Three experiments were conducted to evaluate the performances of the HPE libraries. For the image dataset, an experiment was conducted to compare the performance of each HPE library for each image. For the video dataset, the first experiment was conducted to compare the performance of each HPE library for each video frame, whereas the second experiment investigated how well each HPE library performed for each body part of each action.
4.1. Image Dataset
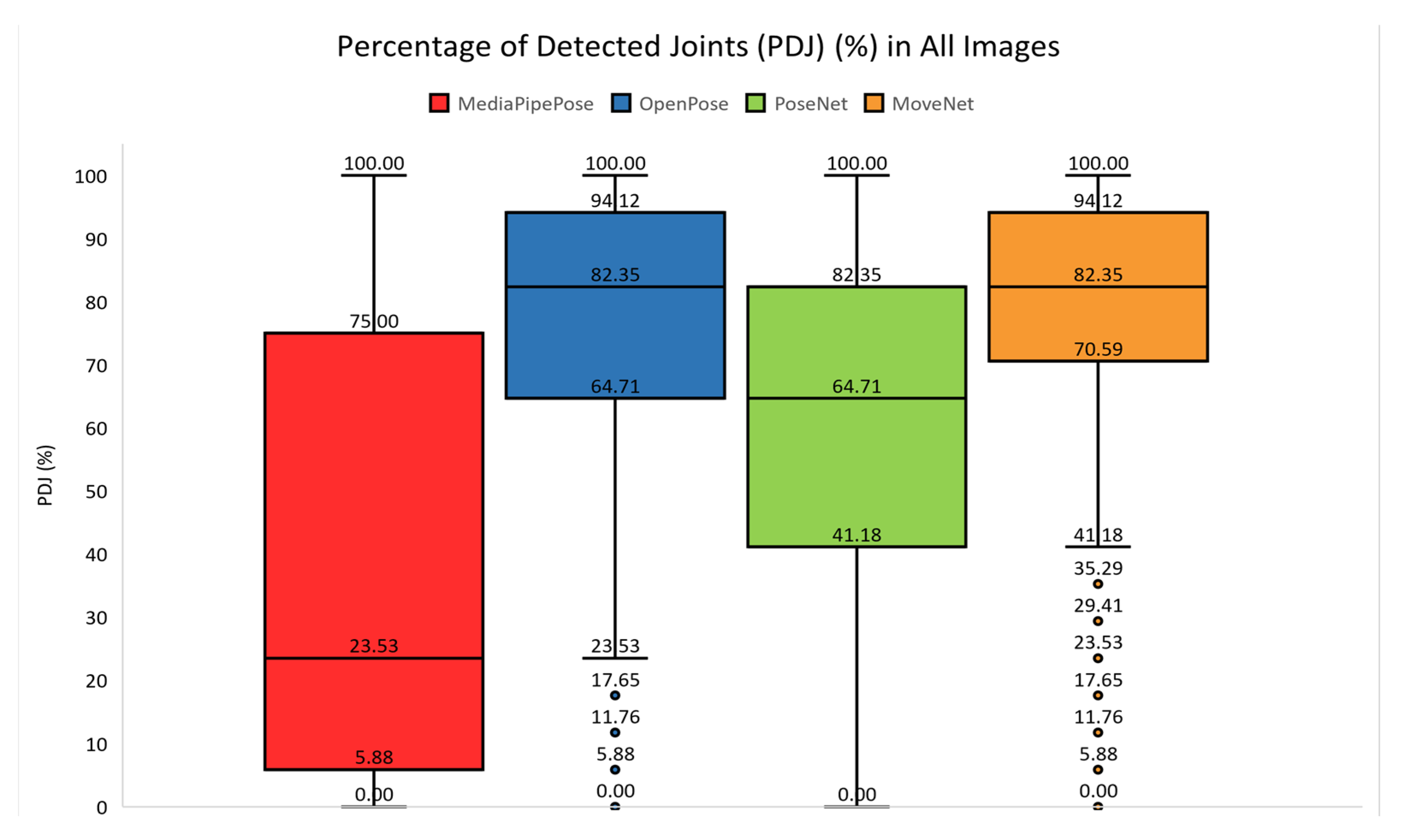
The PDJ value for each image was calculated to compare the performance of the HPE libraries for each image. The results are presented in a box plot, as shown in
Figure 3. Among the four HPE libraries, MoveNet (orange box) achieved the highest PDJ in terms of the lower fence, first quartile, median, and third quartile values. The second best performing HPE library was OpenPose (blue box), which achieved the same median and third quartile values as MoveNet; however, OpenPose had lower first quartile and fence (outlier) values. The third best performing HPE library was PoseNet (green box), followed by MediaPipe Pose (red box). The minimum values of MediaPipe Pose and PoseNet were 0. Meanwhile, the outlier values for MoveNet and OpenPose were also 0. The value of 0 indicated that the keypoints detected in some of the images were incorrectly matched with the ground truth provided by the COCO dataset.
Table 4 divides the performance of the HPE libraries into five groups, including 0%, 0–25%, 25–50%, 50–75%, and 75–100%. Each group shows the number of images that were recognized by the HPE library in the specific range of PDJ values. MoveNet had the least number of images that achieved 0% of PDJ, which included 5 images. OpenPose achieved the second lowest number of images at 0% (8 images), followed by PoseNet (30 images) and MediaPipe Pose (240 images). In the range of 0–25%, MoveNet had the least number of images (33 images), followed by OpenPose (87 images), PoseNet (128 images), and MediaPipe Pose (342 images). Likewise, MoveNet had the least number of images that achieved the PDJ within the range of 25–50% (68 images).
MoveNet achieved superior performance because it had the highest number of images in the last two groups (50–100%), which indicated that more than 50% of the detected keypoints from 994 images were correctly matched with the ground truth. In contrast, MediaPipe Pose was found to have the poorest performance because it had the highest number of images in the first to third groups (0–50%). In a total of 698 images, less than 50% of the detected keypoints were correctly matched with the ground truth. Overall, MoveNet achieved the top performance because it showed the highest number of images in the fifth group, which indicated that 747 out of 1,100 images were recognized by MoveNet with 75–100% detected keypoints. In contrast, MediaPipe Pose showed the poorest performance as it only achieved the lowest number of images in the range of 75–100%, but it received the highest number of images in the 0% group. OpenPose achieved the second highest performance, which was slightly lower than MoveNet. PoseNet and MediaPipe Pose achieved the third and fourth highest performances, respectively.
In the overall comparison, MoveNet was the most robust because it achieved the top performance in terms of lower fence, first quartile, median, and third quartile values compared to the other HPE libraries. MoveNet achieved more than 50% PDJ value for 994 out of 1100 images. In addition, MediaPipe Pose showed the poorest performance in the image dataset as it has the lowest PDJ in terms of first quartile, median, and third quartile values. MediaPipe Pose also showed that less than 50% of detected keypoints could be correctly matched with the ground truth in 698 out of 1100 images. OpenPose and PoseNet achieved the second best and third best performances, respectively.
4.2. Video Dataset
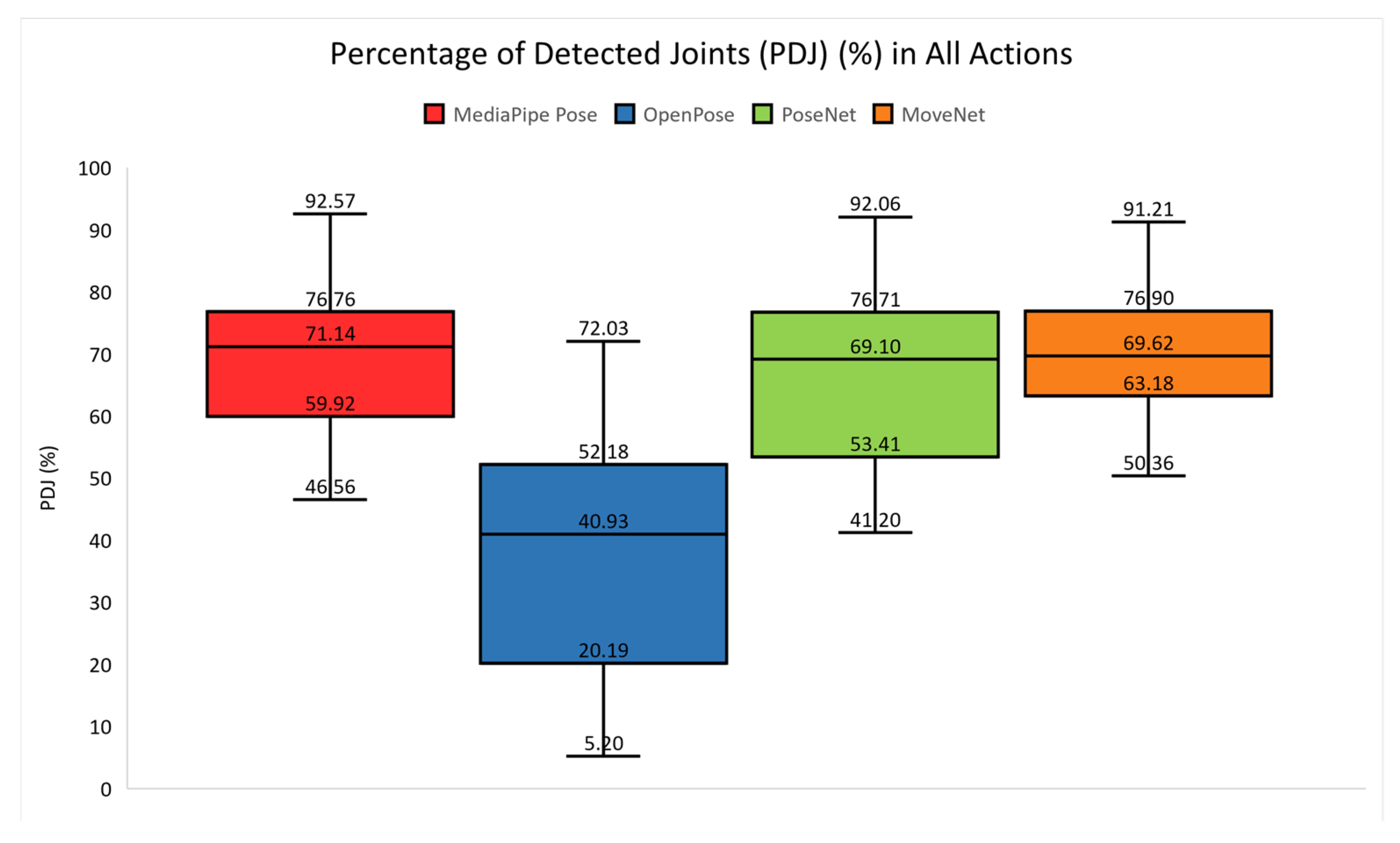
The mean PDJ for each action was calculated and the PDJ values for all actions are shown in
Figure 4. Among three HPE libraries, MoveNet (orange box), MediaPipe Pose (red box), and PoseNet (green box) achieved slightly similar performances in terms of minimum, first quartile, median, maximum, and third quartile values. MediaPipe Pose (red box) had the highest PDJ in terms of maximum and median values, while MoveNet (orange box) scored the highest in terms of minimum, first, and third quartile values. OpenPose (blue box) portrayed a weak performance with the lowest values for all quartiles.
Similar to
Table 4,
Table 5 lists the performance of the HPE libraries for all actions into five groups, which are 0%, 0–25%, 25–50%, 50–75%, and 75–100%. There was no action showing 0% in all HPE libraries. In the range of 75–100%, MediaPipe Pose achieved the greatest number of actions, which was 5 actions. MoveNet and PoseNet achieved 4 actions in this group, while OpenPose showed 0 actions in this group. In the fourth group (50–75%), MoveNet achieved the greatest number of actions (10 actions), followed by PoseNet (7 actions), MediaPipe Pose (6 actions), and OpenPose (4 actions). In the first three groups (0–50%), OpenPose showed the greatest number of actions (10 actions), MediaPipe Pose and MoveNet showed 3 actions, while MoveNet showed 0 actions in these groups. Overall, MoveNet achieved the best performance because it achieved above 50% PDJ in all actions. OpenPose showed the worst performance since the PDJ for 10 actions were lower than 50%.
To get a better understanding of the performance of the HPE libraries for each action, the highest and lowest average PDJ values of each library for each action are highlighted in
Table 6. Among 14 actions, the libraries achieved the best performance in Action 8 (jumping jacks). MediaPipe Pose showed the poorest performance in Action 12 (squat) among all actions. Coincidentally, both OpenPose and PoseNet showed the poorest performance in Action 2 (bench press). On the other hand, MoveNet showed the poorest performance in Action 4 (bowling). The overall average PDJ values for all actions are highlighted in the last row of
Table 6. The performance rank from the highest to lowest PDJ values was MoveNet, MediaPipe Pose, PoseNet, and OpenPose. The performances among MoveNet, MediaPipe Pose, and PoseNet fell between 65% and 70%. The performance of OpenPose was much lower than the others, which fell at approximately 37%. Although MediaPipe Pose successfully detected 5 actions (refer
Table 5), achieving between 75% and 100% PDJ, which was more than MoveNet, its overall performance was 1.38% lower than that of MoveNet.
The ranking of each library for each action is listed in
Table 7. MediaPipe Pose achieved the top performance in 7 of 14 actions. It achieved the second highest performance in 3 actions and the third highest performance in 4 actions. MoveNet achieved the highest performance in 6 actions, second highest performance in 5 actions, and third highest performance in 3 actions. PoseNet showed the highest performance in only Action 4 (bowling), second highest performance in 6 actions, and third highest performance in 7 actions. OpenPose showed the lowest performance in all actions among all the HPE libraries.
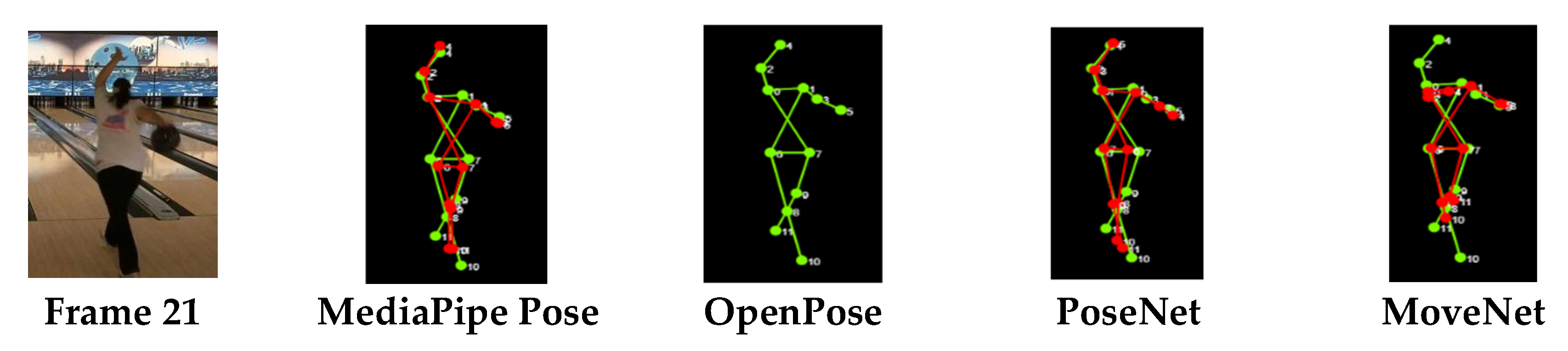
Since the results in
Table 6 show that the four HPE libraries achieved the best performance in Action 8 (jumping jacks) among all actions, a closer analysis was performed. MediaPipe Pose, MoveNet, and PoseNet reached approximately 92% while OpenPose achieved approximately 72% for Action 8.
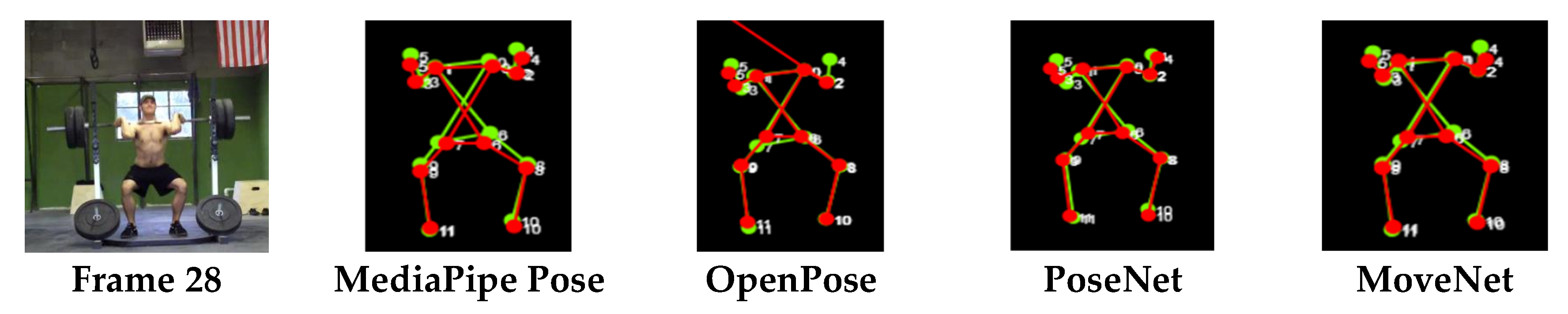
Figure 5 shows the video frame and detection results of Action 8, where the two challenges, self-occlusion and inappropriate camera position, are absent. Hence, the performance of HPE should be better when there are less challenges affecting keypoint detection. On the other hand, the performance of HPE is reduced when there are more challenges. MediaPipe Pose showed the poorest performance in Action 12 (squat); OpenPose and PoseNet showed the worst performance in Action 2 (bench press); while MoveNet showed the poorest performance in Action 4 (bowling).
Figure 6,
Figure 7 and
Figure 8 show the sample video frames and detection results of each HPE library for Actions 12, 2, and 4, respectively.
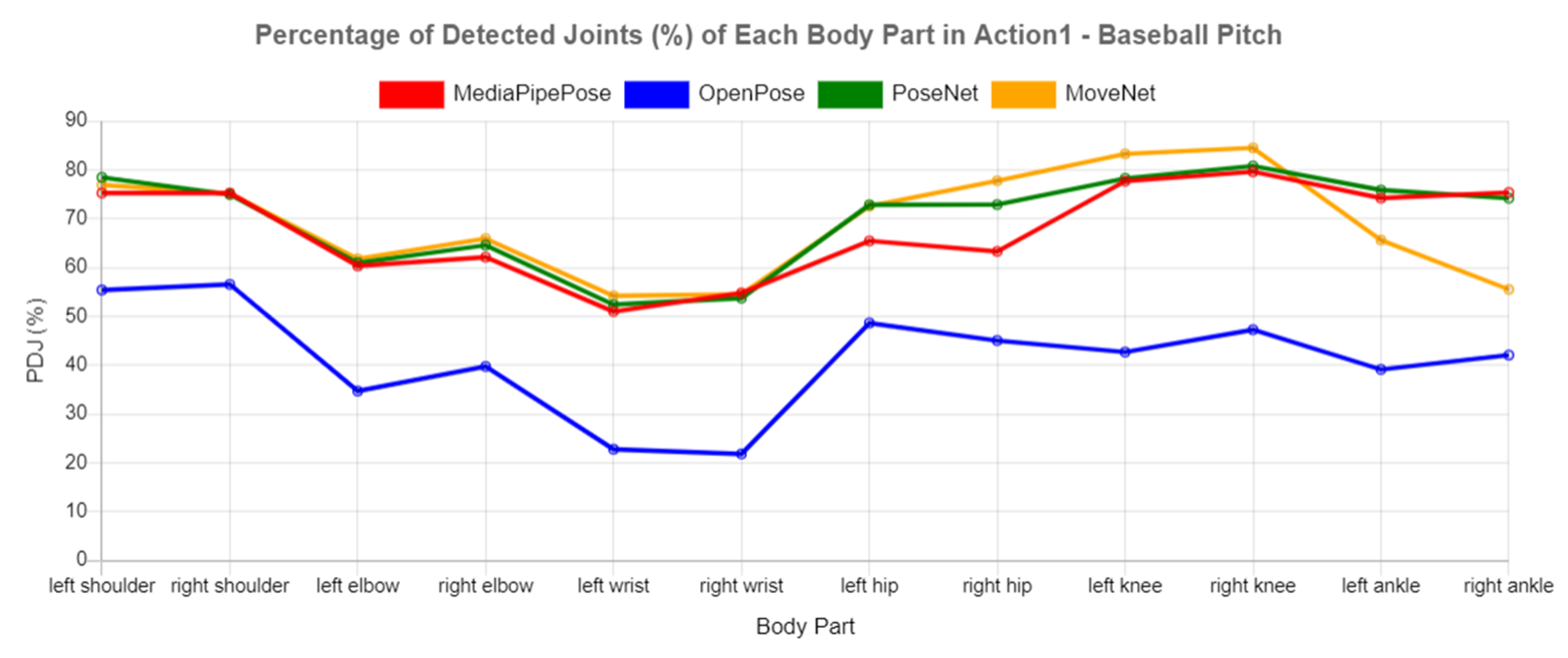
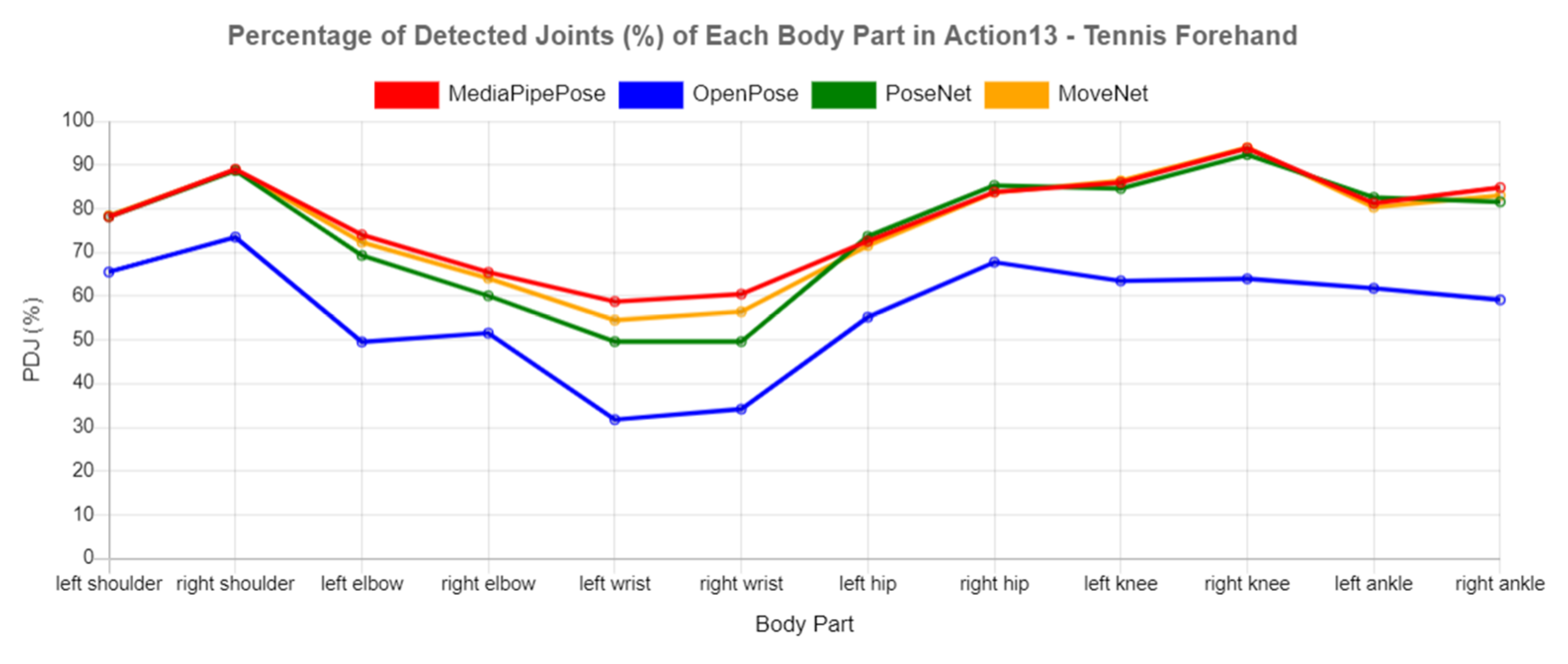
In addition, the PDJ values for each body part in each action were also calculated. Frequent changes in keypoint positions also affects the performance of keypoint detection. In Actions 1, 3, 4, 6, 13, and 14, the PDJ values for elbows and wrists in all the tested libraries were lower than those of other body parts, as shown in
Figure 9,
Figure 10 and
Figure 11. This was due to frequent changes in keypoint positions in the elbows and wrists compared to other body parts. For instance, the person who plays bowling only needs to use his elbow and wrist to release the ball to the bowling lane, hence showing fewer changes of movement in other body parts. Likewise, the performance of OpenPose (blue line) showed the lowest PDJ among these actions, while the fluctuations in PDJ values between other HPE libraries were relatively small.
When the common challenges (self-occlusion and inappropriate camera position) occurred in the videos, the performance of keypoint detection was affected in all HPE libraries.
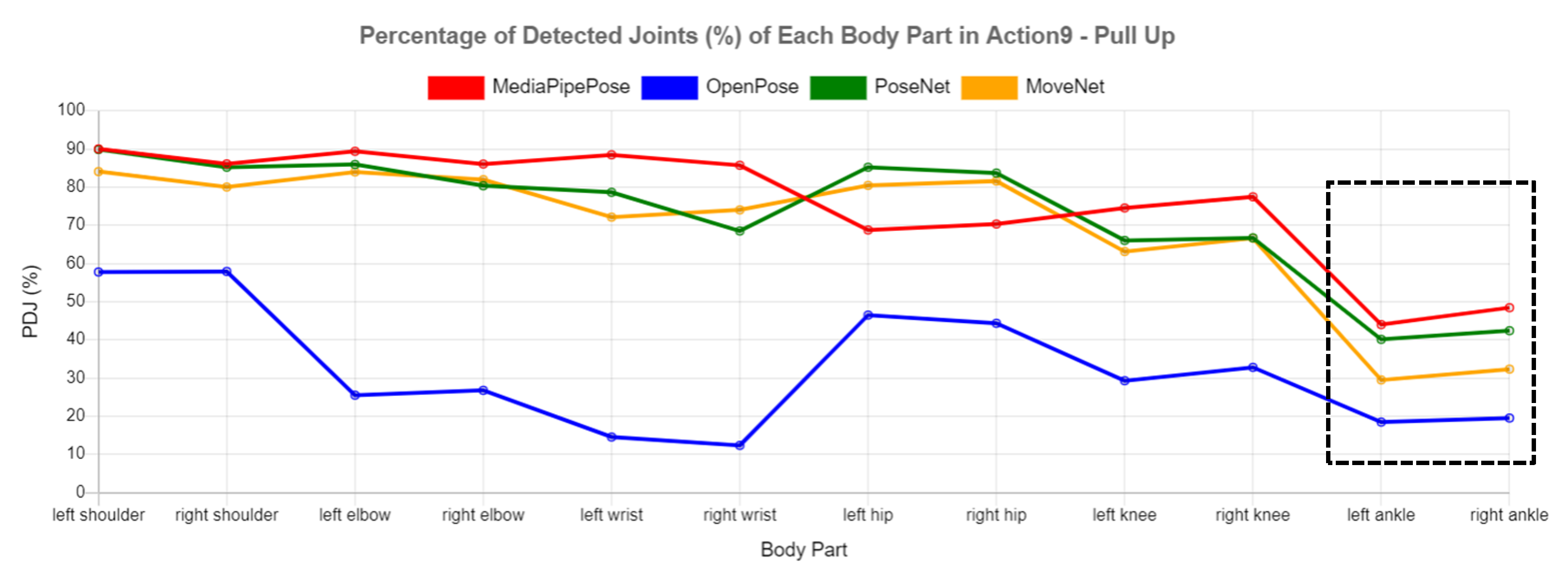
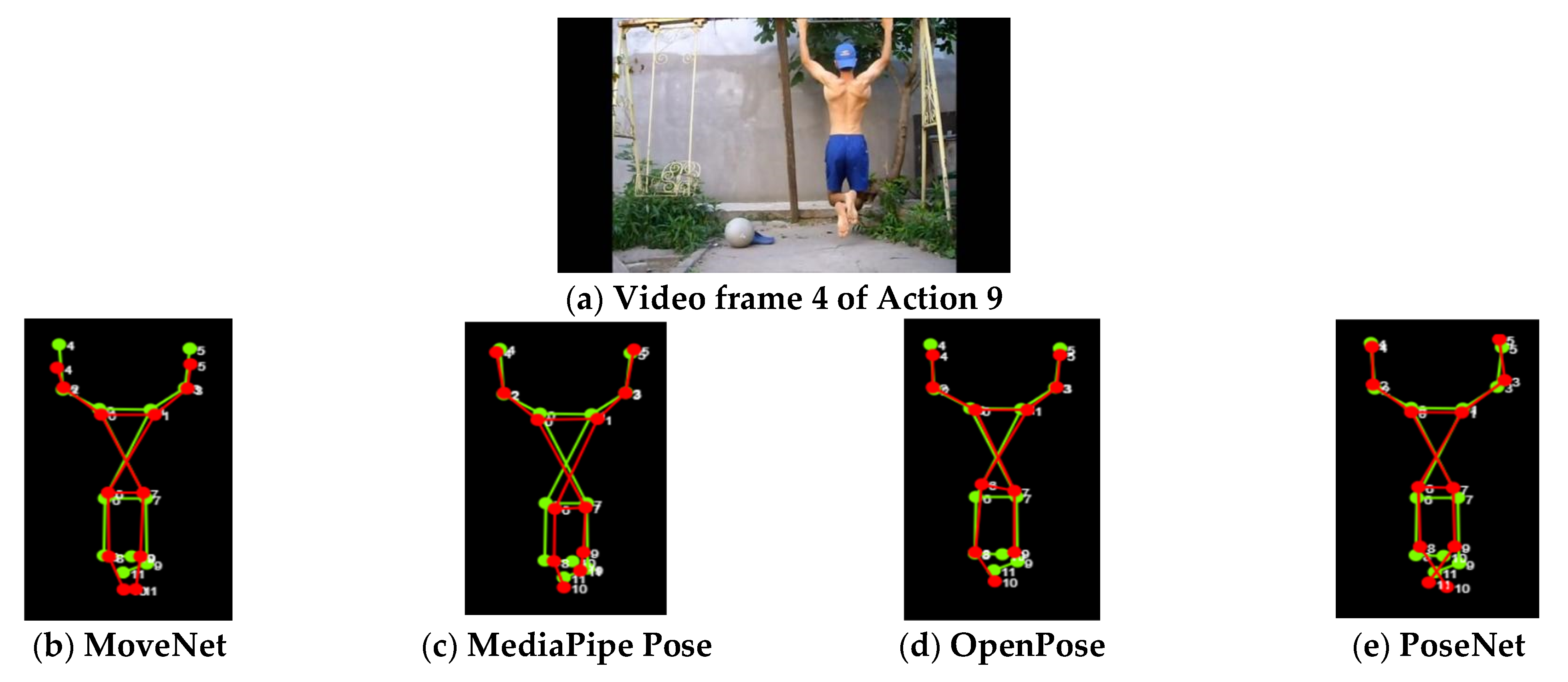
Figure 12 shows the video frames of Action 9 (pull up), showing the self-occlusion effect in the action. In this action, all libraries showed much lower performance in some of the body parts compared to that of other body parts due to this self-occlusion effect. The corresponding PDJ values are reported in
Figure 13. The PDJ values for ankles (black dotted box) were much lower than other parts because of self-occlusion from the crossed ankles, as shown in
Figure 14. OpenPose (blue line) achieved the lowest performance for all body parts, particularly for elbows and wrists. Additionally, the performance of MoveNet for the ankles was lower than that of MediaPipe Pose and PoseNet when facing the self-occlusion effect.
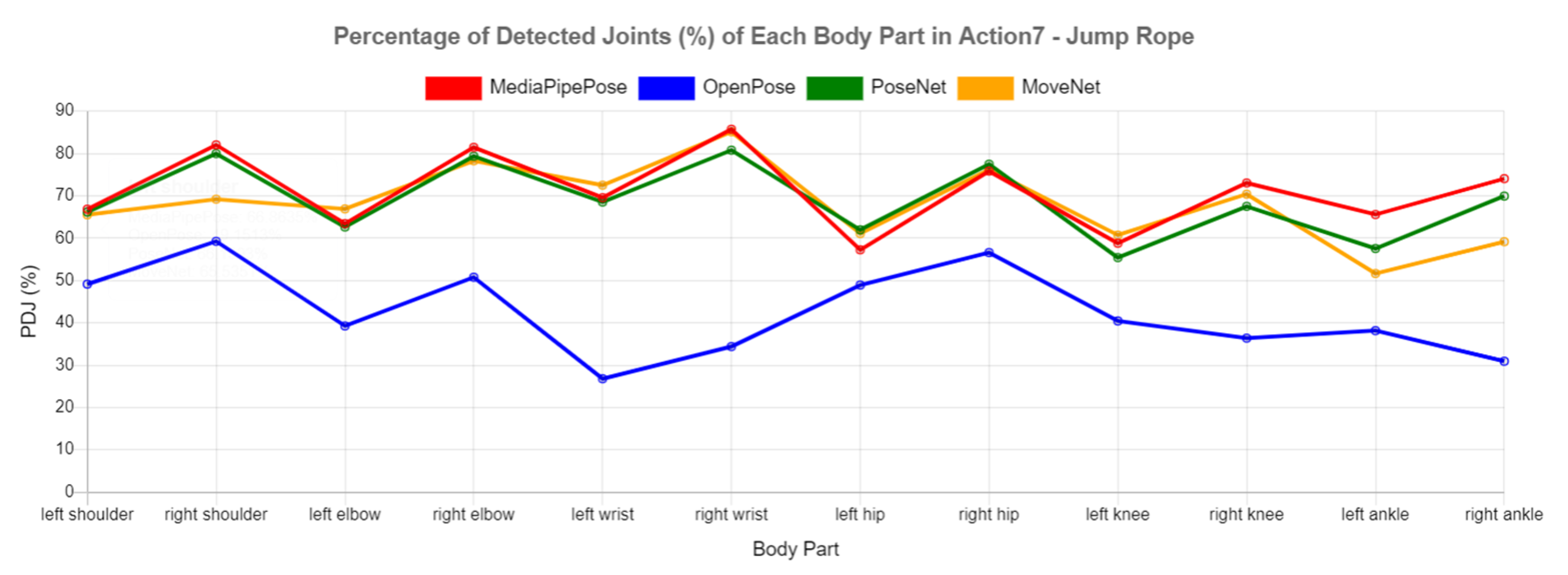
In addition, inappropriate camera position is one of the common challenges for human pose estimation. In Action 7 (jump rope), the camera was placed on the right side of the person and the video frames were recorded from the right side, as shown in
Figure 15. Hence, self-occlusion occurred to the left body parts, which reduced the performance of keypoint detection for the left body parts.
Figure 16 clearly shows that the performance of all HPE libraries for the right body parts was higher than that for the left body parts, where the PDJ values for the right shoulder and right elbow were always higher than those for the left shoulder and left elbow.
In the overall comparison, MoveNet achieved the highest PDJ values in terms of minimum, first quartile, and third quartile values compared to the other HPE libraries. The PDJ values for MoveNet in all actions were more than 50%. MediaPipe Pose achieved the highest PDJ values in terms of maximum and median values. All HPE libraries achieved superior performance in Action 8 (jumping jacks) among all actions, which consists of fewer challenges. Based on the ranking of the HPE libraries in each action, MediaPipe Pose achieved the top performance in 7 actions, followed by MoveNet (6 actions) and PoseNet (1 action). OpenPose showed the poorest performance in all actions. MoveNet achieved the highest average PDJ value, while OpenPose showed the lowest average PDJ value. However, MediaPipe Pose and PoseNet were still competitive with MoveNet because the average PDJ values for these three libraries were in the range of 65–68%.























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}