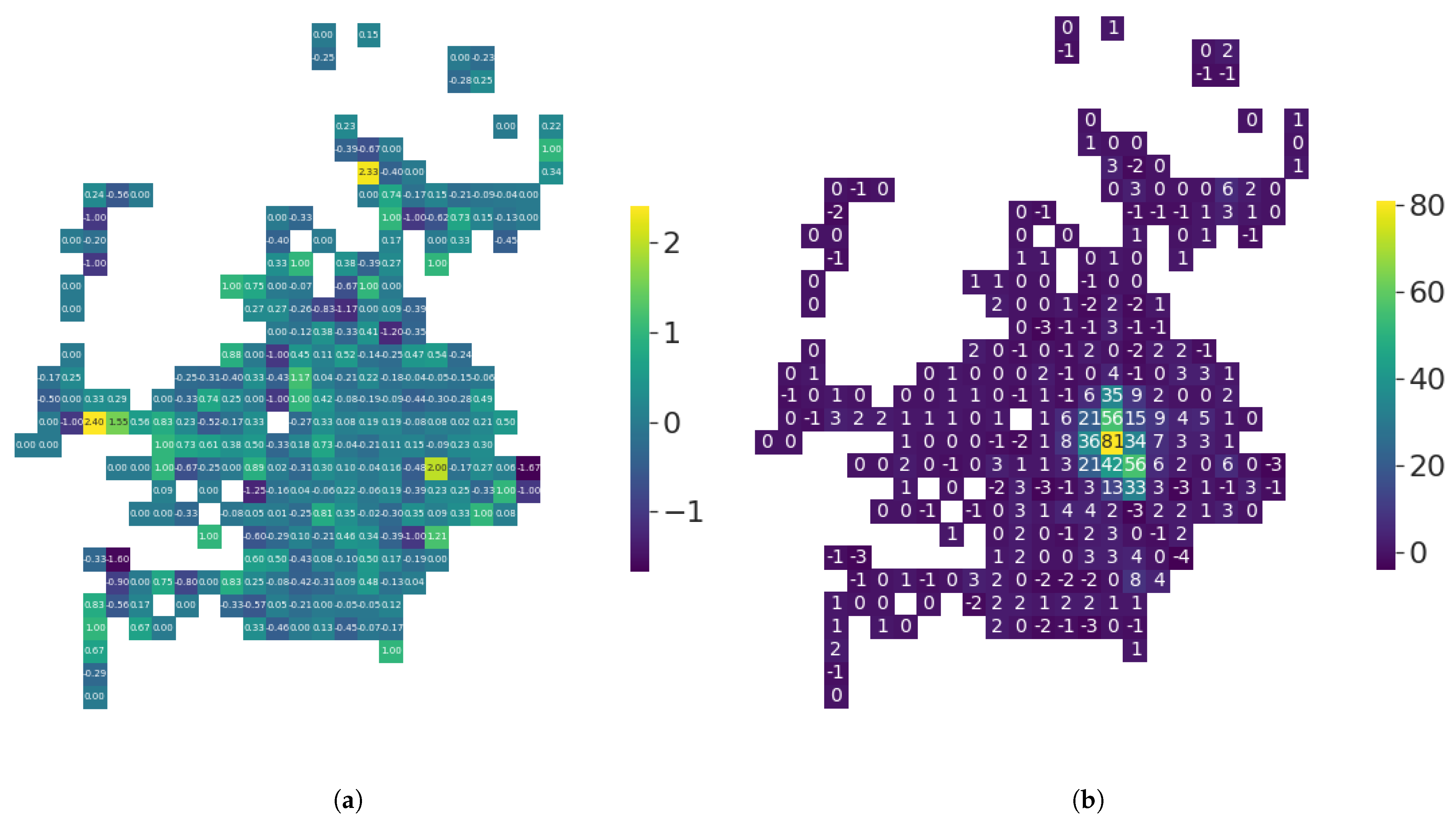
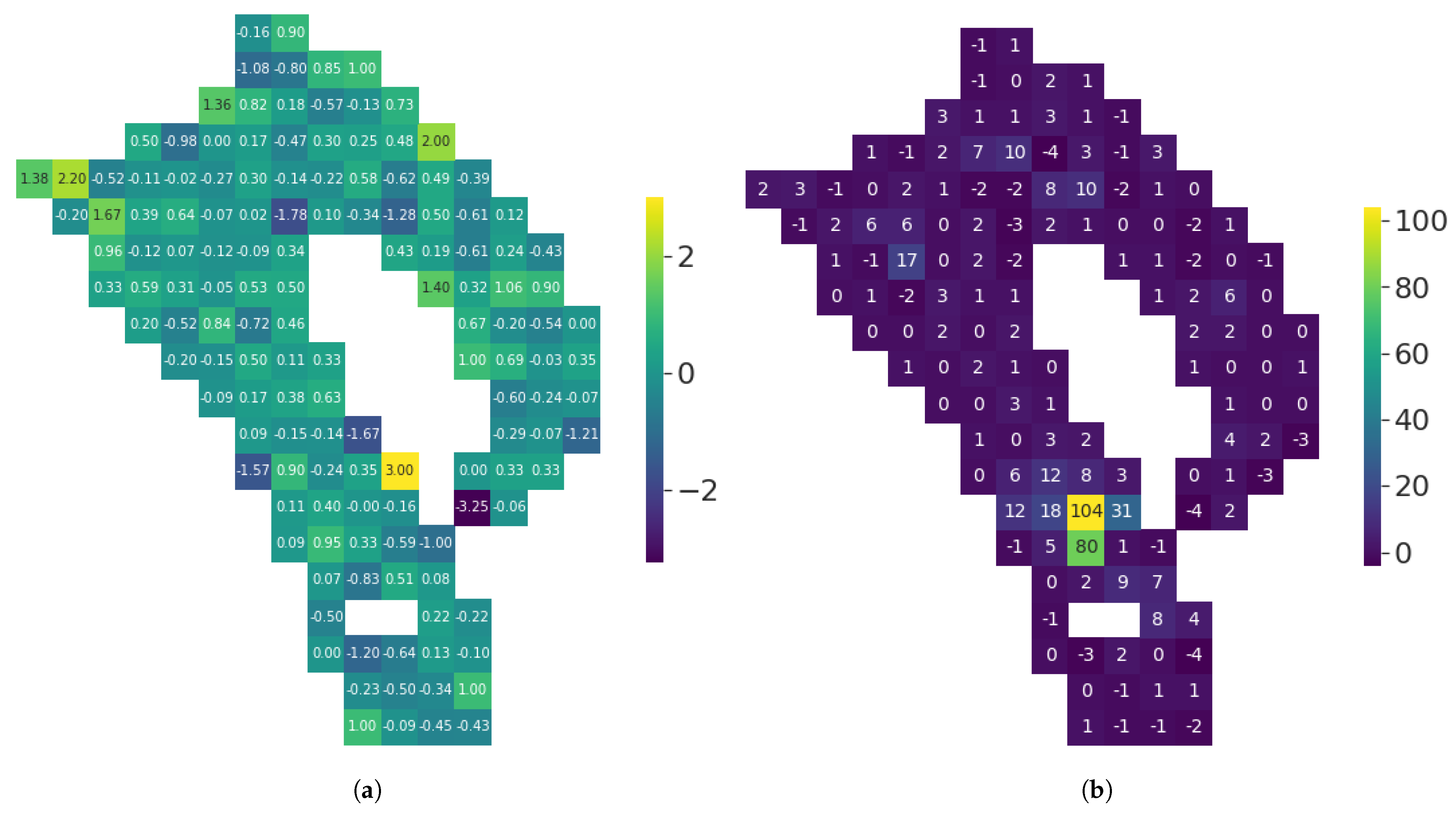
Figure 11.
(Florence) Impact of switching from to on the degree distribution of each tile. In both cases, μ = 10 and . fu has no impact on the mean degree of each tile (a), but setting yields individuals with very different sociability inside each tile (b). (a) Difference of the mean degree of each tile between the configuration with and the configuration with (b) Difference of the maximum degree of each tile between the configuration with and the configuration with .
Figure 11.
(Florence) Impact of switching from to on the degree distribution of each tile. In both cases, μ = 10 and . fu has no impact on the mean degree of each tile (a), but setting yields individuals with very different sociability inside each tile (b). (a) Difference of the mean degree of each tile between the configuration with and the configuration with (b) Difference of the maximum degree of each tile between the configuration with and the configuration with .
Table 1.
Overview of the main parameters used in this paper.
Table 1.
Overview of the main parameters used in this paper.
| Notation | Description | Definition |
|---|
| A layer of edges that represent ties between members of the same household | Data-driven based on ISTAT data (see Section 2.1) |
| A layer of edges that represent ties between people of different households | Generated with a probabilistic model (see Section 2.3) |
| The urban social graph whose edges represent generic “strong” social ties | Obtained flattening the and layers onto a single-layer graph |
| The number of nodes in the graph, equal to the population size | Data-driven, based on the WorldPop database; see Table 3 for the population of all cities |
| The average degree of the layer | Data-driven, ≈2 for all cities (see Table 3) |
| The average degree of the layer | An input parameter, set to 1, 5, or 10 in the experiments (see Section 3 and Section 4) |
| The average degree of the graph G | See above |
| The age label of node u, taking value in , which determines a partition of the population based on age | Drawn from a data-driven age distribution; the list of age-breaks is parametric; in the experiments, we use ISTAT data with age-breaks |
| (and ) | The set of nodes having age label i (and the number of such nodes) | Deduced from the age labels assigned to the nodes of the graph |
| The number of pairs of vertices , with , such that and | Computed based on and (see (1)) |
| The tile label of node u, taking value in , which determines a partition of the population based on the place of residence | Drawn from a data-driven population density; the tessellation is parametric, the tile side is l, the grid is composed of tiles; in the experiments, we used WorldPop data, , and grids, as reported in Table 3 |
| The approximated euclidean distance between u and v | Computed as , where is the euclidean distance between the center of the two tiles |
| A non-increasing function of the distance | An input parameter; in the experiments, we use with |
| The real-valued fitness score of node u, that quantifies its sociability | Drawn from a probability density function specified as an input parameter; in the experiments, we consider a shifted Lognormal or a constant distribution |
| The real-valued social mixing matrix whose element measures the frequency of social ties between age groups i and j | Data driven; in the experiments, we compute S based on contact data from Reference [15] extracted using Reference [16]; we also consider a constant S |
Table 2.
Household types and roles deducible from ISTAT data.
Table 2.
Household types and roles deducible from ISTAT data.
| Household Type | Singles | Single-Parent | Couples | Two-Parents | Various |
|---|
| Role | single | parent | peer | parent | various |
| | child | | child | |
Table 3.
Reconstructed parameters for the three cities. The initials C, Y, A, E stay for children, young people, adults, and elderly people, respectively. is the average degree of the reconstructed household network , and and are the number of tiles along the two axes of the grid used to cover the city territory.
Table 3.
Reconstructed parameters for the three cities. The initials C, Y, A, E stay for children, young people, adults, and elderly people, respectively. is the average degree of the reconstructed household network , and and are the number of tiles along the two axes of the grid used to cover the city territory.
| City | Boundary | N | C% | Y% | A% | E% | | |
|---|
| Florence | City | 363,060 | | | | | | |
| Viterbo | Municipality | 66,598 | | | | | | |
| Sabaudia | Municipality | 21,274 | | | | | | |
Table 4.
(Florence) Percentage of nodes of the graph that belong to the giant component, on average, for the friendship graph and the entire social graph G, as , , and , vary. Five friends are sufficient (on average) to ensure that the giant component covers almost the entirety of the network.
Table 4.
(Florence) Percentage of nodes of the graph that belong to the giant component, on average, for the friendship graph and the entire social graph G, as , , and , vary. Five friends are sufficient (on average) to ensure that the giant component covers almost the entirety of the network.
| | | |
|---|
| | | |
|---|
| 0.5 | 1 | 1.9% | 76.6% | 99.3% | 99.8% |
| 0.5 | | 18.8% | 75.8% | 98.2% | 99.4% |
| 2 | 1 | 8.0% | 76.0% | 99.0% | 99.7% |
| 2 | | 20.9% | 75.1% | 97.9% | 99.3% |
Table 5.
(Florence) Main features of the friendship graph as the population type, and vary, for constant and S. is the average path length, C is the global clustering coefficient, is the degree assortativity, “# comp.” denotes the number of connected components, and “giant %” denotes the percentage of nodes in the giant component. The use of real population density and a distance-based penalization mostly impacts on the assortativity and connectivity of the network, whereas the effect on its clustering is only visible for .
Table 5.
(Florence) Main features of the friendship graph as the population type, and vary, for constant and S. is the average path length, C is the global clustering coefficient, is the degree assortativity, “# comp.” denotes the number of connected components, and “giant %” denotes the percentage of nodes in the giant component. The use of real population density and a distance-based penalization mostly impacts on the assortativity and connectivity of the network, whereas the effect on its clustering is only visible for .
| (a) Friendship Network for . Expected Values for an ER Graph with : , . |
| | | |
| Population | | | | | # Comp. | Giant % |
| homogeneous | 1 | 8.13 | 1.5e-05 | 2.5e-04 | 2497.5 | 99.3% |
| homogeneous | | 8.11 | 1.4e-05 | 0.0018 | 2660.4 | 99.3% |
| homogeneous | | 8.08 | 7.2e-05 | 0.05 | 3385.9 | 99.0% |
| real | 1 | 8.13 | 1.3e-05 | −3.8e-04 | 2504.3 | 99.3% |
| real | | 8.09 | 1.3e-05 | 0.0044 | 2914.1 | 99.2% |
| real | | 7.83 | 5.6e-05 | 0.12 | 12443.8 | 96.3% |
| (b) Friendship Network for . Expected Values for an ER Graph with : , . |
| | | |
| Population | | | | | # Comp. | Giant % |
| homogeneous | 1 | 5.81 | 2.7e-05 | 2.9e-04 | 17.6 | 100.0% |
| homogeneous | | 5.80 | 2.8e-05 | 0.0042 | 23.5 | 100.0% |
| homogeneous | | 5.84 | 1.5e-04 | 0.09 | 53.7 | 100.0% |
| real | 1 | 5.81 | 2.8e-05 | 1.7e-04 | 16.1 | 100.0% |
| real | | 5.80 | 2.9e-05 | 0.0088 | 32.5 | 100.0% |
| real | | 5.79 | 1.1e-04 | 0.2 | 2317.6 | 99.3% |
Table 6.
(Florence) Main features of the social graph as , and vary, for data-driven population and S. is the average degree, is the average path length, C and are the global and average local clustering coefficients, is the degree assortativity, “# comp.” denotes the number of connected components, and “giant %” denotes the percentage of nodes in the giant component. Our data-driven social network has the desired clustering and assortativity. The parameters and have a minor, albeit visible, impact.
Table 6.
(Florence) Main features of the social graph as , and vary, for data-driven population and S. is the average degree, is the average path length, C and are the global and average local clustering coefficients, is the degree assortativity, “# comp.” denotes the number of connected components, and “giant %” denotes the percentage of nodes in the giant component. Our data-driven social network has the desired clustering and assortativity. The parameters and have a minor, albeit visible, impact.
| (a) Social Graph for . |
| | | |
| | | | | | | # Comp. | Giant % |
| 1 | 0.5 | 06.82 | 6.72 | 0.053 | 0.074 | 0.261 | 4071.1 | 98.8% |
| 1 | 2 | 06.81 | 6.72 | 0.050 | 0.089 | 0.334 | 6824.8 | 97.7% |
| 0.5 | 06.82 | 6.57 | 0.049 | 0.085 | 0.203 | 5357.4 | 98.4% |
| 2 | 06.81 | 6.58 | 0.046 | 0.100 | 0.258 | 8109.3 | 97.3% |
| (b) Social Graph for . |
| | | |
| | | | | | | # Comp. | Giant % |
| 1 | 0.5 | 11.81 | 5.36 | 0.017 | 0.027 | 0.317 | 463.1 | 99.9% |
| 1 | 2 | 11.81 | 5.41 | 0.016 | 0.037 | 0.383 | 1726.9 | 99.5% |
| 0.5 | 11.81 | 5.26 | 0.016 | 0.033 | 0.211 | 924.9 | 99.7% |
| 2 | 11.82 | 5.32 | 0.015 | 0.044 | 0.260 | 2333.1 | 99.3% |


 ,
, 



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}






























